1. Introduction
Around the world, countries are taking unprecedented steps to support renewable energy adoption. Currently, the number of photovoltaic (PV) installations is growing faster than any other renewable energy resource, driven mainly by sharp cost reductions and policy support [
1]. In the United States, utility-scale photovoltaic capacity is projected to grow by 127 GW [
2]. South Korea plans to increase its solar power generation fivefold by 2030 [
3]. China, the world’s leading installer of PV, has a goal to reach 1300 GW of solar capacity by 2050 [
4]. This increasing PV adoption is leading to increasing integration of PV into microgrids. To operate PV-based microgrids optimally, an accurate forecast of day-ahead solar power is necessary. However, solar PV power output is calculated from solar irradiance, resulting in a growing interest in solar irradiance forecasting. Some of the applications of solar irradiance forecasting in microgrids include economic dispatch, peak shaving, energy arbitrage, participation in the energy market, and uncertainty impact reduction.
Solar irradiance forecasting has been extensively studied in the literature. Generally, it can be broadly classified in terms of forecast horizons and model types. For the forecast horizon, forecasting can be categorized as very short-term [
5], short-term [
6], and medium-term [
7,
8]. Very short-term forecasting (a few minutes to 1 h) is used for real-time optimization, an important component of an energy management system. Short-term forecasting (3–4 h) is used for intraday market participation. Medium-term forecasting (typically a day ahead) is useful for day-ahead operation optimization and market participation.
Model types can be categorized as either data-driven or physical. Data-driven models use historical time series data. They can be further sub-categorized into statistical or machine learning models. Statistical models include autoregressive integrated moving average (ARIMA) [
9], auto-regressive moving average (ARMA) [
10], coupled autoregressive and dynamic system (CARD) [
11], Lasso [
12], and Markov models [
13,
14,
15]. Machine learning models [
16] include support vector machine (SVM) [
17,
18], feedforward neural network (FFNN) [
19], and recurrent neural network (RNN) [
20]. Data-driven models can be further subdivided according to the type of input features they use to train the model. A forecasting model that uses only a target time-series (solar irradiance in this case) as an input feature is referred to as a nonlinear autoregressive (NAR) model. On the other hand, if a model uses additional exogenous inputs, such as temperature and humidity, it is referred to as a nonlinear autoregressive with exogenous inputs (NARX) model. Physical models use numerical weather prediction (NWP) [
21,
22,
23], which shows good performance for forecast horizons from several hours up to six days.
Until recently, the forecasting domain has been largely influenced by statistical models. There is an increasing shift to machine learning models, due in part to the increasing availability of historical data. These models have come into serious contention with classical statistical models in the forecasting community [
24]. Machine learning models use historical data to learn the stochastic dependency between the past and the future. A wealth of studies conclude that these models outperform statistical models in solar irradiance forecasting.
Table 1 tabulates the previous studies on day-ahead solar irradiance forecasting. We report the study location, dataset size (number of examples, which correspond to a day measurement), and the machine learning model used. The models include FFNN, RNN, and SVM, among others. FFNN is by far the most widely applied algorithm in the literature. Kemmoku et al. [
25] used multi-stage FFNN to forecast a day-ahead solar irradiance in Omaezaki, Japan. The results showed that the mean error reduces from about 30% (by single-stage FFNN) to about 20% (by multi-stage FFNN). Yona et al. [
26] proposed a method for forecasting day-ahead solar irradiance using RNN and a radial basis function neural network (RBFNN). They found that both RNN and RBFNN outperform FFNN. In [
27], Mellit et al. used FFNN with two hidden layers to forecast solar irradiance for day-ahead in Trieste, Italy. The inputs to their model were mean daily solar irradiance, mean daily temperature, and time of day. Paoli et al. [
28] used 19 years of data from Corsica Island, France, to fit an FFNN model to forecast a day-ahead solar irradiance. The study compared the performance of FFNN and Markov chains, Bayesian inference, k-nearest neighbor (KNN), and autoregressive (AR) models, and found that FFNN outperforms all these models. In [
29], Linares et al. used FFNN to generate daily solar irradiance in locations without ground measurement. The model was developed using 10 years of data from 83 ground stations in Andalusia, Spain. In [
30], they applied three models to predict day-ahead solar irradiance over Spain. The models are Bristow–Campbell, FFNN, and Kernel Ridge Regression. They concluded that FFNN produces the most accurate result. In [
31], they used predicted meteorological variables from the US National Weather Service database to predict day-ahead solar irradiance using FFNN. Long et al. [
32] used four different machine learning methods, including FFNN, to forecast day-ahead solar irradiance. They concluded that none of the models can outperform others in all scenarios. In [
33], Voyant et al. applied FFNN to forecast day-ahead solar irradiance. They reported interesting analyses, such as the effects of using endogenous and exogenous data, and the performance of three different FFNN architectures. The findings indicated that using exogenous data improves the model accuracy and that multi-output FFNN has better accuracy than the two other architectures. Other authors that used FFNN and achieved satisfactory results include [
34,
35].
Other machine learning models besides FFNN have been seen in the literature. In [
36], the authors forecasted day-ahead solar irradiance by applying Coral Reefs Optimization (CRO) and trained their neural network using an extreme learning machine (ELM) approach. The ELM was used to solve the forecasting problem, and then CRO was applied to evolve the weights of the neural network in order to improve the solution. In [
37], the authors used a partial function linear regression model to forecast a daily solar power output. In this model, the intra-day time-varying pattern of output power was incorporated into the forecasting framework. In [
38], Chen et al. used RBFNN to forecast solar power output by first training a self-organized map to classify the local weather type for 24-h ahead.
In [
39], Ahmad et al. used an autoregressive RNN with exogenous inputs and weather variables to provide a day-ahead forecast of hourly solar irradiance in New Zealand. In [
40], Cao and Lin combined RNN with a wavelet neural network, forming a diagonal recurrent wavelet neural network to perform day-ahead solar irradiance forecasting. They demonstrated improvement in accuracy using data from Shanghai and Macau. In [
20], a comparative study of long short term memory (LSTM) in forecasting day-ahead solar irradiance was performed. The results suggest that LSTM outperforms many alternative models (including FFNN) by a substantial margin.
In this paper, we propose a deep LSTM-RNN using only exogenous inputs (i.e., without using solar irradiance as an input feature to the model) to forecast day-ahead solar irradiance. We note that we are not the first to use only exogenous inputs, as it was reported in [
29], that exogenous inputs were used exclusively to train FFNN for day-ahead solar irradiance forecasting. However, we found that using this approach with LSTM is more accurate than with FFNN. Notably, the studies in
Table 1 were trained and evaluated using data from a single country (with the exception of [
20]); this makes their findings difficult to generalize because it does not take into account the changing spatial and climatic conditions across different locations. It is also important to point out that none of these studies experimented with a deep learning approach, even though that approach was found to be successful in electricity load forecasting [
41], wind speed forecasting [
42,
43], and electricity price forecasting [
44]. Finally, all the studies reviewed focused on forecasting accuracy without demonstrating the usefulness of the forecast. In this work, we used a microgrid design and analysis model developed in [
45], to simulate a one-year optimal operation of a commercial building microgrid using the actual and forecasted solar irradiance.
In summary, the contributions of this work to the literature are threefold. First, we develop a model to predict solar irradiance using only exogenous inputs; this means the model can generate solar irradiance for a given location without past measurement of solar irradiance at the location. Second, we demonstrate that by using a deep learning approach, LSTM-RNN can achieve higher accuracy than other models; the model achieved higher accuracy in term of forecast skill than the results obtained from the previous studies cited. We demonstrate the performance of our approach using six datasets. Finally, we simulate a one-year operation of a microgrid, thereby demonstrating the usefulness of the forecasting model.
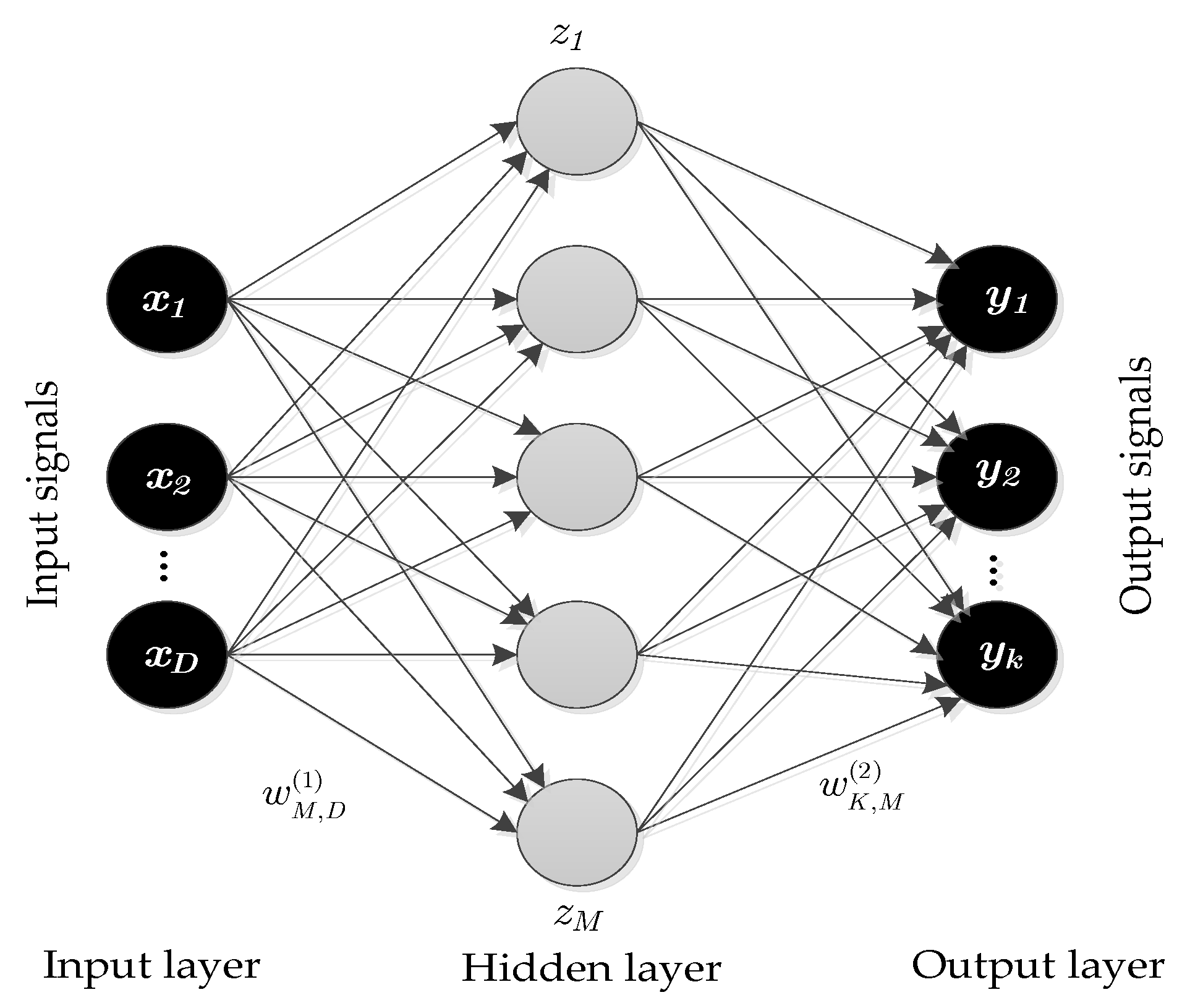
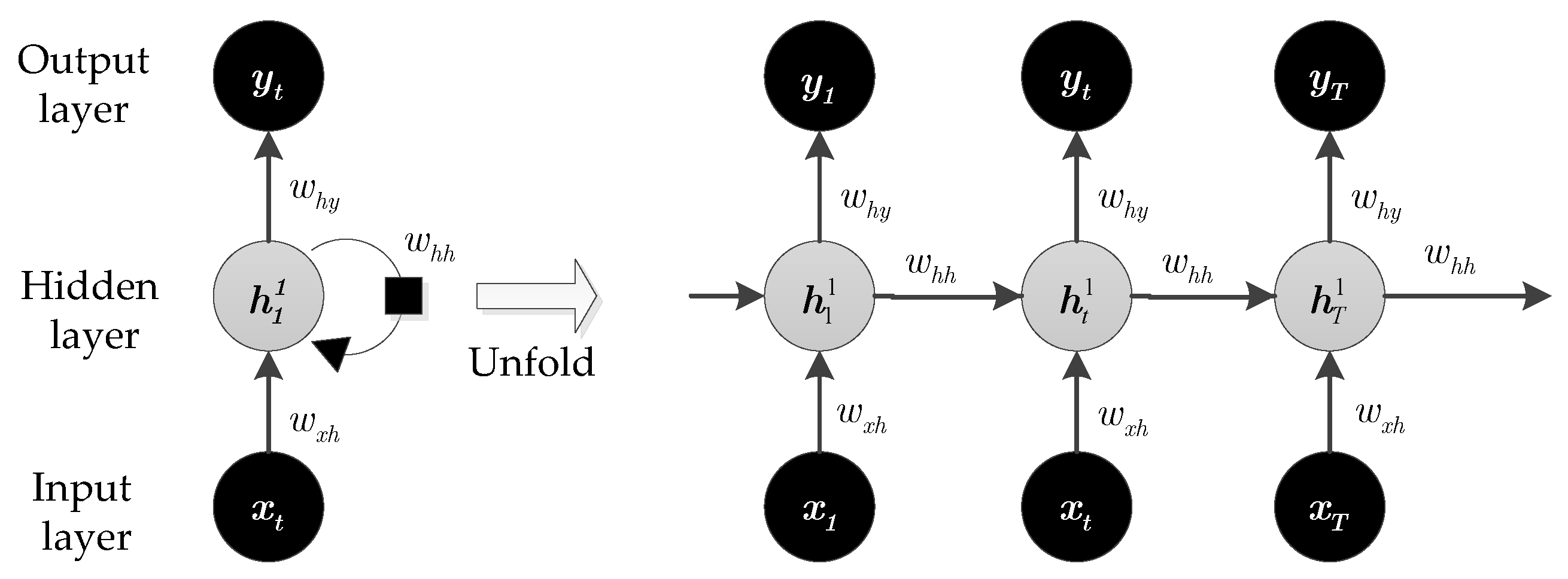
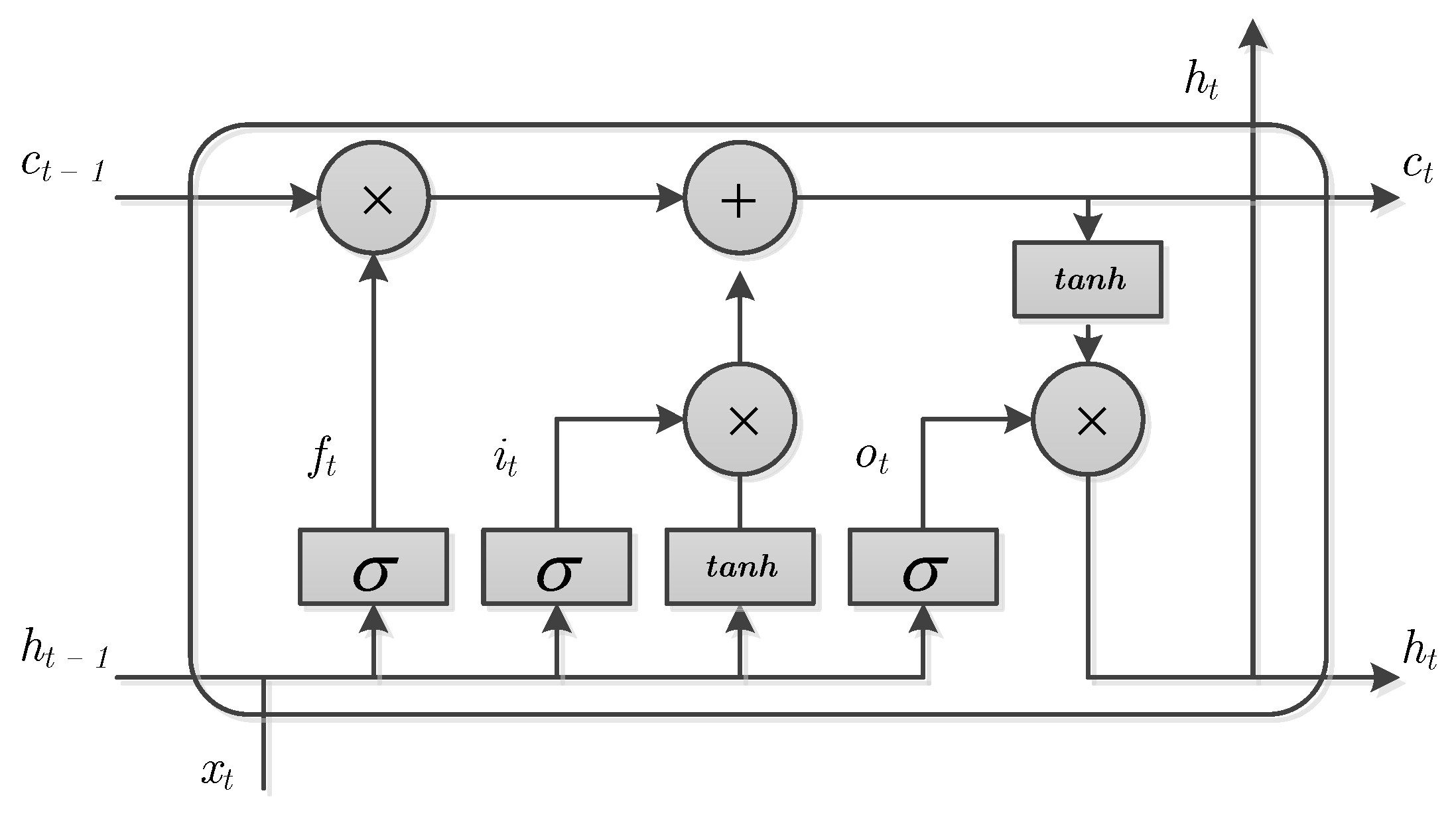
The rest of the paper is organized as follows: The theoretical background of deep learning, LSTM-RNNs, and FFNN are discussed in
Section 2. In
Section 3, we provide the details of the end-to-end problem formulation of an LSTM-RNN model for solving the solar irradiance forecasting problem. The results, analysis, and discussion are presented in
Section 4.
Section 5 provides the conclusion and describes future research work.
3. Problem Formulation
In this section, we develop the model for forecasting the 24-h global horizontal irradiance (GHI). Since GHI is the irradiance falling on a horizontal surface, and PV arrays are usually installed inclined to the horizontal plane, we need to account for this inclination when calculating solar irradiance incident on the PV array. Many models of varying complexity have been developed for calculating incident solar irradiance. Among these models, the HDKR model [
66] is the most widely used. Its results are calculated as shown in Equation (12) below:
where
G is the GHI,
Gb is the beam radiation,
Gd is the diffuse radiation,
is the slope of the surface in degrees,
is the ground reflectance,
Rb is the ratio of the beam radiation on the tilted surface to beam radiation on the horizontal surface,
Ai is the anisotropy index which is a function of the transmittance of the atmosphere for beam radiation, and
f is the factor used to account for cloudiness. The power produced by the PV modules can be calculated from the incident irradiance calculated in Equation (12) as follows [
67,
68]:
where
Ppv,STC is the rated PV power at standard test conditions (kW),
kT is the temperature coefficient of power (%/°C),
Tcell is the PV cell temperature (°C),
Tcell,STC is the PV cell temperature at standard test conditions (25 °C),
Ginc,STC is the incident solar irradiance at standard test conditions (1 kW/m
2), and
Ginc is the incident solar irradiance on the plane of the PV array (kW/m
2). The cell temperature,
Tcell, is calculated in Equation (14):
where
Tamb is the ambient temperature and NOCT is an acronym for the nominal operating cell temperature, a constant that is defined under the ambient temperature of 20 °C, incident solar irradiance of 800 W/m
2, and wind speed of 1 m/s.
3.1. Framing the Problem
Solving a forecasting problem by using historical data has a strong theoretical background. Two approaches to this type of problem come from statistical forecasting theory and dynamic system theory. Statistical forecasting theory assumes that an observed sequence is a specific realization of a random process, where the randomness arises from many independent degrees of freedom interacting linearly [
69]. In dynamic system theory, the view is that apparently random behavior may be generated by deterministic systems interacting nonlinearly with only a small number of degrees of freedom [
70]. The problem of time series forecasting can be framed as a supervised learning problem, which follows from dynamic system theory. Supervised learning is a machine learning algorithm that learns an input to output mapping function from example input-output pairs [
71].
3.1.1. Problem Definition
Given historical weather data together with categorical features such as the hour of day and month of the year, we can forecast a day-ahead solar irradiance. To define the problem formally, we let
represents an example in the dataset where
M is the total number of examples in the dataset,
represents the time step, where
T represents the prediction horizon (24 h for day-ahead forecasting),
W represents the length of the lookback window, and
d denotes feature dimension. Given a dataset
, where
is an input matrix,
is a temporal window,
is a multidimensional output vector over the space of real-valued outputs; determine
, where
and
are the concatenation of all outputs and inputs, respectively, and
represents model parameters, such that:
is minimized.
3.1.2. Performance Metrics
In order to evaluate the model’s performance, we need to choose a metric to measure the prediction accuracy. There are many issues that arise when choosing a metric as noted in [
72,
73]. Those authors observed that many metrics are not generally applicable, can be infinite or undefined in some cases, and can produce misleading results. Nevertheless, root mean square error (RMSE) and mean absolute error (MAE) are widely used in the literature. The equations for calculating RMSE and MAE are given respectively in Equations (16) and (17).
where
M is the number of
examples in the dataset,
x(i) is a vector of feature values of the
ith
example in the dataset,
y(i) is the desired output value of the
ith example,
h is the system prediction function. Note that using only RMSE and MAE as a measure of forecast accuracy can be misleading because they do not convey a measure of variability in the time series data. A metric that tries to address this issue is the forecast skill, proposed in [
74]. Forecast skill gives the relative measure of improvement in prediction over the persistence model, which is also known as the naive model. It is given by Equation (18).
A typical forecast model should have a value of
s between 0–100, with a value of 100 indicating perfect forecast, and a value of 0 indicating the model has an equal skill to persistence model.
U and
V are calculated over the same dataset, where
and
. Even though we used RMSE to evaluate the models in this paper, our motivation for also computing the MAE metric is for comparison with previous works, and to allow comparison with future works. For a comprehensive treatment of various performance metrics used in solar irradiance forecasting, interested readers can refer to [
72,
73].
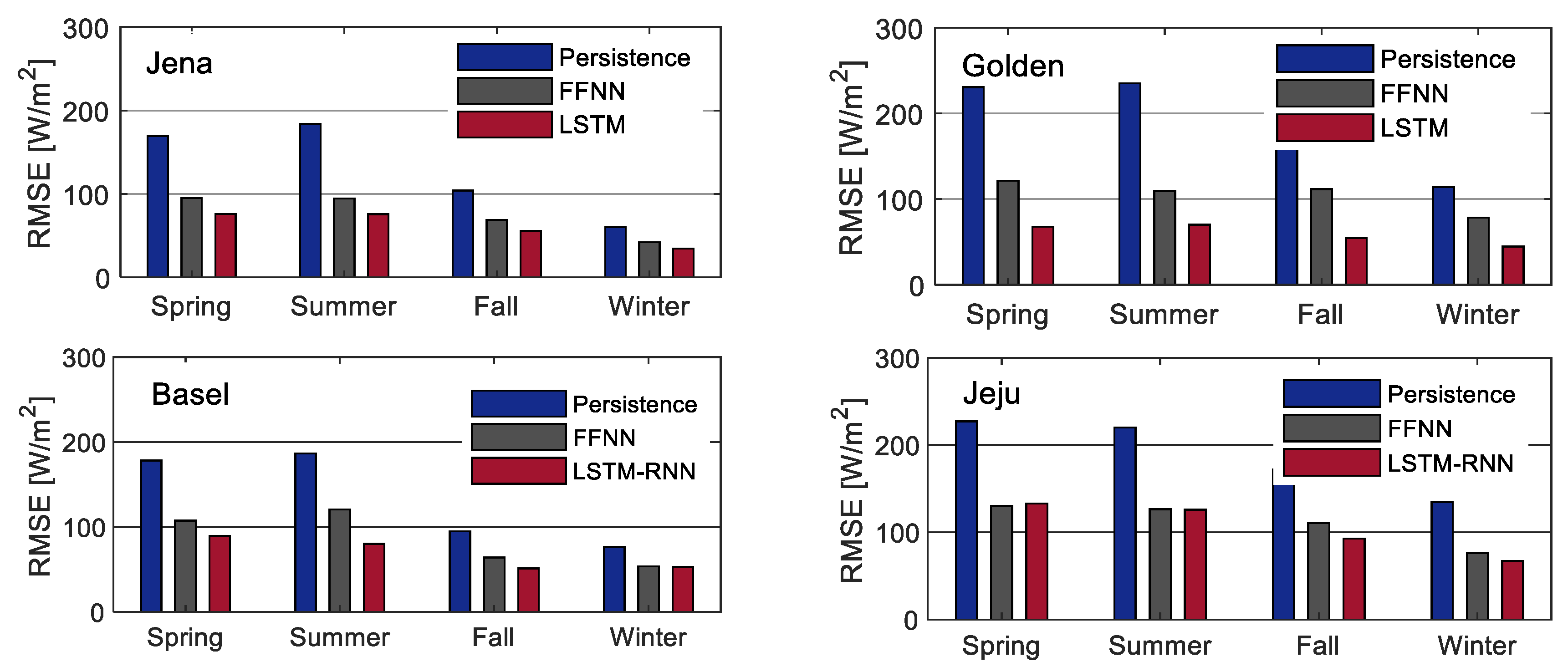
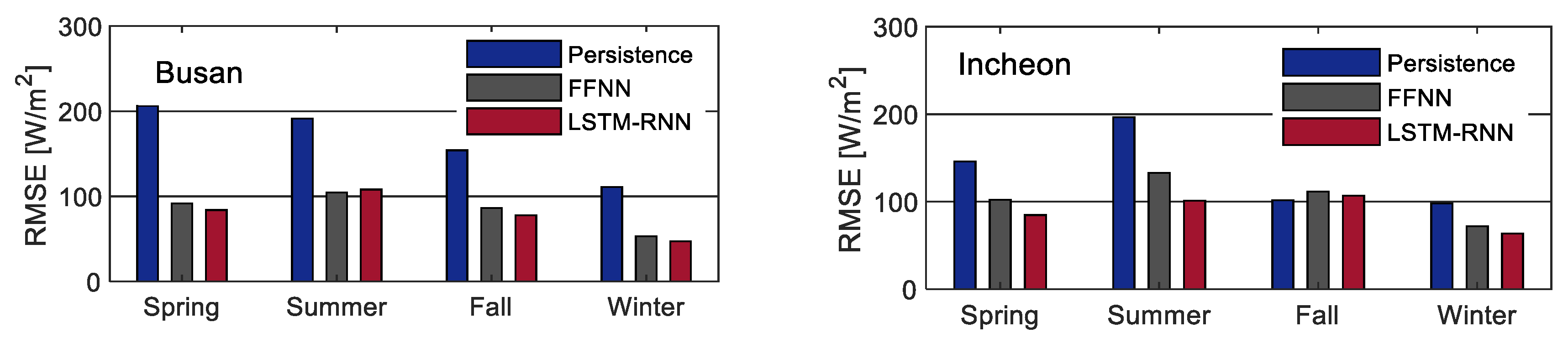
We use a day-ahead persistence model as a reference, which is a standard approach in the irradiance forecasting literature. This model assumes that the current conditions will repeat for the specified time horizon. In particular, the persistence model sets the irradiance value of the previous day to be the day-ahead predicted values.
3.2. Data Engineering
3.2.1. Data Description
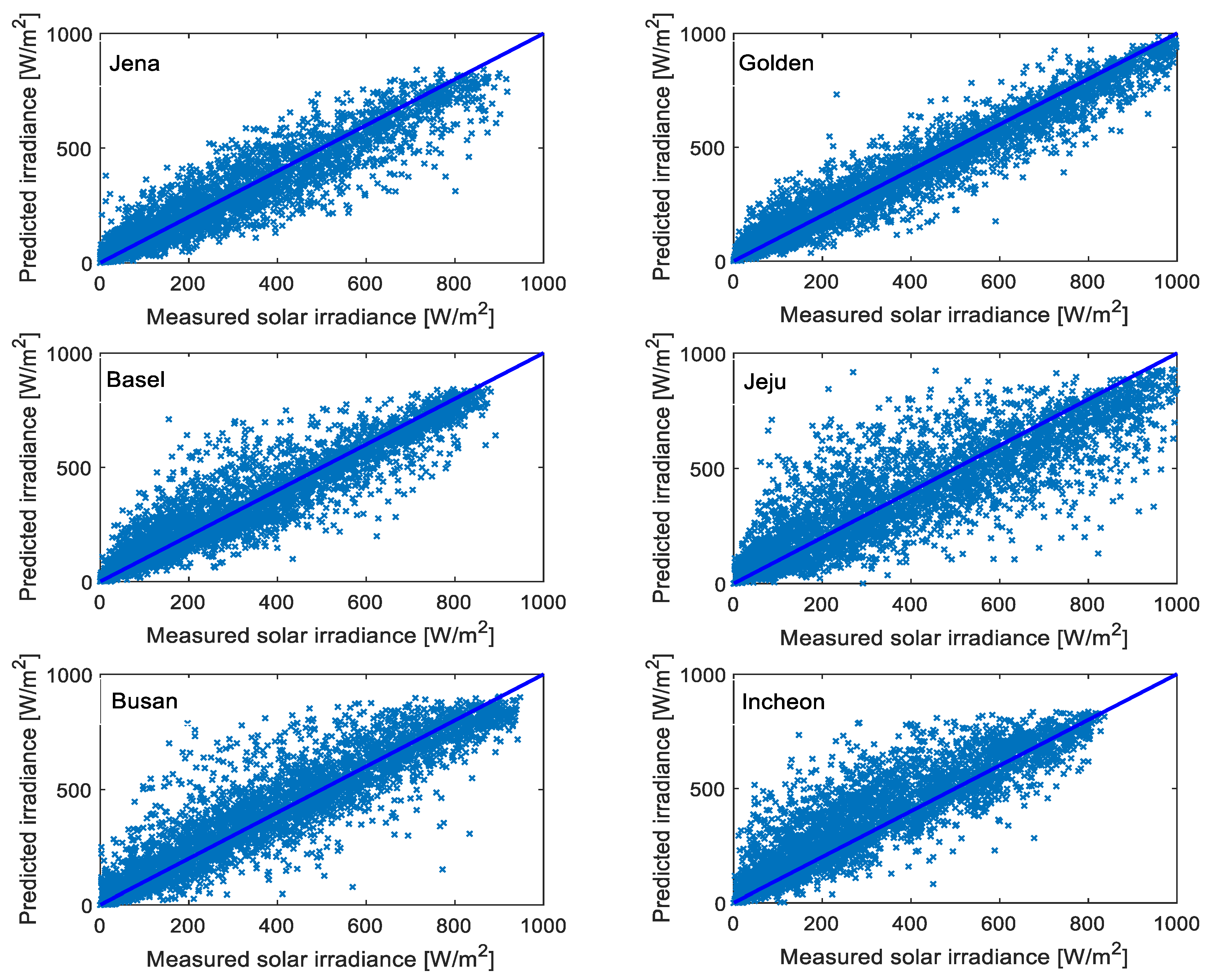
A comprehensive evaluation of solar irradiance forecasting method should include multi-location based experiments, as this will increase confidence in the results. With this in mind, in this work, six datasets from four different countries were used. The countries selected have diverse climatic conditions and topographical features. These datasets are from Saaleaue Weather Station at the Max Planck Institute of Biochemistry in Jena, Germany [
75]; Solar Radiation Research Laboratory (SRRL) in Golden, Colorado, USA [
76]; Weather Station in Basel, Switzerland [
77]; Korea Meteorological Administration (KMA) Weather Stations in Jeju, Busan, and Incheon [
78].
Table 2 summarizes information about latitude, longitude, elevation above sea level, climate type according to the Koppen classification system, and the sizes of the datasets for all the six locations.
The weather variables collected in each location and their Pearson correlation coefficient (PCC) with solar irradiance is shown in
Table 3. PCC is a measure of the correlation between two variables. It has a value between +1 and −1, where 1 is total positive linear correlation and −1 is total negative linear correlation. Given two variables (
X,
G), the formula for computing PCC is given below:
where
and
are the mean and standard deviation of the variables (
X,
G), and
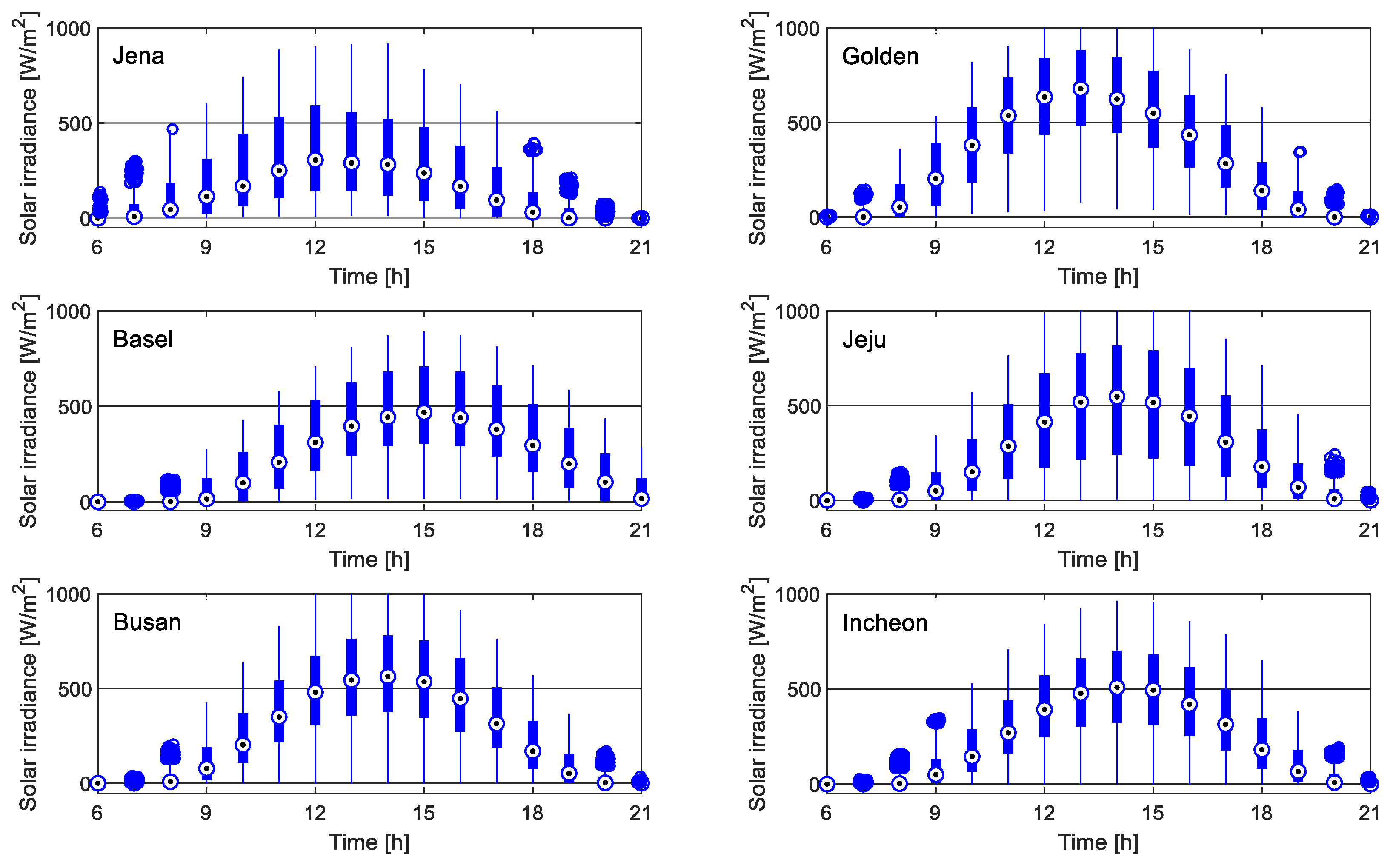
N is the number of observations in each variable. The boxplots of solar irradiance for the six datasets are shown in
Figure 4.
3.2.2. Data Division
We divided the data into three subsets: A training set, a validation set, and a test set. We used the training set to train the models and the validation set for hyperparameter optimization, feature selection, and regularization. The test set, which is the out-of-sample data, was used for final evaluation to select the best model.
Table 4 shows the data division and the number of examples in each subset. Note that in South Korea there are three datasets from Jeju, Busan, and Incheon, which are all divided in the same way.
3.2.3. Feature Selection
One of the central problems of time series supervised learning is identifying and selecting the relevant features for accurate forecasting. Feature selection improves the performance of a prediction by eliminating irrelevant features, reducing the dimension of the data, and increasing training efficiency. For solar irradiance forecasting, previous studies have discussed feature selection extensively [
79,
80,
81,
82]. In this study, the goal is to select the subset of features that are both easily obtainable for any location and that correlate with the solar irradiance. We did not rank the importance of features based on their PCC values because a feature can be irrelevant by itself but can provide a significant performance improvement when taken with other features [
83]. There are two widely used approaches to the feature selection problem [
84]: The wrapper and the filter approach. The
wrapper approach consists of using an evaluation metric (in this paper, RMSE) of the machine learning algorithm to assess the space of all possible variable subsets. In the
filter approach, heuristic measures are used to compute the relevance of a feature in a preprocessing stage without actually using the machine learning algorithm. In this paper, we used the former approach [
85] since we have a small number of features to select from. We found that the subset of dry-bulb temperature, dew point temperature, and relative humidity comprise the most relevant set of features. This implies that to forecast day-ahead solar irradiance, we do not need previous days solar irradiance as an input feature to our forecasting model. Finally, we added two categorical features, the hour of the day (1–24) and the month of the year (1–12), which improved the prediction accuracy of the models.
3.2.4. Data Preparation
Before applying data to a machine learning algorithm, it is necessary to clean the data to fix or remove outliers and fill in any missing values. There are no missing values in the Golden and Basel datasets. In the Jena, Jeju, Busan, and Incheon datasets, there are a few missing values representing less than 1% of the entire dataset. We replaced the missing values using linear regression fit. We note that more sophisticated techniques such as Kalman filters could be used to replace the missing values [
86]; however, considering there are just a few values to replace, this simple method will suffice.
Other data preparation steps in machine learning are feature scaling and encoding. Machine learning algorithms often perform poorly when the input numerical features have very different scales, so we rescaled the data to have a zero mean and unit variance. We encoded categorical features (the hour of the day and the month of the year) with 1-hot encoding. The one-hot encoder maps the original element from the categorical feature vector with M cardinality into a new vector with M elements, where only the corresponding new element is one while the rest of new elements are zeros.
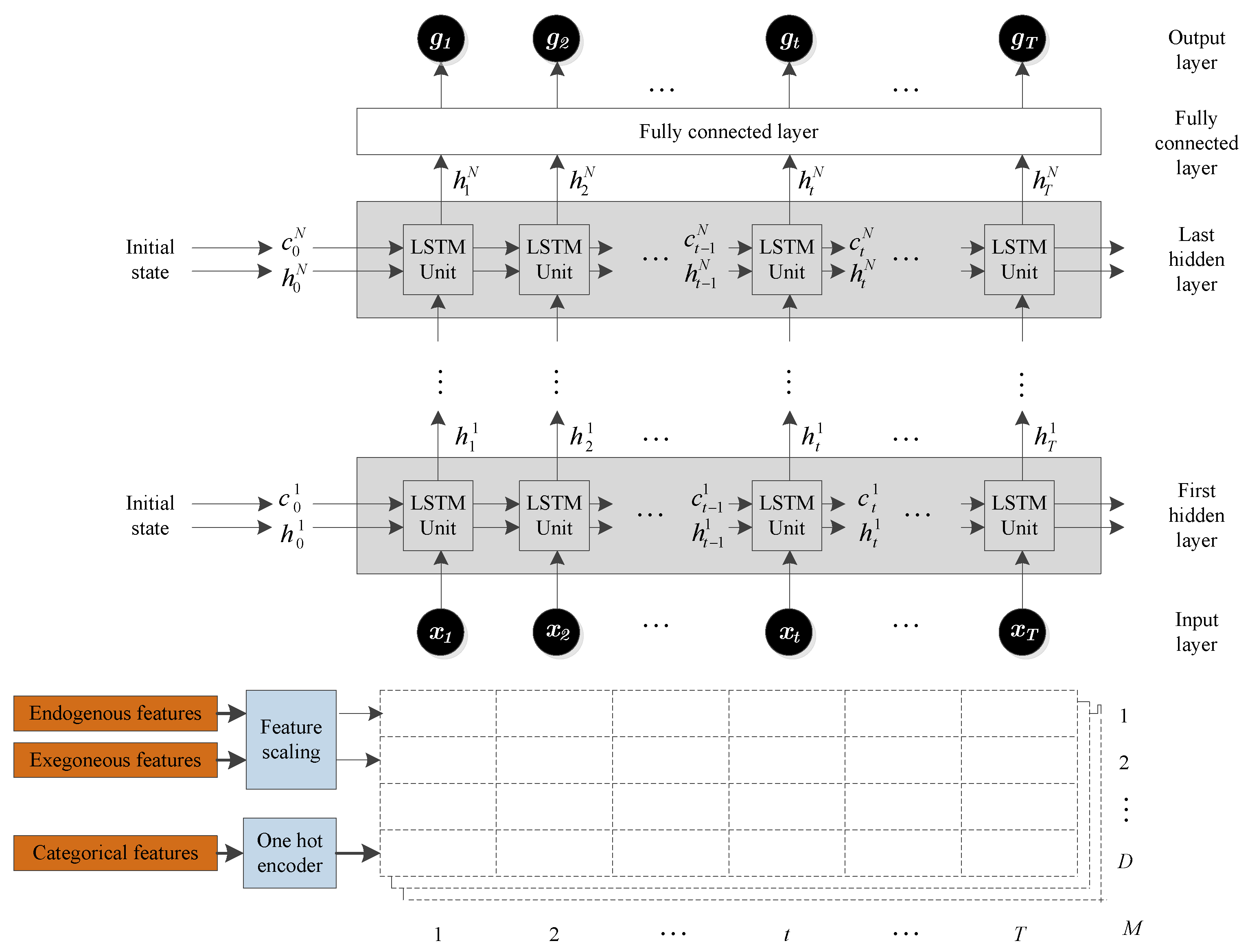
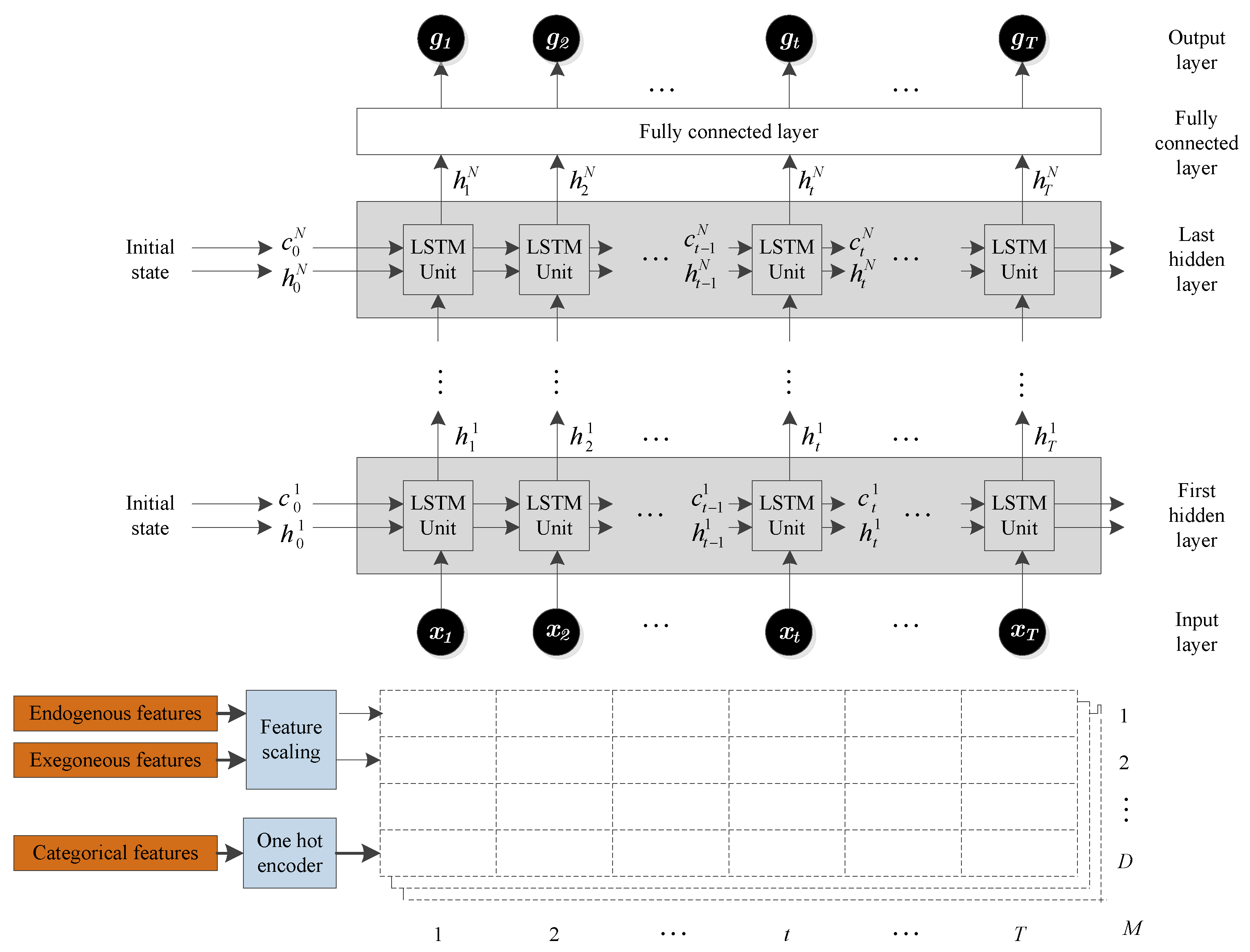
3.3. Implementation Details: Training the LSTM Model
We used the Matlab Deep Learning Toolbox [
87] to develop a forecasting framework used in this paper. The framework, shown in
Figure 5, consists of an input layer, LSTM hidden layers, a fully connected layer, and an output layer. The input layer inputs the time series data into the network. The hidden layers learn long-term dependencies between time steps in the time series data. To make a prediction, the network ends with a fully connected layer and an output layer.
Each dashed-box in
Figure 5 represents a training example that will be fed to the LSTM network. Note that
is the number of features (number of rows in the dashed-boxes),
is the number of time steps in the prediction horizon (number of columns in the dashed-boxes), and
is the number of training examples (total number of dashed-boxes). In summary, the input to the LSTM has three dimensions:
D,
T, and
M.
For our proposed model, there are three exogenous features (dry bulb temperature, dew point temperature, and relative humidity), and two additional categorical features (the hour of the day and the month of the year), bringing the total number of features, D, to five. For the NARX model, there are two additional endogenous features (the solar irradiance for the previous two days), bringing the number of features, D, to seven. The number of columns, T, is the length of the prediction horizon, which is 24 for day-ahead forecasting. Finally, the third dimension, M, is the total number of the training examples in the dataset. The total dimension of the entire training set is .
The first LSTM unit takes the initial state of the network and the first time step of the training example x1, and computes the first output h1 and the updated cell state c1. At time step t, the unit takes the current state of the network (ct−1, ht−1) and the next time step of the training example xt, and computes the output ht and the updated cell state ct. The final outputs are the day-ahead solar irradiance predictions, g1, … gT.
3.4. Hyperparameter Optimization
Achieving good performance with LSTM networks requires the optimization of many hyperparameters. These parameters affect the performance and time/memory cost of running the algorithm. The selection of hyperparameters often makes the difference between a mediocre and state-of-the-art performance for machine learning algorithms [
88]. Even though there are some rules of thumb in the research community about the suitable values of these hyperparameters [
89], optimization is necessary because the optimal values will depend on the type of data used in the comparisons, the particular data sets used, the performance criteria and various other factors. The hyperparameters that we optimized are tabulated in
Table 5. The learning rate is perhaps the most important hyperparameter [
60]. The number of hidden layers in the network is what gives the network its depth. To avoid over tuning the model, we optimized the hyperparameters using only Golden dataset and applied these same parameters to other datasets. We found the optimal number of hidden layers to be three. We tried
adam [
90],
rmsprop [
91], and
sgdm [
92] as optimization solvers, and found that
adam performed better than the other two. We found a standard scaler to be best in all the locations and used a full batch gradient descent. A deep neural network having a large number of parameters is prone to overfitting, so we applied dropout for regularization. Dropout [
93] works by randomly dropping units (with their connection) from the neural network during training.
The hyperparameters used for FFNN are 0.001 learning rate, 10 hidden units, 2 hidden layers, full-batch gradient descent, L2 regularization, standard scaler, and 1000 epochs. These are found to be good parameters in previous studies, and the results we obtained are comparable in accuracy with these previous studies. For this reason, we did not optimize the parameters of FFNN in this paper.



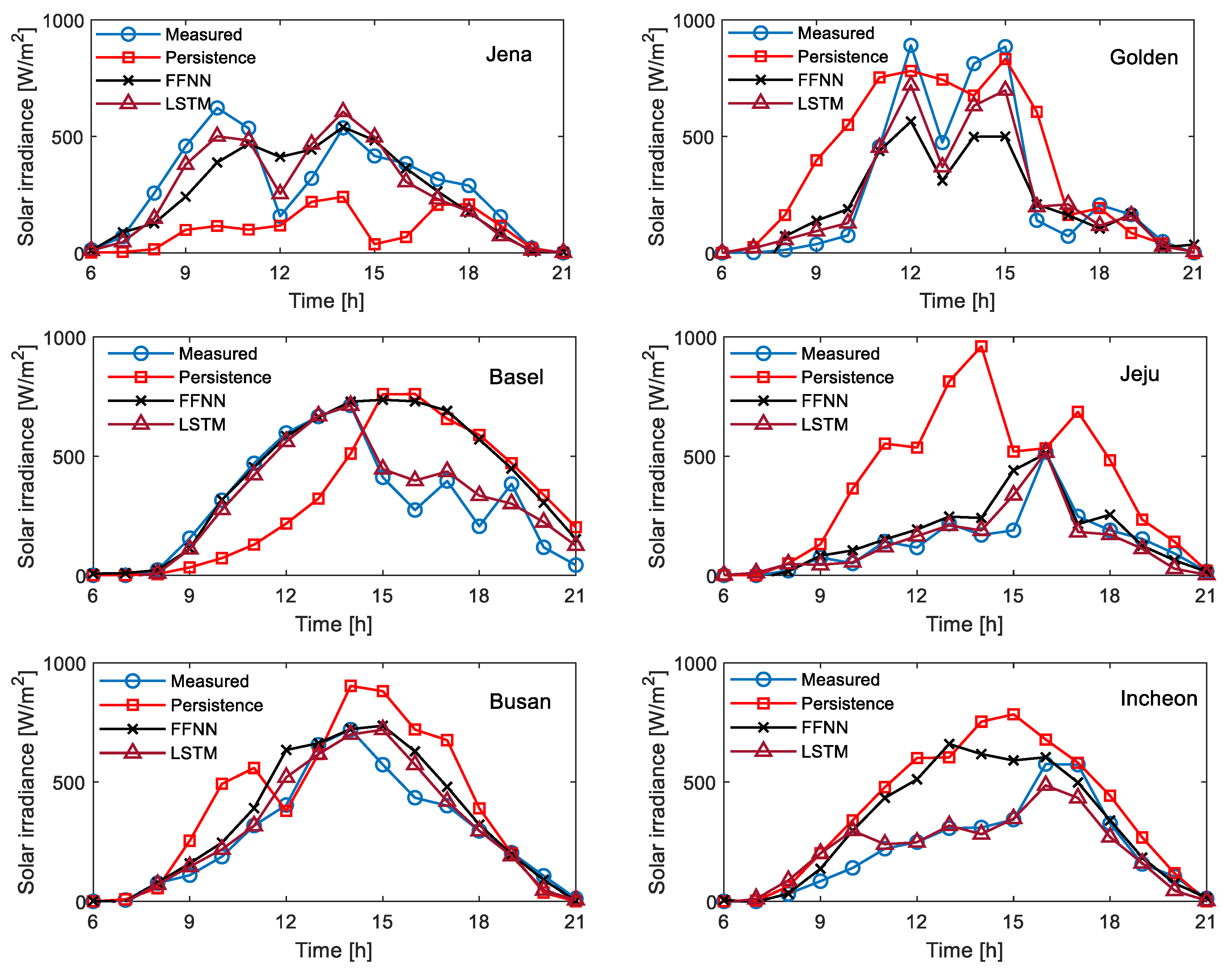
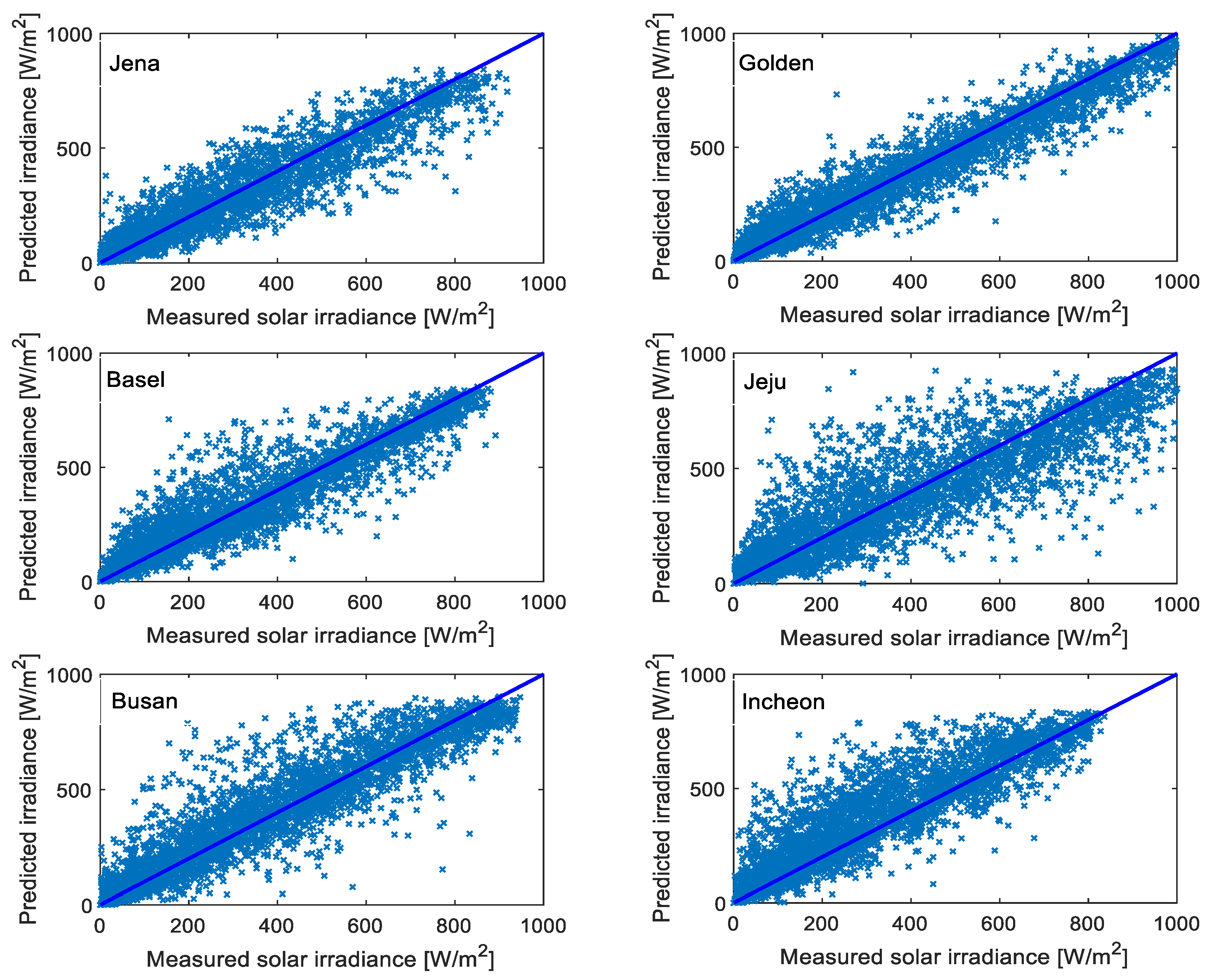
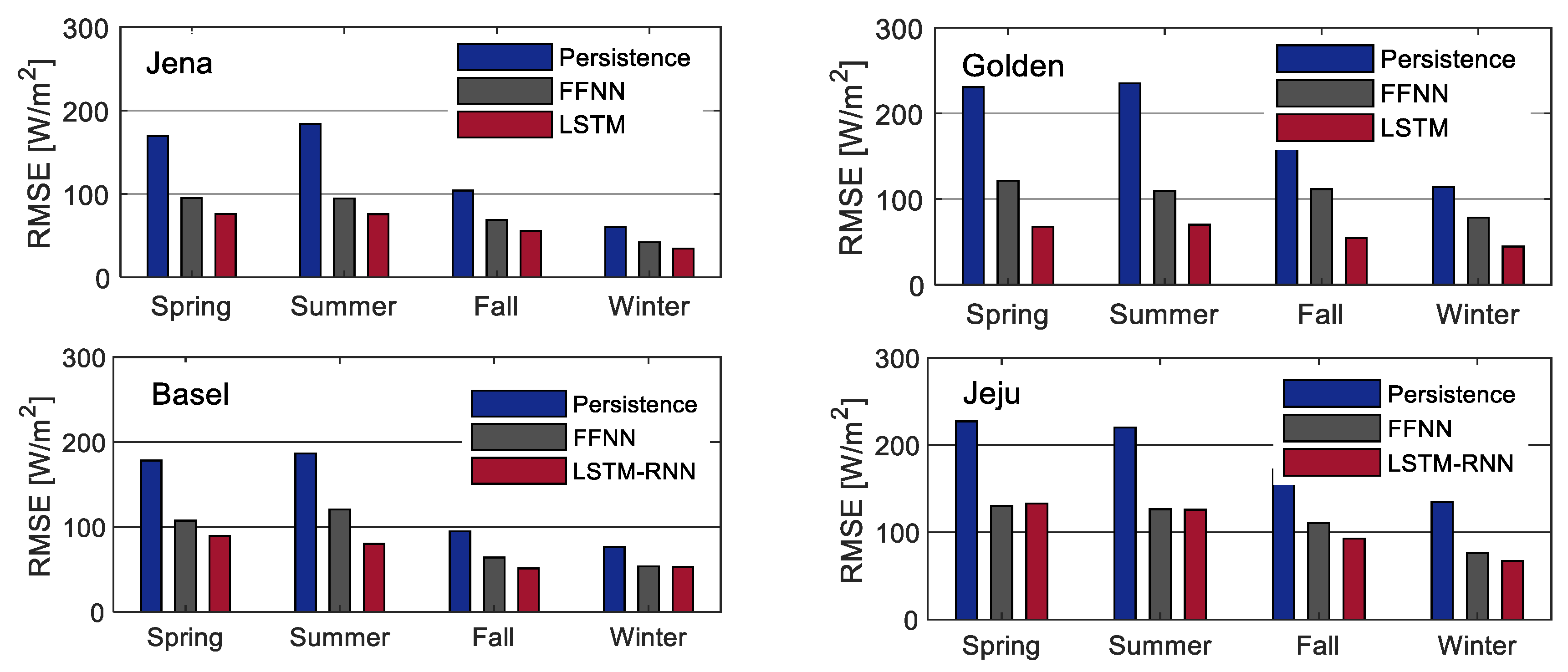
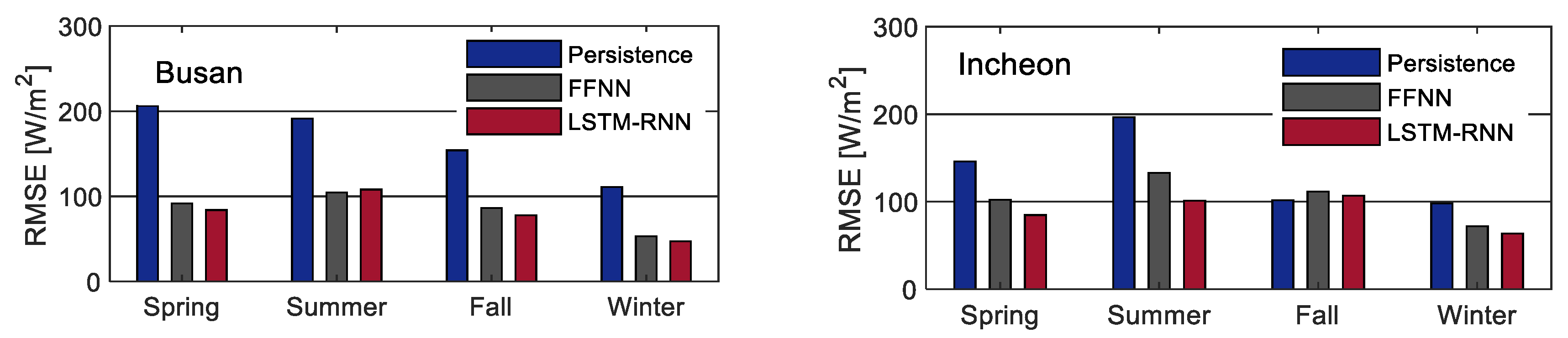

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}