
Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study


Abstract
:1. Introduction
- At first, the performance of machine learning models to forecast univariate wind power time-series data is verified. More specifically, seven machine learning methods, including kernel-based methods (i.e., SVR and GPR models), ensemble learning techniques (Boosting, Bagging, Random Forest, and eXtreme Gradient Boosting (XGBoost)), are evaluated for the wind power forecast. The five-fold cross-validation was carried out on the training set to construct the considered models. In addition, we applied Bayesian optimization (BO) to optimally tune hyperparameters of the Gaussian process regression (GPR) with different kernels. Three different datasets from France, Turkey, and Kaggel are used to assess the performance of the investigated techniques. The results indicate the superior performance of the GPR compared to the other models.
- However, these investigated methods ignored the information from the past data in the forecasting process. In other words, the time dependency in wind power measurements is ignored when constructing machine learning models. Exploiting information from past data is expected to reduce prediction errors and improve forecasting accuracy. To this end, information from lagged data is considered in constructing dynamic machine learning models. This study revealed that incorporating dynamic information into machine learning models improves forecasting performances.
- Meanwhile, after showing the need to include information from past data to improve the prediction accuracy of investigated machine learning models, more input variables (e.g., wind speed and wind direction) are used to further enhance the wind prediction performance. Importantly, the results revealed significant improvement in the prediction accuracy of wind power could be obtained by using input variables.
2. Methodology
2.1. Gaussian Process Regressor
- the mean value
- and variance
- and follows a conditional distribution:with denotes the covariance matrix of the training set; denotes the covariance of the testing set, and denotes the covariance matrix computed based on the training and test sets.
- Rational Quadratic (RQ) kernel: ;
- Squared Exponential (SE) kernel: ;
- Matern 5/2 (M52) kernel: ;
- Exponential (Exp) kernel: ;
Support Vector Regression
- Linear kernel: ;
- Quadratic kernel: ;
- Cubic kernel: ;
- Medium Gaussian kernel: ;
- Coarse Gaussian kernel: .
2.2. Bayesian Optimization
2.3. Ensemble Learning Models
2.3.1. Boosted Trees
2.3.2. Bagged Regression Trees
2.4. XGBoost
Random Forest
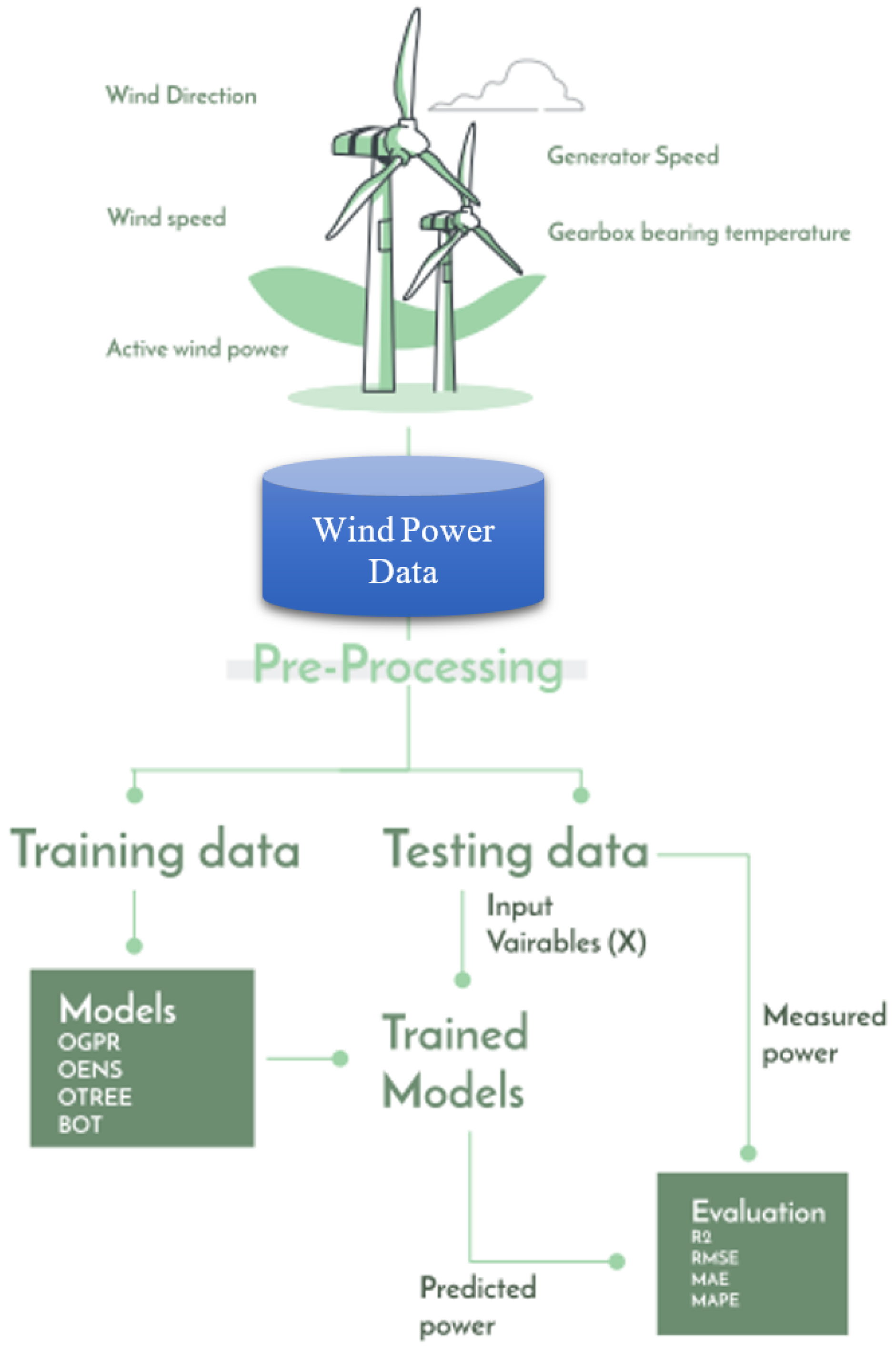
2.5. Wind Power Prediction Strategy
2.6. Evaluation Metrics
- R is a statistical measure that shows how regression line fit the data set, in other words, how much data points are variance from the mean:where is the measured wind power, is its corresponding predicted power, and n is the number of data points;
- RMSE is used to measure the average squared differences between actual and predicted data.
- MAE it is measure the average of absolute errors.
3. Results and Discussion
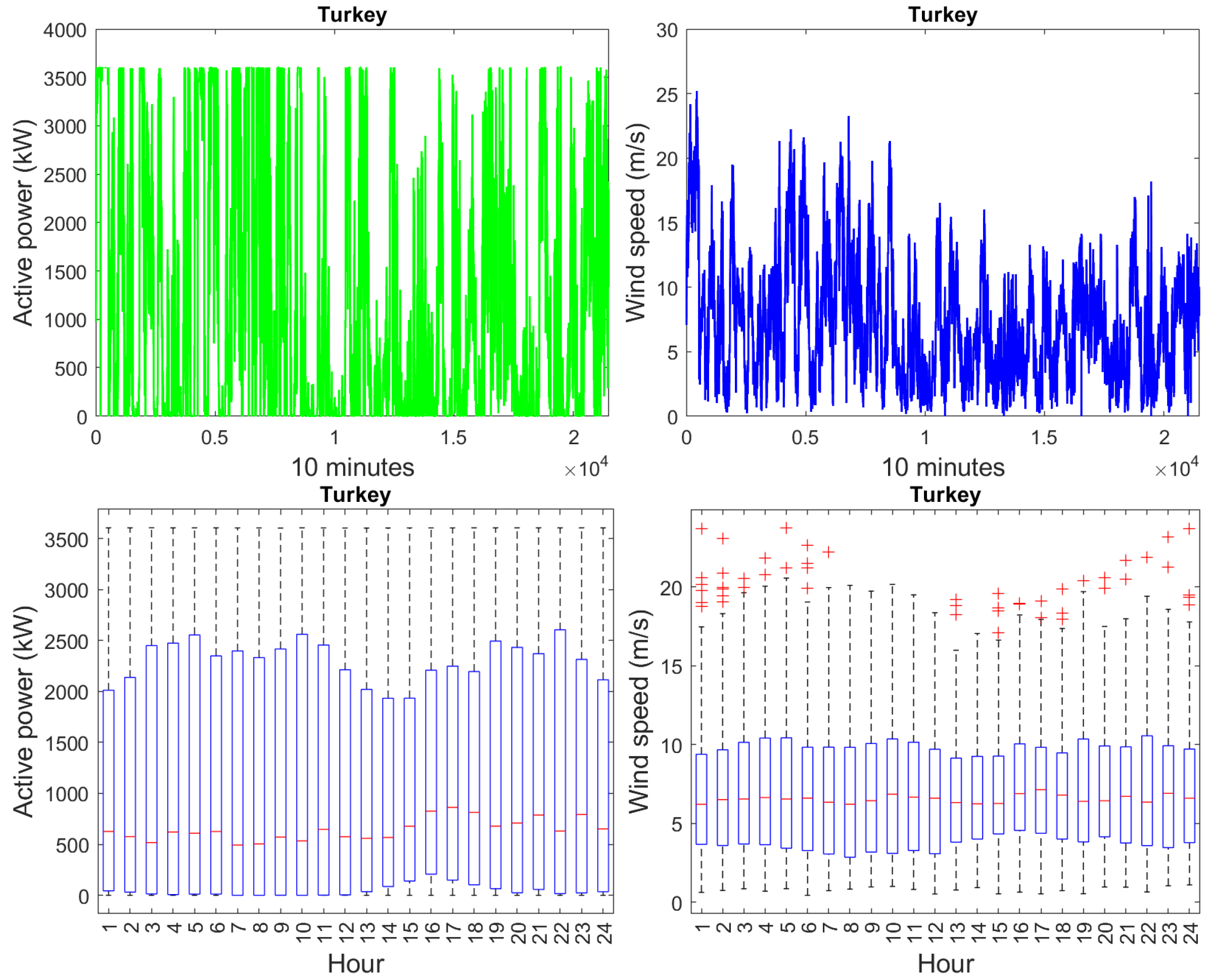
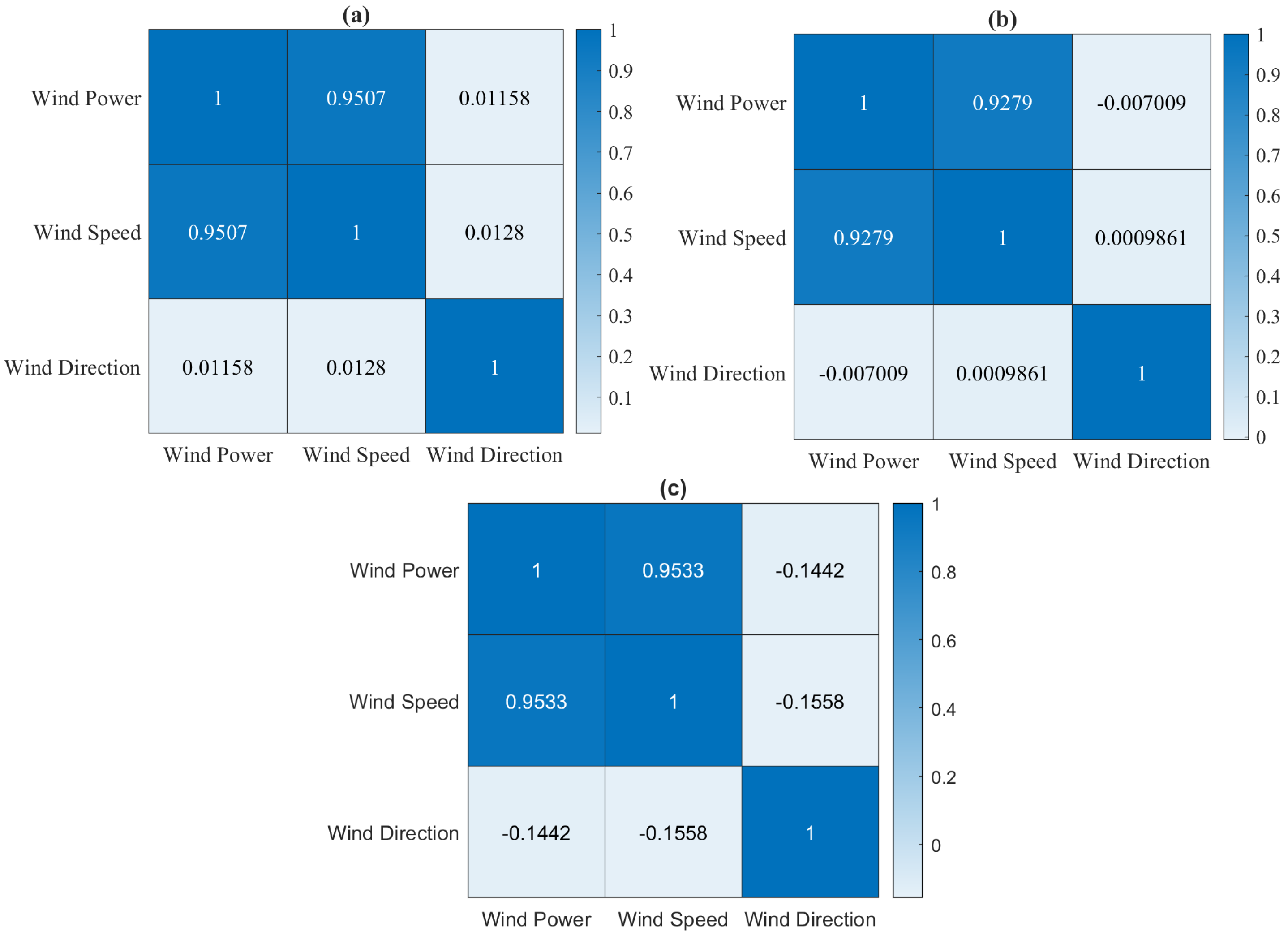
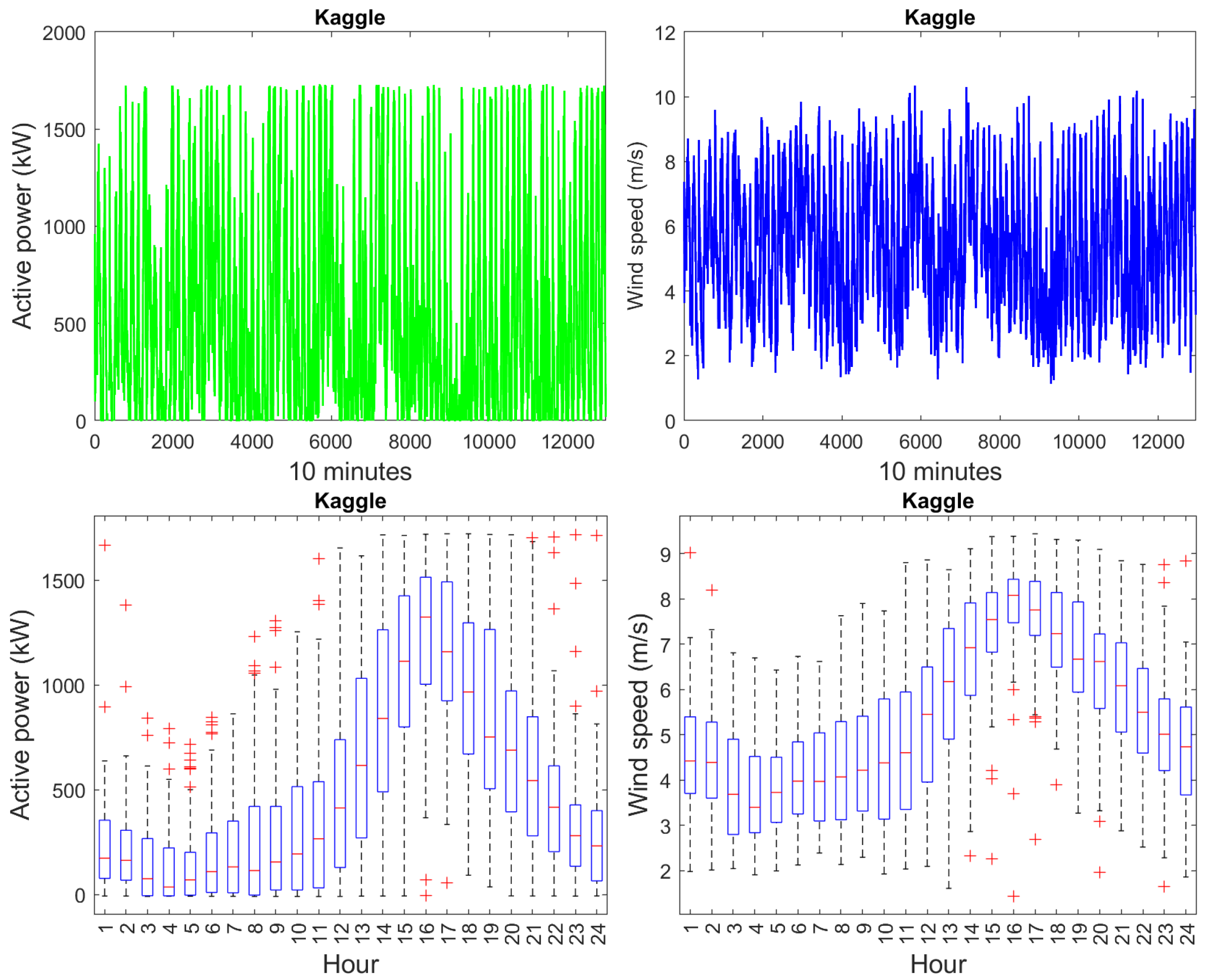
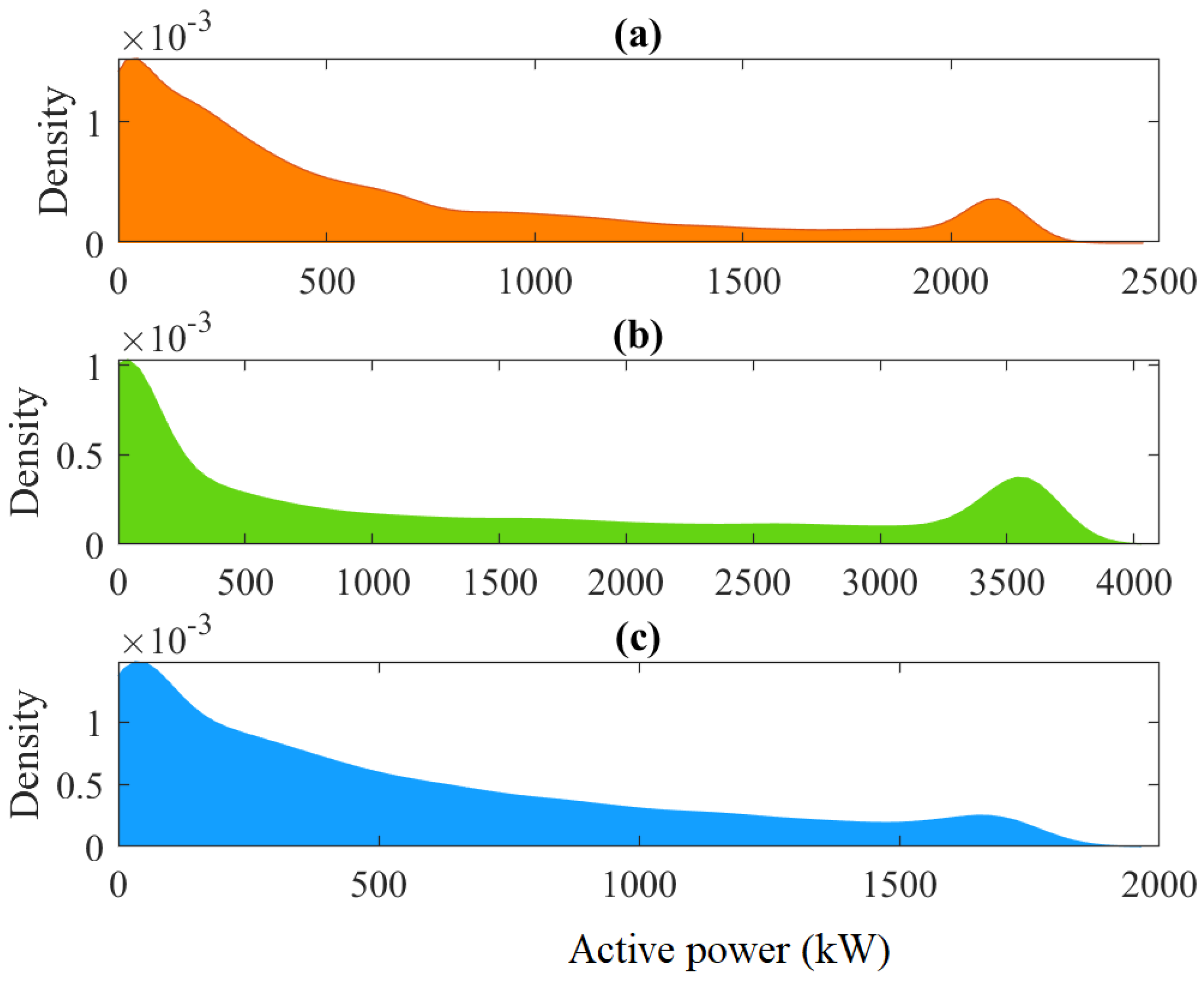
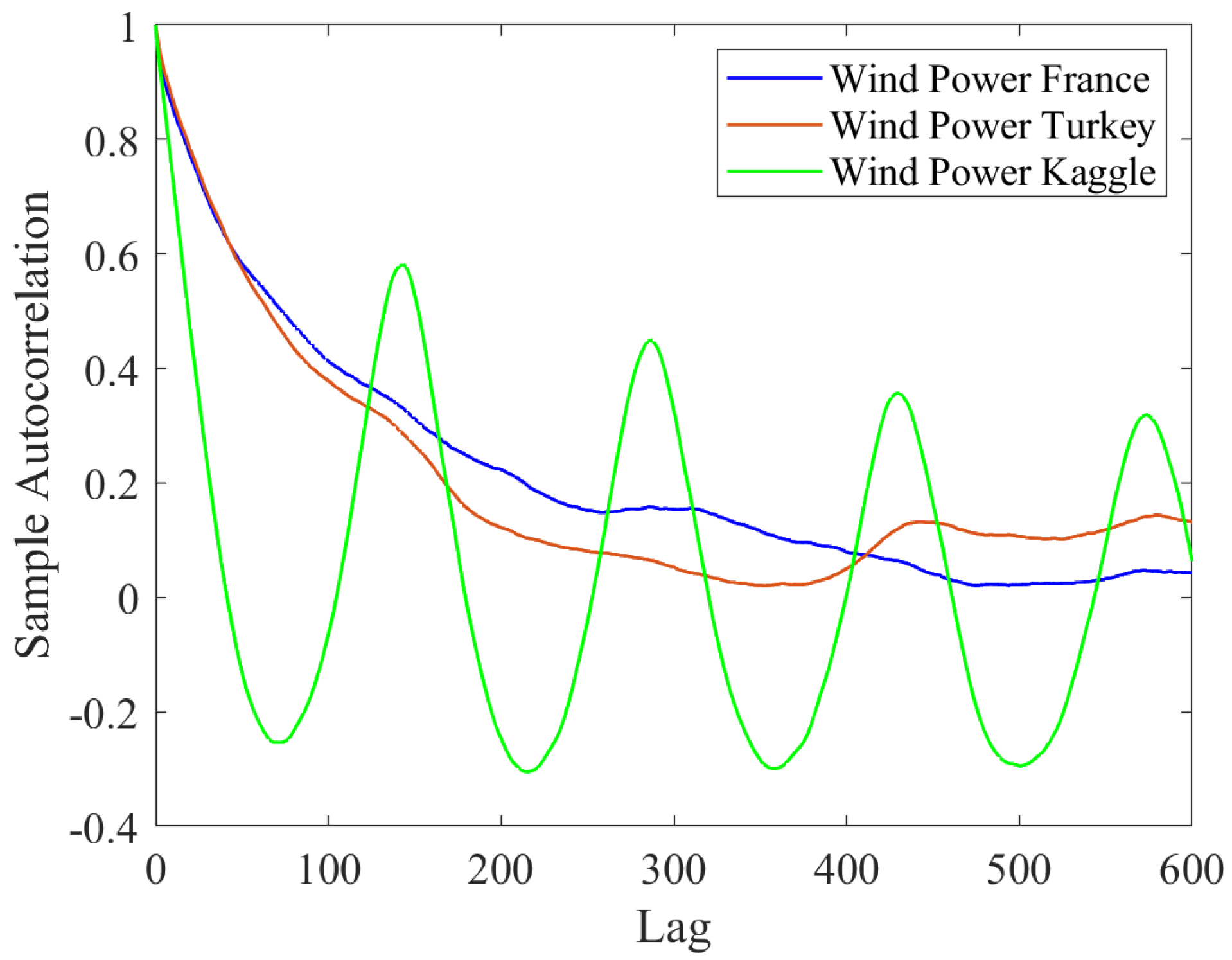
3.1. Data Analysis
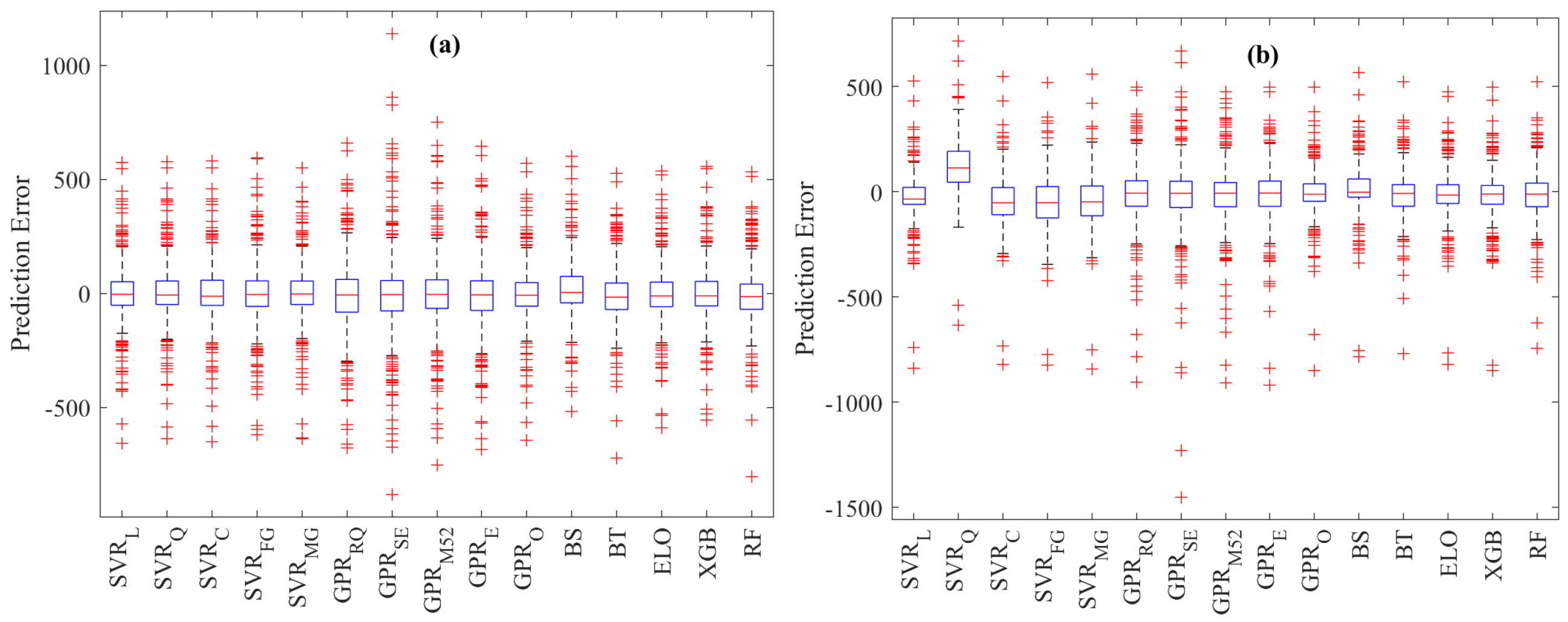
3.2. Forecasting Results
- Univariate forecasting using static models: In this scenario, we only used the past wind power time-series data to forecast the future trend of wind power. Each model is first trained using the wind power data and used to perform wind power forecasting.
- Univariate forecasting using dynamic models: In this experiment, the univariate forecasting of wind power is based on past and actual data. Considering information from lagged data is expected to obtain a better forecasting performance than the static models.
- Prediction of wind power: The prediction of wind power is conducted using other meteorological variables (e.g., wind speed and wind direction) as input. Specifically, we train each model to predict the next value of wind power based on input meteorological variables.
Wind Power Forecasting Using Static Models
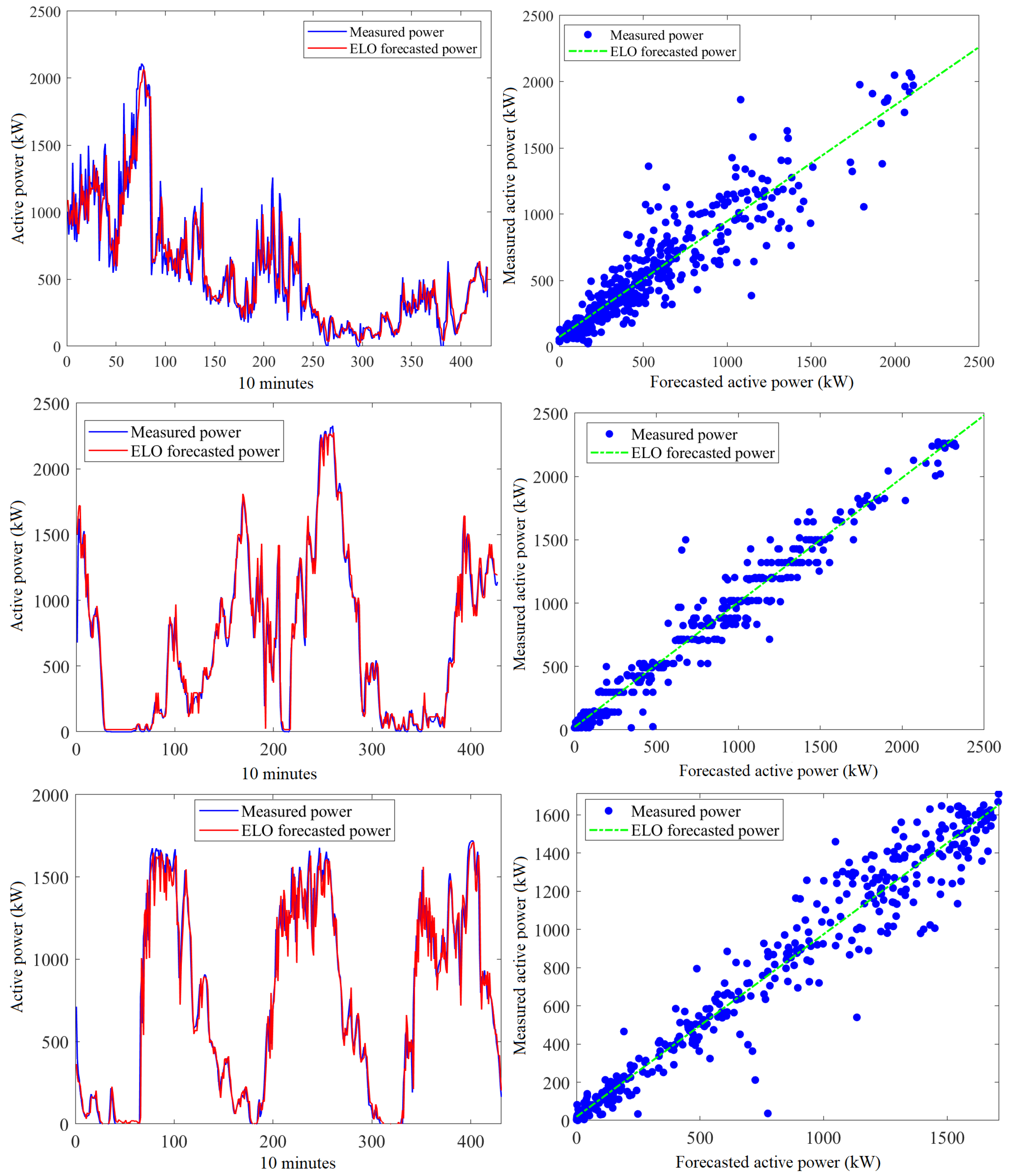
3.3. Wind Power Prediction Using Dynamic Models
3.4. Wind Power Prediction
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- American Wind Energy Association (AWEA). Wind Powers America First Quarter 2020 Report; American Wind Energy Association (AWEA): Washington, DC, USA, 2020. [Google Scholar]
- Hanifi, S.; Liu, X.; Lin, Z.; Lotfian, S. A critical review of wind power forecasting methods—past, present and future. Energies 2020, 13, 3764. [Google Scholar] [CrossRef]
- Treiber, N.A.; Heinermann, J.; Kramer, O. Wind power prediction with machine learning. In Computational Sustainability; Springer: Berlin/Heidelberg, Germany, 2016; pp. 13–29. [Google Scholar]
- Yang, M.; Wang, S. A review of wind power forecasting & prediction. In Proceedings of the 2016 International Conference on Probabilistic Methods Applied to Power Systems (PMAPS), Beijing, China, 16–20 October 2016; pp. 1–7. [Google Scholar]
- Ouyang, T.; Zha, X.; Qin, L.; He, Y.; Tang, Z. Prediction of wind power ramp events based on residual correction. Renew. Energy 2019, 136, 781–792. [Google Scholar] [CrossRef]
- Ding, F.; Tian, Z.; Zhao, F.; Xu, H. An integrated approach for wind turbine gearbox fatigue life prediction considering instantaneously varying load conditions. Renew. Energy 2018, 129, 260–270. [Google Scholar] [CrossRef]
- Han, S.; Qiao, Y.H.; Yan, J.; Liu, Y.Q.; Li, L.; Wang, Z. Mid-to-long term wind and photovoltaic power generation prediction based on copula function and long short term memory network. Appl. Energy 2019, 239, 181–191. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Uzunoglu, M. A review of combined approaches for prediction of short-term wind speed and power. Renew. Sustain. Energy Rev. 2014, 34, 243–254. [Google Scholar] [CrossRef]
- Bouyeddou, B.; Harrou, F.; Saidi, A.; Sun, Y. An Effective Wind Power Prediction using Latent Regression Models. In Proceedings of the 2021 International Conference on ICT for Smart Society (ICISS), Bandung, Indonesia, 2–4 August 2021; pp. 1–6. [Google Scholar]
- Yan, J.; Ouyang, T. Advanced wind power prediction based on data-driven error correction. Energy Convers. Manag. 2019, 180, 302–311. [Google Scholar] [CrossRef]
- Karakuş, O.; Kuruoğlu, E.E.; Altınkaya, M.A. One-day ahead wind speed/power prediction based on polynomial autoregressive model. IET Renew. Power Gener. 2017, 11, 1430–1439. [Google Scholar] [CrossRef] [Green Version]
- Eissa, M.; Yu, J.; Wang, S.; Liu, P. Assessment of wind power prediction using hybrid method and comparison with different models. J. Electr. Eng. Technol. 2018, 13, 1089–1098. [Google Scholar]
- Rajagopalan, S.; Santoso, S. Wind power forecasting and error analysis using the autoregressive moving average modeling. In Proceedings of the 2009 IEEE Power & Energy Society General Meeting, Calgary, AB, Canada, 26–30 July 2009; pp. 1–6. [Google Scholar]
- Singh, P.K.; Singh, N.; Negi, R. Wind Power Forecasting Using Hybrid ARIMA-ANN Technique. In Ambient Communications and Computer Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 209–220. [Google Scholar]
- Bhaskar, K.; Singh, S. AWNN-assisted wind power forecasting using feed-forward neural network. IEEE Trans. Sustain. Energy 2012, 3, 306–315. [Google Scholar] [CrossRef]
- Chen, N.; Qian, Z.; Nabney, I.T.; Meng, X. Wind power forecasts using Gaussian processes and numerical weather prediction. IEEE Trans. Power Syst. 2013, 29, 656–665. [Google Scholar] [CrossRef] [Green Version]
- Azimi, R.; Ghofrani, M.; Ghayekhloo, M. A hybrid wind power forecasting model based on data mining and wavelets analysis. Energy Convers. Manag. 2016, 127, 208–225. [Google Scholar] [CrossRef]
- Yang, L.; He, M.; Zhang, J.; Vittal, V. Support-vector-machine-enhanced markov model for short-term wind power forecast. IEEE Trans. Sustain. Energy 2015, 6, 791–799. [Google Scholar] [CrossRef]
- Ti, Z.; Deng, X.W.; Zhang, M. Artificial Neural Networks based wake model for power prediction of wind farm. Renew. Energy 2021, 172, 618–631. [Google Scholar] [CrossRef]
- Saroha, S.; Aggarwal, S. Wind power forecasting using wavelet transforms and neural networks with tapped delay. CSEE J. Power Energy Syst. 2018, 4, 197–209. [Google Scholar] [CrossRef]
- Dowell, J.; Pinson, P. Very-short-term probabilistic wind power forecasts by sparse vector autoregression. IEEE Trans. Smart Grid 2015, 7, 763–770. [Google Scholar] [CrossRef] [Green Version]
- Wu, J.; Ji, T.; Li, M.; Wu, P.; Wu, Q. Multistep wind power forecast using mean trend detector and mathematical morphology-based local predictor. IEEE Trans. Sustain. Energy 2015, 6, 1216–1223. [Google Scholar] [CrossRef]
- Demolli, H.; Dokuz, A.S.; Ecemis, A.; Gokcek, M. Wind power forecasting based on daily wind speed data using machine learning algorithms. Energy Convers. Manag. 2019, 198, 111823. [Google Scholar] [CrossRef]
- Lekkas, D.; Price, G.D.; Jacobson, N.C. Using smartphone app use and lagged-ensemble machine learning for the prediction of work fatigue and boredom. Comput. Hum. Behav. 2022, 127, 107029. [Google Scholar] [CrossRef]
- Bi, J.W.; Han, T.Y.; Li, H. International tourism demand forecasting with machine learning models: The power of the number of lagged inputs. Tour. Econ. 2020, 1354816620976954. [Google Scholar] [CrossRef]
- Shang, H.L. Dynamic principal component regression for forecasting functional time series in a group structure. Scand. Actuar. J. 2020, 2020, 307–322. [Google Scholar] [CrossRef]
- Liu, Y.; Sun, Y.; Infield, D.; Zhao, Y.; Han, S.; Yan, J. A hybrid forecasting method for wind power ramp based on orthogonal test and support vector machine (OT-SVM). IEEE Trans. Sustain. Energy 2016, 8, 451–457. [Google Scholar] [CrossRef] [Green Version]
- Yuan, X.; Chen, C.; Yuan, Y.; Huang, Y.; Tan, Q. Short-term wind power prediction based on LSSVM–GSA model. Energy Convers. Manag. 2015, 101, 393–401. [Google Scholar] [CrossRef]
- Buturache, A.N.; Stancu, S. Wind Energy Prediction Using Machine Learning. Low Carbon Econ. 2021, 12, 1. [Google Scholar] [CrossRef]
- Liu, T.; Wei, H.; Zhang, K. Wind power prediction with missing data using Gaussian process regression and multiple imputation. Appl. Soft Comput. 2018, 71, 905–916. [Google Scholar] [CrossRef]
- Deng, Y.; Jia, H.; Li, P.; Tong, X.; Qiu, X.; Li, F. A deep learning methodology based on bidirectional gated recurrent unit for wind power prediction. In Proceedings of the 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), Xi’an, China, 19–21 June 2019; pp. 591–595. [Google Scholar]
- Xiaoyun, Q.; Xiaoning, K.; Chao, Z.; Shuai, J.; Xiuda, M. Short-term prediction of wind power based on deep long short-term memory. In Proceedings of the 2016 IEEE PES Asia-Pacific Power and Energy Engineering Conference (APPEEC), Xi’an, China, 25–28 October 2016; pp. 1148–1152. [Google Scholar]
- Bibi, N.; Shah, I.; Alsubie, A.; Ali, S.; Lone, S.A. Electricity Spot Prices Forecasting Based on Ensemble Learning. IEEE Access 2021, 9, 150984–150992. [Google Scholar] [CrossRef]
- Shah, I.; Iftikhar, H.; Ali, S.; Wang, D. Short-term electricity demand forecasting using components estimation technique. Energies 2019, 12, 2532. [Google Scholar] [CrossRef] [Green Version]
- Lisi, F.; Shah, I. Forecasting next-day electricity demand and prices based on functional models. Energy Syst. 2020, 11, 947–979. [Google Scholar] [CrossRef]
- Su, M.; Zhang, Z.; Zhu, Y.; Zha, D.; Wen, W. Data driven natural gas spot price prediction models using machine learning methods. Energies 2019, 12, 1680. [Google Scholar] [CrossRef] [Green Version]
- Ghoddusi, H.; Creamer, G.G.; Rafizadeh, N. Machine learning in energy economics and finance: A review. Energy Econ. 2019, 81, 709–727. [Google Scholar] [CrossRef]
- Toubeau, J.F.; Pardoen, L.; Hubert, L.; Marenne, N.; Sprooten, J.; De Grève, Z.; Vallée, F. Machine learning-assisted outage planning for maintenance activities in power systems with renewables. Energy 2022, 238, 121993. [Google Scholar] [CrossRef]
- Cai, C.; Kamada, Y.; Maeda, T.; Hiromori, Y.; Zhou, S.; Xu, J. Prediction of power generation of two 30 kW Horizontal Axis Wind Turbines with Gaussian model. Energy 2021, 231, 121075. [Google Scholar]
- Cheng, B.; Du, J.; Yao, Y. Machine learning methods to assist structure design and optimization of Dual Darrieus Wind Turbines. Energy 2021, 244, 122643. [Google Scholar] [CrossRef]
- Reddy, S.R. A machine learning approach for modeling irregular regions with multiple owners in wind farm layout design. Energy 2021, 220, 119691. [Google Scholar] [CrossRef]
- Xie, Y.; Zhao, K.; Sun, Y.; Chen, D. Gaussian processes for short-term traffic volume forecasting. Transp. Res. Rec. 2010, 2165, 69–78. [Google Scholar] [CrossRef] [Green Version]
- Harrou, F.; Saidi, A.; Sun, Y.; Khadraoui, S. Monitoring of photovoltaic systems using improved kernel-based learning schemes. IEEE J. Photovolt. 2021, 11, 806–818. [Google Scholar] [CrossRef]
- Lee, J.; Wang, W.; Harrou, F.; Sun, Y. Wind power prediction using ensemble learning-based models. IEEE Access 2020, 8, 61517–61527. [Google Scholar] [CrossRef]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Regression. 1996. Available online: https://is.mpg.de/publications/2468 (accessed on 10 February 2022).
- MacKay, D.J. Gaussian Processes-A Replacement for Supervised Neural Networks? 1997. Available online: http://www.inference.org.uk/mackay/gp.pdf (accessed on 10 February 2022).
- Yang, W.; Deng, M.; Xu, F.; Wang, H. Prediction of hourly PM2. 5 using a space-time support vector regression model. Atmos. Environ. 2018, 181, 12–19. [Google Scholar] [CrossRef]
- Schulz, E.; Speekenbrink, M.; Krause, A. A tutorial on Gaussian process regression: Modelling, exploring, and exploiting functions. J. Math. Psychol. 2018, 85, 1–16. [Google Scholar] [CrossRef]
- Seeger, M. Gaussian processes for machine learning. Int. J. Neural Syst. 2004, 14, 69–106. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, V.H.; Le, T.T.; Truong, H.S.; Le, M.V.; Ngo, V.L.; Nguyen, A.T.; Nguyen, H.Q. Applying Bayesian Optimization for Machine Learning Models in Predicting the Surface Roughness in Single-Point Diamond Turning Polycarbonate. Math. Probl. Eng. 2021, 2021, 6815802. [Google Scholar] [CrossRef]
- García-Nieto, P.J.; García-Gonzalo, E.; Puig-Bargués, J.; Duran-Ros, M.; de Cartagena, F.R.; Arbat, G. Prediction of outlet dissolved oxygen in micro-irrigation sand media filters using a Gaussian process regression. Biosyst. Eng. 2020, 195, 198–207. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Yu, P.S.; Chen, S.T.; Chang, I.F. Support vector regression for real-time flood stage forecasting. J. Hydrol. 2006, 328, 704–716. [Google Scholar] [CrossRef]
- Hong, W.C.; Dong, Y.; Chen, L.Y.; Wei, S.Y. SVR with hybrid chaotic genetic algorithms for tourism demand forecasting. Appl. Soft Comput. 2011, 11, 1881–1890. [Google Scholar] [CrossRef]
- Smola, A.J.; Schölkopf, B. A tutorial on support vector regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Zeroual, A.; Harrou, F.; Sun, Y. Predicting road traffic density using a machine learning-driven approach. In Proceedings of the 2021 International Conference on Electrical, Computer and Energy Technologies (ICECET), Cape Town, South Africa, 9–10 December 2021; pp. 1–6. [Google Scholar]
- Khaldi, B.; Harrou, F.; Benslimane, S.M.; Sun, Y. A Data-Driven Soft Sensor for Swarm Motion Speed Prediction using Ensemble Learning Methods. IEEE Sens. J. 2021, 21, 19025–19037. [Google Scholar] [CrossRef]
- Lee, J.; Wang, W.; Harrou, F.; Sun, Y. Reliable solar irradiance prediction using ensemble learning-based models: A comparative study. Energy Convers. Manag. 2020, 208, 112582. [Google Scholar] [CrossRef] [Green Version]
- Kari, T.; Gao, W.; Tuluhong, A.; Yaermaimaiti, Y.; Zhang, Z. Mixed kernel function support vector regression with genetic algorithm for forecasting dissolved gas content in power transformers. Energies 2018, 11, 2437. [Google Scholar] [CrossRef] [Green Version]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, N. An investigation on multi-objective optimization of feedforward neural network topology. In Proceedings of the 2017 8th International Conference on Information, Intelligence, Systems & Applications (IISA), Larnaca, Cyprus, 27–30 August 2017; pp. 1–6. [Google Scholar]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; De Freitas, N. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2015, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Snoek, J.; Larochelle, H.; Adams, R.P. Practical bayesian optimization of machine learning algorithms. Adv. Neural Inf. Process. Syst. 2012, 25, 1–9. [Google Scholar]
- Alali, Y.; Harrou, F.; Sun, Y. A proficient approach to forecast COVID-19 spread via optimized dynamic machine learning models. Sci. Rep. 2022, 12, 2467. [Google Scholar] [CrossRef]
- Springenberg, J.T.; Klein, A.; Falkner, S.; Hutter, F. Bayesian optimization with robust Bayesian neural networks. Adv. Neural Inf. Process. Syst. 2016, 29, 4134–4142. [Google Scholar]
- Freund, Y.; Schapire, R.E. A decision-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Schapire, R.E.; Freund, Y.; Bartlett, P.; Lee, W.S. Boosting the margin: A new explanation for the effectiveness of voting methods. Ann. Stat. 1998, 26, 1651–1686. [Google Scholar]
- Schapire, R.E. The boosting approach to machine learning: An overview. In Nonlinear Estimation and Classification; Springer: Berlin/Heidelberg, Germany, 2003; pp. 149–171. [Google Scholar]
- Bühlmann, P.; Hothorn, T. Boosting algorithms: Regularization, prediction and model fitting. Stat. Sci. 2007, 22, 477–505. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Breiman, L. Arcing classifiers. Ann. Stat. 1996, 26, 123–140. [Google Scholar]
- Breiman, L. Prediction games and arcing algorithms. Neural Comput. 1999, 11, 1493–1517. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. Additive logistic regression: A statistical view of boosting (with discussion and a rejoinder by the authors). Ann. Stat. 2000, 28, 337–407. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Haghani, A. A gradient boosting method to improve travel time prediction. Transp. Res. Part C Emerg. Technol. 2015, 58, 308–324. [Google Scholar] [CrossRef]
- Harrou, F.; Saidi, A.; Sun, Y. Wind power prediction using bootstrap aggregating trees approach to enabling sustainable wind power integration in a smart grid. Energy Convers. Manag. 2019, 201, 112077. [Google Scholar] [CrossRef]
- Ruiz-Abellón, M.D.C.; Gabaldón, A.; Guillamón, A. Load forecasting for a campus university using ensemble methods based on regression trees. Energies 2018, 11, 2038. [Google Scholar] [CrossRef] [Green Version]
- Bauer, E.; Kohavi, R. An empirical comparison of voting classification algorithms: Bagging, boosting, and variants. Mach. Learn. 1999, 36, 105–139. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; dos Santos Coelho, L. Ensemble approach based on bagging, boosting and stacking for short-term prediction in agribusiness time series. Appl. Soft Comput. 2020, 86, 105837. [Google Scholar] [CrossRef]
- Sutton, C.D. Classification and regression trees, bagging, and boosting. Handb. Stat. 2005, 24, 303–329. [Google Scholar]
- Zheng, H.; Yuan, J.; Chen, L. Short-term load forecasting using EMD-LSTM neural networks with a Xgboost algorithm for feature importance evaluation. Energies 2017, 10, 1168. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chen, W.; Xie, X.; Wang, J.; Pradhan, B.; Hong, H.; Bui, D.T.; Duan, Z.; Ma, J. A comparative study of logistic model tree, random forest, and classification and regression tree models for spatial prediction of landslide susceptibility. Catena 2017, 151, 147–160. [Google Scholar] [CrossRef] [Green Version]
- Zou, M.; Djokic, S.Z. A review of approaches for the detection and treatment of outliers in processing wind turbine and wind farm measurements. Energies 2020, 13, 4228. [Google Scholar] [CrossRef]
- Shah, I.; Akbar, S.; Saba, T.; Ali, S.; Rehman, A. Short-term forecasting for the electricity spot prices with extreme values treatment. IEEE Access 2021, 9, 105451–105462. [Google Scholar] [CrossRef]
- Hocaoglu, F.O.; Kurban, M. The effect of missing wind speed data on wind power estimation. In Proceedings of the International Conference on Intelligent Data Engineering and Automated Learning, Birmingham, UK, 16–19 December 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 107–114. [Google Scholar]
- Lin, W.C.; Tsai, C.F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Honaker, J.; King, G.; Blackwell, M. Amelia II: A program for missing data. J. Stat. Softw. 2011, 45, 1–47. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Kuhn, M.; Johnson, K. Applied Predictive Modeling; Springer: Berlin/Heidelberg, Germany, 2013; Volume 26. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Harrou, F.; Sun, Y.; Hering, A.S.; Madakyaru, M. Statistical Process Monitoring Using Advanced Data-Driven and Deep Learning Approaches: Theory and Practical Applications; Elsevier: Amsterdam, The Netherlands, 2020. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Hyperparameter Search Range | Optimized Hyperparameters |
|---|---|---|
| -Sigma: 0.0001–1441.9316 | -Sigma: 0.0080861 | |
| -Basis function: Constant, Zero, Linear | -Basis function: Constant | |
| GPRO | -Kernel function: Exp, M52, RQ, SE | -Kernel function: SE |
| -Kernel scale: 0.498–2000 | -Kernel scale: 1747.75 | |
| -Standardize: true, false | -Standardize: True | |
| -Ensemble method: Bag, LSBoost | -Ensemble method: LSBoost | |
| ELO | -Number of learners: 10–500 | -Number of learners: 61 |
| -Learning rate: 0.001–1 | -Learning rate: 0.20073 | |
| -Minimum leaf size: 1–249 | -Minimum leaf size: 3 | |
| -Number of predictors to sample: 1–2 | -Number of predictors to sample: 1 |
| France | Turkey | Kaggel | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | RMSE (kW) | MAE (kW) | R2 | RMSE (kW) | MAE (kW) | R2 | RMSE (kW) | MAE (kW) | R2 |
| SVR | 185.50 | 126.07 | 0.83 | 111.48 | 70.01 | 0.97 | 123.43 | 74.88 | 0.95 |
| SVR | 259.41 | 218.69 | 0.68 | 113.48 | 74.47 | 0.97 | 139.28 | 90.10 | 0.94 |
| SVR | 187.64 | 124.63 | 0.83 | 120.46 | 88.44 | 0.96 | 123.49 | 79.41 | 0.95 |
| SVR | 186.16 | 123.82 | 0.83 | 131.25 | 98.08 | 0.95 | 124.30 | 80.81 | 0.95 |
| SVR | 186.32 | 123.68 | 0.83 | 133.22 | 101.86 | 0.95 | 124.32 | 80.10 | 0.95 |
| GPR | 185.81 | 124.21 | 0.83 | 114.87 | 70.77 | 0.97 | 122.49 | 75.19 | 0.96 |
| GPR | 184.40 | 123.98 | 0.84 | 112.89 | 69.96 | 0.97 | 122.62 | 75.15 | 0.96 |
| GPR | 184.70 | 124.49 | 0.84 | 115.09 | 70.88 | 0.96 | 122.48 | 75.17 | 0.96 |
| GPR | 183.23 | 124.42 | 0.84 | 122.63 | 78.13 | 0.96 | 121.62 | 75.47 | 0.96 |
| GPR | 184.57 | 124.22 | 0.84 | 112.79 | 69.96 | 0.97 | 122.60 | 75.13 | 0.96 |
| BS | 183.66 | 124.33 | 0.84 | 114.34 | 71.78 | 0.97 | 129.71 | 82.38 | 0.95 |
| BT | 199.79 | 135.27 | 0.81 | 123.79 | 84.11 | 0.96 | 119.24 | 82.17 | 0.96 |
| ELO | 183.46 | 124.05 | 0.84 | 117.25 | 72.89 | 0.96 | 120.64 | 75.80 | 0.96 |
| XGB | 185.38 | 125.21 | 0.83 | 121.02 | 75.23 | 0.96 | 122.02 | 76.95 | 0.96 |
| RF | 223.40 | 148.95 | 0.76 | 185.13 | 115.01 | 0.91 | 132.52 | 91.95 | 0.95 |
| Model | Hyperparameter Search Range | Optimized Hyperparameters |
|---|---|---|
| -Sigma: 0.0001–1441.9316 | -Sigma: 0.049216 | |
| -Basis function: Constant, Zero, Linear | -Basis function: Linear | |
| GPRO | -Kernel function: Exp, M52, RQ, SE | -Kernel function: RQ |
| -Kernel scale: 0.498–2000 | -Kernel scale: 1145.0171 | |
| -Standardize: true, false | -Standardize: True | |
| -Ensemble method: Bag, LSBoost | -Ensemble method: Bag | |
| ELO | -Number of learners: 10–500 | -Number of learners: 19 |
| -Learning rate: 0.001–1 | -Learning rate: 0.2 | |
| -Minimum leaf size: 1–249 | -Minimum leaf size: 34 | |
| -Number of predictors to sample: 1–5 | -Number of predictors to sample: 4 |
| France | Turkey | Kaggel | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Models | RMSE (kW) | MAE (kW) | R2 | RMSE (kW) | MAE (kW) | R2 | RMSE (kW) | MAE (kW) | R2 |
| SVR | 130.89 | 85.36 | 0.91 | 111.98 | 73.04 | 0.97 | 130.89 | 85.36 | 0.91 |
| SVR | 130.77 | 85.06 | 0.91 | 171.45 | 133.97 | 0.92 | 130.77 | 85.06 | 0.91 |
| SVR | 131.71 | 86.98 | 0.91 | 122.53 | 90.98 | 0.96 | 131.71 | 86.98 | 0.91 |
| SVR | 149.47 | 97.84 | 0.89 | 133.39 | 100.31 | 0.95 | 149.47 | 97.84 | 0.89 |
| SVR | 132.07 | 85.76 | 0.91 | 124.17 | 91.53 | 0.96 | 132.07 | 85.76 | 0.91 |
| GPR | 165.33 | 112.81 | 0.86 | 143.97 | 93.44 | 0.94 | 165.33 | 112.81 | 0.86 |
| GPR | 199.63 | 125.11 | 0.80 | 176.64 | 101.93 | 0.92 | 199.63 | 125.11 | 0.80 |
| GPR | 170.63 | 110.82 | 0.85 | 148.86 | 94.90 | 0.94 | 170.63 | 110.82 | 0.85 |
| GPR | 160.65 | 108.14 | 0.87 | 133.34 | 85.20 | 0.95 | 160.65 | 108.14 | 0.87 |
| GPR | 129.06 | 84.94 | 0.92 | 109.62 | 68.87 | 0.97 | 129.06 | 84.94 | 0.92 |
| BS | 129.26 | 87.08 | 0.92 | 114.71 | 71.94 | 0.96 | 129.26 | 87.08 | 0.92 |
| BT | 129.62 | 88.27 | 0.91 | 112.21 | 75.21 | 0.97 | 129.62 | 88.27 | 0.91 |
| ELO | 127.37 | 86.15 | 0.92 | 114.86 | 72.74 | 0.96 | 127.37 | 86.15 | 0.92 |
| XGB | 129.68 | 88.16 | 0.91 | 117.28 | 73.17 | 0.96 | 129.68 | 88.16 | 0.91 |
| RF | 133.70 | 90.41 | 0.91 | 118.87 | 80.09 | 0.96 | 133.70 | 90.41 | 0.91 |
| Models | RMSE (kW) | MAE (kW) | R2 |
|---|---|---|---|
| SVR | 129.91 | 102.80 | 0.91 |
| SVR | 85.22 | 59.08 | 0.96 |
| SVR | 88.57 | 62.93 | 0.96 |
| SVR | 87.52 | 59.26 | 0.96 |
| SVR | 83.44 | 57.12 | 0.96 |
| GPR | 76.91 | 48.89 | 0.97 |
| GPR | 78.54 | 50.03 | 0.97 |
| GPR | 76.54 | 48.26 | 0.97 |
| GPR | 76.91 | 46.94 | 0.97 |
| GPR | 69.47 | 41.13 | 0.98 |
| BS | 73.77 | 47.54 | 0.97 |
| BT | 42.28 | 21.41 | 0.99 |
| ELO | 84.95 | 52.87 | 0.96 |
| XGB | 78.32 | 46.09 | 0.97 |
| RF | 56.74 | 37.07 | 0.98 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkesaiberi, A.; Harrou, F.; Sun, Y. Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study. Energies 2022, 15, 2327. https://doi.org/10.3390/en15072327
Alkesaiberi A, Harrou F, Sun Y. Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study. Energies. 2022; 15(7):2327. https://doi.org/10.3390/en15072327
Chicago/Turabian StyleAlkesaiberi, Abdulelah, Fouzi Harrou, and Ying Sun. 2022. "Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study" Energies 15, no. 7: 2327. https://doi.org/10.3390/en15072327
APA StyleAlkesaiberi, A., Harrou, F., & Sun, Y. (2022). Efficient Wind Power Prediction Using Machine Learning Methods: A Comparative Study. Energies, 15(7), 2327. https://doi.org/10.3390/en15072327