Author Contributions
Conceptualization, S.M.; Data curation, S.M. and D.A.; Formal analysis, S.M. and D.A.; Funding acquisition, M.A.A.-K., O.A., F.A., I.U. and D.A.; Investigation, S.M., D.A. and I.U.; Methodology, S.M. and D.A.; Project administration, F.Z., D.A. and I.U.; Resources, F.Z.; Software, S.M.; Supervision, F.Z., D.A. and I.U.; Validation, S.M.; Visualization, S.M., M.A.A.-K., O.A. and F.A.; Writing—original draft, S.M., D.A. and I.U.; Writing—review and editing, S.M., F.Z., D.A., I.U., M.A.A.-K., O.A. and F.A. All authors have read and agreed to the published version of the manuscript.
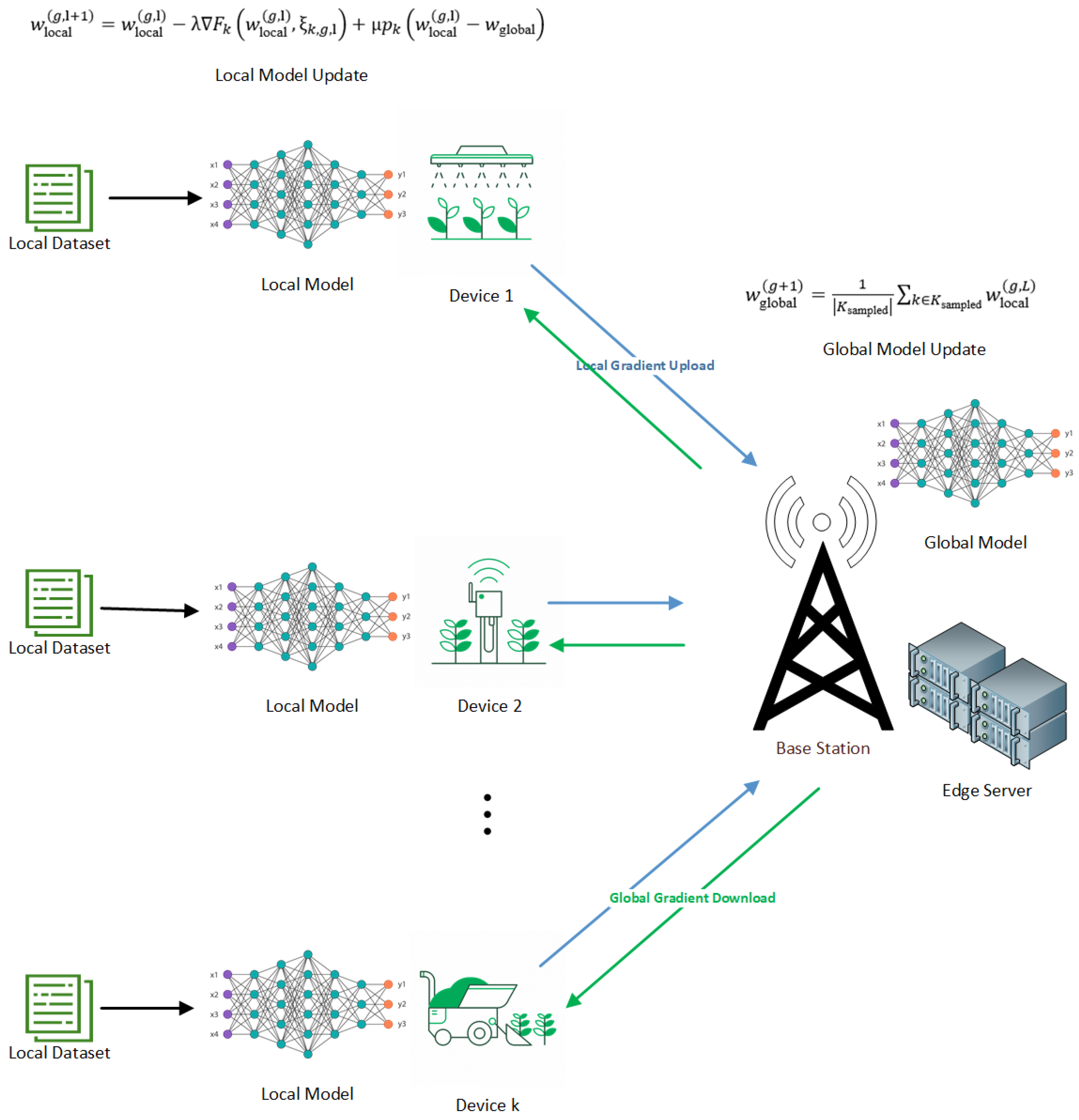
Figure 1.
Edge Computing architecture in an agricultural environmental setting.
Figure 1.
Edge Computing architecture in an agricultural environmental setting.
Figure 2.
Hybrid model architecture.
Figure 2.
Hybrid model architecture.
Figure 3.
Noise level loss.
Figure 3.
Noise level loss.
Figure 4.
Noise level accuracy.
Figure 4.
Noise level accuracy.
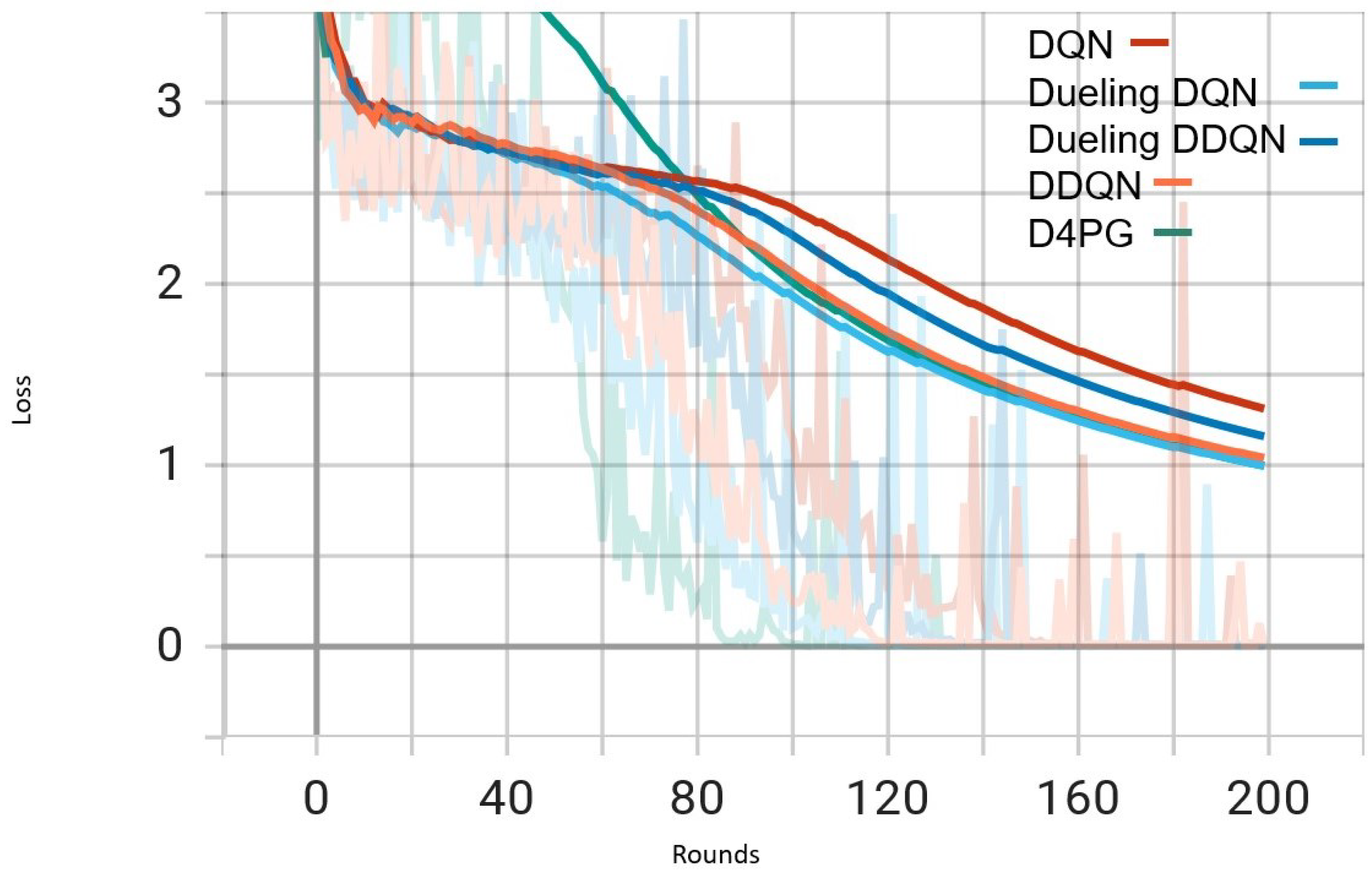
Figure 5.
Comparison of loss: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on IID EMNIST Dataset.
Figure 5.
Comparison of loss: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on IID EMNIST Dataset.
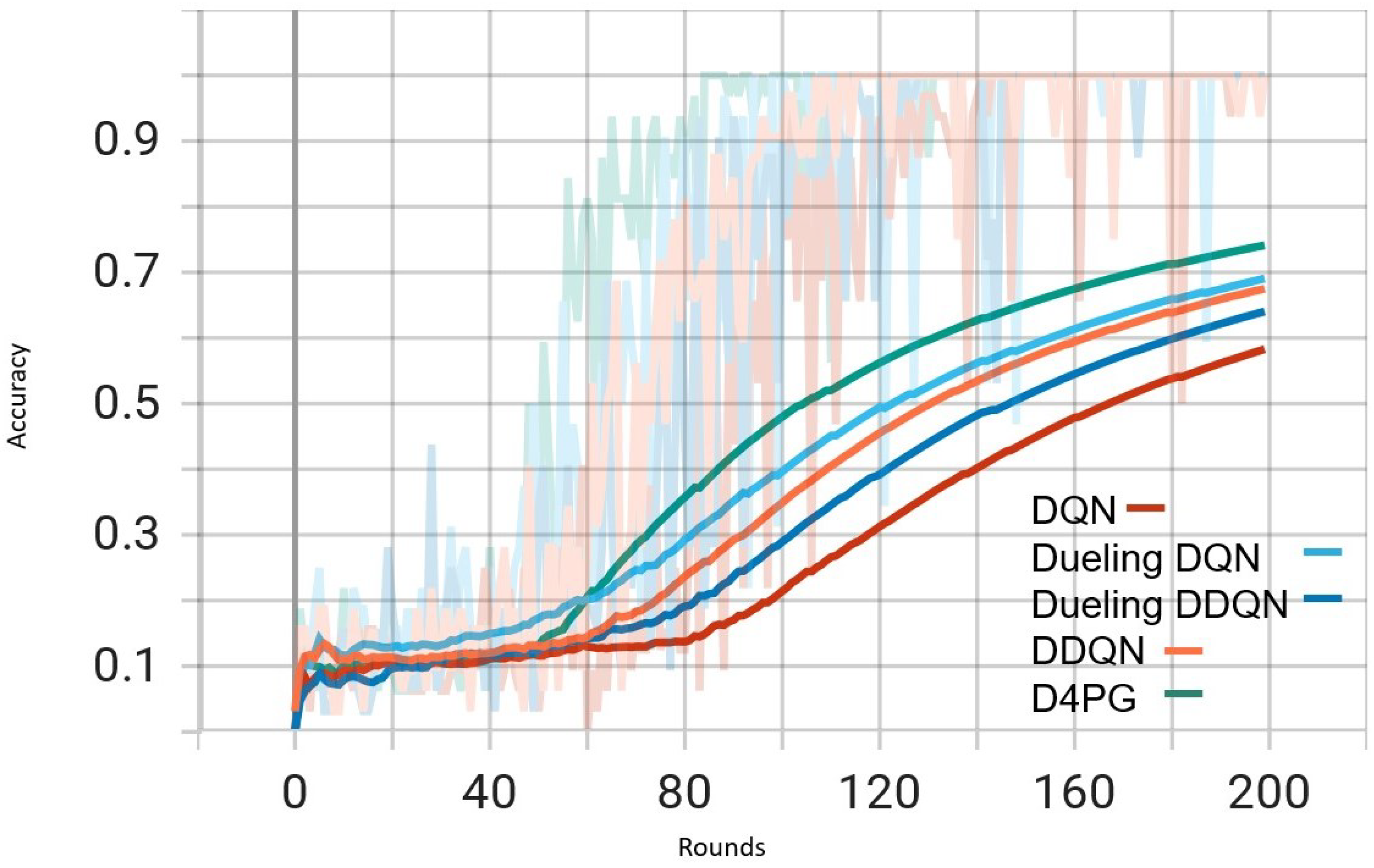
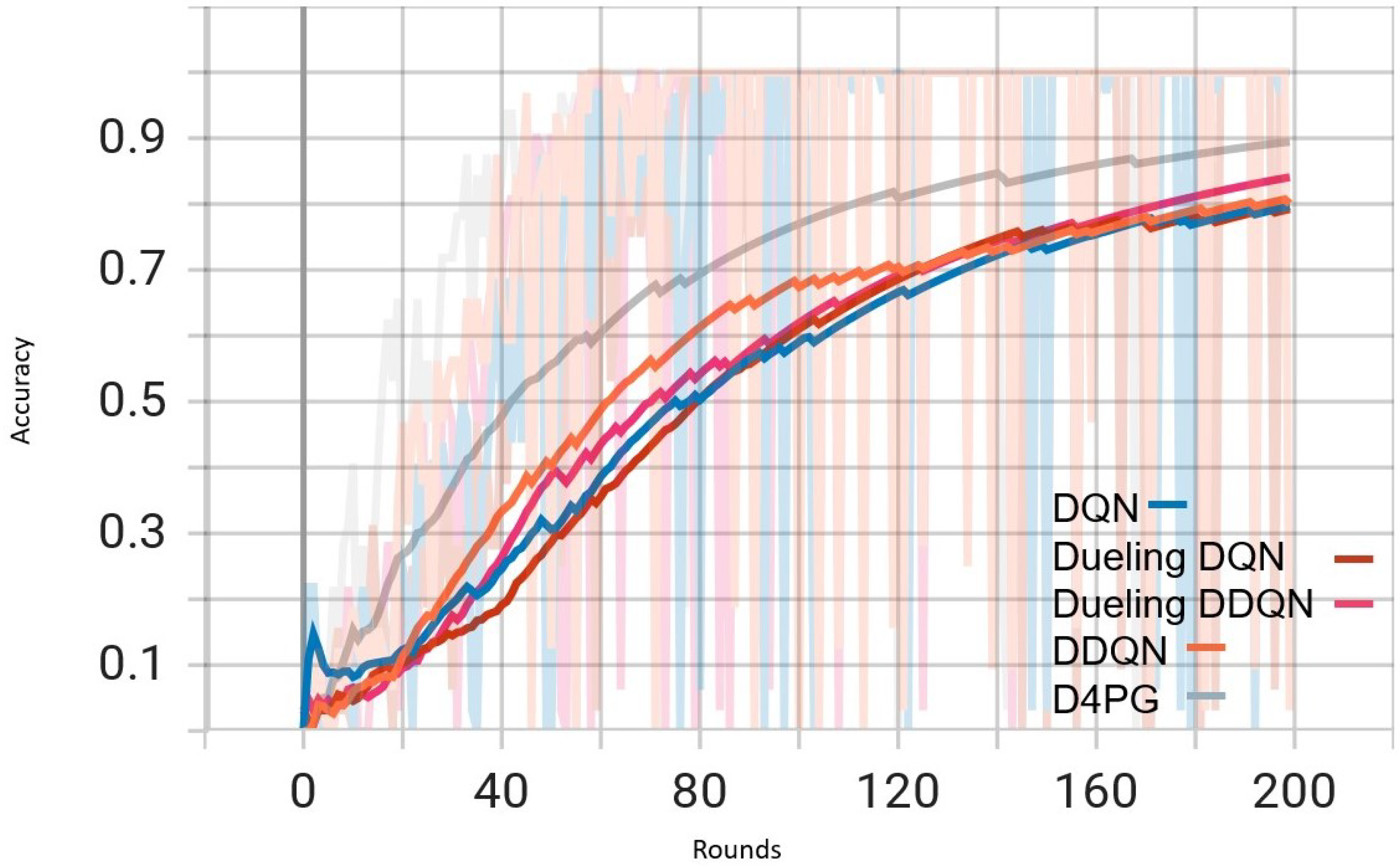
Figure 6.
Comparison of accuracy: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on IID EMNIST Dataset.
Figure 6.
Comparison of accuracy: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on IID EMNIST Dataset.
Figure 7.
Comparison of loss: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on Non IID EMNIST Dataset.
Figure 7.
Comparison of loss: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on Non IID EMNIST Dataset.
Figure 8.
Comparison of accuracy: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on Non IID EMNIST Dataset.
Figure 8.
Comparison of accuracy: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on Non IID EMNIST Dataset.
Figure 9.
Comparison of accuracy: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on 62 classes Non-IID EMNIST Dataset.
Figure 9.
Comparison of accuracy: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on 62 classes Non-IID EMNIST Dataset.
Figure 10.
Comparison of loss: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on 62 classes Non-IID EMNIST Dataset.
Figure 10.
Comparison of loss: DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG models on 62 classes Non-IID EMNIST Dataset.
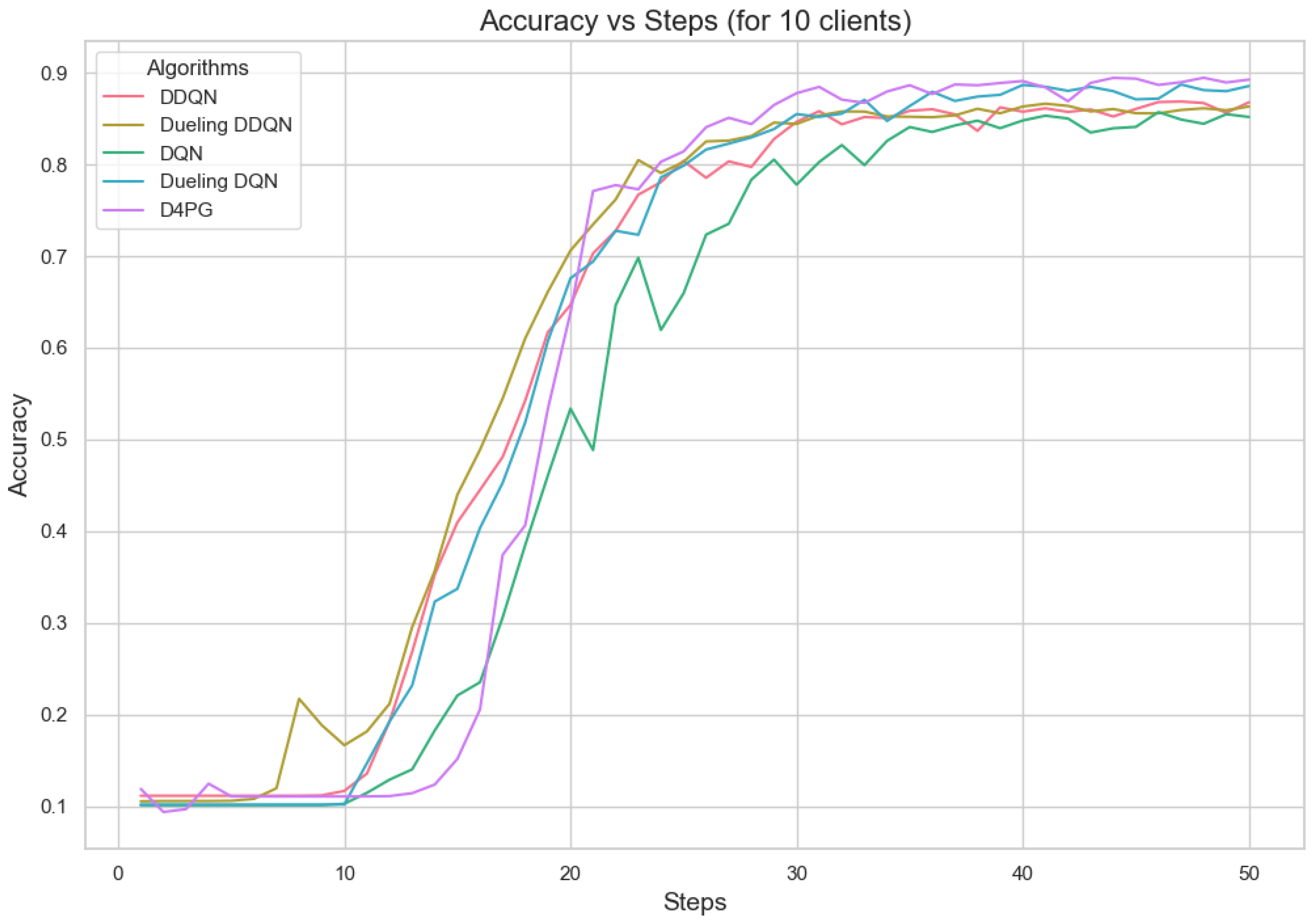
Figure 11.
Accuracy for 10 clients.
Figure 11.
Accuracy for 10 clients.
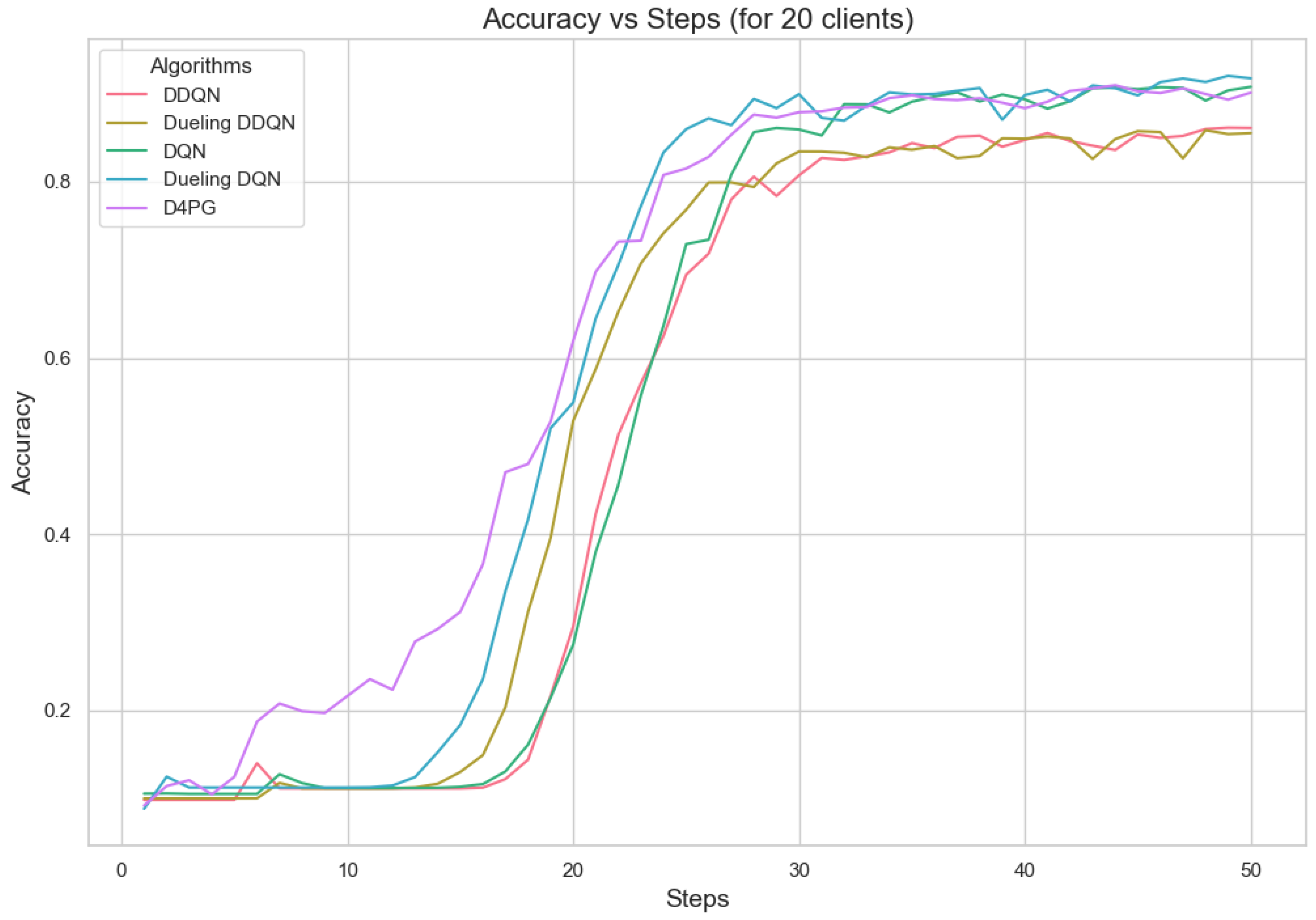
Figure 12.
Accuracy for 20 clients.
Figure 12.
Accuracy for 20 clients.
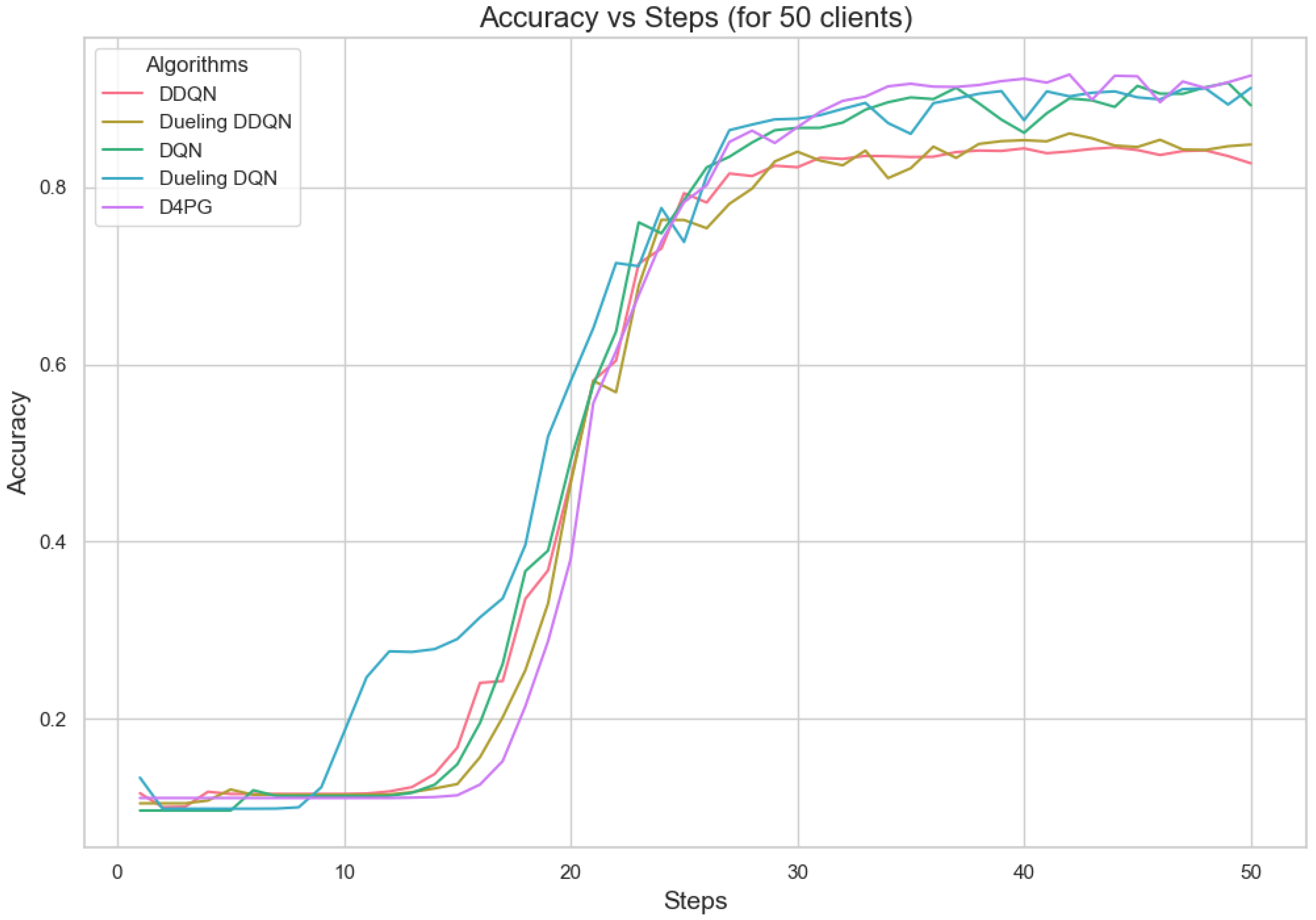
Figure 13.
Accuracy for 50 clients.
Figure 13.
Accuracy for 50 clients.
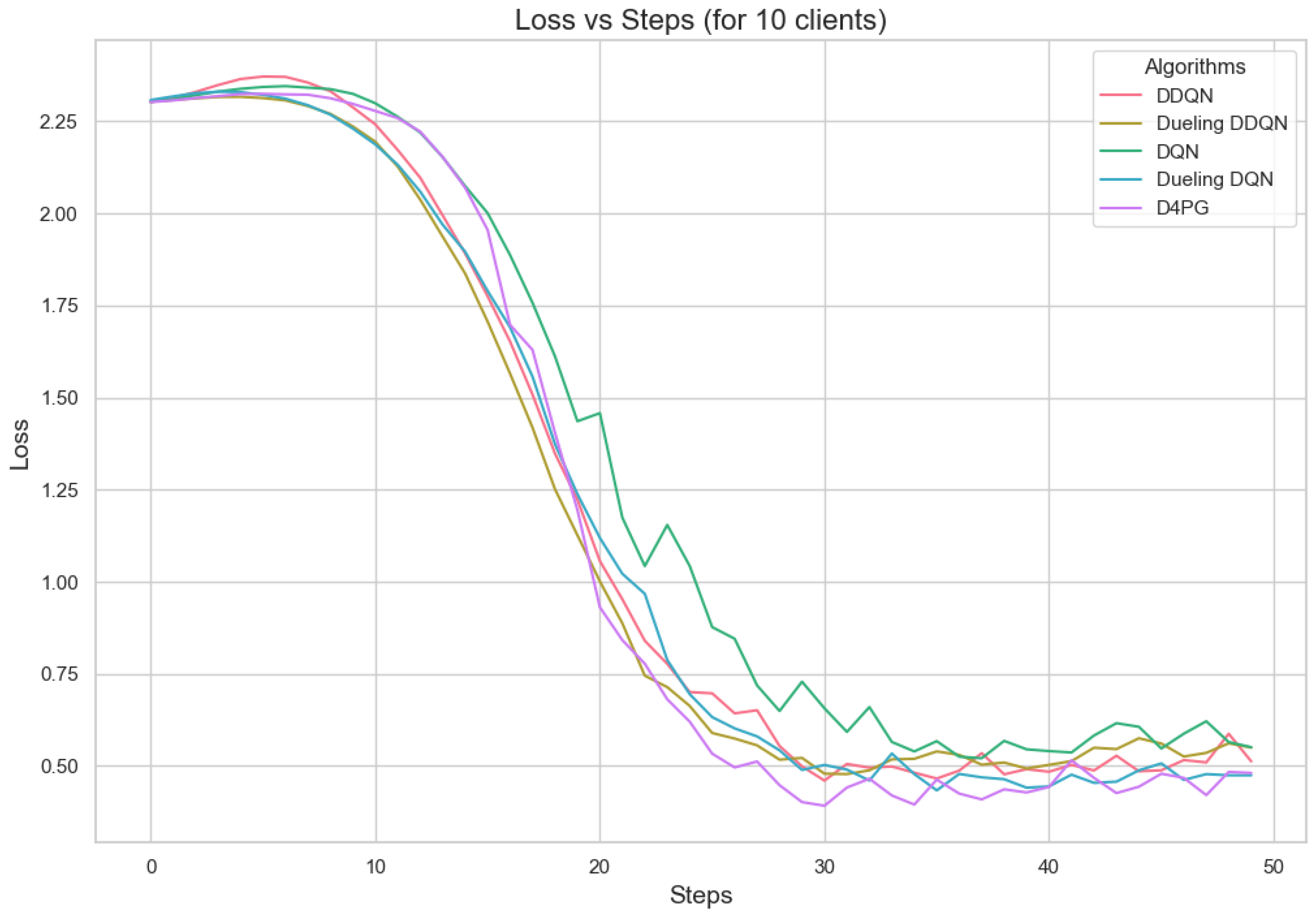
Figure 14.
Loss for 10 clients.
Figure 14.
Loss for 10 clients.
Figure 15.
Loss for 20 clients.
Figure 15.
Loss for 20 clients.
Figure 16.
Loss for 50 clients.
Figure 16.
Loss for 50 clients.
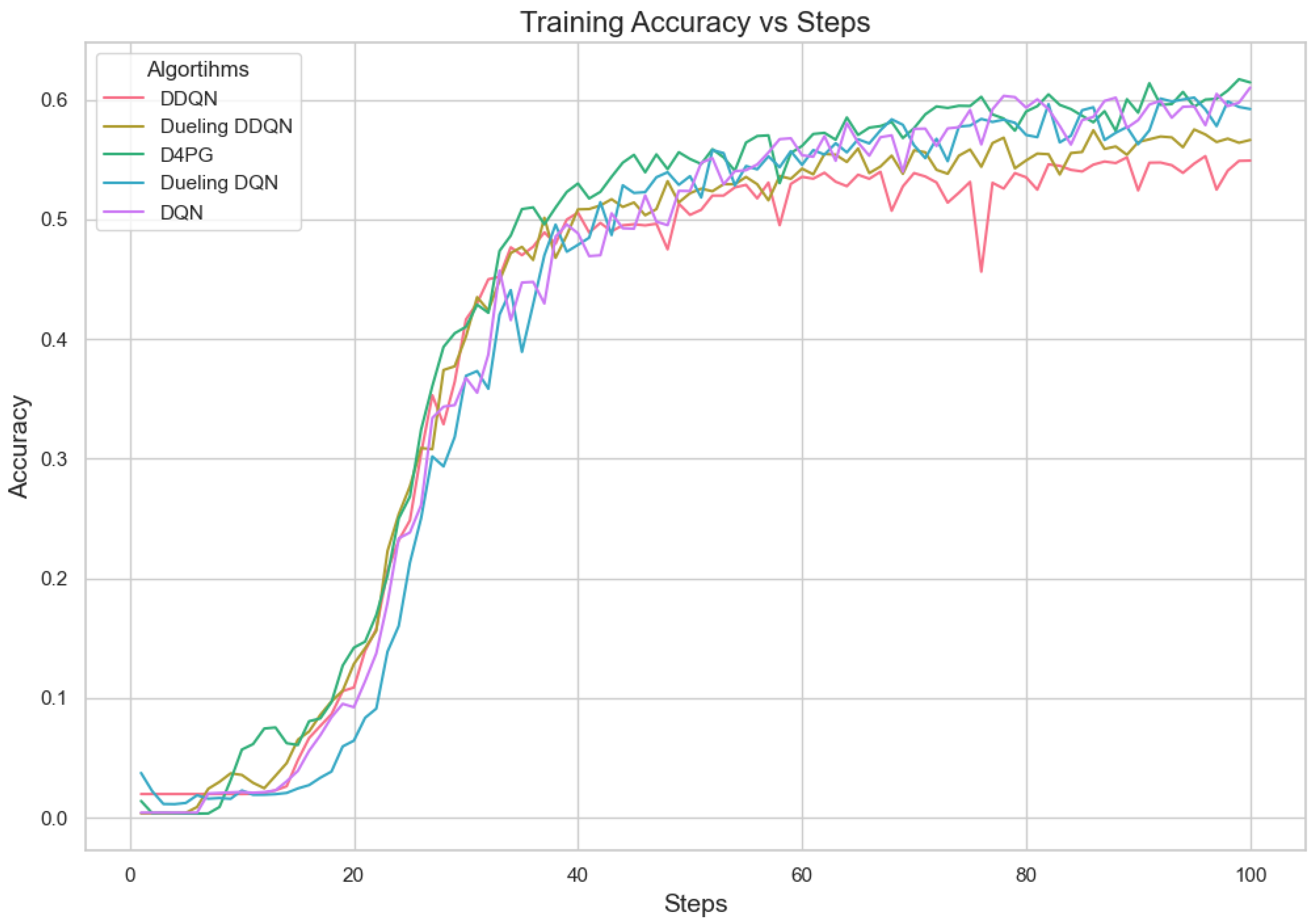
Figure 17.
Training accuracy for crop prediction dataset.
Figure 17.
Training accuracy for crop prediction dataset.
Figure 18.
Training loss for crop prediction dataset.
Figure 18.
Training loss for crop prediction dataset.
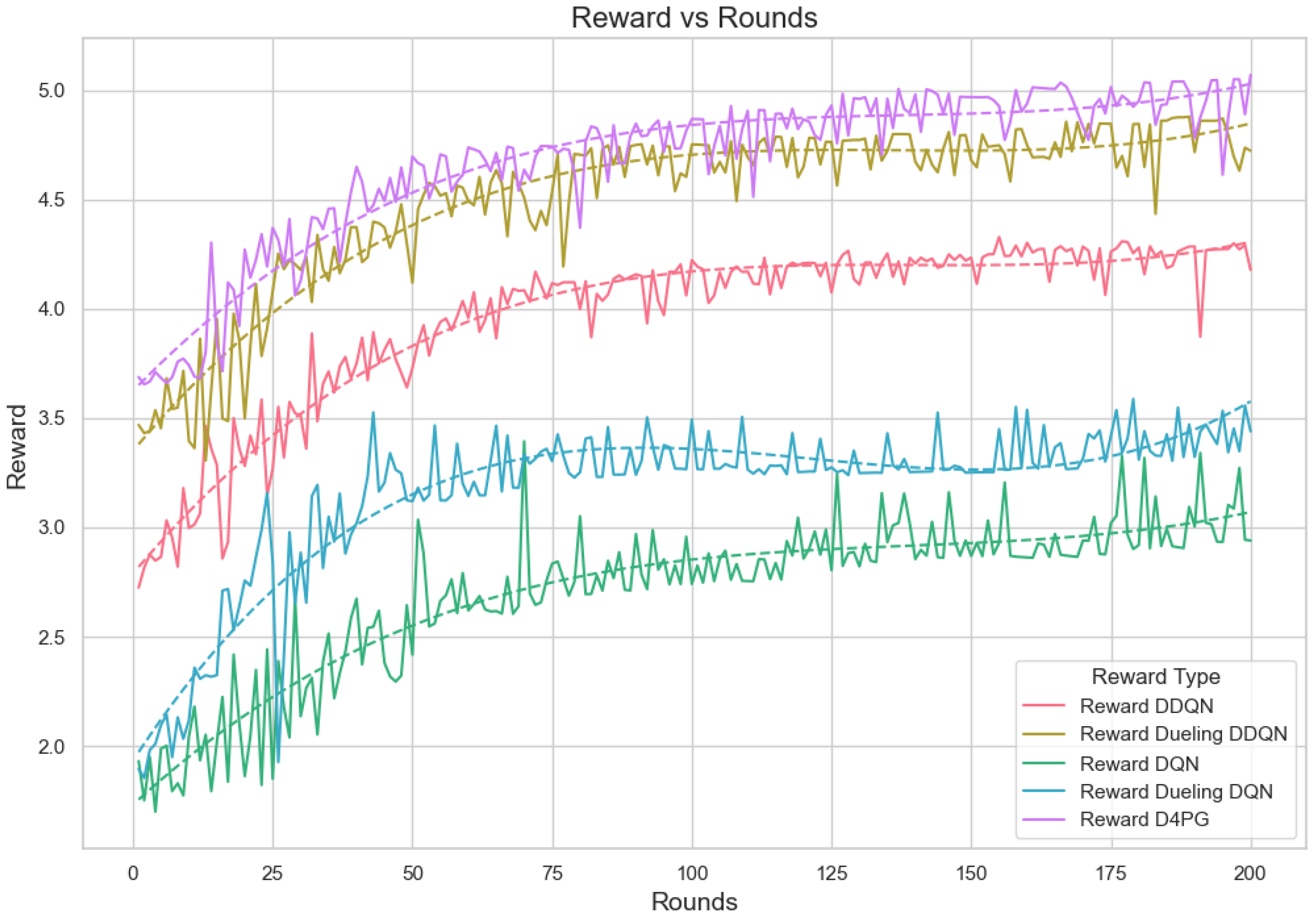
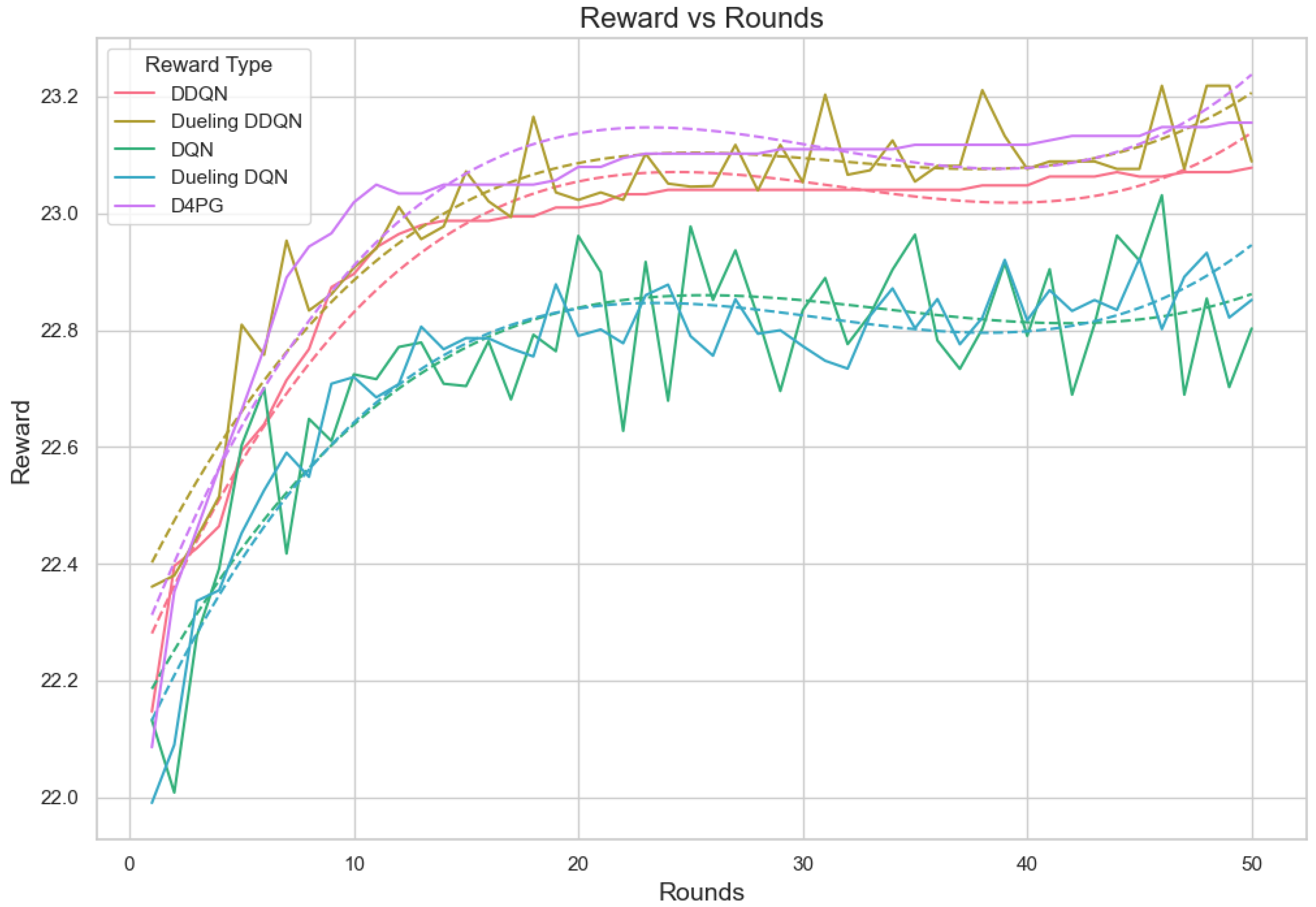
Figure 19.
Analysis of the Reward Per Episode Graph for different Reinforcement Learning algorithms in Federated Learning setup.
Figure 19.
Analysis of the Reward Per Episode Graph for different Reinforcement Learning algorithms in Federated Learning setup.
Figure 20.
Analysis of the Reward Per Episode Graph for different Reinforcement Learning algorithms in Federated Learning setup for crop prediction dataset.
Figure 20.
Analysis of the Reward Per Episode Graph for different Reinforcement Learning algorithms in Federated Learning setup for crop prediction dataset.
Table 1.
Summary of Dynamic Resource Allocation and Task Scheduling in Edge for IoT Applications.
Table 1.
Summary of Dynamic Resource Allocation and Task Scheduling in Edge for IoT Applications.
| Framework | Key Focus | Advantages | Limitations |
|---|
| MLSTM-CEFL [26] | Congestion-aware timing and resource combination | Improves performance in congestion scenarios | Neglects fairness in resource allocation, leading to performance imbalances for some users |
| BiLSTM [27] | Mobile Edge Computing (MEC) in 5G networks | Handles changing conditions over time | Lacks integration of stochastic models for uncertainty in wireless channels and data volumes |
| TrustFedGRU [28] | Dynamic update strategies for FL in IIoT | Improves privacy and security | Does not account for non-IID data distributions or varying computational abilities in clients |
| FedBi-GRU [29] | Virtual Network Functions (VNFs) for local training | Enhances confidentiality and reduces computational burden | Struggles with the dynamic and non-permanent nature of IoT settings, including traffic and resource fluctuations |
| BiLSTM-GRU [30] | Cloud resource prediction model | Improves prediction precision and reduces time | Does not address fairness in resource distribution, especially in shared cloud environments |
| FeDRL-D2D [31] | Energy-efficient resource allocation in D2D-assisted HetNets | Focuses on power control and resource allocation for limited devices | Static reward function, lacks scalability for real-world D2D-assisted 6G networks, does not optimize real-time trade-offs |
| Dueling-DQN [32] | Resource allocation and vehicle participation optimization | High precision in map caching for vehicles | Does not account for non-IID data in real-world driving scenarios; fairness issues in vehicle participation |
| DQN [33] | Node selection in heterogeneous FL networks | Suitable for networks with data and hardware heterogeneity | Does not adapt to dynamic changes in the network or fluctuating performance across devices |
| DDQN [34] | Offloading decisions in MEC environments | Efficient offloading using DDQN agents | Does not consider heterogeneous mobile devices in Federated Learning, neglecting device characteristics like battery life and network connectivity |
Table 2.
Notation and Variable Definitions.
Table 2.
Notation and Variable Definitions.
| Symbol | Description |
|---|
| Performance metric for assigning task to edge device |
| Cost of offloading data from edge device to the edge server |
| Weighting factor to balance performance and offload cost |
| represents the data load associated with assigning task to edge device |
| represents the data offload from edge device to the cloud server |
| is the capacity constraint for edge device |
| N as the total number of UEs (user equipments) | |
| represents the learning progress of UE i, where |
| represents the objective function representing the learning process, which depends on the progress of all UEs |
| represents the learning rate, determining the step size in the learning process |
Table 3.
Notation and variable Definitions.
Table 3.
Notation and variable Definitions.
| Symbol | Description |
|---|
| is a metric representing the performance of assigning task to device |
| is the energy consumption of device |
| is a weighting factor to balance performance and energy consumption |
| signal-to-noise ratio (SNR) for the communication channel between the end user and the edge server for task t |
| transmit power from the end user |
| channel gain between the end user and the edge server for task t |
| noise power at the edge server |
| channel gain between the end user and the edge server for task |
| belongs to the set T of all tasks except t |
| noise power |
Table 4.
Notation and Variable Definitions.
Table 4.
Notation and Variable Definitions.
| Symbol | Description |
|---|
| denotes the global model parameters |
| denotes the local model parameters for UE k |
| denotes the sampling probability for UE k in |
| denotes the regularization strength |
| is the size of the sampled subset of UEs |
| is the local loss function for UE k with model parameters |
| is the squared Euclidean distance between the local model parameters and the global model parameters |
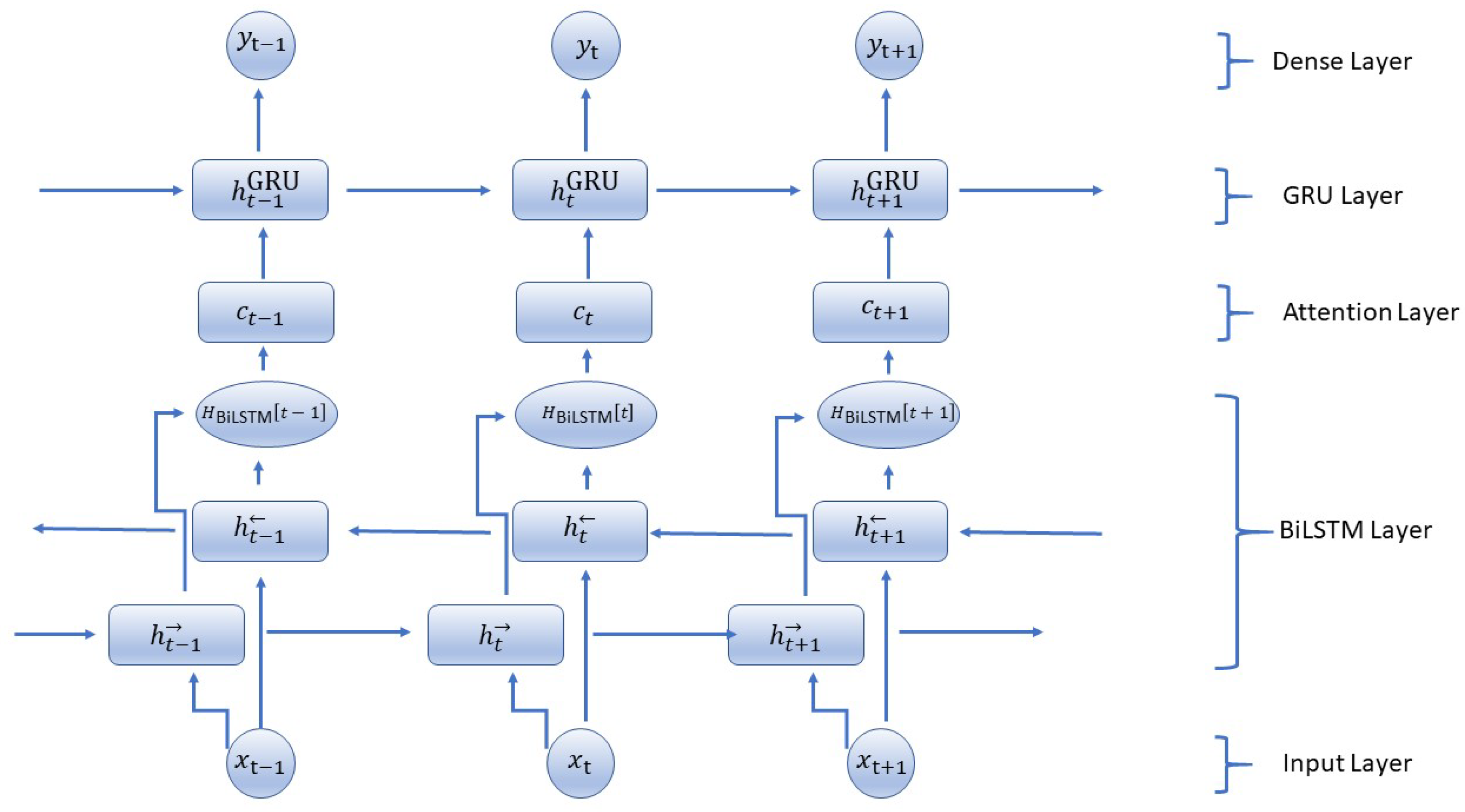
Table 5.
Architecture Details for the BiLSTM-GRU Model with attention mechanism.
Table 5.
Architecture Details for the BiLSTM-GRU Model with attention mechanism.
| Name of Parameter | Details |
|---|
| Input layer neurons | 43 (depends on input feature dimension) |
| BiLSTM layer neurons | 512 in each direction (total 1024 combined) |
| Attention layer | Custom attention layer |
| GRU layer neurons | 128 |
| Final layer (Dense) neurons | 2 |
| Training step/epochs | [20–100] |
| Batch size | [16–256] |
| Optimizer | adam |
| Activation function | ReLU/Tanh/Sigmoid |
| Loss function | Mean squared error |
Table 6.
Comparing The proposed method with and without the attention mechanism.
Table 6.
Comparing The proposed method with and without the attention mechanism.
| Model | Train Accuracy | Train Loss | Eval Accuracy (Client 1) | Eval Loss (Client 1) | Eval Accuracy (Client 2) | Eval Loss (Client 2) |
|---|
| Without Attention Mechanism | 0.54 | 0.0054 | 0.30 | | 0.60 | |
| With Attention Mechanism | 0.70 | 0.0034 | 0.90 | | 0.80 | |
Table 7.
Performance metrics for different Min Probability Thresholds and Noise Levels.
Table 7.
Performance metrics for different Min Probability Thresholds and Noise Levels.
| Min Probability Threshold | Noise Level | Val Loss | Val Accuracy |
|---|
| 0.01 | 0.001 | 0.250866 | 0.928939 |
| 0.01 | 0.248658 | 0.927273 |
| 0.05 | 0.195635 | 0.935303 |
| 0.1 | 0.38984 | 0.901212 |
| 0.2 | 2.405279 | 0.831515 |
| 0.05 | 0.001 | 0.250337 | 0.932879 |
| 0.01 | 0.258329 | 0.927273 |
| 0.05 | 0.24644 | 0.921667 |
| 0.1 | 0.352063 | 0.915303 |
| 0.2 | 2.761476 | 0.801364 |
| 0.1 | 0.001 | 0.909531 | 0.801667 |
| 0.01 | 0.950542 | 0.781667 |
| 0.05 | 1.153836 | 0.764848 |
| 0.1 | 3.187835 | 0.635303 |
| 0.2 | 19.31784 | 0.423636 |
Table 8.
Performance Metrics for Prediction Models.
Table 8.
Performance Metrics for Prediction Models.
| Model | Train Accuracy | Train Loss | Eval Accuracy (Client 1) | Eval Loss (Client 1) | Eval Accuracy (Client 2) | Eval Loss (Client 2) |
|---|
| TrustFedGRU [28] | 0.63 | 0.0062 | 0.80 | | 0.70 | |
| FedBi-GRU [29] | 0.55 | 0.0048 | 0.60 | | 0.50 | 0.0545 |
| MILSTM-CEFL [26] | 0.67 | 0.0069 | 0.80 | | 0.70 | |
| BiLSTM [27] | 0.55 | 0.0056 | 0.60 | | 0.70 | |
| BiLSTM-GRU [30] | 0.68 | 0.0054 | 0.80 | | 0.60 | |
| Proposed Method | 0.70 | 0.0034 | 0.90 | | 0.80 | |
Table 9.
Showing the standard deviation of power consumption for each edge server with Hybrid Offloading, First Fit, Best Fit, and Worst Fit algorithms.
Table 9.
Showing the standard deviation of power consumption for each edge server with Hybrid Offloading, First Fit, Best Fit, and Worst Fit algorithms.
| Edge Server | Algorithm |
|---|
| Hybrid | First | Worst Fit | Best Fit |
|---|
| EdgeServer_1 | 0 | 0 | 0 | 0 |
| EdgeServer_2 | 0 | 0 | 0 | 0 |
| EdgeServer_3 | 24.484 | 24.756 | 25.693 | 24.484 |
| EdgeServer_4 | 24.485 | 24.756 | 25.693 | 26.291 |
| EdgeServer_5 | 12.533 | 20.489 | 19.104 | 5.933 |
| EdgeServer_6 | 0 | 0 | 0 | 10.449 |
Table 10.
Parameter Settings for Training DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models.
Table 10.
Parameter Settings for Training DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models.
| Parameter | Non-IID EMNIST | IID EMNIST | Crop Prediction |
|---|
| G (Global rounds) | 200 | 200 | 50 |
| NUM_CLIENTS | 10 | 10 | 10 |
| BATCH_SIZE | 32 | 32 | 32 |
| L (Local training iterations) | 20 | 20 | 10 |
| LR (Learning rate) | 0.05 | 0.05 | 0.001 |
| MU (Regularization Strength) | 0.01 | 0.01 | 0.01 |
| EPSILON (Exploration rate) | 0.1 | 0.1 | 0.1 |
| TARGET_UPDATE_INTERVAL | 5 | 5 | 5 |
| MAX_BUFFER_SIZE | 10,000 | 10,000 | 10,000 |
| ALPHA (Priority exponent) | 0.6 | 0.6 | 0.6 |
| BETA (Importance sampling exponent) | 0.4 | 0.4 | 0.4 |
| GAMMA (Discount factor for future rewards) | 0.99 | 0.99 | 0.99 |
Table 11.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the Non-IID EMNIST Dataset.
Table 11.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the Non-IID EMNIST Dataset.
| Model | Recall | Precision | F1 Score | Accuracy | Loss |
|---|
| DDQN [31] | 0.8689 | 0.8722 | 0.8689 | 0.8689 | 0.50897 |
| Dueling DDQN [34] | 0.8675 | 0.8693 | 0.8668 | 0.8675 | 0.53662 |
| DQN [33] | 0.8885 | 0.8945 | 0.8888 | 0.8885 | 0.47522 |
| Dueling DQN [32] | 0.8852 | 0.8898 | 0.8847 | 0.8852 | 0.47577 |
| Proposed(D4PG) | 0.8918 | 0.8941 | 0.8916 | 0.8918 | 0.43822 |
Table 12.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the IID EMNIST Dataset.
Table 12.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the IID EMNIST Dataset.
| Model | Recall | Precision | F1 Score | Accuracy | Loss |
|---|
| DQN | 0.76 | 0.77 | 0.75 | 0.76 | 0.86 |
| DDQN | 0.80 | 0.80 | 0.80 | 0.80 | 0.70 |
| Dueling DQN | 0.77 | 0.78 | 0.76 | 0.77 | 0.79 |
| Dueling DDQN | 0.76 | 0.78 | 0.75 | 0.76 | 0.88 |
| Proposed (D4PG) | 0.82 | 0.83 | 0.82 | 0.82 | 0.61 |
Table 13.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the 62 classes Non-IID EMNIST Dataset.
Table 13.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the 62 classes Non-IID EMNIST Dataset.
| Model | Recall | Precision | F1 Score | Accuracy | Loss |
|---|
| DQN | 0.6061 | 0.5659 | 0.5659 | 0.6061 | 1.7372 |
| DDQN | 0.5569 | 0.5386 | 0.5210 | 0.5569 | 1.9808 |
| Dueling DQN | 0.5842 | 0.5603 | 0.5496 | 0.5842 | 1.8222 |
| Dueling DDQN | 0.5640 | 0.5438 | 0.5377 | 0.5640 | 2.0092 |
| Proposed(D4PG) | 0.6106 | 0.5811 | 0.5754 | 0.6106 | 1.6810 |
Table 14.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the different number of clients Non-IID EMNIST Dataset.
Table 14.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on the different number of clients Non-IID EMNIST Dataset.
| Model | Client | Recall | Precision | F1 Score | Accuracy | Loss |
|---|
| DDQN | 10 | 0.8689 | 0.8722 | 0.8689 | 0.8689 | 0.50897 |
| DDQN | 20 | 0.8692 | 0.8710 | 0.8687 | 0.8692 | 0.50758 |
| DDQN | 50 | 0.8285 | 0.8568 | 0.8336 | 0.8285 | 0.64657 |
| Dueling DDQN | 10 | 0.8675 | 0.8693 | 0.8668 | 0.8675 | 0.53662 |
| Dueling DDQN | 20 | 0.8505 | 0.8542 | 0.8504 | 0.8505 | 0.60313 |
| Dueling DDQN | 50 | 0.8494 | 0.8532 | 0.8486 | 0.8494 | 0.61122 |
| DQN | 10 | 0.8885 | 0.8945 | 0.8888 | 0.8885 | 0.47522 |
| DQN | 20 | 0.9026 | 0.9043 | 0.9019 | 0.9026 | 0.40192 |
| DQN | 50 | 0.8788 | 0.8907 | 0.8769 | 0.8788 | 0.53618 |
| Dueling DQN | 10 | 0.8852 | 0.8898 | 0.8847 | 0.8852 | 0.47577 |
| Dueling DQN | 20 | 0.9001 | 0.9121 | 0.9023 | 0.9001 | 0.40195 |
| Dueling DQN | 50 | 0.9161 | 0.9195 | 0.9164 | 0.9161 | 0.30606 |
| D4PG (proposed) | 10 | 0.8918 | 0.8941 | 0.8916 | 0.8918 | 0.43822 |
| D4PG (proposed) | 20 | 0.9095 | 0.9149 | 0.9095 | 0.9095 | 0.40091 |
| D4PG (proposed) | 50 | 0.9192 | 0.9223 | 0.9192 | 0.9192 | 0.32927 |
Table 15.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on Crop Prediction Dataset.
Table 15.
Performance Metrics for DQN, DDQN, Dueling DQN, Dueling DDQN, and D4PG Models on Crop Prediction Dataset.
| Model | Accuracy | Macro Avg | Weighted Avg |
|---|
| Precision | Recall | F1-Score | Precision | Recall |
|---|
| DDQN | 90.91% | 0.91 | 0.91 | 0.90 | 0.92 | 0.91 |
| Dueling DDQN | 91.88% | 0.92 | 0.93 | 0.92 | 0.92 | 0.92 |
| DQN | 91.56% | 0.92 | 0.92 | 0.91 | 0.92 | 0.92 |
| Dueling DQN | 89.29% | 0.90 | 0.90 | 0.89 | 0.90 | 0.89 |
| Proposed(D4PG) | 92.86% | 0.93 | 0.93 | 0.93 | 0.93 | 0.93 |

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}