
Evaluation of the Accuracy of Machine Learning Predictions of the Czech Republic’s Exports to the China


Abstract
1. Introduction
- RQ1: Can there be expected a growth in the CR’s exports to the PRC?
- RQ2: Are MLP networks applicable for predicting the future development of the CR’s exports to the PRC?
2. Literature Research
3. Materials and Methods
- Time series delay of 1 month;
- Time series delay of 5 months;
- Time series delay of 10 months.
- Linear;
- Logistic;
- Atanh;
- Exponential;
- Sine.
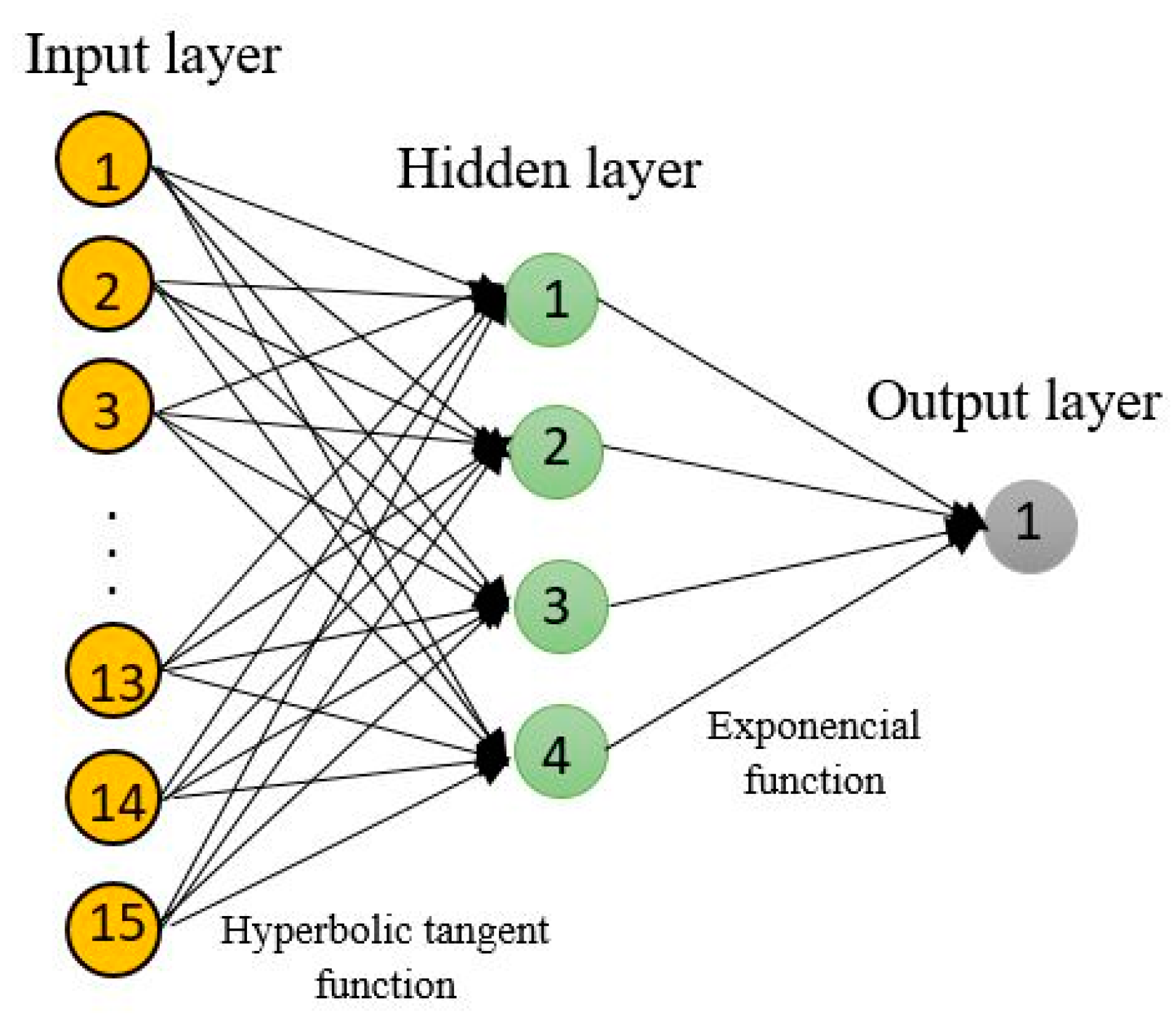
- The overview of the retained networks always contains the structures of the five retained neural networks, the performance of the data sets, errors, the error function, and the activation function of the input and output layers of the neural network.
- Correlation coefficients that characterise the network performance in individual data subsets.
- Basic statistics of equalized time series.
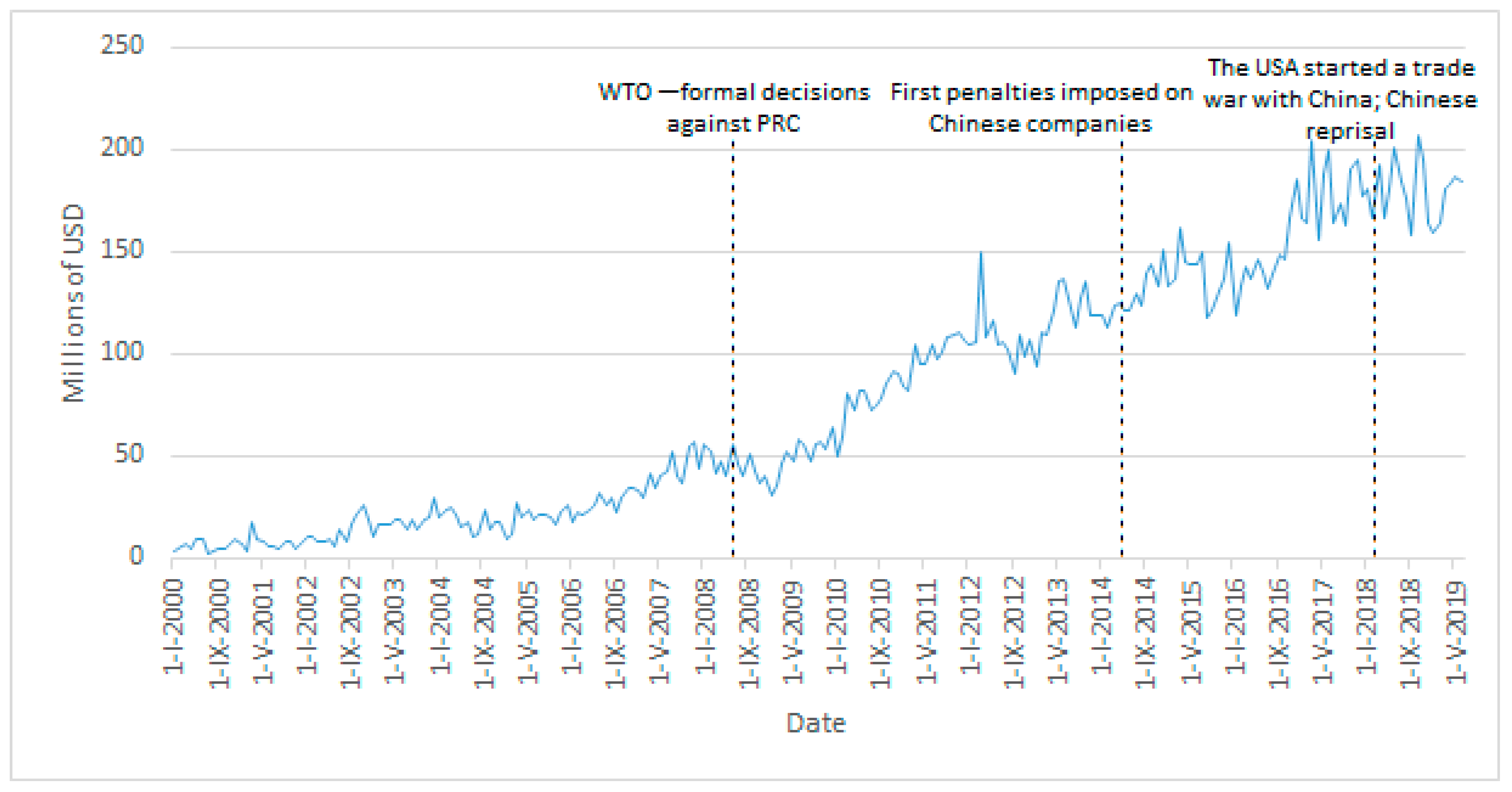
- A diagram of equalized time series.
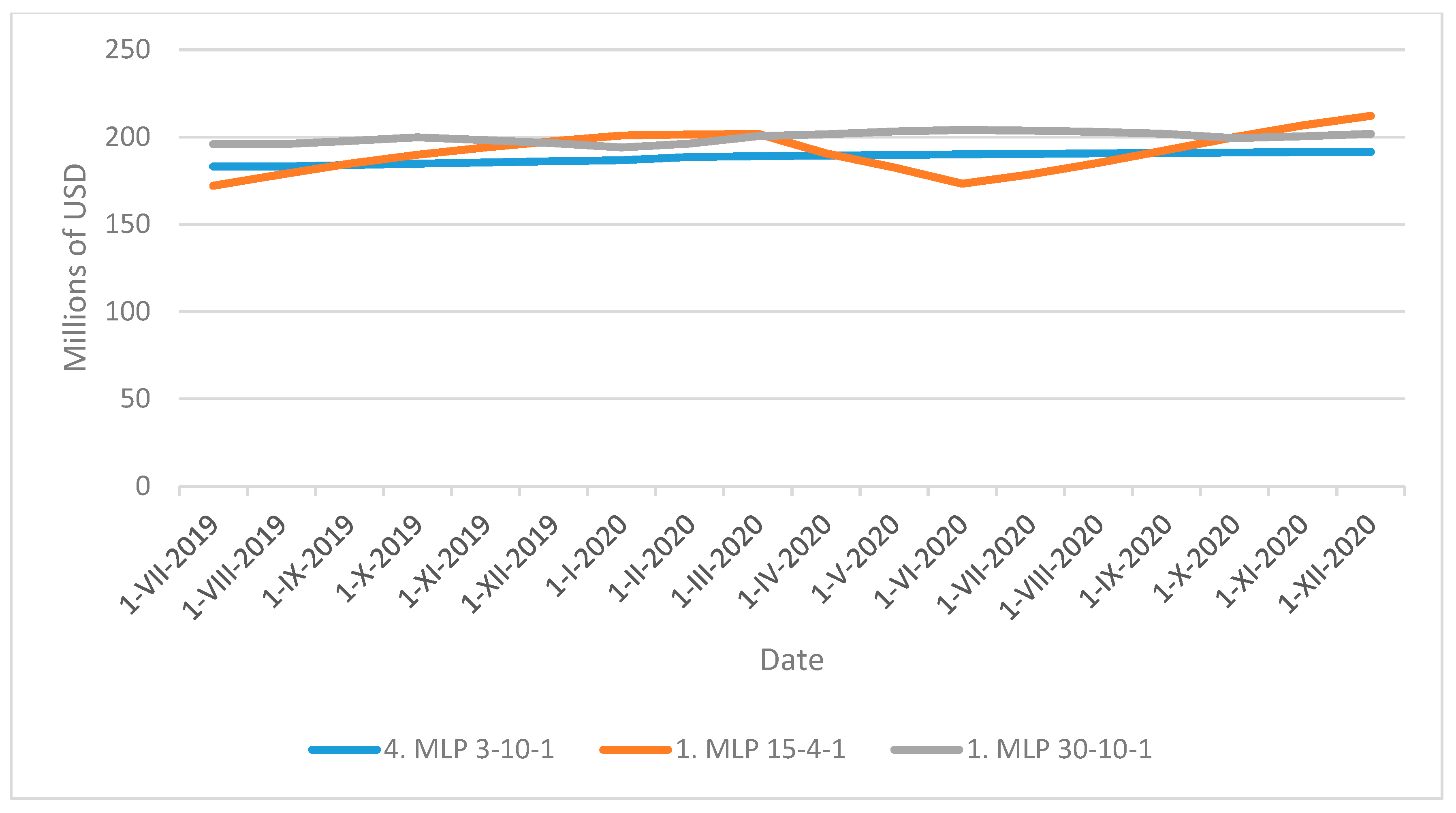
- Predicted values from July 2019 to December 2020.
- A diagram of the development of an actual time series related to the predictions, i.e., possible development of the time series from January 2000 to December 2020.
4. Results
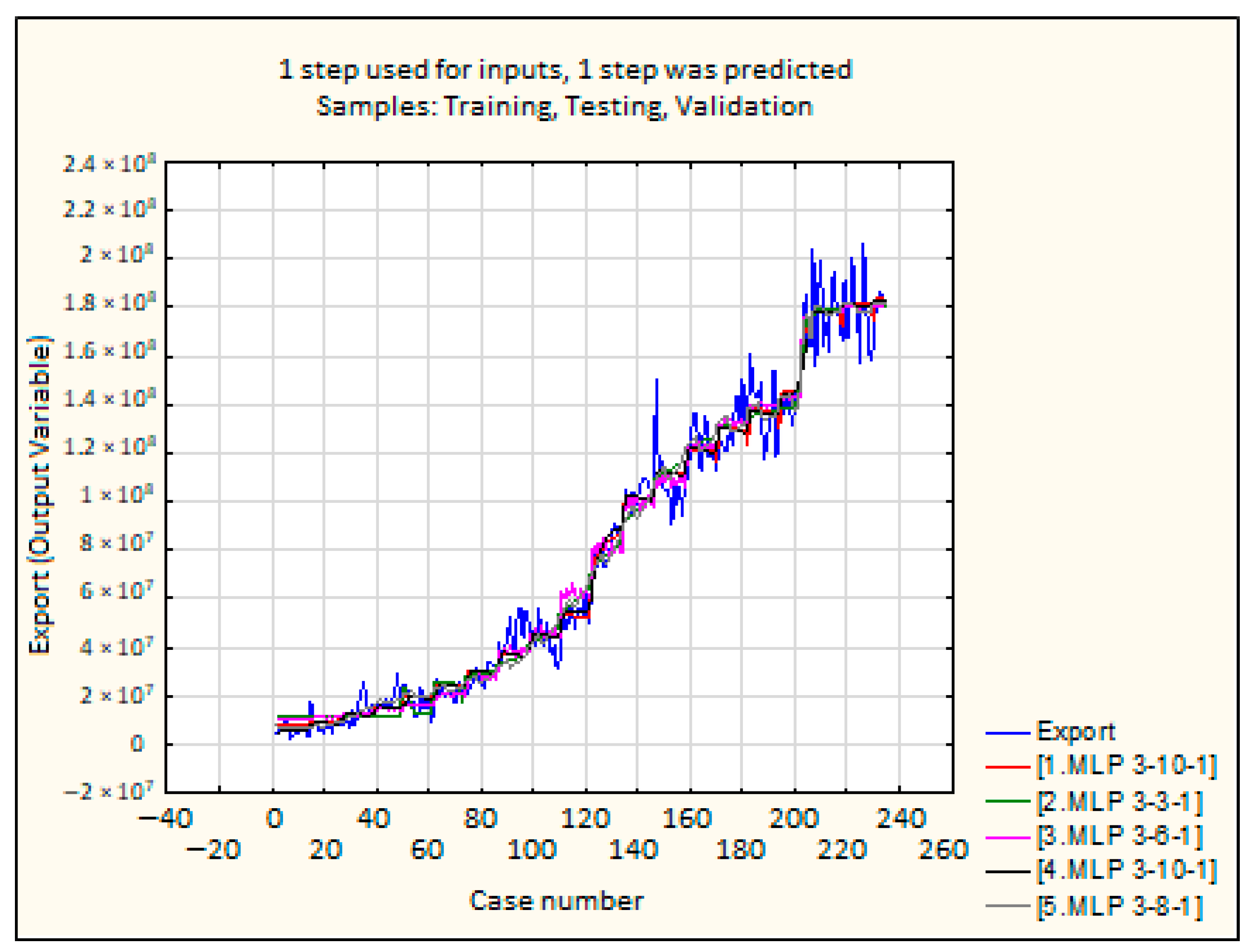
4.1. Experiment 1 (Time Series Delay of 1 Month)
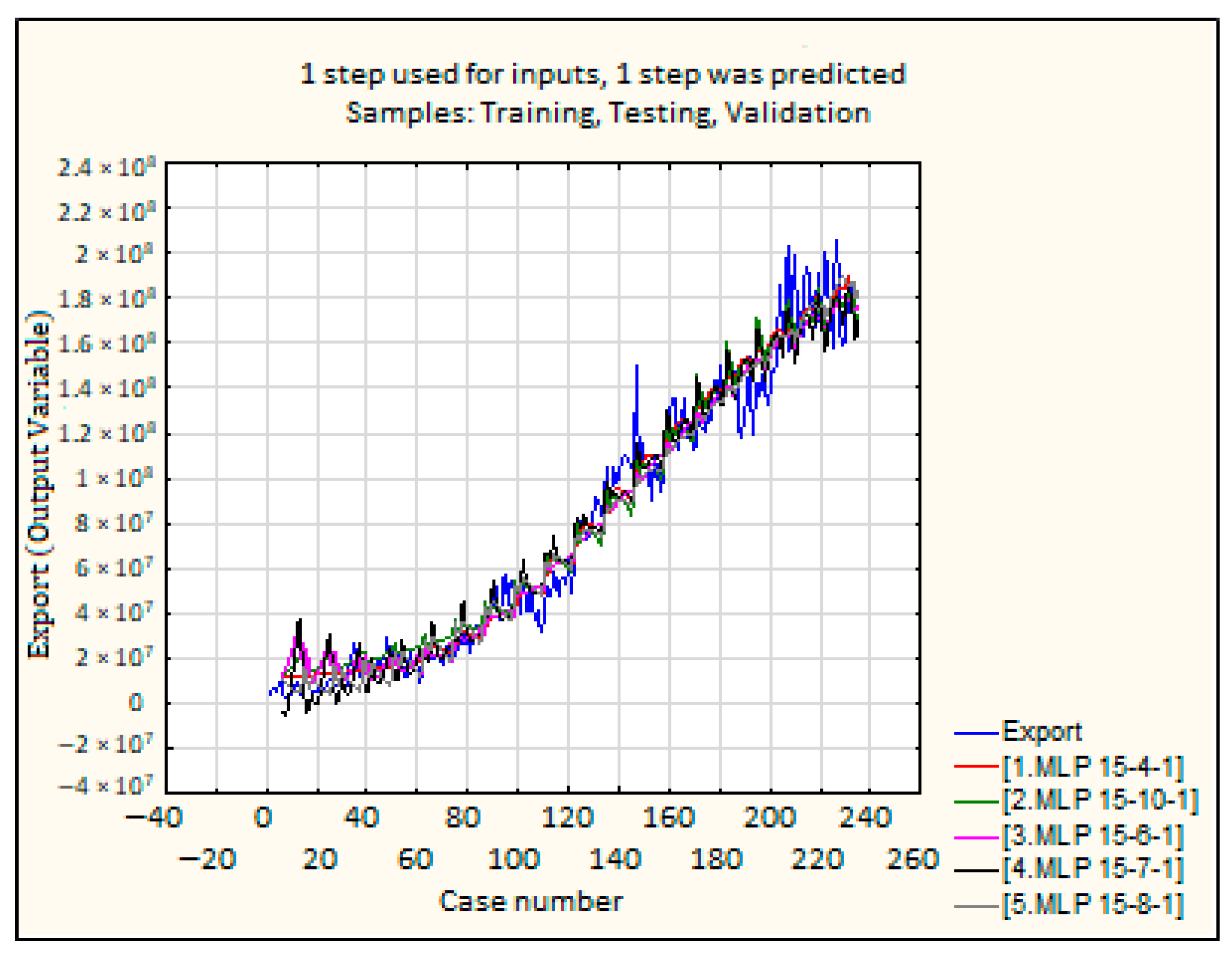
4.2. Experiment 2 (Time Series Delay of 5 Months)
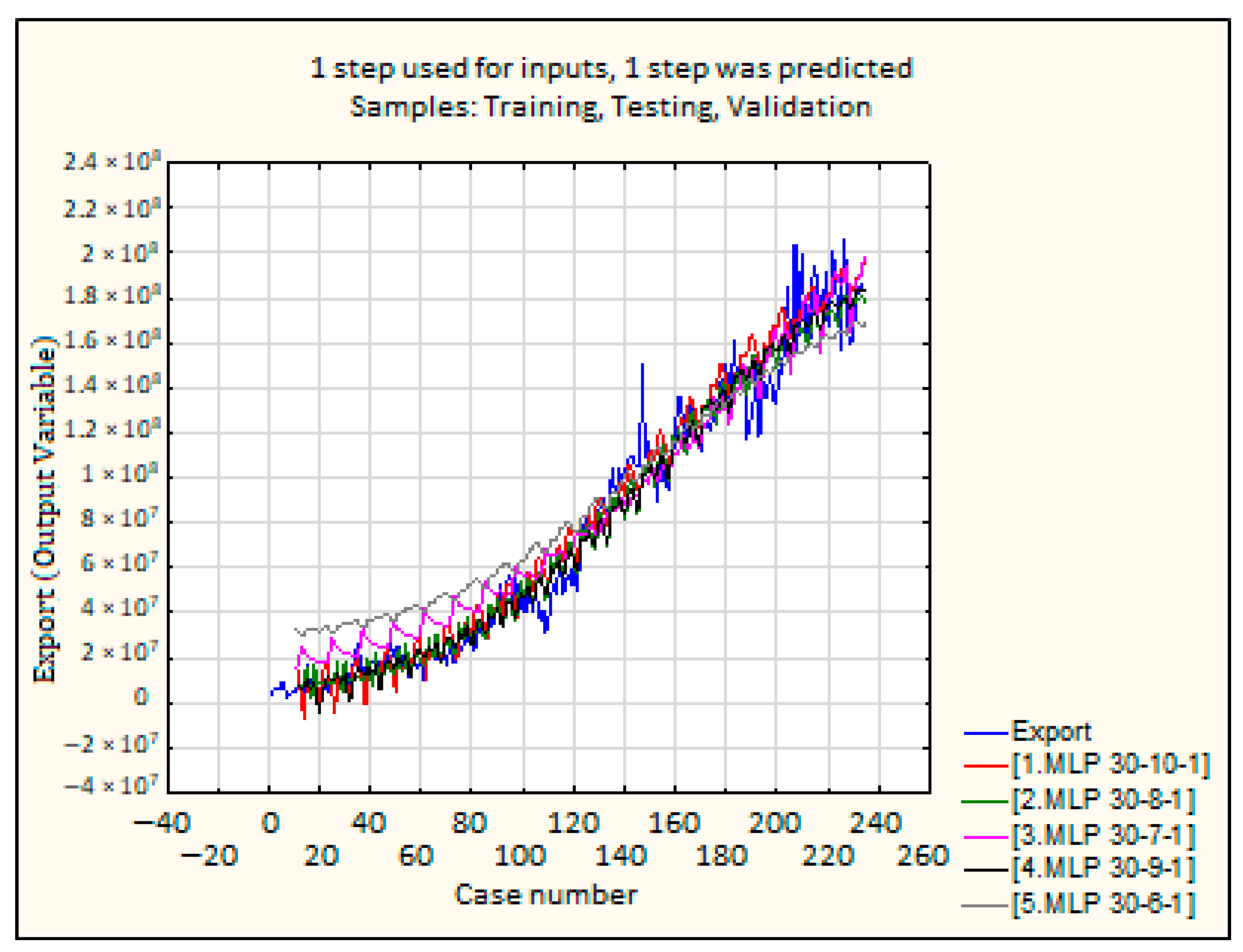
4.3. Experiment 3 (Time Series Delay of 10 Months)
5. Discussion
- RQ1: Can there be expected a growth in the CR’s exports to the PRC?
- RQ2: Are MLP networks applicable for predicting the future development of the CR’s exports to the PRC?
6. Conclusions
- MLP appear to be a useful tool for predicting the development of exports from the CR to the PRC using machine learning prediction.
- MLP networks are able to capture not only the trend throughout the time series, but also most of the local extremes.
- 3
- When equalizing time series, it is necessary to work with a time series delay, whereby a predicted value is determined according to a larger number of parameters. A 5-month delay in the time series produced the most accurate results.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Date | USA Sanctions x PRC | PRC Sanctions x USA | Negative Information against China | Negative Information against the USA |
|---|---|---|---|---|
| 2008 | WTO 1—formal decisions against China—violation of rules | |||
| 19/09/2014 | A Chinese company was fined for violating export rules and banned from importing to the USA | |||
| 2016 | Sanctions against a Chinese company for allegedly supporting North Korea’s nuclear programme | Allegation against a Chinese company | ||
| 2017 | Sanctions against Dalian Global Unity Shipping Company for smuggling luxury goods | |||
| 2017 | Sanctions for involvement in transactions with a banned Russian entity | |||
| 22/01/2018 | Duties on solar panels and washing machines | |||
| 01/03/2018 | Duties on imports of steel and aluminium | |||
| 22/03/2018 | Duties on more than 1300 categories of goods (Chinese imports) | |||
| 02/04/2018 | Duties on 128 products from the USA | |||
| 05/04/2018 | The USA considers imposing duties on goods worth another USD 100 billion | |||
| 29/05/2018 | The USA announces intention to set 25% duty on “industrially important technologies” worth USD 50 billion | China declares it will break off trade negotiations with Washington if sanctions are imposed | ||
| 15/06/2018 | The USA declares imposition of 25% duty on goods worth USD 50 billion | |||
| 18/06/2018 | The USA declares imposition of a 10% duty on additional Chinese imports worth USD 200 billion in 60 days if China imposes retaliatory measures | |||
| 19/06/2018 | Retaliation—China imposes duty on goods worth USD 50 billion | |||
| 06/07/2018 | Duties on Chinese goods worth USD 34 billion came into force | Retaliation—China imposes duties on more goods worth USD 34 billion | ||
| 10/07/2018 | The USA publishes an initial list of Chinese goods worth USD 200 billion to which a 10% duty would apply | |||
| 12/07/2018 | China imposes retaliatory measures through additional duty on American goods worth USD 60 billion | |||
| 08/08/2018 | The USA publishes the final list of 279 Chinese products worth USD 16 billion on which a 25% duty will be imposed as of 23 August | In response, China imposes 25% import duty on goods from the USA worth USD 16 billion | ||
| 14/08/2018 | China files complaint with WTO about American duty on solar panels | |||
| 23/08/2018 | Duties imposed on goods worth USD 16 billion from 8 August 2018 | Duties imposed on goods worth USD 1 billion from 8 August 2018 | ||
| 17/09/2018 | The USA announces that a 10% duty will apply to Chinese goods worth USD 200 billion as of 24 September 2018, increasing to 25% by the end of the year; the USA also threatens to impose a duty on other imports worth USD 267 billion in the event of retaliation | |||
| 18/09/2018 | Retaliation—10% duty on goods worth USD 60 billion | |||
| 30/11/2018 | An agreement between the USA, Mexico and Canada to prevent China from benefitting from agreement perks | |||
| 05/05/2019 | The USA increases the 10% duty on Chinese goods worth USD 200 billion to 25%. Reason: China allegedly withdrew from an already made agreement | |||
| 15/05/2019 | Trump signs an executive order restricting the export of American IT and communication technologies in support of charges made against China relating to espionage on the USA through Chinese telecommunication companies | |||
| 01/06/2019 | China increases duties imposed on American goods worth USD 60 billion | |||
| 01/08/2019 | The USA announces a 10% duty on the “remaining Chinese imports worth USD 300 billion” | |||
| 05/08/2019 | China ordered national enterprises to withdraw from purchasing American agricultural products worth USD 20 billion/year before the trade war | |||
| 23/08/2019 | China announces new retaliative duty on American goods worth USD 75 billion as of 1 September 2019 | |||
| 23/08/2019 | The USA announces a rate increase from 25% to 30% on certain Chinese goods worth USD 250 billion as of 1 October 2019 and from 10% to 15% on the remaining goods worth USD 300 billion as of 15 December 2019 | |||
| 01/09/2019 | USA imposes a new duty of 15% on goods worth USD 112 billion (no less than 2/3 of consumer goods imported from China now subject to taxation) | China imposes 5–10% duty on 1/3 of goods (5078 products) imported from America | ||
| 04/09/2019 | The USA issues interim regulations concerning antidumping duties on metal construction steel from Canada, China and Mexico. It was determined that China was responsible for the dumping, in the USA, of no less than 141.38% of produced construction steel; American customs and border protection was forced to collect cash deposits according to the rate fixed by sales departments. |
Appendix B
| Statistics | 1. MLP 3-10-1 | 2. MLP 3-3-1 | 3. MLP 3-6-1 | 4. MLP 3-10-1 | 5. MLP 3-8-1 |
|---|---|---|---|---|---|
| Minimum prediction (Training) | 7,763,899 | 11,409,737 | 10,198,522 | 5,094,424 | 6,546,283 |
| Maximum prediction (Training) | 184,074,833 | 180,969,470 | 181,121,454 | 183,308,696 | 181,968,424 |
| Minimum prediction (Testing) | 7,253,636 | 11,407,748 | 9,903,034 | 4,966,793 | 7,200,082 |
| Maximum prediction (Testing) | 184,095,364 | 180,928,603 | 181,058,116 | 183,393,233 | 181,897,948 |
| Minimum prediction (Validation) | 7,910,635 | 11,411,864 | 10,217,773 | 5,564,619 | 7,181,583 |
| Maximum prediction (Validation) | 181,356,865 | 180,505,705 | 179,797,257 | 180,984,528 | 181,336,430 |
| Minimum residuals (Training) | −22,572,350 | −23,801,620 | −22,285,028 | −22,305,737 | −24,623,265 |
| Maximum residuals (Training) | 38,047,204 | 40,455,653 | 40,765,398 | 38,122,359 | 40,416,324 |
| Minimum residuals (Testing) | −11,291,835 | −17,950,102 | −16,242,972 | −18,945,110 | −19,759,414 |
| Maximum residuals (Testing) | 24,918,361 | 25,710,271 | 26,116,621 | 25,338,110 | 28,140,995 |
| Minimum residuals (Validation) | −23,823,438 | −22,972,278 | −22,263,830 | −23,451,101 | −20,522,599 |
| Maximum residuals (Validation) | 18,213,404 | 19,393,615 | 15,729,966 | 22,953,336 | 20,998,650 |
| Minimum standard residuals (Training) | −4 | −3 | −3 | −3 | −4 |
| Maximum standard residuals (Training) | 6 | 6 | 6 | 6 | 6 |
| Minimum standard residuals (Testing) | −2 | −3 | −3 | −3 | −3 |
| Maximum standard residuals (Testing) | 5 | 4 | 5 | 4 | 5 |
| Minimum standard residuals (Validation) | −4 | −3 | −4 | −3 | −3 |
| Maximum standard residuals (Validation) | 3 | 3 | 3 | 3 | 3 |
Appendix C
| Statistics | 1. MLP 15-4-1 | 2. MLP 15-10-1 | 3. MLP 15-6-1 | 4. MLP 15-7-1 | 5. MLP 15-8-1 |
|---|---|---|---|---|---|
| Minimum prediction (Training) | 11,279,441 | 12,735,609 | 8,827,290 | −5,431,136 | 3,861,263 |
| Maximum prediction (Training) | 185,066,580 | 183,105,512 | 180,602,039 | 179,463,443 | 189,881,288 |
| Minimum prediction (Testing) | 12,963,348 | 16,573,316 | 10,887,283 | 2,360,630 | 4,723,416 |
| Maximum prediction (Testing) | 189,930,686 | 186,256,473 | 179,786,697 | 185,951,111 | 187,699,542 |
| Minimum prediction (Validation) | 12,605,326 | 15,179,569 | 9,641,294 | −292,243 | 8,361,543 |
| Maximum prediction (Validation) | 178,978,025 | 176,199,123 | 174,574,567 | 177,948,636 | 181,849,424 |
| Minimum residuals (Training) | −32,869,811 | −31,425,688 | −29,744,107 | −30,783,326 | −31,208,184 |
| Maximum residuals (Training) | 42,177,639 | 41,500,775 | 48,506,725 | 48,895,436 | 50,517,223 |
| Minimum residuals (Testing) | −21,021,409 | −20,898,298 | −16,484,716 | −25,056,663 | −24,107,948 |
| Maximum residuals (Testing) | 24,035,298 | 28,055,163 | 29,782,394 | 26,137,517 | 22,053,236 |
| Minimum residuals (Validation) | −33,656,957 | −28,613,210 | −33,275,097 | −24,865,836 | −30,580,605 |
| Maximum residuals (Validation) | 19,982,403 | 22,786,890 | 23,378,932 | 24,680,668 | 22,285,903 |
| Minimum standard residuals (Training) | −4 | −4 | −3 | −3 | −4 |
| Maximum standard residuals (Training) | 5 | 5 | 5 | 5 | 6 |
| Minimum standard residuals (Testing) | −3 | −3 | −2 | −3 | −3 |
| Maximum standard residuals (Testing) | 4 | 4 | 4 | 4 | 3 |
| Minimum standard residuals (Validation) | −5 | −4 | −5 | −3 | -4 |
| Maximum standard residuals (Validation) | 3 | 3 | 3 | 3 | 3 |
Appendix D
| Statistics | 1. MLP 30-10-1 | 2. MLP 30-8-1 | 3. MLP 30-7-1 | 4. MLP 30-9-1 | 5. MLP 30-6-1 |
|---|---|---|---|---|---|
| Minimum prediction (Training) | −7,535,089 | 1,383,468 | 1,5601,575 | 202,759 | 30,036,888 |
| Maximum prediction (Training) | 194,714,321 | 181,432,018 | 196,512,169 | 184,471,204 | 168,610,349 |
| Minimum prediction (Testing) | 2,833,042 | 4,055,518 | 20,790,133 | −151,371 | 32,094,383 |
| Maximum prediction (Testing) | 193,728,014 | 181,643,107 | 189,563,768 | 183,355,199 | 169,693,404 |
| Minimum prediction (Validation) | 338,201 | 9,043,558 | 18,509,515 | −5,134,835 | 31,902,729 |
| Maximum prediction (Validation) | 191,274,620 | 172,697,645 | 185,623,361 | 176,345,309 | 165,464,366 |
| Minimum residuals (Training) | −38,806,558 | −23,026,850 | −37,506,733 | −26,387,685 | −35,711,856 |
| Maximum residuals (Training) | 45,647,527 | 45,028,043 | 53,626,843 | 48,286,845 | 47,268,713 |
| Minimum residuals (Testing) | −21,635,297 | −17,989,406 | −26,713,419 | −21,134,378 | −32,410,540 |
| Maximum residuals (Testing) | 16,733,877 | 26,418,571 | 24,925,722 | 26,459,602 | 40,801,806 |
| Minimum residuals (Validation) | −33,741,193 | −22,784,859 | −28,089,934 | −24,873,688 | −27,222,759 |
| Maximum residuals (Validation) | 17,338,016 | 25,346,237 | 23,198,335 | 25,256,795 | 32,956,970 |
| Minimum standard residuals (Training) | −4 | −3 | −4 | −3 | −3 |
| Maximum standard residuals (Training) | 5 | 6 | 5 | 6 | 3 |
| Minimum standard residuals (Testing) | −3 | −3 | −3 | −3 | −2 |
| Maximum standard residuals (Testing) | 2 | 4 | 3 | 4 | 3 |
| Minimum standard residuals (Validation) | −4 | −3 | −3 | −3 | −2 |
| Maximum standard residuals (Validation) | 2 | 3 | 3 | 3 | 3 |
References
- Allen, Creina, and Garth Den. 2014. Depletion of non-renewable resources imported by China. China Economic Review 30: 235–43. [Google Scholar] [CrossRef]
- Bartl, Mathias, and Simone Krummaker. 2020. Prediction of claims in export credit finance: A comparison of four machine learning techniques. Risks 8: 22. [Google Scholar] [CrossRef]
- BusinessInfo.cz. 2019. China: Trade and Economic Cooperation with CR. Embassy of the Czech Republic in Beijing (China) [online]. Available online: https://www.businessinfo.cz/navody/cina-obchodni-a-ekonomicka-spoluprace-s-cr/# (accessed on 28 January 2021).
- Castillo, Oscar, and Patricia Melin. 1997. Simulation and forecasting of international trade dynamics using non-linear mathematical models and fuzzy logic techniques. Paper presented at the IEEE/IAFE 1997 Computational Intelligence for Financial Engineering (CIFEr), New York, NY, USA, March 24–25; pp. 100–6. [Google Scholar] [CrossRef]
- Chou, Chien Chang. 2010. A mixed fuzzy expert system and regression model for forecasting the volume of international trade containers. International Journal of Innovative Computing, Information and Control 6: 2449–58. [Google Scholar]
- Culkin, Robert, and Sanjiv R. Das. 2017. Machine learning in finance: The case of deep learning for option pricing. Journal of Investment Management 15: 92–100. [Google Scholar]
- Das, Sumanjit, and Sarojananda Mishra. 2019. Advanced deep learning framework for stock value prediction. International Journal of Innovative Technology and Exploring Engineering 8: 2358–67. [Google Scholar]
- Ecer, Fatih, Sina Ardabili, Shabab Band, and Amir Mosavi Amir. 2020. Training multilayer perceptron with genetic algorithms and particle swarm optimization for modeling stock price index prediction. Entropy 22: 1239. [Google Scholar] [CrossRef]
- Ecer, Fatih. 2013. Comparing the bank failure prediction performance of neural networks and support vector machines: The Turkish case. Economics Research 26: 81–98. [Google Scholar] [CrossRef]
- Fojtikova, Lenka, and Yajun Meng. 2018. China in the WTO: The implications for the Czech trade and investment flows with China. Paper presented at the 16th International Scientific Conference on Economic Policy in European Union Member Countries, Celadna, Czech Republic, September 12–14; pp. 76–85. [Google Scholar]
- Fojtikova, Lenka. 2018. China’s market economy status problem: Implications for the Czech steel industry. Paper presented at the 27th International Conference on Metallurgy and Materials (METAL), Brno, Czech Republic, May 23–25; pp. 1870–78. [Google Scholar]
- Gerlein, Eduardo A., Martin McGinnity, Ammar Belatreche, and Sonya Coleman. 2016. Evaluating machine learning classification for financial trading: An empirical approach. Expert Systems with Applications 54: 193–207. [Google Scholar] [CrossRef]
- Ha, Van-Sang, and Ha-Nam Nguyen. 2016. Credit scoring with a feature selection approach based deep learning. Paper presented at the MATEC Web of Conferences, Cape Town, South Africa, February 1–3. [Google Scholar]
- Havrlant, David, and Roman Husek. 2011. Models of factors driving the Czech export. Prague Economic Papers 20: 195–215. [Google Scholar] [CrossRef]
- Hogenboom, Alexander, Wolfgang Ketter, Jan Van Dalen, Uzay Kaymak, John Collins, and Alok Gupta. 2015. Adaptive tactical pricing in multi-agent supply chain markets using economic regimes. Decision Sciences 46: 791–818. [Google Scholar] [CrossRef]
- Horák, Jakub, and Tomáš Krulický. 2019. Comparison of exponential time series alignment and time series alignment using artificial neural networks by example of prediction of future development of stock prices of a specific company. Paper presented at the Innovative Economic Symposium 2018—Milestones and Trends of World Economy: SHS Web of Conferences, Beijing, China, November 8–9. [Google Scholar]
- Humlerova, Veronika. 2018. Czech-Chinese business cooperation case study. Paper presented at the 31st International-Business-Information-Management-Association Conference, Milan, Italy, April 25–26; pp. 3185–91. [Google Scholar]
- Hushani, Phillip. 2019. Using autoregressive modelling and machine learning for stock market prediction and trading. Paper presented at the Third International Congress on Information and Communication Technology, London, UK, February 27–28; pp. 767–74. [Google Scholar] [CrossRef]
- Janda, Karel, Eva Michalikova, and Jiri Skuhrovec. 2013. Credit support for export: Robust evidence from the Czech Republic. The World Economy 36: 1588–610. [Google Scholar] [CrossRef]
- Kiranyaz, Serkan, Turker Ince, Alper Yildirim, and Moncef Gabbouj. 2009. Evolutionary artificial neural networks by multi-dimensional particle swarm optimization. Neural Networks 22: 1448–62. [Google Scholar] [CrossRef]
- Klieštik, Tomas. 2013. Models of autoregression conditional heteroskedasticity GARCH and ARCH as a tool for modeling the volatility of financial time series. Ekonomicko-Manažerské Spectrum 7: 2–10. [Google Scholar]
- Koncikova, Veronika. 2013. Sino-Czech bilateral trade structure resemblances and deviations. Paper presented at the 14th International Scientific Conference on International Relations—Contemporary Issues of World Economics and Politics, Smolenice, Slovakia, December 5–6; pp. 352–65. [Google Scholar]
- Krulicky, Tomas, and Tomas Brabenec. 2020. Comparison of neural networks and regression time series in predicting export from Czech Republic into People’s Republic of China. Paper presented at the Innovative Economic Symposium 2019—Potential of Eurasian Economic Union (IES2019), Ceske Budejovice, Czech Republic, November 7. [Google Scholar]
- Lahmiri, Salim, and Stelios Bekiros. 2019. Cryptocurrency forecasting with deep learning chaotic neural networks. Chaos Solitons Fractals 118: 35–40. [Google Scholar] [CrossRef]
- Lahmiri, Salim. 2014. Entropy-based technical analysis indicators selection for international stock markets fluctuations prediction using support vector machines. Fluctuation and Noise Letters 13. [Google Scholar] [CrossRef]
- Laio, Hongwei, Liangping Yang, Henan Ma, and Jiao Jiao Zheng. 2020. Technology import, secondary innovation, and industrial structure optimization: A potential innovation strategy for China. Pacific Economic Review 25: 145–60. [Google Scholar] [CrossRef]
- Land, Walker H., Jr., John Heine, George Tomko, and Robert Thomas. 2007. Evaluation of two key machine intelligence technologies. Paper presented at the Intelligent Computing: Theory and Applications V, Orlando, Florida, April 9–10. [Google Scholar]
- Li, Der-Chiang, Chuan-Wu Yeh, and Zhen-Yaun Li. 2008. A case study: The prediction of Taiwan’s export of polyester fiber using small-data-set learning methods. Expert Systems with Applications 34: 1983–94. [Google Scholar] [CrossRef]
- Lu, Hongfang, Xin Ma, Kun Hang, and Mohammadamin Azimi. 2020. Carbon trading volume and price forecasting in China using multiple machine learning models. Journal of Cleaner Production 249. [Google Scholar] [CrossRef]
- Machova, Veronika, and Jan Marecek. 2020. Machine learning forecasting of CR import from PRC in context of mutual PRC and USA sanctions. Paper presented at the Innovative Economic Symposium 2019—Potential of Eurasian Economic Union (IES2019): SHS Web of Conferences, Ceske Budejovice, Czech Republic, November 7. [Google Scholar]
- Mosavi, Amirhosein, Yaser Faghan, Pedram Ghamisi, Puhong Duan, Sina Faizollahzadeh Ardabili, Ely Salwana, and Shahab S. Band. 2020. Comprehensive review of deep reinforcement learning methods and applications in economics. Mathematics 8: 1640. [Google Scholar] [CrossRef]
- Nabipour, Mojtaba, Pooyan Nayyeri, Hamed Jabani, Amir Mosavi, Ely Salwana, and Shahab S. Band. 2020a. Deep learning for stock market prediction. Entropy 22: 840. [Google Scholar] [CrossRef] [PubMed]
- Nabipour, Mojtaba, Pooyan Nayyeri, Hamed Jabani, Shahab S. Band, and Amir Mosavi. 2020b. Predicting stock market trends using machine learning and deep learning algorithms via continuous and binary data, a comparative analysis. IEEE Access 8: 150199–212. [Google Scholar] [CrossRef]
- Nosratabadi, Saeed, Amirhosein Mosavi, Puhong Duan, Pedram Ghamisi, Ferdinand Filip, Shahab S. Band, Uwe Reuter, Joao Gama, and Amir H. Gandomi. 2020. Data science in economics: Comprehensive review of advanced machine learning and deep learning methods. Mathematics 8: 1799. [Google Scholar] [CrossRef]
- Ogbuabor, Jonathan E. 2019. Measuring the dynamics of Czech Republic output connectedness with the global economy. Ekonomický Časopis 67: 1070–89. [Google Scholar]
- Ozbek, Ahmet, Mehmet Akalin, Vedat Topuz, and Bahar Sennaroglu. 2011. Prediction of Turkey’s Denim trousers export using artificial neural networks and the autoregressive integrated moving average model. Fibres & Textiles in Eastern Europe 19: 10–16. [Google Scholar]
- Pinter, Gergo, Amir Mosavi, and Imre Felde. 2020. Artificial intelligence for modeling real estate price using call detail records and hybrid machine learning approach. Entropy 22: 1421. [Google Scholar] [CrossRef] [PubMed]
- Polak, Josef. 2019. Determining probabilities for a commercial risk model of Czech exports to China with respect to cultural differences and in financial management. Journal of Competitiveness 11: 109–27. [Google Scholar] [CrossRef]
- Povolna, Lucie, and Jena Svarcova. 2017. The macroeconomic context of investments in the field of machine tools in the Czech Republic. Journal of Competitiveness 9: 110–22. [Google Scholar] [CrossRef]
- Ramchoun, Hassan, Mohammed Amine, Janati Idrissi, Youssef Ghanou, and Mohamed Ettaouil. 2016. Multilayer perceptron: Architecture optimization and training. International Journal of Interactive Multimedia and Artificial Intelligence 4: 26–30. [Google Scholar] [CrossRef]
- Rojicek, Marek. 2010. Competitiveness of the trade of the Czech Republic in the process of globalisation. Politická Ekonomie 58: 147–65. [Google Scholar] [CrossRef]
- Rousek, Pavel, and Jan Marecek. 2019. Use of neural networks for predicting development of USA export to China taking into account time series seasonality. Ad Alta-Journal of Interdisciplinary Research 9: 299–304. [Google Scholar]
- Rowland, Zuzana, and Jaromir Vrbka. 2016. Using artificial neural networks for prediction of key indicators of a company in global world. In Globalization and Its Socio-Economic Consequences, 16th International Scientific Conference Proceedings, 1st ed. Žilina: EDIS-Žilina University, pp. 1896–903. [Google Scholar]
- Sebastião, Helder, and Pedro Godinho. 2021. Forecasting and trading cryptocurrencies with machine learning under changing market conditions. Financial Innovation 7: 1–30. [Google Scholar] [CrossRef]
- Sidehabi, Sitti Wetenriajeng, Indrabayu Indrabayou, and Sofyan Tandungan. 2016. Statistical and machine learning approach in forex prediction based on empirical data. Paper presented at the 2016 International Conference on Computational Intelligence and Cybernetics, Makassar, Indonesia, November 22–24; pp. 63–68. [Google Scholar]
- Sokolov-Mladenovic, Svetlana, Milos Milovancevic, Igor Mladenovic, and Meysam Alizamir. 2016. Economic growth forecasting by artificial neural network with extreme learning machine based on trade import and export parameters. Computers in Human Behavior 65: 43–45. [Google Scholar] [CrossRef]
- Vochozka, Marek, and Zuzana Rowland. 2020. Forecasting trade balance of Czech Republic and People’s Republic of China in equalizing time series and considering seasonal fluctuations. Paper presented at the Innovative Economic Symposium 2019—Potential of Eurasian Economic Union (IES2019): SHS Web of Conferences, Ceske Budejovice, Czech Republic, November 7. [Google Scholar]
- Vrbka, Jaromir, and Marek Vochozka. 2020. Considering seasonal fluctuations on balancing time series with the use of artificial neural networks when forecasting US imports from the PRC. Paper presented at the Innovative Economic Symposium 2019—Potential of Eurasian Economic Union (IES2019): SHS Web of Conferences, Ceske Budejovice, Czech Republic, November 7. [Google Scholar]
- Wang, Yibo, and Wei Xu. 2018. Leveraging deep learning with LDA-based text analytics to detect automobile insurance fraud. Decision Support System 105: 87–95. [Google Scholar] [CrossRef]
- Wu, Chongyu, Jiantao Zhou, Hui Li, Zhongyi Liu, and Xinyi Cai. 2017. Do imported commodities cause inflation in China? An Armington Substitution Elasticity analysis. Emerging Markets Financa and Trade 53: 400–15. [Google Scholar] [CrossRef]
- Wu, Gang, Lan-Cui Liu, and Yi-Ming Wei. 2009. Comparison of China’s oil import risk: Results based on portfolio theory and a diversification index approach. Energy Policy 37: 3557–65. [Google Scholar] [CrossRef]
- Wysokińska, Zofia. 2010. Intra–Industry trade between selected Central and Eastern European countries (Poland, the Czech Republic, Hungary, Slovakia and Slovenia) and the China area: The position of textiles and clothing. Fibres & Textiles in Eastern Europe 18: 7–10. [Google Scholar]
- Yin, Kedong, Danning Lu, and Xuemei Li. 2017. A novel grey wave method for predicting total Chinese trade volume. Sustainability 9: 2367. [Google Scholar] [CrossRef]
- Zhang, Qi. 2016. Prediction on China’s merchandise exports based on BP neural network associated with sensitivity analysis. Paper presented at the International Conference on Modern Computer Science and Applications (MCSA 2016), Wuhan, China, September 18; pp. 351–56. [Google Scholar]
- Zhang, Xin, Tianyuan Xue, and H. Eugene Stanley. 2019. Comparison of econometric models and artificial neural networks algorithms for the prediction of Baltic Dry Index. IEEE Access 7: 1647–57. [Google Scholar] [CrossRef]
- Zhao, Xingjun, and Yanrui Wu. 2007. Determinants of China’s energy imports: An empirical analysis. Energy Policy 35: 4235–46. [Google Scholar] [CrossRef]
- Zlicar, Blaz, and Simon Cousins. 2018. Discrete representation strategies for foreign exchange prediction. Journal of Intelligent Information Systems 50: 129–64. [Google Scholar] [CrossRef]









| Samples | Date (Input Variable) | Month (Input Variable) | Year (Input Variable) | Export (Output) |
|---|---|---|---|---|
| Minimum (Training) | 36,556.00 | 1.00000 | 2000.000 | 2,454,273 |
| Maximum (Training) | 43,646.00 | 12.00000 | 2019.000 | 204,067,342 |
| Average (Training) | 40,050.47 | 6.45455 | 2009.115 | 75,907,200 |
| Standard deviation (Training) | 2001.16 | 3.50688 | 5.473 | 58,800,431 |
| Minimum (Testing) | 36,585.00 | 1.00000 | 2000.000 | 5,358,384 |
| Maximum (Testing) | 43,677.00 | 12.00000 | 2019.000 | 206,248,570 |
| Average (Testing) | 40,130.09 | 6.00000 | 2009.371 | 76,473,006 |
| Standard deviation (Testing) | 2418.96 | 3.38683 | 6.691 | 71,737,610 |
| Minimum (Validation) | 36,646.00 | 1.00000 | 2000.000 | 4,679,970 |
| Maximum (Validation) | 43,373.00 | 12.00000 | 2018.000 | 189,894,269 |
| Average (Validation) | 40,412.86 | 6.71429 | 2010.086 | 86,239,826 |
| Standard deviation (Validation) | 3403.28 | 3.44159 | 9.284 | 78,989,659 |
| Minimum (Overall) | 36,556.00 | 1.00000 | 2000.000 | 2,454,273 |
| Maximum (Overall) | 43,677.00 | 12.00000 | 2019.000 | 206,248,570 |
| Average (Overall) | 40,116.30 | 6.42553 | 2009.298 | 77,534,889 |
| Standard deviation (Overall) | 2069.19 | 3.45140 | 5.669 | 60,870,511 |
| Index | Network | Training Performance | Testing Performance | Validation Performance | Training Error | Testing Error | Validation Error | Training Algorithm | Error Function | Hidden Layer Activation | Output Activation Function |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | MLP 3-10-1 | 0.987846 | 0.994059 | 0.988604 | 4.1043 36 × 1013 | 3.0008 8 × 1013 | 4.1563 62 × 1013 | BFGS 1 (Quasi-Newton) 151 | Sum of squares | Tanh | Logistic |
| 2 | MLP 3-3-1 | 0.985613 | 0.992208 | 0.987883 | 4.8537 20 × 1013 | 3.8755 92 × 1013 | 4.7838 08 × 1013 | BFGS (Quasi-Newton) 136 | Sum of squares | Logistic | Exponential |
| 3 | MLP 3-6-1 | 0.986907 | 0.993292 | 0.990566 | 4.4196 23 × 1013 | 3.2737 15 × 1013 | 3.6707 1013 | BFGS (Quasi-Newton) 101 | Sum of squares | Tanh | Logistic |
| 4 | MLP 3-10-1 | 0.987558 | 0.993045 | 0.987570 | 4.2035 12 × 1013 | 3.4453 43 × 1013 | 4.5812 85 × 1013 | BFGS (Quasi-Newton) 91 | Sum of squares | Tanh | Logistic |
| 5 | MLP 3-8-1 | 0.986632 | 0.992909 | 0.988321 | 4.5124 78 × 1013 | 3.5224 33 × 1013 | 4.5856 8 × 1013 | BFGS (Quasi-Newton) 179 | Sum of squares | Tanh | Logistic |
| Date | MLP 3-10-1 | MLP 3-3-1 | MLP 3-6-1 | MLP 3-10-1 | MLP 3-8-1 |
|---|---|---|---|---|---|
| 31 July 2019 | 184,028,208 | 180,988,842 | 181,182,810 | 183,191,758 | 180,684,018 |
| 31 August 2019 | 184,003,876 | 181,008,014 | 181,034,099 | 183,134,296 | 178,396,787 |
| 30 September 2019 | 183,377,939 | 181,124,647 | 18,468,354 | 183,992,714 | 178,372,303 |
| 31 October 2019 | 182,747,257 | 181,217,353 | 18,468,354 | 184,749,885 | 178,349,071 |
| 30 November 2019 | 182,066,079 | 181,295,712 | 18,468,354 | 185,471,822 | 178,322,700 |
| 31 December 2019 | 181,379,574 | 181,357,971 | 18,468,354 | 186,109,655 | 178,297,677 |
| 31 January 2020 | 180,637,946 | 181,410,579 | 18,468,354 | 186,718,827 | 178,269,273 |
| 29 February 2020 | 174,091,472 | 181,497,391 | 18,468,354 | 188,553,402 | 181,769,980 |
| 31 March 2020 | 182,279,812 | 181,522,947 | 18,468,354 | 189,031,734 | 181,743,705 |
| 30 April 2020 | 181,698,943 | 181,545,300 | 18,468,354 | 189,409,236 | 181,710,847 |
| 31 May 2020 | 180,998,605 | 181,563,050 | 18,468,354 | 189,743,059 | 181,679,664 |
| 30 June 2020 | 180,240,120 | 181,578,042 | 18,468,354 | 190,063,911 | 181,644,264 |
| 31 July 2020 | 179,475,507 | 181,589,946 | 18,468,354 | 190,349,677 | 178,239,752 |
| 31 August 2020 | 178,649,348 | 181,599,999 | 18,468,354 | 190,624,770 | 177,873,100 |
| 30 September 2020 | 177,786,435 | 181,608,205 | 18,468,354 | 190,879,388 | 177,827,878 |
| 31 October 2020 | 176,916,475 | 181,614,721 | 18,468,354 | 191,106,633 | 177,784,964 |
| 30 November 2020 | 175,976,431 | 181,620,224 | 18,468,354 | 191,325,826 | 177,736,246 |
| 31 December 2020 | 175,028,730 | 181,624,593 | 18,468,354 | 191,521,696 | 177,690,013 |
| Index | Network | Training Performance | Testing Performance | Validation Performance | Training Error | Testing Error | Validation Error | Training Algorithm | Error Function | Hidden Layer Activation | Output Activation Function |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | MLP 15-4-1 | 0.978543 | 0.989979 | 0.983787 | 7.1778 47 × 1013 | 3.9067 79 × 1013 | 5.4646 54 × 1013 | BFGS (Quasi-Newton) 12 | Sum of squares | Tanh | Exponential |
| 2 | MLP 15-10-1 | 0.977797 | 0.991030 | 0.983598 | 7.8484 93 × 1013 | 4.6229 19 × 1013 | 5.2254 59 × 1013 | BFGS (Quasi-Newton) 25 | Sum of squares | Sine | Exponential |
| 3 | MLP 15-6-1 | 0.976574 | 0.988310 | 0.983421 | 8.1784 66 × 1013 | 5.1425 67 × 1013 | 5.3678 58 × 1013 | BFGS (Quasi-Newton) 33 | Sum of squares | Sine | Sine |
| 4 | MLP 15-7-1 | 0.973193 | 0.986142 | 0.983858 | 8.9130 29 × 1013 | 5.4771 65 × 1013 | 5.1327 36 × 1013 | BFGS (Quasi-Newton) 49 | Sum of squares | Sine | Sine |
| 5 | MLP 15-8-1 | 0.978088 | 0.987068 | 0.983508 | 7.3630 16 × 1013 | 5.04839 × 1013 | 5.2314 43 × 1013 | BFGS (Quasi-Newton) 32 | Sum of squares | Sine | Identity |
| Date | MLP 15-4-1 | MLP 15-10-1 | MLP 15-6-1 | MLP 15-7-1 | MLP 15-8-1 |
|---|---|---|---|---|---|
| 31 July 2019 | 172,085,976 | 173,383,947 | 177,267,045 | 171,188,690 | 184,032,463 |
| 31 August 2019 | 178,610,635 | 177,220,223 | 179,445,382 | 178,547,110 | 188,236,320 |
| 30 September 2019 | 184,708,986 | 180,211,843 | 181,876,699 | 183,572,486 | 192,644,763 |
| 31 October 2019 | 189,833,524 | 182,393,335 | 184,437,226 | 186,118,002 | 197,281,886 |
| 30 November 2019 | 194,080,437 | 183,239,438 | 187,140,812 | 186,030,035 | 202,122,082 |
| 31 December 2019 | 197,630,682 | 182,220,837 | 189,870,505 | 182,858,384 | 207,156,320 |
| 31 January 2020 | 200,919,286 | 179,080,078 | 192,458,079 | 175,808,449 | 212,219,314 |
| 29 February 2020 | 201,436,611 | 172,425,100 | 192,800,101 | 186,519,165 | 210,530,052 |
| 31 March 2020 | 201,813,408 | 181,984,192 | 192,941,279 | 190,441,065 | 206,889,928 |
| 30 April 2020 | 190,548,337 | 182,061,308 | 193,436,480 | 184,962,130 | 209,417,703 |
| 31 May 2020 | 182,585,752 | 195,542,912 | 193,308,065 | 176,301,596 | 211,552,152 |
| 30 June 2020 | 173,288,416 | 194,206,056 | 194,780,316 | 167,197,955 | 199,586,766 |
| 31 July 2020 | 178,624,641 | 195,832,010 | 196,514,700 | 177,553,626 | 205,811,991 |
| 31 August 2020 | 185,180,396 | 195,075,557 | 197,926,020 | 183,973,610 | 211,240,797 |
| 30 September 2020 | 192,538,221 | 191,880,039 | 199,046,611 | 186,790,961 | 215,823,010 |
| 31 October 2020 | 199,952,841 | 186,343,273 | 199,917,499 | 186,322,552 | 219,518,769 |
| 30 November 2020 | 206,647,795 | 178,666,616 | 200,579,953 | 182,496,166 | 222,296,204 |
| 31 December 2020 | 212,125,976 | 169,174,861 | 201,064,563 | 174,926,978 | 224,137,215 |
| Index | Network | Training Performance | Testing Performance | Validation Performance | Training Error | Testing Error | Validation Error | Training Algorithm | Error Function | Hidden Layer Activation | Output Activation Function |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | MLP 30-10-1 | 0.975319 | 0.988259 | 0.983310 | 8.6279 58 × 1013 | 5.2544 43 × 1013 | 7.2896 68 × 1013 | BFGS (Quasi-Newton) 39 | Sum of squares | Sine | Sine |
| 2 | MLP 30-8-1 | 0.979400 | 0.989330 | 0.982918 | 6.1573 54 × 1013 | 4.2179 46 × 1013 | 5.4345 48 × 1013 | BFGS (Quasi-Newton) 59 | Sum of squares | Logistic | Sine |
| 3 | MLP 30-7-1 | 0.969977 | 0.987142 | 0.982999 | 1.1226 1014 | 9.2583 68 × 1013 | 6.5167 3 × 1013 | BFGS (Quasi-Newton) 25 | Sum of squares | Sine | Exponential |
| 4 | MLP 30-9-1 | 0.979456 | 0.988763 | 0.982620 | 6.1080 61 × 1013 | 4.3361 71 × 1013 | 5.8760 26 × 1013 | BFGS (Quasi-Newton) 38 | Sum of squares | Sine | Tanh |
| 5 | MLP 30-6-1 | 0.976873 | 0.986680 | 0.982661 | 1.8348 99 × 1014 | 2.2079 37 × 1014 | 1.4715 7 × 1014 | BFGS (Quasi-Newton) 91 | Sum of squares | Sine | Logistic |
| Date | MLP 30-10-1 | MLP 30-8-1 | MLP 30-7-1 | MLP 30-9-1 | MLP 30-6-1 |
|---|---|---|---|---|---|
| 31 July 2019 | 195,873,752 | 177,272,678 | 198,573,857 | 183,534,762 | 169,087,560 |
| 31 August 2019 | 195,904,390 | 175,135,814 | 194,997,370 | 182,771,787 | 169,490,637 |
| 30 September 2019 | 197,775,067 | 179,287,167 | 194,077,371 | 183,259,466 | 170,536,650 |
| 31 October 2019 | 199,815,292 | 186,001,218 | 195,820,052 | 186,345,839 | 171,039,355 |
| 30 November 2019 | 198,171,047 | 188,064,823 | 204,567,647 | 187,310,603 | 170,164,328 |
| 31 December 2019 | 196,426,409 | 185,836,259 | 196,604,238 | 186,389,798 | 173,758,635 |
| 31 January 2020 | 194,059,919 | 183,361,682 | 170,823,460 | 185,349,059 | 176,701,654 |
| 29 February 2020 | 196,270,860 | 185,802,452 | 183,336,438 | 188,731,295 | 177,470,684 |
| 31 March 2020 | 200,515,311 | 190,924,822 | 191,710,086 | 192,622,013 | 178,889,076 |
| 30 April 2020 | 201,540,580 | 189,466,585 | 191,861,392 | 193,471,102 | 179,179,352 |
| 31 May 2020 | 203,268,278 | 190,395,328 | 188,914,960 | 194,695,705 | 179,192,881 |
| 30 June 2020 | 204,066,305 | 192,284,819 | 187,295,755 | 195,976,814 | 179,197,237 |
| 31 July 2020 | 203,655,008 | 190,475,013 | 178,674,731 | 196,533,100 | 180,857,354 |
| 31 August 2020 | 202,954,939 | 191,104,492 | 170,587,615 | 197,061,015 | 181,477,263 |
| 30 September 2020 | 201,814,361 | 194,373,816 | 165,604,782 | 197,685,126 | 182,274,610 |
| 31 October 2020 | 199,405,271 | 198,585,962 | 157,321,467 | 199,075,539 | 183,293,485 |
| 30 November 2020 | 200,389,891 | 200,197,117 | 151,295,451 | 199,593,592 | 183,273,755 |
| 31 December 2020 | 201,827,597 | 199,771,802 | 137,354,469 | 199,590,949 | 186,243,605 |
| Date | Experiment 1 | Experiment 2 | Experiment 3 |
|---|---|---|---|
| 4. MLP 3-10-1 | 1. MLP 15-4-1 | 1. MLP 30-10-1 | |
| 31 July 2019 | 183,191,758 | 172,085,976 | 195,873,752 |
| 31 August 2019 | 183,134,296 | 178,610,635 | 195,904,390 |
| 30 September 2019 | 183,992,714 | 184,708,986 | 197,775,067 |
| 31 October 2019 | 184,749,885 | 189,833,524 | 199,815,292 |
| 30 November 2019 | 185,471,822 | 194,080,437 | 198,171,047 |
| 31 December 2019 | 186,109,655 | 197,630,682 | 196,426,409 |
| 31 January 2020 | 186,718,827 | 200,919,286 | 194,059,919 |
| 29 February 2020 | 188,553,402 | 201,436,611 | 196,270,860 |
| 31 March 2020 | 189,031,734 | 201,813,408 | 200,515,311 |
| 30 April 2020 | 189,409,236 | 190,548,337 | 201,540,580 |
| 31 May 2020 | 189,743,059 | 182,585,752 | 203,268,278 |
| 30 June 2020 | 190,063,911 | 173,288,416 | 204,066,305 |
| 31 July 2020 | 190,349,677 | 178,624,641 | 203,655,008 |
| 31 August 2020 | 190,624,770 | 185,180,396 | 202,954,939 |
| 30 September 2020 | 190,879,388 | 192,538,221 | 201,814,361 |
| 31 October 2020 | 191,106,633 | 199,952,841 | 199,405,271 |
| 30 November 2020 | 191,325,826 | 206,647,795 | 200,389,891 |
| 31 December 2020 | 191,521,696 | 212,125,976 | 201,827,597 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Suler, P.; Rowland, Z.; Krulicky, T. Evaluation of the Accuracy of Machine Learning Predictions of the Czech Republic’s Exports to the China. J. Risk Financial Manag. 2021, 14, 76. https://doi.org/10.3390/jrfm14020076
Suler P, Rowland Z, Krulicky T. Evaluation of the Accuracy of Machine Learning Predictions of the Czech Republic’s Exports to the China. Journal of Risk and Financial Management. 2021; 14(2):76. https://doi.org/10.3390/jrfm14020076
Chicago/Turabian StyleSuler, Petr, Zuzana Rowland, and Tomas Krulicky. 2021. "Evaluation of the Accuracy of Machine Learning Predictions of the Czech Republic’s Exports to the China" Journal of Risk and Financial Management 14, no. 2: 76. https://doi.org/10.3390/jrfm14020076
APA StyleSuler, P., Rowland, Z., & Krulicky, T. (2021). Evaluation of the Accuracy of Machine Learning Predictions of the Czech Republic’s Exports to the China. Journal of Risk and Financial Management, 14(2), 76. https://doi.org/10.3390/jrfm14020076