
MHFS-FORMER: Multiple-Scale Hybrid Features Transformer for Lane Detection

Abstract
1. Introduction
- We have proposed a novel end-to-end Transformer-based lane recognition model, MHFS-FORMER. It introduces enhanced multi-scale mixed features into the Transformer model, captures the elongated structures of lanes and the global environment through the multi-reference deformable attention module, and eliminates the complex post-processing procedure at the same time;
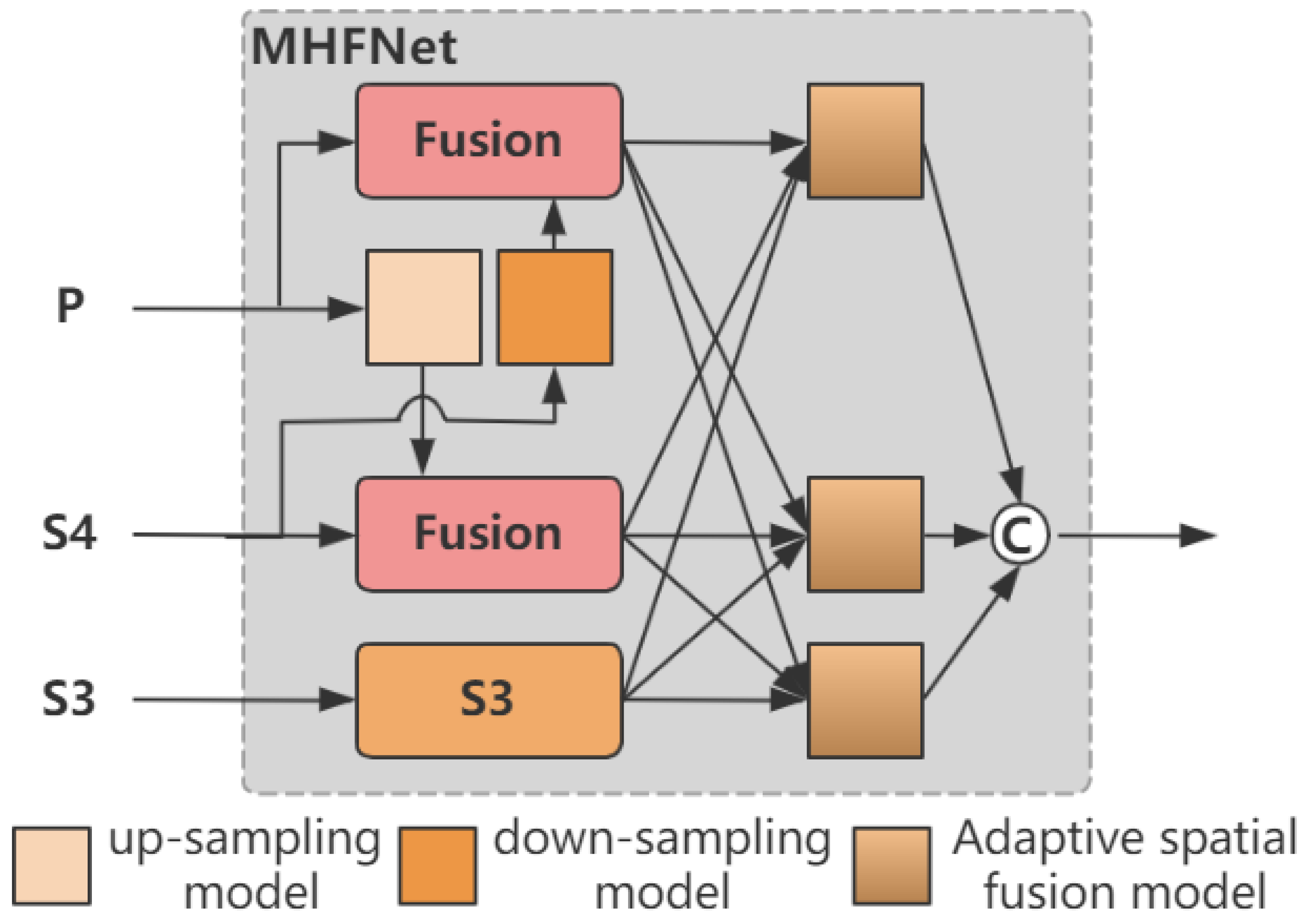
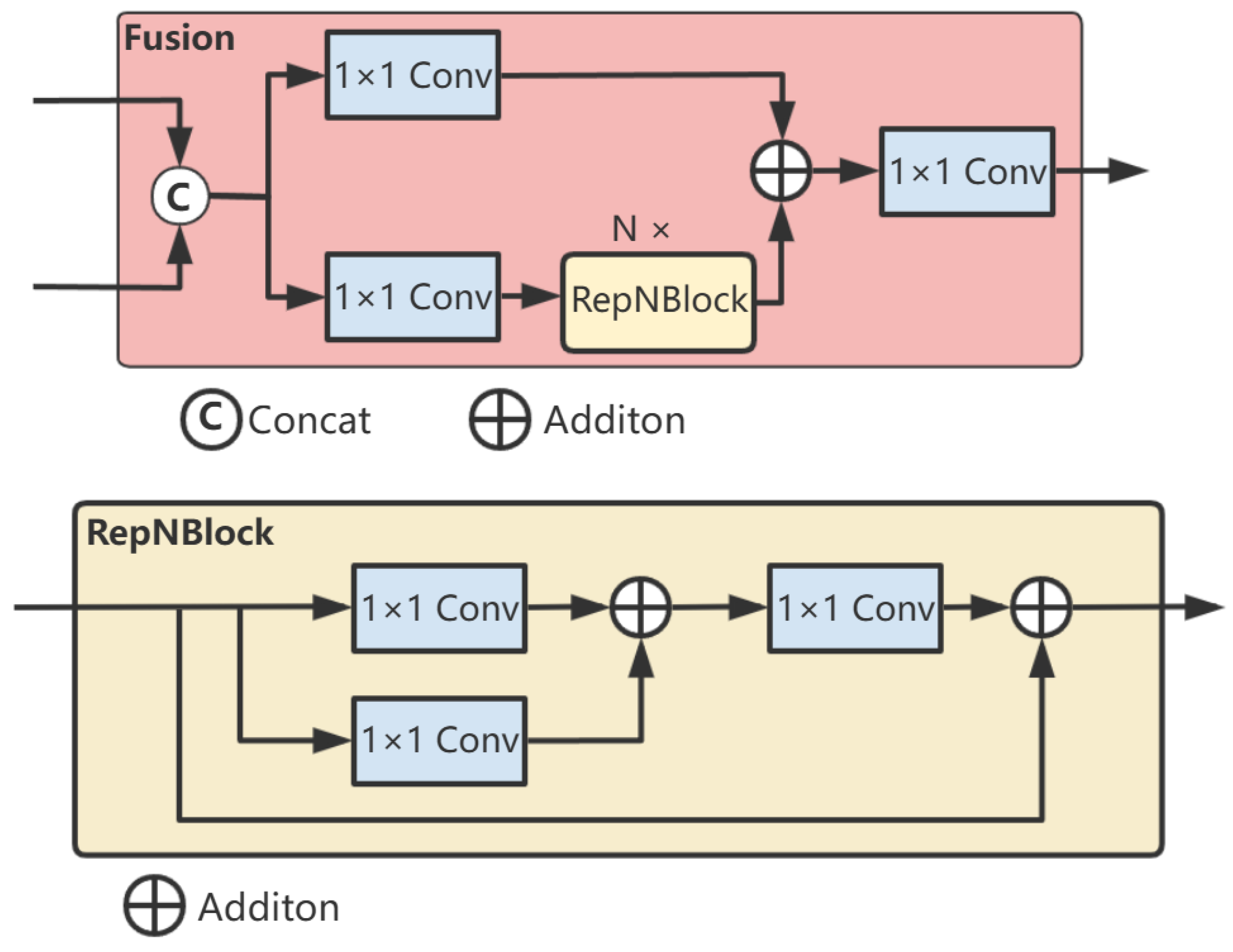
- We propose a multi-scale fused feature network rich in semantic information named MHFNet. It is initiated by fusing two adjacent high-level features. Multiple cascaded stages are combined to iteratively extract and fuse multi-scale features. Moreover, considering the potential information conflicts that may occur during the feature fusion process at each spatial position, adaptive spatial fusion operations are further employed to mitigate these inconsistencies;
- We have designed a network dedicated to the feature mining of lane lines named ShuffleLaneNet. Exploring the channel information and spatial information enhances the lane features. Based on maintaining the number of model parameters, it significantly improves the performance of the model;
- The proposed MHFS-FORMER achieves encouraging performance on the TuSimple and CULane datasets. (That is, it attains an F1 score of 77.38% on CULane, an accuracy score of 96.88%, a real-time processing speed of 87 fps, and a false positive rate (FPR) of 2.34% on TuSimple.).
2. Related Work
2.1. Lane Detection
2.1.1. Methods Based on Segmentation
2.1.2. Methods Based on Anchor Boxes
2.1.3. Methods Based on Parameter Regression
2.1.4. Methods Based on Keypoints
2.2. Vision Transformer
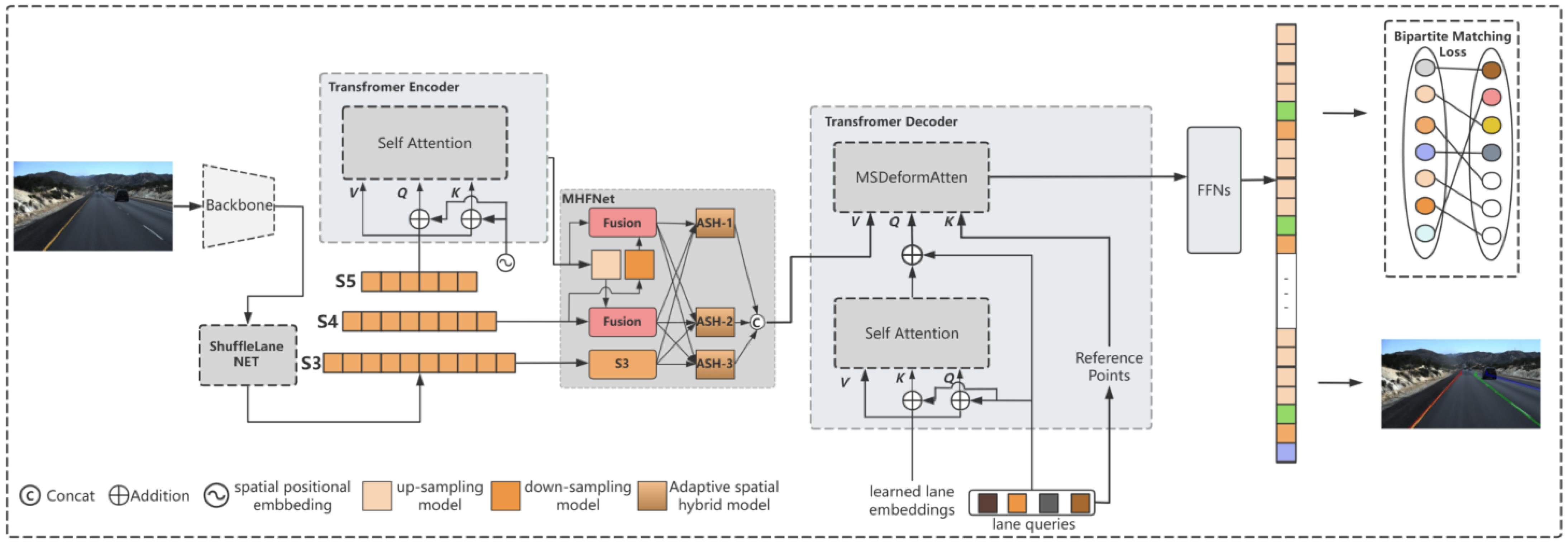
3. Structure
3.1. Network Overview
3.2. Lane Parameter Model
3.3. MHFNet
3.4. ShuffleLaneNet
3.5. Transformer Block
3.6. Loss Function
4. Experiments and Analysis
4.1. Datasets
4.2. Evaluation Metrics
4.3. Experimental Parameters
4.4. Comparison Results
4.5. Limitation and Discussion
4.6. Ablation Experiment Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, G.; Worgotter, F.; Markelic, I. Combining Statistical Hough Transform and Particle Filter for Robust Lane Detection and Tracking. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 993–997. [Google Scholar]
- Kim, Z. Robust Lane Detection and Tracking in Challenging Scenarios. IEEE Trans. Intell. Transport. Syst. 2008, 9, 16–26. [Google Scholar] [CrossRef]
- Zhou, S.; Jiang, Y.; Xi, J.; Gong, J.; Xiong, G.; Chen, H. A Novel Lane Detection Based on Geometrical Model and Gabor Filter. In Proceedings of the 2010 IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 59–64. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial As Deep: Spatial CNN for Traffic Scene Understanding. arXiv 2017, arXiv:1712.06080. [Google Scholar] [CrossRef]
- Neven, D.; Brabandere, B.D.; Georgoulis, S.; Proesmans, M.; Gool, L.V. Towards End-to-End Lane Detection: An Instance Segmentation Approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018. [Google Scholar]
- Zheng, T.; Fang, H.; Zhang, Y.; Tang, W.; Yang, Z.; Liu, H.; Cai, D. RESA: Recurrent Feature-Shift Aggregator for Lane Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 2–9 February 2021. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning Lightweight Lane Detection CNNs by Self Attention Distillation. arXiv 2019, arXiv:1908.00821. [Google Scholar]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. CondLaneNet: A Top-to-down Lane Detection Framework Based on Conditional Convolution. In Proceedings of the IEEE/CVF International Conference On Computer Vision, Montreal, QC, Canada, 17–20 October 2023. [Google Scholar]
- Abualsaud, H.; Liu, S.; Lu, D.; Situ, K.; Rangesh, A.; Trivedi, M.M. LaneAF: Robust Multi-Lane Detection with Affinity Fields. IEEE Robot. Autom. Lett. 2021, 6, 7477–7484. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Hu, X.; Yang, J. Line-CNN: End-to-End Traffic Line Detection With Line Proposal Unit. IEEE Trans. Intell. Transport. Syst. 2020, 21, 248–258. [Google Scholar] [CrossRef]
- Tabelini, L.; Berriel, R.; Paixão, T.M.; Badue, C.; Souza, A.F.D.; Oliveira-Santos, T. Keep Your Eyes on the Lane: Real-Time Attention-Guided Lane Detection. arXiv 2020, arXiv:2010.12035. [Google Scholar]
- Zheng, T.; Huang, Y.; Liu, Y.; Tang, W.; Yang, Z.; Cai, D.; He, X. CLRNet: Cross Layer Refinement Network for Lane Detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA; pp. 888–897. [Google Scholar]
- Qin, Z.; Zhang, P.; Li, X. Ultra Fast Deep Lane Detection with Hybrid Anchor Driven Ordinal Classification. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 46, 2555–2568. [Google Scholar] [CrossRef] [PubMed]
- Tabelini, L.; Berriel, R.; Paixão, T.M.; Badue, C.; Souza, A.F.D.; Oliveira-Santos, T. PolyLaneNet: Lane Estimation via Deep Polynomial Regression. arXiv 2020, arXiv:2004.10924. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-End Object Detection with Transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems 30, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T.; Xiong, Z. End-to-End Lane Shape Prediction with Transformers. arXiv 2020, arXiv:2011.04233. [Google Scholar]
- Zhou, K.; Zhou, R. End-to-End Lane Detection with One-to-Several Transformer. arXiv 2023, arXiv:2305.00675. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. arXiv 2021, arXiv:2305.00675. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs Beat Yolos on Real-Time Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024. [Google Scholar]
- TuSimple. Available online: https://github.com/TuSimple/tusimple-benchmark/ (accessed on 13 January 2025).
- Feng, Z.; Guo, S.; Tan, X.; Xu, K.; Wang, M.; Ma, L. Rethinking Efficient Lane Detection via Curve Modeling. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Ko, Y.; Lee, Y.; Azam, S.; Munir, F.; Jeon, M.; Pedrycz, W. Key Points Estimation and Point Instance Segmentation Approach for Lane Detection. IEEE Trans. Intell. Transp. Syst. 2020, 23, 8949–8958. [Google Scholar] [CrossRef]
- Qu, Z.; Jin, H.; Zhou, Y.; Yang, Z.; Zhang, W. Focus on Local: Detecting Lane Marker from Bottom Up via Key Point. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional DETR for Fast Training Convergence. In Proceedings of the IEEE/CVF International Computer Vision, Montreal, BC, Canada, 11–17 October 2023. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic Feature Pyramid Network for Object Detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Oahu, HI, USA, 1–4 October 2023. [Google Scholar]
- Ding, X.; Zhang, X.; Ma, N.; Han, J.; Ding, G.; Sun, J. RepVGG: Making VGG-Style ConvNets Great Again. In Ding, Xiaohan, et al. Repvgg: Making Vgg-Style Convnets Great Again. arXiv 2021, arXiv:2101.03697. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the European Conference on Computer Vision – ECCV 2018, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Yang, Q.-L.Z.Y.-B. SA-Net: Shuffle Attention for Deep Convolutional Neural Networks. arXiv 2021, arXiv:2102.00240. [Google Scholar]
- Jin, D.; Park, W.; Jeong, S.G. Eigenlanes: Data-driven lane descriptors for structurally diverse lanes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17163–17171. [Google Scholar]
- Han, J.; Deng, X.; Cai, X.; Yang, Z.; Xu, H.; Xu, C.; Liang, X. Laneformer: Object-Aware Row-Column Transformers for Lane Detection. arXiv 2022, arXiv:2203.09830. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | F1 | FPR | FNR | FPS |
|---|---|---|---|---|
| SCNN [4] | 96.53 | 6.17 | 1.80 | 7 |
| RESA-ResNet18 [6] | 96.70 | 3.95 | 2.83 | - |
| RESA-ResNet34 [6] | 96.82 | 3.63 | 2.48 | - |
| SAD-ResNet18 [7] | 96.02 | 7.86 | 4.51 | - |
| SAD-ResNet34 [7] | 96.24 | 7.12 | 3.44 | - |
| CondLaneNet-ResNet18 [8] | 95.48 | 2.18 | 3.80 | 220 |
| CondLaneNet-ResNet34 [8] | 95.37 | 2.20 | 3.82 | 154 |
| LaneATT-ResNet18 [11] | 95.57 | 3.56 | 3.01 | 250 |
| LaneATT-ResNet34 [11] | 95.63 | 3.53 | 2.92 | 171 |
| UFLDv2-ResNet18 [13] | 95.65 | 3.06 | 4.61 | 312 |
| UFLDv2-ResNet34 [13] | 95.56 | 3.18 | 4.37 | 169 |
| PolyLaneNet [14] | 93.36 | 9.42 | 9.33 | 115 |
| LSTR [17] | 96.18 | 2.91 | 3.38 | 420 |
| Eigenlanes [30] | 95.62 | 3.20 | 3.99 | - |
| BézierLaneNet-ResNet18 [22] | 95.41 | 5.30 | 4.60 | - |
| BézierLaneNet-ResNet34 [22] | 96.65 | 5.10 | 3.90 | - |
| MHFS-Former-ResNet18 | 96.42 | 2.28 | 2.70 | 130 |
| MHFS-Former-ResNet34 | 96.88 | 2.34 | 2.43 | 87 |
| Method | Normal | Crowd | Dazzle | Shadow | No Line | Arrow | Curve | Cross | Night | Total |
|---|---|---|---|---|---|---|---|---|---|---|
| SCNN [4] | 90.60 | 69.70 | 58.50 | 66.90 | 43.40 | 84.10 | 64.40 | 1990 | 66.10 | 71.60 |
| RESA-ResNet34 [6] | 91.90 | 72.40 | 66.50 | 72.00 | 46.30 | 88.10 | 68.60 | 1896 | 69.80 | 74.50 |
| SAD-ResNet18 [7] | 89.80 | 68.10 | 59.80 | 67.50 | 42.50 | 83.90 | 65.50 | 1995 | 64.20 | 70.50 |
| SAD-ResNet34 [7] | 89.90 | 68.50 | 59.90 | 67.70 | 42.20 | 83.80 | 66.00 | 1960 | 64.60 | 70.70 |
| LaneAF [9] | 90.12 | 72.19 | 68.70 | 76.34 | 49.13 | 85.13 | 64.40 | 1934 | 68.67 | 74.24 |
| UFLDv2-ResNet18 [13] | 91.80 | 73.30 | 65.30 | 75.10 | 47.60 | 87.90 | 68.50 | 2075 | 70.70 | 75.00 |
| UFLDv2-ResNet34 [13] | 92.50 | 74.80 | 65.50 | 75.50 | 49.20 | 88.80 | 70.10 | 1910 | 70.80 | 76.00 |
| BézierLaneNet-ResNet18 [22] | 90.22 | 71.55 | 62.49 | 70.91 | 45.30 | 84.09 | 58.98 | 996 | 68.70 | 73.67 |
| BézierLaneNet-ResNet34 [22] | 91.59 | 73.20 | 69.20 | 76.74 | 48.05 | 87.16 | 62.45 | 888 | 69.90 | 75.57 |
| Eigenlanes-ResNet18 [30] | 91.50 | 74.80 | 69.70 | 72.30 | 51.10 | 87.70 | 62.00 | 1507 | 71.40 | 76.50 |
| O2SFormer-ResNet18 [18] | 91.89 | 73.86 | 70.40 | 74.84 | 49.83 | 86.08 | 68.68 | 2361 | 70.74 | 76.07 |
| Laneformer-ResNet18 [31] | 88.60 | 69.02 | 64.07 | 65.02 | 45.00 | 81.55 | 60.46 | 25 | 64.76 | 71.71 |
| PINet(4H) [23] | 90.30 | 72.30 | 66.30 | 68.40 | 49.80 | 83.70 | 65.60 | 1427 | 67.70 | 74.40 |
| MHFS-Former-ResNet18 | 92.82 | 77.84 | 67.50 | 77.30 | 52.34 | 85.92 | 65.72 | 1223 | 69.63 | 76.83 |
| MHFS-Former-ResNet34 | 92.89 | 79.25 | 68.86 | 78.80 | 53.78 | 86.70 | 67.70 | 1219 | 69.88 | 77.38 |
| Baseline | ShuffleLaneNet | MHFNet | F1 |
|---|---|---|---|
| √ | 77.11 | ||
| √ | √ | 77.16 | |
| √ | √ | 77.30 | |
| √ | √ | √ | 77.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, D.; Zhang, T. MHFS-FORMER: Multiple-Scale Hybrid Features Transformer for Lane Detection. Sensors 2025, 25, 2876. https://doi.org/10.3390/s25092876
Yan D, Zhang T. MHFS-FORMER: Multiple-Scale Hybrid Features Transformer for Lane Detection. Sensors. 2025; 25(9):2876. https://doi.org/10.3390/s25092876
Chicago/Turabian StyleYan, Dongqi, and Tao Zhang. 2025. "MHFS-FORMER: Multiple-Scale Hybrid Features Transformer for Lane Detection" Sensors 25, no. 9: 2876. https://doi.org/10.3390/s25092876
APA StyleYan, D., & Zhang, T. (2025). MHFS-FORMER: Multiple-Scale Hybrid Features Transformer for Lane Detection. Sensors, 25(9), 2876. https://doi.org/10.3390/s25092876