Text Correction
There were errors in the original publication [
1].
1. In Paragraph 3 of Section 1, the item 2 has been updated as follows:
Proposed a Candidate Point-Target Distance (CPTD) method, an improved heuristic algorithm that integrates a heuristic evaluation function into the navigation system of a four-wheeled mobile robot. This function is used to assess navigation path points and guide the robot toward the global target point.
2. In Section 3.2. Global Navigation, the parts of Paragraph 3 before Equation (6) have been updated as follows:
In the absence of sufficient environmental information, heuristic methods can effectively approximate the optimal solution to a problem. Based on this premise, the CPTD algorithm proposed in our study improves the scoring mechanism in [13], which evaluates all candidate navigation points through a heuristic function to select an optimal navigation point. The robot progressively moves towards each selected navigation point until reaching the global target point. At each step, the robot obtains its own position coordinates, coordinates of each candidate navigation point, coordinates of the global target point, and map data, enabling the calculation of the distances from the robot to each candidate navigation point and the global target point. Subsequently, the score of each candidate navigation point is computed based on the integrated map data. To enable the robot to reach the global target more quickly, we incorporate the previously selected candidate point as an evaluation factor in the function, ensuring that the robot will not choose a candidate point that is farther from the target under normal conditions. Given this information, the score,
of the
i-th candidate navigation point,
, is determined as follows:
where
is the distance score obtained based on the current position of the robot and the candidate navigation point, calculated as shown in Equation (6).
is the Euclidean distance from the candidate navigation point to the global target point, calculated as shown in Equation (7).
is the Euclidean distance from the previously selected candidate point to the global target point, calculated as shown in Equation (8).
is the map information surrounding the candidate navigation point.
3. In Section 3.2. Global Navigation, the parts of Paragraph 4 before Equation (9) have been updated as follows:
Since there is no prior mapping, the robot can only acquire environmental information in real-time through its sensors. With each action, the robot’s map data are continuously refined in real-time. When a candidate navigation point is located within a known environment, the amount of information gained upon reaching that point is significantly less than that of a point situated in an unknown environment. Therefore, we prefer to guide the robot towards navigation points in unknown environments, which aids in discovering potential paths to the global target. Consequently, it is necessary to heuristically score each candidate navigation point based on the map data obtained. The status of every pixel in the map is identified, with unknown pixels marked as , obstacles as , and known pixels with no obstacles marked as . To better reflect the score differences between known environments, unknown environments, and obstacles, we set the divisor to k to calculate the map information around the candidate point. The information score, , for the environment within a [k × k] window around the candidate navigation point, , is calculated as follows:
4. In Section 4.3. Autonomous Exploration and Navigation, the first paragraph has been updated as follows:
To quantitatively evaluate the performance of the proposed method in this study and accurately assess its effectiveness and efficiency in autonomous navigation tasks, we employed a comparative approach, contrasting it with various existing indoor navigation algorithms. Firstly, experiments were conducted using the SAC network without a global planner, referred to as the Local Deep Reinforcement Learning (L-DRL) method. Secondly, to compare the performance of the heuristic evaluation function, we compare the TD3+CPTD framework with the global navigation method [10] used in the heuristic navigation algorithm of [13], referring to them as NTD3 and OTD3, respectively. Considering that non-learning path planning algorithms struggle to achieve autonomous exploration and navigation in the absence of prior map information, experiments replaced the neural network in our proposed framework with the ROS local planner package, referred to as the LP method. Finally, to establish a performance benchmark for comparison, control experiments were conducted using the Dijkstra algorithm based on complete mapping. Each algorithm was tested in three different environments over five trials. Key recorded data included traveled distance (D, in meters), travel time (T, in seconds), and the number of successful goal arrivals (Arrive). Based on the collected experimental data, average traveled distance (Av.D) and average travel time (Av.T) were further calculated, along with maximum (Max.D, Max.T) and minimum (Min.D, Min.T) values for distance and time traveled. In this study, experiments were conducted in three different environments. To evaluate the transferability between simulation and real-world scenarios, Experiment 1 was performed in the Gazebo simulation software, while Experiments 2 and 3 were conducted in real-world environments.
5. In Section 4.3. Autonomous Exploration and Navigation, the second paragraph has been updated as follows:
The first experimental environment, as depicted in Figure 8, was designed with dense obstacles and multiple local optima regions. In this experiment, the method proposed in this study demonstrated efficient and precise navigation performance, successfully guiding the robot to the designated global target point. In contrast, the NTD3 algorithm exceeded the method proposed in this study in terms of travel time, although its travel path length was similar. Because the relationship between candidate point distances is taken into account, the path traveled by NTD3 is shorter than that of OTD3. The LP method, prone to becoming trapped in local optima and requiring a longer time to replan paths, resulted in longer travel distances. The L-DRL method exhibited looping behavior when navigating to local optima regions, especially in narrow gaps between obstacles, ultimately requiring human intervention to guide it out of such areas and into open spaces. Detailed experimental data are provided in Table 2.
6. In Section 4.3. Autonomous Exploration and Navigation, the third paragraph has been updated as follows:
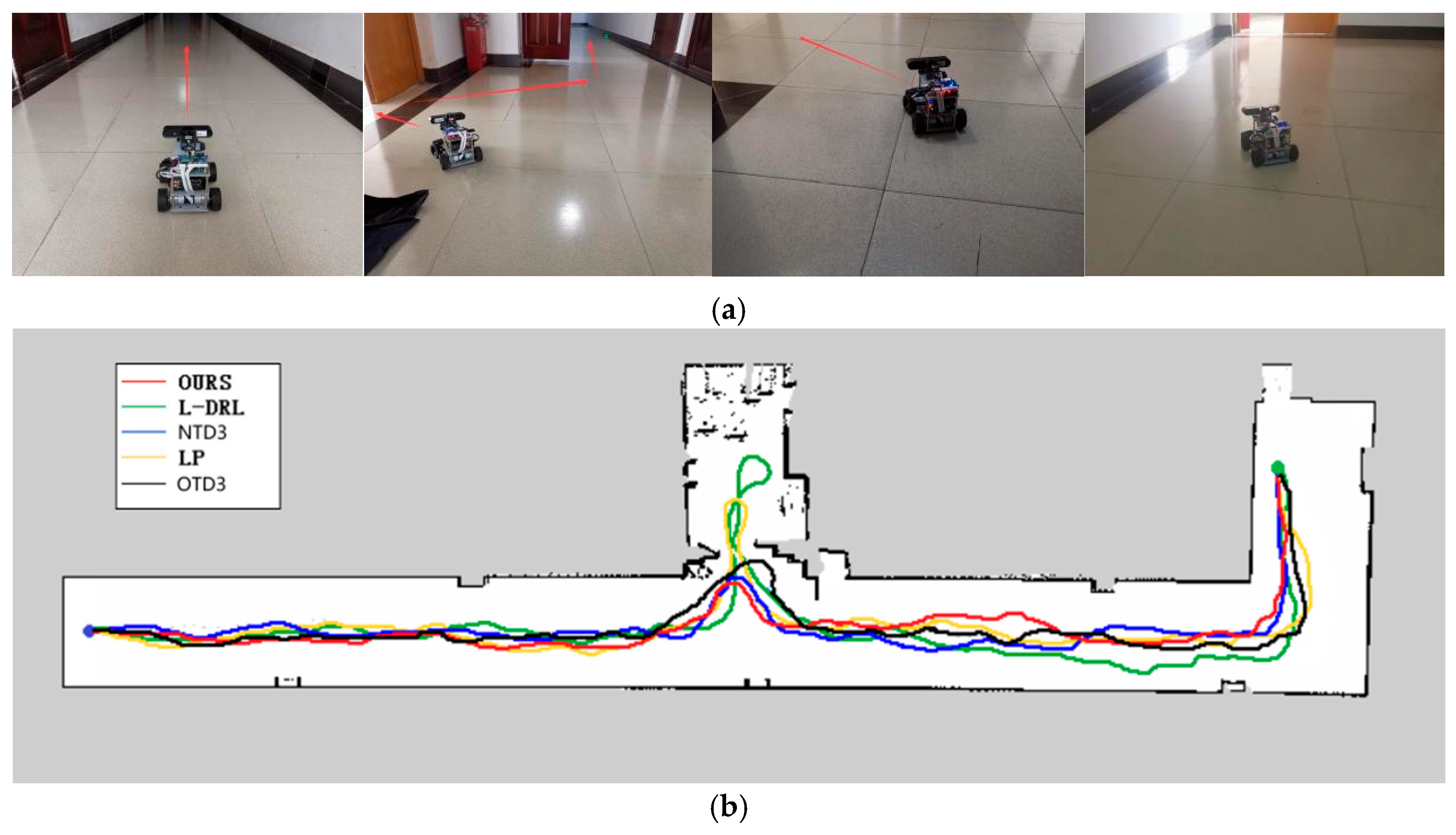
The second experimental environment, as depicted in Figure 9, is primarily composed of a narrow corridor with smooth walls and contains few internal obstacles. The global target point coordinates are located at (33, −5). In this environment, each method was able to reach the global target point, but they exhibited differences in the length of the traveled path and the time required. The method proposed in this study not only rapidly reaches the global target point but also maintains the minimization of travel distance. Although the NTD3 algorithm is similar to our study’s method in terms of travel distance, its lower learning efficiency within the same training period compared to the SAC algorithm results in longer times required to execute certain actions. The path length traveled by OTD3 is still longer than that of NTD3. The LP method has a longer travel time due to the need to wait for the calculation of the next navigation point. The L-DRL method, on the other hand, is prone to falling into local optima, leading to a tendency to enter and delve into side paths. The specific experimental data can be found in Table 3.
7. In Section 4.3. Autonomous Exploration and Navigation, the fourth paragraph has been updated as follows:
The third experimental scenario, as illustrated in Figure 10, was conducted in a more complex environment featuring numerous obstacles such as desks, chairs, cardboard boxes, and keyboards. Particularly in the vicinity of keyboards, the feasible pathways are narrow, and failure to effectively recognize the keyboard may lead the robot to collide and become stuck, impeding its progress. The method proposed in this study can reach the designated global target point in the shortest time possible, with a relatively shorter travel path. Although the NTD3 algorithm is similar to our study’s method in terms of the length of the traveled path, its decision-making process takes longer. The performance of OTD3 is similar to that of NTD3, but its path is slightly longer, resulting in a longer time required. The LP method tends to become trapped in local optima, although it eventually breaks free, resulting in longer overall time and travel distance. Due to the lack of global planning capability, the L-DRL method tends to loop between the aisles of desks, struggling to break free from local optima, ultimately requiring human intervention to guide it into new areas. Detailed experimental data are provided in Table 4.
8. In Section 4.3. Autonomous Exploration and Navigation, the fifth paragraph has been updated as follows:
Synthesizing the experimental results, the method proposed in this study demonstrates consistent performance in both simulation and real-world environments. In simple environments as well as in complex environments with multiple local optima and numerous obstacles, it exhibits significant performance advantages over solutions based on the TD3 algorithm and planning-based methods. Although the TD3 algorithm showed similar performance to the method proposed in this study in some aspects during the experiments, the proposed method exhibited faster convergence and higher learning efficiency within the same training cycles. Compared to planning-based methods, the neural network-driven strategy can learn a wider range of motion patterns, enabling quicker escape from local optima. In contrast to the heuristic scoring method in [13], the CPTD method proposed in this study enables faster arrival at the global target, achieving quicker and more efficient global navigation.






{kind=link}
{kind=link}
{kind=link}