1. Introduction
Traditional supervised learning models, designed for solving single tasks like forecasting, regression, and classification on sensor data, have shown effectiveness for decades [
1,
2,
3]. However, acquiring labels for sensor data largely depends on input from end users. Furthermore, efficiency of these supervised learning methods declines when confronted with multiple tasks simultaneously, as these models overlook cross-task shared information that can be leveraged for improved performance [
4,
5]. Recognizing this limitation, recent research has explored advanced models aiming for enhanced performance, efficiency, and adaptability [
6,
7,
8,
9,
10]. Therefore, multitask learning models (MTLs) have emerged as a viable alternative, directly challenging the conventional approach of employing distinct models for each task [
11].
Leveraging the shared representation of tasks, MTLs learn to mitigate the risk of overfitting up to a certain sharing limit. Adding more tasks into these models reduces the likelihood of overfitting [
5]. Nevertheless, dealing with a set of unrelated tasks can result in negative knowledge transfer, leading to a subpar performance [
12]. In contrast, for a set of related tasks, MTL offers several advantages, including (i) enhanced accuracy through inductive knowledge transfer and the utilization of auxiliary information, (ii) a more compact architecture, (iii) reduced computational costs, and (iv) swift operation—especially beneficial for tasks requiring low latency, such as mobile health applications [
12,
13]. These advantages place MTL as a superior alternative to deploying multiple single-task models.
MTLs, like other supervised machine learning models, require a significant amount of labeled data. While the deployment of a multi-task learning model is highly sought after, a notable challenge lies in providing the model with the necessary labeled data. However, acquiring such labeled data can be challenging due to the associated expense, tedium, and time-consuming nature [
14]. To address this challenge, one approach involves integrating the MTL into an active learning loop, where it receives a strategically chosen subset of labeled data. In this setup, the MTL collaborates with an active learning agent within the multitask active learning (MTAL) ecosystem, aiming for high performance with substantially less data. The agent identifies informative samples located near the decision boundary, where the model is least confident [
15]. These critical data instances are presented to an oracle for labeling and the iterative process continues until the budget is depleted or a predefined accuracy threshold is attained.
In MTAL, we usually pick the most useful samples using strategies like
one-sided,
alternating, and
rank combination (
RC)-based selection, as well as criteria such as
least confidence,
margin sampling, and
entropy [
16,
17,
18,
19]. These strategies are effective in situations where there are limited data available [
20]. However, as far as we are concerned, they have not been tested in mobile health (mHealth) settings. This technology is relatively new and constrained with challenges, like having very little initial training data and a limited annotation budget [
21].
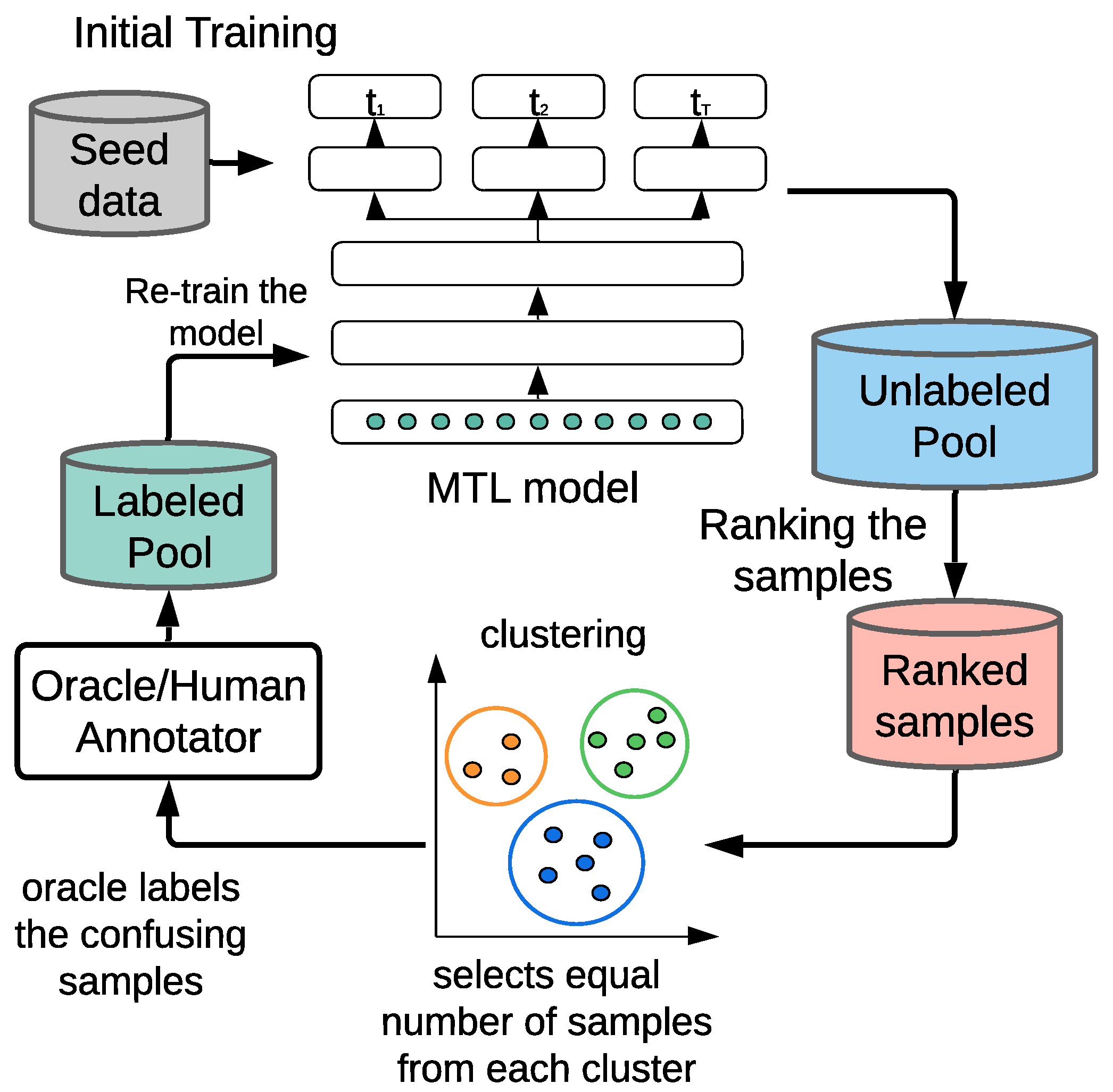
To counter the limitation of the current MTAL framework in wearable sensor systems such as in mHealth settings, we propose a clustered stratified sampling (CSS) algorithm (
Figure 1) that works with these query schemes and ensures effective training of the MTLs. In CSS, our goal is to empower the predictive model, leveraging a clustering technique within the active learning loop such that the model performs better in a substantially low-seed-data environment with small querying budget. We show that although training with the CSS algorithm introduces additional computation, it ensures a substantial performance boost. Because training in mobile health can be performed between microinteraction-based Ecological Momentary Assessment (µEMA) [
22] prompts, this allows us enough time to train the model.
Our contributions are summarized as follows:
First, we study the utility of multitask active learning querying strategies including one-sided selection, alternating selection and RC-based selection under a mobile health setup. To this end, we construct two datasets for multitask learning in mobile health settings and demonstrate the performance of the query strategies.
Second, we introduce a Clustered-Stratified Sampling (CSS) algorithm and employ it in parallel with the query methods to boost the performance compared to their original forms. We show through analysis that CSS exhibits substantial performance elevation for multiple tasks related to human activity and emotion classification from wearable sensor-transmitted signals and brain signals, respectively.
3. Approach
Let {, ⋯, } be a set of T learning tasks in a multi-task active learning setting. Furthermore, let = {(, ), (, ), ⋯, (, )} be the training set of size n for task . Note that the input observations are shared across all the tasks. Each input observation is a D-dimensional vector of form = [, , ⋯, ], which yields as the feature set or raw sensor data and as the target vector for task . Similarly, the unlabeled pool contains m samples, where each sample is also a D-dimensional input. The target vector is an vector unknown to us.
Let
be the prediction vector on test data for task
; we can write the loss for classification task
using cross-entropy as follows.
where
refers to the number of classes associated with task
,
p represents the number of test samples, and
denotes the output of the activation function.
The main objective of our multitask active learning is to minimize the total loss
over the
T tasks given an upper bound,
B, on the number of queries that are made.
subject to:
where
is the weight of task
and
is the maximum allowed queries that can be made. Solving the optimization problem in (
2) will result in finding
W, the parameters of the model.
Given the labeled pool
composed of sensor observations and task-specific labels, an active learning agent initializes training the model. With the obtained knowledge, the model is used to identify the most critical samples from the unlabeled pool as estimated by their informativeness. Informativeness can be estimated for each sample based on the least confidence [
26] method:
or by using margin sampling [
26]:
or by Shannon’s information entropy [
46]:
The critical samples, also known as the samples on which the model is least confident, are identified to be labeled by a human annotator or oracle. There are multiple choices regarding the direction along which the informativeness can be estimated. As referred to in
Figure 2, informativeness can be estimated by considering a reference task and based on the prediction probabilities on
made by the model for that specific task only. Alternatively, the reference task can be altered periodically rather than focusing on one task. Cumulative informativeness can be used as well to sort out the critical samples.
Clustered Stratified Sampling (CSS)
After initial training with seed data (i.e., ), a reference task is set in a typical one-sided selection and alternating selection method or not set at all for RC sampling. The model makes predictions on the unlabeled samples, and using their informativeness, the most critical data points are sorted out.
Setting the selection dependency solely based on informativeness, the agent will end up selecting samples abruptly distributed across different classes, thus biasing towards a specific class. Therefore, we aim to select samples evenly across the classes to alleviate the possibility of biasing towards any specific class. To this end, we employ a clustering method on the unlabeled pool to form clusters of similar data points. We then utilize the least confidence (LC) method to identify an equal number of the most critical data points by least top probabilities from these clustered samples. Note that CSS can be easily applied to the reference task-based approaches (i.e., one-sided and alternating) by simply setting the number of clusters equal to the number of classes of the reference task; however, there is no reference task in RC sampling, which leaves no clue for setting the number of clusters. Hence, we propose to relax the complexity of the approach and choose cluster number on the basis of the task with maximum classes.
This is also an interactive approach between the active learning agent and the oracle, where the agent repeatedly introduces these equally distributed highly informative samples to the oracle and gets them labeled. At each iteration, a mini-batch of
b samples will be pulled from the unlabeled pool
and integrated into the labeled pool
after annotation. So, the
iteration can be defined as:
Since we are developing clusters or strata of samples and performing stratified sampling, we call this method
Clustered Stratified Sampling (
CSS) [
47].
Algorithm 1 and the following lemma are presented for better explaining the methods.
| Algorithm 1 Algorithm for Clustered Stratified Sampling-based sample selection |
Inputs: unlabeled pool, , labeled pool, , Querying budget, B Querying batch size, b Ensure: Outputs: multitask network trained with fewer datapoints Train an multitask model from while do Identify informative instances using Arrange in clusters Create by selecting an equal number of samples from each cluster Query the oracle to obtain label of Train multitask model with end while Train final multitask network with
|
Lemma 1. The time complexity of iterative Clustered Stratified Sampling (Algorithm 1) is quadratic and depends on the iteration number k the number of data points (m and n), querying batch size b, and model architecture l.
Proof. Since Algorithm 1 is an iterative approach, the training time of the neural network is the main contributor to time complexity. On each iteration, the active learning agent has to perform the following steps:
Compute informativeness of the m unlabeled samples.
Cluster the m samples.
Find b samples with the highest informativeness.
Train the network with samples, where k is the iteration number.
The first two operations require time to complete, considering constant time for informativeness estimation. Clustering the m samples may vary in complexity depending on the clustering algorithm used. Assuming a standard clustering algorithm with a time complexity of , where c is the complexity of the clustering algorithm, the total time complexity for step 2 is .
If the training time increases linearly for
samples, step 4 takes
time, where
l is a term associated with the model architecture. So, the final time complexity for
k iterations is:
which is a quadratic complexity and comparable to that of a typical active learning framework. □
4. Experimental Setup
4.1. Datasets
To demonstrate our experiments, we chose KU-HAR [
48] and DEAP [
49] datasets.
KU-HAR contains smartphone recordings of 90 individuals’ (75 M, 15 F) 3-axial accelerometer and gyroscope data while performing 18 different activities. The samples were interpolated to maintain a 100 Hz sampling rate. To process the data, we adopted a sliding window of 5 s with 3 s overlap. The most frequent activity recognition window sizes are 0–1 s or 2–3 s [
50]. The reasoning behind selecting a 5 s window is that lowering the window size further results in detecting atomic actions rather than activity behaviors. Furthermore, because some of the recordings are only 7 s long, adopting a larger window size would result in significant data loss.
Activity classification is a well-suited problem in mobile health. Therefore, to make the mentioned dataset compatible with multitask learning, we split it into three tasks: (1) classification by activity type, (2) classification by Metabolic Equivalent of Task (MET) values, and (3) classification by stress-inducing/relieving/neutral type (
Table 1). MET values, as defined by the American Council on Exercise, measure how many calories are burned during any exercise. Hence, for task 2, we collected MET values [
51] and divided the 18 activities into distinct subcategories [
52]. Similarly, for task 3, all of these activities were categorized as stress-inducing, relieving, or highly relieving [
53,
54,
55].
In DEAP, 32 participants (19–37 years, mean = 26.9, 50% females) watched 40 one-minute long music videos with different emotional orientations while their 32 channel electroencephalograph (EEG) and peripheral physiological signals (PPG, respiratory, GSR, temperature, etc.) were recorded at a rate of 128 Hz. Signals were filtered with a band-pass filter with the cut-off set at 4.0 and 45.0 Hz. DEAP includes user-defined ratings for valence, arousal, dominance, and liking, which we used as target emotions and their levels.
Each signal was segmented into 5 s long windows with an overlap of 2 s, and 70 features, explicitly mentioned in
Table 2, were extracted from each segment using an EEG analysis tool [
56,
57]. Given that mood sensing is a well-matched task in mobile health setups [
58], the function of the multitask model was organized to predict the high or low level of (1) valence, (2) arousal, and (3) dominance based on a threshold of 5 on all dimensions as three different tasks (
Table 3).
4.2. Experiment
We chose a one-dimensional convolutional neural network (CNN)-based
hard-parameter sharing multitask scheme [
5] for KU-HAR. At the initial stages, when the labeled pool was tiny, a shallow model with one layer and eight filters was used to avoid overfitting the model as much as possible. As more labeled data became available, we gradually increased the number of neurons and layers in the predictive model across iterations to enhance its learning capacity. The selection of neurons and layers was guided by two criteria: ensuring convergence of training and test loss when sufficient labeled data were available or minimizing their difference as much as possible during initial iterations when labeled data were scarce. The final model had three layers, with each having 128 filters. The
regularizer was placed with a factor of 0.01, while dropout layer rates ranged between 0.45 and 0.98 depending on the amount of data. Softmax activation was employed in output layers for multiclass classification under each task, and ReLU [
59] was used in hidden layers. Class weights were either set manually or the training set was augmented to deal with unbalanced data. The number of epochs was consistent across all budget levels, i.e., 150 for KU-HAR.
For DEAP, our choice was a self-attention convolutional LSTM model of three layers with a hard-parameter sharing scheme of multitask network. Neuron numbers and dropout rate intensified as more data were introduced. Sigmoid activation was used in output layers under each task, while ReLU was employed in hidden layers. The regularization rate (0.01) and 800 epochs were consistent across all budgets.
Seed data consisted of three samples for initial training of the models. No preference was placed while selecting the seed samples, which means that every time, at least one class was missing a sample.
All the models were trained with an AMD Ryzen 7 2700X Eight-core CPU of 3.7 GHz speed, an NVIDIA GeForce GTX 1660 Ti Graphics Processing Unit (GPU) and 16 gigabytes of RAM. Hyper-parameters were tuned on a trial-and-error basis. All results were generated after identifying the best set of hyper-parameters. Results were evaluated with an accuracy-based performance metric and all the reported accuracy values on the KU-HAR dataset are an average of five attempts, with an average of three attempts for the DEAP dataset.
5. Results
We aim to demonstrate the querying techniques of MTAL in a mobile health setup constrained with low seed data and a low query budget and elevate the performance with CSS. This section highlights and analyzes the performances of all algorithms (one-sided, alternating, RC, CSS) at different query levels in terms of accuracy. Additionally, a comparison based on training time is conducted to examine if time is being compromised for better performance. We set several baselines in order to extensively validate the capability of CSS:
One-sided selection selects samples or sensor observations with respect to only one learning task, assuming that the performance of other learners will also improve as we gather labels about those tasks. This approach is an intrinsic selection for the reference learner and an extrinsic selection for all others. We set the task with maximum combined correlation as the reference task:
Alternating selection alternates the reference task over the training process to identify critical samples. This approach is not biased towards a particular learner.
Rank combination (RC)-based selection involves assigning
T (= number of tasks) ranks, denoted as
, to each sample from the set
. The ranks are determined based on the entropy observed after the model makes predictions on these samples. Lower confidence margin or higher entropy means higher informativeness and, therefore, lower rank. Finally, the ranks belonging to each sample are summed up to develop a combined ranking:
The samples with the least combined rank are the top candidates for annotation.
5.1. Validity of Multitask Network Performance
From the basics of multitask models, deploying a hard-parameter sharing model requires the affiliated tasks to be closely related [
12]. Since there is no concrete way to analyze task relationship [
12,
60], we first demonstrate that classification performance increased compared to that of single-task models as we incorporated multitask models. While supervised single-task accuracy numbers for KU-HAR were 93.4%, 92.6%, and 91.7% for classification by activity type, MET values, and stress, respectively, multitask registered 95.5%, 95.6%, and 93.6% under the same setup (dataset and task division), which were significant improvements from single-task. For DEAP, accuracy numbers were 70.4%, 70% and 70.5% in valence, arousal, and dominance level classification with single-task and slightly improved to 70.6%, 69.8%, and 71.2% after multitask deployment. These improvements validate the use of the multitask or hard-parameter sharing model for the aforementioned datasets and tasks.
Additionally, employing an STL for each task required higher combined execution time (6.9, 7.06, 6.9 min for task 1, 2, and 3 of KU-HAR, respectively, and 21.4, 21.5, 21.5 min for three tasks of DEAP). Also, STLs needed more parameters (291 k and 9 k for each task in two datasets, respectively) to train. In contrast, employing one MTL for all tasks ensured shorter execution time and training fewer parameters (9.9 min and 294 k parameters for KU-HAR and 23.8 min and 13.2 k for DEAP), which ensures a significant upgrade.
Furthermore, considering that the KU-HAR dataset encompasses 18 distinct labeled activities, one might contemplate an 18-class classification approach, subsequently translating it into multiple decisions arising from various tasks. However, this classification resulted in reduced accuracy, reaching only 74%.
5.2. Comparison Among One-Sided, Alternating and RC Sampling
We demonstrated one-sided sampling for different reference tasks and compared them against alternating and RC-based sampling at different querying budgets for both datasets. As mentioned earlier, the active learning agent iteratively utilizes the latest knowledge acquired by the multitask model to identify the best instances from the unlabeled pool.
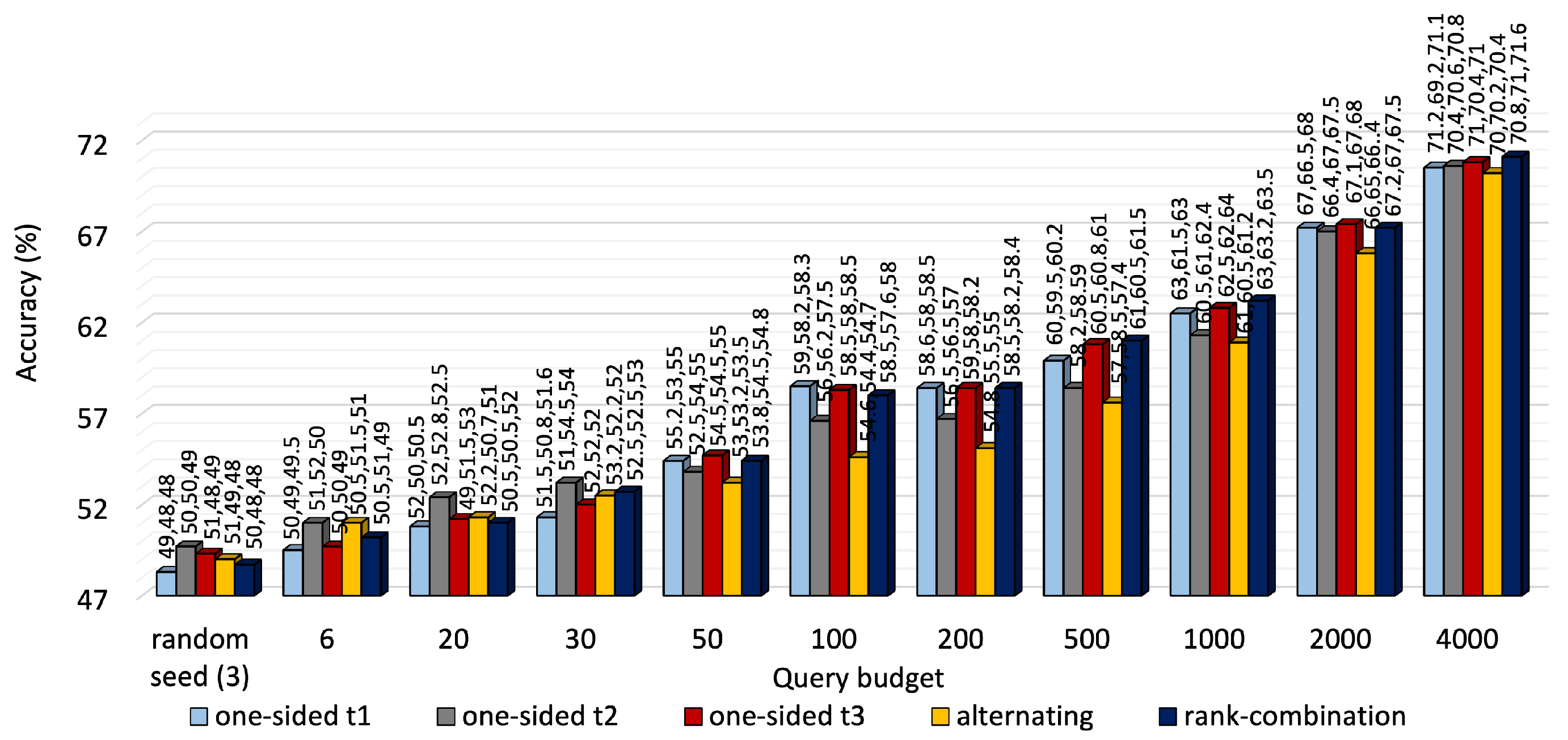
A performance comparison of the three approaches is shown in
Figure 3 for KU-HAR and
Figure 4 for DEAP. For most budget levels, RC-based selection outperforms its counterparts. For example, at 2000 queries, i.e., almost one-fifth of the available unlabeled KU-HAR data, RC sampling achieved 88%, 87% and 83% accuracy levels for three tasks, surpassing alternating sampling—which obtained 86%, 84% and 71% accuracy—and one-sided sampling—which obtained the best record of 91.5%, 92% and 70%—under the same settings. Again, at 4000 queries, RC sampling reached 70.8%, 71% and 71.6% accuracy values, respectively, for three tasks in DEAP against 70%, 70.2% and 70.4% of alternating sampling and 71%, 70.4% and 71% of one-sided sampling (task 3 as reference). As expected, RC seldom prioritized a single task like one-sided sampling; rather, it tried to improve performance for all tasks regardless. While it is quite evident from
Figure 3 that task 3 of KU-HAR achieves substantial improvements, it is capped at 72% for one-sided sampling with task 3 as reference. A similar improvement took place for task 2 of the DEAP dataset.
We notice that task 2 of KU-HAR, when set as the reference task of one-sided selection, performed the best among other reference tasks in terms of average accuracy (≈85%). Our observation is that task 2 for KU-HAR has the highest combined correlation with the other two tasks. Hence, labeling based on task 2 promoted shared learning and elevated the performance better than the other two. As shown in
Table 4, the combined correlation of task 2 is 1.73, compared to 1.55 and 4.68 for task 1 and 2, respectively. For DEAP, task 3 shows the highest combined correlation (0.66) and the best results (average 70.8%) among other the reference task of one-sided selection.
5.3. Performance of CSS
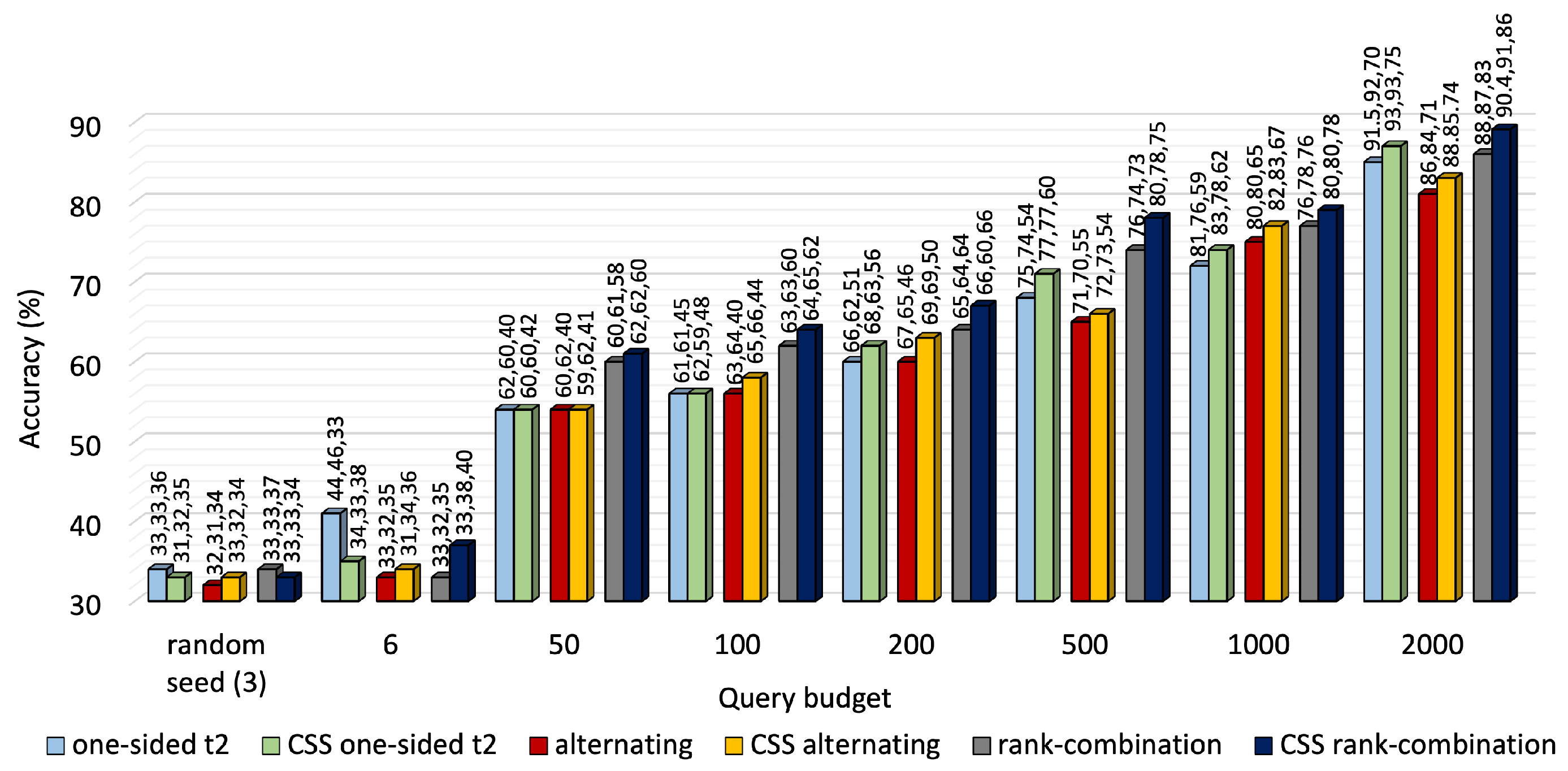
We implemented the clustered stratified sampling (CSS) algorithm for one-sided, alternating, RC sampling and compared their significance against those of plain one-sided, alternating and RC sampling at different budgets.
Figure 5 and
Figure 6 depict more analyses for KU-HAR and DEAP, respectively.
For KU-HAR, we formed three clusters on the unlabeled data. CSS outperformed the baseline selection schemes at most budget levels. At 2000 queries, CSS raised the average accuracy levels of one-sided, alternating and RC sampling to, respectively, 87%, 82.3%, 89.1% from 85%, 81%, 86%, achieved with their plain forms. Hence, CSS with RC sampling ensures a cumulative 9.3% accuracy gain over plain RC sampling.
We went up to 2000 prompts in the plots for KU-HAR, which may appear cumbersome to users. In mobile health, however, data will be generated from all 90 users of the KU-HAR dataset, yielding an average of 23 prompts per individual. Given a two-day data collection period, it would not be troublesome for users and would be compatible with µEMA.
While CSS improved the performance for one-sided selection on DEAP, such improvements were not visible for alternating and RC sampling. CSS depends on the performance of the clustering approach. Given the fact that the tasks of KU-HAR are highly correlated, clustering the unlabeled samples worked well for all tasks in all sampling approaches and helped CSS to identify the critical samples while maintaining equal distribution of samples from all classes. However, tasks of DEAP, not being highly correlated, could not make the most of clustering. Consequently, only one-sided sampling with task 3, with the DEAP dataset as reference, benefited from CSS (average accuracy jumped from 70.8% to 71.4%), and the other two sampling approaches suffered. Two clusters were formed with the unlabeled pool of DEAP, keeping it consistent with the number of classes.
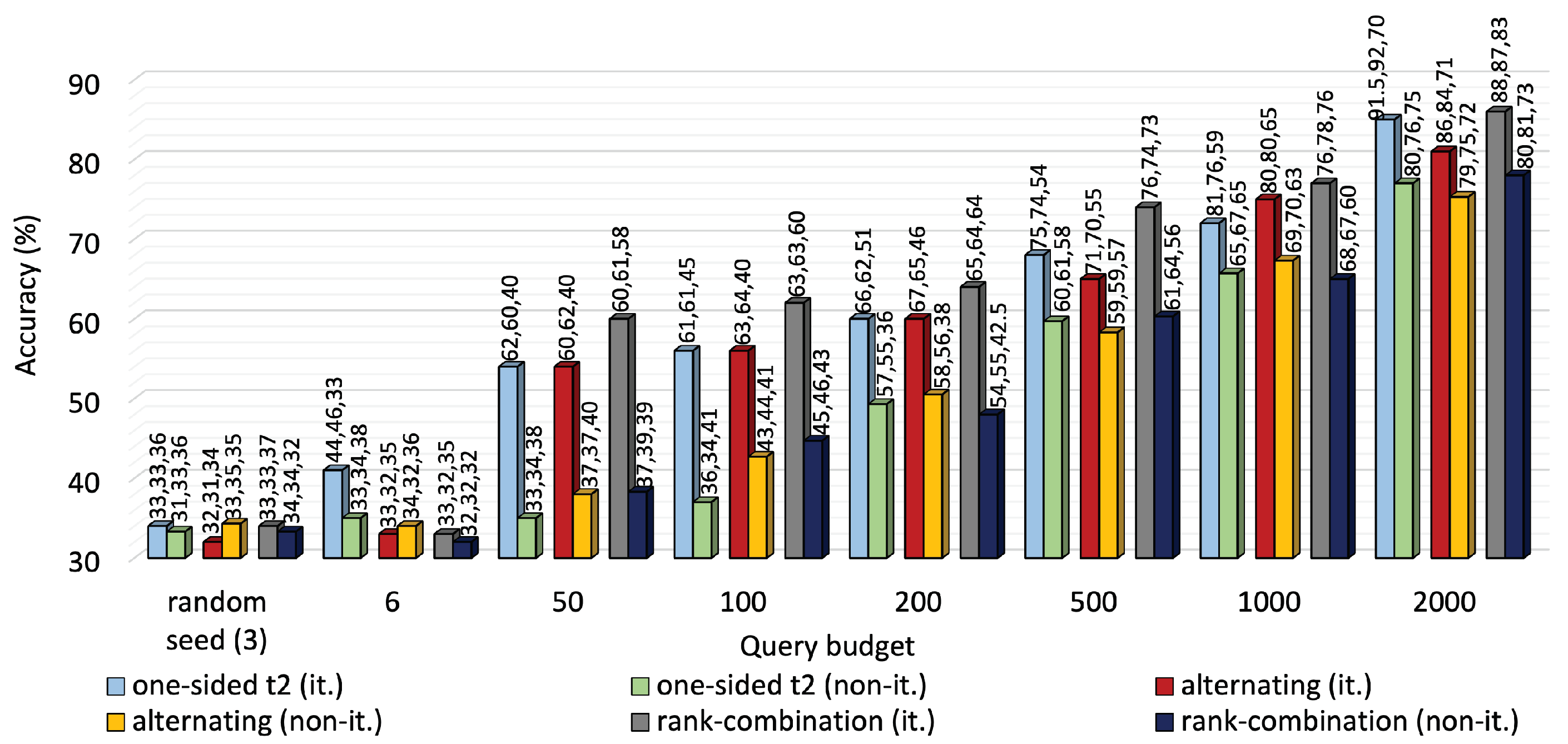
5.4. Is Iterative Interaction Helping?
By the definition of active learning, there must be repetitive interaction between the active learning agent and the oracle. The agent will always train the multitask model with newly acquired labels and utilize the new knowledge to identify the most critical samples iteratively. However, iterative algorithms are computationally expensive. Thus, the question arises of whether repeated contact is truly worthwhile.
To address this, we created a lookalike version of MTAL that operates in a non-iterative mode, with only one interaction between the agent and the oracle regardless of budget. This way, the multitask model is trained with initial seed samples, the agent identifies the least confident samples from the unlabeled pool using the knowledge of the multitask model, contacts the oracle, labels the critical samples based on the querying budget, and finally trains the model.
Figure 7 and
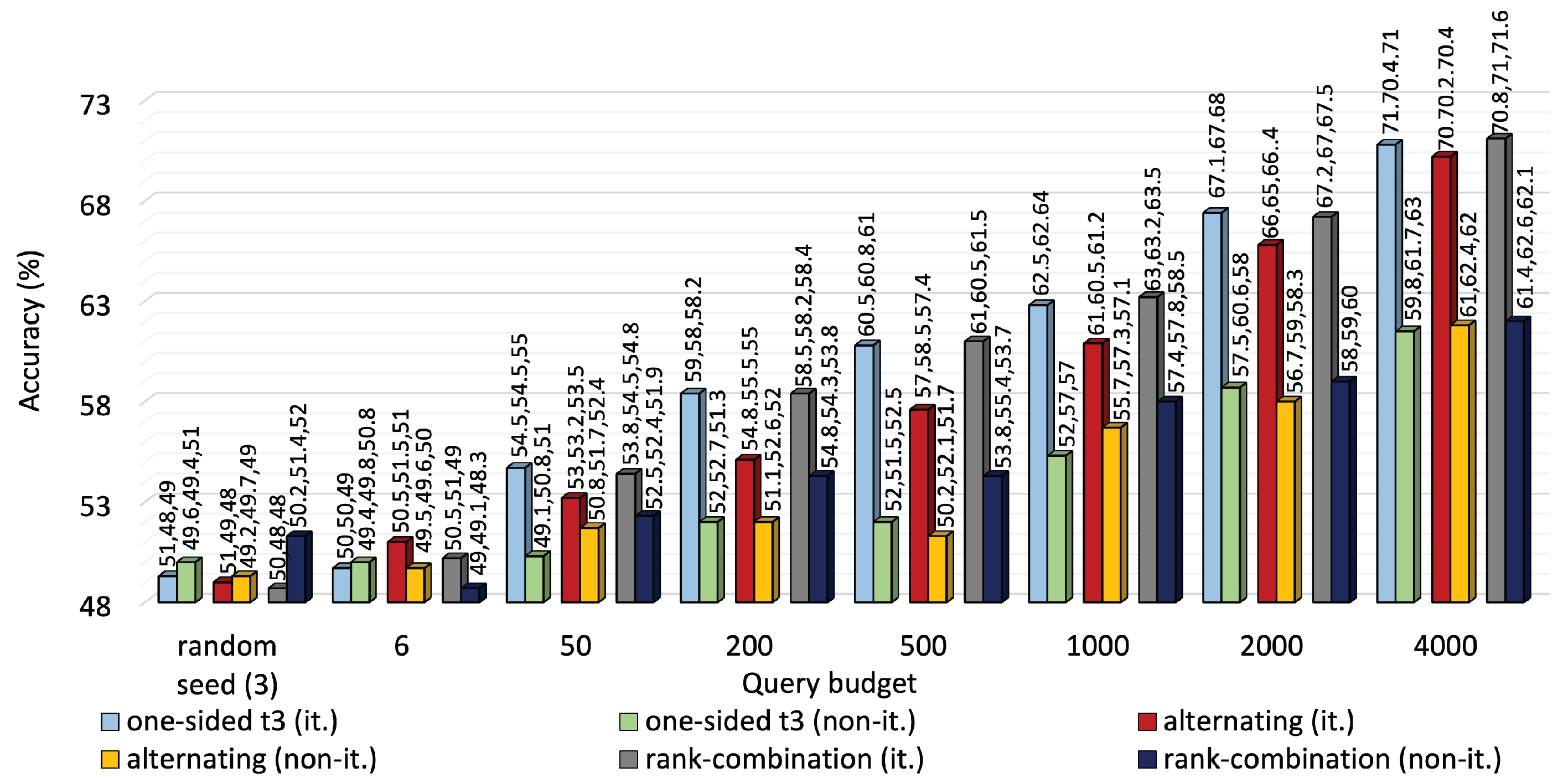
Figure 8 compare the performance of iterative MTAL to its non-iterative counterpart on the two datasets. Average accuracy declined to 77%, 75.3% and 78% from 85%, 81% and 86%, respectively, for one-sided, alternating and RC sampling at 2000 queries on KU-HAR. Also, iterative leverage of new knowledge ensured over 10% higher average accuracy than non-iterative modes of all querying methods at the highest query level on DEAP.
The summary of performances on the two datasets is enlisted in
Table 5 and
Table 6, respectively.
Similarly, iterative exploitation of new knowledge guaranteed almost 10% higher average accuracy than non-iterative modes of all querying techniques at maximum query level on the DEAP dataset.
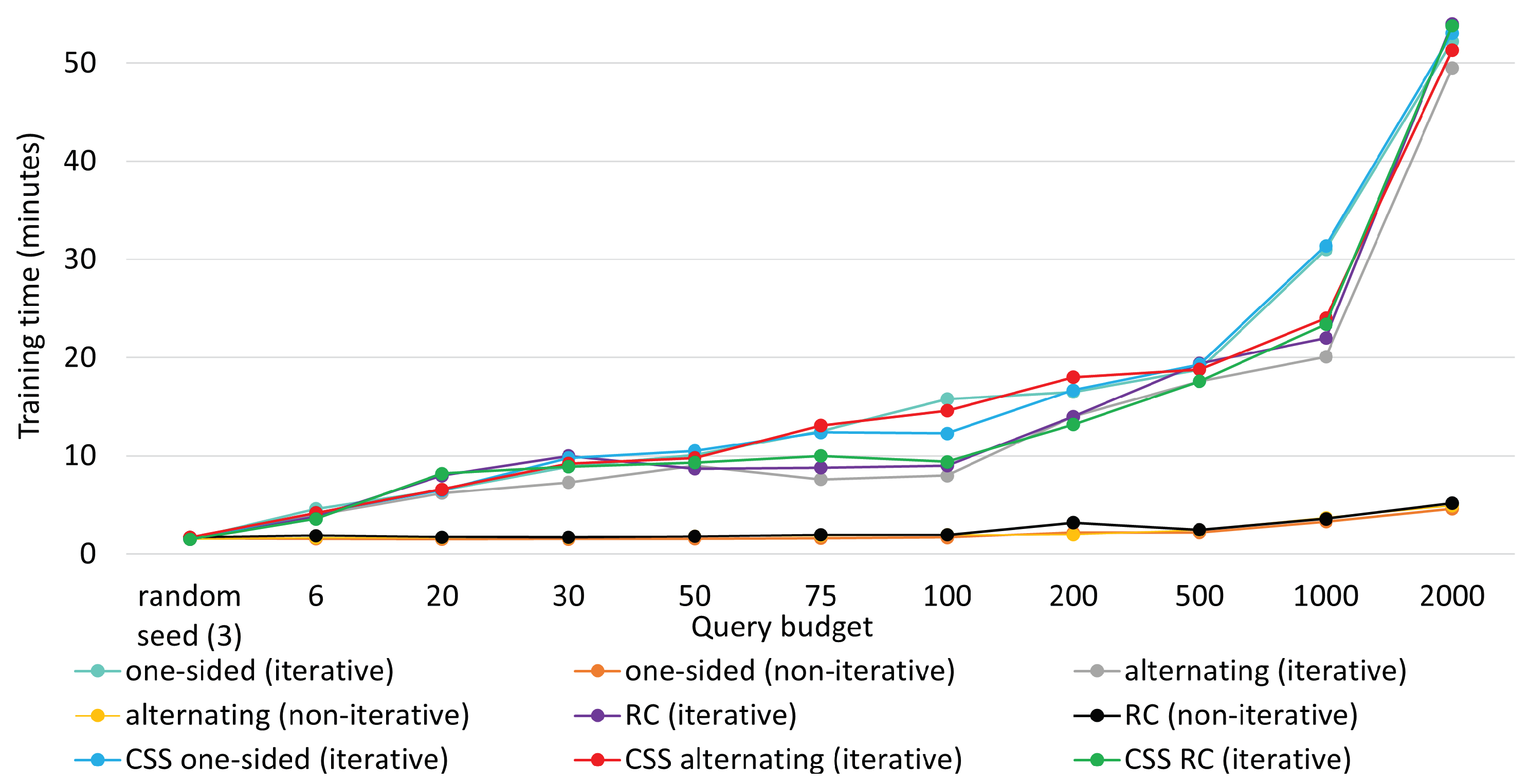
5.5. Training Time Comparison
Lastly, we compared training times for the aforementioned methods in
Figure 9 and
Figure 10, respectively for the two datasets. Note that training time includes sampling time as well, be it an iterative process or a non-iterative one. Thereby, all the iterative mini-batch methods exhibited higher training time. In contrast, the non-iterative ones were trained faster, as new knowledge was not considered to sample critical instances and no repetitive interplay took place between the agent and the annotator.
For iterative queries, training time increased almost linearly until 1000 queries. As the model was made deeper to handle 2000 instances, training time jumped abruptly to 52 min, making it somewhat exponential. Training times remained constant for non-iterative methods. Leveraging the iterative process, MTAL obtained an edge over non-iterative methods at the expense of reasonably higher training time. The plots below also suggest that clustering in CSS does not compromise much in terms of training time.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}