1. Introduction
With the advancement of the Internet, an increasing number of individuals are inclined to express their opinions on social media platforms. Most of these opinions are conveyed through multimodal forms, combining text and images, which encapsulate rich sentiment polarity information directed at various aspects. To capture such nuanced information, the field of aspect-based multimodal sentiment analysis (ABMSA) has emerged.
ABMSA is a subfield of multimodal sentiment analysis (MSA). By integrating information from multiple modalities, MSA offers more accurate extraction of sentiment features compared to single-modal methods. For social media platforms, MSA primarily focuses on text and images. The content in text-image pairs of social media exhibits rich interactions. First, there is a correspondence between the text and the image. For instance, in
Figure 1a, the “client” mentioned in the text corresponds to the “negative people” in the embedded text in the image, while the reclining girl in the image suggests that “I” am trying to calm my emotions. Second, there is often a complementary relationship between modalities. For example, in
Figure 1c, the text alone suggests that the sentimental polarity of “grandma” is likely not negative, but when supplemented with the smiling figure in the image, there is sufficient reason to determine her polarity as positive. Hence, by modeling the interactions between different modalities, MSA can effectively capture sentiment components that may be difficult to infer from a single modality alone, thereby providing more precise sentiment analysis for aspect-based targets.
Nevertheless, accurately capturing cross-modal interactions of the same aspect across different modalities remains one of the key challenges for ABMSA. Currently, researchers [
1,
2,
3,
4,
5] tend to extract image and text features separately and then apply attention mechanisms to fuse them. However, images on social media often contain embedded text (text-in-image), which can influence how users interpret the overall content. For example, the embedded text in
Figure 1a conveys a sentiment polarity that is entirely opposite to the overall sentiment of the image, while the image modality in
Figure 1b consists solely of text, offering little visual information for reference. As a result, disregarding text-in-images may lead to errors in sentiment analysis. Moreover, the model’s performance is also influenced by the differences in modal representations, which may introduce additional noise during the feature fusion phase. Some existing methods [
6,
7,
8,
9] mitigate such noise by converting images into textual representations (e.g., image descriptions, object descriptions, or emotion annotations). However, these approaches require additional image understanding models as support, leading to increased training and inference costs.
To address these challenges, we propose a text-in-image enhanced self-supervised alignment model (TESAM). Specifically, we first design a novel image feature extraction module that simultaneously captures both visual features and text-in-image. Since text-in-image should be regarded as part of the image modality, we have customized the image feature extractor to fuse visual features with these texts, and use aspect words to guide the model’s focus on the image modality. This approach maps visual image and text-in-image to the same embedding space, enhancing the original visual representation. Next, we introduce a bidirectional interaction module to capture the bidirectional interaction between enhanced image representation (EIR) and the extracted textual features, allowing us to identify how the same aspect is expressed across different modalities and extract the associated sentiment components. Before model training, we propose using multiple distance metrics to pre-train the feature extraction module on the image caption dataset using self-supervised learning. This approach aims to narrow the semantic gap between modalities and reduce the introduction of additional noise. Finally, through a classification module, the extracted sentiment features are categorized into distinct sentiment polarity classes for output.
In summary, the main contributions of this paper can be outlined as follows:
- (1)
We propose a text-in-image enhanced self-supervised alignment model (TESAM) for social media sentiment analysis. By incorporating text-in-image, TESAM enables more comprehensive sentiment-level analysis of multimodal content compared to existing models, reducing misjudgments caused by information loss.
- (2)
We design a text-in-image-enhanced image feature extraction module. This module simultaneously extracts visual features and embedded text, employing an early fusion strategy with an aspect-guided attention mechanism to integrate both modalities, thereby obtaining more comprehensive image representations.
- (3)
We introduce a self-supervised pre-training paradigm using an image-caption dataset to align the model’s feature extraction modules before formal training. By learning from highly correlated image-text pairs, this approach mitigates modal gaps, reduces additional noise during subsequent feature fusion, and enhances model performance.
- (4)
We conduct extensive and detailed experiments on three ABMSA benchmarks, demonstrating that the proposed method achieves a performance exceeding that of traditional approaches.
2. Related Works
In this section, we will provide a concise overview of prior contributions, encompassing the fields of ABMSA and optical character recognition (OCR).
2.1. Aspect-Based Multimodal Sentiment Analysis
Aspect-based multimodal sentiment analysis usually detects an aspect’s sentiment by combining expressions across different modalities, such as textual, image, video, and auditory information [
10]. This approach enables a more comprehensive analysis of sentiments, expressions, and context, particularly in applications where sentiments are conveyed through diverse channels [
11,
12].
For social media, the primary modalities are image and text, which contain rich aspect-level sentiment polarities that can be extracted and analyzed. Xu et al. [
13] are pioneers in advancing the ABMSA task, proposing the Multi-Interactive Memory Network (MIMN). This model combines attention and gating modules to learn the interaction effects between multimodal data and the self-influence within unimodal data, enabling aspect-level sentiment analysis. However, the fusion method used in MIMN is relatively basic, and the extraction of sentiment features is not comprehensive enough. Therefore, with the rise of transformer-based models [
14], Yu et al. [
1] introduced an additional image branch into BERT (Bidirectional Encoder Representations from Transformers), enabling aspect words to query images to support text sentiment analysis. They proposed the Target-Oriented Multimodal BERT (TomBERT), characterized by the integration of cross-modal attention to generate aspect-sensitive representations. However, TomBERT still focused primarily on text and did not fully exploit image features. Subsequently, Yu et al. [
4] advanced their work by proposing the Hierarchical Interactive Multimodal Transformer (HIMT). HIMT utilized Faster R-CNN (Region- Convolutional Neural Networks) [
15] to enrich image representations and designed an auxiliary reconstruction module to mitigate the semantic gap between modalities. Nevertheless, these methods overlook the influence of text-in-image, which is widely distributed across social media. Such text is challenging for image feature extractors to capture, but can provide critical insights for sentiment analysis.
Additionally, other efforts to bridge the gap include innovative approaches such as Khan et al.’s method [
8], which employed self-supervised learning to transform image semantics into textual descriptions using image understanding models. Zhao et al. [
5] proposed generating adjective–noun pairs (ANPs) to aid in modality alignment. Li et al. [
6] enriched image modality representation by converting images into textual forms, including image descriptions, facial expressions, and OCR-extracted text. Though these methods effectively align images with the text modality, they rely on additional image understanding models, which can increase training and inference costs. Moreover, their handling of text-in-image remains limited. For instance, Li et al. [
6] simply concatenate textual descriptions of images without leveraging aspect words to guide the alignment process.
To address these limitations, we introduce text-in-image with inserted aspect words to enable a more comprehensive sentiment analysis of multimodal content. We also propose leveraging additional highly correlated image-text pairs to align different modalities, rather than focusing on the low image-text correlation in the ABMSA task datasets.
2.2. Optical Character Recognition
Optical character recognition refers to the technology used for detecting and converting printed or handwritten text in images into machine-readable text.
Traditional OCR methods are generally based on template matching, wherein the similarity between an image region and predefined templates is calculated to select the most similar category, thereby identifying potential characters in the image. These methods are limited to specific fonts and contexts, suffering from poor generalization capabilities, and thus are not widely applicable. More advanced OCR approaches leverage deep learning techniques and typically involve two stages: detection and recognition. In the detection phase, some studies have developed highly accurate algorithms based on Regions with CNN (RCNN) [
16] and its improved model, Faster R-CNN [
15], while others have applied single-step detection models like SSD (Single Shot MultiBox Detector) [
17] or YOLO (You Only Look Once) [
18] to achieve faster detection speeds. Once the character locations are identified, classification is typically handled by visual recognition methods based on CNN or sequence recognition methods based on RNN. These methods achieve higher accuracy by autonomously learning the necessary features, making them more adaptable to various scenarios. However, CNNs struggle to recognize character sequences in images, while RNNs cannot be trained end-to-end. To address these limitations, Shi et al. [
19] proposed the Convolutional Recurrent Neural Network (CRNN) architecture, which combines CNN and RNN (Recurrent Neural Network). This approach preserves the end-to-end training paradigm while enabling sequence recognition, demonstrating state-of-the-art performance in comparative experiments.
In the context of multimodal sentiment analysis, OCR plays an essential role by extracting embedded text from images that can significantly influence interpretation. Incorporating text-in-image in multimodal sentiment analysis allows for a fuller understanding of both visual and textual elements, providing a more comprehensive assessment of the content’s sentiment.
3. Methods
3.1. Task Definition
Given a set of multimodal samples, in which represents one pair of text-image samples with a tagged aspect, Ti is a sequence of word tokens , Ii is an image tensor of shape (3,224,224), and Ai is the aspect word(s) in Ti. Further, is associated with a label , where l is the number of sentiment classes. The value of yi represents the sentiment polarity of the aspect word(s) Ai, from 1 (negative) to l (positive). Our goal is to use to train a model that can correctly predict y for each input of .
3.2. Overview of Our Proposed Model
Figure 2 illustrates the overall architecture of TESAM. Considering that the extraction of sentiment components is a process that progresses from low-level features to high-level features and from unimodal to multimodal, TESAM is divided into three modules: (1) feature extraction module: In this module, we innovatively incorporate the features from text-in-images and fuse them with the pure visual features extracted through convolutional neural networks (CNN). This process encodes both types of features into the same embedding space, resulting in an enhanced image representation (EIR). For the textual modality, we utilize the advanced pre-trained language model BERT to extract semantic features, which serve as the foundation for multimodal analysis. (2) Bidirectional interaction module: This module is designed to capture the bidirectional interactions between EIR and textual representation, then identify how the same aspect is expressed across different modalities. By doing so, it enables more accurate extraction of sentiment components relevant to specific aspects in both image and text. (3) Classification module: After obtaining a comprehensive multimodal representation, the extracted sentiment features are passed through a classification module. This module distinguishes the sentiment polarities (e.g., negative, neutral, positive) and outputs the final sentiment classification based on the combined multimodal analysis.
3.3. Feature Extraction Module
We design a feature extraction module to extract preliminary sentimental representations of images and texts as the basis for sentiment analysis.
3.3.1. BERT for Text Feature Extraction
To convert the text sample
Ti into textural feature
(
N is the length of the input sequence,
d is the dimension of the embeddings), we adopt BERT [
14], a pre-trained masked language model (MLM) that has achieved state-of-the-art performance in many natural language processing (NLP) tasks, as the text feature extractor. As shown in
Table 1, the input text fed into BERT is augmented with “[CLS]” and “[SEP]” tokens to mark the beginning and break or end of the sentence, respectively. For the ABMSA task,
is inserted into the input, indicating the target of sentiment analysis.
BERT accepts a sequence of fixed-length tokens
Ti as input and is able to capture long-distance dependencies in the text through the multi-head self-attention mechanism. First, BERT converts
Ti into
through word embedding:
Then, BERT
base stacks transformer encoder (TE) layers 12 times to obtain
:
3.3.2. Image Encoder for Enhanced Image Feature Extraction
ResNet [
20] is a lightweight residual CNN that has achieved remarkable results on the ImageNet dataset. For the image modality, ResNet-18 is employed to extract pure visual feature
from resized image sample
:
where
is applied to map visual features with
c channels into a
d-dimensional embedding space. Compared to other deeper versions, ResNet-18 has fewer parameters while achieving comparable performance, making it suitable for preliminary visual feature extraction.
Subsequently, to map and encode the pure visual features into the same embedding space as text features, we first utilize patch embedding [
21] and transformer encoder layers:
Here, Conv(·) represents the convolutional layer for dimension mapping, as the foundation for modality alignment. Flatten(·) reshapes the feature map generated by the convolutional layer into a sequence to concatenate with the [CLS] token. “CLS” is a randomly initialized classification token, while
represents the randomly initialized positional encoding. The addition of the positional encoding enables the model to automatically learn and reconstruct the spatial relationships between image patches [
21]. Additionally,
t represents the number of stacked TE layers, the specific value of which will be discussed in detail in the
Section 4.
In addition to pure visual features, the embedded text in images may contain information that is crucial for aspect-based sentiment analysis. Thus, text-in-image is often an essential component that cannot be overlooked. These texts may be presented in various fonts, colors, and orientations, making extraction challenging. Therefore, we chose to employ EasyOCR [
22], an open-source text recognition engine developed by JaidedAI, to identify the text-in-image:
where
is a sequence of text, and “[·, ·]” denotes the concatenation operation. By inserting the aspect word
into the text-in-image, the model’s attention is directed towards image regions associated with
, enabling the extraction of specific sentiment components while minimizing interference from irrelevant noise.
EasyOCR demonstrates state-of-the-art performance, enabling rapid localization and recognition of text-in-images, thereby supplementing the semantic features of the image modality. This enhancement provides more comprehensive contexts for ABMSA, improving classification accuracy and making it suitable for our targeted social media platforms.
Thus, for the text-in-image, we employ BERT to extract its semantic features, thereby enhancing the overall representation of the sample:
where “*” indicates that this BERT shares trainable parameters with BERT in Equation (1). By applying parameter sharing, we significantly reduce the number of trainable parameters in the model while ensuring the effective extraction of features, thereby lowering the costs associated with model training.
Next, we extended self-attention [
14] to a multi-head cross-modal attention (MCA) mechanism. Specifically, in self-attention, the input is copied into queries, keys, and values. The query vector determines what content to focus on in the mechanism, while the key and value vectors represent the information of the queried objects. Therefore, by modifying the queries to vectors that come from visual modality, MCA is able to highlight sentimental relationships from embedded text to image:
where
are the weights of linear layers and
,
,
. In addition,
m is the number of attention heads. This attention mechanism facilitates interaction between the two types of features to capture the full context of the image, including both visual and textual cues.
At last, we utilize skip connections and layer normalization (LN) to construct the image encoder (IE) and output EIR
:
3.4. Bidirectional Interaction Module
The bidirectional interaction (BI) module consists of stacked bidirectional interaction layers, which use cross-modal attention to capture the rich interaction between EIR and text feature, further extracting cross-modal sentimental feature, and ultimately obtaining high-level sentiment representation (HSR). Since the EIR and textual features reside in the same dimensional embedding space, we designed this module with a symmetrical structure, encompassing cross-modal fusion from image to text as well as from text to image.
3.4.1. Image-to-Text Cross-Modal Fusion
To enable interaction from
to
, similar to the cross-modal attention mechanism in the IE, we applied
to highlight a sentimental relationship from image to text:
where
is the weight parameter, and the
j-th head:
where
are attention weight parameters to be trained. In our model,
helps the model highlight the text related to the aspect in the image, thereby achieving the goal of feature fusion.
Next, we use FNN (Feedforward Neural Network) and layer normalization to further extract the fused features:
where
This structure further facilitates the processing and refinement of the extracted features, enabling the model to effectively focus on the sentiment information in the text that is relevant to the image, thereby eliminating the interference of irrelevant components on the classification results.
3.4.2. Text-to-Image Cross-Modal Fusion
Firstly, similar to
, we replace the query input of multi-head attention with image features enhanced by text-in-image to design
:
where
are the weights of the linear layers. This highlights the parts of EIR that are most closely associated with the sentiment in text feature through correlation calculation.
Next,
and FNN together constitute the sentiment encoder on the image side. Through
, the EIR that has been encoded with sentiment in text after interaction becomes the hidden image representation with more prominent sentimental features:
where
enhances the understanding of the sentimental content in images by incorporating textual information, thereby enriching the multimodal representation of sentiments in the high-level image feature.
Finally, the entire bidirectional interaction layer is stacked
s times to fully facilitate multimodal interaction between text and image:
leading to the final sentiment representation
. The impact of the value of
s on the model’s performance will be discussed in the
Section 4.
3.5. Classification Module
The final sentiment representation highly abstracted sentiment features and can be directly utilized for classification. Therefore, we employ fully connected layers to, respectively, map it to decision-level sentiment scores
. To be specific, the hidden state of the [CLS] token
is defined as the holistic representation of the two sequences for classification, so we pick them as the sentiment feature representations for the entire sample. Then,
is passed through FNN to derive
:
Subsequently, a weighted average function combined with softmax normalization is applied to determine the prediction class
for each sentiment category:
where
is a weight parameter, and
selects the index of the maximum value in a vector as its output.
3.6. Self-Supervised Alignment
In multimodal learning, the alignment of features between image and text is crucial. Absence of alignment may increase the difficulty of model training, as there are significant differences in the representations provided by their respective feature extractors in the feature space. Thus, we propose performing self-supervised learning to effectively align image and text representations before the formal training process. This helps to reduce the semantic gap between the two modalities, minimizes the noise interference caused by feature fusion, and ultimately improves the model’s performance. During self-supervised alignment, we use an additional image captioning dataset instead of the task-specific ABMSA dataset. This is because the ABMSA dataset often contains a significant amount of noise and interference, with some instances where the image and text are irrelevant. In contrast, image captioning datasets are designed from the outset with highly relevant image-text pairs. This high semantic consistency between image and text is able to build the foundation for effective modality alignment.
To perform self-supervised alignment, we divide the model training into two stages. In the pre-training stage, we train the feature extraction module of TESAM using an image captioning dataset. First, we input the image and its corresponding caption into the feature extraction module to obtain the representations
for each modality:
In Equation (20),
refers to the removal of the text-in-image-related components in the IE, leaving only the components responsible for pure visual feature extraction. Specifically, EasyOCR and BERT* in the IE module are removed (for images in the image caption dataset almost never contain text), and the output of TE is used as the query sequence for the cross-modal attention, reducing it to self-attention. Since the aligned features from ResNet+TE and BERT are located in the same embedding space and can generate correlated feature representations for semantically related content, the cross-modal attention mechanism is less likely to be affected. Moreover, BERT* in the IE module and the BERT used for textual feature extraction share the same weight parameters, allowing them to benefit from the advantages of self-supervised alignment. Thus, in the next step, we constructed the loss function using mean squared error (MSE) and cosine similarity (CosSim) for self-supervised alignment:
This design aims to comprehensively account for both the Euclidean distance and the angular relationship between modality representations in the embedding space. By doing so, it ensures that the feature extractor produces tightly coupled and consistent multimodal representations for semantically similar image-text pairs.
3.7. Loss Function
After employing self-supervised learning for modal alignment, in the training stage, we use cross-entropy loss to train the whole network. Cross-entropy loss directly measures the discrepancy between the category distribution of the model’s output and the distribution of true labels:
where
indicates the true label of the input multimodal data.
3.8. Training Procedure
The pseudocode in Algorithm 1 outlines the training procedure of TESAM. First, the feature extraction module undergoes self-supervised pre-training on the COCO-Captions dataset to align its image and text feature outputs. Then, the aligned feature extraction module parameters are transferred to TESAM, which is fine-tuned on the ABMSA task dataset. However, at this stage, the bidirectional interaction module and classification module remain untrained, with randomly initialized parameters. Therefore, during the initial fine-tuning phase, the feature extraction module’s parameters are frozen while the other parameters are warmed up. Finally, TESAM undergoes full fine-tuning to achieve multimodal sentiment analysis. The learning rates follow a decay strategy, the specific update rules are listed in
Section 4.2.
| Algorithm 1 Training procedure of TESAM |
Input: Dataset for alignment , task-specific dataset , Image Encoder’s parameters , Text Encoder’s parameters , TESAM’s parameters , training epochs and , learning rates and
# Phase 1: Self-supervised Alignment
1: for epoch in do
2: for in do
3: # extract text feature
4: # extract visual feature
5: # alignment loss
6: # update parameters
7: # update parameters
8: # update learning rate
9: end for
10: end for
# Phase 2: Fine-tuning on task-specific dataset
11: # transfer aligned encoder parameters to TESAM
12: for epoch in do
13: for in do
14: # predict sentiment label
15: # classification loss
16: if () then
17: # warm up other parameters in TESAM
18: else
19: # fine-tune the whole model
20: end if
21: # update learning rate
22: end for
23: end for |
4. Experiment
4.1. Datasets
4.1.1. TWITTER Datasets and Multi-ZOL Dataset for ABMSA Task
To comprehensively demonstrate the effectiveness of our proposed method, we conducted experiments using a finer-grained ABMSA task. So, we choose 3 benchmark datasets—TWITTER-15, TWITTER-17 [
1], and Multi-ZOL [
13]—for our experiments.
The TWITTER datasets comprise tweets gathered from 2015 to 2017. Each data instance in these datasets corresponds to one or more aspect-level texts (targets), with each target assigned one of three sentiment polarities {negative, neutral, positive}.
The Multi-ZOL dataset is used to verify the generalization ability of TESAM in different scenarios. It is collected from the Chinese technology forum ZOL.com, specifically from mobile phone reviews. Each sample includes multiple evaluation aspects, which are cost–performance ratio, performance configuration, battery life, appearance and feel, camera effect, and screen effect. The sentiment tendency for each aspect is represented by a sentiment score ranging from 1 (negative) to 10 (positive).
Details of these datasets are listed in
Table 2 and
Table 3, including the number of samples in each classification category for the subsets of each dataset, as well as the proportion of samples with optical characters in their images. It can be observed that more than 50% of the sample images in the TWITTER-15 dataset contain text, while this proportion exceeds 60% in the TWITTER-17 and Multi-ZOL datasets. This demonstrates the rationality of our improvement in enhancing the model’s visual representations through the introduction of text-in-image.
4.1.2. COCO-Captions for Self-Supervised Alignment
The COCO-Captions dataset [
23] is an extension of the Microsoft Common Objects in Context (COCO) dataset, designed for image captioning tasks. It includes over 120,000 images with around 600,000 captions, making it one of the largest and most widely used datasets for image-to-text research. Each image in the dataset is associated with multiple captions (typically five), providing diverse linguistic descriptions for the same visual content. Thus, COCO-Captions is well-suited as a dataset for self-supervised modal alignment during the pre-training stage of TESAM.
4.2. Parameter Settings
In our experiments, for the text modality, the maximum number of text tokens
N is set to 50 to reduce memory use and match the number of image patches. The number of attention heads
m is 12, and the output text embedding dimension
d is 768. For the image modality, the original images are resized to 256 × 256 and then randomly cropped to 224 × 224 before being normalized and input to the model. The model is trained using the Adam [
24] optimizer with parameters:
betas = (0.9, 0.999),
eps = 1 × 10
−8,
weight_decay = 0 from experience. In the self-supervised alignment stage, the learning rate is set to 3 × 10
−5, with a 50% decrease every epoch. The batch size is 64, and the feature extraction module is pre-trained for a total of 6 epochs. For the Chinese Multi-ZOL dataset, we employed a translated Chinese version of the COCO-Captions dataset for self-supervised alignment. In the training stage, the initial learning rate of the model is set to 5 × 10
−5, and it is decreased by 70% every 2 epochs. Dropout is set to 0.01, and the batch size is set to 32. The model is implemented using PyTorch 2.0.1 and trained on an NVIDIA RTX 4080 GPU (manufactured in Shenzhen, China). For 8 epochs on each dataset. All random seeds are set to 42.
4.3. Baselines
We choose the following baselines for comparison.
CLIP [
20]: Maps images and text into shared embedding spaces through contrast learning to achieve cross-modal alignment
BLIP [
25]: Adopts the encoder-decoder architecture combined with data bootstrap technology to unify visual language understanding and generation capabilities
MIMN [
13]: Includes two interactive memory networks to supervise textual and visual information with a given aspect, capturing both cross-modal and self-influences in the data.
ESAFN [
26]: Integrates textual and visual information by leveraging attention mechanisms to capture intra-modal and inter-modal dynamics.
MTVAF [
6]: Propose a multi-granularity visual-textual feature fusion model, convert images into image captions, facial descriptions, and optical characters, to align visual and text modalities, and enable effective cross-modal fusion.
Res-BERT+BL [
1]: Connects the visual features extracted by ResNet with the hidden representation of BERT, and stacks another BERT Layer on top of it.
EF-CapTrBert [
8]: Translates images into text and combines them with text inputs in the BERT encoder for self-attention fusion.
TomBERT [
1]: Introduces a target attention mechanism inspired by self-attention to perform target-image matching for deriving target-sensitive visual representations, aiming to identify sentiment polarities over opinion targets.
HIMT [
4]: Integrates semantic concepts from images, modeling aspect-text and aspect-image interactions hierarchically, and reducing the semantic gap between text and image representations.
HF-EKCL [
27]: Generates captions for images to supplement text and visual features, utilizing a cross-attention mechanism and graph neural networks to capture interactions between modalities. It also applies contrastive learning to deepen the model’s understanding of sentiment features.
KEF-TomBERT [
5]: Enhancing the visual attention and sentiment prediction capabilities of the ABMSA task by utilizing adjective–noun pairs extracted from images.
AMIFN [
3]: Introduces aspect-guided textual and visual representations while leveraging coarse-grained sentence-image interactions and syntactic dependencies for graph-based aspect-guided text-image fusion, and can also dynamically filter noise.
MG-VTFM [
7]: Integrates multi-granularity semantic, syntactic, and visual features for deep sentiment interactions. It employs a hierarchical graph attention network and progressive multimodal attention fusion to reduce noise, enhance sentiment relevance, and align cross-modal information based on aspect words.
4.4. Comparison with Baselines
Table 4 compares TESAM with existing methods on two ABMSA task datasets, focusing on accuracy and Macro-F1 scores. TESAM outperforms most models across metrics. On the TWITTER-17 dataset, TESAM improves accuracy by 0.08% and Macro-F1 by 0.89% compared to MG-VTFM. This improvement stems from TESAM’s integration of text-in-image information, enhancing visual representations, especially on datasets like TWITTER-17, where over 60% of images contain text. TESAM also handles noise effectively, such as in images consisting solely of text, which traditional models often overlook. On TWITTER-15, where only half of the images contain text, TESAM’s accuracy is 0.31% lower than MG-VTFM, but its F1 score improves by 1.21%. This suggests TESAM’s superior ability to manage noisy data by leveraging self-supervised learning for modal alignment, and TESAM reduces noise during feature fusion. To align different modalities, KEF-TomBERT and HF-EKCL convert images into text descriptions, which can lead to the loss of fine-grained visual information. As a result, their accuracy and F1 scores are slightly lower than those of TESAM, which retains visual features. TESAM’s F1 score on Multi-ZOL is 2.44% higher than that of HIMT, demonstrating its strong multi-scenario generalization capability, thus exhibiting equally outstanding performance in sentiment analysis of product reviews. TomBERT and EF-CapTrBert, while BERT-based, exhibit mixed performance. TomBERT’s approach of concatenating image and text features often introduces noise, affecting its performance on TWITTER-15. EF-CapTrBERT relies on converting images into textual descriptions, which enhances its performance on images with rich visual cues. This advantage enables its superior performance over TomBERT on Multi-ZOL, as the dataset contains substantial explicit complementarity between images and text (e.g., smartphone photos paired with product reviews). Res-BERT+BL offers a simpler fusion method, resulting in weaker performance compared to TomBERT and EF-CapTrBert. Although MTVAF uses text-in-image like TESAM, it relies on basic concatenation of image descriptions and text. In contrast, TESAM uses parallel cross-modal attention for bidirectional interaction between enhanced image representation (EIR) and text features, providing a comprehensive and accurate multimodal sentiment representation. This enables TESAM to achieve superior sentiment analysis performance. CLIP and BLIP exhibit moderate performance in the ABMSA tasks. As general models, their pre-training objectives prioritize global cross-modal alignment. As a result, they lack explicit aspect-word modeling and the ability to capture the fine-grained semantic and sentiment relationships required for ABMSA.
Moreover, in
Table 5, we provide a comparison of different models’ trainable parameter counts. The table shows that TESAM has the fewest parameters and inference memory, the fastest inference speed, and achieves the highest scores. These results demonstrate the advantages of TESAM’s alignment methodology in reducing model complexity. By leveraging image captioning datasets for pre-training, TESAM eliminates the need for additional image understanding models to assist with cross-modal alignment, thereby reducing parameter count (164 M) and increasing inference speed (733.12 FPS). Furthermore, through parameter sharing mechanisms, TESAM achieves memory consumption under 1 GB during inference. As a result, TESAM achieves a balance between computational efficiency and robust performance in the ABMSA task, especially suitable for edge devices (e.g., smartphones and Raspberry Pi) with memory less than 4 GB, and uses limited power consumption for high-speed inference.
4.5. Ablation Study
4.5.1. Impact of Proposed Methods
To demonstrate the effectiveness of each improvement, we conducted ablation experiments and present the results in
Table 6.
Specifically, after masking the text-in-image, the model’s performance declined the most, with a decrease of approximately 3% in accuracy and 4% in F1 score. In this case, the model relies solely on visual cues from the image modality, ignoring the guidance provided by the embedded text, which results in a greater discrepancy between the model’s understanding and that of humans for multimodal samples. This indicates that images with embedded text are meaningful for accurate sentiment analysis in social media contexts, further validating the value of our innovative incorporation of text-in-image. Then, by incorporating aspect words into text-in-image within the IE, the model’s accuracy increased by approximately 1.2%, and the F1 score improved by about 1%. This demonstrates that aspect words play a crucial role in the ABMSA task. By guiding the model to focus on information relevant to the aspect words, we can reduce noise interference, thereby increasing the proportion of relevant information in higher-level sentiment features, ultimately leading to more accurate sentiment analysis. Next, skipping modal alignment with the image captions dataset and proceeding directly to the next training step results in a noticeable drop in accuracy and F1 score. This is because failing to align modal representations beforehand not only increases the model’s training complexity but also leads to weaker cross-modal interactions, especially for samples with ambiguous or noisy data. Finally, by disrupting the bidirectional interaction structure in the multimodal encoder (by replacing cross-modal attention with intra-modal self-attention), the model’s accuracy and F1 score drop by 2.67% and 3.21% on TWITTER-17. This is because ABMSA heavily relies on the comparative representation of aspects across different modalities. Thus, without cross-modal interaction, the model fails to capture deeply integrated sentiment features, leading to a noticeable decrease in performance.
The results show that omitting any of the improvements led to a decline in model effectiveness.
4.5.2. Impact of Different OCR Methods
We compared the performance impact of different OCR tools: Tesseract [
28], an open-source OCR engine based on LSTM, performs well on clear and well-formatted text. PaddleOCR [
29], an OCR tool built on the PaddlePaddle framework, excels in handling complex images. MuggleOCR [
30], a lightweight open-source OCR tool, is suitable for processing printed text and parsing captchas. EasyOCR [
22], implemented with PyTorch, utilizes the CRAFT algorithm for character detection and CRNN for recognition, enabling it to handle various fonts, styles, and complex scenarios. The results are listed in
Table 7.
As shown in the table, TESAM with EasyOCR achieved the best results on the TWITTER-15 dataset. On TWITTER-17, TESAM with PaddleOCR obtained an F1 score 0.07% higher than the former but had an accuracy 0.16% lower. This is because PaddleOCR has better adaptability to complex scenes, leading to improved class balance. Both Tesseract and MuggleOCR are designed for printed and clear text, making them more susceptible to noise when processing social media images, which negatively impacts subsequent sentiment analysis. Consequently, EasyOCR’s robustness in handling complex layouts and fonts enabled TESAM with EasyOCR to achieve the highest accuracy on both social media datasets. Additionally, since both EasyOCR and TESAM are implemented with PyTorch, their compatibility is enhanced. Therefore, we chose EasyOCR as the text recognition engine for TESAM.
4.5.3. Impact of Different Hyperparameters
The purpose of this experiment is to provide a basis for the selection of hyperparameters.
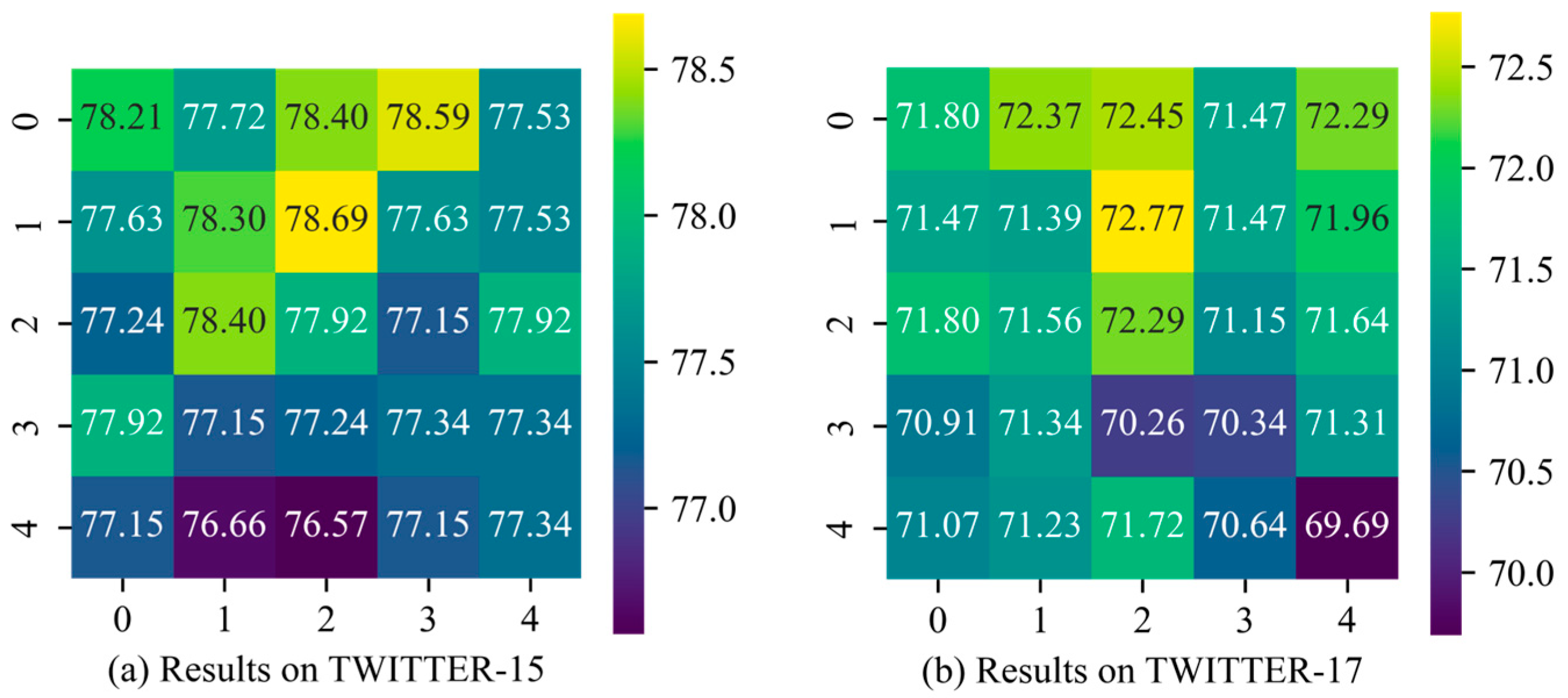
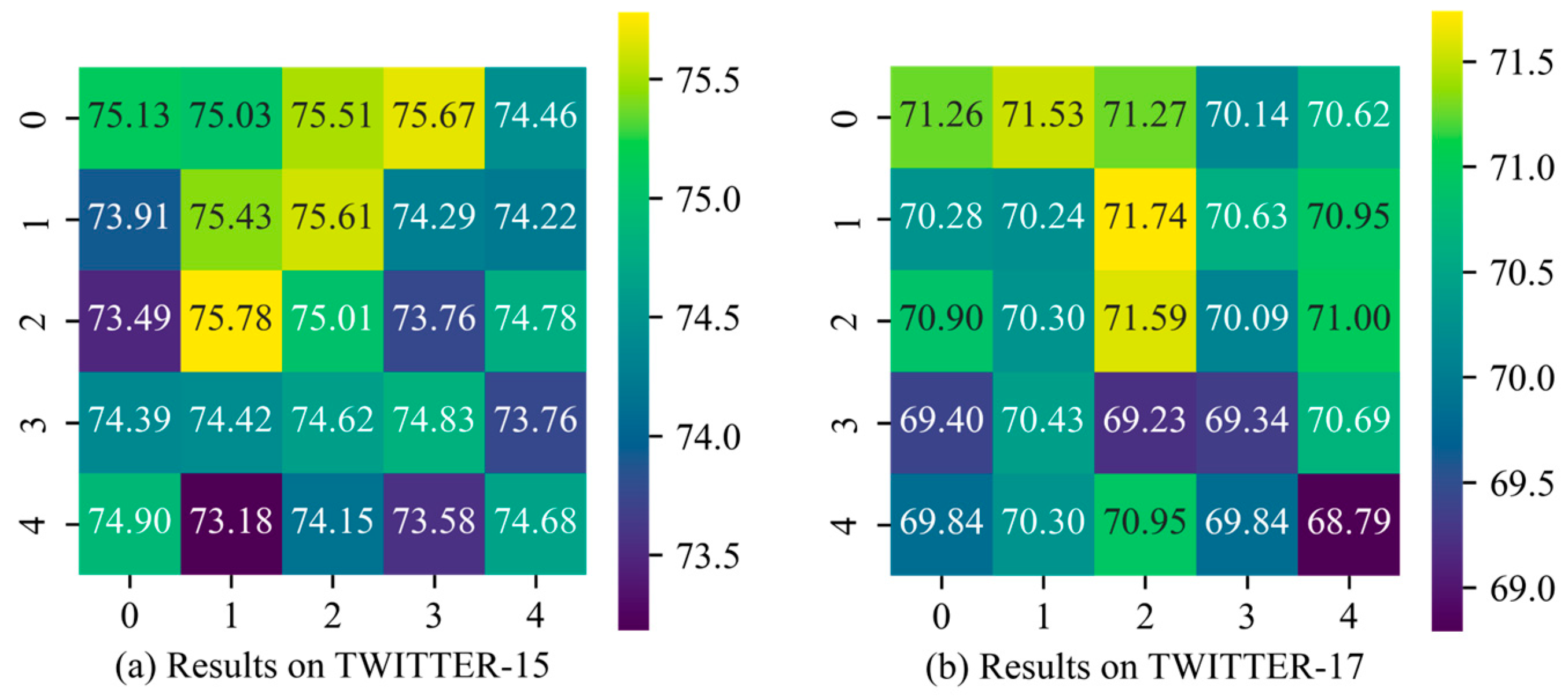
We conducted experiments on the impact of hyperparameters
t (the number of transformer encoder layers in the IE module) and
s (the number of stacked layers in the BI module) on Twitter-15 and Twitter-17 datasets, and the results are shown in
Figure 3 and
Figure 4. The vertical axis represents
t, while the horizontal axis represents
s. The numbers within the grid indicate the model’s accuracy on the corresponding dataset under each hyperparameter configuration. The grid colors range from yellow to purple, with yellow representing higher accuracy and purple indicating lower accuracy.
For parameters
t and
s, we experimented with five values: {0, 1, 2, 3, 4}. Specifically, a value of 0 indicates that the TE layer is excluded from the IE or that the BI module has been removed. From
Figure 4, it can be observed that when
t = 1 and
s = 2, TESAM achieves optimal performance on TWITTER-15 (accuracy: 78.69%), TWITTER-17 (accuracy: 72.77%), and F1 score (71.74%). However, as the value of
t and
s increases, the accuracy decreases. This indicates that increasing the number of internal layers in both encoders tends to make model training more challenging. Specifically, for the IE, when
t > 1, the model accuracy starts to decline. On TWITTER-15, the highest accuracy at
t = 4 is 0.38% lower than the lowest accuracy when the TE layer is absent from the IE. For the BI module, stacking additional BI layers can influence accuracy to some extent. While two BI layers capture more comprehensive cross-modal interactions compared to a single layer, when
s > 2, the added parameters lead to increased training difficulty, causing a downward trend in model performance.
Additionally, when t = 2 and s = 1, TESAM reaches its peak F1 score on TWITTER-15 (75.78%). This phenomenon occurs because the stochastic gradient descent of model parameters causes performance metrics to randomly settle near local optima. Overall, the close alignment between accuracy and F1 score distributions demonstrates that variations in t and s parameters do not significantly affect the class balance (as measured by F1 score) in the model’s outputs.
4.6. Visualization and Case Study
To highlight the performance improvement of TESAM, we present several case studies in
Table 8. For images with rich visual cues (e.g.,
Table 8(c)), TESAM’s bidirectional interaction structure captures relevant areas linked to aspect words and sentiment. For text-heavy images (e.g.,
Table 8(a)), the model extracts meaningful sentiment features from limited visual information, improving classification performance in fine-grained ABMSA tasks. The table includes aspect-level text (in parentheses) and its label (italicized and color-coded) for context. The “Text Attention” and “Text-in-image Attention” rows display the top five words most relevant to the aspect words, drawn from text and text-in-image, respectively. Lastly, the table compares predictions from different models on the same sample.
In case (a), the image feature extraction module with text recognition proposed in TESAM successfully captures key sentiment-related words in the image, such as “regret” and “sorry”, as shown in the Text-in-image Attention row. This enables TESAM to comprehensively extract sentiment features from the sample and establish relationships between features from different modalities, ultimately leading to accurate sentiment polarity classification of the aspect. In contrast, both AMIFN and MG-VTFM incorrectly classified “Roger Federer” as neutral. This error arises because the sentiment inclination of the text is not clearly evident, and both models overlook the text-in-image, missing crucial information in the image itself.
In case (b), AMIFN predicts a positive sentiment for “# Knoxville”, likely due to its use of a dynamic noise-filtering approach. Elements in the image, such as smiling faces and signs, indicate support for a wage increase, which may lead AMIFN to amplify positive sentiment. TESAM, on the other hand, accurately predicts a neutral sentiment for the aspect words. This is due to our approach of inserting aspect words within the text-in-image, guiding the model to focus on image regions related to the specific aspect while ignoring irrelevant features. As seen in the visual attention and Text-in-image Attention results, the model disregards elements that convey positive sentiment, such as faces. This results in a neutral sentiment analysis for the aspect term, demonstrating that our proposed method facilitates more accurate predictions by avoiding the influence of irrelevant sentiment features when the aspect itself is relatively independent.
In case (c), the three models under comparison produced different results, but only our TESAM provided the correct prediction. This accuracy is attributed to TESAM’s integration of text-in-image for the image modality, which enriches image representations by incorporating not only pure visual features (such as facial expressions) but also additional textual semantics that convey sentiment (e.g., “vote for Labour”). This addition enhances the model’s understanding of the sample. Furthermore, during the pre-training stage, TESAM’s self-supervised modal alignment ensures that the feature extraction module maps relevant semantics to relevant feature representations. This facilitates the BI module in effectively capturing the aspect target’s sentiment expressions across modalities. For instance, TESAM is able to interpret facial expressions in an image as strong support for “J. K. Rowling”, resulting in a correct positive classification.
5. Discussion
Although TESAM has achieved promising results on all three ABMSA datasets, and the effectiveness of the proposed method has been validated, there remain several issues that warrant further discussion.
5.1. Error Analysis of TESAM
To further refine our understanding of TESAM’s limitations, we analyze misclassified samples to delineate its applicability and identify potential directions for future research. Specifically, these errors can be categorized into three distinct types.
- (1)
The sample contains rhetorical questions or sarcasm. For example, in
Table 9(a), the author poses a question, but TESAM incorrectly associates the aspect-level target with a smiling face in the image. Additionally, it misinterprets the phrase “will win” as a positive sentiment toward “Donald Trump”, failing to recognize the intended skeptical or ironic tone.
- (2)
The sample lacks explicit sentiment clues. As shown in
Table 9(b), there is no obvious sentiment component related to ”The Zone” in both text and image, so TESAM chooses to classify it as neutral. However, combined with common sense, “The Zone” may be a radio channel, and the author is expressing his expectation for this activity and recommending this channel.
- (3)
Some of the aspects are too emotional when the sample contains multiple aspects. For example, in
Table 9(c), the text is full of negative emotions about ”officialpepe”, when the fallen person and the other players in the image also express negative sentiment. This causes TESAM’s cross-modal attention to be overwhelmed by negative sentiment features, and makes the same judgment on other irrelevant aspects.
To address these issues, we plan to introduce methods such as sarcasm detection, knowledge graphs, and syntactic parsing in future work. These approaches will effectively enhance the model’s capabilities in handling abnormal tones and implicit sentiment expressions, while also equipping it with grammatical understanding to disentangle irrelevant aspect targets, ultimately improving the model’s sentiment analysis performance.
5.2. Potential Deviations in the Datasets
In our experiments, we utilized three types of datasets. The first is the image captioning dataset COCO-Captions, used for modal alignment. The second is the ABMSA task dataset TWITTER-15/17 from the social media domain, and the third is the ABMSA task dataset Multi-ZOL from the product review domain. These datasets may contain potential biases that could affect model performance or cause the model’s judgments to deviate from widely accepted values.
First, both COCO-Captions and TWITTER-15/17 are sourced from the Western-dominated internet. As a result, most images in these datasets feature people and scenes from the Western world, lacking representation of diverse cultures. This may lead to performance biases in cross-cultural scenarios. For example, in some Latin American cultures, a “funeral” is not considered a sorrowful event; instead, it may be understood as a cause for celebration. Therefore, it is necessary to expand existing benchmark datasets to include more diverse cultures. Thus, techniques such as knowledge graphs can be introduced to help models correctly handle the cultural and contextual differences that objectively exist in reality, leveraging rich prior knowledge.
Second, Multi-ZOL, as a Chinese smartphone review dataset, is limited to the single category of “smartphones”, and the brands covered are predominantly domestic Chinese brands. This results in the model learning features that are highly domain-specific, making it difficult to transfer to sentiment analysis tasks for other product reviews. It also introduces brand bias, failing to represent a broader user base. Therefore, in future work, we will incorporate more diverse cross-domain multimodal data to enhance the model’s generalization capabilities. Also, we plan to employ debiasing algorithms or domain adaptation methods to mitigate biases caused by dataset limitations, thereby improving TESAM’s applicability across different product categories and cultural contexts.
6. Conclusions
In this study, we propose the text-in-image enhanced self-supervised alignment model (TESAM) for aspect-based multimodal sentiment analysis (ABMSA), aiming to address the interference caused by images containing text in social media contexts and improve the representational differences between modalities without introducing additional parameters. TESAM introduces an image encoder capable of extracting text-in-image and leveraging it to enhance visual features. By inserting aspect words into the identified text-in-image, the image encoder guides TESAM to focus on regions of the image relevant to the aspect, thereby mitigating noise interference. Furthermore, TESAM leverages self-supervised alignment using the image caption dataset to bridge the semantic gap between modalities, effectively reducing adverse effects and ultimately enhancing ABMSA task performance. In comparative experiments, TESAM demonstrated superior performance in two benchmark ABMSA tests, achieving Macro-F1 values of 75.61% on the TWITTER-15 dataset, 71.74% on the TWITTER17 dataset, and 69.02% on the Multi-ZOL dataset, which is higher than traditional models. Moreover, subsequent ablation and case studies provide compelling evidence supporting the effectiveness of the proposed innovations.
Although our model demonstrates performance improvements, several limitations should be acknowledged. First, TESAM struggles to adapt to samples with rhetorical questions or those containing too little/too much emotional content. Second, the datasets used may contain potential contextual and cultural biases, which could lead to limitations in the model’s cross-cultural generalization capabilities. Third, in an effort to reduce model parameters, we did not treat aspect-level targets as independent textual inputs, unlike approaches such as TomBERT. This decision may have impacted the classification results. Additionally, the loss function used by TESAM for self-supervised alignment only measures feature distance. Therefore, further refining TESAM to ensure its strong performance across a broader range of MSA tasks is crucial. In our future work, we will incorporate methods such as syntactic parsing and knowledge graphs to enhance the model’s adaptability to special contexts and cross-cultural scenarios. We will also introduce distribution alignment techniques to improve cross-modal feature distribution alignment, as well as diversify training samples or employ domain adaptation methods to account for the impact of different domains or cultural elements on sentiment analysis results.
Author Contributions
Conceptualization, X.Z. and Z.Z.; Formal analysis, Y.W.; Funding acquisition, Y.W. and Z.Z.; Investigation, X.Z. and Z.Z.; Methodology, Y.W.; Software, Y.W.; Validation, X.Z.; Visualization, Y.W.; Writing—original draft, X.Z.; Writing—review and editing, X.Z., Y.W. and Z.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This study is supported in part by the Natural Science Foundation of China (No. 72174079), in part by the Natural Science Foundation for Youths of Jiangsu Province (No. SBK2024041254), and in part by the Jiangsu Graduate Student Research Innovation Program (No. KYCX2023-79).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Yu, J.; Jing, J. Adapting BERT for target-oriented multimodal sentiment classification. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 5408–5414. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Z.; Li, X.; Liu, N.; Guo, B.; Yu, Z. ModalNet: An aspect-level sentiment classification model by exploring multimodal data with fusion discriminant attentional network. World Wide Web 2021, 24, 1957–1974. [Google Scholar] [CrossRef]
- Yang, J.; Xu, M.; Xiao, Y.; Du, X. AMIFN: Aspect-guided multi-view interactions and fusion network for multimodal aspect-based sentiment analysis. Neurocomputing 2024, 573, 127222. [Google Scholar] [CrossRef]
- Yu, J.; Chen, K.; Xia, R. Hierarchical Interactive Multimodal Transformer for Aspect-Based Multimodal Sentiment Analysis. IEEE Trans. Affect. Comput. 2023, 14, 1966–1978. [Google Scholar] [CrossRef]
- Zhao, F.; Wu, Z.; Long, S.; Dai, X.; Huang, S.; Chen, J. Learning from Adjective-Noun Pairs: A Knowledge-enhanced Framework for Target-Oriented Multimodal Sentiment Classification. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022; pp. 6784–6794. [Google Scholar]
- Li, Y.; Ding, H.; Lin, Y.; Feng, X.; Chang, L. Multi-level textual-visual alignment and fusion network for multimodal aspect-based sentiment analysis. Artif. Intell. Rev. 2024, 57, 78. [Google Scholar] [CrossRef]
- Chen, Y.; Shi, L.; Lin, J.; Chen, J.; Zhong, J.; Dong, C. Multi-granularity visual-textual jointly modeling for aspect-level multimodal sentiment analysis. J. Supercomput. 2025, 81, 46. [Google Scholar] [CrossRef]
- Khan, Z.; Fu, Y. Exploiting BERT for Multimodal Target Sentiment Classification through Input Space Translation. In Proceedings of the 29th ACM International Conference on Multimedia (MM ‘21), Virtual, China, 20–24 October 2021; pp. 3034–3042. [Google Scholar] [CrossRef]
- Ling, Y.; Yu, J.; Xia, R. Vision-language pre-training for multimodal aspect-based sentiment analysis. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; Association for Computational Linguistics: Stroudsburg, PA, USA, 2022; pp. 2149–2159. [Google Scholar] [CrossRef]
- Zhou, Q.; Liang, H.; Lin, Z.; Xu, K. Multimodal Feature Fusion for Video Advertisements Tagging Via Stacking Ensemble. arXiv 2021, arXiv:2108.00679. [Google Scholar] [CrossRef]
- Karpathy, A.; Li, F.-F. Deep Visual-Semantic Alignments for Generating Image Descriptions. 2015. Available online: https://www.cv-foundation.org/openaccess/content_cvpr_2015/html/Karpathy_Deep_Visual-Semantic_Alignments_2015_CVPR_paper.html (accessed on 13 April 2025).
- Soleymani, M.; Garcia, D.; Jou, B.; Schuller, B.; Chang, S.-F.; Pantic, M. A survey of multimodal sentiment analysis. Image Vis. Comput. 2017, 65, 3–14. [Google Scholar] [CrossRef]
- Xu, N.; Mao, W.; Chen, G. Multi-Interactive Memory Network for Aspect Based Multimodal Sentiment Analysis. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 371–378. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. arXiv 2023, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28 (NIPS 2015), Montreal, QC, Canada, 7–12 December 2015; Curran Associates: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv 2014, arXiv:1311.2524. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer International Publishing: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv 2016, arXiv:1506.02640. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Yao, C. An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition. arXiv 2015, arXiv:1507.05717. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8748–8763. Available online: https://arxiv.org/abs/2103.00020 (accessed on 13 April 2025).
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2021, arXiv:2010.11929. [Google Scholar] [CrossRef]
- EasyOCR. EasyOCR: A Python library for Optical Character Recognition (OCR). 2024. Available online: https://github.com/JaidedAI/EasyOCR (accessed on 13 April 2025).
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Available online: https://cocodataset.org/#download (accessed on 13 April 2025).
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Li, J.; Li, D.; Xiong, C.; Hoi, S. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 12888–12900. Available online: https://arxiv.org/abs/2201.12086 (accessed on 13 April 2025).
- Yu, J.; Jiang, J.; Xia, R. Entity-sensitive attention and fusion network for entity-level multimodal sentiment classification. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 429–439. [Google Scholar] [CrossRef]
- Hu, X.; Yamamura, M. Hierarchical Fusion Network with Enhanced Knowledge and Contrastive Learning for Multimodal Aspect-Based Sentiment Analysis on Social Media. Sensors 2023, 23, 7330. [Google Scholar] [CrossRef] [PubMed]
- Tesseract-ocr. Tesseract OCR. 2024. Available online: https://github.com/tesseract-ocr/tesseract (accessed on 13 April 2025).
- PaddlePaddle. PaddleOCR. 2024. Available online: https://github.com/PaddlePaddle/PaddleOCR (accessed on 13 April 2025).
- litongjava. muggle_ocr. 2024. Available online: https://github.com/litongjava/muggle_ocr (accessed on 13 April 2025).
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).






{kind=link}
{kind=link}
{kind=link}
{kind=link}





