RelVid: Relational Learning with Vision-Language Models for Weakly Video Anomaly Detection

 , and
, and 
Abstract
1. Introduction
- To incorporate additional modalities of information to guide model training, a new framework is proposed, consisting of three key components: the class activation module to improve feature discrimination, the Adapter for capturing temporal dependencies, and two auxiliary tasks that adapt the pre-trained model for weakly supervised anomaly detection;
- To ensure that the features obtained from the fine-tuned feature extractor are more suitable for the video anomaly detection task, the Adapter is proposed to learn class-specific features and capture the temporal dependencies of different video events more flexibly and accurately.
- To enhance the model’s ability to capture diverse information, auxiliary tasks that leverage both textual and visual patterns are proposed, while reconstruction tasks further support feature learning, improving the model’s overall performance.
- The effectiveness of RelVid is demonstrated on two widely used benchmarks, UCF-Crime and XD-Violence, where it achieves state-of-the-art performance with unprecedented results: 87.71% AUC and 80.76% AP, surpassing most previous methods by a significant margin.
2. Related Work
2.1. Weakly-Supervised Video Anomaly Detection
2.2. Vision-Language Learning in VAD
3. Framework
3.1. Overview
3.2. Feature Extraction
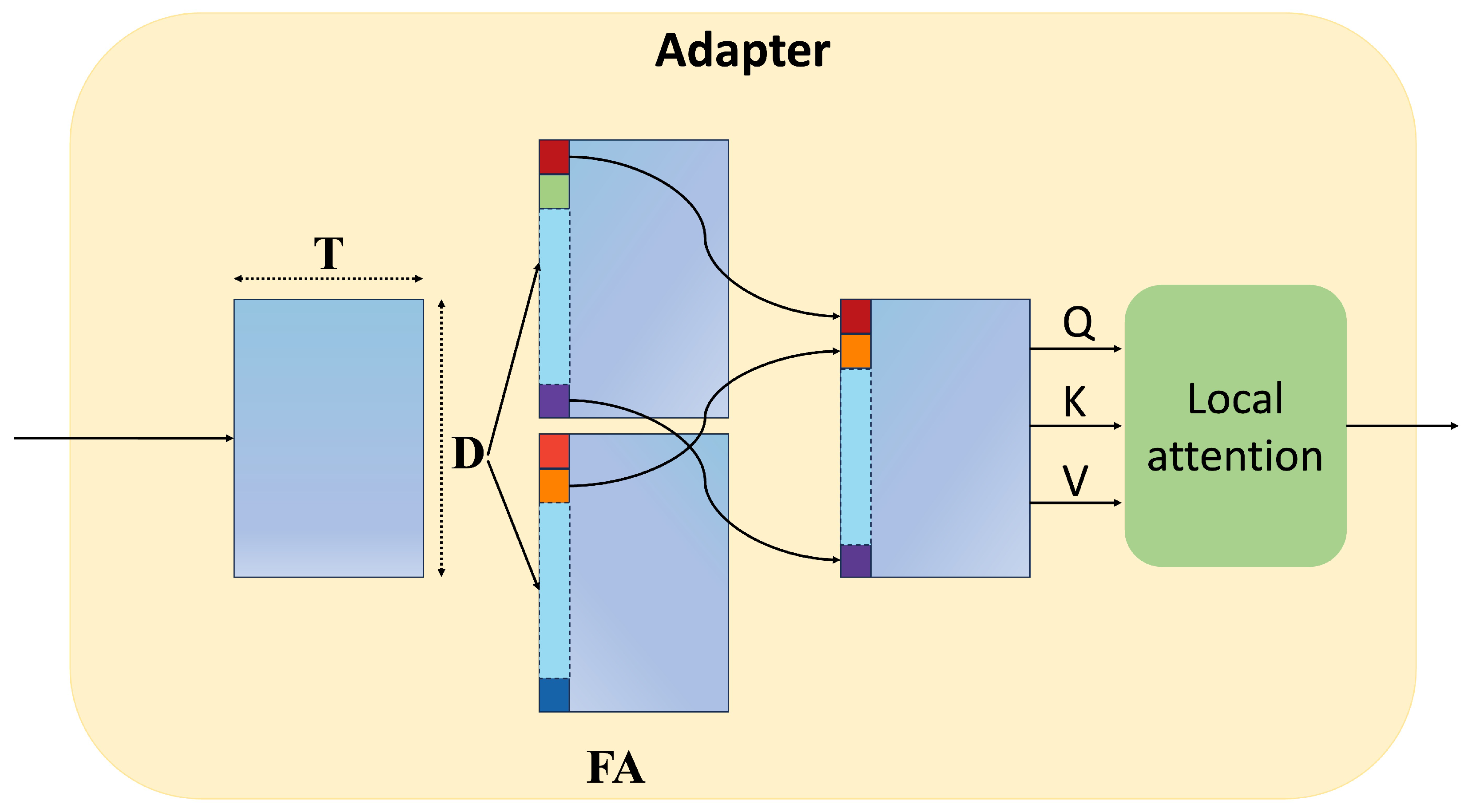
3.3. Adapter
3.3.1. Feature Activate Module
3.3.2. Local Attention
3.4. Auxiliary Tasks
3.5. Objective Function
4. Experiment
4.1. Datasets
4.2. Evaluation Metric
4.3. Implementation Details
4.4. Comparison with State of Art
4.5. Ablation Study
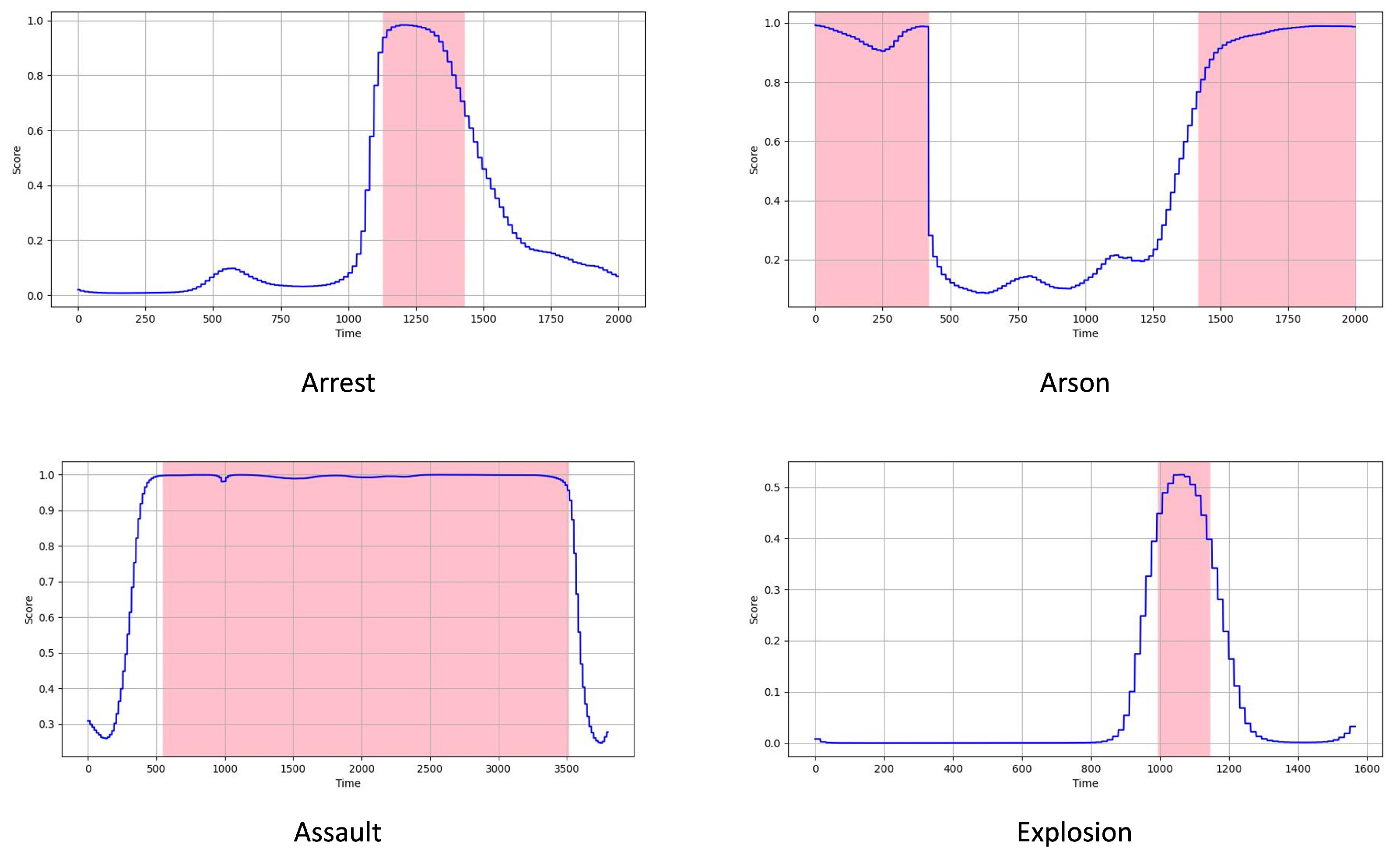
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Astrid, M.; Lee, S.I. Claws: Clustering assisted weakly supervised learning with normalcy suppression for anomalous event detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 358–376. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Wu, P.; Liu, J.; Shi, Y.; Sun, Y.; Shao, F.; Wu, Z.; Yang, Z. Not only look, but also listen: Learning multimodal violence detection under weak supervision. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXX 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 322–339. [Google Scholar]
- Wu, J.C.; Hsieh, H.Y.; Chen, D.J.; Fuh, C.S.; Liu, T.L. Self-supervised sparse representation for video anomaly detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–24 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 729–745. [Google Scholar]
- Zhou, Y.; Qu, Y.; Xu, X.; Shen, F.; Song, J.; Shen, H.T. Batchnorm-based weakly supervised video anomaly detection. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 13642–13654. [Google Scholar]
- AlMarri, S.; Zaheer, M.Z.; Nandakumar, K. A Multi-Head Approach with Shuffled Segments for Weakly-Supervised Video Anomaly Detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 132–142. [Google Scholar]
- Ju, C.; Han, T.; Zheng, K.; Zhang, Y.; Xie, W. Prompting visual-language models for efficient video understanding. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 105–124. [Google Scholar]
- Wan, B.; Fang, Y.; Xia, X.; Mei, J. Weakly supervised video anomaly detection via center-guided discriminative learning. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Zhong, J.X.; Li, N.; Kong, W.; Liu, S.; Li, T.H.; Li, G. Graph convolutional label noise cleaner: Train a plug-and-play action classifier for anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1237–1246. [Google Scholar]
- Tian, Y.; Pang, G.; Chen, Y.; Singh, R.; Verjans, J.W.; Carneiro, G. Weakly-supervised video anomaly detection with robust temporal feature magnitude learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4975–4986. [Google Scholar]
- Lv, H.; Yue, Z.; Sun, Q.; Luo, B.; Cui, Z.; Zhang, H. Unbiased multiple instance learning for weakly supervised video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 8022–8031. [Google Scholar]
- Fan, Y.; Yu, Y.; Lu, W.; Han, Y. Weakly-supervised video anomaly detection with snippet anomalous attention. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 5480–5492. [Google Scholar] [CrossRef]
- Wu, P.; Liu, X.; Liu, J. Weakly supervised audio-visual violence detection. IEEE Trans. Multimed. 2022, 25, 1674–1685. [Google Scholar] [CrossRef]
- Zhang, C.; Li, G.; Qi, Y.; Wang, S.; Qing, L.; Huang, Q.; Yang, M.H. Exploiting completeness and uncertainty of pseudo labels for weakly supervised video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16271–16280. [Google Scholar]
- Feng, J.C.; Hong, F.T.; Zheng, W.S. Mist: Multiple instance self-training framework for video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14009–14018. [Google Scholar]
- Schölkopf, B.; Williamson, R.C.; Smola, A.; Shawe-Taylor, J.; Platt, J. Support vector method for novelty detection. In Proceedings of the 13th International Conference on Neural Information Processing Systems, Denver, CO, USA, 29 November–4 December 1999. [Google Scholar]
- Hasan, M.; Choi, J.; Neumann, J.; Roy-Chowdhury, A.K.; Davis, L.S. Learning temporal regularity in video sequences. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 733–742. [Google Scholar]
- Wang, J.; Cherian, A. Gods: Generalized one-class discriminative subspaces for anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8201–8211. [Google Scholar]
- Zaheer, M.Z.; Mahmood, A.; Khan, M.H.; Segu, M.; Yu, F.; Lee, S.I. Generative cooperative learning for unsupervised video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 14744–14754. [Google Scholar]
- Zhang, J.; Qing, L.; Miao, J. Temporal convolutional network with complementary inner bag loss for weakly supervised anomaly detection. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 4030–4034. [Google Scholar]
- Wu, P.; Liu, J. Learning causal temporal relation and feature discrimination for anomaly detection. IEEE Trans. Image Process. 2021, 30, 3513–3527. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; Wang, P.; Yue, L.; Zhang, Y.; Jia, T. Anomaly detection in surveillance video based on bidirectional prediction. Image Vis. Comput. 2020, 98, 103915. [Google Scholar]
- Ganokratanaa, T.; Aramvith, S.; Sebe, N. Unsupervised anomaly detection and localization based on deep spatiotemporal translation network. IEEE Access 2020, 8, 50312–50329. [Google Scholar]
- Park, C.; Cho, M.; Lee, M.; Lee, S. FastAno: Fast anomaly detection via spatio-temporal patch transformation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 2249–2259. [Google Scholar]
- Dosovitskiy, A. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 8748–8763. [Google Scholar]
- Zhou, X.; Girdhar, R.; Joulin, A.; Krähenbühl, P.; Misra, I. Detecting twenty-thousand classes using image-level supervision. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 350–368. [Google Scholar]
- Xu, H.; Ghosh, G.; Huang, P.Y.; Okhonko, D.; Aghajanyan, A.; Metze, F.; Zettlemoyer, L.; Feichtenhofer, C. Videoclip: Contrastive pre-training for zero-shot video-text understanding. arXiv 2021, arXiv:2109.14084. [Google Scholar]
- Zanella, L.; Liberatori, B.; Menapace, W.; Poiesi, F.; Wang, Y.; Ricci, E. Delving into clip latent space for video anomaly recognition. Comput. Vis. Image Underst. 2024, 249, 104163. [Google Scholar]
- Wu, X.; He, R.; Sun, Z.; Tan, T. A light CNN for deep face representation with noisy labels. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2884–2896. [Google Scholar] [CrossRef]
- Zhou, K.; Yang, J.; Loy, C.C.; Liu, Z. Learning to prompt for vision-language models. Int. J. Comput. Vis. 2022, 130, 2337–2348. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Methods | VAD | VAR | AUC (%) | Ano-AUC (%) |
|---|---|---|---|---|---|
| Semi | SVM baseline | ✓ | × | 50.10 | 50.00 |
| OCSVM | ✓ | × | 63.20 | 51.06 | |
| Hasan et al. [19] | ✓ | × | 51.20 | 39.43 | |
| BODS | ✓ | × | 68.26 | N/A | |
| GODS | ✓ | × | 70.46 | N/A | |
| S3R | ✓ | × | 79.58 | N/A | |
| GCL | ✓ | × | 71.04 | N/A | |
| Weak | Sultani et al. [1] | ✓ | × | 84.14 | 63.29 |
| RTFM | ✓ | × | 85.66 | 63.86 | |
| AVVD | ✓ | × | 82.45 | 60.27 | |
| Ju et al. [9] | ✓ | × | 84.72 | 62.60 | |
| UMIL | ✓ | × | 86.75 | 68.68 | |
| Zhang et al. [16] | ✓ | × | 86.22 | N/A | |
| Fan et al. [14] | ✓ | × | 86.19 | N/A | |
| RelVid (Ours) | ✓ | ✓ | 87.71 | 69.29 |
| Category | Methods | VAD | VAR | AP (%) |
|---|---|---|---|---|
| Semi | SVM baseline | ✓ | × | 50.80 |
| Hasan et al. [19] | ✓ | × | 28.63 | |
| OCSVM | ✓ | × | 31.25 | |
| S3R | ✓ | × | 53.52 | |
| Weak | Sultani et al. [1] | ✓ | × | 75.18 |
| RTFM | ✓ | × | 77.81 | |
| AVVD | ✓ | × | 78.64 | |
| Ju et al. [9] | ✓ | × | 76.57 | |
| Fan et al. [14] | ✓ | × | 83.59 | |
| Zhang et al. [16] | ✓ | × | 78.74 | |
| RelVid (Ours) | ✓ | ✓ | 80.76 |
| Method | mAP@IOU (%) | |||||
|---|---|---|---|---|---|---|
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | AVG | |
| Random Baseline | 0.21 | 0.14 | 0.04 | 0.02 | 0.01 | 0.08 |
| Sultani et al. [1] | 5.73 | 4.41 | 2.69 | 1.93 | 1.44 | 3.24 |
| AVVD | 10.27 | 7.01 | 6.25 | 3.42 | 3.29 | 6.05 |
| RelVid (Ours) | 13.68 | 7.34 | 5.39 | 4.12 | 3.61 | 6.83 |
| Method | mAP@IOU (%) | |||||
|---|---|---|---|---|---|---|
| 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | AVG | |
| Random Baseline | 1.82 | 0.92 | 0.48 | 0.23 | 0.09 | 0.71 |
| Sultani et al. [1] | 22.72 | 15.57 | 9.98 | 6.20 | 3.78 | 11.65 |
| AVVD | 30.51 | 25.75 | 20.18 | 14.83 | 9.79 | 20.21 |
| RelVid | 42.30 | 34.66 | 28.04 | 20.94 | 15.70 | 28.33 |
| FA | Local Attention | Auxiliary Task 1 | Auxiliary Task 2 | AUC (%) |
|---|---|---|---|---|
| ✓ | 84.64 | |||
| ✓ | 86.37 | |||
| ✓ | ✓ | 85.73 | ||
| ✓ | ✓ | 86.86 | ||
| ✓ | ✓ | ✓ | 87.13 | |
| ✓ | ✓ | ✓ | 87.30 | |
| ✓ | ✓ | ✓ | ✓ | 87.71 |
| Source | UCF-Crimes | XD-Violence | XD-Violence | UCF-Crimes |
|---|---|---|---|---|
| Target | UCF-Crimes | XD-Violence | ||
| RTFM | 84.48 | 68.59 (18.80% ↓) | 76.62 | 37.30 (39.32% ↓) |
| Ours | 87.71 | 84.61 (3.1% ↓) | 80.76 | 62.87 (17.89% ↓) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Li, G.; Liu, J.; Xu, Z.; Chen, X.; Wei, J. RelVid: Relational Learning with Vision-Language Models for Weakly Video Anomaly Detection. Sensors 2025, 25, 2037. https://doi.org/10.3390/s25072037
Wang J, Li G, Liu J, Xu Z, Chen X, Wei J. RelVid: Relational Learning with Vision-Language Models for Weakly Video Anomaly Detection. Sensors. 2025; 25(7):2037. https://doi.org/10.3390/s25072037
Chicago/Turabian StyleWang, Jingxin, Guohan Li, Jiaqi Liu, Zhengyi Xu, Xinrong Chen, and Jianming Wei. 2025. "RelVid: Relational Learning with Vision-Language Models for Weakly Video Anomaly Detection" Sensors 25, no. 7: 2037. https://doi.org/10.3390/s25072037
APA StyleWang, J., Li, G., Liu, J., Xu, Z., Chen, X., & Wei, J. (2025). RelVid: Relational Learning with Vision-Language Models for Weakly Video Anomaly Detection. Sensors, 25(7), 2037. https://doi.org/10.3390/s25072037