
GPC-YOLO: An Improved Lightweight YOLOv8n Network for the Detection of Tomato Maturity in Unstructured Natural Environments


Abstract
1. Introduction
2. Materials and Method
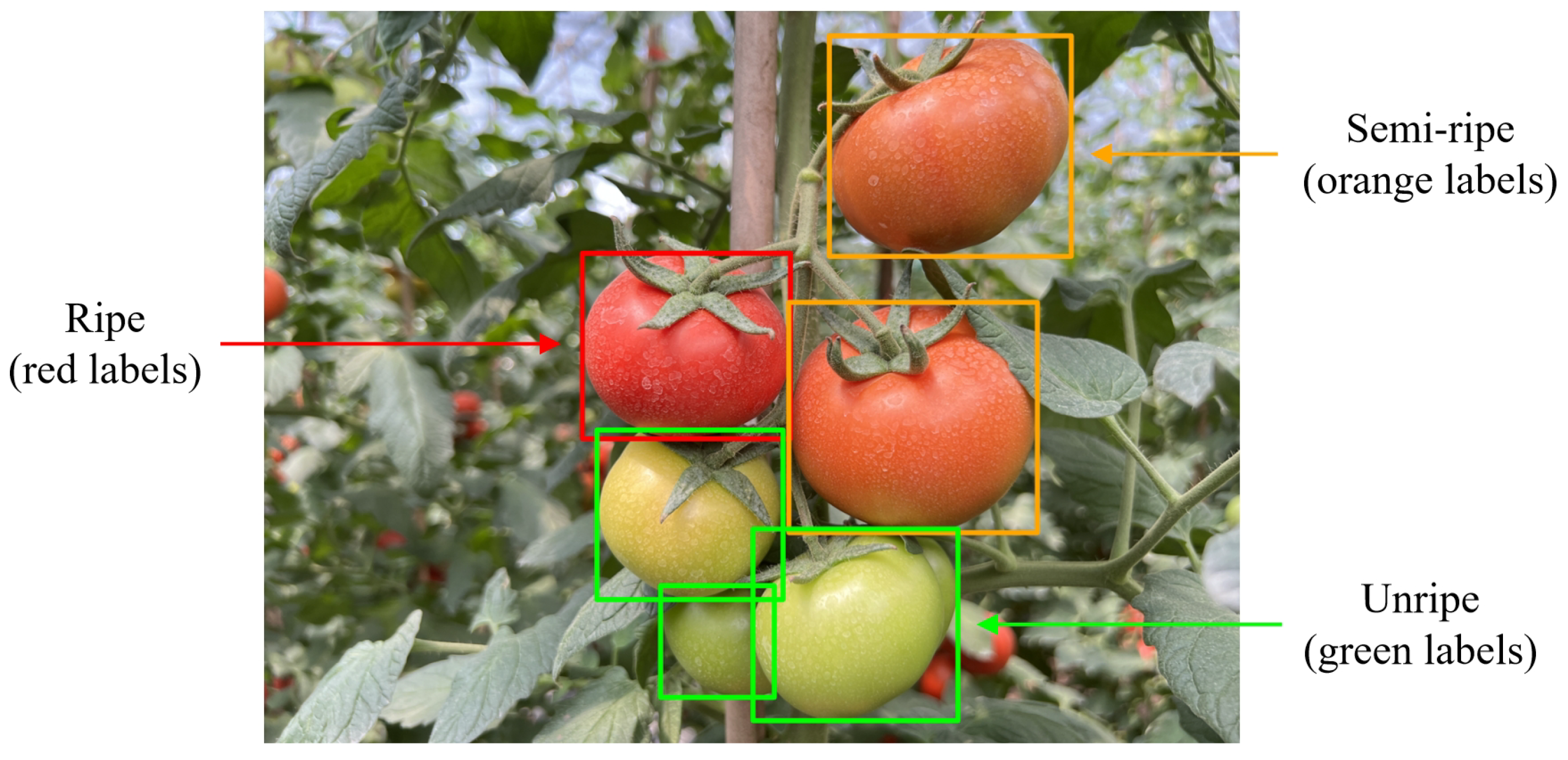
2.1. Dataset Preparation
2.1.1. Image Acquisition
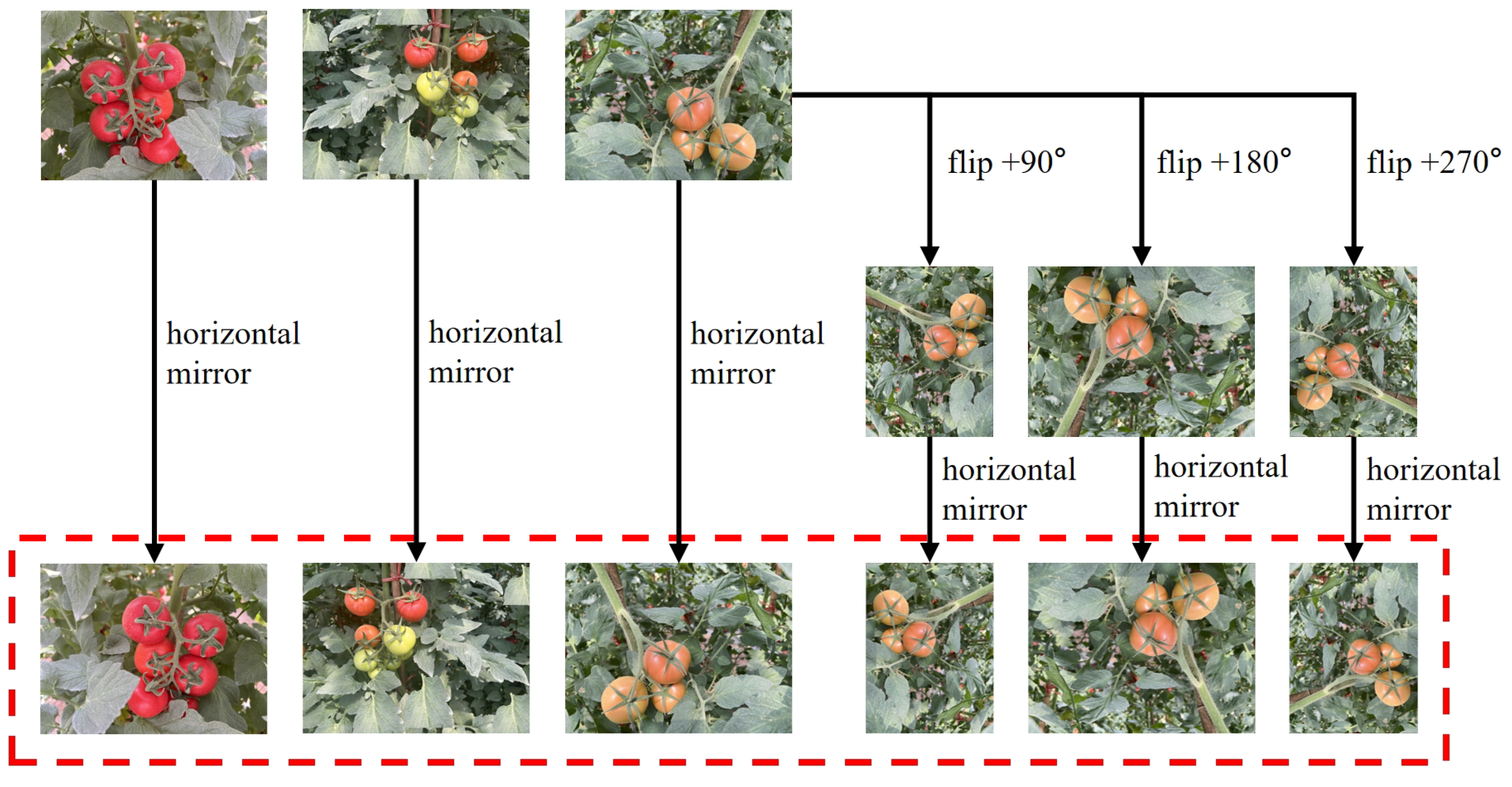
2.1.2. Image Preprocessing
2.2. Model Construction
2.2.1. YOLOv8n Network Structure
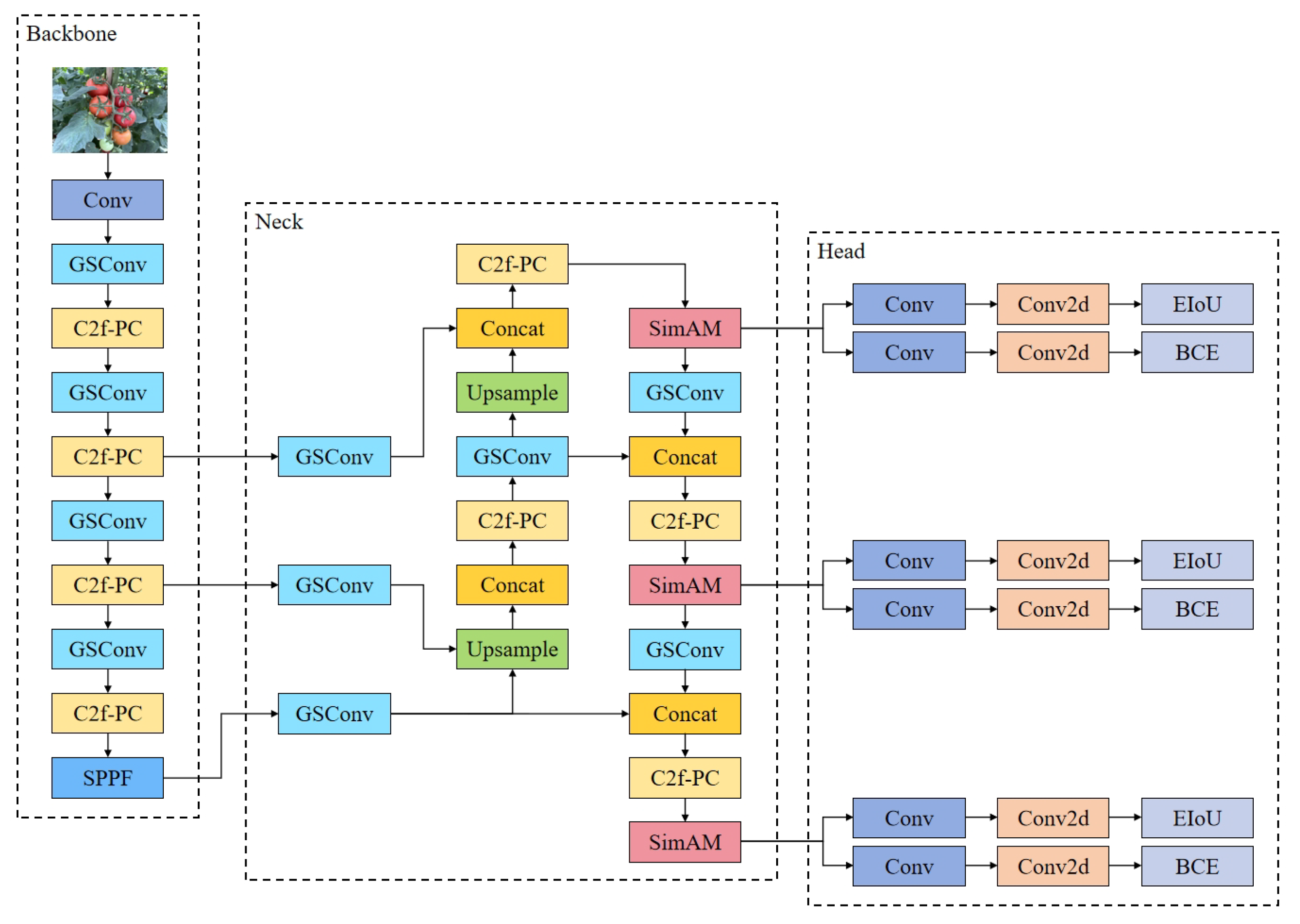
2.2.2. GPC-YOLO Network Structure
2.2.3. Grouped Spatial Convolution Module
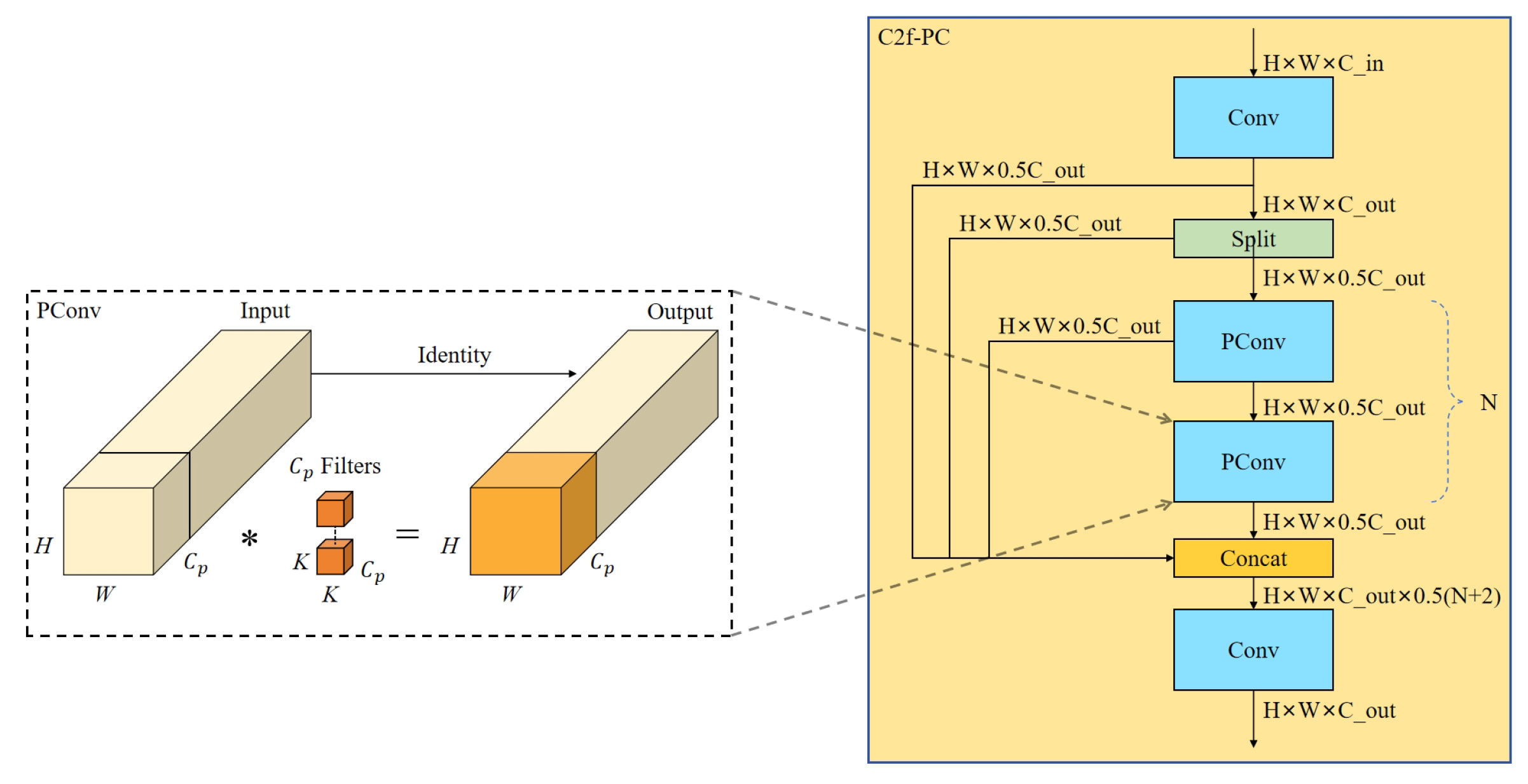
2.2.4. C2f-PC Module
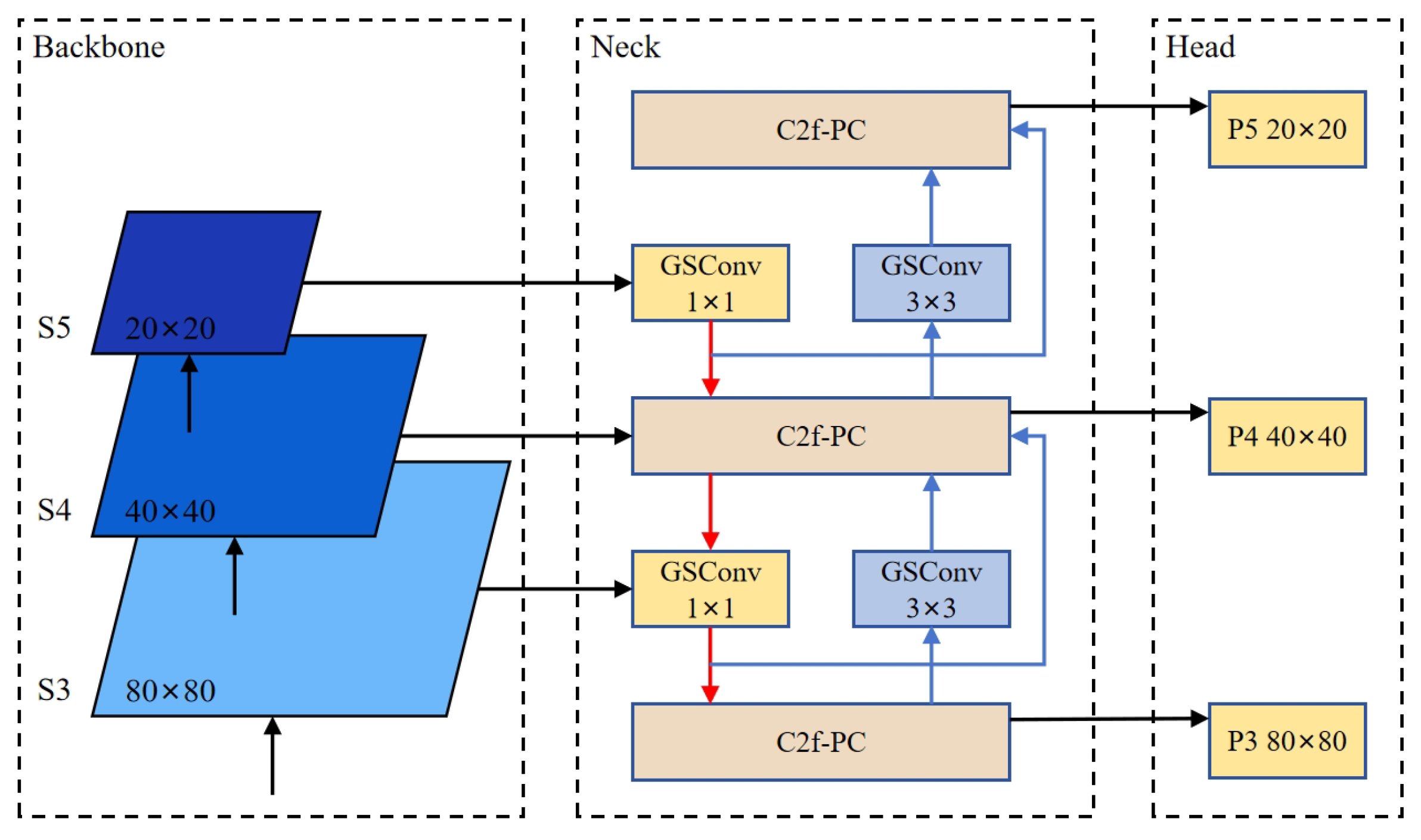
2.2.5. CNN-Based Cross-Scale Feature Fusion
2.2.6. Simple Attention Mechanism
2.2.7. EIoU Loss
2.3. Experimental Setting
2.4. Evaluation Metrics
3. Results
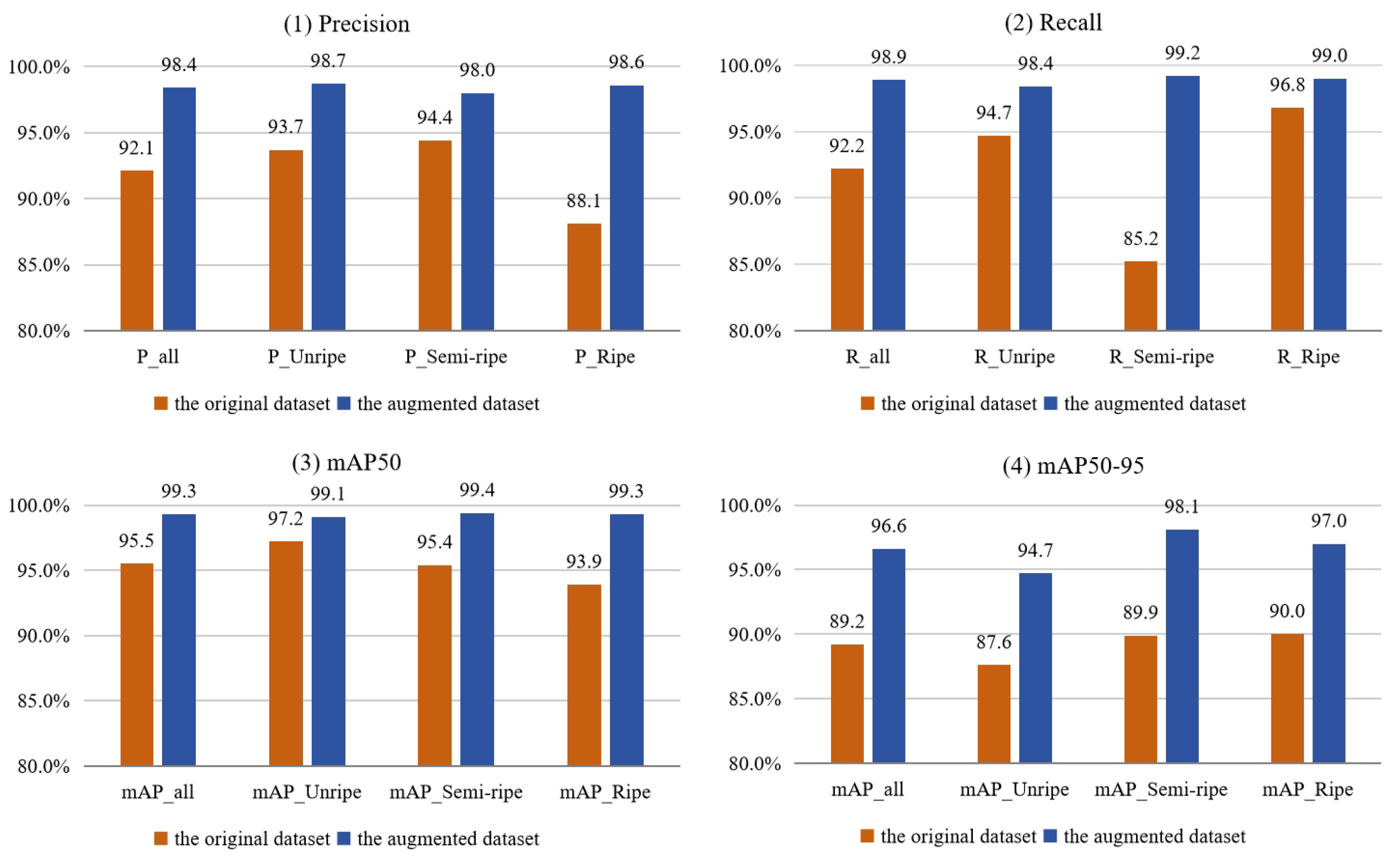
3.1. Performance of the Data Augmentation Method
3.2. Lightweight Module Ablation Experiments
3.3. GPC-YOLO Ablation Experiments
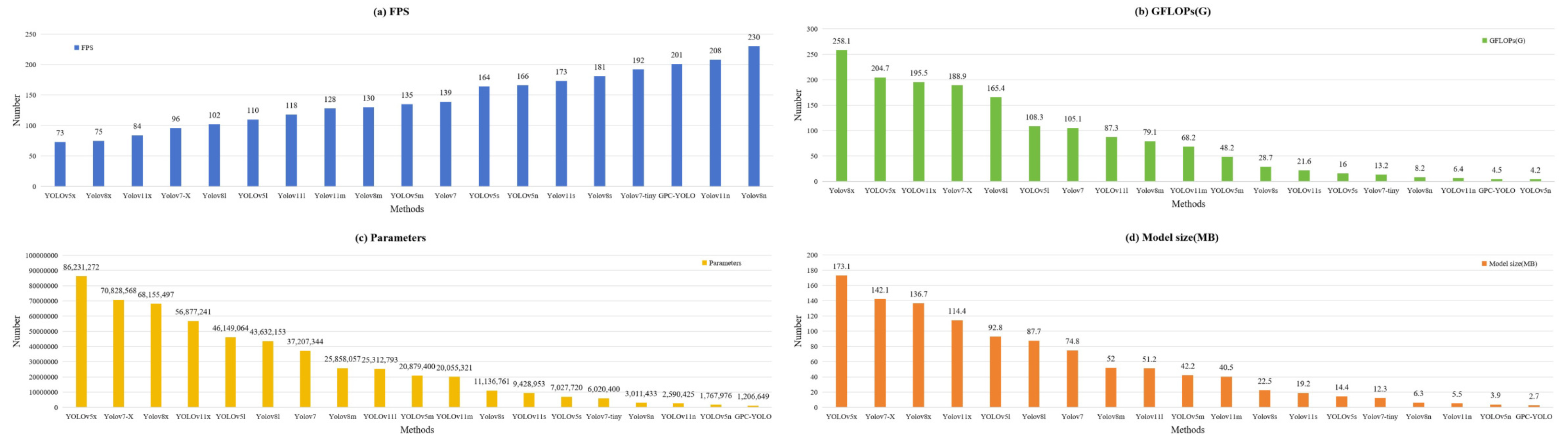
3.4. Comparisons with Other YOLO Versions
3.5. Performance Analysis of GPU Memory Utilization
3.6. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Collins, E.J.; Bowyer, C.; Tsouza, A.; Chopra, M. Tomatoes: An Extensive Review of the Associated Health Impacts of Tomatoes and Factors That Can Affect Their Cultivation. Biology 2022, 11, 239. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Tan, D.; Zhong, X.; Jia, M.; Ke, X.; Zhang, Y.; Cui, T.; Shi, L. Review on toxicology and activity of tomato glycoalkaloids in immature tomatoes. Food Chem. 2024, 447, 138937. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Yang, C.; Zhang, J.; Wang, C.; Ma, Z.; Zhang, L. Study on Quality Characteristics and Processing Availability of Immature Tomatoes in Different Ripening Stages. J. Food Sci. Biotechnol. 2022, 41, 58–66. [Google Scholar]
- Miao, Z.; Yu, X.; Li, N.; Zhang, Z.; He, C.; Li, Z.; Deng, C.; Sun, T. Efficient tomato harvesting robot based on image processing and deep learning. Precis. Agric. 2023, 24, 254–287. [Google Scholar] [CrossRef]
- Gao, F.; Fang, W.; Sun, X.; Wu, Z.; Zhao, G.; Li, G.; Li, R.; Fu, L.; Zhang, Q. A novel apple fruit detection and counting methodology based on deep learning and trunk tracking in modern orchard. Comput. Electron. Agric. 2022, 197, 107000. [Google Scholar] [CrossRef]
- Gao, C.; Jiang, H.; Liu, X.; Li, H.; Wu, Z.; Sun, X.; He, L.; Mao, W.; Majeed, Y.; Li, R.; et al. Improved binocular localization of kiwifruit in orchard based on fruit and calyx detection using YOLOv5x for robotic picking. Comput. Electron. Agric. 2024, 217, 108621. [Google Scholar] [CrossRef]
- Yang, Y.; Han, Y.; Li, S.; Yang, Y.; Zhang, M.; Li, H. Vision based fruit recognition and positioning technology for harvesting robots. Comput. Electron. Agric. 2023, 213, 108258. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, F.; Li, B. A heuristic tomato-bunch harvest manipulator path planning method based on a 3D-CNN-based position posture map and rapidly-exploring random tree. Comput. Electron. Agric. 2023, 213, 108183. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Zhang, R. Fruit Detection and Recognition Based on Deep Learning for Automatic Harvesting: An Overview and Review. Agronomy 2023, 13, 1625. [Google Scholar] [CrossRef]
- Tian, H.; Wang, T.; Liu, Y.; Qiao, X.; Li, Y. Computer vision technology in agricultural automation—A review. Inf. Process. Agric. 2020, 7, 1–19. [Google Scholar] [CrossRef]
- Dhanya, V.G.; Subeesh, A.; Kushwaha, N.L.; Vishwakarma, D.K.; Kumar, T.N.; Ritika, G.; Singh, A.N. Deep learning based computer vision approaches for smart agricultural applications. Artif. Intell. Agric. 2022, 6, 211–229. [Google Scholar] [CrossRef]
- Kaur, R.; Singh, S. A comprehensive review of object detection with deep learning. Digit. Signal Process. 2023, 132, 103812. [Google Scholar] [CrossRef]
- Ghazlane, Y.; Gmira, M.; Medromi, H. Overview of single-stage object detection models: From Yolov1 to Yolov7. In Proceedings of the 2023 International Wireless Communications and Mobile Computing (IWCMC), Marrakesh, Morocco, 19–23 June 2023; pp. 1579–1584. Available online: https://api.semanticscholar.org/CorpusID:260003238 (accessed on 26 February 2025).
- Li, Z.; Li, Y.; Yang, Y.; Guo, R.; Yang, J.; Yue, J.; Wang, Y. A high-precision detection method of hydroponic lettuce seedlings status based on improved Faster RCNN. Comput. Electron. Agric. 2021, 182, 106054. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Fusion of Mask RCNN and attention mechanism for instance segmentation of apples under complex background. Comput. Electron. Agric. 2022, 196, 106864. [Google Scholar] [CrossRef]
- Yuan, T.; Lv, L.; Zhang, F.; Fu, J.; Gao, J.; Zhang, J.; Li, W.; Zhang, C.; Zhang, W. Robust Cherry Tomatoes Detection Algorithm in Greenhouse Scene Based on SSD. Agriculture 2020, 10, 160. [Google Scholar] [CrossRef]
- Latha, R.S.; Sreekanth, G.R.; Rajadevi, R.; Nivetha, S.K.; Kumar, K.A.; Akash, V.; Bhuvanesh, S.; Anbarasu, P. Fruits and Vegetables Recognition using YOLO. In Proceedings of the 2022 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 25–27 January 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Badgujar, C.M.; Poulose, A.; Gan, H. Agricultural object detection with You Only Look Once (YOLO) Algorithm: A bibliometric and systematic literature review. Comput. Electron. Agric. 2024, 223, 109090. [Google Scholar] [CrossRef]
- Chen, Y.; Zheng, L.; Peng, H. Assessing pineapple maturity in complex scenarios using an improved retinanet algorithm. Eng. Agrícola 2023, 43, e20220180. [Google Scholar] [CrossRef]
- Lu, Y.; Zhang, L.; Xie, W. YOLO-compact: An Efficient YOLO Network for Single Category Real-time Object Detection. In Proceedings of the 2020 Chinese Control And Decision Conference (CCDC), Hefei, China, 22–24 August 2020; pp. 1931–1936. [Google Scholar] [CrossRef]
- Liu, Z.; Abeyrathna, R.M.R.D.; Sampurno, R.M.; Nakaguchi, V.M.; Ahamed, T. Faster-YOLO-AP: A Lightweight Apple Detection Algorithm Based on Improved YOLOv8 with a New Efficient PDWConv in Orchard. Comput. Electron. Agric. 2024, 223, 109118. [Google Scholar] [CrossRef]
- Chen, J.; Ma, A.; Huang, L.; Li, H.; Zhang, H.; Huang, Y.; Zhu, T. Efficient and Lightweight Grape and Picking Point Synchronous Detection Model Based on Key Point Detection. Comput. Electron. Agric. 2024, 217, 108612. [Google Scholar] [CrossRef]
- Zeng, T.; Li, S.; Song, Q.; Zhong, F.; Wei, X. Lightweight Tomato Real-time Detection Method Based on Improved YOLO and Mobile Deployment. Comput. Electron. Agric. 2023, 205, 107625. [Google Scholar] [CrossRef]
- Tamrakar, N.; Karki, S.; Kang, M.Y.; Deb, N.C.; Arulmozhi, E.; Kang, D.Y.; Kook, J.; Kim, H.T. Lightweight Improved YOLOv5s-CGhostnet for Detection of Strawberry Maturity Levels and Counting. AgriEngineering 2024, 6, 962–978. [Google Scholar] [CrossRef]
- Xiao, F.; Wang, H.; Xu, Y.; Shi, Z. A Lightweight Detection Method for Blueberry Fruit Maturity Based on an Improved YOLOv5 Algorithm. Agriculture 2024, 14, 36. [Google Scholar] [CrossRef]
- Moreira, G.; Magalhães, S.A.; Pinho, T.; dos Santos, F.N.; Cunha, M. Benchmark of Deep Learning and a Proposed HSV Colour Space Models for the Detection and Classification of Greenhouse Tomato. Agronomy 2022, 12, 356. [Google Scholar] [CrossRef]
- Su, F.; Zhao, Y.; Wang, G.; Liu, P.; Yan, Y.; Zu, L. Tomato Maturity Classification Based on SE-YOLOv3-MobileNetV1 Network under Nature Greenhouse Environment. Agronomy 2022, 12, 1638. [Google Scholar] [CrossRef]
- Li, R.; Ji, Z.; Hu, S.; Huang, X.; Yang, J.; Li, W. Tomato Maturity Recognition Model Based on Improved YOLOv5 in Greenhouse. Agronomy 2023, 13, 603. [Google Scholar] [CrossRef]
- Li, P.; Zheng, J.; Li, P.; Long, H.; Li, M.; Gao, L. Tomato Maturity Detection and Counting Model Based on MHSA-YOLOv8. Sensors 2023, 23, 6701. [Google Scholar] [CrossRef]
- Wang, C.; Wang, C.; Wang, L.; Wang, J.; Liao, J.; Li, Y.; Lan, Y. A Lightweight Cherry Tomato Maturity Real-Time Detection Algorithm Based on Improved YOLOV5n. Agronomy 2023, 13, 2106. [Google Scholar] [CrossRef]
- Wu, M.; Lin, H.; Shi, X.; Zhu, S.; Zheng, B. MTS-YOLO: A Multi-Task Lightweight and Efficient Model for Tomato Fruit Bunch Maturity and Stem Detection. Horticulturae 2024, 10, 1006. [Google Scholar] [CrossRef]
- Wei, J.; Ni, L.; Luo, L.; Chen, M.; You, M.; Sun, Y.; Hu, T. GFS-YOLO11: A Maturity Detection Model for Multi-Variety Tomato. Agronomy 2024, 14, 2644. [Google Scholar] [CrossRef]
- Wang, S.; Xiang, J.; Chen, D.; Zhang, C. A Method for Detecting Tomato Maturity Based on Deep Learning. Appl. Sci. 2024, 14, 11111. [Google Scholar] [CrossRef]
- Gao, X.; Ding, J.; Zhang, R.; Xi, X. YOLOv8n-CA: Improved YOLOv8n Model for Tomato Fruit Recognition at Different Stages of Ripeness. Agronomy 2025, 15, 188. [Google Scholar] [CrossRef]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A Lightweight-Design for Real-time Detector Architectures. J. Real-Time Image Process. 2024, 21, 62. [Google Scholar] [CrossRef]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2024, arXiv:2304.08069. [Google Scholar]
- Yang, L.; Zhang, R.; Li, L.; Xie, X. SimAM: A Simple, Parameter-Free Attention Module for Convolutional Neural Networks. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; Available online: https://api.semanticscholar.org/CorpusID:235825945 (accessed on 26 February 2025).
- Zhang, Y.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Chen, J.; Kao, S.-H.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 12021–12031. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing Geometric Factors in Model Learning and Inference for Object Detection and Instance Segmentation. IEEE Trans. Cybern. 2022, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.; Ye, C.; Akin, B.; et al. MobileNetV4—Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Tang, Y.; Han, K.; Guo, J.; Xu, C.; Xu, C.; Wang, Y. GhostNetV2: Enhance Cheap Operation with Long-Range Attention. arXiv 2022, arXiv:2211.12905. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision 2018, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Lin, Z.; Han, J.; Ding, G. Rep ViT: Revisiting Mobile CNN From ViT Perspective. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 16–22 June 2024; pp. 15909–15920. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | P (%) | R (%) | mAP50 (%) | FPS | GFLOPs (G) | Parameters | Model Size (MB) |
|---|---|---|---|---|---|---|---|
| YOLOv8n | 98.4 | 98.9 | 99.3 | 230 | 8.2 | 3,011,433 | 6.3 |
| YOLOv8n+MobileNetV4 small | 97.1 | 96.8 | 98.9 | 205 | 8.0 | 4,302,073 | 8.9 |
| YOLOv8n+GhostNet V2 | 97.8 | 98.2 | 99.1 | 148 | 8.7 | 6,334,813 | 13.3 |
| YOLOv8n+ShuffleNet V2 small | 98.4 | 98.7 | 99.2 | 218 | 7.5 | 2,793,813 | 5.9 |
| YOLOv8n+RepViT | 98.3 | 98.4 | 99.2 | 186 | 11.7 | 4,125,421 | 8.7 |
| GPC-YOLO | 98.7 | 98.4 | 99.2 | 201 | 4.5 | 1,206,649 | 2.7 |
| Experiments | Settings |
|---|---|
| Ablation | A: GSConv Module |
| B: C2f-PC Module | |
| C: CCFF Module | |
| D: Simple Attention Mechanism | |
| E: EIoU loss |
| Model | P | R | mAP50 | mAP50:95 | FPS | GFLOPs | Parameters | Model Size |
|---|---|---|---|---|---|---|---|---|
| (%) | (%) | (%) | (%) | (G) | (MB) | |||
| YOLOv8n | 98.4 | 98.9 | 99.3 | 96.6 | 230 | 8.2 | 3,011,433 | 6.3 |
| YOLOv8n+A | 99.0 | 98.4 | 99.3 | 96.6 | 222 | 7.6 | 2,731,833 | 5.7 |
| YOLOv8n+A+B | 98.3 | 98.8 | 99.2 | 94.9 | 228 | 5.4 | 1,843,737 | 3.9 |
| YOLOv8n+A+B+C | 98.5 | 97.7 | 99.2 | 94.6 | 222 | 4.5 | 1,206,649 | 2.7 |
| YOLOv8n+A+B+C+D | 98.5 | 98.2 | 99.2 | 95.1 | 205 | 4.5 | 1,206,649 | 2.7 |
| YOLOv8n+A+B+C+D+E | 98.7 | 98.4 | 99.2 | 95.0 | 201 | 4.5 | 1,206,649 | 2.7 |
| (+0.3) | (−3.7) | (−1,804,784) | (−3.6) |
| Model | P (%) | R (%) | mAP50 (%) | mAP50:95 (%) | FPS | GFLOPs (G) | Parameters | Model Size (MB) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 98.9 | 99.1 | 99.3 | 95.8 | 166 | 4.2 | 1,767,976 | 3.9 |
| YOLOv5s | 99.0 | 98.9 | 99.3 | 97.7 | 164 | 16.0 | 7,027,720 | 14.4 |
| YOLOv5m | 99.3 | 99.4 | 99.4 | 98.6 | 135 | 48.2 | 20,879,400 | 42.2 |
| YOLOv5l | 99.2 | 99.2 | 99.4 | 98.7 | 110 | 108.3 | 46,149,064 | 92.8 |
| YOLOv5x | 99.0 | 99.2 | 99.4 | 98.8 | 73 | 204.7 | 86,231,272 | 173.1 |
| Yolov7-tiny | 98.5 | 99.0 | 99.6 | 95.2 | 192 | 13.2 | 6,020,400 | 12.3 |
| Yolov7 | 99.1 | 98.7 | 99.7 | 97.8 | 139 | 105.1 | 37,207,344 | 74.8 |
| Yolov7-X | 98.8 | 99.2 | 99.5 | 98.0 | 96 | 188.9 | 70,828,568 | 142.1 |
| Yolov8n | 98.4 | 98.9 | 99.3 | 96.6 | 230 | 8.2 | 3,011,433 | 6.3 |
| Yolov8s | 99.1 | 99.1 | 99.3 | 98.0 | 181 | 28.7 | 11,136,761 | 22.5 |
| Yolov8m | 99.1 | 98.9 | 99.4 | 98.4 | 130 | 79.1 | 25,858,057 | 52 |
| Yolov8l | 98.5 | 98.8 | 99.2 | 98.4 | 102 | 165.4 | 43,632,153 | 87.7 |
| Yolov8x | 98.5 | 98.5 | 99.3 | 98.4 | 75 | 258.1 | 68,155,497 | 136.7 |
| Yolov11n | 98.9 | 98.4 | 99.2 | 96.7 | 208 | 6.4 | 2,590,425 | 5.5 |
| Yolov11s | 98.8 | 99.1 | 99.3 | 97.9 | 173 | 21.6 | 9,428,953 | 19.2 |
| Yolov11m | 98.9 | 99.2 | 99.3 | 98.4 | 128 | 68.2 | 20,055,321 | 40.5 |
| Yolov11l | 99.3 | 99.0 | 99.4 | 98.6 | 118 | 87.3 | 25,312,793 | 51.2 |
| Yolov11x | 98.9 | 99.1 | 99.4 | 98.7 | 84 | 195.5 | 56,877,241 | 114.4 |
| GPC-YOLO | 98.7 | 98.4 | 99.2 | 95.0 | 201 | 4.5 | 1,206,649 | 2.7 |
| Hardware | Model | GPU Memory Allocated (MB) | GPU Memory Cached (MB) |
|---|---|---|---|
| RTX 3090 | GPC-YOLO | 36.76 | 212.00 |
| RTX 3090 | YOLOv8n | 43.56 | 218.00 |
| GTX 1050 Ti | GPC-YOLO | 36.76 | 84.00 |
| GTX 1050 Ti | YOLOv8n | 43.56 | 90.00 |
| Jetson AGX Xavier | GPC-YOLO | 4.76 | 180.00 |
| Jetson AGX Xavier | YOLOv8n | 11.56 | 294.00 |
| Jetson TX2 NX | GPC-YOLO | 4.76 | 60.00 |
| Jetson TX2 NX | YOLOv8n | 11.56 | 66.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, Y.; Qiao, J.; Liu, N.; He, Y.; Li, S.; Hu, X.; Yu, C.; Zhang, C. GPC-YOLO: An Improved Lightweight YOLOv8n Network for the Detection of Tomato Maturity in Unstructured Natural Environments. Sensors 2025, 25, 1502. https://doi.org/10.3390/s25051502
Dong Y, Qiao J, Liu N, He Y, Li S, Hu X, Yu C, Zhang C. GPC-YOLO: An Improved Lightweight YOLOv8n Network for the Detection of Tomato Maturity in Unstructured Natural Environments. Sensors. 2025; 25(5):1502. https://doi.org/10.3390/s25051502
Chicago/Turabian StyleDong, Yaolin, Jinwei Qiao, Na Liu, Yunze He, Shuzan Li, Xucai Hu, Chengyan Yu, and Chengyu Zhang. 2025. "GPC-YOLO: An Improved Lightweight YOLOv8n Network for the Detection of Tomato Maturity in Unstructured Natural Environments" Sensors 25, no. 5: 1502. https://doi.org/10.3390/s25051502
APA StyleDong, Y., Qiao, J., Liu, N., He, Y., Li, S., Hu, X., Yu, C., & Zhang, C. (2025). GPC-YOLO: An Improved Lightweight YOLOv8n Network for the Detection of Tomato Maturity in Unstructured Natural Environments. Sensors, 25(5), 1502. https://doi.org/10.3390/s25051502