1. Introduction
With the rapid increase in wireless devices and the gradual advancement of 6G networks, the demand for wireless services has surged explosively. This demand further exacerbates the scarcity of wireless spectrum resources. Under the traditional static spectrum allocation policy, licensed users possess exclusive rights to specific frequency bands. However, the utilization rate of these spectrum resources tends to be low, resulting in significant instances of idle or underutilized spectra. This inefficient spectrum usage stands in stark contrast to the dramatic increase in demand for wireless services, leading to a serious waste of spectrum resources. To address this challenge, cognitive radio technology has emerged as a viable solution. As a crucial component of 6G networks, cognitive radio networks are capable of dynamically identifying and utilizing spectrum resources [
1,
2]. Based on this, the opportunistic spectrum access (OSA) model is proposed, which enables other users to dynamically access and reuse spectrum resources when licensed users are not utilizing them, thereby enhancing spectrum utilization and mitigating waste [
3,
4,
5,
6]. In the OSA model, the user with exclusive rights to a particular frequency band is referred to as the primary user (PU), while the user that opportunistically accesses the spectrum is known as the secondary user (SU). The SU aims to access unoccupied licensed frequency bands to enable spectrum sharing. To prevent interference with PUs, SUs must periodically perform spectrum sensing to detect channel availability. The design of opportunistic spectrum access policies presents several challenges, including dynamic and unpredictable communication environments, interactions among multiple SUs, and the impact of communication requirements on access decisions [
7].
To improve spectrum utilization, many researchers have investigated the problem of opportunistic spectrum access [
8,
9]. The spectrum sensing issues related to opportunistic spectrum access were explored in [
10,
11,
12,
13,
14]. Specifically, spectrum detection methods based on Support Vector Machines (SVMs) were proposed in [
10,
11]. The K-means clustering method was employed in [
12] for spectrum sensing. Convolutional Neural Networks (CNNs) were utilized in [
13] to extract features from spectrum data, enhancing sensing accuracy. Additionally, the study in [
14] combined CNNs with long short-term memory (LSTM) networks to further improve sensing performance. However, spectrum access involved not only spectrum sensing but also the dynamic allocation and coordination of spectrum resources among multiple SUs, making it an inherently complex optimization problem that traditional neural networks were poorly equipped to address. Cooperative spectrum sharing between multiple PUs and SUs was modeled as a two-sided matching market in [
15], addressing the pairing problem between PUs and SUs to optimize the allocation of PU access time. A polynomial time-based many-to-one matching scheme was proposed to foster cooperation among SUs and enhance overall efficiency. However, the scheme relied on the assumption that collaborative communication was feasible between PUs and SUs. A queuing policy incorporating a retry mechanism was proposed in [
16], which aimed to improve spectrum access efficiency in cognitive radio networks (CRNs), thereby increasing system throughput and spectrum utilization. In the network scenario discussed in [
16], a central controller collected information from both PUs and SUs and made dynamic channel access decisions accordingly. The power control and spectrum access problem of SUs in uplink opportunistic CRNs was investigated in [
17], where a parameterized power control policy was proposed that allowed SUs to adaptively adjust their transmit power based on channel fading information and battery energy status feedback from the access point (AP), thereby maximizing the total uplink rate between SUs and AP. However, the study did not consider the mobility of the SUs. These methods usually rely on mathematical models and require predefined rules and parameters. However, spectrum access and channel conditions in future network environments will be more complex and dynamic, demanding more flexible and efficient solutions.
In recent years, deep reinforcement learning (DRL) algorithms have been introduced into OSA due to their capacity to adapt to unknown environments [
18,
19]. The study in [
20] addressed the issue of opportunistic access in multi-channel heterogeneous networks (HetNets) and proposed a novel multi-channel MAC protocol to optimize wireless channel access policies, thereby improving network throughput. The study employed a DRL technique, which combined a deep Q-network (DQN) with a gated recurrent unit (GRU). This combination allowed the GRU to effectively capture temporal features in multi-channel HetNets and supported efficient decision-making in dynamic environments. In [
21], a spectrum handoff algorithm based on DQN was designed. Additionally, migration learning was introduced to accelerate the learning process for newly joined SUs, reducing both the time and computational costs associated with initial exploration. The algorithm took into account the priority of SUs and assumed that each channel could only be assigned to one user at a time. Two deep recurrent Q-network (DRQN) architectures based on long short-term memory were proposed to address user conflicts and throughput loss in opportunistic spectrum access in [
22]. The collisions between users were minimized by exploiting the temporal correlation of SU transmissions. Simulation results demonstrated that the proposed DRQN performed well, offering a complexity–performance trade-off for scenarios with partial observations and multiple channels. However, the study did not take into account the changing channel and relative location of the users, whereas, in practice, these communication environments are dynamically changing. The work mode selection and continuous power allocation problem for cognitive nodes was addressed in [
23], where a method based on the deep deterministic policy gradient (DDPG) was proposed, and its effectiveness was verified through simulations. However, the method did not consider scenarios in which multiple nodes could access a channel, as it assumed that each channel allowed only one node to access it.
Furthermore, the interaction among multiple SUs is also a challenge. The objective of SUs is to opportunistically access an idle channel for data transmission. However, in a multi-user network, the spectrum access choices of SUs may lead to channel contention and interference, which can cause SUs to interact with each other in their behavior. Independently optimizing the policy of each SU may lead to system instability, and the observation information of a single SU is insufficient to fully reflect the current network state. On the other hand, the centralized training and execution approach increases the dimensionality of decision-making and reliance on global information, which is detrimental to the scalability and real-time performance of the network.
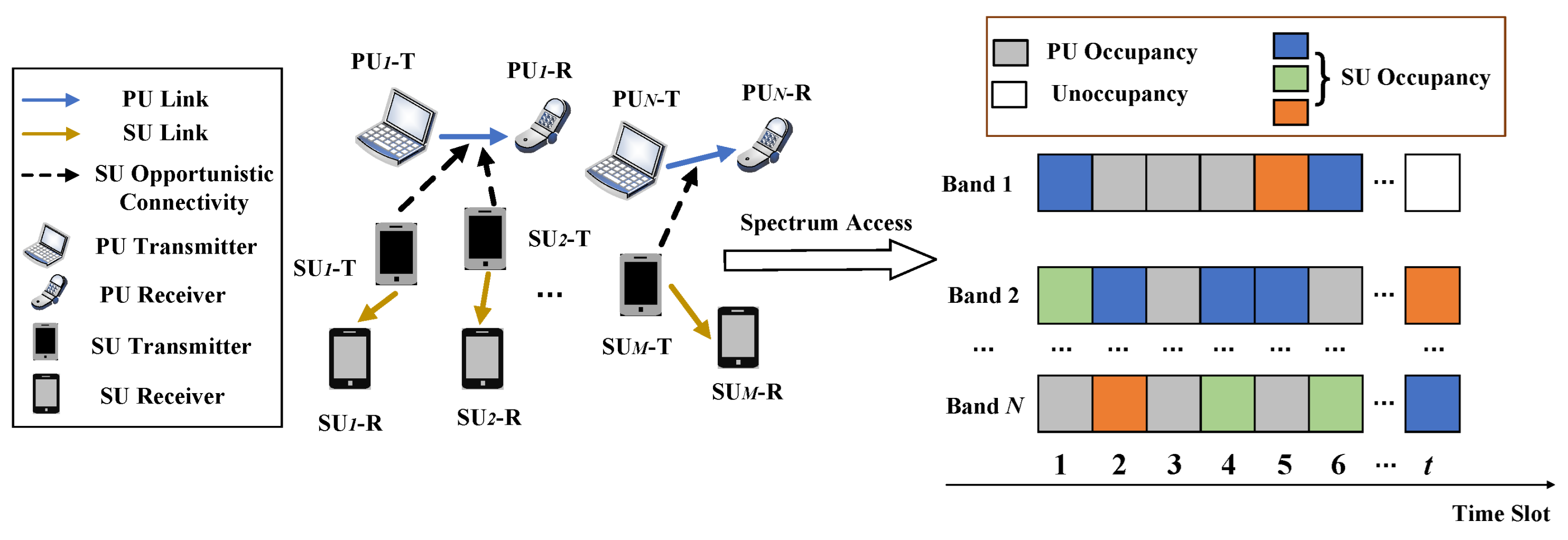
In summary, the system models in existing opportunistic spectrum access methods typically do not take into account changes in the relative positions of users, assume that each channel can be used by only one SU, or simplify the interaction between SUs. These premises may make it difficult for methods to cope with the various challenges in dynamic environments. To address these limitations, this paper proposes a novel OSA model. Specifically, the proposed model incorporates the relative positional changes of users, allows multiple SUs to share the same channel, and considers more complex interactions among SUs. Based on this, a multi-user opportunistic spectrum access method based on multi-head self-attention and multi-agent deep reinforcement learning (MSA-MADRL-OSA) is proposed. This method adopts a centralized training with decentralized execution framework and incorporates a multi-head self-attention (MSA) mechanism to optimize the spectrum access policy. The main contributions of this paper are as follows:
A new OSA model is established. In this model, each SU moves randomly within the designated area in each time slot and selects a channel for access based on spectrum sensing results. Since multiple SUs are allowed to utilize an idle channel, channel contention and interference may occur among SUs sharing the same channel. While ensuring that collisions with PUs are avoided, SUs strive to transmit as much data as possible to maximize the sum throughput of the SUs.
A joint channel selection and power control optimization framework based on multi-agent deep reinforcement learning (MADRL) is proposed. Each SU is treated as an agent, whose actions are joint channel selection and power control. A centralized training with decentralized execution framework is adopted, where global information is used to optimize the decision-making policy during the training phase. In the execution phase, each SU only relies on its observation information to make decisions, which improves the scalability and real-time performance of the system. Meanwhile, a multi-constraint dynamic proportional reward function is designed, which refines the constraints and dynamically adjusts the reward proportion to guide the agent in selecting more rational actions.
An MSA-MADRL-OSA method is proposed. In this method, an MSA mechanism is incorporated into the critic network, enhancing the ability of the critic network to estimate the action value by dynamically allocating attention weights to different SUs. This enables the SUs to efficiently learn and adapt to dynamic changes in the complex multi-agent environment and optimize the spectrum access policy.
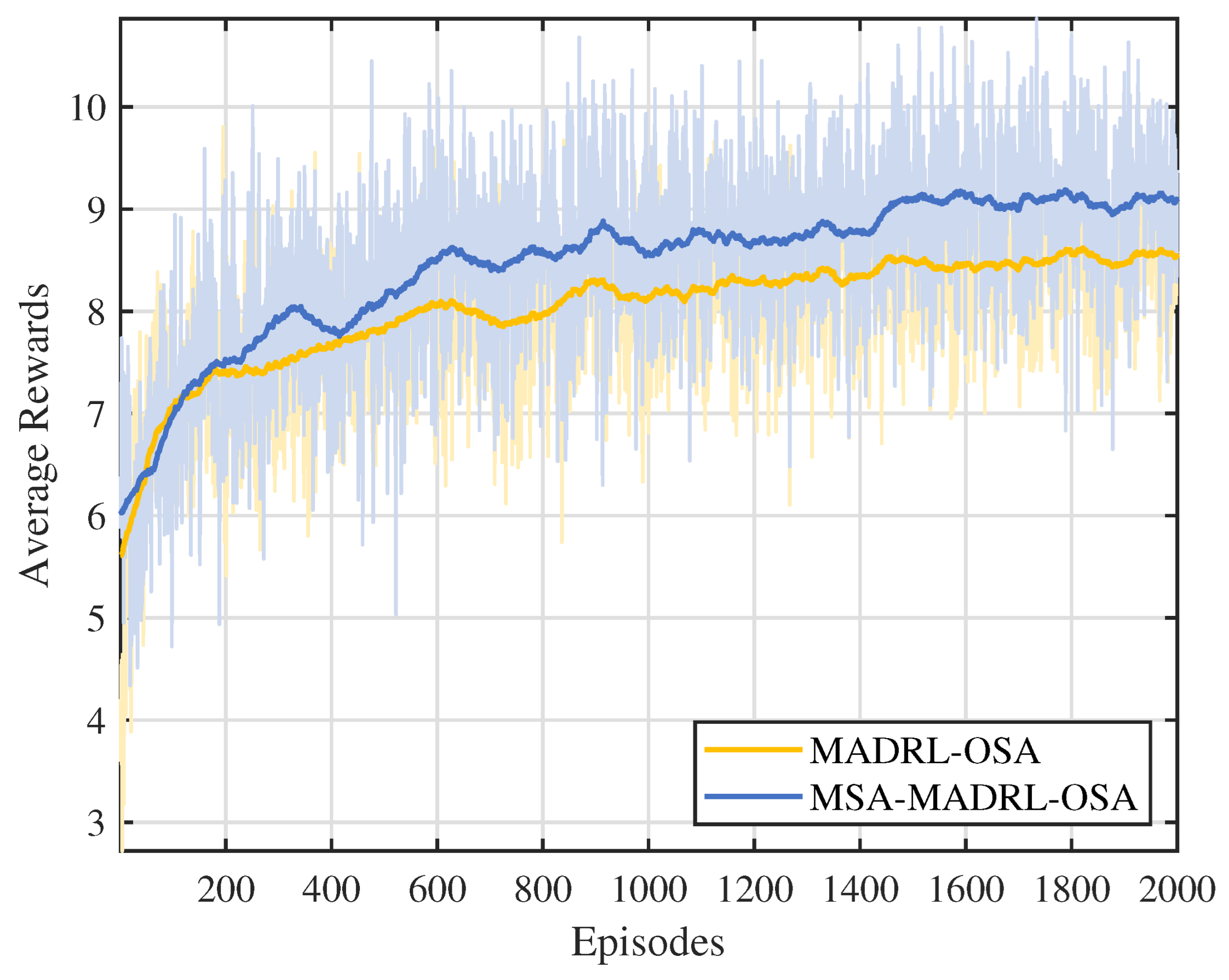
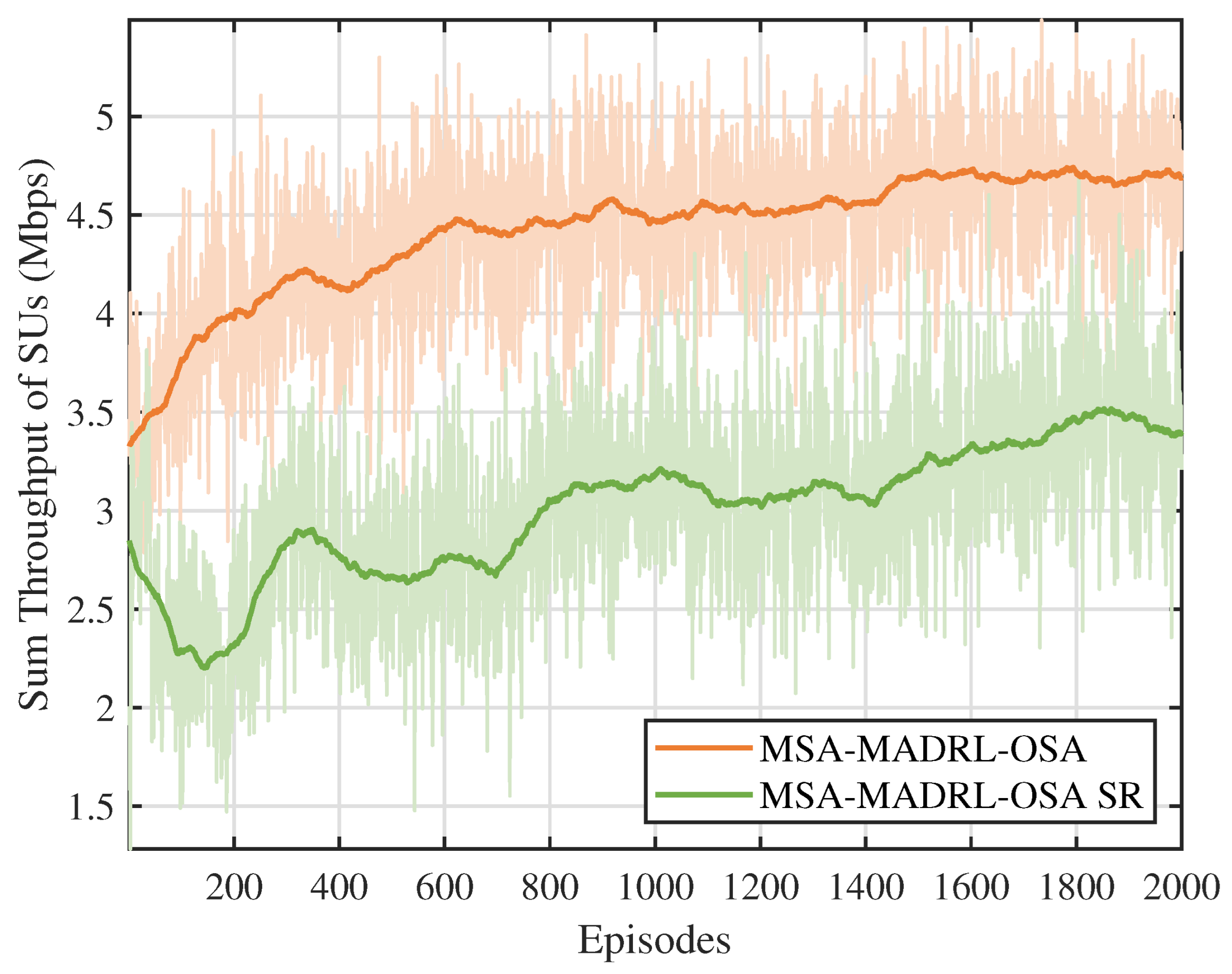
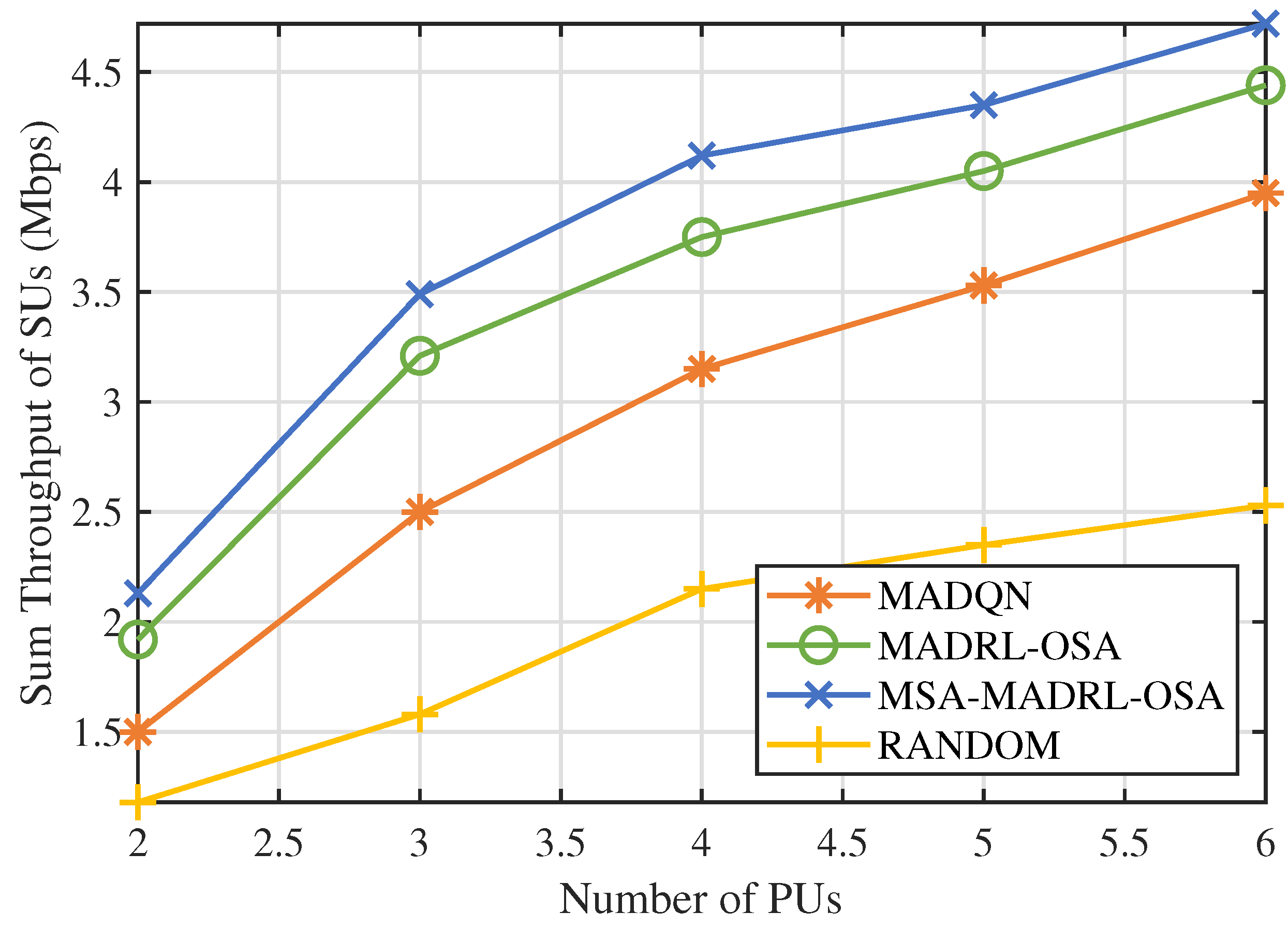
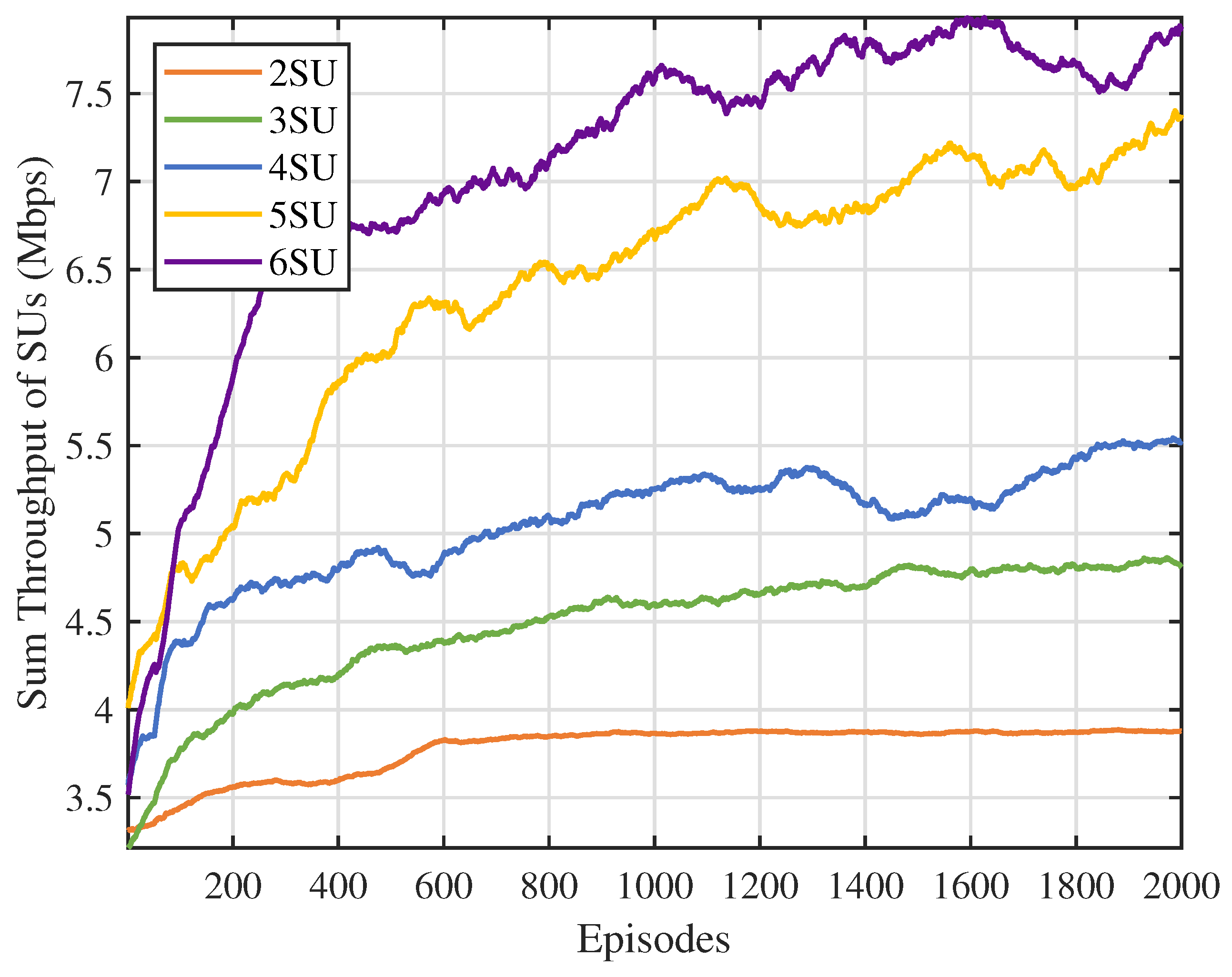
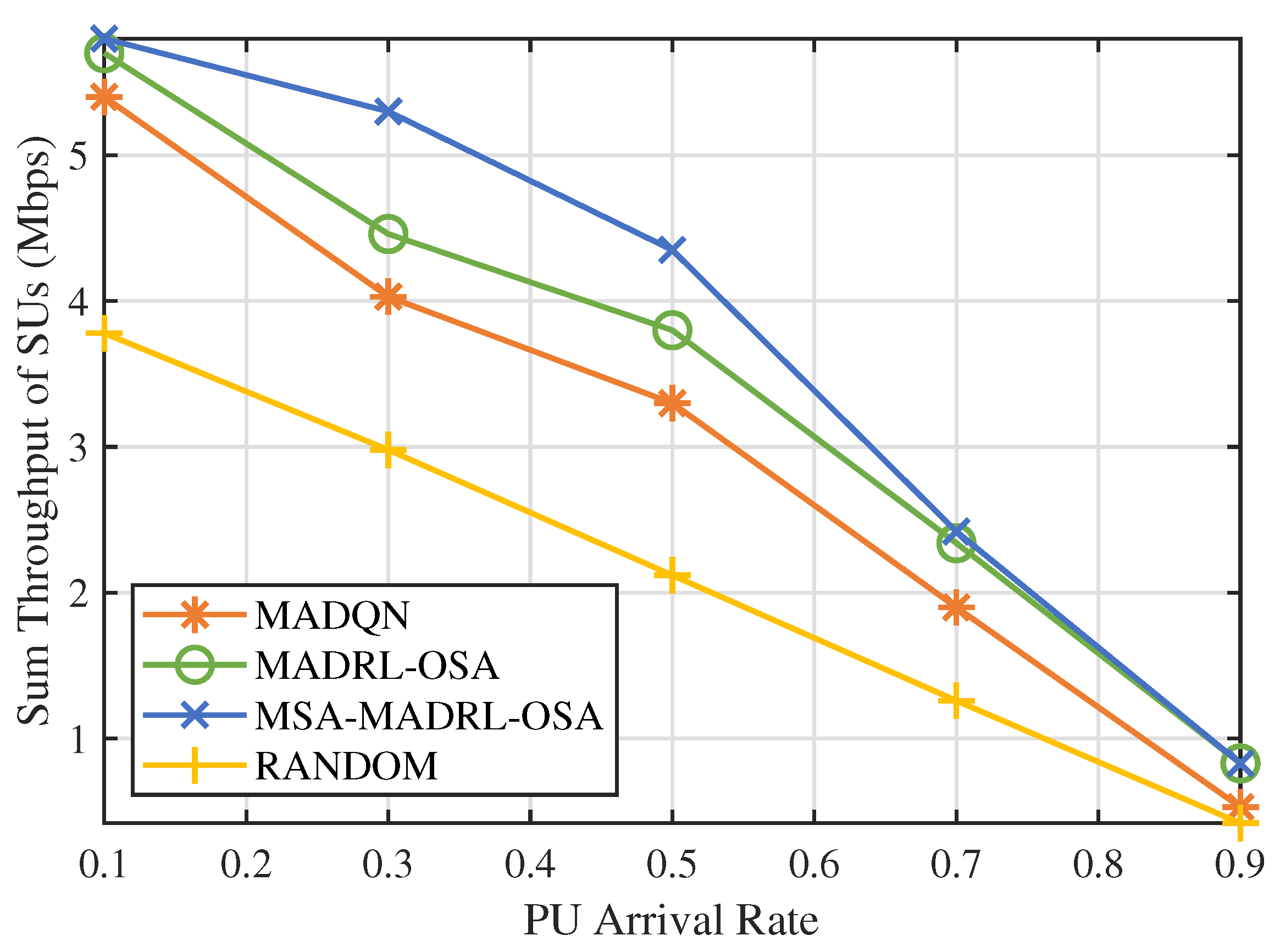
The performance of the proposed method is evaluated in terms of convergence, throughput, and dynamic performance. The simulation results indicate that the proposed method enables SUs to make rational spectrum access decisions, thereby improving the sum throughput of SUs.
3. Problem Statement
Based on the aforementioned system model, to reasonably utilize limited channels for transmission and enhance overall throughput, SUs must adhere to the relevant constraints during dynamic channel access to ensure that PUs maintain priority in spectrum usage. Therefore, the multi-user opportunistic spectrum access problem can be described as follows: given uncertainties in the initial state, system model, and environmental parameters, the goal is to maximize the sum throughput of the SUs by designing effective channel selection and power control policies for SUs, while satisfying constraints such as PU channel priority and minimum SNR for SUs.
In multi-user opportunistic spectrum access, each SU needs to select both a channel and a transmit power within each time slot, combining these actions into a joint action. If the channel access of the
is denoted as
, where
is the channel choice of the
and
is the transmit power of the
, then
where
represents that the SU does not select the channel to transmit data, and
and
denote the minimum and maximum transmit power of the
, respectively.
To maximize the sum throughput of SUs, this paper formulates the multi-user opportunistic spectrum access problem as an optimization problem with multiple constraints, expressed as
According to Equation (
8), the optimization objective is to maximize the sum throughput of all SUs over
T time slots. C1 constrains each SU to select at most one channel transmission each time slot. C2 constrains the transmit power of the SU. C3 constrains the minimum SNR,
, for a successful transmission by an SU. C4 constrains the channel to an unoccupied or occupied state.
Multiple SUs simultaneously access limited channel resources, and the interaction between their transmit power and channel selection adds complexity to the problem. Solving this optimization problem requires a priori information, such as the spectrum access mechanism of the SUs and accurate channel states, which are difficult to obtain in practice, leading to the fact that the traditional solution methods are no longer applicable. Therefore, in this paper, a multi-agent deep reinforcement learning (MADRL) method is used to solve this problem.
4. Multi-Agent Deep Reinforcement Learning-Based Multi-User Opportunistic Spectrum Access (MADRL-OSA) Method
In the OSA scenario, the objective of the SUs is to effectively utilize the unoccupied spectrum resources of the PUs for data transmission through dynamic spectrum sensing and decision-making. However, in a multi-user competitive environment, the decision-making behaviors of multiple SUs will affect each other, which may lead to system performance degradation or even instability if independent optimization strategies are used. Furthermore, in the framework of a partially observable Markov decision process, a single agent can only obtain local observation information, which complicates the accurate assessment of the overall state of the system. To address the aforementioned challenges, we propose an opportunistic spectrum access method for MADRL based on a centralized training with decentralized execution framework.
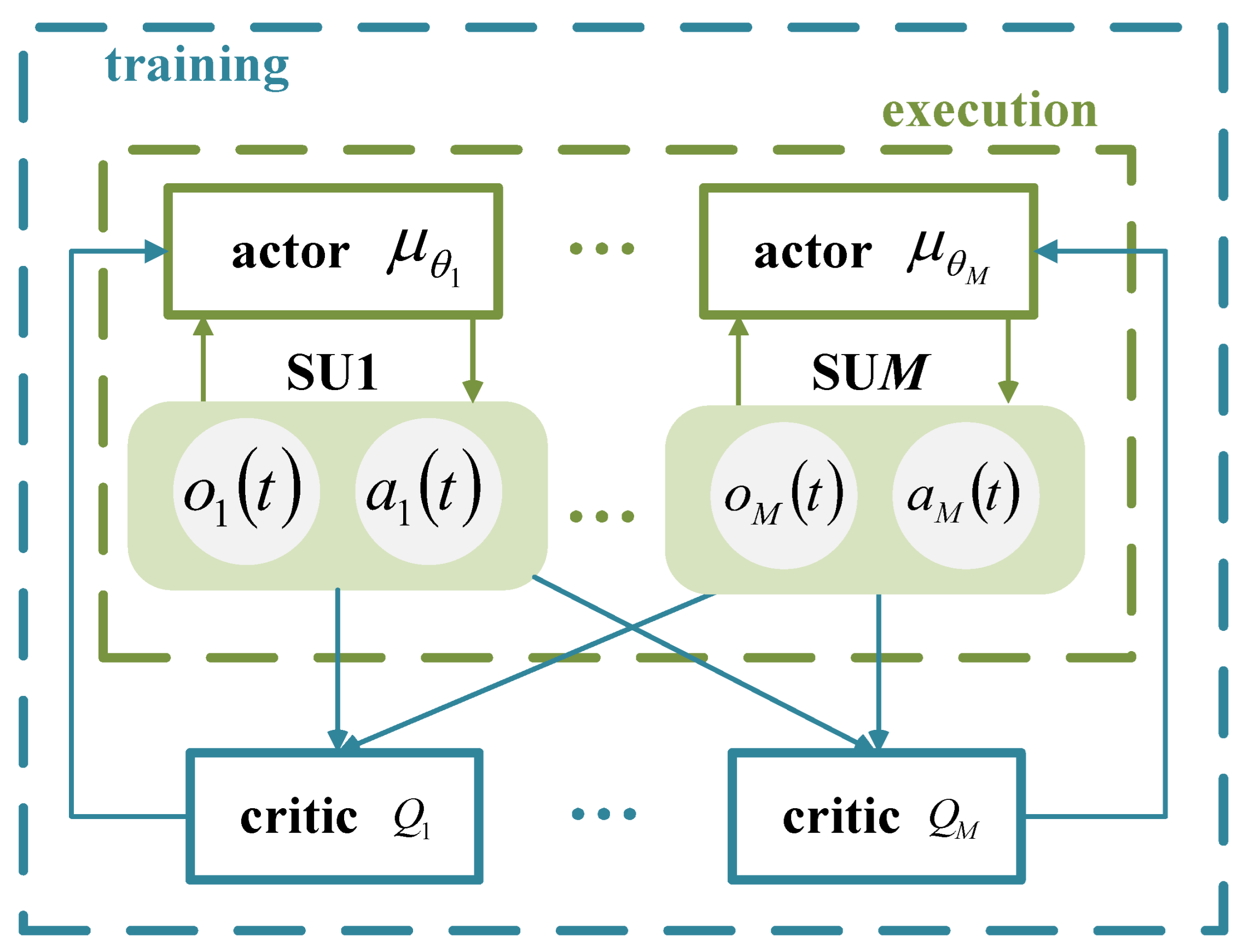
During the training phase, each agent is enabled to acquire global information, ensuring that the overall system performance is thoroughly taken into account during the decision-making process. In the execution phase, each agent relies only on local information for decentralized decision-making, which improves the scalability and real-time performance of the system. This method is particularly suitable for solving the complex interaction problem of SUs in channel selection and power control, which effectively captures and coordinates the interactions among users through shared global information, thus realizing multi-user decision-making in the same time slot. As shown in
Figure 2, the system adopts a training mechanism based on experience replay, where each SU interacts with the environment. First, it obtains the local observation information of the current time slot and inputs it into the deep neural network model to generate the corresponding channel selection and power control decisions. After executing the decision, the SU receives feedback from the environment. During the interaction in each time slot, the generated experience samples are stored in the experience replay buffer. Network parameters are updated by randomly sampling mini-batches of experiences from the experience replay buffer in the training phase. Through this continuous process of interactive learning and policy optimization, SUs can gradually adjust their decision-making strategies, ultimately achieving global optimization of system performance.
4.1. Overview of DRL
In reinforcement learning (RL), the agent observes the current state of the environment, takes an action according to policy , receives a corresponding reward , and transitions to the next state .
The classical RL algorithm Q-learning defines an action-value function, called the Q-function, with which the expected cumulative discounted reward of the agent is denoted as
. The variable
represents the discount factor, which measures the importance of future rewards. The goal of RL is to find the optimal policy
that maximizes the expected cumulative discounted reward. This can be described by the Bellman optimality equation as follows:
where
represents the maximum expected cumulative discounted reward obtained after taking the optimal action
in the next state
. The agent updates the Q-value using the following formula through its interaction with the environment:
where
is the learning rate.
The Q-learning algorithm performs well in scenarios with small state and action spaces. However, when faced with high-dimensional state or action spaces, its performance becomes constrained, making it challenging to effectively address more complex problems. To overcome this limitation, DRL combines the strengths of deep learning and RL by utilizing deep neural networks to approximate both the policy and the Q-function, thus enabling the effective handling of large-scale and complex problems. DQN utilizes deep neural networks to approximate the Q-value function, overcoming the limitations of classic Q-learning in high-dimensional spaces. DDPG separately approximates both the policy and the Q-value function, enabling it to more effectively handle problems with continuous action spaces.
4.2. State, Action and Reward for MADRL-OSA
In this paper, each SU is regarded as an agent. Each agent makes decisions based on its local observations and interacts with the environment through action selection. The joint actions of multiple agents collectively determine the state transition process and the acquisition of immediate rewards of the system. Agents maximize the global cumulative reward through strategic coordination and collaboration. Specifically, the process involves the state, action and reward function are defined as follows.
State: In a multi-agent environment, each agent can obtain an observation in each time slot, denoted as
. Specifically, the observation of each SU at time slot
t includes the following information: the channel state
sensed at time slot
t, which is used to evaluate the availability of each channel, the gain
from its own transmitter to receiver, which reflects the fading characteristics of the signal transmission, the position
at the transmitter and the position
at the receiver, which are utilized to assess the spatial distribution and potential interference among users. Then, the observation of
at time slot is defined as
The state of the multi-agent system includes the observations of all the agents, represented as
Action: The purpose of opportunistic spectrum access is to determine the channel selection and transmit power, then the action
of the
is defined as
where
is channel selection and
denotes transmit power. Therefore, the set of actions of all SUs is represented as
The design of this action considers the dynamics and complexities of real-world communication scenarios. By optimizing both channel selection and power control, the agent can maximize spectrum utilization and enhance its communication performance while avoiding interference with PUs.
Reward: The design of the reward function is crucial in the opportunistic spectrum access problem. It not only directly influences the learning efficiency and policy optimization direction of the agent but also requires a comprehensive consideration of various factors, including spectrum utilization, SU communication performance, and overall system performance. In this paper, two reward functions are designed and compared in the simulation section. First, a sparse reward function is designed. When any SU collides with a PU, the reward is a negative penalty term
. Conversely, when none of the SUs collide with the PU, the reward is the sum of the throughput of the SUs, denoted as
. This design focuses on factors such as collisions and throughput. It is simple and intuitive, effectively preventing interference from SUs to PUs. The sparse reward function expression is as follows:
Moreover, a multi-constraint dynamic proportional reward function is designed, which dynamically adjusts the reward proportion to accurately reflect the various constraints that SUs must satisfy during the access process. The reward function considers the interference between the SUs and the PUs and incorporates multidimensional factors such as channel competition and SNR constraints. This ensures that the agents receive more comprehensive and timely feedback signals during the training process, thereby guiding them to select more rational actions. The specific definition of the reward function is as follows:
where
and
are the reward and throughput of
in time slot
t, respectively.
is a flag indicating the collision status of the PU channel, where 1 means a collision between the SU and the PU, and 0 means no collision. When no collision occurs,
represents the number of SUs sharing the channel,
denotes the SNR of
,
is the minimum SNR threshold,
is the reward coefficient, and
is the penalty term for collision. This reward function is designed from a global perspective, coordinating the actions of multiple SUs to maximize the overall throughput of the SUs. To achieve this, a shared reward mechanism is adopted, where all SUs share the same global reward value,
, which is the sum of the individual reward values of all SUs. The multi-constraint dynamic proportional reward function is described in detail as follows:
- (1)
When an SU selects a channel that collides with the PU, a penalty term is applied, resulting in a negative reward. This design aims to inhibit interference from the SU to the PU, thereby protecting the communication quality of the PU.
- (2)
When multiple SUs select the same channel without colliding with the PU, and the SNR of all SUs meets the minimum requirement, the reward is . In this design, the more collisions between SUs, the lower the reward, which encourages the SUs to select the channel with less competition.
- (3)
When an SU does not collide with the PU or other SUs, and the SNR meets the required threshold, the reward is . At this time, the SU is given higher rewards, and can be used to adjust the magnitude of the reward.
- (4)
In other instances, such as when the SNR of SU fails to meet the minimum requirement or when the SU does not select a channel, the reward is 0.
4.3. Multi-Agent Centralized Training with Decentralized Execution Framework
Each SU operates within a network based on the Actor–Critic (AC) framework, where the actor network generates actions based on the observations of the SU. The critic network provides feedback by evaluating the value of the actions, assisting the actor network in optimizing its policy. The centralized training with decentralized execution framework for multiple SUs is shown in
Figure 3. During training, the input to the actor network is the observation of each SU, denoted as
, and the output is represented as
. To improve the exploration capabilities of the agent, noise
is added to the output of the actor network, and the action of
is represented as
, where
decays with an increase in the training episodes. The input to the critic network consists of the observations and actions of all SUs, represented as
, and the output is the action-value function
. During execution, the input to the actor network is the observation
of each SU, and the output is the action
of the SU, with no exploration noise applied at this phase.
Each SU interacts with the environment as an agent. As shown in
Figure 2, when
takes an action
based on observation
, receiving a reward
and the next observation
, these values are integrated into the experience entry
for that SU.
Subsequently, the experience entries of all SUs are merged into a multidimensional vector and stored in the experience replay buffer to update network parameters. To enhance the stability of training and reduce the overestimation of action values by the critic network, the target network is introduced, including the target actor network and target critic network. The structure of the target network is the same as that of the corresponding actor network and the critic network.
The input of the target actor network is denoted as , and the output is . The input of the target critic network is , and the output is .
When the network is updated, samples of mini-batch size are randomly selected from the experience replay buffer for training, denoting any set of samples as , .
The desired output of the critic network is
where
is the discount factor. The loss function is defined as
where
is the parameter of the critic network, and the optimizer is employed to update the parameter by minimizing the loss function according to the gradient descent method, as outlined below:
where
denotes the gradient of the loss function with respect to
and
is the learning rate of the critic network.
The policy gradient of the actor network is represented as
where
is the parameter of the actor network which is updated using the policy gradient:
where
is the learning rate of the actor network.
The parameters
and
corresponding to the target actor network and target critic network, respectively, are updated using the soft update method as follows:
where
is the soft update coefficient.
5. MSA-MADRL-OSA Method
In the system model presented in this paper, the decisions of SUs are interdependent. The optimal action selection for each SU depends not only on its observations and actions but also on the significant influence of other behaviors of SUs. For example, when one SU selects a particular channel or adjusts its transmit power, it may interfere with the available channels and communication quality for other SUs, thus impacting the overall system performance. MADRL-OSA method, through centralized training with decentralized execution, can address the interdependence issue between agents to some extent. However, its critic network typically employs a simple multilayer perceptron (MLP) to process the observations and actions of all agents, which may struggle to effectively capture the complex dependencies between agents, especially when the number of agents is large or the environment is highly dynamic. Furthermore, the MLP cannot adaptively focus on information that is more important to the decision-making of the current agent, potentially leading to redundant or inefficient learning processes.
To address these limitations, we introduce a multi-head self-attention mechanism in the critic network of the MADRL-OSA method and propose the MSA-MADRL-OSA method. The MSA mechanism computes the similarities between SUs and dynamically assigns attention weights, allowing the network to capture the dynamic behaviors and intricate interactions of other SUs more effectively. This enables the SU to identify which other SUs have a greater impact on its current channel selection and transmit power, thereby improving the ability of the network to estimate action values.
5.1. Multi-Head Self-Attention
The attention mechanism is a computational model miming the human visual or cognitive process of selectively focusing on important information. It dynamically assigns weights to highlight key parts of the input data, thus enhancing the ability of the model to handle complex data. Common types of attention mechanisms include self-attention, channel attention, and spatial attention, each tailored for different tasks. Among them, MSA is particularly effective in capturing internal dependencies within sequences. By performing parallel computations with multiple attention heads, MSA extracts information from different subspaces, allowing it to more comprehensively capture the multidimensional interactions among multiple agents [
28].
The core concept of the self-attention mechanism is to dynamically assign attention weights by calculating the relationships between the query, key, and value. Specifically, the query represents the target that requires attention, the key represents the features of other elements, and the value represents the actual information of those elements. Attention weights are typically computed using scaled dot-product attention, as illustrated in
Figure 4. Given an input sequence
, the query matrix
, key matrix
, and value matrix
are generated through linear transformations, where
,
, and
are earnable weight matrices. The dot product of the query and key matrices,
, is then computed and normalized by a scaling factor of
(where
is the dimension of the key vector), yielding the attention scores. Finally, the attention scores are passed through a softmax function to produce the attention weight matrix.
This matrix represents the importance of each position in the sequence to the other positions. Finally, the attention weights are multiplied with the value matrix V to obtain the output of the self-attention mechanism, which incorporates the contextual information of all the positions in the sequence and serves as an input for subsequent processing.
The multi-head attention mechanism enhances the expressive power of the model by performing parallel calculations with multiple attention heads. Specifically, the Q, K, and V of the input sequence are each projected into low-dimensional spaces via
h sets of distinct learnable linear projections, resulting in representations of dimensions
,
, and
. After projection, each set of Q, K, and V undergoes independent attention function calculations, generating outputs of dimension
. These outputs are then concatenated and mapped back into the original
dimensional space using a learnable linear weight matrix
, yielding the final multi-head attention output. The computation formula for multi-head attention is as follows:
where the calculation for each attention head is
Here, , and are the projection matrices for the i-th attention head, and is the output projection matrix.
5.2. Multi-Head Self-Attention for Critic
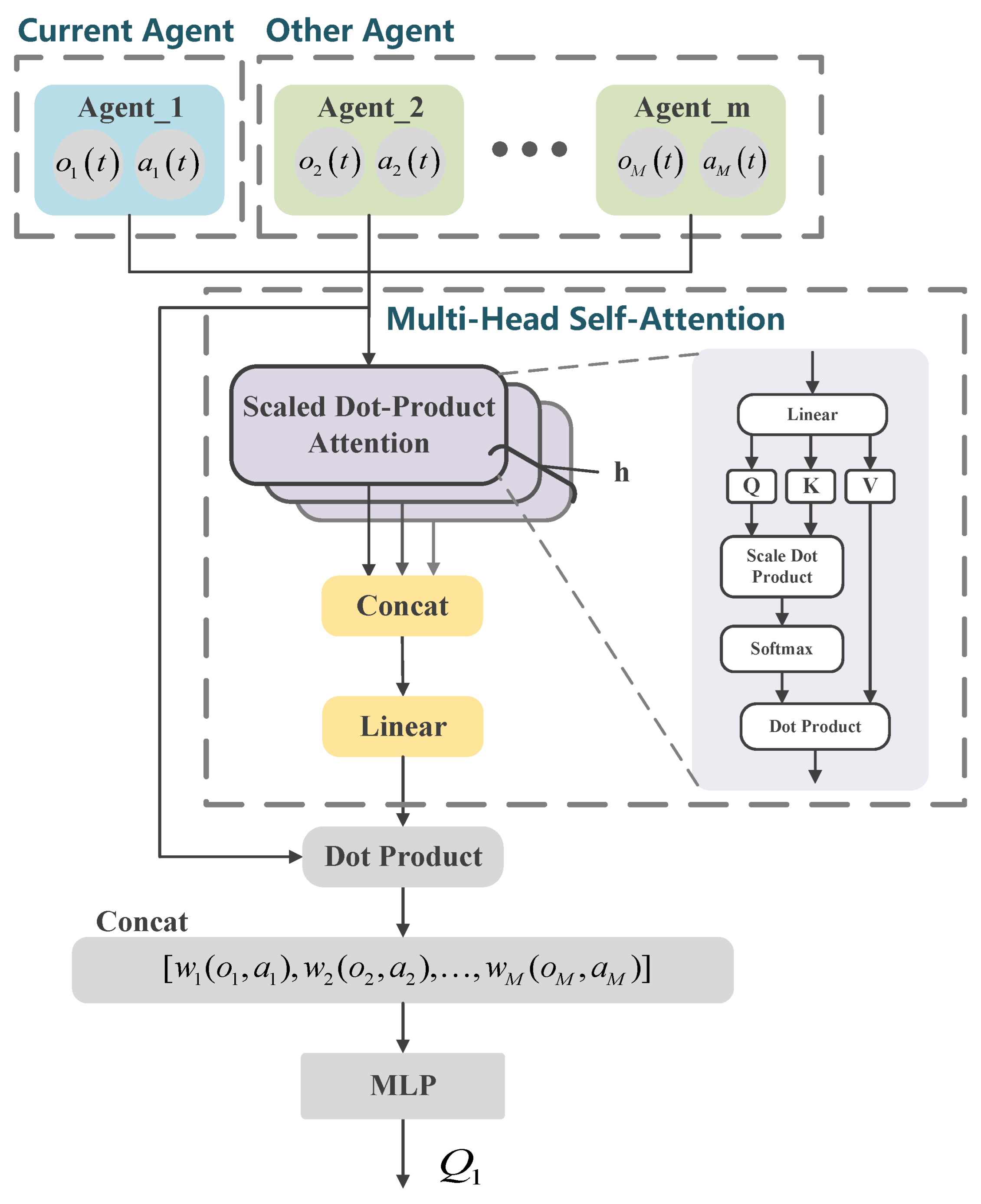
In the MADRL-OSA network described in
Section 4, each agent has an independent critic network. The critic network evaluates the action value of the actions of the current agent in a given state, providing gradient information to optimize the policy of the actor network. To more accurately model the complex interactions among multiple agents, the critic network introduces an MSA mechanism to explicitly capture these interactions, enabling a more precise understanding of how other agents influence the decision-making of the current agent. As shown in
Figure 4, the MSA–critic network takes the observations
and actions
of all agents as input and passes them through the MSA layer. The self-attention mechanism computes attention weights
between the current agent and other agents, quantifying the degree of importance of each other agent on the current agent. These weights are then used to perform a weighted aggregation of the observations and actions of other agents, which are concatenated to form the context information for the current agent.
Next, the context information
is fed into a multilayer perceptron (MLP), where it undergoes several non-linear transformations to yield the action-value estimate
for the current agent. The parameter update rule for the critic network follows the MADRL-OSA algorithm outlined in
Section 4, as shown in Equations (
21) and (
22).
Based on the description of the MSA-MADRL-OSA method above, Algorithm 1 summarizes its implementation process.
| Algorithm 1 MSA-MADRL-OSA algorithm. |
- 1
Initialize neural networks for all agents and experience replay buffer. - 2
for episode = 1 to maximum episodes do - 3
Initialize state . - 4
for time-slot do - 5
Each selects an action . - 6
Execute action, receive reward , and observe next state . - 7
Store for each in experience replay buffer. - 8
Update state: . - 9
Sample a random mini-batch of I samples from experience replay buffer. - 10
for = 1 to M do - 11
Update MSA-critic by minimizing the loss: , . - 12
Update actor networks using the policy gradient: , . - 13
Update target network parameters: , . - 14
end for - 15
end for - 16
end for
|
5.3. Computational Complexity
The computational complexity of the proposed MSA-MADRL-OSA algorithm primarily resides in the actor and critic networks, especially during the training phase. The actor network uses an MLP architecture, while the critic network combines MSA and MLP components. For the actor network, the computational complexity for a single forward pass is denoted as , where represents the input dimension (i.e., state dimension), and refers to the number of neurons in the l-th layer. The computational complexity of the MSA in the MSA–critic network is primarily made up of the following components: First, the input state and action information (with dimensions ) is linearly projected to generate the query, key, and value, which incurs a complexity of , where represents the number of agents and is the action dimension. Next, the complexity for computing the attention scores and weighted sum is , as it requires calculating the dot product of the query and key for each agent, and then applying the attention weights to the value. Finally, the concatenated outputs from the multi-head attention are mapped back to the original space through a linear projection, which has a complexity of . Therefore, the total complexity for the multi-head self-attention mechanism is . The MLP portion has a complexity of for a single forward pass. As a result, the overall computational complexity for one pass through the MSA–critic network is .
At the execution phase, the MSA-MADRL-OSA algorithm relies solely on the actor network to generate actions. The forward propagation complexity for each inference is denoted as , and its comparatively low overhead ensures efficient real-time decision-making. The proposed MSA-MADRL-OSA framework effectively balances computational complexity between the training and execution phases. By leveraging the parallel computing capabilities of GPUs, matrix operations are accelerated, significantly improving overall computational efficiency, thus enabling the framework to meet the stringent real-time requirements of multi-agent environments.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}