
CVNet: Lightweight Cross-View Vehicle ReID with Multi-Scale Localization

 , ,
, ,
Abstract
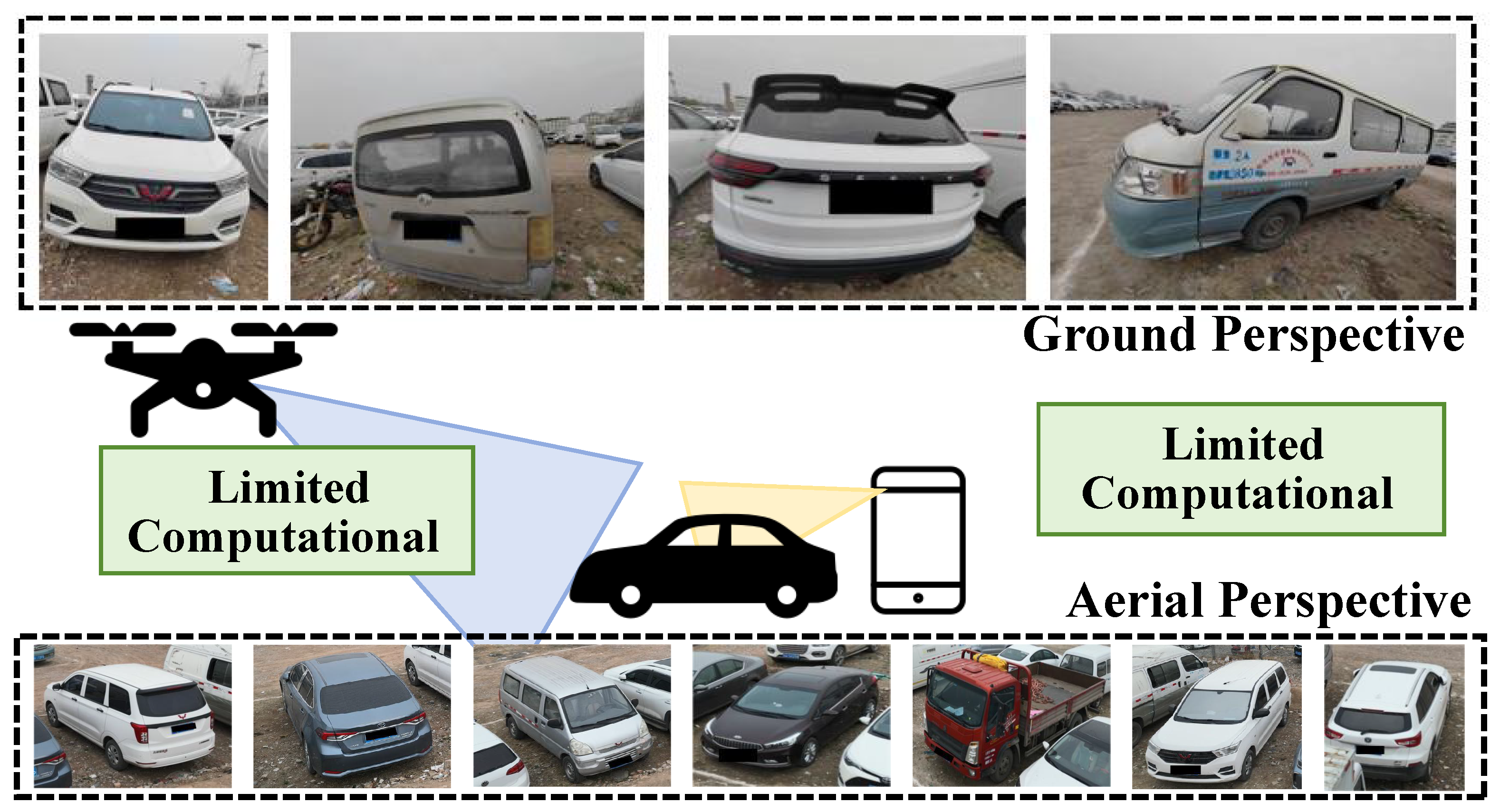
1. Introduction
- We propose CVNet, a lightweight network with only 4.4M parameters, achieving state-of-the-art performance.
- We devise the MSL module, which enhances precise regional positioning through multi-scale feature extraction and fusion, tailored for complex scenarios.
- We develop the DFC module, designed to extract both shared and unique features across diverse perspectives, improving cross-view feature representation.
- We present CVPair v1.0, the first benchmark dataset for cross-view vehicle ReID, offering results of traditional and lightweight methods.
2. Related Work
2.1. Datasets for Vehicle ReID
2.2. Neural Architecture Search Task
3. CVPair v1.0 Dataset
4. Methodology
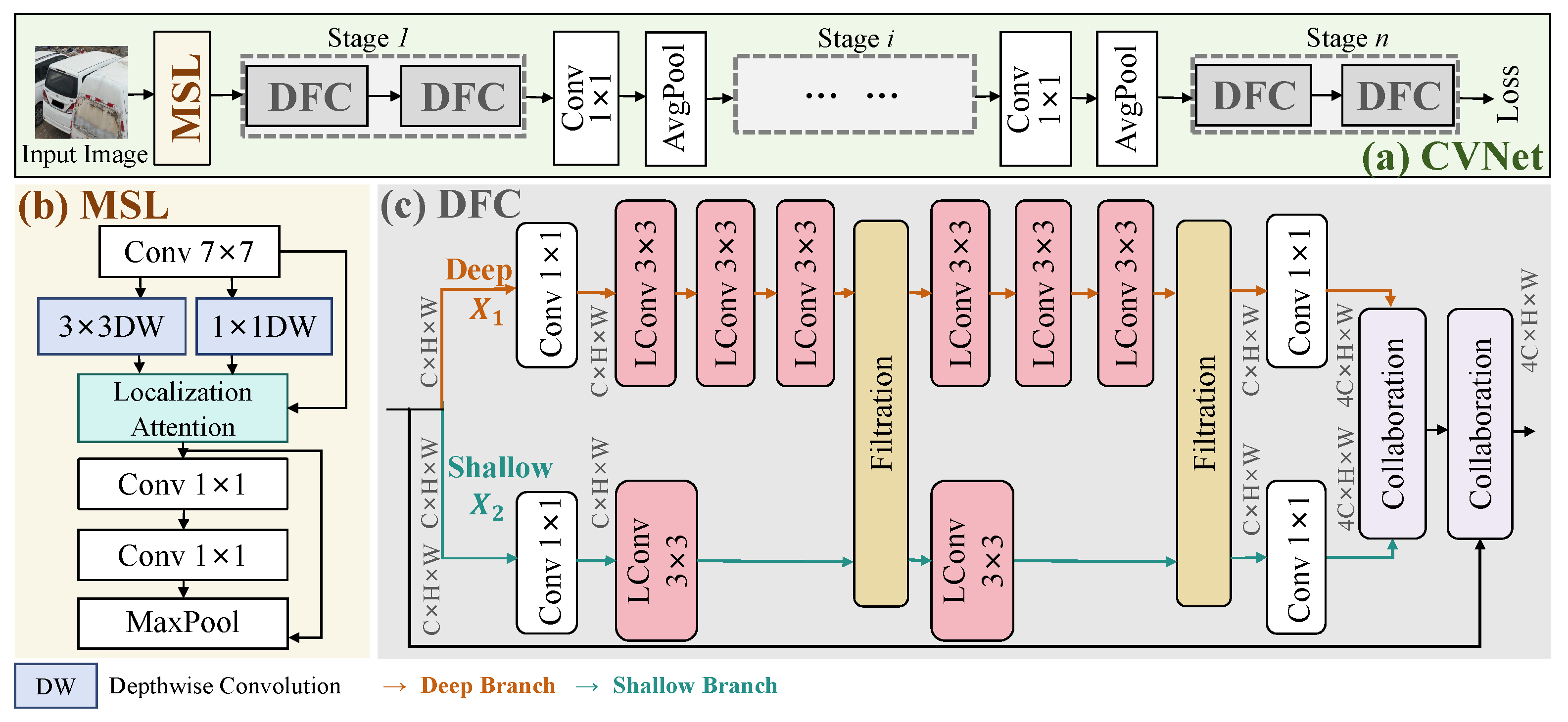
4.1. Overall
4.2. Multi-Scale Localization
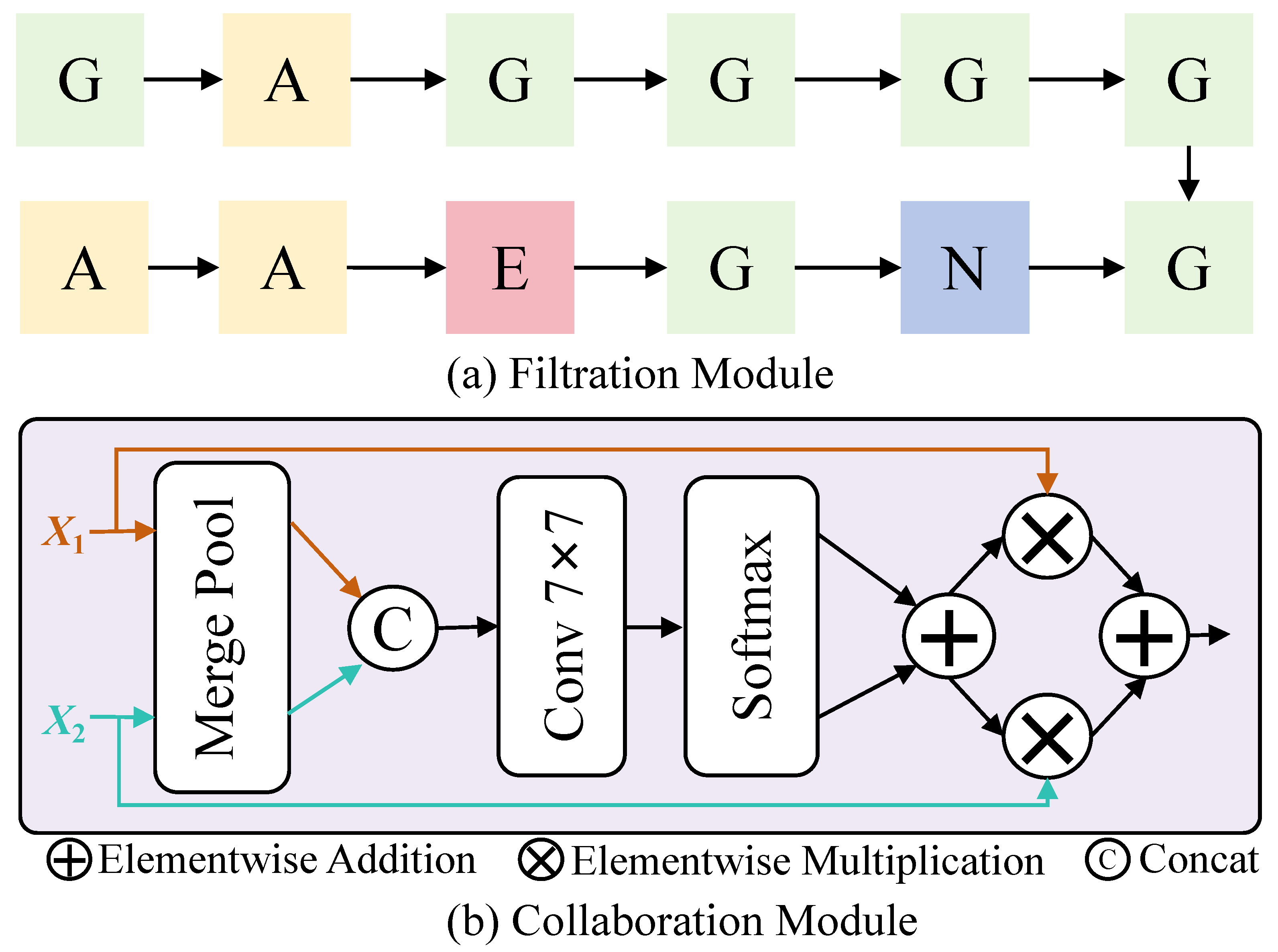
4.3. Deep–Shallow Filtrate Collaboration
4.4. Loss Function
5. Experiment and Analysis
5.1. Implementation Details
5.2. Comparison with State-of-the-Art Methods
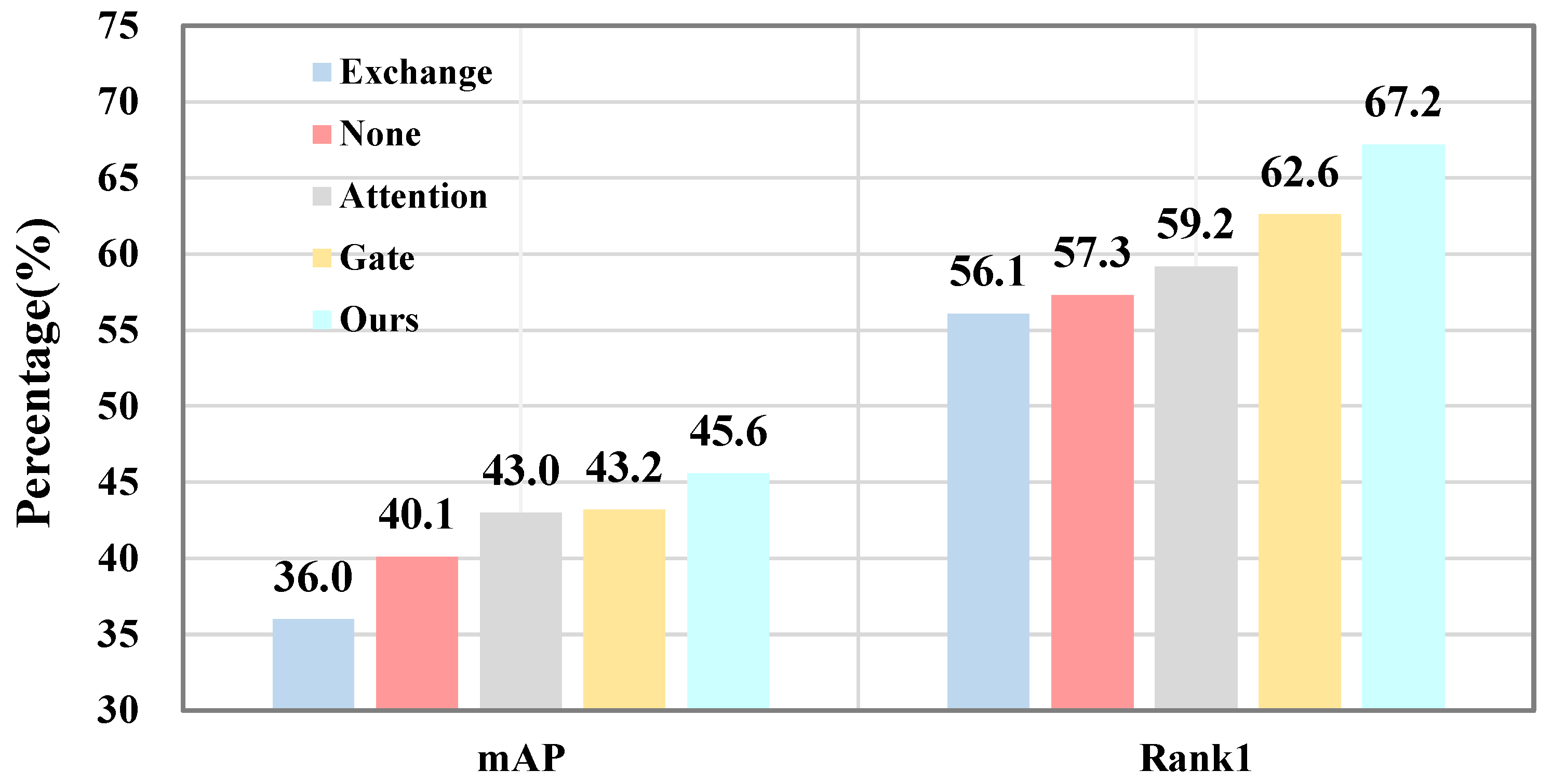
5.3. Ablation Studies and Analysis
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, Z.; Huang, H.; Zheng, A.; Li, C.; He, R. Parallel augmentation and dual enhancement for occluded person re-identification. In Proceedings of the ICASSP 2024–2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 3590–3594. [Google Scholar]
- Yang, B.; Chen, J.; Ye, M. Top-k visual tokens transformer: Selecting tokens for visible-infrared person re-identification. In Proceedings of the ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhong, X.; Su, S.; Liu, W.; Jia, X.; Huang, W.; Wang, M. Neighborhood information-based label refinement for person re-identification with label noise. In Proceedings of the ICASSP 2023–2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Zhu, W.; Wang, Z.; Wang, X.; Hu, R.; Liu, H.; Liu, C.; Wang, C.; Li, D. A dual self-attention mechanism for vehicle re-identification. Pattern Recognit. 2023, 137, 109258. [Google Scholar] [CrossRef]
- Khorramshahi, P.; Peri, N.; Kumar, A.; Shah, A.; Chellappa, R. Attention Driven Vehicle Re-identification and Unsupervised Anomaly Detection for Traffic Understanding. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 239–246. [Google Scholar]
- Xu, Z.; Wei, L.; Lang, C.; Feng, S.; Wang, T.; Bors, A.G. HSS-GCN: A hierarchical spatial structural graph convolutional network for vehicle re-identification. In Proceedings of the ICPR International Workshops and Challenges on Pattern Recognition, Virtual Event, 10–15 January 2021; Proceedings, Part V. Springer: Berlin/Heidelberg, Germany, 2021; pp. 356–364. [Google Scholar]
- Li, Z.; Zhang, X.; Tian, C.; Gao, X.; Gong, Y.; Wu, J.; Zhang, G.; Li, J.; Liu, H. TVG-ReiD: Transformer-based vehicle-graph re-identification. IEEE Trans. Intell. Veh. 2023, 8, 4644–4652. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H.G. Run, don’t walk: Chasing higher FLOPS for faster neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Shen, F.; Jiang, X.; He, X.; Ye, H.; Wang, C.; Du, X.; Li, Z.; Tang, J. IMAGDressing-v1: Customizable Virtual Dressing. arXiv 2024, arXiv:2407.12705. [Google Scholar] [CrossRef]
- Shen, F.; Tang, J. IMAGPose: A Unified Conditional Framework for Pose-Guided Person Generation. In Proceedings of the The Thirty-eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024. [Google Scholar]
- Yang, G.; Lei, J.; Zhu, Z.; Cheng, S.; Feng, Z.; Liang, R. AFPN: Asymptotic feature pyramid network for object detection. In Proceedings of the 2023 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Oahu, HI, USA, 1–4 October 2023; pp. 2184–2189. [Google Scholar]
- Shen, F.; Ye, H.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv 2023, arXiv:2310.06313. [Google Scholar]
- Shen, F.; Ye, H.; Liu, S.; Zhang, J.; Wang, C.; Han, X.; Yang, W. Boosting Consistency in Story Visualization with Rich-Contextual Conditional Diffusion Models. arXiv 2024, arXiv:2407.02482. [Google Scholar] [CrossRef]
- Nguyen, K.; Fookes, C.; Sridharan, S.; Liu, F.; Liu, X.; Ross, A.; Michalski, D.; Nguyen, H.; Deb, D.; Kothari, M.; et al. AG-ReID 2023: Aerial-Ground Person Re-identification Challenge Results. In Proceedings of the 2023 IEEE International Joint Conference on Biometrics (IJCB), Ljubljana, Slovenia, 25–28 September 2023; pp. 1–10. [Google Scholar]
- Zhang, S.; Yang, Q.; Cheng, D.; Xing, Y.; Liang, G.; Wang, P.; Zhang, Y. Ground-to-Aerial Person Search: Benchmark Dataset and Approach. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 789–799. [Google Scholar]
- Shen, F.; Shu, X.; Du, X.; Tang, J. Pedestrian-specific Bipartite-aware Similarity Learning for Text-based Person Retrieval. In Proceedings of the 31th ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023. [Google Scholar]
- Shen, F.; Du, X.; Zhang, L.; Tang, J. Triplet Contrastive Learning for Unsupervised Vehicle Re-identification. arXiv 2023, arXiv:2301.09498. [Google Scholar] [CrossRef]
- Lou, Y.; Bai, Y.; Liu, J.; Wang, S.; Duan, L. VERI-Wild: A Large Dataset and a New Method for Vehicle Re-Identification in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Liu, H.; Tian, Y.; Yang, Y.; Pang, L.; Huang, T. Deep Relative Distance Learning: Tell the Difference Between Similar Vehicles. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Wang, P.; Jiao, B.; Yang, L.; Yang, Y.; Zhang, S.; Wei, W.; Zhang, Y. Vehicle Re-Identification in Aerial Imagery: Dataset and Approach. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Song, Y.; Liu, C.; Zhang, W.; Nie, Z.; Chen, L. View-Decision Based Compound Match Learning for Vehicle Re-identification in UAV Surveillance. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; pp. 6594–6601. [Google Scholar] [CrossRef]
- Lu, M.; Xu, Y.; Li, H. Vehicle Re-Identification Based on UAV Viewpoint: Dataset and Method. Remote Sens. 2022, 14, 4603. [Google Scholar] [CrossRef]
- Teng, S.; Zhang, S.; Huang, Q.; Sebe, N. Viewpoint and scale consistency reinforcement for UAV vehicle re-identification. Int. J. Comput. Vis. 2021, 129, 719–735. [Google Scholar] [CrossRef]
- Umamageswari, A.; Bharathiraja, N.; Irene, D.S. A novel fuzzy C-means based chameleon swarm algorithm for segmentation and progressive neural architecture search for plant disease classification. ICT Express 2023, 9, 160–167. [Google Scholar] [CrossRef]
- Zhou, X.; Wang, Z.; Feng, L.; Liu, S.; Wong, K.C.; Tan, K.C. Towards Evolutionary Multi-Task Convolutional Neural Architecture Search. IEEE Trans. Evol. Comput. 2023, 28, 682–695. [Google Scholar] [CrossRef]
- Jing, K.; Chen, L.; Xu, J. An architecture entropy regularizer for differentiable neural architecture search. Neural Netw. 2023, 158, 111–120. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Zhao, Y.; Jinnai, Y.; Tian, Y.; Fonseca, R. Neural architecture search using deep neural networks and monte carlo tree search. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9983–9991. [Google Scholar]
- Gu, J.; Wang, K.; Luo, H.; Chen, C.; Jiang, W.; Fang, Y.; Zhang, S.; You, Y.; Zhao, J. Msinet: Twins contrastive search of multi-scale interaction for object reid. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 19243–19253. [Google Scholar]
- Cho, Y.; Kim, W.J.; Hong, S.; Yoon, S.E. Part-based pseudo label refinement for unsupervised person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 7308–7318. [Google Scholar]
- Wang, G.; Yuan, Y.; Chen, X.; Li, J.; Zhou, X. Learning discriminative features with multiple granularities for person re-identification. In Proceedings of the 26th ACM International Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 274–282. [Google Scholar]
- Luo, H.; Jiang, W.; Gu, Y.; Liu, F.; Liao, X.; Lai, S.; Gu, J. A strong baseline and batch normalization neck for deep person re-identification. IEEE Trans. Multimed. 2019, 22, 2597–2609. [Google Scholar] [CrossRef]
- Zeng, G.; Wang, R.; Yu, W.; Lin, A.; Li, H.; Shang, Y. A transfer learning-based approach to maritime warships re-identification. Eng. Appl. Artif. Intell. 2023, 125, 106696. [Google Scholar] [CrossRef]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the Stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–18 June 2024; pp. 5694–5703. [Google Scholar]
- Vasu, P.K.A.; Gabriel, J.; Zhu, J.; Tuzel, O.; Ranjan, A. Mobileone: An improved one millisecond mobile backbone. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7907–7917. [Google Scholar]
- Lu, X.; Suganuma, M.; Okatani, T. SBCFormer: Lightweight Network Capable of Full-size ImageNet Classification at 1 FPS on Single Board Computers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1123–1133. [Google Scholar]
- Gu, X.; Chang, H.; Ma, B.; Bai, S.; Shan, S.; Chen, X. Clothes-changing person re-identification with rgb modality only. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 1060–1069. [Google Scholar]
- Yu, Z.; Huang, Z.; Pei, J.; Tahsin, L.; Sun, D. Semantic-oriented feature coupling transformer for vehicle re-identification in intelligent transportation system. IEEE Trans. Intell. Transp. Syst. 2023, 25, 2803–2813. [Google Scholar] [CrossRef]
- Du, L.; Huang, K.; Yan, H. ViT-ReID: A Vehicle Re-identification Method Using Visual Transformer. In Proceedings of the 2023 3rd International Conference on Neural Networks, Information and Communication Engineering (NNICE), Guangzhou, China, 24–26 February 2023; pp. 287–290. [Google Scholar]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. IEEE Trans. Image Process. 2023, 32, 1039–1051. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A deep learning-based approach to progressive vehicle re-identification for urban surveillance. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 869–884. [Google Scholar]
- Tang, Z.; Naphade, M.; Birchfield, S.; Tremblay, J.; Hodge, W.; Kumar, R.; Wang, S.; Yang, X. Pamtri: Pose-aware multi-task learning for vehicle re-identification using highly randomized synthetic data. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 211–220. [Google Scholar]
- Huang, W.; Zhong, X.; Jia, X.; Liu, W.; Feng, M.; Wang, Z.; Satoh, S. Vehicle re-identification with spatio-temporal model leveraging by pose view embedding. Electronics 2022, 11, 1354. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Ground–Ground | Aerial–Aerial | Ground–Aerial | ||||
|---|---|---|---|---|---|---|---|
| VeRi-Wild [18] | VehicleID [19] | VRAI [20] | VeRi-UAV [21] | VRU [22] | UAV-VeID [23] | CVPair v1.0 | |
| Images | 416,314 | 221,567 | 137,613 | 17,515 | 172,137 | 41,917 | 14,969 |
| Views | fixed | fixed | mobile | mobile | mobile | mobile | fixed & mobile |
| Platforms | CCTV | CCTV | UAV | UAV | UAV | UAV | UAV & Phone |
| Altitude | <10 m | <10 m | 15–80 m | 10–30 m | 15–60 m | 15–60 m | 3–13 m |
| UAVs | 0 | 0 | 2 | 1 | 5 | 2 | 1 |
| Target | Vehicle | Vehicle | Vehicle | Vehicle | Vehicle | Vehicle | Vehicle |
| Task | Query and gallery from ground views. | Query and gallery from aerial views. | Query and gallery from ground and aerial views. | ||||
| Models | A2G | G2A | #Params (M) ↓ | FPS ↑ | |||||
|---|---|---|---|---|---|---|---|---|---|
| mAP | Rank1 | Rank5 | mAP | Rank1 | Rank5 | ||||
| Traditional ReID Methods | * PPLR [29] | 12.6 | 15.1 | 37.2 | 7.0 | 10.9 | 22.3 | 26.8 | 3.1 |
| * MGN [30] | 26.8 | 23.9 | 66.0 | 29.7 | 29.6 | 49.7 | 70.4 | 1.2 | |
| * BoT [31] | 31.6 | 43.3 | 69.8 | 24.1 | 35.2 | 58.1 | 23.8 | 3.5 | |
| * Trans-ReID [32] | 31.9 | 42.1 | 73.0 | 28.5 | 38.8 | 59.4 | 86.6 | 1.0 | |
| Lightweight Methods | * StarNet-S1 + CH [33] | 14.8 | 17.1 | 39.4 | 11.8 | 14.5 | 25.3 | 3.2 | 17.8 |
| * MobileOne-S1 + CH [34] | 17.2 | 21.0 | 48.2 | 20.4 | 22.9 | 38.1 | 5.1 | 16.2 | |
| * SBCFormer-XS + CH [35] | 19.4 | 24.9 | 52.6 | 23.8 | 25.1 | 42.2 | 5.9 | 15.4 | |
| * FasterNet-T1 + CH [8] | 28.8 | 39.2 | 65.1 | 27.7 | 28.5 | 46.3 | 7.9 | 13.7 | |
| CVNet (Ours) | 45.6 | 67.2 | 88.1 | 35.8 | 53.9 | 76.3 | 4.4 | 18.2 | |
| Datasets | Method | #Params (M) ↓ | Rank1 ↑ |
|---|---|---|---|
| VehicleID [19] | CAL [36] | 23.8 | 75.1 |
| SOFCT [37] | 57.3 | 77.8 | |
| Vit-reid [38] | 57.3 | 80.5 | |
| GiT [39] | 57.3 | 84.7 | |
| Trans-ReID [32] | 86.6 | 85.2 | |
| Ours | 4.4 | 85.9 | |
| VeRi-776 [40] | PAMTRI [41] | 10.0 | 71.9 |
| Trans-ReID [32] | 86.6 | 85.2 | |
| CAL [36] | 23.8 | 85.9 | |
| KPGST [42] | 11.7 | 92.4 | |
| Ours | 4.4 | 93.6 |
| Methods | mAP | Rank1 | Rank5 |
|---|---|---|---|
| Baseline | 39.4 | 54.3 | 82.5 |
| Res. 1 → MSL | 44.5 | 58.1 | 83.5 |
| Res. S → DFC | 40.6 | 56.2 | 82.7 |
| Ours | 45.6 | 67.2 | 88.1 |
| n | mAP | Rank1 | Rank5 |
|---|---|---|---|
| 1 | 33.2 | 46.0 | 76.1 |
| 2 | 36.5 | 50.3 | 77.9 |
| 3 | 45.6 | 67.2 | 88.1 |
| 4 | 32.6 | 44.7 | 72.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, W.; Han, B.; Peng, Y.; Hao, H.; Ye, Z.; Shen, Y.; Cai, Y.; Kang, W. CVNet: Lightweight Cross-View Vehicle ReID with Multi-Scale Localization. Sensors 2025, 25, 2809. https://doi.org/10.3390/s25092809
Yin W, Han B, Peng Y, Hao H, Ye Z, Shen Y, Cai Y, Kang W. CVNet: Lightweight Cross-View Vehicle ReID with Multi-Scale Localization. Sensors. 2025; 25(9):2809. https://doi.org/10.3390/s25092809
Chicago/Turabian StyleYin, Wenji, Baixuan Han, Yueping Peng, Hexiang Hao, Zecong Ye, Yu Shen, Yanjun Cai, and Wenchao Kang. 2025. "CVNet: Lightweight Cross-View Vehicle ReID with Multi-Scale Localization" Sensors 25, no. 9: 2809. https://doi.org/10.3390/s25092809
APA StyleYin, W., Han, B., Peng, Y., Hao, H., Ye, Z., Shen, Y., Cai, Y., & Kang, W. (2025). CVNet: Lightweight Cross-View Vehicle ReID with Multi-Scale Localization. Sensors, 25(9), 2809. https://doi.org/10.3390/s25092809