
Optimizing the Structure of Distribution Smart Grids with Renewable Generation against Abnormal Conditions: A Complex Networks Approach with Evolutionary Algorithms




Abstract
1. Introduction
- We model a smart grid with RE generators and loads (prosumers) as an undirected graph so that each link allows for the bidirectional exchange of electric energy.
- We propose an objective function to be optimized that combines cost elements (related to the number and average length of links and also to the number of nodes with many links) and several properties that are beneficial for the SG (such as energy exchanges at local scale and high robustness and resilience). Our optimization problem includes some restrictions used in [30] and also others that help our EA find optimal synthetic structures for the SG, starting from scratch. This is a “greenfield” strategy, used by companies in those zones where they do not have infrastructure, deploying thus the new grid starting from scratch. This is another difference when compared to [30], in which the authors have just adopted a “brownfield” approach aiming at evolving the conventional low voltage power grid into a smart grid.
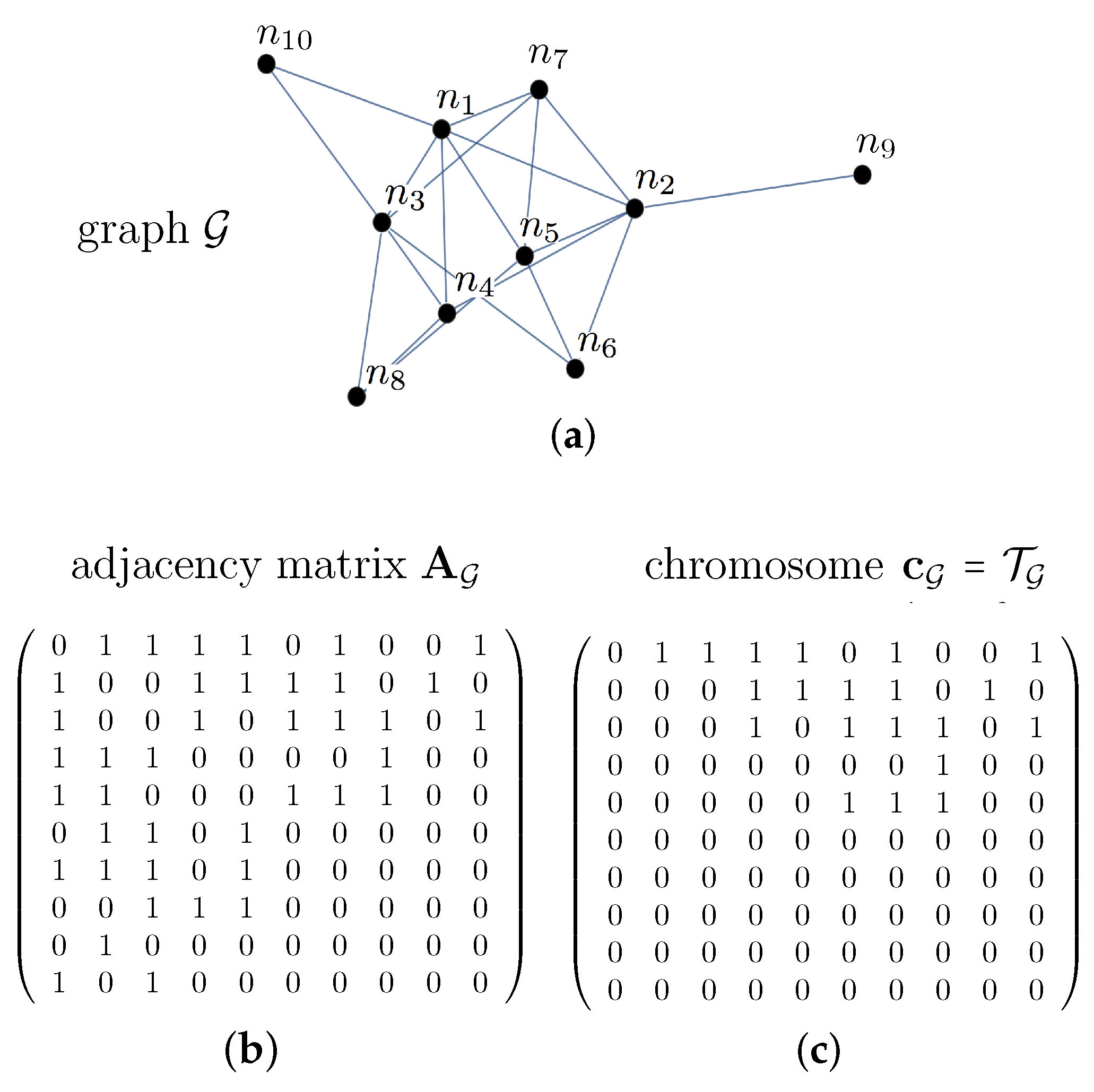
- We use an EA with a problem representation in which the chromosome , which encodes each potential graph (or individual), is the upper triangular matrix of its “adjacency matrix”, . In this formulation, is a square, symmetric and binary matrix in which any element encodes whether node i is linked to node j () or not () [42]. Since there is no self-connected node, the adjacency matrix has zeros on its main (principal) diagonal (). These are the reasons why the connection information in graph is stored by its upper triangular matrix . Thus, chromosome encodes in a compact form the graph . As will be shown in detail in Section 2, this encoding is different from others found in the literature using EAs on graphs, such as, for instance, a chromosome formed by a one-dimensional array with N elements (the number of graph nodes) [43], N-length chromosome of two-dimensional elements [44] (where a node is specified by its location in the graph) or a set of vectors in which each allele (or gene value) represents a community [45]. The mutation and crossover operators are fully adapted to our encoding. This approach could be generalized by considering the strength of the connection between node i and j in terms of its link weight .
2. Related Work
2.1. The Smart Grid as a Complex Network: Related Work
2.2. Evolutionary Computation in Graph Approaches: Related Work
3. Background: Complex Networks Concepts
3.1. Some Useful Definitions in Complex Network
- An “undirected” graph is a graph for which the relationship between pairs of nodes are symmetric, so that each link has no directional character (unlike a “directed graph”). Unless otherwise stated, the term “graph” is assumed to refer to an undirected graph.
- A graph is “connected” if there is a path from any two different nodes of . A disconnected graph can be partitioned into at least two subsets of nodes so that there is no link connecting the two components (“connected subgraphs”) of the graph.
- A “simple graph” is an unweighted, undirected graph containing neither loops nor multiple edges.
- The “order” of a graph is the number of nodes in set , that is the cardinality of set , which we represent as . We label the order of a graph as N, .
- The “size” of a graph is the number of links in the set , , and can be defined (≐) as:where if node i is linked to node j and otherwise. As mentioned before, are the matrix elements of the adjacency matrix.
- The “degree” of a node i is the number of links connecting i to any other node and is simply:
- The node degree is characterized by a probability density function giving the probability that a randomly-selected node has k links.
- A “geodesic path” is the shortest path through the network from one nodes to another; or in other words, a geodesic path is the path that has the minimal number of links between two nodes. Note that there may be and often is more than one geodesic path between two nodes [42].
- The “distance” between two nodes i and j, , is the length of the shortest path (geodesic path) between them, that is the minimum number of links when going from one node to the other.
- The “average path length” of a network is the mean value of distances between any pair of nodes in the network [42]:where is the distance between node i and node j.
- The “clustering coefficient” is a local property capturing the density of triangles in a network. That is, two nodes that are connected to a third node are also directly connected to each other. Thus, a node i in a network has links that connects it to other nodes. The clustering coefficient of node i is defined as the ratio between the number of links that exist between these vertices and the maximum possible number of links (. The clustering coefficient of the whole network is [33]:that is, for a given node, we compute the number of neighboring nodes that are connected to each other and average this number over all of the nodes in the network.
- The “betweenness centrality” quantifies how much a node v is found between the paths linking other pairs of nodes, that is,where is the total number of shortest paths from node s to node t and is the number of those paths that pass through v. A high value for node v means that this node, for certain paths, is critical to support node connections. The attack or failure of v would lead to a number of node pairs either being disconnected or connected via longer paths.
3.2. Small-World Property and Its Importance in Robustness
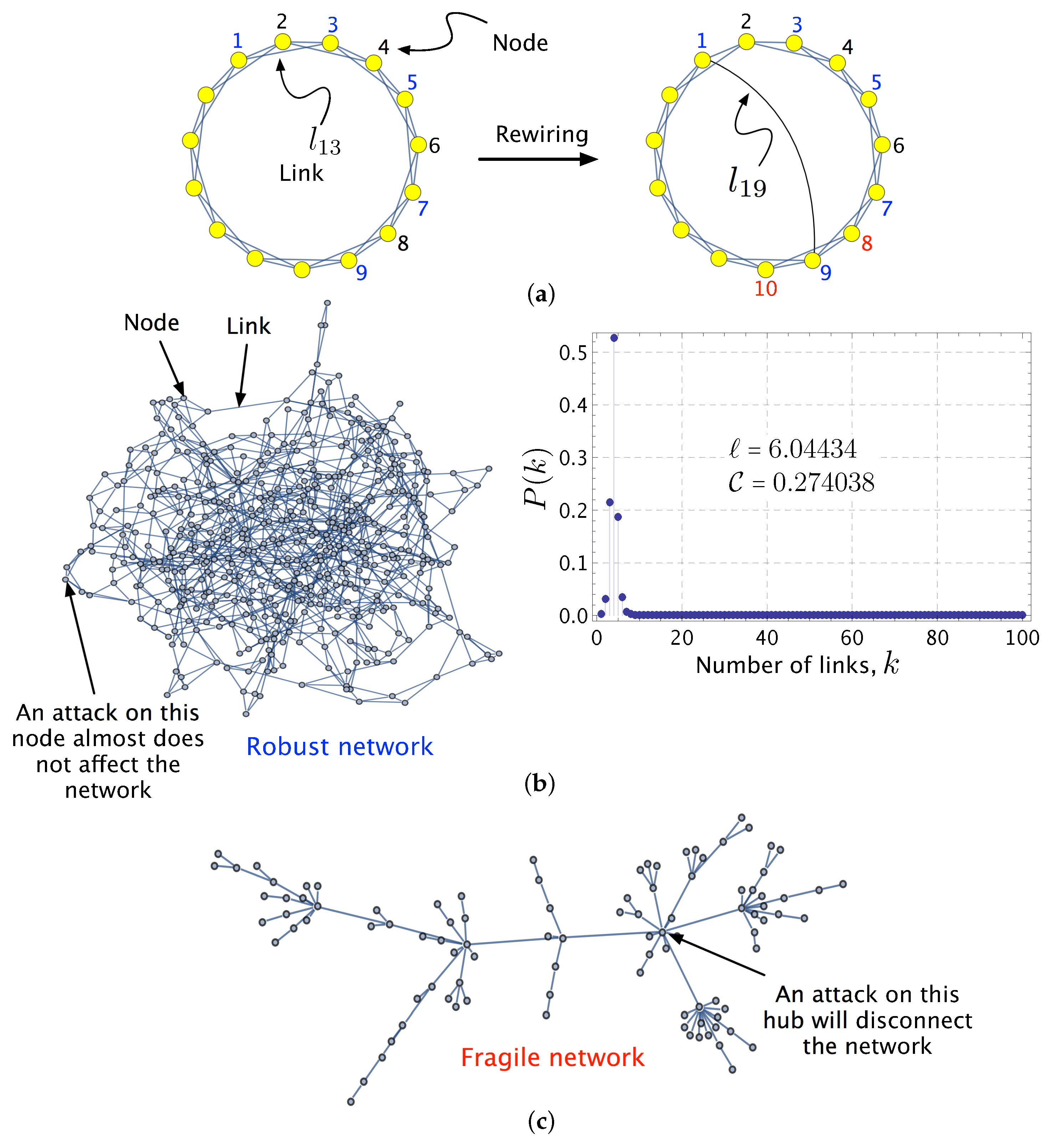
- A small-world network is a complex network in which the mean distance or average path length ℓ is small when compared to the total number of nodes N in the network: as . That is, there is a relatively short path between any pair of nodes [71,72]. The term “small-world networks” is often used to refer Watts–Strogatz (WS) networks, first studied in [72]. It can be generated by the “rewiring” method shown in Figure 1a: Link , which was connecting Node 1 to Node 3, is disconnected (from Node 3) and rewired to connect Node 1 to Node 9. In the resulting network, going from Node 1 to Node 9 only requires one jump via the rewired link (and thus, ). However, in the original regular network, going from Node 1 to Node 9 through the geodesic or shortest path () involves four links (). This leads to networks with small average shortest path lengths between nodes ℓ, and high clustering coefficient . Figure 1b shows the aspect and of a WS we have generated with nodes and “rewiring probability” . It has a short mean distance, , and high clustering, . Most of the small-world networks have exponential degree distributions [73].
- Figure 1b ( and ) also illustrates that the architecture of real small-world networks is extremely heterogeneous: the vast majority of the elements are poorly connected, but simultaneously, few have a large number of connections [74]. The robustness of small-world network has been explored in [75,76] leading to the conclusion that, in a non-sparse WS network (), simultaneously increasing both rewiring probability and average degree improves significantly the robustness of the small-world network.
- An interesting variation of the WS model is the one proposed by Newman and Watts [77] (NW small-world model) in which one does not break any connection between any two nearest neighbors, but instead, adds with probability p a connection between a pair of nodes. It has been found that for sufficiently small p and sufficiently large N, the NW model is basically equivalent to the WS model [78]. At present, these two models are together commonly termed small-world models.
4. Background: Hybrid Approaches Combining Complex Networks and Electric Engineering Concepts
5. Discussion: Is the CN Approach Useful in Power Grids?
5.1. Power Grids: Is There a Dominant Topology?
5.2. Unweighted and Weighted Graphs: Which Is the Best?
6. Proposal: Metrics, Objective Function and Problem Statement
6.1. Metrics to Construct the Objective Function
- It is necessary for the SG to have a structure with reduces losses in the electric cables used to transport electric power from one node to another. This electrical restriction can be modeled using the condition:which, as pointed out in [30], is related to giving a reduced path when moving from one node to another in a general purpose complex network. In the particular case of a smart grid, this may lead to a topology with limited losses in the circuits used to transfer electricity from one node to another. That is, it is a requirement related to the efficiency of the network. Along with the high clustering coefficient, this is also one of the properties of small-world networks, in which the mean distance or average path length ℓ is small when compared to the total number of nodes N in the network: as . A small value of ℓ is also important from the economic viewpoint since it may lead to smaller cost.
- Since the node degree of a node i is the number of links connecting i to any other node, its maximum value gets an upper limit related to the maximum power that a node can support:The value of is related to the maximum power that a node is able to support and is directly related to its economic cost. In [30], average degree values ranging from to lead to a good balance between performance and cost.
- The clustering coefficient defined by Equation (4) of a smart grid should be higher than that of the corresponding random network (RN) with the same order (number of nodes) and size (number of links). This aims at assuring a local clustering among nodes because it is more likely that electricity exchanges occur in the neighborhood in a scenario with many small-scale distributed RE generators [30].
- We measure the network vulnerability by using the concept of multiscale vulnerability of order p of a graph [113,114],where is the betweenness centrality of link l. The multi-scale vulnerability of a graph measures the distribution of shortest paths when links are failing (or attacked) [114] and is very useful when comparing the vulnerability of networks because it helps distinguish between non-identical although very similar network topologies [113]. As shown in [114], if we want to distinguish between two networks with graphs and , one first computes . If , then one takes and computes until . Using this approach, we have considered . A network represented by a graph is less vulnerable (more robust) than another if . Please see [113,114] for further details.
- A coefficient of variation for betweenness [30],where is the standard deviation of betweenness () and is the mean value of betweenness. Distributions with are known as low-variance ones. This requirement leads to network resilience by providing distributions of shortest paths that are more uniform among all nodes. See [30] for further details.
6.2. Proposed Objective Function
- Reducing in the effort of decreasing the economic cost and the electric losses in the links used to transport electricity from one node to another. Reducing makes the network less robust. This is because the minimum value of , [113], is reached for the “fully-connected network” or “completely-connected graph” in which any node is connected with all of the others. As the number of links decreases, the network becomes increasingly fragile and . Reducing to a great extent leads to an inexpensive, but very fragile structure ( [113,114]). Thus, the decrease of the number of links and the increase of the robustness have opposite tendencies. This is why we propose a balance between and via the weight parameter , which controls the linear combination between constituents with opposing trends.
- Reducing (approaching one from above) to increase robustness and also to improve resilience.
- Reducing ℓ along with maximizing leads to a small-world structure.
- Increasing aiming to stimulate the local electricity exchanges in scenarios with many small-scale distributed RE generators.
6.3. Problem Statement
7. Proposed Evolutionary Algorithm
7.1. Basic Concepts
7.1.1. Genotype-Phenotype Relationship
7.1.2. Natural Evolution
7.2. Evolutionary Algorithm Used
7.2.1. Encoding Method
7.2.2. Initial Population
- Fifty percent of are Watts–Strogatz random graphs (with small-world properties, including short average path lengths and high clustering) with rewiring probability ranging from to one.
- Fifty percent of are Erdős–Rényi (ER) random graphs with N nodes and links.
7.2.3. Implementation of Evolutionary Operators
Selection Operator
Crossover Operator
- Select at random () two individuals from the population (father and mother).
- Select at random the same row in the parents.
- Exchange the selected rows between the father and the mother, which leads to two child chromosomes.
Mutation Operator
8. Experimental Work
8.1. Methodology
8.2. Results: Optimizing the Structure
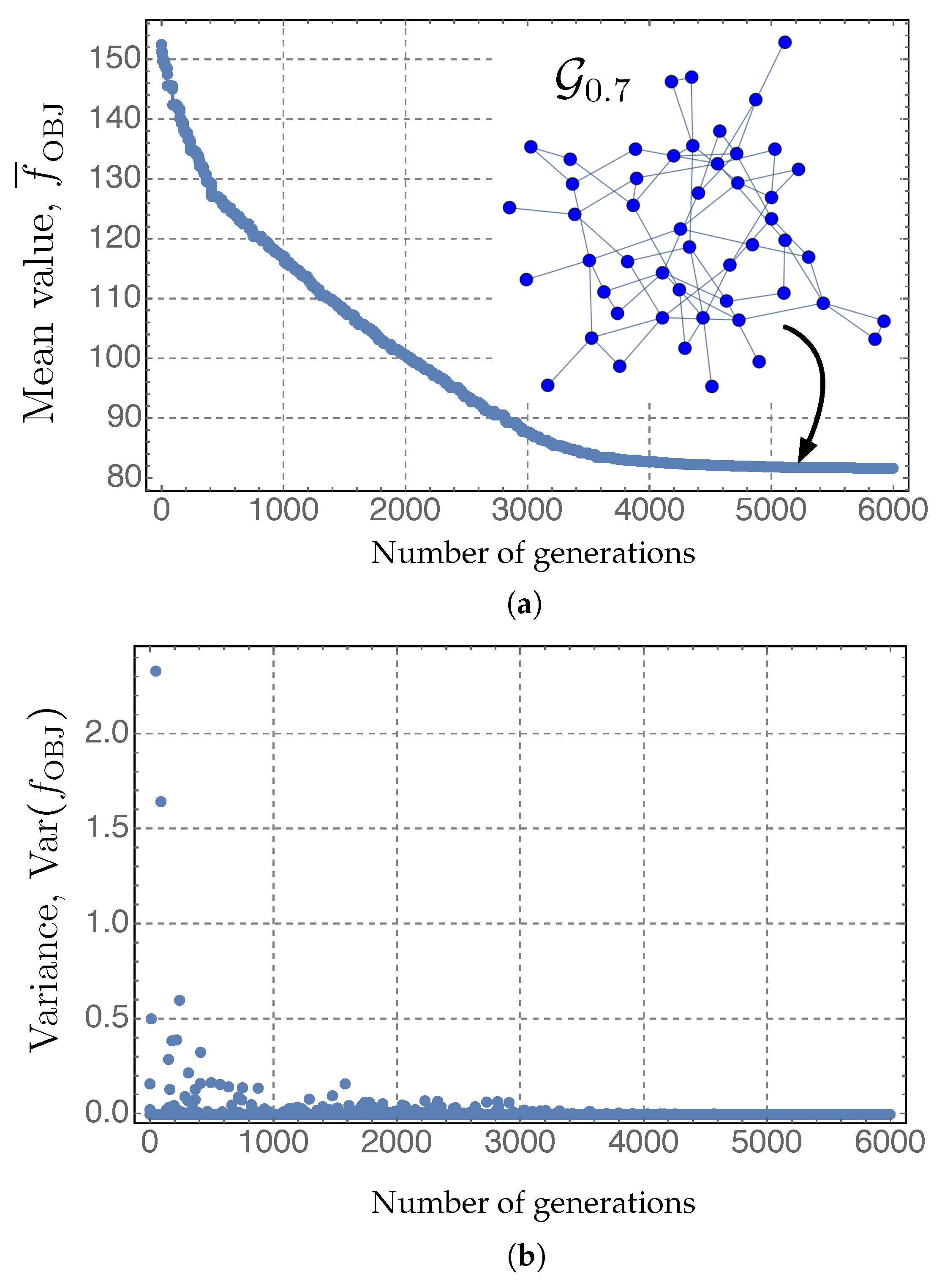
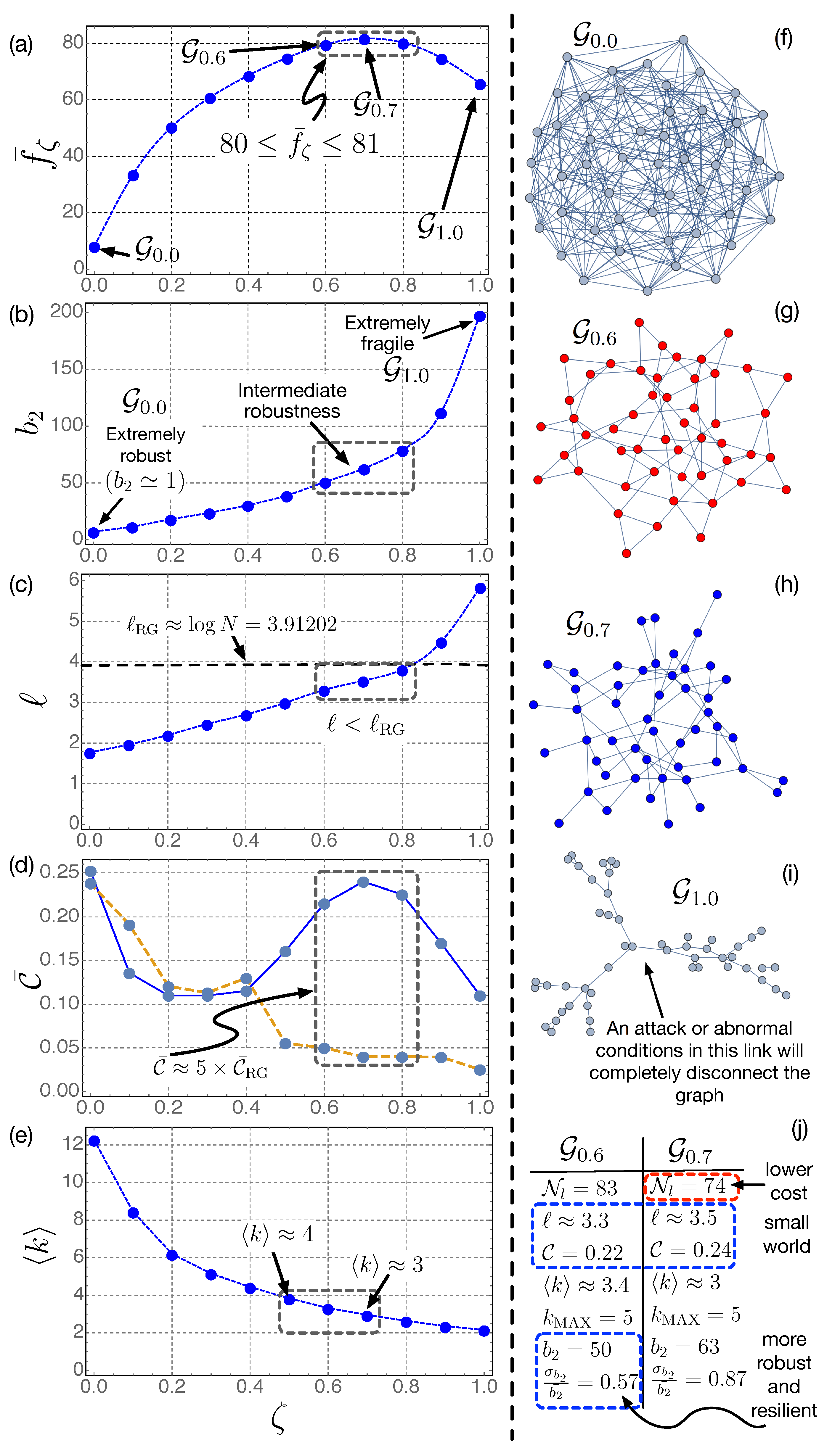
- The optimum value of in Figure 5a is achieved for . This corresponds to the optimum graph shown in Figure 5h. This graph has (Figure 5), which is an intermediate robustness between the one of (Figure 5f) and that corresponding to (Figure 5j). arises from the tradeoff between having a reasonable robustness and efficient power exchange at the local scale (high and low ℓ) with a limited number of links (, the number of links of ). represents a network with high number of links, very interconnected, and thus, potentially very expensive, and with very high robustness (smallest fragility, ). On the contrary, , which has , is thus very fragile: note in Figure 5j that the occurrence of abnormal conditions on the marked link will completely disconnect the power grid. In this limiting case (), the optimum network has only 51 links (very low economical cost), but at the expense of being very vulnerable to targeted attacks on hubs.
- A key point to note in Figure 5a is that, in the interval , the objective function has a slight variation , in which the corresponding optimum graphs , and exhibit some beneficial properties for the smart grid:
- (a)
- Intermediate robustness, ranging from 50 to 80 in Figure 5b.
- (b)
- (c)
- Clustering coefficient considerably higher than that of the random graph (with the same number of nodes and links), (see Figure 5d). This is related to the local exchange of power between neighbor nodes [30]. These two latter conditions are topological features that help the power grid be a smart grid. Furthermore, the two latter features show that the graphs in have the small-world nature. In particular, these graphs with approach non-sparse small-world networks (with ), which, according to [76], are the most robust.
- (d)
- Additionally, in , , in good agreement with the properties described in [30].
- (e)
- The average node degree has values , which has been proven to be beneficial in [30].
- (f)
- ranges between and , which limits the existence of nodes with many links, and therefore, with high capacity (≈ more expensive).
8.3. The Benefits of Adding Links
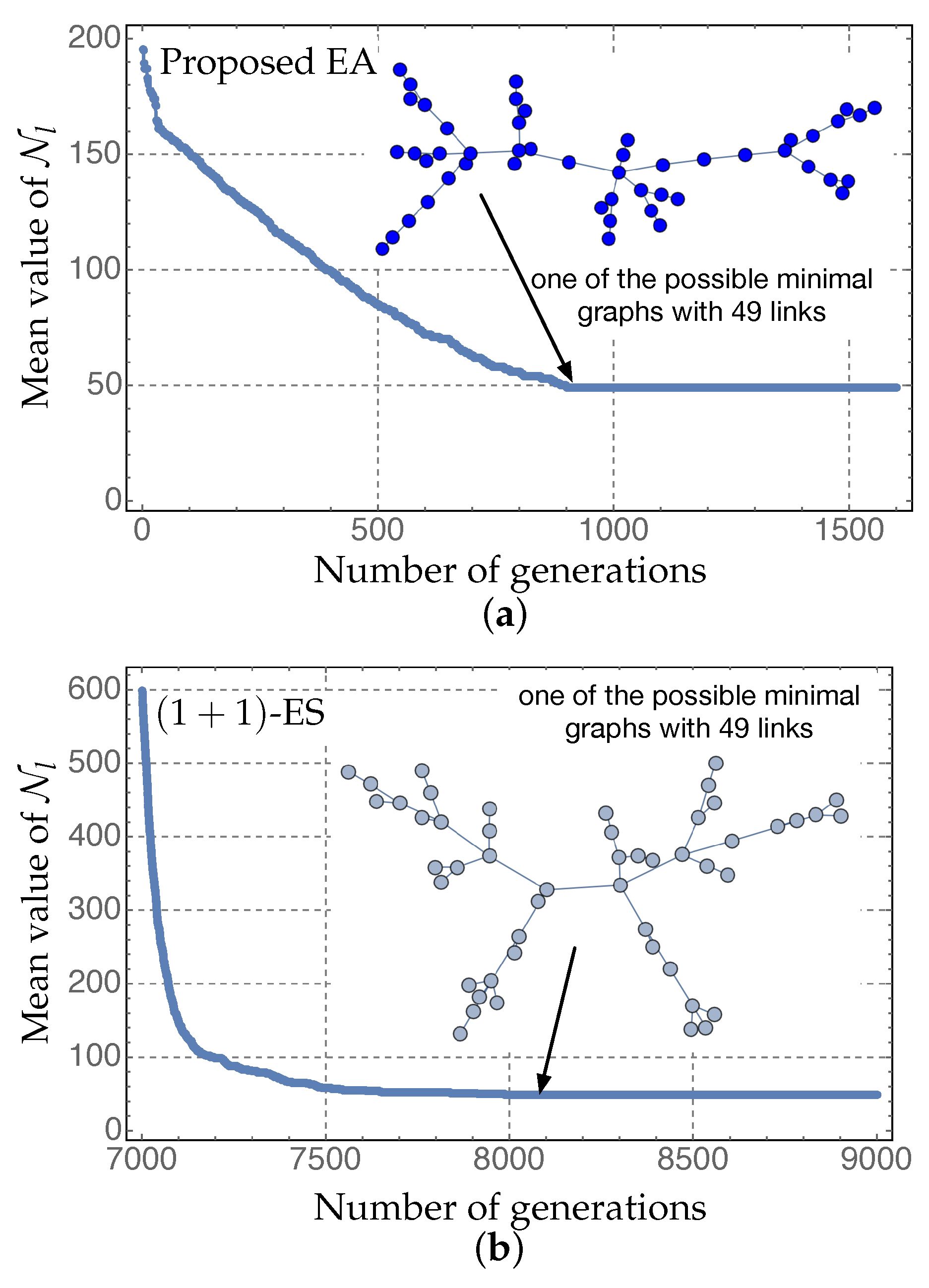
8.4. Comparison with an Evolution Strategy
9. Summary and Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Bauer, N.; Bosetti, V.; Hamdi-Cherif, M.; Kitous, A.; McCollum, D.; Méjean, A.; Rao, S.; Turton, H.; Paroussos, L.; Ashina, S.; et al. CO2 emission mitigation and fossil fuel markets: dynamic and international aspects of climate policies. Technol. Forecast. Soc. Chang. 2015, 90, 243–256. [Google Scholar]
- Peters, G.P.; Andrew, R.M.; Boden, T.; Canadell, J.G.; Ciais, P.; Le Quéré, C.; Marland, G.; Raupach, M.R.; Wilson, C. The challenge to keep global warming below 2 °C. Nat. Clim. Chang. 2013, 3, 4–6. [Google Scholar] [CrossRef]
- Adefarati, T.; Bansal, R. Reliability assessment of distribution system with the integration of renewable distributed generation. Appl. Energy 2017, 185, 158–171. [Google Scholar]
- Chen, J.; Zhu, Q. A game-theoretic framework for resilient and distributed generation control of renewable energies in microgrids. IEEE Trans. Smart Grid 2017, 8, 285–295. [Google Scholar]
- Aghajani, G.; Shayanfar, H.; Shayeghi, H. Demand side management in a smart micro-grid in the presence of renewable generation and demand response. Energy 2017, 126, 622–637. [Google Scholar] [CrossRef]
- Cabrera-Tobar, A.; Bullich-Massagué, E.; Aragüés-Peñalba, M.; Gomis-Bellmunt, O. Review of advanced grid requirements for the integration of large scale photovoltaic power plants in the transmission system. Renew. Sustain. Energy Rev. 2016, 62, 971–987. [Google Scholar]
- Datas, A.; López, E.; Ramiro, I.; Antolín, E.; Martí, A.; Luque, A.; Tamaki, R.; Shoji, Y.; Sogabe, T.; Okada, Y. Intermediate band solar cell with extreme broadband spectrum quantum efficiency. Phys. Rev. Lett. 2015, 114, 157701. [Google Scholar] [CrossRef] [PubMed]
- Cetinay, H.; Kuipers, F.A.; Guven, A.N. Optimal siting and sizing of wind farms. Renew. Energy 2017, 101, 51–58. [Google Scholar]
- Colmenar-Santos, A.; Perera-Perez, J.; Borge-Diez, D.; dePalacio-Rodríguez, C. Offshore wind energy: A review of the current status, challenges and future development in Spain. Renew. Sustain. Energy Rev. 2016, 64, 1–18. [Google Scholar] [CrossRef]
- Cuadra, L.; Salcedo-Sanz, S.; Nieto-Borge, J.; Alexandre, E.; Rodríguez, G. Computational intelligence in wave energy: Comprehensive review and case study. Renew. Sustain. Energy Rev. 2016, 58, 1223–1246. [Google Scholar]
- Santos, S.F.; Fitiwi, D.Z.; Cruz, M.R.; Cabrita, C.M.; Catalão, J.P. Impacts of optimal energy storage deployment and network reconfiguration on renewable integration level in distribution systems. Appl. Energy 2017, 185, 44–55. [Google Scholar] [CrossRef]
- Caramia, P.; Carpinelli, G.; Mottola, F.; Russo, G. An optimal control of distributed energy resources to improve the power quality and to reduce energy costs of a hybrid AC-DC microgrid. In Proceedings of the 2016 IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), Florence, Italy, 7–10 June 2016; pp. 1–7. [Google Scholar]
- Kyritsis, E.; Andersson, J.; Serletis, A. Electricity prices, large-scale renewable integration, and policy implications. Energy Policy 2017, 101, 550–560. [Google Scholar] [CrossRef]
- Salpakari, J.; Lund, P. Optimal and rule-based control strategies for energy flexibility in buildings with PV. Appl. Energy 2016, 161, 425–436. [Google Scholar] [CrossRef]
- Yang, A.S.; Su, Y.M.; Wen, C.Y.; Juan, Y.H.; Wang, W.S.; Cheng, C.H. Estimation of wind power generation in dense urban area. Appl. Energy 2016, 171, 213–230. [Google Scholar] [CrossRef]
- Pagani, G.A.; Aiello, M. Power grid complex network evolutions for the smart grid. Phys. Stat. Mech. Appl. 2014, 396, 248–266. [Google Scholar] [CrossRef]
- Javaid, N.; Javaid, S.; Abdul, W.; Ahmed, I.; Almogren, A.; Alamri, A.; Niaz, I.A. A hybrid genetic wind driven heuristic optimization algorithm for demand side management in smart grid. Energies 2017, 10, 319. [Google Scholar] [CrossRef]
- Good, N.; Ellis, K.A.; Mancarella, P. Review and classification of barriers and enablers of demand response in the smart grid. Renew. Sustain. Energy Rev. 2017, 72, 57–72. [Google Scholar] [CrossRef]
- Yoldaş, Y.; Önen, A.; Muyeen, S.; Vasilakos, A.V.; Alan, İ. Enhancing smart grid with microgrids: Challenges and opportunities. Renew. Sustain. Energy Rev. 2017, 72, 205–214. [Google Scholar] [CrossRef]
- Wang, H.; Huang, J. Joint Investment and Operation of Microgrid. IEEE Trans. Smart Grid 2017, 8, 833–845. [Google Scholar] [CrossRef]
- Wang, H.; Huang, J. Cooperative Planning of Renewable Generations for Interconnected Microgrids. IEEE Trans. Smart Grid 2016, 7, 2486–2496. [Google Scholar] [CrossRef]
- Wang, H.; Huang, J. Incentivizing Energy Trading for Interconnected Microgrids. IEEE Trans. Smart Grid 2017, PP, 1. [Google Scholar] [CrossRef]
- Tan, K.M.; Ramachandaramurthy, V.K.; Yong, J.Y. Integration of electric vehicles in smart grid: A review on vehicle to grid technologies and optimization techniques. Renew. Sustain. Energy Rev. 2016, 53, 720–732. [Google Scholar] [CrossRef]
- Bahari, H.I.; Shariff, S.S.M. Review on data center issues and challenges: Towards the Green Data Center. In Proceedings of the 2016 6th IEEE International Conference on Control System, Computing and Engineering (ICCSCE), Batu Ferringhi, Malaysia, 25–27 November 2016; pp. 129–134. [Google Scholar]
- Carpinelli, G.; Mottola, F.; Proto, D.; Varilone, P. Minimizing unbalances in low-voltage microgrids: Optimal scheduling of distributed resources. Appl. Energy 2017, 191, 170–182. [Google Scholar] [CrossRef]
- Di Fazio, A.R.; Russo, M.; Valeri, S.; De Santis, M. LV distribution system modelling for distributed energy resources. In Proceedings of the 2016 IEEE 16th International Conference on Environment and Electrical Engineering (EEEIC), Florence, Italy, 7–10 June 2016; pp. 1–6. [Google Scholar]
- Carpinelli, G.; Mottola, F.; Proto, D.; Russo, A. A multi-objective approach for microgrid scheduling. IEEE Trans. Smart Grid 2016, PP, 1–10. [Google Scholar] [CrossRef]
- Colak, I.; Sagiroglu, S.; Fulli, G.; Yesilbudak, M.; Covrig, C.F. A survey on the critical issues in smart grid technologies. Renew. Sustain. Energy Rev. 2016, 54, 396–405. [Google Scholar] [CrossRef]
- Tuballa, M.L.; Abundo, M.L. A review of the development of Smart Grid technologies. Renew. Sustain. Energy Rev. 2016, 59, 710–725. [Google Scholar] [CrossRef]
- Pagani, G.A.; Aiello, M. From the grid to the smart grid, topologically. Phys. Stat. Mech. Appl. 2016, 449, 160–175. [Google Scholar] [CrossRef]
- Shi, B.; Liu, J. Decentralized control and fair load-shedding compensations to prevent cascading failures in a smart grid. Int. J. Electr. Power Energy Syst. 2015, 67, 582–590. [Google Scholar] [CrossRef]
- Jiao, Z.; Gong, H.; Wang, Y. A DS Evidence Theory-based Relay Protection System Hidden Failures Detection Method in Smart Grid. IEEE Trans. Smart Grid 2016, PP, 1. [Google Scholar] [CrossRef]
- Cuadra, L.; Salcedo-Sanz, S.; Del Ser, J.; Jiménez-Fernández, S.; Geem, Z.W. A critical review of robustness in power grids using complex networks concepts. Energies 2015, 8, 9211–9265. [Google Scholar] [CrossRef]
- Bompard, E.; Luo, L.; Pons, E. A perspective overview of topological approaches for vulnerability analysis of power transmission grids. Int. J. Crit. Infrastruct. 2015, 11, 15–26. [Google Scholar] [CrossRef]
- Rosas-Casals, M.; Bologna, S.; Bompard, E.F.; D’Agostino, G.; Ellens, W.; Pagani, G.A.; Scala, A.; Verma, T. Knowing power grids and understanding complexity science. Int. J. Crit. Infrastruct. 2015, 11, 4–14. [Google Scholar] [CrossRef]
- Dörfler, F.; Chertkov, M.; Bullo, F. Synchronization in complex oscillator networks and smart grids. Proc. Natl. Acad. Sci. USA 2013, 110, 2005–2010. [Google Scholar] [CrossRef] [PubMed]
- Pagani, G.A.; Aiello, M. The power grid as a complex network: a survey. Phys. Stat. Mech. Appl. 2013, 392, 2688–2700. [Google Scholar] [CrossRef]
- Amin, S.M.; Giacomoni, A.M. Smart Grid as a Dynamical System of Complex Networks: A Framework for Enhanced Security. IFAC Proc. Vol. 2011, 44, 526–531. [Google Scholar] [CrossRef]
- Wang, Z.; Scaglione, A.; Thomas, R.J. Generating statistically correct random topologies for testing smart grid communication and control networks. IEEE Trans. Smart Grid 2010, 1, 28–39. [Google Scholar] [CrossRef]
- Athari, M.H.; Wang, Z. Modeling the uncertainties in renewable generation and smart grid loads for the study of the grid vulnerability. In Proceedings of the 2016 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Minneapolis, MN, USA, 6–9 September 2016; pp. 1–5. [Google Scholar]
- Wang, Z.; Elyas, S.H.; Thomas, R.J. A novel measure to characterize bus type assignments of realistic power grids. In Proceedings of the 2015 IEEE Eindhoven PowerTech, Eindhoven, The Netherlands, 29 June–2 July 2015; pp. 1–6. [Google Scholar]
- Barabási, A.L. Network Science; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Halim, Z.; Waqas, M.; Hussain, S.F. Clustering large probabilistic graphs using multi-population evolutionary algorithm. Inf. Sci. 2015, 317, 78–95. [Google Scholar] [CrossRef]
- Datta, D.; Figueira, J.R.; Fonseca, C.M.; Tavares-Pereira, F. Graph partitioning through a multi-objective evolutionary algorithm: A preliminary study. In Proceedings of the 10th annual conference on Genetic and evolutionary computation, Atlanta, GA, USA, 12–16 July 2008; pp. 625–632. [Google Scholar]
- Bello-Orgaz, G.; Camacho, D. Evolutionary clustering algorithm for community detection using graph-based information. In Proceedings of the 2014 IEEE congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 930–937. [Google Scholar]
- Pagani, G.A.; Aiello, M. Towards decentralization: A topological investigation of the medium and low voltage grids. IEEE Trans. Smart Grid 2011, 2, 538–547. [Google Scholar] [CrossRef]
- Pagani, G.; Aiello, M. Modeling the last mile of the smart grid. In Proceedings of the 2013 IEEE PES Innovative Smart Grid Technologies (ISGT), Washington, DC, USA, 24–27 Feburary 2013; pp. 1–6. [Google Scholar]
- Aiello, M.; Pagani, G.A. The smart grid’s data generating potentials. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems (FedCSIS), Warsaw, Poland, 7–10 September 2014; pp. 9–16. [Google Scholar]
- Luo, L.; Pagani, G.A.; Rosas-Casals, M. Spatial optimality in power distribution networks. In Proceedings of the 2014 Complexity in Engineering (COMPENG), Barcelona, Spain, 16–17 June 2014; pp. 1–5. [Google Scholar]
- Pagani, G.A.; Aiello, M. A complex network approach for identifying vulnerabilities of the medium and low voltage grid. Int. J. Crit. Infrastruct. 2015, 11, 36–61. [Google Scholar] [CrossRef]
- Pagani, G.A.; Aiello, M. Generating realistic dynamic prices and services for the smart grid. IEEE Syst. J. 2015, 9, 191–198. [Google Scholar] [CrossRef]
- Capodieci, N.; Pagani, G.A.; Cabri, G.; Aiello, M. An adaptive agent-based system for deregulated smart grids. Serv. Oriented Comput. Appl. 2016, 10, 185–205. [Google Scholar] [CrossRef]
- Luo, L.; Pagani, G.A.; Rosas-Casals, M. Spatial and Performance Optimality in Power Distribution Networks. IEEE Syst. J. 2016, PP, 1–9. [Google Scholar] [CrossRef]
- Tvrdík, J.; Křivỳ, I. Hybrid differential evolution algorithm for optimal clustering. Appl. Soft Comput. 2015, 35, 502–512. [Google Scholar] [CrossRef]
- Brucker, P. On the complexity of clustering problems. In Optimization and Operations Research; Springer: Berlin/Heidelberg, Germany, 1978; pp. 45–54. [Google Scholar]
- Sun, Y.; Zhang, S.; Ruan, X. Community Detection of Complex Networks Based on the Spectrum Optimization Algorithm. In Proceedings of the 2014 2nd International Conference on Software Engineering, Knowledge Engineering and Information Engineering (SEKEIE 2014)); Atlantis Press: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Liu, J.; Zhong, W.; Abbass, H.A.; Green, D.G. Separated and overlapping community detection in complex networks using multiobjective Evolutionary Algorithms. In Proceedings of the 2010 IEEE Congress on Evolutionary Computation (CEC), Barcelona, Spain, 18–23 July 2010; pp. 1–7. [Google Scholar]
- Menéndez, H.D.; Barrero, D.F.; Camacho, D. A co-evolutionary multi-objective approach for a k-adaptive graph-based clustering algorithm. In Proceedings of the 2014 IEEE Congress onE volutionary computation (CEC), Beijing, China, 6–11 July 2014; pp. 2724–2731. [Google Scholar]
- Wen, X.; Chen, W.N.; Lin, Y.; Gu, T.; Zhang, H.; Li, Y.; Yin, Y.; Zhang, J. A maximal clique based multiobjective evolutionary algorithm for overlapping community detection. IEEE Trans. Evol. Comput. 2016, 21, 363–377. [Google Scholar] [CrossRef]
- Guturu, P.; Dantu, R. An impatient evolutionary algorithm with probabilistic tabu search for unified solution of some NP-hard problems in graph and set theory via clique finding. IEEE Trans. Syst. Man, Cybern. Part B (Cybern.) 2008, 38, 645–666. [Google Scholar]
- Yan, J.; Gong, M.; Ma, L.; Wang, S.; Shen, B. Structure optimization based on memetic algorithm for adjusting epidemic threshold on complex networks. Appl. Soft Comput. 2016, 49, 224–237. [Google Scholar] [CrossRef]
- Harrison, K.R.; Ventresca, M.; Ombuki-Berman, B.M. A meta-analysis of centrality measures for comparing and generating complex network models. J. Comput. Sci. 2015, 17, 205–215. [Google Scholar] [CrossRef]
- Bailey, A.; Ventresca, M.; Ombuki-Berman, B. Genetic programming for the automatic inference of graph models for complex networks. IEEE Trans. Evol. Comput. 2014, 18, 405–419. [Google Scholar] [CrossRef]
- Fister, I.; Mernik, M.; Filipič, B. Graph 3-coloring with a hybrid self-adaptive evolutionary algorithm. Comput. Optim. Appl. 2013, 54, 741–770. [Google Scholar] [CrossRef]
- Bensouyad, M.; Guidoum, N.; Saïdouni, D.E. A New and Fast Evolutionary Algorithm for Strict Strong Graph Coloring Problem. Procedia Comput. Sci. 2015, 73, 138–145. [Google Scholar] [CrossRef]
- Kaveh, A.; Laknejadi, K. A hybrid evolutionary graph-based multi-objective algorithm for layout optimization of truss structures. Acta Mech. 2013, 224, 343–364. [Google Scholar] [CrossRef]
- Su, R.; Gui, L.; Fan, Z. Topology and sizing optimization of truss structures using adaptive genetic algorithm with node matrix encoding. In Proceedings of the ICNC’09 Fifth International Conference on Natural Computation, Tianjin, China, 14–16 October 2009; Volume 4, pp. 485–491. [Google Scholar]
- Giger, M.; Ermanni, P. Evolutionary truss topology optimization using a graph-based parameterization concept. Struct. Multidiscip. Optim. 2006, 32, 313–326. [Google Scholar] [CrossRef]
- Newman, M.; Barabasi, A.L.; Watts, D.J. The Structure and Dynamics of Networks; Princeton University Press: Princeton, NJ, USA, 2006. [Google Scholar]
- Newman, D. Complex Dynamics of the Power Transmission Grid (and other Critical Infrastructures). Bull. Am. Phys. Soc. 2015, 60. BAPS.2015.MAR.S18.2. [Google Scholar]
- Caldarelli, G.; Vespignani, A. (Eds.) Large Scale Structure and Dynamics of Complex Networks: From Information Technology to Finance and Natural Science; World Scientific: Singapore, 2007; Volume 2. [Google Scholar]
- Watts, D.J.; Strogatz, S.H. Collective dynamics of “small-world” networks. Nature 1998, 393, 440–442. [Google Scholar] [CrossRef] [PubMed]
- Amaral, L.A.N.; Scala, A.; Barthelemy, M.; Stanley, H.E. Classes of small-world networks. Proc. Natl. Acad. Sci. 2000, 97, 11149–11152. [Google Scholar] [CrossRef] [PubMed]
- Solé, R.V. Redes Complejas: Del Genoma a Internet; Tusquets Editores: Barcelona, Spain, 2009. [Google Scholar]
- Jamakovic, A.; Uhlig, S. Influence of the network structure on robustness. In Proceedings of the 15th IEEE International Conference on Networks ( ICON), Adelaide, SA, Australia, 19–21 November 2007; pp. 278–283. [Google Scholar]
- Zhang, Z.-Z.; Xu, W.-J.; Zeng, S.-Y.; Lin, J.-R. An effective method to improve the robustness of small-world networks under attack. Chin. Phys. 2014, 23, 088902. [Google Scholar] [CrossRef]
- Newman, M.E.; Watts, D.J. Renormalization group analysis of the small-world network model. Phys. Lett. 1999, 263, 341–346. [Google Scholar] [CrossRef]
- Wang, X.F.; Chen, G. Complex networks: small-world, scale-free and beyond. IEEE Circuits Syst. Mag. 2003, 3, 6–20. [Google Scholar] [CrossRef]
- Barabási, A.L. The architecture of complexity. IEEE Control Syst. 2007, 27, 33–42. [Google Scholar] [CrossRef]
- Barabási, A.L.; Albert, R. Emergence of scaling in random networks. Science 1999, 286, 509–512. [Google Scholar] [PubMed]
- Barabási, A.L.; Albert, R.; Jeong, H. Mean-field theory for scale-free random networks. Phys. A Stat. Mech. Appl. 1999, 272, 173–187. [Google Scholar] [CrossRef]
- Bompard, E.; Napoli, R.; Xue, F. Analysis of structural vulnerabilities in power transmission grids. Int. J. Crit. Infrastruct. Prot. 2009, 2, 5–12. [Google Scholar] [CrossRef]
- Arianos, S.; Bompard, E.; Carbone, A.; Xue, F. Power grid vulnerability: A complex network approach. Chaos Interdiscip. J. Nonlinear Sci. 2009, 19, 013119. [Google Scholar] [CrossRef] [PubMed]
- Bompard, E.; Wu, D.; Xue, F. The concept of betweenness in the analysis of power grid vulnerability. In Proceedings of the COMPENG’10 Complexity in Engineering, Roma, Italy, 22–24 Feburary 2010; pp. 52–54. [Google Scholar]
- Bompard, E.; Pons, E.; Wu, D. Extended topological metrics for the analysis of power grid vulnerability. IEEE Syst. J. 2012, 6, 481–487. [Google Scholar] [CrossRef]
- Brummitt, C.D.; Dsouza, R.M.; Leicht, E. Suppressing cascades of load in interdependent networks. Proc. Natl. Acad. Sci. USA 2012, 109, E680–E689. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Scaglione, A.; Thomas, R.J. The node degree distribution in power grid and its topology robustness under random and selective node removals. In Proceedings of the 2010 IEEE International Conference on Communications Workshops (ICC), Cape Town, South Africa, 23–27 May 2010; pp. 1–5. [Google Scholar]
- Wang, J.W.; Rong, L.L. Cascade-based attack vulnerability on the US power grid. Saf. Sci. 2009, 47, 1332–1336. [Google Scholar] [CrossRef]
- Rosas Casals, M.; Corominas Murtra, B. Assessing European power grid reliability by means of topological measures. WIT Trans. Ecol. Environ. 2009, 122, 515–525. [Google Scholar]
- Solé, R.V.; Rosas-Casals, M.; Corominas-Murtra, B.; Valverde, S. Robustness of the European power grids under intentional attack. Phys. Rev. 2008, 77, 026102. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Kumara, S.; Albert, R. Complex networks: An engineering view. IEEE Circuits Syst. Mag. 2010, 10, 10–25. [Google Scholar] [CrossRef]
- Pahwa, S.; Scoglio, C.; Scala, A. Abruptness of cascade failures in power grids. Sci. Rep. 2014, 4. [Google Scholar] [CrossRef] [PubMed]
- Bashan, A.; Berezin, Y.; Buldyrev, S.V.; Havlin, S. The extreme vulnerability of interdependent spatially embedded networks. Nat. Phys. 2013, 9, 667–672. [Google Scholar] [CrossRef]
- Brummitt, C.D.; Hines, P.D.; Dobson, I.; Moore, C.; D’Souza, R.M. Transdisciplinary electric power grid science. Proc. Natl. Acad. Sci. USA 2013, 110, 12159. [Google Scholar] [CrossRef] [PubMed]
- Zhu, Y.; Yan, J.; Sun, Y.; He, H. Revealing cascading failure vulnerability in power grids using risk-graph. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3274–3284. [Google Scholar] [CrossRef]
- Dewenter, T.; Hartmann, A.K. Large-deviation properties of resilience of power grids. New J. Phys. 2015, 17, 015005. [Google Scholar] [CrossRef]
- Luo, L.; Han, B.; Rosas-Casals, M. Network Hierarchy Evolution and System Vulnerability in Power Grids. IEEE Syst. J. 2017. [Google Scholar] [CrossRef]
- Bilis, E.; Kroger, W.; Nan, C. Performance of electric power systems under physical malicious attacks. IEEE Syst. J. 2013, 7, 854–865. [Google Scholar] [CrossRef]
- Correa, G.J.; Yusta, J.M. Grid vulnerability analysis based on scale-free graphs versus power flow models. Electr. Power Syst. Res. 2013, 101, 71–79. [Google Scholar] [CrossRef]
- Hines, P.; Blumsack, S.; Sanchez, E.C.; Barrows, C. The topological and electrical structure of power grids. In Proceedings of the 2010 43rd Hawaii International Conference on System Sciences (HICSS), Honolulu, HI, USA, 5–8 January 2010; pp. 1–10. [Google Scholar]
- Wang, Z.; Scaglione, A.; Thomas, R.J. Electrical centrality measures for electric power grid vulnerability analysis. In Proceedings of the 2010 49th IEEE Conference on Decision and Control (CDC), Atlanta, GA, USA, 15–17 December 2010; pp. 5792–5797. [Google Scholar]
- Hines, P.; Blumsack, S. A centrality measure for electrical networks. In Proceedings of the 41st Annual IEEE Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 7–10 January 2008; p. 185. [Google Scholar]
- Luo, L.; Rosas-Casals, M. Correlating empirical data and extended topological measures in power grid networks. Int. J. Crit. Infrastruct. 2015, 11, 82–96. [Google Scholar] [CrossRef]
- Cotilla-Sanchez, E.; Hines, P.D.; Barrows, C.; Blumsack, S. Comparing the topological and electrical structure of the North American electric power infrastructure. IEEE Syst. J. 2012, 6, 616–626. [Google Scholar] [CrossRef]
- Albert, R.; Albert, I.; Nakarado, G.L. Structural vulnerability of the North American power grid. Phys. Rev. 2004, 69, 025103. [Google Scholar] [CrossRef] [PubMed]
- Chassin, D.P.; Posse, C. Evaluating North American electric grid reliability using the Barabási–Albert network model. Phys. Stat. Mech. Appl. 2005, 355, 667–677. [Google Scholar] [CrossRef]
- Mei, S.; Zhang, X.; Cao, M. Power Grid Complexity; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Rosato, V.; Bologna, S.; Tiriticco, F. Topological properties of high-voltage electrical transmission networks. Electr. Power Syst. Res. 2007, 77, 99–105. [Google Scholar] [CrossRef]
- Holmgren, Å.J. Using graph models to analyze the vulnerability of electric power networks. Risk Anal. 2006, 26, 955–969. [Google Scholar] [CrossRef] [PubMed]
- Rosas-Casals, M.; Valverde, S.; Solé, R.V. Topological vulnerability of the European power grid under errors and attacks. Int. J. Bifurc. Chaos 2007, 17, 2465–2475. [Google Scholar] [CrossRef]
- Crucitti, P.; Latora, V.; Marchiori, M. Locating critical lines in high-voltage electrical power grids. Fluct. Noise Lett. 2005, 5, L201–L208. [Google Scholar] [CrossRef]
- Kim, C.J.; Obah, O.B. Vulnerability assessment of power grid using graph topological indices. Int. J. Emerg. Electr. Power Syst. 2007, 8. [Google Scholar] [CrossRef]
- Yazdani, A.; Dueñas-Osorio, L.; Li, Q. A scoring mechanism for the rank aggregation of network robustness. Commun. Nonlinear Sci. Numer. Simul. 2013, 18, 2722–2732. [Google Scholar] [CrossRef]
- Boccaletti, S.; Buldú, J.; Criado, R.; Flores, J.; Latora, V.; Pello, J.; Romance, M. Multiscale vulnerability of complex networks. Chaos Interdiscip. J. Nonlinear Sci. 2007, 17, 043110. [Google Scholar] [CrossRef] [PubMed]
- Eiben, A.E.; Smith, J. What is an evolutionary algorithm? In Introduction to Evolutionary Computing; Springer: Berlin/Heidelberg, Germany, 2015; pp. 25–48. [Google Scholar]
- Simon, D. Evolutionary Optimization Algorithms; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- del Arco-Vega, M.A.; Cuadra, L.; Portilla-Figueras, J.A.; Salcedo-Sanz, S. Near-optimal user assignment in LTE mobile networks with evolutionary computing. Trans. Emerg. Telecommun. Technol. 2016. [Google Scholar] [CrossRef]
- Sastry, K.; Goldberg, D.E.; Kendall, G. Genetic algorithms. In Search Methodologies; Springer: Berlin/Heidelberg, Germany, 2014; pp. 93–117. [Google Scholar]
- Deng, Y.; Liu, Y.; Zhou, D. An improved genetic algorithm with initial population strategy for symmetric TSP. Math. Prob. Eng. 2015, 2015, 212794. [Google Scholar] [CrossRef]
- Miller, B.L.; Goldberg, D.E. Genetic algorithms, tournament selection, and the effects of noise. Complex Syst. 1995, 9, 193–212. [Google Scholar]
- Xu, Y.; Gurfinkel, A.J.; Rikvold, P.A. Architecture of the Florida power grid as a complex network. Phys. Stat. Mech. Appl. 2014, 401, 130–140. [Google Scholar] [CrossRef]
- Schultz, P.; Heitzig, J.; Kurths, J. A random growth model for power grids and other spatially embedded infrastructure networks. Eur. Phys. J. Spec. Top. 2014, 223, 2593–2610. [Google Scholar] [CrossRef]
- Han, P.; Zhang, S. Analysis of cascading failures in small-world power grid. Int. J. Energy Sci. 2011, 1, 99–104. [Google Scholar]
- Latora, V.; Marchiori, M. Efficient behavior of small-world networks. Phys. Rev. Lett. 2001, 87, 198701. [Google Scholar] [CrossRef] [PubMed]
- Ding, M.; Han, P. Reliability assessment to large-scale power grid based on small-world topological model. In Proceedings of the PowerCon 2006 International Conference on Power System Technology, Chongqing, China, 22–26 October 2006; pp. 1–5. [Google Scholar]
- Fu, L.; Huang, W.; Xiao, S.; Li, Y.; Guo, S. Vulnerability assessment for power grid based on small-world topological model. In Proceedings of the 2010 Asia-Pacific, IEEE Power and Energy Engineering Conference (APPEEC), Chengdu, China, 28–31 March 2010; pp. 1–4. [Google Scholar]
- Trodden, P.; Bukhsh, W.A.; Grothey, A.; McKinnon, K. Optimization-based islanding of power networks using piecewise linear AC power flow. IEEE Trans. Power Syst. 2014, 29, 1212–1220. [Google Scholar] [CrossRef]
- Pahwa, S.; Youssef, M.; Schumm, P.; Scoglio, C.; Schulz, N. Optimal intentional islanding to enhance the robustness of power grid networks. Phys. Stat. Mech. Appl. 2013, 392, 3741–3754. [Google Scholar] [CrossRef]
- Trodden, P.; Bukhsh, W.; Grothey, A.; McKinnon, K. MILP formulation for controlled islanding of power networks. Int. J. Electr. Power Energy Syst. 2013, 45, 501–508. [Google Scholar] [CrossRef]
- Carreras, B.A.; Newman, D.; Dobson, I. Does size matter? Chaos Interdiscip. J. Nonlinear Sci. 2014, 24, 023104. [Google Scholar] [CrossRef] [PubMed]
- Panteli, M.; Mancarella, P. The Grid: Stronger, Bigger, Smarter? Presenting a Conceptual Framework of Power System Resilience. IEEE Power Energy Mag. 2015, 13, 58–66. [Google Scholar] [CrossRef]
- Cancho, R.F.; Solé, R.V. Optimization in complex networks. In Statistical Mechanics Of Complex Networks; Springer: Berlin/Heidelberg, Germany, 2003; pp. 114–126. [Google Scholar]
- Beyer, H.G.; Schwefel, H.P. Evolution strategies—A comprehensive introduction. Nat. Comput. 2002, 1, 3–52. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition or Meaning |
|---|---|
| Adjacency matrix of graph . | |
| Element of the adjacency matrix that encodes whether node i is linked to node j () or not (). | |
| Mean value of betweenness or multi-scale vulnerability of order 1. | |
| Mean value of of the multi-scale vulnerability of order 2. | |
| Betweenness centrality of link l. | |
| Multi-scale vulnerability of order p of a graph . It is defined by Equation (9) | |
| Mean clustering coefficient of a network. It is defined by Equation (4). | |
| Set of all chromosomes. | |
| Betweenness centrality of node v. It quantifies how much a node v is found between the paths linking other pairs of nodes. It is defined by Equation (5). | |
| Chromosome that encodes the graph . | |
| Clustering coefficient of node i. It is defined as the ratio between the number of links that exist between these vertices and the maximum possible number of links (. | |
| Clustering coefficient of a random graph | |
| Node degree matrix: . It is the diagonal matrix formed from the nodes degrees. | |
| Euclidean distance between any pair of nodes and in a spatial network. | |
| Distance between two nodes i and j. It is the length of the shortest path (geodesic path) between them, that is, the minimum number of links when going from one node to the other. | |
| Coefficient of variation for betweenness. It is defined by Equation (10). | |
| objective function to be minimized. It is defined by Equation (11). | |
| Mean value of the objective function . | |
| Graph representing a network. | |
| Set of all possible connected graphs with N nodes and links. | |
| Set containing all of the candidate graphs. | |
| Optimum graph that solves the objective function with combination parameter . | |
| Average node degree: . | |
| Degree of a node i. It is the number of links connecting i to any other node. It is defined by Equation (2). | |
| Maximum node degree. | |
| ℓ | Average path length of a network. It is the mean value of distances between any pair of nodes in the network. It is defined by Equation (3). |
| Set of links (edges) of a graph. | |
| Laplacian matrix (or Kirchhoff matrix) of graph . It is defined by Equation (14). | |
| Average path length of a random graph. | |
| Algebraic connectivity of graph . | |
| M | Size of a graph . It is the number of links in the set . It is defined by Equation (1). |
| Set of nodes (or vertices) of a graph. | |
| N | Order of a graph . It is the number of nodes in set , that is the cardinality of set : . |
| Probability density function giving the probability that a randomly selected node has k links. | |
| Crossover probability. | |
| Mutation probability. | |
| Selection probability. | |
| Normalized weight of the link between nodes i and j: | |
| Population size. | |
| Average entropic degree. | |
| Entropic degree of node i defined by Equation (6). | |
| Standard deviation of betweenness. | |
| Upper triangular matrix of graph . | |
| Tournament size. | |
| Set of weight elements . | |
| Weight of link . It models the strength of the connection between node i and j. | |
| Parameter that controls the linear combination between components with opposing trends in the objective function to be minimized given by Equation (11). |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cuadra, L.; Pino, M.D.; Nieto-Borge, J.C.; Salcedo-Sanz, S. Optimizing the Structure of Distribution Smart Grids with Renewable Generation against Abnormal Conditions: A Complex Networks Approach with Evolutionary Algorithms. Energies 2017, 10, 1097. https://doi.org/10.3390/en10081097
Cuadra L, Pino MD, Nieto-Borge JC, Salcedo-Sanz S. Optimizing the Structure of Distribution Smart Grids with Renewable Generation against Abnormal Conditions: A Complex Networks Approach with Evolutionary Algorithms. Energies. 2017; 10(8):1097. https://doi.org/10.3390/en10081097
Chicago/Turabian StyleCuadra, Lucas, Miguel Del Pino, José Carlos Nieto-Borge, and Sancho Salcedo-Sanz. 2017. "Optimizing the Structure of Distribution Smart Grids with Renewable Generation against Abnormal Conditions: A Complex Networks Approach with Evolutionary Algorithms" Energies 10, no. 8: 1097. https://doi.org/10.3390/en10081097
APA StyleCuadra, L., Pino, M. D., Nieto-Borge, J. C., & Salcedo-Sanz, S. (2017). Optimizing the Structure of Distribution Smart Grids with Renewable Generation against Abnormal Conditions: A Complex Networks Approach with Evolutionary Algorithms. Energies, 10(8), 1097. https://doi.org/10.3390/en10081097