


Towards AI-Powered Applications: The Development of a Personalised LLM for HRI and HCI



Abstract
1. Introduction
2. Related Work
3. AI Model Personalisation
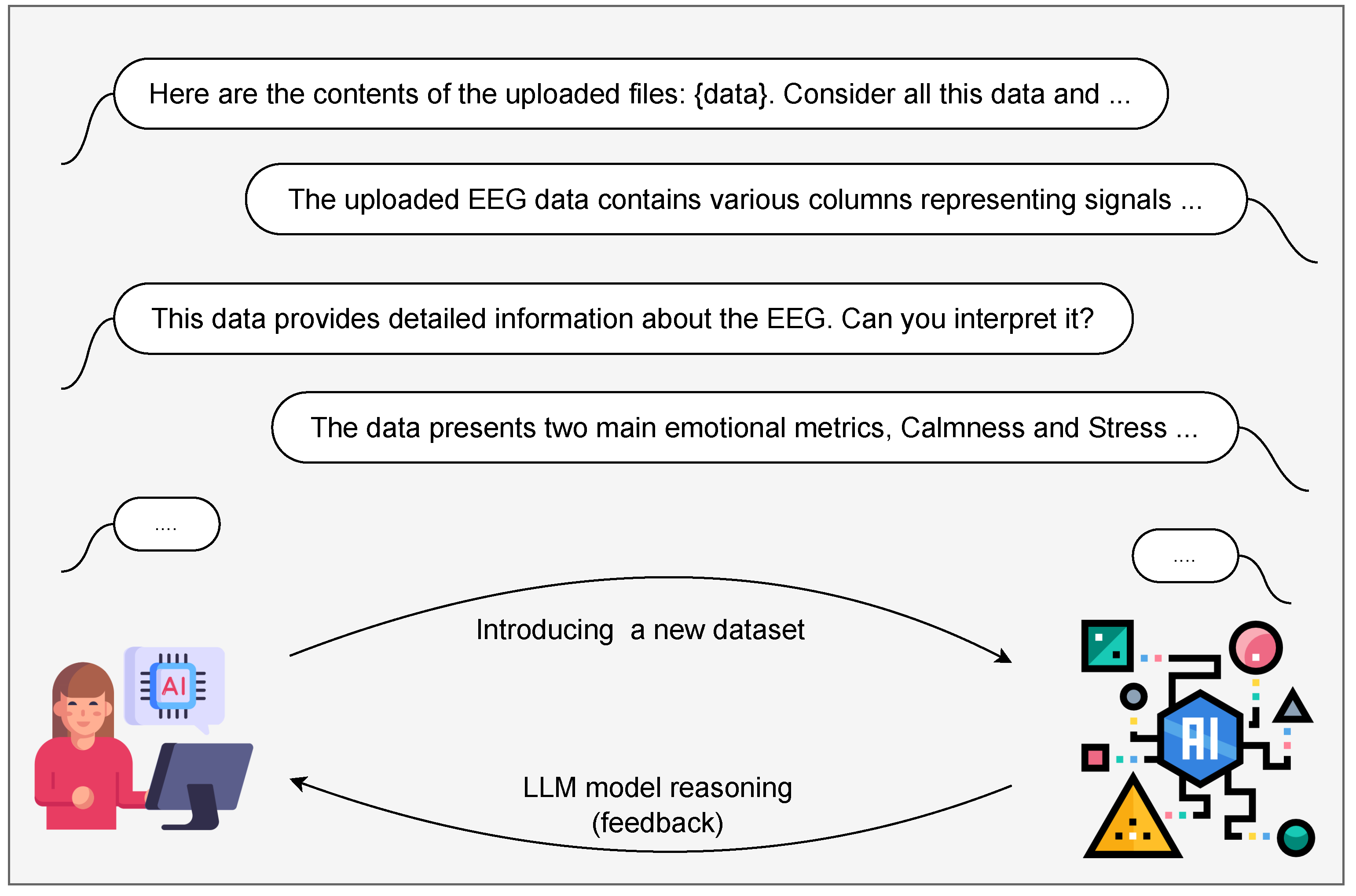
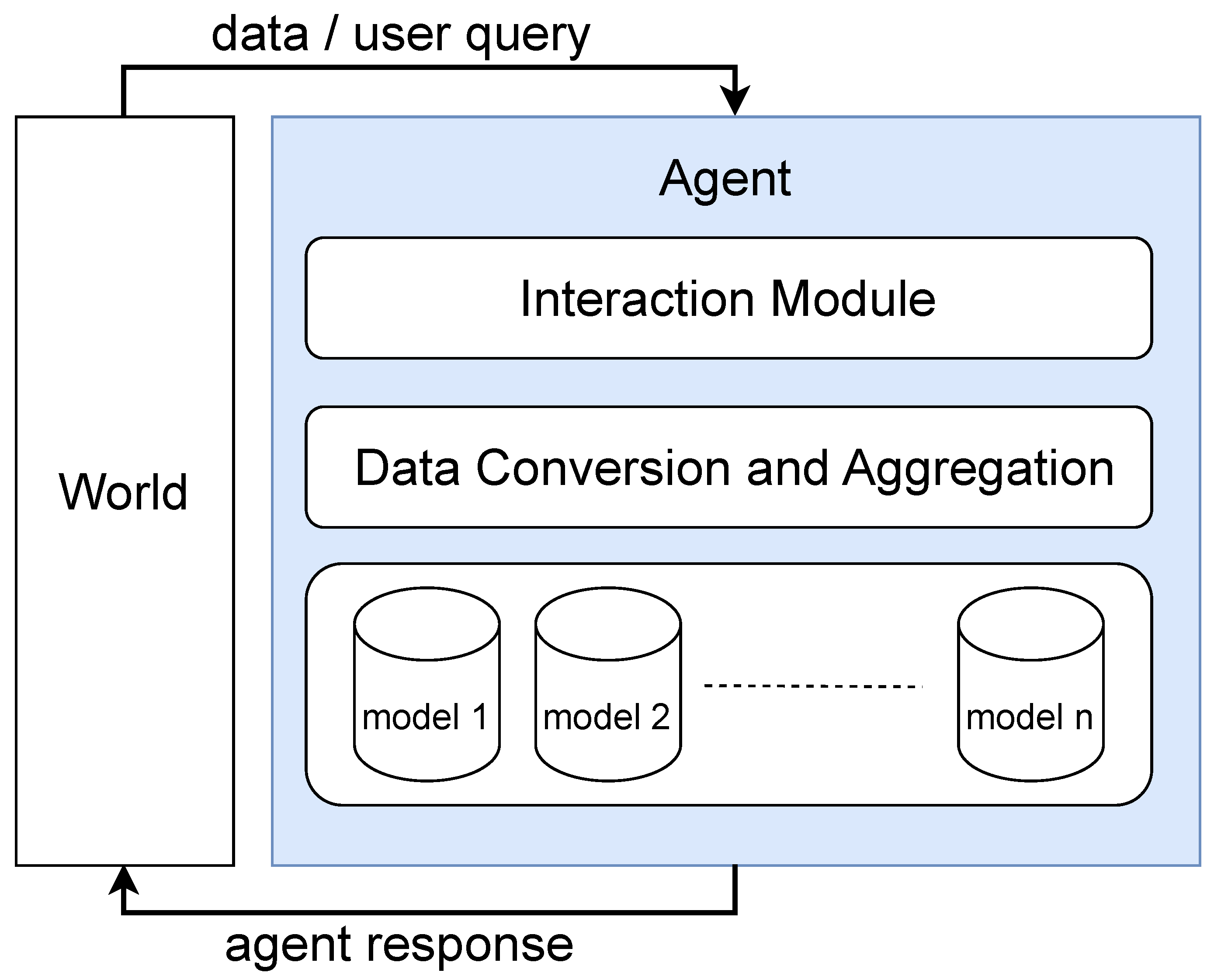
4. AI Agent Creation
4.1. Interaction Layer
4.2. Data Conversion and Aggregation Module
Ethical Challenges and Practical Integration of OpenAI’s Large Language Models
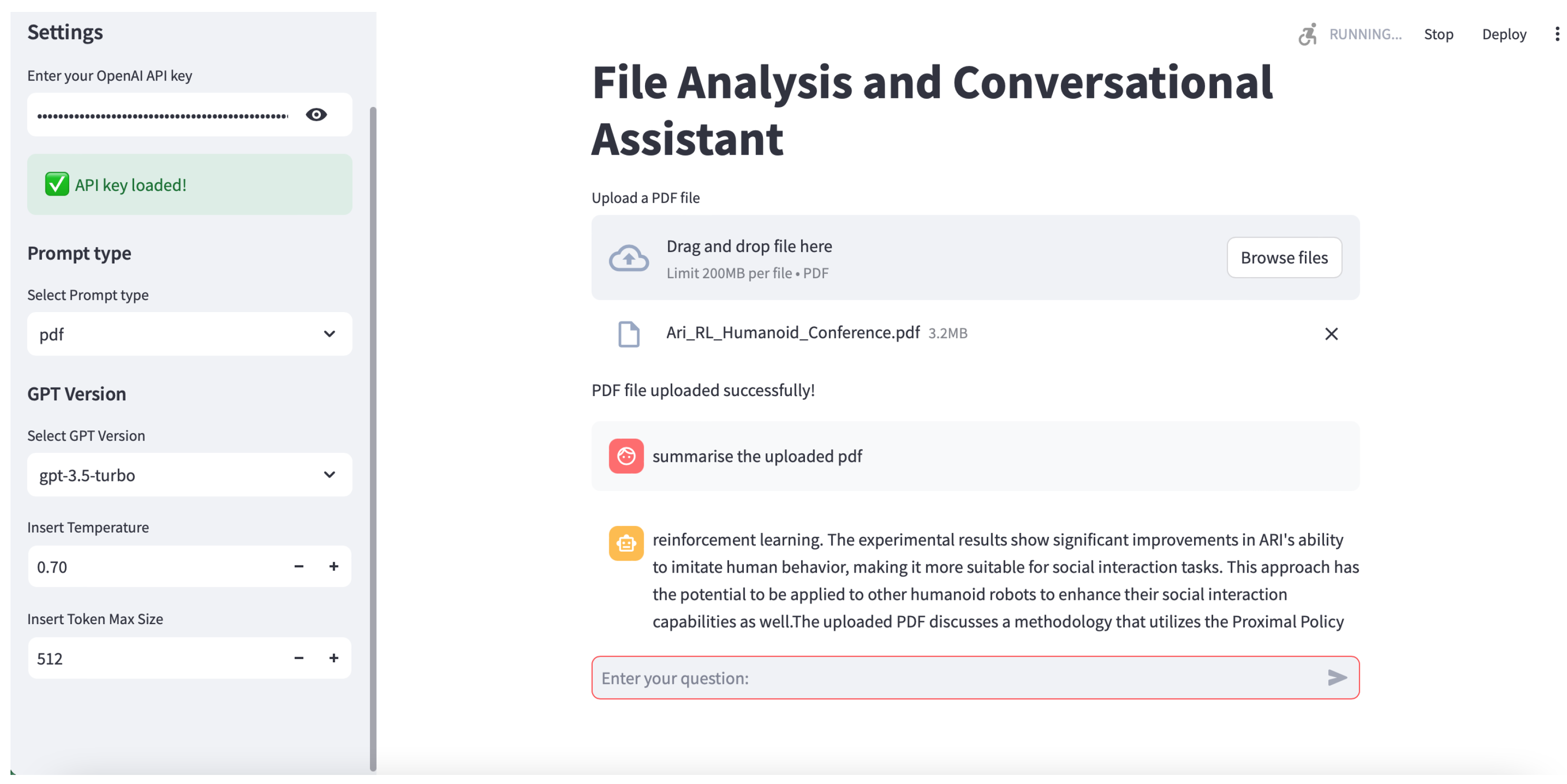
5. Proof of Concept for EEG Case Study
5.1. Electroencephalography Data
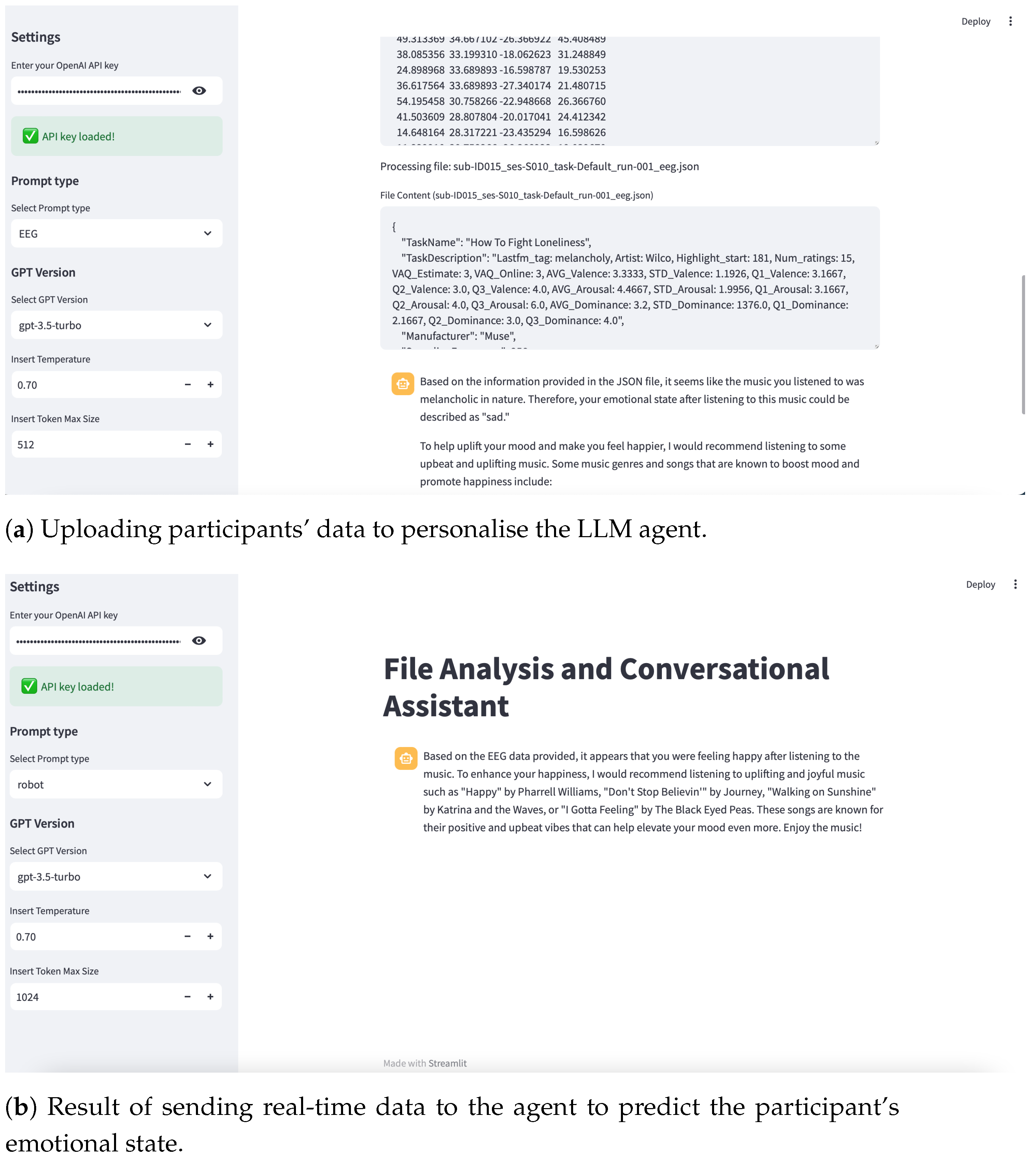
5.2. Personalisation of LLM Model with EEG Data
5.3. Real-Time EEG Signal Acquisition from Muse 2
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hewitt, M.; Ortmann, J.; Rei, W. Decision-based scenario clustering for decision-making under uncertainty. Ann. Oper. Res. 2022, 315, 747–771. [Google Scholar]
- Oliveira, F.R.D.S.; Neto, F.B.D.L. Method to Produce More Reasonable Candidate Solutions With Explanations in Intelligent Decision Support Systems. IEEE Access 2023, 11, 20861–20876. [Google Scholar]
- Nafei, A.; Huang, C.Y.; Chen, S.C.; Huo, K.Z.; Lin, Y.C.; Nasseri, H. Neutrosophic autocratic multi-attribute decision-making strategies for building material supplier selection. Buildings 2023, 13, 1373. [Google Scholar] [CrossRef]
- Zaraki, A.; Pieroni, M.; De Rossi, D.; Mazzei, D.; Garofalo, R.; Cominelli, L.; Dehkordi, M.B. Design and evaluation of a unique social perception system for human–robot interaction. IEEE Trans. Cogn. Dev. Syst. 2016, 9, 341–355. [Google Scholar]
- Samani, H.; Zaraki, A.; Davies, D.R.; Fernando, O.N.N. Robotic Cognitive Behavioural Therapy: rCBT. In Proceedings of the International Conference on Social Robotics, Singapore, 16–18 August 2024; pp. 133–142. [Google Scholar]
- Lee, M.K.; Kim, J.; Lizarazo, M. Human-AI Collaboration in Decision-Making: A Survey and Classification Framework. ACM Comput. Surv. 2021, 54, 1–36. [Google Scholar]
- Montori, V.M.; Hargraves, I.; McNaughton, C.D. Shared Decision Making and Improving Health Care: The Answer Is Not In. J. Am. Med. Assoc. 2017, 318, 617–618. [Google Scholar]
- Head, B.W.; Alford, J. Wicked Problems: Implications for Public Policy and Management. Adm. Soc. 2015, 47, 711–739. [Google Scholar]
- Wood, L.J.; Zaraki, A.; Robins, B.; Dautenhahn, K. Developing kaspar: A humanoid robot for children with autism. Int. J. Soc. Robot. 2021, 13, 491–508. [Google Scholar]
- Power, D.J. Data-Based Decision Making and Decision Support: An Introduction. J. Decis. Syst. 2016, 25, 1–13. [Google Scholar]
- Kahneman, D. Thinking, Fast and Slow; Farrar, Straus and Giroux: New York, NY, USA, 2011. [Google Scholar]
- Zaraki, A.; Mazzei, D.; Giuliani, M.; De Rossi, D. Designing and evaluating a social gaze-control system for a humanoid robot. IEEE Trans. -Hum.-Mach. Syst. 2014, 44, 157–168. [Google Scholar]
- Ghamati, K.; Zaraki, A.; Amirabdollahian, F. ARI humanoid robot imitates human gaze behaviour using reinforcement learning in real-world environments. In Proceedings of the 2024 IEEE-RAS 23rd International Conference on Humanoid Robots (Humanoids), Nancy, France, 22–24 November 2024; pp. 653–660. [Google Scholar] [CrossRef]
- Zaraki, A.; Khamassi, M.; Wood, L.J.; Lakatos, G.; Tzafestas, C.; Amirabdollahian, F.; Robins, B.; Dautenhahn, K. A novel reinforcement-based paradigm for children to teach the humanoid Kaspar robot. Int. J. Soc. Robot. 2020, 12, 709–720. [Google Scholar] [CrossRef]
- Nohooji, H.R.; Zaraki, A.; Voos, H. Actor–critic learning based PID control for robotic manipulators. Appl. Soft Comput. 2024, 151, 111153. [Google Scholar] [CrossRef]
- Bragg, J.; Habli, I. What is acceptably safe for reinforcement learning? In Proceedings of the Computer Safety, Reliability, and Security: SAFECOMP 2018 Workshops, ASSURE, DECSoS, SASSUR, STRIVE, and WAISE, Västerås, Sweden, 18 September 2018; Proceedings 37. Springer: Berlin/Heidelberg, Germany, 2018; pp. 418–430. [Google Scholar]
- Liu, R.; Geng, J.; Peterson, J.C.; Sucholutsky, I.; Griffiths, T.L. Large language models assume people are more rational than we really are. arXiv 2024, arXiv:2406.17055. [Google Scholar]
- Echterhoff, J.; Liu, Y.; Alessa, A.; McAuley, J.; He, Z. Cognitive bias in decision-making with llms. arXiv 2024, arXiv:2403.00811. [Google Scholar]
- Rannen-Triki, A.; Bornschein, J.; Pascanu, R.; Hutter, M.; György, A.; Galashov, A.; Teh, Y.W.; Titsias, M.K. Revisiting Dynamic Evaluation: Online Adaptation for Large Language Models. arXiv 2024, arXiv:2403.01518. [Google Scholar]
- Chen, J.; Liu, Z.; Huang, X.; Wu, C.; Liu, Q.; Jiang, G.; Pu, Y.; Lei, Y.; Chen, X.; Wang, X.; et al. When large language models meet personalization: Perspectives of challenges and opportunities. World Wide Web 2024, 27, 42. [Google Scholar] [CrossRef]
- Salemi, A.; Mysore, S.; Bendersky, M.; Zamani, H. Lamp: When large language models meet personalization. arXiv 2023, arXiv:2304.11406. [Google Scholar]
- Balavadhani Parthasarathy, V.; Zafar, A.; Khan, A.; Shahid, A. The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities. arXiv 2024, arXiv:2408.13296. [Google Scholar]
- Balaguer, A.; Benara, V.; de Freitas Cunha, R.L.; Estevão Filho, R.d.M.; Hendry, T.; Holstein, D.; Marsman, J.; Mecklenburg, N.; Malvar, S.; Nunes, L.O.; et al. RAG vs fine-tuning: Pipelines, tradeoffs, and a case study on agriculture. arXiv 2024, arXiv:2401.08406. [Google Scholar]
- Rao, A.; Khandelwal, A.; Tanmay, K.; Agarwal, U.; Choudhury, M. Ethical reasoning over moral alignment: A case and framework for in-context ethical policies in LLMs. arXiv 2023, arXiv:2310.07251. [Google Scholar]
- Zhang, S.; Ma, Y.; Fang, L.; Jia, H.; D’Alfonso, S.; Kostakos, V. Enabling On-Device LLMs Personalization with Smartphone Sensing. arXiv 2024, arXiv:2407.04418. [Google Scholar] [CrossRef]
- Yeh, K.C.; Chi, J.A.; Lian, D.C.; Hsieh, S.K. Evaluating interfaced llm bias. In Proceedings of the 35th Conference on Computational Linguistics and Speech Processing (ROCLING 2023), Taipei City, Taiwan, 20–21 October 2023; pp. 292–299. [Google Scholar]
- Xu, M.; Niyato, D.; Kang, J.; Xiong, Z.; Mao, S.; Han, Z.; Kim, D.I.; Letaief, K.B. When large language model agents meet 6G networks: Perception, grounding, and alignment. IEEE Wirel. Commun. 2024, 31, 63–71. [Google Scholar] [CrossRef]
- Pandya, K.; Holia, M. Automating Customer Service using LangChain: Building custom open-source GPT Chatbot for organizations. arXiv 2023, arXiv:2310.05421. [Google Scholar]
- Alfirević, N.; Praničević, D.G.; Mabić, M. Custom-Trained Large Language Models as Open Educational Resources: An Exploratory Research of a Business Management Educational Chatbot in Croatia and Bosnia and Herzegovina. Sustainability 2024, 16, 4929. [Google Scholar] [CrossRef]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar]
- Shi, H.; Xu, Z.; Wang, H.; Qin, W.; Wang, W.; Wang, Y.; Wang, Z.; Ebrahimi, S.; Wang, H. Continual learning of large language models: A comprehensive survey. arXiv 2024, arXiv:2404.16789. [Google Scholar]
- Dong, Y.R.; Hu, T.; Collier, N. Can LLM be a Personalized Judge? arXiv 2024, arXiv:2406.11657. [Google Scholar] [CrossRef]
- Zollo, T.P.; Siah, A.; Ye, N.; Li, A.; Namkoong, H. PersonalLLM: Tailoring LLMs to Individual Preferences. arXiv 2024, arXiv:2409.20296. [Google Scholar] [CrossRef]
- Li, C.; Zhang, M.; Mei, Q.; Wang, Y.; Hombaiah, S.A.; Liang, Y.; Bendersky, M. Teach LLMs to Personalize - An Approach inspired by Writing Education. arXiv 2023, arXiv:2308.07968. [Google Scholar] [CrossRef]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large language models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar]
- Felfernig, A.; Benatallah, B.; Motahari-Nezhad, H.R.; Leitner, G.; Reiterer, S. Recommendation and decision technologies for requirements engineering. AI Mag. 2019, 40, 68–77. [Google Scholar]
- Kobsa, A. Generic user modeling systems. User Model.-User-Adapt. Interact. 2007, 17, 421–432. [Google Scholar]
- Zhu, X.; Zhang, C.; Zhang, X. Adaptive AI: A novel framework for adaptive machine learning. IEEE Trans. Emerg. Top. Comput. Intell. 2021, 5, 125–137. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. Llama: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Chowdhery, A.; Narang, S.; Devlin, J.; Bosma, M.; Mishra, G.; Roberts, A.; Barham, P.; Chung, H.W.; Sutton, C.; Gehrmann, S.; et al. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res. 2023, 24, 1–113. [Google Scholar]
- Li, Y.; Wang, Q.; Gao, J. Personalizing dialogue systems via adaptive prompting. Trans. Assoc. Comput. Linguist. 2022, 10, 478–493. [Google Scholar]
- McCloskey, M.; Cohen, N.J. Catastrophic interference in connectionist networks: The sequential learning problem. Psychol. Learn. Motiv. 1989, 24, 109–165. [Google Scholar]
- Mundt, M.; Hong, Y.; Pliushch, I.; Ramesh, V. A wholistic view of continual learning with deep neural networks: Forgotten lessons and the bridge to active and open world learning. Neural Netw. 2023, 160, 306–336. [Google Scholar]
- Kirkpatrick, J.; Pascanu, R.; Rabinowitz, N.; Veness, J.; Desjardins, G.; Rusu, A.A.; Milan, K.; Quan, J.; Ramalho, T.; Grabska-Barwinska, A.; et al. Overcoming catastrophic forgetting in neural networks. Proc. Natl. Acad. Sci. USA 2017, 114, 3521–3526. [Google Scholar]
- Parisi, G.I.; Kemker, R.; Part, J.L.; Kanan, C.; Wermter, S. Continual lifelong learning with neural networks: A review. Neural Netw. 2019, 113, 54–71. [Google Scholar] [CrossRef]
- Qiu, J.; Ke, Z.; Liu, B. Continual Learning Using Only Large Language Model Prompting. In Proceedings of the 31st International Conference on Computational Linguistics, Abu Dhabi, United Arab Emirates, 19–24 January 2025; pp. 6014–6023. [Google Scholar]
- Belouadah, E.; Popescu, A. A comprehensive study of class incremental learning algorithms for visual tasks. Neural Netw. 2021, 135, 38–54. [Google Scholar] [CrossRef] [PubMed]
- Yin, B.; Xie, J.; Qin, Y.; Ding, Z.; Feng, Z.; Li, X.; Lin, W. Heterogeneous knowledge fusion: A novel approach for personalized recommendation via llm. In Proceedings of the 17th ACM Conference on Recommender Systems, New York, NY, USA, 18–22 September 2023; pp. 599–601. [Google Scholar]
- Kirk, H.R.; Vidgen, B.; Röttger, P.; Hale, S.A. Personalisation within bounds: A risk taxonomy and policy framework for the alignment of large language models with personalised feedback. arXiv 2023, arXiv:2303.05453. [Google Scholar]
- Liu, P.; Yuan, W.; Fu, J.; Jiang, Z.; Hayashi, H.; Neubig, G. Pre-train, prompt, and predict: A systematic survey of prompting methods in Natural Language Processing. ACM Comput. Surv. (CSUR) 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Xia, F.; Chi, E.; Le, Q.V.; Zhou, D. Chain of thought prompting elicits reasoning in large language models. Adv. Neural Inf. Process. Syst. 2022, 35, 24824–24837. [Google Scholar]
- De Lange, M.; Aljundi, R.; Masana, M.; Parisot, S.; Jia, X.; Leonardis, A.; Slabaugh, G.; Tuytelaars, T. A continual learning survey: Defying forgetting in classification tasks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 3366–3385. [Google Scholar]
- Amershi, S.; Cakmak, M.; Knox, W.B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120. [Google Scholar] [CrossRef]
- Khoshrounejad, F.; Ebrahimi, M.; Pan, S.; Abbasnejad, E.; Gao, J. Interactive machine learning: Principles, applications, and challenges. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3804–3819. [Google Scholar]
- Zhao, R.; Zhang, W.N.; Chen, Q.; Wang, T.; Liu, X. A survey on personalization and generalization in conversational AI. Artif. Intell. Rev. 2023, 56, 2017–2041. [Google Scholar]
- Wiesinger, J.; Marlow, P.; Vuskovic, V. *Agents*. Whitepaper. Available online: https://www.rojo.me/content/files/2025/01/Whitepaper-Agents---Google.pdf (accessed on 14 December 2024).
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- OpenAI. GPT-4 System Card. 2023. Available online: https://cdn.openai.com/gpt-4o-system-card.pdf (accessed on 21 December 2024).
- OpenAI. Content Moderation. 2023. Available online: https://openai.com/safety/ (accessed on 21 December 2024).
- OpenAI. Pricing and API Documentation. 2023. Available online: https://openai.com/api (accessed on 21 December 2024).
- OpenAI. OpenAI API Documentation; OpenAI: San Francisco, CA, USA, 2023. [Google Scholar]
- Solaiman, I.; Dennison, D. Ethical and social risks of harm from language models. arXiv 2021, arXiv:2102.02503. [Google Scholar]
- OpenAI. GPT Model Capabilities; OpenAI: San Francisco, CA, USA, 2023; Available online: https://platform.openai.com/docs/guides/gpt (accessed on 14 December 2024).
- Colafiglio, T.; Lombardi, A.; Sorino, P.; Brattico, E.; Lofù, D.; Danese, D.; Di Sciascio, E.; Di Noia, T.; Narducci, F. NeuroSense: A Novel EEG Dataset Utilizing Low-Cost, Sparse Electrode Devices for Emotion Exploration. IEEE Access 2024, 12, 159296–159315. [Google Scholar]
- Homan, R.W.; Herman, J.; Purdy, P. Cerebral location of international 10–20 system electrode placement. Electroencephalogr. Clin. Neurophysiol. 1987, 66, 376–382. [Google Scholar] [PubMed]
- Egger, M.; Ley, M.; Hanke, S. Emotion recognition from physiological signal analysis: A review. Electron. Notes Theor. Comput. Sci. 2019, 343, 35–55. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Author | Achievement |
|---|---|---|
| 2024 | Rannen-Triki et al. [19] | Proposes efficient online adaptation strategies to continually update model parameters in real time, mitigate distribution shifts, and maintain performance across evolving domains. |
| 2024 | Chen et al. [20] | Explores how LLMs enhance personalisation through interactive engagement, task expansion, tool integration, and addressing privacy challenges. |
| 2024 | Dong et al. [34] | Proposes a certainty-aware framework for predicting user preferences, achieving high accuracy and surpassing human performance. |
| 2024 | Zollo et al. [35] | Simulates user preferences via reward models, enabling ethical and scalable personalisation. |
| 2024 | Zhang et al. [25] | Combines on-device LLMs with sensing for private, real-time, and personalised services, addressing privacy risks. |
| 2023 | Rao et al. [24] | Proposes a framework for LLMs to reason ethically across diverse contexts, highlighting the need for value pluralism over fixed moral alignment. |
| 2023 | Li et al. [36] | Proposes a multistage framework enhancing LLM personalisation, achieving significant gains in domain-specific text generation. |
| Model | Maximum Tokens (Response + Input) |
|---|---|
| GPT-4 (8K) | 8192 |
| GPT-4 (32K) | 32,768 |
| GPT-3.5-turbo (4K) | 4096 |
| GPT-3.5-turbo (16K) | 16,384 |
| Davinci (text-davinci-003) | 4096 |
| DeepSeek (R1) | 32,768 |
| Curie | 2048 |
| Babbage | 2048 |
| Ada | 2048 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghamati, K.; Banitalebi Dehkordi, M.; Zaraki, A. Towards AI-Powered Applications: The Development of a Personalised LLM for HRI and HCI. Sensors 2025, 25, 2024. https://doi.org/10.3390/s25072024
Ghamati K, Banitalebi Dehkordi M, Zaraki A. Towards AI-Powered Applications: The Development of a Personalised LLM for HRI and HCI. Sensors. 2025; 25(7):2024. https://doi.org/10.3390/s25072024
Chicago/Turabian StyleGhamati, Khashayar, Maryam Banitalebi Dehkordi, and Abolfazl Zaraki. 2025. "Towards AI-Powered Applications: The Development of a Personalised LLM for HRI and HCI" Sensors 25, no. 7: 2024. https://doi.org/10.3390/s25072024
APA StyleGhamati, K., Banitalebi Dehkordi, M., & Zaraki, A. (2025). Towards AI-Powered Applications: The Development of a Personalised LLM for HRI and HCI. Sensors, 25(7), 2024. https://doi.org/10.3390/s25072024