
Research Progress on Data-Driven Industrial Fault Diagnosis Methods

Abstract
1. Introduction
2. Industrial Big Data
2.1. Sources of Industrial Big Data
- Sensors/Equipment: By installing sensors on equipment, various operating parameters such as temperature, pressure, vibration, and current can be monitored in real time. These data reflect the real-time status of the equipment and can be directly utilized for fault detection and predictive maintenance. Additionally, a large amount of data is generated by the built-in sensors of the equipment itself, which can be directly used for assessing the equipment’s health and swiftly identifying potential issues;
- Business Operations and Management: Business operations and management data include information such as production planning, business management, commercial strategy, and inventory management. These data typically originate from enterprise management systems like ERP (Enterprise Resource Planning), SCM (Supply Chain Management), and CRM (Customer Relationship Management). Integrating and analyzing these data help enterprises realize refined management, provide new perspectives for decision-makers, and enhance strategic planning;
- Internet: Internet data is a crucial supplement to industrial big data, especially under the backdrop of widespread internet adoption, which offers more diverse data sources. Such data include user feedback, market demand, weather data, and so on. By combining these external data with internal data, enterprises can carry out more effective product improvements and production planning.
2.2. Industrial Datasets and Platforms
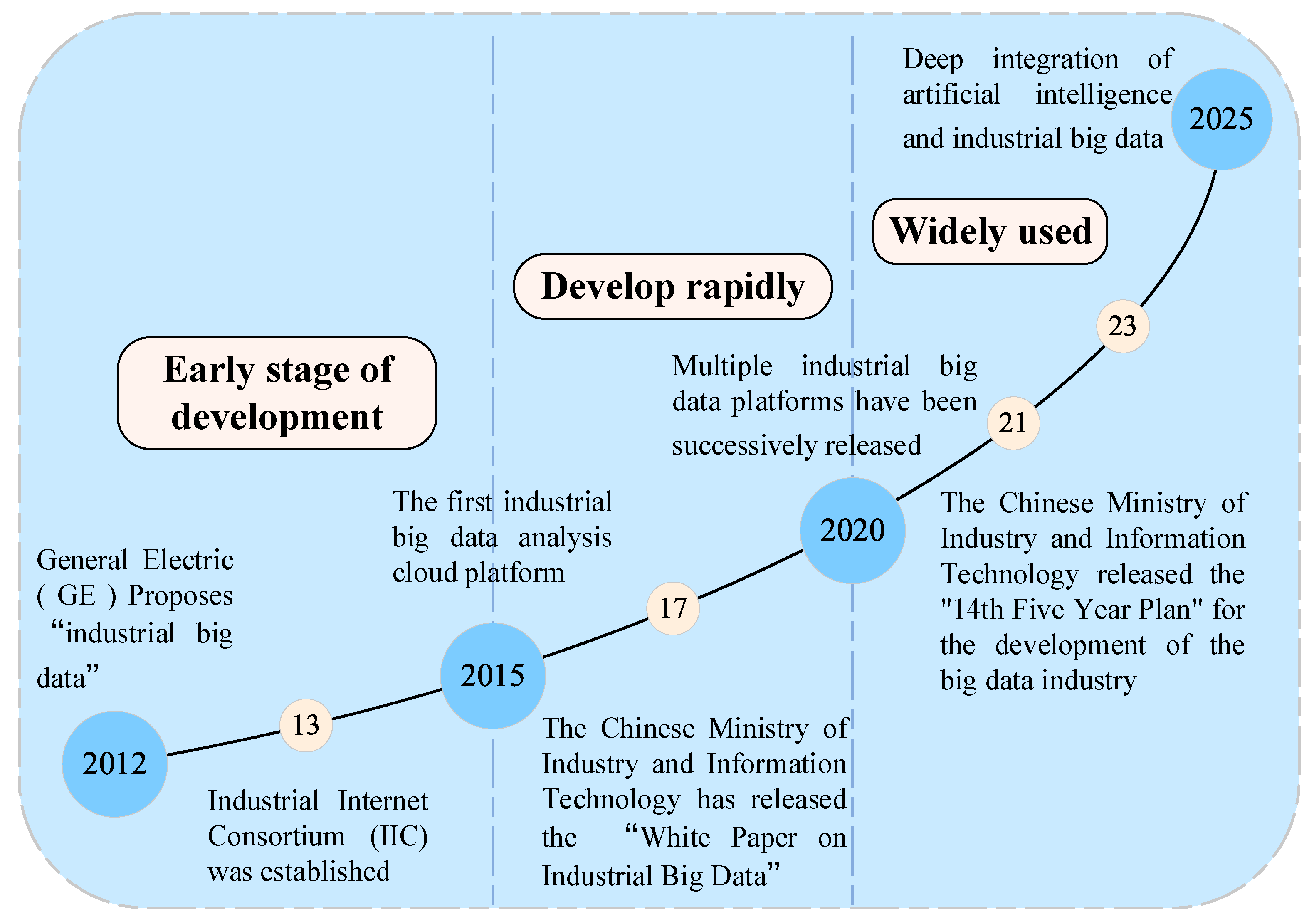
2.3. Evolution of Industrial Big Data and Fault Diagnosis
- Data Availability: Whether diagnostic data are accessible or if data can be obtained for a specific component or system;
- Data Types: The known or acquirable data types, such as vibration, acoustic emission, or characteristic signals;
- Data Quality: Whether the data are recorded comprehensively and accurately and contain all the information needed to analyze the features and behaviors of the specific component or system;
- Data Scale: Whether the data volume is sufficient for training fault diagnosis algorithms.
3. Data-Driven Fault Diagnosis Methods
- Knowledge-Based Methods: Knowledge-based methods employ the accumulated experience and expertise of professionals to carry out fault diagnosis. The core principle is to collect and organize expert insights into equipment operation and failure patterns, thereby establishing a set of rules or a knowledge base to guide fault detection and diagnosis. Expert systems and fault tree analysis exemplify this approach [20,21]. These methods are highly interpretable, making the diagnostic process transparent and facilitating comprehension and use by maintenance personnel. Furthermore, they target specific equipment or fault types, offering in-depth analyses. However, they rely heavily on expert knowledge, and gathering and updating that knowledge can be time-consuming and labor-intensive. It may be challenging to cover all potential fault scenarios. As equipment complexity grows, relying solely on expert experience may not meet the requirement for comprehensive diagnosis nor easily adapt to the emergence of new fault patterns;
- Signal Processing and Analysis Model-Based Methods: These methods utilize various signals produced during equipment operation (e.g., vibration, temperature, acoustic signals) in combination with physical and mathematical models to analyze and diagnose the equipment’s condition. Their fundamental principle is to use signal acquisition and processing techniques to extract fault features, followed by employing analysis models—such as spectral analysis, wavelet transforms, and finite element analysis—to predict equipment performance and possible faults [22]. The advantage of this approach is that it enables real-time monitoring and early warning of failures, providing high diagnostic accuracy for equipment whose physical mechanisms are clearly understood and whose signals are distinct. For instance, vibration signal analysis is widely used for diagnosing faults in rotating machinery. However, these methods demand a high degree of accuracy in the equipment’s physical model and signal quality. Building and validating such models requires specialized domain knowledge, and when confronted with complex, multi-variable systems, models can become overly complex or insufficiently accurate. Additionally, signal noise and environmental interference may reduce diagnostic precision;
- Data-Driven Methods: Data-driven approaches are increasingly important in preventive maintenance. They collect vast amounts of real-time performance and status data through IoT devices, then perform data fusion and feature extraction, ultimately employing machine learning and deep learning algorithms for fault diagnosis [23]. Such methods exhibit robust adaptability and generalizability, as they can autonomously extract decision-making features from large datasets and handle complex, nonlinear relationships and high-dimensional data without the need for extensive domain expertise upfront—making them well-suited for complex, large-scale industrial datasets. Furthermore, the application of Large Language Models in industrial fault diagnosis achieves end-to-end anomaly detection, enhancing industrial intelligence.
3.1. Fault Diagnosis Methods Based on Traditional Machine Learning
3.1.1. Support Vector Machine
- Scalability: When dealing with massive datasets, computational complexity increases dramatically and can lead to a computational burden of catastrophic proportions;
- Sensitivity to Kernel Functions: Model performance is highly sensitive to the selection of the kernel function and its parameters. Inappropriate choices can fail to yield reliable diagnostic results;
- Multi-Class Complexity: Originally designed for binary classification tasks, SVM requires complex strategies—such as one-vs.-rest or one-vs.-one—to integrate multiple SVM models for intelligent fault diagnosis in multi-class scenarios, thus adding to both model complexity and computational overhead.
3.1.2. Other Machine Learning Models
3.2. Deep Learning-Based Fault Diagnosis Methods
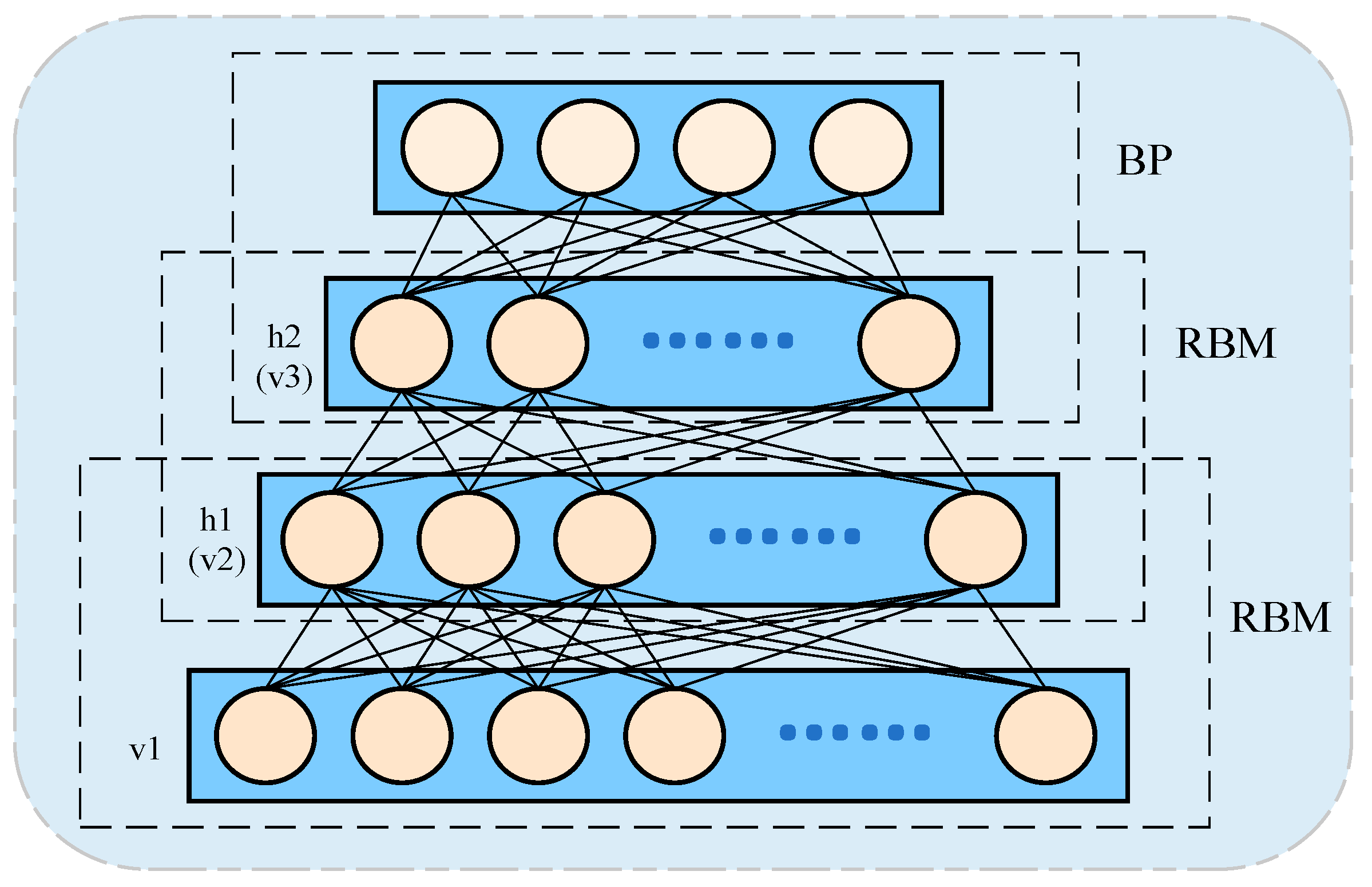
3.2.1. Deep Belief Network
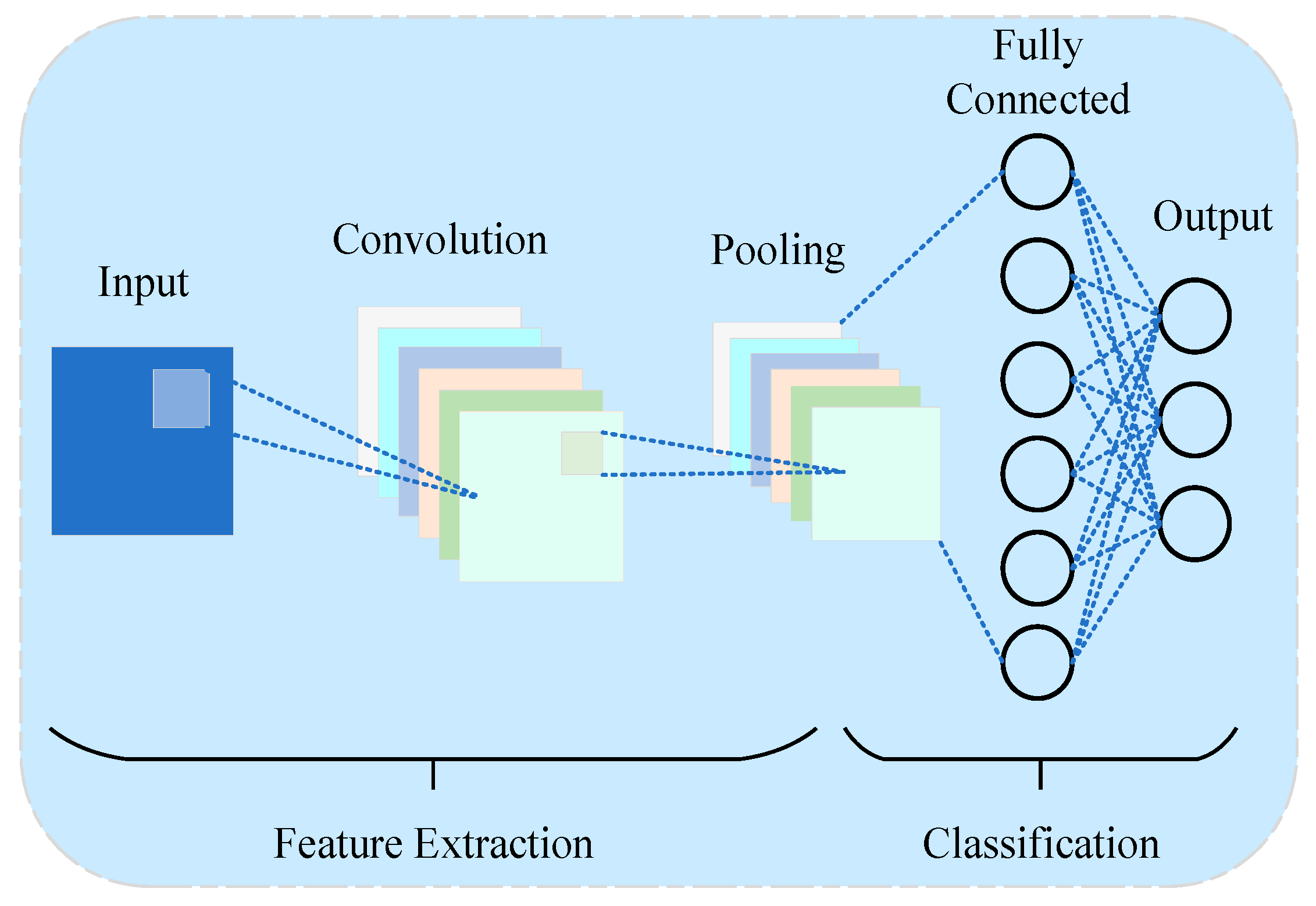
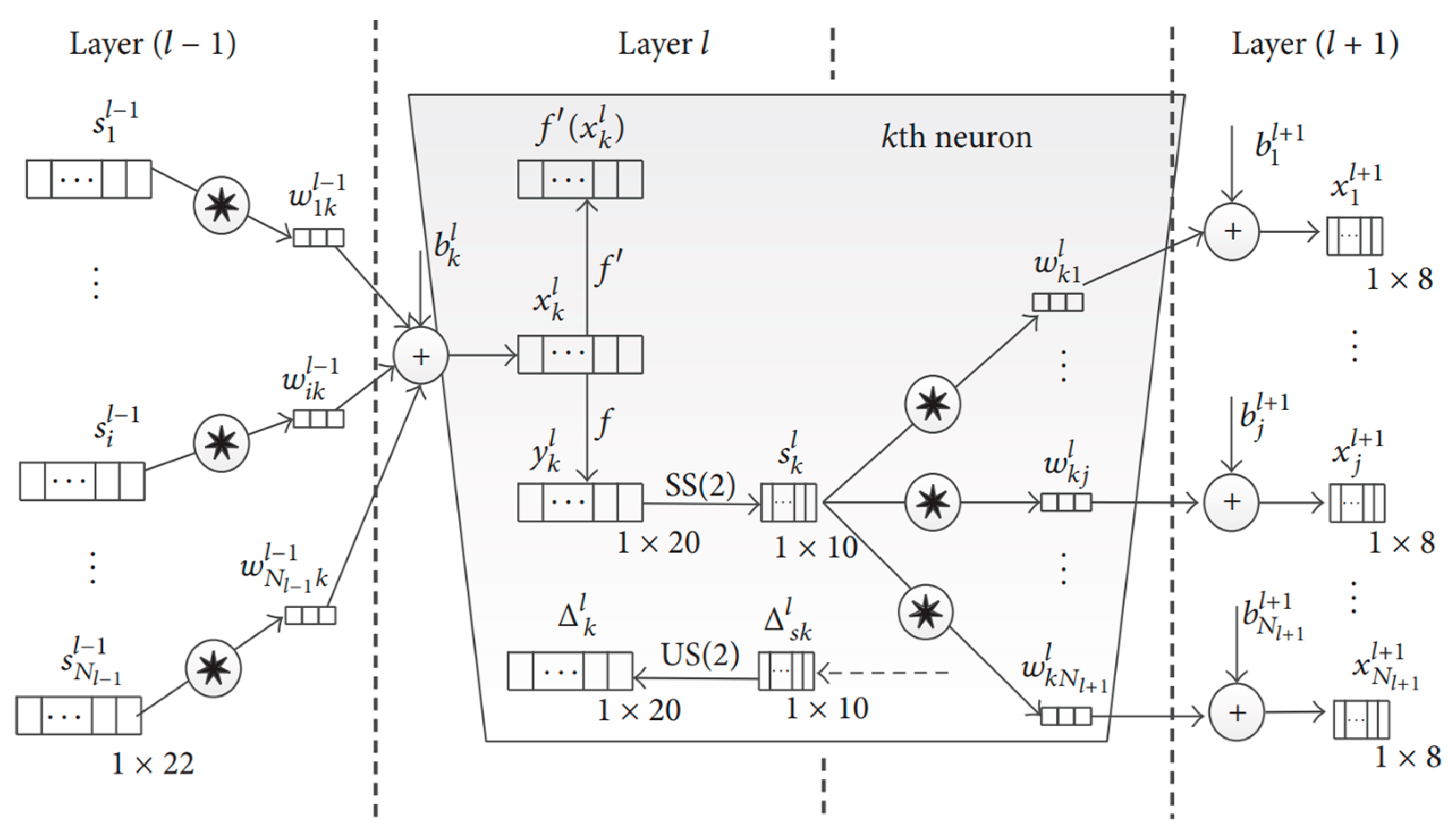
3.2.2. Convolutional Neural Network
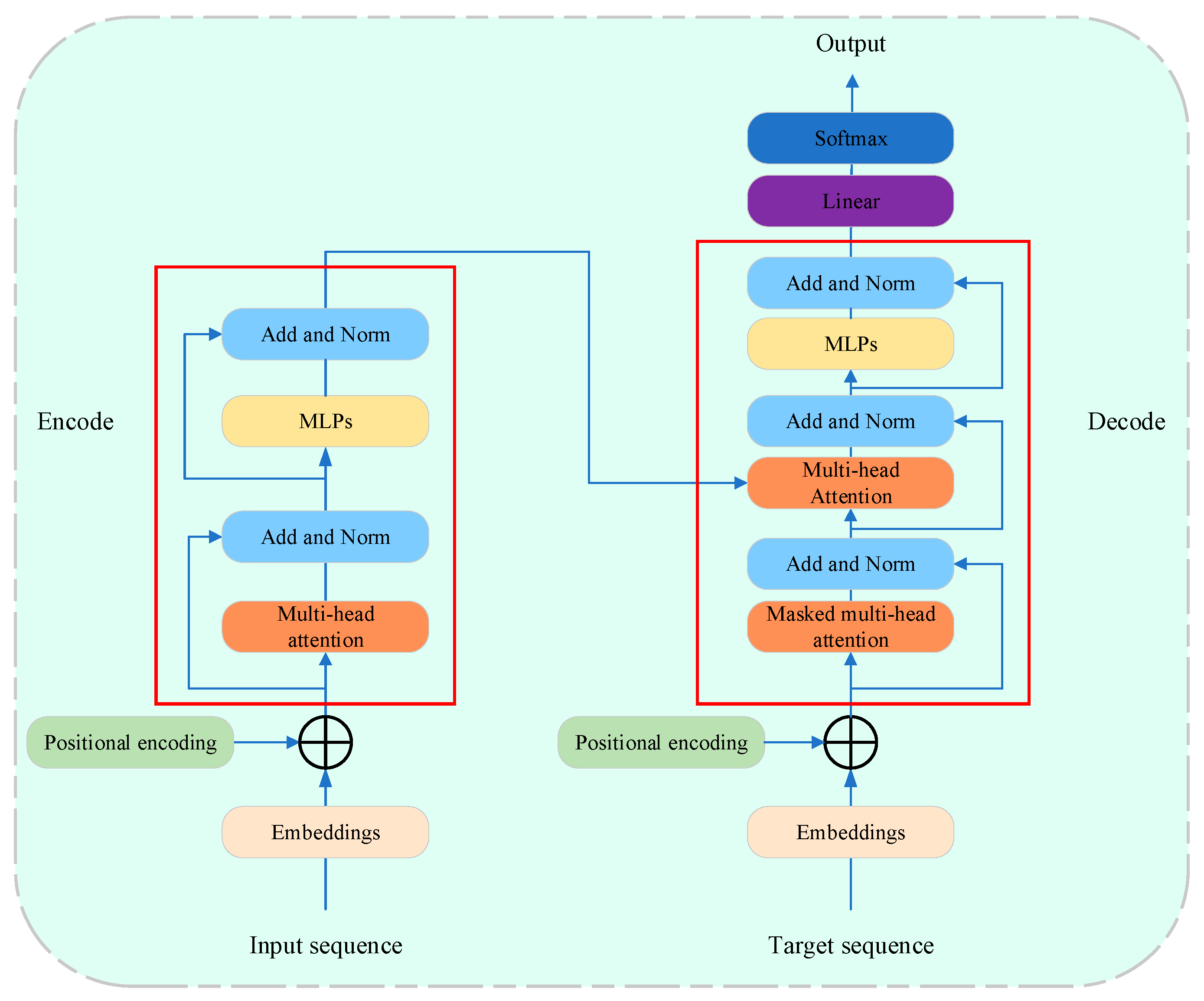
3.2.3. Recurrent Neural Network
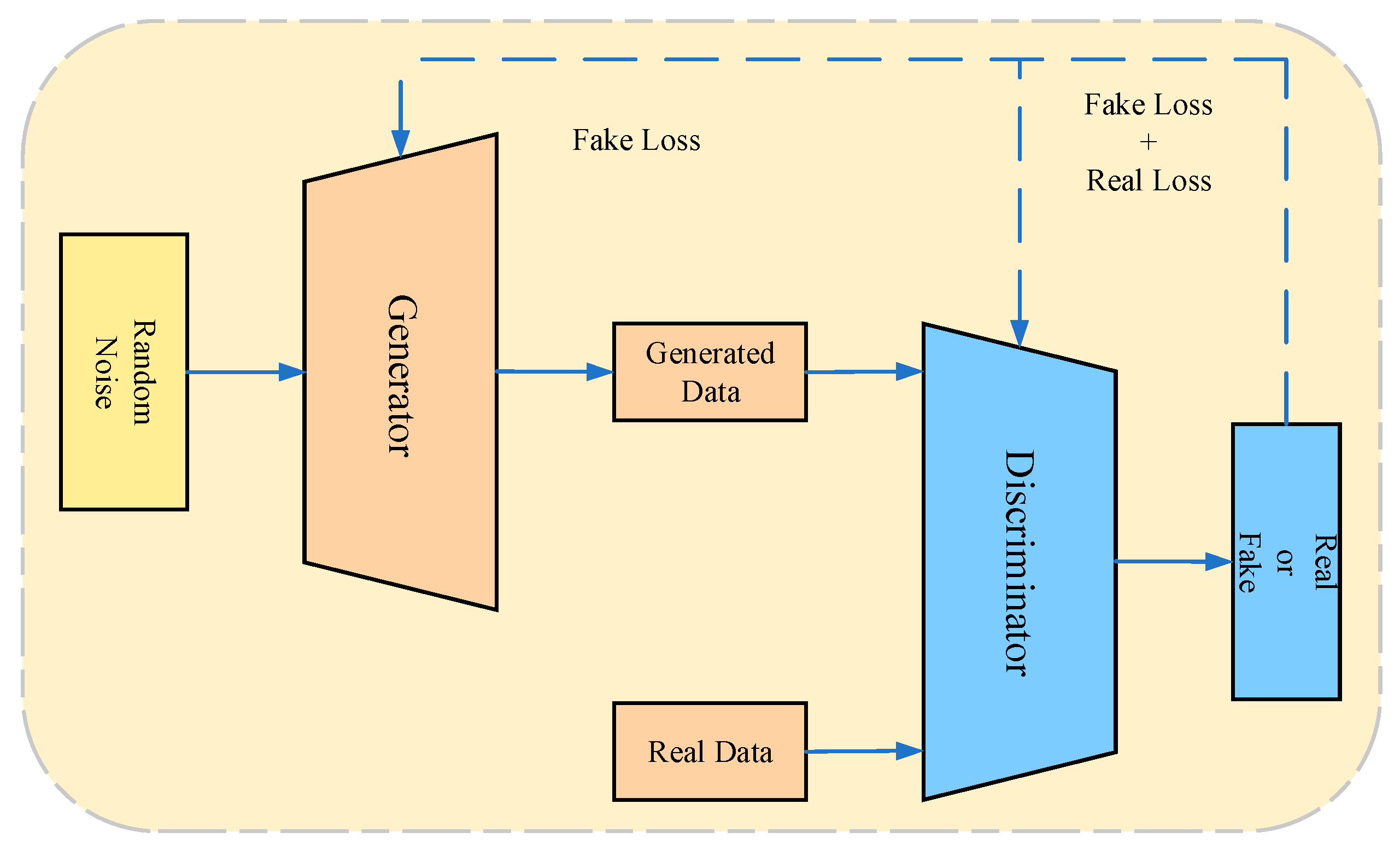
3.2.4. Generative Adversarial Network
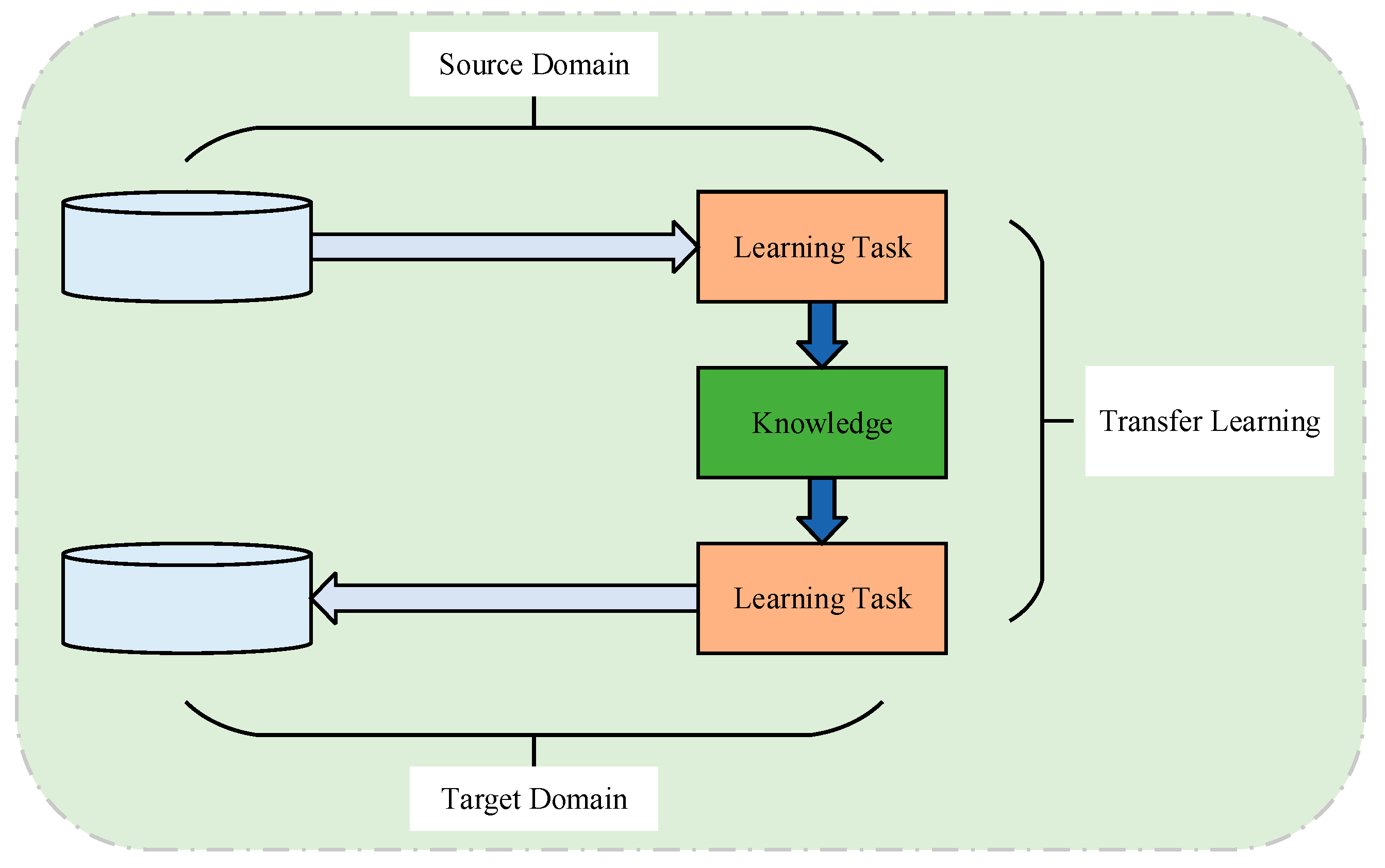
3.2.5. Deep Transfer Network
3.2.6. Reinforcement Learning
3.3. Fault Diagnosis Methods Based on Large Model
4. Case Analysis
4.1. Two-Tank Study Based on Fuzzy C-Means
4.2. LSTM-Based Fault Diagnosis in the Tennessee Eastman (TE) Process
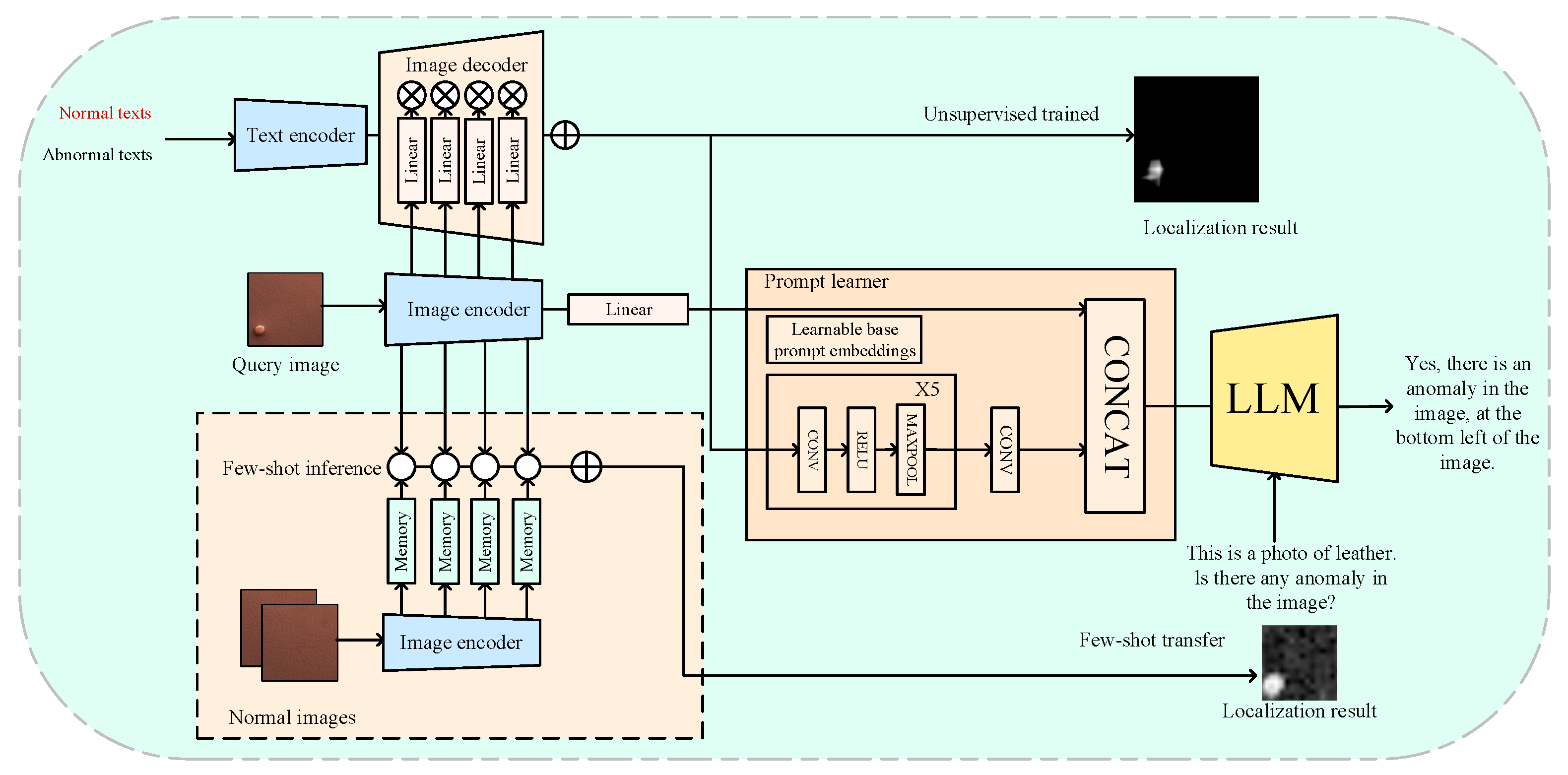
4.3. AnomalyGPT Based on LVLM
5. Current Challenges and Future Outlook
5.1. Problem Summary
5.2. Future Research Trends
5.2.1. Industrial Data Quality
5.2.2. Interpretability of Deep Learning
5.2.3. Edge Large Models
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| Abbreviations | Description |
| GE | General Electric |
| ERP | Enterprise Resource Planning |
| SCM | Supply Chain Management |
| CRM | Customer Relationship Management |
| WRA | Water Research Association |
| SVM | Support Vector Machine |
| PSO | Particle Swarm Optimization |
| MFCC | Mel-Frequency Cepstral Coefficients |
| GTCC | Gammatone Cepstral Coefficients |
| OC-SVM | One-Class Support Vector Machine |
| SVR | Support Vector Regression |
| KNN | K-Nearest Neighbors |
| PGM | probabilistic graphical models |
| DBNs | Deep Belief Networks |
| CNNs | Convolutional Neural Networks |
| RNNs | Recurrent Neural Networks |
| LSTM | Long Short-Term Memory |
| GANs | Generative Adversarial Networks |
| RBMs | Restricted Boltzmann Machines |
| BP | BackPropagation |
| IMFs | Intrinsic Mode Functions |
| EEMD | Ensemble Empirical Mode Decomposition |
| STF-DBN | spatio-temporal features fusion based on deep belief network |
| PCA | Principal Component Analysis |
| SAE-DBN | Sparse Autoencoder–Deep Belief Network |
| DAE | Denoising Autoencoder |
| TCN | Temporal Convolutional Network |
| SVDD | Support Vector Data Description |
| HSFT | Hilbert Spectrum Fusion Technology |
| MSCNN | Multi-Scale CNN |
| TICNN | Training-Interference CNN |
| ECNN | Enhanced CNN |
| GRU-NP-DAE | GRU-based Nonlinear Prediction Denoising Autoencoder |
| DCGAN | Deep Convolutional GAN |
| CGAN | Conditional GAN |
| ACGAN | Auxiliary Classifier GAN |
| HVAC | heating, ventilation, and air conditioning |
| MoGAN | Minority Over-sampling GAN |
| WGAN | Wasserstein GAN |
| LLMs | Large Language Models |
| LVLM | Large Vision-Language Model |
| KG | Knowledge Graph |
| Image-AUC | Image-level AUC |
| Pixel-AUC | Pixel-level AUC |
| TL | Transfer Learning |
| DTL | Deep Transfer Learning |
| RL | Reinforcement Learning |
| SD | source domain |
| TD | target domain |
| RUL | Remaining Useful Life |
| EA-DRL | Environment-Adaptive Deep Reinforcement Learning |
| D3QN | Double Dueling Deep Q-Network |
| WNMI | Weighted Normalized Mutual Information |
| EDR | Environmental Discrimination Reward |
| SIR | State Identification Reward |
| REDTLN | Reinforced Ensemble Deep Transfer Learning Network |
| PER | Prioritized Experience Replay |
| FCM | Fuzzy C-Means |
| TE | Tennessee Eastman process |
References
- Chen, J.; He, J.; Chen, F.; Lv, Z.; Tang, J.; Li, W.; Liu, Z.; Yang, H.H.; Han, G. Towards General Industrial Intelligence: A Survey on IIoT-Enhanced Continual Large Models. arXiv 2024, arXiv:2409.01207. [Google Scholar]
- Daneels, A.; Salter, W. What Is SCADA? In Proceedings of the International Conference on Accelerator and Large Experimental Physics Control Systems, Trieste, Italy, 4–8 October 1999.
- Jieyang, P.; Kimmig, A.; Dongkun, W.; Niu, Z.; Zhi, F.; Jiahai, W.; Liu, X.; Ovtcharova, J. A Systematic Review of Data-Driven Approaches to Fault Diagnosis and Early Warning. J. Intell. Manuf. 2023, 34, 3277–3304. [Google Scholar] [CrossRef]
- Sahu, A.R.; Palei, S.K.; Mishra, A. Data-driven Fault Diagnosis Approaches for Industrial Equipment: A Review. Expert Syst. 2024, 41, e13360. [Google Scholar] [CrossRef]
- Li, C.; Chen, Y.; Shang, Y. A Review of Industrial Big Data for Decision Making in Intelligent Manufacturing. Eng. Sci. Technol. Int. J. 2022, 29, 101021. [Google Scholar] [CrossRef]
- Rohan, A. Holistic Fault Detection and Diagnosis System in Imbalanced, Scarce, Multi-Domain (ISMD) Data Setting for Component-Level Prognostics and Health Management (PHM). Mathematics 2022, 10, 2031. [Google Scholar] [CrossRef]
- Smith, W.A.; Randall, R.B. Rolling Element Bearing Diagnostics Using the Case Western Reserve University Data: A Benchmark Study. Mech. Syst. Signal Process. 2015, 64–65, 100–131. [Google Scholar] [CrossRef]
- Qiu, H.; Lee, J.; Lin, J.; Yu, G. Wavelet Filter-Based Weak Signature Detection Method and Its Application on Rolling Element Bearing Prognostics. J. Sound Vib. 2006, 289, 1066–1090. [Google Scholar] [CrossRef]
- Chen, Y.; Peng, G.; Xie, C.; Zhang, W.; Li, C.; Liu, S. ACDIN: Bridging the Gap between Artificial and Real Bearing Damages for Bearing Fault Diagnosis. Neurocomputing 2018, 294, 61–71. [Google Scholar] [CrossRef]
- Shao, S.; McAleer, S.; Yan, R.; Baldi, P. Highly Accurate Machine Fault Diagnosis Using Deep Transfer Learning. IEEE Trans. Ind. Inform. 2019, 15, 2446–2455. [Google Scholar] [CrossRef]
- Wang, B.; Lei, Y.; Li, N.; Li, N. A Hybrid Prognostics Approach for Estimating Remaining Useful Life of Rolling Element Bearings. IEEE Trans. Reliab. 2020, 69, 401–412. [Google Scholar] [CrossRef]
- Bergmann, P.; Fauser, M.; Sattlegger, D.; Steger, C. MVTec AD—A Comprehensive Real-World Dataset for Unsupervised Anomaly Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9584–9592. [Google Scholar]
- Zorchenko, N.V.; Tyupina, T.G.; Parshutin, M.E. Technologies Used by General Electric to Create Digital Twins for Energy Industry. Power Technol. Eng. 2024, 58, 521–526. [Google Scholar] [CrossRef]
- Nath, S.V.; van Schalkwyk, P.; Isaacs, D. Building Industrial Digital Twins: Design, Develop, and Deploy Digital Twin Solutions for Real-World Industries Using Azure Digital Twins; Packt Publishing Ltd.: Birmingham, UK, 2021; ISBN 978-1-83921-451-6. [Google Scholar]
- Platenius-Mohr, M.; Malakuti, S.; Grüner, S.; Schmitt, J.; Goldschmidt, T. File- and API-Based Interoperability of Digital Twins by Model Transformation: An IIoT Case Study Using Asset Administration Shell. Future Gener. Comput. Syst. 2020, 113, 94–105. [Google Scholar] [CrossRef]
- Fu, C.; Liang, X.; Li, Q.; Lu, K.; Gu, F.; Ball, A.D.; Zheng, Z. Comparative Study on Health Monitoring of a Marine Engine Using Multivariate Physics-Based Models and Unsupervised Data-Driven Models. Machines 2023, 11, 557. [Google Scholar] [CrossRef]
- Zhou, W.; Jin, X.; Ding, L.; Ma, J.; Su, H.; Zhao, A. Research on Vibration Signal Decomposition of Cracked Rotor-Bearing System with Double-Disk Based on CEEMDAN-CWT. Appl. Acoust. 2025, 227, 110254. [Google Scholar] [CrossRef]
- Gu, Z.; Zhu, B.; Zhu, G.; Chen, Y.; Tang, M.; Wang, J. AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models. In Proceedings of the AAAI conference on artificial intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 1932–1940. [Google Scholar] [CrossRef]
- Li, Y.; Wang, H.; Yuan, S.; Liu, M.; Zhao, D.; Guo, Y.; Xu, C.; Shi, G.; Zuo, W. Myriad: Large Multimodal Model by Applying Vision Experts for Industrial Anomaly Detection. arXiv 2023, arXiv:2310.19070. [Google Scholar]
- Liao, S.-H. Expert System Methodologies and Applications—A Decade Review from 1995 to 2004. Expert Syst. Appl. 2005, 28, 93–103. [Google Scholar] [CrossRef]
- Ruijters, E.; Stoelinga, M. Fault Tree Analysis: A Survey of the State-of-the-Art in Modeling, Analysis and Tools. Comput. Sci. Rev. 2015, 15–16, 29–62. [Google Scholar] [CrossRef]
- Miljković, D. Brief Review of Vibration Based Machine Condition Monitoring. HDKBR INFO Mag. 2015, 5, 14–23. [Google Scholar]
- Chen, H.; Jiang, B.; Ding, S.X.; Huang, B. Data-Driven Fault Diagnosis for Traction Systems in High-Speed Trains: A Survey, Challenges, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2022, 23, 1700–1716. [Google Scholar] [CrossRef]
- Zhao, Z.; Morstatter, F.; Sharma, S.; Alelyani, S.; Anand, A.; Liu, H. Advancing Feature Selection Research. ASU Feature Sel. Repos. 2010, 1–28. [Google Scholar]
- Langley, P. Selection of Relevant Features in Machine Learning; Defense Technical Information Center: Fort Belvoir, VA, USA, 1994. [Google Scholar]
- Langley, P. Elements of Machine Learning; Morgan Kaufmann: San Francisco, CA, USA, 1996; ISBN 978-1-55860-301-1. [Google Scholar]
- Crowley, J.L.; Parker, A.C. A Representation for Shape Based on Peaks and Ridges in the Difference of Low-Pass Transform. IEEE Trans. Pattern Anal. Mach. Intell. 1984, PAMI-6, 156–170. [Google Scholar] [CrossRef]
- Sun, Z.-L.; Huang, D.-S.; Cheun, Y.-M. Extracting Nonlinear Features for Multispectral Images by FCMC and KPCA. Digit. Signal Process. 2005, 15, 331–346. [Google Scholar] [CrossRef]
- Sun, Z.-L.; Huang, D.-S.; Cheung, Y.-M.; Liu, J.; Huang, G.-B. Using FCMC, FVS, and PCA Techniques for Feature Extraction of Multispectral Images. IEEE Geosci. Remote Sens. Lett. 2005, 2, 108–112. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support Vector Machine. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Rapur, J.S.; Tiwari, R. On-Line Time Domain Vibration and Current Signals Based Multi-Fault Diagnosis of Centrifugal Pumps Using Support Vector Machines. J. Nondestruct. Eval. 2018, 38, 6. [Google Scholar] [CrossRef]
- Rapur, J.S.; Tiwari, R. Automation of Multi-Fault Diagnosing of Centrifugal Pumps Using Multi-Class Support Vector Machine with Vibration and Motor Current Signals in Frequency Domain. J. Braz. Soc. Mech. Sci. Eng. 2018, 40, 278. [Google Scholar] [CrossRef]
- Pang, B.; Tang, G.; Zhou, C.; Tian, T. Rotor Fault Diagnosis Based on Characteristic Frequency Band Energy Entropy and Support Vector Machine. Entropy 2018, 20, 932. [Google Scholar] [CrossRef]
- Zhang, H.; Guo, X.; Zhang, P. Improved PSO-SVM-Based Fault Diagnosis Algorithm for Wind Power Converter. IEEE Trans. Ind. Appl. 2024, 60, 3492–3501. [Google Scholar] [CrossRef]
- Abdul, Z.K.H.; Al-Talabani, A.K. Highly Accurate Gear Fault Diagnosis Based on Support Vector Machine. J. Vib. Eng. Technol. 2023, 11, 3565–3577. [Google Scholar] [CrossRef]
- Russo, L.; Sarda, K.; Glielmo, L.; Acernese, A. Fault Detection and Diagnosis in Steel Industry: A One Class-Support Vector Machine Approach. In Proceedings of the 2021 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Melbourne, Australia, 17–20 October 2021; pp. 2304–2309. [Google Scholar]
- Lee, H.; Li, G.; Rai, A.; Chattopadhyay, A. Real-Time Anomaly Detection Framework Using a Support Vector Regression for the Safety Monitoring of Commercial Aircraft. Adv. Eng. Inform. 2020, 44, 101071. [Google Scholar] [CrossRef]
- An, X.; Tang, Y. Application of Variational Mode Decomposition Energy Distribution to Bearing Fault Diagnosis in a Wind Turbine. Trans. Inst. Meas. Control 2017, 39, 1000–1006. [Google Scholar] [CrossRef]
- Ma, J.; Xu, F.; Huang, K.; Huang, R. GNAR-GARCH Model and Its Application in Feature Extraction for Rolling Bearing Fault Diagnosis. Mech. Syst. Signal Process. 2017, 93, 175–203. [Google Scholar] [CrossRef]
- Yao, B.; Zhen, P.; Wu, L.; Guan, Y. Rolling Element Bearing Fault Diagnosis Using Improved Manifold Learning. IEEE Access 2017, 5, 6027–6035. [Google Scholar] [CrossRef]
- Park, S.; Kim, S.; Choi, J.-H. Gear Fault Diagnosis Using Transmission Error and Ensemble Empirical Mode Decomposition. Mech. Syst. Signal Process. 2018, 108, 262–275. [Google Scholar] [CrossRef]
- Vanraj; Dhami, S.; Pabla, B. Hybrid Data Fusion Approach for Fault Diagnosis of Fixed-Axis Gearbox. Struct. Health Monit. 2018, 17, 936–945. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, Z. Diagnosis of Stator Faults of the Single-Phase Induction Motor Using Acoustic Signals. Appl. Acoust. 2017, 117, 20–27. [Google Scholar] [CrossRef]
- Yu, J.; Ding, B.; He, Y. Rolling Bearing Fault Diagnosis Based on Mean Multigranulation Decision-Theoretic Rough Set and Non-Naive Bayesian Classifier. J. Mech. Sci. Technol. 2018, 32, 5201–5211. [Google Scholar] [CrossRef]
- Liu, T.; Chen, J.; Dong, G. Singular Spectrum Analysis and Continuous Hidden Markov Model for Rolling Element Bearing Fault Diagnosis. J. Vib. Control 2015, 21, 1506–1521. [Google Scholar] [CrossRef]
- Yu, J.; He, Y. Planetary Gearbox Fault Diagnosis Based on Data-Driven Valued Characteristic Multigranulation Model with Incomplete Diagnostic Information. J. Sound Vib. 2018, 429, 63–77. [Google Scholar] [CrossRef]
- Yu, J.; Bai, M.; Wang, G.; Shi, X. Fault Diagnosis of Planetary Gearbox with Incomplete Information Using Assignment Reduction and Flexible Naive Bayesian Classifier. J. Mech. Sci. Technol. 2018, 32, 37–47. [Google Scholar] [CrossRef]
- Geramifard, O.; Xu, J.-X.; Kumar Panda, S. Fault Detection and Diagnosis in Synchronous Motors Using Hidden Markov Model-Based Semi-Nonparametric Approach. Eng. Appl. Artif. Intell. 2013, 26, 1919–1929. [Google Scholar] [CrossRef]
- Jia, Y.; Xu, M.; Wang, R. Symbolic Important Point Perceptually and Hidden Markov Model Based Hydraulic Pump Fault Diagnosis Method. Sensors 2018, 18, 4460. [Google Scholar] [CrossRef] [PubMed]
- Yang, B.-S.; Di, X.; Han, T. Random Forests Classifier for Machine Fault Diagnosis. J. Mech. Sci. Technol. 2008, 22, 1716–1725. [Google Scholar] [CrossRef]
- Listou Ellefsen, A.; Bjørlykhaug, E.; Æsøy, V.; Ushakov, S.; Zhang, H. Remaining Useful Life Predictions for Turbofan Engine Degradation Using Semi-Supervised Deep Architecture. Reliab. Eng. Syst. Saf. 2019, 183, 240–251. [Google Scholar] [CrossRef]
- Hinton, G.E. Deep Belief Networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- Hopfield, J.J. Hopfield Network. Scholarpedia 2007, 2, 1977. [Google Scholar] [CrossRef]
- Liao, W.; Yang, K.; Fu, W.; Tan, C.; Chen, B.; Shan, Y. A Review: The Application of Generative Adversarial Network for Mechanical Fault Diagnosis. Meas. Sci. Technol. 2024, 35, 062002. [Google Scholar] [CrossRef]
- Pratt, L.Y. Discriminability-Based Transfer Between Neural Networks. Available online: https://papers.nips.cc/paper/1992/hash/67e103b0761e60683e83c559be18d40c-Abstract.html (accessed on 25 April 2025).
- Nian, R.; Liu, J.; Huang, B. A Review On Reinforcement Learning: Introduction and Applications in Industrial Process Control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Zhao, Z.; Li, T.; Wu, J.; Sun, C.; Wang, S.; Yan, R.; Chen, X. Deep Learning Algorithms for Rotating Machinery Intelligent Diagnosis: An Open Source Benchmark Study. ISA Trans. 2020, 107, 224–255. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Yang, B.; Zio, E.; Chen, X. Artificial Intelligence for Fault Diagnosis of Rotating Machinery: A Review. Mech. Syst. Signal Process. 2018, 108, 33–47. [Google Scholar] [CrossRef]
- Tamilselvan, P.; Wang, P. Failure Diagnosis Using Deep Belief Learning Based Health State Classification. Reliab. Eng. Syst. Saf. 2013, 115, 124–135. [Google Scholar] [CrossRef]
- Chen, H.; Wang, J.; Tang, B.; Xiao, K.; Li, J. An Integrated Approach to Planetary Gearbox Fault Diagnosis Using Deep Belief Networks. Meas. Sci. Technol. 2016, 28, 025010. [Google Scholar] [CrossRef]
- Tian, H.; Xu, Q. A Spatio-Temporal Fault Diagnosis Method Based on STF-DBN for Reciprocating Compressor. J. Intell. Manuf. 2024, 35, 199–216. [Google Scholar] [CrossRef]
- Chen, Z.; Li, W. Multisensor Feature Fusion for Bearing Fault Diagnosis Using Sparse Autoencoder and Deep Belief Network. IEEE Trans. Instrum. Meas. 2017, 66, 1693–1702. [Google Scholar] [CrossRef]
- Lv, D.; Wang, H.; Che, C. Semisupervised Fault Diagnosis of Aeroengine Based on Denoising Autoencoder and Deep Belief Network. Aircr. Eng. Aerosp. Technol. 2022, 94, 1772–1779. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ince, T.; Kiranyaz, S.; Eren, L.; Askar, M.; Gabbouj, M. Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Ind. Electron. 2016, 63, 7067–7075. [Google Scholar] [CrossRef]
- Lin, K.; Pan, J.; Xi, Y.; Wang, Z.; Jiang, J. Vibration Anomaly Detection of Wind Turbine Based on Temporal Convolutional Network and Support Vector Data Description. Eng. Struct. 2024, 306, 117848. [Google Scholar] [CrossRef]
- Bai, S.; Kolter, J.Z.; Koltun, V. An Empirical Evaluation of Generic Convolutional and Recurrent Networks for Sequence Modeling. arXiv 2018, arXiv:1803.01271. [Google Scholar]
- Tax, D.M.J.; Duin, R.P.W. Support Vector Data Description. Mach. Learn. 2004, 54, 45–66. [Google Scholar] [CrossRef]
- Zhao, M.; Kang, M.; Tang, B.; Pecht, M. Deep Residual Networks With Dynamically Weighted Wavelet Coefficients for Fault Diagnosis of Planetary Gearboxes. IEEE Trans. Ind. Electron. 2018, 65, 4290–4300. [Google Scholar] [CrossRef]
- Zhao, M.; Kang, M.; Tang, B.; Pecht, M. Multiple Wavelet Coefficients Fusion in Deep Residual Networks for Fault Diagnosis. IEEE Trans. Ind. Electron. 2019, 66, 4696–4706. [Google Scholar] [CrossRef]
- Jiang, G.; He, H.; Yan, J.; Xie, P. Multiscale Convolutional Neural Networks for Fault Diagnosis of Wind Turbine Gearbox. IEEE Trans. Ind. Electron. 2019, 66, 3196–3207. [Google Scholar] [CrossRef]
- Peng, D.; Wang, H.; Liu, Z.; Zhang, W.; Zuo, M.J.; Chen, J. Multibranch and Multiscale CNN for Fault Diagnosis of Wheelset Bearings Under Strong Noise and Variable Load Condition. IEEE Trans. Ind. Inform. 2020, 16, 4949–4960. [Google Scholar] [CrossRef]
- Wang, H.; Li, S.; Song, L.; Cui, L. A Novel Convolutional Neural Network Based Fault Recognition Method via Image Fusion of Multi-Vibration-Signals. Comput. Ind. 2019, 105, 182–190. [Google Scholar] [CrossRef]
- Zhang, W.; Li, C.; Peng, G.; Chen, Y.; Zhang, Z. A Deep Convolutional Neural Network with New Training Methods for Bearing Fault Diagnosis under Noisy Environment and Different Working Load. Mech. Syst. Signal Process. 2018, 100, 439–453. [Google Scholar] [CrossRef]
- Han, Y.; Tang, B.; Deng, L. An Enhanced Convolutional Neural Network with Enlarged Receptive Fields for Fault Diagnosis of Planetary Gearboxes. Comput. Ind. 2019, 107, 50–58. [Google Scholar] [CrossRef]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning Long-Term Dependencies with Gradient Descent Is Difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tang, C.; Xu, L.; Yang, B.; Tang, Y.; Zhao, D. GRU-Based Interpretable Multivariate Time Series Anomaly Detection in Industrial Control System. Comput. Secur. 2023, 127, 103094. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, B.; Gao, D. Bearing Fault Diagnosis Base on Multi-Scale CNN and LSTM Model. J. Intell. Manuf. 2021, 32, 971–987. [Google Scholar] [CrossRef]
- Liu, H.; Zhou, J.; Zheng, Y.; Jiang, W.; Zhang, Y. Fault Diagnosis of Rolling Bearings with Recurrent Neural Network-Based Autoencoders. ISA Trans. 2018, 77, 167–178. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Zhou, T.; Huang, X.; Cao, L.; Zhou, Q. Fault Diagnosis of Rotating Machinery Based on Recurrent Neural Networks. Measurement 2021, 171, 108774. [Google Scholar] [CrossRef]
- Ning, S.; Wang, Y.; Cai, W.; Zhang, Z.; Wu, Y.; Ren, Y.; Du, K. Research on Intelligent Fault Diagnosis of Rolling Bearing Based on Improved ShufflenetV2-LSTM. J. Sens. 2022, 2022, 8522206. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Chang, H.-C.; Wang, Y.-C.; Shih, Y.-Y.; Kuo, C.-C. Fault Diagnosis of Induction Motors with Imbalanced Data Using Deep Convolutional Generative Adversarial Network. Appl. Sci. 2022, 12, 4080. [Google Scholar] [CrossRef]
- Zareapoor, M.; Shamsolmoali, P.; Yang, J. Oversampling Adversarial Network for Class-Imbalanced Fault Diagnosis. Mech. Syst. Signal Process. 2021, 149, 107175. [Google Scholar] [CrossRef]
- Du, Z.; Chen, K.; Chen, S.; He, J.; Zhu, X.; Jin, X. Deep Learning GAN-Based Data Generation and Fault Diagnosis in the Data Center HVAC System. Energy Build. 2023, 289, 113072. [Google Scholar] [CrossRef]
- Li, Z.; Zheng, T.; Wang, Y.; Cao, Z.; Guo, Z.; Fu, H. A Novel Method for Imbalanced Fault Diagnosis of Rotating Machinery Based on Generative Adversarial Networks. IEEE Trans. Instrum. Meas. 2021, 70, 1–17. [Google Scholar] [CrossRef]
- Pan, W. A Survey of Transfer Learning for Collaborative Recommendation with Auxiliary Data. Neurocomputing 2016, 177, 447–453. [Google Scholar] [CrossRef]
- Chen, D.; Zhang, Z.; Zhou, F.; Wang, C. A Real-Time Fault Diagnosis Method for Multi-Source Heterogeneous Information Fusion Based on Two-Level Transfer Learning. Entropy 2024, 26, 1007. [Google Scholar] [CrossRef]
- Shi, J.W.; Hou, L.Q. Bearing Fault Diagnosis Based on 1D CNN Attention. Available online: https://scholar.google.com/scholar_lookup?title=Bearing%20fault%20diagnosis%20based%20on%201D%20CNN%20attention%20gated%20recurrent%20network%20and%20transfer%20learning&publication_year=2023&author=J.%20Shi&author=L.%20Hou (accessed on 25 April 2025).
- Tang, G.; Yi, C.; Liu, L.; Yang, X.; Xu, D.; Zhou, Q.; Lin, J. A Novel Transfer Learning Network with Adaptive Input Length Selection and Lightweight Structure for Bearing Fault Diagnosis. Eng. Appl. Artif. Intell. 2023, 123, 106395. [Google Scholar] [CrossRef]
- Teimourzadeh, H.; Moradzadeh, A.; Shoaran, M.; Mohammadi-Ivatloo, B.; Razzaghi, R. High Impedance Single-Phase Faults Diagnosis in Transmission Lines via Deep Reinforcement Learning of Transfer Functions. IEEE Access 2021, 9, 15796–15809. [Google Scholar] [CrossRef]
- Privacy Reinforcement Learning for Faults Detection in the Smart Grid—ScienceDirect. Available online: https://www.sciencedirect.com/science/article/pii/S1570870521000913 (accessed on 25 April 2025).
- Frontiers|Fault Detection Method Based on Adversarial Reinforcement Learning. Available online: https://www.frontiersin.org/journals/computer-science/articles/10.3389/fcomp.2022.1007665/full (accessed on 25 April 2025).
- Liu, X.; Zhao, Z.; Yang, F.; Liang, F.; Bo, L. Environment Adaptive Deep Reinforcement Learning for Intelligent Fault Diagnosis. Eng. Appl. Artif. Intell. 2025, 151, 110783. [Google Scholar] [CrossRef]
- Li, X.; Jiang, H.; Xie, M.; Wang, T.; Wang, R.; Wu, Z. A Reinforcement Ensemble Deep Transfer Learning Network for Rolling Bearing Fault Diagnosis with Multi-Source Domains. Adv. Eng. Inform. 2022, 51, 101480. [Google Scholar] [CrossRef]
- He, S.; Cui, Q.; Chen, J.; Pan, T.; Hu, C. Contrastive Feature-Based Learning-Guided Elevated Deep Reinforcement Learning: Developing an Imbalanced Fault Quantitative Diagnosis under Variable Working Conditions. Mech. Syst. Signal Process. 2024, 211, 111192. [Google Scholar] [CrossRef]
- Abdullah, M.; Madain, A.; Jararweh, Y. ChatGPT: Fundamentals, Applications and Social Impacts. In Proceedings of the 2022 Ninth International Conference on Social Networks Analysis, Management and Security (SNAMS), Milan, Italy, 14–17 November 2022; pp. 1–8. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. PaLM: Scaling Language Modeling with Pathways. J. Mach. Learn. Res. 2023, 24, 11324–11436. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Gallifant, J.; Fiske, A.; Strekalova, Y.A.L.; Osorio-Valencia, J.S.; Parke, R.; Mwavu, R.; Martinez, N.; Gichoya, J.W.; Ghassemi, M.; Demner-Fushman, D.; et al. Peer Review of GPT-4 Technical Report and Systems Card. PLOS Digit. Health 2024, 3, e0000417. [Google Scholar] [CrossRef] [PubMed]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Vaswani, A. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Minaee, S.; Mikolov, T.; Nikzad, N.; Chenaghlu, M.; Socher, R.; Amatriain, X.; Gao, J. Large Language Models: A Survey. arXiv 2024, arXiv:2402.06196. [Google Scholar]
- Tao, L.; Liu, H.; Ning, G.; Cao, W.; Huang, B.; Lu, C. LLM-Based Framework for Bearing Fault Diagnosis. Mech. Syst. Signal Process. 2024, 224, 112127. [Google Scholar] [CrossRef]
- LIU, P.; Qian, L.; Zhao, X.; Tao, B. Joint Knowledge Graph and Large Language Model for Fault Diagnosis and Its Application in Aviation Assembly. IEEE Trans. Ind. Inform. 2024, 20, 8160–8169. [Google Scholar] [CrossRef]
- A Novel Integrated Fuzzy-Based Strategy for Safety and Cybersecurity in Industrial Plants|Arabian Journal for Science and Engineering. Available online: https://link.springer.com/article/10.1007/s13369-024-09716-w#Tab9 (accessed on 25 April 2025).
- Quevedo, J.; Sánchez, H.; Rotondo, D.; Escobet, T.; Puig, V. A Two-Tank Benchmark for Detection and Isolation of Cyber Attacks. IFAC-PapersOnLine 2018, 51, 770–775. [Google Scholar] [CrossRef]
- Rodríguez-Ramos, A.; Verde, C.; Llanes-Santiago, O. An Integrated Monitoring System Based on Deep Learning Tools for Industrial Process. IFAC-PapersOnLine 2024, 58, 168–173. [Google Scholar] [CrossRef]
- Prieto-Moreno, A.; Llanes-Santiago, O.; García-Moreno, E. Principal Components Selection for Dimensionality Reduction Using Discriminant Information Applied to Fault Diagnosis. J. Process. Control 2015, 33, 14–24. [Google Scholar] [CrossRef]
- Roth, K.; Pemula, L.; Zepeda, J.; Schölkopf, B.; Brox, T.; Gehler, P. Towards Total Recall in Industrial Anomaly Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 14318–14328. [Google Scholar]
- Pirnay, J.; Chai, K. Inpainting Transformer for Anomaly Detection. In Proceedings of the Image Analysis and Processing—ICIAP 2022, Lecce, Italy, 23–27 May 2022; Sclaroff, S., Distante, C., Leo, M., Farinella, G.M., Tombari, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 394–406. [Google Scholar]
- Lei, J.; Hu, X.; Wang, Y.; Liu, D. PyramidFlow: High-Resolution Defect Contrastive Localization Using Pyramid Normalizing Flow. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14143–14152. [Google Scholar]
- Huang, C.; Guan, H.; Jiang, A.; Zhang, Y.; Spratling, M.; Wang, Y.-F. Registration Based Few-Shot Anomaly Detection. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 303–319. [Google Scholar]
- Xie, G.; Wang, J.; Liu, J.; Zheng, F.; Jin, Y. Pushing the Limits of Fewshot Anomaly Detection in Industry Vision: Graphcore. arXiv 2023, arXiv:2301.12082. [Google Scholar]
- Wang, W.; Chen, Z.; Chen, X.; Wu, J.; Zhu, X.; Zeng, G.; Luo, P.; Lu, T.; Zhou, J.; Qiao, Y.; et al. VisionLLM: Large Language Model Is Also an Open-Ended Decoder for Vision-Centric Tasks. Adv. Neural Inf. Process. Syst. 2023, 36, 61501–61513. [Google Scholar]
- Zhu, D.; Chen, J.; Shen, X.; Li, X.; Elhoseiny, M. MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models. arXiv 2023, arXiv:2304.10592. [Google Scholar]
- Liu, H.; Li, C.; Wu, Q.; Lee, Y.J. Visual Instruction Tuning. In Proceedings of the NIPS’23: 37th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 10–16 December 2023; Volume 36, pp. 34892–34916. [Google Scholar]
- Su, Y.; Lan, T.; Li, H.; Xu, J.; Wang, Y.; Cai, D. PandaGPT: One Model To Instruction-Follow Them All. arXiv 2023, arXiv:2305.16355. [Google Scholar]
- Zou, Y.; Jeong, J.; Pemula, L.; Zhang, D.; Dabeer, O. SPot-the-Difference Self-Supervised Pre-Training for Anomaly Detection and Segmentation. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Springer Nature: Cham, Switzerland, 2022; pp. 392–408. [Google Scholar]
- Cohen, N.; Hoshen, Y. Sub-Image Anomaly Detection with Deep Pyramid Correspondences. arXiv 2021, arXiv:2005.02357. [Google Scholar]
- PaDiM: A Patch Distribution Modeling Framework for Anomaly Detection and Localization|SpringerLink. Available online: https://link.springer.com/chapter/10.1007/978-3-030-68799-1_35 (accessed on 12 February 2025).
- Dhar, N.; Deng, B.; Lo, D.; Wu, X.; Zhao, L.; Suo, K. An Empirical Analysis and Resource Footprint Study of Deploying Large Language Models on Edge Devices. In Proceedings of the 2024 ACM Southeast Conference; Association for Computing Machinery, Marietta, GA, USA, 18–20 April 2024; pp. 69–76. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset Name | Characteristics | Collection Object | Fault Type | Limitations |
|---|---|---|---|---|
| CWRU [7] | Includes multiple load conditions, fault severity levels, and fault types. Suitable for various benchmarking experiments and algorithm validation. | Bearings | Inner ring fault, outer ring fault, rolling element fault | Single speed and laboratory artificial defects; single point vibration channel only |
| IMS [8] | Contains three bearings that transitioned from normal operation to failure, suitable for research on Remaining Useful Life prediction and early fault detection. | Bearings | Inner ring fault, outer ring fault, rolling element fault | Fixed 2000 rpm; terabytes of data; high processing cost |
| PU [9] | Contains 32 sets of electrical and vibration signals, covering both artificially induced and real faults. Suitable for multi-sensor data fusion research. | Bearings | Artificial inner and outer ring faults, real outer ring faults | Narrow load range and few rolling element samples; still idealistic |
| SEU [10] | Includes datasets of bearings and gears under different speeds and load conditions. Suitable for studying condition transfer and non-repetitive fault diagnosis. | Gears | Tooth wear, tooth breakage, root crack, surface fault | Most of the gears are wire cutting defects; lack of multimodal signal |
| MFPT [11] | Includes bearing data collected under different load conditions. Suitable for research on condition transfer and the impact of load variation on fault diagnosis. | Bearings | Inner ring fault, outer ring fault | Large file with high sampling rate; no compound fault |
| MVTec AD [12] | Contains multiple types of high-quality normal and abnormal samples. Applicable for surface defect monitoring and anomaly detection in industrial products. | Various industrial products | Surface defects, structural anomalies, etc. | Static visual samples only; lack of operating conditions and fine labels |
| Stage | Data Characteristics | Diagnosis Method | Advantages | Limitations |
|---|---|---|---|---|
| Early Diagnosis Stage | Small data volume, single data type | Principle-based reasoning, expert knowledge | Simple and direct approach | Limited accuracy and reliability |
| Sensor Stage | Medium-scale data, multi-type signals | Signal processing, analytical models | Capable of processing multiple signals, extracting general patterns | Challenging to process high-dimensional, multi-source data |
| Big Data Stage | Massive data, multi-modal signals, heterogeneous data fusion | Machine learning, deep learning, pre-trained large models | Automatically extracts deep features, strong generalization capability | Requires extensive labeled data, high model complexity, challenges in interpretability and transparency |
| Method Category | Typical Techniques/Algorithms | Main Advantages | Main Limitations | Suitable Scenarios |
|---|---|---|---|---|
| Knowledge-based | Expert systems, fault tree analysis (FTA) | Transparent, fully explainable rules; highly targeted for specific equipment | Knowledge elicitation and updates are time-consuming; limited coverage of novel or complex faults | Plants with ample expert know-how and stable operating conditions; applications that require auditable, rule-based diagnosis |
| Signal- and model-based | Spectrum/envelope analysis, wavelet transform, finite element/data assimilation models | Strong early-warning capability; real-time monitoring feasible | Dependence on accurate physical models and high-quality signals; sensitive to multivariate coupling and noise | Machinery whose physics are well understood and whose fault signatures are distinctive (e.g., rotating machines, structural components) |
| Data-driven | Machine learning (SVM, random forest), deep learning (CNN/LSTM), large models (LLM/VLM) | Handles high-dimensional, nonlinear data; cross-condition adaptability; end-to-end learning | Requires large volumes of labeled data and significant compute; limited interpretability; vulnerable to data-shift issues | Modern smart factories with rich sensor networks, large data volumes, and highly variable operating conditions |
| Scenario | Without Noise | 2% Noise Level | 5% Noise Level | |||
|---|---|---|---|---|---|---|
| Sensitivity | 1-Specificity | Sensitivity | 1-Specificity | Sensitivity | 1-Specificity | |
| F1 | 96 | 0 | 94 | 4.08 | 92 | 6.12 |
| A1 | 92 | 9.8 | 88 | 13.63 | 86 | 17.31 |
| F2 | 100 | 0 | 96 | 2.04 | 94 | 6 |
| A2 | 94 | 0 | 92 | 2.13 | 90 | 4.26 |
| NOC | F3 | F9 | F15 | A1 | A2 | A3 | TA (%) | |
|---|---|---|---|---|---|---|---|---|
| NOC | 500 | 0 | 0 | 0 | 0 | 0 | 0 | 100 |
| F3 | 0 | 500 | 0 | 0 | 0 | 0 | 0 | 100 |
| F9 | 7 | 0 | 488 | 5 | 0 | 0 | 0 | 97.6 |
| F15 | 10 | 2 | 0 | 488 | 0 | 0 | 0 | 97.6 |
| A1 | 5 | 3 | 2 | 0 | 490 | 0 | 0 | 98 |
| A2 | 4 | 0 | 2 | 0 | 0 | 494 | 0 | 98.8 |
| A3 | 0 | 0 | 0 | 0 | 0 | 0 | 500 | 100 |
| AVE | 98.86 |
| Methods | Few-Shot Learning | Anomaly Score | Anomaly Localization | Anomaly Judgement | Multi-Turn Dialogue |
|---|---|---|---|---|---|
| Traditional IAD methods | √ | √ | |||
| Few-shot IAD methods | √ | √ | √ | ||
| LVLMs | √ | √ | |||
| AnomalyGPT | √ | √ | √ | √ | √ |
| Setup | Method | MVTec-AD | VisA | ||||
|---|---|---|---|---|---|---|---|
| Image-AUC | Pixel-AUC | Acc | Image-AUC | Pixel-AUC | Acc | ||
| l-shot | SPADE | 81.0 ± 2.0 | 91.2 ± 0.4 | - | 79.5 ± 4.0 | 95.6 ± 0.4 | - |
| PaDiM | 76.6 ± 3.1 | 89.3 ± 0.9 | - | 62.8 ± 5.4 | 89.9 ± 0.8 | - | |
| PatchCore | 83.4 ± 3.0 | 92.0 ± 1.0 | - | 79.9 ± 2.9 | 95.4 ± 0.6 | - | |
| WinCLIP | 93.1 ± 2.0 | 95.2 ± 0.5 | - | 83.8 ± 4.0 | 96.4 ± 0.4 | - | |
| AnomlyGPT | 94.1 ± 1.1 | 95.3 ± 0.1 | 86.1 ± 1.1 | 87.4 ± 0.8 | 96.2 ± 0.1 | 77.4 ± 1.0 | |
| 2-shot | SPADE | 82.9 ± 2.6 | 92.0 ± 0.3 | - | 80.7 ± 5.0 | 96.2 ± 0.4 | - |
| PaDiM | 78.9 ± 3.1 | 91.3 ± 0.7 | - | 67.4 ± 5.1 | 92.0 ± 0.7 | - | |
| PatchCore | 86.3 ± 3.3 | 93.3 ± 0.6 | - | 81.6 ± 4.0 | 96.1 ± 0.5 | - | |
| WinCLIP | 94.4 ± 1.3 | 96.0 ± 0.3 | - | 84.6 ± 2.4 | 96.8 ± 0.3 | - | |
| AnomlyGPT | 95.5 ± 0.8 | 95.6 ± 0.2 | 84.8 ± 0.8 | 88.6 ± 0.7 | 96.4 ± 0.1 | 77.5 ± 0.3 | |
| 4-shot | SPADE | 84.8 ± 2.5 | 92.7 ± 0.3 | - | 81.7 ± 3.4 | 96.6 ± 0.3 | - |
| PaDiM | 80.4 ± 2.5 | 92.6 ± 0.7 | - | 72.8 ± 2.9 | 93.2 ± 0.5 | - | |
| PatchCore | 88.8 ± 2.6 | 94.3 ± 0.5 | - | 85.3 ± 2.1 | 96.8 ± 0.3 | - | |
| WinCLIP | 95.2 ± 1.3 | 96.2 ± 0.3 | - | 87.3 ± 1.8 | 97.2 ± 0.2 | - | |
| AnomlyGPT | 96.3 ± 0.3 | 96.2 ± 0.1 | 85.0 ± 0.3 | 90.6 ± 0.7 | 96.7 ± 0.1 | 77.7 ± 0.4 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lei, L.; Li, W.; Zhang, S.; Wu, C.; Yu, H. Research Progress on Data-Driven Industrial Fault Diagnosis Methods. Sensors 2025, 25, 2952. https://doi.org/10.3390/s25092952
Lei L, Li W, Zhang S, Wu C, Yu H. Research Progress on Data-Driven Industrial Fault Diagnosis Methods. Sensors. 2025; 25(9):2952. https://doi.org/10.3390/s25092952
Chicago/Turabian StyleLei, Liang, Weibin Li, Shiwei Zhang, Changyuan Wu, and Hongxiang Yu. 2025. "Research Progress on Data-Driven Industrial Fault Diagnosis Methods" Sensors 25, no. 9: 2952. https://doi.org/10.3390/s25092952
APA StyleLei, L., Li, W., Zhang, S., Wu, C., & Yu, H. (2025). Research Progress on Data-Driven Industrial Fault Diagnosis Methods. Sensors, 25(9), 2952. https://doi.org/10.3390/s25092952