
Semantic-Aware Remote Sensing Change Detection with Multi-Scale Cross-Attention




Abstract
1. Introduction
- (1)
- Multi-scale feature extraction mechanism: We introduce a multi-scale feature extraction mechanism, which achieves an effective fusion of image information among multiple scales; thus, the model’s effectiveness in capturing image details is enhanced.
- (2)
- Cross-attention module: This module improves the model’s ability to understand semantic information. In this way, the model can better recognize the key change parts of the image.
- (3)
- Experimental validation: Our experiments are conducted on three public datasets. The results show that the algorithm proposed in this paper outperforms some current representative change detection algorithms in several key performance metrics, which validates the effectiveness of our method.
2. Methods
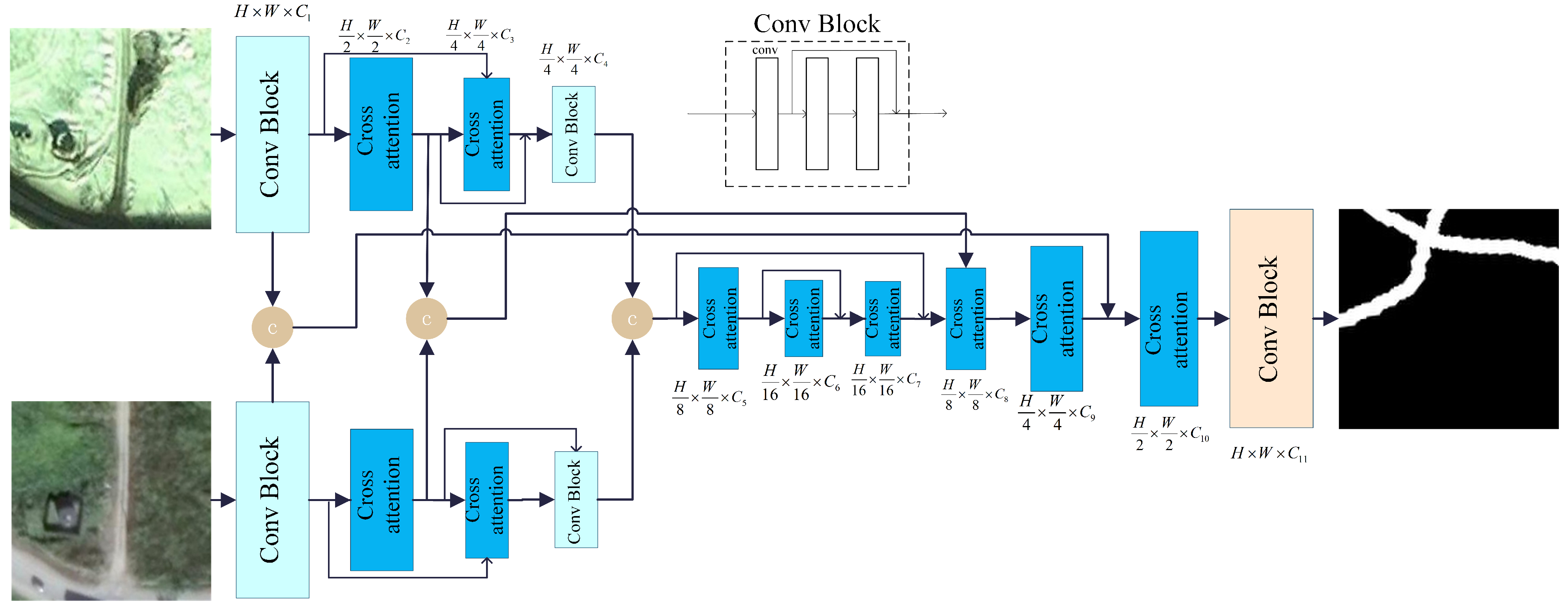
2.1. Network Structure
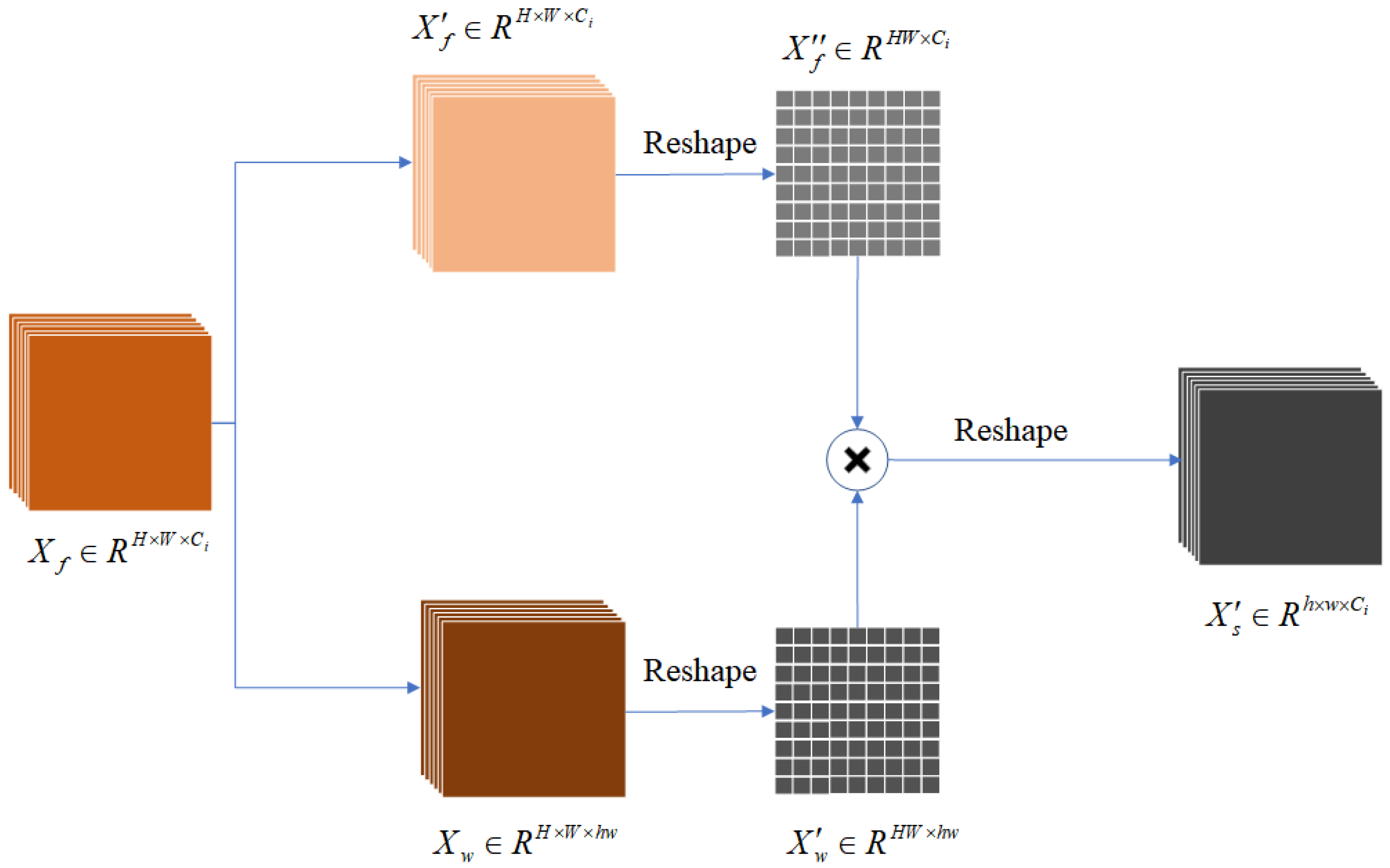
2.2. Semantic Generation Module
2.3. Cross-Attention
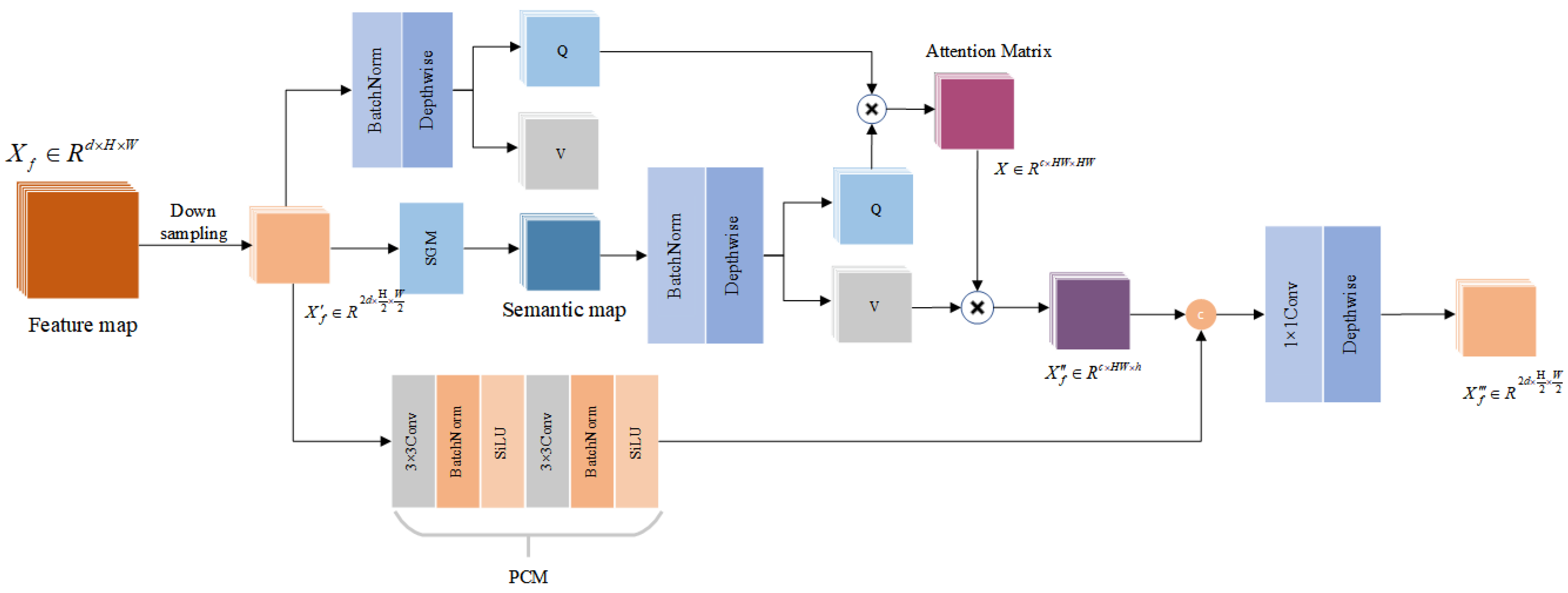
2.4. Loss Function
3. Experiments
3.1. Datasets
- CDD [29]: The CDD dataset, collected from Google Earth and consisting of 16,000 remote sensing image pairs, includes a variety of change scenarios ranging from synthetic images with no or minor relative object movement to real-world scenes exhibiting seasonal variations. The image size is 256 × 256. The dataset is divided into a training set containing 10,000 images and a validation set of 3000 images.
- LEVIR-CD [30]: This dataset comes from 20 different areas of several cities in Texas, USA, which is a large remote sensing building change detection dataset, including houses, apartments, garages, and other types of buildings. The image size is 1024 × 1024.
- SYSU-CD [31]: This dataset contains 20,000 pairs of 0.5 m aerial images with a size of 256 × 256, which were taken in Hong Kong between 2007 and 2014. The classes included in the dataset are recently built buildings, suburban expansion, changes in plantings, and road expansion.
3.2. Baselines
3.3. Metrics
3.4. Comparison Experiments
3.4.1. Results Analysis on CDD Datasets
3.4.2. Results Analysis on LEVIR-CD Datasets
3.4.3. Results Analysis on SYSU-CD Datasets
3.5. Ablation Study
3.6. Impact of Input Noise and Model Robustness
3.7. Visualization and Interpretability of Cross-Attention Mechanism
3.8. Generalization and Overfitting Mitigation
- Data Augmentation: To increase data diversity and reduce the risk of overfitting, we employ various data augmentation techniques during training, including random horizontal and vertical flips, rotations, color jittering, and scaling. These augmentations simulate different spatial arrangements and lighting conditions, helping the model to generalize beyond the training distribution.
- Dropout Regularization: Dropout layers are incorporated within the attention modules to prevent the co-adaptation of neurons and reduce reliance on specific feature patterns. This regularization technique encourages the model to learn more robust, distributed representations, thereby improving its generalizability.
- Semantic Abstraction in Cross-Attention: The semantic map projection embedded in the cross-attention module allows the model to operate on high-level abstractions rather than raw pixel differences. This semantic-level reasoning helps the model to identify meaningful changes across different domains and reduces the risk of overfitting to low-level, domain-specific noise.
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Carvalho, O.A., Jr.; Guimarães, R.F.; Gillespie, A.R.; Silva, N.C.; Gomes, R.A.T. A New Approach to Change Vector Analysis Using Distance and Similarity Measures. Remote Sens. 2011, 3, 2473–2493. [Google Scholar] [CrossRef]
- Celik, T. Unsupervised Change Detection in Satellite Images Using Principal Component Analysis and k-Means Clustering. IEEE Geosci. Remote Sens. Lett. 2009, 6, 772–776. [Google Scholar] [CrossRef]
- Nielsen, A.A.; Müller, A.; Plads, R.P. Change detection by the MAD method in hyperspectral image data. In Proceedings of the the 3rd EARSeL Workshop on Imaging Spectroscopy, Oberpfaffenhofen, Germany, 13–16 May 2003. [Google Scholar]
- Hao, M.; Zhang, H.; Shi, W.; Deng, K. Unsupervised change detection using fuzzy c-means and MRF from remotely sensed images. Remote Sens. Lett. 2013, 4, 1185–1194. [Google Scholar] [CrossRef]
- Malila, W.A. Change Vector Analysis: An Approach for Detecting Forest Changes with Landsat. Change 1980, 1, 1. [Google Scholar]
- Li, H.; Qi, A.; Chen, H.; Chen, S.; Zhao, D. HSIAO Framework in Feature Selection for Hyperspectral Remote Sensing Images Based on Jeffries-Matusita Distance. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5101121. [Google Scholar] [CrossRef]
- Touazi, A.; Bouchaffra, D. A k-Nearest Neighbor approach to improve change detection from remote sensing: Application to optical aerial images. In Proceedings of the 2015 15th International Conference on Intelligent Systems Design and Applications (ISDA), Marrakech, Morocco, 14–16 December 2015; pp. 98–103. [Google Scholar] [CrossRef]
- Nemmour, H.; Chibani, Y. Multiple support vector machines for land cover change detection: An application for mapping urban extensions. ISPRS J. Photogramm. Remote Sens. 2006, 61, 125–133. [Google Scholar] [CrossRef]
- Volpi, M.; Tuia, D.; Bovolo, F.; Kanevski, M.; Bruzzone, L. Supervised change detection in VHR images using contextual information and support vector machines. Int. J. Appl. Earth Obs. Geoinf. 2013, 20, 77–85. [Google Scholar] [CrossRef]
- Liu, J.; Gong, M.; Zhao, J.; Li, H.; Jiao, L. Difference representation learning using stacked restricted Boltzmann machines for change detection in SAR images. Soft Comput. 2014, 20, 4645–4657. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. CoRR 2014, abs/1409.1556. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Medsker, L.; Jain, L.C. Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999. [Google Scholar]
- Du, B.; Ru, L.; Wu, C.; Zhang, L. Unsupervised Deep Slow Feature Analysis for Change Detection in Multi-Temporal Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9976–9992. [Google Scholar] [CrossRef]
- Li, Q.; Gong, H.; Dai, H.; Li, C.; He, Z.; Wang, W. Unsupervised Hyperspectral Image Change Detection via Deep Learning Self-Generated Credible Labels. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2021, 14, 9012–9024. [Google Scholar] [CrossRef]
- Wang, L.; Wang, L.; Wang, Q.; Atkinson, P.M. SSA-SiamNet: Spectral–Spatial-Wise Attention-Based Siamese Network for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5510018. [Google Scholar] [CrossRef]
- Yang, Y.; Qu, J.; Xiao, S.; Dong, W.; Li, Y.; Du, Q. A Deep Multiscale Pyramid Network Enhanced with Spatial–Spectral Residual Attention for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5525513. [Google Scholar] [CrossRef]
- Fang, Y.; Sun, L.; Zheng, Y.; Wu, Z. Deformable Convolution-Enhanced Hierarchical Transformer with Spectral-Spatial Cluster Attention for Hyperspectral Image Classification. IEEE Trans. Image Process. 2025, 34, 701–716. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Wang, L.; Cheng, S.; Li, Y. SwinSUNet: Pure Transformer Network for Remote Sensing Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5224713. [Google Scholar] [CrossRef]
- Bandara, W.G.C.; Patel, V.M. A Transformer-Based Siamese Network for Change Detection. In Proceedings of the IGARSS 2022—2022 IEEE International Geoscience and Remote Sensing Symposium, Kuala Lumpur, Malaysia, 17–22 July 2022; pp. 207–210. [Google Scholar] [CrossRef]
- Chen, H.; Qi, Z.; Shi, Z. Remote Sensing Image Change Detection with Transformers. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5607514. [Google Scholar] [CrossRef]
- Wang, G.; Li, B.; Zhang, T.; Zhang, S. A Network Combining a Transformer and a Convolutional Neural Network for Remote Sensing Image Change Detection. Remote Sens. 2022, 14, 2228. [Google Scholar] [CrossRef]
- Song, F.; Zhang, S.; Lei, T.; Song, Y.; Peng, Z. MSTDSNet-CD: Multiscale Swin Transformer and Deeply Supervised Network for Change Detection of the Fast-Growing Urban Regions. IEEE Geosci. Remote Sens. Lett. 2022, 19, 6508505. [Google Scholar] [CrossRef]
- Feng, Y.; Xu, H.; Jiang, J.; Liu, H.; Zheng, J. ICIF-Net: Intra-Scale Cross-Interaction and Inter-Scale Feature Fusion Network for Bitemporal Remote Sensing Images Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4410213. [Google Scholar] [CrossRef]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide Inventory Mapping From Bitemporal Images Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Fu, Z.; Li, J.; Ren, L.; Chen, Z. SLDDNet: Stagewise Short and Long Distance Dependency Network for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 3000319. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 8007805. [Google Scholar] [CrossRef]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Lebedev, M.; Vizilter, Y.V.; Vygolov, O.; Knyaz, V.A.; Rubis, A.Y. Change Detection in Remote Sensing Images Using Conditional Adversarial Networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, 42, 565–571. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5604816. [Google Scholar] [CrossRef]
- Han, C.; Wu, C.; Guo, H.; Hu, M.; Chen, H. HANet: A Hierarchical Attention Network for Change Detection with Bitemporal Very-High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 16, 3867–3878. [Google Scholar] [CrossRef]
- Huang, Y.; Li, X.; Du, Z.; Shen, H. Spatiotemporal Enhancement and Interlevel Fusion Network for Remote Sensing Images Change Detection. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5609414. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Resolution (m/pixel) | Patch Size (pixels) | Data Source | Region |
|---|---|---|---|---|
| CDD [29] | ∼0.5–1.0 | 256 × 256 | Google Earth imagery | Global urban/rural |
| LEVIR-CD [30] | 0.5 | 1024 × 1024 | Google Earth (Texas, USA) | 20 urban areas in Texas |
| SYSU-CD [31] | 0.5 | 256 × 256 | Aerial imagery (HK Gov.) | Hong Kong (2007–2014) |
| Model | Pre | Rec | F1 | Iou | OA |
|---|---|---|---|---|---|
| SNUNet | 95.62 | 95.24 | 95.42 | 90.37 | 99.10 |
| STANet | 88.97 | 94.31 | 91.56 | 84.44 | 87.95 |
| ChangeFormer | 95.27 | 93.82 | 94.54 | 89.65 | 98.72 |
| BIT-CD | 95.86 | 94.59 | 95.00 | 90.88 | 98.88 |
| HANet | 92.44 | 84.68 | 88.39 | 79.19 | 97.12 |
| SEIFNet | 95.85 | 92.62 | 94.20 | 89.04 | 98.66 |
| MSCA | 96.39 | 95.99 | 96.19 | 92.67 | 99.10 |
| Model | Pre | Rec | F1 | Iou | OA |
|---|---|---|---|---|---|
| SNUNet | 89.18 | 87.17 | 88.16 | 78.83 | 98.82 |
| STANet | 80.99 | 91.92 | 85.79 | 75.12 | 98.46 |
| ChangeFormer | 91.53 | 88.86 | 90.17 | 82.10 | 99.01 |
| BIT-CD | 90.95 | 88.57 | 90.23 | 82.19 | 99.02 |
| HANet | 89.56 | 87.13 | 88.33 | 79.10 | 98.83 |
| SEIFNet | 89.67 | 85.87 | 89.14 | 80.41 | 98.93 |
| MSCA | 90.65 | 87.46 | 91.02 | 80.22 | 98.90 |
| Model | Pre | Rec | F1 | Iou | OA |
|---|---|---|---|---|---|
| SNUNet | 74.55 | 65.15 | 67.68 | 61.11 | 88.78 |
| STANet | 82.36 | 74.30 | 78.12 | 64.10 | 90.18 |
| ChangeFormer | 84.99 | 70.93 | 77.33 | 63.04 | 90.19 |
| BIT-CD | 79.04 | 76.71 | 77.86 | 63.75 | 89.71 |
| HANet | 78.71 | 76.14 | 77.41 | 63.14 | 89.52 |
| SEIFNet | 79.47 | 78.28 | 78.87 | 65.11 | 90.10 |
| MSCA | 82.65 | 78.95 | 80.76 | 67.72 | 91.13 |
| Dataset | Method | Pre (%) | Rec (%) | F1 (%) | IoU (%) | OA (%) |
|---|---|---|---|---|---|---|
| Levir-CD | Baseline | 92.45 | 88.42 | 90.39 | 82.47 | 99.04 |
| MSCA | 90.65 | 87.46 | 91.02 | 80.22 | 98.90 | |
| CDD | Baseline | 95.07 | 95.51 | 95.28 | 91.00 | 98.89 |
| MSCA | 96.39 | 95.99 | 96.19 | 92.67 | 99.10 | |
| SYSU-CD | Baseline | 85.02 | 74.87 | 79.62 | 66.15 | 90.96 |
| MSCA | 82.65 | 78.95 | 80.76 | 67.72 | 91.13 |
| Method | Dataset | Pre (%) | Rec (%) | F1 (%) | Iou (%) | OA (%) |
|---|---|---|---|---|---|---|
| MSCA | CDD | 96.39 | 95.99 | 96.19 | 92.67 | 99.10 |
| CDD+gn | 96.35 | 95.61 | 95.98 | 92.27 | 99.05 | |
| SYSU-CD | 82.65 | 78.95 | 80.76 | 67.72 | 91.13 | |
| SYSU-CD+gn | 86.72 | 74.29 | 80.03 | 66.72 | 91.26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, X.; Lin, X.; Qing, L.; Ou, X. Semantic-Aware Remote Sensing Change Detection with Multi-Scale Cross-Attention. Sensors 2025, 25, 2813. https://doi.org/10.3390/s25092813
Zheng X, Lin X, Qing L, Ou X. Semantic-Aware Remote Sensing Change Detection with Multi-Scale Cross-Attention. Sensors. 2025; 25(9):2813. https://doi.org/10.3390/s25092813
Chicago/Turabian StyleZheng, Xingjian, Xin Lin, Linbo Qing, and Xianfeng Ou. 2025. "Semantic-Aware Remote Sensing Change Detection with Multi-Scale Cross-Attention" Sensors 25, no. 9: 2813. https://doi.org/10.3390/s25092813
APA StyleZheng, X., Lin, X., Qing, L., & Ou, X. (2025). Semantic-Aware Remote Sensing Change Detection with Multi-Scale Cross-Attention. Sensors, 25(9), 2813. https://doi.org/10.3390/s25092813