Short-Term Load Interval Prediction Using a Deep Belief Network


Abstract
:1. Introduction
2. Background
2.1. Evaluation Metrics of Interval Prediction
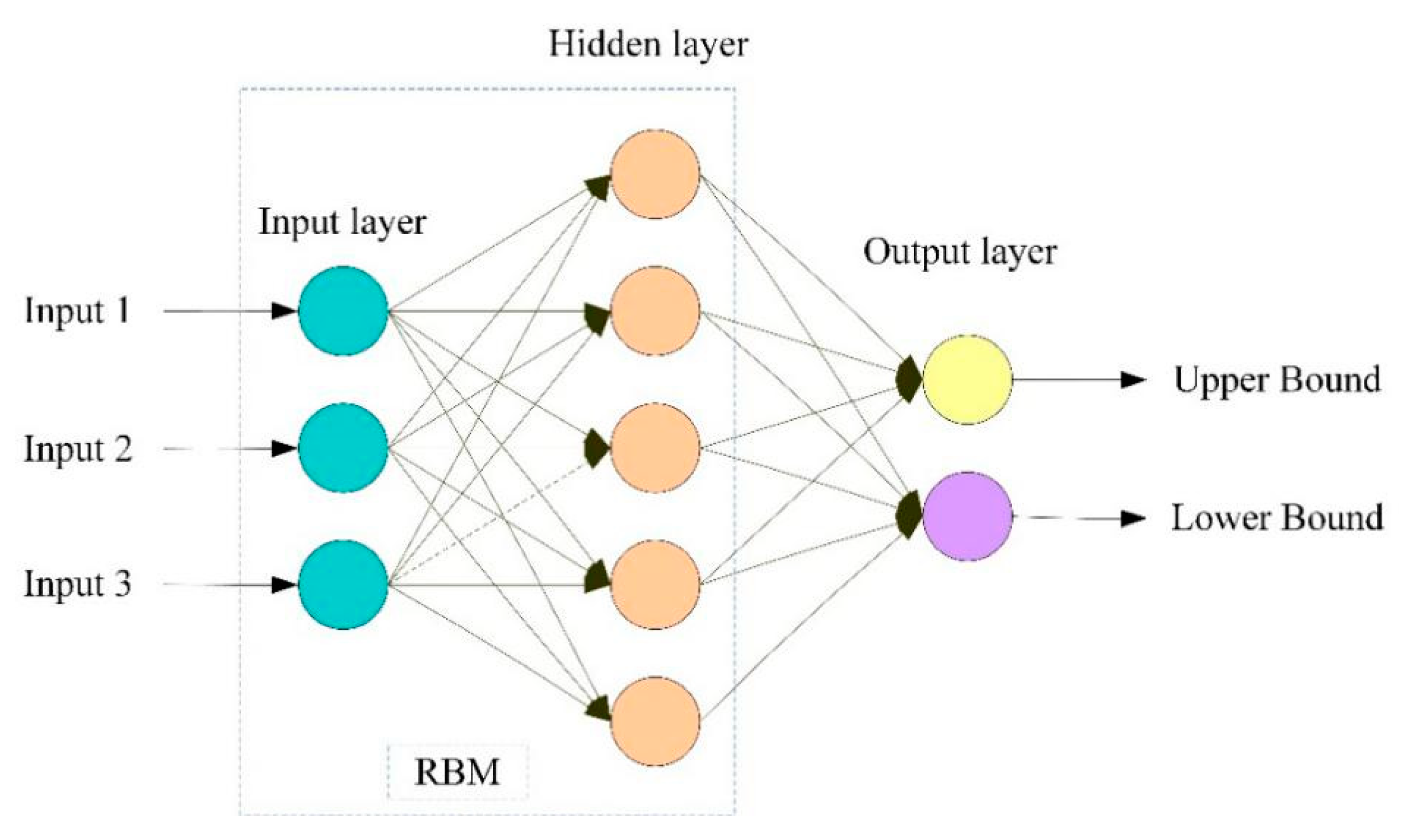
2.2. LUBE Approach
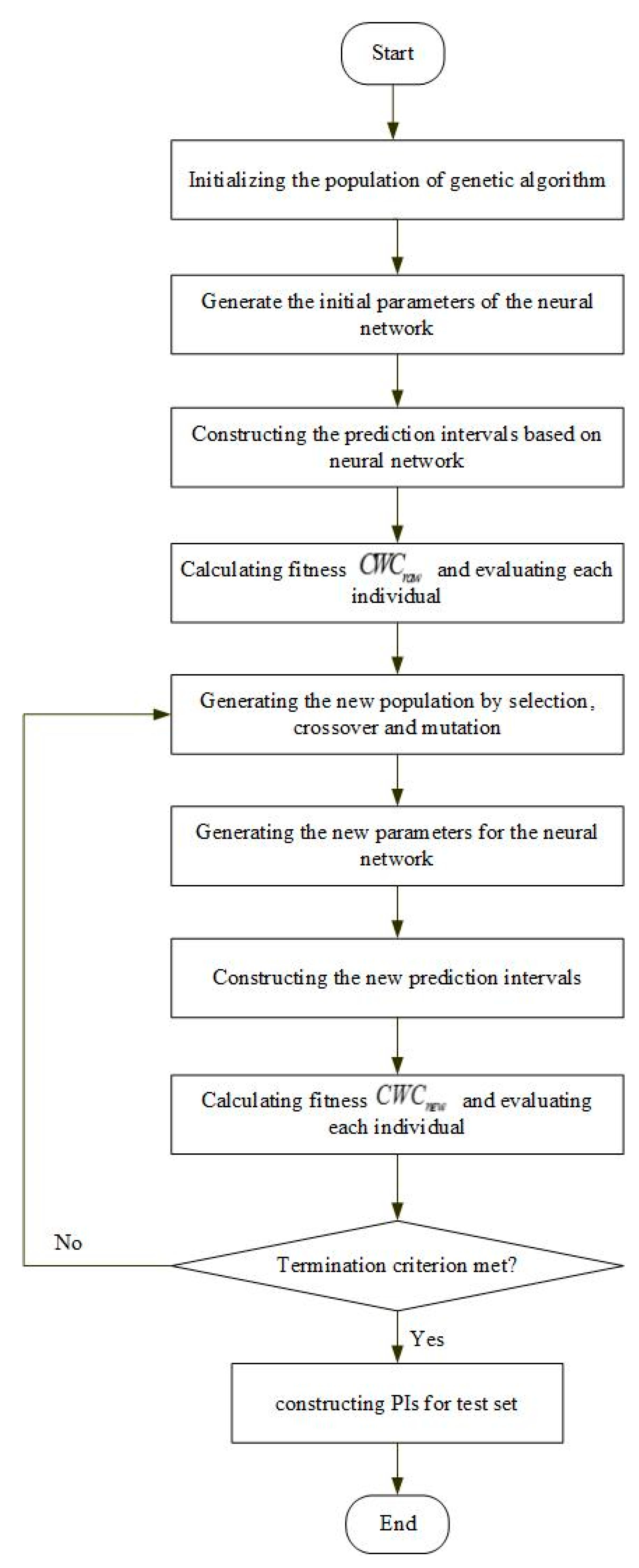
- Step 1
- Population initialization: randomly initialize the population of the genetic algorithm (GA). The weights and thresholds of the NN models are generated based on the population.
- Step 2
- PI construction and calculation: an NN with two outputs is applied to construct PIs for the training data. PICP, PINAW, and CWC are then calculated, which are taken as the initial fitness of the genetic algorithm.
- Step 3
- Generation of a new population: the selection, crossover, and mutation operators are performed on the parent population to produce new offspring.
- Step 4
- PIs construction: a new PI is constructed by using new selected NN parameters. Accordingly, the new metric is calculated by Equation (4).
- Step 5
- Each individual evaluation: The index CWC is considered as the fitness in the GA optimal process. The individual with the minimum fitness is recorded as the global optimal solution. The individual also represents the best model parameters.
- Step 6
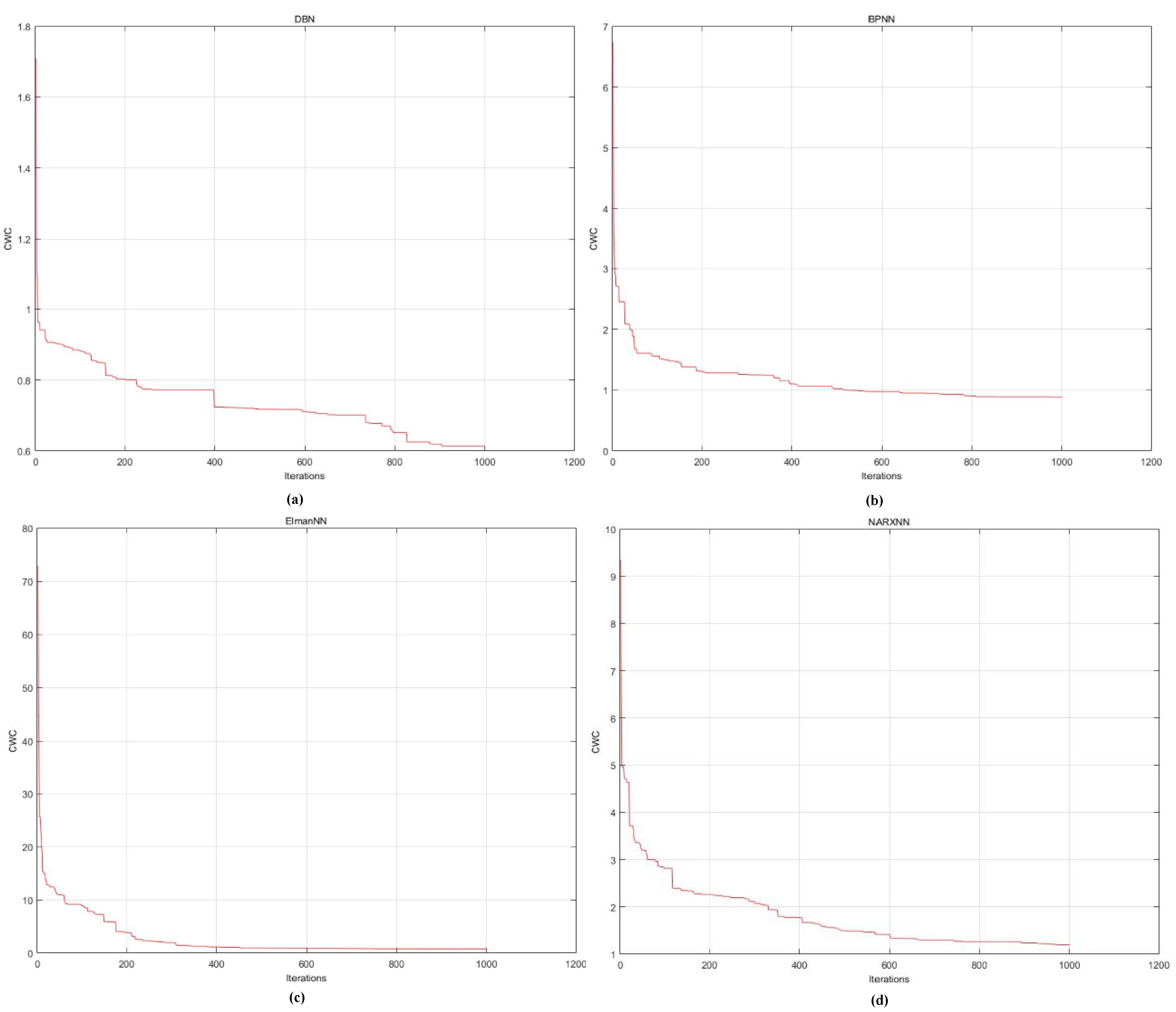
- Termination and Results: usually there are frequently used termination criteria, i.e., the maximum number of iterations is reached, or the evaluation indicator remains unchanged for a number of interactions. If the criteria is not met, then the algorithm returns to Step 3.
3. Single-Objective LUBE Framework for DBN-Based Interval Predication
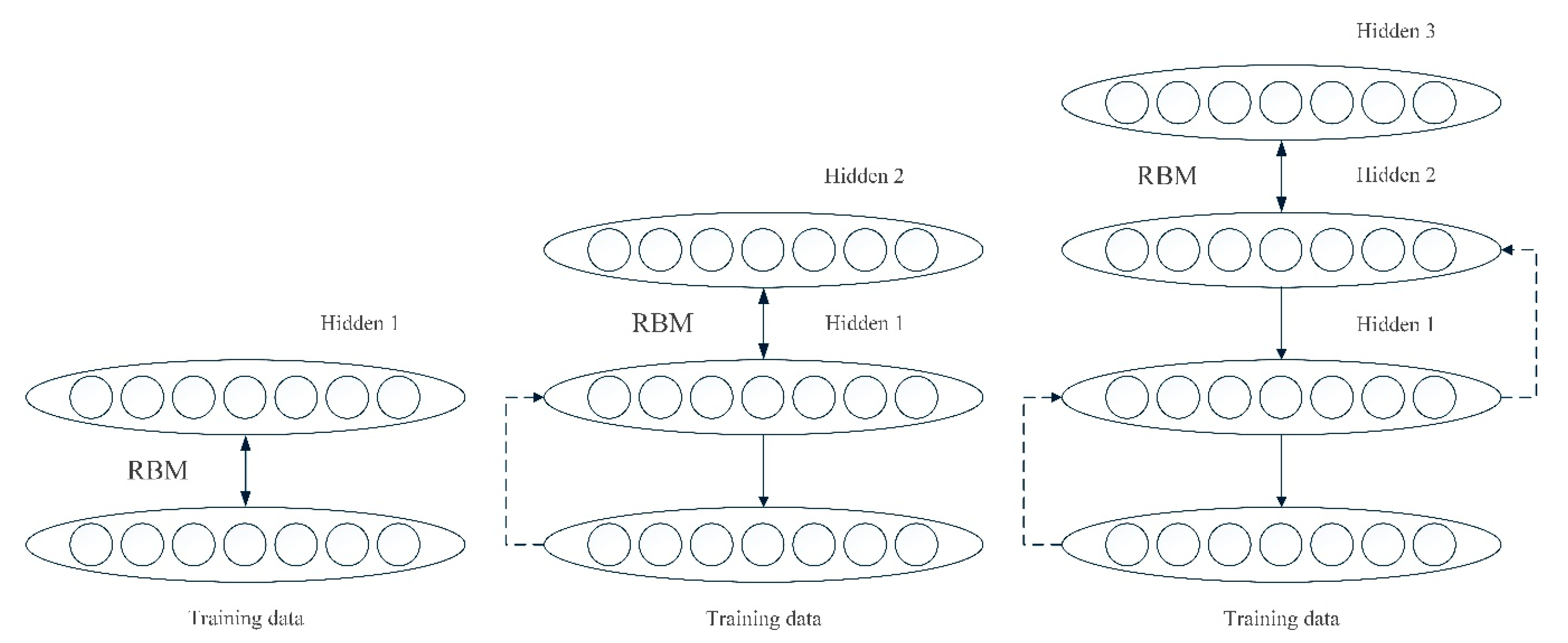
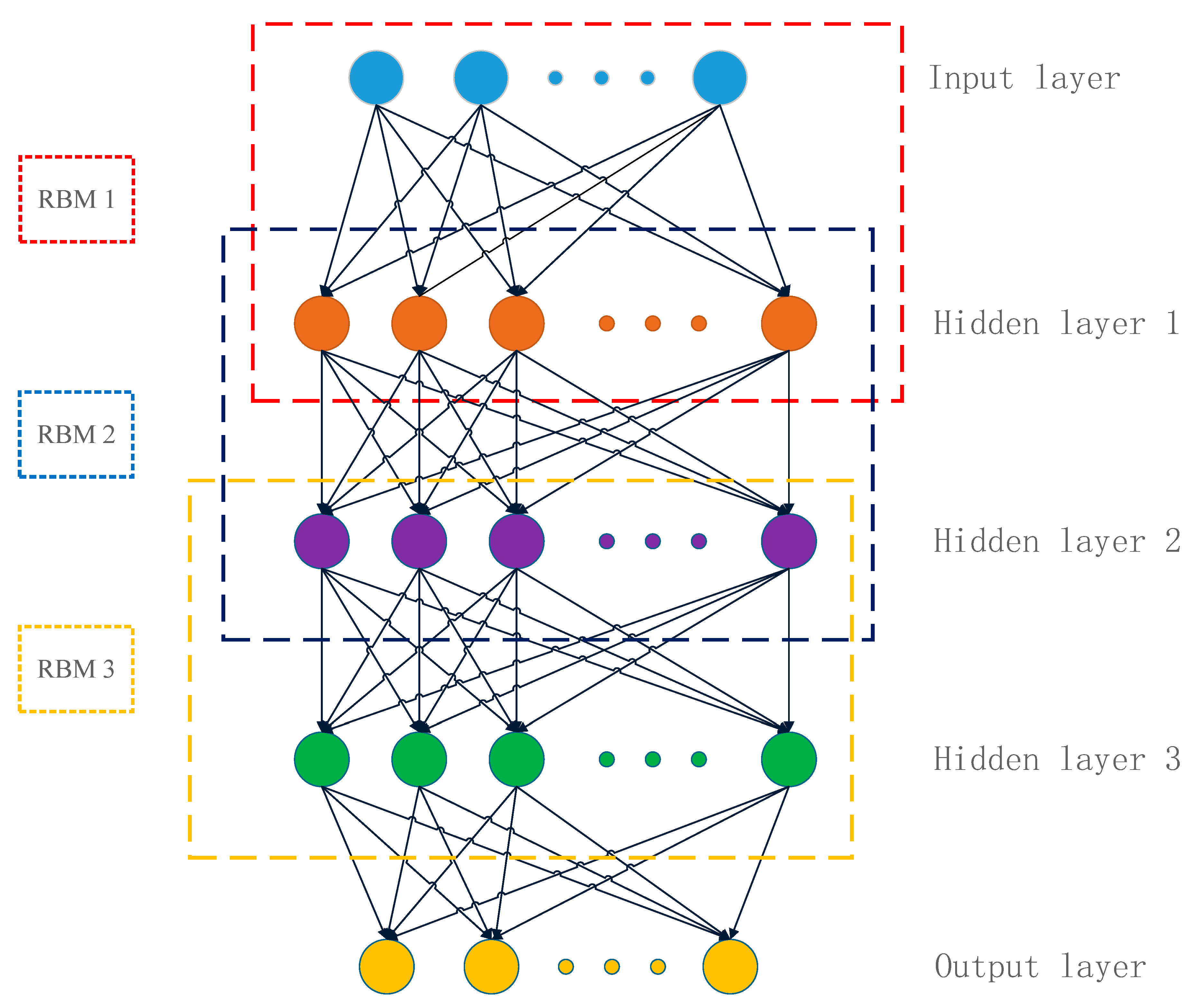
3.1. Deep Belief Network Model
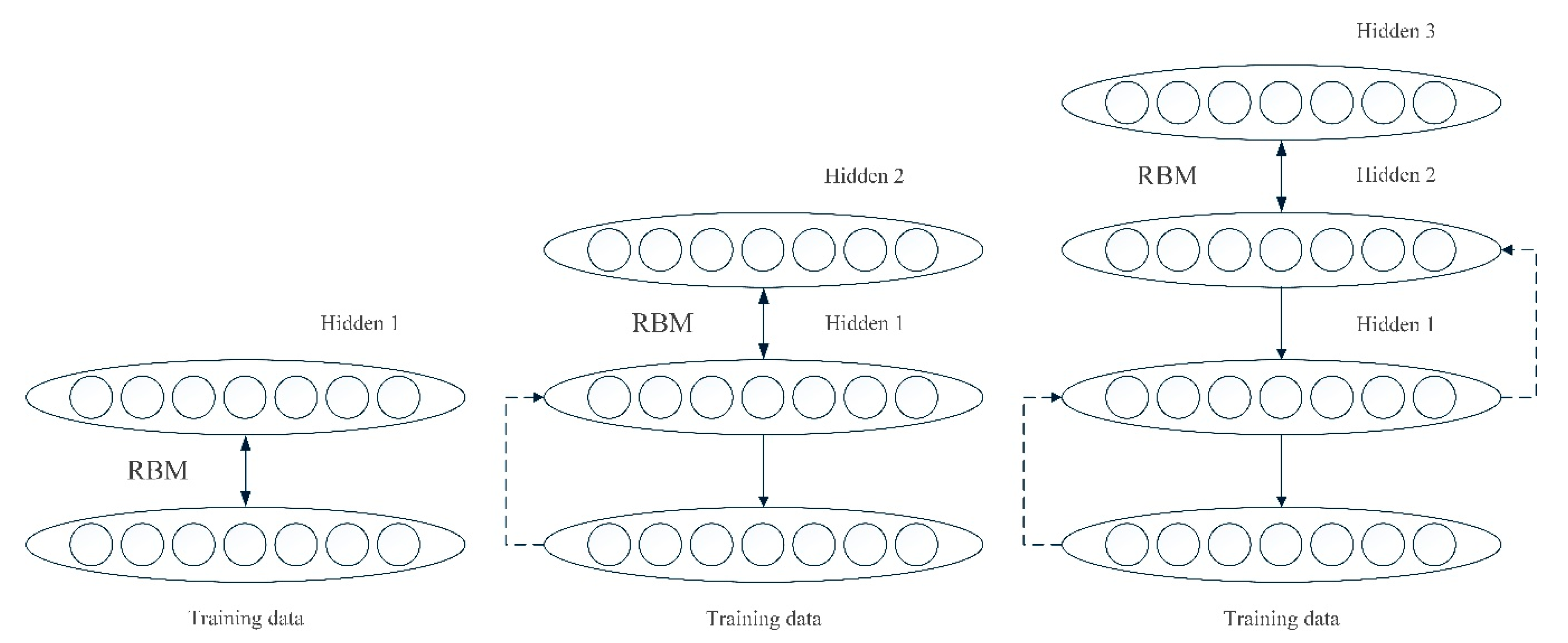
3.1.1. Pre-Training Process
3.1.2. Fine-Tuning Process
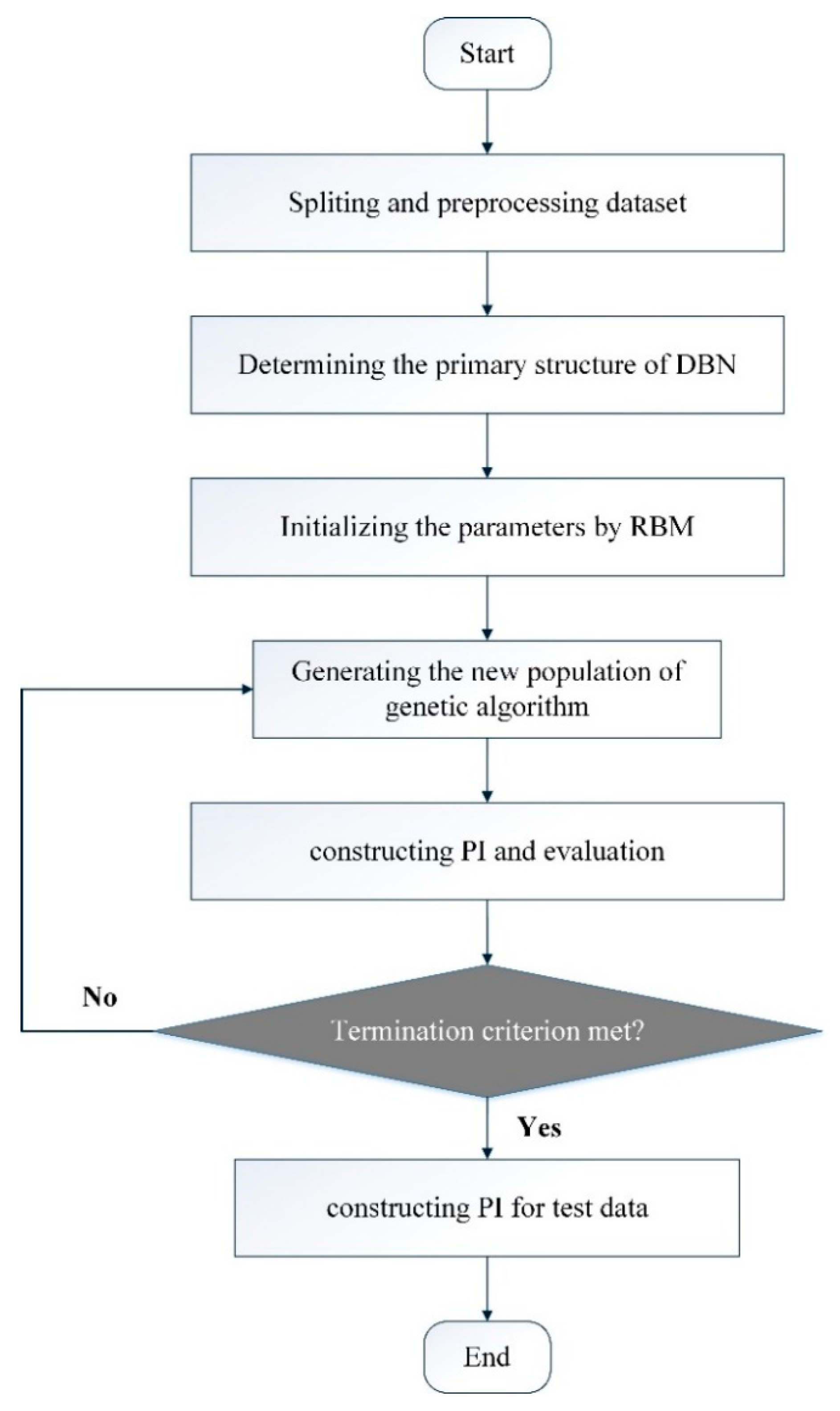
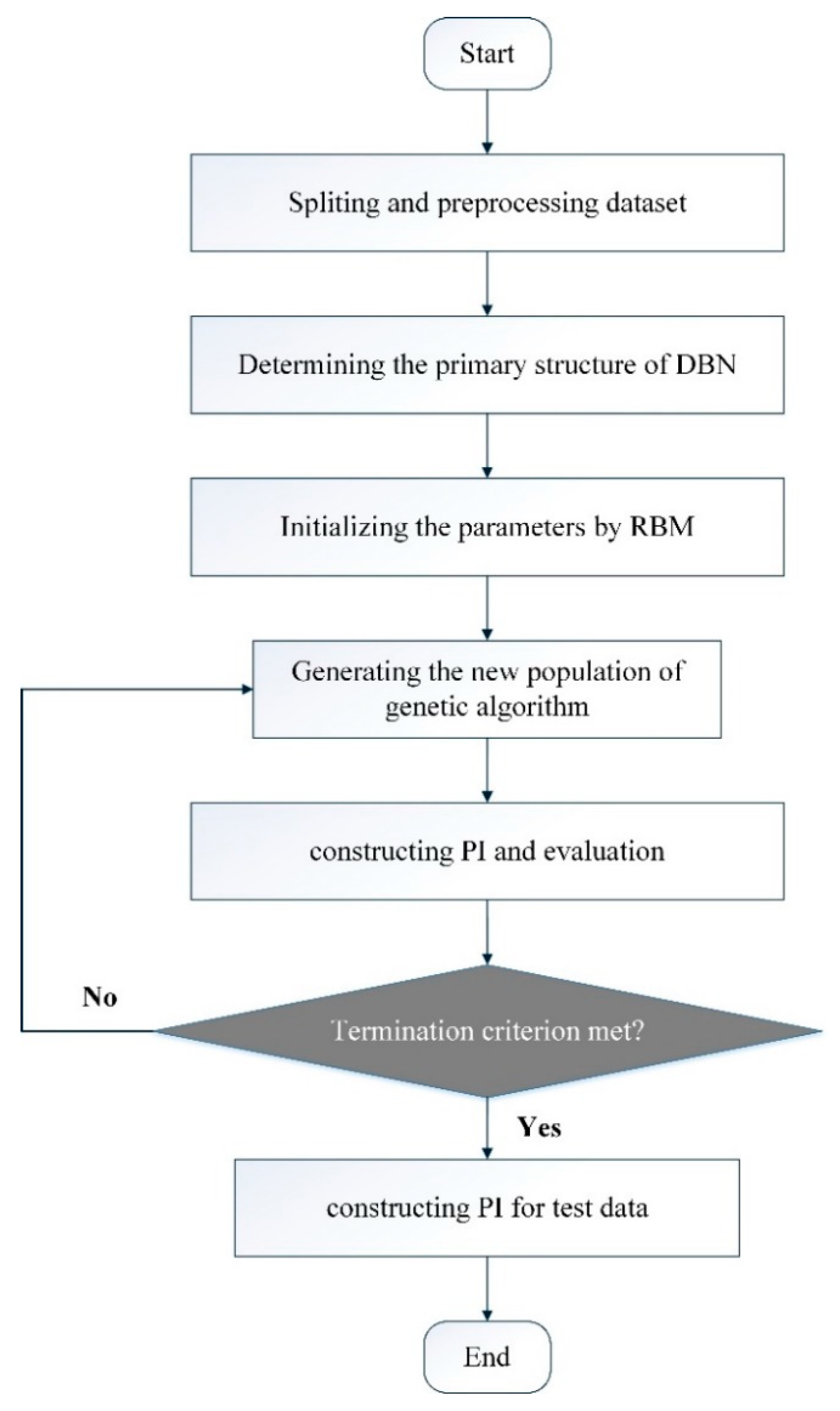
3.2. Model Implementation
- Step 1
- Data processing. As is known, the power system is a typical nonlinear system, which is affected by various natural and social complex factors. In order to establish an accurate prediction model, the load forecasting method needs to quantify the effects of various factors, but such quantification is often very difficult. Since the evolution of any component of the system is determined by the other components that interact with that component, the load time series contains the long-term evolution information of all variables that affect the load. Therefore, studying the regularity of load and predicting the future development trend of load power can only use historical load data. The theoretical basis of this prediction method is the phase space reconstruction theory proposed by Packard et al. [36].
- Step 2
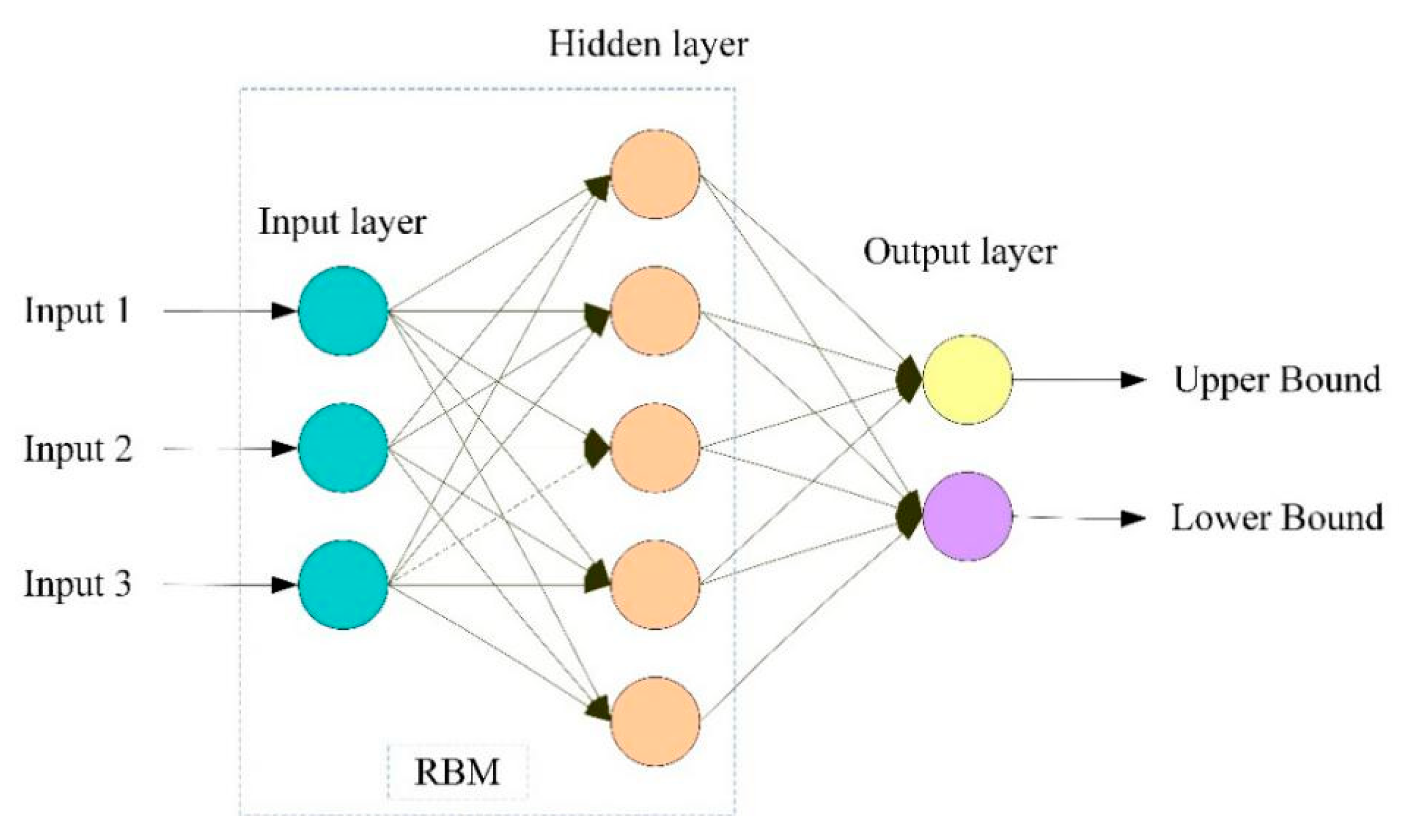
- Determine the primary structure of DBN. In this study, the trial and error method is used to find the appropriate number of hidden units in the DBN model. The number of input units is determined by the delay time.
- Step 3
- Parameter initialization. The parameters of DBN model are initialized by the RBM using Equations (12)–(14).
- Step 4
- Generation of new population of GA. The new population is used to update the weights and thresholds of DBN, and then we can obtain new cost function. A smaller cost function value in this study will be retained.
- Step 5
- Model evaluation. First, predication intervals are constructed by the DBN model, then the corresponding metrics, i.e., PICP and PINAW, are calculated. Finally, CWC (a combination of PICP and PINAW) is used to evaluate the quality of the PI.
- Step 6
- Termination criterion. If the termination condition is met, then the training is terminated. Otherwise return to step 3.
- Step 7
- Construct PI. Construct the predicated intervals by the obtained optimal DBN model.
4. Experiment
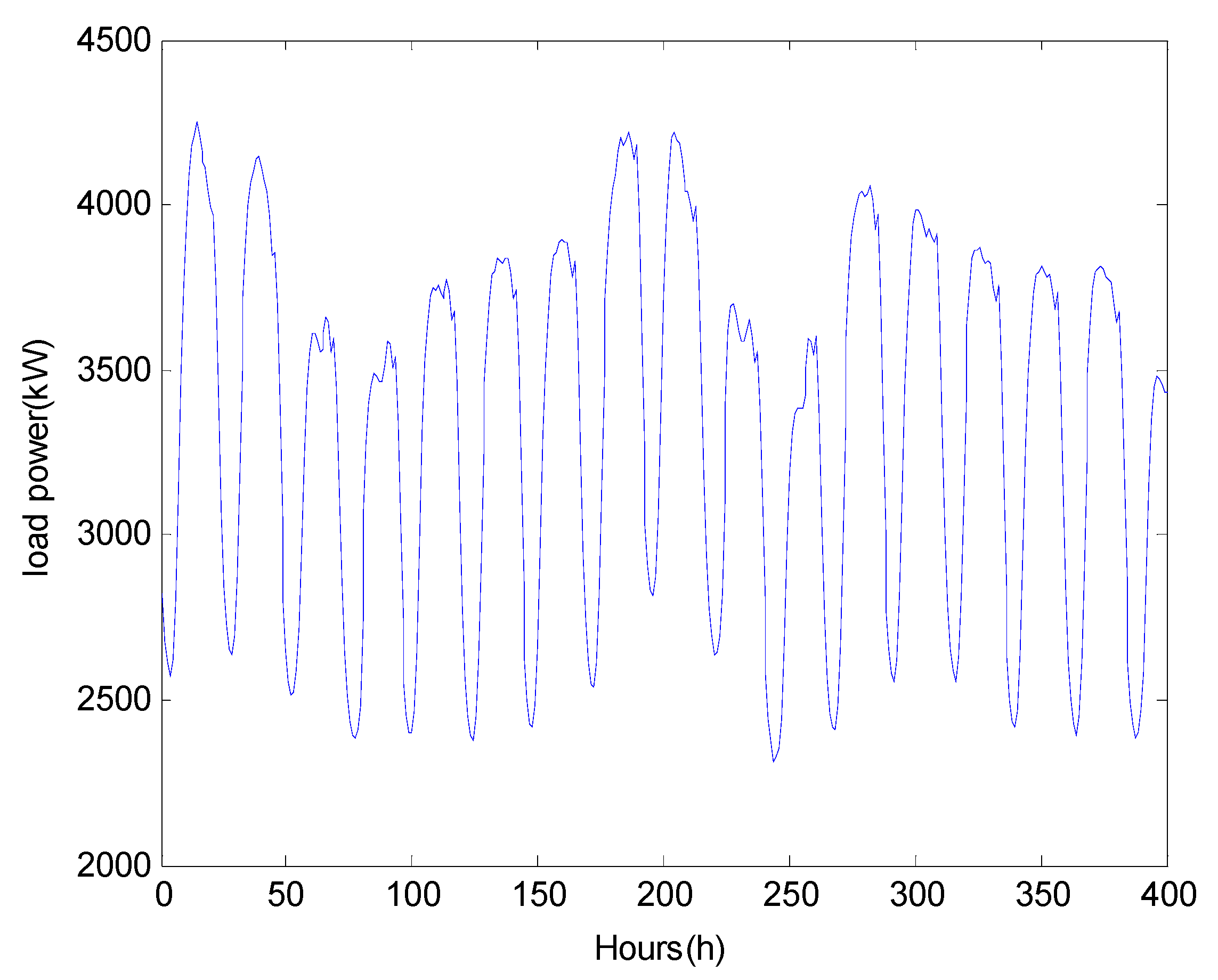
4.1. Preprocessing of Data Set
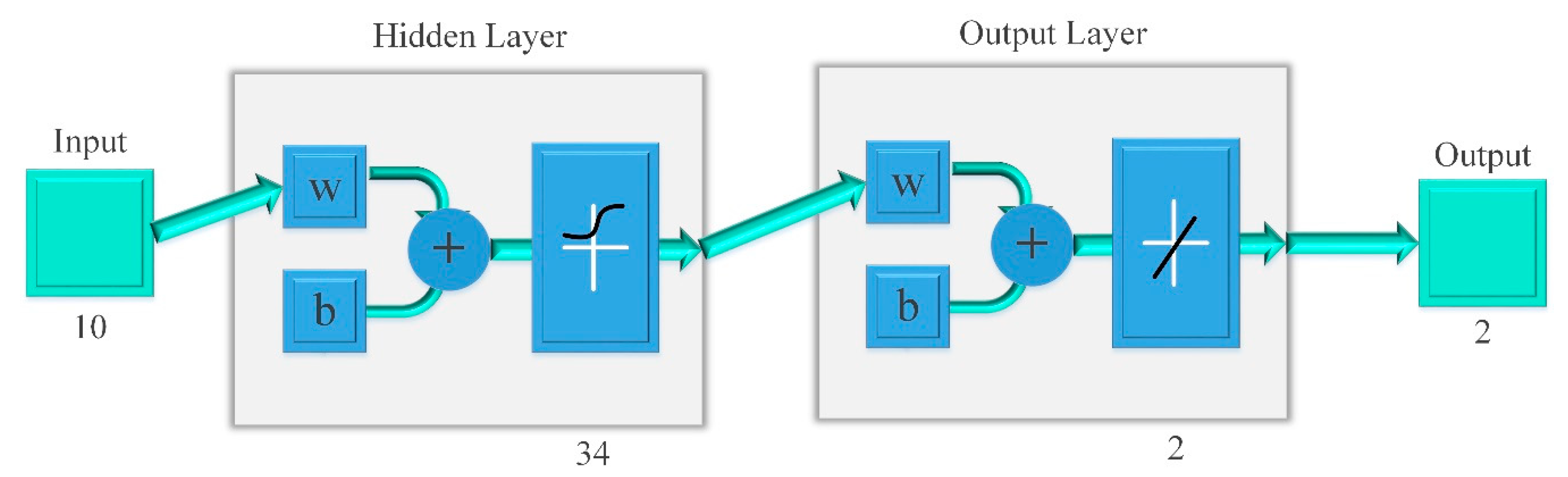
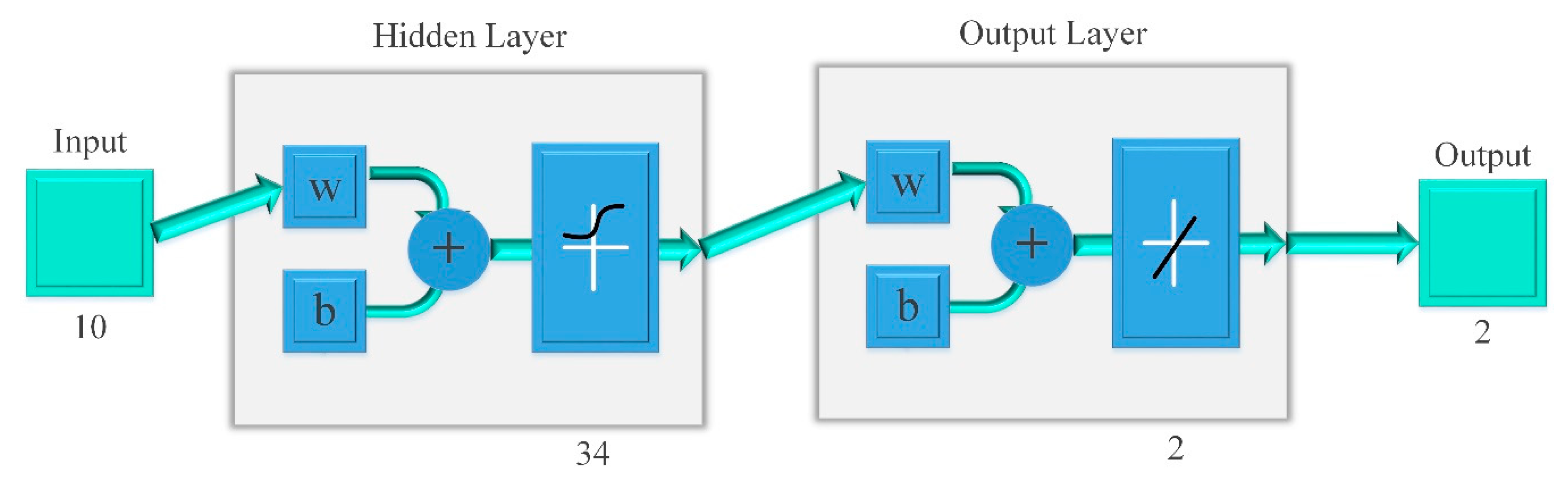
4.2. Parameter Settings
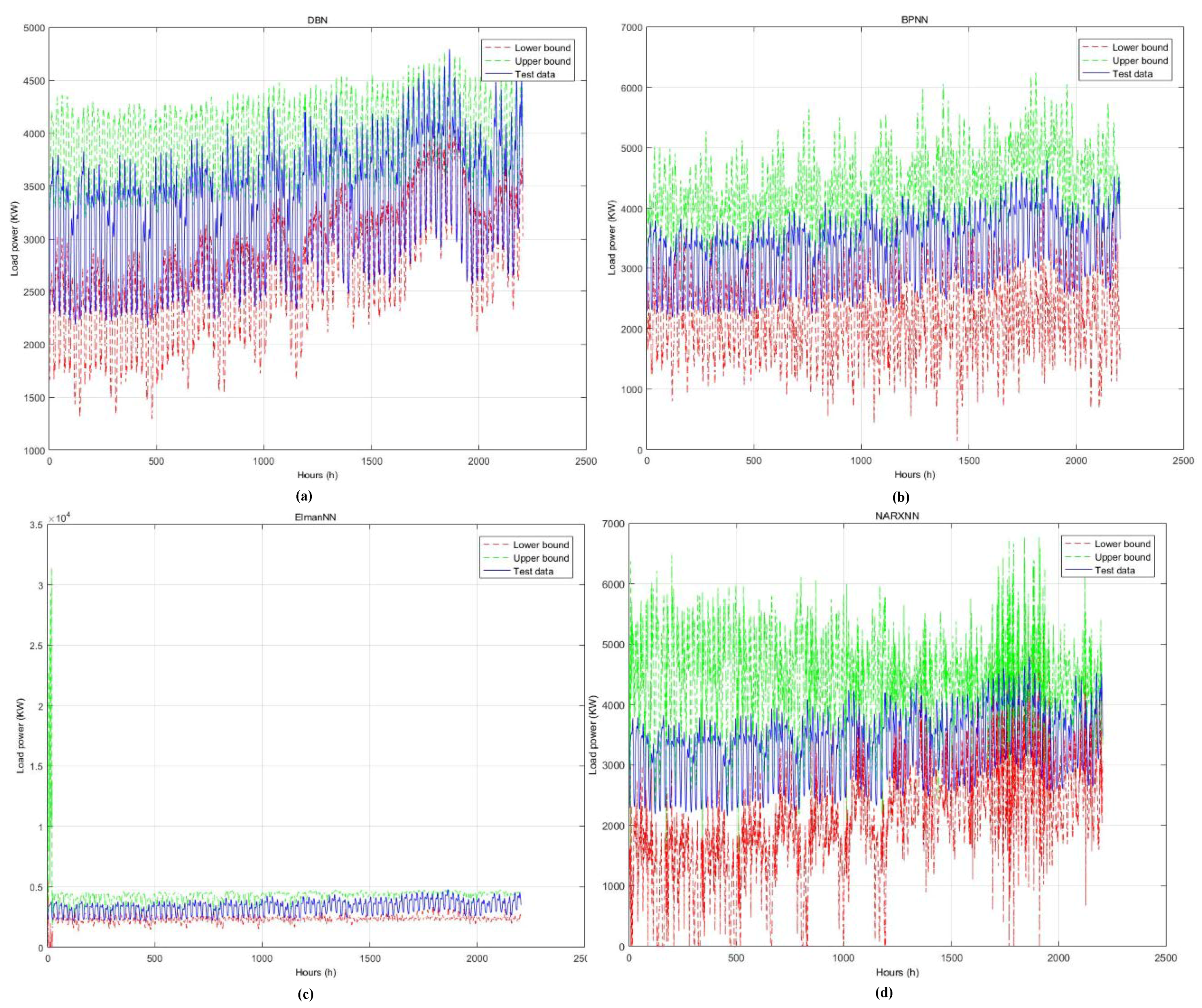
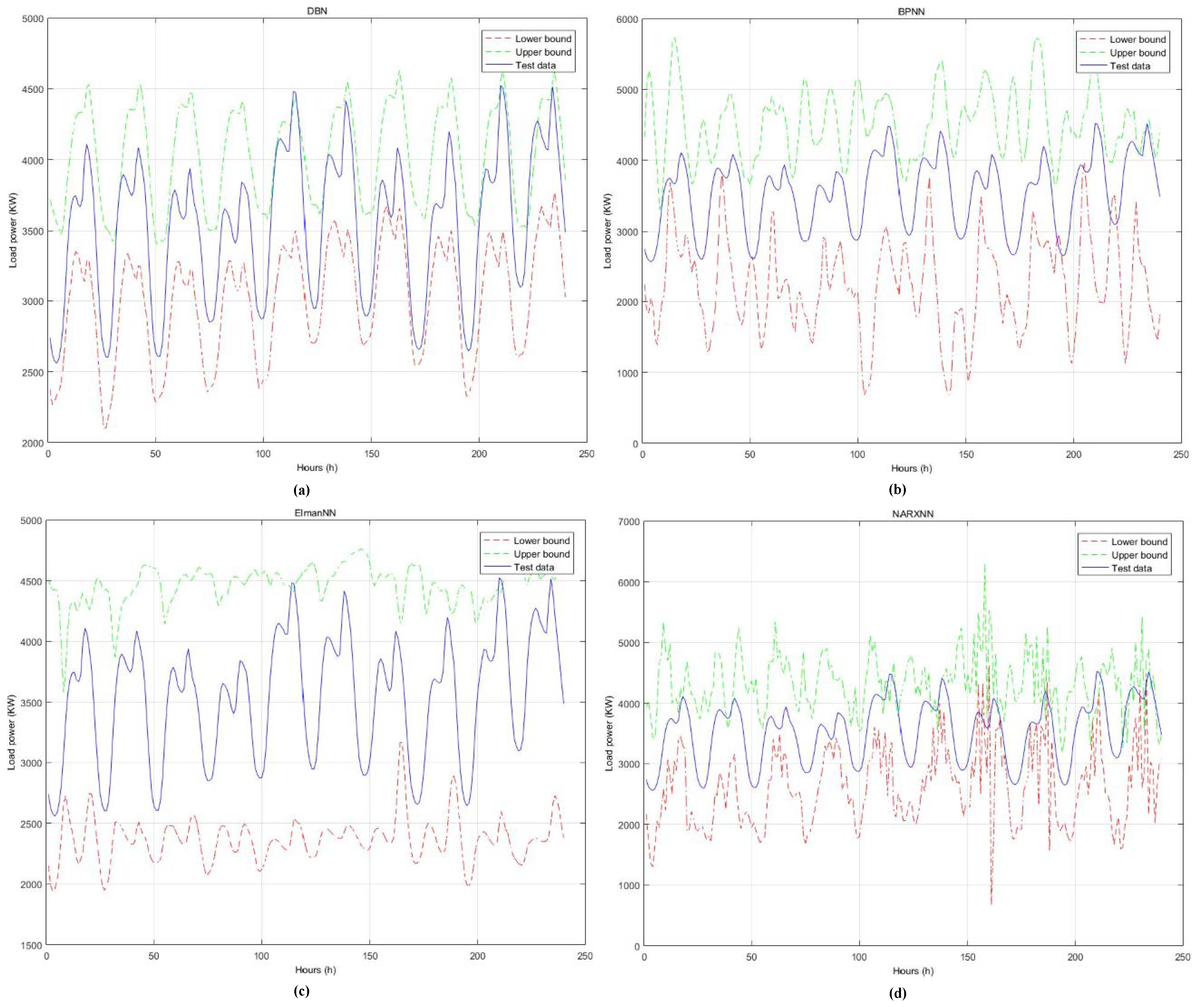
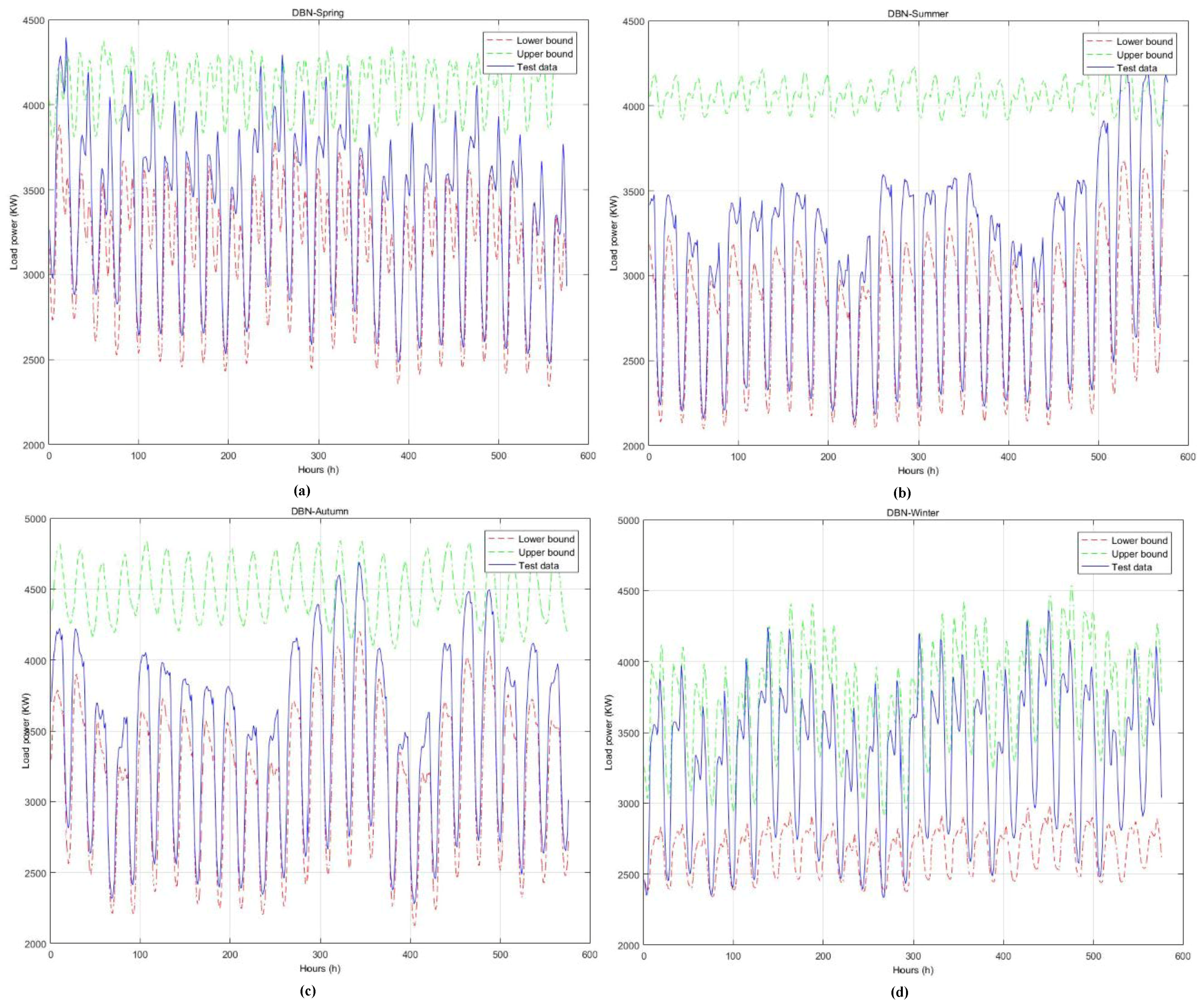
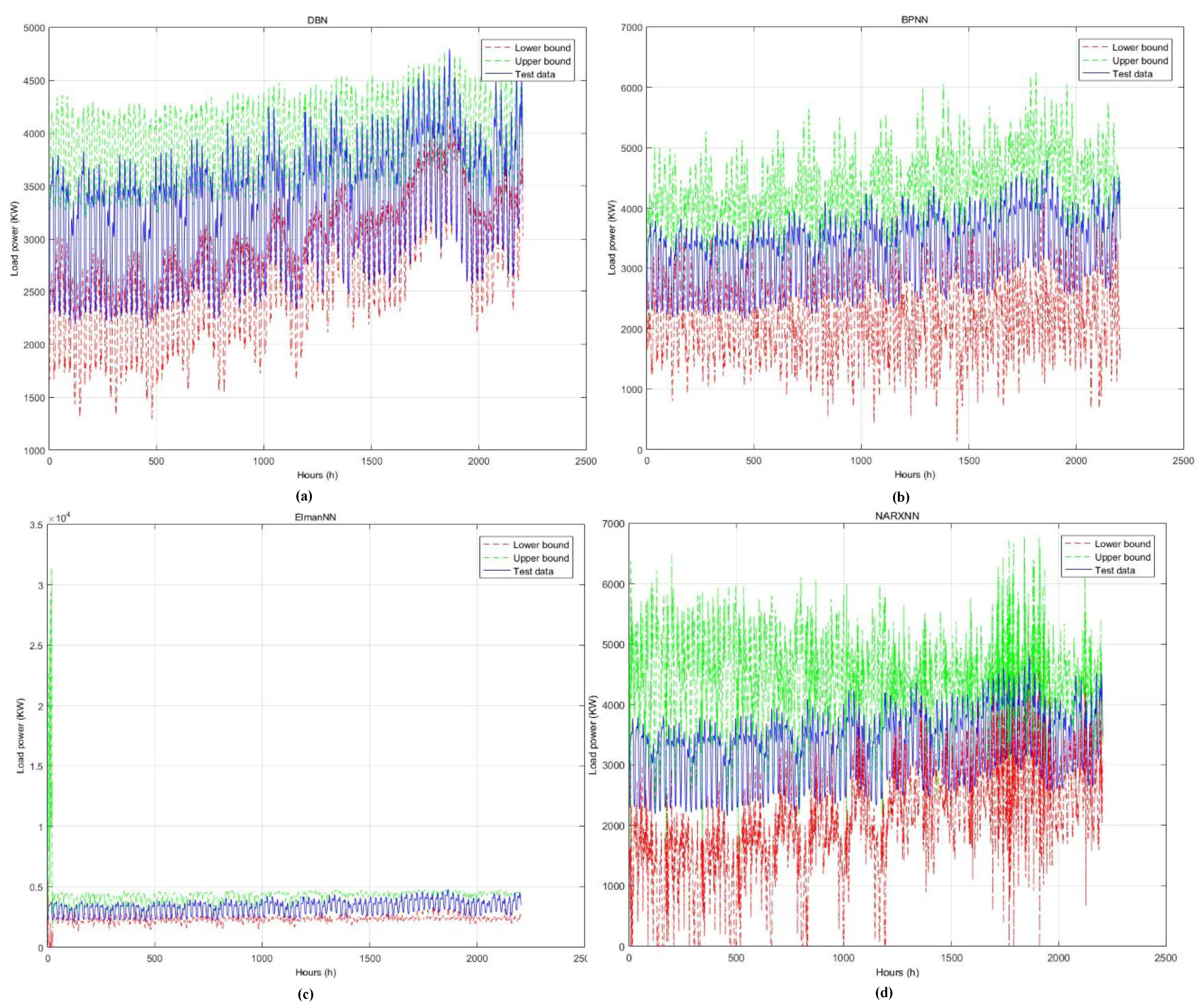
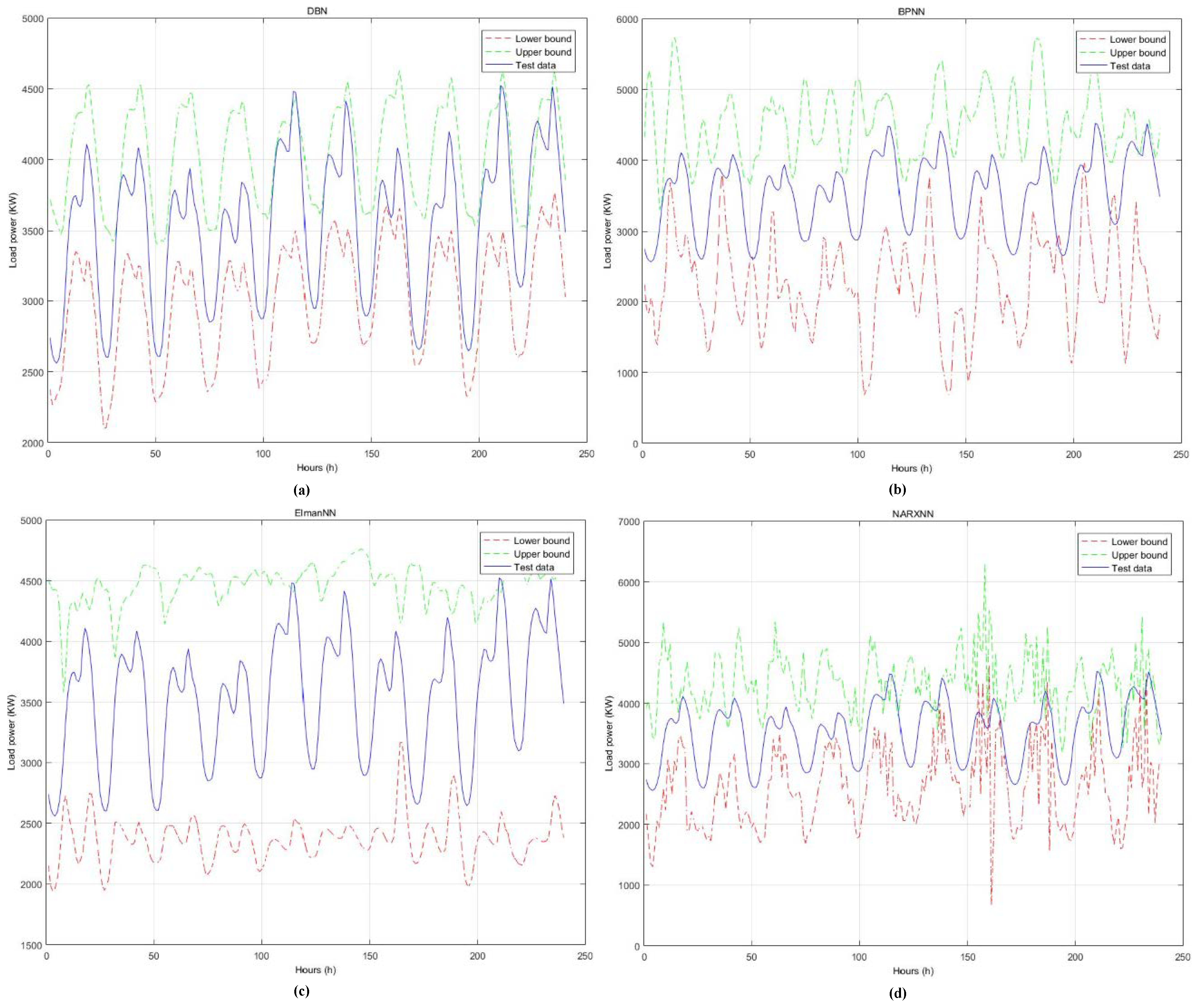
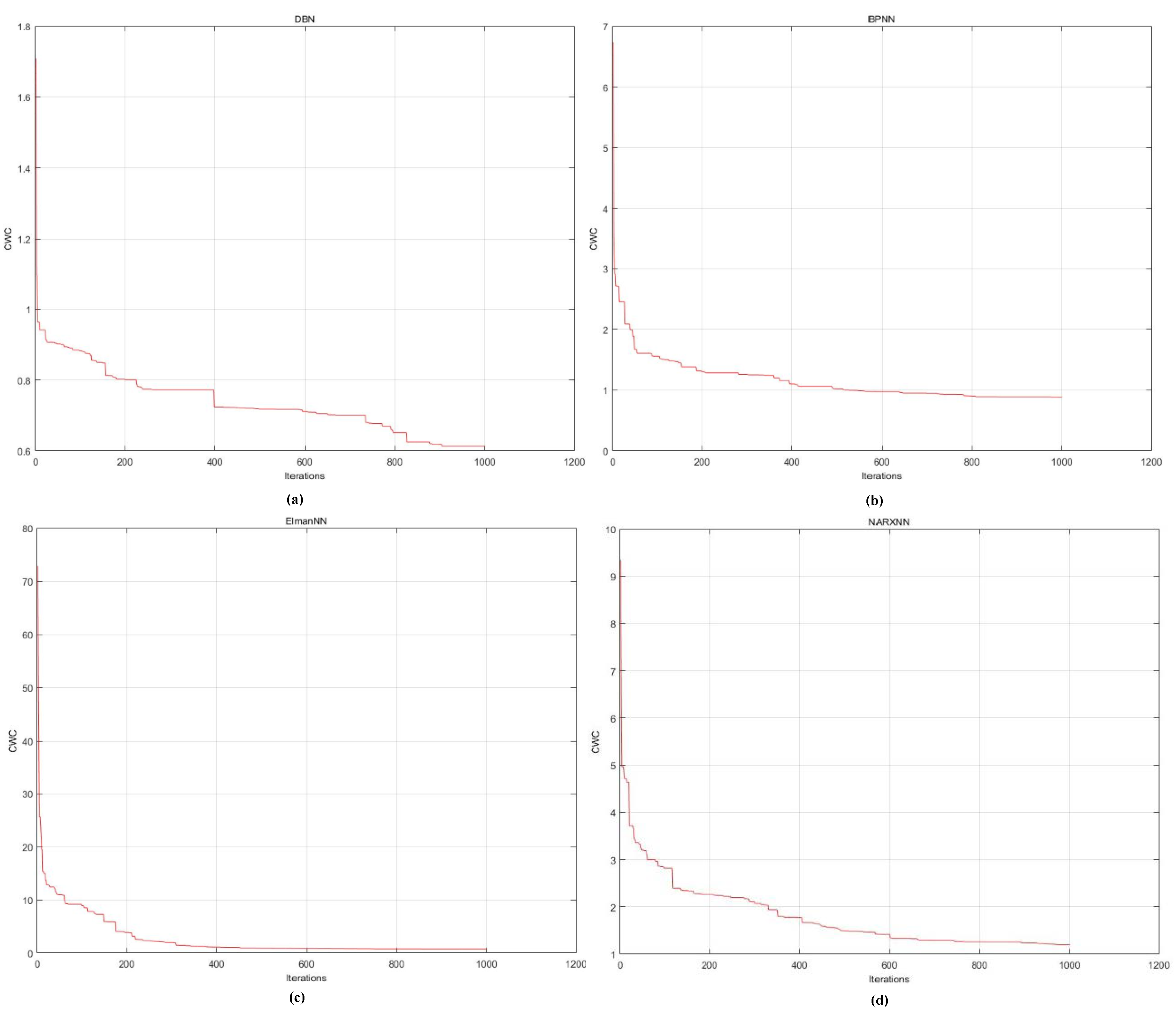
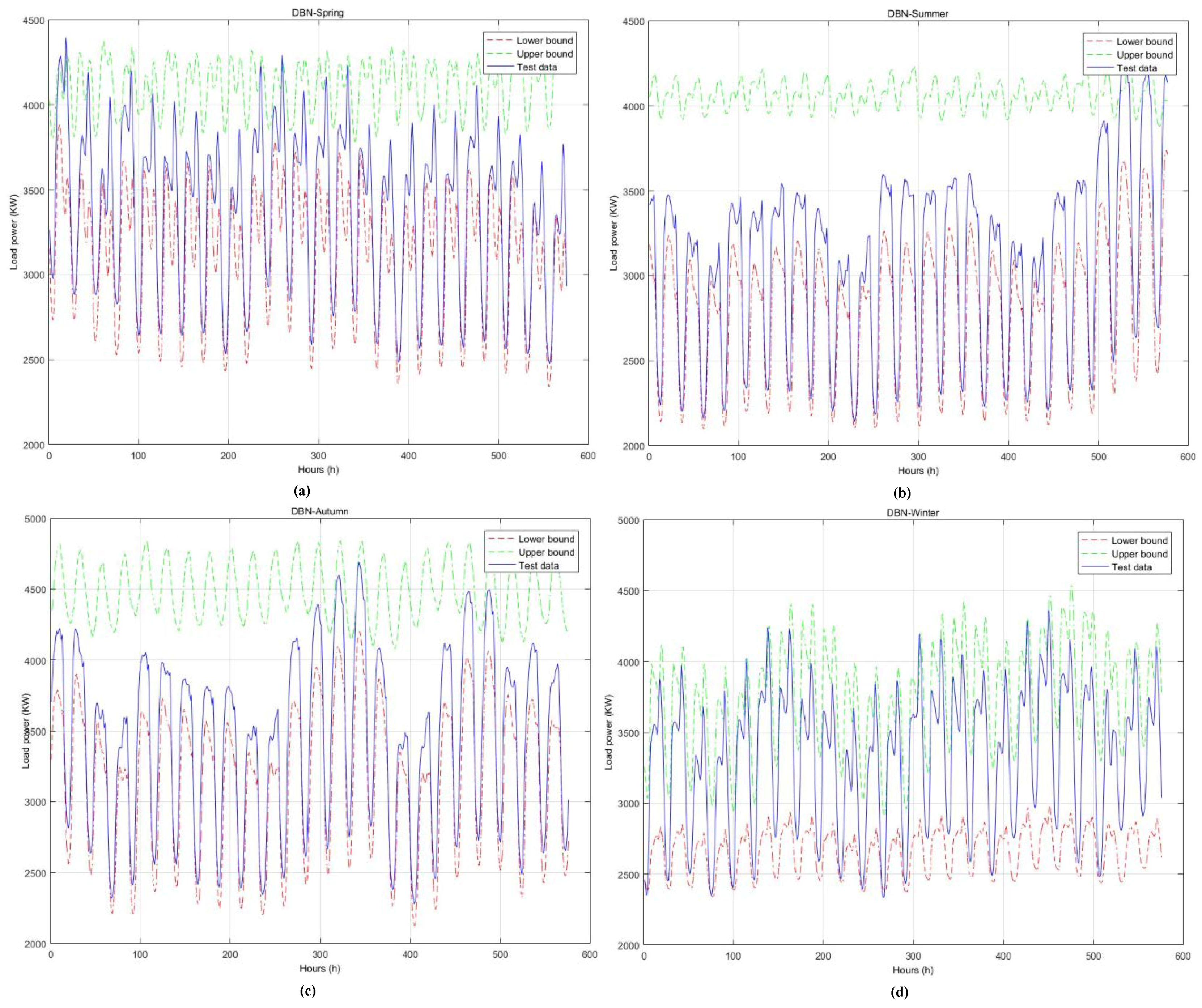
4.3. Results Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| ARIMA | Autoregressive Integrated Moving Average |
| BP | Back Propagation |
| CWC | Coverage Width-based Criterion |
| DBN | Deep Belief Network |
| DTW | Dynamic Time Warping |
| EMD | Empirical Mode Decomposition |
| ES | Exponential Smoothing |
| GA | Genetic Algorithm |
| LUBE | Lower Upper Bound Estimation |
| MAPE | Mean Absolute Percentage Error |
| MSE | Mean Square Error |
| NARX | Nonlinear Autoregressive Exogenous |
| NN | Neural Network |
| PI | Prediction Intervals |
| PICP | PI Coverage Probability |
| PINAW | PI Normalized Average Width |
| PSO | Particle Swarm Optimization |
| RBM | Restricted Boltzmann Machine |
| SVM | Support Vector Machines |
| STLP | Short-term Load Prediction |
| TISEAN | Time Series Analysis |
References
- Patterson, T.A.; Thomas, L.; Wilcox, C.; Ovaskainen, O.; Matthiopoulos, J. State–space models of individual animal movement. Trends Ecol. Evol. 2008, 23, 87–94. [Google Scholar] [CrossRef] [PubMed]
- Hayes, A.F. Introduction to Mediation, Moderation, and Conditional Process Analysis: A Regression-Based Approach; The Guilford Press: New York, NY, USA, 2014. [Google Scholar]
- Li, W.; Zhang, Z. Based on time sequence of ARIMA model in the application of short-term electricity load forecasting. In Proceedings of the 2009 International Conference on Research Challenges in Computer Science, Shanghai, China, 28–29 December 2009. [Google Scholar]
- Shankar, R.; Chatterjee, K.; Chatterjee, T.K. A Very Short-Term Load forecasting using Kalman filter for Load Frequency Control with Economic Load Dispatch. J. Eng. Sci. Technol. Rev. 2012, 5, 97–103. [Google Scholar] [CrossRef]
- Li, X.; Chen, H.; Gao, S. Electric power system load forecast model based on State Space time-varying parameter theory. In Proceedings of the 2010 International Conference on Power System Technology, Hangzhou, China, 24–28 October 2010. [Google Scholar]
- Li, G.; Cheng, C.T.; Lin, J.Y.; Zeng, Y. Short-Term load forecasting using support vector machine with SCE-UA algorithm. In Proceedings of the Third International Conference on Natural Computation (ICNC 2007), Haikou, China, 24–27 August 2007. [Google Scholar]
- Ganesan, S.; Padmanaban, S.; Varadarajan, R.; Subramaniam, U.; Mihet-Popa, L. Study and analysis of an intelligent microgrid energy management solution with distributed energy sources. Energies 2017, 10, 1419. [Google Scholar] [CrossRef]
- Martínez-Álvarez, F.; Troncoso, A.; Asencio-Cortés, G.; Riquelme, J.C. A survey on data mining techniques applied to electricity-related time series forecasting. Energies 2015, 8, 13162–13193. [Google Scholar] [CrossRef]
- Merkel, G.D.; Povinelli, R.J.; Brown, R.H. Short-Term load forecasting of natural gas with deep neural network regression. Energies 2018, 11, 1–12. [Google Scholar] [CrossRef]
- Kavousi-Fard, A.; Kavousi-Fard, F. A new hybrid correction method for short-term load forecasting based on ARIMA, SVR and CSA. J. Exp. Theor. Artif. Intell. 2013, 25, 559–574. [Google Scholar] [CrossRef]
- Quan, H.; Srinivasan, D.; Khosravi, A. Uncertainty handling using neural network-based prediction intervals for electrical load forecasting. Energy 2014, 73, 916–925. [Google Scholar] [CrossRef]
- Shi, Z.; Liang, H.; Dinavahi, V. Direct interval forecast of uncertain wind power based on recurrent neural networks. IEEE Trans. Sustain. Energy 2018, 9, 1177–1187. [Google Scholar] [CrossRef]
- Ni, Q.; Zhuang, S.; Sheng, H.; Wang, S.; Xiao, J. An optimized prediction intervals approach for short term PV power forecasting. Energies 2017, 10, 1669. [Google Scholar] [CrossRef]
- Fan, S.; Hyndman, R.J. Short-term load forecasting based on a semi-parametric additive model. IEEE Trans. Power Syst. 2012, 27, 134–141. [Google Scholar] [CrossRef]
- Khosravi, A.; Nahavandi, S.; Creighton, D. Construction of optimal prediction intervals for load forecasting problems. IEEE Trans. Power Syst. 2010, 25, 1496–1503. [Google Scholar] [CrossRef]
- Khosravi, A.; Mazloumi, E.; Nahavandi, S.; Creighton, D.; van Lint, J.W.C. Prediction intervals to account for uncertainties in travel time prediction. IEEE Trans. Intell. Transp. Syst. 2011, 12, 537–547. [Google Scholar] [CrossRef]
- Mackay, D.J.C. The evidence framework applied to classification networks. Neural Comput. 1992, 4, 720–736. [Google Scholar] [CrossRef]
- Oleng’, N.; Gribok, A.; Reifman, J. Error bounds for data-driven models of dynamical systems. Comput. Biol. Med. 2007, 37, 670–679. [Google Scholar] [CrossRef] [PubMed]
- Nix, D.A.; Weigend, A.S. Estimating the mean and variance of the target probability distribution. In Proceedings of the 1994 IEEE International Conference on Neural Networks (ICNN'94), Orlando, FL, USA, 28 June–2 July 1994. [Google Scholar]
- Khosravi, A.; Nahavandi, S.; Creighton, D.; Atiya, A.F. Lower upper bound estimation method for construction of neural network-based prediction intervals. IEEE Trans. Neural Netw. 2011, 22, 337–346. [Google Scholar] [CrossRef] [PubMed]
- Khosravi, A.; Nahavandi, S.; Creighton, D. Prediction interval construction and optimization for adaptive neurofuzzy inference systems. IEEE Trans. Fuzzy Syst. 2011, 19, 983–988. [Google Scholar] [CrossRef]
- Ak, R.; Vitelli, V.; Zio, E. An interval-valued neural network approach for uncertainty quantification in short-term wind speed prediction. IEEE Trans. Neural Netw. Learn. Syst. 2015, 26, 2787–2800. [Google Scholar] [CrossRef] [PubMed]
- Khodayar, M.; Kaynak, O.; Khodayar, M.E. Rough deep neural architecture for short-term wind speed forecasting. IEEE Trans. Ind. Informa. 2017, 13, 2770–2779. [Google Scholar] [CrossRef]
- Shen, Y.; Wang, X.; Chen, J. Wind power forecasting using multi-objective evolutionary algorithms for wavelet neural network-optimized prediction intervals. Appl. Sci. 2018, 82, 185. [Google Scholar] [CrossRef]
- Wang, J.; Gao, Y.; Chen, X. A novel hybrid interval prediction approach based on modified lower upper bound estimation in combination with multi-objective salp swarm algorithm for short-term load forecasting. Energies 2018, 11, 1561. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Kuremoto, T.; Kimura, S.; Kobayashi, K.; Obayashi, M. Time series forecasting using a deep belief network with restricted Boltzmann machines. Neurocomputing 2014, 137, 47–56. [Google Scholar] [CrossRef]
- Qiu, X.; Ren, Y.; Suganthan, P.N.; Amaratunga, G.A.J. Empirical mode decomposition based ensemble deep learning for load demand time series forecasting. Appl. Soft Comput. 2017, 54, 246–255. [Google Scholar] [CrossRef]
- Kuremoto, T.; Kimura, S.; Kobayashi, K.; Obayashi, M. Time series forecasting using restricted Boltzmann machine. In Proceedings of the 8th International Conference on Intelligent Computing, Huangshan, China, 25–29 July 2012; Huang, D.S., Gupta, P., Zhang, X., Premaratne, P., Eds.; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Kamada, S.; Ichimura, T. Fine tuning method by using knowledge acquisition from Deep Belief Network. In Proceedings of the IEEE 9th International Workshop on Computational Intelligence and Applications (IWCIA2016), Hiroshima, Japan, 5 January 2017. [Google Scholar]
- Papa, J.P.; Scheirer, W.; Cox, D.D. Fine-Tuning deep belief networks using harmony search. Appl. Soft Comput. 2015, 46, 875–885. [Google Scholar] [CrossRef]
- Zheng, Y.; Liu, Q.; Chen, E.; Ge, Y.; Zhao, L.J. Time series classification using multi-channels deep convolutional neural networks. In Proceedings of the International Conference on Web-Age Information Management, Macau, China, 16–18 June 2014; Springer: Cham, Switzerland, 2014. [Google Scholar]
- Zhang, X.; Wang, R.; Zhang, T.; Zha, Y. Short-term load forecasting based on an improved deep belief network. In Proceedings of the 2016 International Conference on Smart Grid and Clean Energy Technologies (ICSGCE), Chengdu, China, 19–22 October 2016. [Google Scholar]
- Zhang, X.; Wang, R.; Zhang, T.; Liu, Y.; Zha, Y. Effect of transfer functions in deep belief network for short-term load forecasting. In Proceedings of the 12th International Conference on Bio-Inspired Computing: Theories and Applications, Harbin, China, 1–3 December 2017; Springer: Singapore, 2017. [Google Scholar]
- Zhang, X.; Wang, R.; Zhang, T.; Liu, Y.; Zha, Y. Short-Term load forecasting using a novel deep learning framework. Energies 2018, 11, 1554. [Google Scholar] [CrossRef]
- Xia, D.; Song, S.; Wang, J.; Shi, J.; Bi, H.; Gao, Z. Determination of corrosion types from electrochemical noise by phase space reconstruction theory. Electrochem. Commun. 2012, 15, 88–92. [Google Scholar] [CrossRef]
- Takens, F. Detecting strange attractors in turbulence. In Dynamical Systems and Turbulence; Rand, D., Young, L.S., Eds.; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Nonlinear Time Series Analysis (TISEAN). Available online: https://www.mpipks-dresden.mpg.de/tisean/ (accessed on 5 June 2018).
- Gao, X.Z.; Ovaska, S.J. Genetic algorithm training of Elman neural network in motor fault detection. Neural Comput. Appl. 2002, 11, 37–44. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, R.; Zhang, T.; Wang, L.; Liu, Y.; Zha, Y. Short-Term load forecasting based on RBM and NARX neural network. In Proceedings of the 14th International Conference on Intelligent Computing, Wuhan, China, 15–18 August 2018; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Li, J.; Wang, R.; Zhang, T. Wind speed prediction using a cooperative coevolution genetic algorithm based on back propagation neural network. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar]
- Wang, R.; Purshouse, R.C.; Fleming, P.J. Preference-inspired Co-evolutionary Algorithms for Many-objective Optimization. IEEE Trans. Evol. Comput. 2013, 17, 474–494. [Google Scholar] [CrossRef]
- Wang, R.; Zhou, Z.; Ishibuchi, H.; Liao, T.; Zhang, T. Localized weighted sum method for many-objective optimization. IEEE Trans. Evol. Comput. 2018, 22, 3–18. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, Q.; Zhang, T. Decomposition-Based algorithms using Pareto adaptive scalarizing methods. IEEE Trans. Evol. Comput. 2016, 20, 821–837. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantage | Disadvantage |
|---|---|---|
| Delta method | NN is enhanced by the nonlinear regression technique | The use of linearization in NN |
| Bayesian method | Strong theoretical foundation of Bayesian concepts | Large computational burden required for the calculation of a Hessian matrix |
| Bootstrap method | Ease of implementation | The need of a large data set to support training and calculation |
| Mean-variance estimation-based method | The low calculation cost of the training process | The low empirical coverage probability |
| Training Sample | Training Objective |
|---|---|
| … | … |
| Model | CWC (%) | PICP (%) | PINAW (%) | Time |
|---|---|---|---|---|
| DBN | 47.02 | 96.60 | 47.02 | 578.41 s |
| BP | 81.84 | 95.83 | 81.84 | 629.97 s |
| Elman | 79.45 | 96.42 | 79.45 | 982.52 s |
| NARX | 91.16 | 91.38 | 91.16 | 970.92 s |
| Season | CWC (%) | PICP (%) | PINAW (%) | Time |
|---|---|---|---|---|
| Spring | 51.08 | 96.01 | 51.08 | 153.46 s |
| Summer | 57.74 | 96.01 | 57.74 | 158.88 s |
| Autumn | 54.94 | 99.83 | 54.94 | 157.53 s |
| Winter | 54.47 | 93.75 | 54.47 | 164.43 s |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Shu, Z.; Wang, R.; Zhang, T.; Zha, Y. Short-Term Load Interval Prediction Using a Deep Belief Network. Energies 2018, 11, 2744. https://doi.org/10.3390/en11102744
Zhang X, Shu Z, Wang R, Zhang T, Zha Y. Short-Term Load Interval Prediction Using a Deep Belief Network. Energies. 2018; 11(10):2744. https://doi.org/10.3390/en11102744
Chicago/Turabian StyleZhang, Xiaoyu, Zhe Shu, Rui Wang, Tao Zhang, and Yabing Zha. 2018. "Short-Term Load Interval Prediction Using a Deep Belief Network" Energies 11, no. 10: 2744. https://doi.org/10.3390/en11102744
APA StyleZhang, X., Shu, Z., Wang, R., Zhang, T., & Zha, Y. (2018). Short-Term Load Interval Prediction Using a Deep Belief Network. Energies, 11(10), 2744. https://doi.org/10.3390/en11102744