
Improved Lightweight Mango Sorting Model Based on Visualization

 ,
,  ,
,  ,
,
Abstract
:1. Introduction
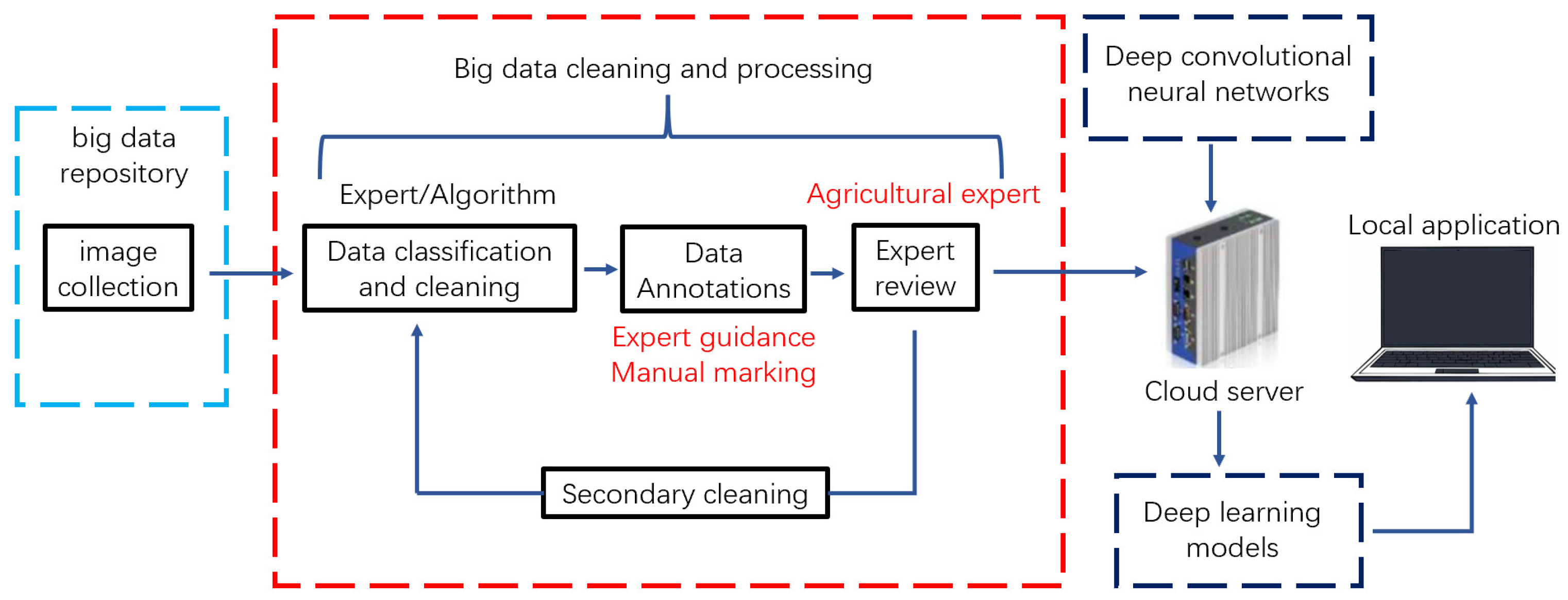
2. Materials and Methods
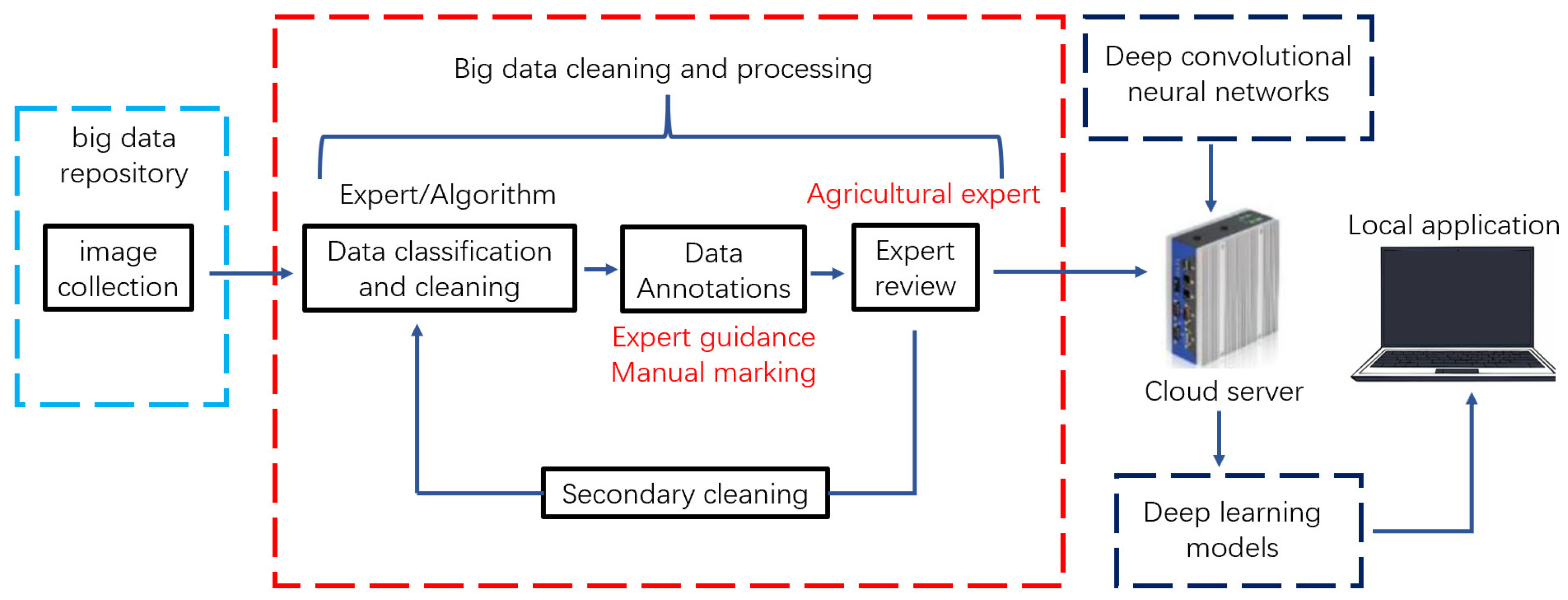
2.1. Experimental Materials
2.2. Experimental Platform
2.3. Model Evaluation Methods
2.4. Model Visualization
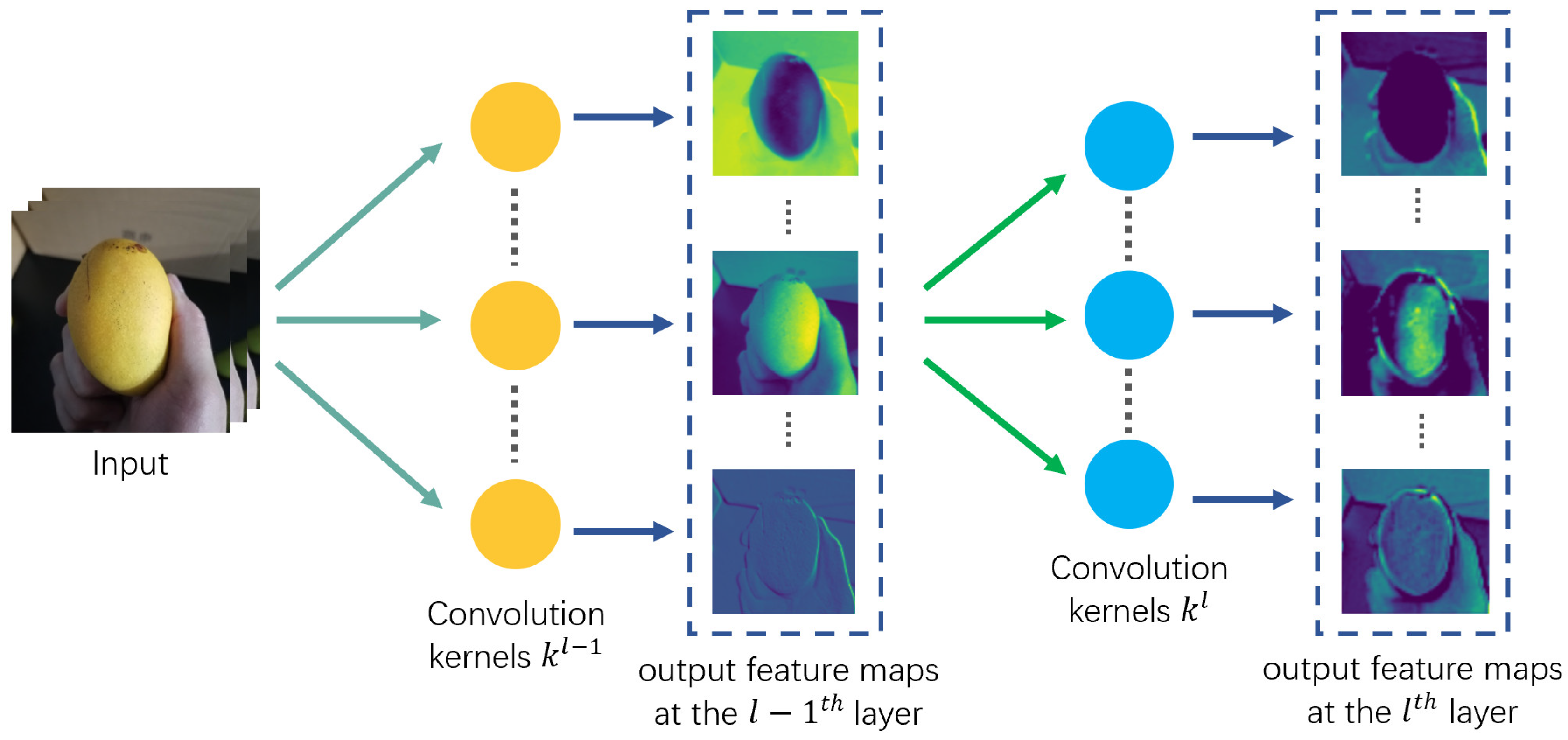
2.4.1. Convolution-Layer Visualization
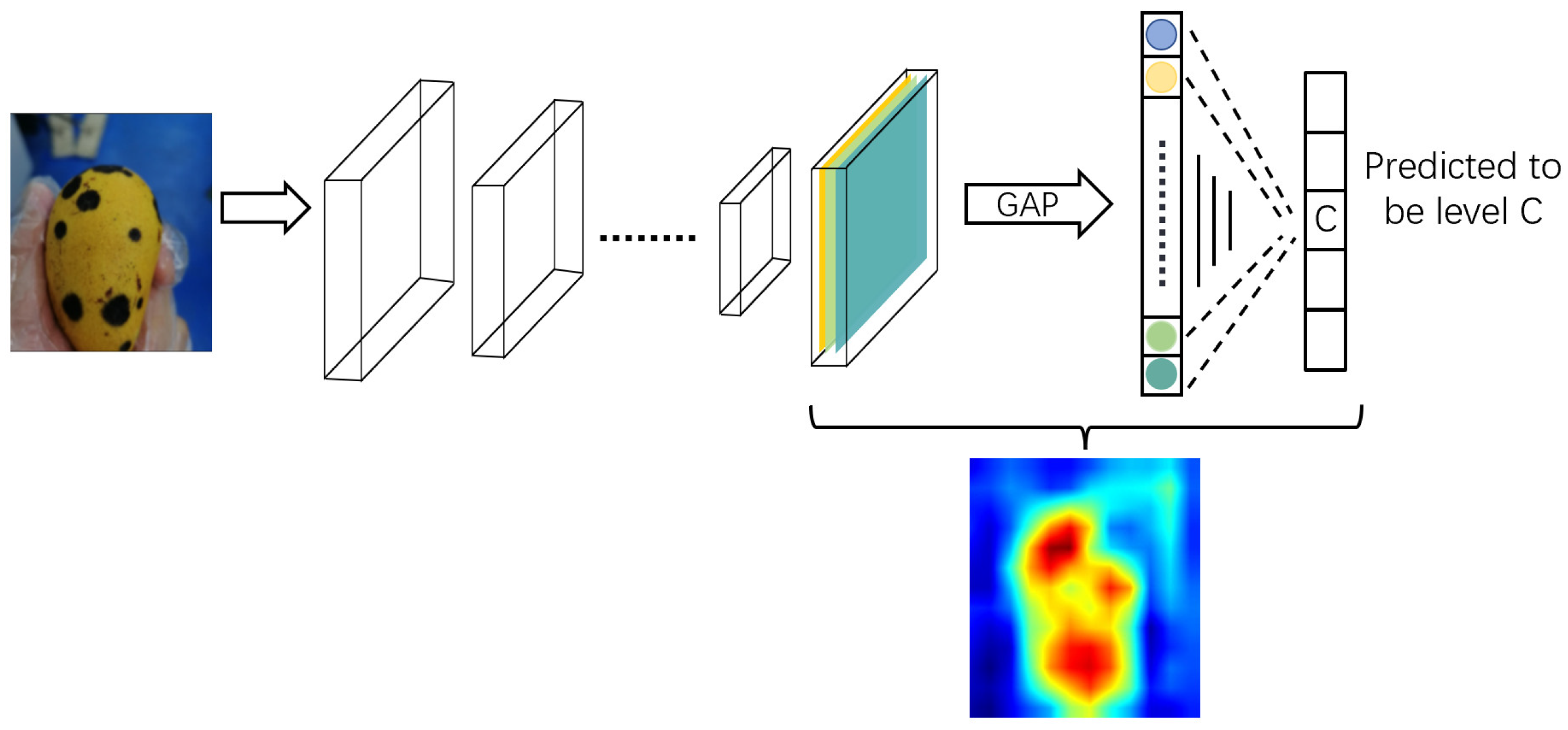
2.4.2. Feature Visualization
3. Model Construction and Training
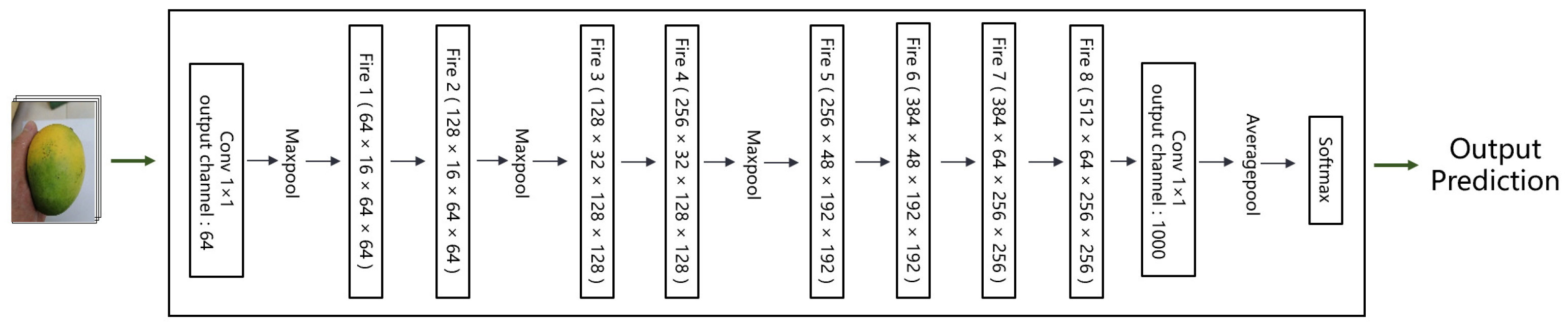
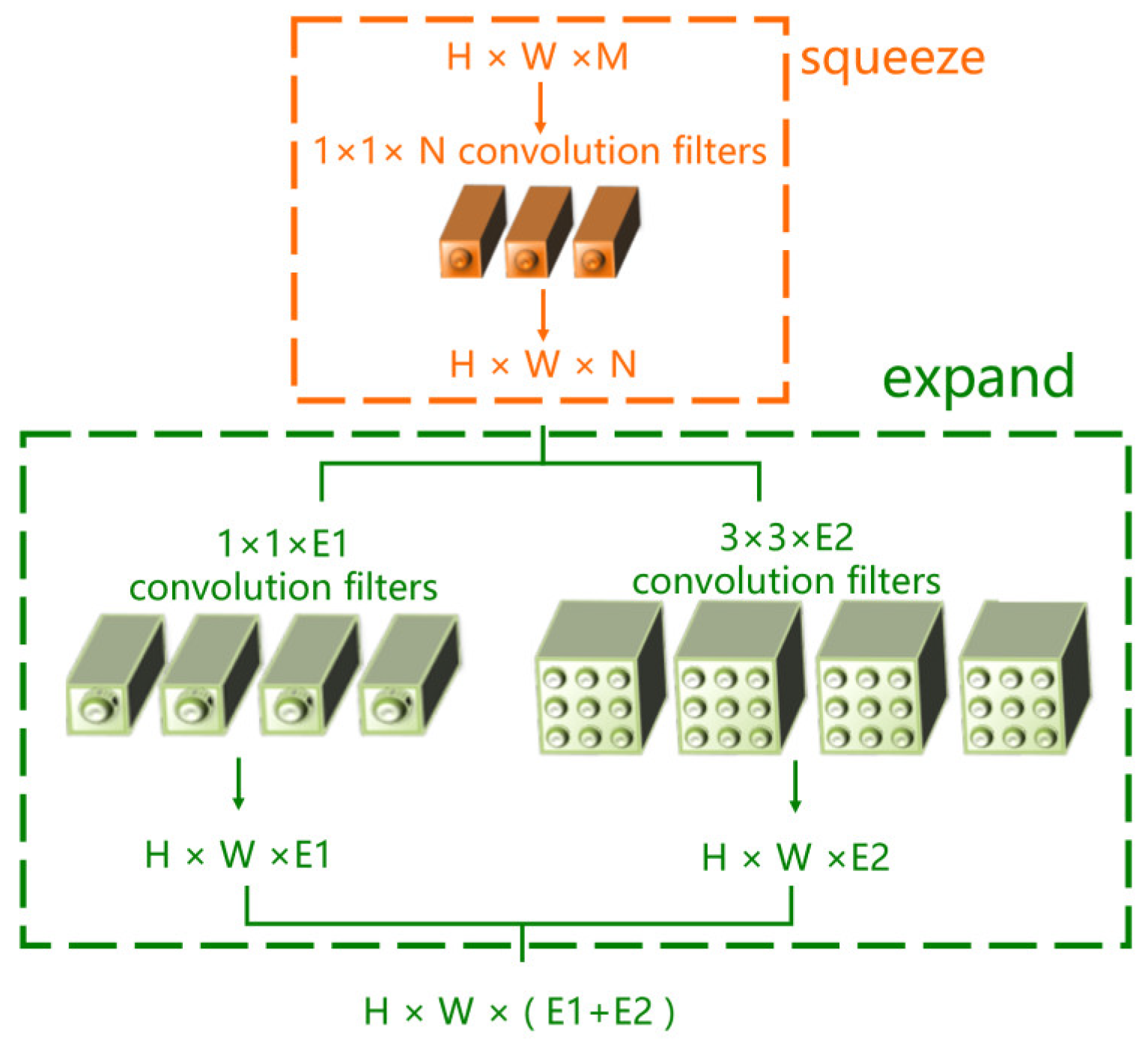
3.1. Classic SqueezeNet
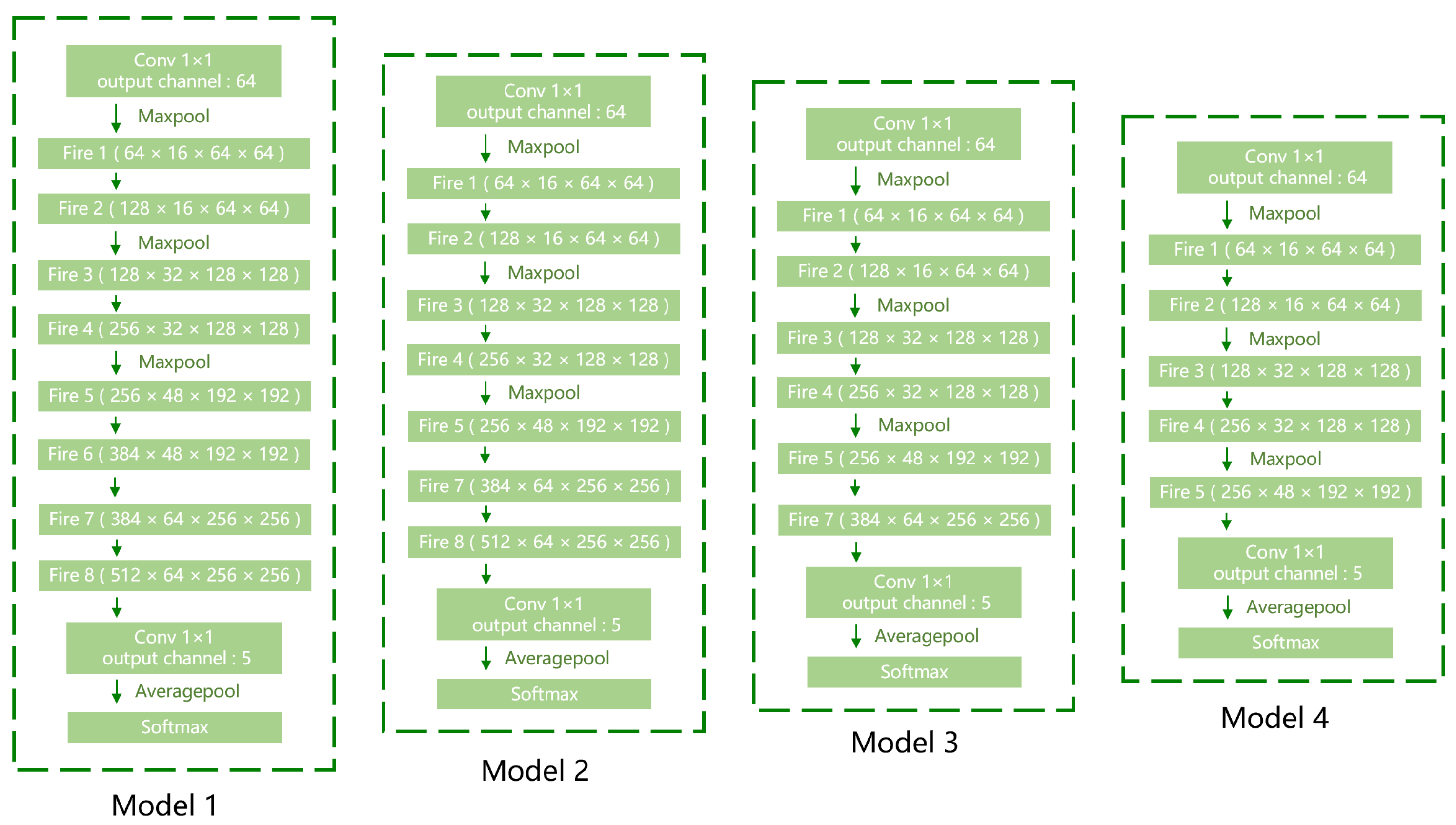
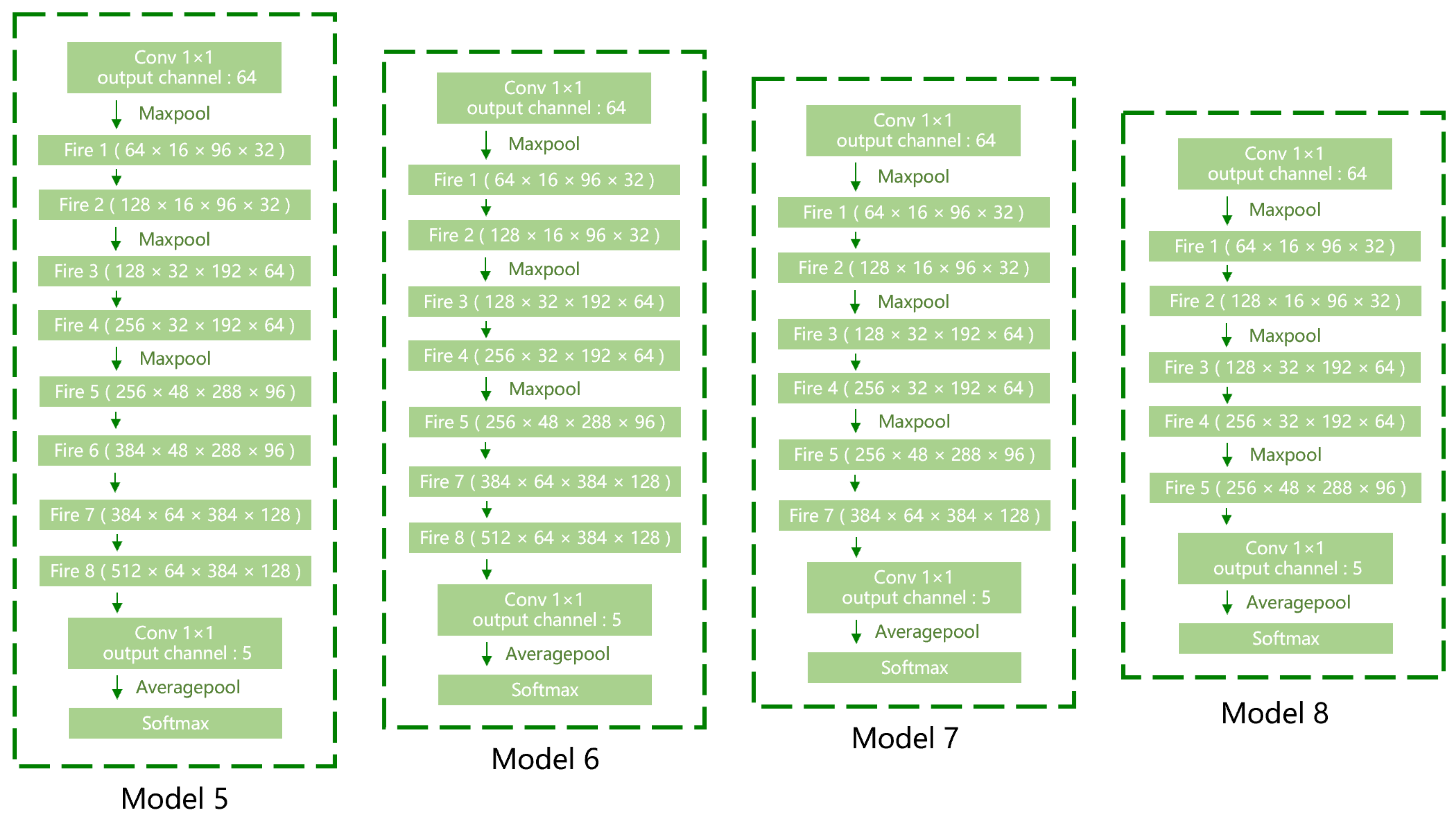
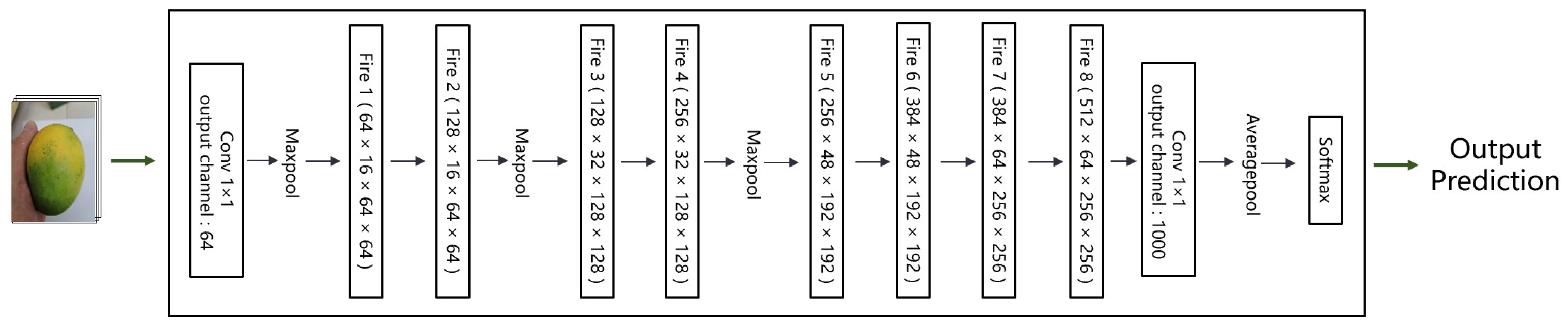
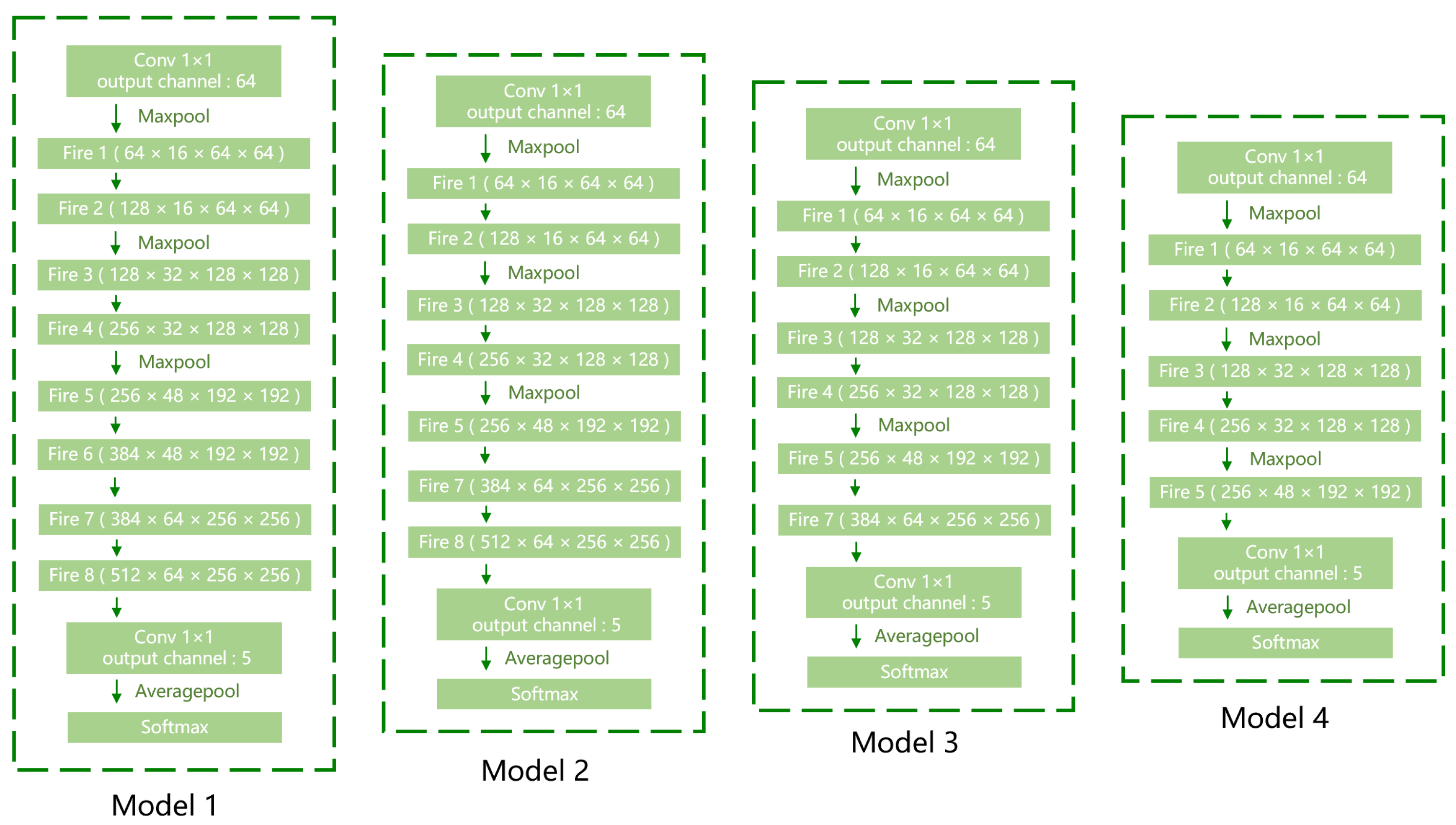
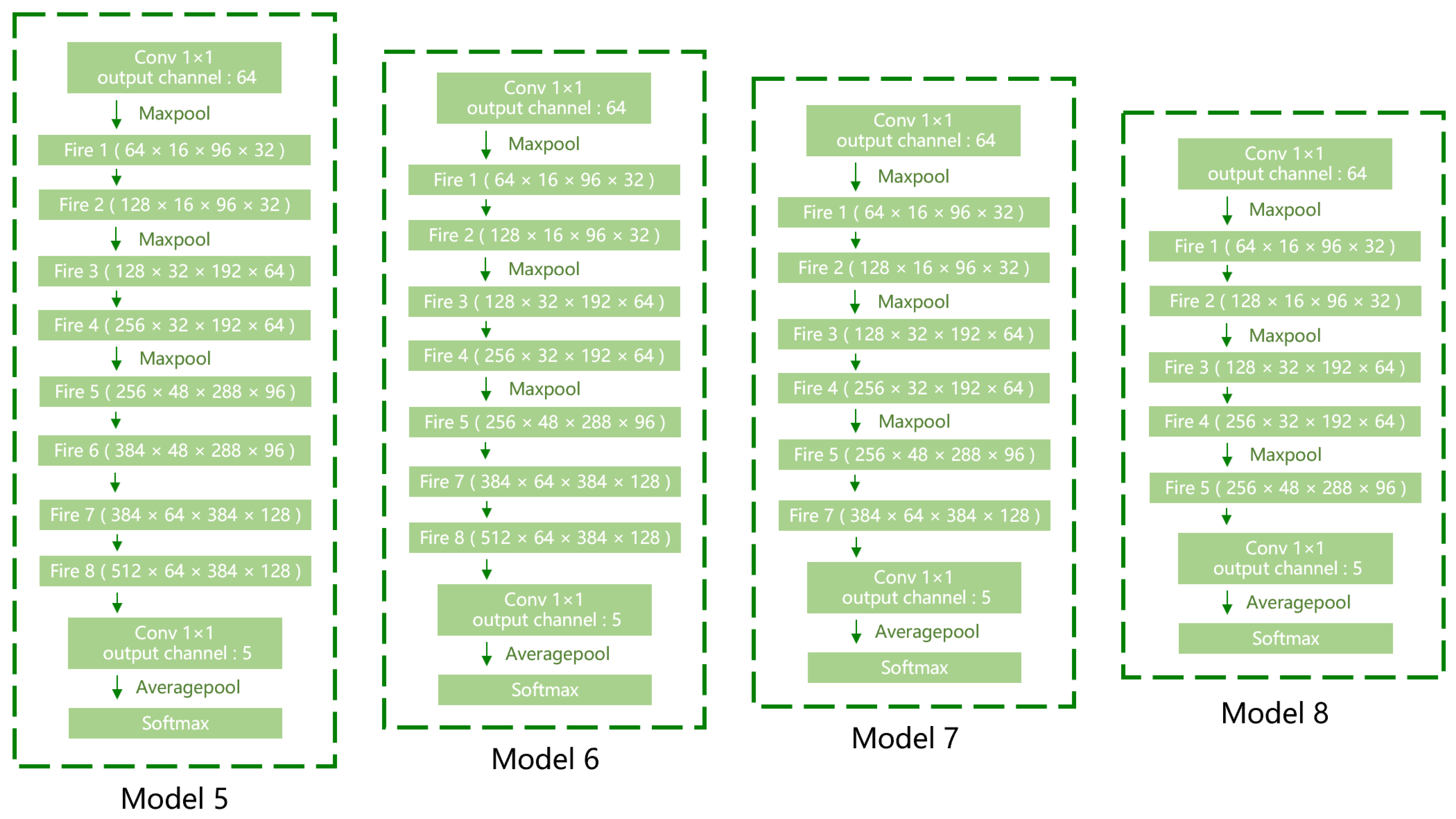
3.2. Network-Structure Modification
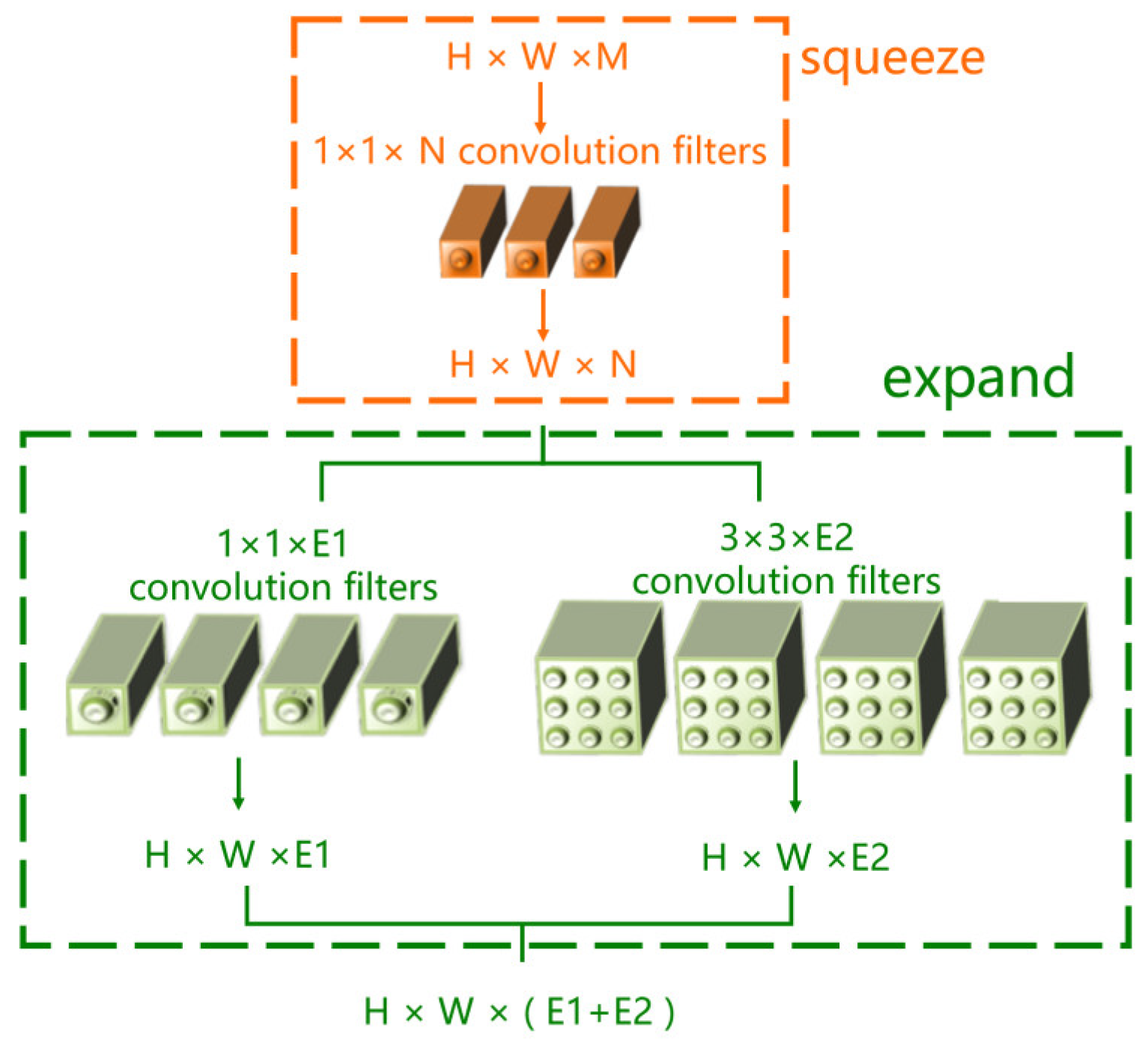
3.3. Fire-Module Modification
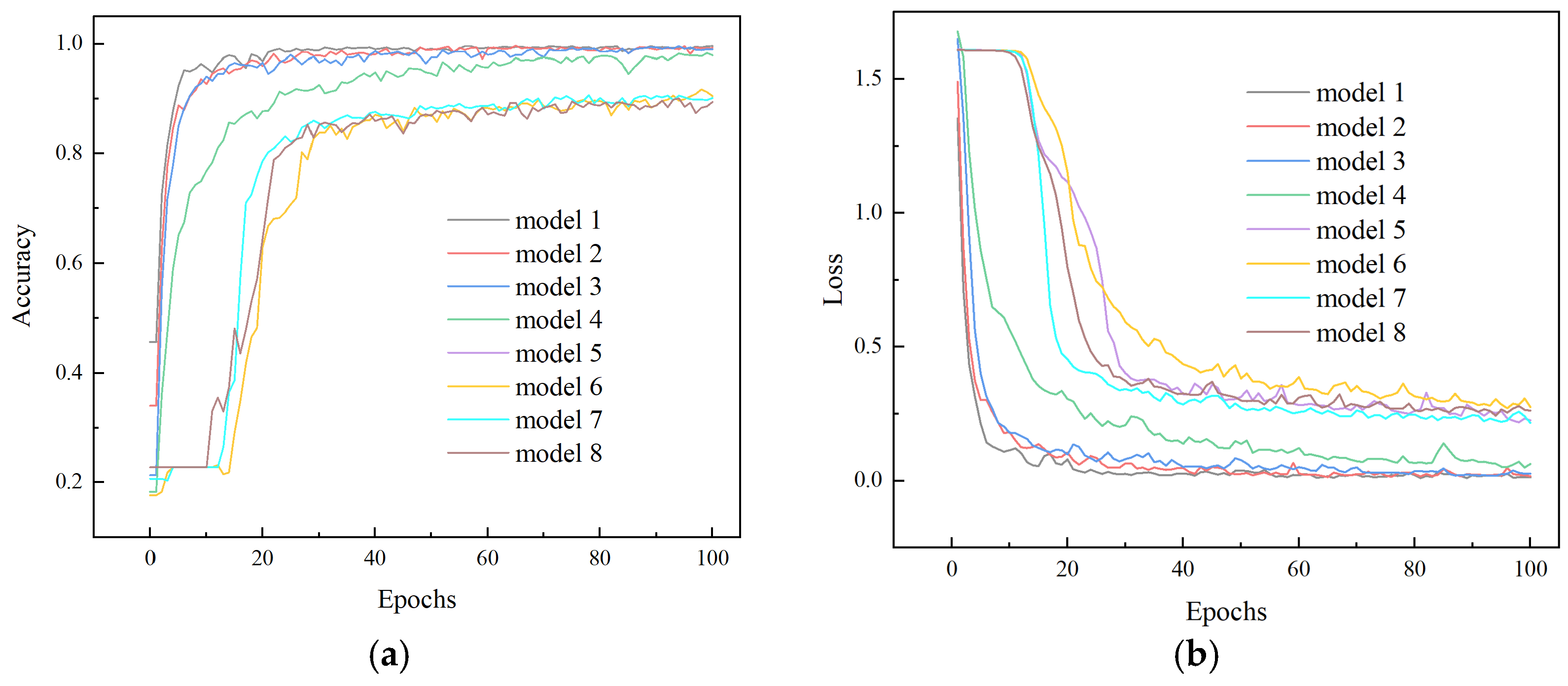
3.4. Model Training
4. Results and Discussion
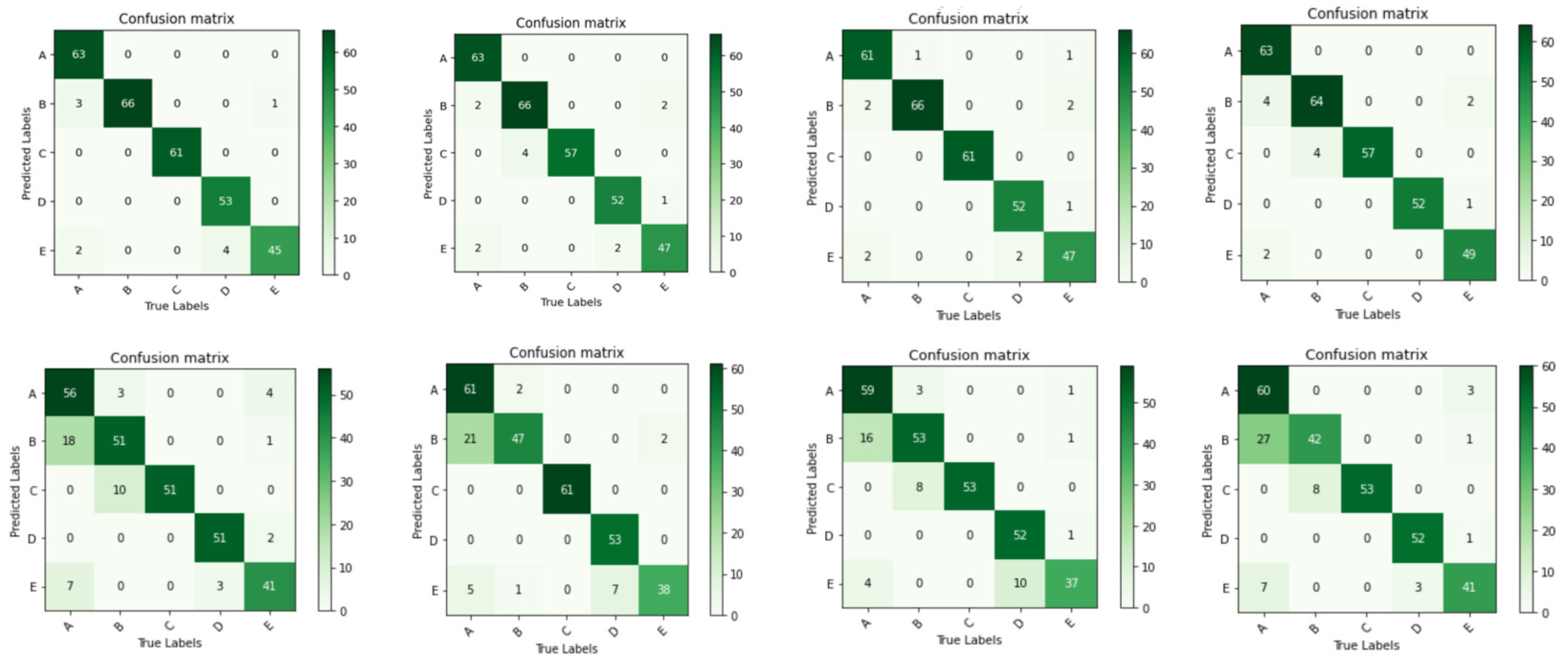
4.1. Model Test and Evaluation
4.2. Comparison with Classical Models
4.3. Visual Output Analysis of Model
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lebaka, V.R.; Wee, Y.J.; Ye, W.; Korivi, M. Nutritional Composition and Bioactive Compounds in Three Different Parts of Mango Fruit. Int. J. Environ. Res. Public Health 2021, 18, 741. [Google Scholar] [CrossRef] [PubMed]
- Thakur, R.; Suryawanshi, G.; Patel, H.; Sangoi, J. An innovative approach for fruit ripeness classification. In Proceedings of the 2020 4th International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 13–15 May 2020; pp. 550–554. [Google Scholar]
- Qiao, Q. Image Processing Technology Based on Machine Learning. IEEE Consum. Electron. Mag. 2022. [Google Scholar] [CrossRef]
- Liu, L.; Wang, Y.; Chi, W. Image Recognition Technology Based on Machine Learning. IEEE Access 2020. [Google Scholar] [CrossRef]
- Truong Minh Long, N.; Truong Thinh, N. Using Machine Learning to Grade the Mango’s Quality Based on External Features Captured by Vision System. Appl. Sci. 2020, 10, 5775. [Google Scholar] [CrossRef]
- Nandi, C.S.; Tudu, B.; Koley, C. A Machine Vision Technique for Grading of Harvested Mangoes Based on Maturity and Quality. IEEE Sens. J. 2016, 16, 6387–6396. [Google Scholar] [CrossRef]
- Pise, D.; Upadhye, G.D. Grading of harvested mangoes quality and maturity based on machine learning techniques. In Proceedings of the 2018 International Conference on Smart City and Emerging Technology (ICSCET), Mumbai, India, 5 January 2018; pp. 1–6. [Google Scholar]
- Kumar, P.R.; Manash, E.B.K. Deep learning: A branch of machine learning. J. Phys. Conf. Ser. 2019, 1228, 012045. [Google Scholar] [CrossRef]
- Naranjo-Torres, J.; Mora, M.; Hernández-García, R.; Barrientos, R.J.; Fredes, C.; Valenzuela, A. A Review of Convolutional Neural Network Applied to Fruit Image Processing. Appl. Sci. 2020, 10, 3443. [Google Scholar] [CrossRef]
- Aherwadi, N.; Mittal, U. Fruit quality identification using image processing, machine learning, and deep learning: A review. Adv. Appl. Math. Sci. 2022, 21, 2645–2660. [Google Scholar]
- Snatkina, O.A.; Kugushev, A.R. Determination of fruit quality by image using deep neural network. In Proceedings of the 2022 Conference of Russian Young Researchers in Electrical and Electronic Engineering (ElConRus), St. Petersburg, Russia, 25–28 January 2022; pp. 1423–1426. [Google Scholar]
- Yang, H.; Wen, T.; Yang, X.; Lin, H. Deep Learning Agricultural Information Classification Combined with Internet of Things Technology in Agricultural Production and Economic Management. IEEE Access 2022, 10, 54713–54719. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic Fruit Classification Using Deep Learning for Industrial Applications. IEEE Trans. Ind. Inform. 2019, 15, 1027–1034. [Google Scholar] [CrossRef]
- Wu, S.-L.; Tung, H.-Y.; Hsu, Y.-L. Deep learning for automatic quality grading of mangoes: Methods and insights. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 14–17 December 2020; pp. 446–453. [Google Scholar]
- Rizwan Iqbal, H.M.; Hakim, A. Classification and Grading of Harvested Mangoes Using Convolutional Neural Network. Int. J. Fruit Sci. 2022, 22, 95–109. [Google Scholar] [CrossRef]
- Tripathi, M.K.; Maktedar, D.D. Optimized deep learning model for mango grading: Hybridizing lion plus firefly algorithm. IET Image Process. 2021, 15, 1940–1956. [Google Scholar] [CrossRef]
- Huang, J.; Lu, X.; Chen, L.; Sun, H.; Wang, S.; Fang, G. Accurate Identification of Pine Wood Nematode Disease with a Deep Convolution Neural Network. Remote Sens. 2022, 14, 913. [Google Scholar] [CrossRef]
- Aqil, M.; Azrai, M.; Mejaya, M.J.; Subekti, N.A.; Tabri, F.; Andayani, N.N.; Wati, R.; Panikkai, S.; Suwardi, S.; Bunyamin, Z.; et al. Rapid Detection of Hybrid Maize Parental Lines Using Stacking Ensemble Machine Learning. Appl. Comput. Intell. Soft Comput. 2022, 2022, 6588949. [Google Scholar] [CrossRef]
- Naik, B.N.; Malmathanraj, R.; Palanisamy, P. Detection and classification of chilli leaf disease using a squeeze-and-excitation-based CNN model. Ecol. Inform. 2022, 69, 101663. [Google Scholar] [CrossRef]
- Chen, X.; Sun, Z.-L.; Chen, X. A machine learning based automatic tomato classification system. In Proceedings of the 2021 33rd Chinese Control and Decision Conference (CCDC), Kunming, China, 22–24 May 2021; pp. 5105–5108. [Google Scholar]
- Zheng, B.; Huang, T.; Houssein, E. Mango Grading System Based on Optimized Convolutional Neural Network. Math. Probl. Eng. 2021, 2021, 2652487. [Google Scholar] [CrossRef]
- Liang, J.; Zhang, T.; Feng, G. Channel Compression: Rethinking Information Redundancy Among Channels in CNN Architecture. IEEE Access 2020, 8, 147265–147274. [Google Scholar] [CrossRef]
- Liu, Y.; Gao, G. Identification of multiple leaf diseases using improved SqueezeNet model. Trans. Chin. Soc. Agric. Eng. 2021, 37, 187–195. [Google Scholar]
- Lipton, Z.C. The mythos of model interpretability: In machine learning, the concept of interpretability is both important and slippery. Queue 2018, 16, 31–57. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? arXiv 2016, arXiv:1611.07450. [Google Scholar]
- Perez, L.; Wang, J. The effectiveness of data augmentation in image classification using deep learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Baird, H.S.; Bunke, H.; Wang, P.S.-P. Document Image Analysis; World Scientific Publishing Company: Los Alamitos, CA, USA, 1994. [Google Scholar]
- Luckow, A.; Cook, M.; Ashcraft, N.; Weill, E.; Djerekarov, E.; Vorster, B. Deep learning in the automotive industry: Applications and tools. In Proceedings of the 2016 IEEE International Conference on Big Data (Big Data), Washington, DC, USA, 5–8 December 2016; pp. 3759–3768. [Google Scholar]
- Shaukat, Z.; Farooq, Q.U.A.; Tu, S.; Xiao, C.; Ali, S. A state-of-the-art technique to perform cloud-based semantic segmentation using deep learning 3D U-Net architecture. BMC Bioinform. 2022, 23, 251. [Google Scholar] [CrossRef] [PubMed]
- Carneiro, T.; Da Nobrega, R.V.M.; Nepomuceno, T.; Bian, G.-B.; de Albuquerque, V.H.C.; Filho, P.P.R. Performance Analysis of Google Colaboratory as a Tool for Accelerating Deep Learning Applications. IEEE Access 2018, 6, 61677–61685. [Google Scholar] [CrossRef]
- Hand, D.; Christen, P. A note on using the F-measure for evaluating record linkage algorithms. Stat. Comput. 2018, 28, 539–547. [Google Scholar] [CrossRef]
- Qin, Z.; Yu, F.; Liu, C.; Chen, X. How convolutional neural networks see the world—A survey of convolutional neural network visualization methods. Math. Found. Comput. 2018, 1, 149–180. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: Berkeley, CA, USA, 2021. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Bock, S.; Weiß, M. A proof of local convergence for the Adam optimizer. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Barranco-Chamorro, I.; Carrillo-García, R.M. Techniques to Deal with Off-Diagonal Elements in Confusion Matrices. Mathematics 2021, 9, 3233. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In NIPS’12: Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Ewe, E.L.R.; Lee, C.P.; Kwek, L.C.; Lim, K.M. Hand Gesture Recognition via Lightweight VGG16 and Ensemble Classifier. Appl. Sci. 2022, 12, 7643. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Training Set | Test Set |
|---|---|---|
| A | 254 | 63 |
| B | 279 | 70 |
| C | 251 | 61 |
| D | 216 | 53 |
| E | 226 | 51 |
| Total | 1226 | 298 |
| Model | Test Accuracy (%) | Average Precision (%) | Average Recall (%) | F1 Score | Parameter Memory (MB) | Computation (MFLOPs) |
|---|---|---|---|---|---|---|
| Model 1 | 96.64 | 96.50 | 96.69 | 0.9659 | 2.78 | 265.48 |
| Model 2 | 95.63 | 95.60 | 95.72 | 0.9566 | 2.36 | 246.72 |
| Model 3 | 96.31 | 96.28 | 96.16 | 0.9622 | 1.60 | 213.39 |
| Model 4 | 95.64 | 95.81 | 95.93 | 0.9587 | 0.87 | 181.34 |
| Model 5 | 83.89 | 84.39 | 85.74 | 0.8506 | 1.85 | 179.78 |
| Model 6 | 87.25 | 87.70 | 89.49 | 0.8859 | 1.56 | 169.67 |
| Model 7 | 85.23 | 85.38 | 86.77 | 0.8607 | 1.05 | 147.42 |
| Model 8 | 83.22 | 84.13 | 86.30 | 0.8520 | 0.58 | 126.44 |
| Test Sets | Classification | Precision (%) | Recall (%) | Accuracy (%) |
|---|---|---|---|---|
| Appearance quality | A | 100.00 | 94.02 | 95.83 |
| B | 91.42 | 94.12 | ||
| C | 93.44 | 100.00 | ||
| Maturity | A | 100.00 | 96.92 | 98.20 |
| D | 98.11 | 100.00 | ||
| E | 96.08 | 98.00 |
| Model | Accuracy (%) | Parameter Memory (MB) | Computation (MFLOPs) |
|---|---|---|---|
| AlexNet | 92.28 | 27.90 | 660.90 |
| VGG16 | 96.64 | 105.65 | 15,483.86 |
| VGG11 | 96.30 | 84.7 | 7616.57 |
| ResNet18 | 94.35 | 43.22 | 1818.69 |
| ResNet34 | 96.01 | 81.84 | 3670.88 |
| GoogleNet | 95.01 | 22.07 | 1503.86 |
| DenseNet | 96.67 | 29.62 | 2865.30 |
| MobileNet | 93.35 | 8.74 | 312.86 |
| ViT-B/16 | 97.17 | 327.37 | 34,529.28 |
| EfficientNet | 89.34 | 15.63 | 27.02 |
| Model 4 | 95.64 | 0.87 | 181.34 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, H.; Chen, W.; Zhu, L.; Chu, X.; Liu, H.; Mu, Y.; Ma, Z. Improved Lightweight Mango Sorting Model Based on Visualization. Agriculture 2022, 12, 1467. https://doi.org/10.3390/agriculture12091467
Wei H, Chen W, Zhu L, Chu X, Liu H, Mu Y, Ma Z. Improved Lightweight Mango Sorting Model Based on Visualization. Agriculture. 2022; 12(9):1467. https://doi.org/10.3390/agriculture12091467
Chicago/Turabian StyleWei, Hongyu, Wenyue Chen, Lixue Zhu, Xuan Chu, Hongli Liu, Yinghui Mu, and Zhiyu Ma. 2022. "Improved Lightweight Mango Sorting Model Based on Visualization" Agriculture 12, no. 9: 1467. https://doi.org/10.3390/agriculture12091467
APA StyleWei, H., Chen, W., Zhu, L., Chu, X., Liu, H., Mu, Y., & Ma, Z. (2022). Improved Lightweight Mango Sorting Model Based on Visualization. Agriculture, 12(9), 1467. https://doi.org/10.3390/agriculture12091467