
TCCDNet: A Multimodal Pedestrian Detection Network Integrating Cross-Modal Complementarity with Deep Feature Fusion

Abstract
1. Introduction
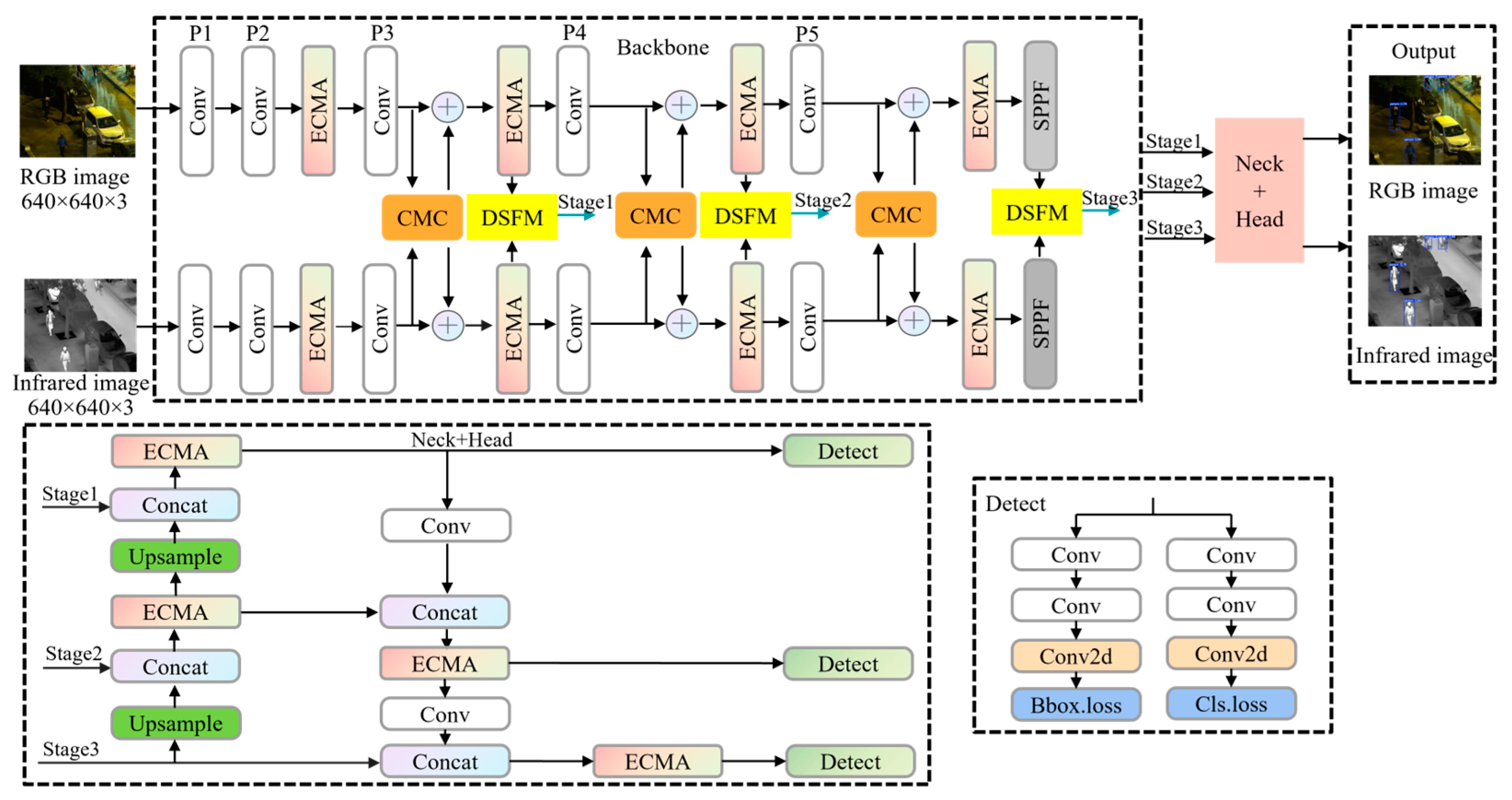
- A novel TCCDNet architecture is proposed. The network is designed based on YOLOv8 with a dual-branch backbone to efficiently process visible and infrared multimodal data in a parallel architecture. It innovatively introduces an EMAC, which employs an adaptive feature weighting mechanism, enhancing the discriminative ability of modal features. This not only improves the capture of detailed information from RGB and infrared images but also effectively addresses the degradation of RGB image quality under low-light conditions, providing richer feature representations.
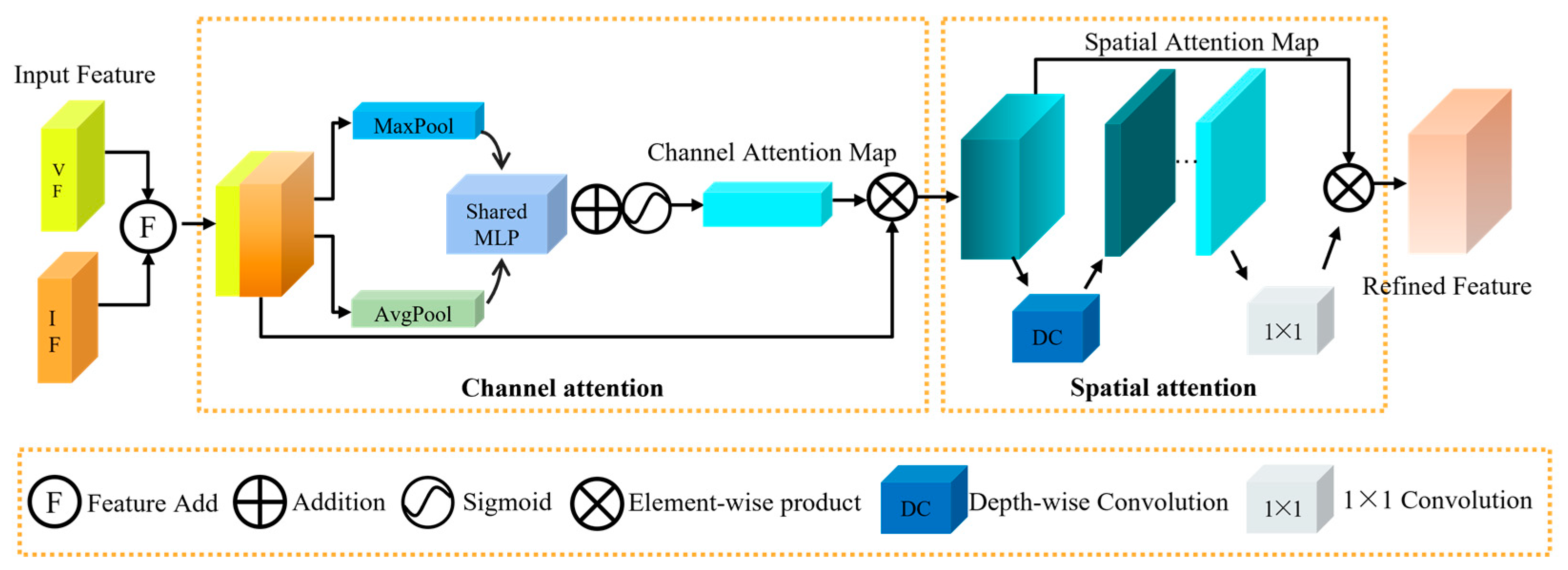
- The CMC module integrates channel attention and spatial attention mechanisms to focus on extracting and fusing key features from dual-modal data. This process not only enhances the discriminative power of feature representation but also achieves inter-modal feature complementarity at different scales. In this way, the CMC module maximizes the complementary information between the two modalities while preserving the unique strengths of each modality.
- The DSFM module achieves the deep integration of RGB and IR image features through a multi-level feature interaction mechanism. It adopts a progressive fusion strategy, optimizing the feature fusion process across different scales via an adaptive weight allocation mechanism. This significantly improves the accuracy and robustness of pedestrian detection. Compared to traditional methods that perform fusion only at the pixel or decision level, DSFM establishes finer inter-modal feature correlations, delivering more precise detection results.
- The proposed approach was rigorously evaluated on three benchmark multispectral datasets: KAIST, FLIR ADAS, and LLVIP. The experimental results indicate that the framework achieves an optimal trade-off between computational efficiency and detection accuracy, highlighting its potential for real-world applications.
2. Related Works
2.1. Unimodal Pedestrian Detection
2.2. Multimodal Pedestrian Detection
3. Methods
3.1. Structure of TCCDNet
3.2. Efficient Multi-Scale Attention C2f Module
3.3. Cross-Modal Complementarity Module
3.4. Deep Semantic Fusion Module
4. Experiments and Discussion
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Implementation Details
4.1.3. Evaluation Metrics
4.2. Qualitative Results and Analysis
4.2.1. Results for the KAIST Dataset
4.2.2. Results for the FLIR ADAS Dataset
4.2.3. Results for the LLVIP Dataset
4.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kuras, A.; Brell, M.; Liland, K.H.; Burud, I. Multitemporal Feature-Level Fusion on Hyperspectral and LiDAR Data in the Urban Environment. Remote Sens. 2023, 15, 632. [Google Scholar] [CrossRef]
- Li, X.; Li, L.; Flohr, F.; Wang, J.; Xiong, H.; Bernhard, M.; Pan, S.; Gavrila, D.M.; Li, K. A Unified Framework for Concurrent Pedestrian and Cyclist Detection. IEEE Trans. Intell. Transport. Syst. 2017, 18, 269–281. [Google Scholar] [CrossRef]
- Luo, Y.; Yin, D.; Wang, A.; Wu, W. Pedestrian Tracking in Surveillance Video Based on Modified CNN. Multimed. Tools Appl. 2018, 77, 24041–24058. [Google Scholar] [CrossRef]
- Guan, D.; Yang, J.; Cao, Y.; Yang, M.Y.; Cao, Y. Multimodal Fusion Architectures for Pedestrian Detection. In Multimodal Scene Understanding; Elsevier: Amsterdam, The Netherlands, 2019; pp. 101–133. [Google Scholar]
- Chen, Y.; Ye, J.; Wan, X. TF-YOLO: A Transformer–Fusion-Based YOLO Detector for Multimodal Pedestrian Detection in Autonomous Driving Scenes. World Electr. Veh. J. 2023, 14, 352. [Google Scholar] [CrossRef]
- He, W.; Feng, W.; Peng, Y.; Chen, Q.; Gu, G.; Miao, Z. Multi-Level Image Fusion and Enhancement for Target Detection. Optik 2015, 126, 1203–1208. [Google Scholar] [CrossRef]
- Wei, J.; Su, S.; Zhao, Z.; Tong, X.; Hu, L.; Gao, W. Infrared Pedestrian Detection Using Improved UNet and YOLO through Sharing Visible Light Domain Information. Measurement 2023, 221, 113442. [Google Scholar] [CrossRef]
- Wang, Z.; Jia, Y.; Huang, H.; Tang, S. Pedestrian Detection Using Boosted HOG Features. In Proceedings of the 11th International IEEE Conference on Intelligent Transportation Systems, Beijing, China, 12–15 October 2008; IEEE: Piscataway, NJ, USA, 2018; pp. 1155–1160. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. [Google Scholar]
- Saeidi, M.; Ahmadi, A. High-Performance and Deep Pedestrian Detection Based on Estimation of Different Parts. J. Supercomput. 2021, 77, 2033–2068. [Google Scholar] [CrossRef]
- Hu, J.; Zhou, Y.; Wang, H.; Qiao, P.; Wan, W. Research on Deep Learning Detection Model for Pedestrian Objects in Complex Scenes Based on Improved YOLOv7. Sensors 2024, 24, 6922. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Wu, T.; Li, X.; Dong, Q. An Improved Transformer-Based Model for Urban Pedestrian Detection. Int. J. Comput. Intell. Syst. 2025, 18, 68. [Google Scholar] [CrossRef]
- Garuda, N.; Prasad, G.; Dev, P.P.; Das, P.; Ghaderpour, E. CNNViT: A robust deep neural network for video anomaly detection. In Proceedings of the 4th International Conference on Distributed Sensing and Intelligent Systems (ICDSIS 2023), Dubai, United Arab Emirates, 21–23 December 2023; IET: Stevenage, UK, 2023; pp. 13–22. [Google Scholar]
- Teutsch, M.; Mueller, T.; Huber, M.; Beyerer, J. Low Resolution Person Detection with a Moving Thermal Infrared Camera by Hot Spot Classification. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 209–216. [Google Scholar]
- Chen, Y.; Shin, H. Pedestrian Detection at Night in Infrared Images Using an Attention-Guided Encoder-Decoder Convolutional Neural Network. Appl. Sci. 2020, 10, 809. [Google Scholar] [CrossRef]
- Zhao, Z.; Su, S.; Wei, J.; Tong, X.; Hu, L. Improving Infrared Pedestrian Detection by Sharing Visible Light Domain Information with Enhanced UNet and YOLO Models. In Proceedings of the 2023 IEEE 16th International Conference on Electronic Measurement & Instruments (ICEMI), Harbin, China, 9 August 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 21–25. [Google Scholar]
- Zhang, Z.; Wang, B.; Sun, W. Pedestrian Detection in Nighttime Infrared Images Based on Improved YOLOv8 Networks. In Proceedings of the 2023 9th International Conference on Computer and Communications (ICCC), Chengdu, China, 8 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2042–2046. [Google Scholar]
- Hao, S. Anchor-Free Infrared Pedestrian Detection Based on Cross-Scale Feature Fusion and Hierarchical Attention Mechanism. Infrared Phys. Technol. 2023, 131, 104660. [Google Scholar] [CrossRef]
- Zhang, J. An Infrared Pedestrian Detection Method Based on Segmentation and Domain Adaptation Learning. Comput. Electr. Eng. 2022, 99, 107781. [Google Scholar] [CrossRef]
- Wang, D.; Lan, J. PPDet: A Novel Infrared Pedestrian Detection Network in a per-Pixel Prediction Fashion. Infrared Phys. Technol. 2021, 119, 103965. [Google Scholar] [CrossRef]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection Using Deep Fusion Convolutional Neural Networks. In Proceedings of the 24th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral Deep Neural Networks for Pedestrian Detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully Convolutional Region Proposal Networks for Multispectral Person Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 243–250. [Google Scholar]
- Cao, Y.; Luo, X.; Yang, J.; Cao, Y.; Yang, M.Y. Locality Guided Cross-Modal Feature Aggregation and Pixel-Level Fusion for Multispectral Pedestrian Detection. Inf. Fusion 2022, 88, 1–11. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, L.; Cao, X. Improving Multispectral Pedestrian Detection by Addressing Modality Imbalance Problems. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2020; Volume 12363, pp. 787–803. [Google Scholar]
- Zhang, L.; Liu, Z.; Zhu, X.; Song, Z.; Yang, X.; Lei, Z.; Qiao, H. Weakly Aligned Feature Fusion for Multimodal Object Detection. IEEE Trans. Neural Netw. Learn. Syst. 2025, 36, 4145–4159. [Google Scholar] [CrossRef]
- Althoupety, A.; Wang, L.-Y.; Feng, W.-C.; Rekabdar, B. DaFF: Dual Attentive Feature Fusion for Multispectral Pedestrian Detection. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 17 June 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 2997–3006. [Google Scholar]
- Lee, S.; Park, J.; Park, J. CrossFormer: Cross-Guided Attention for Multi-Modal Object Detection. Pattern Recognit. Lett. 2024, 179, 144–150. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-Modality Interactive Attention Network for Multispectral Pedestrian Detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Li, R.; Xiang, J.; Sun, F.; Yuan, Y.; Yuan, L.; Gou, S. Multiscale Cross-Modal Homogeneity Enhancement and Confidence-Aware Fusion for Multispectral Pedestrian Detection. IEEE Trans. Multimed. 2024, 26, 852–863. [Google Scholar] [CrossRef]
- Chan, H.T.; Tsai, P.T.; Hsia, C.H. Multispectral Pedestrian Detection Via Two-Stream YOLO with Complementarity Fusion For Autonomous Driving. In Proceedings of the 2023 IEEE 3rd International Conference on Electronic Communications, Internet of Things and Big Data (ICEIB), Taichung, Taiwan, 14 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 313–316. [Google Scholar]
- Ryu, J.; Kim, J.; Kim, H.; Kim, S. Multispectral Interaction Convolutional Neural Network for Pedestrian Detection. Comput. Vis. Vision Image Underst. 2022, 223, 103554. [Google Scholar] [CrossRef]
- Yan, C.; Zhang, H.; Li, X.; Yang, Y.; Yuan, D. Cross-Modality Complementary Information Fusion for Multispectral Pedestrian Detection. Neural Comput. Appl. 2023, 35, 10361–10386. [Google Scholar] [CrossRef]
- Kim, J.; Kim, H.; Kim, T.; Kim, N.; Choi, Y. MLPD: Multi-Label Pedestrian Detector in Multispectral Domain. IEEE Robot. Autom. Lett. 2021, 6, 7846–7853. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; Kweon, I.S. Multispectral Pedestrian Detection: Benchmark Dataset and Baseline. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1037–1045. [Google Scholar]
- Guan, D. Fusion of Multispectral Data through Illumination-Aware Deep Neural Networks for Pedestrian Detection. Inf. Fusion 2019, 50, 148–157. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-Aware Faster R-CNN for Robust Multispectral Pedestrian Detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral Pedestrian Detection via Simultaneous Detection and Segmentation. arXiv 2018, arXiv:1808.04818. [Google Scholar]
- Jocher. Network Data. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 25 November 2024).
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Guided Attentive Feature Fusion for Multispectral Pedestrian Detection. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 72–80. [Google Scholar]
- Qingyun, F.; Dapeng, H.; Zhaokui, W. Cross-Modality Fusion Transformer for Multispectral Object Detection. arXiv 2022, arXiv:2111.00273. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Backbone | MR−2 (IoU = 0.5) (%) | Platform | Speed (s) | ||
|---|---|---|---|---|---|---|
| All | Day | Night | ||||
| ACF [38] | — | 47.32 | 42.65 | 56.17 | MATLAB | 2.73 |
| Halfway Fusion [23] | VGG-16 | 25.75 | 24.89 | 26.59 | TITAN X | 0.43 |
| Fusion RPN+ BF [24] | VGG-16 | 18.29 | 19.57 | 16.27 | MATLAB | 0.80 |
| IATDNN + IASS [39] | VGG-16 | 14.95 | 14.67 | 15.72 | TITAN X | 0.25 |
| IAF-RCNN [40] | VGG-16 | 15.73 | 14.55 | 18.26 | TITAN X | 0.21 |
| CIAN [30] | VGG-16 | 14.12 | 14.78 | 11.13 | 1080Ti | 0.07 |
| MSDS-RCNN [41] | VGG-16 | 11.34 | 10.54 | 12.94 | TITAN X | 0.22 |
| AR-CNN [27] | VGG-16 | 9.39 | 9.94 | 8.38 | 1080Ti | 0.12 |
| MBNet [26] | ResNet-50 | 8.13 | 8.28 | 7.86 | 1080Ti | 0.07 |
| TCCDNet (ours) | CSPDarknet53 | 7.87 | 8.66 | 6.43 | TITAN X | 0.05 |
| Model | Modality | Backbone | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| YOLOv5 [42] | RGB | CSPDarknet53 | 67.8 | 25.9 | 31.8 |
| YOLOv5 [42] | IR | CSPDarknet53 | 73.9 | 35.7 | 39.5 |
| Two-stream YOLOv5 [42] | RGB + IR | CSPDarknet53 | 73.0 | 32.0 | 37.4 |
| GAFF [43] | RGB + IR | VGG16 | 72.7 | 30.9 | 37.3 |
| GAFF [43] | RGB + IR | ResNet18 | 72.9 | 32.9 | 37.5 |
| CFT [44] | RGB + IR | CFB | 78.7 | 35.5 | 40.2 |
| TCCDNet (ours) | RGB + IR | CSPDarknet53 | 83.3 | 36.2 | 42.1 |
| Model | Modality | Backbone | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| YOLOv5 [42] | RGB | CSPDarknet53 | 90.8 | 51.9 | 50.5 |
| YOLOv5 [42] | IR | CSPDarknet53 | 94.6 | 72.2 | 61.9 |
| SSD [10] | RGB | VGG16 | 82.6 | 31.8 | 39.8 |
| GAFF [43] | IR | VGG16 | 90.2 | 57.9 | 53.5 |
| CCIFNet [34] | RGB + IR | ResNet50 | 97.6 | 72.6 | 63.6 |
| CFT [44] | RGB + IR | CFB | 97.5 | 72.9 | 63.6 |
| TCCDNet (ours) | RGB + IR | CSPDarknet53 | 97.3 | 78.4 | 67.8 |
| Model | MR−2 (IoU = 0.5) (%) | ||
|---|---|---|---|
| All | Day | Night | |
| Baseline | 11.70 | 13.14 | 9.18 |
| +CMC | 10.28 (−1.42) | 10.41 (−2.73) | 10.17 (+0.99) |
| +DSFM | 9.33 (−2.37) | 10.33 (−2.81) | 7.97 (−1.21) |
| +EMAC | 8.89 (−2.81) | 9.42 (−3.72) | 8.17 (−1.01) |
| TCCDNet | 7.87 (−3.83) | 8.66 (−4.48) | 6.43 (−2.75) |
| Model | Precision | Recall | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| Baseline | 82.4 | 67.7 | 79.7 | 31.3 | 38.9 |
| +CMC | 81.7 (−0.7) | 70.4 (+3.3) | 80.9 (+1.2) | 34.2 (+2.9) | 40.5 (+1.6) |
| +DSFM | 84.8 (+2.4) | 71.7 (+4.0) | 83.1 (+3.4) | 35.8 (+4.5) | 41.8 (+2.9) |
| +EMAC | 81.4 (−1.0) | 75.8 (+7.1) | 83.2 (+3.5) | 37.2 (+5.9) | 42.6 (+3.7) |
| TCCDNet | 83.9 (+1.5) | 72.5 (+4.8) | 83.8 (+3.6) | 36.2 (+4.9) | 42.1 (+3.2) |
| Model | Precision | Recall | mAP50 | mAP75 | mAP |
|---|---|---|---|---|---|
| Baseline | 93.9 | 89.3 | 95.4 | 73.2 | 63.7 |
| +CMC | 95.0 (+1.1) | 92.7 (+3.4) | 97.1 (+1.7) | 79.1 (+5.9) | 68.1 (+4.4) |
| +DSFM | 94.5 (+0.6) | 92.3 (+3.0) | 96.9 (+1.5) | 76.6 (+3.3) | 66.2 (+2.4) |
| +EMAC | 95.2 (+1.3) | 92.4 (+3.1) | 97.2 (+1.8) | 77.5 (+4.3) | 66.5 (+2.8) |
| TCCDNet | 95.2 (+1.3) | 93.1 (+3.8) | 97.3 (+1.9) | 78.4 (+5.2) | 67.8 (+4.1) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, S.; Chai, C.; Hu, M.; Wang, Y.; Jiao, T.; Wang, J.; Lv, H. TCCDNet: A Multimodal Pedestrian Detection Network Integrating Cross-Modal Complementarity with Deep Feature Fusion. Sensors 2025, 25, 2727. https://doi.org/10.3390/s25092727
Han S, Chai C, Hu M, Wang Y, Jiao T, Wang J, Lv H. TCCDNet: A Multimodal Pedestrian Detection Network Integrating Cross-Modal Complementarity with Deep Feature Fusion. Sensors. 2025; 25(9):2727. https://doi.org/10.3390/s25092727
Chicago/Turabian StyleHan, Shipeng, Chaowen Chai, Min Hu, Yanni Wang, Teng Jiao, Jianqi Wang, and Hao Lv. 2025. "TCCDNet: A Multimodal Pedestrian Detection Network Integrating Cross-Modal Complementarity with Deep Feature Fusion" Sensors 25, no. 9: 2727. https://doi.org/10.3390/s25092727
APA StyleHan, S., Chai, C., Hu, M., Wang, Y., Jiao, T., Wang, J., & Lv, H. (2025). TCCDNet: A Multimodal Pedestrian Detection Network Integrating Cross-Modal Complementarity with Deep Feature Fusion. Sensors, 25(9), 2727. https://doi.org/10.3390/s25092727