1. Introduction
Nowadays, dependence on fossil fuels have caused an environmental crisis and a high production volume of pollutants [
1,
2]. Recently, the benefits of biofuels and comprehensive research in the field of converting renewable resources into the biofuels [
3,
4] have attracted much attention regarding the possibility of producing and using renewable fuels [
5] such as biodiesel [
6].
Waste oils, edible and nonedible oils, and animal fats are common feed-stocks to produce biodiesel [
7,
8,
9]. The biodiesel is produced from a reaction between a short chain alcohol and oils through a transesterification process in the presence of an acidic or alkaline catalyst [
10,
11].
The numerous advantages of biodiesel as an alternative fuel has led many researchers to produce, evaluate, and use this fuel recently. Xue et al. [
12] produced biodiesel from soybean and Jatropha oils using a magnetic catalyst. Ma et al. [
13] produced biodiesel from unrefined methanol during a transesterification process. Román-Figueroa et al. [
14] produced biodiesel from crude castor oil (
Ricinus communis) during a non-catalytic supercritical methanol transesterification process. Raia et al. [
15] produced biodiesel from
Jatropha curcas L. oil during simultaneous esterification and transesterification mechanisms using sulfated zirconia. They found that the esterification mechanism is faster than transesterification in the beginning reaction. Ali et al. [
16] produced biodiesel from waste cooking oil (WCO) using purified lipase of
Pseudomonas aeruginosa. They reached a maximum biodiesel yield of 86% by optimizing the reaction conditions. Carvalho et al. [
17], produced biodiesel from
Mucor circinelloides in the presence of ethanol and impregnated heteropoly acid on alumina as a catalyst during one and two-step transesterification mechanisms.
The production of a desired product needs an effective use of an experimental model [
18]. There are several modeling methods and the simplest method of modeling is a mathematical approach (or sometimes is remembered as a classic model) [
19]. Modeling methods contain a wide range of methods from mathematical to soft computing methods, but modeling an ill-defined system, such as a biodiesel production process, becomes even more pronounced using mathematical and statistical techniques due to the complexity and the biological nature of biodiesel [
20,
21].
Soft computing methods are able to do complex modeling tasks without the need for relations governing the system. Adaptive neuro-fuzzy inference system (ANFIS) and artificial neural networks (ANNs) are different types of soft computing methods. Neural networks are widely applied on biodiesel production by various researchers. Recently models developed with the basis of soft computing methods have been used for the study and prediction of processes. Many of them originated from ANN models. The mentioned models have a high performance and accuracy. The arrival of these models to studies related to the production and the use of biodiesel will improve efficiency.
Sharon et al. [
22] studied trained ANN in a SIMULINK model for biodiesel production and the prediction of a diesel engine performance. They studied the effect of NaOH on transesterification of fried oils. Fahmi and Cremaschi [
23] developed ANN as alternative models to replace the real operation, thermodynamics, and complex models. They found that the ANN method reduces the computation cost. Moradi et al. [
24] studied transesterification of soybean oil to biodiesel using KOH in different conditions. They applied ANN to estimate the biodiesel yield. Chakraborty and Sahu [
25] evaluated the biodiesel production from waste goat tallow using a response surface method (RSM) and ANN. Farobie et al. [
26] employed an
ANN method to model the biodiesel production process in the presence of methanol and ethanol. Maran and Priya [
27] applied ANN and RSM methods to predict the biodiesel production process from
Azadirachta indica oil during an ultrasound-assisted intensification process. They reported ANN has better performance compared to RSM for predicting biodiesel production in the mentioned process. Maran and Priya [
28] in another study employed RSM and ANN methods for modeling biodiesel production from muskmelon oil using an ultrasound-assisted reactor. The prediction ability of the ANN model was much better than RSM. Betiku et al. [
29] developed ANN with a genetic algorithm (GA) and RSM models to model and optimize the transesterification step from the production of biodiesel from shea oil. Sarve et al. [
30] applied RSM and ANN methods in a comparative study to produce biodiesel from
Sesamum indicum L. oil in the presence of barium hydroxide as a catalyst for the reaction. Based on the results, ANN showed better prediction capability than RSM.
In a study by Aghbashlo et al. [
31], the ELM method with wavelet transform (WT) algorithm was applied to predict the performance of diesel engine running on diesel/biodiesel blends from the viewpoint of exergetic theory. They compared the performance of ELM-WT, ELM, genetic programming (GP), and ANN models for the exergetic modeling of the engine.
Nowadays, using hybrid methods has become popular in modeling and estimating studies. These methods combine more than one classifier, estimator, or uses one for estimating and the other for optimizing. This helps to improve the current system performance and accuracy to get better results in the biodiesel production process or to optimize the production process. Based on the developed studies, the hybrid approach performs better than the single approach. Srivastava et al. [
32] employed a hybrid optimization method using RSM, ANN, and GA to optimize the biodiesel production during supercritical methanol transesterification. Saeidi et al. [
33] used a modified data envelopment analysis (MDEA), as a hybrid of data envelopment analysis (DEA) with ANN to design a multi-response problem, which was validated by RSM to optimize the biodiesel production from waste cooking palm oil. Sajjadi et al. [
34] used ANFIS-PSO, ANFIS-GA and ANFIS-DE methods to estimate the effect of ultrasound and mechanically stirring systems on biodiesel synthesis in the transesterification process.
The present study follows from our previous study in reference [
35]. The main point of the present study is to the use ELM and SVR methods to estimate the yield of methyl and ethyl esters through a trans-esterification process from WCO based on American Society for Testing and Materials (ASTM) standards and link them with an RSM to optimize the process (as a hybrid ELM-RSM and ELM-SVR) to provide a novel hybrid approach. To our best knowledge, this is the first report on biodiesel production with these approaches. The results of this study can help achieve efficient production and develop automatic devices and processes for the production of biodiesel. In reference [
35], the main platform of modeling was to employ the single ANN method, RSM, and hybrid ANFIS methods to estimate the yield and cost of biodiesel production. The present study completes the previous study by developing hybrid ELM-RSM and ELM-SVR methods that enable us to focus on both prediction and optimization of the complex production system (biodiesel production system).
3. Extreme Learning Machine
Extreme learning machines (
ELMs) have become an interesting topic for research in recent years. These methods were first introduced by Huang et al. [
42]. The
ELM model operates on generalized single-hidden-layer feed-forward networks (
SLFNs) based on structural risk minimization principles. In the
ELM, the hidden layer does not need to be set and the functions of this layer, which is a feature transfer to the new space, are already specified. Support vector machine (
SVM), radial basis function (
RBF), and single layer feed forward models are special cases of this model.
Figure 2 presents the architecture of the
ELM model [
43].
In this case, the researchers have focused on several main goals:
- (1)
The
ELM model can provide an integrated template for a variety of types of broad features that can be used in a hidden layer, which can be directly used in multi-part and regression categorizations [
31].
- (2)
From the viewpoint of optimizing, ELM contains more restrictive constraints than PSVM and LS-SVM.
- (3)
SVM and LS-SVM models have more computational complexity than ELM.
- (4)
Theoretically, the
ELM model can estimate each integer target function and classify each distinct region. Practical results show that this model has better scalability, for regression and two-class categorization, it has similar generalizability, and for multi-class categorization, it has better generalizable and a much higher computation rate than the conventional
SVM and
LS-SVM methods [
43].
ELM uses the same kernel as SVM, such as the linear kernel and the RBF kernel.
Linear kernel (core function): k (xi, xj) = xi.xj;
RBF kernel (core function): .
Recent research showed that proximal support vector machine (PSVM), least square support vector machine (LS-SVM), and regularization algorithms can be further simplified and placed in an integrated format called ELM.
This model aims to provide an integrated model that incorporates all of the above-mentioned methods not initially referred to as
ELMs. The
ELM model was originally proposed for
SLFNs and then was extended to the generalized
SLFNs. For
L samples (
xi, ti) [
xi = [
xi1, xi2, …, xin]
TϵRn and
ti = [
ti1, ti2, …, tin]Tϵ
Rm], Equation (1) estimates the
SLFNs with
k hidden nodes and
h(
x) activation function.
wi presents the weight vector between input and hidden nodes;
βi presents the weight vector between output and hidden nodes;
bi presents the threshold of the ith hidden node.
Unlike the usual learning methods, the
ELM not only tries to minimize the error of the training data, it also tries to minimize the norm of the weights of the output [
44]. According to the Barlet theory for
SLFNs, a soft weight loss along with the reduction of the training error is better for generalizability [
45]. Therefore, the
ELM target function that attempts to reduce the training error and the weights norm of the output is as Equation (2):
where:
• H is the hidden layer output matrix on the neural network.
The output weights can be calculated using the following equation:
• is the inverse of the hidden layer output matrix H.
More details about the
ELM are available in references [
42,
43]. The user-defined function was obtained using a trial and error method. The parameters of this function are given in
Table 2.
4. Support Vector Machine
SVM is considered to be a soft computing method, which
i based on statistical learning theory with a wide application in many fields of science for classification and regression problems [
46,
47]. One of the advantages of this method is that the
SVM reduces the generalized upper bound error rather than the local training error which makes it more particular compared to other machine learning methods.
For
xi input data and
yi target data with data size of
n (
), Equations (7) and (8) give the
SVM estimation:
is defined as the high dimensional space feature that mapped the input space vector x;
w is defined as the normal vector;
is defined as the empirical error.
The parameters
w and
b can be calculated by minimizing the
RSVMs for a regular couple of
.
C is defined as positive regularization parameter for minimizing the empirical error;
are the penalties of the training error by the loss function;
ε is the chosen error tolerance.
In natural processes, the predictor variables (from the input space) and objective variables (from output space) have a nonlinear relation. Mapping the input space onto the feature space using a kernel function can solve this limitation. Lagrange multipliers solve Equation (10). Any function satisfying the Mercer condition qualifies as a kernel function. The generalization ability is affected by the kernel function. Linear, sigmoid, polynomial, and
RBFs are four basic kernel functions. Among these four, the
RBF is the simplest, and most efficient and adaptive function. The RBF kernel function is as follows:
The accuracy and performance of the RBF kernel function depends on γ, C, and ε. In the present study, these parameters are determined during a trial and error method as 0.35, 1000 and 0.05 respectively for γ, C, and ε.
6. Results
Data were collected during a transesterification process for producing ethyl and methyl esters (
Table 1). The study used temperature (°C), time (min),
A/
O, catalyst (wt. %), mixing intensity (rev/min), and ethyl and methyl esters yields (%).
Based on
Table 1, the results of the experimental approach show that the high production yield for ethyl and methyl esters were 93.5% and 95.5%, respectively, which was accrued at a temperature of 70 °C, a process time of 90 min, an
A/
O of 6:1, a catalyst value of 1 wt. %, and a mixing intensity of 600 rpm. Selecting the input variables is one of the most important issues when developing prediction models.
Table 3 and
Table 4 present the variance analysis of biodiesel production data for ethanol and methanol, respectively. The effect of all parameters on biodiesel production for both alcohol types were significant effects at probability level of 1%, therefore all parameters were effective in biodiesel production and were involved. Using them can provide a good prediction, therefore it can be presented as a model with one output and five inputs, as given in Equation (14). Therefore, data were divided into two categories: input data (including temperature (°C), time (min),
A/
O, catalyst (wt. %), and mixing intensity) and output data (methyl ester/ethyl ester yield (%)).
Accordingly, due to the correlation of input variables and output variables, it was possible to model the output variables against the input variables. In the following, the results of modeling are presented.
7. The Results of Modeling
In this section, the results of modeling using
ELM and
SVM methods are presented and compared with the results of a study previously developed by Najafi et al. [
35].
Table 5 reports the results of the training process for the best predictor of both
ELM and
SVM methods. The training process was performed by choosing the best predictor and accordingly choosing the parameters of the user-defined functions. The training process was performed using 75% of data. The models were developed using MATLAB Software R2012a (MathWork Inc., New York, NY, USA). Based on
Table 5, the best
ELM-based predictor, which was obtained using 15 neurons on a hidden layer and a sigmoid function as an activation function, provided a correlation of 0.9815 and 0.9863 and
RMSE of 1.78 and 1.7 for estimating methyl and ethyl esters, respectively; on the other hand, in the case of using the
SVM methodology, the best predictor was obtained by using the RBF kernel with parameters of 1000, 0.05, and 0.35 for
C,
ε, and
γ, respectively, with high correlation coefficients of 0.9656 and 0.9769 and low
RMSEs of 2.407 and 2.148 for methyl and ethyl esters, respectively.
As is clear from
Table 5, the ability of the developed models in estimating ethyl ester was a little more than predicting methyl ester (based off high correlation values of estimating ethyl ester and low
RMSE values for
ELM,
SVM,
MLP,
RBF, and
ANFIS).
However, in the case of comparing models in the training stage, the ability of the
ELM method to estimate both of the methyl and ethyl esters was significantly higher than that of the
SVM method, which was developed in the present study (with a higher correlation coefficient of 0.9815 and 0.9863 and lower
RMSE values of 1.78 and 1.7 for methyl and ethyl esters, respectively), and
MLP,
RBF and
ANFIS techniques, which were developed by Najafi et al. [
35].
In the case of testing the developed methods using the other 25% of the data, the results were a little different compared to the training stage (
Table 6). More specifically, the ability of
SVM in the testing stage for estimating methyl ester production was higher than that of ethyl ester production, unlike the training stage (with correlation coefficients of 0.915 and 0.8945 and
RMSE values of 2.805 and 2.105 for methyl and ethyl esters, respectively). On the other hand, it can be seen that the ability of each predictor has been reduced in the testing stage compared to the training stage. To see the reduction of the modeling capability quantitatively, the factor of comparison of training and testing capability (
CTTC) was employed (Equation (15)). In fact, this factor indicates the difference percentage of each parameter in testing and training stages. Based on these two factors, the
CTTCr indicates the difference percentage for the correlation coefficient in the testing stage compared to the training stage where this parameter describes the reduction or increase of modeling performance of the testing stage compared to the training stage:
where
rtrain is the correlation coefficient of the training stage and
rtest is the correlation coefficient of the testing stage.
As is clear from
Table 6, both
ELM and
SVM had a reduction in modeling performance as seen by the negative sign for
CTTCr. In the
ELM model, the reduction of modeling performance in the case of methyl ester production was higher than that of ethyl ester production (−5.2% and −2.9% for methyl and ethyl esters, respectively), but in the case of the
SVM model, the reduction of the modeling performance in the case of ethyl ester production was higher than that of methyl ester production (−5.2 and −8.4 for methyl and ethyl esters, respectively).
Figure 3 also indicates the scatter plot of the testing stage for
ELM and
SVM for the production of methyl and ethyl esters. Based on
Figure 3, it is clear that the ability of
ELM in the case of ethyl ester production was higher than that of methyl ester production (with
R2 values of 0.9179 and 0.8649 for methyl and ethyl esters, respectively) but in the case of the
SVM method, the result is the opposite such that the ability of the
SVM in the case of methyl ester production was higher than that of ethyl ester production (with
R2 values of 0.8387 and 0.8002 for methyl and ethyl esters, respectively).
8. Hybrid Modeling
This section describes a novel hybrid method by merging
RSM,
SVM, and
ELM methods (i.e.,
RSM-SVM and
RSM-ELM). In statistics,
RSM provides the relationships among several explanatory variables and response variables. The method was introduced by Box and Wilson in 1951 [
48]. This methodology was performed on Design Expert Software Version 7.0 (Stat-Ease Inc., Minneapolis, MN, USA, 2005). The quadratic process order and manual selection were selected using a trial and error method to model the production of methyl and ethyl esters based on input variables. Modeling results had very good results so that the relation of predicted and target values had correlation coefficients of 0.983 and 0.9743 for methyl and ethyl esters, respectively.
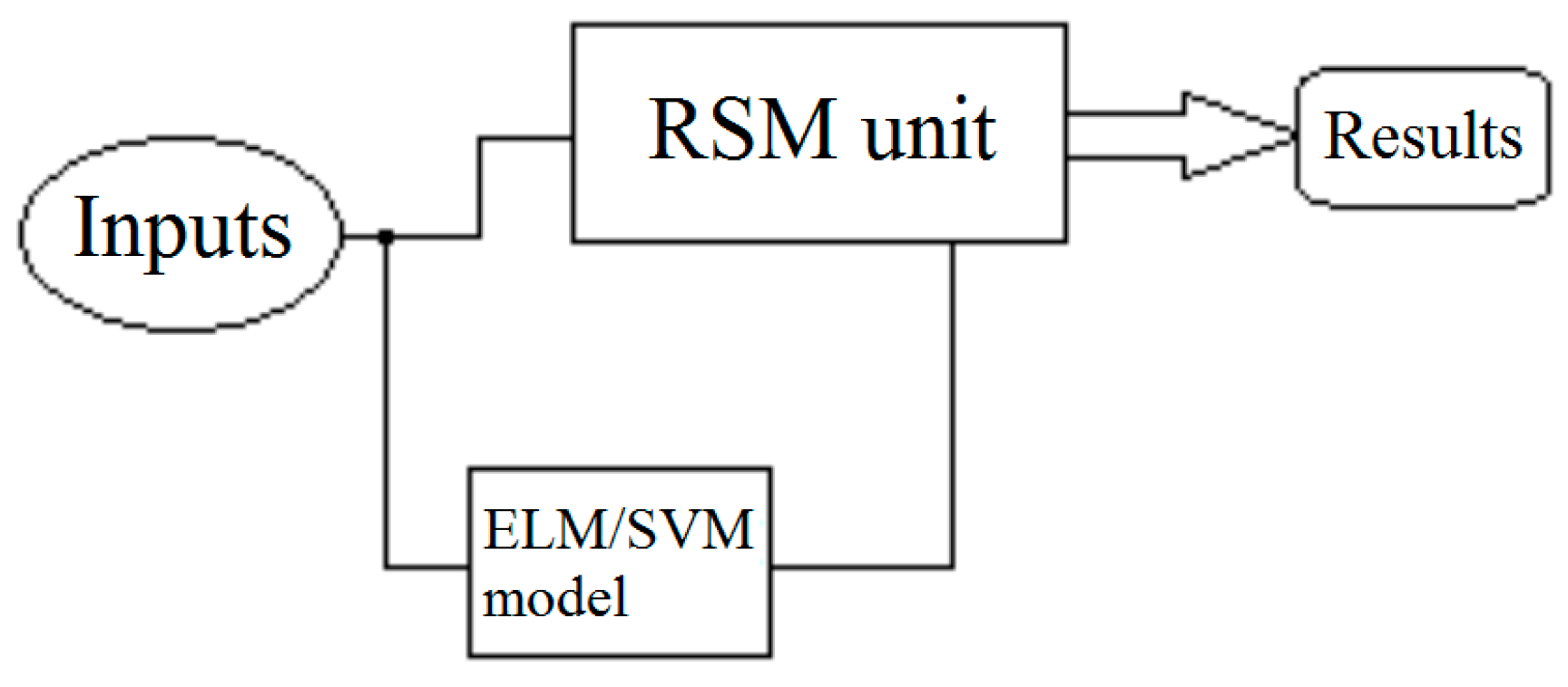
Figure 4 indicates the schematic diagram of the developed hybrid models.
The general logic of this model was that the inputs were imported to both RSM and ELM or SVM predictor simultaneously, then the output of the predictor was imported to the RSM method as the response of the system. Finally, the RSM method exports the desired results.
After preparing the model, data were imported to the model and the output of the model were extracted. In this stage, the mode was employed as a predictor model. The results are presented in
Table 7.
Using a hybrid method improved and increased the system prediction efficiency compared to the testing stage of each predictor (
Table 6). In this case, the
RSM-ELM method had a high prediction capability compared to that of the
RSM-SVM method.
After ensuring the accurate operation of the developed hybrid methods, it was the time for entering the optimization phase. The optimization phase was performed in three stages, one with experimental data, a second with data generated using the ELM method, and the third with data generated using the SVM method. All three phases were performed to maximize the methyl or ethyl esters production yield.
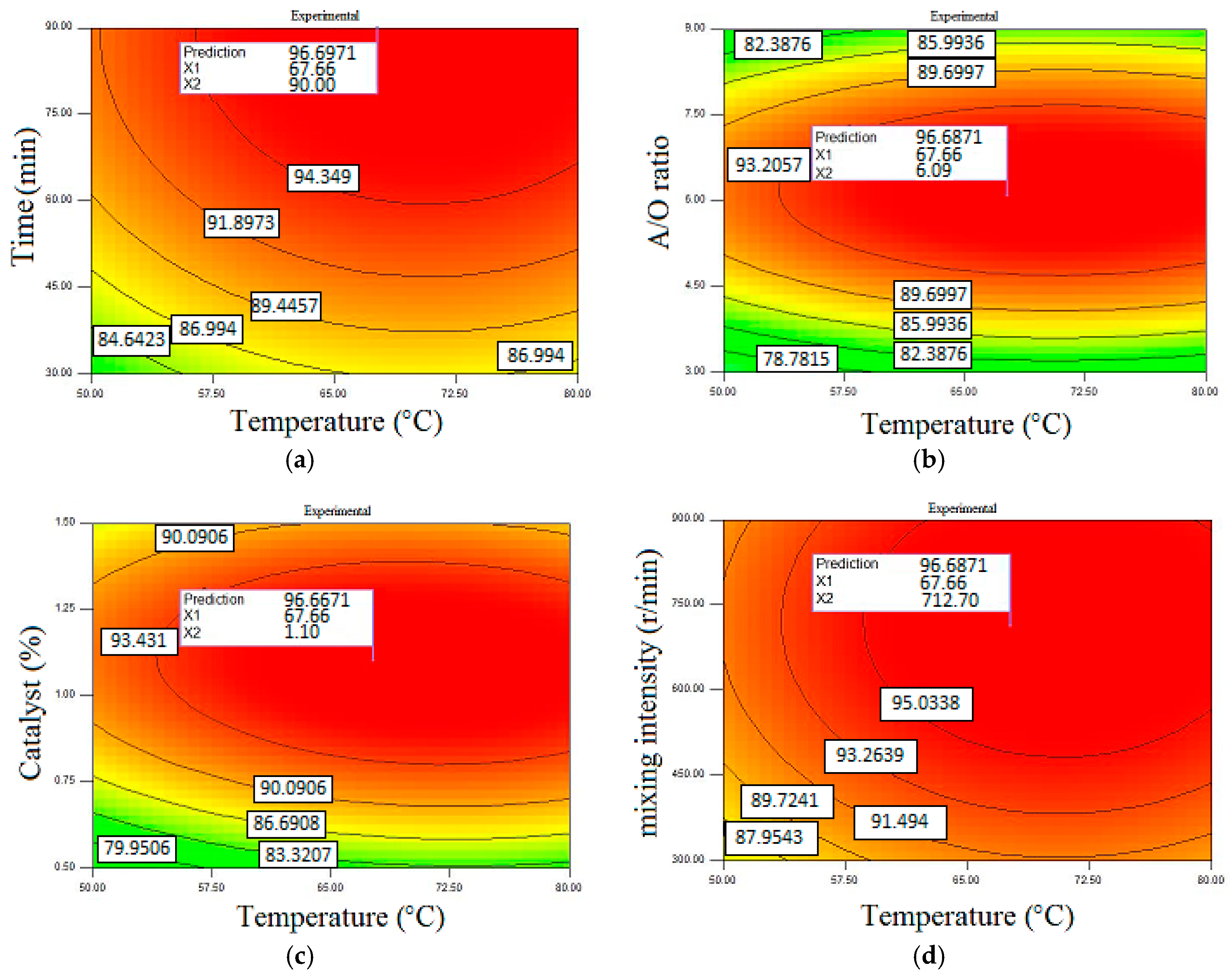
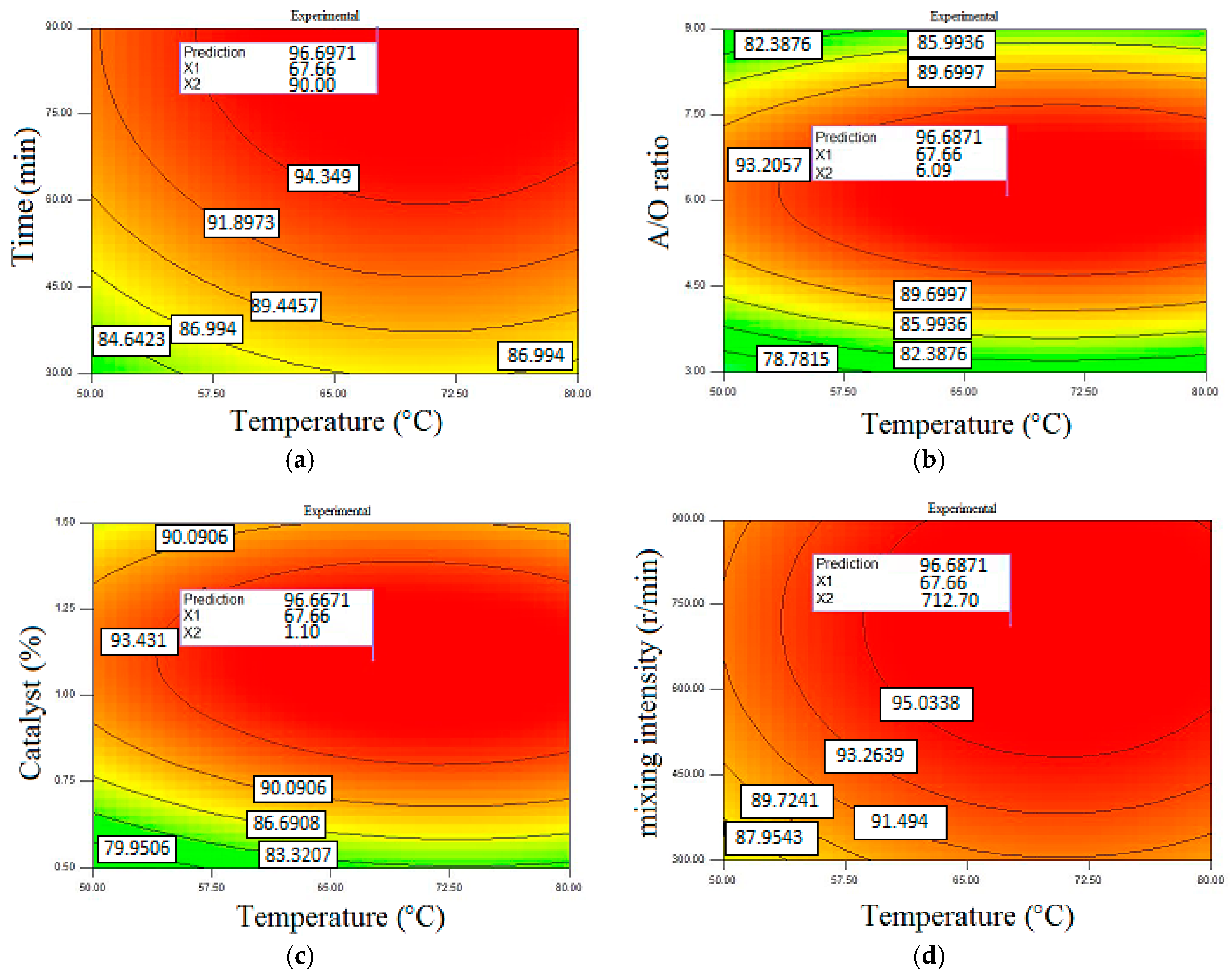
Figure 5 presents the optimization conditions of methyl ester production in the case of importing experimental data. This model provided the maximum methyl ester yield of 96.68% with a reaction time of 90 min, temperature of 67.66 °C,
A/
O of 6.09, catalyst of 1.1 wt. %, and mixing intensity of 712.7 rev/min.
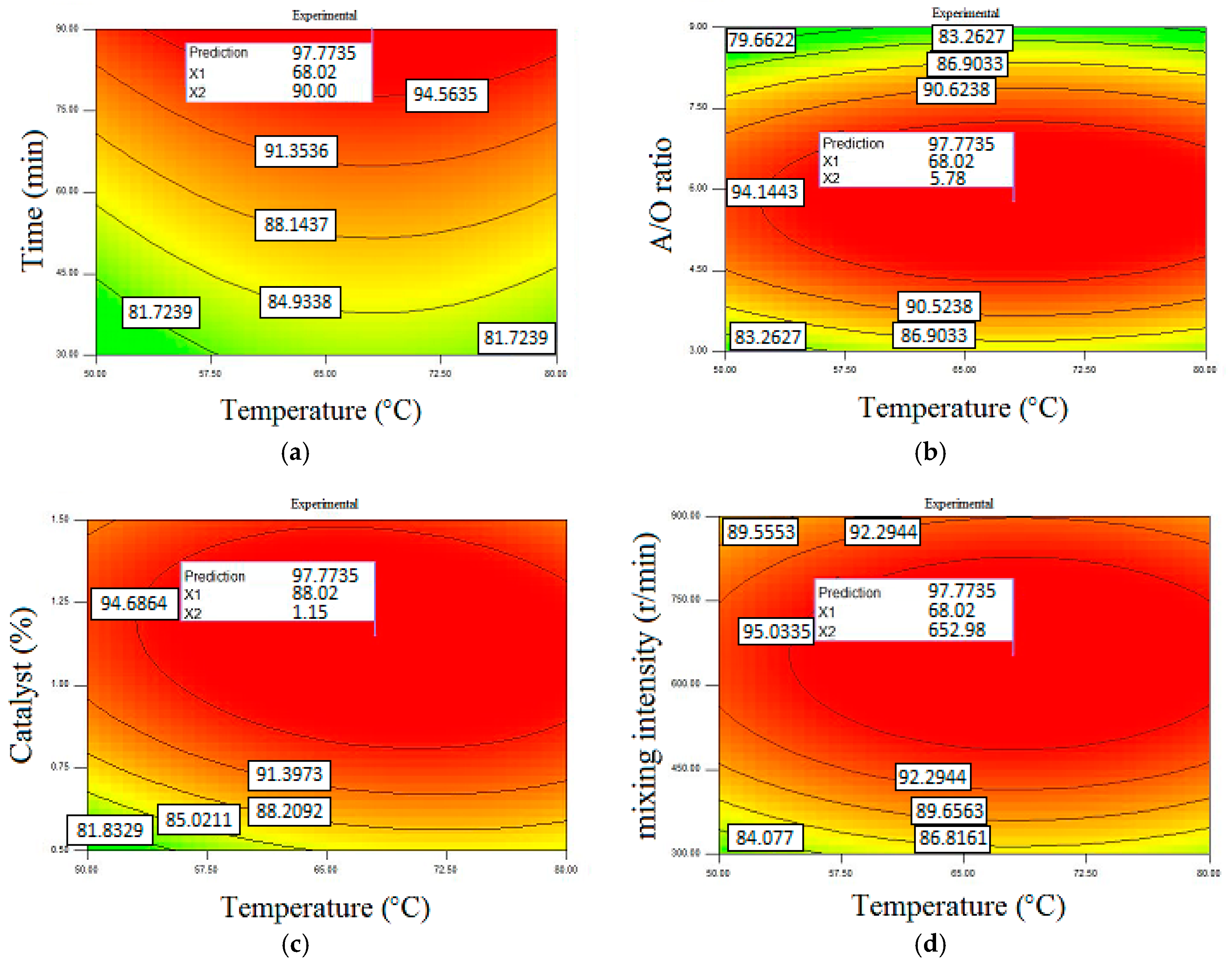
Figure 6 presents the optimization conditions of ethyl ester production in the case of importing experimental data. This model provided the maximum ethyl ester yield of 97.77% with a reaction time of 90 min, temperature of 68.02 °C,
A/
O of 5.78, catalyst of 1.15 wt. %, and mixing intensity of 652.96 rev/min.
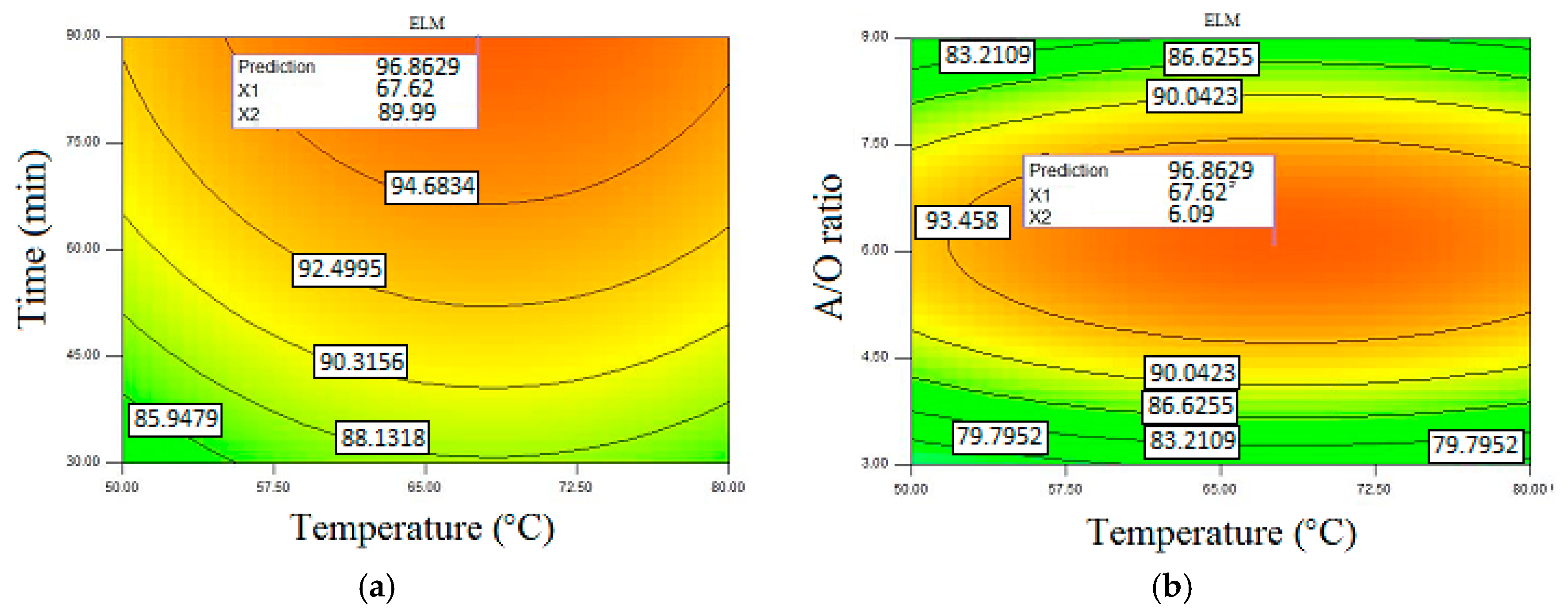
Figure 7 presents the optimization condition of methyl ester production in the case of importing the generated data of the
ELM method. This model provided the maximum methyl ester yield of 96.86% with a reaction time of 89.9 min, temperature of 67.62 °C,
A/
O of 6.09, catalyst of 1.1 wt. %, and mixing intensity of 709.42 rev/min.
Figure 8 presents the optimization condition of ethyl ester production in the case of importing the generated data of the
ELM method. This model provided the maximum ethyl ester yield of 98.46% with a reaction time of 90 min, temperature of 68.48 °C,
A/
O of 5.77, catalyst of 1.15 wt. %, and mixing intensity of 650.07 rev/min.
Figure 9 presents the optimization condition of methyl ester production in the case of importing the generated data of the
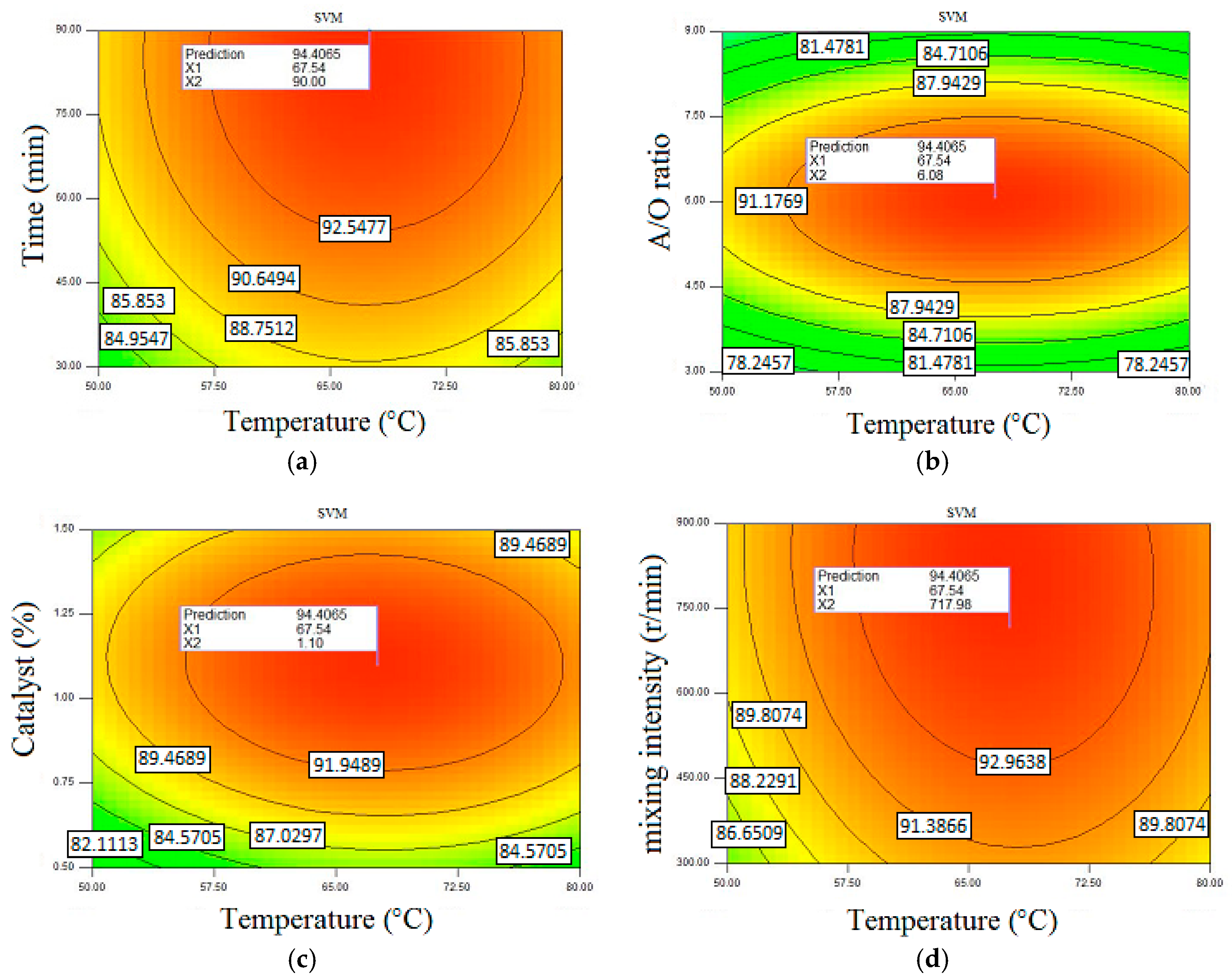
SVM method. This model provided the maximum methyl ester yield of 94.406% with a reaction time of 90 min, temperature of 67.54 °C,
A/
O of 6.08, catalyst of 1.1 wt. %, and mixing intensity of 717.98 rev/min.
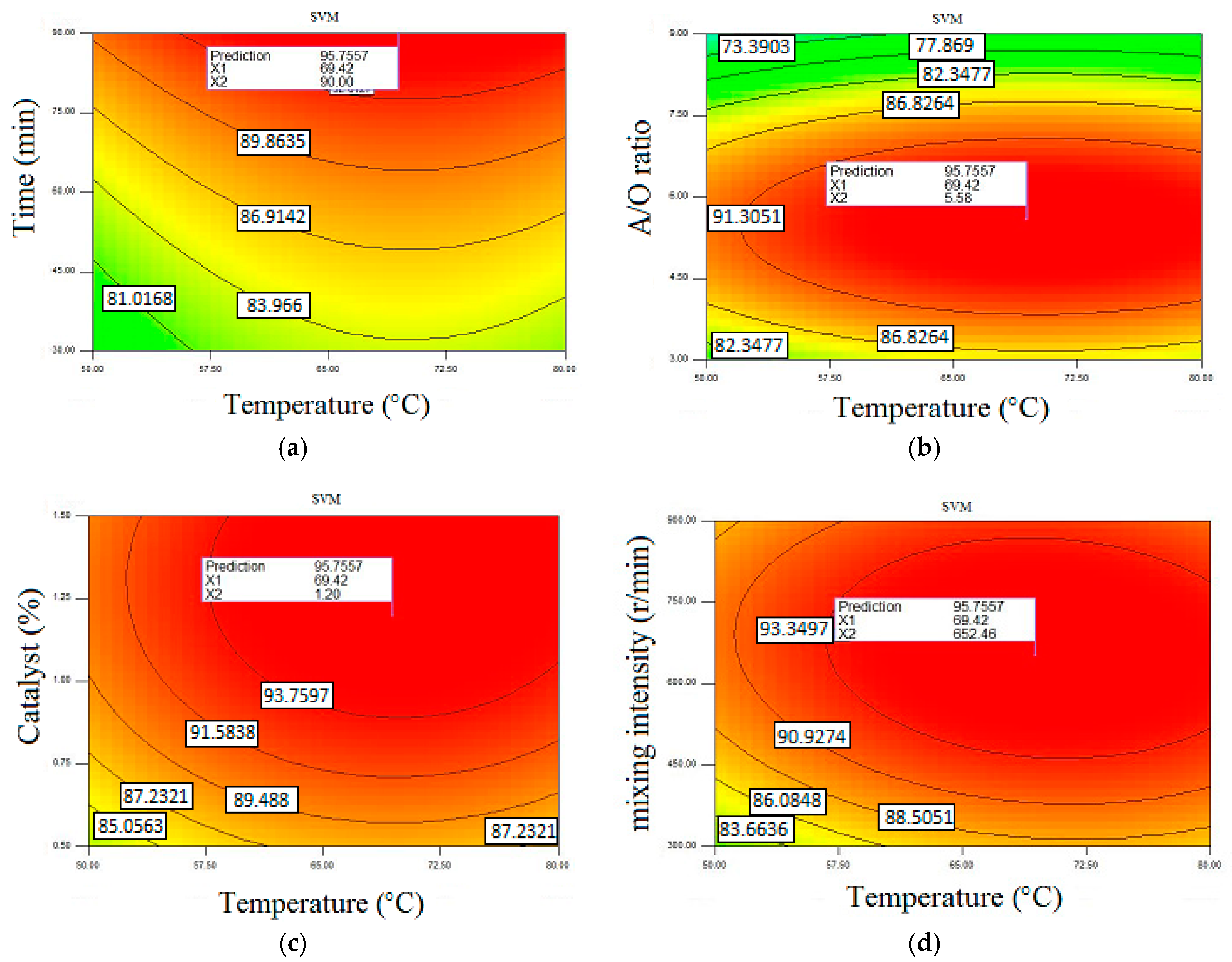
Figure 10 presents the optimization condition of ethyl ester production in the case of importing the generated data of the
SVM method. This model provided the maximum ethyl ester yield of 95.75% with reaction time of 90 min, temperature of 69.42 °C,
A/
O of 5.58, catalyst of 1.2 wt. %, and mixing intensity of 652.46 rev/min.
The total results are collected in
Table 8 with separated inputs and outputs. Based on
Table 8, using the
RSM and
RSM-ELM provided a high production yield of methyl and ethyl esters compared to experimental condition, while in case of production of methyl ester,
RSM-SVM provided the lowest methyl ester production yield. The maximum methyl ester production was related to the use of the
RSM-ELM method with a yield of 96.86%, and maximum ethyl ester production yield was also related to the
RSM-ELM method with a yield of 98.46%. Using the
RSM-ELM method reduced the reaction temperature to 67.62 °C and 68.48 °C for methyl and ethyl esters, respectively, which reduced the required thermal energy for production, but increased other parameters including
A/
O, catalyst, and mixing intensity.
9. Conclusions
The present study employed novel hybrid ELM-RSM and SVR-RSM techniques to obtain a maximum yield of methyl and ethyl esters through a trans-esterification process from WCO based on ASTM standards and also to explain the importance of hybrid approaches from the viewpoint of accuracy and functionality. Given that the biodiesel production process is a time-consuming and costly process, any trial and error in the production process will be detrimental to the manufacturer. Using the policy in this study can reduce additional errors and in fact increase production efficiency. This study can also encourage interested scholars to study further in the field of using hybrid methods for the optimization of processes.
Input variables were temperature (°C), time (min), A/O, catalyst (wt. %), and mixing intensity (rev/min), and output variables were the production yield (%) of ethyl or methyl esters. Based on the results, the ability of both models (ELM and SVR) in estimating ethyl ester was a little more than that for the prediction of methyl ester, where this ability in the case of using the SVM methodology was more sensible. Using the hybrid method improved and increased the optimization of the system efficiency. Based on the results of the optimizing stage, the RSM-ELM technique could increase the methyl and ethyl esters production from 93.5% (in case of using experimental data) to 96.86% and from 95.5% (in case of using experimental data) to 98.46%, respectively.
In general, using the ELM method provided a high accuracy for estimation of the production yield and employing the RSM-ELM method increased the production yield, and the increase of the ethyl ester production was more sensible compared to that of the methyl ester production. Due to the time-consuming nature of the optimization process in using different methods, this study could provide a new approach for the optimum production of the ethyl or methyl esters for researchers. Therefore, by using the results of this study, there is no need for trial and error in modeling and optimizing the production process in different ways.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}