1. Introduction
Poultry meat and eggs are playing an increasingly important role in human dietary structure [
1]. Among them, chickens constitute a significant portion of poultry consumption. In broiler production, male chicks are preferred due to their higher feed conversion efficiency and faster growth rates. In contrast, in layer production, female chicks are favored to maximize egg yield. As a result, more than 7 billion male chicks worldwide are culled annually via carbon dioxide suffocation or immersion [
2,
3]. Generally, female chicks reach sexual maturity earlier, produce more eggs, and consume less feed, while male chicks can be sold as premium poultry upon reaching maturity. Performing sex identification on day-old chicks enables precise management based on sex differences, which not only improves farming efficiency and economic benefits but also mitigates ethical concerns. Therefore, developing a rapid and non-invasive sex identification method for day-old chicks is an urgent necessity with significant practical implications.
Traditional chick sex identification methods primarily include vent sexing and molecular biology techniques. Vent sexing requires a high level of expertise and causes stress and potential injury to the chicks. Additionally, it is labor-intensive and subject to human error due to the operator’s subjective judgment [
4,
5,
6,
7]. Some researchers have applied well-established computer vision algorithms to chick sex identification by leveraging vent sexing experience to construct deep learning-based intelligent classification models [
8,
9,
10]. However, these methods still rely on manually obtaining images through vent sexing and have yet to achieve full automation. Molecular-level techniques, such as DNA-based assays and PCR, provide high accuracy but are complex and time-consuming [
11]. Otsuka M et al. utilized an endoscopic probe to observe chick gonads for sex determination, but this approach is invasive, time-consuming, and poses a risk of injury to the chicks [
12]. Other studies have analyzed the acoustic features of chick vocalizations to determine sex [
13,
14,
15], but this method is highly susceptible to environmental noise, requires independent data collection, and is challenging to implement in automated production settings. These conventional methods suffer from drawbacks such as potential harm to the chicks, inefficiency, and unsuitability for rapid and non-invasive detection.
With advancements in poultry breeding technology, sex identification based on the wing feather growth rate, a significantly sex-linked trait in chicks, has gained widespread adoption both domestically and internationally. This method identifies sex based on feather characteristics that differ between male and female chicks. Researchers have explored image-based approaches to replace traditional vent sexing, reducing chick stress and significantly lowering labor costs [
16]. Latina M. A. et al. developed an image processing and support vector machine-based system for sex identification via wing feather growth rate, achieving an accuracy of 89% for male chicks and 90% for female chicks [
17]. However, this method still requires manual positioning of the primary and covert wing feathers in front of the camera, introducing operational complexity and reliance on human intervention. Additionally, both two-stage and one-stage object detection algorithms, known for their balance between accuracy and speed, have demonstrated promising applications in poultry posture recognition and behavior analysis [
18,
19,
20,
21,
22,
23,
24,
25], providing a reference for wing feather growth rate-based sex identification of day-old chicks.
To address the issues of low efficiency, reliance on manual operation, and potential harm in existing chick sex identification methods, this study proposes a novel approach for the rapid and non-invasive identification of day-old chick sex based on wing feather growth rate. By integrating an improved lightweight neural network model, this method aims to enhance detection efficiency, reduce dependency on manual intervention, and minimize chick stress. The proposed approach offers a new avenue for precision management in poultry farming.
The main contributions of this study are as follows:
(1) A dedicated dataset for day-old chick sex identification was created, encompassing challenging scenarios such as mixed feather colors, indistinct feather characteristics due to similar hues, occlusion by fine down feathers, incomplete wing extension, and blurred features. This dataset provides a diverse and challenging testbed for algorithm optimization, facilitating more robust and generalized model performance.
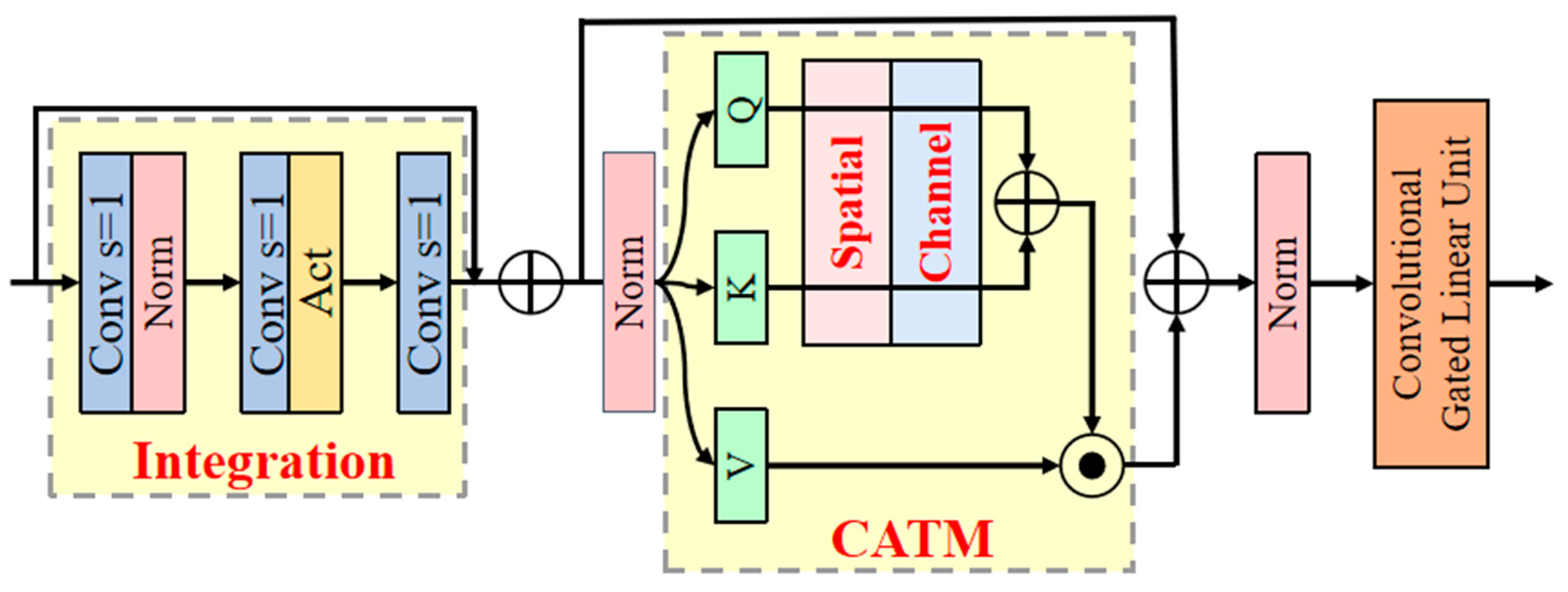
(2) This study proposes three improvements to address the high computational complexity, insufficient multi-scale feature fusion, and large parameter volume of existing models. First, a StarNet lightweight backbone network is employed, which integrates spatial features through star operations. This approach increases the feature dimension without additional computational overhead, significantly reducing model complexity and parameter count, while enhancing feature extraction efficiency in complex scenes. Second, an Additive CGLU module is designed to improve the C2f structure. The additive similarity function and gating mechanism enhance multi-scale feature fusion capability, strengthening detail capture and model robustness, while maintaining the advantage of lightweight computation. Lastly, a GN Head is constructed, which reinforces feature correlation through group normalization and shared convolutional layers. This reduces the parameter volume while improving generalization ability, achieving a simultaneous optimization of both detection accuracy and efficiency.
(3) Ablation experiments were designed to assess the contribution of each improvement. Additionally, SAG-YOLO was compared with mainstream object detection models, including YOLO v5n, YOLO v7tiny, YOLO v8n, YOLO v10n, Faster R-CNN, and Cascade-RCNN, to evaluate its advantages in detecting wing feather growth rate in one-day-old chicks compared to existing models.
(4) In practical testing, when the chicks spread their wings, the wings that are not fully extended result in indistinct differences between the primary feathers and covert feathers of male and female chicks. This causes a decrease in recognition accuracy, leading to false positives or missed detections. To address this issue, a gender-detection sequence method was designed, based on the detection results of each frame of the image, by calculating ratios to determine the gender. The method was evaluated for its practical application performance of SAG-YOLO through testing and statistical analysis of detection results deployed on low-cost devices.
3. Results and Discussion
3.1. Experimental Environment Configuration and Model Training Parameters
The hardware configuration for model training is as follows: 128 GB of memory, an AMD Ryzen Threadripper 2920X CPU, and an NVIDIA RTX 2080Ti GPU with 12 GB of VRAM. The operating environment is Windows 10, Python version 3.8, with the PyTorch 1.9 framework and CUDA version 11.3. The input image size is 640 × 640 pixels, the batch size is 32, and the SGD optimizer is used with a momentum factor of 0.937, a weight decay factor of 0.0005, and an initial learning rate of 0.01. The model is trained for a total of 300 epochs.
3.2. Model Evaluation Metrics
The detection accuracy of the model is evaluated using P, R, and mAP. The complexity and computational cost of the deep learning model are measured Parameters, Giga Floating Point Of Operations (GFLOPs), and Size. The average inference time per image is used as the metric to evaluate the model’s speed. The calculation methods for P, R, and mAP are as follows:
In this context, True Positive (TP) refers to the number of samples predicted as positive and that actually are positive, False Positive (FP) refers to the number of samples predicted as positive but actually are negative, False Negative (FN) refers to the number of samples that are actually positive but predicted as negative, and N represents the total number of classes.
3.3. Ablation Study
An ablation study was designed to assess the contribution of each improvement point. Specifically, SAG-YOLO refers to the complete improved model, which incorporates StarNet as the Backbone, the C2f-Additive CGLU module as the improved Neck, and GN Head as the detection Head. AG-YOLO refers to the model with StarNet removed as the Backbone; SG-YOLO refers to the model with the C2f-Additive CGLU module removed from the Neck; and SA-YOLO refers to the model with GN Head removed as the detection Head. The results of the ablation study are shown in
Table 2.
From
Table 2, it can be observed that compared to SAG-YOLO, AG-YOLO has increased parameters by 0.4691 M, floating point operations by 1.4 GFLOPs, and memory usage by 0.9 MB. Additionally, its inference speed on the GPU is slower by 0.3 ms, and its P, R, and mAP have decreased by 0.1%, 1.1%, and 0.8%, respectively. This demonstrates that using the lightweight feature extraction network, StarNet, as the backbone for YOLO v10n significantly reduces computational load and network complexity while maintaining good feature extraction capabilities. When the C2f-Additive CGLU module is removed from SG-YOLO, compared to SAG-YOLO, its P, R, and mAP decrease by 3.0%, 3.6%, and 2.2%, respectively. Although this model is similar to the improved version in terms of parameters, floating point operations, memory usage, and inference speed, the results suggest that the C2f-Additive CGLU module effectively enhances the attention distribution of spatial and channel features. It retains low-level features while improving the model’s representational capability, thus, increasing detection accuracy. For SA-YOLO, which combines only StarNet and the C2f-Additive CGLU module, compared to SAG-YOLO, its P, R, and mAP decrease by 1.1%, 1.7%, and 1.1%, while parameters and floating point operations increase by 0.3223 M and 0.3 GFLOPs, respectively. This shows that the GN Head not only reduces model parameters and network complexity but also improves computational efficiency and reduces memory usage. Additionally, the shared convolutional layers in the end-to-end training mode further strengthen the connection between feature extraction and object detection, allowing the model to better learn general features and enhance generalization capability for different inputs. SAG-YOLO, which incorporates all the improved modules, achieves increases of 1.3%, 2.6%, and 1.5% in P, R, and mAP, respectively. It also has the lowest parameters at 1.4023 M and the lowest floating-point operations at 4.5 GFLOPs. Furthermore, its inference speed increases by 0.2 ms on a GPU with ample computing resources. SAG-YOLO demonstrates a comprehensive optimization of model size, accuracy, and inference speed, showcasing its strong potential in efficient detection scenarios.
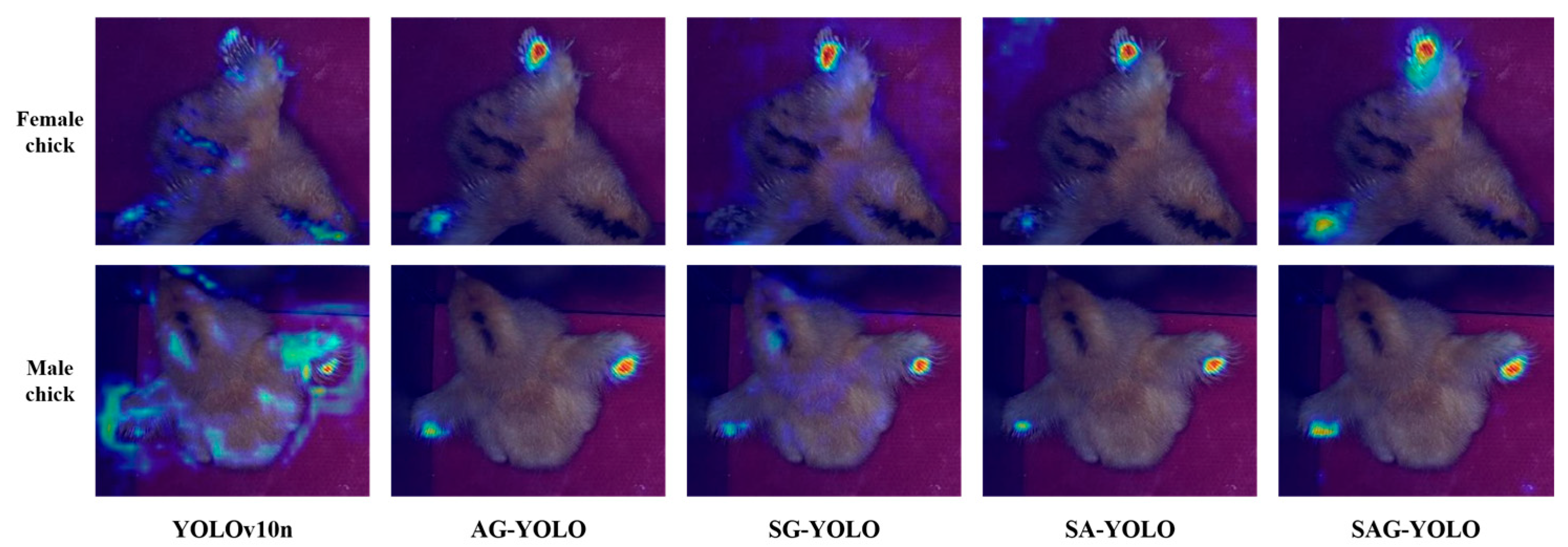
To visualize the attention distribution of the models in the ablation study, Gradient-weighted Class Activation Mapping (Grad-CAM) was used. The visualization results are shown in
Figure 8. In the image, the color gradient from blue to red indicates increasing levels of attention by the model. The base model’s attention focuses mainly on areas with no significant differences in fast and slow feathers. After introducing the C2f-Additive CGLU module, the model’s attention distribution on both spatial and channel features is effectively enhanced. Compared to the models without this module, YOLO v10n and SG-YOLO show significantly improved focus on the fast and slow feather regions. With the collaborative effects of the various improved modules, SAG-YOLO demonstrates significantly enhanced activation in the target areas, focusing more on the features with significant differences.
3.4. Comparison of Performance of Different Detection Models
To better evaluate the performance of the SAG-YOLO model, it was compared with Faster-RCNN, Cascade-RCNN, YOLO v5n, YOLO v7tiny, and YOLO v8n. The results are presented in
Table 3.
From
Table 3, it is evident that, as two-stage object detection models, Faster R-CNN and Cascade R-CNN did not achieve high precision in the chick feather recognition task, despite their fine detection capabilities. Additionally, they exhibited slower inference speeds and higher computational costs. In contrast, the SAG-YOLO model proposed in this study, which performs end-to-end prediction and detects objects across the entire image, is faster with lower computational complexity, making it more suitable for real-time detection applications, particularly in resource-constrained environments. Furthermore, when compared with YOLO series models, the SAG-YOLO model demonstrates significant advantages. In the chick gender detection task, YOLO v7tiny shows good inference performance, with a P of 87.7%, R of 90.1%, mAP of 94.7%, and an inference time of 6.2 milliseconds. However, the proposed SAG-YOLO model achieves a 2.3% improvement in mAP and significantly reduces the inference time to 1.9 milliseconds, more than three times faster than YOLO v7tiny. Additionally, the SAG-YOLO model reduces the number of parameters and floating-point operations by 76.7% and 65.4%, respectively, highlighting its significant advantages in resource usage and detection efficiency.
The model’s parameter count, average inference time, and mAP are shown in
Figure 9. The proposed SAG-YOLO model has achieved lightweight design and high efficiency, validating the effectiveness of the improvements.
The detection results are visualized in
Figure 10, where the first column shows the Ground Truth, which provides accurate annotations of the target object positions and categories, and the remaining columns show the detection results of each model. For samples with distinct features, both YOLO series models and two-stage detection models can achieve efficient and accurate recognition for the gender sorting task. However, in complex scenarios, such as interference caused by the similarity in the color of black chicks, interference from the fluffy characteristics of light-colored chicks, and motion blur or incomplete wing extension of chick samples, other models tend to have issues like missed detections, false positives, or duplicate bounding boxes. In contrast, the SAG-YOLO model is capable of effectively learning the deep features of these challenging scenarios, demonstrating exceptional robustness and generalization ability. The SAG-YOLO model consistently achieves robust detection performance in challenging environments.
3.5. Practical Testing
To evaluate the model’s performance and generalization ability for chick sex detection under limited computational resources, 80 male and 80 female chicks of the same breed at one day old were selected for testing. Comparative experiments were conducted using the original models of Faster-RCNN, Cascade-RCNN, YOLO v5n, YOLO v7tiny, YOLO v8n, YOLO v10n, and the proposed SAG-YOLO model. The testing was performed on a laptop without a dedicated GPU, with inference carried out using the CPU, to validate the model’s lightweight performance.
During the process of the chicks spreading their wings, the camera captures several frames of images where the chick’s wings are not fully extended. At this stage, the differences between the male and female chicks’ primary feathers and covert feathers are not fully revealed, leading to a decrease in the model’s detection accuracy, which results in false positives or missed detections. However, when detecting individual chicks, no occlusion or interference from multiple targets occurs. In this study, only the detection results for the same target are considered. The accuracy of the model’s sex determination for one-day-old chicks is further evaluated based on the statistical proportion of correct classifications. During testing, the detection results of each frame are combined into a sequence of chick sex detections, where 0 represents a female chick and 1 represents a male chick. The final determination of the detection result is made based on the proportion (ratio) of the male/female classifications, which is greater than the threshold of 0.5. A portion of the chick detection sequences is shown in
Table 4.
Based on the above statistical detection method, real-time video stream detection was performed on male and female chick samples. The test statistics for each model are shown in
Table 5. The number of correctly identified samples, misjudged samples, and missed samples were separately counted. Accuracy is defined as the proportion of correctly identified samples out of the total number of detected samples. The average inference speed per frame is the average time taken by the model to infer the valid frames of the video stream during a single detection process.
As shown in
Table 5, no missed detections occurred for female chicks in any of the target detection models. The two-stage object detection models, Faster-RCNN and Cascade-RCNN, each missed two and three male chick samples during detection, respectively. In contrast, all single-stage detection models missed only one male chick sample. In comparing the accuracy of correct and incorrect detections, except for the YOLO v5n model, which misidentified one female chick, all other models achieved 100% accurate detection for female chick samples. Faster-RCNN and Cascade-RCNN misidentified seven and six male chick samples, respectively. YOLO v5n achieved an accuracy of 93.75% for male chicks, while YOLO v5n, YOLO v7tiny, YOLO v8n, and YOLO v10n all achieved an accuracy of 92.50%. SAG-YOLO demonstrated the highest accuracy at 96.25%. Although the two-stage models, Faster-RCNN and Cascade-RCNN, performed similarly in terms of accuracy, their inference speeds were slower, reaching 4971.3 ms and 7949.1 ms, respectively, making them unsuitable for real-time applications. In comparison, SAG-YOLO, while maintaining the highest accuracy, achieved an average inference speed of 129.4 ms per frame. Overall, SAG-YOLO demonstrated the greatest potential for practical application in chick sex recognition tasks, owing to its outstanding accuracy and inference speed.
As shown in
Figure 11, when testing male chick samples with motion blur and difficult-to-distinguish features, the Faster-RCNN model made three feature misidentifications and two correct detections. Cascade-RCNN misidentified all five feature detections during the detection process. According to statistical analysis, two-stage detection models generally suffer from misidentification issues. The single-stage detection models YOLO v5n and YOLO v7tiny exhibited repeated bounding boxes around the same feature during detection, particularly for motion-blurred male chick samples. They failed to effectively suppress duplicate boxes, resulting in redundant outputs of multiple bounding boxes around the same target. The final sex determination was incorrect, showing the models’ limited adaptability in complex scenarios. YOLO v8n made four incorrect determinations and only one correct detection when identifying the wing feather growth rate features, indicating its inability to effectively extract features for inference in such scenarios. In contrast, both YOLO v10n and SAG-YOLO made correct determinations. SAG-YOLO, in particular, demonstrated superior feature recognition capabilities, successfully identifying the wing feather growth rate features of male chicks four times and providing accurate results, showing greater robustness and generalization ability.
3.6. Discussion
The SAG-YOLO model proposed in this study achieves a synergistic optimization of both accuracy and efficiency in the task of chick gender detection, compared to existing mainstream models. StarNet utilizes star operations to exponentially expand feature dimensions without incurring additional computational overhead. This design allows the model to efficiently extract key features even in complex scenarios, such as when feather colors are similar or when the wings are not fully spread. The Additive CGLU module strengthens the interaction of multi-scale features through an additive similarity function and gating mechanism. Ablation experiments show that removing this module results in a 2.2% drop in mAP, and Grad-CAM visualization results indicate a significant reduction in the focus on feature regions. This suggests that the module effectively mitigates the missed detection issue caused by information loss in traditional feature fusion by dynamically adjusting channel and spatial attention weights. The GN Head reduces parameter redundancy by sharing convolutional layers, while utilizing group normalization to enhance the model’s adaptability to different input distributions.
In real-time video stream testing, the SAG-YOLO model achieves detection accuracies of 100% and 96.25% for female and male chicks, respectively, with an inference speed of 129.4 ms per frame, significantly outperforming both two-stage models and YOLO series models. Its low computational complexity makes it suitable for low-cost devices, providing a feasible solution for automated sorting in poultry farms. However, future performance validation is needed to further assess its generalization capability under multi-variety and complex lighting conditions. Additionally, while the model performs excellently on GPUs, real-time performance in a pure CPU environment still requires optimization.
This study offers an efficient and lightweight solution for one-day-old chick gender detection, with a technical framework that can be extended to other poultry or agricultural object detection tasks. Future work will focus on constructing larger-scale, multi-scenario cross-variety datasets; exploring model quantization and deployment optimization on edge devices; and incorporating temporal information to further improve the robustness of video stream detection. With continuous improvement, this technology has the potential to drive the intelligent and sustainable development of the poultry industry, reducing resource waste and ethical concerns.
4. Conclusions
To address the challenge of automated chick sex detection, this study proposes the SAG-YOLO model. By replacing the backbone network with StarNet to reduce computational complexity, the model incorporates the Additive CGLU module to enhance multi-scale feature fusion, and the GN Head is designed to improve generalization and detection efficiency. The model achieves P of 90.5%, R of 90.7%, and mAP of 97.0%, representing improvements of 1.3%, 2.6%, and 1.5%, respectively, over the original model. Simultaneously, the number of parameters has been reduced by 0.8633 M, and the inference speed on the GPU has increased by 0.2 ms, achieving a comprehensive optimization in terms of lightweight design, accuracy, and inference speed. Furthermore, a model deployment method was designed, where the sex of the chick is determined based on the proportion of detection results in each frame’s sequence, effectively reducing misidentifications. The final test results demonstrate that the improved model achieves 100% detection accuracy for female chicks and 96.25% for male chicks. The overall accuracy significantly outperforms other detection models. With an average inference speed of 129.4 ms per frame, it still exhibits excellent feature recognition capabilities. The model’s low computational complexity allows for automated, non-destructive, one-day-old chick sex classification on low-cost devices, reducing labor costs, minimizing misidentification rates, and enhancing efficiency and economic benefits.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}