1. Introduction
Non-adherence to antihypertensive medication is a major barrier to effective blood pressure control, and it refers to a patient’s failure to follow the prescribed treatment regimen as recommended by a healthcare provider. Non-adherence may involve delays in starting therapy, missing doses, incorrect timing or dosage, or prematurely discontinuing treatment [
1]. It can be intentional (e.g., due to concerns about side effects or cost) or unintentional (e.g., forgetfulness or misunderstanding instructions) [
2].
Non-adherence to medication leads to poorer clinical outcomes, increased patient suffering, and higher morbidity and mortality. It also results in greater healthcare-related costs, reduced productivity, and a lower quality of life [
3]. A recent meta-analysis of 12 studies involving over 2 million patients found that poor adherence to antihypertensive therapy is significantly associated with increased all-cause mortality and cardiovascular mortality. The risk was notably higher among patients undergoing long-term treatment [
4].
Studies report varying levels of adherence to antihypertensive medication. Cross-sectional research conducted across diverse global populations has found adherence rates ranging from 27.9% to 85% [
5]. This wide variability likely reflects differences in patient demographics, healthcare systems, cultural beliefs, and the methods used to measure adherence. The heterogeneity across studies highlights the need for standardized assessment tools and further investigation into context-specific barriers and facilitators of adherence. Identifying these factors is essential for designing targeted interventions to improve long-term treatment outcomes in hypertension management.
In the management of hypertension, medication adherence is a critical determinant of therapeutic success, yet it remains suboptimal in many cases due to the asymptomatic nature of the condition. Factors such as an older age, low health literacy, cognitive decline, and polypharmacy further complicate adherence, particularly in elderly patients who are the primary users of antihypertensive drugs. Complex therapeutic regimens have been consistently associated with lower adherence rates. Beliefs and attitudes toward medication also play a vital role; patients who understand the risks of uncontrolled hypertension (e.g., stroke, myocardial infarction) and believe in the efficacy of treatment are more likely to adhere, while those concerned about side effects or long-term dependence are more likely to interrupt therapy. A strong, trust-based relationship between the patient and the physician, effective communication, and the continuity of care have all been associated with better adherence outcomes. System-level barriers, such as high out-of-pocket costs or limited access to healthcare services, can significantly hinder adherence. Moreover, social and familial support can enhance adherence by promoting routines and reinforcing the importance of health behaviors [
6,
7,
8]. The optimal management of arterial hypertension requires educating the patient about adherence to the antihypertensive treatment, including diuretics, lifestyle modifications, and monitoring for adverse effects [
9].
Machine learning (ML) algorithms are capable of processing and integrating diverse data types, including the prescription history, insurance claims, patient demographic information, and real-time data from medication adherence monitoring systems. Through this approach, ML models can uncover complex associations and behavioral patterns that are often undetectable using traditional analytical methods. By learning from these patterns, ML algorithms can accurately estimate patient adherence to prescribed treatments [
10]. These predictive models enable the stratification of patients based on their risk of non-adherence, thus supporting the implementation of personalized and proactive interventions. In this way, ML-driven technologies play a critical role in enhancing the quality of the healthcare delivery and mitigating the negative consequences of non-adherence on both patient outcomes and healthcare system costs [
11].
Given the significant impact of non-adherence on hypertension management and the limitations of current predictive approaches [
12], our study aims to move beyond a descriptive analysis and toward an actionable prediction. After outlining the multifactorial nature of non-adherence, we advance the discussion by constructing and validating machine learning models designed to identify patients at risk of poor adherence based on a real-world dataset of 3095 ARMS questionnaires. The models were mainly built on sociodemographic and behavioral data, as collected through a structured, non-clinical questionnaire, reflecting a pragmatic approach applicable in settings where pharmacological or clinical data may be unavailable.
4. Discussion
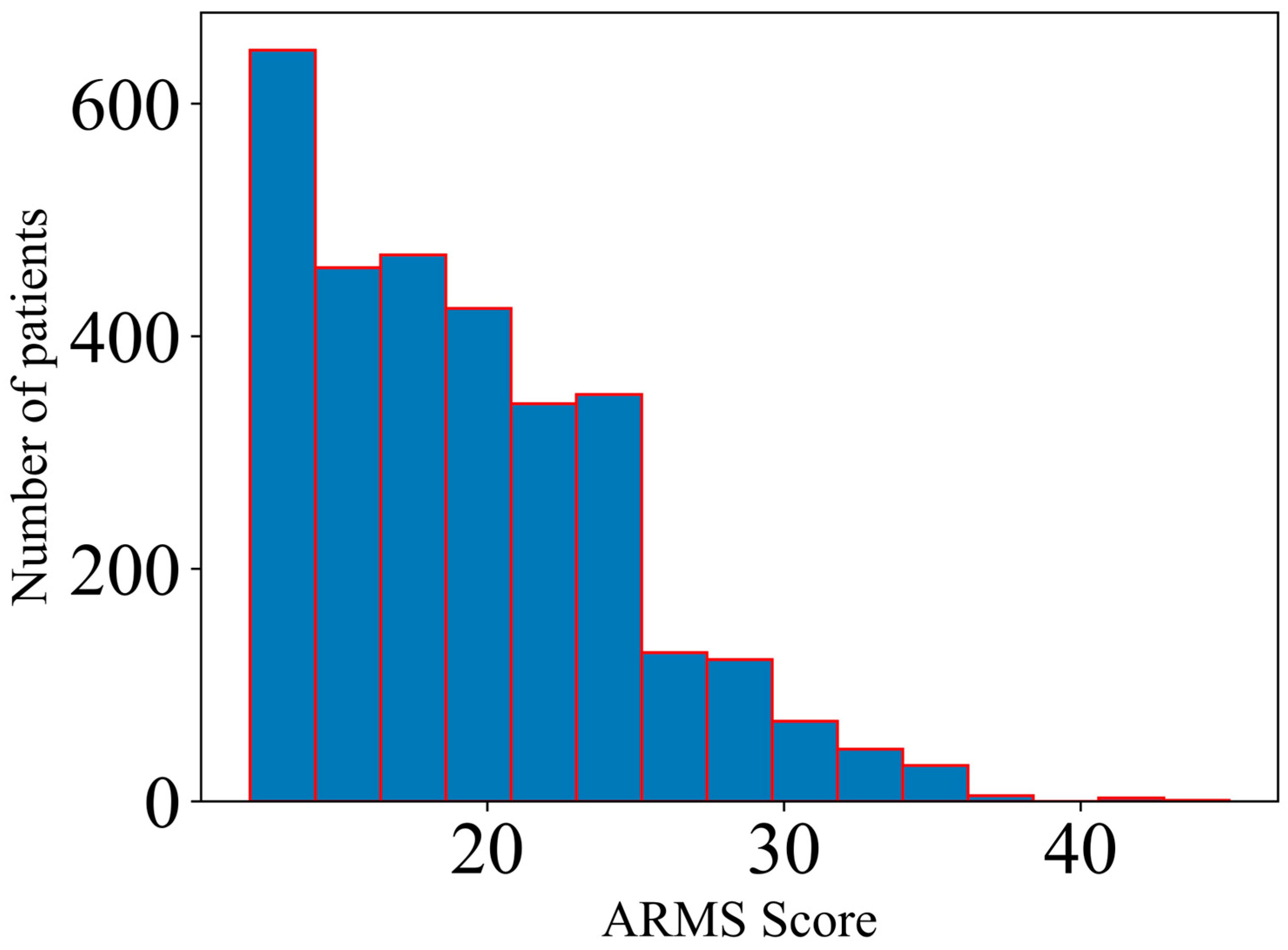
In the current study, several machine learning models were developed and validated based on their ability to estimate the non-adherence status based on specific ARMS (Adherence to Refills and Medications Scale) quartile-based thresholds (Q1 = 15, Q2 = 18, Q3 = 22), taking into account various sociodemographic and clinical characteristics from 3095 patients as predictive features.
The first step of the analysis involved evaluating the differences across groups in terms of ARMS Scores and computing age- and sex-adjusted Spearman’s correlation coefficients between the included variables and the non-adherence status, quantified both by the total ARMS Score and by the three binary outcomes which were further used for building the machine learning algorithms. The results obtained in terms of the inter-group comparison for the categorical variables (
Table 1) yielded statistically significant differences for the majority of the variables; in terms of the level of significance, it should be noted that
p values lower than 0.001 were obtained for family support; the level of education; respiratory, rheumatic, and central nervous system diseases; blood pressure (BP) self-monitoring; and the frequency of adding salt in food and of reading patient information leaflets (PILs), as well as for the majority of the PIL- and pharmacist-related information, therefore implying that the majority of the variables included in this study might be used for patient stratification in terms of adherence levels.
On the other hand, the results obtained in terms of adjusted Spearman’s correlation coefficients (
Table 2) highlighted statistically significant (
p < 0.05) associations between the majority of the predictive variables and the adherence status of the patients. More specifically, for the total ARMS Score, the highest positive correlations were obtained for the frequency of adding salt in food (r = 0.254), followed by a high blood pressure during self-monitoring (r = 0.215) and the number of daily administered supplements (r = 0.106). On the other hand, the most significant negative correlations were obtained for the frequency of reading patient information leaflets (r = −0.239), followed by the normal blood pressure during self-monitoring (r = −0.214) and the frequency of blood pressure self-monitoring (r = −0.184). The binary quartile-based outcomes showed similar patterns with regard to their age- and sex-adjusted associations with the predictive variables. For example, the number of daily administered supplements had identical values of Spearman’s correlation coefficients for both the Q1- (the status of ARMS ≥ 15) and Q2- (the status of ARMS ≥ 18) based outcomes (r = 0.118), while for the Q3-based binary outcome (corresponding to the status of ARMS ≥ 22, hence less adherent patients), a smaller and non-significant correlation coefficient was obtained (r = 0.033,
p = 0.068). The influence of the blood pressure self-monitoring and the results of the monitoring (whether normal or high blood pressure) were similar for all three binary outcomes but slightly more pronounced for Q2 and Q3 thresholds (for example the normal blood pressure during self-monitoring yielded Spearman’s correlation coefficients of −0.139 for Q1, −0.189 for Q2, and −0.188 for Q3). A similar pattern was observed for the frequency of adding salt in food, while for the frequency of reading patient information leaflets, the associations were more similar between all three binary outcomes, with a slightly stronger association with the Q3-based outcome (r = −0.177, −0.17, and −0.207, respectively, for Q1, Q2, and Q3). Moreover, with regard to the type of information that the patients received from the leaflets, the adverse drug reactions had the highest associations, even though to a lower magnitude than for the already mentioned variables, while the method of administration of the pharmacist-related counselling information most highly correlated to all binary non-adherence measures (r = −0.084, −0.066, and −0.065, respectively, for Q1, Q2, and Q3). Overall, blood pressure self-monitoring, a lower frequency of adding salt in food, a lower number of daily administered supplements, reading patient information leaflets to a higher degree, and the specific information received from the community pharmacists were found to have small to moderate, but statistically significant, age- and sex-adjusted associations with being more adherent to the drug therapy—findings already highlighted in various studies from different countries [
25,
26,
27,
28,
29].
More specifically, with regard to the influence of various factors on adherence levels, it is worth mentioning that multiple studies confirm that higher education levels are strongly associated with a better adherence to antihypertensive treatment. Zyoud et al. (2013) found that university-educated patients showed significantly higher adherence and a better health-related quality of life compared to less educated individuals [
30]. Similarly, Hussein et al. (2020) reported that patients with a secondary or higher education were more adherent than those with only a primary education [
31]. These results highlight education as a key predictor of adherence, supporting our study’s findings, where the higher the education level, the lower the ARMS adherence score, indicating a better adherence (Spearman correlation coefficient ρ = −0.168,
p < 0.001) [
32].
In general, the greater the number of medications taken per day and the higher the dosing frequency, the lower the adherence [
33,
34]. Our research reveals similar findings: the more complex the medication regimen, the lower the adherence to treatment. Over 40% of respondents did not regularly self-monitor their blood pressure, with 17.3% measuring it only during doctor visits and 24.7% doing so only when they felt unwell. These individuals had higher ARMS adherence scores—indicating lower adherence—and poorer blood pressure control compared to those who monitored their blood pressure regularly, either daily or at least weekly. This finding aligns with other studies showing that regular blood pressure monitoring is positively associated with a better adherence to antihypertensive medication [
35].
In addition, a belief in the necessity and effectiveness of medications increases adherence [
34]. In our study, knowledge about medications—as indicated by the frequency with which patients read the patient information leaflets [
36]—was associated with a higher adherence to medication and refills. Adverse drug reactions, or the fear of such reactions, reduce treatment adherence. Studies show that non-adherent patients generally experience more frequent or more severe side effects compared to those who are adherent [
37]. This highlights the importance of managing adverse drug reactions and educating patients on how to recognize them early. The fear of side effects and concerns about therapy are also associated with decreased adherence [
38]. It is noteworthy that, in our investigation, the section of the medication leaflet that attracted the most interest among patients was the one concerning adverse effects.
The adjusted correlation analysis was followed by the development of several predictive algorithms, with the main aim of predicting, based on both the probability estimation and raw classification, the non-adherence status, defined based on the ARMS status of at least Q1 (ARMS = 15), Q2 (ARMS = 18), or Q3 (ARMS = 22), respectively. The validation results, presented in
Table 3, yielded the highest results in terms of ROC AUC Scores for CatBoost for all three outcomes (ROC AUC = 0.728 for Q1, 0.718 for Q2, and 0.734 for Q3). The ROC AUC Score, which was the indicator for estimating the reliability of the predicted probabilities of belonging to class 1 (the non-adherent group for all three binary outcomes), was considered the most important machine learning validation indicator, since its use as an optimization metric ensures an enhanced stratification of patients based on their adherence levels. The obtained values were higher than 0.7 for all five machine learning models (but were the highest for the CatBoost model, an important type of gradient boosting algorithm, which is designed to reduce bias and improve handling of categorical variables [
21]) and were considered satisfactory, given the moderate sample size of the included dataset (3095 patients) and the relatively low total number of included predictors (28 variables).
With regard to other studies which aimed at implementing machine learning for estimating patients’ adherence, Lucas et al. used Electronic Health Records data from more than 100,000 patients to estimate the adherence to statin treatment through Random Forest. The c-statistic obtained during the cross-validation process, which estimated the ability of the model to rank individuals based on statin adherence levels, was 0.736, which was almost identical to the optimal ROC AUC Score obtained for the Q3-based outcome (0.734), even though the current study used a significantly lower number of patients and potential predictors; nevertheless, the study conducted by Lucas et al. focused on a specific subtype of drug therapy adherence, while in our analysis, we used a broader, even though much smaller, patient cohort with regard to the medication types [
39]. In another research project that involved the use of machine learning for estimating adherence, Karanasiou et al. implemented various algorithms (such as Support Vector Machines, Multi-Layer Perceptron, Random Forest, and Naïve Bayes) to classify 90 heart failure patients based on their global adherence and medication adherence [
40]. However, despite using various types of machine learning models, the study only performed raw classification and only reported accuracy as a performance metric, which might be biased, especially in the case of an imbalanced class task [
41]. Moreover, it is worth mentioning that in our study we additionally reported the accuracy, precision, recall, and Matthews Correlation Coefficient (MCC); the MCC is frequently considered a more robust and reliable classification evaluation metric, even when comparing it to the more classical F1 Score; for the Q1-based outcome we obtained an optimal MCC of 0.279 by using XGBoost; in addition, a maximum MCC of 0.320 was computed for the Q2-based outcome with the CatBoost algorithm, while for the Q3-based outcome the best MCC was 0.317 when using the XGBoost model. These values were considered satisfactory, especially given the fact that the MCC can obtain values from a minimum of −1 and a maximum of 1, which is different than the 0–1 scale of the traditional classification evaluation indicators [
42]. The precision and recall showed relatively balanced values, but precision had a higher variability, with a minimum of 0.445 (for the Q3-based outcome) and a maximum of 0.874 (for the Q1-based outcome with Logistic Regression); on the other hand, the computation of the recall yielded values between 0.611 (for the Q3-based outcome) and 0.773 (for the Q1-based outcome with XGBoost). Therefore, the focus on minimizing false negative values was more robust, regardless of the adherence threshold.
In addition, other similar studies which implemented machine learning in patient adherence estimations involved the use of the LASSO regression on medical claims data from more than 10,000 patients with myocardial infarction, with a focus on statin therapy [
43], while Galozy et al. implemented tree-, Logistic Regression-, and K-nearest neighbors-based algorithms for predicting the medication refill adherence from Electronic Health Records data; in addition, Lee et al. used Logistic Regression and Support Vector Machines for estimating adherence (quantified through the Morisky Scale) in 293 patients with chronic diseases, with the AUC being the main measure for validating the classification performance [
44,
45]. In our study, we mainly focused on tree-based algorithms due to the size and structure of the dataset (relatively small sample size, few continuous variables, and cases with imbalanced classes). Moreover, it should be mentioned that the studies which implemented various machine learning algorithms for adherence predictions did not use an uniform adherence definition or scale, which makes performing a standardized comparison to our study more difficult [
1,
10,
46,
47].
One of the main advantages of the current study was the computation of the importance of each predictive variable in the estimation of the probability of belonging to the non-adherent group for each three quartile-based binary outcomes. While it was not the first time that the permutation feature importance was used to assess the explainability of the predictors in adherence estimations (for example, Choe et al. used it when estimating adherence to physical activity guidelines [
48]; Mirzadeh et al. also computed the contribution of predicting variables in machine learning models for estimating adherence to drug therapy in patients at risk of atherosclerotic cardiovascular disease, even though this was not through permutation feature importance [
49]), to our knowledge it is the first time that the permutation feature importance has been used in combination with a stratification based on a probability estimation. The results (presented in
Table 4,
Table 5 and
Table 6) highlight the percentage of the ROC AUC Score improvement on the test set for each feature when comparing it to the improvement in ROC AUC Score for all features combined. The obtained percentages followed a similar pattern to the one observed in the adjusted correlation analysis. Hence, it is worth mentioning that the frequency of adding salt in food, of reading patient information leaflets, and of blood pressure self-monitoring were the most informative features for all three outcomes, with a percentual importance of at least 5% in all cases and a maximum importance of over 25–30%, as observed by the CatBoost model (which was the best model in terms of the probability estimation, as validated through the ROC AUC Score). Other important predictors in terms of the ROC AUC improvement were the number of daily administered supplements (only for Q1- and Q2-based outcomes), the level of education (especially for the Q3-based outcome, corresponding to identifying the most non-adherent patients), and the pharmacist-related counselling method of administration (especially for the Q1-based outcome). In addition, in order to quantify the clinical utility of the predictive variables in the final, best performing model in terms of ROC AUC Scores (CatBoost) and to evaluate the interpretability of the ML algorithm, a SHapley Additive exPlanations (SHAP) analysis was also undertaken, based on the whole dataset; the results are presented in
Table 7. In this regard, it is worth mentioning that the contributions of each variable followed similar patterns to the ones observed for the permutation feature importance. The highest contributions were observed for all quartile-based thresholds for the frequency of adding salt in food (11.02% for an ARMS Score of 15, 15.88% for an ARMS Score of 18, and 20.52% for an ARMS Score of 22) and of reading PILs (11% for an ARMS Score of 15, 8.28% for an ARMS Score of 18, and 13.55% for an ARMS Score of 22), while a high BP during self-monitoring had almost a double contribution for the highest quartile-based threshold (Q1—ARMS Score ≥ 22) when compared to the two other thresholds (approximately 10%, compared to 5%), and the number of daily administered supplements contributed the most for the first quartile, followed by the second quartile. Therefore, given the similar trends that were observed by implementing two different feature importance methods, this study presents an important justification for considering specific predictors for explaining, in a clinically relevant manner, the levels of the non-adherence of Romanian patients taking antihypertensive medication. Overall, it is worth mentioning that the blood pressure self-monitoring, the frequency of adding salt in food, and the frequency of patient information leaflet reading helped in stratifying patients regardless of their adherence levels, while the use of supplements, the level of education, and specific pharmacist counselling might help in discerning specific adherence levels only, which reflects the personalized and non-linear characteristics of medication adherence with regard to its associations with relevant influencing factors [
29].
One important limitation of this study is the exclusion of pharmacological variables known to influence adherence, such as the antihypertensive drug class, treatment complexity (monotherapy vs. combination therapy), and packaging features. This exclusion was a deliberate design choice aligned with this study’s main objective: to assess the feasibility of predicting antihypertensive adherence using easily obtainable, non-clinical variables. The predictor set was defined during the questionnaire development, with a focus on sociodemographic and behavioral factors that are modifiable and relevant for educational and public health interventions. Although this approach limited the scope of the models, it reflects a pragmatic and scalable design. Moreover, although some differences in the adherence between antihypertensive drug classes have been reported, the overall adherence remains suboptimal across all classes [
50], emphasizing the relevance of the behavioral dimensions targeted in this study. Future research could expand on our findings by integrating clinical and pharmacological data to enhance the predictive performance and broaden applicability.
In conclusion, in the current study several predictive models were developed and validated based on their ability to estimate the medication non-adherence, as quantified though various thresholds. The validation results through the ROC AUC Score show the potential of machine learning to identify and stratify patients based on their adherence levels. While the ROC AUC values of 0.70–0.74 indicate a moderate predictive performance, the models were developed using only non-clinical, self-reported data, which makes them highly feasible for use in real-world settings. Their practical utility lies in serving as low-cost, scalable tools for the early identification of patients at risk of non-adherence, particularly in primary care or public health contexts where the access to clinical data may be limited. Despite the inherent disadvantages of the current study (relatively small patient cohort, when compared to other studies; lack of universally accepted standardized adherence scales; lack of external validation for the developed machine learning models), such results, after being included along with the optimized prediction algorithms in an online platform, might help to develop personalized intervention recommendations related to the adherence to medication, with a consequent improvement in the control of chronic illnesses and the quality of life.

 ,
, 

{kind=link}