
Bridging Domain Gaps in Computational Pathology: A Comparative Study of Adaptation Strategies
 , , ,
, , ,  , ,
, , 
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
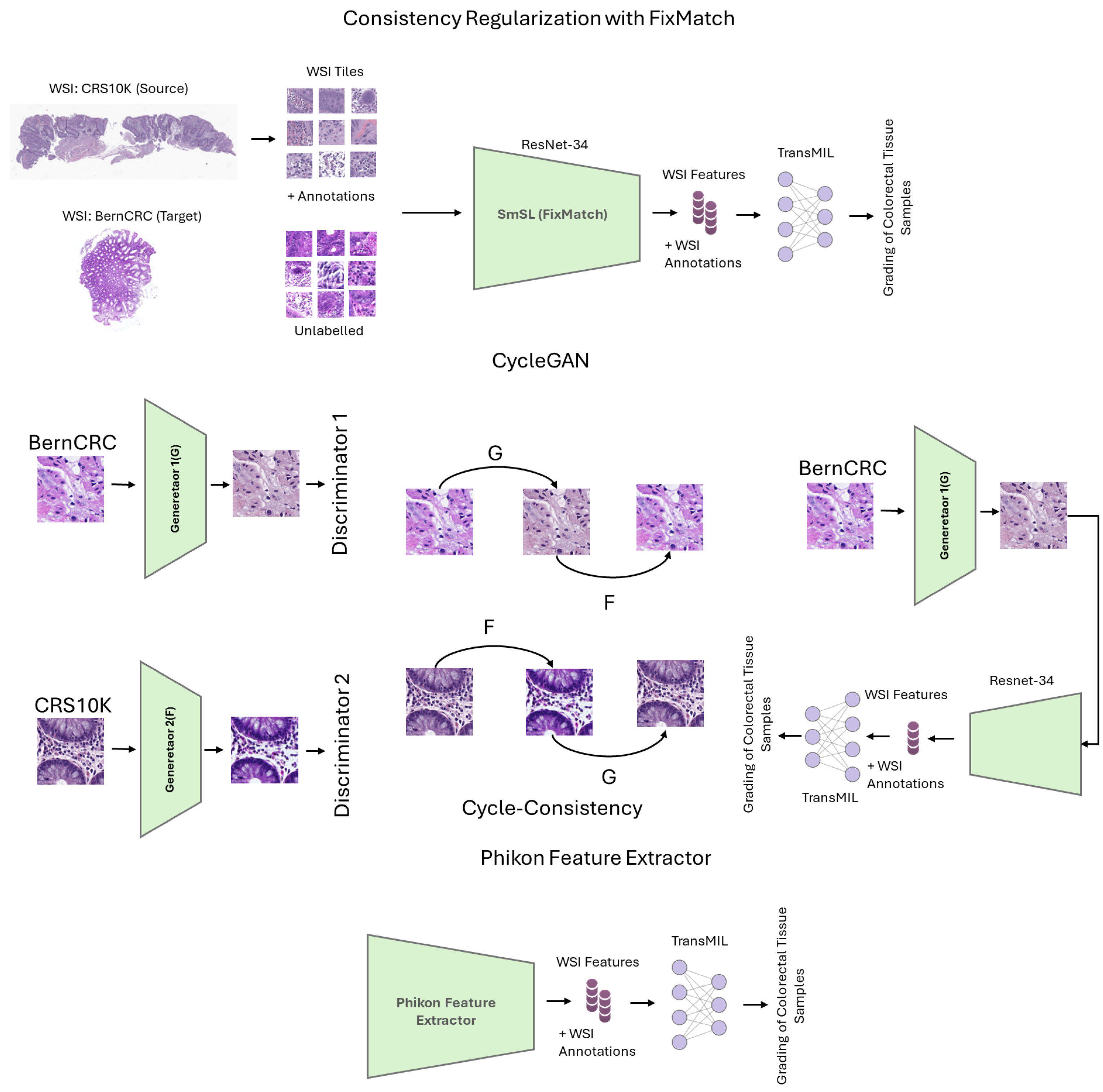
3.1. Domain Adaptation with FixMatch
3.2. Domain Transformation Using CycleGAN
3.3. Self-Supervised Feature Extraction
3.4. Evaluation Protocol: Grading of Colorectal Biopsies and Polypectomies
4. Experimental Details
4.1. Datasets
4.2. Data Pre-Processing
4.3. Data Augmentation
4.4. Training
4.4.1. Tile-Level Feature Learning
4.4.2. CycleGAN
4.4.3. TransMIL
4.5. Evaluation Metrics
4.5.1. Quadratic Weighted Kappa
4.5.2. Accuracy
4.5.3. Sensitivity
4.5.4. Specificity
4.5.5. Precision
4.5.6. F1 Score
4.5.7. Area Under the Receiver Operating Characteristic Curve (AUC)
5. Results
5.1. Source Domain Results
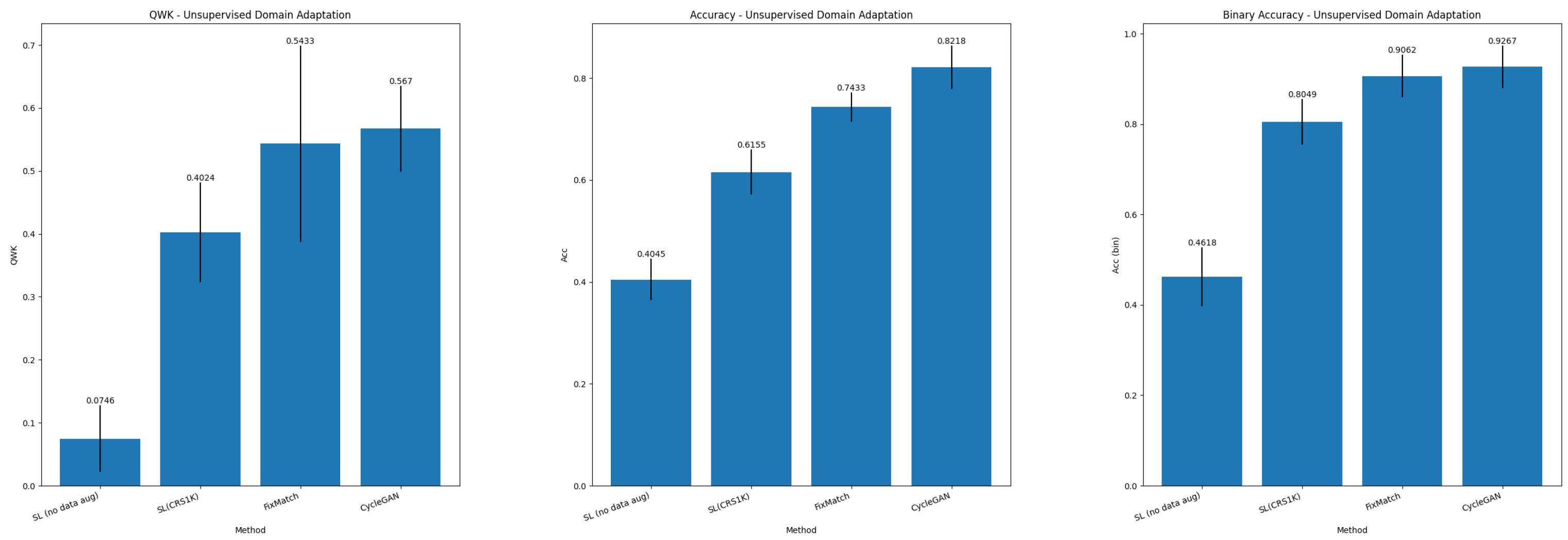
5.2. Unsupervised Domain Adaptation
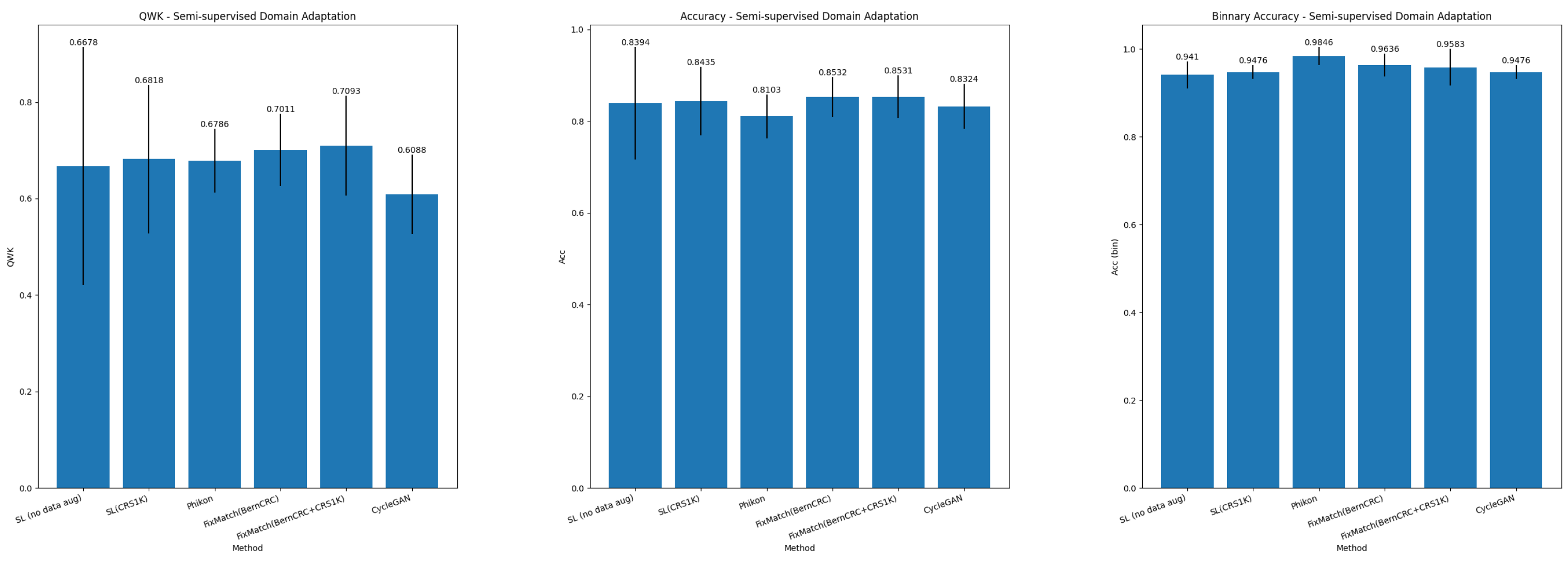
5.3. Semi-Supervised Domain Adaptation
6. Discussion
6.1. Unsupervised Domain Adaptation
6.2. Semi-Supervised Domain Adaptation
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| Acc | Accuracy |
| AUC | Area Under the Receiver Operating Characteristic Curve |
| CPath | Computational Pathology |
| DA | Domain Adaptation |
| DL | Deep Learning |
| H&E | Hematoxylin and Eosin |
| HG | High-Grade |
| IID | Independent and Identically Distributed |
| LG | Low-Grade |
| MIL | Multiple Instance Learning |
| ML | Machine Learning |
| NNeo | Non-neoplastic |
| Prec | Precision |
| QWK | Quadratic Weighted Kappa |
| Sens | Sensitivity |
| SL | Supervised Learning |
| SmSL | Semi-supervised Learning |
| Spec | Specificity |
| SSDA | Semi-supervised Domain Adaptation |
| UDA | Unsupervised Domain Adaptation |
| WSI | Whole Slide Image |
| WSL | Weakly Supervised Learning |
References
- Bilal, M.; Jewsbury, R.; Wang, R.; AlGhamdi, H.M.; Asif, A.; Eastwood, M.; Rajpoot, N. An aggregation of aggregation methods in computational pathology. Med. Image Anal. 2023, 88, 102885. [Google Scholar] [CrossRef] [PubMed]
- Shao, Z.; Bian, H.; Chen, Y.; Wang, Y.; Zhang, J.; Ji, X.; Zhang, Y. TransMIL: Transformer based Correlated Multiple Instance Learning for Whole Slide Image Classification. In Proceedings of the NeurIPS, online, 6–14 December 2021; pp. 2136–2147. [Google Scholar]
- Li, B.; Li, Y.; Eliceiri, K.W. Dual-Stream Multiple Instance Learning Network for Whole Slide Image Classification With Self-Supervised Contrastive Learning. Computer Vision Foundation/IEEE. In Proceedings of the CVPR, Nashville, TN, USA, 20–25 June 2021; pp. 14318–14328. [Google Scholar]
- Chen, R.J.; Chen, C.; Li, Y.; Chen, T.Y.; Trister, A.D.; Krishnan, R.G.; Mahmood, F. Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning. In Proceedings of the CVPR, New Orleans, LA, USA, 18–24 June 2022; pp. 16123–16134. [Google Scholar]
- Kang, M.; Song, H.; Park, S.; Yoo, D.; Pereira, S. Benchmarking Self-Supervised Learning on Diverse Pathology Datasets. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 3344–3354. [Google Scholar]
- Wang, X.; Yang, S.; Zhang, J.; Wang, M.; Zhang, J.; Yang, W.; Huang, J.; Han, X. Transformer-based unsupervised contrastive learning for histopathological image classification. Med. Image Anal. 2022, 81, 102559. [Google Scholar] [CrossRef] [PubMed]
- Ciga, O.; Xu, T.; Martel, A.L. Self supervised contrastive learning for digital histopathology. Mach. Learn. Appl. 2022, 7, 100198. [Google Scholar] [CrossRef]
- Srinidhi, C.L.; Kim, S.W.; Chen, F.; Martel, A.L. Self-supervised driven consistency training for annotation efficient histopathology image analysis. Med. Image Anal. 2022, 75, 102256. [Google Scholar] [CrossRef]
- Neto, P.C.; Montezuma, D.; Oliveira, S.P.; Oliveira, D.; Fraga, J.; Monteiro, A.; Monteiro, J.; Ribeiro, L.; Gonçalves, S.; Reinhard, S.; et al. An interpretable machine learning system for colorectal cancer diagnosis from pathology slides. Npj Precis. Oncol. 2024, 8, 56. [Google Scholar] [CrossRef]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.; Cubuk, E.D.; Kurakin, A.; Li, C. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence. In Proceedings of the NeurIPS, online, 6–12 December 2020. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Filiot, A.; Ghermi, R.; Olivier, A.; Jacob, P.; Fidon, L.; Mac Kain, A.; Saillard, C.; Schiratti, J.B. Scaling Self-Supervised Learning for Histopathology with Masked Image Modeling. medRxiv 2023, 2023-07. [Google Scholar]
- Cortes, C.; Mansour, Y.; Mohri, M. Learning Bounds for Importance Weighting. In NIPS; Curran Associates, Inc.: Newry, UK, 2010; pp. 442–450. [Google Scholar]
- Zhao, P.; Wang, W.; Lu, Y.; Liu, H.; Yao, S. Transfer robust sparse coding based on graph and joint distribution adaption for image representation. Knowl. Based Syst. 2018, 147, 1–11. [Google Scholar] [CrossRef]
- Courty, N.; Flamary, R.; Tuia, D.; Rakotomamonjy, A. Optimal Transport for Domain Adaptation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1853–1865. [Google Scholar] [CrossRef]
- Ferreira, P.M.; Pernes, D.; Rebelo, A.; Cardoso, J.S. DeSIRe: Deep Signer-Invariant Representations for Sign Language Recognition. IEEE Trans. Syst. Man. Cybern. Syst. 2021, 51, 5830–5845. [Google Scholar] [CrossRef]
- Zhao, H.; des Combes, R.T.; Zhang, K.; Gordon, G.J. On Learning Invariant Representations for Domain Adaptation. In Proceedings of the Proceedings of Machine Learning Research, ICML, PMLR, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 7523–7532. [Google Scholar]
- Pernes, D.; Cardoso, J.S. Tackling unsupervised multi-source domain adaptation with optimism and consistency. Expert Syst. Appl. 2022, 194, 116486. [Google Scholar] [CrossRef]
- Berthelot, D.; Roelofs, R.; Sohn, K.; Carlini, N.; Kurakin, A. Adamatch: A unified approach to semi-supervised learning and domain adaptation. arXiv 2021, arXiv:2106.04732. [Google Scholar]
- Ren, J.; Hacihaliloglu, I.; Singer, E.A.; Foran, D.J.; Qi, X. Adversarial Domain Adaptation for Classification of Prostate Histopathology Whole-Slide Images. In Lecture Notes in Computer Science, Proceedings of the MICCAI (2), Granada, Spain, 16–20 September 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11071, pp. 201–209. [Google Scholar]
- Koohbanani, N.A.; Unnikrishnan, B.; Khurram, S.A.; Krishnaswamy, P.; Rajpoot, N.M. Self-Path: Self-Supervision for Classification of Pathology Images With Limited Annotations. IEEE Trans. Med. Imaging 2021, 40, 2845–2856. [Google Scholar] [CrossRef] [PubMed]
- Abbet, C.; Studer, L.; Fischer, A.; Dawson, H.; Zlobec, I.; Bozorgtabar, B.; Thiran, J. Self-rule to multi-adapt: Generalized multi-source feature learning using unsupervised domain adaptation for colorectal cancer tissue detection. Med. Image Anal. 2022, 79, 102473. [Google Scholar] [CrossRef] [PubMed]
- Marini, N.; Otalora, S.; Wodzinski, M.; Tomassini, S.; Dragoni, A.F.; Marchand-Maillet, S.; Morales, J.P.D.; Duran-Lopez, L.; Vatrano, S.; Müller, H.; et al. Data-driven color augmentation for H&E stained images in computational pathology. J. Pathol. Inform. 2023, 14, 100183. [Google Scholar] [CrossRef]
- de Bel, T.; Bokhorst, J.M.; van der Laak, J.; Litjens, G. Residual cyclegan for robust domain transformation of histopathological tissue slides. Med. Image Anal. 2021, 70, 102004. [Google Scholar] [CrossRef]
- Runz, M.; Rusche, D.; Schmidt, S.; Weihrauch, M.R.; Hesser, J.; Weis, C.A. Normalization of HE-stained histological images using cycle consistent generative adversarial networks. Diagn. Pathol. 2021, 16, 71. [Google Scholar] [CrossRef]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The Cancer Imaging Archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef]
- Kirk, S.; Lee, Y.; Sadow, C.; Levine, S.; Roche, C.; Bonaccio, E.; Filiippini, J. Radiology Data from The Cancer Genome Atlas Colon Adenocarcinoma [TCGA-COAD] Collection. The Cancer Imaging Archive. 2016. Available online: https://www.cancerimagingarchive.net/collection/tcga-coad/ (accessed on 29 May 2020).
- Zhou, J.; Wei, C.; Wang, H.; Shen, W.; Xie, C.; Yuille, A.L.; Kong, T. Image BERT Pre-training with Online Tokenizer. In Proceedings of the ICLR, online, 25 April 2022; Available online: https://arxiv.org/abs/2111.07832 (accessed on 25 April 2022).
- Oliveira, S.P.; Neto, P.C.; Fraga, J.; Montezuma, D.; Monteiro, A.; Monteiro, J.; Ribeiro, L.; Gonçalves, S.; Pinto, I.M.; Cardoso, J.S. CAD systems for colorectal cancer from WSI are still not ready for clinical acceptance. Sci. Rep. 2021, 11, 14358. [Google Scholar] [CrossRef]
- Neto, P.C.; Oliveira, S.P.; Montezuma, D.; Fraga, J.; Monteiro, A.; Ribeiro, L.; Gonçalves, S.; Pinto, I.M.; Cardoso, J.S. iMIL4PATH: A semi-supervised interpretable approach for colorectal whole-slide images. Cancers 2022, 14, 2489. [Google Scholar] [CrossRef]
- Tellez, D.; Litjens, G.; Bándi, P.; Bulten, W.; Bokhorst, J.; Ciompi, F.; van der Laak, J. Quantifying the effects of data augmentation and stain color normalization in convolutional neural networks for computational pathology. Med. Image Anal. 2019, 58, 101544. [Google Scholar] [CrossRef]
- de La Torre, J.; Puig, D.; Valls, A. Weighted kappa loss function for multi-class classification of ordinal data in deep learning. Pattern Recognit. Lett. 2018, 105, 144–154. [Google Scholar] [CrossRef]
- Zhang, M.R.; Lucas, J.; Ba, J.; Hinton, G.E. Lookahead Optimizer: K steps forward, 1 step back. In Proceedings of the NeurIPS, Vancouver, Canada, 8–14 December 2019; pp. 9593–9604. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the Variance of the Adaptive Learning Rate and Beyond. In Proceedings of the ICLR, Addis Ababa, Ethiopia, 30 April 2020; Available online: https://iclr.cc/virtual_2020/poster_rkgz2aEKDr.html (accessed on 30 April 2020).
- Graham, S.; Vu, Q.D.; Jahanifar, M.; Raza, S.E.A.; Minhas, F.; Snead, D.; Rajpoot, N. One model is all you need: Multi-task learning enables simultaneous histology image segmentation and classification. Med. Image Anal. 2023, 83, 102685. [Google Scholar] [CrossRef] [PubMed]
- Yu, X.; Liang, X.; Zhou, Z.; Zhang, B. Multi-task learning for hand heat trace time estimation and identity recognition. Exp. Syst. Appl. 2014, 255, 124551. [Google Scholar] [CrossRef]
- Chen, R.J.; Lu, M.Y.; Williamson, D.F.K.; Chen, T.Y.; Lipkova, J.; Noor, Z.; Shaban, M.; Shady, M.; Williams, M.; Joo, B.; et al. Pan-cancer integrative histology-genomic analysis via multimodal deep learning. Cancer Cell 2022, 40, 865–878.e6. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Transform | Confounding Factor(s) | Hyperparameters |
|---|---|---|
| Hue Shift | Staining | shift limits |
| Contrast Shift | Staining/Whole-slide scanner | shift limits |
| Saturation Shift | Staining/Whole-slide scanner | shift limits |
| HED Jitter | Staining | |
| Flips (Horizontal/Vertical) | Viewpoint | - |
| Rotation | Viewpoint | limits = |
| Scaling | Whole-slide scanner | limits = |
| Gaussian Blur | Whole-slide scanner | max kernel size = 15, limits = |
| Gaussian Noise | Whole-slide scanner |
| Method | MIL Train/Val Set | QWK | Acc | AUC (NNeo vs. Rest) | AUC (LG vs. Rest) | AUC (HG vs. Rest) |
|---|---|---|---|---|---|---|
| SL (no data aug) | CRS1K | 0.8759 | 0.8919 | 0.9911 | 0.9627 | 0.9661 |
| SL (CRS1K) | CRS1K | 0.8977 | 0.9097 | 0.9955 | 0.9707 | 0.9780 |
| FixMatch | CRS1K | 0.9120 ± 0.0096 | 0.9222 ± 0.0052 | 0.9956 ± 0.0011 | 0.9768 ± 0.0021 | 0.9815 ± 0.0031 |
| FixMatch | BernCRC+CRS1K | 0.9189 ± 0.0086 | 0.9289 ± 0.0060 | 0.9953 ± 0.0006 | 0.9781 ± 0.0016 | 0.9834 ± 0.0011 |
| Method | Train/Val set | Acc (Bin) | Sens | Spec | Prec | F1 |
|---|---|---|---|---|---|---|
| SL (no data aug) | CRS1K | 0.9688 | 0.9819 | 0.9157 | 0.9792 | 0.9464 |
| SL (CRS1K) | CRS1K | 0.9744 | 0.9847 | 0.9326 | 0.9833 | 0.9573 |
| FixMatch | CRS1K | 0.9792 ± 0.0044 | 0.9864 ± 0.0027 | 0.9506 ± 0.0157 | 0.9877 ± 0.0038 | 0.9688 ± 0.0100 |
| FixMatch | BernCRC+CRS1K | 0.9810 ± 0.0028 | 0.9878 ± 0.0010 | 0.9539 ± 0.0120 | 0.9886 ± 0.0030 | 0.9709 ± 0.0076 |
| FID BernCRC (Target) Transformed—CRS10K (Source) | FID BernCRC (Target)—crs10k (Source) |
|---|---|
| 9.9940 | 21.2732 |
| Method | MIL Train/Val Set | QWK | Acc | AUC (NNeo vs. Rest) | AUC (LG vs. Rest) | AUC (HG vs. Rest) |
|---|---|---|---|---|---|---|
| SL (no data aug) | CRS1K | 0.0746 ± 0.0529 | 0.4045 ± 0.0409 | 0.7034 ± 0.0800 | 0.5593 ± 0.0712 | 0.3055 ± 0.0433 |
| SL (CRS1K) | CRS1K | 0.4024 ± 0.0792 | 0.6155 ± 0.0443 | 0.9302 ± 0.0343 | 0.8025 ± 0.0793 | 0.7159 ± 0.1220 |
| FixMatch | CRS1K | 0.5433 ± 0.1561 | 0.7433 ± 0.0288 | 0.9607 ± 0.0288 | 0.8330 ± 0.0887 | 0.8187 ± 0.1128 |
| CycleGAN | CRS1K | 0.5670 ± 0.0685 | 0.8218 ± 0.0424 | 0.9748 ± 0.0091 | 0.8654 ± 0.0668 | 0.7435 ± 0.0814 |
| Method | MIL Train/Val Set | Acc (bin) | Sens | Spec | Prec | F1 |
|---|---|---|---|---|---|---|
| SL (no data aug) | CRS1K | 0.4618 ± 0.0649 | 0.4000 ± 0.0895 | 0.8333 ± 0.1491 | 0.9389 ± 0.0560 | 0.8797 ± 0.1084 |
| SL (CRS1K) | CRS1K | 0.8049 ± 0.0502 | 0.7835 ± 0.0630 | 0.9333 ± 0.0817 | 0.9856 ± 0.0177 | 0.9576 ± 0.0519 |
| FixMatch | CRS1K | 0.9062 ± 0.0472 | 0.9265 ± 0.0558 | 0.8000 ± 0.2667 | 0.9650 ± 0.04608 | 0.8529 ± 0.2030 |
| CycleGAN | CRS1K | 0.9267 ± 0.0473 | 0.91362 ± 0.0564 | 1 ± 0 | 1 ± 0 | 1 ± 0 |
| Method | MIL Train/Val Set | QWK | Acc | AUC (NNeo vs. Rest) | AUC (LG vs. Rest) | AUC (HG vs. Rest) |
|---|---|---|---|---|---|---|
| SL (no data aug) | BernCRC | 0.6678 ± 0.2469 | 0.8394 ± 0.1228 | 0.9277 ± 0.0434 | 0.8236 ± 0.1248 | 0.8450 ± 0.1641 |
| SL (CRS1K) | BernCRC | 0.6816 ± 0.1541 | 0.8435 ± 0.0747 | 0.98662 ± 0.0107 | 0.8238 ± 0.1005 | 0.7767 ± 0.1707 |
| Phikon | BernCRC | 0.6786 ± 0.0657 | 0.8103 ± 0.0476 | 0.9949 ± 0.0078 | 0.8793 ± 0.0287 | 0.8283 ± 0.0395 |
| FixMatch | BernCRC | 0.7011 ± 0.0748 | 0.8532 ± 0.0431 | 0.9906 ± 0.0086 | 0.8503 ± 0.0630 | 0.8181 ± 0.0645 |
| FixMatch | BernCRC+CRS1K | 0.7093 ± 0.1037 | 0.8531 ± 0.0464 | 0.9865 ± 0.0145 | 0.8466 ± 0.0484 | 0.8241 ± 0.0573 |
| CycleGAN | BernCRC | 0.6088 ± 0.0828 | 0.8324 ± 0.0488 | 0.9914 ± 0.0095 | 0.8642 ± 0.0754 | 0.8071 ± 0.1150 |
| Method | MIL Train/Val Set | Acc (Bin) | Sens | Spec | Prec | F1 |
|---|---|---|---|---|---|---|
| SL (no data aug) | BernCRC | 0.9410 ± 0.0312 | 0.9812 ± 0.0375 | 0.7000 ± 0.1265 | 0.9523 ± 0.0218 | 0.8016 ± 0.0954 |
| SL (CRS1K) | BernCRC | 0.9476 ± 0.0158 | 0.9691 ± 0.0198 | 0.8201 ± 0.1066 | 0.9699 ± 0.0186 | 0.8860 ± 0.0699 |
| Phikon | BernCRC | 0.9846 ± 0.0205 | 0.9939 ± 0.0121 | 0.9333 ± 0.0817 | 0.9881 ± 0.0146 | 0.9586 ± 0.0507 |
| FixMatch | BernCRC | 0.9636 ± 0.0262 | 0.9814 ± 0.0249 | 0.8600 ± 0.1272 | 0.9763 ± 0.0221 | 0.9108 ± 0.0828 |
| FixMatch | BernCRC+CRS1K | 0.9583 ± 0.0419 | 0.9691 ± 0.0275 | 0.9000 ± 0.1333 | 0.9814 ± 0.0245 | 0.9351 ± 0.0875 |
| CycleGAN | BernCRC | 0.9476 ± 0.0158 | 0.9629 ± 0.0230 | 0.8600 ± 0.1272 | 0.9761 ± 0.0217 | 0.9107 ± 0.0826 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nunes, J.D.; Montezuma, D.; Oliveira, D.; Pereira, T.; Zlobec, I.; Pinto, I.M.; Cardoso, J.S. Bridging Domain Gaps in Computational Pathology: A Comparative Study of Adaptation Strategies. Sensors 2025, 25, 2856. https://doi.org/10.3390/s25092856
Nunes JD, Montezuma D, Oliveira D, Pereira T, Zlobec I, Pinto IM, Cardoso JS. Bridging Domain Gaps in Computational Pathology: A Comparative Study of Adaptation Strategies. Sensors. 2025; 25(9):2856. https://doi.org/10.3390/s25092856
Chicago/Turabian StyleNunes, João D., Diana Montezuma, Domingos Oliveira, Tania Pereira, Inti Zlobec, Isabel Macedo Pinto, and Jaime S. Cardoso. 2025. "Bridging Domain Gaps in Computational Pathology: A Comparative Study of Adaptation Strategies" Sensors 25, no. 9: 2856. https://doi.org/10.3390/s25092856
APA StyleNunes, J. D., Montezuma, D., Oliveira, D., Pereira, T., Zlobec, I., Pinto, I. M., & Cardoso, J. S. (2025). Bridging Domain Gaps in Computational Pathology: A Comparative Study of Adaptation Strategies. Sensors, 25(9), 2856. https://doi.org/10.3390/s25092856