

Lightweight CNN-Based Visual Perception Method for Assessing Local Environment Complexity of Unmanned Surface Vehicle


Abstract
1. Introduction
2. Materials and Methods
2.1. Study Foundation
2.1.1. Establishment of Environmental Model
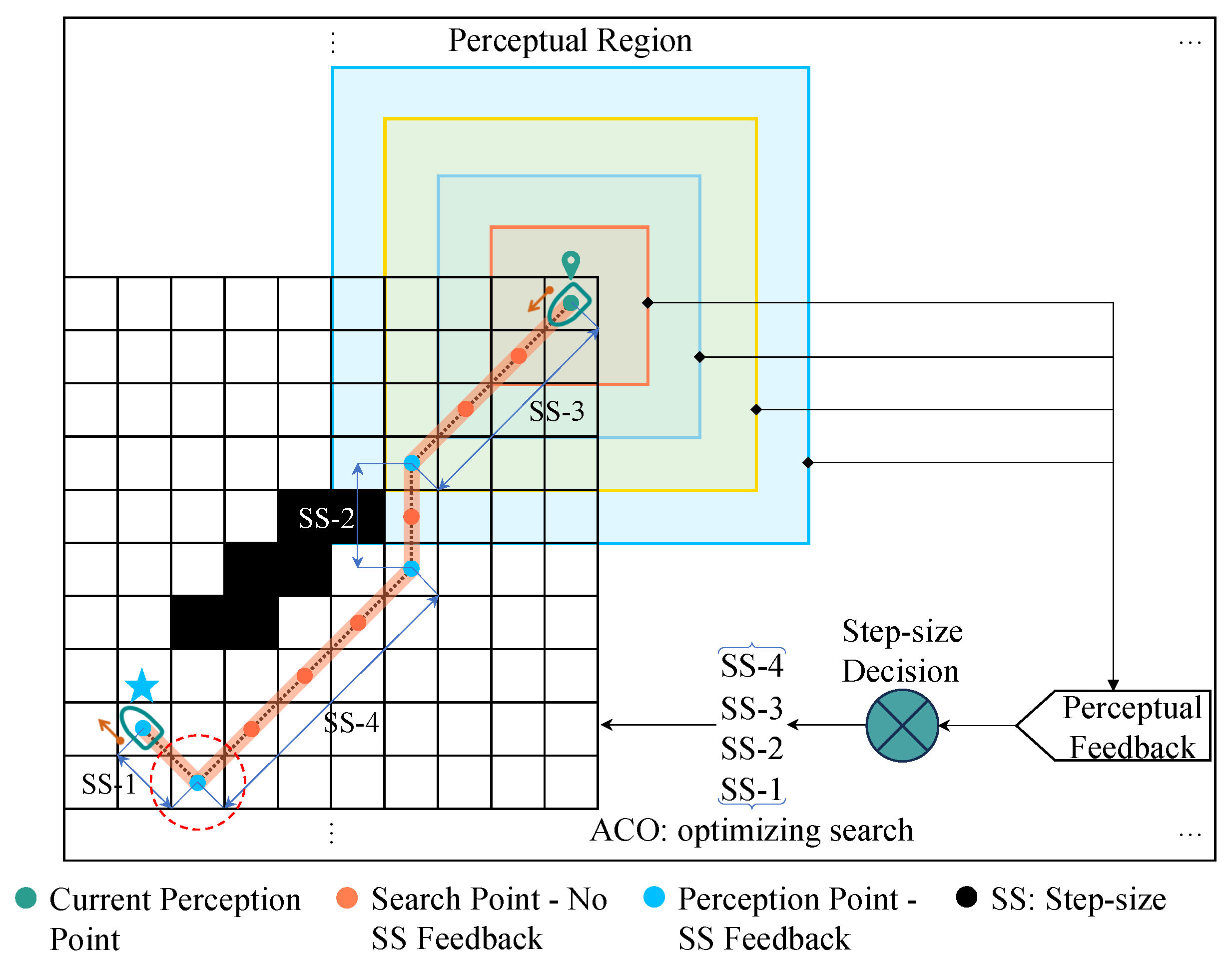
2.1.2. Updating Dynamic Obstacle Environments
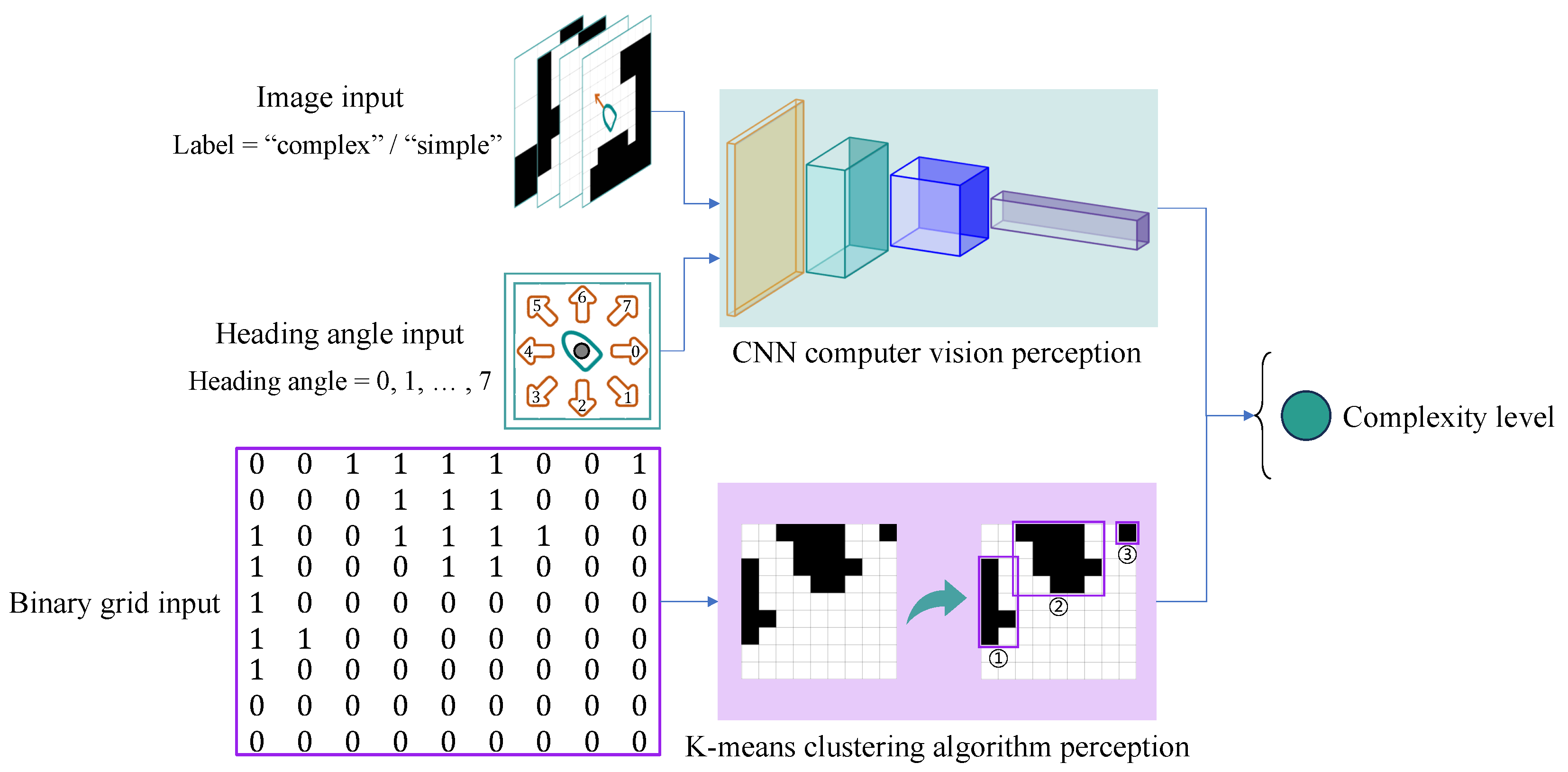
2.2. Perception of Environmental Complexity in Computer Vision
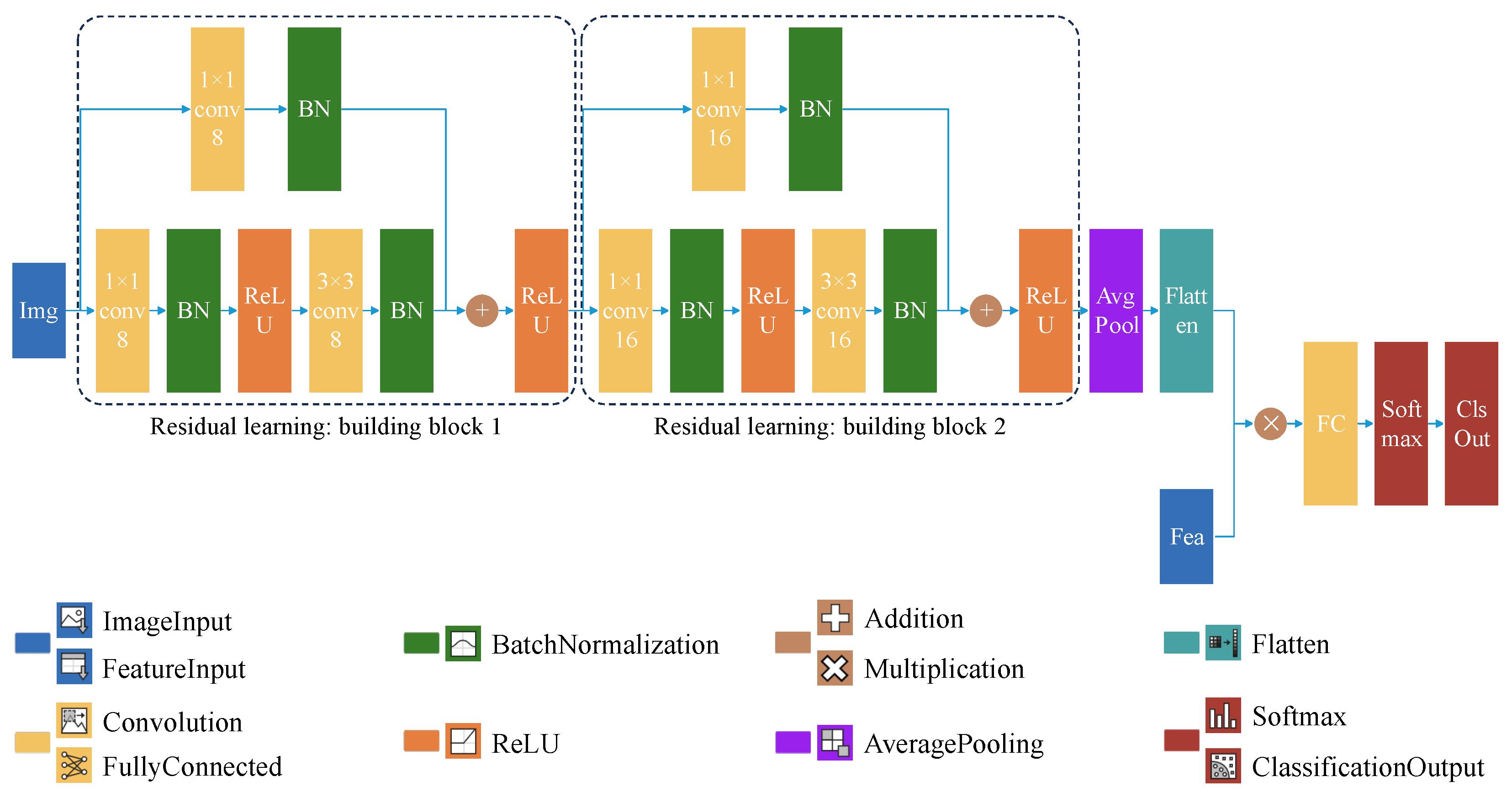
2.2.1. Lightweight Residual Learning Multi-Feature Fusion CNN
- Custom Lightweight CNN Architecture
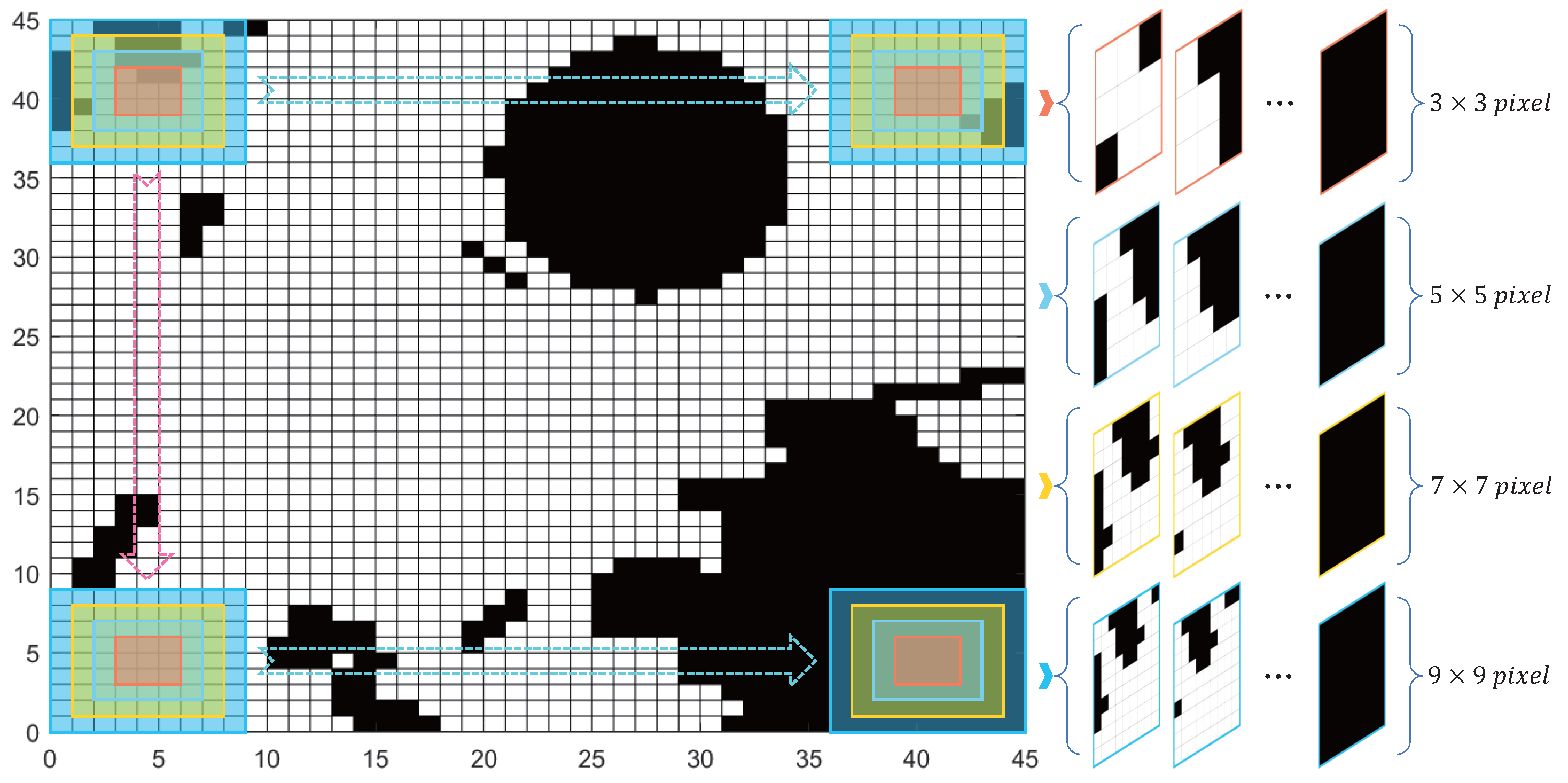
- Creation of Image Datasets
- Definition of Heading Angle Characteristics
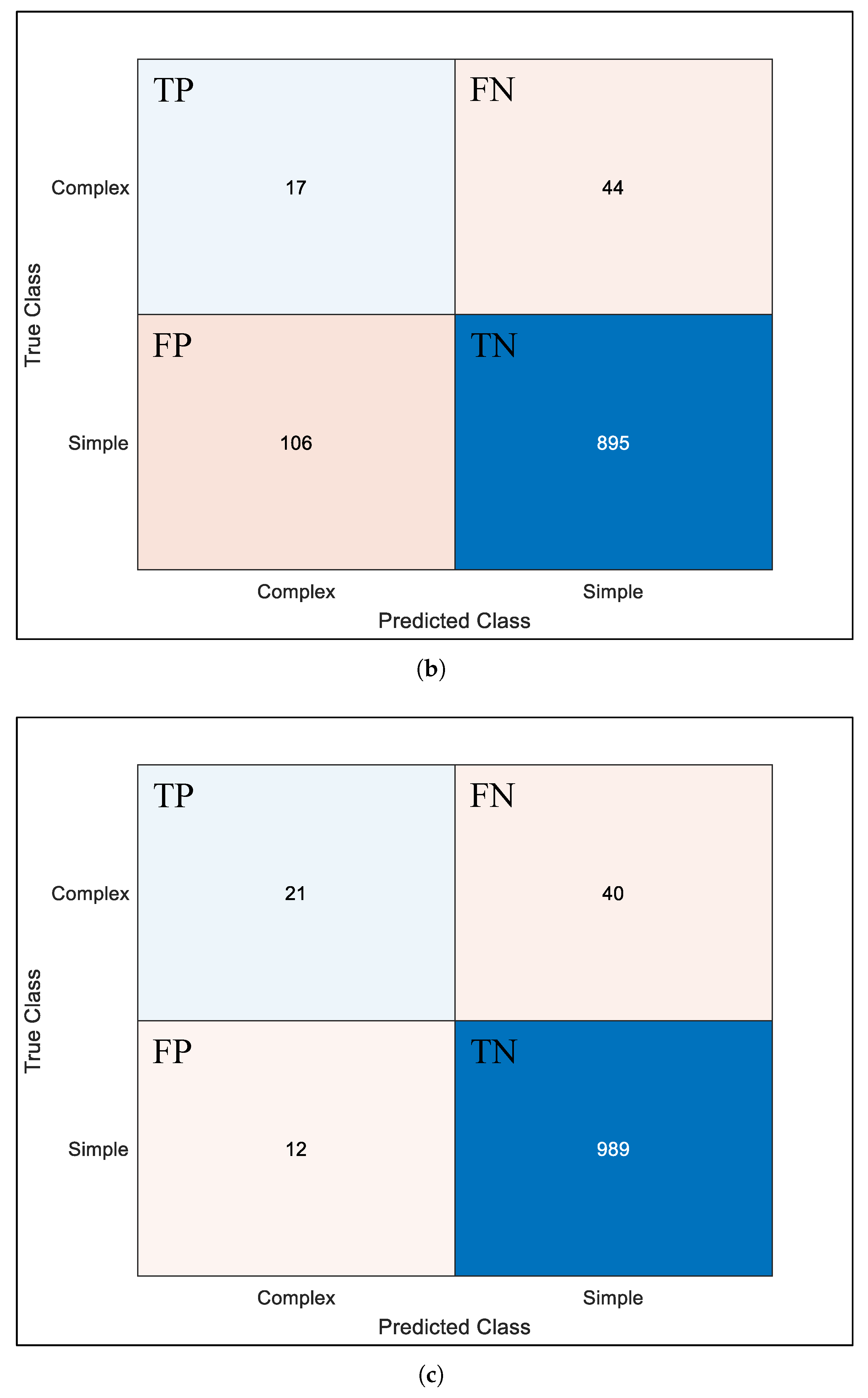
2.2.2. Model Training, Testing, and Evaluation
2.2.3. Ablation Experiment
| Algorithm 1 CNN complexity recognition and level evaluation matching strategy. |
| Input: , , G, |
| Output: , |
| 1: |
| 2: if “Complex” then |
| 3: |
| 4: else if “Simple” then |
| 5: if “Complex” then |
| 6: |
| 7: else if “Simple” then |
| 8: |
| 9: if “Complex” then |
| 10: |
| 11: else if “Simple” then |
| 12: |
| 13: if “Complex” then |
| 14: |
| 15: else if “Simple” then |
| 16: |
| 17: end if |
| 18: end if |
| 19: end if |
| 20: end if |
3. Methods Validation and Analysis
3.1. Configuration of Simulation
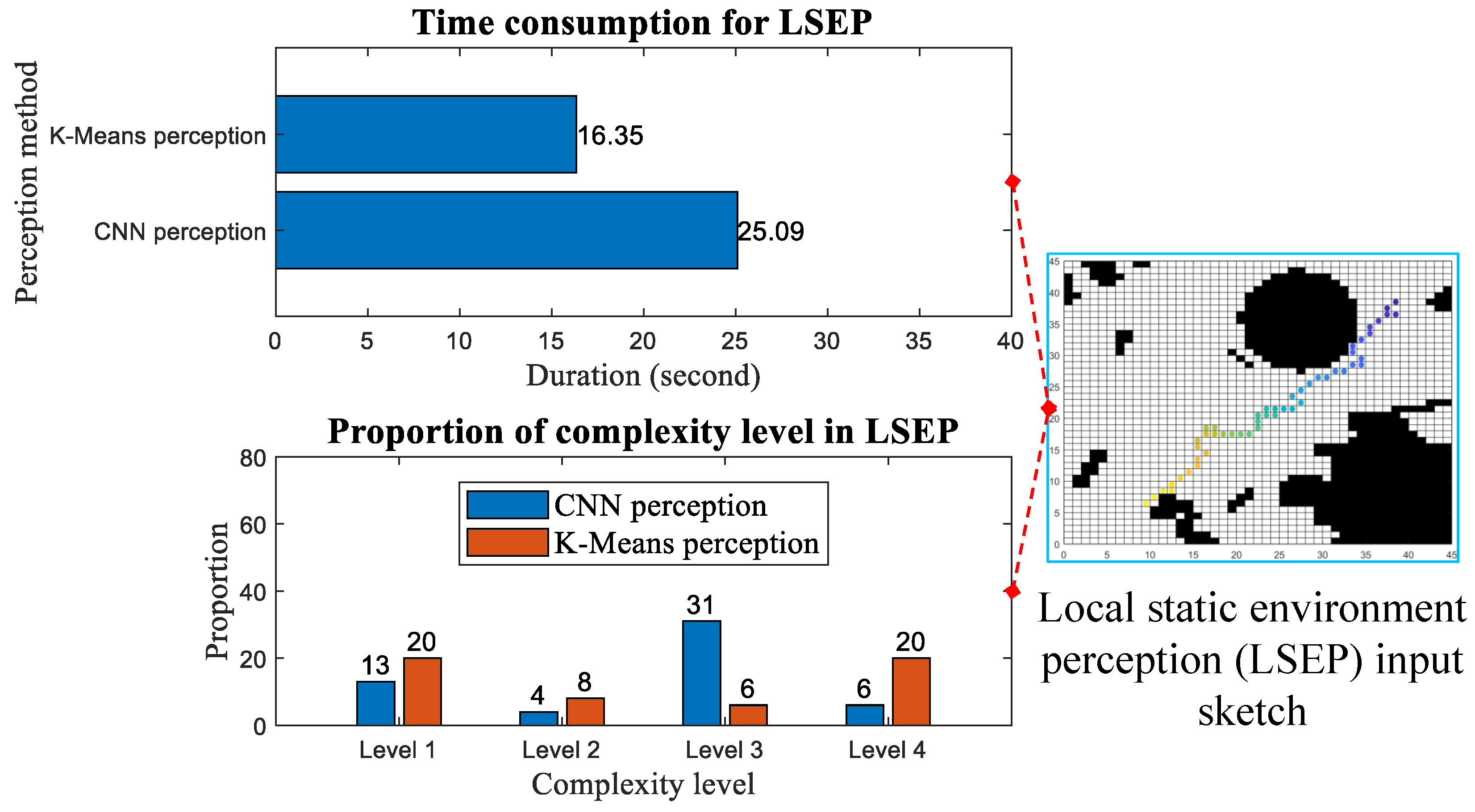
3.2. Perception of Local Static Environment
3.3. Perception of Global Dynamic Environment
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, L.; Wu, D.; Huang, Y.; Yuan, Z.M. A path planning strategy unified with a COLREGS collision avoidance function based on deep reinforcement learning and artificial potential field. Appl. Ocean Res. 2021, 113, 102759. [Google Scholar] [CrossRef]
- Zhou, B.; Huang, B.; Su, Y.; Wang, W.; Zhang, E. Two-layer leader-follower optimal affine formation maneuver control for networked unmanned surface vessels with input saturations. Int. J. Robust Nonlinear Control 2024, 34, 3631–3655. [Google Scholar] [CrossRef]
- Huang, B.; Song, S.; Zhu, C.; Li, J.; Zhou, B. Finite-time distributed formation control for multiple unmanned surface vehicles with input saturation. Ocean Eng. 2021, 233, 109158. [Google Scholar] [CrossRef]
- Vagale, A.; Bye, R.T.; Oucheikh, R.; Osen, O.L.; Fossen, T.I. Path planning and collision avoidance for autonomous surface vehicles II: A comparative study of algorithms. J. Mar. Sci. Technol. 2021, 26, 1307–1323. [Google Scholar] [CrossRef]
- Yin, L.; Zhang, R.; Gu, H.; Li, P. Research on cooperative perception of MUSVs in complex ocean conditions. Sensors 2021, 21, 1657. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Yang, H.; Zhu, M.; Wang, F.; Vaa, T.; Wang, Y. Real-Time Multi-Task Environmental Perception System for Traffic Safety Empowered by Edge Artificial Intelligence. IEEE Trans. Intell. Transp. Syst. 2024, 25, 517–531. [Google Scholar] [CrossRef]
- Öztürk, Ü.; Akdağ, M.; Ayabakan, T. A review of path planning algorithms in maritime autonomous surface ships: Navigation safety perspective. Ocean Eng. 2022, 251, 111010. [Google Scholar] [CrossRef]
- Zhang, Y.; Peng, P.; Jie, C. Local path planning for USV based on improved APF algorithm. J. Ordnance Equip. Eng. 2023, 44. [Google Scholar]
- Liu, X.; Tan, L.; Yang, C.; Zhai, C. Self-adjustable dynamic path planning of unknown environment based on ant colony-clustering algorithm. J. Front. Comput. Sci. Technol. 2019, 13, 846–857. [Google Scholar]
- Yuan, X.; Feng, Z. A Study of Path Planning for Multi- UAVs in Random Obstacle Environment Based on Improved Artificial Potential Field Method. In Proceedings of the 2022 China Automation Congress (CAC), Xiamen, China, 25–27 November 2022; pp. 5241–5245. [Google Scholar]
- Zitong, Z.; Xiaojun, C.; Chen, W.; Ruili, W.; Wei, S.; Feiping, N. Structured multi-view k-means clustering. Pattern Recognit. 2025, 160, 111113. [Google Scholar]
- Vardakas, G.; Likas, A. Global k-means++: An effective relaxation of the global k-means clustering algorithm. Appl. Intell. 2024, 54, 8876–8888. [Google Scholar] [CrossRef]
- Zhao, Y. Research on Environment Sensing Technology of Electricity Distribution Room Inspection Robot Based on Semantic Segmentation. Master’s Thesis, Xi’an Technological University, Xi’an, China, 2024. [Google Scholar]
- Jiang, P. Lightweight Object Detection Method for Unmanned Surface Vehicles Under Few Shot Scenario. Master’s Thesis, Harbin Engineering University, Harbin, China, 2023. [Google Scholar]
- Sorial, M.; Mouawad, I.; Simetti, E.; Odone, F.; Casalino, G. Towards a real time obstacle detection system for unmanned surface vehicles. In Proceedings of the OCEANS 2019 MTS/IEEE SEATTLE, Seattle, WA, USA, 27–31 October 2019; pp. 1–8. [Google Scholar]
- Li, Q.; Pei, B.; Chang, F. SAR image classificationmethod based on multilayer convolution neural network. J. Detect. Control 2018, 40, 85–90. [Google Scholar]
- Zhu, B.; Wang, Y. Lightweight small target detection algorithm based on multi-scale cross-layer feature fusion. J. Detect. Control 2023, 45, 77–86. [Google Scholar]
- Yang, R.; Liu, F.; Hao, Y. YOLOX-S based acousto-optical information fusion target recognition algorithm. J. Detect. Control 2024, 46, 71–79. [Google Scholar]
- Zhang, W.; Goerlandt, F.; Montewka, J.; Kujala, P. A method for detecting possible near miss ship collisions from AIS data. Ocean Eng. 2015, 107, 60–69. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Bishop, C.M.; Nasrabadi, N.M. Pattern Recognition and Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4. [Google Scholar]
- Bianco, S.; Cadene, R.; Celona, L.; Napoletano, P. Benchmark analysis of representative deep neural network architectures. IEEE Access 2018, 6, 64270–64277. [Google Scholar] [CrossRef]
- Pan, S.Q.; Qiao, J.F.; Rui, W.; Yu, H.L.; Cheng, W.; Taylor, K.; Pan, H.Y. Intelligent diagnosis of northern corn leaf blight with deep learning model. J. Integr. Agric. 2022, 21, 1094–1105. [Google Scholar] [CrossRef]
- Hua, C.; Chen, S.; Xu, G.; Lu, Y.; Du, B. Defect identification method of carbon fiber sucker rod based on GoogLeNet-based deep learning model and transfer learning. Mater. Today Commun. 2022, 33, 104228. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Input Resolution | Evaluation Indicators | |||
|---|---|---|---|---|---|
| Layers | Total Learnables | FLOPs (M) | Acc (%) | ||
| Proposed | 26 | 223.2K | 163.37 | 89.36 | |
| SqueezeNet | 68 | 722.3K | 35,019.96 | 90.07 | |
| MobileNetV2 | 154 | 2.2M | 306.18 | 90.67 | |
| ShuffleNet | 176 | 862.3K | 300.72 | 90.56 | |
| Models | Evaluation Indicators | |||
|---|---|---|---|---|
| Pre (%) | Rec (%) | F1 | Acc (%) | |
| CNN_SS1 | 76.67 | 38.98 | 51.68 | 89.86 |
| CNN_SS2 | 53.57 | 38.46 | 44.77 | 89.84 |
| CNN_SS3 | 32.00 | 23.19 | 26.89 | 90.74 |
| CNN_SS4 | 22.92 | 36.07 | 28.03 | 89.36 |
| Parameters | Initial Value | |
|---|---|---|
| CNN | K-Means | |
| Pheromone factor | 1 | 1 |
| Heuristic factor | 14 | 14 |
| Pheromone volatilization coefficient | 0.3 | 0.3 |
| Pheromone concentration enhancement factor | 1 | 1 |
| Number of ants | 12 | 12 |
| Maximum iterations | 10 | 10 |
| Number of relay points | 2 | 2 |
| Step size | 1–4 | 1–4 |
| Number of clusters (k) | - | 4 |
| Perception Point | Perception Methods | Complexity Levels of VHA | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| 366 | CNN | 2 | 3 | 3 | 3 | 4 | 4 | 4 | 4 |
| K-Means | 2 | ||||||||
| 1556 | CNN | 4 | 4 | 4 | 4 | 4 | 4 | 1 | 1 |
| K-Means | 3 | ||||||||
| 1445 | CNN | 1 | 1 | 3 | 4 | 4 | 4 | 4 | 4 |
| K-Means | 4 | ||||||||
| Perception Methods | Evaluation Metrics | |||||
|---|---|---|---|---|---|---|
| NTN | TT | TA | TC | PL | APR | |
| CNN ⊝ | 77 | 41 | 35.3 | 32.3 | 58.4 | 96.6 |
| K-Means ⊝ | 90 | 46 | 36.1 | 48.2 | 66.0 | 73.3 |
| CNN ⊚ | 63 | 26 | 21.9 | 38.3 | 52.5 | 96.6 |
| K-Means ⊚ | 73 | 31 | 24.3 | 45.4 | 58.4 | 90.0 |
| CNN ⊛ | 50 | 21 | 18.1 | 30.3 | 41.5 | 96.6 |
| K-Means ⊛ | 51 | 19 | 21.2 | 31.5 | 42.1 | 86.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, T.; Zhang, X.; Huang, Y.; Yang, C. Lightweight CNN-Based Visual Perception Method for Assessing Local Environment Complexity of Unmanned Surface Vehicle. Sensors 2025, 25, 980. https://doi.org/10.3390/s25030980
Li T, Zhang X, Huang Y, Yang C. Lightweight CNN-Based Visual Perception Method for Assessing Local Environment Complexity of Unmanned Surface Vehicle. Sensors. 2025; 25(3):980. https://doi.org/10.3390/s25030980
Chicago/Turabian StyleLi, Tulin, Xiufeng Zhang, Yingbo Huang, and Chunxi Yang. 2025. "Lightweight CNN-Based Visual Perception Method for Assessing Local Environment Complexity of Unmanned Surface Vehicle" Sensors 25, no. 3: 980. https://doi.org/10.3390/s25030980
APA StyleLi, T., Zhang, X., Huang, Y., & Yang, C. (2025). Lightweight CNN-Based Visual Perception Method for Assessing Local Environment Complexity of Unmanned Surface Vehicle. Sensors, 25(3), 980. https://doi.org/10.3390/s25030980