
Pavement-DETR: A High-Precision Real-Time Detection Transformer for Pavement Defect Detection


Abstract
1. Introduction
- (1)
- We introduce a CSS attention mechanism composed of channel attention, channel shuffle, and spatial attention at the S3 and S4 feature layers. This mechanism reduces redundant information between channels, enhances information fusion across different channels, and simultaneously captures spatial dependencies, enabling the model to focus more on learning road defect features.
- (2)
- We improve the feature fusion module by adopting a Conv3XC structure, combining multi-level convolutions, channel expansion, and skip connections. This improvement significantly enhances the model’s feature extraction capabilities, especially in complex scenarios, enabling better differentiation between road defects and other objects. Additionally, this design strengthens gradient flow, ensuring stable training and efficient inference, thus meeting real-time detection requirements.
- (3)
- We propose a loss function that combines PIoU v2 and NWD weighted averaging. By combining these two, the loss function simultaneously optimizes the overlapping part, and the position and size of the bounding boxes, thereby improving the model’s accuracy comprehensively. Moreover, this weighted loss function smooths the optimization process, promotes a faster convergence of the model, and improves training efficiency and final detection performance.
2. Related Work
2.1. Pavement Defect Detection
2.2. Transformer-Based Object Detection Network
3. Method
3.1. RT-DETR
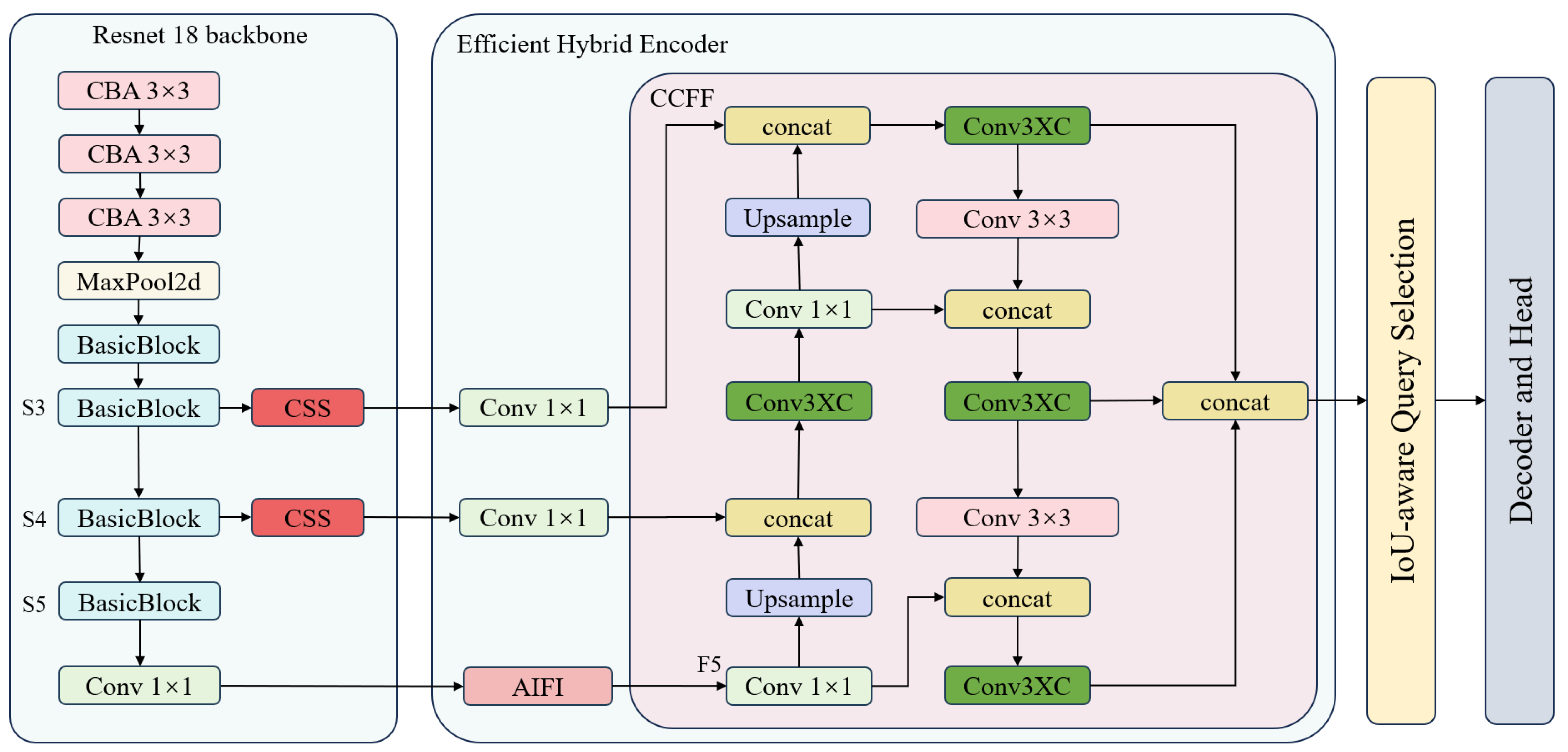
3.2. Pavement-DETR
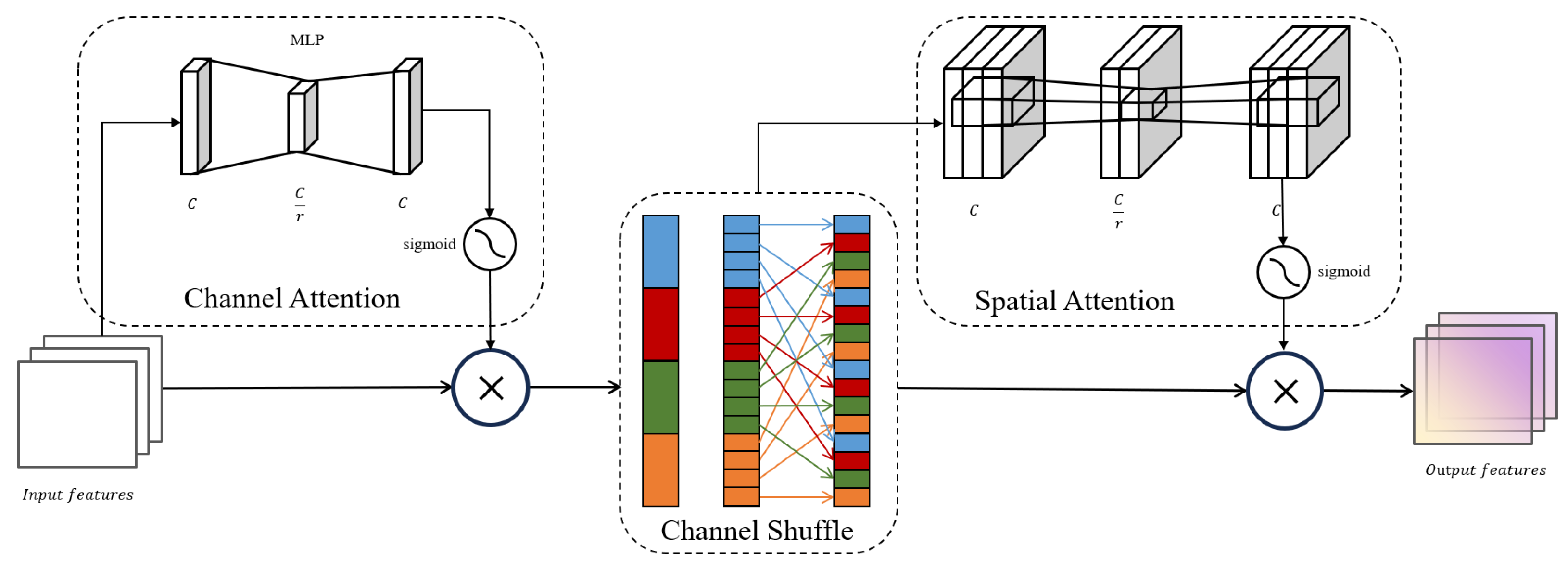
3.2.1. CSS Attention Mechanism
- Channel attention: This module utilizes a two-layer multilayer perceptron to capture the interdependencies among feature map channels. Initially, the first layer of the MLP reduces the number of channels using a preset compression ratio, aimed at decreasing the model’s complexity and mitigating the risk of overfitting. Subsequently, a ReLU activation function introduces necessary non-linearity, enhancing the model’s capability to process features. The second layer of the MLP then restores the number of channels to the original size to preserve essential feature information. After this process, the output is mapped to a range between 0 and 1 through a Sigmoid activation function, creating a finely tuned channel attention map. This attention map is then element-wise multiplied with the original feature map, effectively adjusting the contribution of each channel and emphasizing features in critical channels, thereby significantly improving the model’s ability to recognize features in complex scenarios.
- Channel shuffle: This module is a key component of the CSS attention mechanism. Its main function is to enhance the exchange and sharing of information between different channels by rearranging the order of channels in the input feature map. In operation, the channels of the feature map are first grouped according to a preset number of groups. Then, a transpose operation is performed, which rearranges the order of channels within each group, breaking the original organizational structure and facilitating better integration of cross-channel features. This reorganized channel structure allows the model to gather information from a broader context when processing subsequent features, enhancing its ability to capture complex features.
- Spatial attention: This module utilizes two 7 × 7 large convolutional kernels to enhance the model’s ability to capture spatial details of feature maps and improve its contextual understanding. Initially, the first 7 × 7 convolutional kernel processes the input feature map, reducing the number of channels to a predetermined value. This not only significantly reduces the model’s parameter count but also, with the broad spatial coverage of the large kernel, helps capture more extensive contextual information. Subsequently, batch normalization is employed to stabilize the training process, and a ReLU activation function is introduced to increase non-linearity, enabling the model to better recognize complex spatial patterns. Then, the second 7 × 7 convolutional kernel restores the channel count to its original scale, ensuring the integrity of feature information. Finally, a spatial attention map generated by the Sigmoid function is element-wise multiplied with the original feature map, allowing the model to adjust its focus at each position of the feature map based on the weights of spatial attention, thus more accurately highlighting critical areas and enhancing overall recognition accuracy.
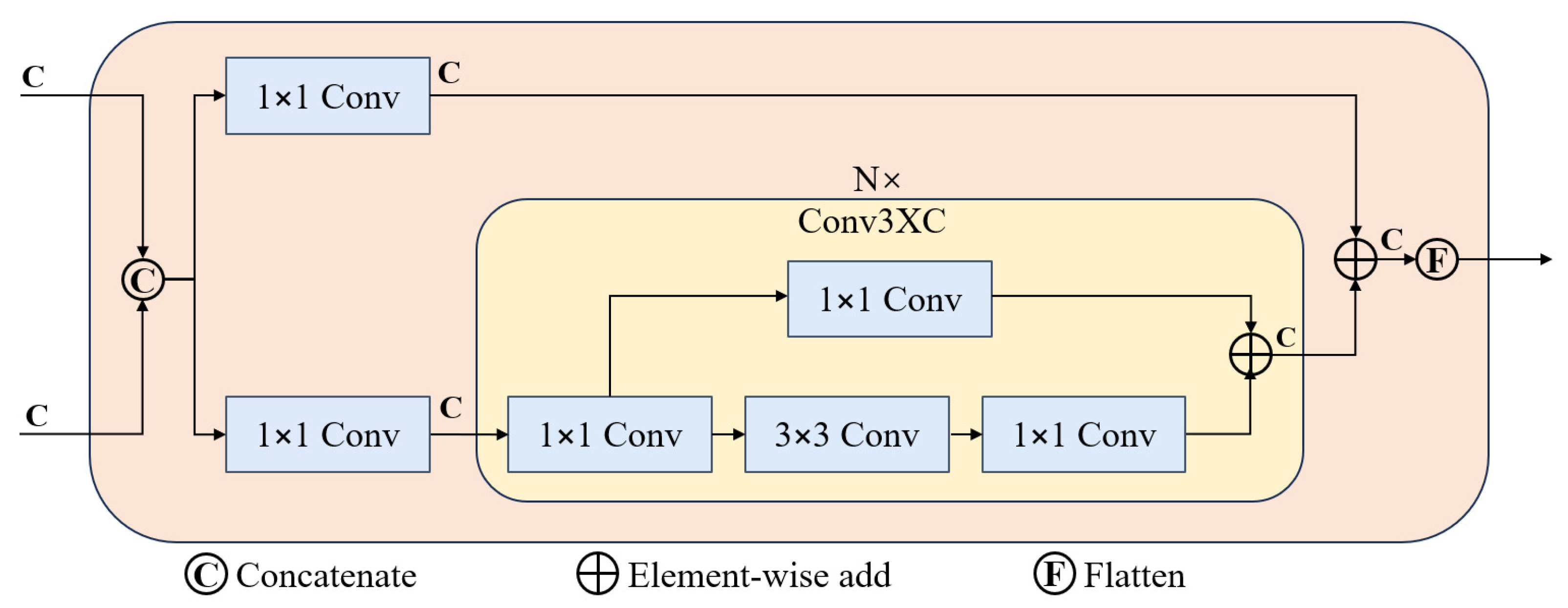
3.2.2. Conv3XC
3.2.3. Improved Loss Function
4. Experiment and Result
4.1. Dataset
4.2. Experimental Environment
4.3. Evaluation Indicators
4.4. Analysis of Experimental Results
4.4.1. Performance Evaluation
4.4.2. Ablation Experiment
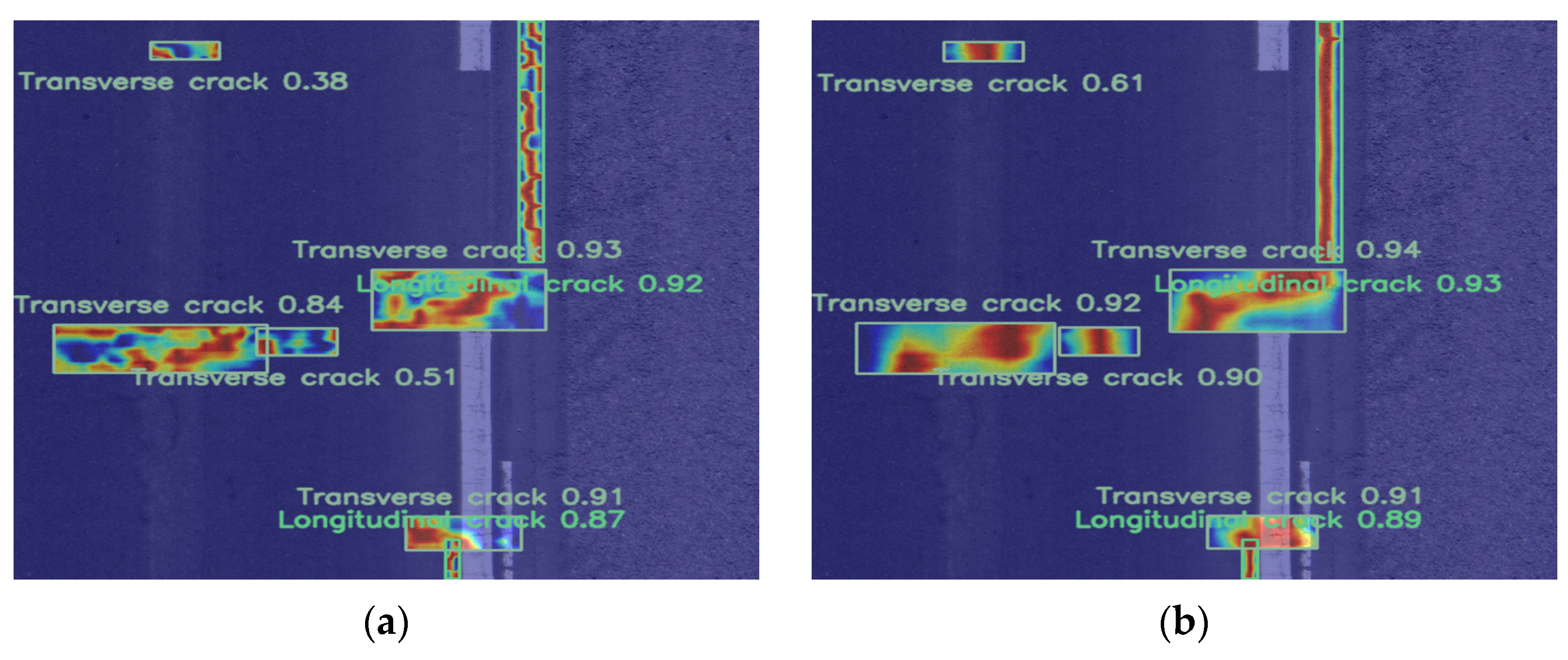
4.4.3. Grad-CAM++ Visualization
4.4.4. Robustness Evaluation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Slabej, M.; Grinč, M.; Kováč, M.; Decký, M.; Šedivý, S. Non-invasive diagnostic methods for investigating the quality of Žilina airport’s runway. Contrib. Geophys. Geod. 2015, 45, 237–254. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. arXiv 2015, arXiv:1504.08083. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade r-cnn: Delving into high quality object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6154–6162. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Mark Liao, H.-Y. Yolov9: Learning what you want to learn using programmable gradient information. In Proceedings of the European Conference on Computer Vision, Paris, France, 26–27 March 2025; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. Yolov10: Real-time end-to-end object detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, S.; Li, F.; Zhang, H.; Yang, X.; Qi, X.; Su, H.; Zhu, J.; Zhang, L. Dab-detr: Dynamic anchor boxes are better queries for detr. arXiv 2022, arXiv:2201.12329. [Google Scholar]
- Meng, D.; Chen, X.; Fan, Z.; Zeng, G.; Li, H.; Yuan, Y.; Sun, L.; Wang, J. Conditional detr for fast training convergence. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3651–3660. [Google Scholar]
- Zhang, H.; Li, F.; Liu, S.; Zhang, L.; Su, H.; Zhu, J.; Ni, L.M.; Shum, H.-Y. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv 2022, arXiv:2203.03605. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16965–16974. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Wan, B.; Zhou, X.; Sun, Y.; Wang, T.; Wang, S.; Yin, H.; Yan, C. ADNet: Anti-noise dual-branch network for road defect detection. Eng. Appl. Artif. Intell. 2024, 132, 107963. [Google Scholar] [CrossRef]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road damage detection and classification using deep neural networks with smartphone images. Comput. Aided Civ. Infrastruct. Eng. 2018, 33, 1127–1141. [Google Scholar] [CrossRef]
- Gou, C.; Peng, B.; Li, T.; Gao, Z. Pavement crack detection based on the improved faster-rcnn. In Proceedings of the 2019 IEEE 14th International Conference on Intelligent Systems and Knowledge Engineering (ISKE), Dalian, China, 14–16 November 2019; pp. 962–967. [Google Scholar]
- Shen, T.; Nie, M. Pavement damage detection based on cascade R-CNN. In Proceedings of the 4th International Conference on Computer Science and Application Engineering, Sanya, China, 22–24 October 2020; pp. 1–5. [Google Scholar]
- Xiang, X.; Wang, Z.; Qiao, Y. An improved YOLOv5 crack detection method combined with transformer. IEEE Sens. J. 2022, 22, 14328–14335. [Google Scholar] [CrossRef]
- Wang, X.; Gao, H.; Jia, Z.; Li, Z. BL-YOLOv8: An improved road defect detection model based on YOLOv8. Sensors 2023, 23, 8361. [Google Scholar] [CrossRef] [PubMed]
- Youwai, S.; Chaiyaphat, A.; Chaipetch, P. YOLO9tr: A lightweight model for pavement damage detection utilizing a generalized efficient layer aggregation network and attention mechanism. J. Real Time Image Process. 2024, 21, 163. [Google Scholar] [CrossRef]
- OU, J.; Zhang, J.; Li, H.; Duan, B. An Improved Yolov10-Based Lightweight Multi-Scale Feature Fusion Model for Road Defect Detection and its Applications. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4970753 (accessed on 3 March 2025).
- Dosovitskiy, A. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- Wan, C.; Yu, H.; Li, Z.; Chen, Y.; Zou, Y.; Liu, Y.; Yin, X.; Zuo, K. Swift parameter-free attention network for efficient super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 6246–6256. [Google Scholar]
- Liu, C.; Wang, K.; Li, Q.; Zhao, F.; Zhao, K.; Ma, H. Powerful-IoU: More straightforward and faster bounding box regression loss with a nonmonotonic focusing mechanism. Neural Netw. 2024, 170, 276–284. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Xu, C.; Yang, W.; Yu, L. A normalized Gaussian Wasserstein distance for tiny object detection. arXiv 2021, arXiv:2110.13389. [Google Scholar]
- Yan, H.; Zhang, J. UAV-PDD2023: A benchmark dataset for pavement distress detection based on UAV images. Data Brief 2023, 51, 109692. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Configuration | Parameter |
|---|---|
| Operating System | Ubuntu 20.04 |
| Memory | 256 GB |
| CPU | Intel Xeon Silver 4316 |
| GPU | NVIDIA A30 |
| GPU Memory | 24 G |
| Programming Language | Python 3.10.9 |
| CUDA Version | CUDA 12.1 |
| Deep Learning Framework | Pytorch 2.1.2 |
| Parameter | Value |
|---|---|
| Epoch | 900 |
| Batch Size | 16 |
| Workers | 8 |
| Input Size | 640 × 640 |
| Optimizer | AdamW |
| Initial Learning Rate | 0.0001 |
| Momentum | 0.9 |
| Weight Decay Coefficient | 0.0001 |
| Algorithm | P/% | R/% | mAP@0.5% | mAP@0.5:0.95% | FLOPs/G |
|---|---|---|---|---|---|
| RT-DETR-R18 | 0.861 | 0.769 | 0.794 | 0.509 | 57.0 |
| YOLOv8s | 0.834 | 0.713 | 0.793 | 0.482 | 28.4 |
| YOLOv8m | 0.848 | 0.691 | 0.791 | 0.523 | 78.7 |
| YOLOv9s | 0.802 | 0.674 | 0.74 | 0.459 | 26.7 |
| YOLOv9m | 0.833 | 0.767 | 0.811 | 0.564 | 76.5 |
| YOLOv10s | 0.826 | 0.772 | 0.825 | 0.545 | 24.5 |
| YOLOv10m | 0.861 | 0.622 | 0.73 | 0.489 | 63.4 |
| Deformable-DETR | 0.848 | 0.737 | 0.776 | 0.43 | 165 |
| Dab-DETR | 0.869 | 0.711 | 0.767 | 0.407 | 86.9 |
| Conditional-DETR | 0.881 | 0.695 | 0.766 | 0.405 | 85.6 |
| Dino-DETR | 0.864 | 0.752 | 0.797 | 0.535 | 235 |
| Ours | 0.893 | 0.838 | 0.871 | 0.598 | 67.5 |
| CSS | Conv3XC | Loss | AP% | mAP @0.5% | mAP @0.5:0.95% | F1 Score/% | FLOPs/G | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| D1 | D2 | D3 | D4 | D5 | D6 | |||||||
| 0.825 | 0.837 | 0.79 | 0.816 | 0.614 | 0.886 | 0.794 | 0.509 | 0.80 | 57.0 | |||
| √ | 0.847 | 0.866 | 0.799 | 0.827 | 0.678 | 0.862 | 0.813 | 0.548 | 0.81 | 67.5 | ||
| √ | √ | 0.871 | 0.859 | 0.844 | 0.838 | 0.737 | 0.962 | 0.852 | 0.584 | 0.86 | 67.5 | |
| √ | √ | √ | 0.888 | 0.905 | 0.871 | 0.884 | 0.704 | 0.976 | 0.871 | 0.598 | 0.87 | 67.5 |
| Model | Normal mAP@0.5% | Brightness mAP@0.5% | Performance Drop (%) | Rain mAP@0.5% | Performance Drop (%) | Shadow mAP@0.5% | Performance Drop (%) |
|---|---|---|---|---|---|---|---|
| RT-DETR | 0.794 | 0.774 | 2.52 | 0.706 | 11.08 | 0.713 | 10.2 |
| Ours | 0.871 | 0.866 | 0.57 | 0.806 | 7.46 | 0.809 | 7.12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zuo, C.; Huang, N.; Yuan, C.; Li, Y. Pavement-DETR: A High-Precision Real-Time Detection Transformer for Pavement Defect Detection. Sensors 2025, 25, 2426. https://doi.org/10.3390/s25082426
Zuo C, Huang N, Yuan C, Li Y. Pavement-DETR: A High-Precision Real-Time Detection Transformer for Pavement Defect Detection. Sensors. 2025; 25(8):2426. https://doi.org/10.3390/s25082426
Chicago/Turabian StyleZuo, Cuihua, Nengxin Huang, Cao Yuan, and Yaqin Li. 2025. "Pavement-DETR: A High-Precision Real-Time Detection Transformer for Pavement Defect Detection" Sensors 25, no. 8: 2426. https://doi.org/10.3390/s25082426
APA StyleZuo, C., Huang, N., Yuan, C., & Li, Y. (2025). Pavement-DETR: A High-Precision Real-Time Detection Transformer for Pavement Defect Detection. Sensors, 25(8), 2426. https://doi.org/10.3390/s25082426