1. Introduction
Mobile edge computing (MEC) is a transformative technology that brings significant advances to wireless networks. These advances are made by maximizing the computational capabilities of edge servers embedded in mobile base stations and access points. These edge servers play a crucial role in the enhancement of the computing capabilities of mobile devices (MDs). The main advantages of MEC include its low-latency services, which are achieved by facilitating the fast response of real-time applications and minimizing the amount of data that must travel to centralized cloud servers [
1]. This technology not only improves network efficiency by transferring computationally intensive tasks to edge servers, but also improves energy conservation and increases the battery life of resource-limited devices. Furthermore, MEC facilitates efficient use of network resources, reduces congestion and improves network capacity and performance in general [
2]. In addition, integration of energy-harvesting technology with MEC promotes sustainability by minimizing the power consumption of MDs. In general, MEC can substantially enhance wireless networks through low-latency services, energy conservation, improved network efficiency and the integration of sustainable energy practices [
3].
The computational demands of ultra-low-latency applications, such as autonomous driving and the Internet of Things, can be efficiently managed by integrating MEC with energy harvesting (EH). While MEC reduces latency by processing data at the network edge, EH ensures sustained operation of energy-constrained devices, which is particularly beneficial in fifth-generation (5G) networks [
4]. MEC leverages computational resources at the network edge and facilitates fast and efficient data processing, reducing latency by offloading tasks from MDs. Thus, MEC is particularly important given the limited battery capacity of MDs [
5]. The energy efficiency of the network can be further enhanced using EH techniques, ensuring the uninterrupted execution of computation-intensive tasks through relying on renewable energy sources. This integration is pivotal for supporting applications in intelligent vehicular mobile networks, such as autonomous driving and real-time video streaming, which require low-latency and high-reliability connectivity. Overall, the challenges encountered due to latency-sensitive applications are addressed by MEC with EH in 5G networks, which also promotes sustainability through green computing practices [
6].
Ultra-dense network (UDN) architectures rely heavily on MEC, which provides decentralized application services and computing resources. The technical benefits of this strategy include reduced network congestion, optimized data privacy and security, and increased application speed [
7]. Low-latency processing, which is essential for real-time decision-making in very dense networks, is possible through MEC. This processing is realized by placing computing power at the network edge. Moreover, transferring computation-intensive jobs from small-cell base stations to edge computing servers is possible, which reduces device stress and extends battery life [
8]. MEC and UDNs work together to improve the computing capabilities of MDs while simultaneously expanding the network capacity. The implementation of this architecture necessitates a system model that considers the very dense deployment of edge servers and base stations. An optimization problem should also be established to determine the best resource-allocation plan and computation-offloading technique [
9]. Overall, the installation of edge computing servers within small-cell base stations is necessary for the MEC design of UDNs to provide low-latency processing and realize the offloading of computation-intensive tasks.
This work investigates the difficulties related to computation offloading and resource allocation in MEC within the setting of UDN. The study looks at how limited computing resources and task delays affect system performance, with a focus on how to best offload computations and distribute resources. The key contributions can be encapsulated as follows:
The UDN is built on an MEC architecture integrated with EH technology. A task-execution cost model that accounts for execution latency and energy consumption is developed. The integration of task offloading with resource allocation is characterized as an NP-hard optimization issue.
The challenges related to computation offloading and resource allocation are resolved using the LYMOC approach. This technique combines the Lyapunov algorithm with mixed-integer linear programming (MILP)-based optimum cost. The Lyapunov algorithm was selected due to its ability to successfully handle the dynamic and stochastic characteristics of MEC settings by stabilizing the energy queue, hence guaranteeing efficient energy use over a period of time. MILP was used due to its ability to efficiently address the intricate resource-allocation issue through determining the appropriate method of distributing jobs from many mobile devices to various MEC servers.
LYMOC effectively addresses the need for real-time resource allocation in high-user-density networks. This method ensures fairness-oriented allocation, balancing resource distribution among users in dense environments, preventing service degradation and improving overall network efficiency.
The subsequent sections of this document are organized in the following manner:
Section 2 provides a comprehensive analysis of the existing research in the area of MEC and UDNs.
Section 3 introduces the system model and outlines the problem formulation.
Section 4 provides a comprehensive explanation of the proposed LYMOC approach.
Section 5 presents the experimental results and offers a comparison analysis with the baseline algorithms.
Section 6 provides a discussion, concludes the work and proposes options for further research.
2. Related Work
The integration of MEC with UDN optimizes network velocity, reduces latency and facilitates efficient deployment of advanced services through the use of distributed processing capabilities and multiple small cells. The deployment of MEC in UDNs to enhance the performance of 5G networks is examined in [
7]. The proposed MEC architecture provides a system model within the UDN and formulates optimization problems. This study uses the action-classification (AC) method, particularly the DQN-AC algorithm, to identify the most effective solutions for computation offloading and resource allocation. Similarly, a system model for an MEC-assisted UDN is presented in [
10], with the aim of minimizing the system overhead. The proposed methodology decomposes the problem into smaller components, including offloading strategies, channel assignments and power distribution. Joint offloading and resource-allocation algorithms enable the implementation of optimal solutions. The challenges posed by the increasing number of intelligent terminal devices in 5G, AI and IoT environments are addressed by a dense edge computing system that integrates MEC with UDN, as discussed in [
11]. The challenges related to task offloading and resource scheduling in UDNs are explored in [
12], where MEC is used to minimize overall system costs, including latency and energy consumption. Solutions for task offloading, base station selection and resource scheduling for mobile devices are also proposed. Furthermore, ref. [
13] introduces a cost-efficient hierarchical approach (HACO) to improve computation offloading and resource allocation in ultra-dense multi-cell MEC networks. This method reduces financial expenditures and addresses non-convex challenges using the Artificial Fish Swarm Algorithm (IAFSA) and Particle Swarm Optimization (IPSO).
The integration of computation offloading and resource allocation in MEC systems aims to reduce latency by intelligently selecting offloaded tasks and efficiently allocating resources, thus optimizing system performance. By leveraging edge servers for intensive processing, this strategy can effectively reduce energy consumption and enhance application responsiveness. Deep reinforcement learning (DRL) is applied in [
14] to provide energy-efficient task offloading, optimizing rewards while considering task deadline constraints. Additionally, DRL methods are employed in various offloading scenarios. The study in [
15] utilizes deep Q-learning for decision-making in distributed offloading while considering edge node load dynamics. Another approach to leveraging distributed DRL is introduced in HOODIE [
16], which implements hybrid offloading in Cloud-Edge frameworks to improve resource allocation in dynamic latency conditions. Researchers in [
17] demonstrate that the Stackelberg game framework is an effective approach for multiple agents to collaboratively optimize the trade-off between latency and energy efficiency in vehicular networks. A novel stochastic game-based computation-offloading model and a multi-agent reinforcement learning algorithm, namely SGRA-PER, are proposed in [
18], exhibiting superior performance in dynamic resource allocation.
Trajectory control for MEC is also explored in various studies. Two trajectory-control algorithms are introduced in [
19], consisting of a convex optimization-based trajectory-control algorithm and a DRL-based trajectory-control algorithm. The Lyapunov-based multi-agent deep deterministic policy gradient technique, which jointly optimizes task distribution and radio resource allocation, is proposed in [
20]. A task-offloading optimization strategy is presented in [
21], employing Lyapunov optimization and a DRL-based resource-allocation approach. However, a major limitation of conventional DRL methods is their slow adaptation to environmental changes. To overcome this challenge, the study in [
22] introduces DMRO, a meta-reinforcement learning framework designed to accelerate decision-making in dynamic environments. This method enhances performance by integrating DRL with meta-learning, enabling faster model adaptation in MEC environments. A novel approach called JVFRS-CO-RA-MADDPG, based on DRL, is proposed in [
23], which optimizes video frame resolution, computation offloading and resource allocation collectively. Additionally, a comprehensive framework is developed in [
24] to manage task delegation, resource allocation and trajectory planning for cooperative edge computing among multiple UAVs, emphasizing the importance of task prioritization in optimizing system performance.
Several studies have examined the trade-off between execution latency and energy consumption to enhance MEC efficiency. The study in [
25] explores task-offloading strategies in wireless-powered MEC networks (WP-MEC), which integrate wireless energy transfer and offload optimization to minimize energy consumption. This model employs a two-stage multi-agent deep reinforcement learning-based distributed computation-offloading (TMADO) framework to optimize task distribution and maintain low energy costs. The efficient management of computational activities in MEC systems enhances resource utilization, reduces operational costs and mitigates network congestion. The WiDaS method, described in [
26], utilizes Lyapunov optimization and the water-filling concept for task scheduling, aiming to minimize average task-response time while adhering to resource constraints. The stochastic computation-offloading problem is analyzed in [
27], where a virtual queueing technique based on Lyapunov optimization is implemented to ensure system stability. Our preliminary research [
28] contributes to this discussion by analyzing energy efficiency based on data-transmission distance, data rate, CPU frequency and transmission power, and by investigating energy trade-off in computing offloading. The DAEE method is proposed for adaptive offloading, with the goal of maintaining low latency while minimizing long-term energy consumption. An online resource-offloading and -allocation technique, based on Lyapunov optimization, is introduced in [
29], effectively addressing dynamic computational demands and user mobility while balancing energy efficiency and service latency. A cost-minimization offloading model is formulated in [
30], optimizing edge computing resources, signal-detection vectors, transmission power and IRS coefficients to achieve a balance between latency and energy consumption. A mixed optimization problem is described in [
31], where the authors propose PATA and DHC methods to efficiently address the energy-latency trade-off by optimizing power allocation, task scheduling and clustering mechanisms.
This research distinguishes itself from previous studies by incorporating energy-harvesting technology into MEC and improving the efficiency of task offloading and resource allocation in UDNs. The primary objective is to enhance sustainability and reduce mobile device power consumption, particularly in 5G networks requiring ultra-low latency and high reliability. This study differs from prior research by evaluating system performance in highly dense UDN scenarios and employing a more realistic energy-harvesting model. Furthermore, it emphasizes fairness-oriented resource allocation to ensure equitable resource distribution among users in UDN environments, which is critical for maintaining user satisfaction and balanced system performance.
This paper provides significant advantages compared to prior studies, as shown in
Table 1, especially in terms of integrating energy-collection technology with MEC. This connection enhances sustainability by decreasing the power consumption of mobile devices. The LYMOC technique, which is an optimization approach, successfully deals with the dynamic and stochastic characteristics of the MEC setup by stabilizing the energy queue, enhancing energy efficiency and achieving fairness in resource allocation. In addition, the system model takes into account UDN situations that involve numerous MD and MEC servers. It also addresses the specific issues linked to interference and coordination among devices. The cost function in this optimization issue incorporates both execution delays and penalties for completed jobs, thereby guaranteeing optimization of performance, fairness and dependability.
3. System Model and Problem Formulation
This section provides an explanation of the system model and problem formulation for our research on computing offloading and resource allocation in MEC combined with EH in a UDN. MEC has become an essential technology to address the growing need for high processing power and fast response times in current applications, especially in the context of 5G networks and beyond. Integrating EH technologies with MEC improves sustainability through decreasing the dependence on conventional power sources and prolonging the lifespan of MDs.
3.1. System Model
This study explores an MEC architecture within a UDN, as illustrated in
Figure 1. The system comprises a set of MDs, denoted as
,each equipped with EH capabilities. Concurrently, a small base station (SBS) equipped with an MEC server exists. A set of MEC servers, which are denoted as
, provide essential computing resources and services. The suggested system model takes into account the distinctive attributes of UDN, including the reduced distance between devices and increased interference. When there are a lot of devices and base stations in UDN, the environment is very complex and changes dynamically. As a result, interference among devices becomes severe. It is important for devices and MECs to collaborate to complete the task. Hence, this system model considers the unique attributes of UDN, such as precise device and server spacing and rigorous interference management. Additionally, the communication infrastructure employs orthogonal frequency division multiple access (OFDMA), which establishes connections among users, communication channels and MEC servers. In this system, each MD is allocated a dedicated communication channel to the MEC server and prevents direct task collisions at the transmission level. However, if multiple tasks are transferred simultaneously to MEC servers, processing delays may occur due to resource conflicts. The work does not include additional scheduling mechanisms on the MEC server to resolve these conflicts, which can be considered in future improvements. OFDMA facilitates efficient frequency resource allocation by dividing the frequency channel into subchannels, each assignable to a specific user. This algorithm enables simultaneous and effective communication between MDs and MEC in the UDN. Each MD is assumed to traverse the SBS area at a specific distance, which is quantified using the Euclidean distance formula.
Within this framework, the temporal dimension of the MEC system is organized into slots,
t, where
represents its index set. In addition, each MD-based application initiates a time slot with a probability of success,
, and failure, with a probability of
. This condition indicates that computation tasks follow an independent and identically distributed (i.i.d.) Bernoulli process, contributing to the dynamic and probabilistic nature of the system. Each MD is tasked with computing-intensive operations that can be executed either locally on the MD itself or offloaded to the MEC servers for processing. Additionally, neither of the two calculation modes is feasible; for example, if the energy supply of the MD is inadequate, then the computation task will be dropped. Thus, the computation mode of MD indicates the time frame as
, where
denote the execution of the processing task at the MD, offloading or dropping it to the MEC server. The edge server has unlimited computational capabilities, resulting in minimal execution time. The feedback time is disregarded due to the substantial disparity in size between the outcome and the raw data [
32]. This assumption is based on the fact that the results of the computation task are much smaller than the input data, and in most scenarios the transfer delay of the returned results is negligible.
The parameters and notations used in this study are summarized in
Table 2.
3.2. Communication Model
The system model comprises several SBSs and MDs in the UDN scenario. Each MD has a job that requires considerable computing power that can be sent to a single MEC server over the wireless channel. The feasible offloading-transmission rate can be computed as follows, assuming that the system employs OFDMA techniques [
33]:
where
is the bandwidth of the wireless channel,
is the MD transmission power for data offloading,
is the white Gaussian noise that occurs during data transmission and
is the wireless channel gain [
7].
To mitigate severe inter-cell interference caused by the high density of MDs and SBSs in UDNs, co-channel deployment is not utilized. Instead, OFDMA is employed to assign orthogonal sub-channels to each MD, ensuring interference-free communication and more stable transmission rates, albeit at the cost of reduced spectral efficiency.
The wireless channel gain
is represented by:
where
is the path loss exponent,
r is the distance between the MD and MEC servers,
is the carrier frequency and
is the antenna gain. Therefore, if the calculation task is performed by the MEC server, then the execution delay is equivalent to the transmission delay for the input bits,
.
Consequently, considering energy consumption, the energy used for transmission can be computed as follows [
32]:
The transmission power is assumed to be limited to address practical considerations; that is, .
3.3. Local Computing Model
The energy usage and time delay in local execution depend on the resources of the MD. The execution of applications and local management of tasks are realized by using the computational resources available on the MD, such as its CPU and memory. The energy consumption of local computing in the MD can be stated as follows [
32]:
Furthermore, the local computing task-execution time can be determined in accordance with
where
is the effective switched capacitance determined by the chip architecture,
c is the number of CPU cycles necessary for processing a single-bit input and
is the CPU cycle frequencies that are planned for local execution during time slot
t. The top limit of the CPU-cycle frequency of any MD is denoted as
; that is,
.
3.4. Energy Model
This EH model considers factors such as the availability and intensity of renewable energy sources and the efficiency of the energy conversion process. The model helps determine the amount of energy that can be stored in the battery of an MD based on the assumption of uniformly distributed harvestable energy
with a maximum value
. The assumption of uniformly distributed harvested energy
is employed as a simplifying assumption to enhance the problem’s tractability [
34]. While dynamic energy variations are typically captured using linear or nonlinear energy-harvesting models, this approach focuses on a statistical representation that facilitates optimization. A portion of the energy that occurs during each time slot, designated as
and satisfying
, is collected, stored in a battery and made accessible for local execution or computation offloading at the next time slot. Furthermore, the model considers the energy consumption of the device and its battery storage capacity. Let
represent the energy spent by the MD during time slot
t. The energy consumption is dependent on the chosen computation method, which is represented as follows:
The energy usage during each time slot must not exceed the level of the battery; that is,
. Therefore, the battery energy level changes in accordance with the following formula:
The formula actually ensures that the battery level stays within the range of feasible scope at all times. Since each time slot energy consumption is limited by , the battery level is updated based on available energy and harvested energy and prevents overflow and violation of physical storage limitations.
3.5. Problem Formulation
The optimization problem in the setting of UDN exhibits numerous fundamental distinctions when compared to typical MEC. The large number of devices and base stations in UDN increases interference, and therefore there is a need for effective resource allocation. Thus, this problem formulation takes into account the distinct limitations encountered in a densely populated setting, such as effectively handling interference and promoting improved coordination among devices. The proposed Lyapunov–MILP optimization technique is specifically developed to efficiently tackle the unique issues of UDN. It ensures proper resource allocation and computation offloading to minimize both delay and energy usage. Given these complexities, optimization problems are combinatorial due to decisions on the allocation of binary tasks and continuous resource constraints, making them mixed integer optimization problems. These characteristics require the use of an optimization method that can efficiently handle both discrete and continuous decision variables, which is why MILP is selected for this problem.
The execution cost function comprises two components: the time required to execute the task and the penalty associated with dropping or not completing the activity, expressed as
where
denotes the decision to pair each MD with MEC containing the least cost, and
is the weight of the task-dropping cost.
and
are dimensionless coefficients that equilibrate the effects of
and
, whereas
is a binary variable devoid of dimensions that signifies the connection decision between a mobile device and a server. Simultaneously,
denotes the penalty weight for omitted tasks, articulated in seconds, in accordance with the time units of
and
.
Identifying the optimal option for offloading and allocating resources accordingly is necessary to reduce the overall cost of the system. The current issue is delineated in the following manner:
where
C1 represents the zero-one indicator restriction of the computation mode indicators. The ranges of the MD CPU cycle frequency and transmission power values are denoted by
C2 and
C3, respectively. The MD obtains energy in the form of
C4. The conversion loss prevents the energy obtained during the current period from exceeding its value.
C5 ensures that the computing task’s energy consumption does not exceed the remaining energy available during time slot
t. Constraint
C6 assures that the cumulative demand on a server does not exceed its maximum capacity,
, while
C7 guarantees that every mobile device establishes a connection with at least one server, facilitating job execution.
C8 explicitly designates
as a binary variable to signify the connection decision between a mobile device and a server. These constraints function at different levels—
C6 operates at the server level to regulate resource capacity, whereas
C7–
C8 manage individual device connectivity—ensuring that the system operates in harmony without conflict.
4. Proposed Method
Two methodologies are utilized to tackle the task-offloading and resource-allocation issues in UDN-based multi-user MEC systems with EH devices, as delineated in the problem specification. The Lyapunov drift-plus-penalty method is employed to dynamically optimize offloading decisions, reducing execution costs while accounting for task failures and execution delays. Second, the MILP method is used to make the best use of each MD’s resources at every time slot. This makes sure that computational tasks are assigned to MEC servers efficiently while still meeting capacity limits. The method also makes the best use of transmission power and computational resources to lower the cost of execution.
The MILP method is selected because of its effective management of both binary and continuous decision variables, rendering it ideal for optimizing task offloading and resource allocation in UDN. The binary nature of the decision to execute tasks locally or remotely, contrasted with the continuous nature of resource allocations like transmission power and CPU frequency, makes MILP an effective optimization framework that guarantees feasibility within the constraints of execution time, energy consumption and server constraints (
C6-C8). While DRL may be utilized to address P1, it necessitates long training and meticulous hyperparameter optimization, and does not consistently ensure optimal solutions in dynamic environments [
35]. Conversely, MILP ensures global optimality for structured issues such as P1, rendering it especially beneficial for optimizing task-to-server assignments and resource allocation in UDN, where deterministic solutions are preferred over exploration-based learning [
36]. The suggested method uses MILP to make sure that resources are used efficiently, fair task distribution and execution costs are kept low. This makes it a strong and reliable choice for task offloading in high-density MEC settings.
4.1. Lyapunov Algorithm
The perturbation parameter was initially established, and the virtual energy line at the MD was constructed. Perturbation parameters are used to alleviate the existing energy causality limitations inside the optimized dynamical system, thus enabling the estimation of the upper limit of energy consumption for local execution and offloading [
6]. The perturbation parameter,
, is expressed as
where
and
V is a control parameter (in
).
A displaced representation of the actual battery energy level on an MD is referred to as the concept of a virtual energy queue. The virtual energy queue, which serves as a metric for reducing the energy consumption from the mobile battery and optimizing the use of renewable energy sources, is quantified as follows:
This method ensures adherence to constraint C5. This constraint controls energy causality by making sure that the energy used for local computation and offloading does not go over the energy that is available in the MD’s battery at any given time. The virtual energy queue and the perturbation parameter are used by the system to dynamically control the amount of energy used, which makes operations more sustainable and efficient.
Lyapunov theory is used to ensure the stability of the queue. Initially, the quadratic sum of the queue backlog is computed as follows:
Thus, the Lyapunov drift function can be mathematically represented as
and the expression for the Lyapunov drift-plus-penalty function is
Lyapunov’s theorem indicates that the stability of the virtual energy queue and the finiteness of the queue backlog is guaranteed when the above equation is satisfied.
According to (
16), Problem
may be reformulated as Problem
, which incorporates minimal drift-plus-penalty.
This reformulation is conditioned on all constraints in . This reformulation is unrelated to the stability and dependability of the system. Thus, the second optimum objective in the deterministic problem mentioned above will be temporarily disregarded. In addition, the second optimum objective is directly addable to .
4.2. Optimal Computation Offloading
The best amount of harvested energy can be determined by solving a linear programming problem that reduces the amount of energy harvested from the battery while maintaining a non-negative virtual energy queue.
The best EH choice of each MD is independent of others. Thus, the optimal may be calculated individually for each MD. This equation effectively addresses constraint C4 by ensuring that the harvested energy does not exceed the available battery energy and maintains a non-negative virtual energy queue.
In relation to the computing modes, obtaining the corresponding mode to the smallest
value for every individual MD is necessary. The formula in [
6] allows for the calculation of the optimal CPU cycle frequencies,
, and optimal transmission power,
.
The optimization of
, the CPU-cycle frequency for local execution, is performed by minimizing the cost function, which includes both energy consumption and execution delay. The cost function
is defined as:
The optimal frequency is determined by setting the first-order derivative of to zero, which results in .
The optimization of
, the transmission power for offloading to the MEC server, is performed by minimizing the cost function, which includes both energy consumption and communication delay. The cost function
is defined as:
The first-order derivative of , solved using the Newton-Raphson method and set to zero, is used to determine the optimal transmission power :
The optimal objective may be realized using
, as indicated by the following formula:
where
and
, which are subproblems for the local and remote execution modes, respectively, have
and
as their corresponding optimum objectives. The optimal values of
for the three computing modes can be analyzed to determine the optimal computation-offloading choice, which can be defined as follows:
4.3. Resource Allocation
The alignment of MD and MEC servers—with the objective of optimizing resource allocation and minimizing the geographical distance between the edge server and MD—is realized utilizing the MILP approach. This approach considers several characteristics, including the execution cost and the server load, to identify the most appropriate server. The decision to pair each MD with one of the MEC servers,
, may be obtained using
to resolve the allocation of MD task resources to a server.
The objective is to reduce the overall cost while adhering to limitations C6, C7 and C8. The MILP strategy incorporates the selection of the server with the lowest cost as the decision variable while also considering the constraints of maximum server capacity and the need for each MD to be connected to at least one server. The MILP issue is resolved by the use of a conventional optimization solver. This solver systematically explores possible combinations of while adhering to all constraints in order to locate the optimum solution. The solver utilizes branch-and-bound methods and cutting planes to effectively explore the solution space, guaranteeing the selection of the most suitable server for each MD.
4.4. LYMOC Algorithm
The specific implementation process is described in Algorithm 1 The LYMOC method efficiently manages task allocation and resource utilization in MEC inside UDNs by dynamically optimizing computation offloading for MDs. At first, the characteristics and placements of MDs and MEC servers are established. MD positions are randomly updated for each time slot. The method computes the distance between MDs and MEC servers, modifies the gathered energy if necessary and verifies task requests. When a task request is present, the system calculates the local execution latency and energy consumption. It then assesses the transmission delay and energy consumption for each server and selects the most suitable server using a MILP method. The selection of the appropriate computing mode is based on the generalized computing offloading,
, value and the execution cost, energy consumption and chosen mode are recorded. Ultimately, the battery level is refreshed, and the cycle is repeated for the subsequent time interval.
| Algorithm 1: LYMOC Algorithm |
![Sensors 25 01722 i001]() |
4.5. LYMOC Algorithm Computational Complexity
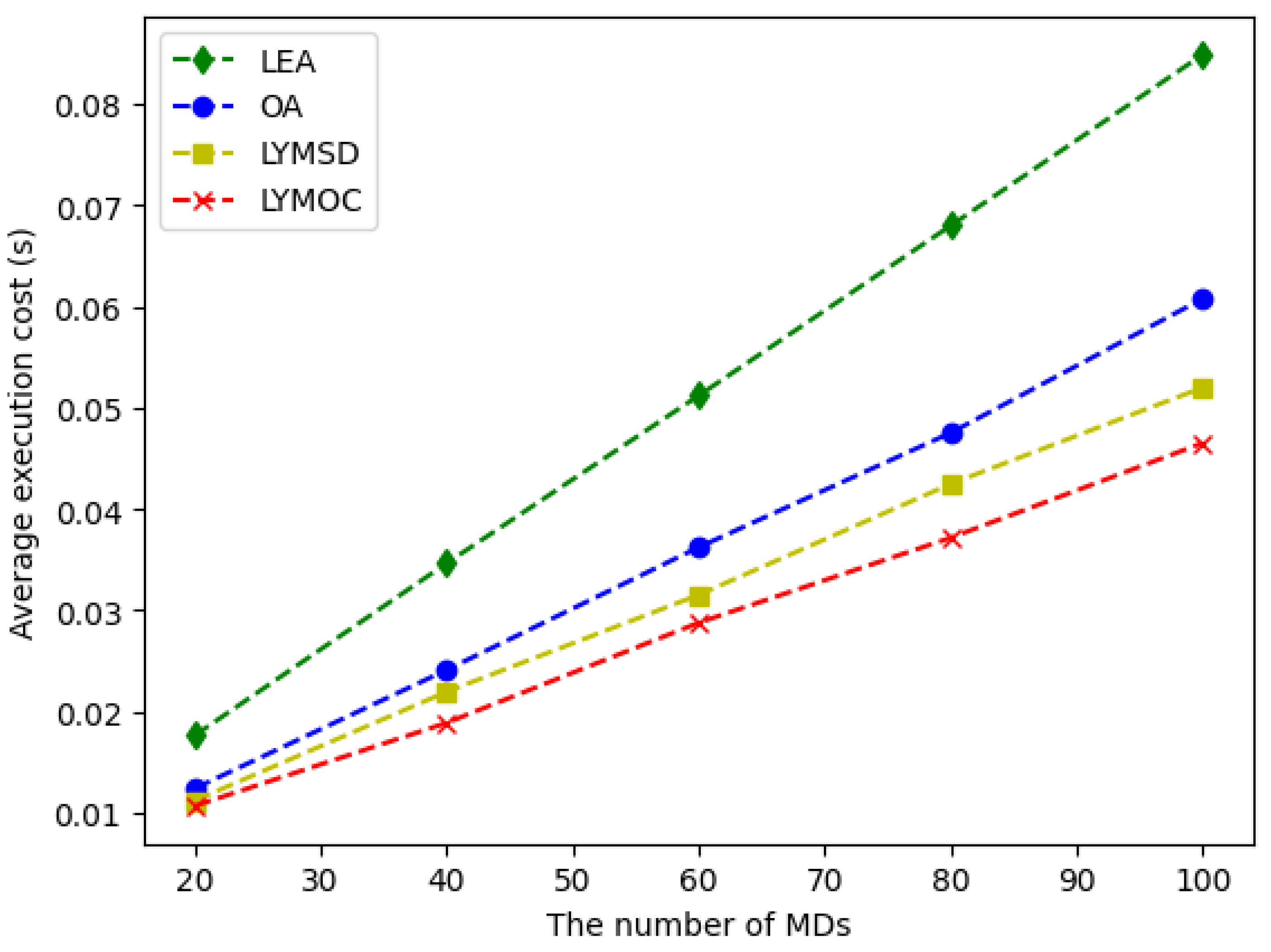
The LYMOC algorithm’s computational complexity is assessed in the manner described below. Time slots T, mobile devices (MDs) M and MEC servers S are present. The LYMOC algorithm’s system input complexity is , meaning that the number of time slots, mobile devices and MEC servers all cause the input size to rise linearly. In this case, the complexity of resource allocation using the MILP method is , which is exponential in the number of mobile devices (M) and MEC servers (S). Thus, is the total complexity of the LYMOC method, which integrates time complexity, input size and resource allocation using MILP. This demonstrates that the total complexity grows linearly with the number of time slots (T) and exponentially with the number of mobile devices (M) and MEC servers (S). The MILP-based LYMOC algorithm offers an optimum solution for resource allocation in MEC systems, resulting in a substantial reduction in execution costs when compared to other approaches. Although there is a greater computational burden, the advantages in terms of energy efficiency and the time it takes to complete tasks make it worthwhile to utilize.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}