
High-Accuracy Clothing and Style Classification via Multi-Feature Fusion

Abstract
:1. Introduction
2. Related Work
2.1. Clothes and Accessories Attributes
2.2. Discover Style
2.3. Attributes in Style
3. Methods and Methodology
3.1. Clothing Multiclass Classification
3.2. Category Classification Network
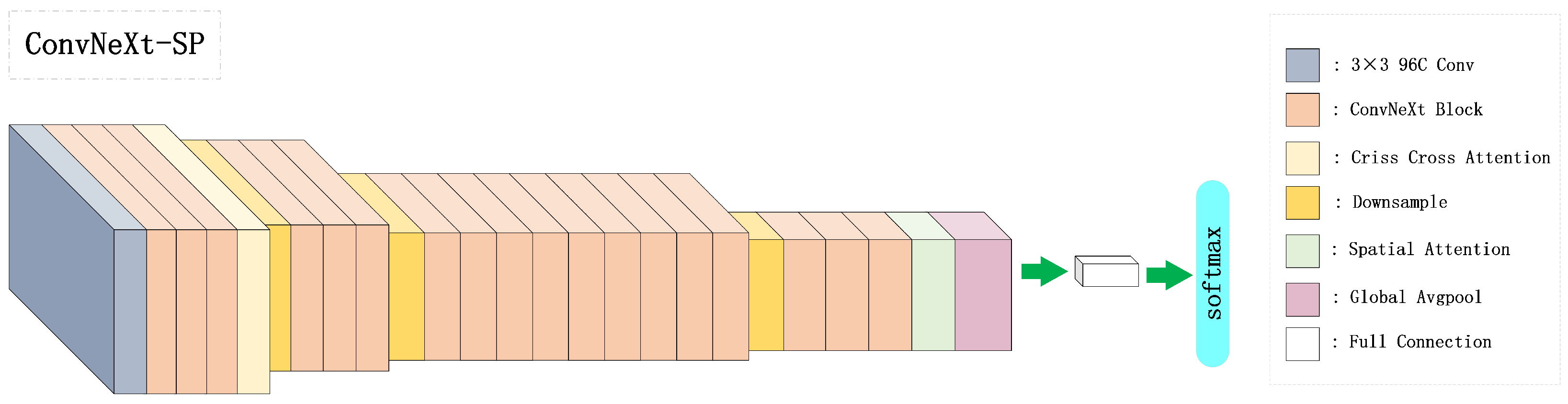
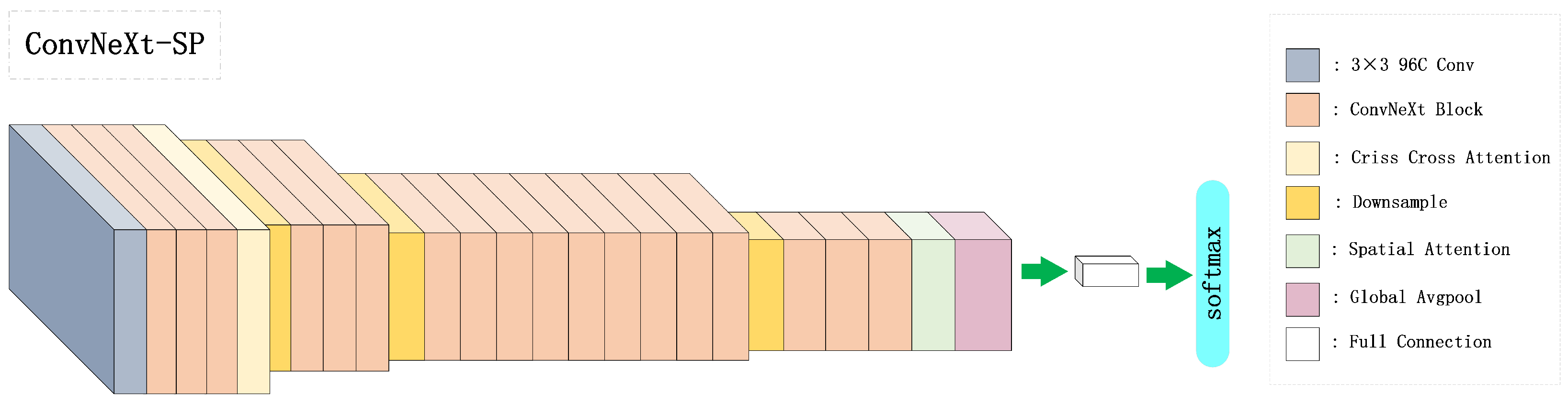
3.3. Improved Network Architecture
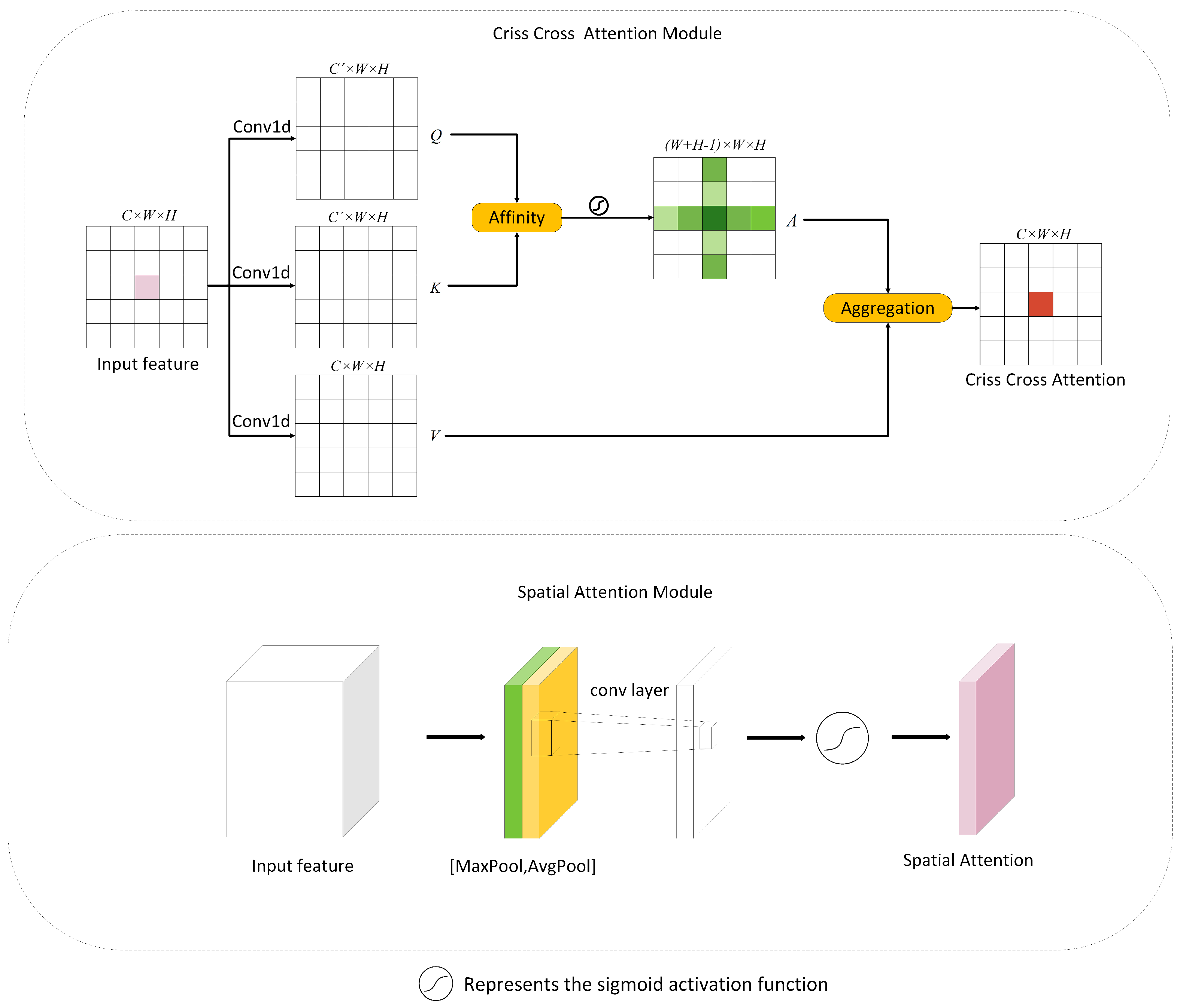
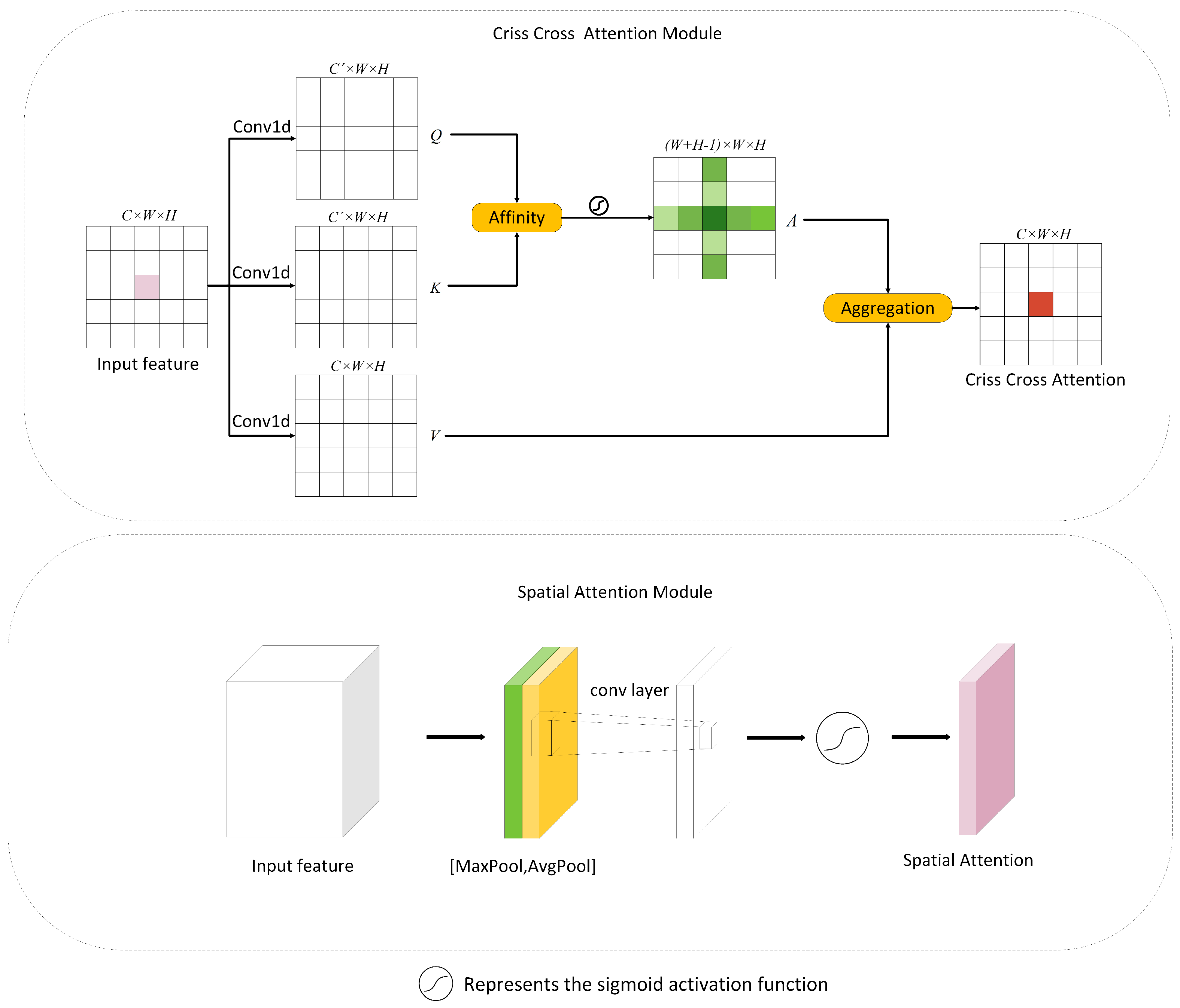
3.4. Dual Attention Module
3.5. Multiclass Classification and Prediction
3.6. Clothing Style Classification
3.7. Classification Network of Fashion Style
3.8. Transfer Learning Process
4. Experiments
4.1. Data Set and Augmentation
4.2. Device and Training
4.3. Category Classification Network
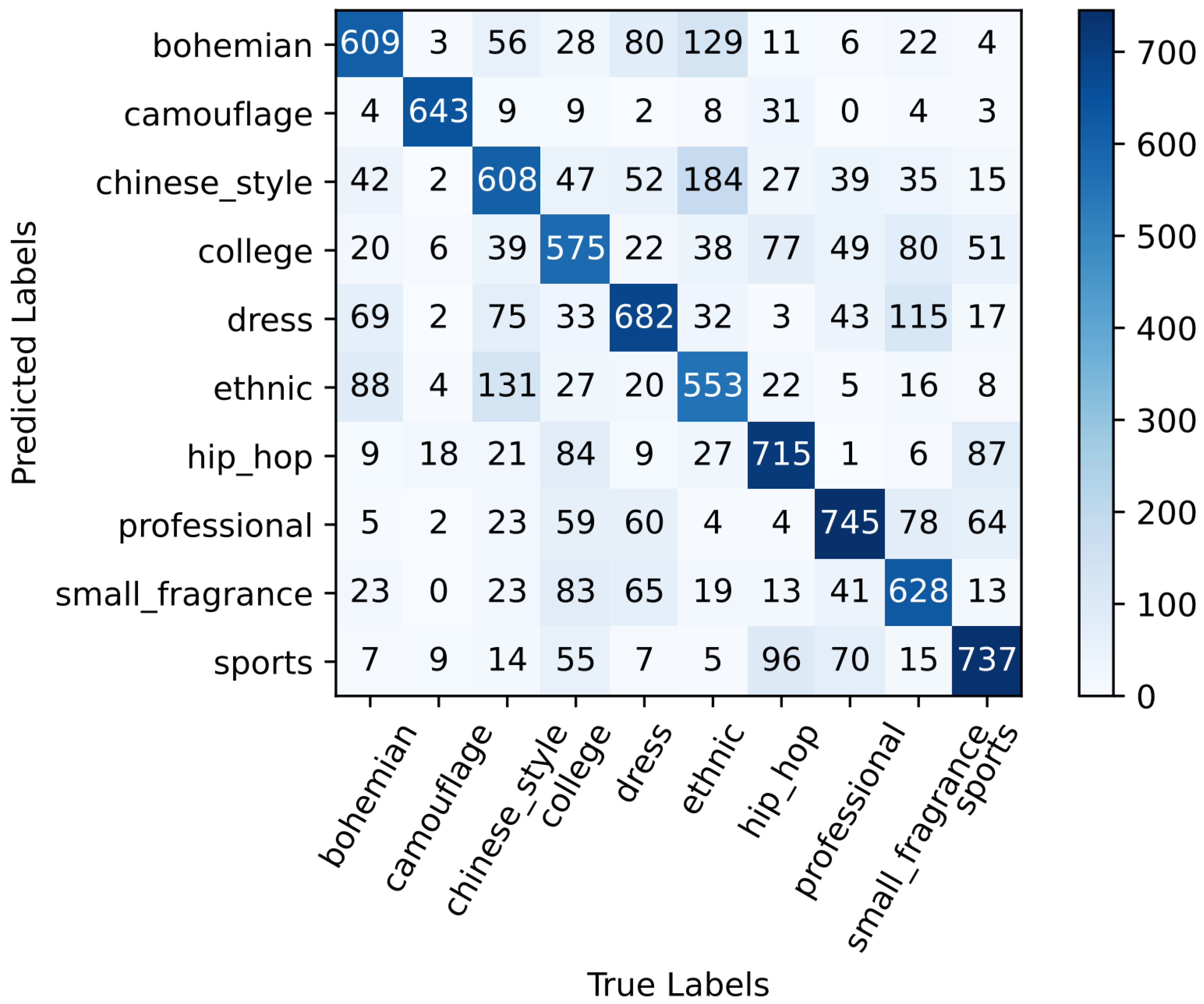
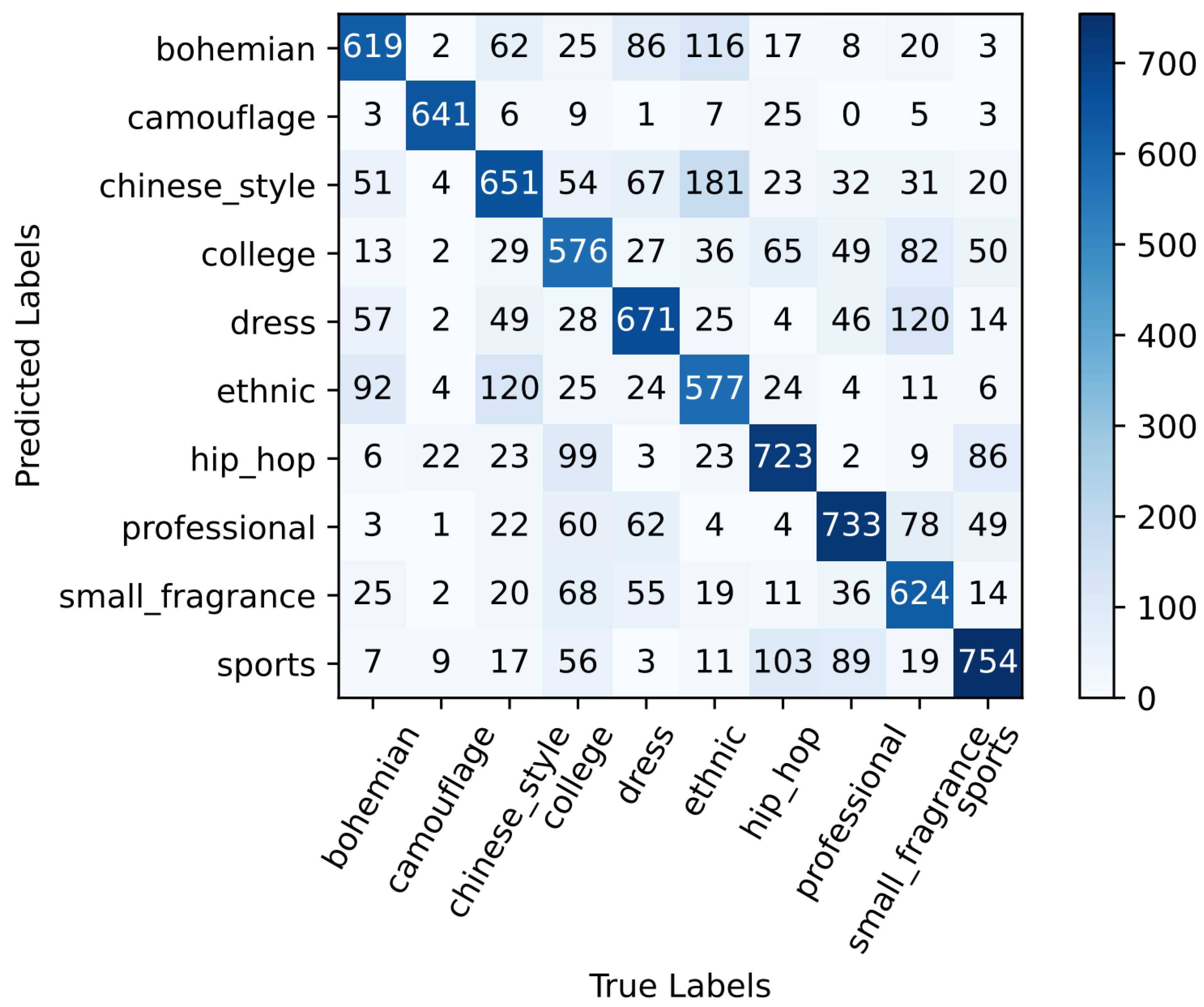
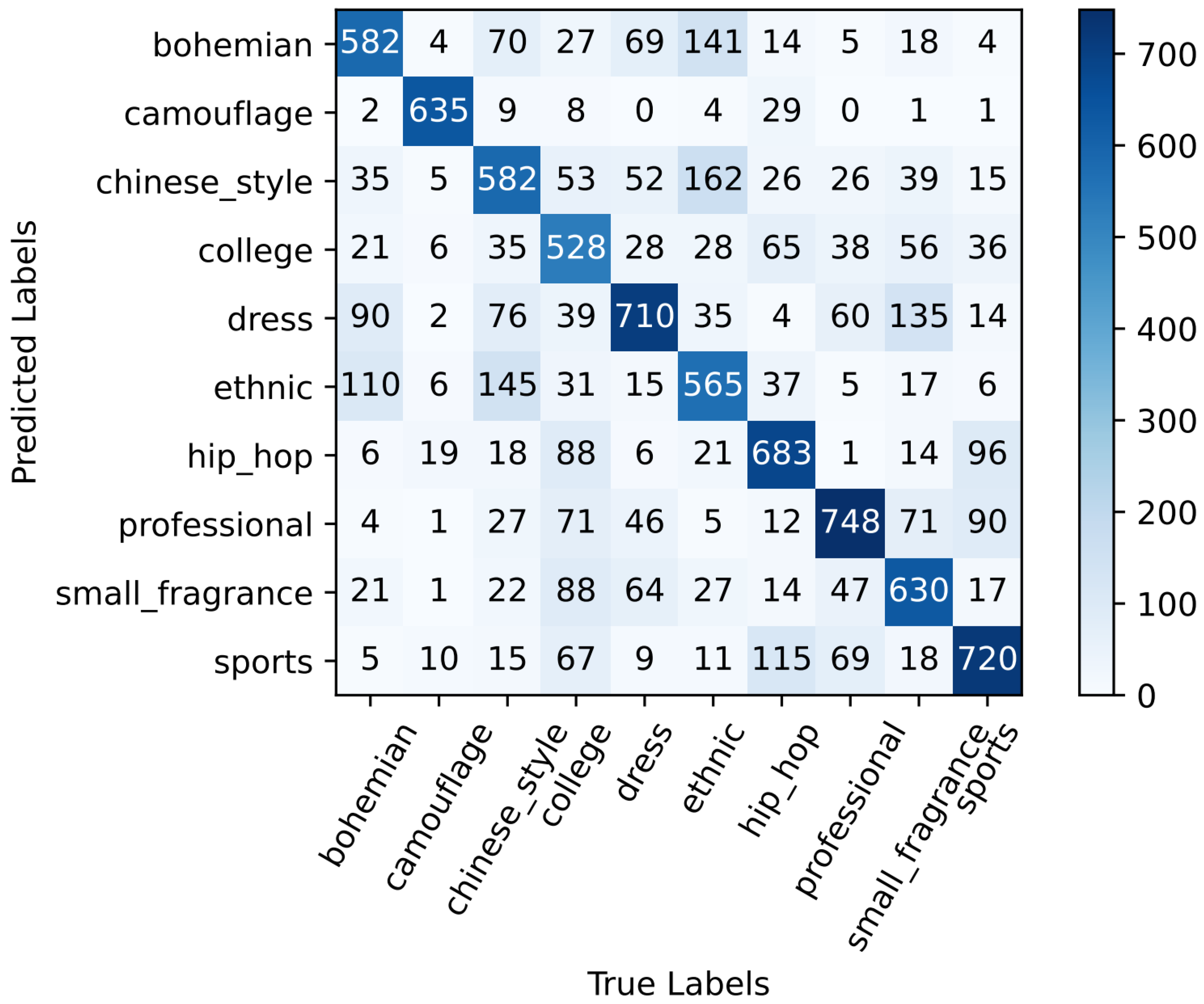
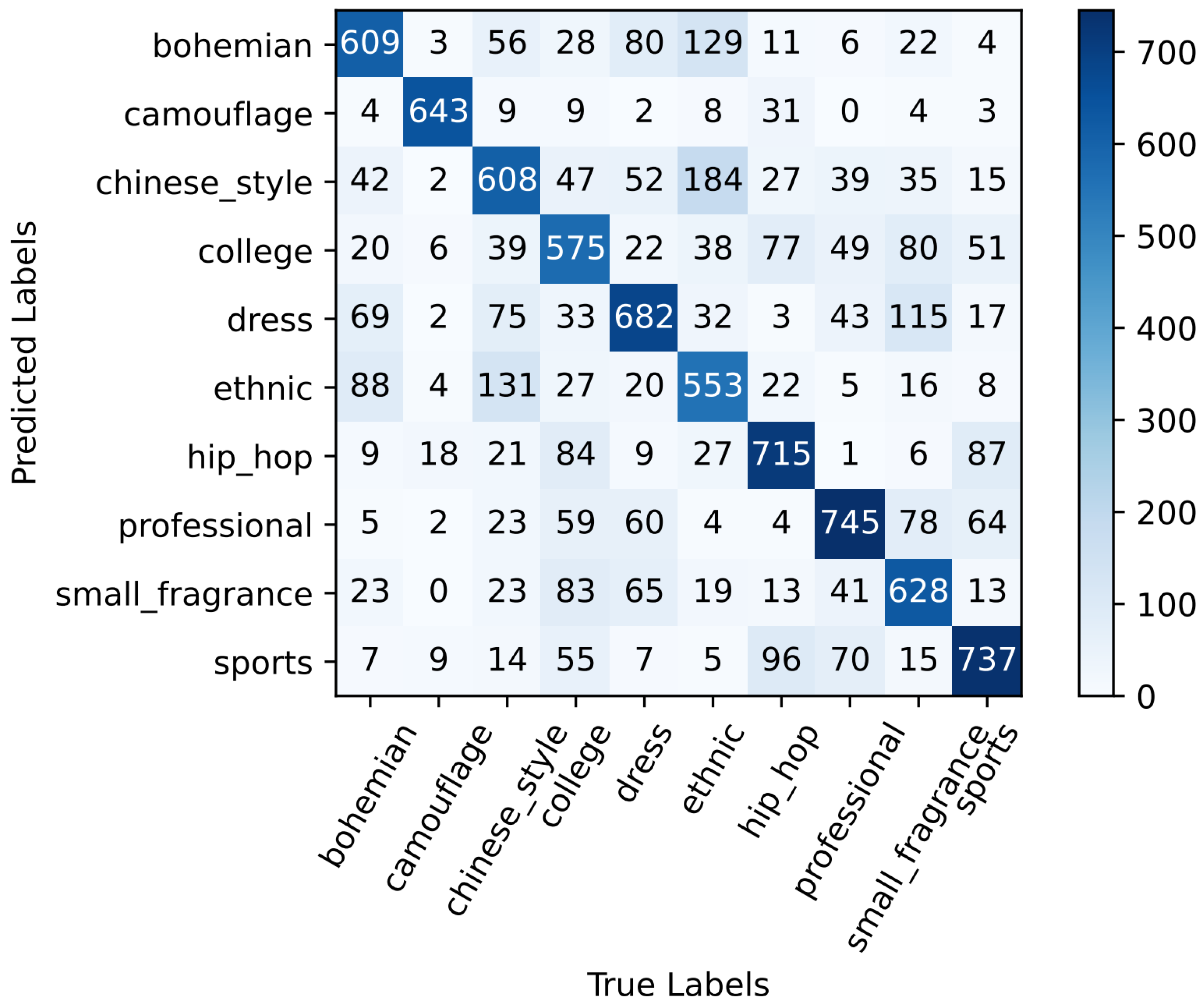
4.4. Style Classification Network
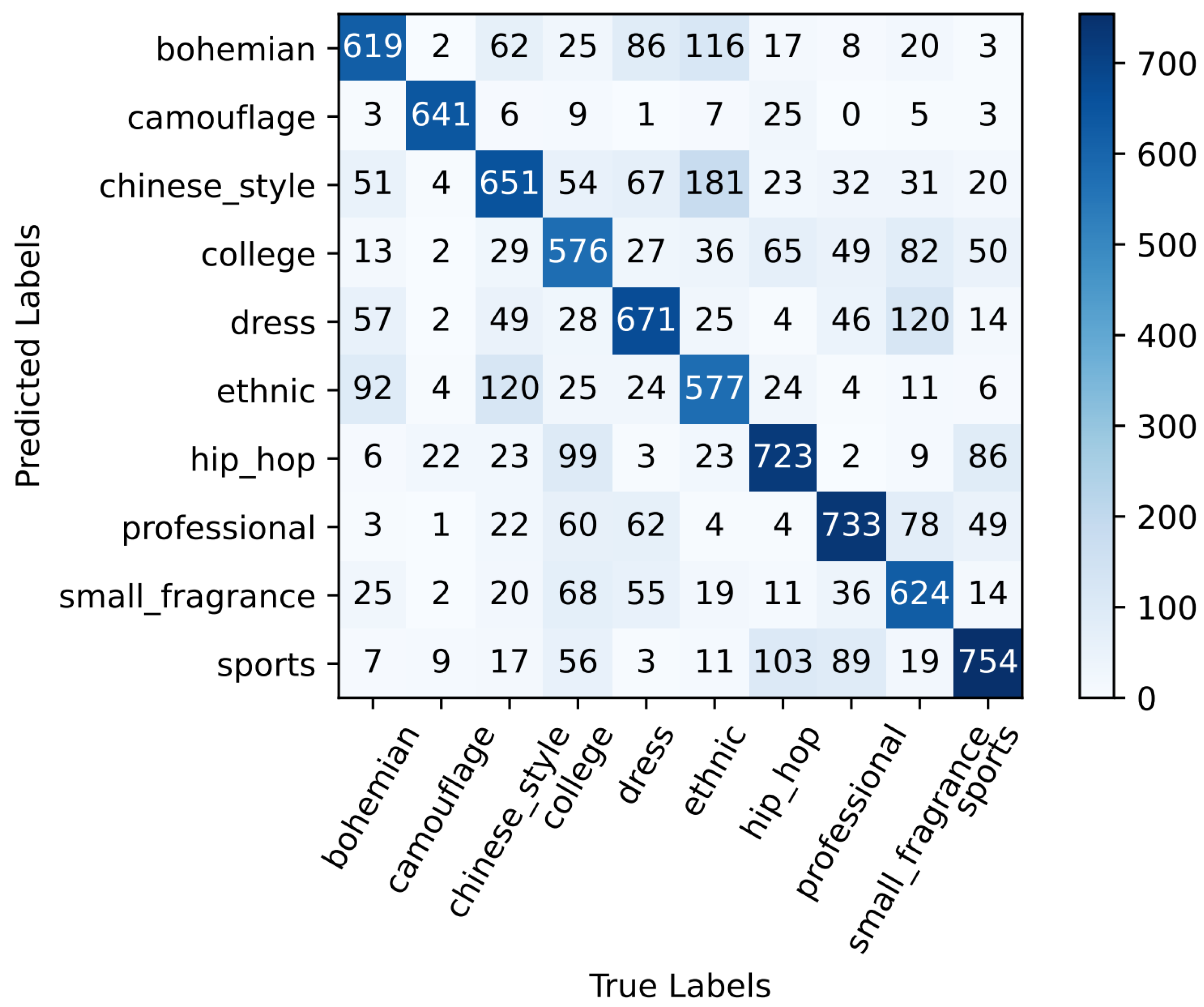
4.5. Result
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Singh, M.; Katiyar, A.K. Consumers buying behavior towards Online Shopping—A study of Literature Review. Asian J. Manag. 2018, 9, 490–492. [Google Scholar] [CrossRef]
- Changchenkit, C. The Social Media Exposure and Online Clothes Buying Behavior in Thailand. In Proceedings of the International Academic Conferences; International Institute of Social and Economic Sciences: London, UK, 1 January 2018. [Google Scholar]
- Yang, F.; Li, X.; Huang, Z. Buy-online-and-pick-up-in-store Strategy and Showroom Strategy in the Omnichannel Retailing. In Advances in Business and Management Forecasting; Emerald Publishing Limited: York, UK, 6 September 2019. [Google Scholar]
- Sun, L.; Aragon-Camarasa, G.; Rogers, S.; Stolkin, R.; Siebert, J.P. Single-Shot Clothing Category Recognition in Free-Configurations with Application to Autonomous Clothes Sorting. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2017), Vancouver, BC, Canada, 24–28 September 2017. [Google Scholar]
- Hu, J.; Kita, Y. Classification of the category of clothing item after bringing it into limited shapes. In Proceedings of the 2015 IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 588–594. [Google Scholar]
- Chen, L.; Han, R.; Xing, S.; Ru, S. Research on Clothing Image Classification by Convolutional Neural Networks. In Proceedings of the 2018 11th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), Beijing, China, 13–15 October 2018. [Google Scholar]
- Pan, H.; Wang, Y.; Liu, Q. A Part-Based and Feature Fusion Method for Clothing Classification. In Proceedings of the Pacific Rim Conference on Multimedia, Xi’an, China, 15–16 September 2016; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Sun, F.; Xu, P.; Ding, X. Multi-core SVM optimized visual word package model for garment style classification. Clust. Comput. 2019, 22, 1–7. [Google Scholar] [CrossRef]
- Geršak, J. 1–Clothing classification systems. Des. Cloth. Manuf. Process. 2013, 1–20. [Google Scholar]
- Willimon, B.; Birchfield, S.; Walker, I. Classification of clothing using interactive perception. In Proceedings of the IEEE International Conference on Robotics & Automation, Shanghai, China, 9–13 May 2011. [Google Scholar]
- Willimon, B.; Walker, I.; Birchfield, S. A new approach to clothing classification using mid-level layers. In Proceedings of the IEEE International Conference on Robotics & Automation, Karlsruhe, Germany, 6–10 May 2013. [Google Scholar]
- Yamazaki, K.; Inaba, M. Clothing classification using image features derived from clothing fabrics, wrinkles and cloth overlaps. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013. [Google Scholar]
- An, Y.; Rao-fen, W. Clothing Classification Method Based on CNN Improved Model Network. Tech. Autom. Appl. 2019. [Google Scholar]
- Wang, W.; Xu, Y.; Shen, J.; Zhu, S.C. Attentive Fashion Grammar Network for Fashion Landmark Detection and Clothing Category Classification. In Proceedings of the IEEE CVPR, San Francisco, CA, USA, 17 December 2018. [Google Scholar]
- Chen, K.; Yao, L.; Zhang, D.; Wang, X.; Chang, X.; Nie, F. A semisupervised recurrent convolutional attention model for human activity recognition. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 1747–1756. [Google Scholar] [CrossRef] [PubMed]
- Luo, M.; Chang, X.; Nie, L.; Yang, Y.; Hauptmann, A.G.; Zheng, Q. An adaptive semisupervised feature analysis for video semantic recognition. IEEE Trans. Cybern. 2017, 48, 648–660. [Google Scholar] [CrossRef]
- Zhang, D.; Yao, L.; Chen, K.; Wang, S.; Chang, X.; Liu, Y. Making sense of spatio-temporal preserving representations for EEG-based human intention recognition. IEEE Trans. Cybern. 2019, 50, 3033–3044. [Google Scholar] [CrossRef] [PubMed]
- Hong, Q.; Zhang, J. Introduction to Garment Style Classification. J. Chengdu Text. Coll. 2005. [Google Scholar]
- Bossard, L.; Dantone, M.; Leistner, C.; Wengert, C.; Gool, L.V. Apparel Classification with Style. In Proceedings of the Asian Conference on Computer Vision-Volume Part IV; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Kiapour, M.H.; Han, X.; Lazebnik, S.; Berg, A.C.; Berg, T.L. Where to Buy It: Matching Street Clothing Photos in Online Shops. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Qiang, C.; Huang, J.; Feris, R.; Brown, L.M.; Yan, S. Deep Domain Adaptation for Describing People Based on Fine-Grained Clothing Attributes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 15 October 2015. [Google Scholar]
- Li, G.; Feng, J. Unsupervised image clustering based on attribute method. Microcomput. Its Appl. 2012. [Google Scholar]
- Vaccaro, K.; Shivakumar, S.; Ding, Z.; Karahalios, K.; Kumar, R. The Elements of Fashion Style. In Proceedings of the 29th Annual ACM Symposium on User Interface Software and Technology, Tokyo, Japan, 16–19 October 2016; pp. 777–785. [Google Scholar] [CrossRef]
- Seo, Y.; shik Shin, K. Image classification of fine-grained fashion image based on style using pre-trained convolutional neural network. In Proceedings of the IEEE International Conference on Big Data Analysis, Shanghai, China, 9–12 March 2018. [Google Scholar]
- Liu, T.; Rubing Wang, J.C.; Han, S.; Yang, J. Fine-Grained Classification of Product Images Based on Convolutional Neural Networks. Adv. Mol. Imaging 2018, 8, 69. [Google Scholar] [CrossRef] [Green Version]
- Hidayati, S. Clothing genre classification by exploiting the style elements. In Proceedings of the ACM Multimedia Conference, Nara, Japan, 29 October–2 November 2012. [Google Scholar]
- Di, W.; Wah, C.; Bhardwaj, A.; Piramuthu, R.; Sundaresan, N. Style Finder: Fine-Grained Clothing Style Recognition and Retrieval. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef] [Green Version]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 1 June 2016; pp. 770–778. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 3, 1–40. [Google Scholar]
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; Tang, X. Large-Scale Fashion (DeepFashion) Database. Available online: http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion.html (accessed on 18 June 2016).
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 7–14 September 2018; pp. 801–818. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Size | Channel | Kernel Size/Stride |
|---|---|---|---|
| Convolution | 56 × 56 | 96 | 4 × 4 / 4 |
| ConvNeXt Block | 56 × 56 | 96 | |
| Criss Cross Attention | 56 × 56 | 96 | - |
| Downsample | 28 × 28 | 192 | 2 × 2 / 2 |
| ConvNeXt Block | 28 × 28 | 192 | |
| Downsample | 14 × 14 | 384 | 2 × 2 / 2 |
| ConvNeXt Block | 14 × 14 | 384 | |
| Downsample | 7 × 7 | 768 | 2 × 2 / 2 |
| ConvNeXt Block | 7 × 7 | 768 | |
| Spatial Attention | 7 × 7 | 768 | - |
| Global Avgpool | 7 × 7 | 1024 | 7 × 7 /1 |
| Full Connection | 1 × 1 | 1000 | - |
| ImageName | Category Name | Label |
|---|---|---|
| 0000001.jpg | Skirts | 0000010...000 |
| 0000002.jpg | Blouses_Shirts | 0000000...010 |
| 0000003.jpg | Cardigans | 0010000...000 |
| 0000004.jpg | Denim | 0100000...000 |
| 0000005.jpg | Dresses | 0000000...100 |
| 0000006.jpg | Jackets_Coats | 0000100...000 |
| Methods | Precision | CPU |
|---|---|---|
| VGG19 | 59.60% | 1224 ms |
| GoogleNet | 63.41% | 185 ms |
| Resnet50 | 65.67% | 549 ms |
| DenseNet201 | 65.59% | 771 ms |
| SWIN-T | 64.75% | 744 ms |
| ConvNeXt-T(baseline) | 65.98% | 635 ms |
| Ours w/o transfer | 66.17% | 752 ms |
| Ours w/ transfer | 69.66% | 752 ms |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Deng, Y.; Di, C.; Li, H.; Tang, G.; Cai, H. High-Accuracy Clothing and Style Classification via Multi-Feature Fusion. Appl. Sci. 2022, 12, 10062. https://doi.org/10.3390/app121910062
Chen X, Deng Y, Di C, Li H, Tang G, Cai H. High-Accuracy Clothing and Style Classification via Multi-Feature Fusion. Applied Sciences. 2022; 12(19):10062. https://doi.org/10.3390/app121910062
Chicago/Turabian StyleChen, Xiaoling, Yun Deng, Cheng Di, Huiyin Li, Guangyu Tang, and Hao Cai. 2022. "High-Accuracy Clothing and Style Classification via Multi-Feature Fusion" Applied Sciences 12, no. 19: 10062. https://doi.org/10.3390/app121910062
APA StyleChen, X., Deng, Y., Di, C., Li, H., Tang, G., & Cai, H. (2022). High-Accuracy Clothing and Style Classification via Multi-Feature Fusion. Applied Sciences, 12(19), 10062. https://doi.org/10.3390/app121910062