1. Introduction
Rolling bearings play a crucial role in rotating machinery, with their condition having a direct influence on the performance of the entire system [
1,
2]. Statistics show that approximately one-third of failures in electromechanical drive systems and motor systems are attributed to rolling bearing faults. Therefore, timely fault diagnosis of rolling bearings is crucial for maintaining the performance and reliability of rotating machinery [
3].
Intelligent fault diagnosis algorithms generally comprise sensor signal acquisition, feature extraction, and fault classification techniques [
4]. In signal acquisition, accelerometers are typically employed to capture bearing vibration signals. Time–frequency analysis is commonly utilized for feature extraction, as it analyzes signals in both the time and frequency domains, providing a clear representation of the relationship between frequency and time for non-stationary signals [
5]. This approach transforms vibration signals into the time–frequency domain, extracts fault features, and then feeds them into fault classification algorithms. Prominent fault classification techniques currently rely on machine learning and deep learning methods [
6].
Various machine learning methods, including artificial neural networks, decision trees, and support vector machines, have been utilized for fault diagnosis [
7]. However, these methods heavily depend on expert knowledge for feature extraction and selection, have limited feature representation capabilities, and lack generalization ability, and their shallow structures hinder the capture of deep features and complex relationships in the data [
8].
In contrast, deep learning methods offer superior feature extraction and processing capabilities, as well as improved generalization and model transferability, leading to their widespread adoption in fault diagnosis applications [
9].
He et al. [
10] introduced a residual network that addresses the issue of gradient vanishing in backpropagation by incorporating skip connections, thus enhancing the model’s ability to extract deep features. Zhang et al. [
11] tackled the issue of inadequate feature extraction in deep learning models by utilizing the Short-Time Fourier Transform (STFT) to transform raw signals into a two-dimensional time–frequency representation, which is then input into an improved convolutional neural network (CNN) for efficient classification. Tao et al. [
12] introduced an unsupervised fault diagnosis approach for rolling bearings. This method combines time–frequency information fusion via wavelet packet decomposition with an enhanced maximum mean discrepancy algorithm, leading to enhanced accuracy and robustness. Guo [
13] proposed a fault diagnosis approach for complex scenarios, using variational mode decomposition, sensitive component analysis, and time–frequency feature extraction, along with a hybrid deep learning model, demonstrating high diagnostic accuracy and robustness. Peng et al. [
14] employed data fusion techniques and residual neural networks for efficient rolling bearing fault diagnosis. Despite the excellent performance in feature extraction and classification accuracy, these methods still exhibit limitations in fault diagnosis performance under complex multi-condition scenarios. Variations in operating conditions significantly affect bearing vibration signals, and traditional methods often struggle to handle these variations, leading to decreased classification accuracy [
15].
To improve fault classification under complex conditions, Wen et al. [
16] proposed a TCNN (ResNet-50) model that leverages transfer learning. By transforming raw signals into RGB images and utilizing ResNet-50 as a feature extractor, this model achieved an accuracy of up to 99.99%, outperforming both traditional and deep learning methods. However, its performance is highly dependent on the pre-trained model and may struggle with significant distribution shifts under variable operating conditions. To address the challenge of label imbalance in rolling bearing fault diagnosis, Que et al. [
17] introduced an inter-class feature transfer mechanism. This approach mitigates the impact of outliers and enhances classification accuracy. Nevertheless, its performance may be constrained when handling highly non-stationary signals. Lei [
18] proposed an unsupervised graph transfer network that integrates multi-scale and multi-structure information for fault diagnosis across varying conditions. By combining node feature extraction, multi-scale convolutional layers, attention mechanisms, and Graph Neural Networks (GNNs), this method improves adaptability to complex scenarios. However, it does not fully exploit fine-grained time–frequency features, which are crucial for early fault detection.
While these methods have advanced fault diagnosis performance, they still face key limitations. One major challenge is their limited ability to capture high-resolution time–frequency features, which are crucial for early fault detection. Additionally, they often lack an effective mechanism to integrate both local and global fault representations, restricting their adaptability to varying operating conditions.
Motivated by these challenges, this paper proposes a fault diagnosis method for rolling bearings based on the synchronized wavelet transform (SWT) and ResCAA-ViT, aiming to improve fault classification under varying operating conditions. Unlike conventional methods that either rely solely on time–frequency analysis or employ standalone neural networks, our approach uniquely integrates SWT’s high-resolution time–frequency features with the ResCAA-ViT hybrid architecture. The SWT offers superior energy concentration and time–frequency resolution, enabling more precise fault detection, particularly under non-stationary conditions. The ResCAA-ViT model further enhances this by integrating local feature extraction with the CAA attention mechanism and global feature capture via a Vision Transformer, providing a more informative and comprehensive fault representation. Unlike ResNet-based models, which heavily depend on pre-trained CNN architectures, our approach improves adaptability to varying operating conditions. Compared to feature transfer and GNN-based methods, our dual-branch model not only enhances robustness but also explicitly captures both fine-grained local features and global fault structures, resulting in more precise and interpretable diagnostics.
The innovations and contributions of this study are as follows:
(1) This study innovatively applies the Synchrosqueezed Wavelet Transform (SWT) to process raw vibration signals, generating high-resolution time–frequency representations. By compressing and reordering wavelet coefficients in the frequency domain, the SWT enhances energy concentration, resulting in clearer and more focused time–frequency maps. This approach enables the effective capture of instantaneous changes and localized features of the signal, which are often difficult to detect using conventional techniques such as the Continuous Wavelet Transform (CWT) or Short-Time Fourier Transform (STFT). As a result, the SWT significantly improves the fault diagnosis capabilities of the model, offering superior resolution and sensitivity in detecting faults, particularly under complex and non-stationary conditions.
(2) A novel ResCAA-ViT hybrid architecture is proposed, combining the strengths of CNNs and Vision Transformers (ViTs) for enhanced fault diagnosis. The left branch integrates a residual network with the CAA (Channel Attention Aggregation) attention mechanism, which combines local feature extraction, strip convolution, and adaptive channel weighting to improve feature representation. The right branch utilizes a Vision Transformer to capture global dependencies through its self-attention mechanism. Transfer learning accelerates model training in small-sample scenarios, while multi-loss constraints ensure effective network convergence. The proposed model demonstrates superior classification accuracy and generalization ability, outperforming traditional methods in complex fault detection tasks.
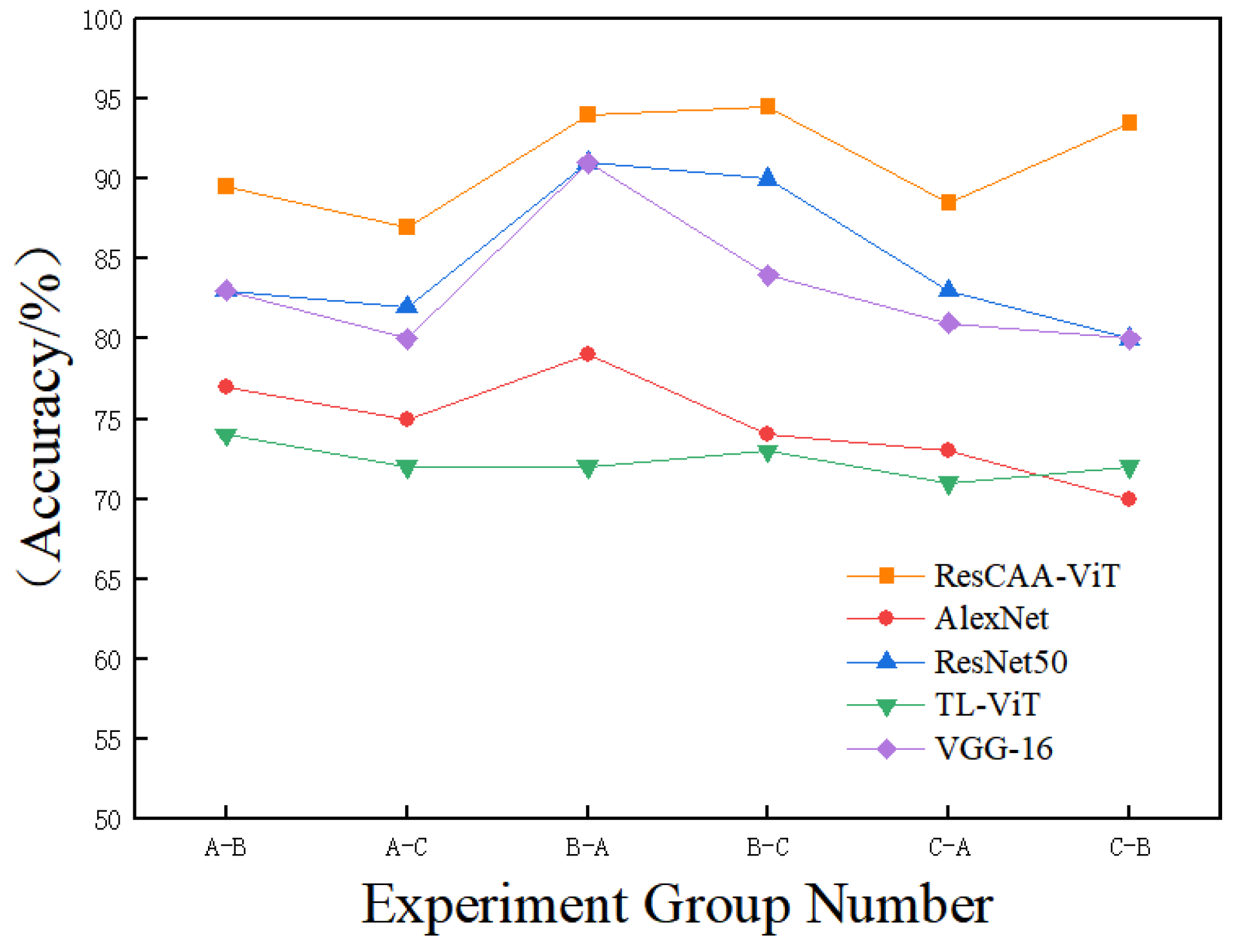
(3) In the context of rolling bearing operating under variable load and noisy conditions, experimental validation was conducted using the CWRU dataset. The results show that the proposed method surpasses the alternative approaches in both fault diagnosis accuracy and generalization ability. Furthermore, validation using a real-world dataset from the non-drive end bearing of wind turbines further substantiates the method’s potential for practical industrial applications.
2. Related Theories and Methods
2.1. Synchrosqueezed Wavelet Transform
The Synchrosqueezed Wavelet Transform (SWT) is a time–frequency analysis method that offers high resolution in both time and frequency. This is accomplished by compressing and rearranging the wavelet transform coefficients along the frequency dimension [
19]. The application of the SWT to the time–frequency analysis of vibration signals typically involves three main steps, as outlined below:
Step 1: Continuous Wavelet Transform (CWT).
The signal is first transformed using the CWT, which produces wavelet coefficients . These coefficients represent the signal in both time and frequency domains.
Step 2: Instantaneous Frequency Calculation.
The instantaneous frequency is calculated by analyzing the phase of the wavelet coefficients. This step extracts the frequency information associated with the signal’s time-varying characteristics.
Step 3: Synchrosqueezing Transformation.
The synchrosqueezing step refines the time–frequency representation by compressing wavelet coefficients according to their instantaneous frequencies. This results in a more accurate and concentrated time–frequency map.
The synchrosqueezed wavelet transform is defined by the following formula:
2.2. Loss Function
Commonly used loss functions include cross-entropy loss and mean squared error (MSE) loss. Cross-entropy loss quantifies the difference between predicted values and true labels, while MSE loss measures the discrepancy between the outputs of two branches.
The overall loss function used in this study is as follows:
In the equation, denotes the total loss, represents the cross-entropy losses for the two branches, represents the mean squared error (MSE) loss between the two cross-entropy losses, and denotes the weight parameter. This multi-loss constraint combines the cross-entropy losses from the two branches with their MSE loss, thereby enhancing the model’s consistency and collaborative learning capabilities.
2.3. CAA Module
The Context Anchor Attention (CAA) module, discussed in this study, is derived from the Poly Kernel Inception Network (PKINet) proposed by Cai et al. As a crucial component of PKINet, the CAA module is intended to capture long-range contextual dependencies and enhance the representation of crucial features [
20].
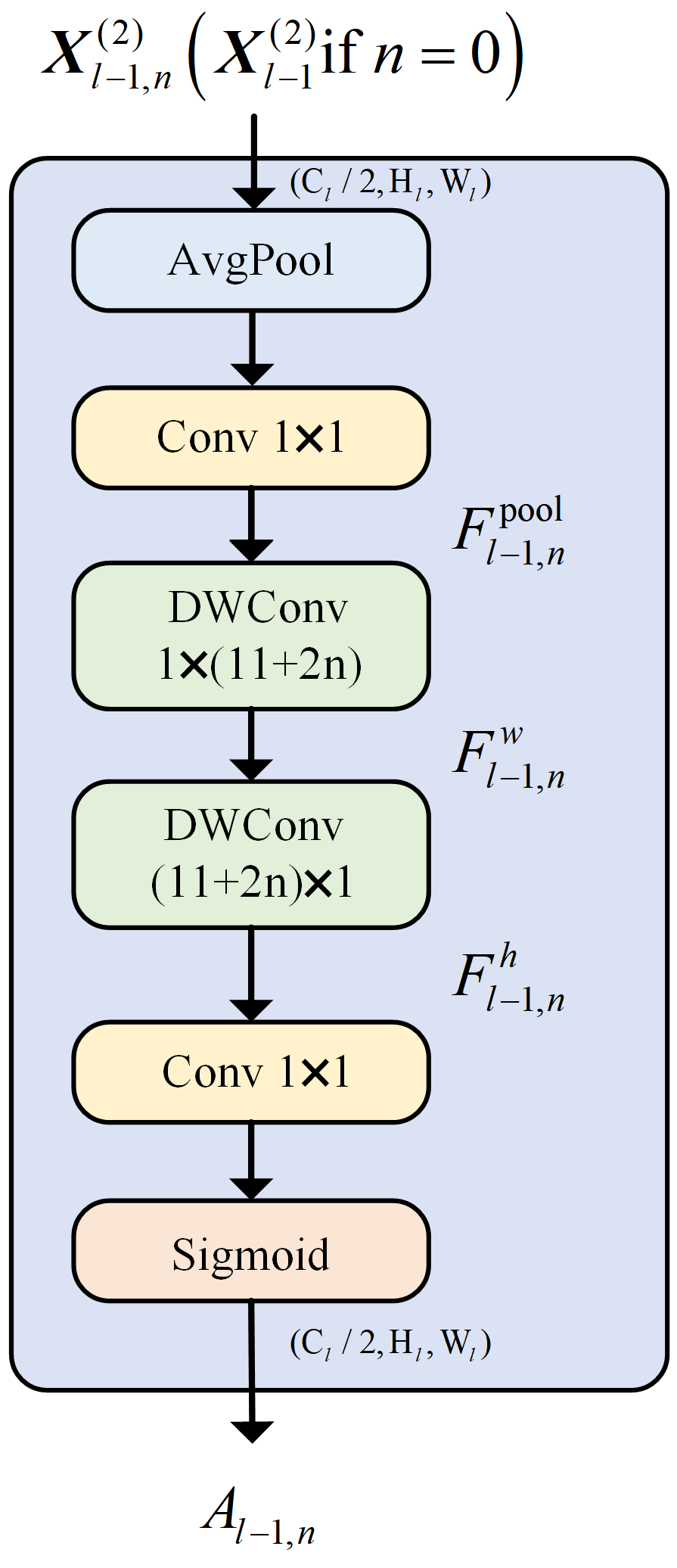
The CAA module consists of key stages: local feature extraction, strip convolution, attention weight generation, and feature enhancement, as shown in
Figure 1. Initially, average pooling is applied to the input feature map, followed by a 1 × 1 convolution to produce local region features. The module then captures long-range contextual information using strip convolutions. A vertical convolution (
) extracts vertical features, and a horizontal convolution (
) captures horizontal features. Strip convolutions reduce the number of parameters compared to standard
convolutions while maintaining performance. The kernel size
is dynamically adjusted based on the network depth, allowing the receptive field to grow progressively. The CAA module generates attention weights using a 1 × 1 convolution followed by a Sigmoid activation. These attention weights are multiplied element-wise with the input features, and residual connections are used to preserve the original features. This process enhances the feature representation, as important regions are emphasized. Finally, a 1 × 1 convolution is applied to reduce the channel dimensions, producing the final output.
By integrating local feature extraction with global contextual modeling, the CAA module enhances feature representation while maintaining a low computational cost. Specifically, the CAA module improves feature representation in two key aspects: first, contextual enhancement, where the module extracts local features through average pooling followed by 1 × 1 convolutions and then uses lightweight strip depth-wise convolutions to capture both vertical and horizontal contextual information. This approach enables the model to focus on important features at multiple scales, improving its robustness in handling complex tasks. Second, the attention mechanism, where the generated attention weights, obtained through a Sigmoid activation applied to the convolution results, highlights key regions of the feature map. This mechanism effectively guides the model to prioritize the most relevant areas of the input, allowing it to disregard irrelevant information and perform better in complex scenarios. Moreover, the CAA module’s strip convolutions offer a significant computational advantage over conventional 2D convolutions by reducing the number of parameters while maintaining the model’s ability to capture long-range dependencies. The dynamic adjustment of the kernel size based on network depth further expands the receptive field, thereby enhancing the quality of contextual modeling.
The Context Anchor Attention (CAA) module outperforms standard attention mechanisms like Squeeze-and-Excitation (SE) and self-attention by efficiently capturing long-range dependencies with strip convolutions. Unlike SE, which uses global average pooling and 1 × 1 convolutions, CAA first extracts local features and then applies strip convolutions to capture both vertical and horizontal contextual information. This approach enhances feature representation at multiple scales, improving robustness in complex tasks. Additionally, strip convolutions reduce computational complexity compared to self-attention mechanisms, which require pairwise attention between all features, making CAA both more effective and computationally efficient.
In the proposed model architecture, the CAA attention module is placed both before and after Layer 4 of ResNet50. This dual placement enhances feature extraction at different stages of the network. The CAA module before Layer 4 improves local feature extraction and contextual enhancement, strengthening the representation of low-level features. Placing it after Layer 4 refines these features, enabling the model to capture more complex, high-level dependencies. This design ensures the effective integration of both local and global contextual information, facilitating multi-scale feature fusion. Consequently, the model captures intricate patterns and improves robustness across varying conditions.
2.4. Vision Transformer Model
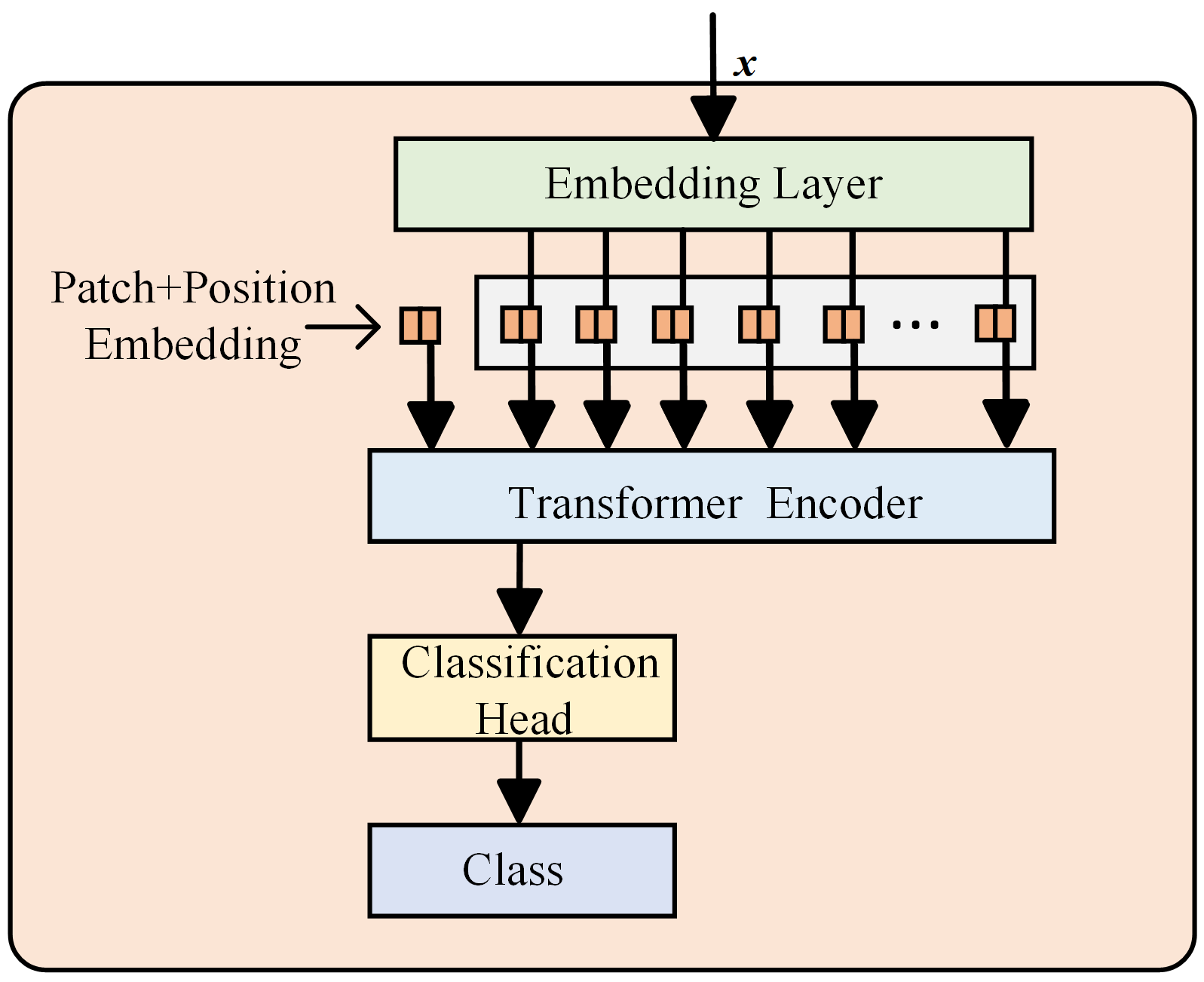
Dosovitskiy et al. introduced the Vision Transformer (ViT) model, which partitions an image into sequences of patches and embeds them into a Transformer for image classification and feature extraction [
21]. The ViT model consists of an embedding layer where the image is divided into patches, which are flattened and projected into a higher-dimensional space; patch and position embeddings that add spatial information to preserve relationships; Transformer encoder layers that process patch embeddings and capture global dependencies; a classification head typically based on the Class Token; and a final class module that maps the output to class labels for classification. The architecture of the ViT model is depicted in
Figure 2.
The proposed ResCAA-ViT’s right branch incorporates the Vision Transformer (ViT) model, which leverages its self-attention mechanism and global receptive field to capture complex, long-range dependencies in the time–frequency spectrogram. The integration of ResNet and ViT in this branch represents a novel combination of convolutional and transformer-based architectures, enabling the model to benefit from the unique strengths of both. ResNet, with its residual connections and ability to learn hierarchical feature representations, efficiently captures local, low-level features in the initial layers. In contrast, ViT excels at modeling global contextual information and high-level features. By combining these two architectures, the proposed model effectively captures multi-scale features, enhancing its robustness and performance across a wide range of tasks and complex multi-dimensional data, such as time–frequency spectrograms.
2.5. Pretraining and Transfer Learning
Pre-trained networks are deep learning models with parameters learned from extensive training on large-scale datasets, resulting in optimal configurations of model parameters and hyperparameters. Training large-scale neural networks typically demands extensive labeled data and significant computational resources. Transfer learning mitigates this challenge by leveraging parameters or learned representations from pre-trained models, significantly improving model performance, particularly in data-scarce scenarios.
In rolling bearing fault diagnosis, where labeled data are often limited, transfer learning provides an effective solution to enhance model accuracy. By utilizing parameters from models pre-trained on large-scale datasets, transfer learning effectively alleviates overfitting caused by limited samples while expediting model convergence and optimization. Pei et al. [
22] proposed a rolling bearing fault diagnosis method based on transfer learning, employing ResNet-50 as the backbone network. They integrated a Wasserstein Generative Adversarial Network with Gradient Penalty (WGAN-GP) to generate synthetic samples and utilized Multi-Kernel Maximum Mean Discrepancy (MK-MMD) to minimize the distribution discrepancy between the source and target domains. The experimental results showed that this method attained a fault diagnosis accuracy of 96.58% on the CWRU dataset. Similarly, Chen et al. [
23] froze the parameters of the Conv1 layer and the first three residual layers in ResNet-50, transferring them to a Deep Transfer Convolutional Neural Network (DTCNN) for fault classification. Their experimental results indicated that freezing these layers significantly enhanced training efficiency, mitigated overfitting on small datasets, and improved model classification accuracy. These findings suggest that selectively freezing pre-trained layers can effectively boost model generalization and classification performance in rolling bearing fault diagnosis. ResNet-50, pre-trained on the ImageNet dataset, has learned generic low-level features such as edges and textures, which are transferable and valuable for rolling bearing fault diagnosis. Freezing the Conv1 layer and the first three residual layers not only prevents overfitting on small datasets but also reduces computational overhead. Additionally, this strategy allows the network to focus on high-level feature extraction, improving both training efficiency and diagnostic accuracy.
Building upon previous studies, this research adopts a transfer learning strategy by freezing the Conv1 layer and the first three residual layers of ResNet-50 while transferring pre-trained ImageNet parameters to the ResCAA-ViT model. By fully leveraging the advantages of transfer learning, this study aims to enhance the accuracy and generalization capability of rolling bearing fault diagnosis models, providing a more reliable solution for fault identification under variable operating conditions.
3. Fault Diagnosis Model
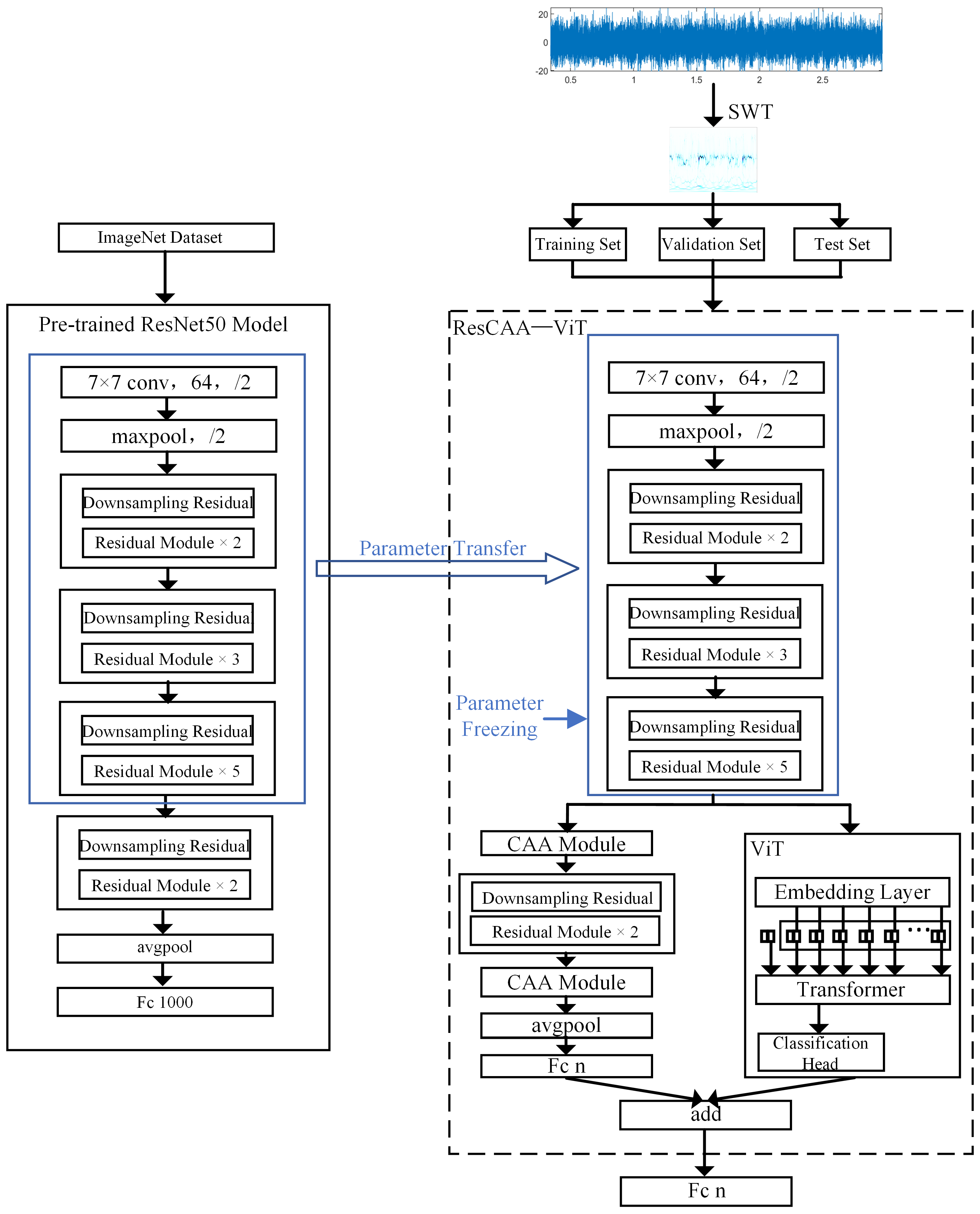
This paper presents a method for fault diagnosis in rolling bearing, integrating the Synchronized Compressed Wavelet Transform (SWT) and the ResCAA-ViT architecture. The ResCAA-ViT network is an enhanced version of the ResNet-50 and Vision Transformer (ViT) networks. The architecture of the proposed method is shown in
Figure 3.
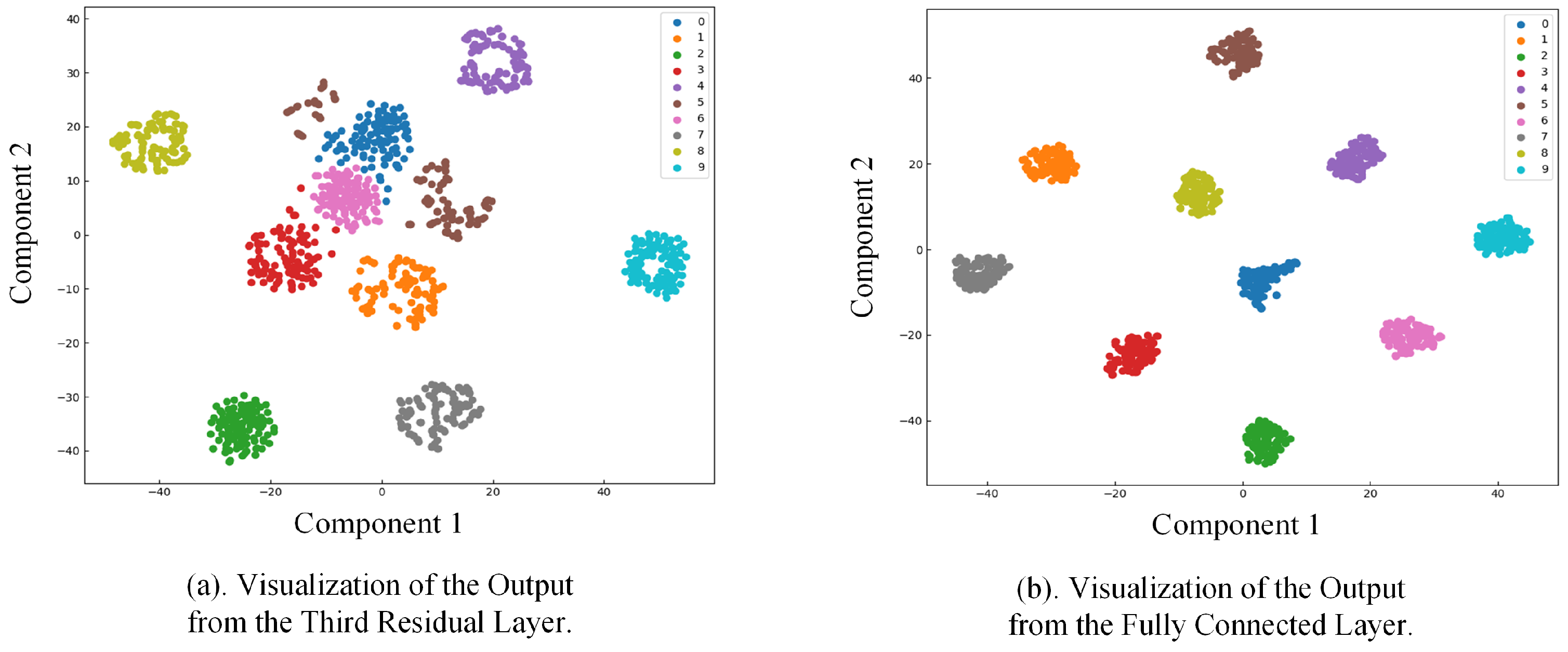
First, the vibration signal is processed using the Synchrosqueezed Wavelet Transform (SWT) to generate a high-resolution time–frequency map, which is then input into the ResCAA-ViT model. The model’s convolutional and residual modules leverage parameters transferred from the pre-trained ResNet50. Next, the feature information output from the third residual module is directed into a dual-branch architecture for further processing. The left branch employs a residual network with the Context Anchor Attention (CAA) mechanism, aiming to fully utilize feature information from different layers. The CAA module in the early layers captures relationships between low-level features, while the CAA module in the later layers enhances the contextual modeling of high-level features, enabling the network to effectively extract both local and global features. Additionally, the CAA module integrates local feature extraction, strip convolution, and attention mechanisms, thereby enhancing the network’s focus on important fault features and improving classification accuracy and robustness. The right branch utilizes the Vision Transformer (ViT) model, which captures global features through a self-attention mechanism and leverages its global receptive field to better capture complex time–frequency features in the spectrogram. The outputs from both branches are combined through an addition operation, and the final diagnosis is performed using a Softmax classifier. The loss function combines cross-entropy loss and mean squared error (MSE) loss to improve the model’s consistency and collaborative learning capability. This hybrid architecture takes advantage of convolutional neural networks’ ability to efficiently extract local features, while the CAA attention mechanism improves the modeling of local feature contexts. In combination with the Transformer’s capacity to capture global dependencies, it significantly boosts the model’s ability to identify intricate fault characteristics.
The procedure for bearing fault diagnosis using the combination of SWT and ResCAA-ViT is outlined as follows:
- (1)
Sliding Window Sample Augmentation
The sliding window method generates multiple overlapping subsequences by applying a fixed-size window over the raw vibration signal and sliding it with a defined step size. This process augments the number of samples for model training, improving the model’s generalization ability and classification performance.
- (2)
SWT to Generate Time–Frequency Maps
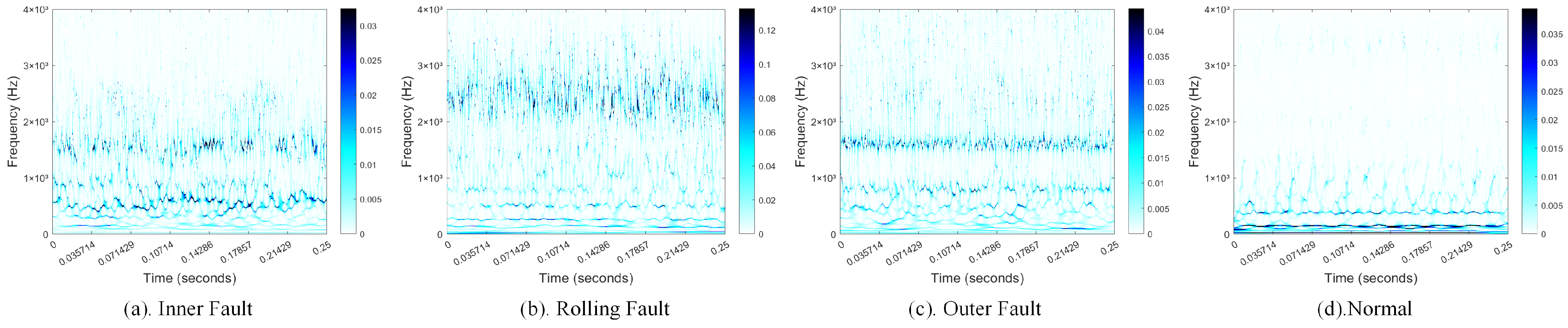
For the augmented data samples of different fault types from step (1), the SWT is employed to produce high-resolution time–frequency representations. The images are then resized to 224 × 224 pixels. The time–frequency maps are randomly split into training, validation, and test sets with a ratio of 6:2:2.
- (3)
Model Training
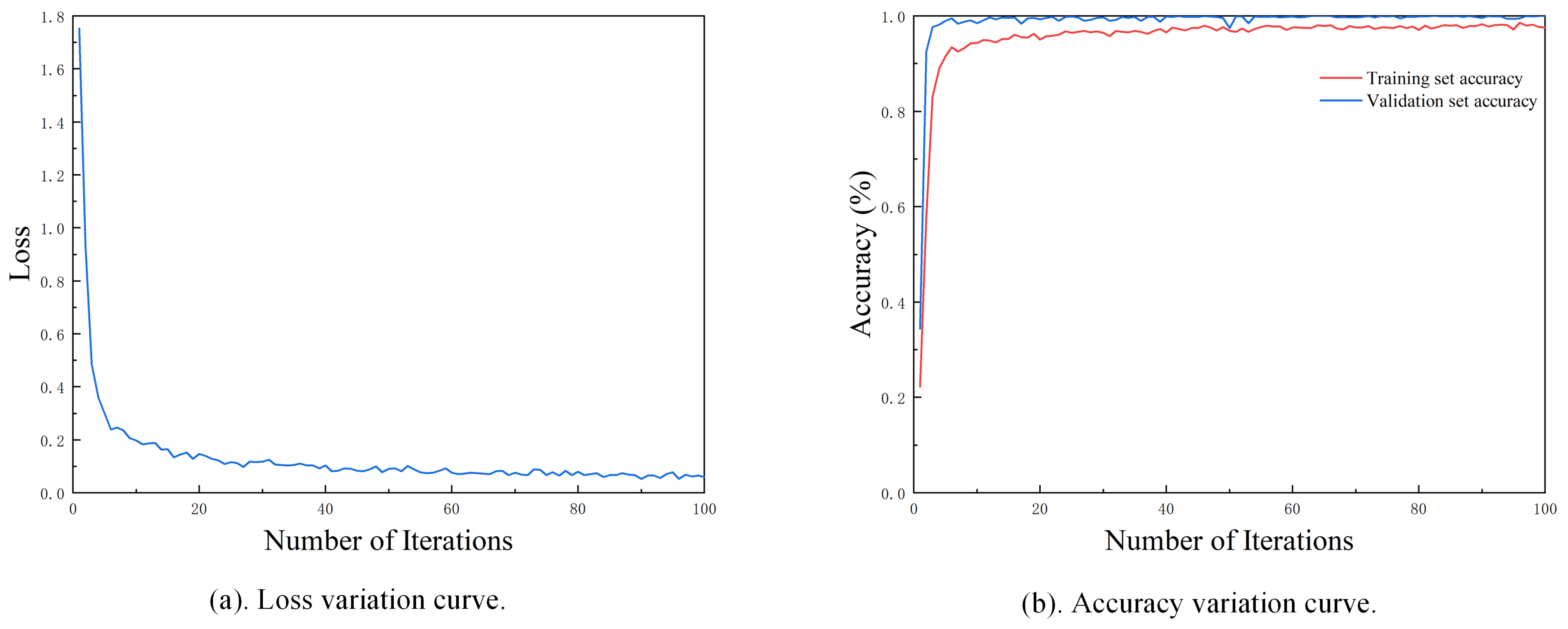
The training set samples from step (2) are input into the ResCAA-ViT model. The parameters of the Conv1 layer and the first three residual layers are frozen, utilizing parameters pre-trained on the ImageNet dataset for the ResNet-50 model. Forward propagation is then applied to compute the predicted output, followed by backpropagation, which iteratively updates and optimizes the weights of the unfrozen layers. Finally, the trained network model is saved.
- (4)
Model Testing and Application
The test set samples from step (2) are fed into the trained ResCAA-ViT model, which then generates the fault diagnosis results. The classification accuracy of these test set samples is used to evaluate the model’s performance in fault diagnosis.
5. Conclusions
This paper presents a fault diagnosis approach for rolling bearings utilizing the SWT in combination with the ResCAA-ViT network, demonstrating its effectiveness under complex and variable operating conditions.
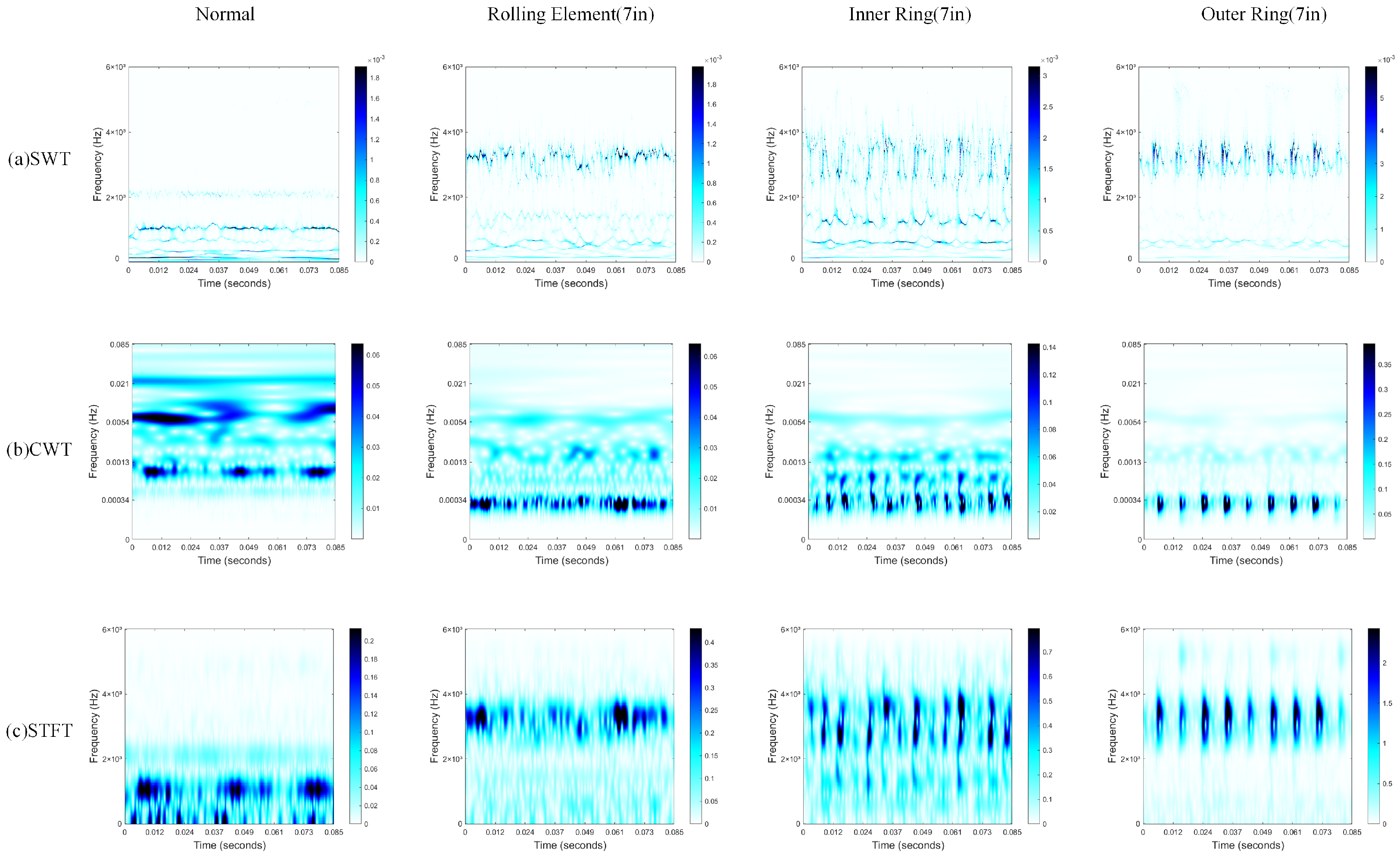
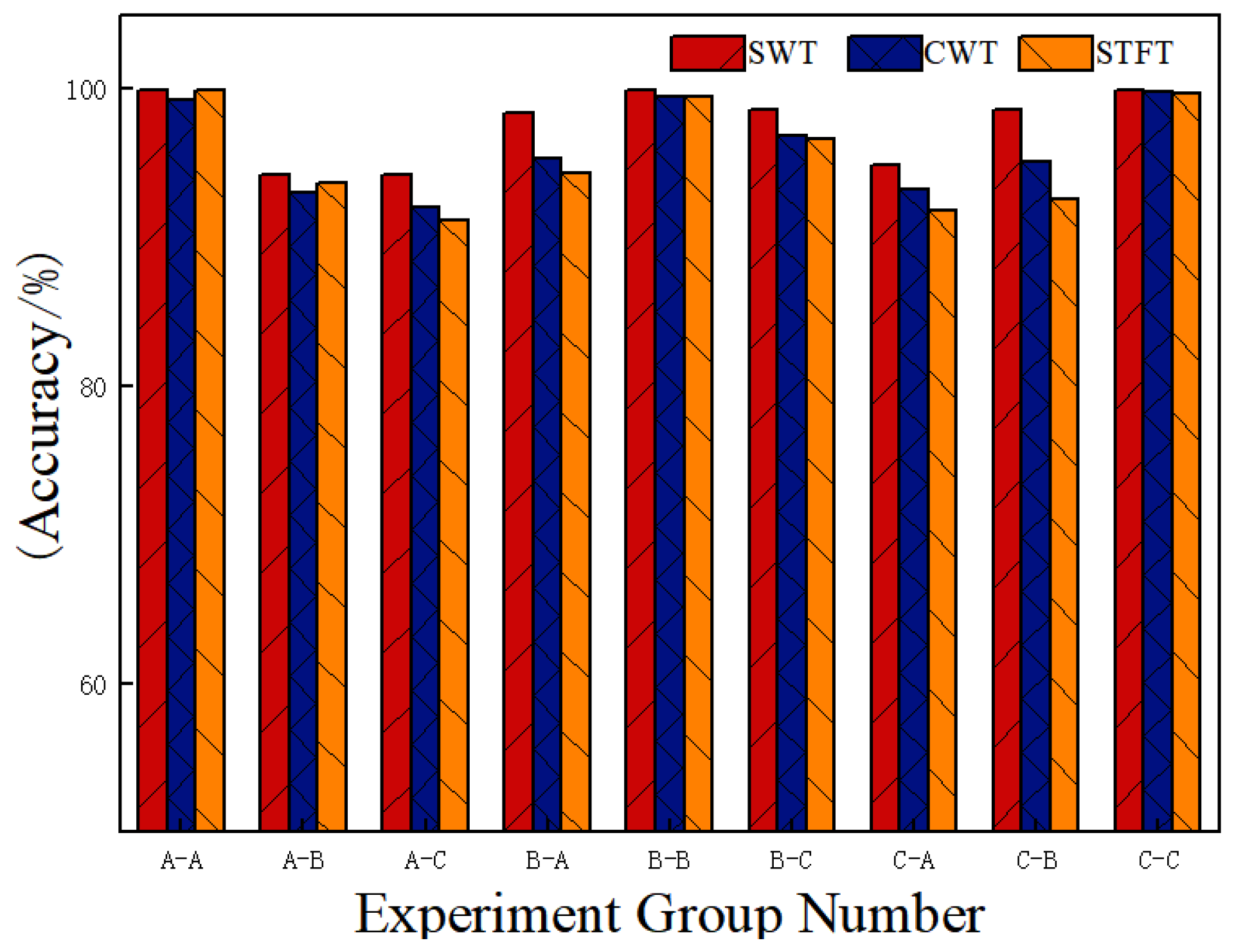
The method utilizes the SWT to transform vibration signals into high-resolution time–frequency maps. Compared to time–frequency maps generated by the CWT and STFT, the SWT more effectively captures instantaneous changes and local features in the signal, which enhances fault diagnosis performance when processed by the network model.
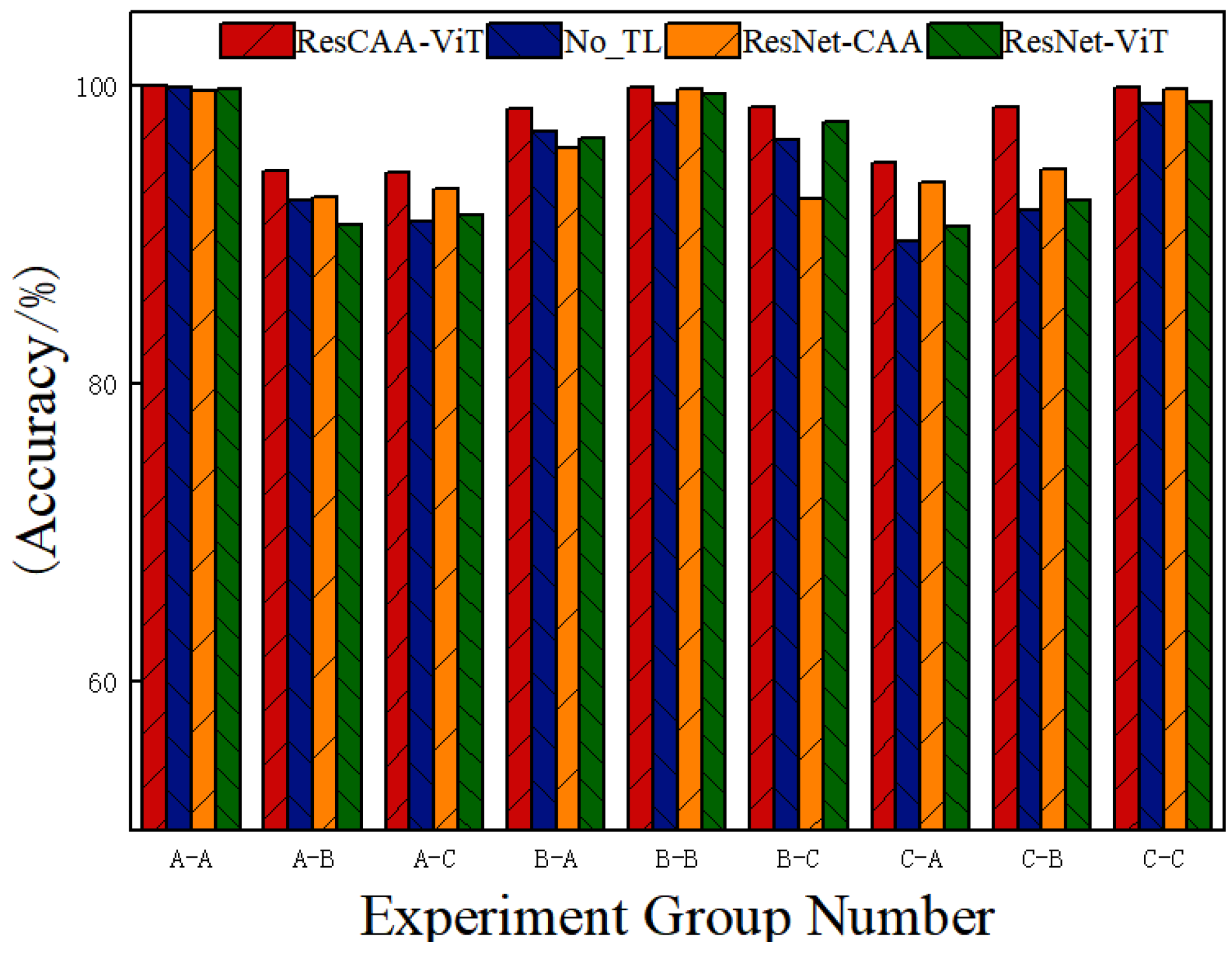
The ResCAA-ViT model introduced in this study combines the advantages of convolutional neural networks (CNNs) for extracting local features with the capability of Transformers to model global dependencies effectively. By incorporating transfer learning with a pre-trained ResNet50 model, the method addresses the challenges of limited data and accelerates model training and optimization. Furthermore, the CAA attention mechanism improves the model’s ability to represent features effectively, while the multi-loss constraint method improves consistency and collaborative learning.
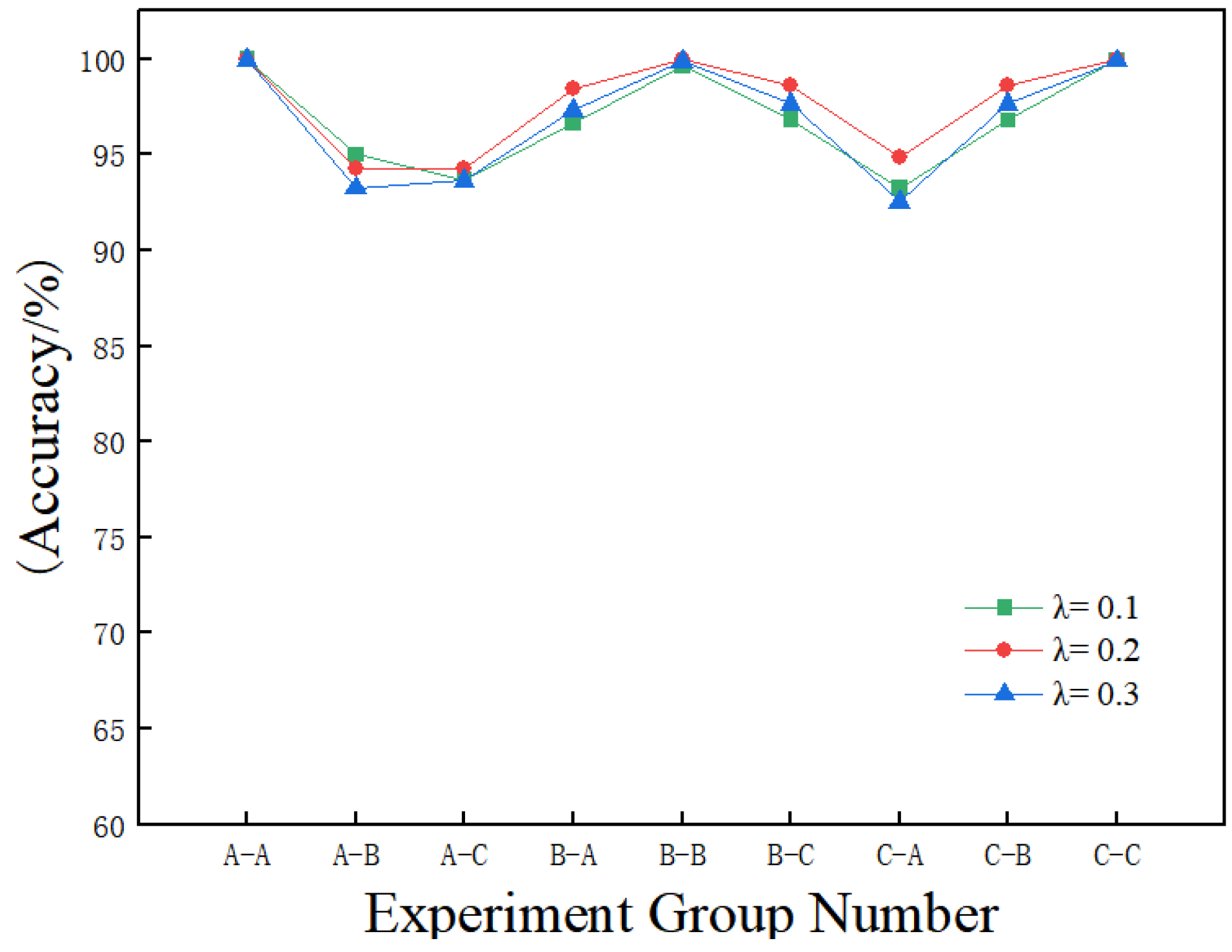
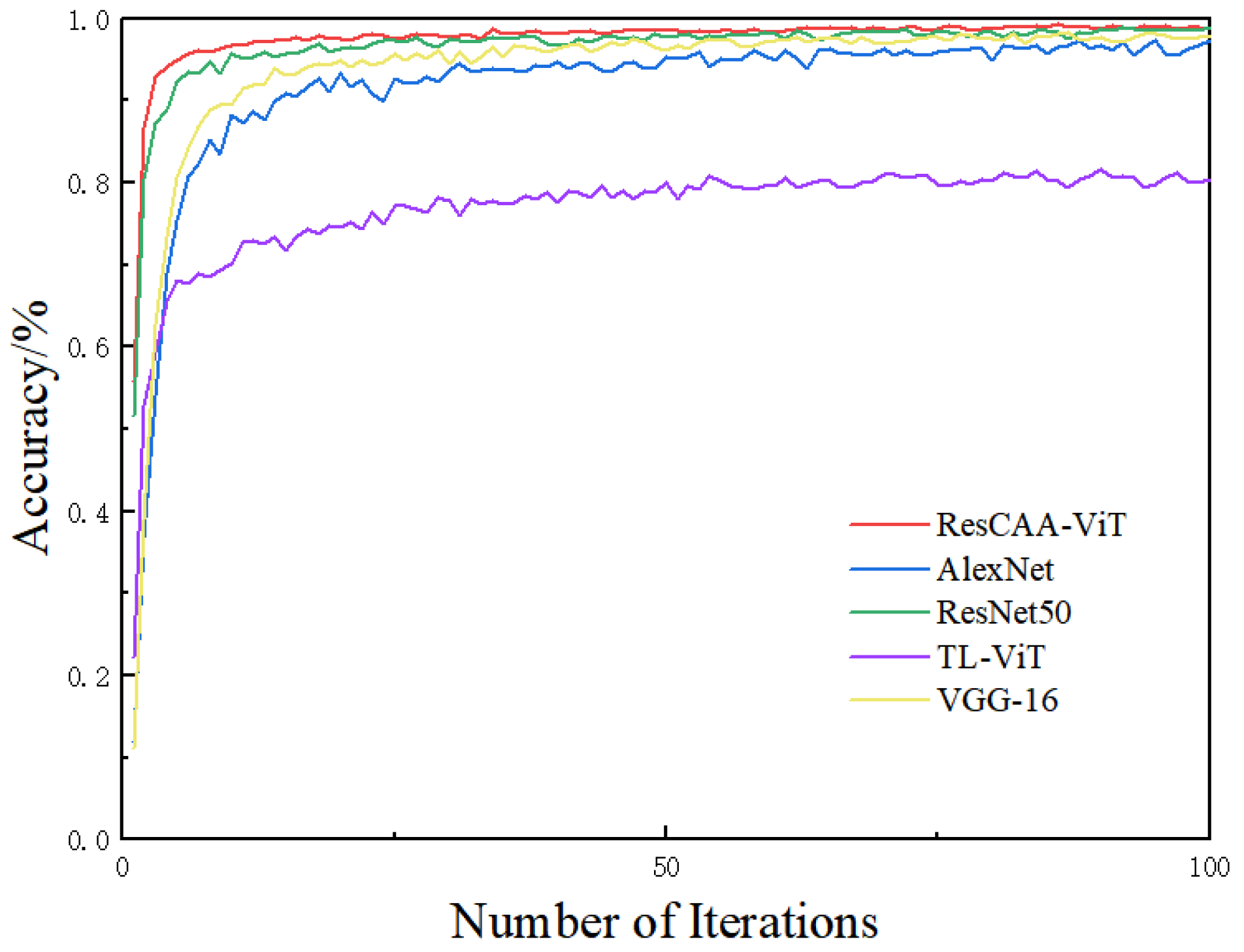
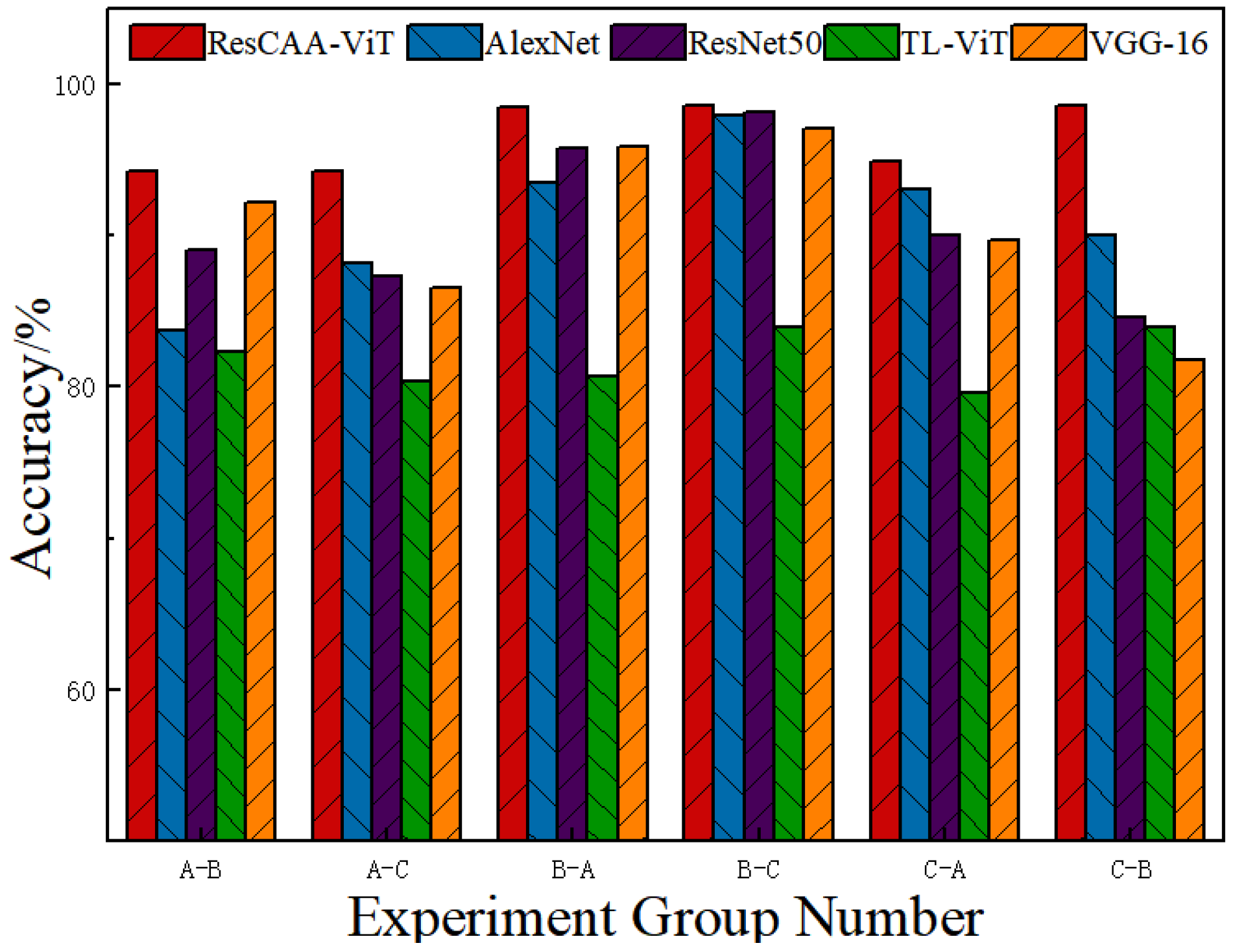
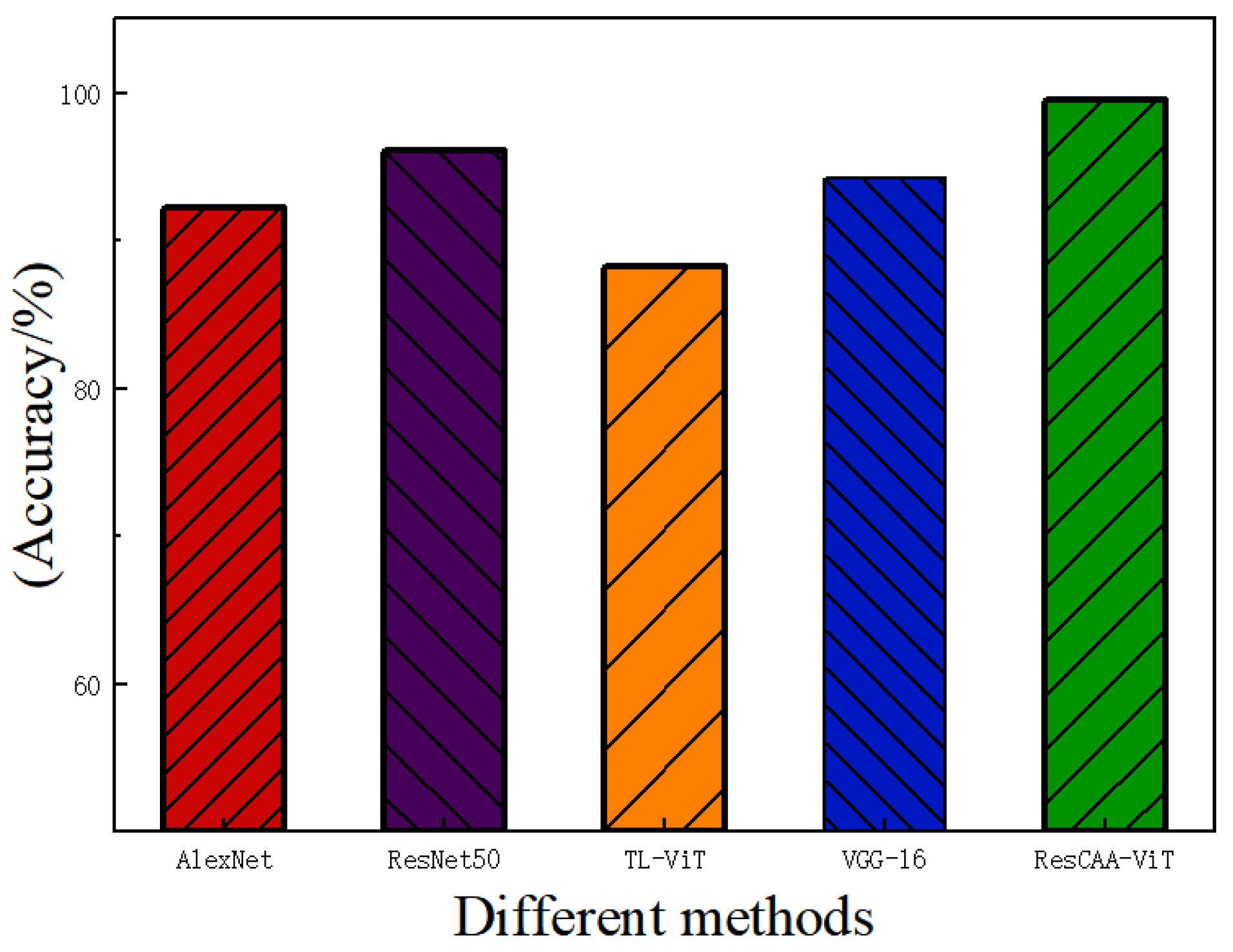
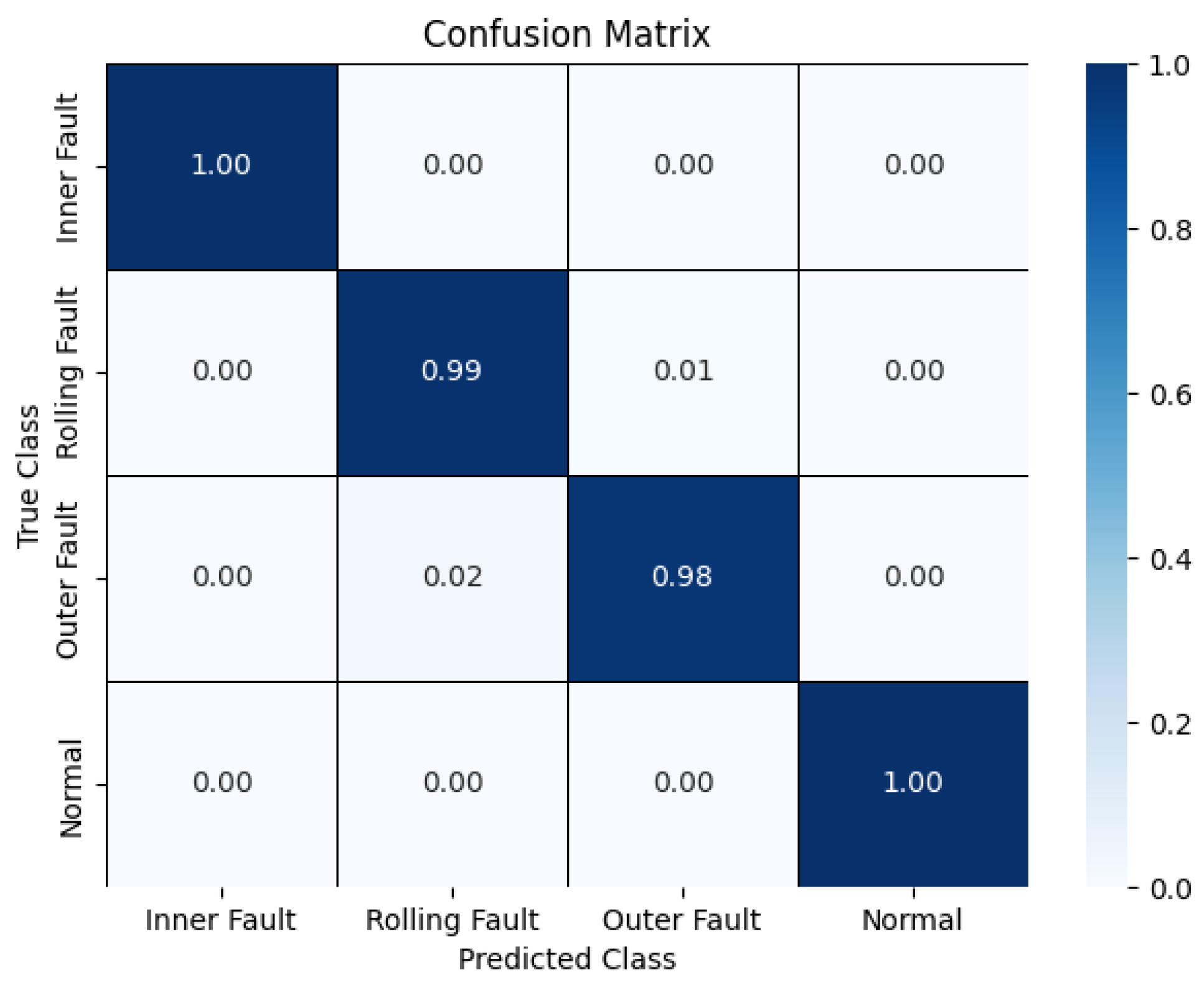
Validation on the CWRU dataset demonstrates that the proposed method achieves average accuracies of 99.96% under constant load and 96.51% under variable load conditions, outperforming other methods. Additionally, the average diagnostic accuracy on the real-world dataset of the non-drive end bearing of wind turbines is 99.25%, which surpasses that of the comparison methods. These results highlight the high accuracy and strong generalization ability of the proposed method, making it suitable for real-world industrial applications.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}