
A Lightweight Approach to Comprehensive Fabric Anomaly Detection Modeling


Abstract
1. Introduction
2. Related Work
3. GH-YOLOx
3.1. Network Structure
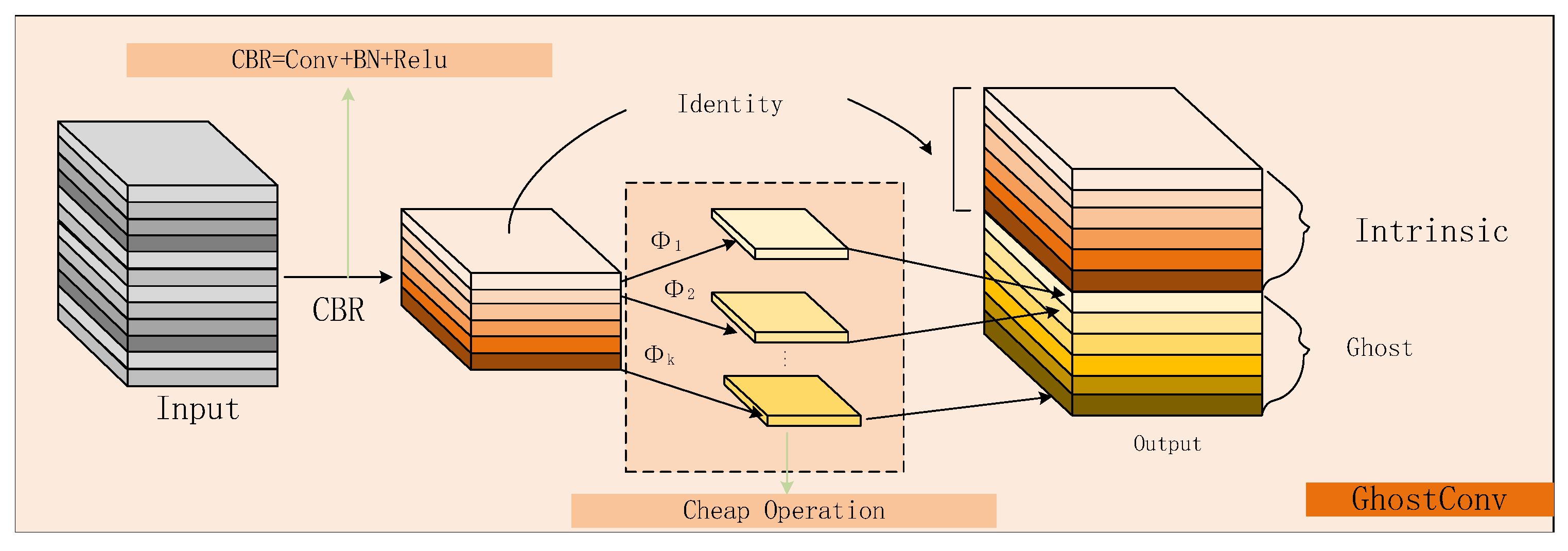
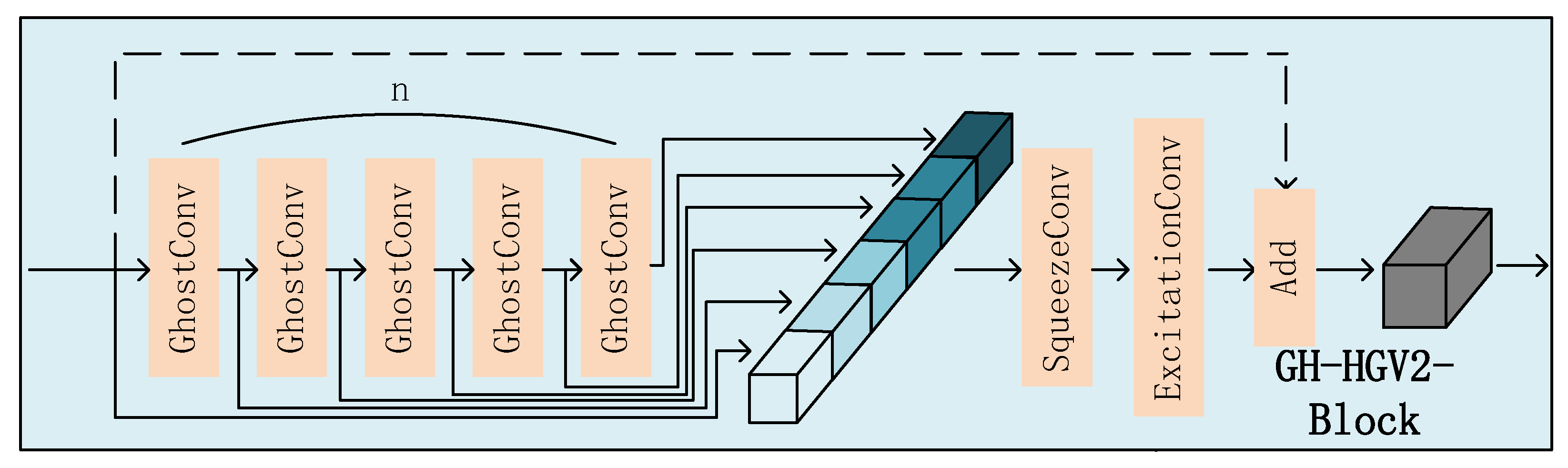
3.1.1. Backbone
3.1.2. Neck
3.1.3. Head
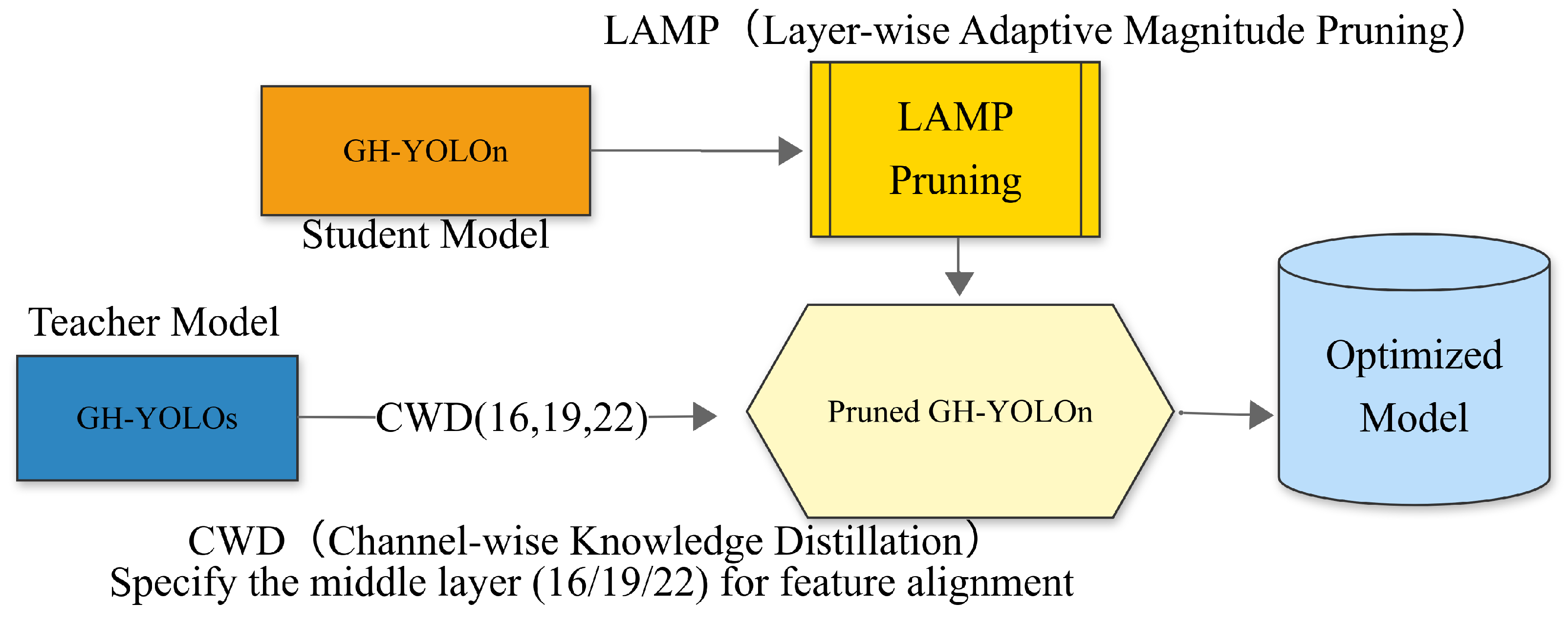
4. Lamp
5. Channel-Wise Knowledge Distillation
6. Experiment and Result Analysis
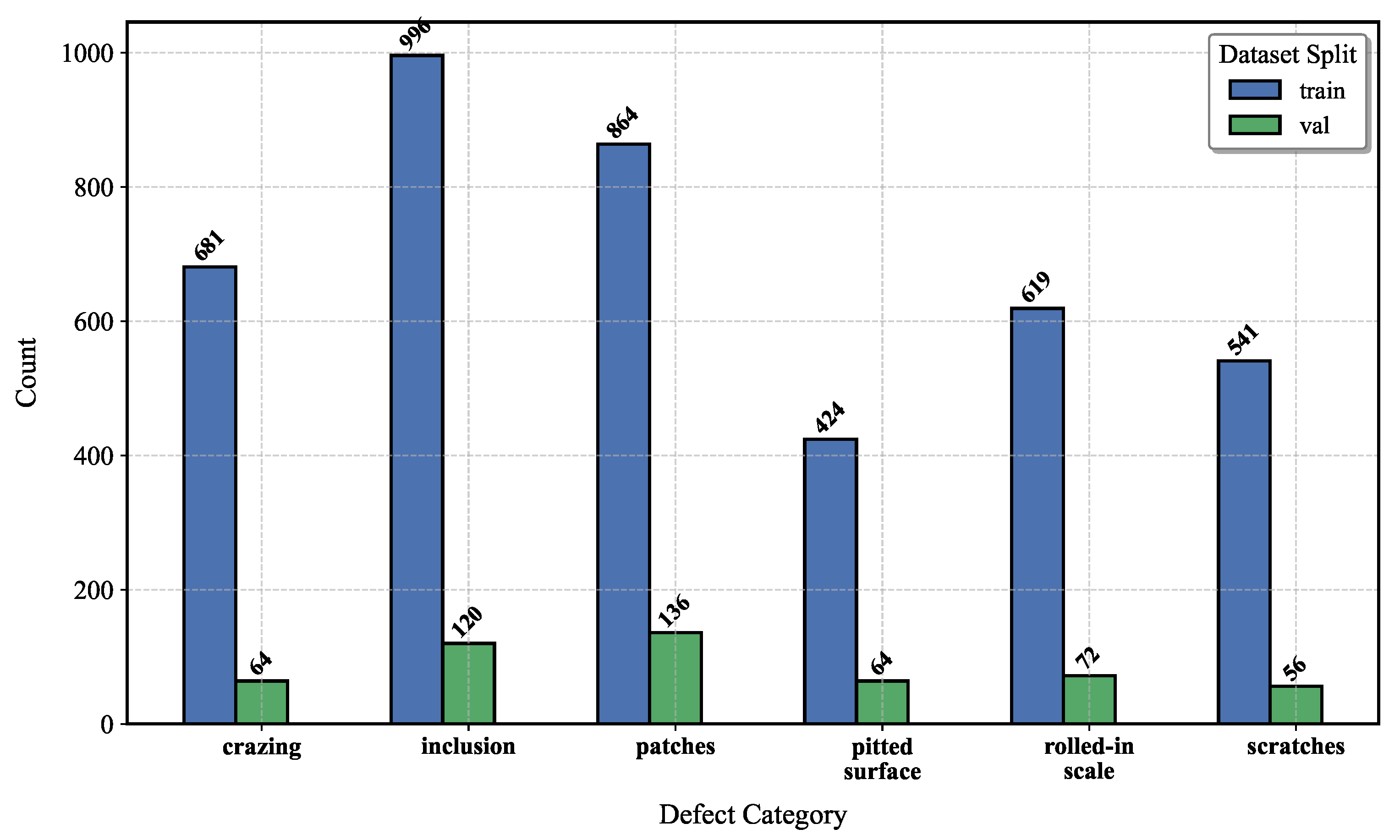
6.1. Dataset
6.2. Training Parameters
6.3. Ablation Experiment
7. Performance Comparison of Different Models and Dataset
Detection Result
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, Q.; Mei, J.; Zhang, Q.; Wang, S.; Chen, G. Semi-supervised fabric defect detection based on image reconstruction and density estimation. Text. Res. J. 2021, 91, 962–972. [Google Scholar]
- Shen, S.; Zhu, C.; Fan, C.; Wu, C.; Huang, X.; Zhou, L. Research on the evolution and driving forces of the manufacturing industry during the “13th five-year plan” period in Jiangsu province of China based on natural language processing. PLoS ONE 2021, 16, e0256162. [Google Scholar] [CrossRef] [PubMed]
- Szarski, M.; Chauhan, S. An unsupervised defect detection model for a dry carbon fiber textile. J. Intell. Manuf. 2022, 33, 2075–2092. [Google Scholar]
- Jia, Z.; Shi, Z.; Quan, Z.; Mei, S. Fabric defect detection based on transfer learning and improved Faster R-CNN. J. Eng. Fibers Fabr. 2022, 17, 15589250221086647. [Google Scholar]
- Capstone Project. BKDN-HUYLV-DATN-BOX Dataset. Roboflow Universe. 2023. Available online: https://universe.roboflow.com/capstone-project-baym7/bkdn-huylv-datn-box (accessed on 1 April 2024).
- Bao, Y.; Song, K.; Liu, J.; Wang, Y.; Yan, Y.; Yu, H.; Li, X. Triplet-Graph Reasoning Network for Few-Shot Metal Generic Surface Defect Segmentation. IEEE Trans. Instrum. Meas. 2021, 70, 1–11. [Google Scholar] [CrossRef]
- Mei, S.; Wang, Y.; Wen, G. Automatic Fabric Defect Detection with a Multi-Scale Convolutional Denoising Autoencoder Network Model. Sensors 2018, 18, 1064. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, T.; Yin, J.; See, S.; Liu, J. Learning Gabor Texture Features for Fine-Grained Recognition. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 1621–1631. [Google Scholar]
- Liu, X.; Li, Z.; Wen, H.; Miao, M.; Wang, Y.; Wang, Z. A PAM4 Transceiver Design Scheme with Threshold Adaptive and Tap Adaptive. EURASIP J. Adv. Signal Process. 2023, 2023, 70. [Google Scholar]
- Zheng, R.; Sun, S.; Liu, H. Deep Frequency Attention Networks for Single Snapshot Sparse Array Interpolation. arXiv 2025, arXiv:2503.05486. [Google Scholar]
- Wang, F.; Qian, W.; Qian, Y.; Ma, C.; Zhang, H.; Wang, J.; Wan, M.; Ren, K. Maritime Infrared Small Target Detection Based on the Appearance Stable Isotropy Measure in Heavy Sea Clutter Environments. Sensors 2023, 23, 9838. [Google Scholar] [CrossRef]
- Hao, Z.; Gai, S.; Li, P. Multi-Scale Self-Calibrated Dual-Attention Lightweight Residual Dense Deraining Network Based on Monogenic Wavelets. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2642–2655. [Google Scholar]
- Liu, Y.C.; Shahid, M.; Sarapugdi, W.; Lin, Y.X.; Chen, J.C.; Hua, K.L. Cascaded Atrous Dual Attention U-Net for Tumor Segmentation. Multimed. Tools Appl. 2021, 80, 30007–30031. [Google Scholar] [CrossRef]
- Xu, S.; Chang, D.; Xie, J.; Ma, Z. Grad-CAM Guided Channel-Spatial Attention Module for Fine-Grained Visual Classification. In Proceedings of the 2021 IEEE 31st International Workshop on Machine Learning for Signal Processing (MLSP), Gold Coast, Australia, 25–28 October 2021; pp. 1–6. [Google Scholar]
- Zhao, L.; Wang, L. A New Lightweight Network Based on MobileNetV3. KSII Trans. Internet Inf. Syst. 2022, 16, 1–15. [Google Scholar]
- Cheng, J.; Chen, Q.; Huang, X. An Algorithm for Crack Detection, Segmentation, and Fractal Dimension Estimation in Low-Light Environments by Fusing FFT and Convolutional Neural Network. Fractal Fract. 2023, 7, 820. [Google Scholar] [CrossRef]
- Zhang, L.; Wei, Y.; Wang, H.; Shao, Y.; Shen, J. Real-Time Detection of River Surface Floating Object Based on Improved RefineDet. IEEE Access 2023, 9, 81147–81160. [Google Scholar] [CrossRef]
- Zhang, X.; Ying, J.; Peng, H. Infrared Arrester Detection Based on Improved YOLOv4. In Proceedings of the 20th International Conference on AC and DC Power Transmission 2024 (ACDC 2024), Shanghai, China, 12–15 July 2024; pp. 492–497. [Google Scholar]
- Chen, J.; Kao, S.; He, H.; Zhuo, W.; Wen, S.; Lee, C.H.; Chan, S.H. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar]
- Li, Z.; Ouyang, B.; Qiu, S.; Xu, X.; Cui, X.; Hua, X. Change Detection in Remote Sensing Images Using Pyramid Pooling Dynamic Sparse Attention Network with Difference Enhancement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 7052–7067. [Google Scholar] [CrossRef]
- Ding, W.; Cheng, X.; Geng, Y.; Huang, J.; Ju, H. C2F-Explainer: Explaining Transformers Better Through a Coarse-to-Fine Strategy. IEEE Trans. Knowl. Data Eng. 2024, 36, 7708–7724. [Google Scholar]
- Kim, K.; Wu, F.; Peng, Y.; Pan, J.; Sridhar, P.; Han, K.J.; Watanabe, S. E-Branchformer: Branchformer with Enhanced Merging for Speech Recognition. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; pp. 84–91. [Google Scholar]
- Wang, N.; Liu, D.; Zeng, J.; Mu, L.; Li, J. HGRec: Group Recommendation with Hypergraph Convolutional Networks. IEEE Trans. Comput. Soc. Syst. 2024, 11, 4214–4225. [Google Scholar] [CrossRef]
- Das, R.J.; Sun, M.; Ma, L.; Shen, Z. Beyond Size: How Gradients Shape Pruning Decisions in Large Language Models. arXiv 2023, arXiv:2311.04902. [Google Scholar]
- Pei, Z.; Yao, X.; Zhao, W.; Yu, B. Quantization via Distillation and Contrastive Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 17164–17176. [Google Scholar] [CrossRef]
- Frousiou, E.; Tonis, E.; Rotas, G.; Pantelia, A.; Chalkidis, S.G.; Heliopoulos, N.S.; Kagkoura, A.; Siamidis, D.; Galeou, A.; Prombona, A.; et al. Kevlar, Nomex, and VAR Modification by Small Organic Molecules Anchoring: Transfusing Antibacterial Properties and Improving Water Repellency. Molecules 2023, 28, 5465. [Google Scholar] [CrossRef]
- Tang, Q.; Li, J.; Shi, Z.; Hu, Y. Lightdet: A lightweight and accurate object detection network. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2243–2247. [Google Scholar]
- Xiaogang, Y.; Fan, G.; Ruitao, L.; Weipeng, L.; Tao, Z.; Jun, Z. Lightweight aviation object detection method based on improved YOLOv5 [J/OL]. Inf. Control. 2022, 10, 1–7. [Google Scholar]
- Wang, Y.; Zhang, X.; Xie, L.; Zhou, J.; Su, H.; Zhang, B.; Hu, X. Pruning from scratch. Proc. AAAI Conf. Artif. Intell. 2020, 34, 12273–12280. [Google Scholar]
- Zhang, H.; Liu, S.; Lu, S.; Yao, L.; Li, P. Knowledge distillation for unsupervised defect detection of yarn-dyed fabric using the system DAERD: Dual attention embedded reconstruction distillation. Color. Technol. 2024, 140, 125–143. [Google Scholar]

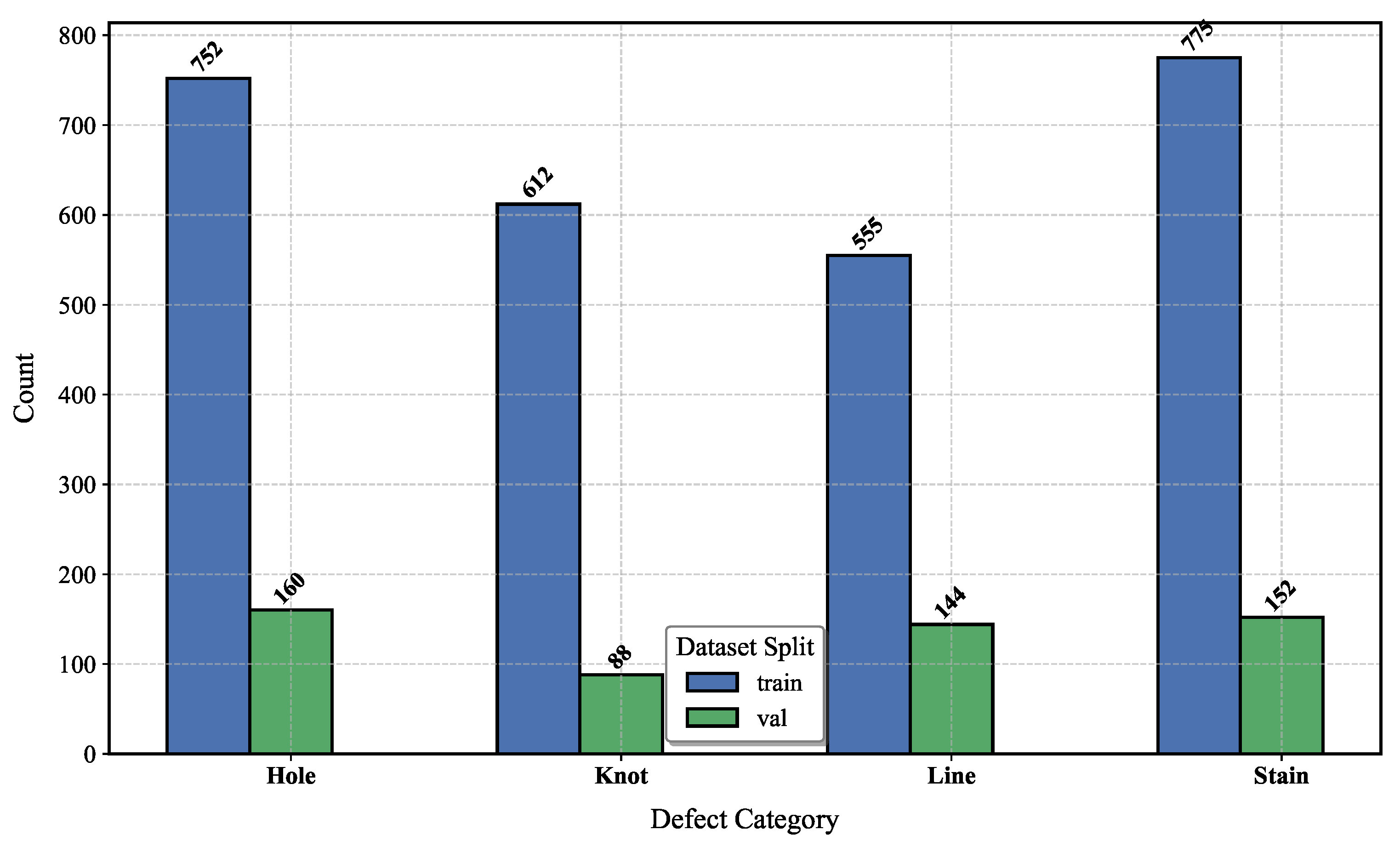




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Configuration | mAP@0.5 (%) | FPS (ms) | Params (M) |
|---|---|---|---|---|
| YOLOv5 | Baseline | 88.3 | 4.7 | 2.5 |
| +A | 89.2 | 4.0 | 2.0 | |
| +B | 89.4 | 4.9 | 2.2 | |
| +C | 88.9 | 3.5 | 1.8 | |
| A+B+C | 88.7 | 3.5 | 1.1 | |
| YOLOv8 | Baseline | 87.8 | 4.0 | 3.2 |
| +A | 88.6 | 3.9 | 2.3 | |
| +B | 88.2 | 4.3 | 2.5 | |
| +C | 89.1 | 3.8 | 2.3 | |
| A+B+C | 89.1 | 3.4 | 1.6 | |
| GH-YOLOn | A+B+C | 89.1 | 3.4 | 1.6 |
| Model | Model Size (MB) | FPS (S) | Params (M) | mAP@0.5 (%) |
|---|---|---|---|---|
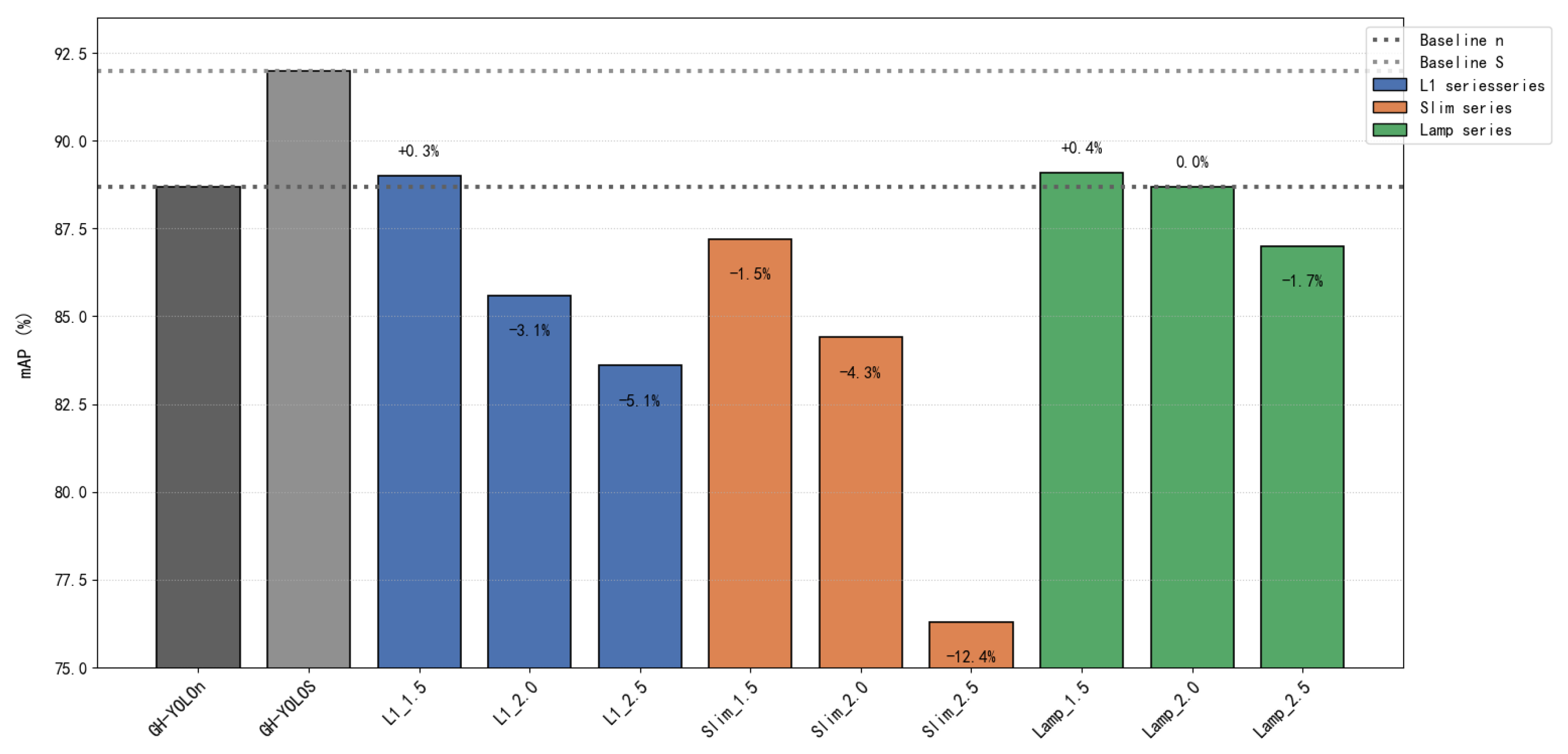
| Our(A+B+C)n | 2.7 | 25 | 1.1 | 88.7 |
| Our(A+B+C)S | 9.9 | 15 | 4.7 | 92.0 |
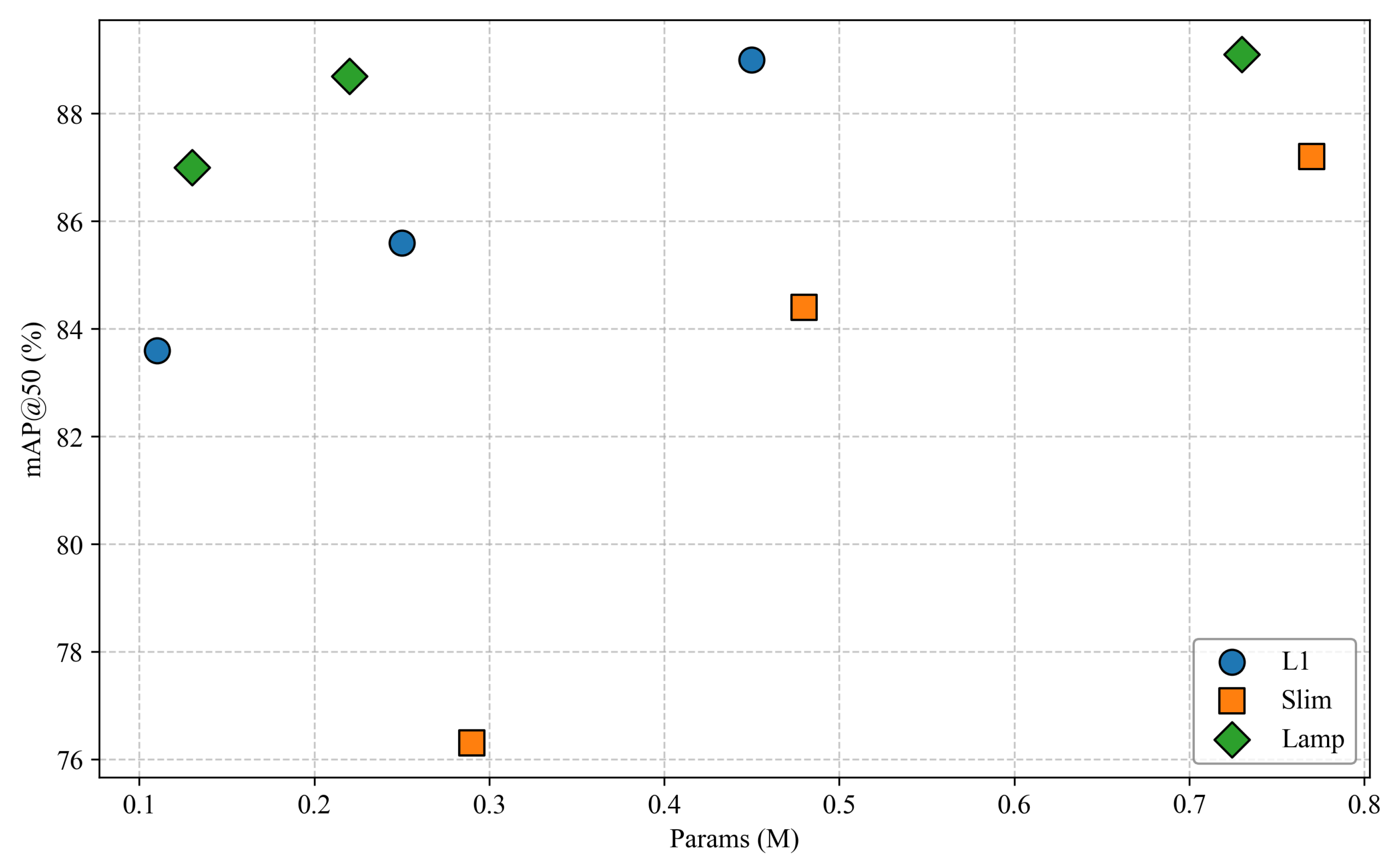
| L1_1.5 | 1.2 (−1.5) | 33 (+8) | 0.45 (−0.65) | 89.0 (+0.3) |
| L1_2.0 | 0.8 (−1.9) | 38 (+13) | 0.25 (−0.85) | 85.6 (−3.1) |
| L1_2.5 | 0.5 (−2.2) | 43 (+18) | 0.11 (−0.99) | 83.6 (−5.1) |
| Slim_1.5 | 1.9 (−0.8) | 31 (+6) | 0.77 (−0.33) | 87.2 (−1.5) |
| Slim_2.0 | 1.3 (−1.4) | 41 (+16) | 0.48 (−0.62) | 84.4 (−4.3) |
| Slim_2.5 | 0.9 (−1.8) | 51 (+26) | 0.29 (−0.81) | 76.3 (−12.4) |
| Lamp_1.5 | 1.5 (−1.2) | 30 (+5) | 0.73 (−0.37) | 89.1 (+0.4) |
| Lamp_2.0 | 0.7 (−2.0) | 36 (+11) | 0.22 (−0.88) | 88.7 (+0.0) |
| Lamp_2.5 | 0.6 (−2.1) | 45 (+20) | 0.13 (−0.97) | 87.0 (−1.7) |
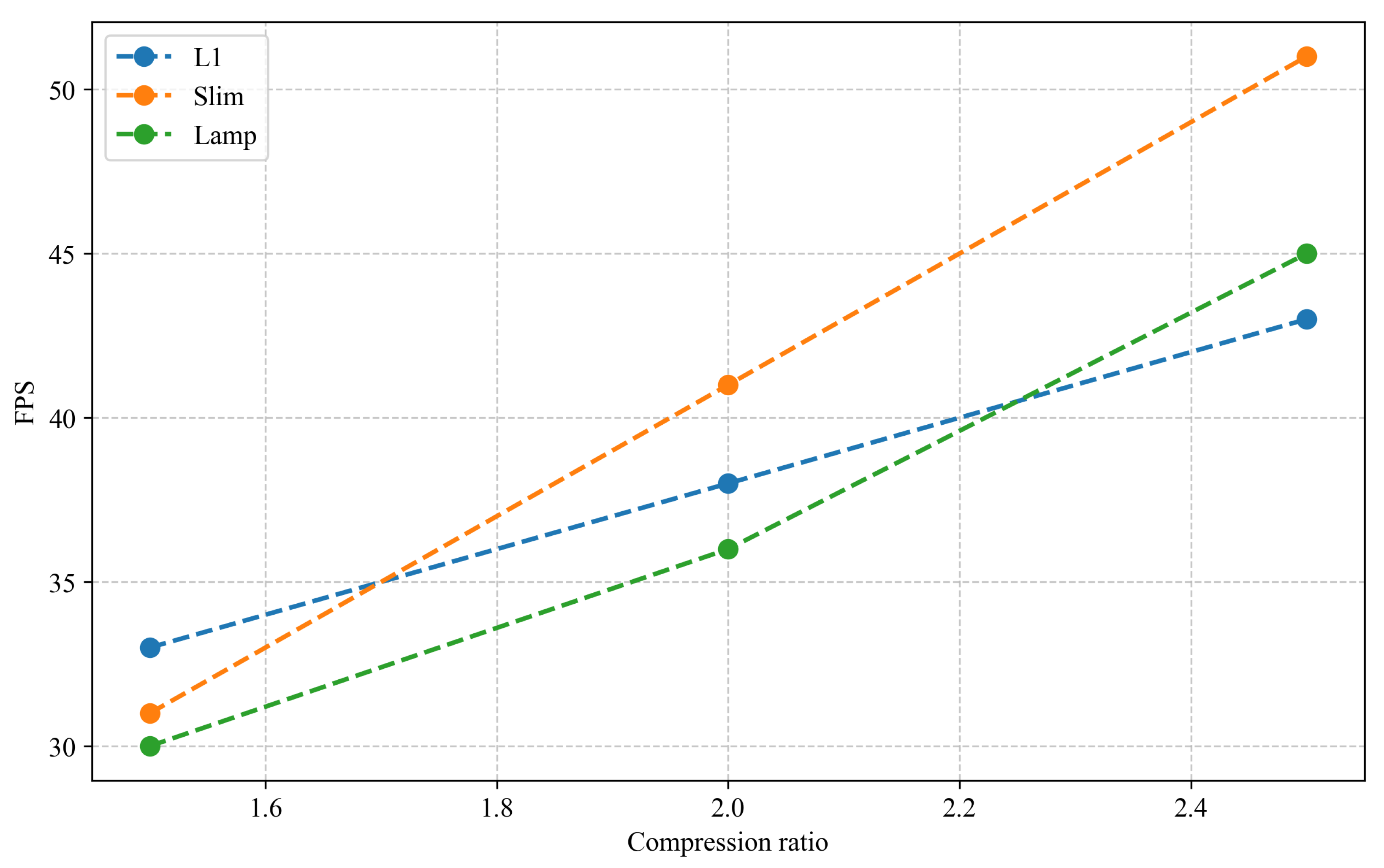
| Metric\Method | L1_1.5 | Lamp_1.5 | Lamp_2.0 | Slim_2.5 |
|---|---|---|---|---|
| Model compression ratio | 1.5× | 1.5× | 2.0× | 2.5× |
| mAP change | ||||
| FPS improvement |
| Method | mAP@0.5 (%) |
|---|---|
| CWD distillation | 90.1 (+1.3%) |
| MIMIC distillation | 88.9 (+0.2%) |
| MGD distillation | 88.4 (−0.3%) |
| Model | Params Size (M) | Model Size (Mb) | mAP@0.5 (%) | |
|---|---|---|---|---|
| Data1 | Data2 | |||
| YOLOv5 | 2.5 | 5.3 | 88.3 | 80.3 |
| YOLOv6 | 4.2 | 8.7 | 83.5 | 80.0 |
| YOLOv8 | 3.2 | 6.3 | 87.8 | 81.0 |
| YOLOv5_lite-e | 0.78 | 1.7 | 34.0 | 30.0 |
| NanoDet-m | 0.95 | 1.8 | 38.2 | 34.2 |
| Our | 0.22 | 0.7 | 90.1 | 83.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, S.; Liu, W.; Li, M. A Lightweight Approach to Comprehensive Fabric Anomaly Detection Modeling. Sensors 2025, 25, 2038. https://doi.org/10.3390/s25072038
Cui S, Liu W, Li M. A Lightweight Approach to Comprehensive Fabric Anomaly Detection Modeling. Sensors. 2025; 25(7):2038. https://doi.org/10.3390/s25072038
Chicago/Turabian StyleCui, Shuqin, Weihong Liu, and Min Li. 2025. "A Lightweight Approach to Comprehensive Fabric Anomaly Detection Modeling" Sensors 25, no. 7: 2038. https://doi.org/10.3390/s25072038
APA StyleCui, S., Liu, W., & Li, M. (2025). A Lightweight Approach to Comprehensive Fabric Anomaly Detection Modeling. Sensors, 25(7), 2038. https://doi.org/10.3390/s25072038