We tested the improved model on the rail fastening dataset and the rail surface dataset, with the mAP@0.5 metrics for each category shown in
Table 4 and
Table 5. Combining the insights from
Table 1 and
Table 2, it is evident that the sample sizes across categories do not correlate with detection performance. For instance, the track fastening dataset has the highest number of normal samples, yet its detection accuracy is similar to that of other samples. In the track surface dataset, the number of scar samples far exceeds that of break samples; however, due to the small size of the scar samples, the detection accuracy is quite low. Despite the differences in sample sizes, the model effectively addresses class imbalance and maintains a high detection accuracy.
3.4.1. Ablation Experiment
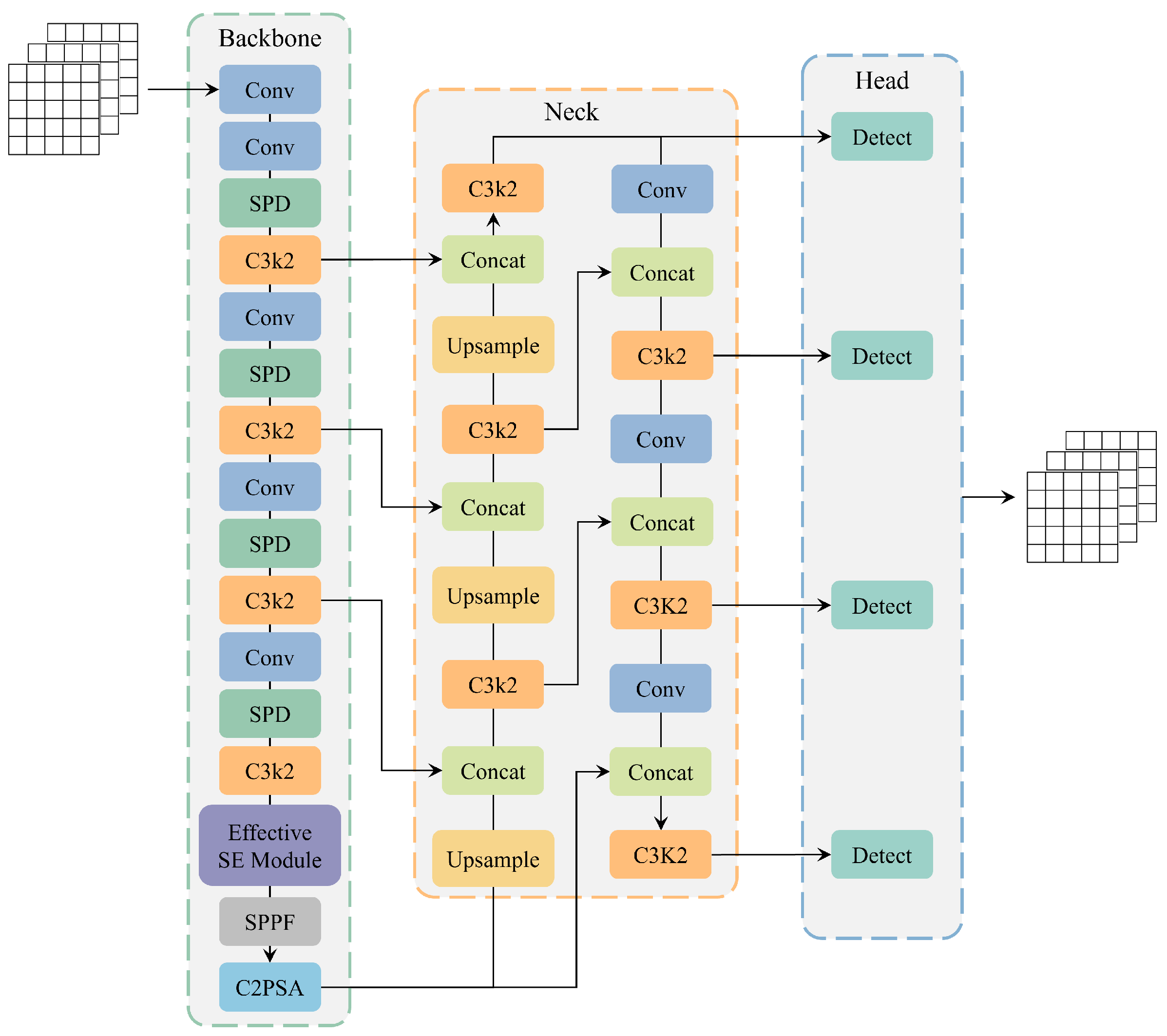
To systematically assess the performance gains brought about by the introduction of the SPD-Conv block, the EffectiveSE attention mechanism, and the small object detection head in the YOLO11n model, this study meticulously designed and executed a series of ablation experiments. These experiments were carried out based on the track fastener dataset and the track surface dataset, using the original YOLO11n model as a baseline for comparison. We comprehensively evaluated the impact of each improvement on model performance by examining metrics such as model size, parameter count, Precision (P), Recall (R), mAP@0.5, and mAP@0.5:0.95.
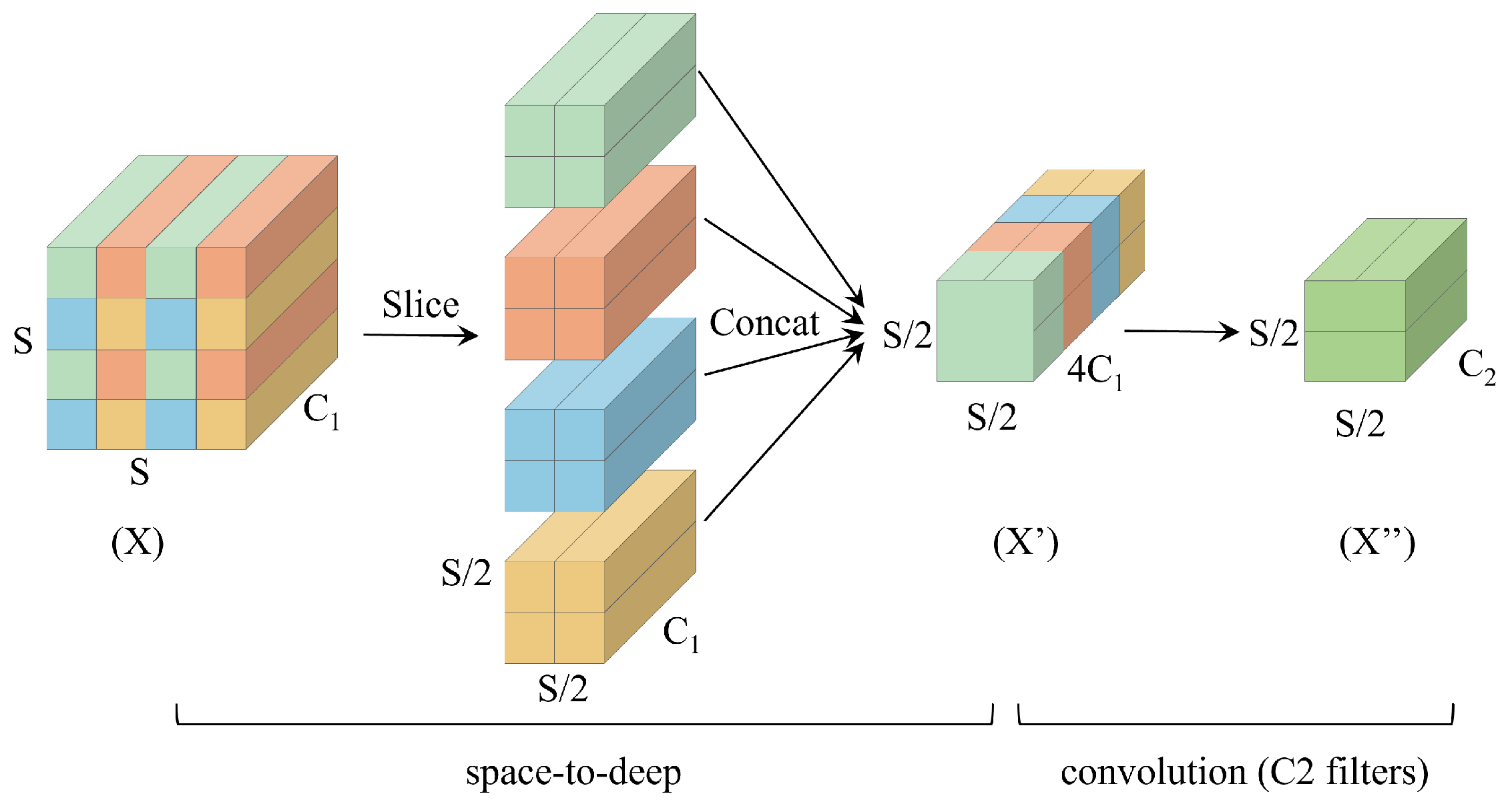
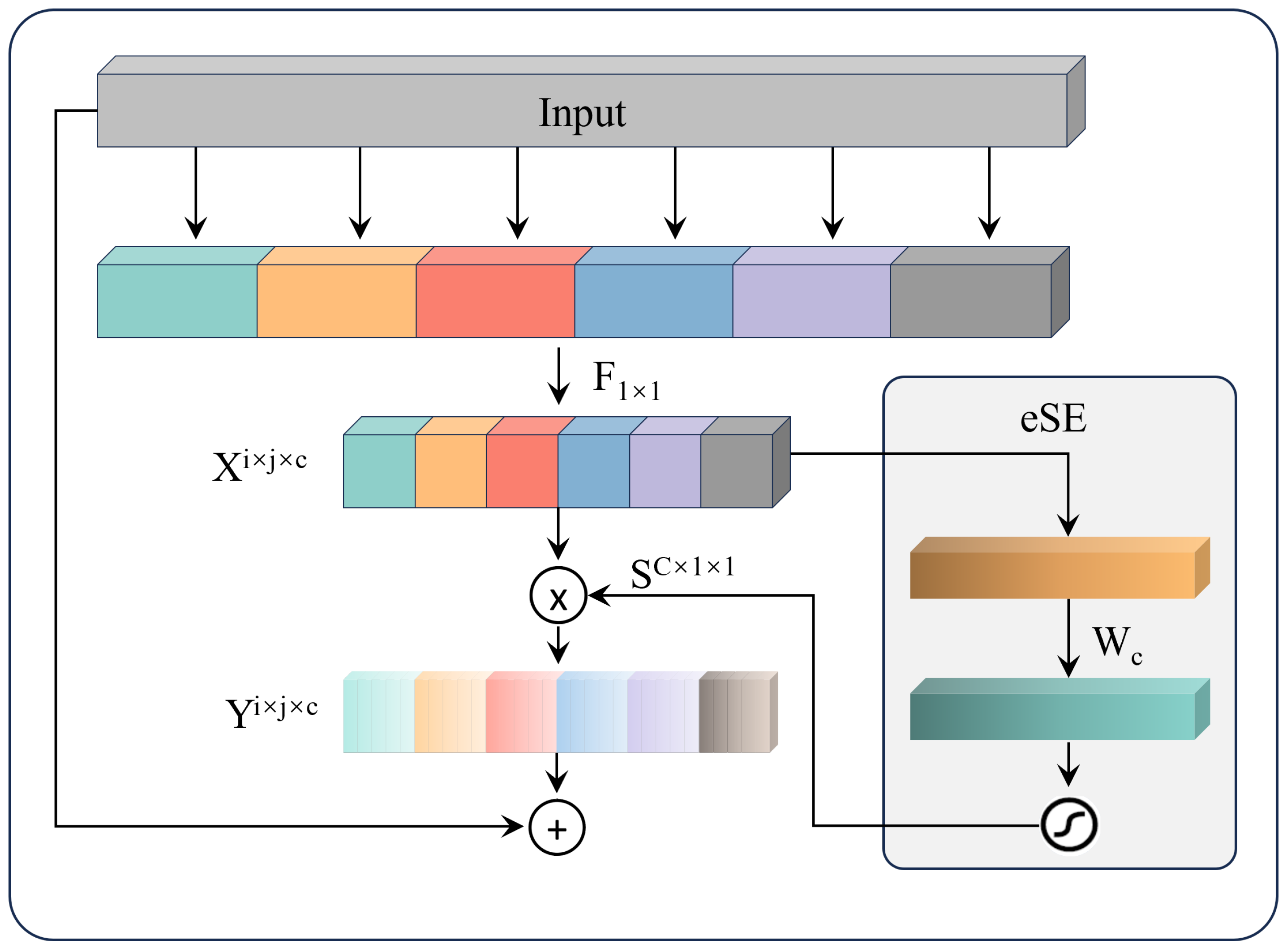
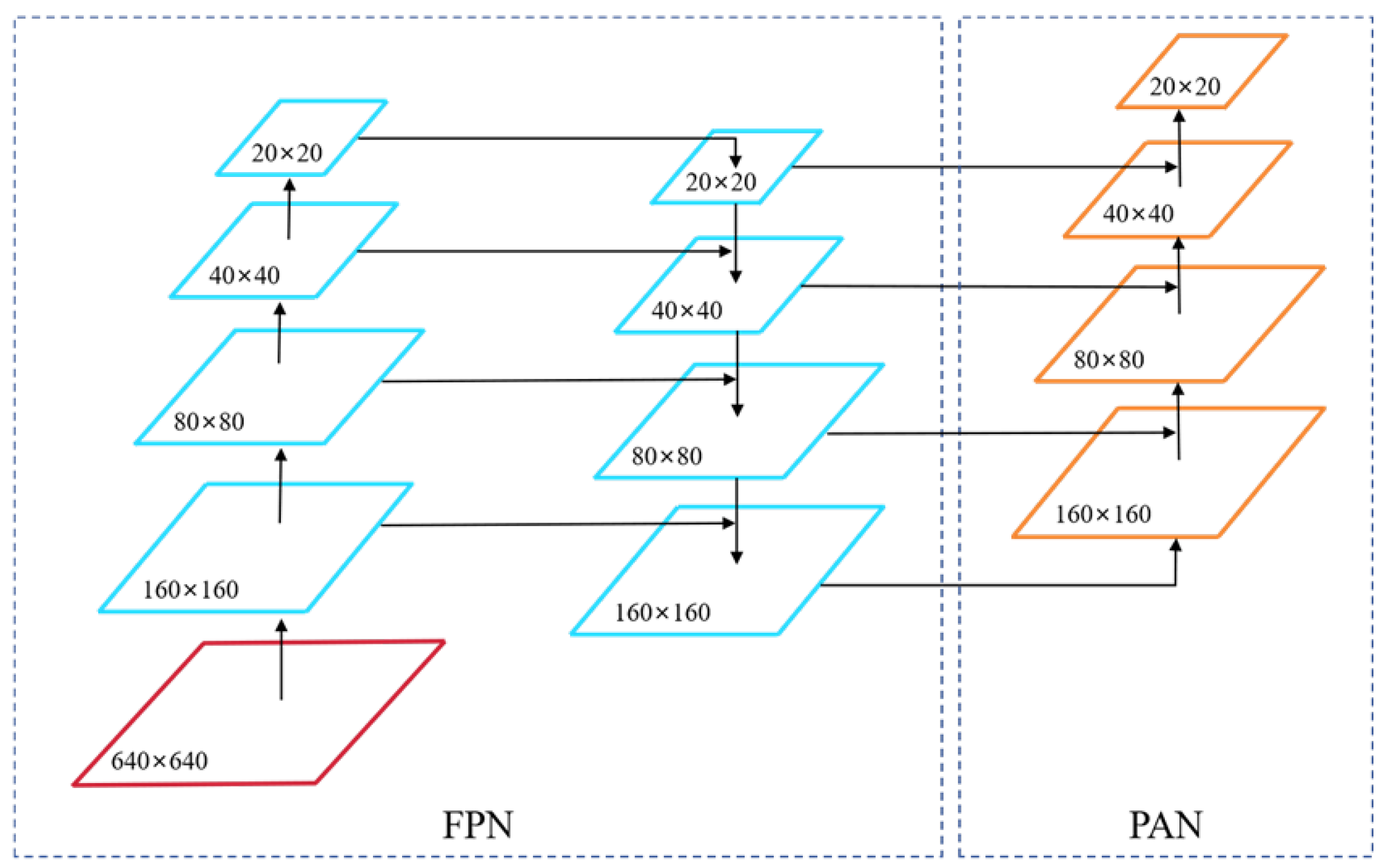
The experiments employed various module combination strategies to explore the synergetic effects among the different components. The results indicate that each component, whether used individually or in combination, enhances model performance from different dimensions. For example, the SPD-Conv module preserves more spatial details by avoiding information loss in traditional downsampling operations; the EffectiveSE module enhances the channel attention mechanism, enabling the model to better focus on key features. The combination of these two modules allows the model to retain rich spatial information while efficiently leveraging the channel attention mechanism, thereby significantly improving detection performance. However, the optimal overall performance is achieved when all three modules work together. Specifically, on the track fastener dataset, the improved model demonstrated a 2.7% increase in Precision (P), a 0.9% increase in Recall (R), a 1.8% increase in mAP@0.5, and a significant 5.8% improvement in mAP@0.5:0.95 compared to the baseline model. Similarly, on the track surface dataset, P, R, mAP@0.5, and mAP@0.5:0.95 improved by 1.4%, 0.8%, 0.9%, and 1.7%, respectively.
To validate the model’s generalization ability, we conducted experiments on the test sets of the track fastener dataset and the track surface dataset, which were not involved in the model’s training. The original YOLO11 achieved mAP@0.5 scores of 94.0% and 87.3% on the two test sets, while the improved algorithm achieved mAP@0.5 scores of 95.4% and 88.6%, respectively. These results indicate that the model performs excellently on new data outside of the training set, demonstrating that the method effectively enhances the model’s generalization ability in new scenarios.
The actual detection results of the model are shown in
Figure 8. Panels (a), (c), (e), (g), and (i) present the detection results of the original YOLO11 model, while panels (b), (d), (f), (h), and (j) display the results of the improved YOLO11 model. A comparison between
Figure 8a,b clearly illustrates that, due to the shooting angle of the visual sensor, the distant fastener appears relatively small in the image. The original YOLO11 model fails to identify this fastener, whereas the improved YOLO11 model accurately recognizes it as a normal fastener. Additionally, in
Figure 8c,d, the original YOLO11 incorrectly classifies the rotated fastener as normal, while the improved YOLO11 model successfully categorizes it as a rotated fastener. Similarly, in
Figure 8e,j, the improved YOLO11 model demonstrates an enhanced ability to detect small targets. The comparative results indicate that, in contrast to the original YOLO11 model, the improved YOLO11 model significantly reduces false positives and missed detections in track defect detection, and particularly in small target recognition. This improvement leads to a notable increase in detection accuracy, further highlighting the robustness of our model.
Our improved model shows a significant enhancement in recognition capability. Although its storage space increased by approximately 1.1 MB, and the number of parameters increased by about 0.2 million, these improvements are still significant in practical applications, especially in safety-critical fields like railway defect detection. The timely identification and repair of defects can effectively mitigate potential substantial losses. Nevertheless, with the rapid development of AI (Artificial Intelligence) in recent years, the computing power of edge devices is also increasing swiftly, and cloud computing platforms provide scalable resources, which are sufficient to meet the increased computational demands of the model. All the data are shown in
Table 6 and
Table 7.
3.4.2. Comparison Experiment
To evaluate the effectiveness of the improved model proposed in this paper, we designed a comprehensive comparative experimental scheme. The experiments selected representative algorithms in the field of object detection as baseline models, including the two-stage detector Faster R-CNN [
25] and the single-stage detector SSD [
26], as well as YOLO v5, YOLOv6, YOLOv8, and the original YOLO11. The experimental data were sourced from three rail inspection datasets with distinct characteristics: the track fastener dataset, the track surface dataset, and the railway track fault detection dataset [
27]. In addition to conventional performance metrics such as Precision (P), Recall (R), and Mean Average Precision (mAP), we also introduced frame rate (fps) as a real-time evaluation metric, which was tested on a ordinary laptop equipped with an NVIDIA GeForce RTX 3060 GPU (NVIDIA, Santa Clara, CA, USA). Detailed experimental results are presented in
Table 8,
Table 9 and
Table 10.
In the testing of the track fastener dataset, the experimental data showed that Faster R-CNN achieved an outstanding performance in mean average precision (mAP@0.5), reaching 96.2%, outperforming other algorithms. However, the two-stage detection mechanism of this algorithm significantly increased its computational complexity, resulting in a frame rate of only 12 fps, making it difficult to meet real-time detection requirements in rail scenarios. In contrast, the single-stage SSD algorithm achieved a higher detection frame rate but exhibited noticeable shortcomings in other metrics. Notably, the improved YOLO11 model proposed in this paper demonstrated significant advantages among the YOLO series algorithms, achieving the highest levels in precision (P = 92.2%) and mean average precision (mAP@0.5 = 95.9%, mAP@0.5:0.95 = 74.4%). This advantage was consistently validated in the testing of the other two datasets.
Beyond detection performance, the improved model maintained a compact size and low parameter count. Additionally, the model achieved a detection frame rate of approximately 90 fps, with a single-frame processing time of 11 ms. Each frame captured by our image sensor covers an area of about 0.5 m × 0.5 m. Assuming a 10% overlap area for every 10 images, the model can achieve a rail inspection speed of 40 m per second, equivalent to 145 km per hour. This fully meets the inspection requirements of high-speed railways. These results demonstrate that the optimization strategies proposed in this study effectively achieve an optimal balance between detection accuracy and computational efficiency.
In conclusion, the enhanced method presented in this paper substantially improves the accuracy of the YOLO11 algorithm. Through a series of targeted optimizations, the revised model exhibits exceptional performance across multiple datasets, showcasing stronger generalization capabilities in complex and variable track environments. These findings provide valuable insights and references for future research and lay a solid foundation for further advancements in track safety detection technology.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}