

Diagnostic Performance of ChatGPT-4o in Analyzing Oral Mucosal Lesions: A Comparative Study with Experts

 ,
,  ,
,  , , , ,
, , , ,  , ,
, ,  ,
,  ,
,  ,
,  ,
,  , , ,
, , ,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Image Selection and Dataset Construction
2.2. AI-Based Image Assessment
2.3. Expert Panel Evaluation
2.4. Statistical Analysis
3. Results
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- McCullough, M.J.; Prasad, G.; Farah, C.S. Oral mucosal malignancy and potentially malignant lesions: An update on the epidemiology, risk factors, diagnosis and management. Aust. Dent. J. 2010, 55, 61–65. [Google Scholar] [CrossRef]
- Warnakulasuriya, S. Oral potentially malignant disorders: A comprehensive review on clinical aspects and management. Oral Oncol. 2020, 102, 104550. [Google Scholar] [CrossRef]
- de Carvalho, L.F.D.C.E.S.; Zanatta, R.F. Editorial: Technological innovations for improved prevention and diagnosis of oral disease. Front. Oral Health 2024, 5, 1481890. [Google Scholar] [CrossRef]
- Kulkarni, P.A.; Singh, H. Artificial Intelligence in Clinical Diagnosis: Opportunities, Challenges, and Hype. JAMA 2023, 330, 317–318. [Google Scholar] [CrossRef] [PubMed]
- Roume, M.; Azogui-Levy, S.; Lescaille, G.; Descroix, V.; Rochefort, J. Knowledge and practices of dentists in France regarding oral mucosal diseases: A national survey. J. Oral Med. Oral Surg. 2019, 25, 10. [Google Scholar] [CrossRef]
- Algudaibi, L.Y.; AlMeaigel, S.; AlQahtani, N.; Shaheen, N.A.; Aboalela, A. Oral and oropharyngeal cancer: Knowledge, attitude and practices among medical and dental practitioners. Cancer Rep. 2021, 4, e1349. [Google Scholar] [CrossRef]
- Huang, X.; Wang, H.; She, C.; Feng, J.; Liu, X.; Hu, X.; Chen, L.; Tao, Y. Artificial intelligence promotes the diagnosis and screening of diabetic retinopathy. Front. Endocrinol. 2022, 13, 946915. [Google Scholar] [CrossRef] [PubMed]
- Dack, E.; Christe, A.; Fontanellaz, M.; Brigato, L.; Heverhagen, J.T.; Peters, A.A.; Huber, A.T.; Hoppe, H.; Mougiakakou, S.; Ebner, L. Artificial Intelligence and Interstitial Lung Disease: Diagnosis and Prognosis. Investig. Radiol. 2023, 58, 602–609. [Google Scholar] [CrossRef] [PubMed]
- Wells, A.; Patel, S.; Lee, J.B.; Motaparthi, K. Artificial intelligence in dermatopathology: Diagnosis, education, and research. J. Cutan. Pathol. 2021, 48, 1061–1068. [Google Scholar] [CrossRef]
- Revilla-León, M.; Gómez-Polo, M.; Barmak, A.B.; Inam, W.; Kan, J.Y.K.; Kois, J.C.; Akal, O. Artificial intelligence models for diagnosing gingivitis and periodontal disease: A systematic review. J. Prosthet. Dent. 2023, 130, 816–824. [Google Scholar] [CrossRef]
- Zayed, S.O.; Abd-Rabou, R.Y.M.; Abdelhameed, G.M.; Abdelhamid, Y.; Khairy, K.; Abulnoor, B.A.; Ibrahim, S.H.; Khaled, H. The innovation of AI-based software in oral diseases: Clinical-histopathological correlation diagnostic accuracy primary study. BMC Oral Health 2024, 24, 598. [Google Scholar] [CrossRef] [PubMed]
- Sultan, A.S.; Elgharib, M.A.; Tavares, T.; Jessri, M.; Basile, J.R. The use of artificial intelligence, machine learning and deep learning in oncologic histopathology. J. Oral Pathol. Med. 2020, 49, 849–856. [Google Scholar] [CrossRef]
- Lee, T.; Kim, H.; Parkm, S.H.; Chae, S.; Yoon, S.H. Evaluation of Vision-Language Models for Detection and Deidentification of Medical Images with Burned-In Protected Health Information. Radiology 2025, 315, e243664. [Google Scholar] [CrossRef] [PubMed]
- Sozer, A.; Sahin, M.C.; Sozer, B.; Erol, G.; Tufek, O.Y.; Nernekli, K.; Demirtas, Z.; Celtikci, E. Do LLMs Have ‘the Eye’ for MRI? Evaluating GPT-4o, Grok, and Gemini on Brain MRI Performance: First Evaluation of Grok in Medical Imaging and a Comparative Analysis. Diagnostics 2025, 15, 1320. [Google Scholar] [CrossRef]
- Kaczmarczyk, R.; Wilhelm, T.I.; Martin, R.; Roos, J. Evaluating multimodal AI in medical diagnostics. NPJ Digit. Med. 2024, 7, 205. [Google Scholar] [CrossRef]
- Ren, Y.; Guo, Y.; He, Q.; Cheng, Z.; Huang, Q.; Yang, L. Exploring whether ChatGPT-4 with image analysis capabilities can diagnose osteosarcoma from X-ray images. Exp. Hematol. Oncol. 2024, 13, 71. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Lai, Z.; Ruan, K.; Chen, S.; Liu, J.; Liu, Z. R-llava: Improving med-vqa understanding through visual region of interest. arXiv 2024, arXiv:2410.20327. [Google Scholar]
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Allevi, F.; Audino, G.; Beltramini, G.A.; Bergonzani, M.; Bolzoni, A.; Committeri, U.; Crimi, S.; et al. Accuracy of ChatGPT-Generated Information on Head and Neck and Oromaxillofacial Surgery: A Multicenter Collaborative Analysis. Otolaryngol.-Head Neck Surg. 2024, 170, 1492–1503. [Google Scholar] [CrossRef] [PubMed]
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Allevi, F.; Audino, G.; Beltramini, G.A.; Bergonzani, M.; Boscolo-Rizzo, P.; Califano, G.; Cammaroto, G.; et al. Validation of the Quality Analysis of Medical Artificial Intelligence (QAMAI) tool: A new tool to assess the quality of health information provided by AI platforms. Eur. Arch. Oto-Rhino-Laryngol. 2024, 281, 6123–6131. [Google Scholar] [CrossRef]
- Borsetto, D.; Sia, E.; Axon, P.; Donnelly, N.; Tysome, J.R.; Anschuetz, L.; Bernardeschi, D.; Capriotti, V.; Caye-Thomasen, P.; West, N.C.; et al. Quality of Information Provided by Artificial Intelligence Chatbots Surrounding the Management of Vestibular Schwannomas: A Comparative Analysis Between ChatGPT-4 and Claude 2. Otol. Neurotol. 2025, 46, 432–436. [Google Scholar] [CrossRef]
- Gan, W.; Ouyang, J.; Li, H.; Xue, Z.; Zhang, Y.; Dong, Q.; Huang, J.; Zheng, X.; Zhang, Y. Integrating ChatGPT in Orthopedic Education for Medical Undergraduates: Randomized Controlled Trial. J. Med. Internet Res. 2024, 26, e57037. [Google Scholar] [CrossRef]
- Iqbal, U.; Tanweer, A.; Rahmanti, A.R.; Greenfield, D.; Lee, L.T.; Li, Y.J. Impact of large language model (ChatGPT) in healthcare: An umbrella review and evidence synthesis. J. Biomed. Sci. 2025, 32, 45. [Google Scholar] [CrossRef] [PubMed]
- Topaz, M.; Peltonen, L.M.; Michalowski, M.; Stiglic, G.; Ronquillo, C.; Pruinelli, L.; Song, J.; O′Connor, S.; Miyagawa, S.; Fukahori, H. The ChatGPT Effect: Nursing Education and Generative Artificial Intelligence. J. Nurs. Educ. 2025, 64, e40–e43. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Qin, P.; Cheng, X.; Shao, M.; Ren, Z.; Zhao, Y.; Li, Q.; Liu, L. ChatGPT in Oncology Diagnosis and Treatment: Applications, Legal and Ethical Challenges. Curr. Oncol. Rep. 2025, 27, 336–354. [Google Scholar] [CrossRef]
- Douma, H.; McNamara, C.; Bakola, M.; Stuckler, D. Leveraging ChatGPT to strengthen pediatric healthcare systems: A systematic review. Eur. J. Pediatr. 2025, 184, 478. [Google Scholar] [CrossRef] [PubMed]
- Lotto, C.; Sheppard, S.C.; Anschuetz, W.; Stricker, D.; Molinari, G.; Huwendiek, S.; Anschuetz, L. ChatGPT Generated Otorhinolaryngology Multiple-Choice Questions: Quality, Psychometric Properties, and Suitability for Assessments. OTO Open 2024, 8, e70018. [Google Scholar] [CrossRef]
- ISO/IEC TR 24028:2020; Information Technology—Artificial Intelligence—Overview of Trustworthiness in Artificial Intelligence. ISO: Geneva, Switzerland, 2020. Available online: https://www.iso.org/standard/77608.html (accessed on 20 July 2025).
- Vaira, L.A.; Lechien, J.R.; Abbate, V.; Gabriele, G.; Frosolini, A.; De Vito, A.; Maniaci, A.; Mayo-Yáñez, M.; Boscolo-Rizzo, P.; Saibene, A.M.; et al. Enhancing AI Chatbot Responses in Health Care: The SMART Prompt Structure in Head and Neck Surgery. OTO Open 2025, 9, e70075. [Google Scholar] [CrossRef]
- Lechien, J.R.; Maniaci, A.; Gengler, I.; Hans, S.; Chiesa-Estomba, C.M.; Vaira, L.A. Validity and reliability of an instrument evaluating the performance of intelligent chatbot: The Artificial Intelligence Performance Instrument (AIPI). Eur. Arch. Oto-Rhino-Laryngol. 2024, 281, 2063–2079. [Google Scholar] [CrossRef]
- Tessler, I.; Wolfovitz, A.; Alon, E.E.; Gecel, N.A.; Livneh, N.; Zimlichman, E.; Klang, E. ChatGPT’s adherence to otolaryngology clinical practice guidelines. Eur. Arch. Oto-Rhino-Laryngol. 2024, 281, 3829–3834. [Google Scholar] [CrossRef]
- Hassan, M.G.; Abdelaziz, A.A.; Abdelrahman, H.H.; Mohamed, M.M.Y.; Ellabban, M.T. Performance of AI-Chatbots to Common Temporomandibular Joint Disorders (TMDs) Patient Queries: Accuracy, Completeness, Reliability and Readability. Orthod. Craniofacial Res. 2025. epub ahead of print. [Google Scholar] [CrossRef]
- Teixeira-Marques, F.; Medeiros, N.; Nazaré, F.; Alves, S.; Lima, N.; Ribeiro, L.; Gama, R.; Oliveira, P. Exploring the role of ChatGPT in clinical decision-making in otorhinolaryngology: A ChatGPT designed study. Eur. Arch. Oto-Rhino-Laryngol. 2024, 281, 2023–2030. [Google Scholar] [CrossRef]
- Marchi, F.; Bellini, E.; Iandelli, A.; Sampieri, C.; Peretti, G. Exploring the landscape of AI-assisted decision-making in head and neck cancer treatment: A comparative analysis of NCCN guidelines and ChatGPT responses. Eur. Arch. Oto-Rhino-Laryngol. 2024, 281, 2123–2136. [Google Scholar] [CrossRef]
- Medela, A.; Sabater, A.; Montilla, I.H.; MacCarthy, T.; Aguilar, A.; Chiesa-Estomba, C.M. The utility and reliability of a deep learning algorithm as a diagnosis support tool in head & neck non-melanoma skin malignancies. Eur. Arch. Oto-Rhino-Laryngol. 2024, 282, 1585–1592. [Google Scholar]
- Busch, F.; Han, T.; Makowski, M.R.; Truhn, D.; Bressem, K.K.; Adams, L. Integrating Text and Image Analysis: Exploring GPT-4V’s Capabilities in Advanced Radiological Applications Across Subspecialties. J. Med. Internet Res. 2024, 26, e54948. [Google Scholar] [CrossRef]
- Setzen, S.A.; Andreadis, K.; Elemento, O.; Rameau, A. AI-Powered Laryngoscopy: Exploring the Future with Google Gemini. Laryngoscope 2025, 135, 1851–1853. [Google Scholar] [CrossRef]
- Chiesa-Estomba, C.M.; Andueza-Guembe, M.; Maniaci, A.; Mayo-Yanez, M.; Betances-Reinoso, F.; Vaira, L.A.; Saibene, A.M.; Lechien, J.R. Accuracy of ChatGPT-4o in Text and Video Analysis of Laryngeal Malignant and Premalignant Diseases. J. Voice 2025. epub ahead of print. [Google Scholar] [CrossRef]
- Collins, G.S.; Moons, K.G.M.; Dhiman, P.; Riley, R.D.; Beam, A.L.; Van Calster, B.; Ghassemi, M.; Liu, X.; Reitsma, J.B.; van Smeden, M.; et al. TRIPOD+AI statement: Updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ 2024, 385, e078378. [Google Scholar] [CrossRef]
- Vasey, B.; Nagendran, M.; Campbell, B.; Clifton, D.A.; Collins, G.S.; Denaxas, S.; Denniston, A.K.; Faes, L.; Geerts, B.; Ibrahim, M.; et al. Reporting guideline for the early-stage clinical evaluation of decision support systems driven by artificial intelligence: DECIDE-AI. Nat. Med. 2022, 28, 924–933. [Google Scholar] [CrossRef]
- Liu, X.; Cruz Rivera, S.; Moher, D.; Calvert, M.J.; Denniston, A.K. The SPIRIT-AI and CONSORT-AI Working Group. Reporting guidelines for clinical trial reports for interventions involving artificial intelligence: The CONSORT-AI extension. Nat. Med. 2020, 26, 1364–1374. [Google Scholar] [CrossRef] [PubMed]
- European Union Artificial Intelligence Act. Available online: https://artificialintelligenceact.eu/the-act/ (accessed on 15 July 2025).
- FDA Guidance on Predetermined Change Control Plan for AI/ML-SaMD. Available online: https://www.fda.gov/regulatory-information/search-fda-guidance-documents/marketing-submission-recommendations-predetermined-change-control-plan-artificial-intelligence (accessed on 15 July 2025).
- Swaminathan, D.; George, N.A.; Thomas, S.; Iype, E.M. Factors associated with delay in diagnosis of oral cancers. Cancer Treat. Res. Commun. 2024, 40, 100831. [Google Scholar] [CrossRef]
- Shruti, T.; Khanna, D.; Khan, A.; Dandpat, A.; Tiwari, M.; Singh, A.G.; Mishra, A.; Shetty, A.; Birur, P.; Chaturvedi, P. Status and Determinants of Early Detection of Oral Premalignant and Malignant Lesions in India. Cancer Control 2023, 30, 10732748231159556. [Google Scholar] [CrossRef] [PubMed]

| Seeker | I am a head and neck surgeon with a decade of experience in oral pathology. |
| Mission | A colleague has sent me an image of an oral mucosal lesion in a patient, asking for my help with the diagnosis. |
| AI role | You are the world’s leading expert in oral pathology. |
| Register | Correct and specialized scientific language. The information must be based on the most recent and solid scientific evidence. |
| Targeted question | Analyze the attached image, assess whether mucosal lesions are present, and, if so, provide the diagnosis that you consider the most probable. If no lesions are detected, state it explicitly. Additionally, provide the most appropriate diagnostic and therapeutic pathway for the patient. |
| Image | ChatGPT4o Response |
|---|---|
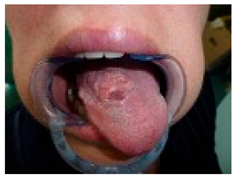 | Analysis and Probable Diagnosis Observations: Exophytic, Ulcerated, and Indurated Lesion on the Dorsal Tongue: The lesion presents as an irregular, proliferative mass with ulceration and induration. The surface exhibits an irregular, verrucous texture with areas of erosion and leukoplakia. These features raise a strong suspicion of a malignant process, likely squamous cell carcinoma (SCC). Localization on the Mid-Dorsal Tongue: While SCC is most common on the lateral and ventral tongue, the dorsal tongue can also be affected. The lesion’s non-healing nature, ulceration, and infiltrative characteristics make malignancy highly probable. Leukoplakic and Erythroplakic Areas: Presence of mixed white and red patches suggests epithelial dysplasia or carcinoma in situ. Erythroleukoplakia carries a significantly higher malignant transformation potential than leukoplakia alone. Verrucous-Like Features: The lesion displays verrucous and exophytic growth, which could indicate verrucous carcinoma (if slow-growing, non-ulcerative, and well-differentiated) or squamous cell carcinoma (if ulcerated, infiltrative, and rapidly progressing). Most Probable Diagnosis: oral squamous cell carcinoma (OSCC). Key clinical features supporting SCC diagnosis include non-healing ulceration with induration, exophytic and infiltrative growth pattern, presence of erythroleukoplakia, irregular, roughened, and verrucous surface. Given these features, OSCC is the leading differential diagnosis and must be ruled out with a biopsy. Differential Diagnoses to Consider:
1. Urgent Incisional Biopsy for Histopathological Diagnosis. A deep incisional biopsy with adequate sampling of the lesion’s central and peripheral areas is mandatory. Preferred biopsy site: the most representative area, avoiding necrotic or superficial regions. The histopathological report should assess: presence of keratin pearls, dysplastic changes, and invasive epithelial nests (indicative of SCC). Differentiation grade (well, moderately, or poorly differentiated). Depth of invasion (critical for staging and prognosis). Presence of lymphovascular or perineural invasion. 2. Imaging for Tumor Staging. If SCC is confirmed, imaging is required to evaluate local invasion and regional metastasis. Recommended imaging modalities: MRI of the tongue and floor of the mouth—to assess tumor extent and muscular infiltration. CT scan (head, neck, and chest)—to evaluate lymph node involvement and distant metastases. Ultrasound with fine-needle aspiration biopsy (FNAB)—if cervical lymphadenopathy is detected. 3. Comprehensive Oncologic Evaluation. Referral to a head and neck cancer multidisciplinary team (MDT). TNM Staging (AJCC 8th Edition) should be established to guide treatment planning. If SCC is confirmed, a treatment plan must be discussed based on tumor size (T staging), lymph node involvement (N staging), and the presence of distant metastasis (M staging). 4. Risk Factor Assessment and Patient Optimization. Evaluate for risk factors contributing to malignant transformation: tobacco use (smoking or smokeless tobacco), heavy alcohol consumption, HPV-associated carcinogenesis (p16 immunohistochemistry if suspected). The management of predisposing factors should be part of the long-term strategy. 5. Definitive Treatment (Based on Staging). If SCC is confirmed and localized (T1–T2, N0), surgery is the preferred treatment: wide local excision with adequate margins (≥1 cm); neck dissection (if nodal involvement is suspected). If SCC is advanced (T3–T4, N+), multimodal therapy is indicated: surgery + adjuvant radiation ± chemotherapy. Definitive chemoradiotherapy if unresectable. Conclusions: This lesion exhibits high-risk clinical features for oral squamous cell carcinoma (OSCC). Immediate incisional biopsy is mandatory for histopathological confirmation. If SCC is confirmed, comprehensive staging with imaging and multidisciplinary oncologic assessment must follow. Treatment planning should be based on TNM staging, patient comorbidities, and functional outcomes. Given the aggressive nature of OSCC, early diagnosis and timely intervention are critical for optimizing prognosis. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Published by MDPI on behalf of the Lithuanian University of Health Sciences. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vaira, L.A.; Lechien, J.R.; Maniaci, A.; De Vito, A.; Mayo-Yáñez, M.; Troise, S.; Consorti, G.; Chiesa-Estomba, C.M.; Cammaroto, G.; Radulesco, T.; et al. Diagnostic Performance of ChatGPT-4o in Analyzing Oral Mucosal Lesions: A Comparative Study with Experts. Medicina 2025, 61, 1379. https://doi.org/10.3390/medicina61081379
Vaira LA, Lechien JR, Maniaci A, De Vito A, Mayo-Yáñez M, Troise S, Consorti G, Chiesa-Estomba CM, Cammaroto G, Radulesco T, et al. Diagnostic Performance of ChatGPT-4o in Analyzing Oral Mucosal Lesions: A Comparative Study with Experts. Medicina. 2025; 61(8):1379. https://doi.org/10.3390/medicina61081379
Chicago/Turabian StyleVaira, Luigi Angelo, Jerome R. Lechien, Antonino Maniaci, Andrea De Vito, Miguel Mayo-Yáñez, Stefania Troise, Giuseppe Consorti, Carlos M. Chiesa-Estomba, Giovanni Cammaroto, Thomas Radulesco, and et al. 2025. "Diagnostic Performance of ChatGPT-4o in Analyzing Oral Mucosal Lesions: A Comparative Study with Experts" Medicina 61, no. 8: 1379. https://doi.org/10.3390/medicina61081379
APA StyleVaira, L. A., Lechien, J. R., Maniaci, A., De Vito, A., Mayo-Yáñez, M., Troise, S., Consorti, G., Chiesa-Estomba, C. M., Cammaroto, G., Radulesco, T., di Stadio, A., Tel, A., Frosolini, A., Gabriele, G., Iannella, G., Saibene, A. M., Boscolo-Rizzo, P., Soro, G. M., Salzano, G., & De Riu, G. (2025). Diagnostic Performance of ChatGPT-4o in Analyzing Oral Mucosal Lesions: A Comparative Study with Experts. Medicina, 61(8), 1379. https://doi.org/10.3390/medicina61081379