
Applying the FAIR4Health Solution to Identify Multimorbidity Patterns and Their Association with Mortality through a Frequent Pattern Growth Association Algorithm

 , , ,
, , ,  , ,
, ,  , ,
, ,  , ,
, ,  and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Variables
2.2. FAIRification Workflow and Tools Developed
2.3. Analysis
3. Results
3.1. Identification of Multimorbidity Patterns
3.2. Impact of Multimorbidity Patterns on Mortality
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- WHO. WHO Global Strategy and action Plan on Aging and Health; WHO: Geneva, Switzerland, 2017; ISBN 9789241513500.
- Prados-Torres, A.; Calderón-Larrañaga, A.; Hancco-Saavedra, J.; Poblador-Plou, B.; van den Akker, M. Multimorbidity patterns: A systematic review. J. Clin. Epidemiol. 2014, 67, 254–266. [Google Scholar] [CrossRef] [PubMed]
- Barnett, K.; Mercer, S.W.; Norbury, M.; Watt, G.; Wyke, S.; Guthrie, B. Epidemiology of multimorbidity and implications for health care, research, and medical education: A cross-sectional study. Lancet 2012, 380, 37–43. [Google Scholar] [CrossRef] [Green Version]
- Masnoon, N.; Shakib, S.; Kalisch-Ellett, L.; Caughey, G.E. What is polypharmacy? A systematic review of definitions. BMC Geriatr. 2017, 17, 230. [Google Scholar] [CrossRef] [Green Version]
- Bradley, M.C.; Motterlini, N.; Padmanabhan, S.; Cahir, C.; Williams, T.; Fahey, T.; Hughes, C.M. Potentially inappropriate prescribing among older people in the United Kingdom. BMC Geriatr. 2014, 14, 72. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Muth, C.; van den Akker, M.; Blom, J.W.; Mallen, C.D.; Rochon, J.; Schellevis, F.G.; Becker, A.; Beyer, M.; Gensichen, J.; Kirchner, H.; et al. The Ariadne principles: How to handle multimorbidity in primary care consultations. BMC Med. 2014, 12, 223. [Google Scholar] [CrossRef] [PubMed]
- Palmer, K.; Marengoni, A.; Forjaz, M.J.; Jureviciene, E.; Laatikainen, T.; Mammarella, F.; Muth, C.; Navickas, R.; Prados-Torres, A.; Rijken, M.; et al. Multimorbidity care model: Recommendations from the consensus meeting of the Joint Action on Chronic Diseases and Promoting Healthy Ageing across the Life Cycle (JA-CHRODIS). Health Policy 2018, 122, 4–11. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- FAIR4Health FAIR4Health Project. Available online: https://www.fair4health.eu/ (accessed on 12 January 2022).
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. Comment: The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sinaci, A.A.; Núñez-Benjumea, F.J.; Gencturk, M.; Jauer, M.L.; Deserno, T.; Chronaki, C.; Cangioli, G.; Cavero-Barca, C.; Rodríguez-Pérez, J.M.; Pérez-Pérez, M.M.; et al. From Raw Data to FAIR Data: The FAIRification Workflow for Health Research. Methods Inf. Med. 2020, 59, E21–E32. [Google Scholar] [CrossRef] [PubMed]
- FAIR4Health Project. Data Curation Tool. Available online: https://github.com/fair4health/data-curation-tool (accessed on 12 January 2022).
- Gencturk, M.; Teoman, A.; Alvarez-Romero, C.; Martinez-Garcia, A.; Parra-Calderon, C.L.; Poblador-Plou, B.; Löbe, M.; Sinaci, A.A. End user evaluation of the FAIR4Health data curation tool. In Public Health and Informatics; Proc. MIE 2021; IOS Press: Amsterdam, The Netherlands, 2021; pp. 8–12. [Google Scholar]
- FAIR4Health Project Data Privacy Tool. Available online: https://github.com/fair4health/data-privacy-tool (accessed on 12 January 2022).
- Onder, G.; Carpenter, I.; Finne-Soveri, H.; Gindin, J.; Frijters, D.; Henrard, J.; Nikolaus, T.; Topinkova, E.; Tosato, M.; Liperoti, R.; et al. Assessment of nursing home residents in Europe: The Services and Health for Elderly in Long TERm care (SHELTER) study. BMC Health Serv. Res. 2012, 12, 5. [Google Scholar] [CrossRef] [PubMed]
- Onder, G.; Liperoti, R.; Fialova, D.; Topinkova, E.; Tosato, M.; Danese, P.; Gallo, P.F.; Carpenter, I.; Finne-Soveri, H.; Gindin, J.; et al. Polypharmacy in nursing home in Europe: Results from the SHELTER study. J. Gerontol.-Ser. A Biol. Sci. Med. Sci. 2012, 67, 698–704. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Midao, L.; Sá, C.; Marques, E.; Duarte, M.; Paúl, C.; Viana, J.; Costa, E. Ehealth on Frailty: Frailsurvey, a Reliable Smartphone Application for Self-Assessment of Frailty. Innov. Aging 2019, 3, 336. [Google Scholar] [CrossRef]
- Prados-Torres, A.; Poblador-Plou, B.; Gimeno-Miguel, A.; Calderón-Larrañaga, A.; Poncel-Falcó, A.; Gimeno-Feliú, L.A.; González-Rubio, F.; Laguna-Berna, C.; Marta-Moreno, J.; Clerencia-Sierra, M.; et al. Cohort Profile: The Epidemiology of Chronic Diseases and Multimorbidity. The EpiChron Cohort Study. Int. J. Epidemiol. 2018, 47, 382–384. [Google Scholar] [CrossRef] [PubMed]
- GO FAIR Initiative. Available online: https://www.go-fair.org/fair-principles/fairification-process/ (accessed on 12 January 2022).
- FAIR4Health Project FAIR4Health Common Data Model. Available online: https://github.com/fair4health/common-data-model (accessed on 12 January 2022).
- HL7_FHIR HL7 FHIR. Available online: http://hl7.org/fhir/ (accessed on 12 January 2022).
- FAIR4Health D5.5. Report on the Demonstrators Performance; FAIR4Health Consortium. 2021. Available online: https://www.fair4health.eu/storage/files/Resource/58/D55%20Report%20on%20the%20demonstrators%20performance_v2_vf.pdf (accessed on 12 January 2022).
- OnFHIR.io_Repository onFHIR.io Repository. Available online: https://onfhir.io (accessed on 12 January 2022).
- Han, J.; Pei, J.; Yin, Y. Mining FrequentPatterns without Candidate Generation. SIGMOD 2000, 29, 1–12. [Google Scholar] [CrossRef]
- Busija, L.; Lim, K.; Szoeke, C.; Sanders, K.M.; McCabe, M.P. Do replicable profiles of multimorbidity exist? Systematic review and synthesis. Eur. J. Epidemiol. 2019, 34, 1025–1053. [Google Scholar] [CrossRef] [PubMed]
- Ioakeim-Skoufa, I.; Poblador-Plou, B.; Carmona-Pírez, J.; Díez-Manglano, J.; Navickas, R.; Gimeno-Feliu, L.A.; González-Rubio, F.; Jureviciene, E.; Dambrauskas, L.; Prados-Torres, A.; et al. Multimorbidity Patterns in the General Population: Results from the EpiChron Cohort Study. Int. J. Environ. Res. Public Health 2020, 17, 4242. [Google Scholar] [CrossRef] [PubMed]
- Carmona-Pírez, J.; Poblador-Plou, B.; Díez-Manglano, J.; Morillo-Jiménez, M.J.; Marín Trigo, J.M.; Ioakeim-Skoufa, I.; Gimeno-Miguel, A.; Prados-Torres, A. Multimorbidity networks of chronic obstructive pulmonary disease and heart failure in men and women: Evidence from the EpiChron Cohort. Mech. Ageing Dev. 2021, 193, 111392. [Google Scholar] [CrossRef] [PubMed]
- Carmona-Pírez, J.; Poblador-Plou, B.; Ioakeim-Skoufa, I.; González-Rubio, F.; Gimeno-Feliú, L.A.; Díez-Manglano, J.; Laguna-Berna, C.; Marin, J.M.; Gimeno-Miguel, A.; Prados-Torres, A. Multimorbidity clusters in patients with chronic obstructive airway diseases in the EpiChron Cohort. Sci. Rep. 2021, 11, 4784. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
| Institutions | Population (n, %) | Age (Mean) | Sex, Women (%) |
|---|---|---|---|
| Université de Genève | 244 (2.2) | 81.8 | 47.1 |
| Università Cattolica del Sacro Cuore | 331 (3.0) | 95.5 | 71.6 |
| University of Porto | 861 (7.8) | 76.6 | 57.5 |
| Instituto Aragonés de Ciencias de la Salud | 3786 (34.3) | 82.1 | 49.9 |
| Andalusian Health Service | 5812 (52.7) | 82.2 | 49.4 |
| Total | 11,034 (100) | 82.1 | 50.8 |
| Parameters Used | Generated Patterns | Institutions Providing Datasets in Each Model | ||||
|---|---|---|---|---|---|---|
| Minimum Support | Minimum Confidence | Antecedent (A) | Consequent (C) | Confidence | Correlation (Lift) | |
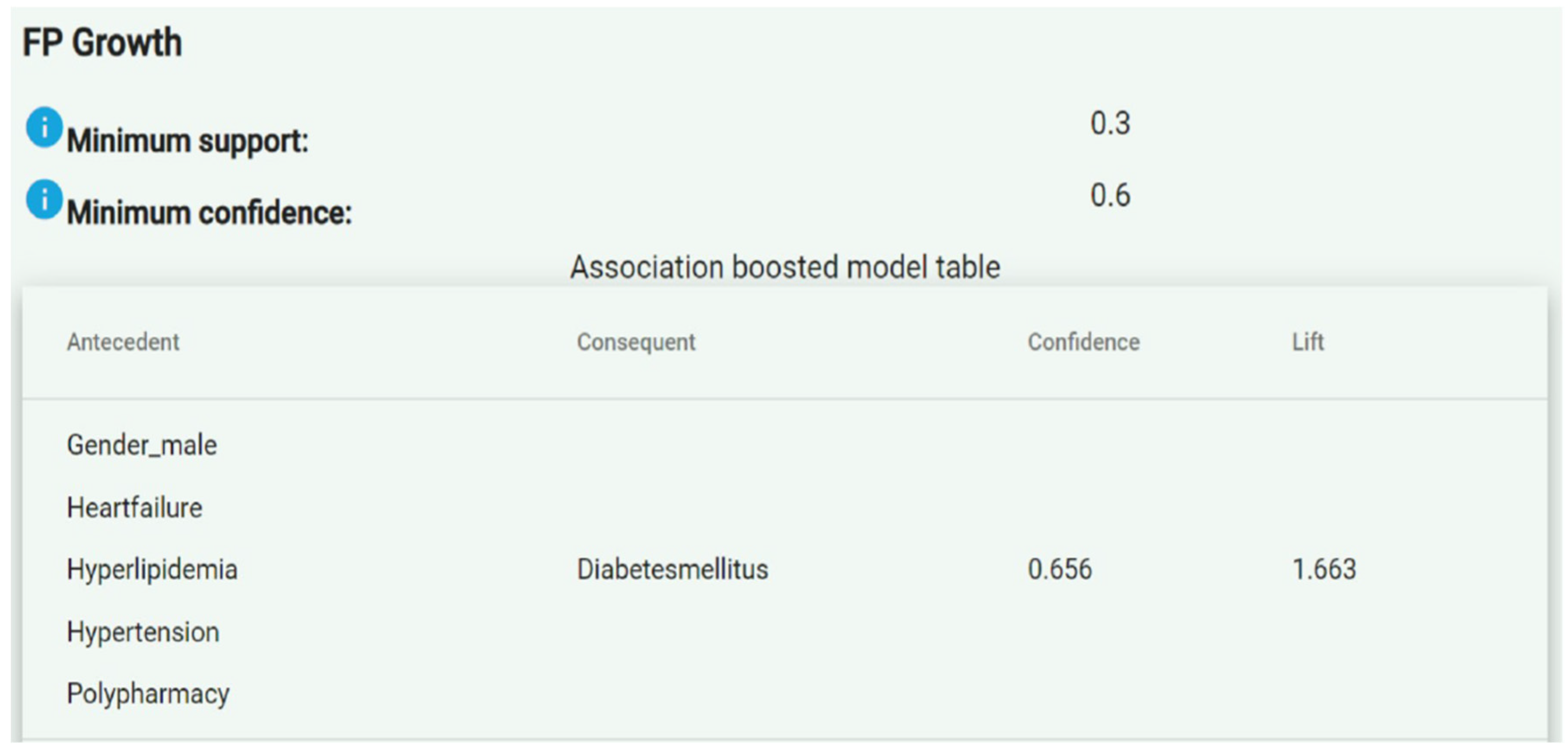
| 0.2 | 0.5 | Atrial fibrillation Chronic anemia Chronic kidney disease Coronary heart disease Hypertension Polypharmacy | Heart failure | 0.86 | 2.80 | UNIGE, UCSC, IACS, and SAS |
| 0.2 | 0.5 | Atrial fibrillation Chronic anemia Chronic kidney disease Coronary heart disease Diabetes Mellitus Heart failure Hyperlipidemia Polypharmacy | Hypertension | 1.00 | 1.33 | UNIGE, UCSC, IACS, and SAS |
| 0.3 | 0.5 | Gender male Age 70–80 Feeling down or depressed lately Feeling nervous or anxious lately Memory complaints Vision difficulties | Hearing difficulties | 0.909 | 2.52 | UP |
| 0.3 | 0.5 | Gender male Age 80 and older Feeling down or depressed lately Feeling nervous or anxious lately Hearing difficulties Memory complaints Vision difficulties | Polymedicated | 1.00 | 1.65 | UP |
| Parameters Used | Generated Patterns | ||||
|---|---|---|---|---|---|
| Minimum Support | Minimum Confidence | Antecedent (A) | Consequent (C) | Confidence | Correlation (Lift) |
| 0.2 | 0.8 | Chronic anemia Chronic kidney disease Coronary heart disease Diabetes mellitus Heart failure | Mortality | 0.58 | 1.96 |
| 0.2 | 0.8 | Chronic anemia Chronic kidney disease Coronary heart disease Diabetes mellitus Heart failure Hyperlipidemia Hypertension | Mortality | 0.55 | 1.85 |
| 0.2 | 0.8 | Chronic anemia Chronic kidney disease Coronary heart disease Diabetes mellitus Heart failure Hyperlipidemia Polypharmacy | Mortality | 0.54 | 1.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carmona-Pírez, J.; Poblador-Plou, B.; Poncel-Falcó, A.; Rochat, J.; Alvarez-Romero, C.; Martínez-García, A.; Angioletti, C.; Almada, M.; Gencturk, M.; Sinaci, A.A.; et al. Applying the FAIR4Health Solution to Identify Multimorbidity Patterns and Their Association with Mortality through a Frequent Pattern Growth Association Algorithm. Int. J. Environ. Res. Public Health 2022, 19, 2040. https://doi.org/10.3390/ijerph19042040
Carmona-Pírez J, Poblador-Plou B, Poncel-Falcó A, Rochat J, Alvarez-Romero C, Martínez-García A, Angioletti C, Almada M, Gencturk M, Sinaci AA, et al. Applying the FAIR4Health Solution to Identify Multimorbidity Patterns and Their Association with Mortality through a Frequent Pattern Growth Association Algorithm. International Journal of Environmental Research and Public Health. 2022; 19(4):2040. https://doi.org/10.3390/ijerph19042040
Chicago/Turabian StyleCarmona-Pírez, Jonás, Beatriz Poblador-Plou, Antonio Poncel-Falcó, Jessica Rochat, Celia Alvarez-Romero, Alicia Martínez-García, Carmen Angioletti, Marta Almada, Mert Gencturk, A. Anil Sinaci, and et al. 2022. "Applying the FAIR4Health Solution to Identify Multimorbidity Patterns and Their Association with Mortality through a Frequent Pattern Growth Association Algorithm" International Journal of Environmental Research and Public Health 19, no. 4: 2040. https://doi.org/10.3390/ijerph19042040
APA StyleCarmona-Pírez, J., Poblador-Plou, B., Poncel-Falcó, A., Rochat, J., Alvarez-Romero, C., Martínez-García, A., Angioletti, C., Almada, M., Gencturk, M., Sinaci, A. A., Ternero-Vega, J. E., Gaudet-Blavignac, C., Lovis, C., Liperoti, R., Costa, E., Parra-Calderón, C. L., Moreno-Juste, A., Gimeno-Miguel, A., & Prados-Torres, A. (2022). Applying the FAIR4Health Solution to Identify Multimorbidity Patterns and Their Association with Mortality through a Frequent Pattern Growth Association Algorithm. International Journal of Environmental Research and Public Health, 19(4), 2040. https://doi.org/10.3390/ijerph19042040