
A Lightweight Intrusion Detection System for Internet of Things: Clustering and Monte Carlo Cross-Entropy Approach


Abstract
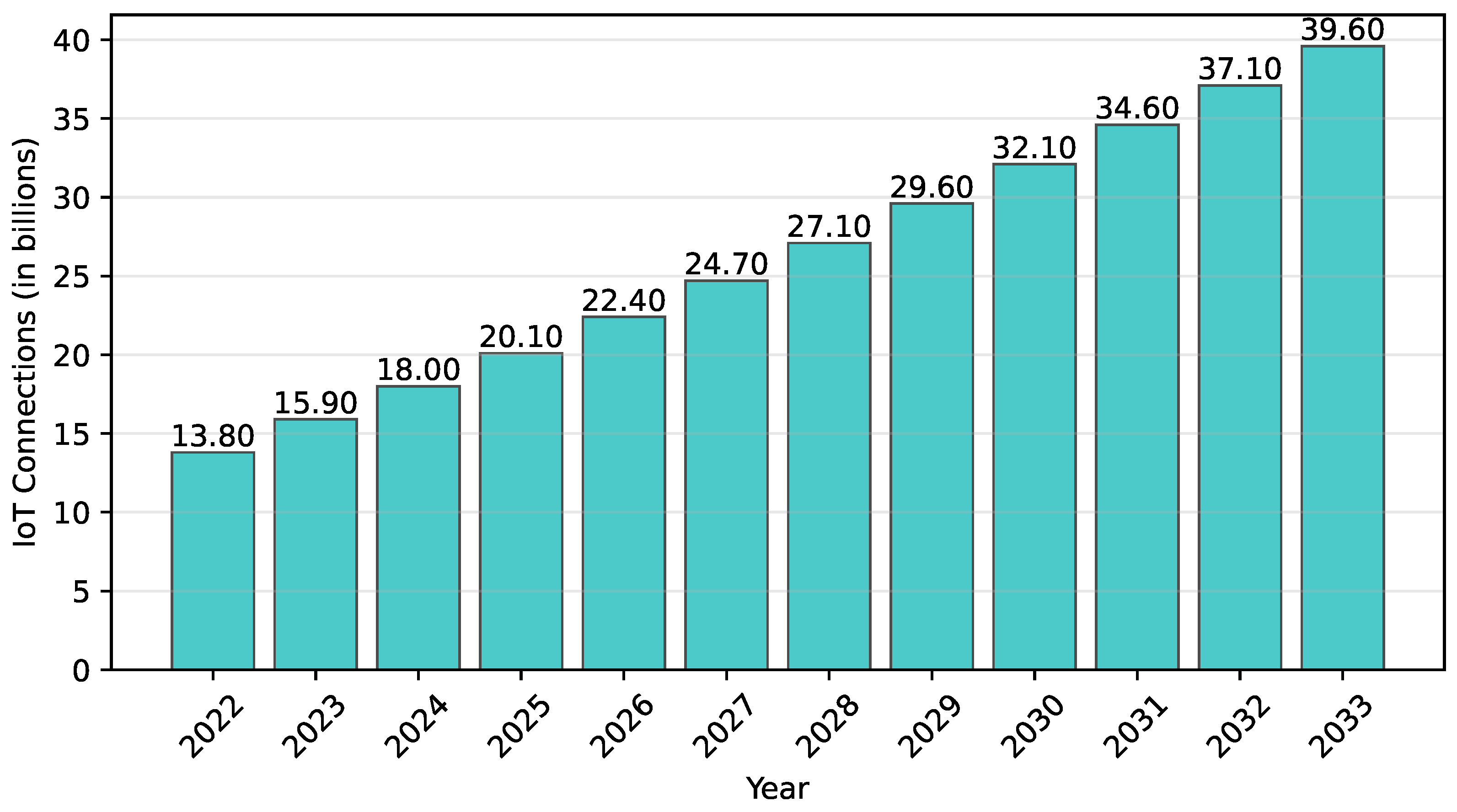
1. Introduction
1.1. Motivation and Problem Statement
1.2. Our Contributions
- Recursive Clustering for Data Condensation: We propose a recursive clustering method that integrates compactness and entropy-driven sampling to select a small, highly representative set of observations from the larger training dataset, while preserving key behavioral patterns.
- Monte Carlo Cross-Entropy-Based Feature Selection: We adopt a Monte Carlo Cross-Entropy approach combined with a stability metric of features to consistently select the most stable and relevant features, enhancing the performance of a lightweight IoT-based IDS.
- Efficient IoT-based lightweight IDS: This approach utilizes data condensation and feature selection to reduce computational overhead while preserving or enhancing classification performance. Such efficiency is critical for IoT environments, where both computational resources and memory are often limited.
1.3. Structure
2. Related Work
2.1. IoT Security Mechanisms
2.2. Feature Selection in IDS
2.3. Observation Reduction in IDS
3. The Proposed Approach
| Algorithm 1: The general steps for proposed approach |
 |
3.1. Representative Observations
3.1.1. Recursive Clustering
| Algorithm 2: Recursive k-means clustering |
 |
3.1.2. Cluster Compactness
3.1.3. Cluster Entropy
3.1.4. Sample Size Determination
An Illustrative Example
| Algorithm 3: Representative observation selection. |
 |
3.2. Dimensionality Reduction
| Algorithm 4: Dimensionality reduction. |
 |
3.3. Complexity Analysis
4. Evaluation
4.1. Training and Testing Data
4.2. The Selected Classifiers
- 1.
- LinearSVC is a discriminative model that employs an optimization algorithm known as “hinge loss” combined with L2 regularization [37]. The hinge loss penalizes both misclassified observations and those within the margin, while L2 regularization prevents overfitting by adding a penalty for large coefficients. LinearSVC utilizes the “liblinear” solver to find the optimal hyperplane that maximizes the margin between classes in high-dimensional data [38].
- 2.
- Naïve Bayes is a simple Bayesian classifier based on Bayes’ theorem, which assumes that features are independent of each other. It is widely used in many real-world applications, such as spam filtering, text classification, and intrusion detection systems. This classifier selects the class label with the highest probability, making it well suited for large databases and real-time applications due to its low computational cost [39].
- 3.
- J48 is a classification algorithm that employs a tree-based approach, building upon the C4.5 decision tree algorithm [40]. It constructs a tree-like structure leveraging the training data features, based on the concept of information gain. The algorithm recursively divides the dataset into subsets until each subset either belongs to a single class or can no longer be split further. Additionally, this classifier can handle both categorical and numerical data, and it is known for its robustness in dealing with noisy observations.
- 4.
- RandomForest is an ensemble learning classifier that constructs multiple decision trees using the training dataset. It achieves this by randomly selecting subsets of the training data through a process known as bootstrapping. Additionally, during the construction of each tree, random subsets of features are chosen at each split—a process known as feature bagging—which introduces another layer of randomness [41]. This random selection of features helps reduce correlation between the trees and mitigates overfitting by averaging the predictions of many diverse decision trees. As a result, random forests are more robust and less sensitive to noise in the training data, providing higher accuracy and better generalization compared to individual decision trees.
- 5.
- The K-Nearest Neighbor (KNN) is a simple, non-parametric algorithm widely used for both classification and regression tasks. This algorithm classifies a query observation based on its “k” nearest neighbors, using the majority class for classification or the average for regression. While KNN can achieve high accuracy, it is computationally expensive as the size of the training dataset increases. To address this, various optimization techniques, such as KD-trees, Ball-trees, etc. [42], have been developed to speed up the search process and reduce the need to examine the entire dataset. The performance of KNN is influenced by the choice of “k” and the distance metric, with traditional KNN often relying on the Euclidean distance to determine neighborhood boundaries.
- 6.
- Logistic Regression is a statistical method widely used for both binary and multiclass classification problems. In its simplest form, it models the relationship between input features and the probability of a specific outcome using the logistic function, also known as the sigmoid function, which maps any real-valued number into the range [0, 1]. For multiclass classification, logistic regression can be extended using techniques such as “one-vs-rest” or “softmax regression”. During training, logistic regression learns decision boundaries to separate classes by calculating the weights and bias, which are optimized using algorithms like Gradient Descent. In the prediction phase, the model uses the calculated probabilities to predict the class of new observations.
4.3. Performance Evaluation Metrics
4.4. Experimental Settings
5. Experimental Results and Comparisons
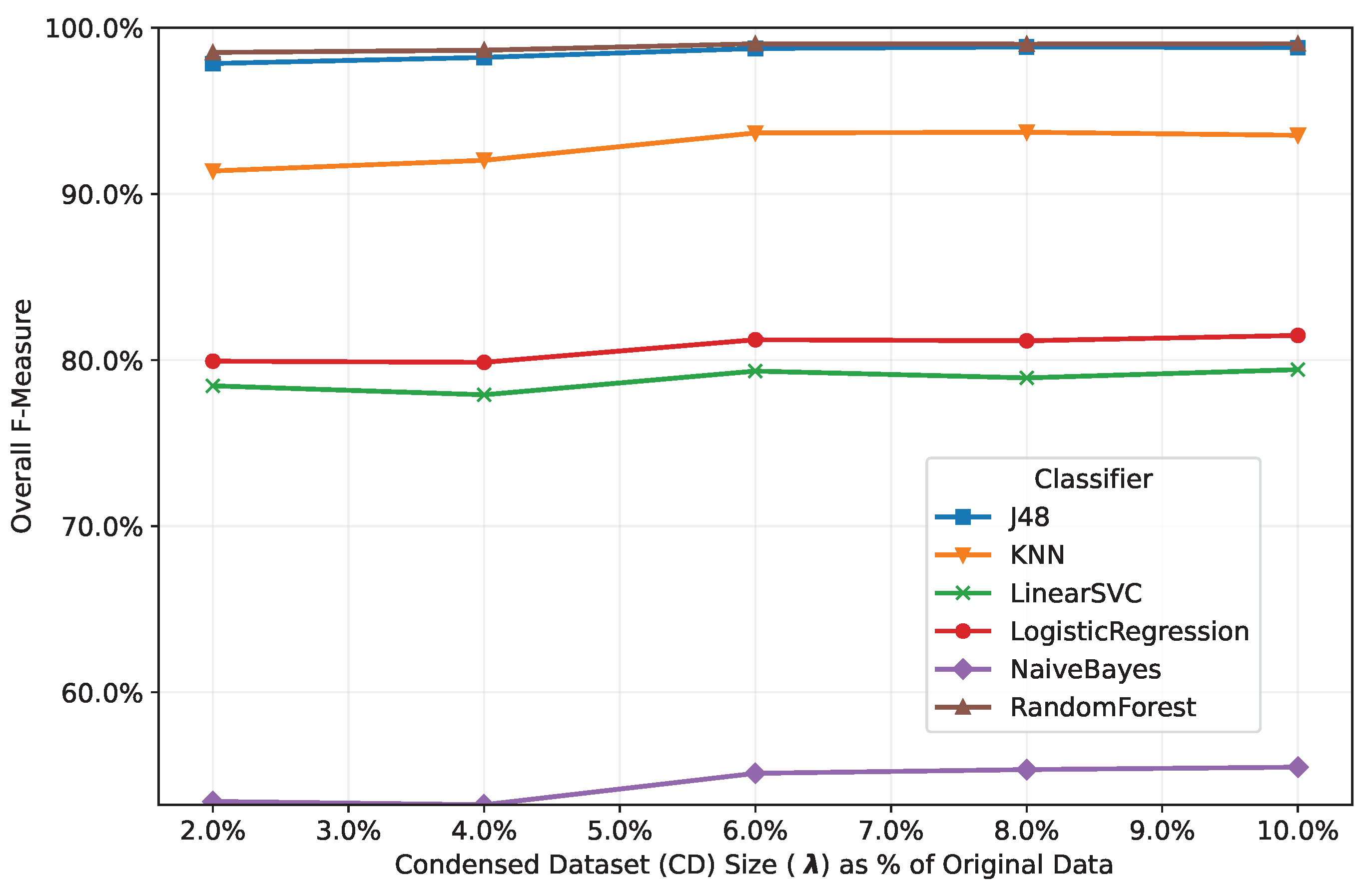
5.1. ClassificationPerformance Analysis
5.2. Runtime Performance
5.3. RAM Usage
6. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- NCTA—The Internet & Television Association Behind the Numbers: Growth in the Internet of Things. 2024. Available online: https://www.ncta.com/whats-new/behind-the-numbers-growth-in-the-internet-of-things-2 (accessed on 22 October 2023).
- Transforma Insights Global IoT Forecast Highlights (2023–2033). 2024. Available online: https://transformainsights.com/research/forecast/highlights (accessed on 24 October 2024).
- Cisco Systems Cisco Annual Internet Report (2018–2023). 2020. Available online: https://www.cisco.com/c/en/us/solutions/executive-perspectives/annual-internet-report/index.html (accessed on 22 October 2024).
- Saheed, Y.K.; Abdulganiyu, O.H.; Tchakoucht, T.A. A Novel Hybrid Ensemble Learning for Anomaly Detection in Industrial Sensor Networks and SCADA Systems for Smart City Infrastructures. J. King Saud Univ. Comput. Inf. Sci. 2023, 35, 101532. [Google Scholar] [CrossRef]
- Asif, M.; Abbas, S.; Khan, M.A.; Fatima, A.; Khan, M.A.; Lee, S.W. MapReduce-Based Intelligent Model for Intrusion Detection Using Machine Learning Technique. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 9723–9731. [Google Scholar]
- Zarpelão, B.B.; Miani, R.S.; Kawakani, C.T.; Alvarenga, S.C.D. A survey of intrusion detection in Internet of Things. J. Netw. Comput. Appl. 2017, 84, 25–37. [Google Scholar]
- Jamalipour, A.; Murali, S. A taxonomy of machine-learning-based intrusion detection systems for the internet of things: A survey. IEEE Internet Things J. 2021, 9, 9444–9466. [Google Scholar]
- Thakkar, A.; Lohiya, R. A Review on Challenges and Future Research Directions for Machine Learning-Based Intrusion Detection System. Arch. Comput. Methods Eng. 2023, 30, 4245–4269. [Google Scholar]
- Farooq, U.; Tariq, N.; Asim, M.; Baker, T.; Al-Shamma’a, A. Machine Learning and the Internet of Things Security: Solutions and Open Challenges. J. Parallel Distrib. Comput. 2022, 162, 89–104. [Google Scholar]
- Wang, J.; Xiong, X.; Chen, G.; Ouyang, R.; Gao, Y.; Alfarraj, O. Multi-Criteria Feature Selection Based Intrusion Detection for Internet of Things Big Data. Sensors 2023, 23, 7434. [Google Scholar] [CrossRef] [PubMed]
- Shafiq, M.; Tian, Z.; Bashir, A.K.; Du, X.; Guizani, M. IoT malicious traffic identification using wrapper-based feature selection mechanisms. Comput. Secur. 2020, 94, 101863. [Google Scholar]
- Haddadpajouh, H.; Mohtadi, A.; Dehghantanaha, A.; Karimipour, H.; Lin, X.; Choo, K.K.R. A multikernel and metaheuristic feature selection approach for IoT malware threat hunting in the edge layer. IEEE Internet Things J. 2020, 8, 4540–4547. [Google Scholar]
- Meng, W.; Li, W.; Su, C.; Zhou, J.; Lu, R. Sampling: Enhancing Trust Management for Wireless Intrusion Detection via Traffic Sampling in the Era of Big Data. IEEE Access 2017, 6, 7234–7243. [Google Scholar] [CrossRef]
- Hajj, S.; Azar, J.; Bou Abdo, J.; Demerjian, J.; Guyeux, C.; Makhoul, A.; Ginhac, D. Sampling-based Cross-layer Federated Learning for Lightweight IoT Intrusion Detection Systems. Sensors 2023, 23, 7038. [Google Scholar]
- Nimbalkar, P.; Kshirsagar, D. Feature Selection for Intrusion Detection System in Internet-of-Things (IoT). ICT Express 2021, 7, 177–181. [Google Scholar]
- Abawajy, J.; Darem, A.; Alhashmi, A.A. Feature Subset Selection for Malware Detection in Smart IoT Platforms. Sensors 2021, 21, 1374. [Google Scholar] [CrossRef]
- Fatima, M.; Rehman, O.; Ali, S.; Niazi, M.F. ELIDS: Ensemble Feature Selection for Lightweight IDS against DDoS Attacks in Resource-Constrained IoT Environment. Future Gener. Comput. Syst. 2024, 159, 172–187. [Google Scholar]
- Meidan, Y.; Bohadana, M.; Mathov, Y.; Mirsky, Y.; Breitenbacher, D.; Shabtai, A. N-BaIoT Dataset: Detection of IoT Botnet Attacks. UCI Machine Learning Repository. 2018. Available online: https://archive.ics.uci.edu/dataset/442/detection+of+iot+botnet+attacks+n+baiot (accessed on 24 October 2024).
- Ferrag, M.A.; Friha, O.; Hamouda, D.; Maglaras, L.; Janicke, H. Edge-IoTset: A new comprehensive realistic cyber security dataset of IoT applications for centralized and federated learning. IEEE Access 2022, 10, 40281–40306. [Google Scholar]
- Neto, E.C.P.; Dadkhah, S.; Ferreira, R.; Zohourian, A.; Lu, R.; Ghorbani, A.A. CICIoT2023: A real-time dataset and benchmark for large-scale attacks in IoT environment. Sensors 2023, 23, 5941. [Google Scholar] [CrossRef]
- Bhardwaj, A.; Kaushik, K.; Kumar, M. Taxonomy of Security Attacks on Internet of Things. In Security and Privacy in Cyberspace; Springer: Berlin/Heidelberg, Germany, 2022; pp. 1–24. [Google Scholar]
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A survey on internet of things: Architecture, enabling technologies, security and privacy, and applications. IEEE Internet Things J. 2017, 4, 1125–1142. [Google Scholar]
- Sasi, T.; Lashkari, A.H.; Lu, R.; Xiong, P.; Iqbal, S. A comprehensive survey on IoT attacks: Taxonomy, detection mechanisms and challenges. J. Inf. Intell. 2023, 2, 455–513. [Google Scholar]
- Khan, M.N.; Rao, A.; Camtepe, S. Lightweight cryptographic protocols for IoT-constrained devices: A survey. IEEE Internet Things J. 2020, 8, 4132–4156. [Google Scholar]
- Nair, J.; Jain, K. Cryptography based Identity Management for IoT Devices. In Proceedings of the 2023 Second International Conference on Augmented Intelligence and Sustainable Systems (ICAISS), Trichy, India, 23–25 August 2023; pp. 1211–1218. [Google Scholar]
- Iqbal, U.; Mir, A.H. Secure and scalable access control protocol for IoT environment. Internet Things 2020, 12, 100291. [Google Scholar]
- Pinno, O.J.A.; Grégio, A.R.A.; Bona, L.C.D. ControlChain: A new stage on the IoT access control authorization. Concurr. Comput. Pract. Exp. 2020, 32, e5238. [Google Scholar]
- Chakraborty, B.; Divakaran, D.M.; Nevat, I.; Peters, G.W.; Gurusamy, M. Cost-aware feature selection for IoT device classification. IEEE Internet Things J. 2021, 8, 11052–11064. [Google Scholar]
- Li, P.; Wang, H.; Tian, G.; Fan, Z. IDS_IoT: A Cooperative Intrusion Detection System for the Internet of Things Using Convolutional Neural Networks and Black Hole Optimization. Sensors 2024, 24, 4766. [Google Scholar] [PubMed]
- Azimjonov, J.; Kim, T. Stochastic Gradient Descent Classifier-Based Lightweight Intrusion Detection Systems Using the Efficient Feature Subsets of Datasets. Expert Syst. Appl. 2024, 237, 121493. [Google Scholar]
- Jiang, W.; Han, H.; Zhang, Y.; Mu, J.; Shankar, A. Intrusion detection with federated learning and conditional generative adversarial network in satellite-terrestrial integrated networks. Mob. Netw. Appl. 2024; Early access. [Google Scholar]
- Quyen, N.H.; Duy, P.T.; Nguyen, N.T.; Khoa, N.H.; Pham, V.H. FedKD-IDS: A robust intrusion detection system using knowledge distillation-based semi-supervised federated learning and anti-poisoning attack mechanism. Inf. Fusion 2025, 117, 102807. [Google Scholar]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, Oakland, CA, USA, 21 June–18 July 1965 and 27 December 1965–7 January 1966; Volume 1, pp. 281–297. [Google Scholar]
- Bagirov, A.M.; Aliguliyev, R.M.; Sultanova, N. Finding compact and well-separated clusters: Clustering using silhouette coefficients. Pattern Recognit. 2023, 135, 109144. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Entropy, Relative Entropy, and Mutual Information; Wiley-Interscience: Hoboken, NJ, USA, 1991; Volume 2, pp. 12–13. [Google Scholar]
- Xu, J. An empirical comparison of weighting functions for multi-label distance-weighted k-nearest neighbour method. In Proceedings of the 1st International Conference on Artificial Intelligence, Soft Computing and Applications, Tirunelveli, India, 23–25 September 2011; pp. 13–20. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Vapnik, V. The Nature of Statistical Learning Theory; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson: Boston, MA, USA, 2016. [Google Scholar]
- Quinlan, J.R. C4.5: Programs for Machine Learning; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar]
- Almalawi, A.M.; Fahad, A.; Tari, Z.; Cheema, M.A.; Khalil, I. k-NNVWC: An Efficient k-Nearest Neighbors Approach Based on Various-Widths Clustering. IEEE Trans. Knowl. Data Eng. 2015, 28, 68–81. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Acronym | Full Form |
|---|---|
| IoT | Internet of Things |
| IDS | Intrusion Detection System |
| ML | Machine Learning |
| DoS | Denial of Service |
| DDoS | Distributed Denial of Service |
| IIoT | Industrial Internet of Things |
| CE | Cross-Entropy |
| IC | Intra-Cluster Compactness |
| SES | Spatial Entropy Score |
| KL | Kullback–Leibler (Divergence) |
| FSD | Feature-Selected Data |
| CD | Condensed Dataset |
| RAM | Random Access Memory |
| KNN | K-Nearest Neighbor |
| SVM | Support Vector Machine |
| TCP/IP | Transmission Control Protocol/Internet Protocol |
| N-BaIoT | Network-Based IoT Botnet Dataset |
| Edge-IIoTset | Edge-Industrial IoT Dataset |
| CICIoT2023 | Collaborative and Intelligent Cybersecurity for IoT 2023 Dataset |
| FL | Federated Learning |
| Dataset | Total | Normal | Abnormal | Attack Types | Features |
|---|---|---|---|---|---|
| Edge-IIoTset-Training | 525,273 | 335,606 | 189,667 | 13 | 70 |
| Edge-IIoTset-Testing | 225,117 | 143,831 | 81,286 | 13 | 70 |
| N-BaIoT-Training | 146,618 | 61,566 | 85,052 | 8 | 115 |
| N-BaIoT-Testing | 62,837 | 26,386 | 36,451 | 8 | 115 |
| CICIoT2023-Training | 352,282 | 7687 | 344,595 | 7 | 46 |
| CICIoT2023-Testing | 150,978 | 3294 | 147,684 | 7 | 46 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| ack | 1.00 | 0.99 | 1.00 | 0.96 | 0.75 | 1.00 | 0.95 | 0.41 | 0.36 | 0.96 | 0.43 | 0.48 | 0.32 | 0.40 | 0.31 | 1.00 | 1.00 | 1.00 |
| combo | 1.00 | 0.96 | 1.00 | 0.98 | 0.91 | 0.93 | 0.81 | 0.66 | 0.65 | 0.80 | 0.67 | 0.74 | 0.71 | 0.76 | 0.68 | 1.00 | 0.98 | 1.00 |
| junk | 1.00 | 0.94 | 1.00 | 0.95 | 0.93 | 0.86 | 0.61 | 0.42 | 0.52 | 0.60 | 0.53 | 0.49 | 0.50 | 0.58 | 0.03 | 1.00 | 0.97 | 1.00 |
| normal | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 | 0.99 | 0.98 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| scan | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 | 0.99 | 0.95 | 0.82 | 0.99 | 0.98 | 0.77 | 0.27 | 0.40 | 0.18 | 1.00 | 1.00 | 1.00 |
| syn | 1.00 | 1.00 | 1.00 | 1.00 | 0.96 | 1.00 | 1.00 | 0.77 | 0.72 | 0.99 | 0.89 | 0.84 | 0.53 | 0.78 | 0.47 | 1.00 | 1.00 | 1.00 |
| tcp | 0.38 | 0.20 | 0.67 | 0.50 | 0.00 | 1.00 | 0.25 | 0.00 | 0.00 | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.40 | 1.00 | 0.67 |
| udp | 1.00 | 0.99 | 1.00 | 0.97 | 0.85 | 1.00 | 0.88 | 0.64 | 0.64 | 0.93 | 0.67 | 0.67 | 0.43 | 0.67 | 0.01 | 1.00 | 1.00 | 1.00 |
| udpplain | 1.00 | 0.98 | 1.00 | 0.99 | 0.91 | 1.00 | 0.97 | 0.86 | 0.97 | 0.97 | 0.84 | 0.96 | 0.95 | 0.61 | 0.87 | 1.00 | 1.00 | 1.00 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| ack | 1.00 | 0.99 | 1.00 | 0.93 | 0.67 | 1.00 | 0.75 | 0.18 | 0.20 | 0.86 | 0.22 | 0.27 | 1.00 | 0.44 | 1.00 | 1.00 | 1.00 | 1.00 |
| combo | 1.00 | 0.97 | 1.00 | 0.98 | 0.94 | 0.93 | 0.79 | 0.75 | 0.74 | 0.79 | 0.75 | 0.71 | 0.90 | 0.79 | 0.81 | 1.00 | 0.98 | 1.00 |
| junk | 1.00 | 0.93 | 0.99 | 0.95 | 0.89 | 0.86 | 0.64 | 0.28 | 0.26 | 0.61 | 0.41 | 0.32 | 0.04 | 0.17 | 0.02 | 1.00 | 0.97 | 1.00 |
| normal | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.63 | 0.66 | 0.51 | 1.00 | 1.00 | 1.00 |
| scan | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.83 | 0.69 | 1.00 | 0.96 | 0.89 | 0.37 | 0.97 | 0.33 | 1.00 | 1.00 | 1.00 |
| syn | 1.00 | 1.00 | 1.00 | 1.00 | 0.95 | 1.00 | 1.00 | 0.86 | 0.88 | 0.99 | 0.87 | 0.80 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| tcp | 0.27 | 0.18 | 0.73 | 0.09 | 0.00 | 0.09 | 0.18 | 0.00 | 0.00 | 0.09 | 0.00 | 0.00 | 0.55 | 0.00 | 0.27 | 0.18 | 0.09 | 0.55 |
| udp | 1.00 | 0.99 | 1.00 | 0.98 | 0.89 | 1.00 | 0.97 | 0.90 | 0.90 | 0.98 | 0.84 | 0.85 | 0.00 | 0.66 | 0.00 | 1.00 | 1.00 | 1.00 |
| udpplain | 1.00 | 0.99 | 1.00 | 1.00 | 0.94 | 1.00 | 1.00 | 0.64 | 0.63 | 0.99 | 0.87 | 0.88 | 0.62 | 0.59 | 0.62 | 1.00 | 1.00 | 1.00 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| ack | 1.00 | 0.99 | 1.00 | 0.94 | 0.71 | 1.00 | 0.83 | 0.25 | 0.25 | 0.91 | 0.29 | 0.34 | 0.48 | 0.42 | 0.47 | 1.00 | 1.00 | 1.00 |
| combo | 1.00 | 0.97 | 1.00 | 0.98 | 0.93 | 0.93 | 0.80 | 0.70 | 0.69 | 0.80 | 0.71 | 0.72 | 0.79 | 0.77 | 0.74 | 1.00 | 0.98 | 1.00 |
| junk | 1.00 | 0.93 | 0.99 | 0.95 | 0.91 | 0.86 | 0.63 | 0.34 | 0.35 | 0.61 | 0.46 | 0.39 | 0.07 | 0.26 | 0.03 | 1.00 | 0.97 | 1.00 |
| normal | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.99 | 0.99 | 0.78 | 0.80 | 0.67 | 1.00 | 1.00 | 1.00 |
| scan | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.89 | 0.75 | 1.00 | 0.97 | 0.83 | 0.31 | 0.57 | 0.23 | 1.00 | 1.00 | 1.00 |
| syn | 1.00 | 1.00 | 1.00 | 1.00 | 0.95 | 1.00 | 1.00 | 0.82 | 0.79 | 0.99 | 0.88 | 0.82 | 0.70 | 0.88 | 0.64 | 1.00 | 1.00 | 1.00 |
| tcp | 0.32 | 0.19 | 0.70 | 0.15 | 0.00 | 0.17 | 0.21 | 0.00 | 0.00 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | 0.01 | 0.25 | 0.17 | 0.60 |
| udp | 1.00 | 0.99 | 1.00 | 0.97 | 0.87 | 1.00 | 0.93 | 0.75 | 0.75 | 0.95 | 0.75 | 0.75 | 0.00 | 0.66 | 0.00 | 1.00 | 1.00 | 1.00 |
| udpplain | 1.00 | 0.99 | 1.00 | 0.99 | 0.93 | 1.00 | 0.98 | 0.73 | 0.77 | 0.98 | 0.86 | 0.92 | 0.75 | 0.60 | 0.72 | 1.00 | 1.00 | 1.00 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| BenignTraffic | 0.84 | 0.81 | 0.57 | 0.56 | 0.50 | 0.54 | 0.56 | 0.45 | 0.52 | 0.56 | 0.54 | 0.55 | 0.22 | 0.39 | 0.32 | 0.85 | 0.82 | 0.63 |
| Brute Force | 0.62 | 0.55 | 0.13 | 0.33 | 0.11 | 0.17 | 1.00 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.37 | 0.02 | 0.00 | 0.94 | 0.79 | 0.46 |
| DDoS | 1.00 | 1.00 | 0.89 | 0.97 | 0.97 | 0.89 | 0.81 | 0.82 | 0.79 | 0.81 | 0.83 | 0.80 | 0.99 | 0.98 | 1.00 | 1.00 | 1.00 | 0.90 |
| DoS | 1.00 | 1.00 | 0.67 | 0.91 | 0.76 | 0.65 | 0.73 | 0.36 | 0.20 | 0.78 | 0.33 | 0.80 | 0.31 | 0.21 | 0.27 | 1.00 | 1.00 | 0.71 |
| Mirai | 1.00 | 1.00 | 0.99 | 1.00 | 0.99 | 1.00 | 0.97 | 0.90 | 0.96 | 0.98 | 0.95 | 0.98 | 1.00 | 0.10 | 1.00 | 1.00 | 1.00 | 1.00 |
| Recon | 0.86 | 0.83 | 0.63 | 0.66 | 0.63 | 0.61 | 0.54 | 0.53 | 0.45 | 0.54 | 0.45 | 0.44 | 0.87 | 0.91 | 0.46 | 0.84 | 0.82 | 0.64 |
| Spoofing | 0.82 | 0.80 | 0.58 | 0.71 | 0.58 | 0.69 | 0.79 | 0.59 | 0.66 | 0.62 | 0.62 | 0.70 | 0.80 | 0.58 | 0.68 | 0.86 | 0.81 | 0.75 |
| Web-based | 0.73 | 0.70 | 0.34 | 0.44 | 0.31 | 0.36 | 0.23 | 0.00 | 0.13 | 0.36 | 0.00 | 0.13 | 0.30 | 0.04 | 0.10 | 0.73 | 0.72 | 0.47 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| BenignTraffic | 0.84 | 0.81 | 0.57 | 0.70 | 0.60 | 0.67 | 0.64 | 0.55 | 0.46 | 0.63 | 0.49 | 0.47 | 0.97 | 0.59 | 0.51 | 0.90 | 0.88 | 0.72 |
| Brute Force | 0.67 | 0.56 | 0.13 | 0.19 | 0.10 | 0.10 | 0.15 | 0.00 | 0.00 | 0.15 | 0.00 | 0.00 | 0.18 | 0.90 | 0.00 | 0.48 | 0.44 | 0.08 |
| DDoS | 1.00 | 1.00 | 0.94 | 0.98 | 0.93 | 0.93 | 0.99 | 0.83 | 0.99 | 0.99 | 0.82 | 0.99 | 0.46 | 0.12 | 0.34 | 1.00 | 1.00 | 0.94 |
| DoS | 1.00 | 1.00 | 0.53 | 0.87 | 0.90 | 0.51 | 0.12 | 0.40 | 0.00 | 0.12 | 0.39 | 0.04 | 0.95 | 0.25 | 0.96 | 1.00 | 1.00 | 0.55 |
| Mirai | 1.00 | 1.00 | 0.99 | 0.99 | 0.96 | 0.99 | 0.99 | 0.94 | 0.99 | 0.98 | 0.90 | 0.98 | 0.99 | 0.99 | 0.99 | 1.00 | 1.00 | 0.99 |
| Recon | 0.86 | 0.84 | 0.62 | 0.71 | 0.68 | 0.69 | 0.60 | 0.37 | 0.61 | 0.61 | 0.45 | 0.65 | 0.21 | 0.20 | 0.02 | 0.88 | 0.87 | 0.75 |
| Spoofing | 0.82 | 0.78 | 0.59 | 0.58 | 0.54 | 0.52 | 0.34 | 0.23 | 0.25 | 0.50 | 0.25 | 0.31 | 0.06 | 0.27 | 0.16 | 0.80 | 0.78 | 0.61 |
| Web-based | 0.73 | 0.70 | 0.35 | 0.33 | 0.16 | 0.24 | 0.01 | 0.00 | 0.01 | 0.04 | 0.00 | 0.01 | 0.34 | 0.01 | 0.80 | 0.72 | 0.61 | 0.39 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| BenignTraffic | 0.84 | 0.81 | 0.57 | 0.62 | 0.54 | 0.60 | 0.60 | 0.49 | 0.49 | 0.59 | 0.51 | 0.51 | 0.36 | 0.47 | 0.39 | 0.87 | 0.85 | 0.67 |
| Brute Force | 0.64 | 0.55 | 0.13 | 0.24 | 0.11 | 0.12 | 0.26 | 0.00 | 0.00 | 0.26 | 0.00 | 0.00 | 0.24 | 0.03 | 0.00 | 0.63 | 0.56 | 0.14 |
| DDoS | 1.00 | 1.00 | 0.91 | 0.97 | 0.95 | 0.91 | 0.89 | 0.82 | 0.88 | 0.89 | 0.82 | 0.88 | 0.63 | 0.22 | 0.50 | 1.00 | 1.00 | 0.92 |
| DoS | 1.00 | 1.00 | 0.59 | 0.89 | 0.83 | 0.57 | 0.20 | 0.38 | 0.00 | 0.20 | 0.36 | 0.08 | 0.47 | 0.23 | 0.42 | 1.00 | 1.00 | 0.62 |
| Mirai | 1.00 | 1.00 | 0.99 | 1.00 | 0.98 | 1.00 | 0.98 | 0.92 | 0.98 | 0.98 | 0.92 | 0.98 | 0.99 | 0.18 | 0.99 | 1.00 | 1.00 | 1.00 |
| Recon | 0.86 | 0.83 | 0.63 | 0.69 | 0.65 | 0.65 | 0.57 | 0.44 | 0.52 | 0.57 | 0.45 | 0.53 | 0.33 | 0.33 | 0.03 | 0.86 | 0.85 | 0.69 |
| Spoofing | 0.82 | 0.79 | 0.59 | 0.64 | 0.56 | 0.60 | 0.48 | 0.33 | 0.36 | 0.55 | 0.36 | 0.43 | 0.11 | 0.37 | 0.26 | 0.83 | 0.79 | 0.68 |
| Web-based | 0.73 | 0.70 | 0.34 | 0.37 | 0.21 | 0.29 | 0.02 | 0.00 | 0.01 | 0.08 | 0.00 | 0.01 | 0.32 | 0.02 | 0.18 | 0.73 | 0.66 | 0.43 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| Backdoor | 0.98 | 0.91 | 0.58 | 0.95 | 0.69 | 0.24 | 0.82 | 0.00 | 0.00 | 0.83 | 0.00 | 0.00 | 0.05 | 0.00 | 0.44 | 0.99 | 1.00 | 0.65 |
| DDoS_HTTP | 1.00 | 1.00 | 0.87 | 1.00 | 1.00 | 0.83 | 0.77 | 0.03 | 0.42 | 0.83 | 0.56 | 0.54 | 1.00 | 1.00 | 0.00 | 1.00 | 1.00 | 0.84 |
| DDoS_ICMP | 1.00 | 1.00 | 1.00 | 0.99 | 0.99 | 1.00 | 0.99 | 0.98 | 0.97 | 0.99 | 0.97 | 0.97 | 1.00 | 1.00 | 0.97 | 1.00 | 1.00 | 1.00 |
| DDoS_TCP | 1.00 | 1.00 | 1.00 | 1.00 | 0.98 | 1.00 | 1.00 | 0.88 | 0.80 | 1.00 | 0.90 | 0.84 | 0.96 | 0.95 | 0.56 | 1.00 | 1.00 | 1.00 |
| DDoS_UDP | 1.00 | 1.00 | 0.50 | 1.00 | 1.00 | 0.50 | 0.60 | 1.00 | 0.00 | 1.00 | 0.00 | 0.00 | 1.00 | 1.00 | 0.50 | 1.00 | 1.00 | 0.50 |
| Normal | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.98 | 0.92 | 0.81 | 0.98 | 0.95 | 0.84 | 1.00 | 1.00 | 0.90 | 1.00 | 1.00 | 1.00 |
| OS_Fingerprinting | 0.99 | 0.96 | 0.84 | 0.83 | 0.71 | 0.59 | 1.00 | 0.00 | 0.00 | 0.80 | 0.00 | 0.00 | 0.63 | 0.67 | 0.00 | 0.99 | 0.92 | 0.84 |
| Password | 0.98 | 0.95 | 0.89 | 0.88 | 0.88 | 0.82 | 0.72 | 0.53 | 0.60 | 0.79 | 0.57 | 0.63 | 0.43 | 0.16 | 0.99 | 0.95 | 0.95 | 0.87 |
| Port_Scanning | 0.96 | 0.94 | 0.82 | 0.93 | 0.91 | 0.92 | 0.85 | 0.00 | 1.00 | 0.93 | 0.00 | 0.99 | 0.09 | 0.29 | 0.06 | 0.96 | 0.97 | 0.84 |
| Ransomware | 0.99 | 0.94 | 0.75 | 0.89 | 0.73 | 0.57 | 0.63 | 0.44 | 0.00 | 0.61 | 0.32 | 0.00 | 0.04 | 0.63 | 0.03 | 0.98 | 0.95 | 0.73 |
| SQL_injection | 0.99 | 1.00 | 0.46 | 0.80 | 0.80 | 0.39 | 0.50 | 0.00 | 0.00 | 0.16 | 0.00 | 0.00 | 0.80 | 0.61 | 0.25 | 1.00 | 1.00 | 0.57 |
| Uploading | 0.99 | 0.91 | 0.64 | 0.93 | 0.83 | 0.69 | 0.88 | 0.83 | 0.00 | 0.83 | 0.81 | 0.83 | 0.94 | 0.79 | 0.44 | 1.00 | 0.98 | 0.77 |
| Vulnerability_scanner | 0.97 | 0.89 | 0.91 | 0.93 | 0.71 | 0.93 | 0.94 | 0.00 | 0.92 | 0.95 | 0.00 | 0.93 | 0.94 | 0.38 | 0.80 | 1.00 | 0.94 | 0.98 |
| XSS | 0.55 | 0.21 | 0.18 | 0.67 | 0.00 | 0.89 | 0.51 | 0.00 | 0.00 | 1.00 | 0.00 | 0.00 | 0.71 | 0.01 | 0.00 | 0.88 | 0.21 | 0.65 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| Backdoor | 0.98 | 0.83 | 0.62 | 0.82 | 0.63 | 0.14 | 0.11 | 0.00 | 0.00 | 0.26 | 0.00 | 0.00 | 0.89 | 0.00 | 0.15 | 0.97 | 0.93 | 0.54 |
| DDoS_HTTP | 1.00 | 1.00 | 0.91 | 0.99 | 1.00 | 0.94 | 0.54 | 0.00 | 0.01 | 0.73 | 0.32 | 0.17 | 0.97 | 1.00 | 0.00 | 1.00 | 1.00 | 0.94 |
| DDoS_ICMP | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.98 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| DDoS_TCP | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.94 | 0.63 | 1.00 | 0.96 | 0.74 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 |
| DDoS_UDP | 0.83 | 0.83 | 1.00 | 1.00 | 0.17 | 1.00 | 1.00 | 0.17 | 0.00 | 0.50 | 0.00 | 0.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.83 | 1.00 |
| Normal | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.98 | 0.97 | 0.99 | 0.98 | 0.97 | 0.67 | 0.54 | 0.75 | 1.00 | 1.00 | 1.00 |
| OS_Fingerprinting | 0.99 | 0.97 | 0.70 | 0.55 | 0.15 | 0.46 | 0.23 | 0.00 | 0.00 | 0.16 | 0.00 | 0.00 | 1.00 | 0.08 | 0.00 | 1.00 | 0.97 | 0.72 |
| Password | 0.98 | 0.94 | 0.88 | 0.96 | 0.88 | 0.89 | 0.92 | 0.67 | 0.29 | 0.95 | 0.81 | 0.34 | 0.38 | 0.78 | 0.05 | 1.00 | 0.98 | 0.94 |
| Port_Scanning | 0.97 | 0.96 | 0.82 | 0.79 | 0.69 | 0.75 | 0.76 | 0.00 | 0.01 | 0.76 | 0.00 | 0.12 | 1.00 | 0.06 | 0.36 | 0.96 | 0.94 | 0.82 |
| Ransomware | 0.99 | 0.93 | 0.74 | 0.93 | 0.62 | 0.41 | 0.38 | 0.04 | 0.00 | 0.42 | 0.01 | 0.00 | 0.77 | 0.02 | 0.39 | 0.99 | 0.97 | 0.79 |
| SQL_injection | 1.00 | 1.00 | 0.42 | 0.50 | 0.63 | 0.24 | 0.00 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.42 | 1.00 | 0.14 | 1.00 | 1.00 | 0.23 |
| Uploading | 1.00 | 0.93 | 0.66 | 0.69 | 0.64 | 0.56 | 0.90 | 0.58 | 0.00 | 0.99 | 0.33 | 0.02 | 0.44 | 1.00 | 0.10 | 1.00 | 0.99 | 0.58 |
| Vulnerability_scanner | 0.97 | 0.91 | 0.90 | 0.83 | 0.84 | 0.83 | 0.83 | 0.00 | 0.83 | 0.83 | 0.00 | 0.83 | 0.83 | 1.00 | 0.81 | 0.91 | 0.91 | 0.88 |
| XSS | 0.58 | 0.24 | 0.17 | 0.07 | 0.00 | 0.10 | 0.04 | 0.00 | 0.00 | 0.04 | 0.00 | 0.00 | 0.07 | 0.01 | 0.00 | 0.27 | 0.01 | 0.15 |
| Class Label | J48 | KNN | LinearSVC | LogisticRegression | NaiveBayes | RandomForest | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| Backdoor | 0.98 | 0.87 | 0.60 | 0.88 | 0.66 | 0.18 | 0.20 | 0.00 | 0.00 | 0.40 | 0.00 | 0.00 | 0.09 | 0.00 | 0.23 | 0.98 | 0.96 | 0.59 |
| DDoS_HTTP | 1.00 | 1.00 | 0.89 | 0.99 | 1.00 | 0.88 | 0.64 | 0.01 | 0.02 | 0.78 | 0.41 | 0.26 | 0.98 | 1.00 | 0.00 | 1.00 | 1.00 | 0.89 |
| DDoS_ICMP | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 | 0.99 | 0.99 | 0.97 | 0.99 | 0.99 | 0.98 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 1.00 |
| DDoS_TCP | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 1.00 | 1.00 | 0.91 | 0.71 | 1.00 | 0.92 | 0.79 | 0.98 | 0.97 | 0.71 | 1.00 | 1.00 | 1.00 |
| DDoS_UDP | 0.91 | 0.91 | 0.67 | 1.00 | 0.29 | 0.67 | 0.75 | 0.29 | 0.00 | 0.67 | 0.00 | 0.00 | 1.00 | 1.00 | 0.67 | 1.00 | 0.91 | 0.67 |
| Normal | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 0.99 | 0.95 | 0.88 | 0.99 | 0.97 | 0.90 | 0.80 | 0.70 | 0.82 | 1.00 | 1.00 | 1.00 |
| OS_Fingerprinting | 0.99 | 0.97 | 0.76 | 0.66 | 0.25 | 0.52 | 0.37 | 0.00 | 0.00 | 0.27 | 0.00 | 0.00 | 0.77 | 0.14 | 0.00 | 1.00 | 0.94 | 0.77 |
| Password | 0.98 | 0.95 | 0.88 | 0.92 | 0.88 | 0.86 | 0.81 | 0.59 | 0.39 | 0.86 | 0.67 | 0.44 | 0.41 | 0.27 | 0.09 | 0.98 | 0.97 | 0.90 |
| Port_Scanning | 0.97 | 0.95 | 0.82 | 0.86 | 0.78 | 0.83 | 0.80 | 0.00 | 0.03 | 0.84 | 0.00 | 0.21 | 0.17 | 0.10 | 0.11 | 0.96 | 0.96 | 0.83 |
| Ransomware | 0.99 | 0.93 | 0.74 | 0.91 | 0.67 | 0.48 | 0.48 | 0.07 | 0.00 | 0.50 | 0.03 | 0.00 | 0.07 | 0.04 | 0.05 | 0.99 | 0.96 | 0.76 |
| SQL_injection | 1.00 | 1.00 | 0.44 | 0.61 | 0.70 | 0.30 | 0.00 | 0.00 | 0.00 | 0.09 | 0.00 | 0.00 | 0.55 | 0.76 | 0.18 | 1.00 | 1.00 | 0.32 |
| Uploading | 1.00 | 0.92 | 0.65 | 0.79 | 0.72 | 0.62 | 0.89 | 0.68 | 0.00 | 0.90 | 0.47 | 0.03 | 0.60 | 0.88 | 0.16 | 1.00 | 0.98 | 0.66 |
| Vulnerability_scanner | 0.97 | 0.90 | 0.91 | 0.88 | 0.77 | 0.88 | 0.88 | 0.00 | 0.87 | 0.88 | 0.00 | 0.88 | 0.88 | 0.55 | 0.80 | 0.95 | 0.92 | 0.93 |
| XSS | 0.57 | 0.23 | 0.17 | 0.13 | 0.00 | 0.18 | 0.08 | 0.00 | 0.00 | 0.07 | 0.00 | 0.00 | 0.13 | 0.01 | 0.00 | 0.41 | 0.02 | 0.24 |
| Dataset | J48 | KNN | LinearSVC | Logistic Regression | NaiveBayes | RandomForest | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CD | FSD | CD | FSD | CD | FSD | CD | FSD | CD | FSD | CD | FSD | |
| N-BaIoT | 8 / 9 | 9 / 9 | 6 / 9 | 9 / 9 | 1 / 9 | 1 / 9 | 2 / 9 | 3 / 9 | 6 / 9 | 6 / 9 | 8 / 9 | 9 / 9 |
| CICIoT2023 | 7 / 8 | 2 / 8 | 4 / 8 | 5 / 8 | 3 / 8 | 3 / 8 | 3 / 8 | 3 / 8 | 3 / 8 | 3 / 8 | 7 / 8 | 2 / 8 |
| Edge-IIoTset | 12 / 14 | 4 / 14 | 8 / 14 | 7 / 14 | 3 / 14 | 2 / 14 | 3 / 14 | 3 / 14 | 6 / 14 | 4 / 14 | 13 / 14 | 5 / 14 |
| Classifier | N-BaIoT | CICIoT2023 | Edge-IIoTset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| LinearSVC | 17,073 | 63 | 2325 | 107,377 | 449 | 23,941 | 120,607 | 269 | 151,133 |
| NaiveBayes | 179 | 10 | 41 | 195 | 4 | 78 | 470 | 17 | 158 |
| J48 | 5422 | 133 | 2919 | 2498 | 74 | 2941 | 2574 | 53 | 1357 |
| RandomForest | 56,620 | 3247 | 47,878 | 35,287 | 1874 | 80,371 | 33,025 | 1376 | 43,326 |
| KNN | 1759 | 15 | 184 | 2122 | 21 | 590 | 5485 | 40 | 954 |
| LogisticRegression | 65,510 | 658 | 23,070 | 73,650 | 1011 | 46,532 | 394,870 | 4219 | 171,205 |
| Classifier | N-BaIoT | CICIoT2023 | Edge-IIoTset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| LinearSVC | 20 | 14 | 18 | 26 | 19 | 16 | 46 | 32 | 43 |
| NaiveBayes | 396 | 48 | 53 | 347 | 142 | 120 | 1368 | 362 | 427 |
| J48 | 15 | 6 | 19 | 30 | 6 | 29 | 47 | 33 | 32 |
| RandomForest | 500 | 446 | 542 | 1392 | 1123 | 3049 | 2350 | 2100 | 3909 |
| KNN | 207,015 | 1938 | 8999 | 2,204,285 | 10,745 | 331,032 | 10,658,362 | 26,787 | 295,290 |
| LogisticRegression | 22 | 6 | 22 | 16 | 16 | 16 | 48 | 25 | 52 |
| Classifier | N-BaIoT | CICIoT2023 | Edge-IIoTset | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Full | CD | FSD | Full | CD | FSD | Full | CD | FSD | |
| J48 | 2.88 | 0.0859 | 2.43 | 2.46 | 0.0039 | 5.88 | 1.15 | 0.3477 | 4.80 |
| KNN | 140.60 | 1.15 | 20.21 | 135.11 | 3.02 | 47.58 | 307.16 | 5.05 | 72.89 |
| LinearSVC | 5.61 | 0.0938 | 6.20 | 12.55 | 0.6836 | 0.0508 | 7.32 | 0.2109 | 4.64 |
| LogisticRegression | 130.68 | 2.08 | 33.77 | 128.90 | 2.79 | 78.67 | 288.55 | 4.12 | 107.91 |
| NaiveBayes | 1.19 | 0.2188 | 0.7383 | 1.14 | 0.1523 | 0.0508 | 7.76 | 2.47 | 0.2383 |
| RandomForest | 5.97 | 0.3320 | 0.2148 | 146.45 | 8.27 | 488.91 | 102.88 | 18.41 | 7.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almalawi, A. A Lightweight Intrusion Detection System for Internet of Things: Clustering and Monte Carlo Cross-Entropy Approach. Sensors 2025, 25, 2235. https://doi.org/10.3390/s25072235
Almalawi A. A Lightweight Intrusion Detection System for Internet of Things: Clustering and Monte Carlo Cross-Entropy Approach. Sensors. 2025; 25(7):2235. https://doi.org/10.3390/s25072235
Chicago/Turabian StyleAlmalawi, Abdulmohsen. 2025. "A Lightweight Intrusion Detection System for Internet of Things: Clustering and Monte Carlo Cross-Entropy Approach" Sensors 25, no. 7: 2235. https://doi.org/10.3390/s25072235
APA StyleAlmalawi, A. (2025). A Lightweight Intrusion Detection System for Internet of Things: Clustering and Monte Carlo Cross-Entropy Approach. Sensors, 25(7), 2235. https://doi.org/10.3390/s25072235