Abstract
Micro-expressions (MEs), characterized by their brief duration and subtle facial muscle movements, pose significant challenges for accurate recognition. These ultra-fast signals, typically captured by high-speed vision sensors, require specialized computational methods to extract spatio-temporal features effectively. In this study, we propose a lightweight dual-stream network with an adaptive strategy for efficient ME recognition. Firstly, a motion magnification network based on transfer learning is employed to magnify the motion states of facial muscles in MEs. This process can generate additional samples, thereby expanding the training set. To effectively capture the dynamic changes of facial muscles, dense optical flow is extracted from the onset frame and the magnified apex frame, thereby obtaining magnified dense optical flow (MDOF). Subsequently, we design a dual-stream spatio-temporal network (DSTNet), using the magnified apex frame and MDOF as inputs for the spatial and temporal streams, respectively. An adaptive strategy that dynamically adjusts the magnification factor based on the top-1 confidence is introduced to enhance the robustness of DSTNet. Experimental results show that our proposed method outperforms existing methods in terms of on the SMIC, CASME II, SAMM, and composite dataset, as well as in cross-dataset tasks. Adaptive DSTNet significantly enhances the handling of sample imbalance while demonstrating robustness and featuring a lightweight design, indicating strong potential for future edge sensor deployment.
1. Introduction
Different from macro-expression, micro-expressions (MEs) are fleeting, subtle facial movements that occur when people unconsciously reveal their genuine emotions while attempting to suppress them [1,2]. Accurately capturing and recognizing MEs can provide insight into a person’s genuine emotions. Therefore, ME recognition is of great significance in social interactions [3], medical treatment [4], lie detection [5], and national security [6].
As a complex emotional expression, MEs are difficult to elicit due to their short duration and weak facial muscle movements. Furthermore, the acquisition of ME data relies on high-frame-rate cameras as primary sensors to capture these transient phenomena, resulting in substantial data collection difficulties and consequent scarcity of relevant data resources. These characteristics of MEs pose a challenge for accurate ME recognition. Currently, to promote studies on ME recognition, researchers commonly follow a three-step process [7]: preprocessing, MEs generation, and recognition model.
In the preprocessing, various techniques are employed to eliminate irrelevant factors from the original ME video, thereby enhancing the recognition performance. Among them, face detection and face alignment are the most common preprocessing methods [8,9]. Face detection aims to remove the background and keep only the face; face alignment reduces the effects of changes in facial shape and pose through aligning facial keypoints and using affine transformations. Additionally, motion magnification, as a unique preprocessing technique, addresses the problem of the low intensity of ME muscle movements by magnifying them [10,11], which contributes to improving recognition accuracy. However, most motion magnification methods are linear, exhibiting poor robustness and susceptibility to noise. They struggle to effectively magnify subtle and complex muscle movements.
In the MEs generation, the Generative Adversarial Network (GAN) [12] has been a prevailing method widely used by lots of researchers. The ULME-GAN [13] generates controllable ME sequences by re-encoding the action unit (AU) matrix, and it has been proven on public datasets that the generated training data can enhance the performance of recognition models. In the literature [14], two independent GAN models are employed to generate horizontal and vertical optical flow images, thereby expanding the training data for classification models. Additionally, the First Order Motion Model (FOMM) [15] and temporal interpolation technique [16] have also been applied to the MEs generation and data augmentation. However, due to the lack of MEs datasets and insufficient data for training ME generation networks, the quality of generated ME images still falls short of the desired level.
In the recognition model, the characteristics of low intensity and short duration make the ME recognition task highly challenging. Depending on the input, it is typically divided into three technical approaches: image, video, and optical flow. Among these, the image-based method often employs apex frame analysis [17], which simplifies processing but sacrifices temporal information. Video and optical flow inputs, capable of capturing temporal dynamics, are also crucial in ME recognition. Optical flow methods encompass sparse optical flow and dense optical flow. Sparse optical flow typically calculates the primary direction of localized muscle movements for MEs [18], but may overlook subtle motions. Dense optical flow calculates the global optical flow variation from the onset frame to the apex frame [19], even yielding a histogram of optical flow directions for different regions on the face, thereby extracting temporal information of MEs. However, dense optical flow comes with excessive computational load. In contrast to optical flow, when video is used as an input, it is an end-to-end approach that extracts both spatial and temporal information and can be directly processed without additional operations [20]. Nonetheless, when the input is video, it still faces the challenge of large computational costs. Furthermore, current ME recognition models exhibit limited robustness when applied to cross-dataset recognition tasks.
In summary, there are the following issues with ME recognition: (1) The mainstream method for motion magnification is mainly linear magnification, which exhibits poor robustness and is susceptible to noise interference; (2) ME generation networks struggle to generate controllable MEs, and ME data are still insufficient; (3) Sparse optical flow with the ability to capture temporal information tends to ignore subtle muscle movements, while dense optical flow and video have high computational complexity; (4) The existing recognition models are deficient in robustness.
To solve the above issues and fully leverage network characteristics, this study carefully designs feature extraction methods and network architectures aimed at developing a lightweight model for efficient ME recognition. Firstly, to solve issue (1), we employ a motion magnification network based on transfer learning. This method not only improves the robustness compared to the traditional linear magnification but also effectively addresses the problem of insufficient training data for the magnification network. To address issue (2), a magnification factor is introduced to control the degree of motion magnification. By adjusting this factor to obtain ME images with different magnification levels, we successfully expand the data for training the recognition model. For issue (3), we employ the recurrent all-parallel field transform (RAFT) [21] to calculate the correlation of each pixel point between the onset frame and the magnified apex frame to obtain the magnified dense optical flow (MDOF). This approach significantly reduces the computational effort while still capturing the feeble muscle motion of MEs. Subsequently, we design a dual-stream spatio-temporal network (DSTNet) to extract spatial features from the magnified apex frame and temporal features from the MDOF. For issue (4), we incorporate an adaptive mechanism into DSTNet, which dynamically adjusts the magnification factor based on the top-1 confidence output via the model, thus, enhancing its robustness. Our proposed method demonstrates superior performance on three public datasets and composite datasets, especially when dealing with imbalanced datasets where its is particularly outstanding. In addition, the method also exhibits excellent performance in cross-dataset recognition tasks, demonstrating the robustness of the recognition model. While effectively addressing various issues faced by ME recognition, the adaptive DSTNet also possesses lightweight characteristics, significantly enhancing recognition efficiency in practical applications. The main contributions of this paper are as follows:
- The utilization of transfer learning-based motion magnification network effectively amplifies feeble motion of facial muscles in MEs and also expands the training dataset.
- The pixel-level dense optical flow MDOF is innovatively designed to extract only once from the magnified apex frame. This design not only maintains the accurate capture of subtle facial muscle movements but also significantly reduces computational complexity.
- DSTNet with an adaptive strategy is constructed to extract deep representations from spatio-temporal information for ME recognition. Experimental results on various tasks demonstrate its effectiveness.
The paper is organized as follows: Section 2 introduces the related work on ME recognition. Section 3 details the proposed adaptive DSTNet and its module. Section 4 presents the ablation experiments, recognition results on three tasks, and comparisons with other methods. Section 5 summarizes and discusses this study.
2. Related Work
MEs often reveal the genuine emotions of human beings, so the task of researching ME recognition is becoming more and more important. However, due to the subtle and fleeting characteristics of MEs, simple processing methods often fail to achieve better performance. With the development of computer hardware and deep learning, the use of neural networks has greatly improved the accuracy of ME recognition. One of the most common approaches in ME recognition is the single-feature input strategy. This involves designing a high-performance deep network architecture tailored to the characteristics of different input methods. Given the complementarity between different information, another commonly-used approach is to employ a multi-feature input strategy [22,23], where various sub-streams are utilized to extract deep features from image, video, and optical flow inputs, respectively. These features are then fused and processed to enhance accuracy. For example, there are methods that learn facial features and AU matrices for ME recognition, where facial features refer to connecting facial feature points to form a graph containing node values and edge weights [24]. Despite their success, these methods often prioritize accuracy over computational efficiency, leading to complex models with high resource demands. This motivates our investigation of efficient feature representation that maintains discriminative power while reducing resource consumption.
Another critical challenge in ME recognition stems from the limited and imbalanced training data, which significantly compromises deep network performance. Although GANs have been employed to synthesize additional training samples, their effectiveness for MEs remains fundamentally constrained by both the subtle nature of facial muscle movements and the inherently small dataset scale [25]. Furthermore, FOMM-based techniques demonstrate insufficient AU controllability while being further limited by the scarcity of source ME videos for driving large-scale generation [26]. These compounded challenges highlight the urgent need for more efficient data augmentation solutions to prompt ME recognition with enhanced accuracy and real-world applicability.
Transfer learning is a method of transferring knowledge from a source task to a target task to improve learning of the target task. It has been widely used to solve the problem of applying complex networks to small datasets [27]. Currently, motion magnification networks are primarily trained on macro-expression datasets, whereas ME datasets are relatively smaller. Therefore, in this study, we introduce a transfer learning approach to the motion magnification network. We use large-scale datasets of macro-expressions to initialize the weights, and then fine-tune these weights on smaller ME datasets to ensure that the motion magnification network can effectively magnify subtle facial muscle movements in MEs. Importantly, this magnification process simultaneously serves as a data augmentation mechanism, generating enhanced training samples while improving feature extraction, thereby addressing two critical challenges in ME recognition simultaneously.
While the field of ME recognition has seen significant progress, with various sophisticated methods being proposed to improve performance, one critical aspect that has often been overlooked is the model’s complexity and computational requirements. Many existing approaches focus solely on maximizing recognition accuracy, employing deep neural networks with hundreds of millions of parameters and requiring substantial computational resources. This trend towards more complex models not only increases the computational burden but also limits their practical applications. In this study, we combine network structure design to address the various challenges faced by MEs with reduced computational resources. By meticulously designing a lightweight model and incorporating the adaptive strategy, we achieve a reasonable balance between recognition performance and model scale.
3. Proposed Method
3.1. Overview of Adaptive DSTNet
In this study, we propose a lightweight dual-stream spatio-temporal network with an adaptive strategy, named adaptive DSTNet, for efficient ME recognition. This approach specifically addresses the challenges posed by the subtle facial movements, short duration, and limited data samples inherent in MEs. The algorithmic framework of this method is illustrated in Figure 1.
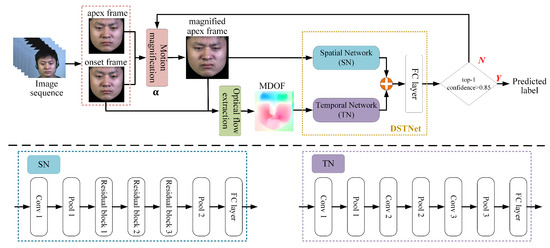
Figure 1.
The framework of adaptive DSTNet for ME recognition.
The adaptive DSTNet framework processes onset and apex frames extracted from publicly available ME datasets using their provided temporal annotations. It amplifies the motion of the apex frame to enhance facial muscle movements, which are then fed into a Spatial Network (SN) to extract spatial features representing facial muscle state. Additionally, these amplified frames serve as augmented samples for the training dataset, mitigating the issue of limited ME data. MDOF is extracted between the onset and magnified apex frames for further processing via a Temporal Network (TN) to capture temporal dynamics of facial movement trends. DSTNet deeply extracts and fuses spatio-temporal features to achieve ME recognition. To enhance model robustness, an adaptive strategy is implemented: if the top-1 confidence level is below 0.85, the magnification factor is increased, and the images are reprocessed to extract new magnified apex and MDOF for re-recognition. This iterative process continues until the top-1 confidence exceeds 0.85 or a predefined termination condition is met. This approach effectively represents muscle movement states and trends in ME sequences, and the integration of the dual-stream network with the adaptive strategy significantly improves ME-related feature representation, thereby enhancing recognition performance.
3.2. Motion Magnification
Because the motion of ME is very feeble, it is difficult for it to be recognized by computers. To solve this issue, the study employs a deep learning-based motion magnification network to magnify ME facial muscle movements. As shown in Figure 2, the network consists of three main parts: encoder, manipulator, and decoder.
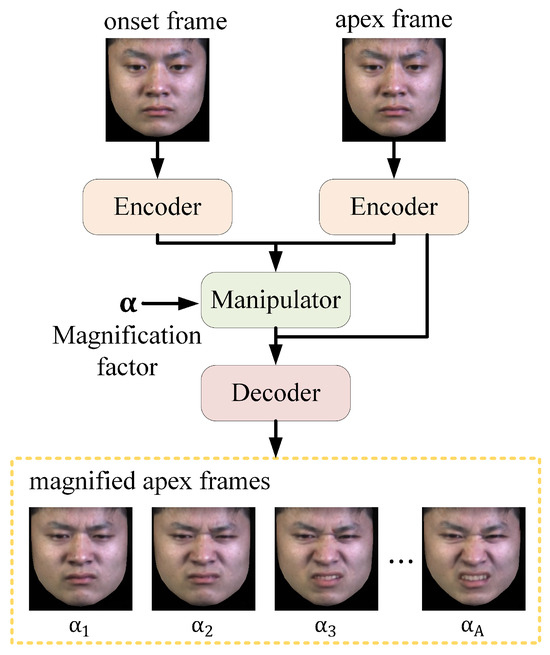
Figure 2.
Motion magnification structure. The magnified apex frames with different factors are shown in the yellow dashed box, with the subscript indicating the value of .
The encoder serves as a spatial decomposition filter, extracting shape features and texture features from a single frame. In the manipulator, a magnification factor is introduced. By calculating the difference in shape features between two given frames (the onset frame a and the apex frame b) and multiplying it by , the magnified shape feature can be obtained. The calculation is as follows:
where represents a convolution and ReLU, and represents a convolution and a residual block.
Different from other motion magnification models, this study generates a single magnified apex frame, independent of temporal factors. Consequently, the decoder simplifies the time-related processing component. It primarily fuses inputs from the encoder and manipulator, superimposing the magnified shape features onto the onset frame texture features to generate the magnified apex frame . This means that the output magnified apex frame can be controlled solely by adjusting the magnification factor. The calculation is as follows:
where represents the function that reconstructs the texture features with the magnified shape features, and represents the magnified apex frame.
Transfer learning enables deep CNNs to be applied to small ME datasets by pre-training on larger macro-expression datasets. In this study, we selected 10,431 images from four macro-expression datasets: CK+ [28], Oulu-CASIA NIR&VIS [29], Jaffe [30], and MUGFE [31], expanding each category to 5000 images to form a new dataset for transfer learning. The magnification network is pre-trained on this expanded dataset and then fine-tuned on ME datasets: SMIC [32], CASME II [33], and SAMM [34]. As shown in the yellow dashed box in Figure 2, using a disgust sample from CASME II [33], a notable change in expression amplitude is observed as the magnification factor increases from 1 to A. This change is particularly evident in the disgust-related action units: AU4 (brow lower), AU9 (nose more wrinkled), and AU10 (upper lip raised).
Magnifying the facial muscle movements has a dual benefit: it emphasizes the distinct patterns of MEs, and generates more apex frames by adjusting different magnification factors, effectively expanding data for training. The developed motion magnification network not only enhances subtle muscle movements but also increases the perceptibility of MEs that would otherwise be lost due to sensor limitations (e.g., motion blur under low illumination).
3.3. MDOF
Magnifying facial muscle movements alone has limitations for recognition due to varying initial states. Therefore, extracting the overall trend of movements from ME sequences is necessary. Traditional optical flow methods struggle with subtle ME movements. Thus, we introduced RAFT [21] to capture these movements accurately. For real-time extraction, RAFT is applied to the onset and magnified apex frames, yielding MDOF to characterize movement trends.
In this study, the MDOF is obtained by first extracting the feature vectors for each pixel in the onset frame a and the magnified apex frame . These feature vectors are denoted as and , where H, W, and D represent the height, width, and depth of the feature maps, respectively. To reduce the computational load, the feature extraction network is designed as a multi-layer network with shared weights. Subsequently, the dot product is used to calculate the correlation between any two points, thereby obtaining a correlation matrix that contains information about all the pixels:
where represents the correlation matrix, i, j and k, and l are spatial index positions in the feature maps, and h represents channel index of the feature maps.
Next, a multi-scale 4D correlation pyramid is constructed using pooling operations. This pyramid captures multi-scale image similarity features, providing key information for pixel displacement. Finally, a recurrent mechanism based on the Gated Recurrent Unit (GRU) is employed to update the optical flow [21]. Specifically, in conjunction with the current optical flow estimate, relevant features are retrieved from the correlation pyramid to update the optical flow. This process can be simplified and represented as:
where denotes the optical flow estimate at the t-th iteration, represents the correlation values retrieved from the correlation pyramid based on the current optical flow estimate, and denotes the updated optical flow. Through this pixel-by-pixel correlation lookup and optical flow update process, we achieve high-precision optical flow estimation, thereby obtaining the MDOF that accurately reflects subtle muscle motion changes of MEs.
As shown in Figure 3, the first column presents onset frames, the second column presents original apex frame () and magnified apex frames with varying (), and the third column visualizes original optical flow (computed between onset and original apex frame) and the MDOFs (computed between onset and magnified apex frames). Darker colors in optical flow indicate more intense motion. By observing the original dense optical flow extracted from the onset frame and the original apex frame, it can be noted that although it successfully captures the motion feature of AU4, the capture of motions in other regions is less satisfactory. However, when the MDOF is extracted for the magnified apex frames (the last three rows of the third column in Figure 3), a clear similarity in motion patterns emerges, indicating that all facial muscle movements associated with the expression of disgust are effectively captured, such as AU9 (nose wrinkler) and AU10 (upper lip raiser). Furthermore, as the magnification factor increases (from upper to lower), the visualized images of MDOF become darker, providing richer information for the model to more accurately recognize MEs. This feature extraction method effectively standardizes raw sensor outputs into unified spatio-temporal representations, thereby significantly facilitating subsequent ME analysis.

Figure 3.
Visualization of the onset frames (left), the apex frames (middle), and corresponding optical flow images (right) for a disgust sample in CASME II [33]. (a) is the original apex frame and dense optical flow (), and (b–d) are magnified apex frames and MDOFs produced via the sequentially enhanced ().
3.4. DSTNet
DSTNet consists of SN and TN, which represents a spatial stream network and a temporal stream network, respectively. The details of DSTNet are shown in Table 1. SN extracts multi-level features from the magnified apex frame using convolutions, employing residual blocks to mitigate gradient vanishing. TN uses a shallow convolutional layer to capture subtle temporal features from MDOF input, reducing computational load. The average pooling is to reduce the dimension of feature output, effectively mitigating the influence of irrelevant data on model training. The FC layer integrates the features of the previous layer and improves the model’s nonlinear fitting performance. Subsequently, the features output via SN and TN are fused, and the top-1 confidence level is output for subsequent adaptive adjustment and ME recognition.

Table 1.
The architecture of DSTNet.
In the field of ME recognition, the trade-off between computational efficiency and recognition performance is particularly crucial. By concentrating the computational load on motion magnification and MDOF calculation, DSTNet features as high computational efficiency and performance. It requires only 64.77 M floating point operations (FLOPs) and 3.15 M parameters to achieve outstanding recognition capabilities for three-channel ME images. This lightweight architecture offers the feasibility of implementing real-time inference on edge computing devices, allowing it to constitute a complete real-time ME analysis system together with high frame rate imaging sensors. The subtle facial muscle movements of MEs pose a significant challenge for deep networks in capturing key features. However, our proposed method is capable of extracting and utilizing these information more directly and rapidly.
3.5. Adaptive Strategy
To enhance ME recognition performance, we introduced an adaptive magnification factor adjustment algorithm into the DSTNet framework. This strategy initiates after obtaining the top-1 confidence score by using the DSTNet to recognize the magnified apex frame and its corresponding MDOF. If the current confidence exceeds the previous highest, the model updates its highest confidence and recognition result. If it meets or exceeds the preset threshold (set at 0.85 in this study), the loop terminates without further magnification, and results are output. During iteration, the magnification coefficient increases until reaching the maximum (set at seven in this study). Ultimately, the algorithm outputs the highest confidence and corresponding result. The detailed algorithm flow is presented in Algorithm 1.
| Algorithm 1: Adaptive adjustment strategy for DSTNet |
Input: ME image sequence: initial magnification factor: confidence threshold: maximum magnification factor: Output: top-1 confidence: Recognition result: Initialize:  return |
Through this adaptive adjustment mechanism, the motion magnification factor can be dynamically adjusted according to the difficulty of ME recognition task, thereby improving the accuracy of the recognition model. When dealing with challenging recognition tasks, such as cross-dataset ME recognition, it can adaptively enhance subtle motion features and fully utilize spatial and temporal information for precise recognition, thereby enhancing the model’s robustness and enabling it to better handle various complex scenarios. It is worth noting that this adaptive strategy does not increase the model’s parameters or FLOPs.
4. Experimental Results and Analysis
4.1. Datasets and Parameter Settings
Experiments were conducted on SMIC [32], CASME II [33], and SAMM [34] with 164, 246, and 136 samples respectively. Among them, SMIC is a three-class problem, while CASME II and SAMM are both five-class problem. In addition, we also conducted experiments on the dataset of the Composite Dataset Evaluation (CDE) of the Micro-Expression Grand Challenge 2019 (MEGC 2019) [35], which incorporates SMIC, CASME II, and SAMM data, totaling 442 samples in three classes.
During model training, unified parameters were used: DSTNet with a learning rate = 0.001, weight decay = 0.0005, batch size = 4, epochs = 50, Adam optimizer, and cross-entropy loss. Magnified apex frames were generated by adjusting different values to ensure that each category contains 150 samples. In the adaptive adjustment, confidence threshold = 0.85, initial = 3, and max = 7. Notably, DSTNet parameters remain unchanged when applying the adaptive strategy. The adaptive strategy is only used in the composite dataset and cross-dataset recognition.
4.2. Validation Methods and Evaluation Metrics
In this study, we addressed three types of classification problems: single dataset, composite dataset, and cross-dataset recognition. We followed ME field conventions and primarily used two cross-validation methods to evaluate recognition models [35].
The first method was Leave-One-Subject-Out (LOSO), which divides the dataset by the subjects. In each validation, one subject’s data is used as the test set, and the rest as the training set. This process cycles until all data is tested. LOSO is applicable to single and composite dataset recognition. The second method was Leave-One-Dataset-Out (LODO), where one dataset is reserved as the test set, and all others as the training set. This process repeats until each dataset is tested. LODO evaluates the model’s generalization across datasets and is used for cross-dataset recognition.
For single dataset tasks, we assessed performance using accuracy () and F1-score (). For the composite dataset tasks, MEGC 2019 requires unweighted F1-score () and unweighted average recall () [35]. For cross-dataset tasks, we adopted , , and for comparison with other methods.
4.3. Ablation Analysis
This section mainly conducts ablation experiments on the proposed motion magnification method, MDOF extraction method, and the DSTNet structure. All experiments were performed on the five-class classification task of CASME II.
4.3.1. Motion Magnification Visualization of Transfer Learning Ablation
To validate the effectiveness of our proposed transfer learning-based motion magnification method, we performed an ablation analysis on the motion magnification network regarding the use of transfer learning. As shown in Figure 4, while both motion magnification approaches successfully enhance facial muscle movements, distinct differences emerge in their magnification quality. The non-transfer-learning-based magnification (second column) results in unnatural over-magnification of facial muscle movements, distorting the subtle characteristics of MEs and even introducing artifacts (e.g., the mouth region in the surprise expression). In contrast, our transfer learning strategy—pre-trained on macro-expressions and fine-tuned on MEs—enables the motion magnification network to achieve more precise magnification (third column). This approach neither exaggerates nor misses subtle facial dynamics, effectively preserving the subtle facial patterns of MEs.

Figure 4.
Visualization comparison of motion magnification effects: (a) original apex frames; (b) magnified apex frames without transfer learning; (c) magnified apex frames with transfer learning.
4.3.2. Optical Flow Visualization of Different Methods
This study designed MDOF to characterize temporal dynamics in MEs, which is extracted via the dense optical flow method RAFT between motion-magnified apex frames and onset frames, effectively enhancing subtle motion information in MEs. To validate the effectiveness of MDOF, we compare other optical flow extraction methods. As shown in Figure 5, the original RAFT optical flow (first column), derived from the original apex and onset frames, can feature facial region motion but fails to distinguish between ME categories clearly. In contrast, the proposed MDOF (second column) effectively captures crucial muscle movements in different ME categories, such as AU5 (upper lid raiser) in surprise, AU4 (brow lowerer) and AU9 (nose wrinkler) in disgust, as well as AU12 (lip corner puller) in happiness. The sparse optical flow method (third column) demonstrates poor suppression of non-motion regions, introducing considerable noise. These results indicate that MDOF doubly optimizes ME representation by employing a more refined dense optical flow extraction method on magnified apex frames. Without substantially increasing computational cost, MDOF not only highlights motion pattern differences between categories but also suppresses irrelevant noise, thereby providing more discriminative temporal features for improving model performance.
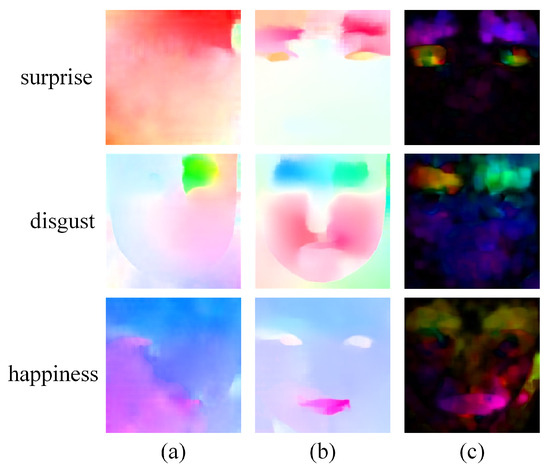
Figure 5.
Visualization comparison of optical flow fields extracted using different methods: (a) RAFT between original apex and onset frames; (b) RAFT between magnified apex and onset frames, i.e., MDOF; (c) Sparse optical flow between magnified apex and onset frames.
4.3.3. Ablation
To explore the optimal range of the factor in the motion magnification network, we feed magnified apex frames with varying degrees into the single-stream network SN for validation. As shown in Figure 6, when is set to 0, indicating no motion amplification and the use of original apex frames as input, the model’s is relatively low. As increases, there is a notable upward trend in , peaking at . However, when exceeds 7, both the and of the model decline. Therefore, we chose to expand the training dataset within the range of 3 to 7 in subsequent experiments.
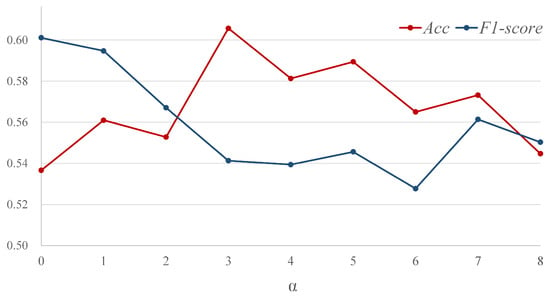
Figure 6.
Results of the magnified apex frames with different on SN, where indicates using original apex frame.
4.3.4. Input Ablation
We conducted an input ablation analysis to verify the enhancing effect of the proposed motion magnification network and MDOF on ME recognition, which served as inputs for SN and TN, respectively. In this experiment, the magnification factor was set to 3, and the experimental results are presented in Table 2.
Table 2.
Results of model input ablation.
In the first set of experiments, compared to the original apex frames, the magnified apex frames increase the model’s by approximately 7%. In the second set of experiments, using the MDOF extracted from magnified apex frames raises the to 0.6179, and the also experiences a significant improvement. The experimental results fully demonstrate that the motion magnification network based on transfer learning can effectively enhance the information of facial muscle movement states, and the designed MDOF can capture the motion trends of facial muscles evolution. These enhancements make the pattern differences of MEs more pronounced, thereby improving the recognition performance.
4.3.5. Data Balance Ablation
When employing the motion magnification network to magnify apex frames, this process can also increase the samples to balance the training dataset. As demonstrated in Section 4.3.3, in this ablation experiment, for the imbalanced dataset, we only adopted to magnify ME samples, with the sample size remaining consistent with the original dataset. For a balanced dataset, we generated magnified apex frames by setting different values () to ensure that each category contains 150 samples. The experimental results are presented in Table 3.
Table 3.
Results of data balance ablation.
Compared to training with an imbalanced dataset, using a balanced dataset to train the model reduces the gap between and . In terms of , the “magnified apex + SN” combination after data balancing achieves a 6.34% improvement over the imbalanced dataset; this improvement is even more pronounced using the “MDOF + TN” method, reaching 9.19%. The above findings suggest that the model’s recognition performance across various categories has been well improved, thereby confirming that the issue of data imbalance is effectively alleviated. Additionally, this also enables the model to learn to capture the facial muscle movements of MEs under different magnification factors, laying the foundation for subsequent adaptive magnification strategy.
4.3.6. Backbone Depth Ablation
To preserve the lightweight characteristics of DSTNet, this study employed an efficient shallow ResNet architecture for the SN and a basic CNN structure for TN. While keeping the backbone architecture fixed, we systematically investigated the impact of network depth on recognition performance. The ablation analysis validates the recognition performance of using two to four residual blocks in the SN and three to five convolutional layers in the TN. The experimental results are presented in Table 4.
Table 4.
Results of SN and TN backbone depth ablation.
The experimental results demonstrate that the model achieves optimal recognition and when SN contains three residual blocks and TN adopts three convolutional layers. Under this configuration, DSTNet maintains its lightweight advantage, requiring only 64.77 M FLOPs and 3.15 M parameters. Given our preprocessed input data (magnified apex and MDOF) specifically designed for micro-expression recognition, these shallow network architectures prove sufficient for extracting key discriminative features. The performance analysis confirms that deeper networks do not guarantee improved results, as they may induce overfitting while increasing computational demands.
4.3.7. Network Structure Ablation
In DSTNet, both the spatial and temporal networks share the same depth, with the difference lying in: the SN features residual connections to process spatial information across different scales, while the TN employs a traditional convolutional structure without residual blocks. Therefore, we designed relevant ablation experiments to demonstrate the effectiveness of the structural setup of DSTNet. All experiments used a balanced training dataset, as demonstrated in Section 4.3.5, and the experimental results are shown in Table 5.
Table 5.
Results of network structure ablation.
The experimental results indicate that the dual-stream network structure generally exhibits advantages over the single-stream network in ME recognition. Specifically, the results of the third row (“magnified apex + SN, magnified apex + TN”) show that indiscriminately inputting the same input into different types of networks may actually impair model performance. Similarly, the results of the fourth row also indicate that, although a dual-stream network structure is adopted, using MDOF as input for both networks results in an of 0.6911, which is only slightly higher than that of “MDOF + single-stream TN”. These results suggest that merely adopting a dual-stream structure is not enough to guarantee performance improvement; the selection of input data for different networks is also crucial. In the last row of experiments, namely the DSTNet proposed in this paper, the reaches its highest at 0.7398, and the also reaches its highest at 0.7424. This validates the effectiveness of the DSTNet designed for specific inputs in ME recognition.
4.4. Results Comparison with Other Methods
4.4.1. Single Dataset Recognition
The detailed comparison results of single dataset recognition are presented in Table 6. The comparison results show that DSTNet achieves the highest in the classification tasks across all three single datasets, specifically reaching 0.7245 on SMIC, 0.7424 on CASME II, and 0.7186 on SAMM. These achievements highlight the outstanding performance in recognizing various ME categories, which is particularly crucial when dealing with class-imbalanced datasets. Furthermore, DSTNet also attains of 0.7134 and 0.7426 on the SMIC and SAMM datasets, respectively, further demonstrating its superiority and reliability. Although on the CASME II dataset, DSTNet’s is slightly lower than that of GEME and AUGCN + AUFusion, this is mainly because DSTNet focuses more on improving the overall recognition rate of each category rather than solely pursuing the highest accuracy. Overall, DSTNet exhibits good performance across all datasets.
Table 6.
Results of single dataset recognition. The best results are highlighted in bold, and the second-best results are underlined.
4.4.2. Composite Dataset Recognition
The detailed comparison results for composite dataset recognition are shown in Table 7. On the CDE dataset, DSTNet outperforms others, achieving the highest of 0.7979, with 20.97% and 19.73% improvements in and over LBP-TOP, respectively. On CASME II, DSTNet also achieves the top of 0.9287 and the second of 0.9232. Compared with SelfME, although DSTNet is slightly lower in terms of , it increases the by 2.09%. Moreover, DSTNet outperforms the optical flow-based Bi-WOOF method, enhancing and by 14.82% and 12.06%, respectively. Compared to STSTNet, which also uses a multi-stream design, DSTNet improves and by 9.05% and 5.46%. On the SAMM dataset, DSTNet’s is second only to AUGCN + AUFusion. Meanwhile, it is noted that adaptive DSTNet performs slightly poorer than DSTNet overall on the CDE, CASME II, and SAMM datasets. This could be attributed to the low top-1 confidence of ME recognition models. However, on the lower-quality SMIC dataset, adaptive DSTNet shows the best performance, outperforming all other methods. This suggests that the adaptive strategy enhances model robustness with complex data, particularly benefiting subsequent cross-dataset recognition tasks.
Table 7.
Results of composite dataset recognition. The best results are highlighted in bold, and the second-best results are underlined.
4.4.3. Cross-Dataset Recognition
The cross-dataset recognition results are detailed in Table 8. Adaptive DSTNet outperforms all other methods on the SMIC and CASME II datasets in all metrics, showcasing its strong generalization and robustness. On SAMM, while adaptive DSTNet achieves a marginally lower compared to RN and micro-attention methods, it demonstrates substantially superior performance in terms of , with improvements of 7.7% and 9%, respectively. This performance discrepancy suggests that while RN and micro-attention may achieve higher due to overfitting to specific expression categories, they fail to maintain balanced recognition across all classes. In contrast, adaptive DSTNet has a more balanced performance in recognizing different categories of MEs, effectively reducing the missed and false detections. Compared to basic DSTNet, adaptive DSTNet consistently improves all evaluation metrics, validating the adaptive strategy’s effectiveness in complex data environments, especially for cross-dataset recognition.
Table 8.
Results of cross-dataset recognition. The best results are highlighted in bold, and the second-best results are underlined.
4.5. Model Comparison with Other Methods
In the field of ME recognition, previous researches often focus on improving recognition performance while overlooking the significance of model size, such as the number of parameters and computational complexity. This brings notable drawbacks: large models not only increase computational resource consumption but also limit their applicability in resource-constrained environments. To comprehensively evaluate a model’s overall performance, it is essential to consider both its recognition performance and computational efficiency. Given that some studies do not provide the original code, we replicated the codes based on the network architectures described in the literature or tested the provided trained model to measure the model’s metrics, including the number of parameters, FLOPs, and results of the CASME II dataset, with a detailed comparison presented in Table 9.
Table 9.
Results of model comparison with other methods.
The comparison results demonstrate that our proposed DSTNet and adaptive DSTNet achieved a reasonable balance between model size and recognition performance. Compared to methods with numerous parameters and complex computations, such as DSSN and ELRCN, DSTNet/adaptive DSTNet attains superior recognition results with only 3.15 M parameters and 64.77 M FLOPs. On CASME II, DSTNet/adaptive DSTNet exhibits stable recognition performance for both single-dataset and composite-dataset metrics, even surpassing other lightweight methods like micro-attention and RCN. Although STSTNet has a smaller model size than our proposed method, its performance is significantly lower. On CASME II in the composite dataset recognition, STSTNet achieves the of only 0.8382, whereas our proposed method achieves 0.9287. Furthermore, its performance in cross-dataset tests attests to its excellent generalization capability. In summary, our proposed method not only provides an efficient and lightweight solution for the field of ME recognition but also showcases the potential to achieve high-accuracy performance in practical applications.
5. Conclusions
In this study, we addressed the various issues in ME recognition by proposing targeted and feasible solutions. We designed a lightweight network named DSTNet, which is aimed at enhancing the performance of ME recognition. The motion magnification module serves as a virtual sensor enhancer to overcome physical sensor limitations, while the MDOF transforms raw sensor data into standardized spatio-temporal representations for efficient analysis. It is validated across various tasks, including single dataset, composite dataset, and cross-dataset scenarios. DSTNet exhibits efficient feature extraction capabilities, and the adaptive strategy devised in accordance with the network’s traits genuinely and effectively enhances the performance of ME recognition in complex tasks.
Addressing the challenges posed by the subtlety of movement and scarcity of data in ME recognition, we constructed a motion magnification network based on transfer learning. This network magnifies the facial muscle movements in apex frame images and introduces a magnification factor, which not only significantly enhances the facial muscle movement features closely associated with ME but also effectively expands the dataset. This method successfully overcomes the difficulties in extracting weak muscle movements from original images, achieving more precise spatial feature extraction. For brevity of duration in MEs, we applied a dense optical flow method to the onset frame and the magnified apex frame to capture the motion changes in ME sequences, i.e., MDOF. MDOF highlights the motion differences between frames, and by feeding it into the temporal stream for feature extraction, it delicately depict the subtle changes in muscle movement across frames. Combining the motion states and motion evolution features of ME facial muscle, we designed DSTNet, a dual-stream network architecture capable of simultaneously learning spatial and temporal representations to capture more discriminative information. Results on both single datasets and composite datasets demonstrate the effectiveness of DSTNet, particularly as evidenced by its , which underscores DSTNet’s exceptional performance in handling imbalanced data tasks.
To bolster the robustness of DSTNet, we also devised an adaptive strategy. For the most challenging cross-dataset recognition task in the field of ME recognition, we designed an adaptive strategy based on the top-1 confidence output from the model. The introduction of an adaptive magnification factor adjustment algorithm significantly enhances the robustness and generalization ability of the model in cross-dataset recognition tasks. Adaptive DSTNet achieves cross-dataset recognition results that surpass the state-of-the-art methods on both SMIC and CASME II. Furthermore, this simple yet effective strategy does not increase the size of recognition model and can serve as an inspiration for similar tasks.
However, it is important to acknowledge the limitations of this study. Despite the encouraging results, we obtained the facial muscle movement features of MEs in the quickest and simplest manner, and the model design is relatively lightweight, leaving room for improvement in model performance. In practical applications, the trade-off between model parameters and performance is crucial. Future work will focus on exploring alternative backbone architectures to improve model capability without compromising computational efficiency, as well as developing more sophisticated motion magnification techniques and adaptive magnification strategies to better capture subtle ME characteristics. Additionally, we aim to investigate the incorporation of multi-modal information, such as thermal imaging or non-contact physiological signals, to provide richer supplementary cues for ME recognition. Ultimately, our goal is to develop a comprehensive ME recognition system that can effectively function in practical applications.
Author Contributions
Methodology, X.L.; Software, F.C.; Validation, H.W.; Investigation, J.Z.; Writing—original draft, X.L. and J.Z.; Writing—review & editing, Y.S.; Visualization, Y.J.; Supervision, S.L. and Y.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Fundamental Research Funds for the Central Universities (SWU120083) and the Project of Chongqing Science and Technology Bureau (CSTB2023TIAD-STX0037).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data derived from public domain resources.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Li, J.; Dong, Z.; Lu, S.; Wang, S.J.; Yan, W.J.; Ma, Y.; Liu, Y.; Huang, C.; Fu, X. CAS(ME)3: A third generation facial spontaneous micro-expression database with depth information and high ecological validity. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2782–2800. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Zhang, K.; Luo, W.; Sankaranarayana, R. HTNet for micro-expression recognition. Neurocomputing 2024, 602, 128196. [Google Scholar] [CrossRef]
- Wahid, Z.; Bari, A.H.; Gavrilova, M. Human Micro-Expressions in Multimodal Social Behavioral Biometrics. Sensors 2023, 23, 8197. [Google Scholar] [CrossRef]
- Zhou, X.; Jin, K.; Shang, Y.; Guo, G. Visually interpretable representation learning for depression recognition from facial images. IEEE Trans. Affect. Comput. 2018, 11, 542–552. [Google Scholar] [CrossRef]
- Porter, S.; Ten Brinke, L. Reading between the lies: Identifying concealed and falsified emotions in universal facial expressions. Psychol. Sci. 2008, 19, 508–514. [Google Scholar] [CrossRef]
- Weinberger, S. Airport security: Intent to deceive? Nat. News 2010, 465, 412–415. [Google Scholar] [CrossRef]
- Zhao, G.; Li, X.; Li, Y.; Pietikäinen, M. Facial Micro-expressions: An overview. Proc. IEEE 2023, 111, 1215–1235. [Google Scholar] [CrossRef]
- Ranjan, R.; Patel, V.M.; Chellappa, R. Hyperface: A deep multi-task learning framework for face detection, landmark localization, pose estimation, and gender recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 121–135. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint face detection and alignment using multitask cascaded convolutional networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Oh, T.H.; Jaroensri, R.; Kim, C.; Elgharib, M.; Durand, F.; Freeman, W.T.; Matusik, W. Learning-based video motion magnification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 633–648. [Google Scholar]
- Niu, W.; Zhang, K.; Li, D.; Luo, W. Four-player GroupGAN for weak expression recognition via latent expression magnification. Knowl.-Based Syst. 2022, 251, 109304. [Google Scholar] [CrossRef]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar] [CrossRef]
- Zhou, J.; Sun, S.; Xia, H.; Liu, X.; Wang, H.; Chen, T. ULME-GAN: A generative adversarial network for micro-expression sequence generation. Appl. Intell. 2023, 54, 490–502. [Google Scholar] [CrossRef]
- Yu, J.; Zhang, C.; Song, Y.; Cai, W. ICE-GAN: Identity-Aware and Capsule-Enhanced GAN with Graph-Based Reasoning for Micro-Expression Recognition and Synthesis. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Liong, S.T.; Gan, Y.S.; Zheng, D.; Li, S.M.; Xu, H.X.; Zhang, H.Z.; Lyu, R.K.; Liu, K.H. Evaluation of the spatio-temporal features and gan for micro-expression recognition system. J. Signal Process. Syst. 2020, 92, 705–725. [Google Scholar] [CrossRef]
- Li, Y.; Huang, X.; Zhao, G. Micro-expression action unit detection with spatial and channel attention. Neurocomputing 2021, 436, 221–231. [Google Scholar] [CrossRef]
- Gan, Y.S.; Lien, S.E.; Chiang, Y.C.; Liong, S.T. LAENet for micro-expression recognition. Vis. Comput. 2024, 40, 585–599. [Google Scholar] [CrossRef]
- Liu, Y.J.; Zhang, J.K.; Yan, W.J.; Wang, S.J.; Zhao, G.; Fu, X. A main directional mean optical flow feature for spontaneous micro-expression recognition. IEEE Trans. Affect. Comput. 2015, 7, 299–310. [Google Scholar] [CrossRef]
- Xia, Z.; Hong, X.; Gao, X.; Feng, X.; Zhao, G. Spatiotemporal Recurrent Convolutional Networks for Recognizing Spontaneous Micro-Expressions. IEEE Trans. Multimed. 2020, 22, 626–640. [Google Scholar] [CrossRef]
- Xie, H.X.; Lo, L.; Shuai, H.H.; Cheng, W.H. AU-Assisted Graph Attention Convolutional Network for Micro-Expression Recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 2871–2880. [Google Scholar] [CrossRef]
- Zachary Teed, J.D. RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In Proceedings of the European Conference on Computer Vision (ICCV) Workshops, Glasgow, UK, 23–28 August 2020; pp. 402–419. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, M.; Jiao, Q.; Xu, L.; Han, B.; Li, Y.; Tan, X. Two-level spatio-temporal feature fused two-stream network for micro-expression recognition. Sensors 2024, 24, 1574. [Google Scholar] [CrossRef]
- Zhang, K.; Huang, Y.; Du, Y.; Wang, L. Facial expression recognition based on deep evolutional spatial-temporal networks. IEEE Trans. Image Process. 2017, 26, 4193–4203. [Google Scholar] [CrossRef]
- Lei, L.; Chen, T.; Li, S.; Li, J. Micro-Expression Recognition Based on Facial Graph Representation Learning and Facial Action Unit Fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 1571–1580. [Google Scholar] [CrossRef]
- Pumarola, A.; Agudo, A.; Martinez, A.M.; Sanfeliu, A.; Moreno-Noguer, F. GANimation: Anatomically-aware Facial Animation from a Single Image. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X.; Zhao, Y.; Wen, Y.; Tang, Z.; Liu, M. Facial prior guided micro-expression generation. IEEE Trans. Image Process. 2023, 33, 525–540. [Google Scholar] [CrossRef]
- Iman, M.; Arabnia, H.R.; Rasheed, K. A review of deep transfer learning and recent advancements. Technologies 2023, 11, 40. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; IEEE: New York, NY, USA, 2010; pp. 94–101. [Google Scholar] [CrossRef]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; PietikäInen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; IEEE: New York, NY, USA, 1998; pp. 200–205. [Google Scholar] [CrossRef]
- Aifanti, N.; Papachristou, C.; Delopoulos, A. The MUG facial expression database. In Proceedings of the 11th International Workshop on Image Analysis for Multimedia Interactive Services WIAMIS 10, Desenzano del Garda, Italy, 12–14 April 2010; IEEE: New York, NY, USA, 2010; pp. 1–4. [Google Scholar]
- Li, X.; Pfister, T.; Huang, X.; Zhao, G.; Pietikäinen, M. A spontaneous micro-expression database: Inducement, collection and baseline. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; IEEE: New York, NY, USA, 2013; pp. 1–6. [Google Scholar] [CrossRef]
- Yan, W.J.; Li, X.; Wang, S.J.; Zhao, G.; Liu, Y.J.; Chen, Y.H.; Fu, X. CASME II: An improved spontaneous micro-expression database and the baseline evaluation. PLoS ONE 2014, 9, e86041. [Google Scholar] [CrossRef] [PubMed]
- Davison, A.K.; Lansley, C.; Costen, N.; Tan, K.; Yap, M.H. SAMM: A spontaneous micro-facial movement dataset. IEEE Trans. Affect. Comput. 2016, 9, 116–129. [Google Scholar] [CrossRef]
- Micro-Expression Grand Challenge 2019 (MEGC 2019)-Recognition Challenge. 2019. Available online: https://facial-micro-expressiongc.github.io/MEGC2019/ (accessed on 29 April 2025).
- Xu, F.; Zhang, J.; Wang, J.Z. Microexpression identification and categorization using a facial dynamics map. IEEE Trans. Affect. Comput. 2017, 8, 254–267. [Google Scholar] [CrossRef]
- Liong, S.T.; Wong, K. Micro-expression recognition using apex frame with phase information. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; IEEE: New York, NY, USA, 2017; pp. 534–537. [Google Scholar] [CrossRef]
- Yong-Jin, L.; Bing-Jun, L.; Yu-Kun, L. Sparse MDMO: Learning a Discriminative Feature for Spontaneous Micro-Expression Recognition. IEEE Trans. Affect. Comput. 2018, 12, 254–261. [Google Scholar] [CrossRef]
- Khor, H.Q.; See, J.; Liong, S.T.; Phan, R.C.; Lin, W. Dual-stream shallow networks for facial micro-expression recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: New York, NY, USA, 2019; pp. 36–40. [Google Scholar] [CrossRef]
- Wang, C.; Peng, M.; Bi, T.; Chen, T. Micro-attention for micro-expression recognition. Neurocomputing 2020, 410, 354–362. [Google Scholar] [CrossRef]
- Nie, X.; Takalkar, M.A.; Duan, M.; Zhang, H.; Xu, M. GEME: Dual-stream multi-task GEnder-based micro-expression recognition. Neurocomputing 2021, 427, 13–28. [Google Scholar] [CrossRef]
- Feng, W.; Xu, M.; Chen, Y.; Wang, X.; Guo, J.; Dai, L.; Wang, N.; Zuo, X.; Li, X. Nonlinear deep subspace network for micro-expression recognition. In Proceedings of the 3rd Workshop on Facial Micro-Expression: Advanced Techniques for Multi-Modal Facial Expression Analysis, Ottawa, ON, Canada, 29 October 2023; pp. 1–8. [Google Scholar] [CrossRef]
- Gan, Y.S.; Liong, S.T.; Yau, W.C.; Huang, Y.C.; Tan, L.K. OFF-ApexNet on micro-expression recognition system. Signal Process. Image Commun. 2019, 74, 129–139. [Google Scholar] [CrossRef]
- Van Quang, N.; Chun, J.; Tokuyama, T. CapsuleNet for micro-expression recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Zhou, L.; Mao, Q.; Xue, L. Dual-inception network for cross-database micro-expression recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Liong, S.T.; Gan, Y.S.; See, J.; Khor, H.Q.; Huang, Y.C. Shallow triple stream three-dimensional cnn (ststnet) for micro-expression recognition. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Xia, Z.; Peng, W.; Khor, H.Q.; Feng, X.; Zhao, G. Revealing the invisible with model and data shrinking for composite-database micro-expression recognition. IEEE Trans. Image Process. 2020, 29, 8590–8605. [Google Scholar] [CrossRef]
- Zhou, L.; Mao, Q.; Huang, X.; Zhang, F.; Zhang, Z. Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition. Pattern Recognit. 2022, 122, 108275. [Google Scholar] [CrossRef]
- Wang, G.; Huang, S.; Tao, Z. Shallow multi-branch attention convolutional neural network for micro-expression recognition. Multimed. Syst. 2023, 29, 1967–1980. [Google Scholar] [CrossRef]
- Fan, X.; Chen, X.; Jiang, M.; Shahid, A.R.; Yan, H. SelfME: Self-supervised motion learning for micro-expression recognition. In Proceedings of the the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 13834–13843. [Google Scholar]
- Yap, M.H.; See, J.; Hong, X.; Wang, S.J. Facial micro-expressions grand challenge 2018 summary. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: New York, NY, USA, 2018; pp. 675–678. [Google Scholar] [CrossRef]
- Talluri, K.K.; Fiedler, M.A.; Al-Hamadi, A. Deep 3D convolutional neural network for facial Micro-expression analysis from video images. Appl. Sci. 2022, 12, 11078. [Google Scholar] [CrossRef]
- Peng, M.; Wu, Z.; Zhang, Z.; Chen, T. From macro to micro expression recognition: Deep learning on small datasets using transfer learning. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: New York, NY, USA, 2018; pp. 657–661. [Google Scholar] [CrossRef]
- Zhang, M.; Huan, Z.; Shang, L. Micro-expression recognition using micro-variation boosted heat areas. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision (PRCV), Nanjing, China, 16–18 October 2020; Springer: Cham, Switzerland, 2020; pp. 531–543. [Google Scholar] [CrossRef]
- Zong, Y.; Zheng, W.; Hong, X.; Tang, C.; Cui, Z.; Zhao, G. Cross-database micro-expression recognition: A benchmark. In Proceedings of the 2019 on International Conference on Multimedia Retrieval, Ottawa, ON, Canada, 10–13 June 2019; pp. 354–363. [Google Scholar] [CrossRef]
- Peng, M.; Wang, C.; Bi, T.; Shi, Y.; Zhou, X.; Chen, T. A novel apex-time network for cross-dataset micro-expression recognition. In Proceedings of the 2019 8th International Conference on Affective Computing and Intelligent Interaction (ACII), Cambridge, UK, 3–6 September 2019; IEEE: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Takalkar, M.A.; Thuseethan, S.; Rajasegarar, S.; Chaczko, Z.; Xu, M.; Yearwood, J. LGAttNet: Automatic micro-expression detection using dual-stream local and global attentions. Knowl.-Based Syst. 2021, 212, 106566. [Google Scholar] [CrossRef]
- Chen, Z.; Lu, C.; Zhou, F.; Zong, Y. TKRM: Learning a Transfer Kernel Regression Model for Cross-Database Micro-Expression Recognition. Mathematics 2023, 11, 918. [Google Scholar] [CrossRef]
- Wang, H.; Zhou, J.; Liu, X.; Jia, Y.; Chen, T. A cross-database micro-expression recognition framework based on meta-learning. Appl. Intell. 2025, 55, 58. [Google Scholar] [CrossRef]
- Khor, H.Q.; See, J.; Phan, R.C.W.; Lin, W. Enriched long-term recurrent convolutional network for facial micro-expression recognition. In Proceedings of the 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), Xi’an, China, 15–19 May 2018; IEEE: New York, NY, USA, 2018; pp. 667–674. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).