Abstract
Despite being an important economic component of Taif region and the Kingdom of Saudi Arabia (KSA) as a whole, Taif rose experiences challenges because of uncontrolled conditions. In this study, we developed a phenotyping prediction model using deep learning (DL) that used simple and accurate methods to obtain and analyze data collected from ten rose farms. To maintain broad applicability and minimize computational complexity, our model utilizes a complementary learning approach in which both spatial and temporal instances of each dataset are processed simultaneously using three state-of-the-art deep neural networks: (1) convolutional neural network (CNN) to treat the image, (2) long short-term memory (LSTM) to treat the timeseries and (3) fully connected multilayer perceptions (MLPs)to obtain the phenotypes. As a result, this approach not only consolidates the knowledge gained from processing the same data from different perspectives, but it also leverages on the predictability of the model under incomplete or noisy datasets. An extensive evaluation of the validity of the proposed model has been conducted by comparing its outcomes with comprehensive phenotyping measurements taken from real farms. This evaluation demonstrates the ability of the proposed model to achieve zero mean absolute percentage error () and mean square percentage error (MSPE) within a small number of epochs and under different training to testing schemes.
1. Introduction
Among the most important Rosa species, the damask rose (Rosa damascene Mill) is used for making rose water, attar, dried petals and essential oils for perfume, cosmetic, and for pharmaceutical applications. It is called Damask rose, due to its origin from Damascus [1,2]. Ward Taify is a Damask rose type (Rosa damascena trigintipetala Dieck), which is regarded as one of the most abundant harvests in the King Abdullah governorate in Saudi Arabia (KSA). Saudi Arabia ranks among the largest exporters and producers of rose oil. Currently, 800 tons of rose water and 40,000 tons of rose oil are produced annually. Damacena roses are grown in Al Hada and Al Shafa areas and are known to produce precious oil attar in 2000 farms. Due to the growing demand for rose oil on the international market, it is imperative to expand the cultivation of R. damascena over a larger area and improve its production technology. This study will provide valuable information for selecting high-yielding stress-tolerant oil roses, avoiding losses, and ensuring sustainability. Achieving a high yield and sustainable production of Taif rose benefits all parties without reducing the use of natural resources and human energy [3].
Taif rose longevity has been a breeding objective for many years, but despite this, the loss of fragrance has been noticed during breeding programs. However, the specific reasons behind the loss of fragrance remain a mystery. Breeding is a dynamic branch of agricultural science, which began with the simple selection of plants with superior characteristics. As a result of global warming (climate change) and the decline in cultivation land [4], it is crucial to increase the productivity of existing agricultural lands. To meet this demand, scientists are developing efficient and sustainable methods to increase crop yields [5].
Precision agriculture techniques have gained a lot of attention for this purpose. As part of precision agriculture, crops are monitored, data are gathered, and informed decisions are made about crop management such as choosing pesticides, accordingly, selecting the optimum amount of water, and reducing environmental impact. A precise monitoring system will help farmers make the right decisions to get the best yield possible.
Agricultural technology advancements, which include robotics, drones, cameras, censored machines, and geographic information systems, are effective in capturing data through the application of artificial intelligence (AI). Furthermore, there is a possibility of applying machine learning to phenotypic data, which can be used to predict the most appropriate season for planting and harvesting crops based on weather, soil, humidity, and previous crop performance [5,6]. The use of AI technology may improve worker safety, minimize the effect on natural ecosystems, and increase sustainability [6]. There have been many studies recently on how to increase the yield of crops via machine learning concerning plant breeding. Some of these include soybean [7], oil palm [5], brassica [8], and spring wheat [9].
Plant breeding research using both classical and in vitro methods has applied machine learning (ML) extensively to categorize observable phenotypes based on DNA sequences. Research in horticulture needs to focus on modern technologies that will revolutionize productivity to meet the forthcoming challenges [4]. Producing high-quality crops using advanced technologies, equipment, and systems to decrease human labor use and increase efficiency is the primary goal of intelligent horticulture [6]. Moreover, it is important to identify horticultural crops rapidly, accurately, and automatically as well as to acquire postharvest data.
High-throughput plant phenotyping (HTPP), a fast-emerging research area, plays a crucial role in understanding crop-related traits, characterizing and quantifying the physical and physiological characteristics of a plant. Crop management relies heavily on understanding these properties. Phenotypic traits (variations in a plant’s characteristics caused by its genetics and its environment) are important in crop breeding because they help breeders select varieties with desirable physical characteristics, such as high yields, resistance to stress, and ease of harvest. Traditionally, phenotypic measurements are performed manually, which is time-consuming and labor-intensive. The use of image-based automated phenotypic traits estimation is emerging as a means of improving crop production by capturing more precise information at a large scale.
Breeders have been able to reduce evaluation time and costs in their breeding programs by utilizing high-throughput genotyping and phenotyping technologies [10]. However, most breeding programs are still limited by the difficulty in obtaining high-throughput field phenotyping [11,12,13]. Despite the considerable progress in basic knowledge and technology, plant phenotyping still faces a variety of practical, financial, and political challenges that prevent the implementation of HTPP approaches in the field. In addition to the high costs of HTPP infrastructure, the limited availability of skilled personnel may also be a factor that hinders implementation. Moreover, plant breeding programs face challenges in analyzing large datasets, which require rigorous computations and statistical analyses [14]. The development of model-based breeding methods that will improve the efficacy of breeding programs is currently being pursued using machine learning algorithms [15]. In recent years, artificial neural networks (ANNs), such as the one developed by Pal and Mitra [16], have been widely used for modeling and predicting complex traits, such as yield, across breeding programs [17]. Artificial neural networks and densely connected networks are used to train models in deep learning [18]. Deep Learning (DL) is based on the biological networks of brain neurons in which different layers are used to obtain a better fit by transforming data across each layer. As well, DL uses nonlinear activation functions to predict the genetic building blocks of traits precisely [19,20], and so can be successfully applied to biological sciences [21,22].
It is our main objective to examine how ML may be applied to Taif rose breeding (TRB) with criteria other than genetic data. This paper also provides knowledge regarding the dataset required for plant survival, especially regarding TRB variations, phenotypic traits, and machine learning. As an initial step, the work presented here is the first in which deep learning is used to predict the phenotypic characteristics of Taif roses. Because this is the first time deep learning has been used in this domain and the system is based on a dataset of 10 Taif rose accessions, we have named it TRBR. While we evaluate our strategy on Taif rose, our design enables frameworks to be generalized to other types of high-value crops in Saudi Arabia with minimal manual intervention. The key contributions of this work are as follows:
- Develop a deep learning model that can predict the phenotyping measurement of Taif rose from the satellite imagery datasets.
- Evaluate the accuracy of the developed model from different perspectives using standard evaluation strategies.
The remainder of this manuscript is organized as follows: Section 2 explores the related works, Section 3 reviews the materials used in this study; Section 4 is devoted to providing information about the methods used to develop the model. Section 5 provides the assessments for the proposed model and discusses its results. Finally, Section 6 concludes this work.
2. Related Works
This section reviews related works in phenotyping prediction and deep learning models (DLs). It aims to highlight the related works’ underlying theories, approaches, and concepts, identify any seminal contributions, and point out any limitations to emphasize the work’s value to society.
The computer vision community has been interested in plant classification for many years due to its importance in agriculture and ecological conservation [23]. Several studies have been conducted based on photographs of plant leaves [24]. Studies on how to recognize plant diseases [25], symptoms of environmental stress [26], and the difference between crops and weeds [27] have previously been conducted. In these studies, plant/leaf segmentation, feature extraction, and classification are the three main steps. The performance and interaction of each of these steps determine the performance of the whole phenotyping pipeline.
The development of manually engineered image-processing methods has been successful in the past, but these methods are not able to manage more complex morphological traits. The problem arises especially in the study of complex plants, in the presence of noise, and in environments that are uncontrolled and cluttered. For these reasons, machine learning (ML) has been recommended for phenotyping plants [28] specifically for image data [29]. Traditional approaches in computer vision take two steps: feature extraction using manual processing and decision-making using machine-learning algorithms. Machine learning (ML) is a subfield of artificial intelligence that develops algorithms based on a data set to learn how to perform specific tasks. It is widely used in the field of research and in industry. An important distinction is between supervised and unsupervised learning tasks.
Supervised learning tasks attempt to predict an output (either a discrete label, in the case of classification, or a numerical value, in the case of regression), for a given object, given a set of input features that describe the object. The goal of supervised learning is to optimize a predictive model by fitting its parameters to perform well on labeled training data. These models can then make predictions for new, unseen test data. Training must be performed carefully to avoid overfitting, which occurs when a model performs well on training data but is unable to generalize well to new test data. Unlike supervised methods, unsupervised approaches seek patterns in unlabeled data. Since unsupervised approaches do not consider outputs, there are typically no such things as “training data”, as compared to supervised methods. Using unsupervised algorithms to find relevant patterns can help interpret large datasets, and can also be used to prepare data for more effective supervised learning. Several algorithms have been developed for both supervised and unsupervised machine learning, each with their own advantages and disadvantages. The performance of some novel strategies, such as transfer learning [30], few-shot learning [31], generative adversarial networks (GAN) [32], and semi-supervised learning [33], have yet to be fully evaluated.
A supervised machine learning technique is typically used to learn from examples, which allows the algorithm to detect patterns that humans cannot find in the often high-dimensional feature space. However, this method is limited by the quality of the features. The development of deep learning (DL) methods in recent years has addressed this limitation by introducing the concept of integrating feature learning and decision-making on the same platform with remarkable results for general applications [34] and agricultural applications in particular [35].
Along with deep learning, other modern and often high-performing supervised machine learning techniques for regression and classification problems that aggregate an ensemble of weak individual models to obtain a more accurate final model, e.g., Random Forests (RF) and boosting algorithms [36,37].
The model presented by Pound et al. [38] constitutes one of the pioneers works that appeared in the open literature and aimed to construct a DL model that has the capability to identify and classify spikes and spikelets of wheat from images. The proposed model features four convolutional layers that were constructed in an encoding/decoding manner. The encoding layers were used to down-sample the fed images so that their salient features can be treated fairly without being subjected to any distortions due to the capture process. The decoding layers then reconstructed the encoding layers’ findings in a way that enables the subsequent layers to classify the image’s contents as spikes or spikelets. Moreover, the proposed model was based on pixelwise regression to identify those images that have a high likelihood of belonging to a particular class. Total of 520 images were used to train and validate the model, and an 80:20 train-to-validate ratio was employed, as well as random augmentation techniques to enhance the model’s learnability. Binary cross-entropy with root mean squared propagation was used to classify the dataset at the image level. The results provided by the authors of this work showed that classification errors rise inversely with image dimensions, reaching up to 14.46% for spike tip at 256 × 256 pixels and to 4.09 at 512 × 512 pixels.
Shi et al. [39] utilized fully and masked region-based CNNs to develop a multi-view approach that can incorporate the information from the two-dimensional (2D) images with a three-dimensional (3D) point-cloud model of the plant. The model is designed to provide a fine-grained classification for each part of the plant image; therefore, rather than classifying the whole image as described by Pound et al. [38], this model labels each point of interest as either background, stem, leaf, or node. The proposed model is based on the pre-trained Visual Geometry Group (VGG-16) architecture that is composed of 13 convolutional layers and 3 fully connected layers. VGG-16, however, has undergone some modifications to facilitate segmenting images into sections to conduct subclassification for each section. Furthermore, several skip connections and dropout layers are used to minimize the generalization error that might be raised due to using the pre-trained weights of VGG. The proposed model uses stochastic gradient descent (SGD) optimization with weighted cross-entropy loss over 500 iterations and a learning rate of 103. The datasets used to train and evaluate the proposed model were collected using a set of cameras fitted into tomato plants approximately 900 mm from the seedlings. There are 620 gray-scale images of 1280 × 900 pixels used for the training, validation, and testing of the model, of which 420 images are used for training purposes, and the remaining images for validation and testing evenly. Using 3D images in this work improves classification accuracy for leaves and stem parts at the pixel and object levels.
According to Taghavi Namin et al. [40], the classification performance can be enhanced by considering temporal variation alongside plant images. The model presented in this work integrates a long short-term memory (LSTM), a special kind of artificial neural network (AN) with the ability to detect salient features of timeseries. As a dataset, the model uses several Arabidopsis images taken chronologically by the authors.
Though previous deep learning models reported outstanding performance, they can still be limited in their applicability because they rely only on images gathered from farms for training and validation. The need to acquire and preprocess large datasets of consistent images adds significant overheads, making the model only suitable for this dataset. Hence, scientists and researchers are proposing to overcome these shortcomings by using satellite imagery for their modeling. By utilizing a dataset like this, they cite the possibility of reducing time and effort spent collecting and managing datasets as well as providing timely and rich data.
Fang et al. [41] present another work utilizing several datasets from the Moderate Resolution Imaging Spectroradiometer (MODIS) system to investigate soil moisture. The proposed model was designed based on LSTM architecture and utilized soil moisture active and passive sensor data, brightness temperature, and soil temperature as multi-variates for the LSTM model. The results reported in this work showed that DL can make accurate predictions based on image sensory data. With the same approach, Mahdianpari et al. [42] constructed a deep learning framework that employs CNN architecture to classify wetland conditions. The study used two Rapid Eye optical images as the dataset for training and validating the CNN model using radiometrically and geometrically corrected images taken from the Alexnet network. The results reported in this study demonstrated the ability of the model to provide 0.95, precision and 0.88 recall.
The work proposed by Sakura et al. [43] is an example of how deep learning techniques have been applied as regression tools for predicting plant phenotypes and genotypes. The encoder-decoder architecture has been utilized in this study for predicting the growth of plant leaves, owing to its ability to construct a sequence of outputs from the given input, so that a multi-phase head can be derived throughout time based on the instance of input. As demonstrated in this study, the proposed model provided an accurate prediction.
Another seminal work that has been published in the open literature is that of Yasrab, et al. [44], who used the Generative Adversarial Network (GAN) approach to simulate the future growth of plants based on their spatiotemporal features map. GAN is one of the leading deep learning models that incorporates two different networks: the first, called the generator, uses ground truth datasets to generate new instances of the dataset, and the second, called the discriminator, attempts to categorize the newly generated samples as real or fake. The maximum performance of the model is achieved when the generator succeeds in deluding the discriminator about the originality of the sample. GAN model used in this study consists of 15 convolutional layers to generate the synthetic sample and 10 layers to discriminate. The performance of the model was evaluated on the Komatsuna leaf dataset, and the results reported by the authors show that the model can provide useful predictions.
The work proposed in Mishra et al. [45] is another example of those works that has been devoted to predicting the growth rate of weed using the soil characteristics. This work captured images from the fields and applied some preprocessing techniques to remove noises before feeding them into a CNN network comprising 11 convolutional layers distributed over four parallel branches. This output was then fed into a deconvolution layer whose main purpose was to visualize the captured features. A variety of performance metrics were employed to evaluate the performance of the proposed model on the rabi crop field.
From the above-mentioned section, it becomes evident that some researchers design their DL models based on a single dataset that is either taken from in situ [38,39,40] or satellite imagery data [46,47,48,49,50,51,52] sources while others using multisource data for phenotyping in plant breeding [41]. As each source has its own benefits and shortcomings, and combining several sources can yield good results, this study proposes a multitier deep learning model that can handle several types of data simultaneously. We designed our model with the objective of promoting the learnability of the model by enabling it to complement scarce information from one data source with that of others. To the best of our knowledge, this is the first study aimed at developing such networks and using them to examine how ML might be applied to Taif rose breeding (TRB).
3. Materials
To predict the phenotyping of the Taif rose, we developed a deep learning-based spatiotemporal model. For training and validation of this model, two types of datasets are used: first, phenotyping data captured from farms inside Taif city, and second, sensory images captured by satellites. In this section, detailed descriptions of these datasets are provided. In Section 3.1, a description of the study area is presented, whereas in Section 3.2 and Section 3.3, descriptions of phenotyping and satellite images are presented.
3.1. Study Area
The present study was conducted in Taif city located in Makkah Province, Saudi Arabia on the eastern slopes of the Al-Sarawat Mountains at 1879 m (6165 ft) elevation. Taif is located between 21°262′03″ north latitude and 40°212′03″ east longitude; its average temperature in summer is 34 °C and in winter it is 10 °C. Rain falls throughout all months, but spring and late fall have even more rain than other months. Approximately 2.065% of the Saudi Arabian population lives in Taif [53]; over the past few years, Al-Taif has experienced a rapid urbanization process and has displayed a wide range of land use and land cover types. Located within the Taif area is an agricultural area that is one of the best-known in Saudi Arabia. It has a total area of approximately 594,000 m2 and a farming area of approximately 25,500 acres.
There are two highlands southwest of Taif City called the Al-Shafa and Al-Hada (Figure 1) which are famous for their agriculture crops and moderate climates, while the Taif neighboring areas consist of weathered black schist hills which are overgrazed and arid. Climates are tropical in summer and comparatively cool in winter, with rainfall measured at 250–300 mm near Al-Shafa and at 170–250 mm near Al-Hada [54,55].
Figure 1.
Map of the studied area (Alshafa and Alhada), (Adopted from https://www.google.com/maps/place/Alhuda/@21.3576171,40.2116973,30169m/data=!3m1!1e3!4m5!3m4!1s0x15e9f53ca39b5a35:0xbdbc9ddc70a2f409!8m2!3d21.3648223!4d40.2803491 (accessed on 10 March 2022).
In the selected study area, the pink damask rose (Rosa damascena trigintipetala) is the most famous and significant crop. It necessitates a well-draining, well-watered, highly fertilized, and slightly acidic soil. Rose shrubs are generally planted at the edges of the fields to benefit from irrigation in the center; harvesting is done in the morning for about a month in the spring before the oils evaporate. Roses thrive in a temperature range from 20–30 °C during the day to 18–20 °C at night [56,57,58,59,60,61,62]. The ideal temperature range for rose cultivation is 19–27 °C, which is compatible with the Al-Hada and Al-Shafa climates. The long period of 5–15 °C in spring ensures a high concentration of oil in many flowers per plant [63]. Rosa damascena needs watering from 10–12 times throughout the year. Watering should be done twice a week during spring and summer, but not throughout the rainy season [64].
3.2. Phenotyping Datasets
Fresh plants were harvested from 10 farms spread across two different areas of Taif (Al-Hada and Al-Shafa) in April 2021. Then, samples were transferred from the farms to the Research Center at Taif University in Saudi Arabia. To account for the variation of rose plants within the same farm, each farm was divided into four blocks; 50 flowering plants were collected from each block, yielding a total of 2000 samples. Figure 2 depicts the locations of the farms, and Figure 3 illustrates the statistical summary of the phenotypic datasets. Canopy diameter (CD), leaf dry weight (LFW), leaf fresh weight (LFW), leaf area (LA), number of leaflets (NL), number of anthers (NA), number of petals (NP), trunk diameter (TD), number of branches (NB), plant height (PH), bud length (BL), bud width (BW), receptacle length/receptacle width (RL/RW), flower fresh weight (FFW), and flower dry weight (FDW).
Figure 2.
Geographical locations of the 10 Taif roses farms (Al Hada (a) and Al Shafa (b)), from which samples are collected.
Figure 3.
Boxplot of the phenotyping dataset: (a) Canopy diameter (CD), (b) leaf dry weight (LFW), (c) leaf fresh weight (LFW), (d) leaf area (LA), (e) number of leaflets (NL), (f) number of anthers (NA), (g) number of petals (NP), (h) trunk diameter (TD), (i) number of branches (NB), (j) plant height (PH), (k) bud length (BL), (l) bud width (BW), (m) receptacle length/receptacle width (RL/RW), (n) flower fresh weight (FFW) and (o) flower dry weight (FDW). Units of measurements are: cm (CD, TD, PH, BL, BW, RL/RW); g (LDW, LFW, FFW, FDW); No. (NL, NA, NP, NB) and cm2 (LA).
We collected statistical and biometric data from subsets of Rosa x damascena accessions grown in Taif realistic rose farms and evaluated the phenotypic characteristics of plants from each plot using a complete random block design. Figure 4 represents Taif rose samples collected from the study area. As described by Rusanov et al. [65], and Osorio-Guarín et al. [66], all 15 traits were evaluated in both morphological and yield-related categories for heritability and genetic architecture. Plant height, number of branches, trunk diameter, number of petals, number of anthers, number of leaflets, leaf area, leaf fresh weight, leaf dry weight, and canopy diameter were evaluated as morphological-associated traits. The traits that determine flower yield included: flower fresh weight, fresh and dry weight of petals, and receptacle length and width. Figure 4 shows images of Taif rose samples taken from the study area.
Figure 4.
Samples of the Taif rose plants.
3.3. Satellite Imageries Datasets
Plenty of geospatial datasets harvested from different satellite imagery sources are combined with phenotyping measurements taken from several rose farms to form the knowledge base of TRBRS. These datasets are collected from their sources as Image Collections or Feature Collections data types and then filtered based on the time and province’s geographical boundaries using Google Earth Engine Pythons’ Application Programming Interfaces (APIs). The filtered data are then processed using customized Python scripts to extract the embedded temporal and spatial datasets and then store them in multiple comma-separated values (CSV) files that are fed into the proposed model. In this study, the first dataset used consists of land surface temperature (LST) readings observed during the day and night, derived from the Moderate Resolution Imaging Spectroradiometer (MODIS)’s MOD11A1 Version 6 which is operating on the TERRA satellite by the National Aeronautics and Space Administration (NASA) Earth Observing System Data and Information System. MOD11A1 provides daily readings per pixel at a spatial resolution of 1 × 103 m over a grid of 1 × 1012 m, which makes it among the most accurate for monitoring land surface temperatures.
The major reason to take measurements of land surface temperatures during the day and nighttime is to assess the effects of land emissions on the rose’s phenotyping without considering the variations of day/night cycles with the seasons. In addition, this study uses the datasets of Normalized Difference Vegetation Index (NDVI) and Enhanced Vegetation Index (EVI) to determine the vegetation fluctuation within farms of Taifs’ Rose. Both datasets were adopted from the MODIS MYD13A2 version 6 collection, which uses atmospherically corrected blue, red, and near-infrared reflectance readings to produce daily forecasts. A MODIS specific compositing algorithm is then applied to the readings to remove low quality pixels and apply a constrained view angle approach to generate 16-day intervals at 500 m for the vegetation indices at high spatiotemporal resolution. Incorporating both NDVI and EVI indices in this study allows us to gather comprehensive information about crop growth and expected yields from different perspectives. NDVI [42] is designed to detect pigment absorption in the 660 nm and near 860 nm electromagnetic spectrum, making it suitable for detecting weeds as well as diseases. On the contrary, the EVI uses signals from 450 nm of red, blue, and infrared wavelengths, which is more resistant to fluctuations in the soil backgrounds.
In view of the importance of irrigation scheduling and water quality on yields of Taif roses, this study examines 10 datasets quantifying climatic water balances. The Actual Evapotranspiration (AE) dataset refers to the amount of water that is effectively removed from the land surface by evaporation or transpiration processes; Dataset on Climate Water Deficit (CWD) indicates the amount of water demanded each year by plants over the available supply of water. A combination of AE and CWD was used in this study to assess the irrigation demand and landscape street. The Palmer Drought Severity Index (PDSI) dataset constitutes the third dataset used in this study to quantify the climatic water balance. This dataset utilizes precipitation and temperature data to determine relative dryness and moisture of the geographical area considered; this dataset differs from CWD and AE in that it is able to estimate long term drought considering global warming effects.
Two datasets within the TRBRS Knowledge Base address land water storage and vapor: Runoff (Roff) and Vapor Pressure Deficit (VPD). The first dataset provides information about how much water runs off the land, and the second indicates how much vapor pressure is existing in the air in comparison with what it should be under saturated conditions. Lastly, the Wind Speed at 10 Meters dataset is used to determine the effect of wind on crop growth.
All the datasets presented are read from IDAHO_EPSCOR/TERRACLIMATE image collections provided by the University of California Merced with a spatial resolution of 4638.3 m and several temporal resolutions. Table 1 lists the details of these datasets: the first column provides the identifier of each dataset, and the second column provides a brief description of each dataset, the unit column specifies the physical units of data, and this study uses the international system to represent the datasets. The fourth and fifth columns indicate the spatial and temporal resolutions at which the dataset was generated by a satellite’s instrument, and the reference column indicates the source of dataset. Satellite imageries datasets used in this study; are also presented in Figure 5.
Figure 5.
Samples of the dataset used in this study; (a) image of daytime land surface temperature of Makkah province, (b) timeseries of the daytime land surface temperature of Makkah province, (c) image of nighttime land surface temperature of Makkah province, (d) timeseries of the nighttime land surface temperature of Makkah province, (e) image of EVI of Makkah province, (f) timeseries of EVI of Makkah province, (g) image of CWD of Makkah province, (h) timeseries of CWD of Makkah province, (i) image of PDSI of Makkah province, (j) timeseries of PDSI of Makkah province.
Table 1.
Summary of the satellite imagery datasets used in this study.
4. Methods
The artificial neural networks (ANNs) are among the state-of-the-art techniques being used in a wide range of fields, including but not limited to image classification and generation, timeseries prediction and forecasting as well as natural language processing. ANNs consist of artificial neurons (AN) that have been created to mimic the actions of biological neurons [70]. Each AN comprises a mathematical transformer-dubbed activation function that maps the given input into the corresponding output by adjusting a set of learnable parameters called weights and biases. Multitude numbers of networks can be generated by arranging ANs in different layers and cascading them in layers in order to illustrate the operations of ANN formally, let denotes an ANN consisting of layers numbered from to , each of which has its own input, activation function, weights, a bias and outputs that are denoted by , and respectively; . Thus, the devised artificial neural network can be defined as:
The proposed model employs three different types of ANs to maintain broad application without increasing computational complexity: (1) convolutional neural networks (CNNs), (2) long short-term memory (LSTM), and (3) fully connected multilayer perception (MLP). Overviews of the network types are provided in the following subsections, while detailed descriptions of the proposed model are described in Section 4.
4.1. Convolution Neural Network
Convolutional neural network (CNN) has been widely used to analyze images because it can automatically extract latent features [71]. A CNN layer consists of a set of filter banks of learnable parameters that scan a collection of images, trying to find common features. A CNN uses a special mathematical operator dubbed two-dimensional convolution from which the name of the CNN is derived. A two-dimensional convolution multiplies each instance of a predefined filter bank by the commensurate sets of the given image’s pixels and then adds the multiplication results at that given instance. In this way, the result of the convolution operation adds all the features present in the pixels of the original image into a smaller dimension. Since the parameters of the filter do not have fixed values, but rather vary based on the contents of the image, these types of networks can be used to summarize the features of the original image. The majority of ANN’s monographs refer to CNNs as feature extracting networks due to their ability to obtain salient information from images without requiring a priori knowledge of their structure. Equation (2) describes the convolution operator between the pixel of an image whose dimension is denoted by and an instance of filter bank of dimension conditioning that and .
The resultant of convolution operation is referred to as receptive field because it allows us to recognize the most obvious properties discovered in the subsets of the original image’s pixels in the context of the used filter. The filter’s size is one of the essential criteria that needs to be carefully chosen. With a larger filter, there is more information in each receptive field, but fewer receptive fields; that is to say, using a large filter size reduces the likelihood of vanishing gradients, but at the cost of increasing the model’s parametric space. Despite the fact that the outputs of the convolutional layer are condensed versions of the original inputs, their high-dimensional space hinders further processing by the subsequent layers. Consequently, multiple dimensional reduction layers are added after the convolutional layer. These layers usually include nonlinearity, drop out, and pooling. Nonlinearity applies a nonlinear function, namely an activation function, into its input to remove pixels that are below a certain threshold. There are a number of activation functions that have been described in the literature; this work utilizes the rectified linear unit () which is defined as:
The key advantages of are two-folds: first, its low computational complexity since it uses a simple mathematical operator, allowing us to deepen the network without using significant amounts of computing resources. The second benefit of using is that is that it accelerates the convergence of the model to the optimal value since it drives the gradients of the errors between the predicted value and its ground truth value.
After the nonlinearity layer, the dropout layer is added with the aim of removing those parts of neurons or connections that do not contribute significantly to the coverage of the deep learning model. Among the several approaches to defining the number and conditions for drop-out layers, we adopt the technique of gradually increasing the likelihood of drop-out connections between neurons and their connections across layers.
Finally, a pooling layer is applied to the dropout layers in order to down sample the outcomes of the previous layers; down sampling is performed by applying an aggregation operator, such as maximum, minimum, average, or median, to a set of pixels. To enhance the contrast between the outcomes of our model, we define the max-pooling layer as follows in this study:
where is a set of the pixels that is passed to the max pooling function as an argument, in this study we use a widow of four which has the effect of halving the dimensions of the given images.
4.2. Long Short-Term Memory
Long short-term memory (LSTM) is the second type of ANN that is used in this study. LSTM belongs to the recurrent neural network family that is well-known for its ability to treat sequential datasets, i.e., those types of data in which each element has a particular chronological relationship to the other elements. Typically, LSTM network comprises a set of LSTM cells that is linked with two vectors: state-vector and hidden vector. A state-vector is used to propagate the information downstream across the LSTM cells, whereas the hidden vector stores the important information extracted by the earlier cells. By combining the information contained within these two vectors, the network will be able to determine the pattern that generated the dataset, as well as predict the future behavior based on that information. Each LSTM uses three types of gates to determine what information should be included in each vector: input, forget, and output gates. Figure 6 shows a schematic diagram of an LSTM network comprising three cells along with the internal structure of a typical cell.
Figure 6.
Schematic diagram for the Bi-LSTM.
As shown in Figure 6, the forget gate is the first building block of an LSTM cell. An important function of this gate is to fade away undesirable information passed to it from the processing cells in the hidden vector and state. Consequently, only the relevant information can be considered by the current cell. The forget cell uses a fully connected MLP network with the Sigmoid activation function, denoted here by (σ). At a time instance , the forget gate takes the corresponding input at that instance and the instance of the hidden state vector that is generated at the previous instance and manipulating them to generate a vector of length , i.e., the cardinality of the hidden vector; ranging over the interval [0,1] quantify which information is required to remove from the hidden vectors. In mathematical notation can be expressed as:
where and are the transposes of weighting vectors of the forget gate and its bias term respectively, whereas denotes the concatenate operator that is used to add the contents of and literally.
The input gate is the second building block of an LSTM cell, which updates the cell state with the information that is commensurate with the new information. Although the ingress of the input gate is identical to the ingress of the forget gate, i.e., and , their internal structure differs substantially. Input gate consists of two fully connected MLP layers, where the first layer employs the hyperbolic tangent as an activation function to identify information that needs to be added to the input and hidden vector, respectively, and the second layer utilizes the Sigmoid function to remove meaningless information from the input. The following two equations describe the output of these two layers:
The output of these two layers is then combined and sent downstream to the output gate, which integrates the findings of the LSTM cell. The output gate employs the tanh function in order to write the necessary information into the cell and hidden state, so that subsequent cells are able to use the newly added information. The following two equations illustrate these operations.
4.3. The Proposed Model
Figure 7 illustrates the block diagram of the proposed model in terms of the number of layers representing inputs, outputs, and how they are connected. In this model, both images and timeseries are taken from the ten satellite images listed in Table 2. A convolutional neuronal network (CNN) is formed by combining two “convolutional- nonlinearity- dropout-max pooling” units and two “bidirectional long short-term memory” (BiLSTM) units for each input. The output of CNN and BiLSTM are then concatenated and passed downstream to three fully connected layers from which the output (i.e., the 15 phonotypes listed in Figure 2) is obtained.
Figure 7.
Block diagram of the proposed model.
Table 2.
Dimensions and parameters of the proposed model.
Using satellite images as input and phenotypes as output allows the model to be able to acquire the various forms of relationships between them effectively. To develop the proposed model, two different approaches have been used. First, we have used a complementary approach in which both spatial and temporal information are considered simultaneously for each satellite image instance. In such a way, the model can leverage the knowledge gained from processing the same data from different perspectives, thus enhancing predictability even when the dataset is incomplete or noisy.
An additional design approach that has been applied in the model is the contextualization learning, by which all timeseries of the image sensors except one that is used by the considered Bi-LSTM unit are utilized as features for that timeseries. For example, the Daytime Land surface Temperature (DLT), Nighttime land surface Temperature (NLT), Normalized Difference Vegetation Index (NDVI), Enhanced Vegetation Index (EVI), Actual Evapotranspiration (AE), Climate Water Deficit (CWD), Palmer Drought Severity Index (PDSI), and Runoff (Roff) are used as feature set for the Vapor Pressure Deficit (VPD) input. By utilizing contextualization learning approach, we aim to enable the model to grasp the correlations between the different timeseries, which is vital for understanding the effects of each factor on the others. Further details about the mechanism by which the model processes the inputs, reveals the latent relations among them, and generates the output are provided in Table 2 which shows the dimensions, input, output, and number of learnable parameters (weight and bias) of each layer explaining in terms of width (W), length (L), and depth (D) of a single instance of input. The length and width of the image input is adjusted to length and width of each image (which are 255 and 255 respectively) whereas the depth of this layer is set to the number of image channel (red, green, and blue). The main purpose of this layer is to arrange the images in such a manner that the subsequent layers can process them; thus, its dimension, input, and output are of the same shape, while the number of parameters is 0. The output of the image input layer is then passed to the first convolutional layer (i.e., Convolutional_1) that consists of 32 filters each of which is . This bank of filters reduces the width and length of the Convolutional_1′ input by 2 units and increases its death to 32. Although the output of this layer, also known as features map, as discussed in Section 3, is smaller than its input, the contents of features map represent a concentrated version of the input. The learnable parameters of the Convolutional_1 layer is 896 which is the result of multiplying the length (3), width (3), and number of filters (32) of this layer by the number of its input’s depth (3) then adding up the multiplication results to the number of biases of this layer (32) as each filter has a single bias.
Table 2 shows that Nonlinearltiy_1 layer has zero parameters and does not change the shape of its input, which is consistent with its primary function being to apply a nonlinear function (ReLU here) to each pixel of the input. Nevertheless, the main advantage of this layer is highlighting the salient feature in a more concise manner by removing all the cells on the features map that are less than a given value. Following Nonlinearity_1, Dropout_1 is used to prune certain parts of the models that do not contribute significantly to the learning process according to specific percentage (which is set to 0.4 here). It is clear that the Dropout_1 layer preserves the dimensions of its inputs.
The last layer in the first CNN tuple is MaxPooiling_1, which is used to select the maximum values among the adjacent input’s cell of a given dimension, in our case. This in turn enables the MaxPooiling_1 to halve its input. As it can be seen from Table 2 that the second tuple of the CNN (i.e., Convolutional_2, Nonlinearltiy_2, Dropout_2, MaxPooiling_2) have identical characteristics as of the first tuple. It is noteworthy that one of the main functions of the Flatten layer is to convert the multiple dimensions generated by the preceding layers into a vector of a single dimension for seamless integration into the outcomes of the BiLSTM units. For the purpose of processing the timeseries of the satellite imagery datasets, the timeseries input forms the first block of the architecture. In this layer, the width and depth are set to 1 and 9 respectively, indicating in how many steps the first BiLSTM layer processes the dataset and the number of features associated with each input instance. These values are set in accordance with the contextualization learning strategy discussed earlier. The length of the timeseries input varies across datasets depending on the time resolution (given in Table 2) at which the measured dataset is sampled per year multiplied by the number of sampling years, which is 5 in the current study. This means that the length of the timeseries input designed to treat the daytime land surface temperature dataset can be calculated as since the temporal resolution of this dataset is one per day whereas the length of the Runoff dataset is as the frequency of this dataset is monthly.
As shown in Table 2, the first layer of BiLSTM has a width and depth of 100 and 9 respectively. This reflects the fact that there are 100 neurons in this layer, each of which reacts to the inputted dataset. By considering the BiLSTM layer that conducts learning processes in both forward and reversal directions, it appears to be the output of this . A number of parameters in the first BilSTM layer are independent of timesteps as can be seen in Table 2. Notably, the number of Bi-LSTM parameters is calculated by summing three terms: first, the number of parameters required to extract the features of the incoming readings is determined by multiplying the directions of the Bi-LSTM (2) by the number of features (i.e., 9), by the number of neurons in each BiLSTM (i.e., 100), by the number of gates in each BiLSTM (i.e., 4) yielding (7200) parameters. The second term contributing toward computing the BiLSTM parameters is the multiplication of Bi-LSTM directions (2) by the number of gates (4) by the square root of BiLSTM’s neurons (100), which yields (800,000) parameters. These parameters quantify the adjustable weights used by the BiLSTM to process the extracted data. The last term used to calculate the BiLSTM parameters is that it counts its basis which can be computed by multiplying the directions of the BiLSTM (2) by the number of neurons (i.e., ). By adding the three terms together, we can calculate BiLSTM’s total parameters to be 8800.
The second BiLSTM has the same structure as the first BiLSTM, however, its depth is 200, resulting in an increase in parameters of about 2.7. The concatenate layer derived at the end of the second BiLSTM and flatten layer is used to make the findings of these two layers suitable for the fully connected layer that is used to calculate the predicted value. As its name implies, the primary responsibility of the concatenate is to migrate the findings of these two layers into a vector, hence the output’s dimension of this layer reflects the sum of the two layers.
The above description may be applied to all the layers utilized to analyze the inputted datasets; therefore, the remainder of this section will focus on the fully connected layers.
In Table 2, it is evident that the first layer (FullConnected_1) is composed of 100 neurons and its input is an array which comprises the outputs from all concatenate layers of the 10 satellite imaging datasets described in Section 2. Consequently, the number of parameters of this layer can be calculated by multiplying the number of neurons (100) by the number of inputs (1,230,080) and adding the biases (100) to it. Since fully connected layers use their neurons to encode inputs, their outputs are equivalent to the number of neurons in that layer. The second full connected layer (FullyConnected_2) has the same structure as the first layer except that its input is 100, the output of FullyConnected_1. This maintains the output of this layer as 100.
The fact that the prediction of the model is based on the last fully connected layer, FullyConnected_3 allows us to explain why the number of neurons in that layer is set to 15 (i.e., the number of phenotyping datasets).
It is also essential here to discuss the methods used to train the proposed model with the division included. Model implementation has been tested on a single machine that runs Ubuntu operating system in the 11th generation Intel core processor whose speed is 5.3 GHz with 8 core/16 threads. The machine consists of 62 GB of memory and a GeoForce RTX 2060 graphics processor unit. The model was developed in Python 3.10 using Tensorflow and Keras libraries. Both satellite imagery and phenotyping datasets were divided into two classes: training and testing and were fed into the model in an 80:20 ratio. The Huber loss function is used to compute the losses of the model during the train and test phases. This function has been selected because of its ability to mitigate the effects of outer liners present in the multivariant regression datasets. Adam optimizer with and are used to derive the loss function toward the optimal values whereas the back propagation and back propagation through time with gradient descent are used as learning strategies for the CNN and BiLSTM respectively. The learning rate is set to 0.001 and the number of learning epochs to 500.
In this regard, concatenating CNN and LSTM neural networks enriches the flow of information inside the model and improves prediction accuracy. Feature-level fusion is a term commonly used in artificial neuron communities to describe this process, as it enables the seamless integration of the findings of different models. There are two main advantages of employing the principles of fusion at the feature level: first, it allows us to merge both spatial and temporal features from each of the 10 satellite images before passing them on to the fully connected layers where phenotyping is applied. In turn, this can facilitate consolidating input knowledge concisely. Two other benefits of using this principle involve the ability to deepen the model by cascading LSTMs and CNN architecture to other models.
5. Results and Discussion
It is the objective of this section to evaluate the performance of the proposed model by comparing its outcomes to phenotyping readings taken from Taif rose plants. The following statistical measures are used to quantify this assessment: mean absolute error (). The mean absolute error () is a primary method for evaluating the overall performance of the model. It operates by using Manhattan distances between the predicted values, (the output of the last fully connected layer, denoted here by ) and their corresponding ground truth (i.e., phenotyping readings taken from Taif roses fields, denoted by ). Mathematically, can be expressed as:
where is the number of samples over which the average is computed. Intuitively, can be interpreted as the magnitude of errors that we expect from the model on average; thus, the closer to zero the higher prediction accuracy the model has.
Mean absolute percentage error () is defined as the proportion of the average absolute differences between the forecasted and ground truth readings with respect to the ground truth values; hence MAPE can be defined formally as:
Comparing Equations (8) and (9) reveals that the key difference between and is that the reading of the latter metric is divided by the true values, which makes the result more sensitive to deviations from the true values. The values of can be interpreted similarly to ; i.e., the larger values indicate a large disparity between them and the ground truth, and vice versa. It is worth noting that employing the Manhattan distance in and hinders their ability to exhibit abnormal errors, i.e., outliers. Hence, a new family of statistical measurements based on replacing the Manhattan distance with Euclidean distance was proposed. Mean squared error () and mean square percentage error () are examples of this family, and both can be computed using similar procedures of MAE expect that the squared differences between the actual and predicted values are used instead of absolute differences, hence it can be expressed as:
Obviously, incorporating squared errors in and makes the larger error have greater effect on the value of the metrics and vice versa which in turn allows them to identify the underprediction and overprediction readily.
5.1. Assessing the Complementary and Contextualization Learning Approaches
A complementary learning approach and a contextualization approach are analyzed in the first assessment of the proposed model. In the complementary learning approach, the model uses both spatial and temporal instances of each dataset simultaneously whereas the contextualization learning approach employs all timeseries datasets except one that is used by the considered Bi-LSTM unit as features for that timeseries. This assessment was based on the implementation of three variants of the proposed model, denoted here by model_org. First, model_v1 analyzed only images from image sensors, and therefore timeseries data could not be incorporated at all. This is accomplished by removing all of the BiLSTM units and their connections from the model_org. In the second model version (model_v2), only the timeseries datasets are considered for input, and they are treated using contextualization learning as described above. This makes model version 2 free of CNN units. The third model variant, i.e., model_v3, uses the timeseries and imaging datasets as inputs in a manner similar to that of the original model (model_org). However, in the model_v3 the contextualization learning approach is suspended. As a result, each timeseries in the dataset has been treated independently without considering the other timeseries. To achieve this, we set the depth of the temporal model to 1.
Assessments for the proposed model and its variants using the four statistical measurements mentioned above are given in Figure 8.
Figure 8.
(a) MAE, (b) MAPE, (c) MSE, and (d) MSPE of the proposed model and its variants.
In general, it can be seen from Figure 8a that the MAE characteristics of all models at initial learning phases are about the same, the highest values of the MAEs readings are recorded at epoch 0 and then they start to decay as more epochs elapsed. Nevertheless, the rate at which decay occurs and the region in which decay stops vary significantly between these models. It is clear, for example, that this model reaches the zero region in less than 100 epochs, whereas other models need more time to reach the same region or settle to a nonzero region. This superior performance can be attributed to the fact that model_org is able to encode all possible relationships between satellite images and phenotyping datasets, using both complementary and contextual learning approaches. Consequently, model_org consolidates learning over time, resulting in a continuous decrease in the difference between the value generated by the model and its corresponding ground truth. Furthermore, the characteristics of other models that have MAE are consistent with this interpretation. The characteristics of model_v3 reveal that removing the complementary learning approach and depending on the imaging part of the dataset delay approaching the zero-MAE-region by roughly five-folds compared to model_org. The delay can be attributed to the extensive processing power needed to extract salient features from images and then incorporating them into the learning hypothesis of the model.
As shown in Table 2, manipulating a single instance of image requires 123,008 units whereas manipulating a timeseries instance requires only 200 units. This comparison highlights the benefit of using timeseries instead of images as training datasets, however, the MAE assessment results for model_v1 and v2, which use timeseries as their sole dataset, show a modest performance in comparison with other models. It is noteworthy that both model_v1 and v2 do not approach the zero-MAE region, but instead settle at 0.1 and 0.15, respectively. These characteristics may be attributed to satellites gathering images of phenomena occurring on the earth and transforming it into a time-series by utilizing one or more dimensional reduction algorithms. Additionally, these operations not only leak some information, but also create noise in the resulting timeseries. While postprocessing algorithms can remove noise from timeseries, employing such algorithms may further reduce the depth of projected information. It is interesting that discontinuing the contextualization learning approach from model_v1 requires the model to exert more effort to gain all of its knowledge from a single timeseries, which in turn causes the MAE to fluctuate in accordance with the noises in the single dataset.
Figure 8b shows that the normalized MAPE has similar characteristics to the normalized MAE, which can be explained by the fact that the MAPE is obtained by normalizing the MAE with respect to the true values. However, using MAPE allows us to see highly detailed information due to normalization.
The results of MSE and MSPE measurements for the four models are shown in Figure 8c,d respectively. These results reveal some of the interesting behavior of these models. The model_v3 MSE for instance, behaves stochastically rather than asymptotically as the MAE curve, i.e., it goes up and down at some epochs before settling down at a steady-state value. The reason for this is that the image datasets used as a sole training source by this model have a great degree of color depth, which raises the chance of generating erroneous outliers during some learning epochs. As a result of the high sensitivity of the MSE to outlier errors, its fluctuations can be justified. It is evident that the model_v1 and model_v2, which employ only timeseries data without and with contextualization learning approach respectively suffer from such fluctuations, in addition to substantial residual errors. BiLSTM’s gradient vanishing problems are the cause of these characteristics. Gradient vanishing occurs when no further improvements in the mode’s learning process are possible with decreasing gradients for the parameters. The comparison between MSE performance for model_v1 and model_v2 shows the improvements that contextualization learning strategies can generate in terms of reducing fluctuations and residual errors. This reduction results from the fact that the contextualization learning approach empowers the model with sufficient capabilities to recognize timeseries instances from a variety of perspectives. Obviously, combining the benefits of complementary and contextualization learning approaches allows the original model (model_org) to achieve the best results comparing to its variants.
5.2. Assessing the Performance under Training and Testing Datasets
The second assessment for the proposed model and its variants is conducted by evaluating their ability to predict the phenotyping readings from a collection of satellite images datasets that have not been used during the training phase. This assessment uses the k-fold cross-validation schemes in which the whole datasets are divided randomly into k sub-datasets. Subsequently, a portion of these sub-datasets is used to train the model (i.e., the satellite images and their phenotyping measurements are fed into the model with the aim of adjusting the learnable parameters) whereas the remaining sub-datasets are used to test the model (i.e., only the satellite images without the associated phenotyping measurements are fed into the model). A rotation between the training and testing sub-datasets is performed until all the sub-datasets are used in both training and testing phases.
Consequently, the performance of models can be validated comprehensively based on multiple folds of datasets. To thoroughly examine the models, two ratios of training to testing are used: the first one is 10:1 where the whole dataset is divided into 10 sub-sets; 9 instances are used in training and modeling, and 1 instance is used for testing; and the second one is 5:2 where the entire dataset is divided into five folds, two of which are used for training, and the remaining three for testing. The MAPE and MSPE readings at the end of the training and testing phases (i.e., at 600 epochs) of the original model (model_org) and its three variants are given in Table 3. Figure 9 shows high level abstract for how the datasets are divided in the two k-fold cross-validation schemes.
Table 3.
MAPE and MSPE of k-fold assessment.
Figure 9.
High level abstract for how the datasets are divided in the two k-fold cross-validation schemes.
It can be seen from Table 3 that the and readings of the original model are fixed at zero whereas the readings of its variants vary among folds and increase significantly when a smaller number of folds are used. Based on the high fluctuations in metrics of the non-original model between the training and testing phases, it is likely that the suspension of both complementary and contextualizing learning approaches resulted in a greater generalization gap between the three variant models. By using only one instance of each dataset, the models would be unable to extract salient features from the input data. This in turn leads the models’ parameters toward saturation region (also referred to as overfitting) where the model’s parameters are adjusted to suit only a training dataset, leading to poor performance when different datasets are used. By comparing the performance metrics of the 9:1 and 5:2 assessment strategies of the three variants model, we find that a smaller number of folds leads to a noticeable decrease in metrics. In the 10:1 strategy, 90% of the datasets are used for training the model and the remaining 10% for testing, while in the 5:2 strategy, only 60% of the datasets are used for training and 40% for testing. By reducing the training datasets, the model becomes unfit for making accurate predictions on the new datasets, and this issue is known as underfitting. The zero-readings of the original model in all cases indicate its resistance to overfitting and underfitting problems, which reflects the appropriateness of the model’s architectures and parameters to the characteristics of the satellite images and to the phenotyping of Taif roses.
As an illustration of the superior performance of the new model, i.e., model_org, the scatter plots of the 15 phenotypes of the Taif rose are shown in Figure 10, which compare the real values associated with the Taif rose farms with the predicted values. The results are obtained under the 5:2 training to testing datasets whose and values are summarized in Table 3. As can be seen from these results, all the real and predicted values fall on the diagonal red lines, which demonstrate the ability of the proposed model to generate zero and values as shown in Table 3. The results can be attributed to the capability of the approaches utilized in the design of the proposed model to identify latent features from the inputs and the outputs of the model, embed them into the model’s hypothesis space and exploit them to generate the desired outputs. It is noteworthy that the 5:2 datasets scheme is used here since it provides the most thorough assessment for the model since only 40% of the total datasets are used to train the model and the remaining for testing its performance. Particularly, we have generated scatter plots to visualize the 9:1 training to test datasets scheme and obtained the same results.
Figure 10.
Scatter plots for the real versus predicted values of the 15 phenotypes of Taif rose. Canopy diameter (CD), leaf dry weight (LFW), leaf fresh weight (LFW), leaf area (LA), number of leaflets (NL), number of anthers (NA), number of petals (NP), trunk diameter (TD), number of branches (NB), plant height (PH), bud length (BL), bud width (BW), receptacle length/receptacle width (RL/RW), flower fresh weight (FFW), and flower dry weight (FDW).
5.3. Assessment of Different Loss Functions
The previous two sections investigated whether utilizing complementary and contextualized learning approaches can improve the ability of the proposed deep learning model to treat both spatial and temporal datasets simultaneously. Despite this, the loss function used to compute the output considers all 15 different phenotypes at once, which raises the question of whether or not using a single loss function for each phenotype will result in improved performance. In order to address this question, 15 new models are constructed, each of which uses the same sort of input, i.e., the image and timeseries of the satellite imagery datasets listed in Table 2, while the output is obtained as a single instance of one of the 15 phenotypes described in Section 3.2. The MAE, MAPE, MSE, and MSPE readings of each model vs. the number of epochs are computed and normalized with respect to the peers of the original model. The results of the assessment are shown in Figure 11, Figure 12, Figure 13 and Figure 14. The performance provided by these new models is modest when compared to the original model; it can be seen for instance that the MAE readings of L/RW and NB are about 100 times lower than their counterparts of the original model. Outperforming the original model illustrates the benefit of using a single loss function to predict the phenotyping readings as opposed to utilizing a single loss function for each instance. This is due to the spatiotemporal datasets that are input to the model that encompass all of the phenotyping instances.
Figure 11.
MAE of the newly constructed models normalized to the original model.
Figure 12.
MAPE of the newly constructed models normalized to the original model.
Figure 13.
MSE of the newly constructed models normalized to the original model.
Figure 14.
MSPE of the newly constructed models normalized to the original model.
6. Conclusions and Future Work
Our study presents a new deep learning model that enables us to predict Taif rose phenotypic traits from satellite images of the earth; this allows us to get real-time and comprehensive information about all factors that influence farming initiatives at no cost. The model uses a complementary learning approach that considers both spatial and temporal instances of data, which not only enables us to understand the same data through a variety of perspectives, but also enhance its predictability when dealing with incomplete or noisy datasets. Three different types of artificial neural networks are employed in the proposed model to ensure broader application without increasing computational complexity: (1) convolutional neural networks (CNNs), (2) long short-term memory (LSTM), and (3) fully connected multilayer perception (MLP). By comparing the proposed model’s outcomes with a comprehensive phenotyping measure taken from real-size data, extensive assessments have been conducted to assess its validity. It is noteworthy that in all cases the zero-readings of the model demonstrate a high level of accuracy in its prediction due to the model’s architectures and parameters being relevant to the characteristics of the satellite-images as well as the Taif rose. The design of our model has been evaluated only on Taif rose species; however, we expect our design methodology to allow generalization to other types of crops with minimal modifications. Future work will include evaluating our networks with other important crops in Taif that have different plant morphologies. Additionally, future research will be conducted to determine if estimation accuracy can be improved by using larger datasets in subsequent growing seasons, and by using a combination of association genetics methods and markers derived from the genome of Taif Rose to accomplish an integrated TRBS approach.
Author Contributions
Conceptualization, H.M.A. and M.B.; methodology, M.B.; software, H.G.Z.; validation, M.B., M.A.A. and J.F.A.-A.; formal analysis, M.B.; investigation, M.A.A.; resources, M.M.M. and A.A.; data curation, M.B.; writing—original draft preparation, M.B. and M.A.; writing—review and editing, H.M.A.; visualization, M.A.A.; supervision, H.M.A.; project administration, H.M.A.; funding acquisition, H.M.A. All authors have read and agreed to the published version of the manuscript.
Funding
This work was financially supported by a research project No. [1-441-126] from the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia.
Data Availability Statement
All data generated or analyzed during this study are included in this published article.
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia for funding this research work through the project number [1-441-126].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rusanov, K.; Kovacheva, N.; Vosman, B.; Zhang, L.; Rajapakse, S.; Atanassov, A.; Atanassov, I. Microsatellite analysis of Rosa damascena Mill. accessions reveal genetic similarity between genotype s used for rose oil pro-duction and old Damask rose varieties. Theor. Appl. Genet. 2005, 111, 804–809. [Google Scholar] [CrossRef]
- Kashefi, B.; Matinizadeh, M.; Tabaei-Aghdaei, S.R. Superoxide dismutase and α-amylase changes of Damask rose (Rosa damascena Mill.) tissues seasonally. Afr. J. Agric. Res. 2012, 7, 5671–5679. [Google Scholar]
- Teo, C.J.; Chin, S.Y.; Wong, C.K.; Tan, C.C.; Goh, K.J. Planting Materials for High Sustainable Oil Palm Yields. In Proceedings of the Malaysian Oil Science and Technology (MOST); Malaysian Oil Scientists’ and Technologists’ Association: Petaling Jaya, Malaysia, 2017; Volume 26, pp. 58–119. [Google Scholar]
- Niazian, M.; Sadat-Noori, S.A.; Abdipour, M.; Tohidfar, M.; Mortazavian, S.M.M. Image Processing and Artificial Neural Network-Based Models to Measure and Predict Physical Properties of Embryogenic Callus and Number of Somatic Embryos in Ajowan (Trachyspermum ammi (L.) Sprague). Vitr. Cell. Dev. Biol. Plant 2018, 54, 54–68. [Google Scholar] [CrossRef]
- Ahmad Latif, N.; Mohd Nain, F.N.; Ahamed Hassain Malim, N.H.; Abdullah, R.; Abdul Rahim, M.F.; Mohamad, M.N.; Mohamad Fauzi, N.S. Predicting Heritability of Oil Palm Breeding Using Phenotypic Traits and Machine Learning. Sustainability 2021, 13, 12613. [Google Scholar] [CrossRef]
- Eli-Chukwu, N.; Ogwugwam, E.C. Applications of Artificial Intelligence in Agriculture: A Review. J. Eng. Technol. Appl. Sci. Res. 2019, 9, 4377–4383. [Google Scholar] [CrossRef]
- Yoosefzadeh-Najafabadi, M.; Earl, H.J.; Tulpan, D.; Sulik, J.; Eskandari, M. Application of Machine Learning Algorithms in Plant Breeding: Predicting Yield From Hyperspectral Reflectance in Soybean. Front. Plant Sci. 2021, 11, 624273. [Google Scholar] [CrossRef]
- Jung, M.; Song, J.S.; Hong, S.; Kim, S.; Go, S.; Lim, Y.P.; Park, J.; Park, S.G.; Kim, Y.-M. Deep Learning Algorithms Correctly Classify Brassica rapa Varieties Using Digital Images. Front. Plant Sci. 2021, 12, 738685. [Google Scholar] [CrossRef]
- Sandhu, K.S.; Lozada, D.N.; Zhang, Z.; Pumphrey, M.O.; Carter, A.H. Deep Learning for Predicting Complex Traits in Spring Wheat Breeding Program. Front. Plant Sci. 2021, 11, 613325. [Google Scholar] [CrossRef]
- Rutkoski, J.; Poland, J.; Mondal, S.; Autrique, E.; Pérez, L.G.; Crossa, J.; Reynolds, M.P.; Singh, R. Canopy Temperature and Vegetation Indices from High-Throughput Phenotyping Improve Accuracy of Pedigree and Genomic Selection for Grain Yield in Wheat. G3 Genes Genomes Genet. 2016, 6, 2799–2808. [Google Scholar] [CrossRef] [Green Version]
- Araus, J.L.; Cairns, J.E. Field high-throughput phenotyping: The new crop breeding frontier. Trends Plant Sci. 2014, 19, 52–61. [Google Scholar] [CrossRef]
- Tardieu, F.; Cabrera-Bosquet, L.; Pridmore, T.; Bennett, M. Plant phenomics, from sensors to knowledge. Curr. Biol. 2017, 27, R770–R783. [Google Scholar] [CrossRef]
- Araus, J.L.; Kefauver, S.C.; Zaman-Allah, M.; Olsen, M.S.; Cairns, J.E. Translating high-throughput phenotyping into genetic gain. Trends Plant Sci. 2018, 23, 451–466. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lopez-Cruz, M.; Olson, E.; Rovere, G.; Crossa, J.; Dreisigacker, S.; Mondal, S.; Singh, R.P.; Campos, G.D.L. Regularized selection indices for breeding value prediction using hyper-spectral image data. Sci. Rep. 2020, 10, 8195. [Google Scholar] [CrossRef] [PubMed]
- Hesami, M.; Jones, A.M.P. Application of artificial intelligence models and optimization algorithms in plant cell and tissue culture. Appl. Microbiol. Biotechnol. 2020, 104, 9449–9485. [Google Scholar] [CrossRef] [PubMed]
- Pal, S.; Mitra, S. Multilayer perceptron, fuzzy sets, and classification. IEEE Trans. Neural Netw. 1992, 3, 683–697. [Google Scholar] [CrossRef] [PubMed]
- Geetha, M. Forecasting the crop yield production in trichy district using fuzzy C-Means algorithm and multilayer pceptron (MLP). Int. J. Knowl. Syst. Sci. (IJKSS) 2020, 11, 83–98. [Google Scholar] [CrossRef]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2017, 18, 851–869. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Angermueller, C.; Pärnamaa, T.; Parts, L.; Stegle, O. Deep learning for computational biology. Mol. Syst. Biol. 2016, 12, 878. [Google Scholar] [CrossRef]
- Wang, H.; Cimen, E.; Singh, N.; Buckler, E. Deep learning for plant genomics and crop improvement. Curr. Opin. Plant Biol. 2020, 54, 34–41. [Google Scholar] [CrossRef]
- Rangarajan, A.K.; Purushothaman, R.; Ramesh, A. Tomato crop disease classification using pre-trained deep learning algorithm. Procedia Comput. Sci. 2018, 133, 1040–1047. [Google Scholar] [CrossRef]
- Abdulridha, J.; Ampatzidis, Y.; Roberts, P.; Kakarla, S.C. Detecting powdery mildew disease in squash at different stages using UAV-based hyperspectral imaging and artificial intelligence. Biosyst. Eng. 2020, 197, 135–148. [Google Scholar] [CrossRef]
- Pahikkala, T.; Kari, K.; Mattila, H.; Lepistö, A.; Teuhola, J.; Nevalainen, O.; Tyystjärvi, E. Classification of plant species from images of overlapping leaves. Comput. Electron. Agric. 2015, 118, 186–192. [Google Scholar] [CrossRef]
- Mouine, S.; Yahiaoui, I.; Verroust-Blondet, A. A shape-based approach for leaf classification using multiscale triangular representation. In Proceedings of the ICMR’13—3rd ACM International Conference on Multimedia Retrieval, Dallas, TX, USA, 16–20 April 2013. [Google Scholar]
- Schikora, M.; Schikora, A.; Kogel, K.; Koch, W.; Cremers, D. Probabilistic classification of disease symptoms caused by salmonella on Arabidopsis plants. GI Jahrestag 2010, 10, 874–879. [Google Scholar]
- Fahlgren, N.; Feldman, M.; Gehan, M.A.; Wilson, M.S.; Shyu, C.; Bryant, D.W.; Hill, S.T.; McEntee, C.J.; Warnasooriya, S.N.; Kumar, I.; et al. A versatile phenotyping system and analytics platform reveals diverse temporal responses to water availability in setaria. Mol. Plant. 2015, 8, 1520–1535. [Google Scholar] [CrossRef] [Green Version]
- Haug, S.; Michaels, A.; Biber, P.; Ostermann, J. Plant classification system for crop/weed discrimination without segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Singh, A.; Ganapathysubramanian, B.; Singh, A.K.; Sarkar, S. Machine learning for high-throughput stress phenotyping in plants. Trends Plant Sci. 2016, 21, 110–124. [Google Scholar] [CrossRef] [Green Version]
- Tsaftaris, S.A.; Minervini, M.; Scharr, H. Machine learning for plant phenotyping needs image processing. Trends Plant Sci. 2016, 21, 989–991. [Google Scholar] [CrossRef] [Green Version]
- Suh, H.K.; Ijsselmuiden, J.; Hofstee, J.W.; van Henten, E.J. Transfer learning for the classification of sugar beet and volunteer potato under field conditions. Biosyst. Eng. 2018, 174, 50–65. [Google Scholar] [CrossRef]
- Argüeso, D.; Picon, A.; Irusta, U.; Medela, A.; San-Emeterio, M.G.; Bereciartua, A.; Alvarez-Gila, A. Few-shot learning approach for plant disease classification using images taken in the field. Comput. Electron. Agric. 2020, 175, 105542. [Google Scholar] [CrossRef]
- Abbas, A.; Jain, S.; Gour, M.; Vankudothu, S. Tomato plant disease detection using transfer learning with C-GAN synthetic images. Comput. Electron. Agric. 2021, 187, 106279. [Google Scholar] [CrossRef]
- Khaki, S.; Pham, H.; Han, Y.; Kuhl, A.; Kent, W.; Wang, L. Deepcorn: A semi-supervised deep learning method for high-throughput image-based corn kernel counting and yield estimation. Knowl. Based Syst. 2021, 218, 106874. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: London, UK, 2016; Available online: https://books.google.com/books/about/Deep_Learning.html?hl=&id=Np9SDQAAQBAJ (accessed on 15 February 2022).
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- González-Recio, O.; Forni, S. Genome-wide prediction of discrete traits using Bayesian regressions and machine learning. Genet. Sel. Evol. 2011, 43, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- González-Recio, O.; Jiménez-Montero, J.A.; Alenda, R. The gradient boosting algorithm and random boosting for genome assisted evaluation in large data sets. J. Dairy Sci. 2013, 96, 614–624. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pound, M.P.; Atkinson, J.A.; Pridmore, T.P.; Wells, D.M.; French, A.P. Deep Learning for Multi-task Plant Phenotyping. In Proceedings of the 2017 IEEE International Conference on Computer Vision Workshops (ICCVW), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Shi, W.; Van de Zedde, R.; Jiang, H.; Kootstra, G. Plant-part segmentation using deep learning and multi-view vision. Biosyst. Eng. 2019, 187, 81–95. [Google Scholar] [CrossRef]
- Taghavi Namin, S.; Esmaeilzadeh, M.; Najafi, M.; Brown, T.B.; Borevitz, J.O. Deep phenotyping: Deep learning for temporal phenotype/genotype classification. Plant Methods 2018, 14, 66. [Google Scholar] [CrossRef] [Green Version]
- Fang, B.; Lakshmi, V.; Bindlish, R.; Jackson, T.J.; Cosh, M.; Basara, J. Passive Microwave Soil Moisture Downscaling Using Vegetation Index and Skin Surface Temperature. Vadose Zone J. 2013, 12. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very Deep Convolutional Neural Networks for Complex Land Cover Mapping Using Multispectral Remote Sensing Imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef] [Green Version]
- Sakurai, S.; Uchiyama, H.; Shimada, A.; Taniguchi, R. Plant Growth Prediction using Convolutional LSTM. In Proceedings of the 14th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP 2019), Prague, Czech Republic, 25–27 February 2019; pp. 105–113. [Google Scholar] [CrossRef]
- Yasrab, R.; Zhang, J.; Smyth, P.; Pound, M.P. Predicting Plant Growth from Time-Series Data Using Deep Learning. Remote Sens. 2021, 13, 331. [Google Scholar] [CrossRef]
- Mishra, A.M.; Harnal, S.; Mohiuddin, K.; Gautam, V.; Nasr, O.A.; Goyal, N.; Alwetaishi, M.; Singh, A. A Deep Learning-Based Novel Approach for Weed Growth Estimation. Intell. Autom. Soft Comput. 2022, 31, 1157–1173. [Google Scholar] [CrossRef]
- Xi, Y.; Ren, C.; Wang, Z.; Wei, S.; Bai, J.; Zhang, B.; Xiang, H.; Chen, L. Mapping Tree Species Composition Using OHS-1 Hyperspectral Data and Deep Learning Algorithms in Changbai Mountains, Northeast China. Forests 2019, 10, 818. [Google Scholar] [CrossRef] [Green Version]
- Zhang, M.; Lin, H.; Wang, G.; Sun, H.; Fu, J. Mapping Paddy Rice Using a Convolutional Neural Network (CNN) with Landsat 8 Datasets in the Dongting Lake Area, China. Remote Sens. 2018, 10, 1840. [Google Scholar] [CrossRef] [Green Version]
- Du, L.; McCarty, G.W.; Zhang, X.; Lang, M.W.; Vanderhoof, M.K.; Li, X.; Huang, C.; Lee, S.; Zou, Z. Mapping Forested Wetland Inundation in the Delmarva Peninsula, USA Using Deep Convolutional Neural Networks. Remote Sens. 2020, 12, 644. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Li, Y.; Chen, Y.; Du, K.; Zheng, F.; Zhang, L.; Sun, Z. Estimating above ground biomass of winter wheat at early growth stages using digital images and deep convolutional neural network. Eur. J. Agron. 2019, 103, 117–129. [Google Scholar] [CrossRef]
- Dong, L.; Du, H.; Han, N.; Li, X.; Zhu, D.; Mao, F.; Zhang, M.; Zheng, J.; Liu, H.; Huang, Z.; et al. Application of Convolutional Neural Network on Lei Bamboo Above-Ground-Biomass (AGB) Estimation Using Worldview-2. Remote Sens. 2020, 12, 958. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep Learning Based Oil Palm Tree Detection and Counting for High-Resolution Remote Sensing Images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef] [Green Version]
- Malambo, L.; Popescu, S.; Ku, N.-W.; Rooney, W.; Zhou, T.; Moore, S. A Deep Learning Semantic Segmentation-Based Approach for Field-Level Sorghum Panicle Counting. Remote Sens. 2019, 11, 2939. [Google Scholar] [CrossRef] [Green Version]
- Alqurashi, A.F.; Kumar, L. Land Use and Land Cover Change Detection in the Saudi Arabian Desert Cities of Makka and Al-Taif Using Satellite Data. Adv. Remote Sens. 2014, 3, 106–119. [Google Scholar] [CrossRef]
- Abdullh, M.A.; AL-Yasee, H.; AL-Sudani, Y.; Khandaker, M.M. Developing weeds of Agricultural Crops at different levels of Heights, in Taif Area Of Saudia Arabia. Bulg. J. Agric. Sci. 2017, 23, 762–769. Available online: https://www.researchgate.net/publication/320864744 (accessed on 15 February 2022).
- Climate Atlas of Saudi Arabia; Ministry of Agriculture and Water: Riyad, United Arab Emirates, 1990.
- Ady, J. The Taif Escarpment, Saudi Arabia: A Study For Nature Conservation And Recreational Development. Mt. Res. Dev. 1995, 15, 101–120. [Google Scholar] [CrossRef]
- Majrashi, A.; Khandaker, M.M. Survey of Portulacaceae family flora in Taif, Saudi Arabia. Braz. J. Biol. 2021, 84, e249230. [Google Scholar] [CrossRef]
- Beeson, R.C. Ribulose 1, 5-bisphosphate carboxylase/oxygenase activities in leaves of greenhouse roses. J. Exp. Bot. 1990, 41, 59–65. [Google Scholar] [CrossRef]
- Kool, M.T.N.; Westerman, A.D.; Rou-Haest, C.H.M. Importance and use of carbohydrate reserves in above-ground stem parts of rose cv. Motrea. J. Hort Sci. 1996, 71, 893–900. [Google Scholar] [CrossRef]
- Bredmose, N.B. Growth, flowering, and postharvest performance of single-stemmed rose (Rosa hibrida L.) plants in response to light quantum integral and plant population density. J. Am. Soc. Hortic. Sci. 1998, 123, 569–576. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez-Real, M.M.; Baille, A. Change in leaf photosynthetic parameters with leaf position and nitrogen content within a rose plant canopy (Rosa hibrida). Plant Cell Environ. 2000, 23, 351–363. [Google Scholar] [CrossRef]
- Kim, S.H.; Lieth, J.H. A coupled model of photosynthesis, stomatal conductance, and transpiration for a rose leaf (Rosa hybrida L.). Ann. Bot. 2003, 9, 771–781. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Weiss, E.A. Essential Oil Crops; CAB International: Wallingford, UK, 1997. [Google Scholar]
- Pal, P.K.; Singh, R. Understanding crop-ecology and agronomy of Rosa damascena Mill. for higher productivity. Aust. J. Crop Sci. 2013, 7, 196–205. [Google Scholar]
- Rusanov, K.E.; Kovacheva, N.M.; Atanassov, I.I. Comparative GC/MS analysis of Rose flower and distilled oil volatiles of the oil-bearing Rose Rosa Damascena. Biotechnol. Biotechnol. Eq. 2011, 25, 2210–2216. [Google Scholar] [CrossRef] [Green Version]
- Osorio-Guarín, J.A.S.; Garzón-Martínez, G.A.; Delgadillo-Duran, P.; Bastidas, S.; Moreno, L.P.; Enciso-Rodríguez, F.E.; Cornejo, O.E.; Barrero, L.S. Genome-wide association study (GWAS) for morphological and yield-related traits in an oil palm hybrid (Elaeis oleifera × Elaeis guineensis) population. BMC Plant Biol. 2019, 19, 533. [Google Scholar] [CrossRef] [Green Version]
- MOD11A1.006 Terra Land Surface Temperature and Emissivity Daily Global 1 km|Earth Engine Data Catalog|Google Developers. Available online: https://developers.google.com/earth-engine/datasets/catalog/MODIS_006_MOD11A1 (accessed on 15 February 2022).
- MYD13A2.006 Aqua Vegetation Indices 16-Day Global 1 km|Earth Engine Data Catalog|Google Developers. Available online: https://developers.google.com/earth-engine/datasets/catalog/MODIS_006_MYD13A2 (accessed on 15 February 2022).
- TerraClimate: Monthly Climate and Climatic Water Balance for Global Terrestrial Surfaces, University of Idaho|Earth Engine Data Catalog|Google Developers. Available online: https://developers.google.com/earth-engine/datasets/catalog/IDAHO_EPSCOR_TERRACLIMATE (accessed on 15 February 2022).
- da Silva, I.N.; Spatti, D.H.; Flauzino, R.A.; Liboni, L.H.B.; dos Reis Alves, S.F. Artificial Neural Networks: A Practical Course—Google Books; Springer International Publishing: Basel, Switzerlands, 2017. [Google Scholar]
- Baz, A.; Baz, M. PCN2: Parallel CNN to Diagnose COVID-19 from Radiographs and Metadata. Intell. Autom. Soft Comput. 2022, 31, 1051–1069. [Google Scholar] [CrossRef]
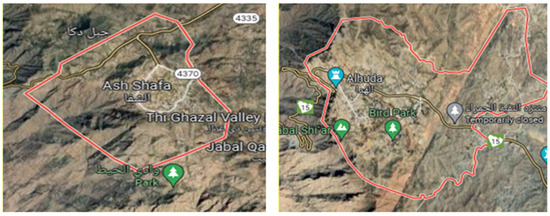
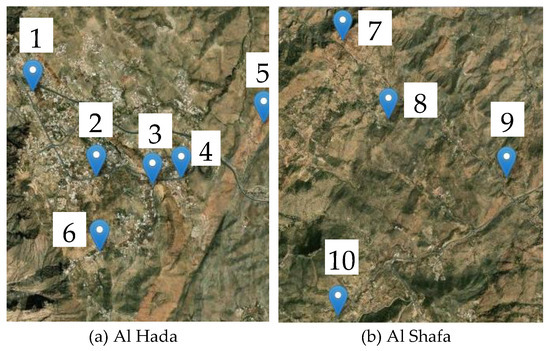
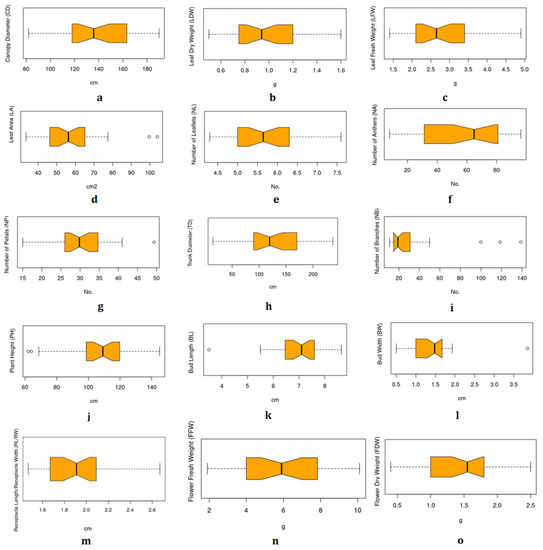
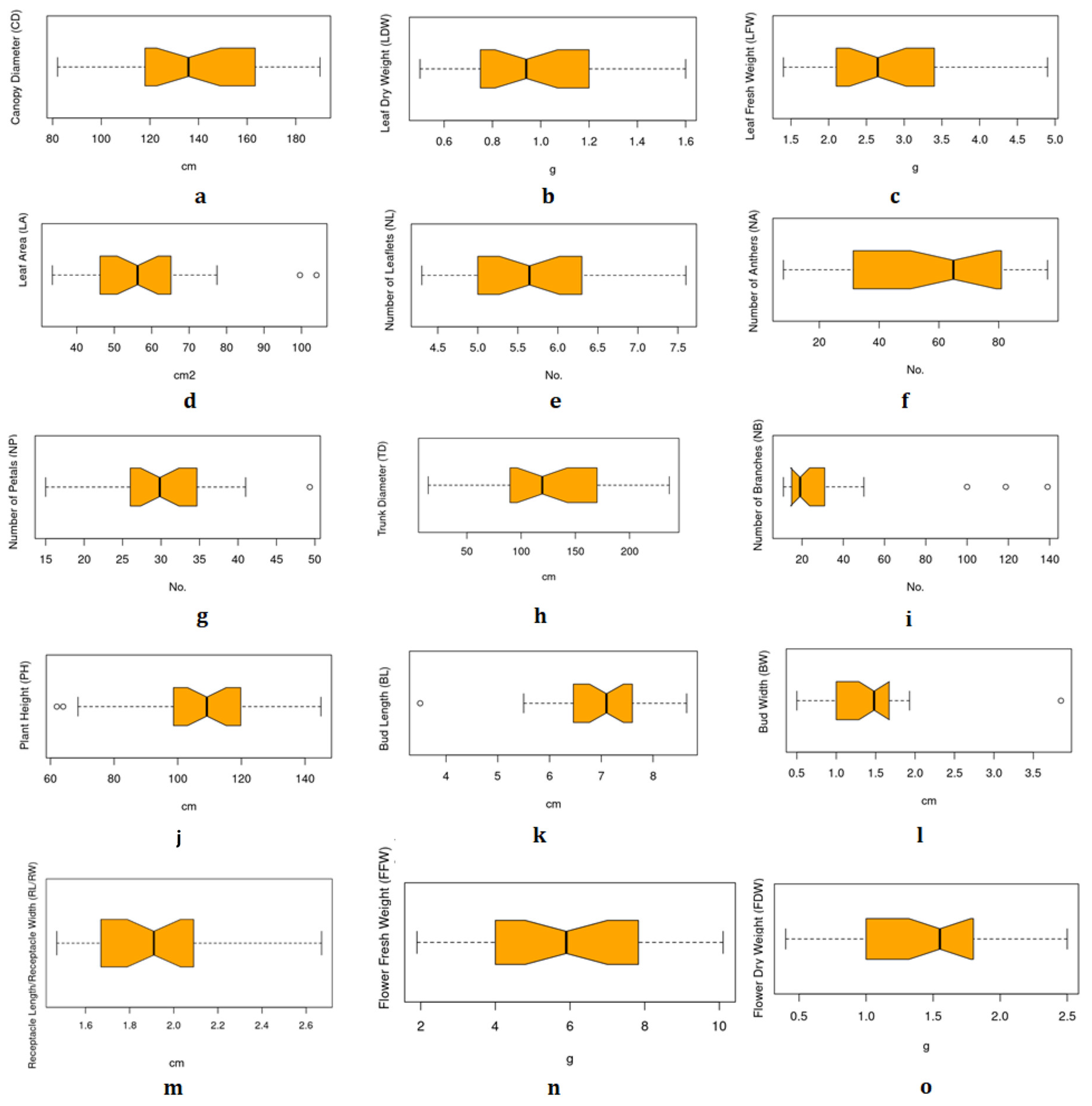


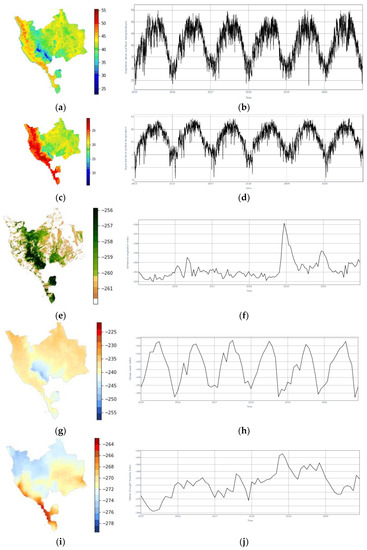
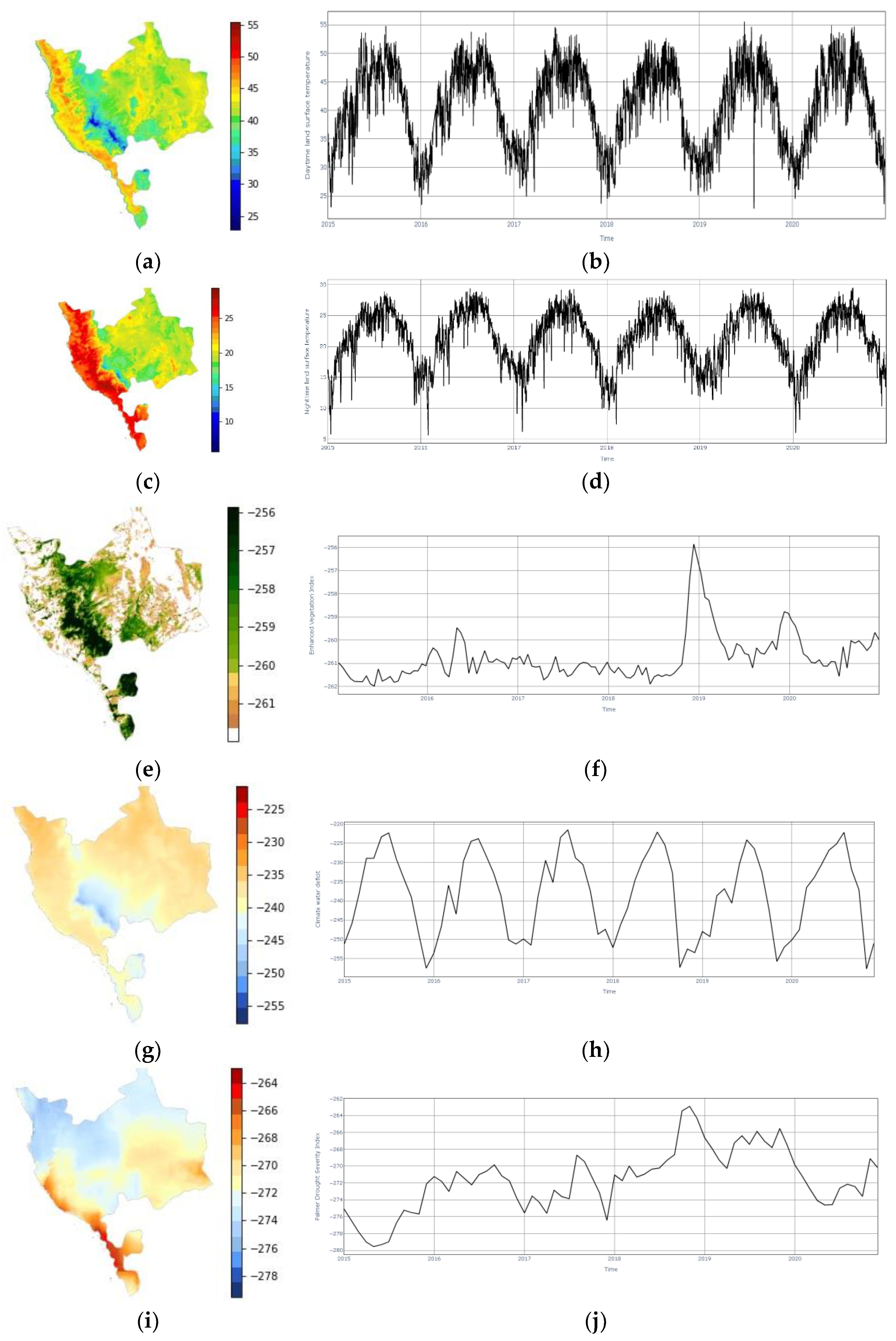
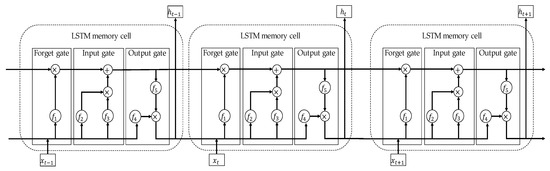
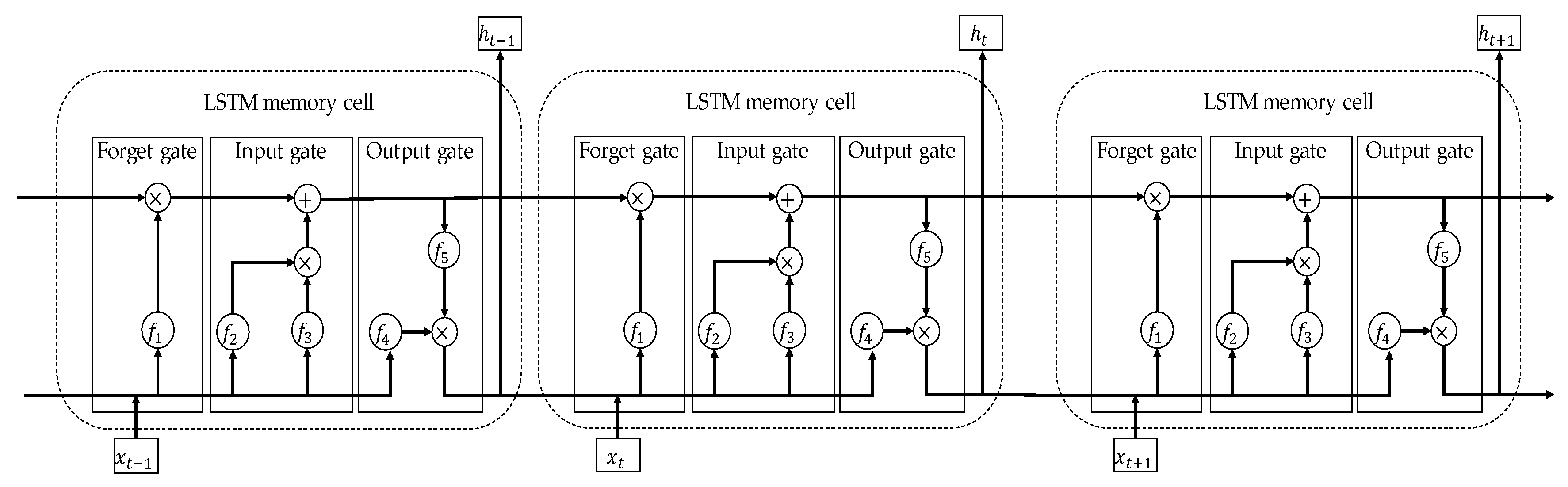
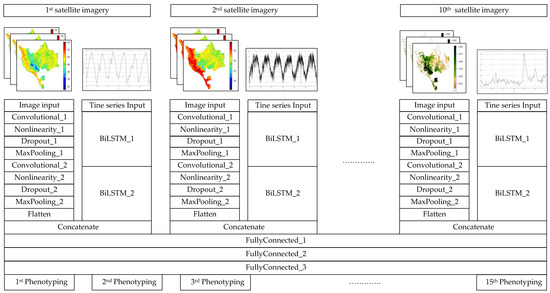
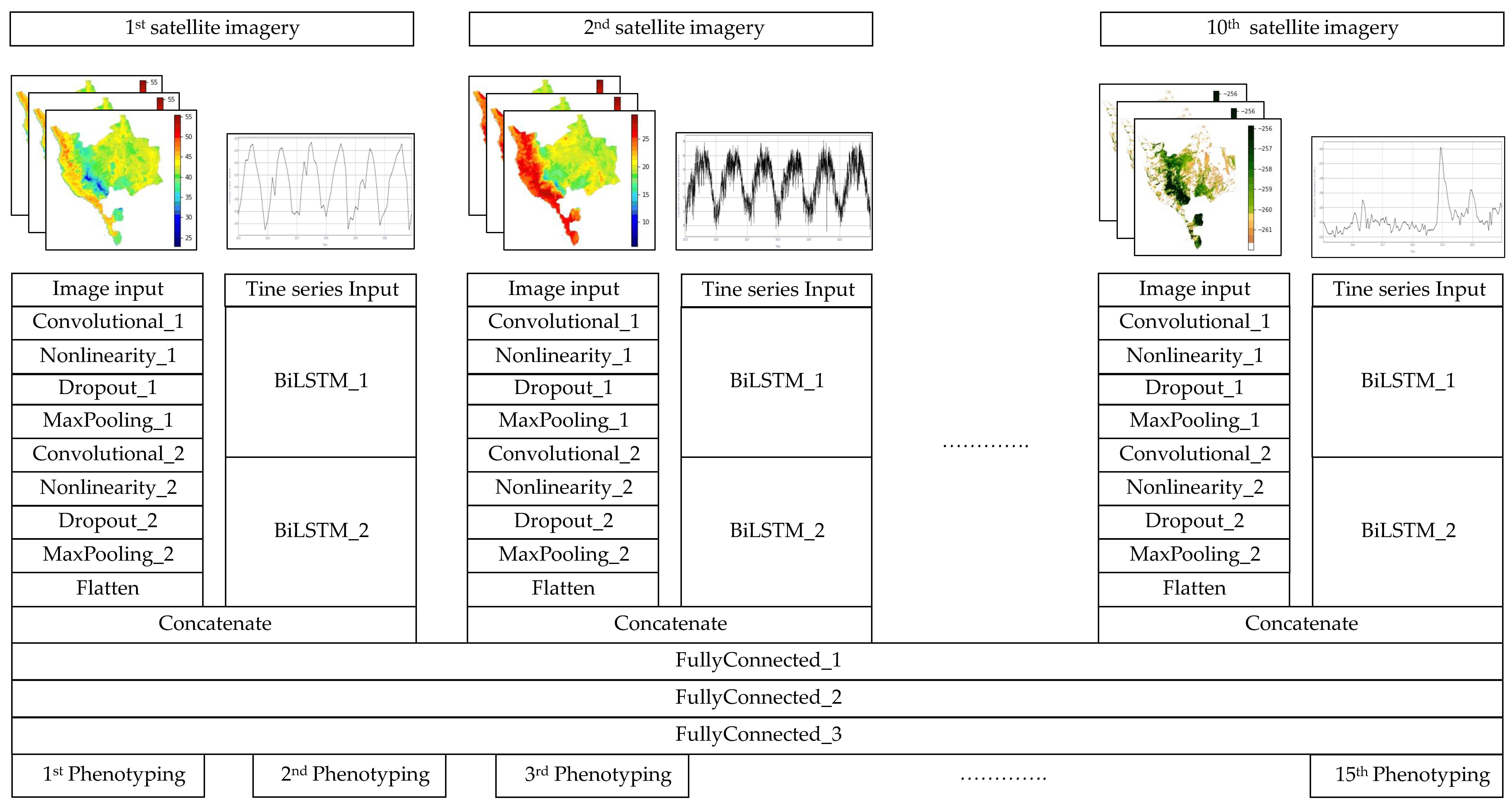
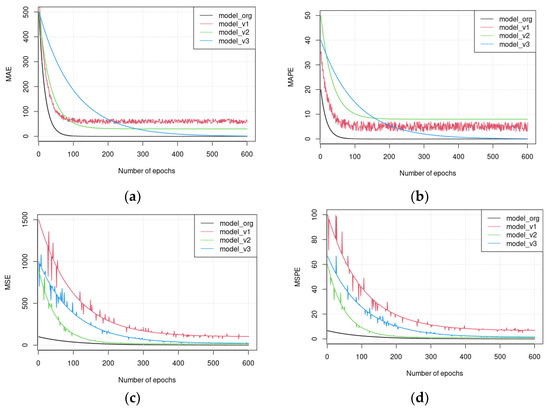
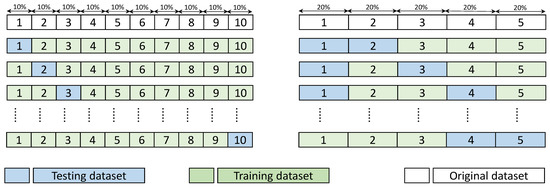
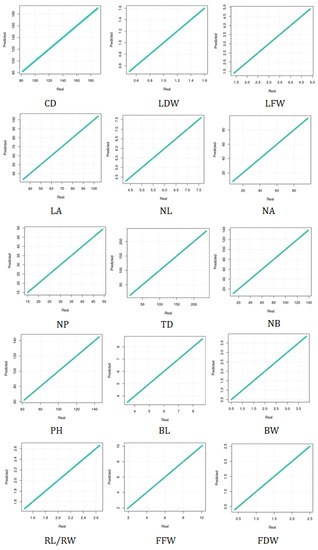
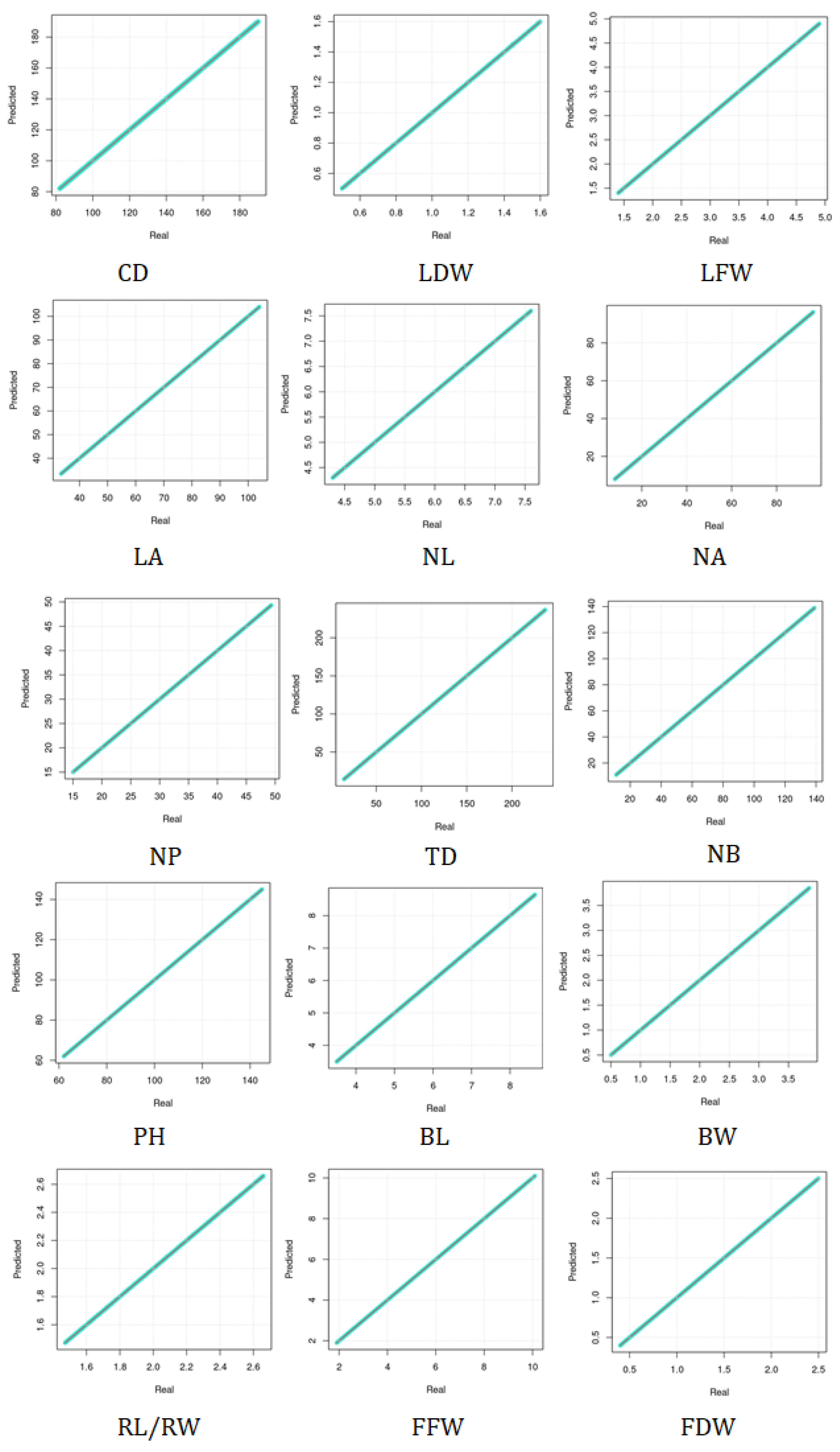
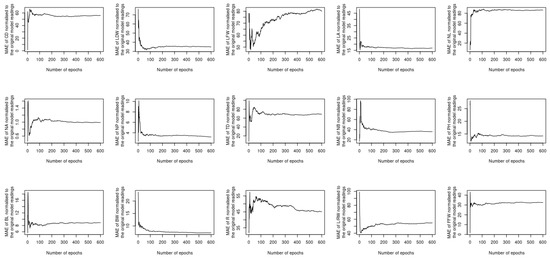
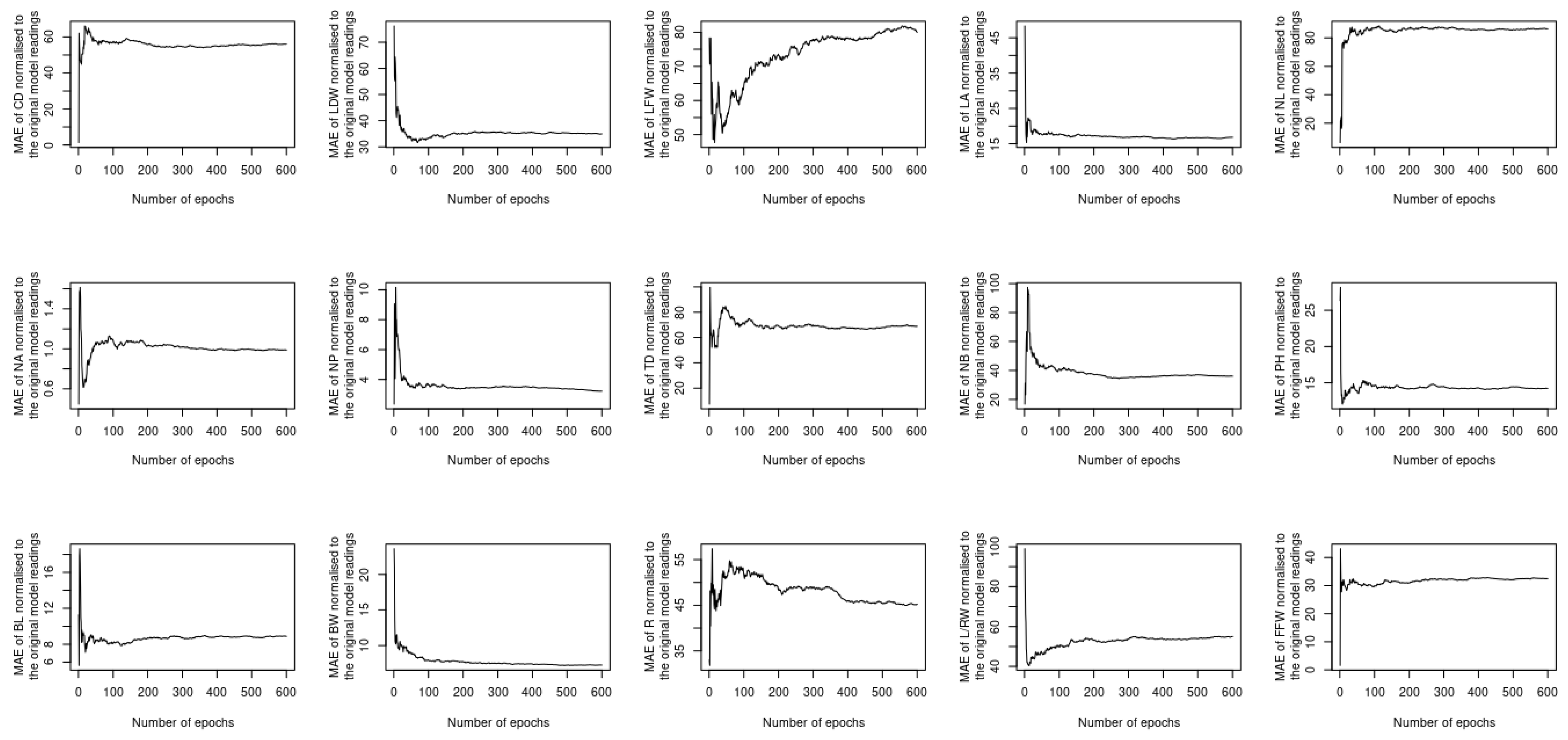
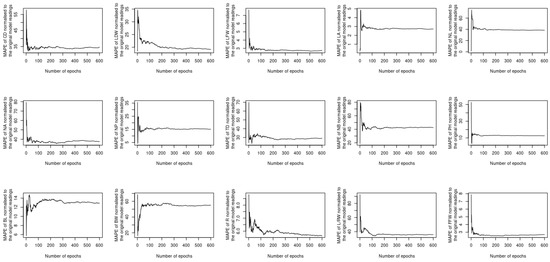
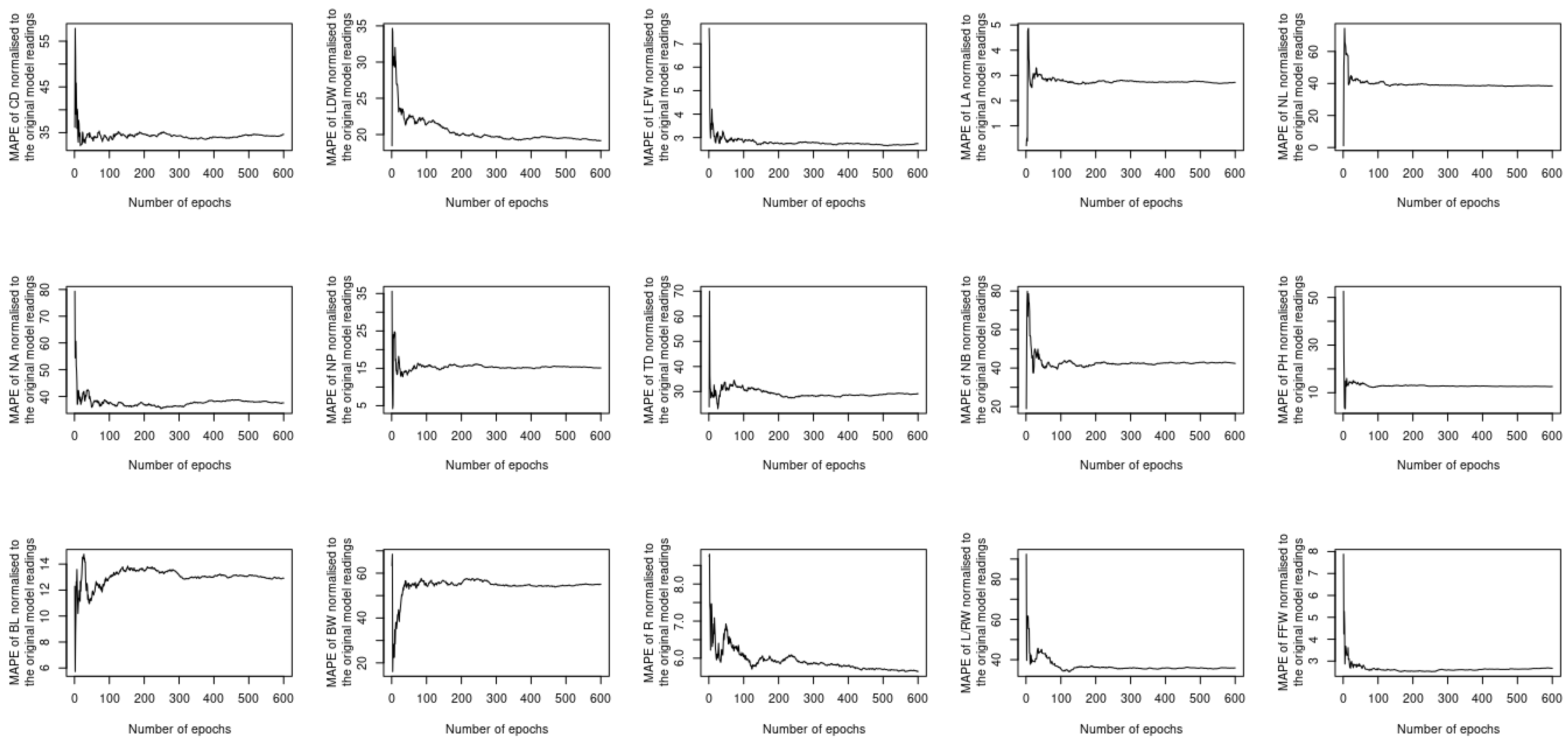
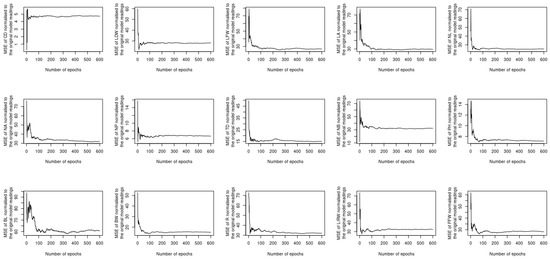
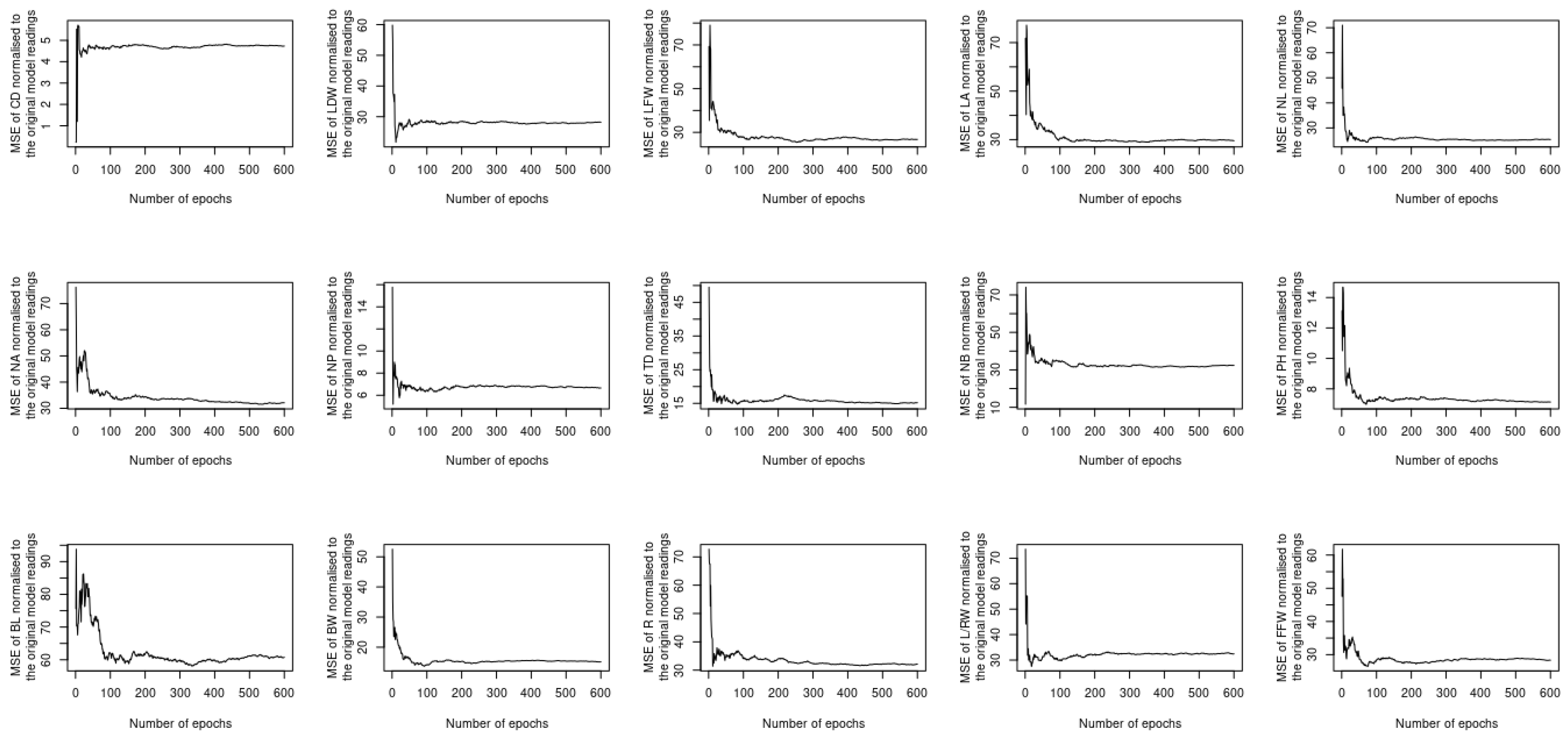
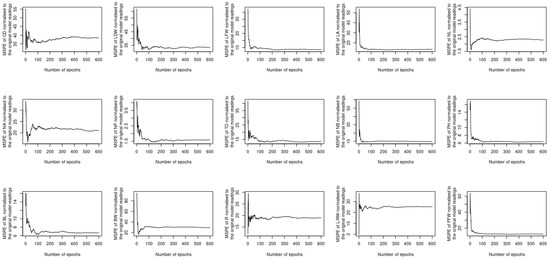
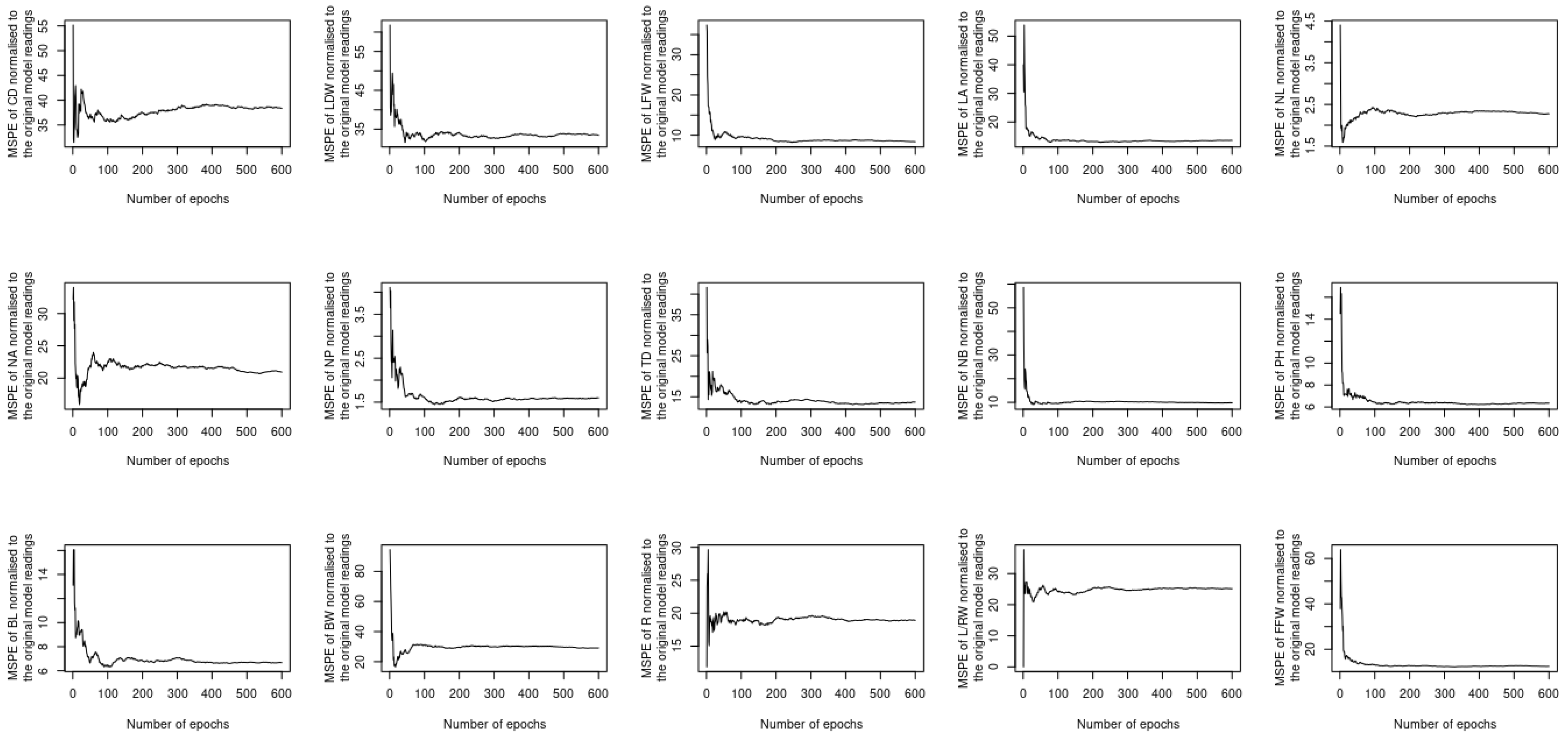

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).