Mapping the Human Exposome to Uncover the Causes of Breast Cancer


Abstract

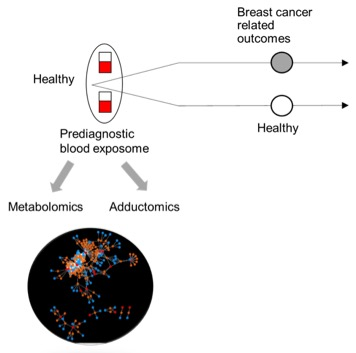{kind=link}
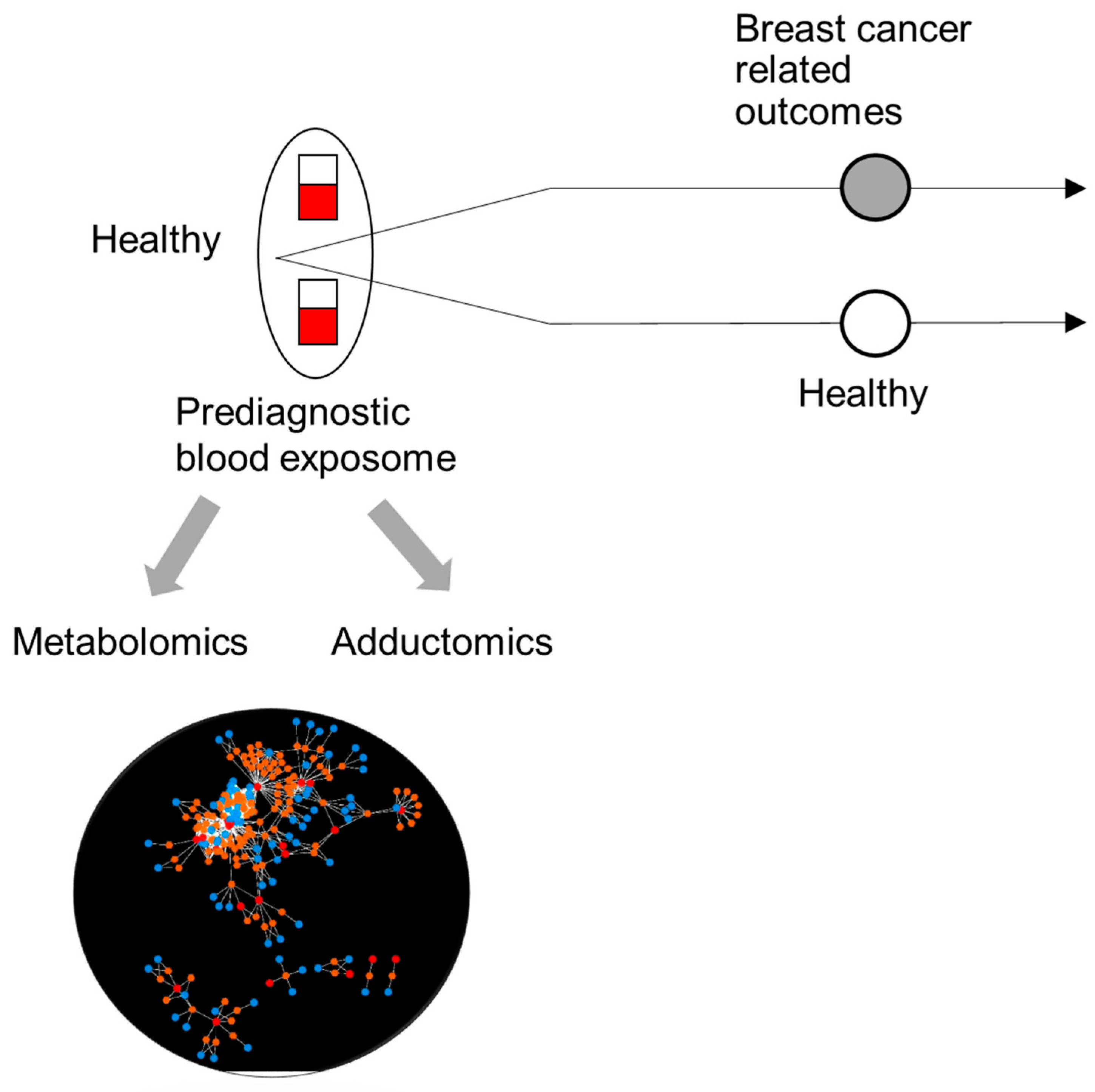{kind=link}
1. Introduction
2. Approaches and Methods
2.1. Capturing Molecular Information Using Omics
2.2. Resources Needed
3. Expected Results and Discussion
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Brody, J.G.; Rudel, R.A.; Michels, K.B.; Moysich, K.B.; Bernstein, L.; Attfield, K.R.; Gray, S. Environmental pollutants, diet, physical activity, body size, and breast cancer. Cancer 2007, 109, 2627–2634. [Google Scholar] [CrossRef]
- Ward, E.M.; Sherman, R.L.; Henley, S.J.; Jemal, A.; Siegel, D.A.; Feuer, E.J.; Firth, A.U.; Kohler, B.A.; Scott, S.; Ma, J.; et al. Annual Report to the Nation on the Status of Cancer, Featuring Cancer in Men and Women Age 20–49 Years. J. Natl. Cancer Inst. 2019, 111, 1279–1297. [Google Scholar] [CrossRef]
- Lichtenstein, P.; Holm, N.V.; Verkasalo, P.K.; Iliadou, A.; Kaprio, J.; Koskenvuo, M.; Pukkala, E.; Skytthe, A.; Hemminki, K. Environmental and heritable factors in the causation of cancer--analyses of cohorts of twins from Sweden, Denmark, and Finland. N. Engl. J. Med. 2000, 343, 78–85. [Google Scholar] [CrossRef]
- Breast Cancer and the Environment: A Life Course Approach: Health and Medicine Division. Available online: http://www.nationalacademies.org/hmd/Reports/2011/Breast-Cancer-and-the-Environment-A-Life-Course-Approach.aspx (accessed on 19 December 2019).
- Rappaport, S.M. Genetic Factors Are Not the Major Causes of Chronic Diseases. PLoS ONE 2016, 11, e0154387. [Google Scholar] [CrossRef]
- Mucci, L.A.; Hjelmborg, J.B.; Harris, J.R.; Czene, K.; Havelick, D.J.; Scheike, T.; Graff, R.E.; Holst, K.; Möller, S.; Unger, R.H.; et al. Familial Risk and Heritability of Cancer Among Twins in Nordic Countries. JAMA 2016, 315, 68–76. [Google Scholar] [CrossRef]
- Yaghjyan, L.; Mahoney, M.C.; Succop, P.; Wones, R.; Buckholz, J.; Pinney, S.M. Relationship between breast cancer risk factors and mammographic breast density in the Fernald Community Cohort. Br. J. Cancer 2012, 106, 996–1003. [Google Scholar] [CrossRef]
- Huo, C.W.; Chew, G.L.; Britt, K.L.; Ingman, W.V.; Henderson, M.A.; Hopper, J.L.; Thompson, E.W. Mammographic density–A review on the current understanding of its association with breast cancer. Breast Cancer Res. Treat. 2014, 144, 479–502. [Google Scholar] [CrossRef]
- Miller, G.W.; Jones, D.P. The Nature of Nurture: Refining the Definition of the Exposome. Toxicol. Sci. 2014, 137, 1–2. [Google Scholar] [CrossRef]
- Rodgers, K.M.; Udesky, J.O.; Rudel, R.A.; Brody, J.G. Environmental chemicals and breast cancer: An updated review of epidemiological literature informed by biological mechanisms. Environ. Res. 2018, 160, 152–182. [Google Scholar] [CrossRef]
- Rappaport, S.M. Biomarkers intersect with the exposome. Biomarkers 2012, 17, 483–489. [Google Scholar] [CrossRef]
- Wild, C.P.; Scalbert, A.; Herceg, Z. Measuring the exposome: A powerful basis for evaluating environmental exposures and cancer risk. Environ. Mol. Mutagen. 2013, 54, 480–499. [Google Scholar] [CrossRef]
- Rappaport, S.M. Implications of the exposome for exposure science. J. Expo. Sci. Environ. Epidemiol. 2011, 21, 5–9. [Google Scholar] [CrossRef]
- Rappaport, S.M.; Barupal, D.K.; Wishart, D.; Vineis, P.; Scalbert, A. The blood exposome and its role in discovering causes of disease. Environ. Health Perspect. 2014, 122, 769–774. [Google Scholar] [CrossRef]
- Bessonneau, V.; Pawliszyn, J.; Rappaport, S.M. The Saliva Exposome for Monitoring of Individuals’ Health Trajectories. Environ. Health Perspect. 2017, 125. [Google Scholar] [CrossRef]
- Patel, C.J.; Bhattacharya, J.; Butte, A.J. An Environment-Wide Association Study (EWAS) on Type 2 Diabetes Mellitus. PLoS ONE 2010, 5, e10746. [Google Scholar] [CrossRef]
- Tzoulaki, I.; Patel, C.J.; Okamura, T.; Chan, Q.; Brown, I.J.; Miura, K.; Ueshima, H.; Zhao, L.; Van Horn, L.; Daviglus, M.L.; et al. A nutrient-wide association study on blood pressure. Circulation 2012, 126, 2456–2464. [Google Scholar] [CrossRef]
- Patel, C.J.; Rehkopf, D.H.; Leppert, J.T.; Bortz, W.M.; Cullen, M.R.; Chertow, G.M.; Ioannidis, J.P. Systematic evaluation of environmental and behavioural factors associated with all-cause mortality in the United States national health and nutrition examination survey. Int. J. Epidemiol. 2013, 42, 1795–1810. [Google Scholar] [CrossRef]
- Nicholson, J.K.; Wilson, I.D. Opinion: Understanding “global” systems biology: Metabonomics and the continuum of metabolism. Nat. Rev. Drug Discov. 2003, 2, 668–676. [Google Scholar] [CrossRef]
- German, J.B.; Hammock, B.D.; Watkins, S.M. Metabolomics: Building on a century of biochemistry to guide human health. Metabolomics 2005, 1, 3–9. [Google Scholar] [CrossRef]
- Playdon, M.C.; Ziegler, R.G.; Sampson, J.N.; Stolzenberg-Solomon, R.; Thompson, H.J.; Irwin, M.L.; Mayne, S.T.; Hoover, R.N.; Moore, S.C. Nutritional metabolomics and breast cancer risk in a prospective study. Am. J. Clin. Nutr. 2017, 106, 637–649. [Google Scholar] [CrossRef]
- Wishart, D.S.; Feunang, Y.D.; Marcu, A.; Guo, A.C.; Liang, K.; Vázquez-Fresno, R.; Sajed, T.; Johnson, D.; Li, C.; Karu, N.; et al. HMDB 4.0: The human metabolome database for 2018. Nucleic Acids Res. 2018, 46, D608–D617. [Google Scholar] [CrossRef] [PubMed]
- METLIN: A Technology Platform for Identifying Knowns and Unknowns. Available online: https://pubs.acs.org/doi/pdf/10.1021/acs.analchem.7b04424 (accessed on 25 November 2019).
- US EPA Organization. Distributed Structure-Searchable Toxicity (DSSTox) Database. Available online: https://www.epa.gov/chemical-research/distributed-structure-searchable-toxicity-dsstox-database (accessed on 6 September 2017).
- Kim, S.; Thiessen, P.A.; Bolton, E.E.; Chen, J.; Fu, G.; Gindulyte, A.; Han, L.; He, J.; He, S.; Shoemaker, B.A.; et al. PubChem Substance and Compound databases. Nucleic Acids Res. 2016, 44, D1202–D1213. [Google Scholar] [CrossRef] [PubMed]
- Grashow, R.; Bessonneau, V.; Gerona, R.R.; Wang, A.; Trowbridge, J.; Lin, T.; Buren, H.; Rudel, R.A.; Morello-Frosch, R. Integrating exposure knowledge and serum suspect screening as a new approach to biomonitoring: An application in firefighters and office workers. bioRxiv 2019. [Google Scholar] [CrossRef]
- Ring, C.L.; Arnot, J.A.; Bennett, D.H.; Egeghy, P.P.; Fantke, P.; Huang, L.; Isaacs, K.K.; Jolliet, O.; Phillips, K.A.; Price, P.S.; et al. Consensus Modeling of Median Chemical Intake for the U.S. Population Based on Predictions of Exposure Pathways. Environ. Sci. Technol. 2019, 53, 719–732. [Google Scholar] [CrossRef]
- Grigoryan, H.; Edmands, W.; Lu, S.S.; Yano, Y.; Regazzoni, L.; Iavarone, A.T.; Williams, E.R.; Rappaport, S.M. Adductomics Pipeline for Untargeted Analysis of Modifications to Cys34 of Human Serum Albumin. Anal. Chem. 2016, 88, 10504–10512. [Google Scholar] [CrossRef]
- Grigoryan, H.; Edmands, W.M.B.; Lan, Q.; Carlsson, H.; Vermeulen, R.; Zhang, L.; Yin, S.-N.; Li, G.-L.; Smith, M.T.; Rothman, N.; et al. Adductomic signatures of benzene exposure provide insights into cancer induction. Carcinogenesis 2018, 39, 661–668. [Google Scholar] [CrossRef]
- Grigoryan, H.; Schiffman, C.; Gunter, M.J.; Naccarati, A.; Polidoro, S.; Dagnino, S.; Dudoit, S.; Vineis, P.; Rappaport, S.M. Cys34 Adductomics Links Colorectal Cancer with the Gut Microbiota and Redox Biology. Cancer Res. 2019, 79, 6024–6031. [Google Scholar] [CrossRef]

© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bessonneau, V.; Rudel, R.A. Mapping the Human Exposome to Uncover the Causes of Breast Cancer. Int. J. Environ. Res. Public Health 2020, 17, 189. https://doi.org/10.3390/ijerph17010189
Bessonneau V, Rudel RA. Mapping the Human Exposome to Uncover the Causes of Breast Cancer. International Journal of Environmental Research and Public Health. 2020; 17(1):189. https://doi.org/10.3390/ijerph17010189
Chicago/Turabian StyleBessonneau, Vincent, and Ruthann A. Rudel. 2020. "Mapping the Human Exposome to Uncover the Causes of Breast Cancer" International Journal of Environmental Research and Public Health 17, no. 1: 189. https://doi.org/10.3390/ijerph17010189
APA StyleBessonneau, V., & Rudel, R. A. (2020). Mapping the Human Exposome to Uncover the Causes of Breast Cancer. International Journal of Environmental Research and Public Health, 17(1), 189. https://doi.org/10.3390/ijerph17010189