
Structured Literature Review of Electricity Consumption Classification Using Smart Meter Data

Abstract
:1. Introduction
2. Systematic Literature Review Methodology—An Empirical Study
- 1:
- Purpose of the literature review. Clearly state the purpose of the review. What is the scope and contribution of the work presented?
- 2:
- Protocol and training. Ensure consistency, alignment, and reproducibility by formally defining rules and evaluation criteria.
- 3:
- Searching for literature. Explicitly describe the search for literature search, the “what and where.”
- 4:
- Practical screen. Crude inclusion and exclusion of articles not based on quality appraisal but on “applicability to the research question.” The reviewer normally only reads the title and abstract at this stage. “The practical screen is to screen articles for inclusion. If the reviewer thinks that an article matches the superficial qualities of the practical screen it should be included” [3]; if in doubt the article should be included.
- 5:
- Quality appraisal. Screen for exclusion, and explicitly define the criteria for judging articles. All articles need to be read and scored for their quality, depending on the research methodologies employed by the articles [3].
- 6:
- Data extraction and synthesis of studies. Systematically extract the applicable information of the identified articles and combine the facts.
- 7:
- Writing the review.
2.1. Purpose of the Literature Review
2.2. Protocol and Training
3. Article Selection
3.1. Searching for Literature
3.2. Screening I: Title
3.3. Screening II: Abstract and Removal of Non-Peer-Reviewed Papers
3.4. Quality Appraisal
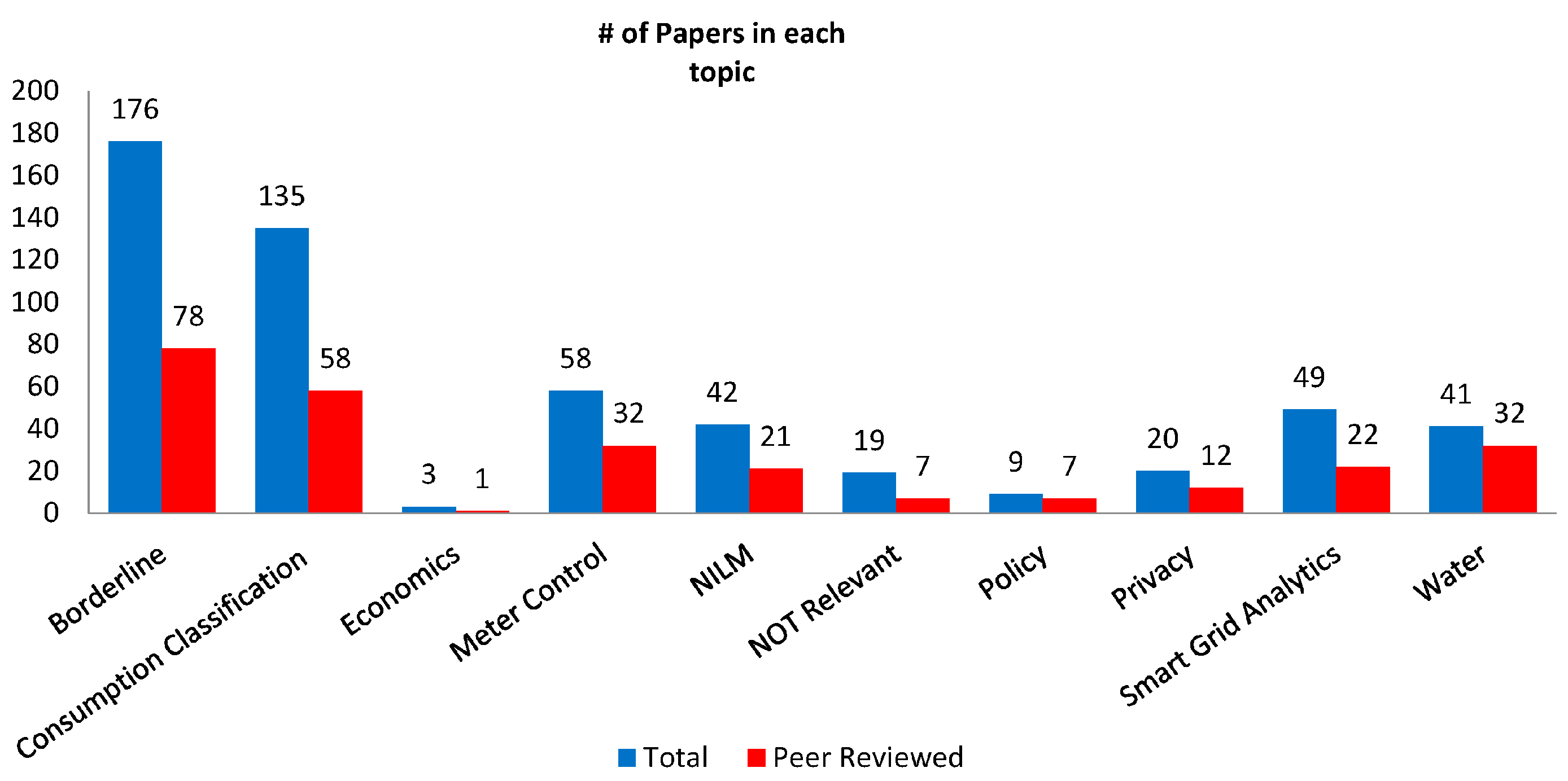
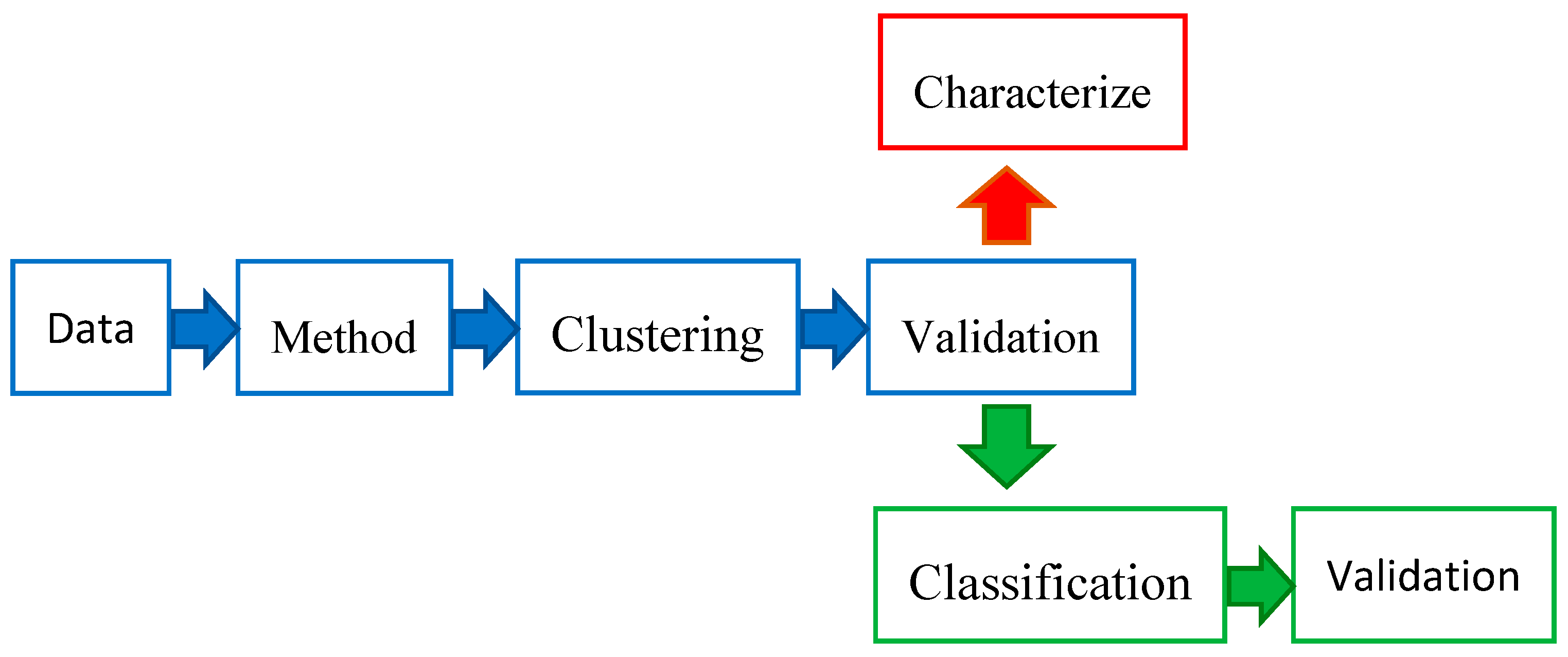
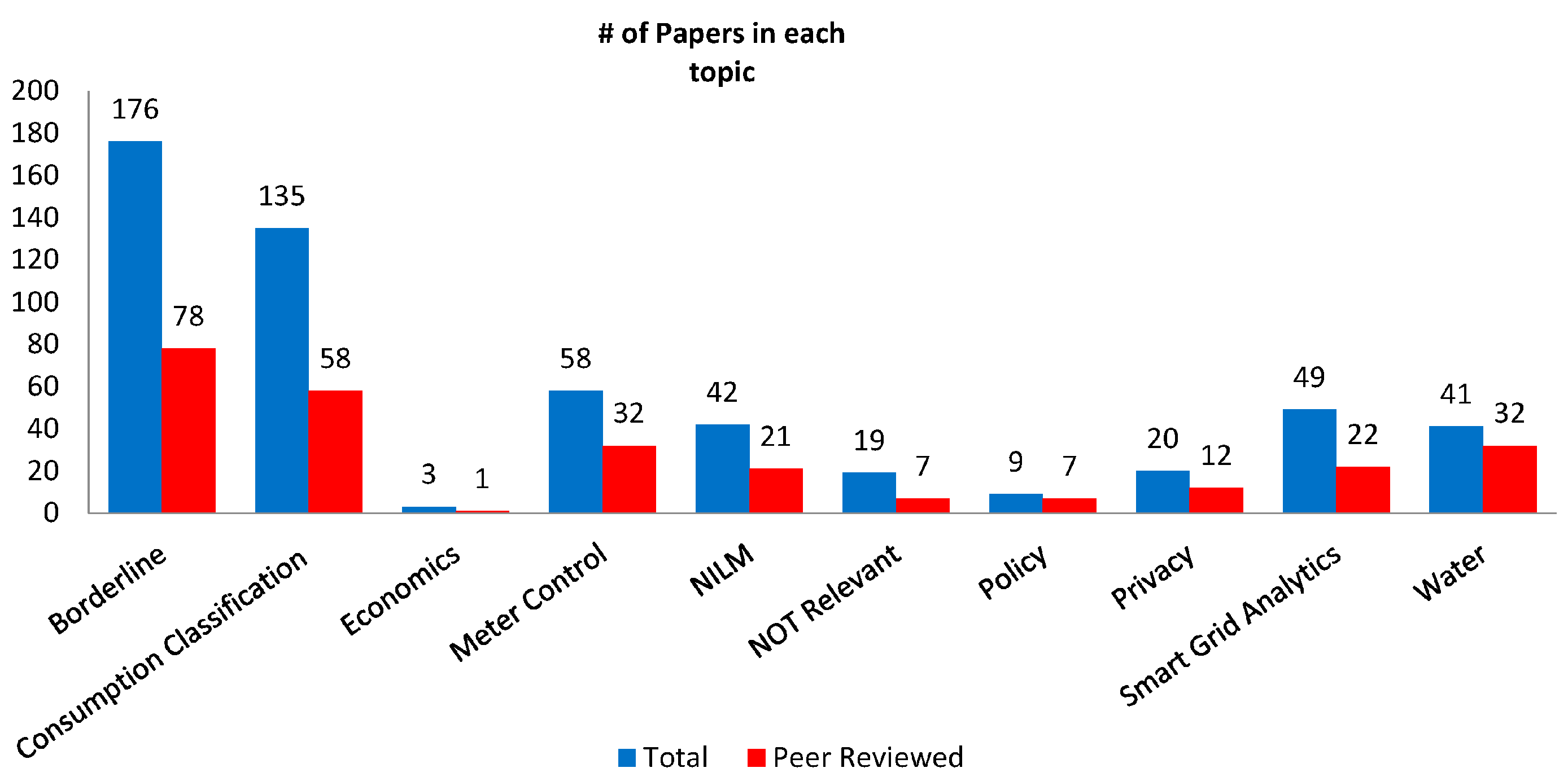
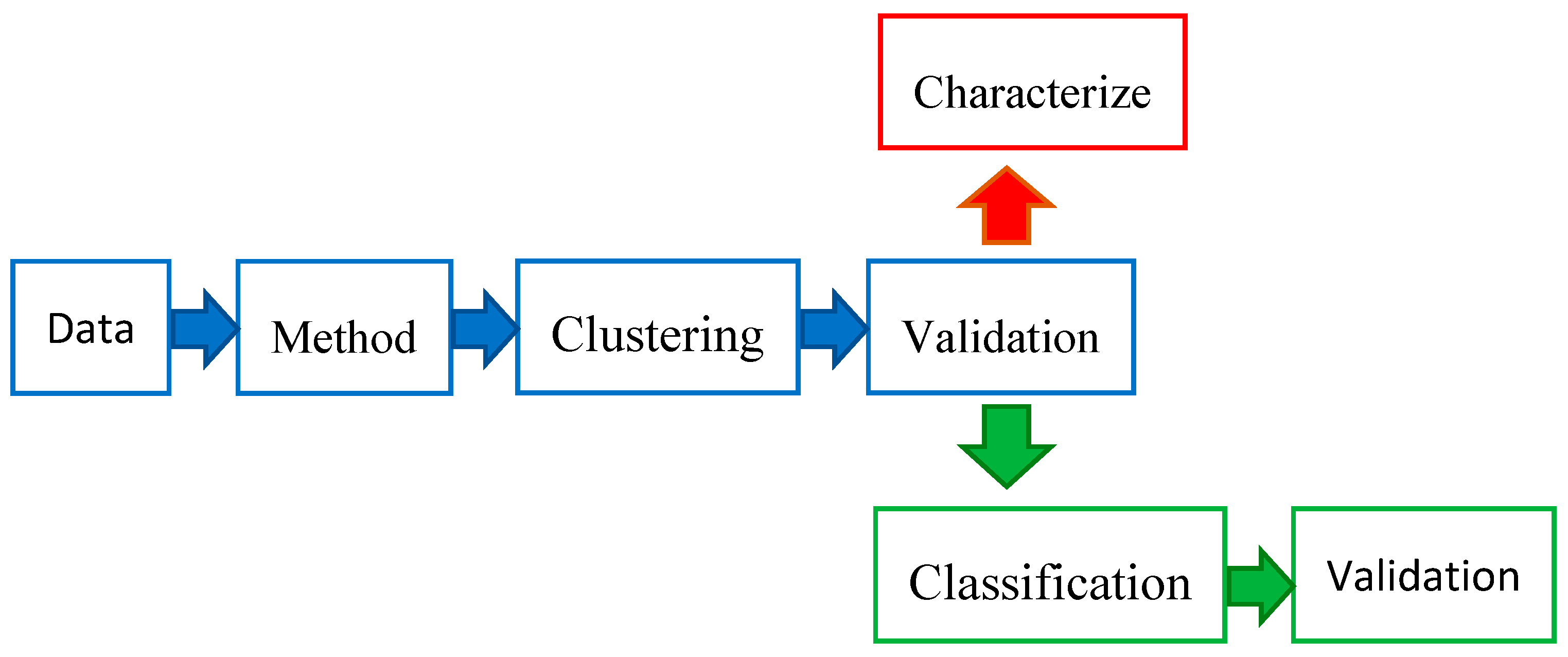
4. Data Extraction and Synthesis of Studies
4.1. Data Description and Empirical Findings
4.2. Classification
4.3. Dimensionality Reduction and Feature Extraction
4.4. Cluster Validity Check
5. Findings and Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. List of Search Phrases

{kind=link}
{kind=link}
| Search Phrase | Non-Unique Hits |
|---|---|
| Electricity customer classification | 123 |
| Electricity customer segmentation | 34 |
| Residential electricity classification | 59 |
| Residential electricity segmentation | 16 |
| Smart meter analysis | 767 |
| Smart meter analytics | 61 |
| Smart meter big data | 65 |
| Smart meter classification | 187 |
| Smart meter clustering | 125 |
| Smart meter consumption classification | 47 |
| Smart meter consumption data | 704 |
| Smart meter consumption profiling | 112 |
| Smart meter consumption segmentation | 22 |
| Smart meter customer classification | 25 |
| Smart meter customer segmentation | 15 |
| Smart meter data analysis | 443 |
| Smart meter data mining | 46 |
| Smart meter feature construction | 12 |
| Smart meter feature extraction | 21 |
| Smart meter learning | 117 |
| Smart meter load monitoring | 262 |
| Smart meter load profiling | 147 |
| Smart meter machine learning | 47 |
| Smart meter profiling | 280 |
| Smart meter segmentation | 27 |
| Smart meter statistical learning | 6 |
| Smart meter statistics | 52 |
| Smart meter supervised learning | 7 |
| Smart meter time series | 86 |
| Smart meter unsupervised learning | 7 |
| Sum | 3922 |
Appendix B. Quantitative Summary Table
| Category | Split | Paper(s) |
|---|---|---|
| Classification | ||
| K-means | [1–23] | |
| Hierarchical | [1–3,10,15,17,19,20,22,24] | |
| Fuzzy K-means | [1,15,17,19] | |
| Follow the leader | [1,9,19,25,26] | |
| K-medoid | [9,14] | |
| Mixture models | [10,27,28] | |
| Fast Fourier Transform | [15] | |
| Others | [15–21,29] | |
| Forecasting | ||
| Regression | [8,13,27,30–33] | |
| HMM | [16,23] | |
| Other | [13,34] | |
| Dimension reduction | ||
| Principal Components | [16,34] | |
| Self-organizing-Maps | [2,9,11,19,21] | |
| Validation | ||
| DBI | [1,6,9–11,13,15,17,20,26] | |
| CDI | [1,10,17,18,22,25,26] | |
| Dunn & Silhouette | [11,13,14,20] | |
| Entropy | [19,21,22,28] | |
| MIA | [6,10,17,25,26] | |
| Other | [1–3,10,12–18,20–22,26,27,30] | |
| Size | ||
| 0–250 | [1,4,6,8,10,16,18,19,22,25,26,34] | |
| 250–500 | [17,24] | |
| 500–1000 | [5,23,27,30] | |
| 1000–2500 | [7,11,12,15,20,21] | |
| 2500–5000 | [2,9,13,14,28,29,31–33] | |
| Other | [3] | |
| Region | ||
| Europe | [1,2,4–6,9,10,13,14,16–20,24–26,28,29,31–33] | |
| North America | [3,8,12,23,27,30,34] | |
| Asia | [11,15,21,22] | |
| Other | [7] | |
| Period | ||
| 1 day | [1,18,19,26] | |
| 1 month | [7,21,22] | |
| 2–6 months | [9,30] | |
| 7–12 months | [17,23] | |
| 1 year | [2,6,8,10,20,27,28,31,34] | |
| 1–2 years | [3,5,13–15,29,32] | |
| 2+ years | [11,24,33] | |
| Missing | [4,12,16,25] | |
| Recording frequency | ||
| <1 min | [10] | |
| 1 min | [8,15] | |
| 10 min | [16,23,30] | |
| 15 min | [1,4,7,17–20,22,24–26] | |
| 30 min | [9,13,14,28,29,31,32] | |
| 60 min | [2,3,5,6,11,12,21,33,34] | |
| 24 h | [27] | |
| Type of customer | ||
| Industrial | [1,12,17–20,22,25,26] | |
| Residential | [3–5,8–11,13–16,23,24,28–32,34] | |
| Mix | [2,6,7,21,27,33] | |
Appendix C. List of Articles
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among clustering techniques for electricity customer classification. IEEE Trans. Power Syst. 2006, 21, 1–7.
- Räsänen, T.; Voukantsis, D.; Niska, H.; Karatzas, K.; Kolehmainen, M. Data-based method for creating electricity use load profiles using large amount of customer-specific hourly measured electricity use data. Appl. Energy 2010, 87, 3538–3545.
- Kwac, J.; Flora, J.; Rajagopal, R. Household energy consumption segmentation using hourly data. IEEE Trans. Smart Grid 2014, 5, 420–430.
- Flath, C.; Nicolay, D.; Conte, T.; Van Dinther, C.; Filipova-Neumann, L. Cluster analysis of smart metering data: An implementation in practice. Bus. Inf. Syst. Eng. 2012, 4, 31–39.
- Benítez, I.; Quijano, A.; Díez, J.; Delgado, I. Dynamic clustering segmentation applied to load profiles of energy consumption from Spanish customers. Int. J. Electr. Power Energy Syst. 2014, 55, 437–448.
- López, J.J.; Aguado, J.A.; Martín, F.; Mu, F.; Rodríguez, A.; Ruiz, J.E. Hopfield—K-Means clustering algorithm: A proposal for the segmentation of electricity customers. Electr. Power Syst. Res. 2011, 81, 716–724.
- Macedo, M.N.Q.; Galo, J.J.M.; De Almeida L.A.L.; Lima, A.C.D.C. Demand side management using artificial neural networks in a smart grid environment. Renew. Sustain. Energy Rev. 2015, 41, 128–133.
- Rhodes, J.D.; Cole, W.J.; Upshaw, C.R.; Edgar, T.F.; Webber, M.E. Clustering analysis of residential electricity demand profiles. Appl. Energy 2014, 135, 461–471.
- Mcloughlin, F.; Duffy, A.; Conlon, M. A clustering approach to domestic electricity load profile characterisation using smart metering data. Appl. Energy 2015, 141, 190–199.
- Granell, R.; Axon, C.J.; Wallom, D.C.H. Impacts of raw data temporal resolution using selected clustering methods on residential electricity load profiles. IEEE Trans. Power Syst. 2015, 30, 3217–3224.
- Park, S.; Ryu, S.; Choi, Y.; Kim, J.; Kim, H. Data-driven baseline estimation of residential buildings for demand response. Energies 2015, 8, 10239–10259.
- Lavin, A.; Klabjan, D. Clustering time-series energy data from smart meters. Energy Effic. 2014, 8, 681–689.
- Viegas, J.L.; Vieira, S.M.; Melício, R.; Mendes, V.M.F.; Sousa, J.M.C. Classification of new electricity customers based on surveys and smart metering data Commission for Energy Regulation. Energy 2016, 107, 804–817.
- Al-otaibi, R.; Jin, N.; Wilcox, T.; Flach, P. Feature construction and calibration for clustering daily load curves from smart-meter data. IEEE Trans. Ind. Inform. 2016, 12, 645–654.
- Ozawa, A.; Furusato, R.; Yoshida, Y. Determining the relationship between a household’s lifestyle and its electricity consumption in Japan by analyzing measured electric load profiles. Energy Build. 2016, 119, 200–210.
- Basu, K.; Debusschere, V.; Douzal-chouakria, A.; Bacha, S. Time series distance-based methods for non-intrusive load monitoring in residential buildings. Energy Build. 2015, 96, 109–117.
- Tsekouras, G.J.; Hatziargyriou, N.D.; Member, S.; Dialynas, E.N.; Member, S. Two-stage pattern recognition of load curves for classification of electricity customers. IEEE Trans. Power Syst. 2007, 22, 1120–1128.
- Chicco, G.; Ionel, O.M.; Porumb, R. Electrical load pattern grouping based on centroid model with ant colony clustering. IEEE Trans. Power Syst. 2013, 28, 1706–1715.
- Chicco, G.; Sumaili Akilimali, J. Renyi entropy-based classification of daily electrical load patterns. IET Gener. Transm. Distrib. 2010, 4, 736–745.
- Ramos, S.; Duarte, J.M.; Duarte, F.J.; Vale, Z. A data-mining-based methodology to support MV electricity customers’ characterization. Energy Build. 2015, 91, 16–25.
- Piao, M.; Shon, H.; Lee, J.; Ryu, K. Subspace projection method based clustering analysis in load profiling. IEEE Trans. Power Syst. 2014, 29, 2628–2635.
- Kang, J.; Lee, J. Electricity customer clustering following experts’ principle for demand response applications. Energies 2015, 8, 12242–12265.
- Albert, A.; Rajagopal, R. Smart meter driven segmentation: What your consumption says about you. IEEE Trans. Power Syst. 2013, 28, 4019–4030.
- Gouveia, J.P.; Seixas, J. Unraveling electricity consumption profiles in households through clusters: Combining smart meters and door-to-door surveys. Energy Build. 2016, 116, 666–676.
- Chicco, G.; Napoli, R.; Piglione, F.; Postolache, P.; Scutariu, M.; Toader, C. Load pattern-based classification of electricity customers. IEEE Trans. Power Syst. 2004, 19, 1232–1239.
- Carpaneto, E.; Chicco, G.; Napoli, R.; Scutariu, M. Electricity customer classification using frequency—Domain load pattern data. Int. J. Electr. Power Energy Syst. 2006, 28, 13–20.
- Coke, G.; Tsao, M. Random effects mixture models for clustering electrical load series. J. Time Ser. Anal. 2010, 31, 451–464.
- Haben, S.; Singleton, C.; Grindrod, P. Analysis and clustering of residential customers energy behavioral demand using smart meter data. IEEE Trans. Smart Grid 2015, 7, 136–144.
- Tong, X.; Li, R.; Li, F.; Kang, C. Cross-domain feature selection and coding for household energy behavior. Energy 2016, 107, 9–16.
- Kavousian, A.; Rajagopal, R.; Fischer, M. Determinants of residential electricity consumption: Using smart meter data to examine the effect of climate , building characteristics, appliance stock and occupants’ behavior. Energy 2013, 55, 184–194.
- Mcloughlin, F.; Duffy, A.; Conlon, M. Characterising domestic electricity consumption patterns by dwelling and occupant socio-economic variables: An Irish case study. Energy Build. 2012, 48, 240–248.
- Jin, N.; Flach, P.; Wilcox, T.; Sellman, R.; Thumim, J.; Knobbe, A. Subgroup discovery in smart electricity meter data. IEEE Trans. Ind. Infrom. 2014, 10, 1327–1336.
- Andersen, F.M.; Larsen H, V.; Boomsma, T.K. Long-term forecasting of hourly electricity load: Identification of consumption profiles and segmentation of customers. Energy Convers. Manag. 2013, 68, 244–252.
- Ndiaye, D.; Gabriel, K. Principal component analysis of the electricity consumption in residential dwellings. Energy Build. 2011, 43, 446–453.
References
- EU Commission. Smart Grids and Meters. Available online: https://ec.europa.eu/energy/en/topics/markets-and-consumers/smart-grids-and-meters (accessed on 20 December 2016).
- Fink, A. Conducting Research Literature Reviews: From the Internet to Paper, 2nd ed.; Sage Publications: Thousand Oaks, CA, USA, 2005. [Google Scholar]
- Okoli, C. A guide to conducting a standalone systematic literature review. Commun. Assoc. Inf. Syst. 2015, 37, 879–910. [Google Scholar]
- Thomson Reuters. Web of Science 1 Billion Cited References and Counting. Thomson Reuters 2017. Available online: http://stateofinnovation.thomsonreuters.com/web-of-science-1-billion-cited-references-and-counting?utm_source=false&utm_medium=false&utm_campaign=false (accessed on 5 January 5 2017).
- Benítez, I.; Quijano, A.; Díez, J.; Delgado, I. Dynamic clustering segmentation applied to load profiles of energy consumption from Spanish customers. Int. J. Electr. Power Energy Syst. 2014, 55, 437–448. [Google Scholar] [CrossRef]
- Gouveia, J.P.; Seixas, J. Unraveling electricity consumption profiles in households through clusters: Combining smart meters and door-to-door surveys. Energy Build. 2016, 116, 666–676. [Google Scholar] [CrossRef]
- Kavousian, A.; Rajagopal, R.; Fischer, M. Determinants of residential electricity consumption: Using smart meter data to examine the effect of climate, building characteristics, appliance stock, and occupants’ behavior. Energy 2013, 55, 184–194. [Google Scholar] [CrossRef]
- Mcloughlin, F.; Duffy, A.; Conlon, M. Characterising domestic electricity consumption patterns by dwelling and occupant socio-economic variables: An Irish case study. Energy Build. 2012, 48, 240–248. [Google Scholar] [CrossRef]
- Flath, C.; Nicolay, D.; Conte, T.; Van Dinther, C.; Filipova-Neumann, L. Cluster analysis of smart metering data: An implementation in practice. Bus. Inf. Syst. Eng. 2012, 4, 31–39. [Google Scholar] [CrossRef]
- Chicco, G.; Napoli, R.; Piglione, F. Comparisons among clustering techniques for electricity customer classification. IEEE Trans. Power Syst. 2006, 21, 1–7. [Google Scholar] [CrossRef]
- Mcloughlin, F.; Duffy, A.; Conlon, M. A clustering approach to domestic electricity load profile characterisation using smart metering data. Appl. Energy 2015, 141, 190–199. [Google Scholar] [CrossRef]
- Ozawa, A.; Furusato, R.; Yoshida, Y. Determining the relationship between a household’s lifestyle and its electricity consumption in Japan by analyzing measured electric load profiles. Energy Build. 2016, 119, 200–210. [Google Scholar] [CrossRef]
- Granell, R.; Axon, C.J.; Wallom, D.C.H. Impacts of raw data temporal resolution using selected clustering methods on residential electricity load profiles. IEEE Trans. Power Syst. 2015, 30, 3217–3224. [Google Scholar] [CrossRef]
- Al-otaibi, R.; Jin, N.; Wilcox, T.; Flach, P. Feature construction and calibration for clustering daily load curves from smart-meter data. IEEE Trans. Ind. Inform. 2016, 12, 645–654. [Google Scholar] [CrossRef]
- Coke, G.; Tsao, M. Random effects mixture models for clustering electrical load series. J. Time Ser. Anal. 2010, 31, 451–464. [Google Scholar] [CrossRef]
- Chicco, G.; Sumaili Akilimali, J. Renyi entropy-based classification of daily electrical load patterns. IET Gener. Transm. Distrib. 2010, 4, 736–745. [Google Scholar] [CrossRef]
- Macedo, M.N.Q.; Galo, J.J.M.; De Almeida, L.A.L.; Lima, A.C.D.C. Demand side management using artificial neural networks in a smart grid environment. Renew. Sustain. Energy Rev. 2015, 41, 128–133. [Google Scholar] [CrossRef]
- Albert, A.; Rajagopal, R. Smart meter driven segmentation: What your consumption says about you. IEEE Trans. Power Syst. 2013, 28, 4019–4030. [Google Scholar] [CrossRef]
- Gulbinas, R.; Khosrowpour, A.; Taylor, J. Segmentation and classification of commercial building occupants by energy-use efficiency and predictability. IEEE Trans. Smart Grid 2015, 6, 1414–1424. [Google Scholar] [CrossRef]
- Viegas, J.L.; Vieira, S.M.; Melício, R.; Mendes, V.M.F.; Sousa, J.M.C. Classification of new electricity customers based on surveys and smart metering data Commission for Energy Regulation. Energy 2016, 107, 804–817. [Google Scholar] [CrossRef]
- Bishop, C.M. Pattern Recognition and Machine Learning, 1st ed.; Springer: New York, USA, 2007. [Google Scholar]
- Räsänen, T.; Voukantsis, D.; Niska, H.; Karatzas, K.; Kolehmainen, M. Data-based method for creating electricity use load profiles using large amount of customer-specific hourly measured electricity use data. Appl. Energy 2010, 87, 3538–3545. [Google Scholar] [CrossRef]
- Park, S.; Ryu, S.; Choi, Y.; Kim, J.; Kim, H. Data-driven baseline estimation of residential buildings for demand response. Energies 2015, 8, 10239–10259. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T. The Elements of Statistical Learning, 1st ed.; Springer: New York, NY, USA, 2001. [Google Scholar]
- Kang, J.; Lee, J. Electricity customer clustering following experts’ principle for demand response applications. Energies 2015, 8, 12242–12265. [Google Scholar] [CrossRef]
- López, J.J.; Aguado, J.A.; Martín, F.; Mu, F.; Rodríguez, A.; Ruiz, J.E. Hopfield—K-Means clustering algorithm: A proposal for the segmentation of electricity customers. Electr. Power Syst. Res. 2011, 81, 716–724. [Google Scholar] [CrossRef]
- Tong, X.; Li, R.; Li, F.; Kang, C. Cross-domain feature selection and coding for household energy behavior. Energy 2016, 107, 9–16. [Google Scholar] [CrossRef]
- Simshauser, P.; Downer, D. On the inequity of flat-rate electricity tariffs. Energy J. 2016, 37, 199–229. [Google Scholar] [CrossRef]
- Haben, S.; Singleton, C.; Grindrod, P. Analysis and clustering of residential customers energy behavioral demand using smart meter data. IEEE Trans. Smart Grid 2015, 7, 136–144. [Google Scholar] [CrossRef]
- Dansk, E. Giv Energien Videre: Nye Energipolitiske Visioner Og Udfordringer 2020–2030; Dansk Energi: Copenhagen, Denmark, 2015. [Google Scholar]
- Governmental Offices of Sweden. Fossil Free Sweden N.D. Available online: http://www.government.se/government-policy/fossil-free-sweden/ (accessed on 27 January 2017).
| Waterfall Statistics | Bulk | Reduced |
|---|---|---|
| Initial | 3922 | - |
| Unique | 2099 | 1823 |
| Screening I: Title | 552 | 1271 |
| Screening II: Abstract | 311 | 241 |
| Removal of non-peer-reviewed | 136 | 175 |
| Screening III: Borderline revisited | 71 | 65 |
| Screening IV: Reading of articles | 34 | 37 |
| Final number of papers synthesized | 34 | - |
| # of Different Datasets | Country | Type | Length | Recording Frequency | Final Size (m) | K-Mean | Hierarchical | Follow the Leader | Mixture Models | Fourier Transform |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Brazil | Mix | 1 month | 15 min | 2000 | x | - | - | - | - |
| 2 | Canada | Mix | 12 months | 60 min | 62,923 | - | - | - | x | |
| 1 | Denmark | Mix | 36 months | 60 min | 4500 | - | - | - | - | - |
| 1 | Finland | Mix | 12 months | 60 min | 3989 | x | x | - | - | - |
| 1 | France | Residential | UNKNOWN | 10 min | 100 | x | - | - | - | - |
| 1 | Germany | Residential | UNKNOWN | 15 min | 215 | x | - | - | - | - |
| 1 | Greece | Industrial | 10 months | 15 min | 292 | x | x | - | - | - |
| 1 | Ireland | Residential | >24 months | 30 min | 3941, 3440, 3622, 3487 | x | - | x | x | - |
| 1 | Japan | Residential | 18 months | 1 min | 1072 | x | x | - | - | - |
| 3 | Korea | Mix | 27 months | 15 min, 60 min | 1735, 1205, 135 | x | x | - | - | - |
| 2 | Portugal | Residential | 48 months | 15 min | 265, 1022 | x | x | - | - | - |
| 1 | Romania | Industrial | 1 day | 15 min | 234 | x | x | x | - | - |
| 2 | Spain | Mix | 24 months | 60 min | 711, 230 | x | - | - | - | x |
| 2 | UK | Residential | 18 months | 30 min | 5000 | x | - | - | - | - |
| 1 | UK, Bulgarian | Residential | 12 months | 7 s | 197 | x | x | - | x | - |
| 5 | USA | Mix | >8 months | 1 min, 10 min, 60 min | 952, 123,150, 952, 103, 2000 | x | x | - | - | - |
| Reference Article # | [7] | [8] |
|---|---|---|
| Country | x | x |
| Region | x | x |
| Supplier | x | - |
| Initial Size | x | x |
| Clear Reduction | x | x |
| Missing Values | x | x |
| Final Size | x | x |
| Recording Frequency | x | x |
| Start | x | x |
| End | x | x |
| Length | x | x |
| Type | x | x |
| Referral | - | x |
| Category | Attribute | Prevalence | Prevalence% |
|---|---|---|---|
| Geographical information | Country | 33 | 97% |
| Region | 27 | 79% | |
| Origin | 27 | 79% | |
| Data Information | Initial Size | 33 | 97% |
| Clear Reduction | 32 | 94% | |
| Missing Values | 17 | 50% | |
| Final Size | 31 | 91% | |
| Time Information | Recording Frequency | 33 | 97% |
| Start | 23 | 68% | |
| End | 22 | 65% | |
| Length | 30 | 88% | |
| Type Information | Type | 32 | 94% |
| Referencing Data | Referral | 13 | 38% |
| Score | Quantity |
|---|---|
| 7 | 4 |
| 8 | 1 |
| 9 | 3 |
| 10 | 8 |
| 11 | 8 |
| 12 | 7 |
| 13 | 3 |
| Grand Total | 34 |
| Method | Advantages | Caveats |
|---|---|---|
| K-means | Fast, well documented. | Risk of Local optimum. Difficult to find optimum cluster number and interpret clusters. |
| Hierarchical | Visual interpretation, fast. | Careful selection of link function is required. |
| Follow-the-leader | No initial number of clusters to fit. | Needed Distance threshold is chosen by trial-and-error |
| Mixture Models | Advanced modelling of systems. | Complex setup compared to K-means |
| Neural Network | Supervised, taking into account prior knowledge. | Risk of overfitting, needs prior knowledge |
| Link Function | Distance between Clusters | Cluster Behavior |
|---|---|---|
| Single (Euclidian) | Closest | Long non-convex cluster shapes |
| Average | Average | - |
| Complete | Largest | Convex clusters, sensitive to outliers |
| Centroid | Cluster center | Robust vs outliers |
| Ward | smallest variance | Equally sized clusters |
| Index | Mathematics | Interpretation |
|---|---|---|
| DBI (Davies-Bouldin Indictor) | is the average diameter of a cluster. And is the distance between centroids. K is the number of clusters. DBI relates the mean distance of each class with the distance to the closest class [26]. Smaller values of DBI implies that K-means clustering algorithm separates the data set properly [23] | |
| CDI (Cluster Dispersion Indicator) | CDI prefers Long inter-cluster distance and short intra-cluster distance [25]. Small values indicate good clustering. d2 is the squared average distance within cluster k. High. While d is max cluster distance in data. | |
| Dunn | where and | The ratio between “minimum distance between clusters” and “maximum distance within clusters”. When minimum dissimilarity between clusters get large and max cluster diameter gets small the Dunn value gets large and indicates good separation. Ci is cluster i, d is distance and m is total number of clusters. |
| Silhouette | c(x) is the average distance between vector x and all other vectors of the cluster c to which x belongs. c’(x) is the minimum distance between vector x and all other vectors in cluster [23]. SI is between [–1, 1] higher is better. Negative is miss-clustering. | |
| Entropy | denotes the proportion of correct classified vector i in cluster t. Entropy is a supervised index as the true classes needs to be known. Entropy is used as a measure of misclassification in each cluster. Entropy is small when the clustering result is similar to the expected result [25]. c is total clusters. | |
| MIA | Average distance within class to class centroid, summarized across all classes. k is number of clusters; d2 is the squared average distance within cluster k. High MIA indicates large distances within the classes. e.g., large dispersion. |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tureczek, A.M.; Nielsen, P.S. Structured Literature Review of Electricity Consumption Classification Using Smart Meter Data. Energies 2017, 10, 584. https://doi.org/10.3390/en10050584
Tureczek AM, Nielsen PS. Structured Literature Review of Electricity Consumption Classification Using Smart Meter Data. Energies. 2017; 10(5):584. https://doi.org/10.3390/en10050584
Chicago/Turabian StyleTureczek, Alexander Martin, and Per Sieverts Nielsen. 2017. "Structured Literature Review of Electricity Consumption Classification Using Smart Meter Data" Energies 10, no. 5: 584. https://doi.org/10.3390/en10050584
APA StyleTureczek, A. M., & Nielsen, P. S. (2017). Structured Literature Review of Electricity Consumption Classification Using Smart Meter Data. Energies, 10(5), 584. https://doi.org/10.3390/en10050584