Quasi-Maximum Likelihood Estimation for Long Memory Stock Transaction Data—Under Conditional Heteroskedasticity Framework


Abstract
:1. Introduction
2. The Model
3. Estimation
4. Monte Carlo Experiment
5. Data and Descriptive
6. Empirical Results
7. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Al-Osh, M. A., and Aus A. Alzaid. 1987. First Order Integer-Valued Autoregressive INAR(1)) Process. Journal of Time Series Analysis 8: 261–75. [Google Scholar] [CrossRef]
- Al-Osh, M. A., and Aus A. Alzaid. 1988. Integer-Valued Moving Average (INMA) Process. Statistical Papers 29: 281–300. [Google Scholar] [CrossRef]
- Andersen, Torben G., Tim Bollerslev, Francis X. Diebold, and Heiko Ebens. 2001. The distribution of realizedstockreturn volatility. Journal of Financial Economics 61: 43–76. [Google Scholar] [CrossRef]
- Bhardwaj, Geetesh, and Norman R. Swanson. 2005. An Empirical Investigation of the Usefulness of ARFIMA Models for Predicting Macroeconomic and Financial Time Series. Journal of Econometrics 131: 539–78. [Google Scholar] [CrossRef]
- Box, George E. P., and David A. Pierce. 1970. Distribution of Residual Autocorrelations in Autoregressive-Integrated Moving Average Time Series Models. Journal of the American Statistical Association 65: 1509–26. [Google Scholar] [CrossRef]
- Brännäs, Kurt, and Eva Brännäs. 2004. Conditional Variance in Count Data Regression. Communication in Statistics; Theory and Methods 33: 2745–58. [Google Scholar] [CrossRef]
- Brännäs, Kurt, and Andreia Hall. 2001. Estimation in Integer-Valued Moving Average Models. Applied Stochastic Models in Business and Industry 17: 277–91. [Google Scholar] [CrossRef]
- Brännäs, Kurt, and A. M. M. Shahiduzzaman Quoreshi. 2010. Integer-Valued Moving Average Modelling of the Number of Transactions in Stocks. Applied Financial Economics 20: 129–440. [Google Scholar] [CrossRef]
- Demsetz, Harold. 1968. The Cost of Transacting. Quarterly Journal of Economics 82: 33–53. [Google Scholar] [CrossRef]
- Diamond, Douglas W., and Robert E. Verrecchia. 1987. Constraints on Short-Selling and Asset Price Adjustments to Private Information. Journal of Financial Economics 18: 277–311. [Google Scholar] [CrossRef]
- Drost, Feike C., Ramon Van den Akker, and Bas J. M. Werker. 2009. Efficient estimation of auto-regression parameters and innovation distributions for semiparametric integer-valued AR(p) models. Journal of the Royal Statistical Society: Series B (Statistical Methodology) 71: 467–85. [Google Scholar] [CrossRef]
- Easley, David, and Maureen O’hara. 1992. Time and the Process of Security Price Adjustment. Journal of Finance 47: 905–27. [Google Scholar] [CrossRef]
- Engle, Robert F. 2000. The Econometrics of Ultra-High Frequency Data. Econometrica 68: 1–22. [Google Scholar] [CrossRef]
- Gourieroux, Christian, Alain Monfort, and Alain Trognon. 1984. Pseudo Maximum Likelihood Methods: Application to Poisson Models. Econometrica 52: 701–20. [Google Scholar] [CrossRef]
- Granger, Clive W. J. 1980. Long Memory Relationships and the Aggregation of Dynamic Models. Journal of Econometrics 14: 227–38. [Google Scholar] [CrossRef]
- Granger, Clive W. J., and Zhuanxin Ding. 1996. Varieties of Long Memory Models. Journal of Econometrics 73: 61–77. [Google Scholar] [CrossRef]
- Granger, Clive W. J., and Roselyne Joyeux. 1980. An Introduction to Long-Memory Time Series Models and Fractional Differencing. Journal of Time Series Analysis 1: 15–29. [Google Scholar] [CrossRef]
- Heinen, Andréas, and Erick Rengifo. 2003. Multivariate Modelling of Time Series Count Data: An Autoregressive Conditional Poisson Model. CORE Discussion Paper 2003/25. Louvain-la-Neuve: Université Catholique de Louvain. [Google Scholar]
- Hosking, J. R. M. 1981. Fractional Differencing. Biometrika 68: 165–76. [Google Scholar] [CrossRef]
- Hurst, Harold Edwin. 1951. Long-Term Storage Capacity of Reservoirs. Transactions of the American Society of Civil Engineers 116: 770–808. [Google Scholar]
- Hurst, Harold Edwin. 1956. Methods of Using Long-Term Storage in Reservoirs. Proceedings of the Institute of Civil Engineers 1: 519–43. [Google Scholar] [CrossRef]
- Jacobs, Patricia A., and Peter A. W. Lewis. 1978a. Discrete Time Series Generalized by Mixtures I: Correlational and Runs Properties. Journal of the Royal Statistical Society B 40: 94–105. [Google Scholar]
- Jacobs, Patricia A., and Peter A. W. Lewis. 1978b. Discrete Time Series Generalized by Mixtures II: Asymptotic Properties. Journal of the Royal Statistical Society B 40: 222–28. [Google Scholar]
- Jacobs, Patricia A., and Peter A. W. Lewis. 1983. Stationary Discrete Autoregressive Moving Average Time Series Generated by Mixtures. Journal of Time Series Analysis 4: 19–36. [Google Scholar] [CrossRef]
- Ljung, Greta M., and George E. P. Box. 1978. On a Measure of a Lack of Fit in Time Series Models. Biometrika 65: 297–303. [Google Scholar] [CrossRef]
- Mandelbrot, Benoit B., and John W. van Ness. 1968. Fractional Brownian Motions, Fractional Noises and Applications. SIAM Review 10: 422–37. [Google Scholar] [CrossRef]
- McKenzie, Ed. 1986. Autoregressive Moving-Average Processes with Negative Binomial and Geometric Marginal Distributions. Advances in Applied Probability 18: 679–705. [Google Scholar] [CrossRef]
- Quoreshi, A. M. M. Shahiduzzaman. 2006. Bivariate Time Series Modelling of Financial Count Data. Communications in Statistics: Theory and Methods 35: 1343–58. [Google Scholar] [CrossRef]
- Quoreshi, A. M. M. Shahiduzzaman. 2008. A vector integer-valued moving average model for high frequency financial count data. Economics Letters 101: 258–61. [Google Scholar] [CrossRef]
- Quoreshi, A. M. M. Shahiduzzaman. 2014. A Long Memory, Count Data, Time Series Model for Financial Application. Quantitative Finance 14: 2225–35. [Google Scholar] [CrossRef]
- Quoreshi, A. M. M. Shahiduzzaman. 2017. A bivariate integer-valued long-memory model for high-frequency financial count data. Communications in Statistics: Theory and Methods 46. [Google Scholar] [CrossRef]
- Ristic, Miroslav M., Yuvraj Sunecher, Naushad Ali Mamode Khan, and Vandna Jowaheer. 2018. A GQL-based Inference in non-stationary BINMA(1) Time Series. TEST, 1–13. [Google Scholar] [CrossRef]
- Rydberg, Tina Hviid, and Neil Shephard. 1999. BIN Models for Trade-by-Trade Data. Modelling the Number of Trades in a Fixed Interval of Time. Working Paper Series W23. Oxford: Nuffield College. [Google Scholar]
- Smith, Jeremy, Nick Taylor, and Sanjay Yadav. 1996. Comparing the bias and Misspecification in ARFIMA models. Journal of Time Series Analysis 18: 507–27. [Google Scholar] [CrossRef]
- Sunecher, Yuvraj, Naushad Mamode Khan, and Vandna Jowaheer. 2018. BINMA(1) Model with COM-Poisson Innovations: Estimation and Application. Communication in Statistics: Simulation and Computation, 1–22. [Google Scholar] [CrossRef]
- Weiss, Andrew A. 1986. Asymptotic theory for ARCH models: Estimation and testing. Econometric Theory 2: 107–31. [Google Scholar] [CrossRef]
- Working, Holbrook. 1953. Futures Trading and Hedging. American Economic Review 43: 314–43. [Google Scholar]
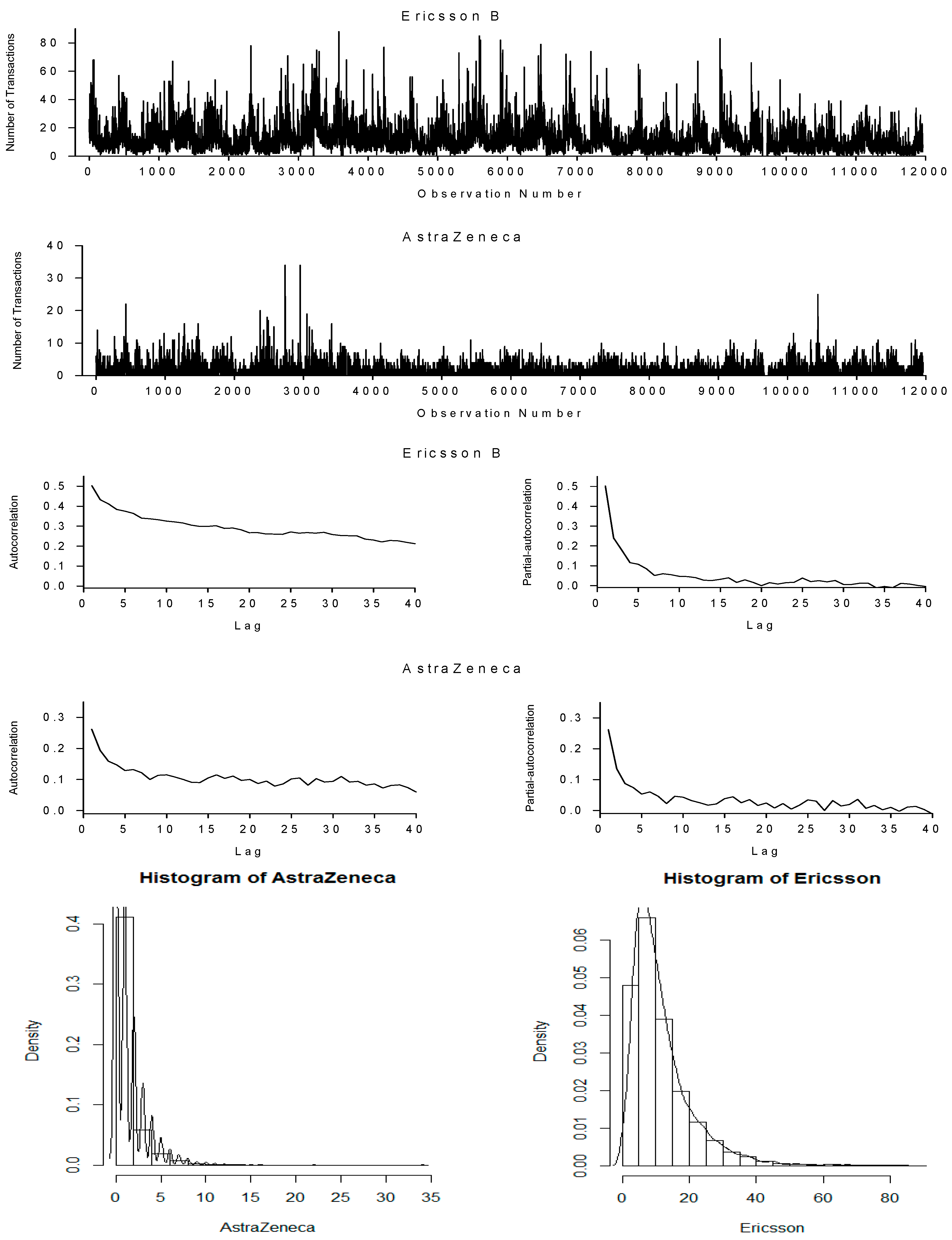

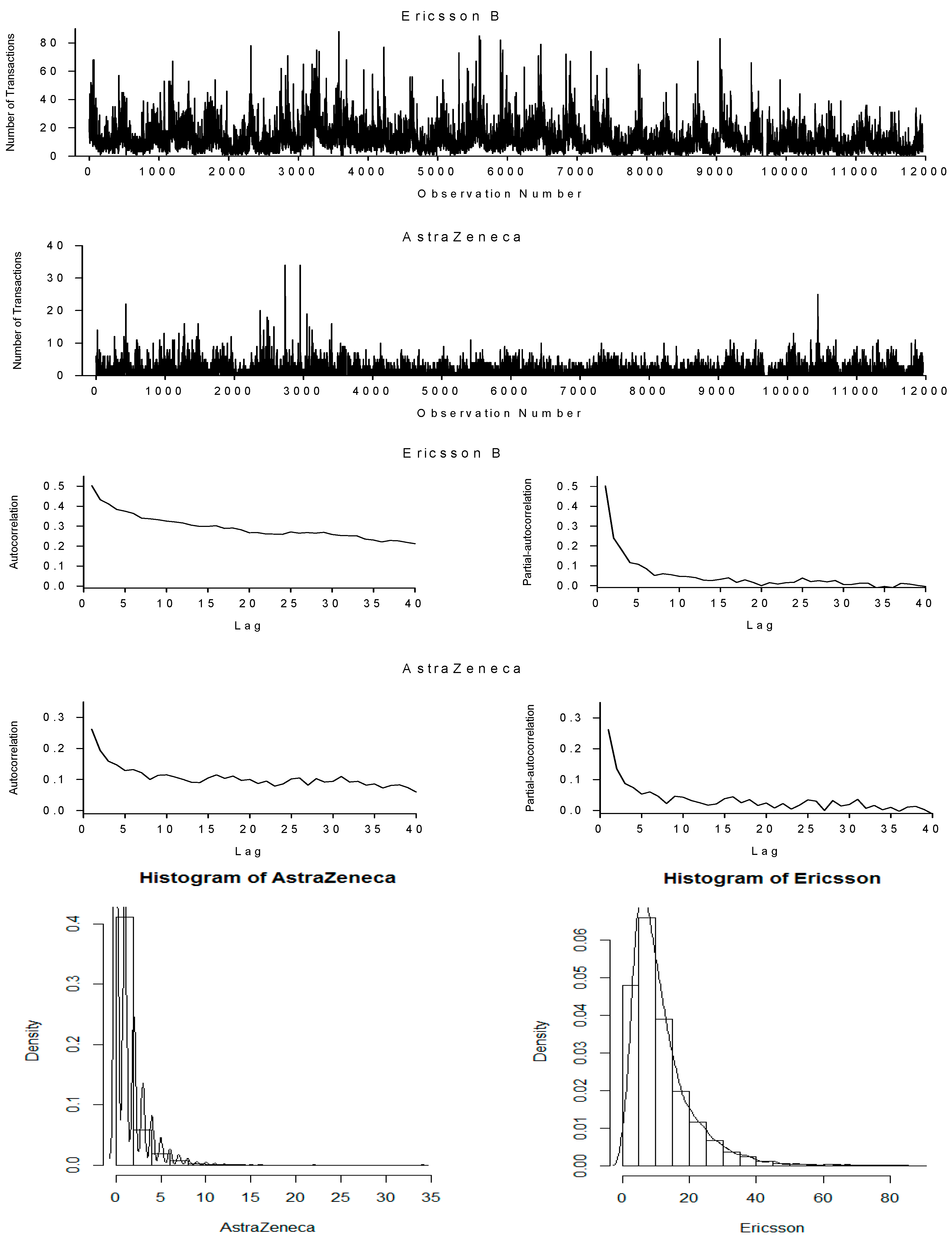{kind=link}
| Lag | Parameters | T = 2000 and d = 0.1 | T = 10,000 and d = 0.1 | ||||
|---|---|---|---|---|---|---|---|
| CLS | FGLS | ML | CLS | FGLS | ML | ||
| M10 | 0.171 | 0.171 | 0.171 | 0.167 | 0.167 | 0.167 | |
| (s.e.) | 0.001 | 0.003 | 0.003 | 0.000 | 0.001 | 0.001 | |
| BIAS | 0.071 | 0.071 | 0.071 | 0.067 | 0.067 | 0.067 | |
| MSE | 8.286 | 8.286 | 8.286 | 8.117 | 8.117 | 8.117 | |
| QLB100 | 135.447 | 135.447 | 135.447 | 207.628 | 207.628 | 207.628 | |
| QLB200 | 210.680 | 210.680 | 210.680 | 302.137 | 302.137 | 302.137 | |
| AIC | 4239.785 | 4239.785 | 4239.785 | 20,943.299 | 20,943.299 | 20,943.299 | |
| SBIC | 4312.395 | 4312.395 | 4312.395 | 21,033.613 | 21,033.613 | 21,033.613 | |
| M30 | 0.126 | 0.126 | 0.126 | 0.123 | 0.123 | 0.123 | |
| (s.e.) | 0.001 | 0.002 | 0.002 | 0.000 | 0.001 | 0.001 | |
| BIAS | 0.026 | 0.026 | 0.026 | 0.023 | 0.023 | 0.023 | |
| MSE | 8.226 | 8.226 | 8.226 | 8.034 | 8.034 | 8.034 | |
| QLB100 | 127.753 | 127.753 | 127.753 | 129.387 | 129.387 | 129.387 | |
| QLB200 | 200.223 | 200.223 | 200.223 | 220.119 | 220.119 | 220.119 | |
| AIC | 4246.408 | 4246.408 | 4246.408 | 20,867.821 | 20,867.821 | 20,867.821 | |
| SBIC | 4451.036 | 4451.036 | 4451.036 | 21,122.341 | 21,122.341 | 21,122.341 | |
| M50 | 0.112 | 0.112 | 0.112 | 0.109 | 0.109 | 0.109 | |
| (s.e.) | 0.001 | 0.002 | 0.002 | 0.000 | 0.001 | 0.001 | |
| BIAS | 0.012 | 0.012 | 0.012 | 0.009 | 0.009 | 0.009 | |
| MSE | 8.188 | 8.188 | 8.188 | 8.018 | 8.018 | 8.018 | |
| QLB100 | 124.244 | 124.244 | 124.244 | 110.770 | 110.770 | 110.770 | |
| QLB200 | 197.235 | 197.235 | 197.235 | 199.517 | 199.517 | 199.517 | |
| AIC | 4257.168 | 4257.168 | 4257.168 | 20,868.726 | 20,868.726 | 20,868.726 | |
| SBIC | 4593.814 | 4593.814 | 4593.814 | 21,287.453 | 21,287.453 | 21,287.453 | |
| M70 | 0.104 | 0.104 | 0.104 | 0.101 | 0.101 | 0.101 | |
| (s.e.) | 0.001 | 0.002 | 0.002 | 0.000 | 0.001 | 0.001 | |
| BIAS | 0.004 | 0.004 | 0.004 | 0.001 | 0.001 | 0.001 | |
| MSE | 8.190 | 8.190 | 8.190 | 8.016 | 8.016 | 8.016 | |
| QLB100 | 122.988 | 122.988 | 122.988 | 104.384 | 104.384 | 104.384 | |
| QLB200 | 195.961 | 195.961 | 195.961 | 193.215 | 193.215 | 193.215 | |
| AIC | 4277.888 | 4277.888 | 4277.888 | 20,886.425 | 20,886.425 | 20,886.425 | |
| SBIC | 4746.552 | 4746.552 | 4746.552 | 21,469.359 | 21,469.359 | 21,469.359 | |
| M90 | 0.099 | 0.099 | 0.099 | 0.096 | 0.096 | 0.096 | |
| (s.e.) | 0.001 | 0.002 | 0.002 | 0.000 | 0.001 | 0.001 | |
| BIAS | −0.001 | −0.001 | −0.001 | −0.004 | −0.004 | −0.004 | |
| MSE | 8.168 | 8.168 | 8.168 | 8.021 | 8.021 | 8.021 | |
| QLB100 | 121.982 | 121.982 | 121.982 | 99.539 | 99.539 | 99.539 | |
| QLB200 | 192.315 | 192.315 | 192.315 | 188.162 | 188.162 | 188.162 | |
| AIC | 4292.417 | 4292.417 | 4292.417 | 20,911.714 | 20,911.714 | 20,911.714 | |
| SBIC | 4893.099 | 4893.099 | 4893.099 | 21,658.855 | 21,658.855 | 21,658.855 | |
| Lag | Parameters | T = 2000 and d = 0.25 | T = 10,000 and d = 0.25 | ||||
|---|---|---|---|---|---|---|---|
| CLS | FGLS | ML | CLS | FGLS | ML | ||
| M10 | 0.397 | 0.397 | 0.397 | 0.404 | 0.404 | 0.404 | |
| (s.e.) | 0.001 | 0.004 | 0.005 | 0.000 | 0.002 | 0.002 | |
| BIAS | 0.147 | 0.147 | 0.147 | 0.154 | 0.154 | 0.154 | |
| MSE | 17.428 | 17.428 | 17.428 | 17.469 | 17.469 | 17.469 | |
| QLB100 | 252.360 | 252.360 | 252.360 | 861.417 | 861.418 | 861.418 | |
| QLB200 | 330.591 | 330.592 | 330.591 | 951.603 | 951.604 | 951.603 | |
| AIC | 5705.874 | 5705.875 | 5705.874 | 28,504.208 | 28,504.210 | 28,504.209 | |
| SBIC | 5778.484 | 5778.485 | 5778.484 | 28,594.522 | 28,594.523 | 28,594.523 | |
| M30 | 0.292 | 0.292 | 0.292 | 0.298 | 0.298 | 0.298 | |
| (s.e.) | 0.001 | 0.003 | 0.003 | 0.000 | 0.001 | 0.001 | |
| BIAS | 0.042 | 0.042 | 0.042 | 0.048 | 0.048 | 0.048 | |
| MSE | 16.219 | 16.219 | 16.219 | 16.202 | 16.202 | 16.202 | |
| QLB100 | 173.555 | 173.555 | 173.555 | 434.016 | 434.016 | 434.016 | |
| QLB200 | 246.801 | 246.801 | 246.801 | 511.413 | 511.413 | 511.413 | |
| AIC | 5599.729 | 5599.729 | 5599.729 | 27,861.795 | 27,861.795 | 27,861.795 | |
| SBIC | 5804.357 | 5804.357 | 5804.357 | 28,116.315 | 28,116.316 | 28,116.315 | |
| M50 | 0.260 | 0.260 | 0.260 | 0.264 | 0.264 | 0.264 | |
| (s.e.) | 0.001 | 0.003 | 0.003 | 0.000 | 0.001 | 0.001 | |
| BIAS | 0.010 | 0.010 | 0.010 | 0.014 | 0.014 | 0.014 | |
| MSE | 15.951 | 15.951 | 15.951 | 15.956 | 15.956 | 15.956 | |
| QLB100 | 152.446 | 152.446 | 152.446 | 343.686 | 343.686 | 343.686 | |
| QLB200 | 222.466 | 222.466 | 222.466 | 418.824 | 418.824 | 418.824 | |
| AIC | 5588.694 | 5588.694 | 5588.694 | 27,738.271 | 27,738.271 | 27,738.271 | |
| SBIC | 5925.340 | 5925.340 | 5925.340 | 28,156.998 | 28,156.998 | 28,156.998 | |
| M70 | 0.242 | 0.242 | 0.242 | 0.245 | 0.245 | 0.245 | |
| (s.e.) | 0.001 | 0.003 | 0.003 | 0.000 | 0.001 | 0.001 | |
| BIAS | −0.008 | −0.008 | −0.008 | −0.005 | −0.005 | −0.005 | |
| MSE | 15.845 | 15.845 | 15.845 | 15.848 | 15.848 | 15.848 | |
| QLB100 | 136.373 | 136.373 | 136.373 | 294.513 | 294.513 | 294.513 | |
| QLB200 | 212.107 | 212.107 | 212.107 | 370.136 | 370.136 | 370.136 | |
| AIC | 5596.148 | 5596.148 | 5596.148 | 27,694.288 | 27,694.288 | 27,694.288 | |
| SBIC | 6064.812 | 6064.812 | 6064.812 | 28,277.222 | 28,277.222 | 28,277.223 | |
| M90 | 0.230 | 0.230 | 0.230 | 0.233 | 0.233 | 0.233 | |
| (s.e.) | 0.001 | 0.003 | 0.003 | 0.000 | 0.001 | 0.001 | |
| BIAS | −0.020 | −0.020 | −0.020 | −0.017 | −0.017 | −0.017 | |
| MSE | 15.909 | 15.909 | 15.909 | 15.809 | 15.809 | 15.809 | |
| QLB100 | 132.433 | 132.433 | 132.433 | 268.457 | 268.457 | 268.457 | |
| QLB200 | 210.826 | 210.826 | 210.826 | 343.640 | 343.640 | 343.640 | |
| AIC | 5624.678 | 5624.678 | 5624.678 | 27,691.884 | 27,691.884 | 27,691.884 | |
| SBIC | 6225.360 | 6225.360 | 6225.360 | 28,439.025 | 28,439.025 | 28,439.025 | |
| Lag | Parameters | T = 2000 and d = 0.4 | T = 10,000 and d = 0.4 | ||||
|---|---|---|---|---|---|---|---|
| CLS | FGLS | ML | CLS | FGLS | ML | ||
| M10 | 0.598 | 0.598 | 0.598 | 0.605 | 0.605 | 0.605 | |
| (s.e.) | 0.001 | 0.004 | 0.005 | 0.000 | 0.002 | 0.002 | |
| BIAS | 0.198 | 0.198 | 0.198 | 0.205 | 0.205 | 0.205 | |
| MSE | 41.798 | 41.798 | 41.798 | 40.197 | 40.197 | 40.197 | |
| QLB100 | 549.235 | 549.235 | 549.235 | 1949.879 | 1949.878 | 1949.877 | |
| QLB200 | 665.178 | 665.177 | 665.177 | 2136.378 | 2136.377 | 2136.375 | |
| AIC | 7349.147 | 7349.147 | 7349.146 | 36,337.152 | 36,337.151 | 36,337.149 | |
| SBIC | 7421.757 | 7421.757 | 7421.756 | 36,427.466 | 36,427.465 | 36,427.463 | |
| M30 | 0.461 | 0.461 | 0.461 | 0.463 | 0.463 | 33.105 | |
| (s.e.) | 0.001 | 0.004 | 0.004 | 0.000 | 0.002 | 0.331 | |
| BIAS | 0.061 | 0.061 | 0.061 | 0.063 | 0.063 | 0.063 | |
| MSE | 34.030 | 34.030 | 34.030 | 33.105 | 33.105 | 33.105 | |
| QLB100 | 340.270 | 340.270 | 340.270 | 964.972 | 964.973 | 964.972 | |
| QLB200 | 436.152 | 436.152 | 436.152 | 1108.871 | 1108.872 | 1108.871 | |
| AIC | 7064.123 | 7064.124 | 7064.123 | 34,917.597 | 34,917.598 | 34,917.597 | |
| SBIC | 7268.751 | 7268.752 | 7268.751 | 35,172.117 | 35,172.119 | 35,172.117 | |
| M50 | 0.410 | 0.410 | 0.410 | 0.412 | 0.412 | 0.412 | |
| (s.e.) | 0.001 | 0.004 | 0.004 | 0.000 | 0.002 | 0.002 | |
| BIAS | 0.010 | 0.010 | 0.010 | 0.012 | 0.012 | 0.012 | |
| MSE | 32.758 | 32.758 | 32.758 | 31.692 | 31.692 | 31.692 | |
| QLB100 | 301.374 | 301.375 | 301.374 | 742.921 | 742.922 | 742.921 | |
| QLB200 | 393.018 | 393.018 | 393.018 | 878.651 | 878.652 | 878.651 | |
| AIC | 7017.857 | 7017.858 | 7017.857 | 34,553.008 | 34,553.010 | 34,553.008 | |
| SBIC | 7354.503 | 7354.504 | 7354.503 | 34,971.736 | 34,971.737 | 34,971.736 | |
| M70 | 0.382 | 0.382 | 0.382 | 0.384 | 0.384 | 0.384 | |
| (s.e.) | 0.001 | 0.004 | 0.003 | 0.000 | 0.002 | 0.002 | |
| BIAS | −0.018 | −0.018 | −0.018 | −0.016 | −0.016 | −0.016 | |
| MSE | 31.907 | 31.907 | 31.907 | 31.152 | 31.152 | 31.152 | |
| QLB100 | 275.290 | 275.291 | 275.290 | 657.154 | 657.154 | 657.154 | |
| QLB200 | 365.202 | 365.202 | 365.202 | 789.378 | 789.379 | 789.378 | |
| AIC | 6988.464 | 6988.464 | 6988.464 | 34,418.475 | 34,418.476 | 34,418.475 | |
| SBIC | 7457.128 | 7457.128 | 7457.128 | 35,001.409 | 35,001.410 | 35,001.409 | |
| M90 | 0.364 | 0.364 | 0.364 | 0.364 | 0.364 | 0.364 | |
| (s.e.) | 0.001 | 0.003 | 0.004 | 0.000 | 0.002 | 0.001 | |
| BIAS | −0.036 | −0.036 | −0.036 | −0.036 | −0.036 | −0.036 | |
| MSE | 31.430 | 31.430 | 31.430 | 30.826 | 30.826 | 30.826 | |
| QLB100 | 255.701 | 255.701 | 255.701 | 602.208 | 602.208 | 602.208 | |
| QLB200 | 346.677 | 346.677 | 346.677 | 733.237 | 733.238 | 733.237 | |
| AIC | 6980.709 | 6980.709 | 6980.709 | 34,340.862 | 34,340.862 | 34,340.862 | |
| SBIC | 7581.391 | 7581.391 | 7581.391 | 35,088.002 | 35,088.003 | 35,088.002 | |
| Ericsson | AstraZeneca | |||||
|---|---|---|---|---|---|---|
| CLS | FGLS | ML | CLS | FGLS | ML | |
| 0.324 | 0.324 | 0.324 | 0.204 | 0.204 | 0.204 | |
| (s.e) | 0.008 | 0.008 | 0.008 | 0.012 | 0.012 | 0.011 |
| 2.625 | 2.625 | 2.625 | 0.507 | 0.507 | 0.507 | |
| (s.e) | 0.091 | 0.092 | 0.088 | 0.027 | 0.027 | 0.026 |
| Var | - | - | 54.722 | - | - | 3.303 |
| (s.e.) | - | - | 1.809 | - | - | 0.151 |
| AIC | 48,010.160 | 48,010.160 | 48,010.160 | 14,433.565 | 14,433.565 | 14,433.565 |
| SBIC | 48,534.802 | 48,534.802 | 48,534.802 | 14,958.207 | 14,958.207 | 14,958.207 |
| QLB100 | 335.111 | 335.111 | 335.111 | 235.586 | 235.586 | 235.587 |
| QLB200 | 422.191 | 422.191 | 422.191 | 352.309 | 352.309 | 352.309 |
| MSE | 54.722 | 54.722 | 54.722 | 3.303 | 3.303 | 3.303 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quoreshi, A.M.M.S.; Uddin, R.; Mamode Khan, N. Quasi-Maximum Likelihood Estimation for Long Memory Stock Transaction Data—Under Conditional Heteroskedasticity Framework. J. Risk Financial Manag. 2019, 12, 74. https://doi.org/10.3390/jrfm12020074
Quoreshi AMMS, Uddin R, Mamode Khan N. Quasi-Maximum Likelihood Estimation for Long Memory Stock Transaction Data—Under Conditional Heteroskedasticity Framework. Journal of Risk and Financial Management. 2019; 12(2):74. https://doi.org/10.3390/jrfm12020074
Chicago/Turabian StyleQuoreshi, A. M. M. Shahiduzzaman, Reaz Uddin, and Naushad Mamode Khan. 2019. "Quasi-Maximum Likelihood Estimation for Long Memory Stock Transaction Data—Under Conditional Heteroskedasticity Framework" Journal of Risk and Financial Management 12, no. 2: 74. https://doi.org/10.3390/jrfm12020074
APA StyleQuoreshi, A. M. M. S., Uddin, R., & Mamode Khan, N. (2019). Quasi-Maximum Likelihood Estimation for Long Memory Stock Transaction Data—Under Conditional Heteroskedasticity Framework. Journal of Risk and Financial Management, 12(2), 74. https://doi.org/10.3390/jrfm12020074