PV System Performance Evaluation by Clustering Production Data to Normal and Non-Normal Operation



Abstract
1. Introduction
1.1. Importance of Reference Data in PV Monitoring
- The inliers, the measurements that fit the linear regression model and which will be used for the real performance evaluation of a PV system.
- The outliers, the measurements that do not fit the linear regression model and after further study could be used for the detection of any occurred malfunctions.
1.2. Performance Evaluation
1.2.1. Performance Ratio
1.2.2. Comparison of Neighboring PV Systems
1.3. Research Purpose and Paper Organization
- To detect and exclude any data input anomalies during the monitoring process, especially in case of residential PV systems where GTI is obtained by satellite observations and solar models.
- To detect and separate measurements where the PV system is functioning properly from the measurements that show that the PV system is malfunctioning or shaded. Measurements showing proper functioning can then be used for the performance analysis while the rest can be further studied for malfunction characterization.
2. Data Outliers in Performance Evaluation
2.1. Irradiance Data from Pyranometers
2.2. Irradiance Data from Other Sources
2.3. Neighboring PV Systems Used as Reference
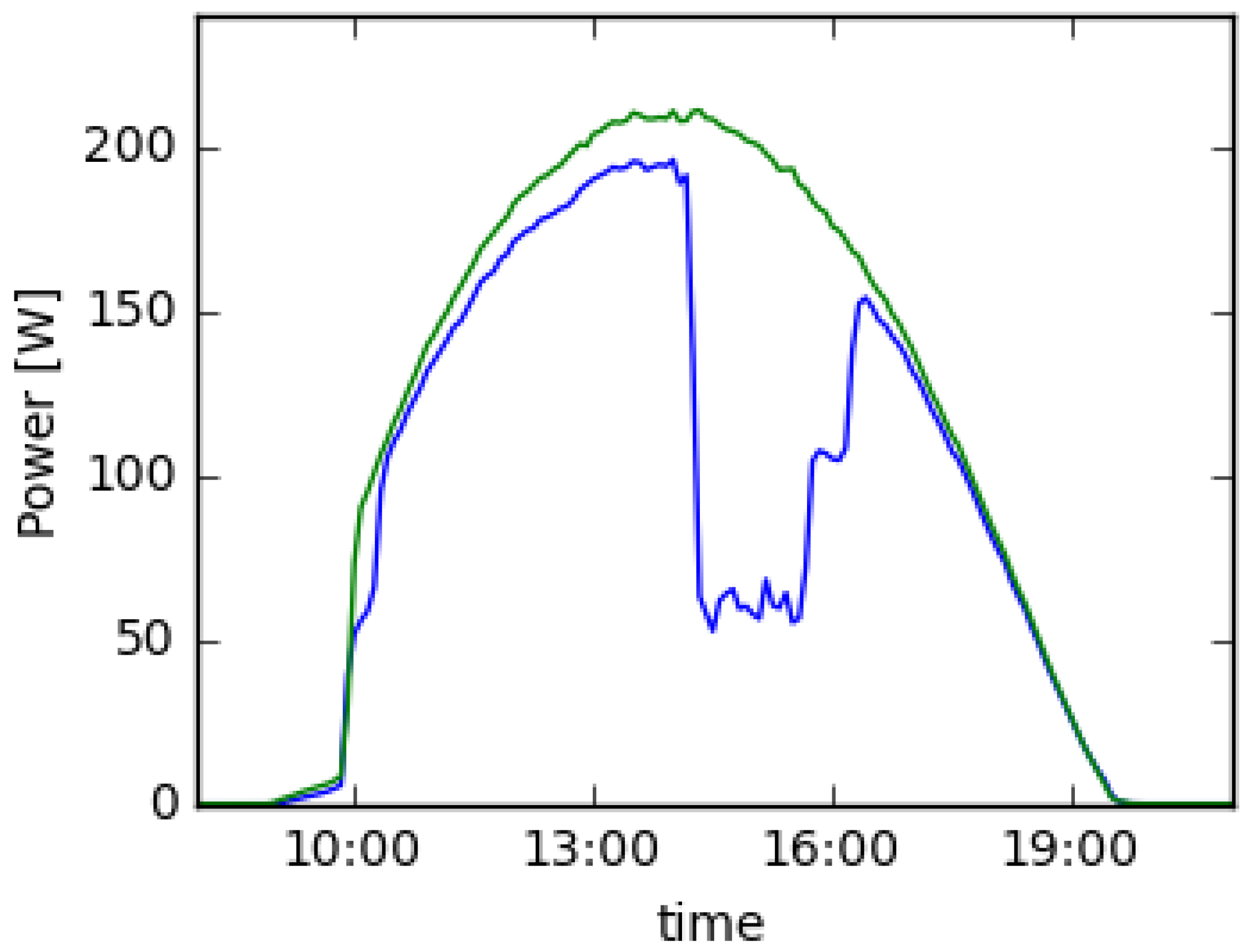
2.3.1. Shade in One of the Systems
2.3.2. Difference in Energy Production
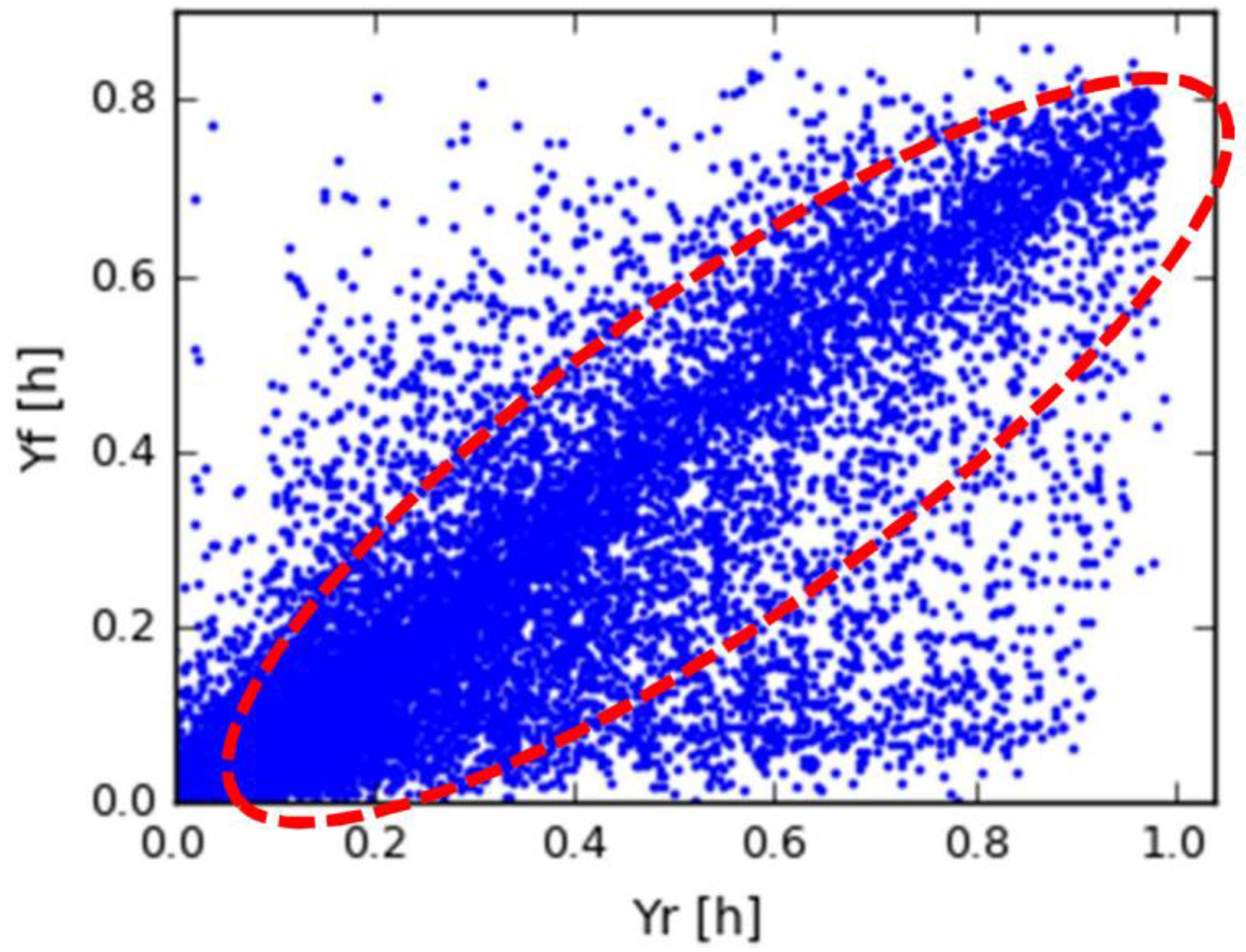
3. Methodology
3.1. Data Preparation
3.2. Scope of the Algorithm
3.3. Description of the Algorithm
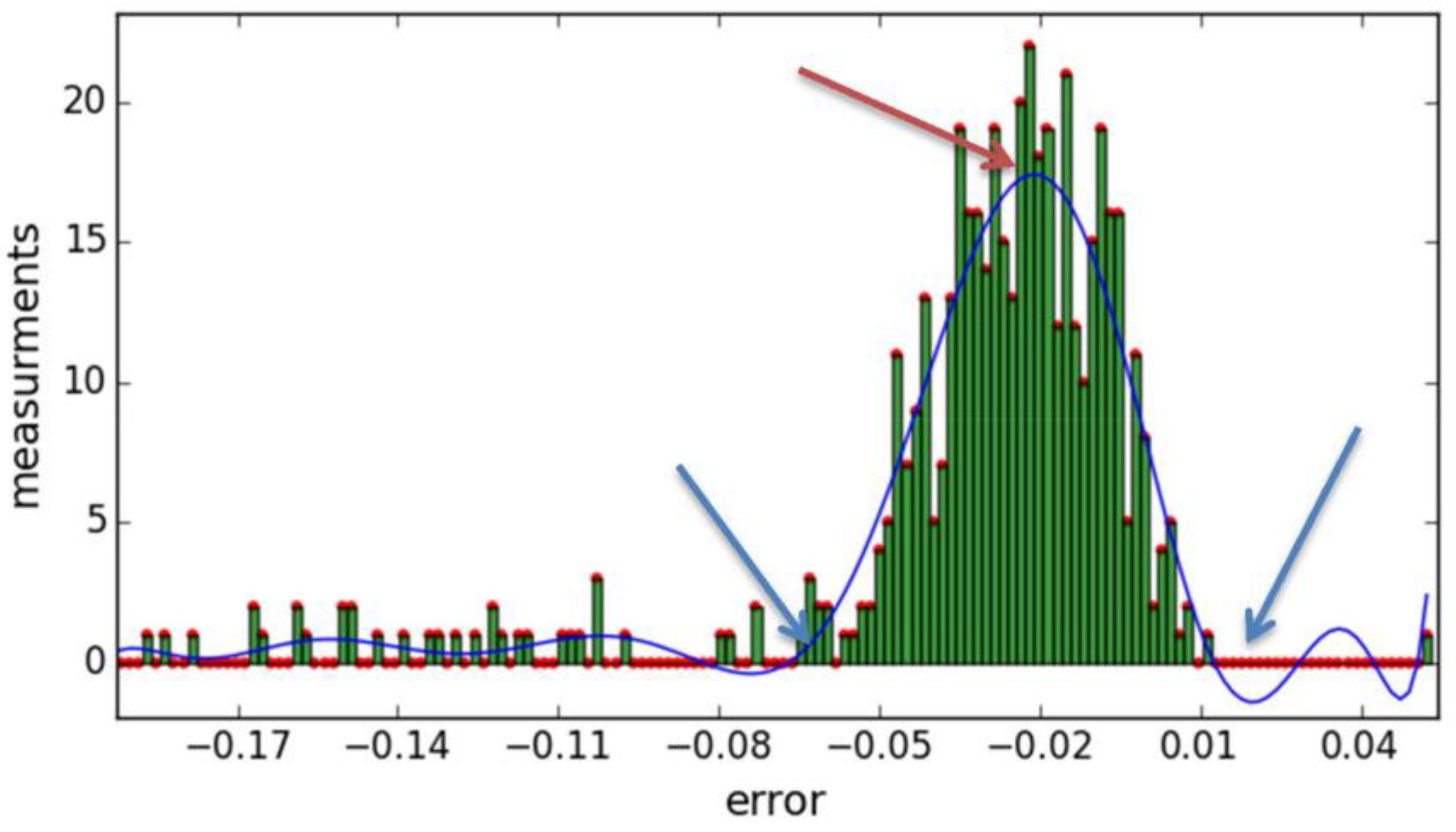
3.3.1. First Step—Inliers Determination Using Ran.Sa.C.
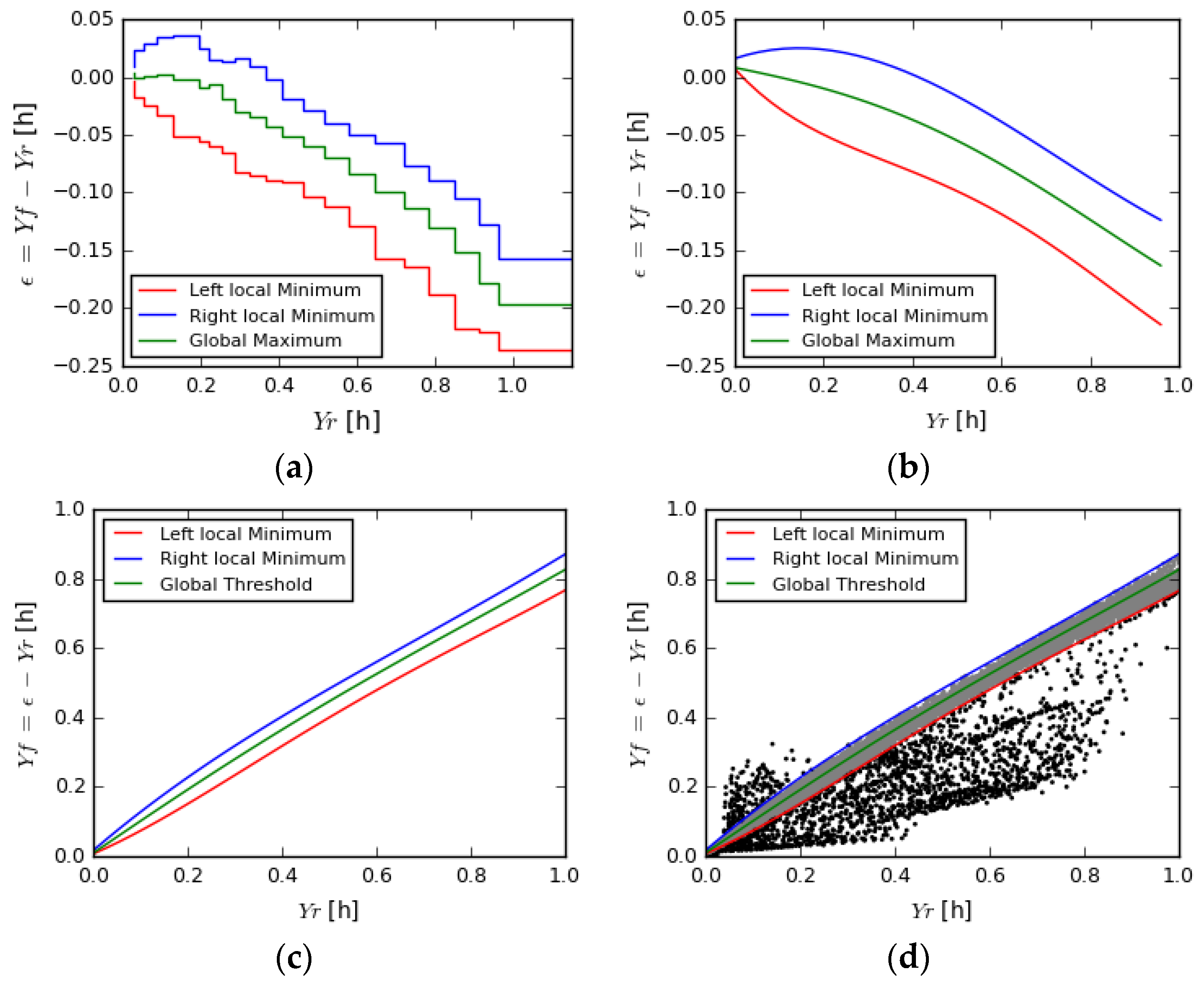
3.3.2. Second Step—Data Clustering and Polynomial Regression
3.3.3. Third Step—Determine the Thresholds of Each Group
3.3.4. Fourth Step—Normalization and Connection of All Limits
3.3.5. Fifth Step—Pplication of the Limits to the Data
3.4. Calculation of Energy Loss
- Error is equal to the higher frequent error (global maximums), thus the most probable value
- Error of outliers is slightly higher (105%) than the smaller threshold (εleft)
- Error is slightly lower (95%) than the higher threshold (εright)
4. Application of the Method—Examples
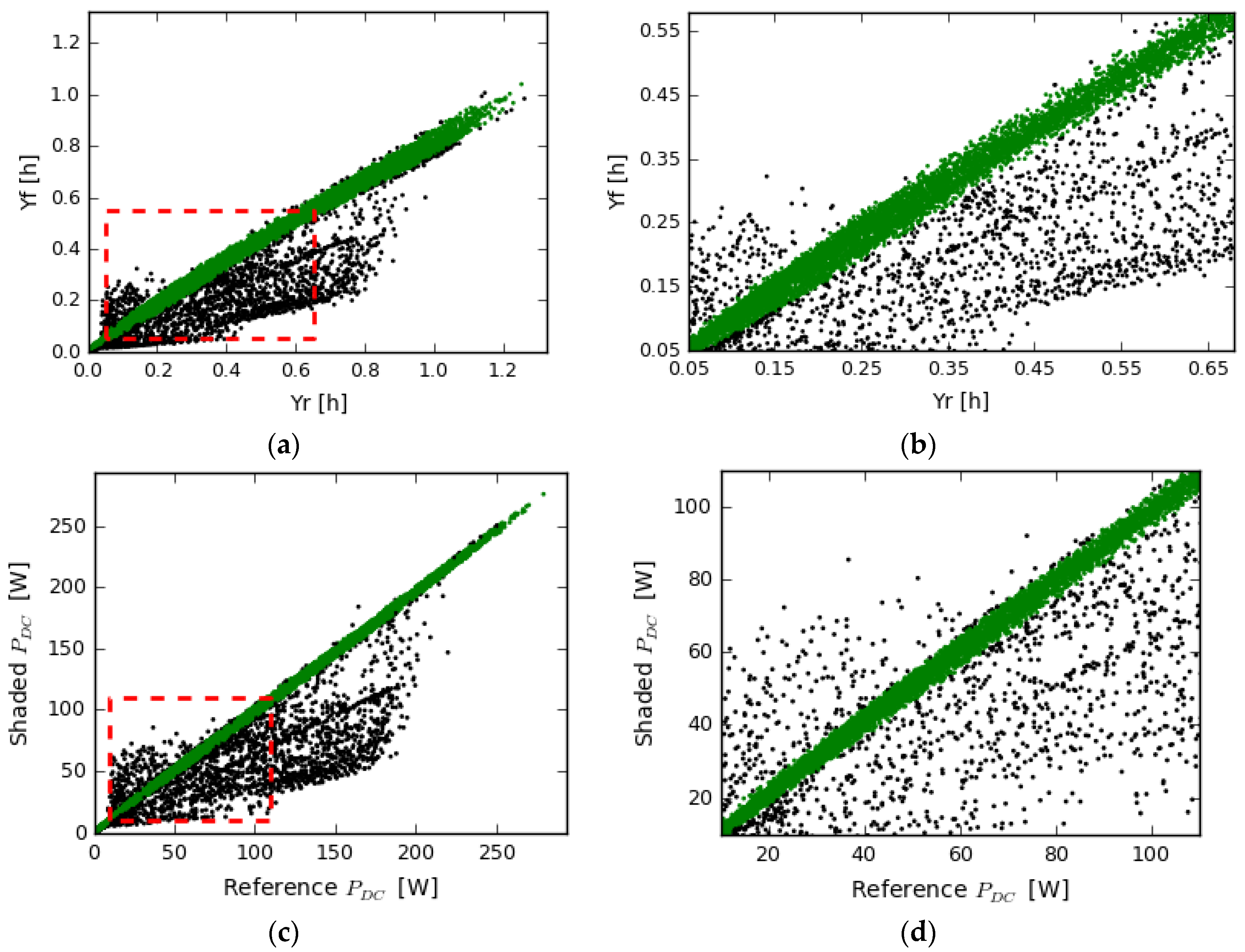
4.1. Shaded Panel with Power Optimizer
4.2. PV System with String Inverter
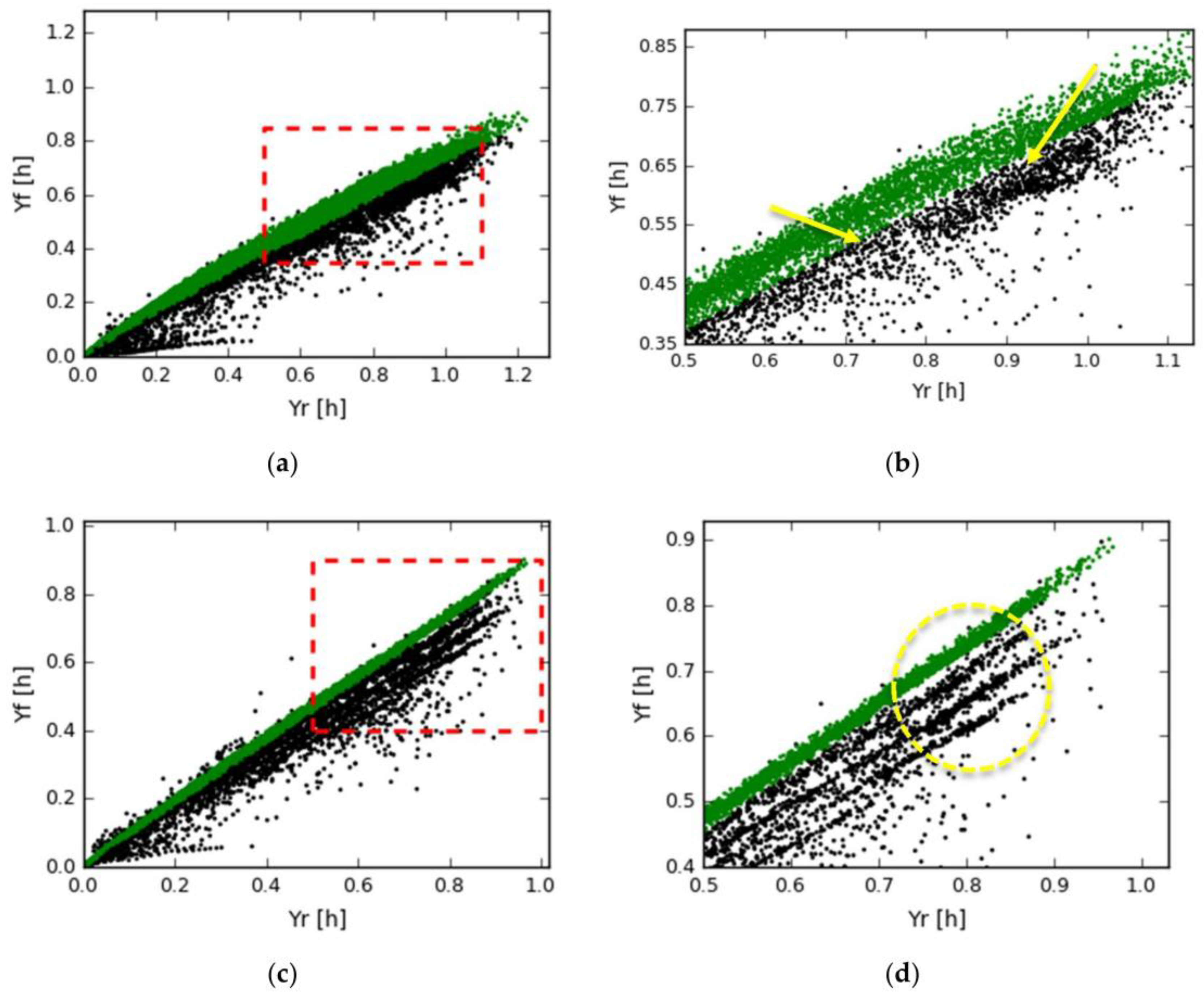
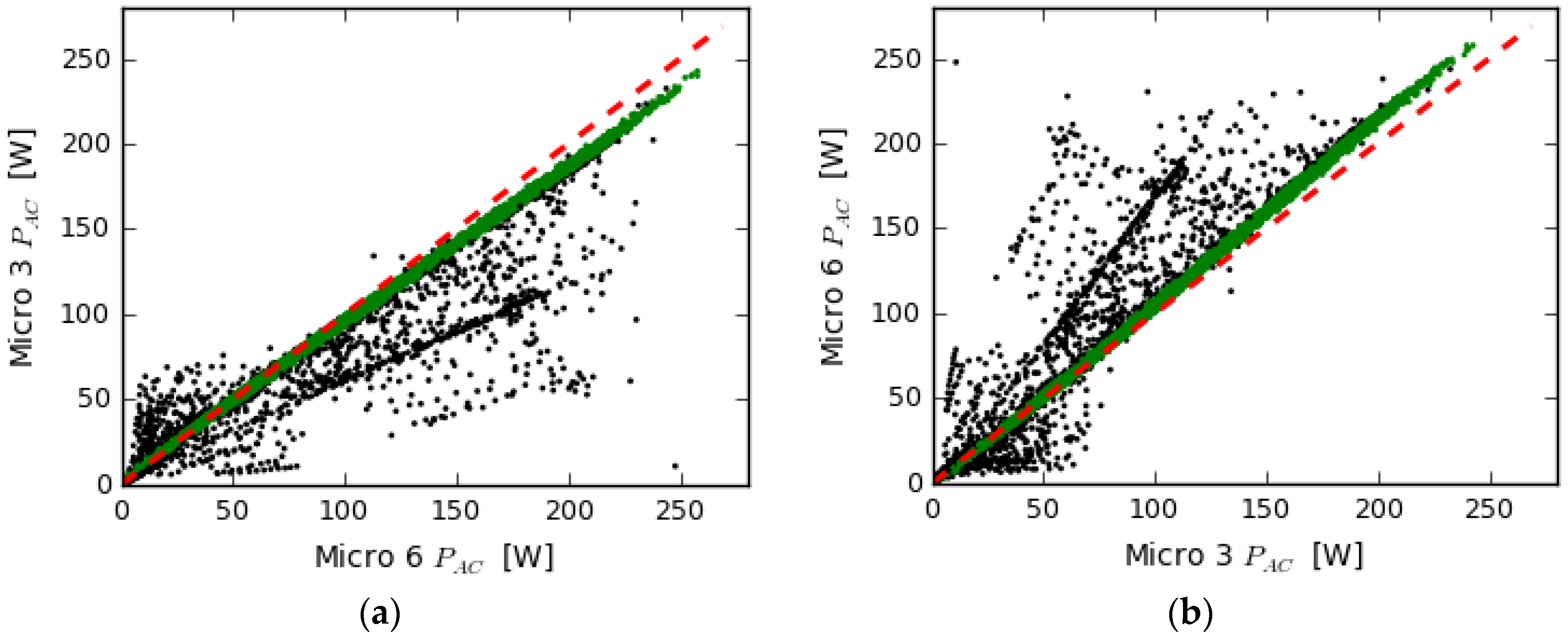
4.3. Systems with Same Capacity, Different Production and Different Shadows
- Energy loss of system 3 due to shadow
- Energy loss of system 6 due to shadow
- Energy loss of system 3 due to the older panel
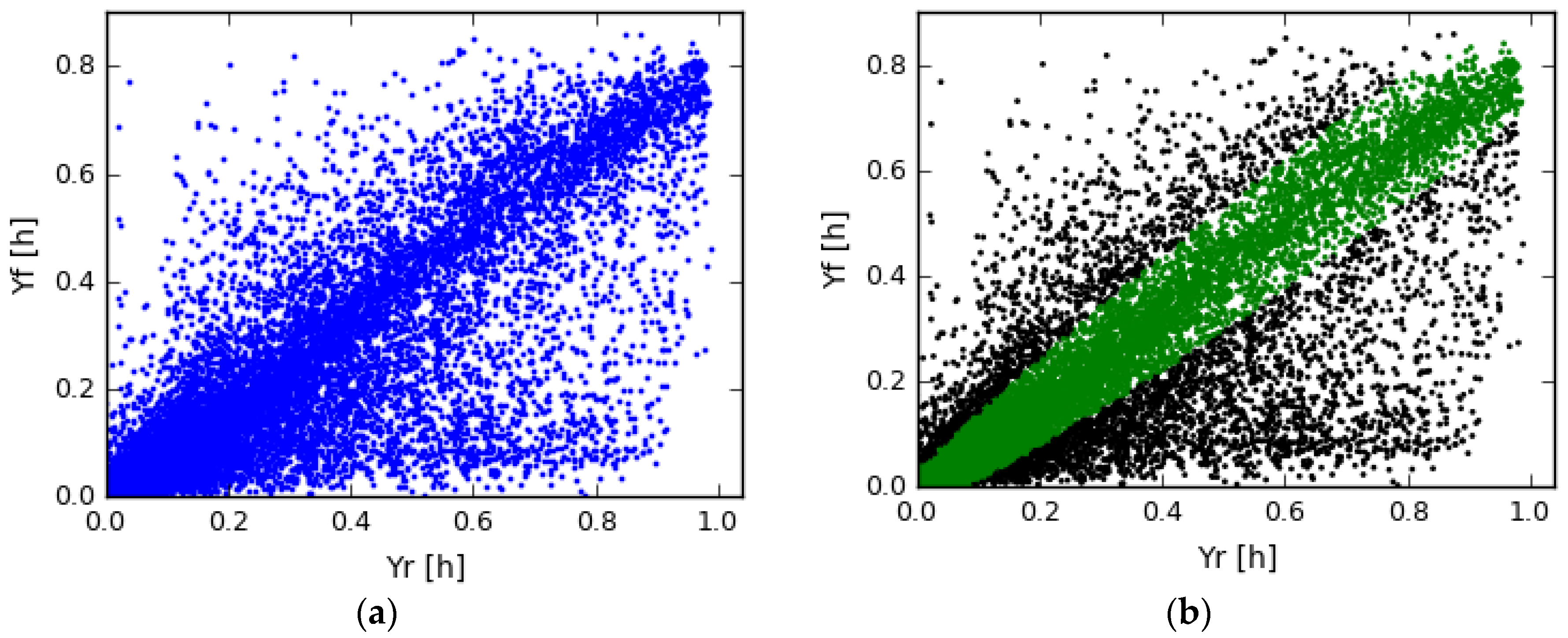
4.4. System of a Regular House in The Netherlands, Monitored with MeteoSat Data
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Centraal Bureau voor de Statistiek (CBS). Bijgeplaatst Vermogen Zonnestroom Bijgesteld. Available online: https://www.cbs.nl/nl-nl/achtergrond/2015/51/bijgeplaatst-vermogen-zonnestroom-bijgesteld (accessed on 17 December 2015).
- Reich, N.H.; Mueller, B.; Armbruster, A.; Van Sark, W.G.J.H.M.; Kiefer, K.; Reise, C. Performance ratio revisited: Is PR > 90% realistic ? Prog. Photovolt. 2012, 20, 717–726. [Google Scholar] [CrossRef]
- Silvestre, S.; Chouder, A.; Karatepe, E. Automatic fault detection in grid connected PV systems. Sol. Energy 2013, 94, 119–127. [Google Scholar] [CrossRef]
- Firth, S.K.; Lomas, K.J.; Rees, S.J. A simple model of PV system performance and its use in fault detection. Sol. Energy 2010, 84, 624–635. [Google Scholar] [CrossRef]
- Platon, R.; Martel, J.; Woodruff, N.; Chau, T.Y. Online Fault Detection in PV Systems. IEEE Trans. Sustain. Energy 2015, 6, 1200–1207. [Google Scholar] [CrossRef]
- Eke, R.; Senturk, A. Monitoring the performance of single and triple junction amorphous silicon modules in two building integrated photovoltaic (BIPV) installations. Appl. Energy 2013, 109, 154–162. [Google Scholar] [CrossRef]
- Woyte, A.; Richter, M.; Moser, D.; Green, M.; Mau, S.; Beyer, H.G. Analytical Monitoring of Grid-Connected Photovoltaic Systems; NET Ltd.: St. Ursen, Switzerland, 2014; Volume 13. [Google Scholar]
- Perez, R.; Seals, R.; Ineichen, P.; Stewart, R.; Menicucci, D. A new simplified version of the Perez diffuse irradiance model for tilted surfaces. Sol. Energy 1987, 39, 221–231. [Google Scholar] [CrossRef]
- Hay, J.E. Calculating solar radiation for inclined surfaces: Practical approaches. Renew. Energy 1993, 3, 373–380. [Google Scholar] [CrossRef]
- Davies, J.A.; McKay, D.C. Evaluation of selected models for estimating solar radiation on horizontal surfaces. Sol. Energy 1989, 43, 153–168. [Google Scholar] [CrossRef]
- Olmo, F.J.; Vida, J.; Foyo, I.; Castro-Diez, Y.; Alados-Arboledas, L. Prediction of global irradiance on inclined surfaces from horizontal global irradiance. Energy 1999, 24, 689–704. [Google Scholar] [CrossRef]
- Tsafarakis, O.; Moraitis, P.; Kausika, B.B.; Van Der Velde, H.; Hart’T, S.; de Vries, A.; de Rijk, P.; De Jong, M.M.; Van Leeuwen, H.P.; van Sark, W. Three years experience in a Dutch public awareness campaign on photovoltaic system performance. IET Renew. Power Gener. 2017, 11, 1229–1233. [Google Scholar] [CrossRef]
- Leloux, J.; Narvarte, L.; Pereira, A.D.; Leader, W.P.; Madrid, R.; SENES, C.; de Navarra, P. Analysis of the State of the Art of PV Systems in Europe; Universidad Politécnica de Madrid: Madrid, Spain, 2015. [Google Scholar]
- Taylor, J.; Leloux, J.; Everard, A.M.; Briggs, J.; Buckley, A.; Solar, S.; Building, H.; Road, H.; Sheffield, S. Monitoring Thousands of Distributed PV Systems in the UK: Energy Production and Performance; Universidad Politécnica de Madrid: Madrid, Spain, 2011. [Google Scholar]
- Leloux, J.; Narvarte, L.; Trebosc, D. Review of the performance of residential PV systems in France. Renew. Sustain. Energy Rev. 2012, 16, 1369–1376. [Google Scholar] [CrossRef]
- Leloux, J.; Narvarte, L.; Trebosc, D. Review of the performance of residential PV systems in Belgium. Renew. Sustain. Energy Rev. 2012, 16, 178–184. [Google Scholar] [CrossRef]
- Leloux, J.; Taylor, J.; Moretón Villagrá, R.; Narvarte Fernández, L.; Trebosc, D.; Desportes, A. Monitoring 30,000 PV Systems in Europe: Performance, Faults, and State of the Art. In Proceedings of the 31st European PV Solar Energy Conference and Exhibition, Hamburg, Germany, 14–18 September 2015; Volume 153, pp. 1574–1582. [Google Scholar]
- Mallor, F.; León, T.; de Boeck, L.; van Gulck, S.; Meulders, M.; Van Der Meerssche, B. A method for detecting malfunctions in PV solar panels based on electricity production monitoring. In Proceedings of the 31st European PV Solar Energy Conference and Exhibition, Hamburg, Germany, 14–18 September 2015; Volume 153, pp. 51–63. [Google Scholar]
- IEC 61724. Photovoltaic System Performance Monitoring—Guidelines for Measurement, Data Exchange and Analysis, 10th ed.; International Electrotechnical Commission: Geneva, Switzerland, 1998. [Google Scholar]
- Van Sark, W.; Hart, S.; de Jong, M.; de Rijk, P.; Moraitis, P.; Kausika, B.B.; van der Velde, H. “Counting the Sun”—A Dutch Public Awareness Campaign on Pv Performance. In Proceedings of the 29th European Photovoltaic Solar Energy Conference and Exhibition, Amsterdam, The Netherlands, 22–26 September 2014; Volume 2014, pp. 3545–3548. [Google Scholar]
- Tsafarakis, O.; van Sark, W.G.J.H.M. Development of a data analysis methodology to assess PV system performance. In Proceedings of the 29th European Photovoltaic Solar Energy Conference, Amsterdam, The Netherlands, 22–26 September 2014; pp. 2908–2910. [Google Scholar]
- Sinapis, K.; Tzikas, C.; Litjens, G.; Van Den Donker, M.; Folkerts, W.; Van Sark, W.G.J.H.M.; Smets, A. A comprehensive study on partial shading response of c-Si modules and yield modeling of string inverter and module level power electronics. Sol. Energy 2016, 135, 731–741. [Google Scholar] [CrossRef]
- Alam, M.; Johnson, J. PV faults: Overview, modeling, prevention and detection techniques. In Proceedings of the 2013 IEEE 14th Workshop on Control and Modeling for Power Electronics (COMPEL), Salt Lake City, UT, USA, 23–26 June 2013; pp. 2–9. [Google Scholar]
- Alam, M.K.; Khan, F.; Member, S.; Johnson, J.; Flicker, J. A Comprehensive Review of Catastrophic Faults in PV Arrays: Types, Detection, and Mitigation Techniques. IEEE J. Photovolt. 2015, 5, 982–997. [Google Scholar] [CrossRef]
- Eumetsat. Meteosat Second Generation (MSG) Provides Images of the Full Earth Disc, and Data for Weather Forecasts. Available online: https://www.eumetsat.int/website/home/Satellites/CurrentSatellites/Meteosat/index.html (accessed on 16 April 2018).
- Cucumo, M.; De Rosa, A.; Ferraro, V.; Kaliakatsos, D.; Marinelli, V. Experimental testing of models for the estimation of hourly solar radiation on vertical surfaces at Arcavacata di Rende. Sol. Energy 2007, 81, 692–695. [Google Scholar] [CrossRef]
- Gueymard, C.A. Direct and indirect uncertainties in the prediction of tilted irradiance for solar engineering applications. Sol. Energy 2009, 83, 432–444. [Google Scholar] [CrossRef]
- Yang, D.; Dong, Z.; Nobre, A.; Khoo, Y.S.; Jirutitijaroen, P.; Walsh, W.M. Evaluation of transposition and decomposition models for converting global solar irradiance from tilted surface to horizontal in tropical regions. Sol. Energy 2013, 97, 369–387. [Google Scholar] [CrossRef]
- Ineichen, P.; Perez, R.R.; Seal, R.D.; Maxwell, E.L.; Zalenka, A. Dynamic global-to-direct irradiance conversion models. ASHRAE Trans. 1992, 98, 354–369. [Google Scholar]
- Maxwell, E.L. A Quasi-Physical Model for Converting Hourly Global Horizontal to Direct Normal Insolation; Solar Energy Research Institute: Golden, CO, USA, 1987. [Google Scholar]
- Erbs, D.G.; Klein, S.A.; Duffle, J.A. Estimation of the diffuse radiation fraction for hourly, daily and monthly-average global radiation. Sol. Energy 1982, 28, 293–302. [Google Scholar] [CrossRef]
- Aler, R.; Galván, I.M.; Ruiz-arias, J.A.; Gueymard, C.A. Improving the separation of direct and diffuse solar radiation components using machine learning by gradient boosting. Sol. Energy 2017, 150, 558–569. [Google Scholar] [CrossRef]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applicatlons to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Sinapis, K.; Litjens, G.; Van Den Donker, M.; Folkerts, W.; Van Sark, W. Outdoor characterization and comparison of string and MLPE under clear and partially shaded conditions. Energy Sci. Eng. 2015, 15, 510–519. [Google Scholar] [CrossRef]
- Akram, M.N.; Lotfifard, S. Modeling and Health Monitoring of DC Side of Photovoltaic Array. IEEE Trans. Sustain. Energy 2015, 6, 1245–1253. [Google Scholar] [CrossRef]
- Chohfi, R.E. Calibration and Installation of a Pyranometer; Department of Geography, University of California: Los Angeles, CA, USA, 2017. [Google Scholar]
- Clive, L. Kipp & Zonen Pyranometer & Pyrheliometer Calibration Frequency. Kipp & Zonen Website. Available online: http://www.kippzonen.com/Download/553/Kipp-Zonen-Pyranometer-Pyrheliometer-Calibration-Frequency?ShowInfo=true (accessed on 16 April 2018).
- Gengenbach, M. What Is the Calibration Frequency of a Pyranometer? Gengenbach Messtechnik Website. Available online: http://www.rg-messtechnik.de/faq-pyranometer.php (accessed on 16 April 2018).
- Costanzo, V.; Yao, R.; Essah, E.; Shao, L.; Shahrestani, M.; Oliveira, A.C.; Araz, M.; Hepbasli, A.; Biyik, E. A method of strategic evaluation of energy performance of Building Integrated Photovoltaic in the urban context. J. Clean. Prod. 2018, 184, 82–91. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference Data | Reason of Outliers (Shorted by the Most Frequent) |
|---|---|
| Direct measured GTI (Pyranometer, ref. cell) |
|
| Indirect measured GTI (Satellite/local weather stations + solar models) |
|
| Neighbouring PV systems |
|
| Reference Data | GTI | Neighboring PV System | ||
|---|---|---|---|---|
| Data | Same Capacity | Different Capacity | ||
| Studied PV | Yf | Pstudied (DC or AC) | Yf,studied | |
| Reference data | YR | Pref (DC or AC) | Yf,ref | |
| Reference Data | Error | ||
|---|---|---|---|
| Left | Most Frequent | Right | |
| Pyranometer | 4.9% | 6.7% | 8.1% |
| Neighboring PV | 5.4% | 6.1% | 6.8% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsafarakis, O.; Sinapis, K.; Van Sark, W.G.J.H.M. PV System Performance Evaluation by Clustering Production Data to Normal and Non-Normal Operation. Energies 2018, 11, 977. https://doi.org/10.3390/en11040977
Tsafarakis O, Sinapis K, Van Sark WGJHM. PV System Performance Evaluation by Clustering Production Data to Normal and Non-Normal Operation. Energies. 2018; 11(4):977. https://doi.org/10.3390/en11040977
Chicago/Turabian StyleTsafarakis, Odysseas, Kostas Sinapis, and Wilfried G. J. H. M. Van Sark. 2018. "PV System Performance Evaluation by Clustering Production Data to Normal and Non-Normal Operation" Energies 11, no. 4: 977. https://doi.org/10.3390/en11040977
APA StyleTsafarakis, O., Sinapis, K., & Van Sark, W. G. J. H. M. (2018). PV System Performance Evaluation by Clustering Production Data to Normal and Non-Normal Operation. Energies, 11(4), 977. https://doi.org/10.3390/en11040977