
Clustering of Small Territories Based on Axes of Inequality


Abstract
:1. Background
2. Methods
2.1. Methods Prior to Carrying out the Study, the Data Set, and the Data Sources
2.1.1. Data Sources
2.1.2. Demographic Area
2.1.3. Economic Area
2.1.4. The Job Market Area
2.1.5. Area of Public Spending
2.1.6. Area of Health
2.1.7. Area of Population Incidences and Emergences
2.1.8. Geographic Area
2.1.9. Alternative Data Sets
2.2. Control of Missing Value or Statistical Confidentiality
2.3. Variable Selection
2.4. Cluster Analysis
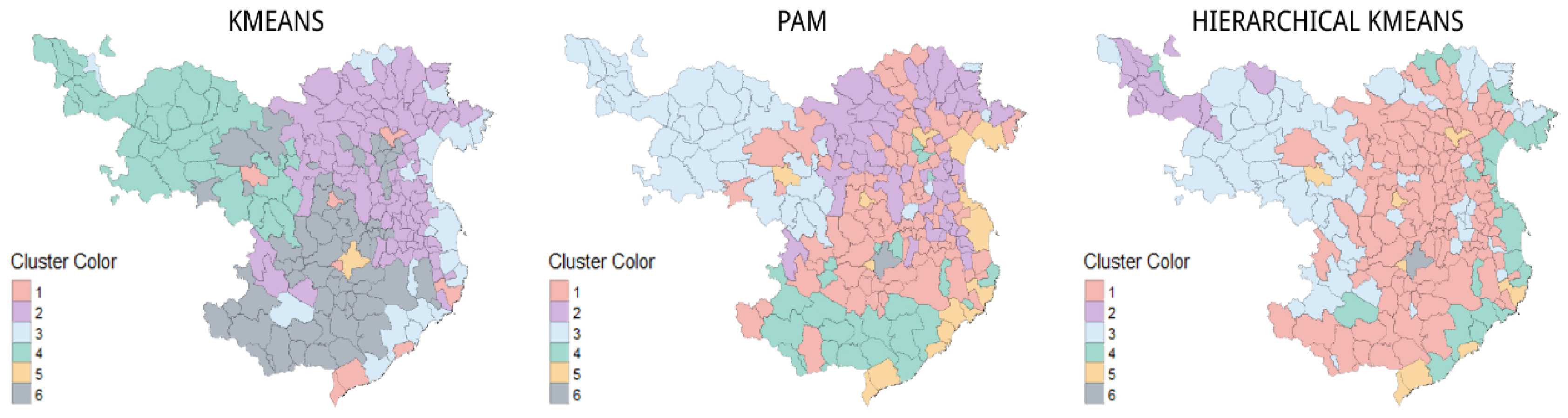
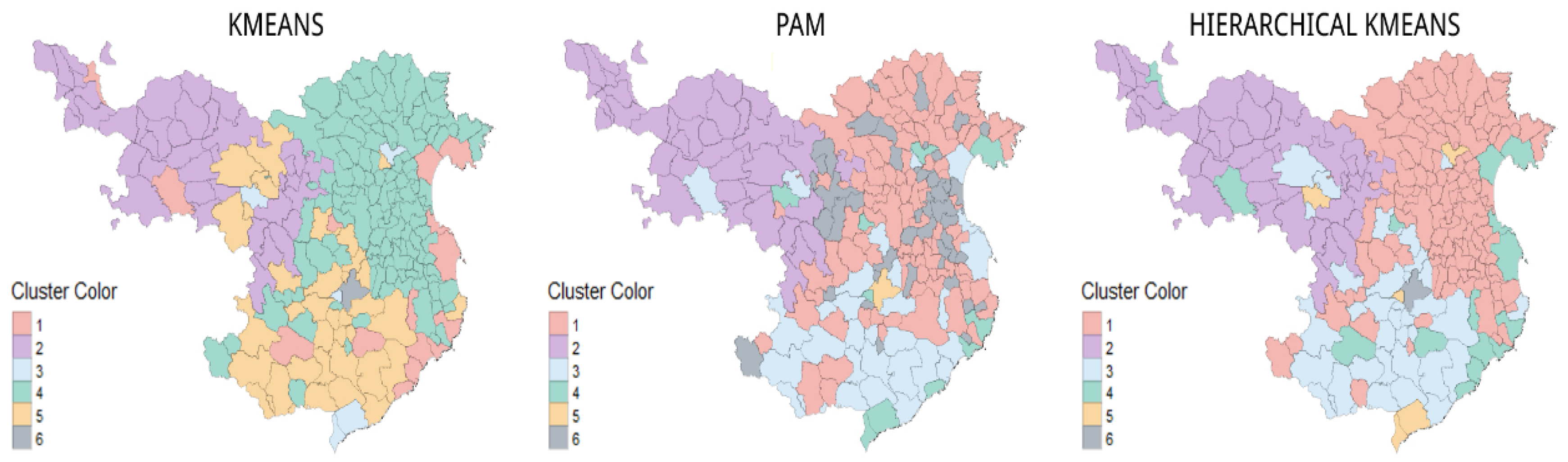
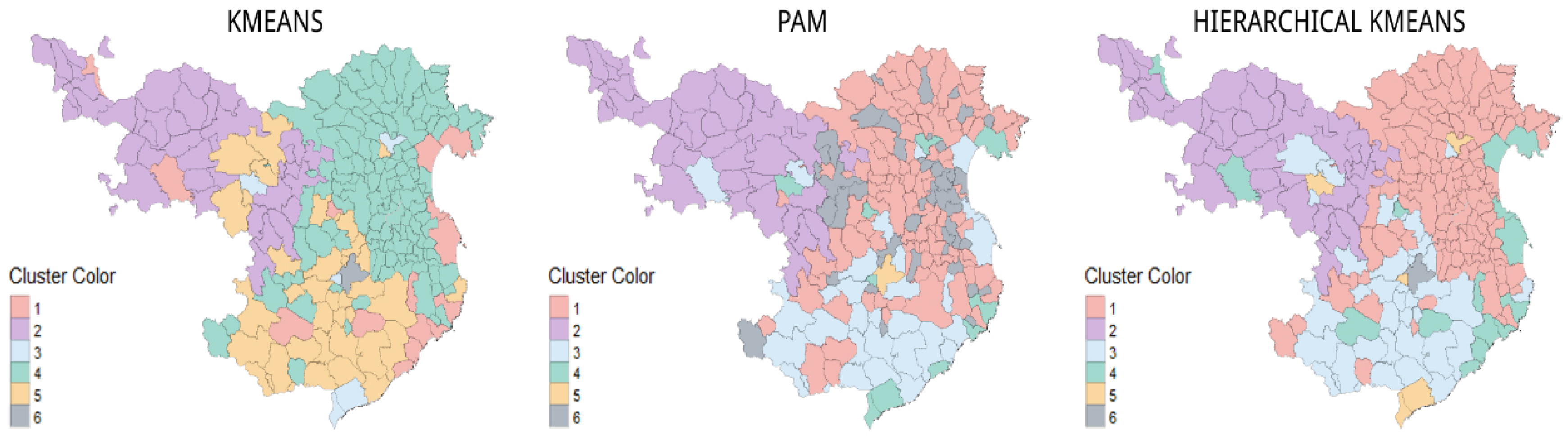
Mapping of the Clustering
2.5. Data Analysis
2.6. Software
3. Results
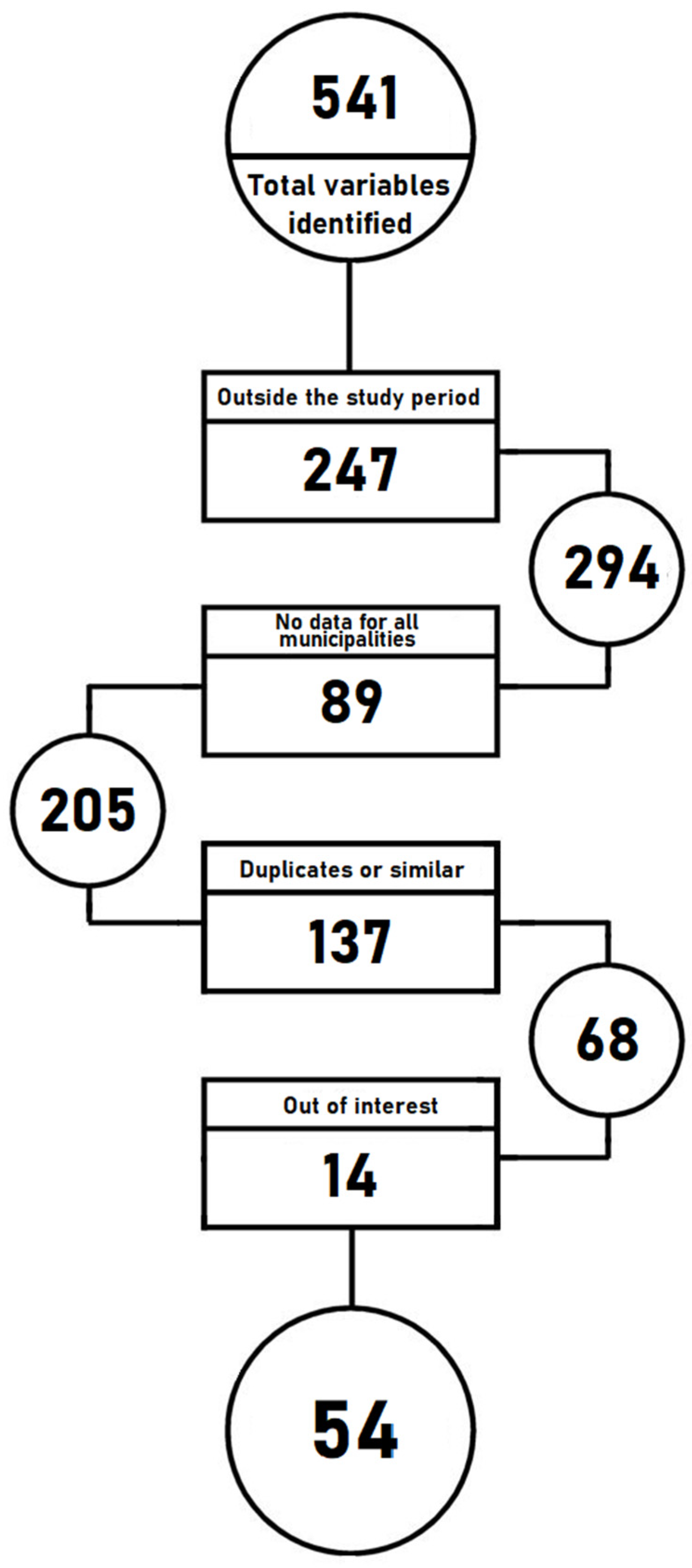
3.1. Area and Period of Study
3.2. Variable Selection
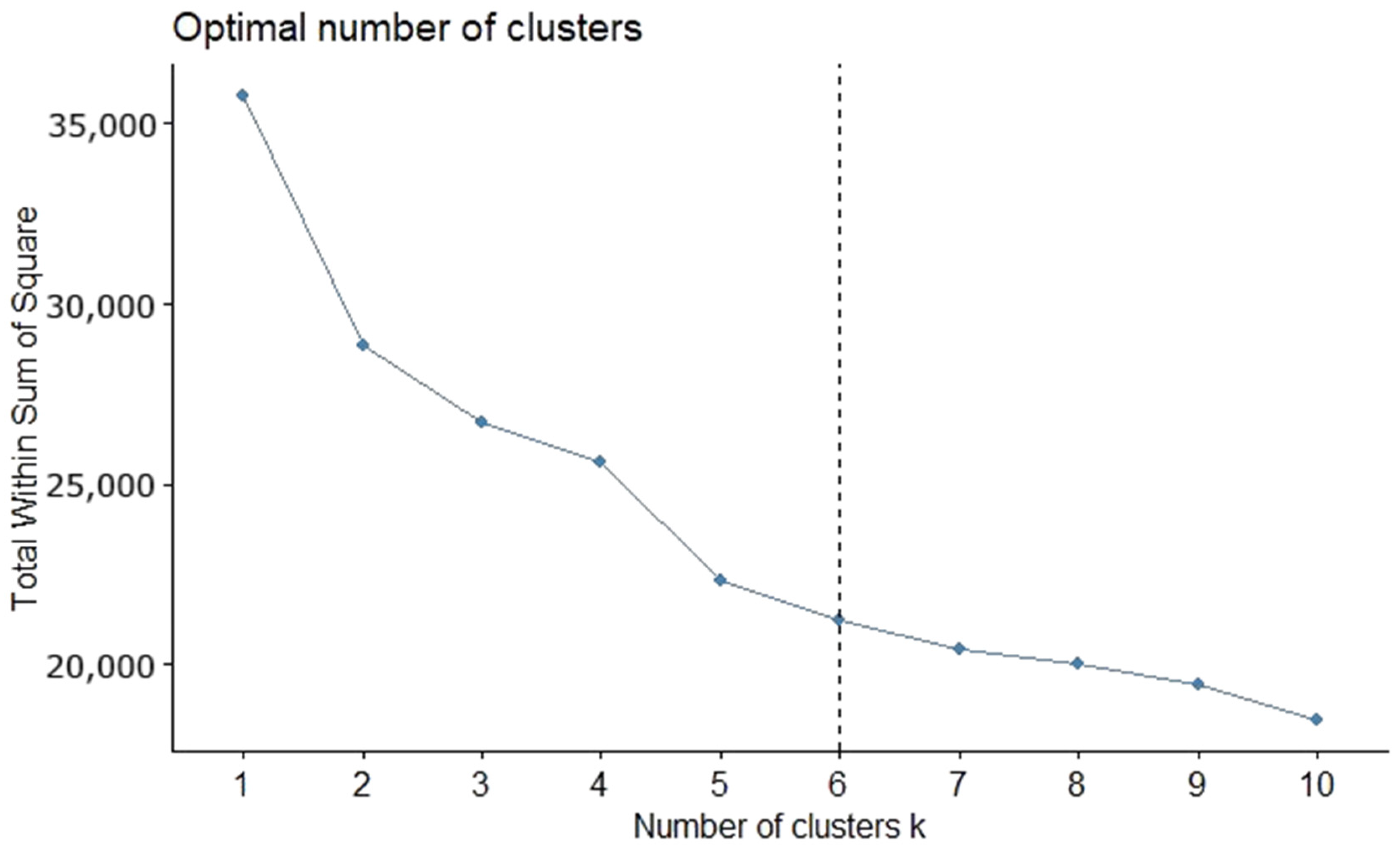
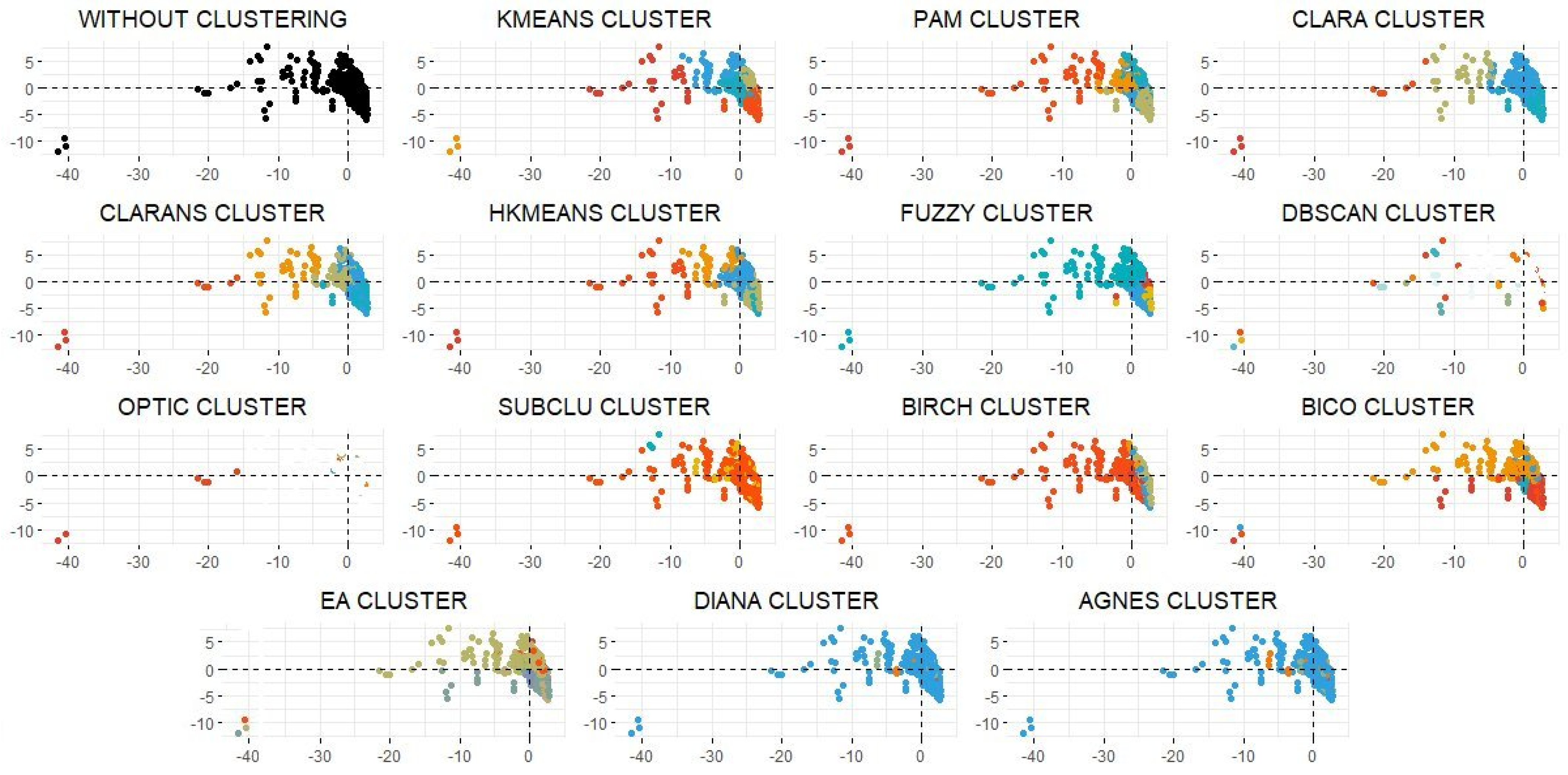
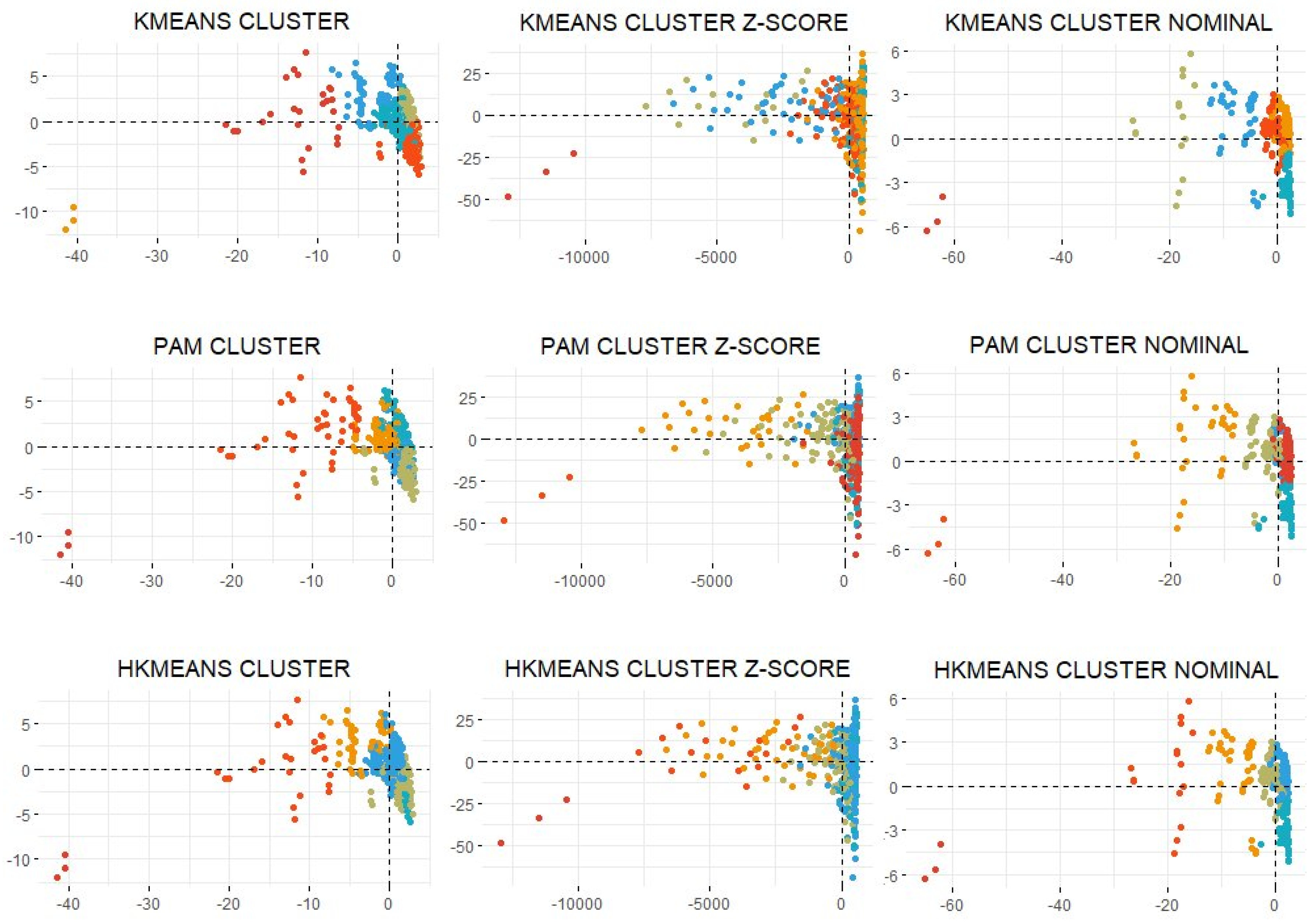
3.3. Clustering
3.4. Mapping of the Clustering
3.5. Descriptive Study of the Clustering
3.6. Inference
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AGNES | Agglomerative nesting |
| CLARA | Clustering large applications |
| DIANA | Divisive analysis |
| Dipsalut | Public Health Observatory of Girona Province |
| IDESCAT | Statistical Institute of Catalonia |
| MSE | Mean squared error |
| PAM | Partitioning around methods |
References
- Acheson, D. Independent Inquiry into Inequalities in Health Report; The Stationary Office: London, UK, 1998. [Google Scholar]
- Lalonde, M. A New Perspective on the Health of Canadians. A Working Document; Government of Canada: Ottawa, ON, Canada, 1974.
- Department of Health and Social Security. Inequalities in Health: Report of a Research Working Group; Department of Health and Social Security: London, UK, 1980.
- Deguen, S.; Zmirou-Navier, D. Social inequalities resulting from health risks related to ambient air quality—A European review. Eur. J. Public Health 2010, 28, 27–35. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bowen, W. An analytical review of environmental justice research: What do we really know? Environ. Manag. 2002, 29, 3–15. [Google Scholar] [CrossRef] [PubMed]
- Long, M.T.; Fox, C.S. The framingham heart study-67 years of discovery in metabolic disease. Nat. Rev. Endocrinol. 2016, 12, 177–183. [Google Scholar] [CrossRef] [PubMed]
- Cannata-Andía, J.B.; Fernández-Martín, J.L.; Cannata-Andia, J.B.; Fernandez-Martin, J.L.; Zoccali, C.; London, G.M.; Locatelli, F.; Ketteler, M.; Ferreira, A.; Covic, A.; et al. Current management of secondary hyperparathyroidism: A multicenter observational study (COSMOS). J. Nephrol. 2008, 21, 290–298. [Google Scholar] [PubMed]
- Hercberg, S.; Castetbon, K.; Czernichow, S.; Malon, A.; Mejean, C.; Kesse, E.; Touvier, M.; Galan, P. The nutrinet-santé study: A web-based prospective study on the relationship between nutrition and health and determinants of dietary patterns and nutritional status. BMC Public Health 2002, 10, 142. [Google Scholar] [CrossRef] [PubMed]
- Chatzitheochari, S.; Fisher, K.; Gilbert, E.; Calderwood, L.; Huskinson, T.; Cleary, A.; Gershuny, J. Using new technologies for time diary data collection: Instrument design and data quality findings from a mixed-mode pilot survey. Soc. Indic. Res. 2017, 137, 379–390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McManus, D.D.; Trinquart, L.; Benjamin, E.J.; Manders, E.S.; Fusco, K.; Jung, L.S.; Spartano, N.L.; Kheterpal, V.; Nowak, C.; Sardana, M.; et al. Design and preliminary findings from a new electronic cohort embedded in the framingham heart study. J. Med. Internet Res. 2019, 21, e12143. [Google Scholar] [CrossRef] [PubMed]
- Pouchieu, C.; Méjean, C.; Andreeva, V.A.; Kesse-Guyot, E.; Fassier, P.; Galán, P.; Hercberg, S.; Touvier, M.; Paolotti, D.; Kaliraman, V. How Computer literacy and socioeconomic status affect attitudes toward a web-based cohort: Results from the nutrinet-santé study. J. Med. Internet Res. 2015, 17, e34. [Google Scholar] [CrossRef]
- Toledano, M.B.; Smith, R.B.; Brook, J.P.; Douglass, M.; Elliott, P. How to establish and follow up a large prospective cohort study in the 21st century—Lessons from UK COSMOS. PLoS ONE 2015, 10, e0131521. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kesse-Guyot, E.; Assmann, K.; Andreeva, V.; Castetbon, K.; Méjean, C.; Touvier, M.; Salanave, B.; Deschamps, V.; Péneau, S.; Fezeu, L.; et al. Lessons learned from methodological validation research in e-epidemiology. JMIR Public Health Surveill. 2016, 2, e160. [Google Scholar] [CrossRef]
- Spartano, N.L.; Lin, H.; Sun, F.; Lunetta, K.L.; Trinquart, L.; Valentino, M.; Manders, E.S.; Pletcher, M.J.; Marcus, G.M.; McManus, D.D.; et al. Comparison of on-site versus remote mobile device support in the framingham heart study using the health eheart study for digital follow-up: Randomized pilot study set within an observational study design. JMIR mHealth uHealth 2019, 7, e13238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Methodology—Rural Development—Eurostat. Available online: https://ec.europa.eu/eurostat/web/rural-development/methodology (accessed on 11 June 2021).
- Amat, P.B.; Lazaro-Lasheras, L.; Oliveras, S.; Perafita, X.; Tarrés, A.; Vilà, A. Promoting equity through monitoring inequalities in the semi-rural region of Girona. Eur. J. Public Health 2020, 30 (Suppl. 5), ckaa166.306. [Google Scholar] [CrossRef]
- IDESCAT. Afiliats I Afiliacions a la Seguretat Social Segons Residència Padronal de L’afiliat. Available online: https://www.idescat.cat/pub/?id=afi (accessed on 10 March 2021).
- IDESCAT. Enquesta de Biblioteques. Available online: https://www.idescat.cat/pub/?id=bib (accessed on 31 December 2021).
- IDESCAT. Estadística de Naixements. Available online: https://www.idescat.cat/pub/?id=naix (accessed on 31 December 2021).
- IDESCAT. Impost Sobre la Renda de les Persones Físiques. Available online: http://www.idescat.cat/pub/?id=irpf (accessed on 31 December 2021).
- IDESCAT. Indicadors Demogràfics I de Territori. Available online: http://www.idescat.cat/pub/?id=inddt&n=215 (accessed on 31 December 2021).
- IDESCAT. Moviments Migratoris. Available online: https://www.idescat.cat/pub/?id=mm (accessed on 31 December 2021).
- IDESCAT. Padró D’inhabitants Residents a L’estranger. Available online: https://www.idescat.cat/pub/?id=phre (accessed on 31 December 2021).
- XIFRA. Cadastre. Available online: http://xifra16.ddgi.cat/qualitat/cadastre2.asp?opCad=A&IdMenu=03031201 (accessed on 31 December 2021).
- XIFRA. Atur Registrat. Available online: https://www.ddgi.cat/xifra/atur/aturPeriodes.asp?IdMenu=03060602&agrupat=7 (accessed on 31 December 2021).
- XIFRA. Atur Registrat Estrangers. Available online: https://www.ddgi.cat/xifra/atur/aturEstPeriodes.asp?IdMenu=03060802&agrupat=7 (accessed on 31 December 2021).
- XIFRA. Característiques de la Població. Available online: https://www.ddgi.cat/xifra/Indicadors/demografia/dpt_TEG.asp?IdMenu=04020303 (accessed on 31 December 2021).
- XIFRA. Impost Sobre la Renda de Les Persones Físiques (IRPF). Available online: https://www.ddgi.cat/xifra/indicadors/ActivEcon/irpf2.asp?IdMenu=04051002 (accessed on 31 December 2021).
- XIFRA. Moviment Natural de la Població. Available online: https://www.ddgi.cat/xifra/Indicadors/demografia/dnd_TBM.asp?IdMenu=04020402 (accessed on 31 December 2021).
- XIFRA. Població. Recomptes. Available online: https://www.ddgi.cat/xifra/Indicadors/demografia/dpt_km2.asp?IdMenu=04020103 (accessed on 31 December 2021).
- Government of Catalonia. Dades de Trucades Operatives Gestionades Pel CAT112|Dades Obertes de Catalunya. Available online: https://analisi.transparenciacatalunya.cat/Seguretat/Dades-de-trucades-operatives-gestionades-pel-CAT11/mfqb-sbx4 (accessed on 31 December 2021).
- Government of Catalonia. Espais Esportius I Complementaris Censats Per Municipality|Dades Obertes de Catalunya. Available online: https://analisi.transparenciacatalunya.cat/Esport/Espais-esportius-i-complementaris-censats-per-muni/v99k-i424 (accessed on 31 December 2021).
- Government of Catalonia. Preu Mitjà del Lloguer D’habitatges Per Municipality|Dades Obertes de Catalunya. Available online: https://analisi.transparenciacatalunya.cat/Habitatge/Preu-mitj-del-lloguer-d-habitatges-per-municipality/qww9-bvhh (accessed on 31 December 2021).
- Government of Catalonia. Superfícies Municipals Dels Conreus Herbacis A Catalunya|Dades Obertes de Catalunya. Available online: https://analisi.transparenciacatalunya.cat/Medi-Rural-Pesca/Superf-cies-municipals-dels-conreus-herbacis-a-Cat/nuvr-btxv (accessed on 31 December 2021).
- Departament de la Vicepresidència i de Polítiques Digitals i Territori. Per Municipality. Available online: https://territori.gencat.cat/ca/06_territori_i_urbanisme/observatori_territori/litoral/regim_sol_litoral/per_municipality (accessed on 31 December 2021).
- Departament de la Vicepresidència i de Polítiques Digitals i Territori. Territoris de Muntanya. Available online: https://territori.gencat.cat/ca/06_territori_i_urbanisme/politica_de_muntanya/territoris_de_muntanya/ (accessed on 31 December 2021).
- INE. Atlas de Distribución de Renta de Los Hogares. Available online: https://www.ine.es/dynt3/inebase/es/index.htm?padre=7132 (accessed on 31 December 2021).
- Bove, V.; Elia, L. Migration, diversity, and economic growth. World Dev. 2017, 89, 227–239. [Google Scholar] [CrossRef]
- Foulkes, M.; Schafft, K.A. The Impact of migration on poverty concentrations in the United States, 1995–2000. Rural Sociol. 2010, 75, 90–110. [Google Scholar] [CrossRef]
- Banerjee, A.; Duflo, E. Poor Economics: A Radical Rethinking of the Way to Fight Global Poverty; Public Affairs: New York, NY, USA, 2011; p. 320. [Google Scholar]
- Lozano, M.; Rentería, E. Work in Transition: Labour Market Life Expectancy and Years Spent in Precarious Employment in Spain 1986–2016. Soc. Indic. Res. 2019, 145, 185–200. [Google Scholar] [CrossRef]
- Anderson, E.; d’Orey, M.A.J.; Duvendack, M.; Esposito, L. Does government spending affect income poverty? A meta-regression analysis. World Dev. 2018, 103, 60–71. [Google Scholar] [CrossRef]
- Ravallion, M. Growth, inequality and poverty: Looking beyond averages. World Dev. 2001, 29, 1803–1815. [Google Scholar] [CrossRef] [Green Version]
- Son, H.H.; Kakwani, N. Global estimates of pro-poor growth. World Dev. 2008, 36, 1048–1066. [Google Scholar] [CrossRef] [Green Version]
- Filmer, D.; Pritchett, L. The impact of public spending on health: Does money matter? Soc. Sci. Med. 1999, 49, 1309–1323. [Google Scholar] [CrossRef]
- Birdsall, N. Public spending on higher education in developing countries: Too much or too little? Econ. Educ. Rev. 1996, 15, 407–419. [Google Scholar] [CrossRef]
- Ameratunga, S.; Hijar, M.; Norton, R. Road-traffic injuries: Confronting disparities to address a global-health problem. Lancet 2006, 367, 1533–1540. [Google Scholar] [CrossRef]
- Bloom, D.E.; Luca, D.L. The Global Demography of Aging; Elsevier: Amsterdam, The Netherlands, 2016; Volume 1, pp. 3–56. [Google Scholar]
- Observatori de la Seguretat Viària. Accidents de Trànsit Amb Morts o Ferits Greus a Catalunya. Available online: http://transit.gencat.cat/ca/observatori/dades_obertes/ (accessed on 31 December 2021).
- Agarwal, G.; Lee, J.; McLeod, B.; Mahmuda, S.; Howard, M.; Cockrell, K.; Angeles, R. Social factors in frequent callers: A description of isolation, poverty and quality of life in those calling emergency medical services frequently. BMC Public Health 2019, 19, 684. [Google Scholar] [CrossRef] [PubMed]
- Barbaree, H.; Mewhort, D. The effects of the z-score transformation on measures of relative erectile response strength: A re-appraisal. Behav. Res. Ther. 1994, 32, 547–558. [Google Scholar] [CrossRef]
- Ishwaran, H.; Rao, J.S. Spike and slab variable selection: Frequentist and Bayesian strategies. Ann. Stat. 2005, 33, 730–773. [Google Scholar] [CrossRef] [Green Version]
- Hoerl, A.E. Application of ridge analysis to regression problems. Chem. Eng. Prog. 1962, 58, 54–59. [Google Scholar]
- Hoerl, A.E.; Kennard, R.W. Ridge regression: Biased estimation for nonorthogonal problems. Technometrics 1970, 12, 55–67. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B Methodol. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Antoniadis, A.; Fan, J.; Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 67, 301–320. [Google Scholar]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, C.H. Nearly unbiased variable selection under minimax concave penalty. Ann. Stat. 2010, 38, 894–942. [Google Scholar] [CrossRef] [Green Version]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–451. [Google Scholar] [CrossRef] [Green Version]
- Hartigan, J.A.; Wong, M.A. Algorithm AS 136: A K-means clustering algorithm. J. R. Stat. Soc. Ser. C Appl. Stat. 1979, 28, 100–108. [Google Scholar] [CrossRef]
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data; Ltd, ch2, ch3, ch4, ch5, ch6; John Wiley & Sons: New York, NY, USA, 1990; pp. 68–279. [Google Scholar]
- Ng, R.; Han, J. CLARANS: A method for clustering objects for spatial data mining. Knowl. Data Eng. IEEE Trans. 2002, 14, 1003–1016. [Google Scholar] [CrossRef] [Green Version]
- Carnein, M.; Trautmann, H. EvoStream—Evolutionary stream clustering utilizing idle times. Big Data Res. 2018, 14, 101–111. [Google Scholar] [CrossRef]
- Arai, K.; Barakbah, A.R. Hierarchical K-means: An algorithm for centroids initialization for K-means. Rep. Fac. Sci. Eng. 2007, 36, 25–31. [Google Scholar]
- Kröger, P.; Kriegel, H.P.; Kailing, K. Density-connected subspace clustering for high-dimensional data. In Proceedings of the 2004 SIAM International Conference on Data Mining (SDM), Lake Buena Vista, FL, USA, 22–24 April 2004; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2004; pp. 246–257. [Google Scholar]
- Hahsler, M.; Piekenbrock, M.; Doran, D. Dbscan: Fast density-based clustering with R. J. Stat. Softw. 2019, 91, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Fichtenberger, H.; Gillé, M.; Schmidt, M.; Schwiegelshohn, C.; Sohler, C. BICO: BIRCH meets coresets for k-means clustering. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2013; Volume 8125, pp. 481–492. [Google Scholar]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: A new data clustering algorithm and its applications. Data Min. Knowl. Discov. 1997, 1, 141–182. [Google Scholar] [CrossRef]
- ICGC. Base Municipal. Available online: https://www.icgc.cat/Administracio-i-empresa/Descarregues/Capes-de-geoinformacio/Base-municipal (accessed on 31 December 2021).
- Allen, D.M. Mean square error of prediction as a criterion for selecting variables. Technometrics 1971, 13, 469. [Google Scholar] [CrossRef]
- Celeux, G.; Soromenho, G. An entropy criterion for assessing the number of clusters in a mixture model. J. Classif. 1996, 13, 195–212. [Google Scholar] [CrossRef] [Green Version]
- Calinski, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat.—Simul. Comput. 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Hollander, M.; Wolfe, D.A. Nonparametric Statistical Methods; John Wiley & Sons: New York, NY, USA, 1973. [Google Scholar]
- Neuhäuser, M. Wilcoxon—Mann—Whitney test. In International Encyclopedia of Statistical Science; Miodrag, L., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 1656–1658. [Google Scholar]
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S-PLUS; Springer: New York, NY, USA, 2003. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | MSE | Number of Variables | |
|---|---|---|---|
| Selected | Non-Selected | ||
| Ridge Regression | 25,981.73 | 54 | 0 |
| Lasso | 55,404.96 | 12 | 42 |
| Elastic Net | 70,199.54 | 53 | 1 |
| SCAD | 50,711.94 | 14 | 40 |
| MCP | 50,711.94 | 16 | 38 |
| LARS | 41,167.40 | 34 | 17 |
| Spike and Slab | 25,302.36 | 53 | 1 |
| Name | Nº Clusters | Noise Point | Avg Between | Avg Within | Avg Silhouette | DUNN Index | Entropy | WB Ratio | CH Index | Separation Index |
|---|---|---|---|---|---|---|---|---|---|---|
| Data Set: Original | ||||||||||
| K-MEANS | 6 | 0 | 9.962 | 7.569 | 0.084 | 0.087 | 1.407 | 0.760 | 91.998 | 2.877 |
| PAM | 6 | 0 | 9.836 | 7.639 | 0.065 | 0.065 | 1.509 | 0.777 | 85.240 | 2.567 |
| CLARA | 6 | 0 | 10.499 | 8.070 | 0.074 | 0.038 | 0.961 | 0.769 | 59.973 | 2.488 |
| CLARANS | 6 | 0 | 10.064 | 7.766 | 0.070 | 0.068 | 1.206 | 0.772 | 83.459 | 2.739 |
| HKMEANS | 6 | 0 | 10.407 | 7.639 | 0.120 | 0.078 | 1.217 | 0.734 | 89.323 | 3.174 |
| FUZZY | 3 | 0 | 9.928 | 9.000 | 0.067 | 0.025 | 0.580 | 0.907 | 27.103 | 1.716 |
| BIRCH | 6 | 0 | 9.232 | 8.614 | −0.073 | 0.029 | 1.671 | 0.933 | 18.810 | 2.437 |
| BICO | 6 | 0 | 9.560 | 8.539 | −0.030 | 0.024 | 1.343 | 0.893 | 16.487 | 2.304 |
| EA | 6 | 0 | 9.560 | 8.539 | −0.030 | 0.024 | 1.343 | 0.893 | 16.487 | 2.304 |
| DIANA | 4 | 0 | 12.017 | 9.128 | 0.024 | 0.044 | 0.256 | 0.760 | 6.536 | 3.020 |
| AGNES | 4 | 0 | 10.363 | 9.130 | −0.072 | 0.044 | 0.422 | 0.881 | 5.193 | 2.886 |
| Data set: Nominal | ||||||||||
| K-MEANS | 6 | 0 | 9.191 | 5.266 | 0.196 | 0.065 | 1.241 | 0.573 | 278.179 | 2.232 |
| PAM | 6 | 0 | 7.641 | 7.379 | −0.101 | 0.011 | 1.509 | 0.966 | 3.012 | 1.006 |
| CLARA | 6 | 0 | 8.728 | 5.459 | 0.123 | 0.037 | 1.228 | 0.625 | 244.045 | 1.403 |
| CLARANS | 6 | 0 | 8.694 | 5.358 | 0.137 | 0.037 | 1.293 | 0.616 | 256.041 | 1.499 |
| HKMEANS | 6 | 0 | 9.195 | 5.268 | 0.195 | 0.065 | 1.240 | 0.573 | 278.081 | 2.241 |
| FUZZY | 4 | 0 | 9.109 | 6.255 | 0.077 | 0.015 | 0.862 | 0.687 | 141.029 | 1.567 |
| BIRCH | 6 | 0 | 7.609 | 6.744 | −0.137 | 0.008 | 1.563 | 0.886 | 25.802 | 1.031 |
| BICO | 6 | 0 | 7.808 | 6.465 | −0.008 | 0.012 | 1.517 | 0.828 | 26.727 | 1.259 |
| EA | 6 | 0 | 7.808 | 6.465 | −0.008 | 0.012 | 1.517 | 0.828 | 26.727 | 1.259 |
| DIANA | 4 | 0 | 7.158 | 7.470 | −0.089 | 0.012 | 0.243 | 1.044 | 0.789 | 1.440 |
| AGNES | 4 | 0 | 6.461 | 7.451 | −0.233 | 0.008 | 0.422 | 1.153 | 1.680 | 1.165 |
| Data set: Z-score | ||||||||||
| K-MEANS | 6 | 0 | 10.149 | 7.759 | 0.061 | 0.104 | 1.241 | 0.765 | 83.072 | 2.789 |
| PAM | 6 | 0 | 9.352 | 9.103 | −0.039 | 0.036 | 1.509 | 0.973 | 3.456 | 2.374 |
| CLARA | 6 | 0 | 10.013 | 7.846 | 0.060 | 0.093 | 1.228 | 0.784 | 78.518 | 2.382 |
| CLARANS | 6 | 0 | 10.014 | 7.766 | 0.079 | 0.099 | 1.293 | 0.775 | 83.033 | 2.422 |
| HKMEANS | 6 | 0 | 10.15 | 7.758 | 0.061 | 0.104 | 1.240 | 0.764 | 83.097 | 2.771 |
| FUZZY | 4 | 0 | 10.263 | 8.413 | 0.038 | 0.049 | 0.862 | 0.820 | 65.039 | 2.406 |
| BIRCH | 6 | 0 | 9.266 | 8.711 | −0.116 | 0.040 | 1.563 | 0.940 | 16.763 | 2.478 |
| BICO | 6 | 0 | 9.434 | 8.515 | −0.028 | 0.039 | 1.517 | 0.903 | 20.023 | 2.400 |
| EA | 6 | 0 | 9.434 | 8.515 | −0.028 | 0.039 | 1.517 | 0.903 | 20.023 | 2.400 |
| DIANA | 4 | 0 | 8.796 | 9.185 | −0.087 | 0.051 | 0.243 | 1.044 | 1.643 | 3.160 |
| AGNES | 4 | 0 | 8.491 | 9.194 | −0.156 | 0.039 | 0.422 | 1.083 | 1.554 | 2.841 |
| Name | Cluster 1 (C1) | Cluster 2 (C2) | Cluster 3 (C3) | Cluster 4 (C4) | Cluster 5 (C5) | Cluster 6 (C6) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| O 1 | N 2 | Z 3 | O 1 | N 2 | Z 3 | O 1 | N 2 | Z 3 | O 1 | N 2 | Z 3 | O 1 | N 2 | Z 3 | O 1 | N 2 | Z 3 | |
| K-MEANS | 25 | 44 | 127 | 258 | 127 | 15 | 62 | 15 | 3 | 121 | 360 | 360 | 3 | 114 | 114 | 194 | 3 | 4 |
| PAM | 235 | 235 | 235 | 165 | 117 | 117 | 122 | 97 | 97 | 92 | 30 | 30 | 46 | 3 | 3 | 3 | 181 | 181 |
| CLARA | 425 | 239 | 328 | 163 | 95 | 115 | 58 | 284 | 25 | 5 | 38 | 6 | 10 | 4 | 2 | 2 | 3 | 187 |
| CLARANS | 347 | 277 | 235 | 166 | 122 | 117 | 101 | 49 | 97 | 41 | 5 | 30 | 5 | 3 | 3 | 3 | 207 | 181 |
| HKMEANS | 355 | 360 | 360 | 41 | 132 | 132 | 183 | 109 | 109 | 57 | 44 | 44 | 24 | 15 | 15 | 3 | 3 | 3 |
| FUZZY | 170 | 345 | 597 | 492 | 33 | 34 | 1 | 1 | 1 | 0 | 284 | 28 | 0 | 0 | 3 | 0 | 0 | 0 |
| BIRCH | 44 | 32 | 32 | 96 | 43 | 44 | 161 | 219 | 170 | 50 | 132 | 53 | 126 | 50 | 128 | 186 | 187 | 236 |
| BICO | 95 | 198 | 193 | 35 | 48 | 101 | 6 | 3 | 3 | 331 | 179 | 122 | 151 | 74 | 153 | 45 | 161 | 91 |
| EA | 95 | 3 | 3 | 45 | 161 | 91 | 331 | 198 | 193 | 151 | 179 | 122 | 35 | 74 | 153 | 6 | 48 | 101 |
| DIANA | 627 | 630 | 612 | 24 | 18 | 33 | 9 | 12 | 15 | 3 | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| AGNES | 594 | 594 | 594 | 33 | 33 | 33 | 33 | 33 | 33 | 3 | 3 | 3 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 Changes | 1 Changes | 2 Changes | 0 Changes | 1 Changes | 2 Changes | 0 Changes | 1 Changes | 2 Changes | |
|---|---|---|---|---|---|---|---|---|---|
| Data Set: Original | Data Set: Nominal | Data Set: Z-Score | |||||||
| K-MEANS | 202 | 19 | 0 | 217 | 4 | 0 | 217 | 4 | 0 |
| PAM | 120 | 98 | 3 | 74 | 142 | 5 | 74 | 142 | 5 |
| CLARA | 155 | 65 | 1 | 56 | 162 | 3 | 56 | 162 | 3 |
| CLARANS | 181 | 40 | 0 | 56 | 162 | 3 | 56 | 162 | 3 |
| HKMEANS | 196 | 25 | 0 | 217 | 4 | 0 | 217 | 4 | 0 |
| FUZZY | 54 | 167 | 0 | 10 | 210 | 1 | 10 | 210 | 1 |
| BIRCH | 172 | 46 | 3 | 197 | 24 | 0 | 197 | 24 | 0 |
| BICO | 172 | 46 | 3 | 196 | 25 | 0 | 173 | 48 | 0 |
| EA | 172 | 46 | 3 | 197 | 24 | 0 | 173 | 48 | 0 |
| DIANA | 172 | 46 | 3 | 197 | 24 | 0 | 221 | 0 | 0 |
| AGNES | 172 | 46 | 3 | 197 | 24 | 0 | 221 | 0 | 0 |
| FRENCH BORDER (C1) | MOUNTAIN (C2) | INLAND (C3) | COASTAL (C4) | OTHERS (C5) | CAPITAL (C6) | FRENCH BORDER (C1) | MOUNTAIN (C2) | INLAND (C3) | COASTAL (C4) | OTHERS (C5) | CAPITAL (C6) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| n = 360 | n = 132 | n = 109 | n = 44 | n = 15 | n = 3 | n = 360 | n = 132 | n = 109 | n = 44 | n = 15 | n = 3 |
| pob_res_alestranger | cadastre_parcel_u | ||||||||||
| 12 (6–25) | 10 (4–16) | 35 (14–65.25) | 324 (276–456) | 855 (685–1263) | 4160 (3941–4339.5) | 407.5 (235.25–698.5) | 407.5 (194.75–608.75) | 1330.5 (957.5–2527.5) | 4540 (2292–7232) | 6541 (5850.5–9234) | 10,649 (10,645–10,677) |
| saldo_migratori_intern | cadastre_inmo_u | ||||||||||
| 1 ((−7)–8.25) | 1 ((−5)–6) | 4.5 ((−8)–30.25) | −8 ((−42)–33) | −2 ((−30.5)–55) | 9 ((−39.5)–51) | 463.5 (247.25–878.5) | 579.5 (242–1139) | 2372.5 (1166–4260.75) | 15,982 (8132–21,720) | 32,691 (26,451.5–38,173.5) | 79,579 (79,242–79,713.5) |
| saldo_migratori_extern | cadastre_valor | ||||||||||
| 2 (0–6) | 1 (0–4) | 8 (0–18) | 48 (2–85) | 3 ((−16.5)–212.5) | 546 (310–699) | 22,797.5 (13,956.5–44,019.5) | 24,778.5 (11,902–70,339.75) | 144,625.5 (64,595–250,763.25) | 686,228 (312,990–12,862,52) | 1,374,697 (1,291,656–2,110,633.5) | 4005,166 (3,806,792.5–4,036,354.5) |
| saldo_migratori_total | atur_mig | ||||||||||
| 2 ((−5)–11) | 3 ((−2.25)–7) | 14.5 ((−4.5)–40.25) | 22 ((−11)–107) | 28 ((−6.5)–202.5) | 555 (361–659.5) | 22.71 (9.79–43.46) | 10.5 (4.83–36.605) | 124.915 (56.603–279.955) | 625.17 (477.92–948.83) | 2190.42 (1582.955–3230.75) | 5730.42 (5447.835–6093.585) |
| irpf_base_imp | atur_mig_estranger | ||||||||||
| 20,129 (18,708.25–21,803.5) | 19,582.5 (17,367–21,283.5) | 20,578.5 (19,228.75–21,582.5) | 18,577 (17,700–19,991) | 18,736 (17,123–19,331.5) | 24,800 (24,443–25,100) | 2.96 (1.08–7.123) | 0.96 (0.06–3.455) | 15.54 (3.958–36.293) | 184.33 (127.67–346.58) | 619.08 (432.5–820.5) | 1644.83 (1552.415–1774.29) |
| irpf_couta_auto | inde_env | ||||||||||
| 5129.5 (4538.25–5815) | 4831.5 (4158–5676) | 4745 (4381.25–5296) | 4749 (4540–5065) | 4513 (4197–4740.5) | 6647 (6615.5–6733) | 130.255 (101.812–157.438) | 154.23 (119.182–192.27) | 93.6 (82.613–117.955) | 97.55 (88.81–120.07) | 81.53 (77.885–116.02) | 81.95 (81.38–85.05) |
| nascuts_vius | tax_bruta_mort | ||||||||||
| 4 (2–9) | 3 (1–7) | 27.5 (14–55.25) | 100 (84–143) | 302 (290–342.5) | 1048 (1041.5–1074.5) | 9.16 (6.455–12.795) | 9.05 (5.695–13.413) | 7.805 (6.412–9.773) | 8.42 (7.85–9.32) | 7.68 (6.265–8.95) | 7.22 (7.215–7.42) |
| morts_num | index_rec | ||||||||||
| 2 (1–4) | 1 (0.75–3) | 13.5 (7–23.25) | 42 (29–61) | 131 (106–137.5) | 344 (338.5–357) | 147.22 (110–196.243) | 158.57 (124.52–217.957) | 109.7 (99.032–129.367) | 107.47 (100.38–146.15) | 108.23 (101.18–112.64) | 96.05 (95.695–96.14) |
| saldo_pobl | index_dep_glob | ||||||||||
| 2 (0–5) | 1 (0–4) | 16 (6–29.25) | 65 (40–88) | 193 (161.5–208.5) | 704 (684.5–736) | 60.595 (54.788–64.713) | 56.185 (49.905–62.543) | 54.47 (52.33–56.37) | 54.04 (52.64–54.87) | 51.12 (42.165–52.085) | 50.06 (49.785–50.24) |
| mobilitat_estudiants_uni_foramun | edat_mitja | ||||||||||
| 33.511 (5–20) | 57.586 (0–11.25) | 44.974 (40–105) | 111.312 (135–300) | 272.496 (597.5–660) | 58.381 (1120–1177.5) | 44.15 (42.2–45.725) | 45.40 (43.6–47.2) | 41.50 (40.275–43.225) | 41.50 (40.8–43) | 41.30 (39.9–42.5) | 40.0 (39.9–40.1) |
| mobilitat_estudiants_uni_mun | creix_natu | ||||||||||
| 0 (0–0) | 0 (0–0) | 0 (0–0) | 0 (0–0) | 0 (0–0) | 10,785 (10,737.5–10,890) | −1 ((−3)–1) | −1 ((−3)–1) | 2 ((−4)–11.25) | 12 (0–28) | 3 ((−22.5)–120.5) | 326 (313–336) |
| renda_mitja | index_sint_fecund | ||||||||||
| 12,195 (11,375.5–13,261.5) | 13,084 (12,102.75–14,568.25) | 12,304 (11,315.25–13,375.25) | 10,629 (9818–11,665) | 10,104 (9600.5–10,938.5) | 13,183 (12,930.5–13,355) | 1.28 (0.838–1.74) | 1.3 (0.768–1.74) | 1.415 (1.175–1.675) | 1.45 (1.3–1.61) | 1.350 (1.2–1.74) | 1.45 (1.435–1.49) |
| total_pobl | taxa_estreng | ||||||||||
| 579 (284.75–1035.75) | 340.5 (181.75–829) | 3525.5 (1713.5–5474.5) | 10,709 (10,231–17,677) | 37,042 (33,972–39,096) | 98,255 (97,920.5–98,634) | 0.101 (0.066–0.138) | 0.061 (0.049–0.112) | 0.082 (0.044–0.117) | 0.217 (0.164–0.298) | 0.225 (0.161–0.258) | 0.18 (0.179–0.182) |
| biblio | index_autoc | ||||||||||
| 0 (0–0) | 0 (0–0) | 1 (0–1) | 1 (1–3) | 3 (1–5) | 18 (18–18) | 30.685 (24.788–34.858) | 35.03 (24.377–40.385) | 28.525 (23.395–35.197) | 33.11 (21.49–38.24) | 32.88 (20.445–37.505) | 40.22 (40.175–40.22) |
| ss_total_mig | densitat_pob | ||||||||||
| 228 (113–405) | 145 (83–326) | 1539 (793–2293) | 4109 (3671–6547) | 13,633 (12,460–14,595) | 39,427 (38,747–40,147) | 41 (20–76) | 16 (5–34) | 135 (60.75–190) | 423 (175–630) | 1171 (758.5–2214) | 2512 (2503.5–2521.5) |
| ss_ext_mig | contract_tempo | ||||||||||
| 9.83 (6.332–14.315) | 5.42 (2.015–9.15) | 7.535 (3.947–11.123) | 17.08 (14.14–22.09) | 17.37 (13.51–24.36) | 16.77 (16.405–17.125) | 0.812 (0.5–1) | 0.883 (0.702–1) | 0.834 (0.75–0.906) | 0.838 (0.794–0.886) | 0.861 (0.819–0.902) | 0.898 (0.893–0.9) |
| ss_agricultura_per | gini | ||||||||||
| 6.606 (3.541–12.228) | 7.23 (2.91–12.821) | 2.61 (1.487–5.697) | 2.572 (1.55–4.059) | 1.277 (0.384–2.425) | 0.627 (0.596–0.633) | 31.3 (28.8–33.6) | 31.9 (28.975–34.8) | 28.5 (27.4–30.6) | 34.6 (32.7–36.1) | 34.1 (31.7–36.6) | 36 (35.45–36.1) |
| ss_industria_per | renda_bruta_mitja | ||||||||||
| 11.765 (8.747–16.981) | 15.155 (6.744–23.149) | 20.977 (15.936–28.685) | 9.818 (7.502–14.758) | 11.207 (10.869–19.345) | 12.768 (12.647–12.857) | 14,791 (13,581.5–16,171.5) | 15,874 (14,383.75–17,778.25) | 14,926.5 (13,472.5–16,295.75) | 12,626 (11,634–13,970) | 12,011 (11,342.5–12,968) | 16,303 (16,006.5–16,559) |
| ss_construccio_per | renda_salari | ||||||||||
| 8.889 (6.589–10.714) | 7.833 (5.66–10.086) | 7.93 (6.58–9.378) | 9.756 (7.456–10.343) | 6.298 (5.141–6.65) | 4.661 (4.655–4.77) | 8258.5 (7528–9185) | 8732.5 (7775–10,044.5) | 9430 (8399–10,639) | 7393 (6793–8117) | 7218 (6956–7662.5) | 10,277 (10,067.5–10,454.5) |
| ss_serveis_per | renda_pensions | ||||||||||
| 70.588 (64.057–74.803) | 67.458 (60.34–75.506) | 65.896 (61.232–72.396) | 75.795 (65.677–78.832) | 79.983 (69.048–80.24) | 81.937 (81.779–82.07) | 2861 (2546–3379.75) | 3209 (2814.75–3747.25) | 2717 (2463.75–2959.75) | 2488 (2174–2744) | 2221 (1795–2749.5) | 2963 (2920.5–3007) |
| equipament | renda_atur | ||||||||||
| 0 (0–3.978) | 0 (0–6.082) | 2.61 (1.768–4.425) | 2.06 (1.32–2.78) | 0.81 (0.44–2.05) | 1.83 (1.825–1.835) | 237.5 (189.75–294) | 234.5 (184.75–287) | 242.5 (209–283.5) | 326 (282–358) | 305 (255.5–401.5) | 245 (235–263.5) |
| preu_mig_lloguer | capitalcomarca | ||||||||||
| 487.73 (432.805–522.745) | 472.56 (387.272–514.478) | 498.545 (435.03–545.448) | 454.62 (408.96–480.18) | 422.2 (378.66–434.205) | 515.46 (500.545–538.245) | 0 (0–0) | 0 (0–0) | 0 (0–0) | 0 (0–1) | 0 (0–1) | 1 (1–1) |
| num_habitatges | geo_altitud | ||||||||||
| 6 (3–13) | 4 (1.75–11.25) | 34.5 (16.75–78.25) | 190 (141–296) | 842 (712.5–917) | 3267 (3199–3291.5) | 82 (33.75–161) | 953.5 (362–1180.5) | 111 (89.75–172) | 31 (12–148) | 39 (13–260) | 70 (70–70) |
| transit_victim | munt | ||||||||||
| 111.5 (1–280.25) | 121 (1–298.5) | 132 (2–260.5) | 111 (1–263) | 92 (2–263.5) | 76 (38.5–186.5) | 0 (0–0) | 0 (0–0) | 0 (0–0) | 1 (0–1) | 0 (0–1) | 0 (0–0) |
| trucades_emer | costa | ||||||||||
| 2 (1–6) | 2 (1–5) | 3 (1–10) | 5 (2–23) | 5 (1.5–12.5) | 1 (1–253.5) | 0 (0–0) | 1 (1–1) | 0 (0–0) | 0 (0–0) | 0 (0–1) | 0 (0–0) |
| super_conreu_herb | latitud | ||||||||||
| 15 (4–67.5) | 10.5 (3–23.75) | 10 (3–21) | 36 (9–102) | 4 (2–30.5) | 3 (3–9.5) | 42.175 (42.038–42.298) | 42.257 (42.144–42.35) | 41.935 (41.827–42.03) | 42.125 (41.917–42.219) | 42.182 (41.699–42.237) | 41.982 (41.982–41.982) |
| super_conreu_lleny | longitud | ||||||||||
| 110.5 (0–279.25) | 120 (0–297.5) | 131 (0–259.5) | 110 (0–262) | 91 (0–262.5) | 75 (37.5–185.5) | 2.946 (2.812–3.04) | 2.327 (2.072–2.612) | 2.76 (2.638–2.883) | 3.073 (2.662–3.129) | 2.792 (2.657–2.848) | 2.824 (2.824–2.824) |
| French Border | Mountain | Inland | Coastal | Others | |
|---|---|---|---|---|---|
| Intercept | 0.9992802 (***) | 1.0002685 (***) | 0.9998384 (***) | 1.0004043 (***) | 1.0006086 |
| Population residing abroad | 1.0083055 (***) | 1.0002468 (*) | 0.9887537 (***) | 1.0011125 (***) | 0.9988869 |
| Internal migratory balance | 0.9902796 (***) | 0.9960504 (***) | 1.0013632 (***) | 0.9811316 (***) | 0.9980404 |
| External migratory balance | 1.0023456 (***) | 0.9995994 (***) | 0.995847 (***) | 0.9994775 (***) | 0.999062 |
| Taxable base of personal income tax | 0.999858 | 0.999797 | 1.0000104 | 1.0009097 (**) | 0.9995569 |
| Self-employed income tax contributions | 1.000437 | 1.00045 | 1.000327 | 1.000503 | 1.000133 |
| Number of births | 0.9866577 (***) | 1.0149668 (***) | 0.9957985 (***) | 1.0328247 (***) | 0.9798185 |
| Number of deaths | 0.9873149 (***) | 1.0627083 (***) | 1.0011853 (***) | 1.0125107 (***) | 0.9523698 |
| Population balance | 0.9993343 (***) | 0.9550756 (***) | 0.9946195 (***) | 1.020063 (***) | 1.0288215 |
| Mobility of university students outside the municipality | 0.9887809 (***) | 0.9835925 (***) | 1.0066694 (***) | 1.0053018 (***) | 1.0113427 |
| Mobility of university students within the municipality | 1.0010445 (·) | 0.9985847 (***) | 1.0020055 (***) | 0.9969711 (***) | 0.9982406 |
| Average income | 0.9991602 (*) | 0.9999274 | 0.9992583 (·) | 0.9990069 (·) | 0.9996053 |
| Total population | 0.9979256 (***) | 1.0011634 (***) | 0.9986322 (***) | 0.9928825 (***) | 0.9990906 |
| Library count | 0.9920155 (***) | 0.9969202 (***) | 1.0082681 (***) | 1.0105826 (***) | 0.9944124 |
| Average number of people registered with social security | 1.0036874 (***) | 0.9979587 (**) | 1.0018299 (**) | 1.0142032 (***) | 1.0004368 |
| Average number of foreigners registered with social security | 0.9832582 (***) | 0.9783802 (***) | 1.0052646 (***) | 1.0045112 (***) | 1.0420857 |
| Percentage of workers engaged in the agricultural sector registered with social security | 0.9919438 (***) | 0.9796335 (***) | 0.981117 (***) | 1.0864516 (***) | 0.9754141 |
| Percentage of workers in industry registered with social security | 0.9765902 (***) | 1.0136796 (***) | 1.0162364 (***) | 0.9900073 (***) | 1.0222547 |
| Percentage of workers in the construction sector registered with social security | 1.0616384 (***) | 1.0078621 (***) | 0.9817759 (***) | 0.9884191 (***) | 0.9674953 |
| Percentage of workers in the services sector registered with social security | 1.0120162 (***) | 0.9976513 (***) | 0.9992377 (***) | 0.9597444 (***) | 1.0410581 |
| Sports facilities count | 0.9866832 (***) | 1.0077482 (***) | 0.9896743 (***) | 1.0081863 (***) | 1.0040921 |
| Average rental price | 0.9997722 | 1.0005119 | 1.0012895 (·) | 0.9906604 (***) | 0.9999714 |
| Count of homes available for rent | 0.9943651 (***) | 0.9992177 (***) | 0.9999074 (·) | 0.9828655 (***) | 1.0073002 |
| Emergency calls count | 0.9970014 (***) | 1.0067798 (***) | 1.0035279 (***) | 1.015406 (***) | 1.0054075 |
| Area of woody cultivation | 1.0163713 (***) | 0.9976557 (***) | 0.9898313 (***) | 1.0010048 (·) | 0.9971145 |
| Number of properties according to land register | 1.0001438 | 0.9999955 | 1.0003972 (·) | 1.0017136 (***) | 1.0002099 |
| Average unemployment | 1.007197 (***) | 1.001434 (***) | 1.006958 (***) | 1.005407 (***) | 1.004737 |
| Aging ratio | 0.9945135 (***) | 0.9960614 (***) | 0.9962998 (***) | 0.9685533 (***) | 0.9920995 |
| Active population replacement rate | 1.0006615 | 0.9971274 (**) | 0.9963596 (***) | 0.9999958 | 1.0030382 |
| Middle age | 1.0023732 (***) | 1.0010506 (***) | 0.9681195 (***) | 1.0175038 (***) | 1.0253728 |
| Synthetic fertility rate | 0.9998299 (***) | 0.9925758 (***) | 0.999746 (***) | 1.0019436 (***) | 1.0064768 |
| Proportion of native born population | 0.9526581 (***) | 0.993467 (***) | 1.0901165 (***) | 1.0573994 (***) | 0.9445746 |
| Percentage of the number of temporary contracts | 1.004969 (***) | 0.9980301 (***) | 0.9977705 (***) | 1.002199 (***) | 0.9973226 |
| Average gross income | 1.0006414 (*) | 1.0004035 | 1.0006079 (·) | 0.9984342 (**) | 1.0003484 |
| Average income from pensions | 1.0004604 | 1.000368 | 0.9998378 | 1.0016645 (**) | 1.0009924 |
| County capital (no) | 0.9981343 (***) | 0.9978039 (***) | 0.9988672 (***) | 1.007165 (***) | 0.9986435 |
| Municipality located in the mountains (no) | 1.0027483 (***) | 1.0010293 (***) | 0.9967967 (***) | 1.0005993 (***) | 0.9989383 |
| Latitude | 0.9739104 (***) | 1.011893 (***) | 0.9863013 (***) | 1.0184511 (***) | 1.0271034 |
| Number of traffic deaths | 0.9848847 (***) | 1.0027088 (***) | 1.0106366 (***) | 0.9989089 (·) | 1.0035241 |
| Area for herbal cultivation | 1.0016808 (*) | 0.9997817 | 0.9872208 (***) | 1.0102234 (***) | 1.0029894 |
| Number of plots according to land register | 1.0003769 | 1.0006836 | 1.0015421 (**) | 0.9990165 (*) | 1.000732 |
| Total cadastral value | 0.999998 | 0.9999899 (*) | 0.9999944 | 0.9999917 (*) | 1.0000028 |
| Average foreign born unemployment | 1.0109255 (***) | 0.9937618 (***) | 0.9975241 (***) | 1.0235579 (***) | 0.9959258 |
| Gross mortality rate | 1.0067221 (***) | 1.0322658 (***) | 0.9621324 (***) | 1.0172427 (***) | 0.9872505 |
| Overall dependency ratio | 1.0779853 (***) | 0.9850141 (***) | 0.9621172 (***) | 1.0158033 (***) | 0.9834363 |
| Natural population growth | 0.9792645 (***) | 1.0495036 (***) | 0.9959008 (***) | 0.9769135 (***) | 0.9939988 |
| Immigration rate | 0.9994612 (***) | 0.999584 (***) | 0.9999851 (***) | 1.0002735 (***) | 1.0007975 |
| Population density | 0.9987993 (*) | 0.9982249 (**) | 0.9990685 (·) | 0.9983053 (*) | 0.9988891 |
| Gini index | 0.9536537 (***) | 1.0278178 (***) | 0.9691616 (***) | 1.013044 (***) | 1.048768 |
| Average income from salary | 1.0003585 | 0.9998022 | 1.0004226 | 1.000985 (·) | 1.0003853 |
| Average income from unemployment benefits | 1.0049536 (***) | 1.0021693 (**) | 1.0039937 (***) | 1.0138551 (***) | 0.9964328 |
| Altitude | 0.9969976 (***) | 1.0022741 (***) | 0.9995159 | 1.0034163 (***) | 0.9988485 |
| Municipality located on the coast (no) | 0.9786072 (***) | 1.0144727 (***) | 0.9987252 (***) | 1.0047179 (***) | 1.0041124 |
| Length | 1.002225 (***) | 0.9997354 (***) | 0.9968903 (***) | 1.0015902 (***) | 1.0005632 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Perafita, X.; Saez, M. Clustering of Small Territories Based on Axes of Inequality. Int. J. Environ. Res. Public Health 2022, 19, 3359. https://doi.org/10.3390/ijerph19063359
Perafita X, Saez M. Clustering of Small Territories Based on Axes of Inequality. International Journal of Environmental Research and Public Health. 2022; 19(6):3359. https://doi.org/10.3390/ijerph19063359
Chicago/Turabian StylePerafita, Xavier, and Marc Saez. 2022. "Clustering of Small Territories Based on Axes of Inequality" International Journal of Environmental Research and Public Health 19, no. 6: 3359. https://doi.org/10.3390/ijerph19063359
APA StylePerafita, X., & Saez, M. (2022). Clustering of Small Territories Based on Axes of Inequality. International Journal of Environmental Research and Public Health, 19(6), 3359. https://doi.org/10.3390/ijerph19063359