
Determining Extreme Still Water Levels for Design and Planning Purposes Incorporating Sea Level Rise: Sydney, Australia


Abstract
1. Introduction
2. Materials and Methods
2.1. Data Sources Used in the Study
2.2. Step by Step Methodology
3. Results
4. Discussion
4.1. Potential Future Changes to Storm Drivers That Could Influence Extreme Water Levels along the NSW Coast
4.2. Sensitivity of EVA to Declustering
4.3. Sensitivity of EVA to Length of Dataset
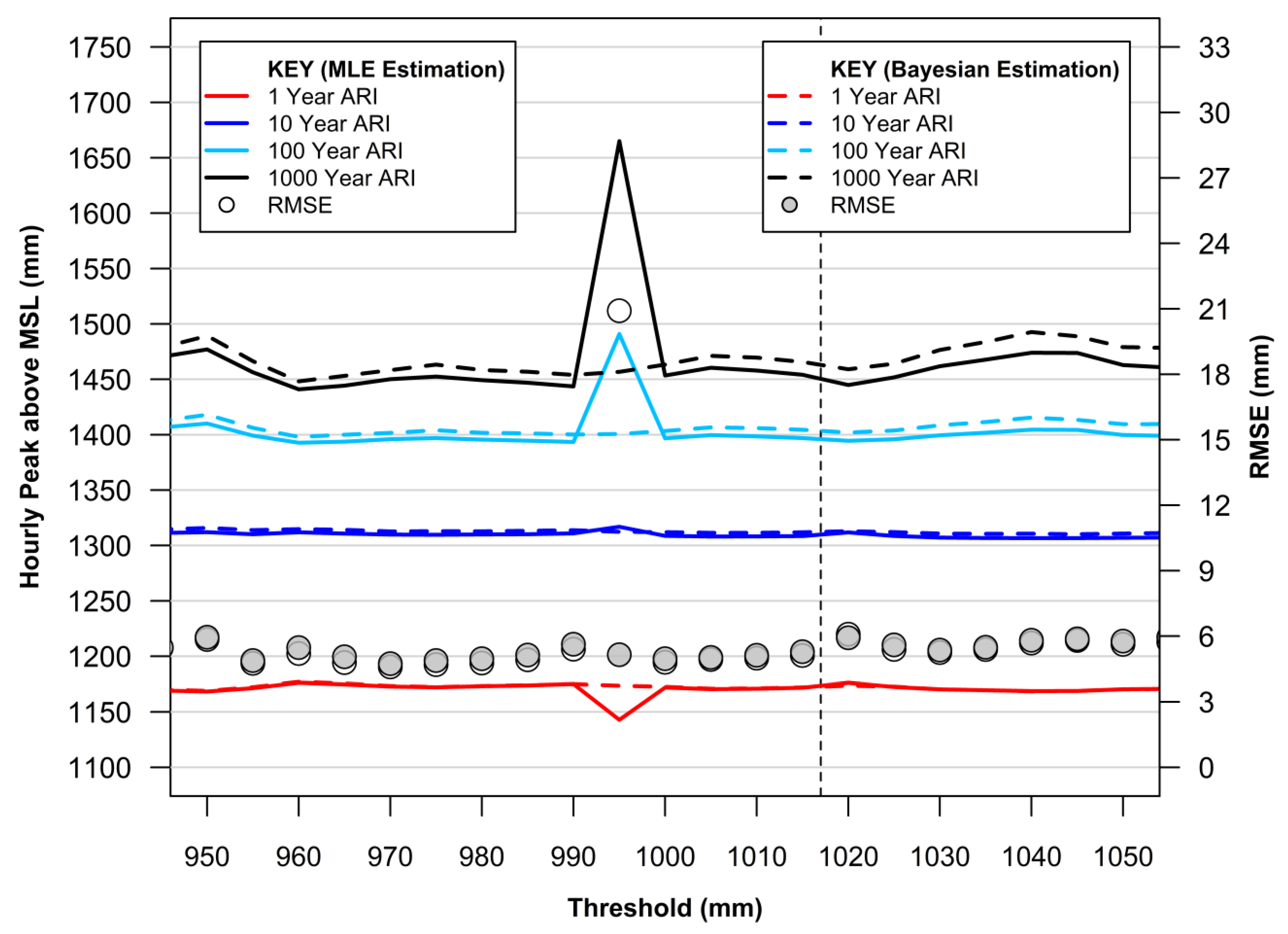
4.4. Threshold Selection and GPD Fitting for POT Analysis
4.5. Spatial Utility of EVA
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Steffen, W.; Mallon, K.; Kompas, T.; Dean, A.; Rice, M. Compound Costs: How Climate Change Is Damaging Australia’s Economy; Climate Council of Australia: Potts Point, Australia, 2019; ISBN 978-1-925573-97-8. [Google Scholar]
- Nauels, A.; Gütschow, J.; Mengel, M.; Meinshausen, M.; Clark, P.U.; Schleussner, C.-F. Attributing long-term sea-level rise to Paris Agreement emission pledges. Proc. Natl. Acad. Sci. USA 2019, 116, 23487–23492. [Google Scholar] [CrossRef] [PubMed]
- IPCC; Masson-Delmotte, V.; Zhai, P.; Pirani, A.; Connors, S.L.; Péan, C.; Berger, S.; Caud, N.; Chen, Y.; Goldfarb, L.; et al. Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change. 2021. Available online: https://elib.dlr.de/137584/ (accessed on 21 September 2021).
- Watson, P.J. Status of mean sea level rise around the USA (2020). GeoHazards 2021, 2, 80–100. [Google Scholar] [CrossRef]
- Woodworth, P.L.; Hunter, J.R.; Marcos, M.; Caldwell, P.; Menéndez, M.; Haigh, I. Towards a global higher-frequency sea level dataset. Geosci. Data J. 2016, 3, 50–59. [Google Scholar] [CrossRef]
- Modra, B. NSW Ocean Water Levels; Report No. MHL1881; Technical Report Prepared by Public Works Manly Hydraulics Laboratory; NSW Government: Sydney, Australia, March 2011.
- Queensland Government. Tropical Cyclone Yasi February 2011. Report from Department of Environment and Resource Management, Queensland Government. 2011. Available online: https://www.publications.qld.gov.au/dataset/19c20822-f29e-494c-880a-113ccd13a04b/resource/3bf0ac2c-565a-4400-8d5b-6a4c15236c82/download/tc-yasi.pdf (accessed on 21 September 2021).
- Rashid, M.M.; Wahl, T.; Chambers, D.P. Extreme sea level variability dominates coastal flood risk changes at decadal time scales. Environ. Res. Lett. 2021, 16, 024026. [Google Scholar] [CrossRef]
- Thompson, P.R.; Widlansky, M.J.; Hamlington, B.D.; Merrifield, M.A.; Marra, J.J.; Mitchum, G.T.; Sweet, W. Rapid increases and extreme months in projections of United States high-tide flooding. Nat. Clim. Chang. 2021, 11, 584–590. [Google Scholar] [CrossRef]
- Hague, B.S.; McGregor, S.; Murphy, B.F.; Reef, R.; Jones, D.A. Sea level rise driving increasingly predictable coastal inundation in Sydney, Australia. Earth’s Future 2020, 8, e2020EF001607. [Google Scholar] [CrossRef]
- Pattiaratchi, C.; Wijeratne, E.M.S. Observations of Meteorological Tsunamis along the South-West Australian Coast. Nat. Hazards 2014, 74, 281–303. [Google Scholar] [CrossRef][Green Version]
- Ozsoy, O.; Haigh, I.D.; Wadey, M.P.; Nicholls, R.J.; Wells, N.C. High-frequency sea level variations and implications for coastal flooding: A case study of the Solent, UK. Cont. Shelf Res. 2016, 122, 1–13. [Google Scholar] [CrossRef]
- Tebaldi, C.; Ranasinghe, R.; Vousdoukas, M.; Rasmussen, D.J.; Vega-Westhoff, B.; Kirezci, E.; Kopp, R.E.; Sriver, R.; Mentaschi, L. Extreme sea levels at different global warming levels. Nat. Clim. Chang. 2021, 11, 746–751. [Google Scholar] [CrossRef]
- Buchanan, M.K.; Oppenheimer, M.; Kopp, R.E. Amplification of flood frequencies with local sea level rise and emerging flood regimes. Environ. Res. Lett. 2017, 12, 064009. [Google Scholar] [CrossRef]
- Fréchet, M. On the law of probability of the maximum deviation. Ann. Pol. Math. Soc. 1927, 6, 93–116. [Google Scholar]
- Fisher, R.A.; Tippett, L.H.C. Limiting forms of the frequency distribution of the largest or smallest member of a sample. Math. Proc. Camb. Philos. Soc. 1928, 24, 180–190. [Google Scholar] [CrossRef]
- Gumbel, E.J. The maxima of the mean largest value and of the range. Ann. Math. Stat. 1954, 25, 76–84. [Google Scholar] [CrossRef]
- Weibull, W. A statistical distribution function of wide applicability. J. Appl. Mech. 1951, 18, 293–297. [Google Scholar] [CrossRef]
- Jenkinson, A.F. The frequency distribution of the annual maximum (or minimum) values of meteorological elements. Q. J. R. Meteorol. Soc. 1955, 81, 158–171. [Google Scholar] [CrossRef]
- Coles, S. An Introduction to Statistical Modeling of Extreme Values; Springer: London, UK, 2001; ISBN 978-1-84996-874-4. [Google Scholar]
- Pickands, J. The two-dimensional poisson process and extremal processes. J. Appl. Probab. 1971, 8, 745–756. [Google Scholar] [CrossRef]
- Pickands, J. Statistical inference using extreme order statistics. Ann. Stat. 1975, 3, 119–131. [Google Scholar]
- Beirlant, J.; Goegebeur, Y.; Teugels, J.; Segers, J. Statistics of Extremes; John Wiley & Sons, Ltd.: Chichester, UK, 2004; ISBN 9780470012383. [Google Scholar]
- Shane, R.M.; Lynn, W.R. Mathematical model for flood risk evaluation. J. Hydraul. Div. 1964, 90, 1–20. [Google Scholar] [CrossRef]
- Charras-Garrido, M.; Lezaud, P. Extreme value analysis: An introduction. J. Société Française Stat. Rev. Stat. Appliquée 2013, 154, 66–97. [Google Scholar]
- Dupuis, D.J. Exceedances over high thresholds: A guide to threshold selection. Extremes 1999, 1, 251–261. [Google Scholar] [CrossRef]
- Arns, A.; Wahl, T.; Haigh, I.D.; Jensen, J.; Pattiaratchi, C. Estimating extreme water level probabilities: A comparison of the direct methods and recommendations for best practise. Coast. Eng. 2013, 81, 51–66. [Google Scholar] [CrossRef]
- Caires, S. Extreme Value Analysis: Wave Data; JCOMM Technical Report; WMO: Geneva, Switzerland, 2011. [Google Scholar]
- Watson, P.J. Improved Techniques to Estimate Mean Sea Level, Velocity and Acceleration from Long Ocean Water Level Time Series to Augment Sea Level (and Climate Change) Research; University of New South Wales: Sydney, Australia, 2018. [Google Scholar]
- R Development Core Team R. A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Gilleland, E. ExtRemes: Extreme Value Analysis; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Gilleland, E.; Katz, R.W. ExtRemes 2.0: An extreme value analysis package in R. J. Stat. Softw. 2016, 72, 1–39. [Google Scholar] [CrossRef]
- PSMSL. Permanent Service for Mean Sea Level. Available online: https://www.psmsl.org/data/obtaining (accessed on 21 September 2021).
- Holgate, S.J.; Matthews, A.; Woodworth, P.L.; Rickards, L.J.; Tamisiea, M.E.; Bradshaw, E.; Foden, P.R.; Gordon, K.M.; Jevrejeva, S.; Pugh, J. New data systems and products at the permanent service for mean sea level. J. Coast. Res. 2013, 29, 493–504. [Google Scholar] [CrossRef]
- UHSLC. University of Hawaii Sea Level Centre. Available online: http://uhslc.soest.hawaii.edu/data (accessed on 22 September 2021).
- Caldwell, P.C.; Merrifield, M.A.; Thompson, P.R. Sea Level Measured by Tide Gauges from Global Oceans—The Joint Archive for Sea Level Holdings (JASL); NOAA National Centers for Environmental Information: Asheville, NC, USA, 2001.
- Watson, P.J. Identifying the Best Performing Time Series Analytics for Sea Level Research. In Time Series Analysis and Forecasting: Contributions to Statistics; Rojas, I., Pomares, H., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 261–278. [Google Scholar]
- Watson, P.J.; Lim, H.S. An update on the status of mean sea level rise around the Korean peninsula. Atmosphere 2020, 11, 1153. [Google Scholar] [CrossRef]
- Kondrashov, D.; Ghil, M. Spatio-temporal filling of missing points in geophysical data sets. Nonlinear Processes Geophys. 2006, 13, 151–159. [Google Scholar] [CrossRef]
- Alexandrov, T.; Golyandina, N. Automatic Extraction and Forecast of Time Series Cyclic Components within the Framework of SSA. In Proceedings of the 5th St. Petersburg Workshop on Simulation, St. Petersburg, Russia, 26 June–2 July 2005; pp. 45–50. [Google Scholar]
- Mann, M.E.; Steinman, B.A.; Miller, S.K. Absence of internal multidecadal and interdecadal oscillations in climate model simulations. Nat. Commun. 2020, 11, 49. [Google Scholar] [CrossRef]
- Katz, R.W.; Parlange, M.B.; Naveau, P. Statistics of extremes in hydrology. Adv. Water Resour. 2002, 25, 1287–1304. [Google Scholar] [CrossRef]
- IPCC. Summary for Policymakers. In Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Masson-Delmotte, V., Zhai, P., Pirani, A., Connors, S.L., Péan, C., Berger, S., Caud, N., Chen, Y., Goldfarb, L., Gomis, M.I., et al., Eds.; Cambridge University Press: Cambridge, UK, 2021. [Google Scholar]
- Dowdy, A.J.; Mills, G.A.; Timbal, B. Large-Scale Indicators of Australian East Coast Lows and Associated Extreme Weather Events; CAWCR Technical Report No. 037; Centre for Australian Weather and Climate Research: Aspendale, Australia, 2011. [Google Scholar]
- Australian Government, Bureau of Meteorology. About East Coast Lows. Available online: http://www.bom.gov.au/nsw/sevwx/facts/ecl.shtml (accessed on 21 September 2021).
- Ji, F.; Evans, J.P.; Argueso, D.; Fita, L.; di Luca, A. Using large-scale diagnostic quantities to investigate change in east coast lows. Clim. Dyn. 2015, 45, 2443–2445. [Google Scholar] [CrossRef]
- Grose, M.R.; Pook, M.J.; McIntosh, P.C.; Risbey, J.S.; Bindoff, N.L. The simulation of cutoff lows in a regional climate model: Reliability and future trends. Clim. Dyn. 2012, 39, 445–459. [Google Scholar] [CrossRef]
- Palmen, E. On the formation and structure of tropical hurricanes. Geophysica 1948, 3, 26–38. [Google Scholar]
- Dare, R.A.; Mcbride, J.L. The threshold sea surface temperature condition for tropical cyclogenesis. J. Clim. 2011, 24, 4570–4576. [Google Scholar] [CrossRef]
- Laffoley, D.; Baxter, J.M. (Eds.) Explaining Ocean Warming: Causes, Scale, Effects and Consequences; Full Report; International Union for Conservation of Nature: Gland, Switzerland, 2016; 456p. [Google Scholar] [CrossRef]
- MHL. Manly Hydraulics Laboratory. Available online: https://www.mhl.nsw.gov.au/Data-Wave (accessed on 30 September 2021).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | IPCC (AR6) Sea Level Rise Scenarios | ||||
|---|---|---|---|---|---|
| SSP1-1.9 | SSP1-2.6 | SSP2-4.5 | SSP3-7.0 | SSP5-8.5 | |
| 2020 | 208 | 208 (198, 218) | 208 | 208 (198, 218) | 208 |
| 2030 | 248 | 248 (238, 278) | 248 | 248 (238, 278) | 258 |
| 2040 | 288 | 298 (268, 328) | 298 | 298 (278, 338) | 318 |
| 2050 | 338 | 348 (318, 408) | 358 | 368 (338, 428) | 388 |
| 2060 | 368 | 388 (348, 468) | 418 | 438 (398, 518) | 468 |
| 2070 | 418 | 448 (388, 548) | 488 | 528 (468, 638) | 558 |
| 2080 | 458 | 498 (428, 628) | 558 | 618 (538, 758) | 668 |
| 2090 | 508 | 548 (458, 698) | 638 | 718 (618, 898) | 788 |
| 2100 | 538 | 598 (478, 768) | 718 | 838 (798, 1058) | 928 |
| Measurements above MSL (mm) | Date (Time) |
|---|---|
| 1456 | 25 May 1974 (13:00) |
| 1396 | 10 June 1956 (11:00) |
| 1395 | 27 April 1990 (12:00) |
| 1348 | 3 August 1921 (10:00) |
| 1326 | 10 July 1964 (11:00) |
| 1319 | 30 June 1984 (12:00) |
| 1305 | 12 December 1950 (0:00 h) |
| 1301 | 19 June 1947 (11:00 h) |
| 1300 | 19 August 2001 (10:00 h) |
| 1293 | 22 July 1978 (12:00 h) |
| 1281 | 6 December 2017 (0:00 h) |
| Cut-off Hourly Height above MSL (mm) | Slope (mm/year) | Slope Error (95% CI) (mm/year) | Data Points for Analysis |
|---|---|---|---|
| 850 | −0.03 | (−0.07, 0.01) | 11,504 |
| 900 | −0.08 | (−0.14, −0.02) | 5549 |
| 950 | 0.05 | (−0.05, 0.15) | 2440 |
| 1000 | −0.02 | (−0.20, 0.16) | 696 |
| 1050 | 0 | (−0.22, 0.22) | 441 |
| 1100 | 0.12 | (−0.12, 0.36) | 264 |
| 1150 | 0.02 | (−0.27, 0.31) | 146 |
| 1200 | −0.09 | (−0.48, 0.30) | 69 |
| 1250 | 0.03 | (−0.64, 0.70) | 31 |
| 1300 | 0.18 | (−1.45, 1.81) | 9 |
| 1350 | 0.04 | (−4.00, 4.08) | 3 |
| Return Period (Years) | Height (mm) |
|---|---|
| 1 | 1173 |
| 2 | 1221 |
| 5 | 1275 |
| 10 | 1310 |
| 20 | 1340 |
| 50 | 1374 |
| 100 | 1396 |
| 200 | 1415 |
| 500 | 1436 |
| 1000 | 1450 |
| Year | Return Period (Years) | IPCC (AR6) Sea Level Rise Scenarios (mm Australian Height Datum) | ||||
|---|---|---|---|---|---|---|
| SSP1-1.9 | SSP1-2.6 | SSP2-4.5 | SSP3-7.0 | SSP5-8.5 | ||
| 2020 | 1 | 1242 | 1242 | 1242 | 1242 | 1242 |
| 2 | 1290 | 1290 | 1290 | 1290 | 1290 | |
| 5 | 1344 | 1344 | 1344 | 1344 | 1344 | |
| 10 | 1379 | 1379 | 1379 | 1379 | 1379 | |
| 20 | 1409 | 1409 | 1409 | 1409 | 1409 | |
| 50 | 1443 | 1443 | 1443 | 1443 | 1443 | |
| 100 | 1465 | 1465 | 1465 | 1465 | 1465 | |
| 200 | 1484 | 1484 | 1484 | 1484 | 1484 | |
| 500 | 1505 | 1505 | 1505 | 1505 | 1505 | |
| 1000 | 1519 | 1519 | 1519 | 1519 | 1519 | |
| 2050 | 1 | 1368 | 1383 | 1392 | 1401 | 1422 |
| 2 | 1416 | 1431 | 1440 | 1449 | 1470 | |
| 5 | 1470 | 1485 | 1494 | 1503 | 1524 | |
| 10 | 1505 | 1520 | 1529 | 1538 | 1559 | |
| 20 | 1535 | 1550 | 1559 | 1568 | 1589 | |
| 50 | 1569 | 1584 | 1593 | 1602 | 1623 | |
| 100 | 1591 | 1606 | 1615 | 1624 | 1645 | |
| 200 | 1610 | 1625 | 1634 | 1643 | 1664 | |
| 500 | 1631 | 1646 | 1655 | 1664 | 1685 | |
| 1000 | 1645 | 1660 | 1669 | 1678 | 1699 | |
| 2070 | 1 | 1452 | 1482 | 1522 | 1561 | 1592 |
| 2 | 1500 | 1530 | 1570 | 1609 | 1640 | |
| 5 | 1554 | 1584 | 1624 | 1663 | 1694 | |
| 10 | 1589 | 1619 | 1659 | 1698 | 1729 | |
| 20 | 1619 | 1649 | 1689 | 1728 | 1759 | |
| 50 | 1653 | 1683 | 1723 | 1762 | 1793 | |
| 100 | 1675 | 1705 | 1745 | 1784 | 1815 | |
| 200 | 1694 | 1724 | 1764 | 1803 | 1834 | |
| 500 | 1715 | 1745 | 1785 | 1824 | 1855 | |
| 1000 | 1729 | 1759 | 1799 | 1838 | 1869 | |
| 2100 | 1 | 1578 | 1635 | 1753 | 1872 | 1962 |
| 2 | 1626 | 1683 | 1801 | 1920 | 2010 | |
| 5 | 1680 | 1737 | 1855 | 1974 | 2064 | |
| 10 | 1715 | 1772 | 1890 | 2009 | 2099 | |
| 20 | 1745 | 1802 | 1920 | 2039 | 2129 | |
| 50 | 1779 | 1836 | 1954 | 2073 | 2163 | |
| 100 | 1801 | 1858 | 1976 | 2095 | 2185 | |
| 200 | 1820 | 1877 | 1995 | 2114 | 2204 | |
| 500 | 1841 | 1898 | 2016 | 2135 | 2225 | |
| 1000 | 1855 | 1912 | 2030 | 2149 | 2239 | |
| Return Period (Years) | Height (1) (mm) | Height (2) (mm) |
|---|---|---|
| 1 | 1173 | 1175 |
| 2 | 1221 | 1223 |
| 5 | 1275 | 1276 |
| 10 | 1310 | 1311 |
| 20 | 1340 | 1340 |
| 50 | 1374 | 1374 |
| 100 | 1396 | 1395 |
| 200 | 1415 | 1414 |
| 500 | 1436 | 1435 |
| 1000 | 1450 | 1448 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Watson, P.J. Determining Extreme Still Water Levels for Design and Planning Purposes Incorporating Sea Level Rise: Sydney, Australia. Atmosphere 2022, 13, 95. https://doi.org/10.3390/atmos13010095
Watson PJ. Determining Extreme Still Water Levels for Design and Planning Purposes Incorporating Sea Level Rise: Sydney, Australia. Atmosphere. 2022; 13(1):95. https://doi.org/10.3390/atmos13010095
Chicago/Turabian StyleWatson, Phil J. 2022. "Determining Extreme Still Water Levels for Design and Planning Purposes Incorporating Sea Level Rise: Sydney, Australia" Atmosphere 13, no. 1: 95. https://doi.org/10.3390/atmos13010095
APA StyleWatson, P. J. (2022). Determining Extreme Still Water Levels for Design and Planning Purposes Incorporating Sea Level Rise: Sydney, Australia. Atmosphere, 13(1), 95. https://doi.org/10.3390/atmos13010095