FL is a privacy-preserving distributed ML model that enables FL clients to learn a shared ML model collaboratively without disclosing local data. The application of FL for IoT networks has been used recently, as the ML model is distributed among FL clients, which helps in preserving the computation resources. Three FL architectures are commonly used: centralized FL (client–server), decentralized FL (device-to-device), and semi-decentralized FL.
2.3.1. Centralized FL (Client–Server)
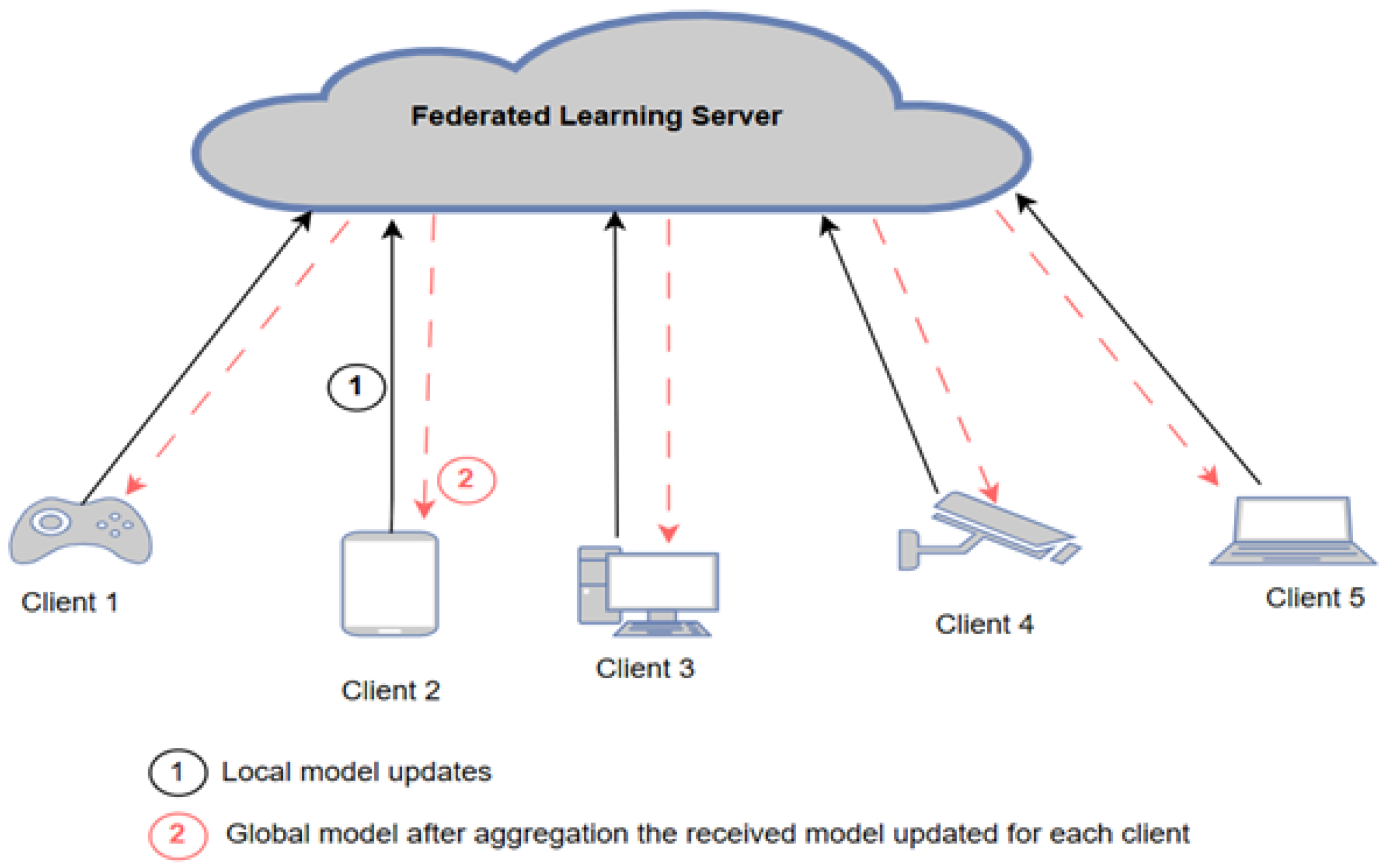
In this architecture, each device independently trains its local models using its own data. The parameters or weights from these local models are then aggregated to form a global model, which is managed by a central entity, such as a server or coordinator, as shown in
Figure 1. The training process involves several rounds. In each round, clients send their weights to the server, which updates the global model. This process continues until the desired accuracy is achieved or a predetermined number of rounds is completed [
7,
8].
The deployment of centralized FL for IoT networks comes in two schemes: first, the edge–cloud architecture, in which a cloud server functions as an FL server and an edge device functions as an FL client; second, the edge layer architecture, in which the edge device functions as the FL server and the IoT device (end node) functions as the FL client. Many studies have been proposed based on cloud–edge architecture. Huong et al. [
22] developed a low-complexity cyberattack detection in IoT edge computing (LocKedge), in which the cloud server extracts the most relevant features using the principal component analysis (PCA) method, and the NN model’s hyper-parameters and initial weights can be set. This information is then sent to all edge devices to train their models with their own data using SGD. Once all edge devices finish the training process, they send the updated weights of their model to the server for the aggregation process. LocKedge is evaluated in two modes, traditional ML and FL, and the results showed that traditional ML has a higher detection rate than FL because of uneven data distribution—non-IID (non-independent and identically distributed among edge devices). Rashid et al. [
23] developed an FL-based model for cyberattack detection in IIoT networks. They applied CNN and RNN for both traditional ML and FL. According to their results, the FL model with a low number of rounds and the traditional ML model differ considerably (both CNN and RNN). However, as the number of FL rounds increases, the margin shrinks, and at the 50th round, the FL-based model reaches the same intrusion detection accuracy as traditional ML. Similar work is presented in [
24] but with datasets distributed in a different ratio among clients. Their results show that the variation in dataset distributions would be the cause of the performance gap between FL and traditional ML. This is because the non-IID data could cause local updates from different clients to clash, which results in performance degradation of the global model. Zhang et al. [
25] proposed a federated learning framework known as FedDetect for IoT cybersecurity. The proposed model has improved the performance by utilizing a local adaptive optimizer and a cross-round learning rate scheduler instead of FedAvg for local training. According to the evaluation results of two settings—traditional ML and FL—FL’s detection accuracy is worse than traditional ML because, with the former, the server cannot directly learn the data’s features, as with traditional ML, making FL worse for feature learning. However, the system efficiency analysis indicates that both end-to-end training time and memory costs are affordable and promising for resource-constrained IoT devices. Another FL-based IDS model was developed by [
26] using a deep autoencoder to detect botnet attacks using on-device decentralized traffic data. They installed a virtual machine on each edge device to conduct the local model training, and they used port mirroring on the edge devices so that network traffic flow toward the IoT devices was not interrupted. However, using a virtual machine comes with many issues, such as complexity, less efficiency, and high cost. An ensemble, multiview, FL-based model was proposed by [
27], which categorizes packet information into three groups: bidirectional features, unidirectional features, and packet features. Each view is trained using NN, and then their predicted results are sent to the rain forest (RF) classifier, which acts as an ensembler that combines the three views’ predictions and provides a single attack prediction based on its probability and occurrence. Similarly, Driss et al. [
28] also proposed FL-based attack detection that uses RF to ensemble the global ML models—GRU with different window sizes—to detect attacks in vehicular sensor networks (VSN). According to the experimental results of both studies [
27,
28], the use of an ensembler unit increases the attack prediction accuracy. Friha et al. [
29] applied FL in an agricultural IoT network using three DL models—DNN, CNN, and RNN— on three different datasets. Their results show that one of the datasets—namely InSDN—outperformed the traditional ML model. The results also demonstrate that time and energy consumption have been affected by the DL model and number of clients involved in the FL process.
The communication burden is one of the biggest issues in centralized FL as each client sends their model weights/parameters to the server and then receives the new weights/parameters (after aggregation) from the server. Thus, a client selection is proposed to reduce the number of participating clients in the learning process. An FL-based model deployed in the edge layer, in which the edge device is the FL server and the IoT device is the FL client, was proposed by [
30,
31]. Considering that IoT devices vary in their resource capabilities, one that satisfies the requirements of ML/DL algorithms must be selected. Chen et al. [
30] developed an asynchronous FL model to improve training efficiency for heterogeneous IoT devices. The selection algorithm is based on the node’s computing resources and its communication condition. Thus, instead of waiting for all nodes to send their weight vectors to be aggregated by the server, only the selected clients can send their updates, which accelerates the learning process in its convergence. Rjoub et al. [
31] developed a client selection method based on two metrics—resource availability (in terms of energy level) and IoT devices’ trustworthiness—to make appropriate scheduling decisions. They measure the IoT device’s trust level (trust score) based on utilizing the resources (over/under a specific threshold value) during the local training. Even though the client selection mechanism helps in improving the learning process, it may affect the prediction accuracy, where not all clients are involved in the learning process. On the other hand, Chen et al. [
32] proposed communication-efficient federated learning (CEFL), which assures communication efficiency and resource optimization that differ from [
30,
31]. Specifically, a client selection method is proposed based on the calculation of the gradient difference between the current model parameter and the model parameter from the previous round. Then, the client sends its new local model only if the gradient difference is large; otherwise, the server will reuse the stale copy of that client. Even though the CEFL algorithm has succeeded in reducing the communication burden, it adds additional computational overhead for calculating the gradient difference.
Transfer learning (TL) is combined with FL to improve learning performance. Nguyen et al. [
33] introduced a new compression approach—known as high-compression federated learning (HCFL)—to handle FL processes in a massive IoT network. HCFL applies TL to enhance learning performance by training a pre-model with a small amount of the dataset on the server. Abosata et al. [
34] also incorporated TL with FL to develop accurate IDS models with minimum learning time. The main goal of the TL model is to transfer the local parameters generated using gradient-based weights from the clients to the server. Their experimental results show that their model succeeded in minimizing the complexity of the learning model and maximizing the accuracy of global model generation. Nguyen et al. [
35] were the first researchers to employ FL in anomaly-based IDSs; they developed a device-type-specific model in which IoT devices are mapped to the corresponding device type for anomaly detection because IoT devices that belong to the same manufacturer have similar hardware and software configurations, resulting in highly identical communication behavior. Wang et al. [
36] applied the same device-type-specific model to develop an IDS model for each type of IoT device, which improves the model’s accuracy. It also addresses IoT device heterogeneity in terms of communication protocols and coexisting technologies. However, this approach cannot be applied in large-scale IoT networks where there are various types of IoTs that need to be mapped, which will result in delay. Tabassum et al. [
37] developed the first FL-based IDS utilizing GAN to train local data, addressing class imbalance by generating synthetic data to balance the distribution across FL clients. They evaluated their model using different datasets, with the results showing that the proposed model converged earlier than the state-of-the-art standalone IDS. Bukhari et al. [
38] proposed an FL-based IDS using a stacked CNN and bidirectional long–short-term memory (SCNN-Bi-LSTM). They addressed the statistical heterogeneity of the data by applying a personalized method that could divide the model into global and local layers. Specifically, the global layers are used in the FL, and each FL client is provided with the global layers with unique customization layers designed for their specific needs. The experimental results show a significant improvement in detection accuracy compared with traditional DL approaches.
2.3.2. Decentralized FL (Device-to-Device)
The decentralized FL architecture relies on device-to-device (D2D) communication, where devices collaboratively train their local models using stochastic gradient descent (SGD) and consensus-based methods. During each consensus step, devices share their local model updates with their one-hop neighbors. Each device then integrates the model updates received from its neighbors and inputs the results into the SGD process [
9,
10]. In 6G networks, devices are anticipated to be interconnected in a machine-to-machine (M2M) manner, making D2D communication a promising technology for decentralized FL [
7,
8].
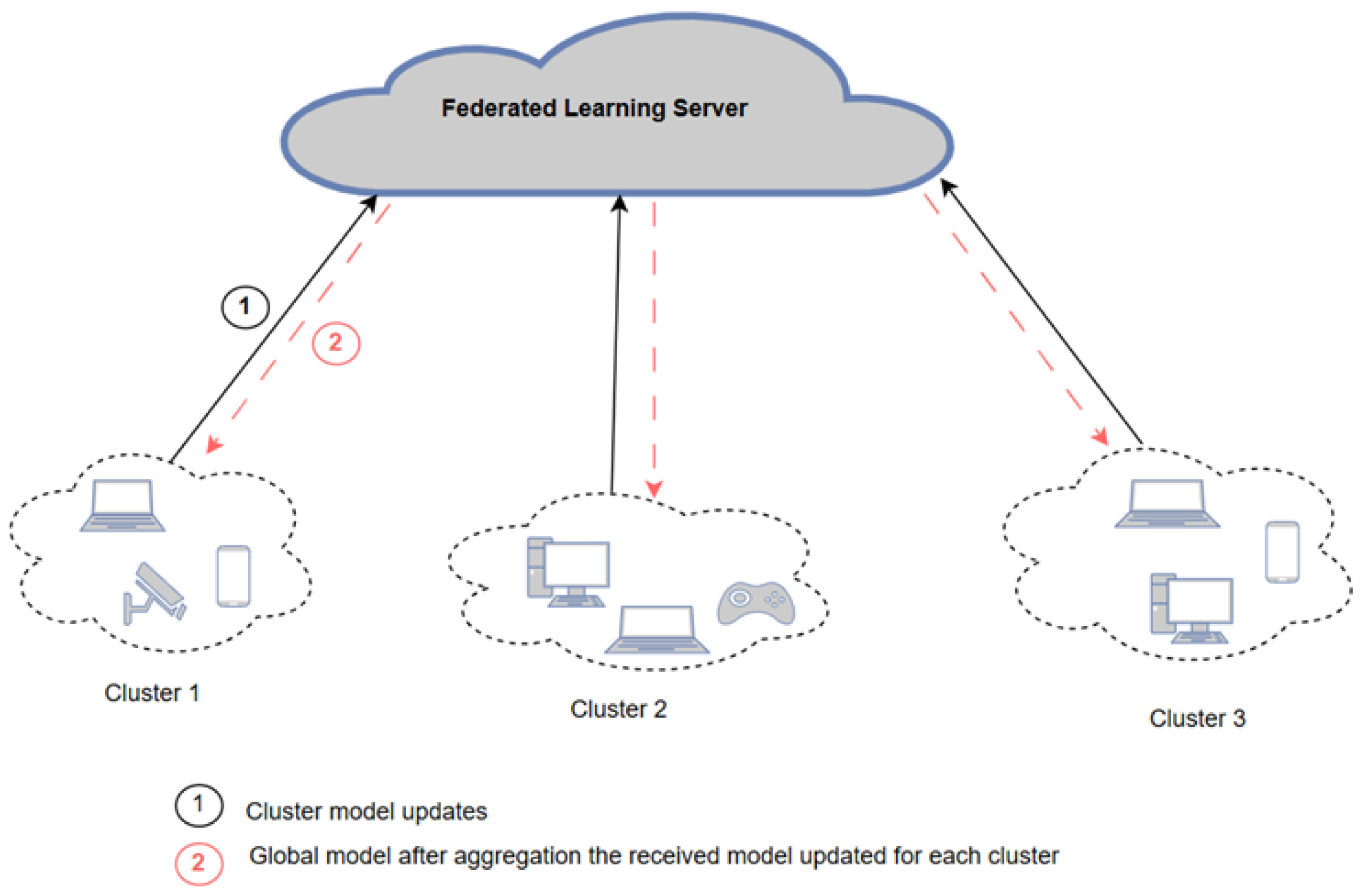
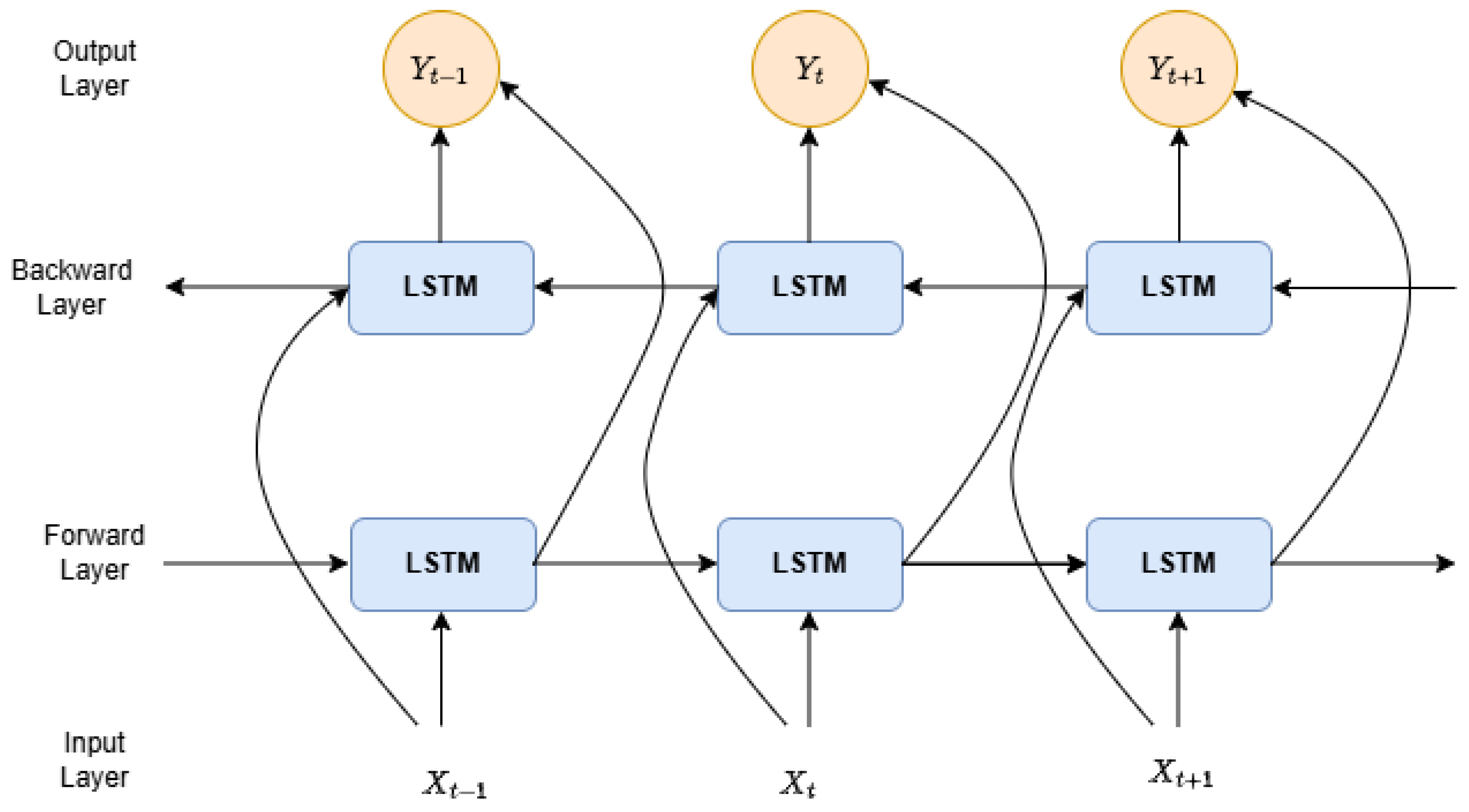
Figure 2 shows the decentralized FL architecture.
Although the centralized FL has demonstrated success in the IoT environment in terms of preserving computation resources as well as improving the learning process, it includes some drawbacks, that is, single-point-of-failure and scaling issues for increasing network size. This leads to the FL being fully distributed (server-less), in which the end devices collaborate to perform data operations inside the network by iterating local computations and mutual interactions. Savazzi et al. [
9] proposed a decentralized FL-based consensus approach for IoT networks that can enable direct device-to-device (D2D) collaboration without relying on a central coordinator. This approach has been viewed as a promising framework for IoT networks because of its flexible model optimization over networks characterized by decentralized connectivity patterns. However, they applied their methods to a simple NN, which would be difficult to apply to deeper networks. A trusted decentralized FL-based algorithm was integrated with the consensus approach in [
10]. Their results indicate that the trusted decentralized FL algorithm makes the model robust against poisoning attacks. Blockchain federated learning (B-FL) based on a consensus approach was proposed in [
11] to prevent model tampering from malicious attacks in both local and global models. The B-FL system comprises multiple edge servers and devices that generate a blockchain based on a consensus protocol to confirm that the data in the block are correct and immutable. They applied digital signatures to guarantee that others were not tampering with the data packet information. Although digital signatures ensure the authenticity and integrity of the data, they require computation overheads that are beyond the IoT devices’ capabilities.
Al-Abiad et al. [
39] proposed a decentralized FL model based on device-to-device (D2D) communications and overlapped clustering to allow aggregation in a decentralized scheme without a central aggregation. The proposed model is based on the overlap between clusters. Specifically, within a cluster, the cluster head (CH) is associated with each cluster. On the other hand, the bridge device (BD) is located between two adjacent clusters. The BDs receive the updated models from the CHs and calculate the summation of the received aggregated models. As a result, CHs collect all the local models from the corresponding devices and models from the BDs to update their cluster models. Their experimental results show that the proposed model outperformed the centralized and hierarchical FL models in terms of energy consumption and accuracy, here considering efficient overlapped clustering and increasing the number of iterations, respectively.
2.3.3. Semi-Decentralized FL
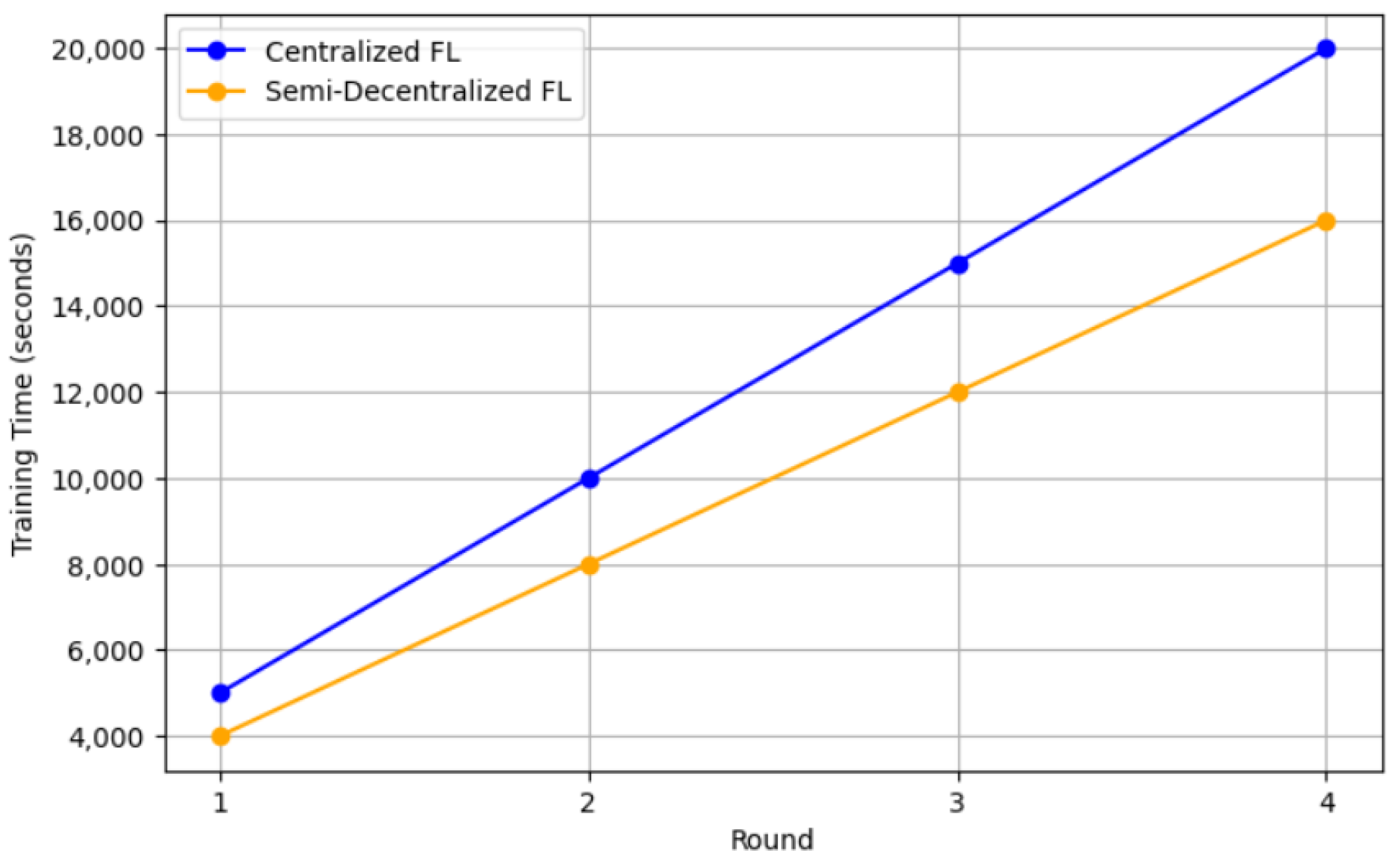
The semi-decentralized FL architecture aims to strike a balance between fully centralized and fully decentralized FL architectures. This approach employs multiple servers, each responsible for coordinating a group of client devices to perform local model updates and inner model aggregation. Periodically, each server shares its updated models with neighboring servers for outer model aggregation. This multi-server aggregation process, as opposed to relying on a single centralized entity, helps to speed up the learning process [
12,
13,
14].
Figure 3 illustrates the semi-decentralized FL architecture.
A semi-decentralized approach was developed by [
12] to accelerate the learning process by considering multiple edge servers. Each edge server coordinates a cluster of client nodes to perform local model updating and intra-cluster model aggregation. The edge servers periodically share their updated models with neighboring edge servers for inter-cluster model aggregation. Even though their model accelerates the learning process, it poses computation overhead on the edge server because it needs to perform aggregation for the cluster and for the neighboring servers. To overcome this problem, a hierarchical architecture was presented in [
13,
14] with two levels of model aggregation: the edge and cloud levels. More specifically, the edge node is responsible for local aggregation of clients, whereas the cloud facilitates global aggregation because it has a reliable connection. Both studies’ experimental results demonstrate a reduction in the model training time and energy consumption of the end devices when compared to traditional cloud-based FL. The author of [
40] introduced hierarchical FL based on semi-synchronous communications to solve the heterogeneity of IoT devices. The proposed model performs edge-based aggregations and then cloud-based aggregation, resulting in a significant communication overhead reduction. This is because edge-based aggregation is performed via local communications, which require fewer resources than cloud-based aggregation. Moreover, a semi-synchronous communication in both the cloud and edge layers is proposed to prevent the deadlock that comes as a result of waiting for local updates from dropped devices. Thus, a timeout is defined such that if all local models are not received by this timeout, then the edge server sends the latest aggregated edge model to the cloud server without waiting for the remaining local models to arrive. Huang et al. [
41] proposed a semi-decentralized cloud–edge-device hierarchical federated learning framework, incorporating an incremental sub-gradient optimization algorithm within each ring cluster to mitigate the effects of data heterogeneity. This hierarchical FL architecture not only reduces communication overhead but also enhances overall performance.
Alotaibi and Barnawi [
42] developed IDSoft, an innovative software-based solution that operates throughout the network infrastructure, using 6G technologies such as virtualization of network functions, mobile edge computing and software-defined networking. This solution is designed to support FL-based IDSs. Additionally, they designed a hierarchical federated learning (HFL) model within IDSoft to detect cyberattacks in 6G networks. Synchronous and asynchronous schemes are used in the aggregation process. The results show that asynchronous HFL has faster convergence and stable training loss compared with the centralized FL model. In addition, the HFL model achieves lower communication overhead than the centralized FL model because the centralized FL architecture requires communication between each client and the server for aggregation; however, in HFL, clustering helps in reducing the total communication load by allowing the CH to act on the behalf of the clients. However, they did not mention other hierarchical FL-based IDSs, which may indicate that they were the first to introduce this model. The same authors developed LightFIDS (Lightweight and Hierarchical Federated IDS for Massive IoT in 6G Networks) [
43], a module within the IDSoft architecture they previously introduced. In IDSoft, there are two detection phases: a fast detection phase that identifies abnormal flows at the far edge, followed by a deep detection phase that provides further analysis of malicious flows. The proposed LightFID model is implemented with fast-converging HFL. The local learning models used in the federated architecture are low-complexity models with fewer parameters. However, the hierarchical federated learning architecture is more complex, requiring the cluster head to perform aggregation for multiple rounds in order to obtain the cluster model. The head master (server) also aggregates the received cluster models to get the global model. This process is computationally intensive due to the repeated aggregation and distribution within clusters.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}