


Creating Refined Datasets for Better Chaos Detection
 , , , , and
, , , , and
Abstract
1. Introduction
- A general method of refining signals that are dedicated to chaotic property detection (https://draugustyn.gitlab.io/refined-signals-4-chaos-detection (accessed on 16 January 2025)),
- Datasets of the resulting refined signals named “Refined Datasets for Better Chaos Detection” (https://figshare.com/projects/Refined_Data_Sets_for_Better_Chaos_Detection/206641 (accessed on 16 January 2025)).
- The validation of the newly defined datasets in the classification task with the usage of a recurrent neural network.
2. Materials and Methods
2.1. The Method of Obtaining Refined Signals
| Algorithm 1: Obtaining Refined Signals |
|
2.2. Explanation of the Algorithm Steps Applied for a 3D Chaotic Dynamical Model
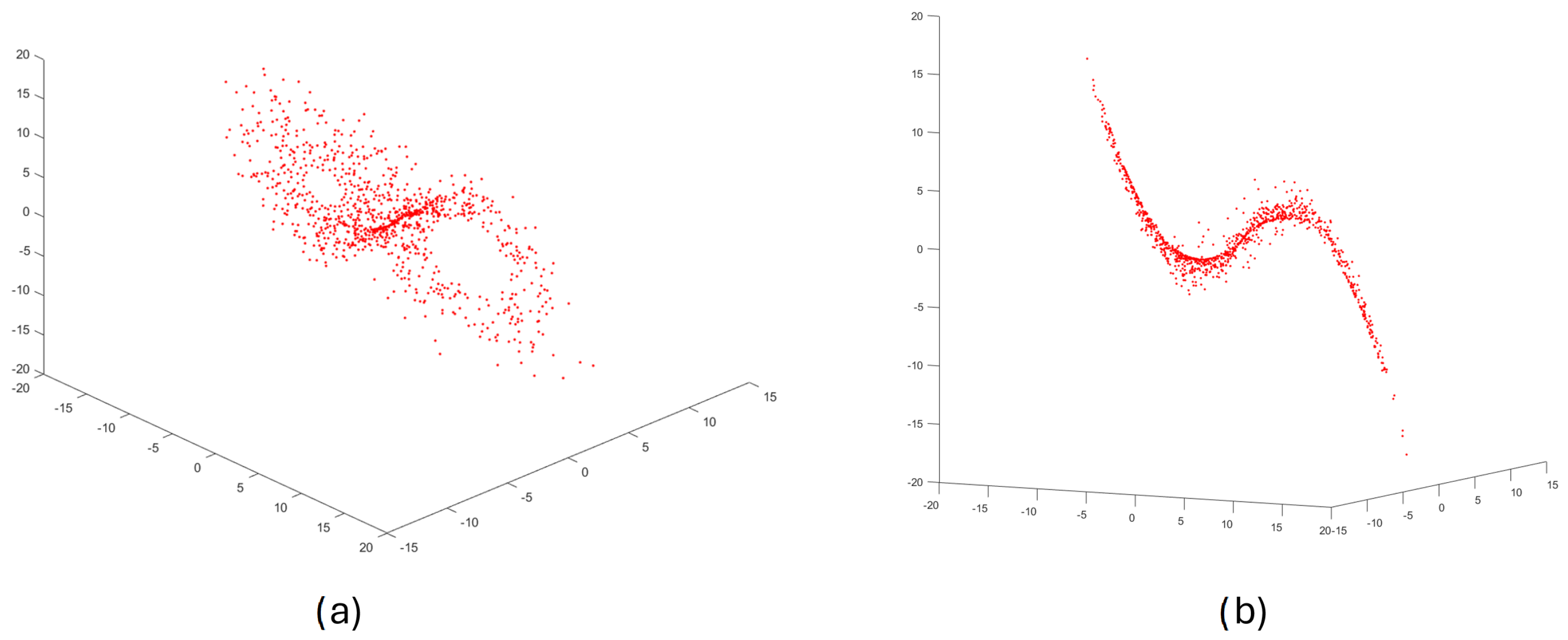
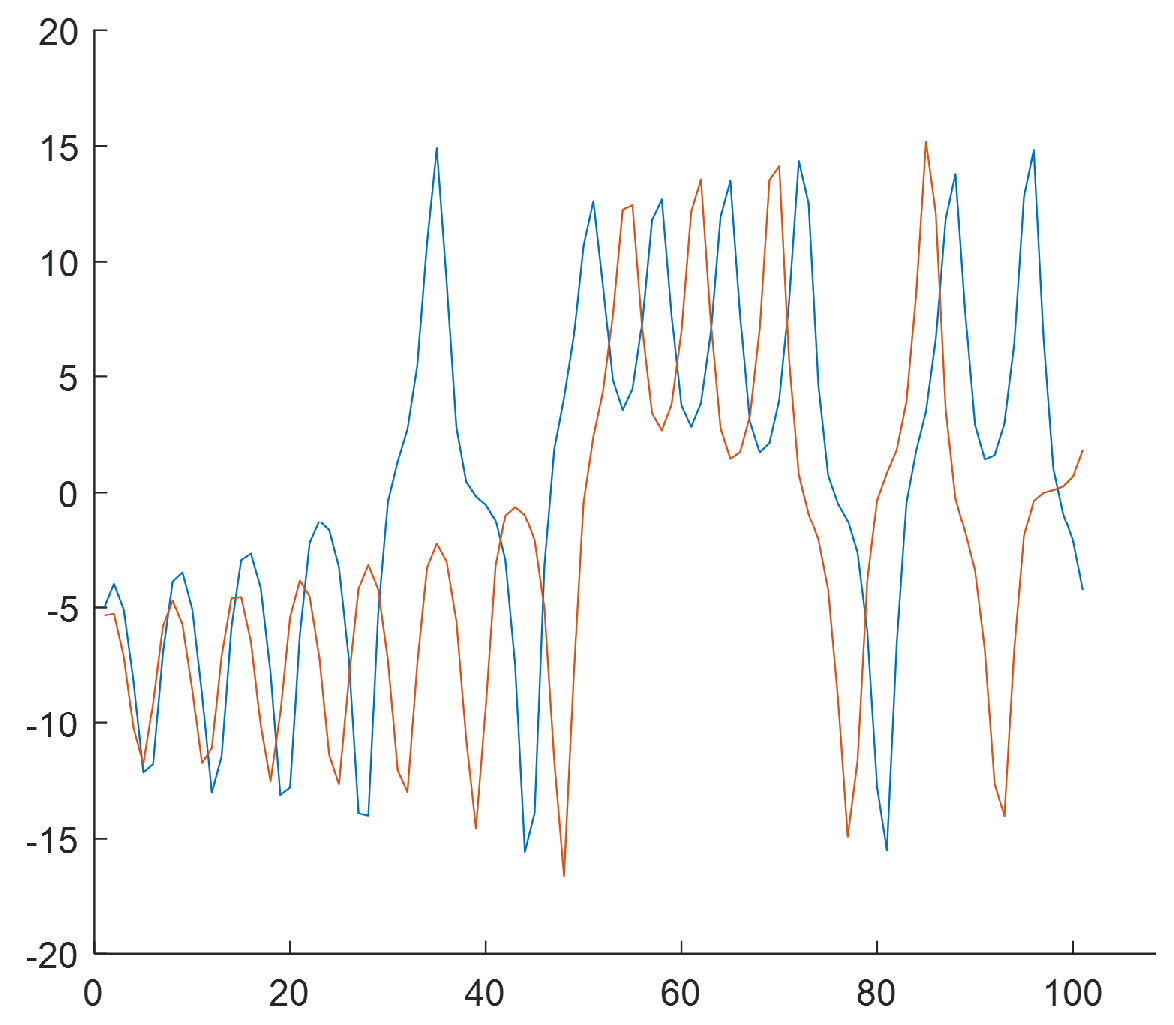
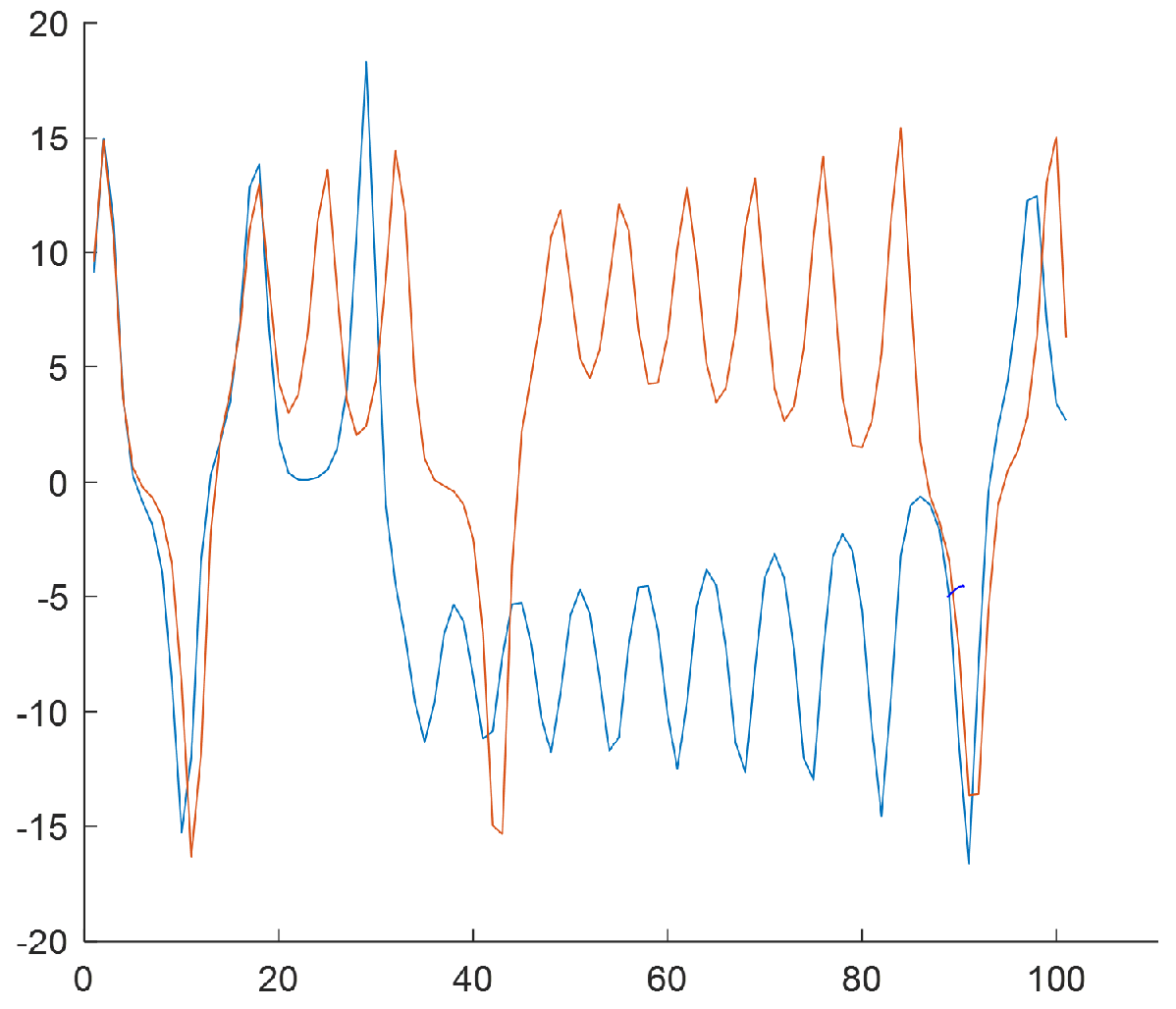
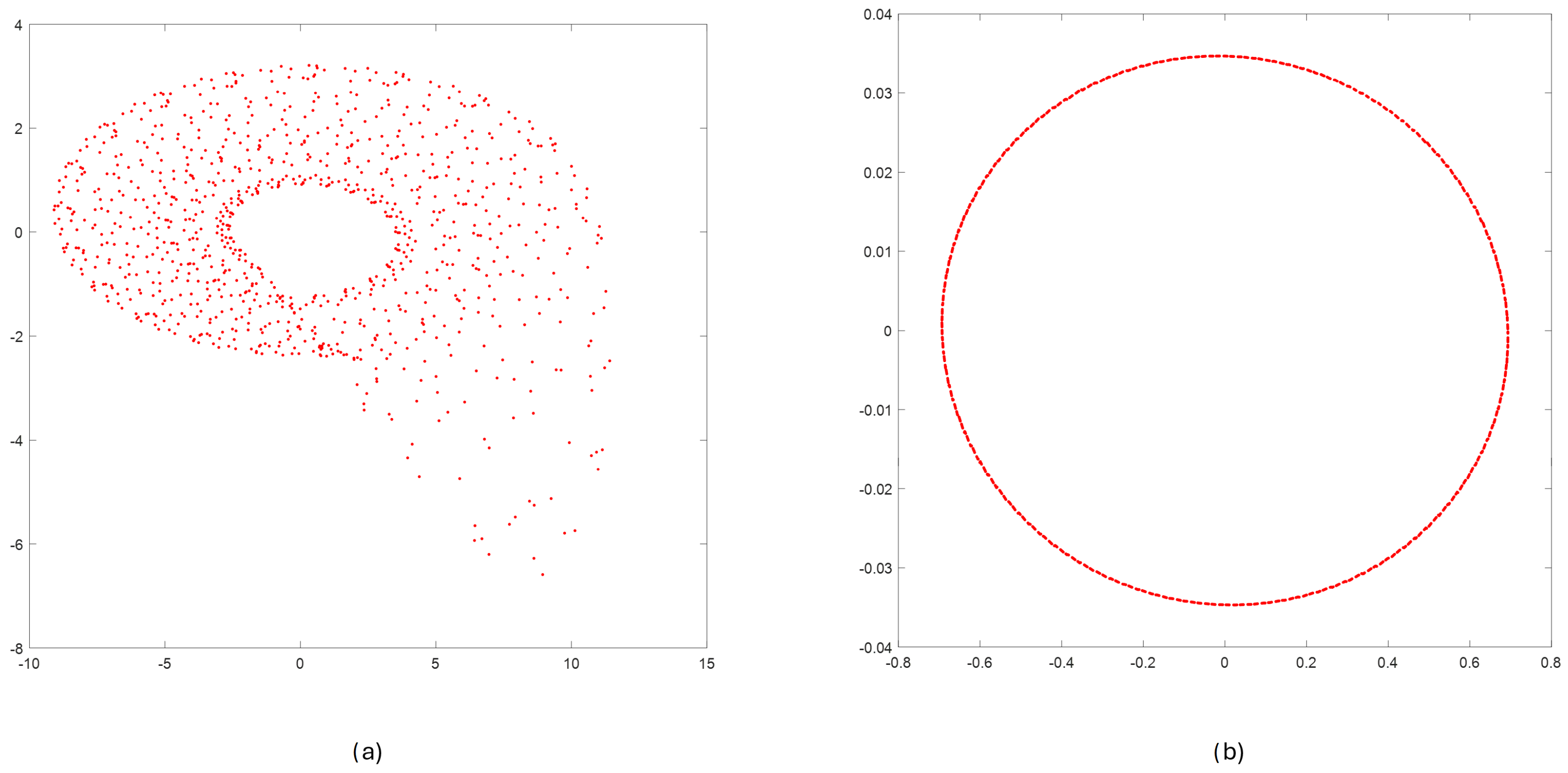
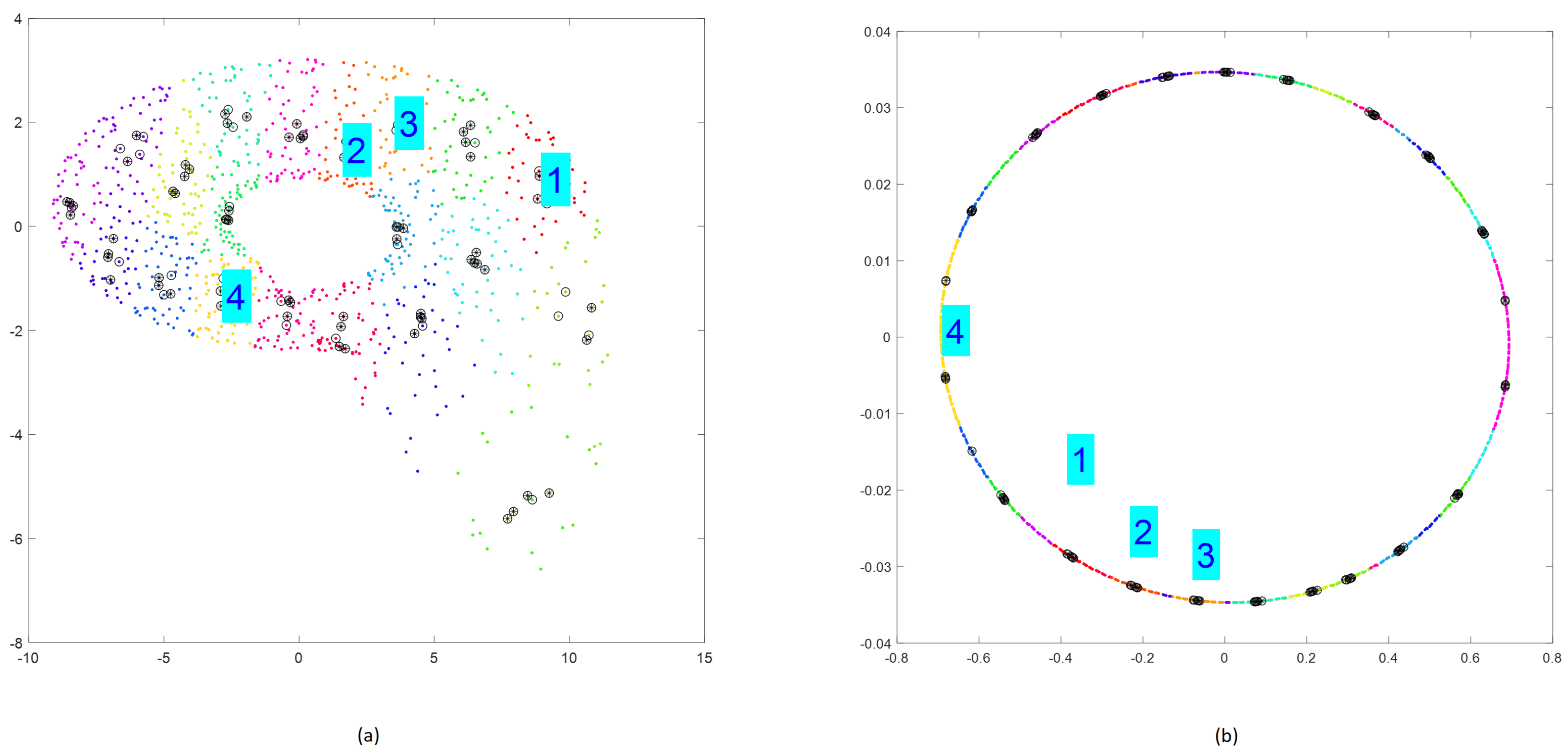
2.2.1. Step 1—Reconstructing a Phase Portrait
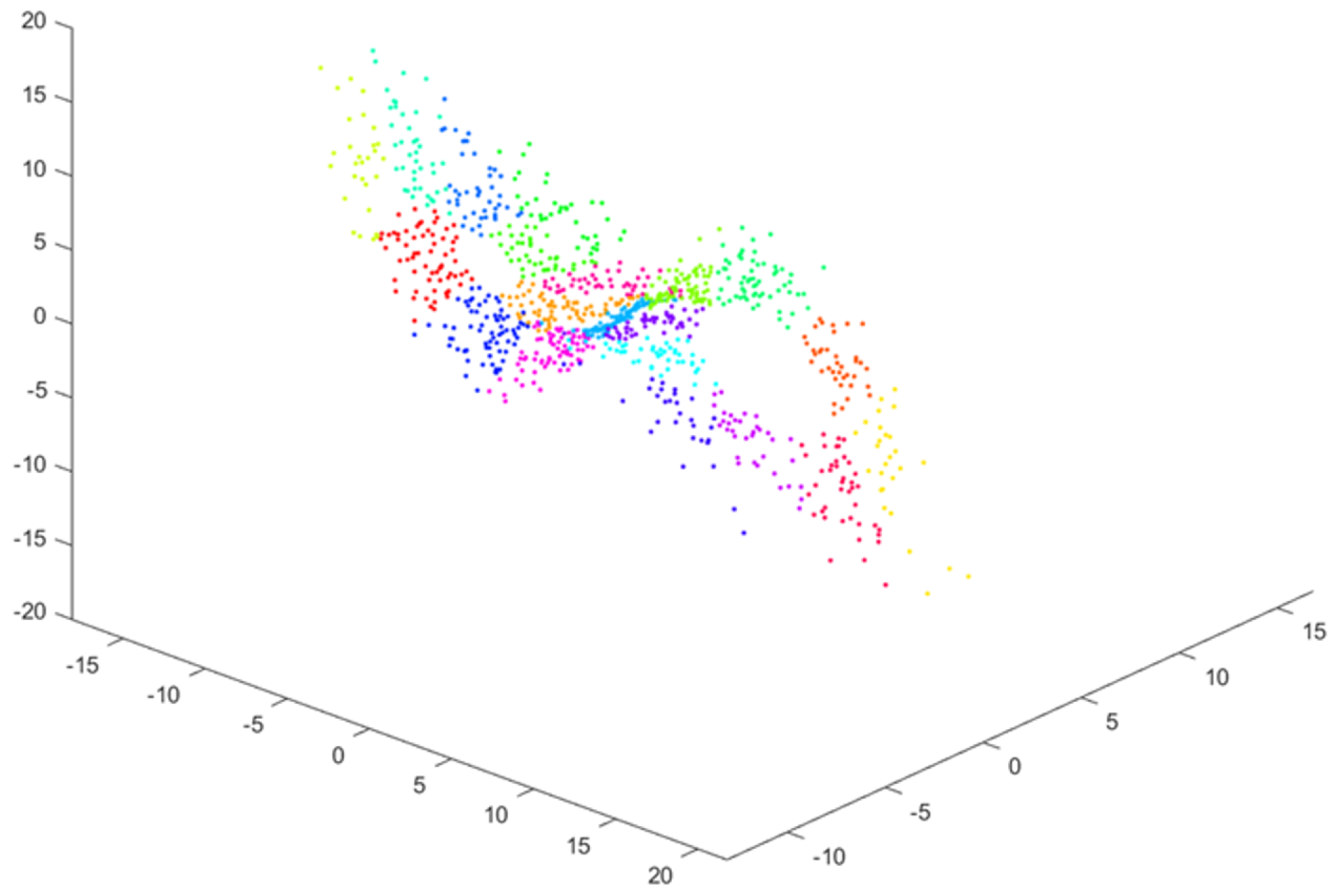
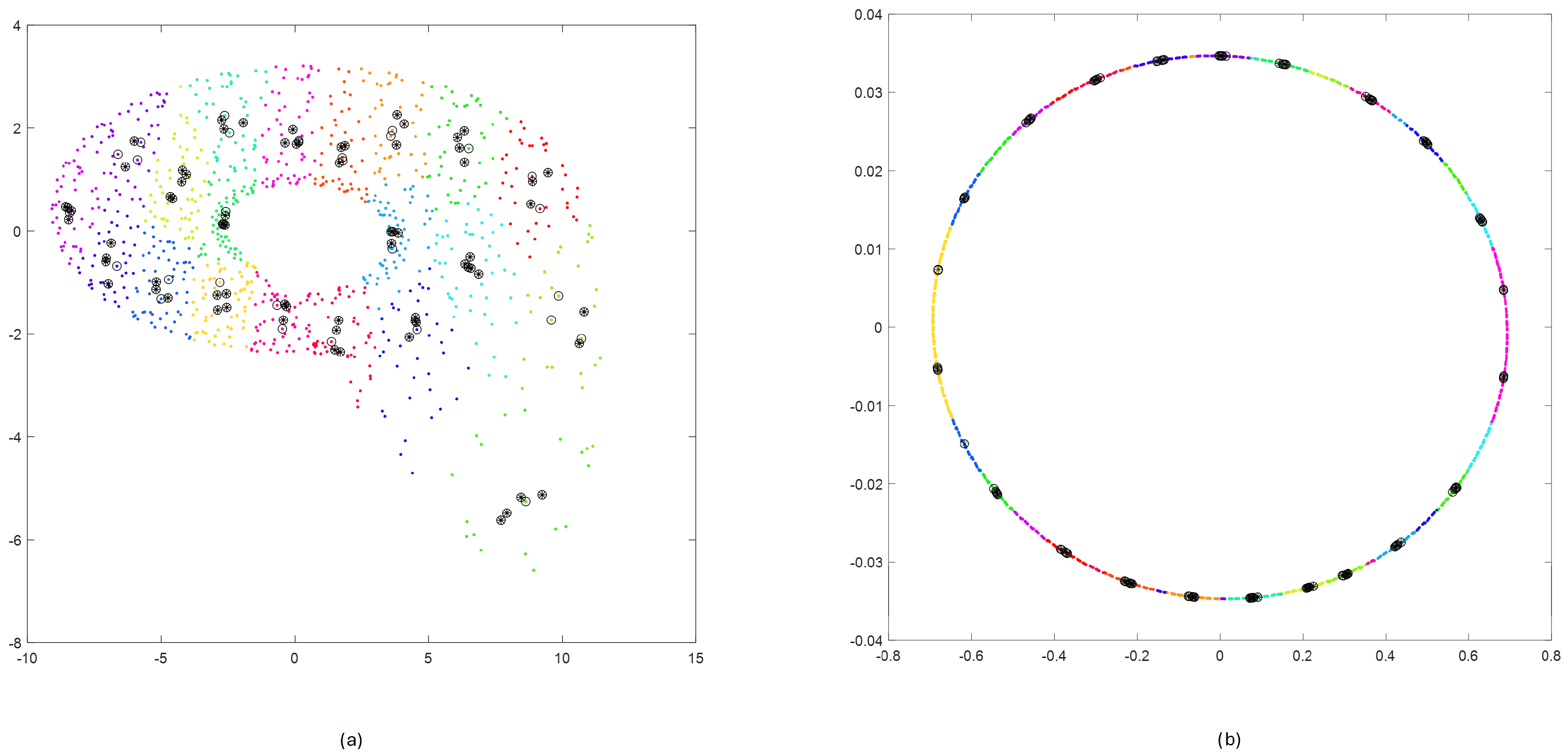
2.2.2. Step 2—Clustering M-Dimensional Data
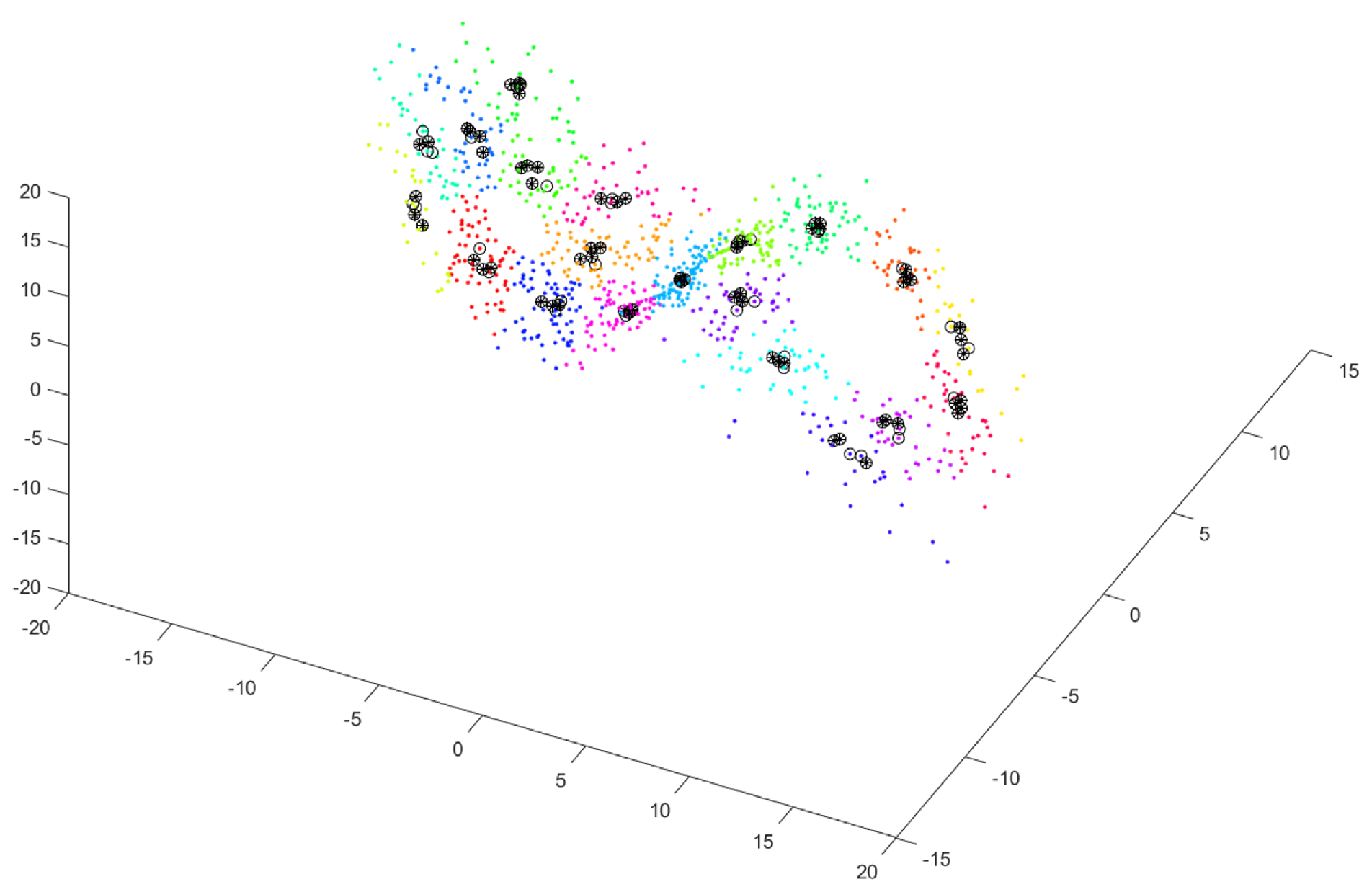
2.2.3. Step 3—Selecting the Nearest Vectors in Clusters
2.2.4. Step 4—Selecting Members of Subclusters Distant Enough in Time
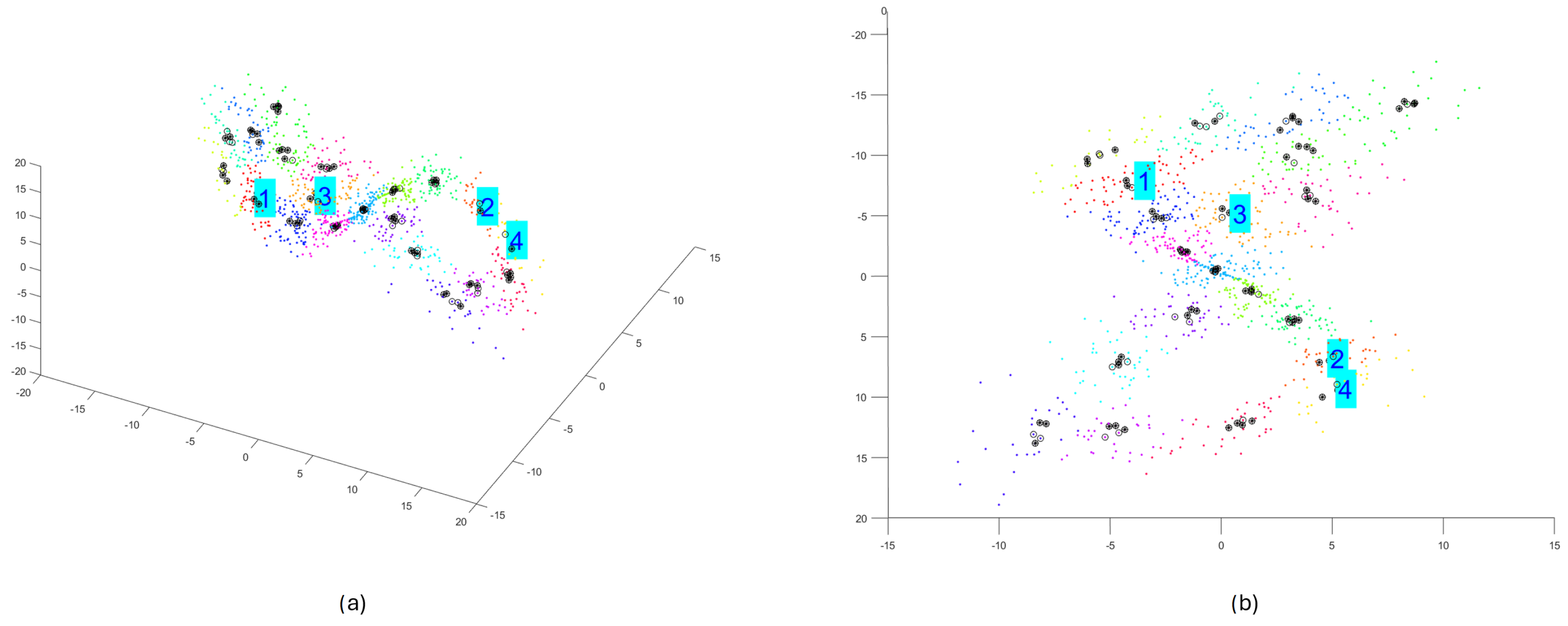
2.2.5. Step 5—Random Selecting Subclusters with Enough Size
2.2.6. Step 6—Generating Refined Subsequences with Enough Size
2.3. Example of Applying the Method for Chaotic Dynamical Model and Non-Chaotic One
3. Results
3.1. Refined Datasets for Better Chaos Detection
- Refined signals—a few (2–4) subsequences (each with a length equal to 100 samples) belonging to a subcluster, with a similar initial condition;
- A source signal—an input sequence with a length equal to 1000 samples.
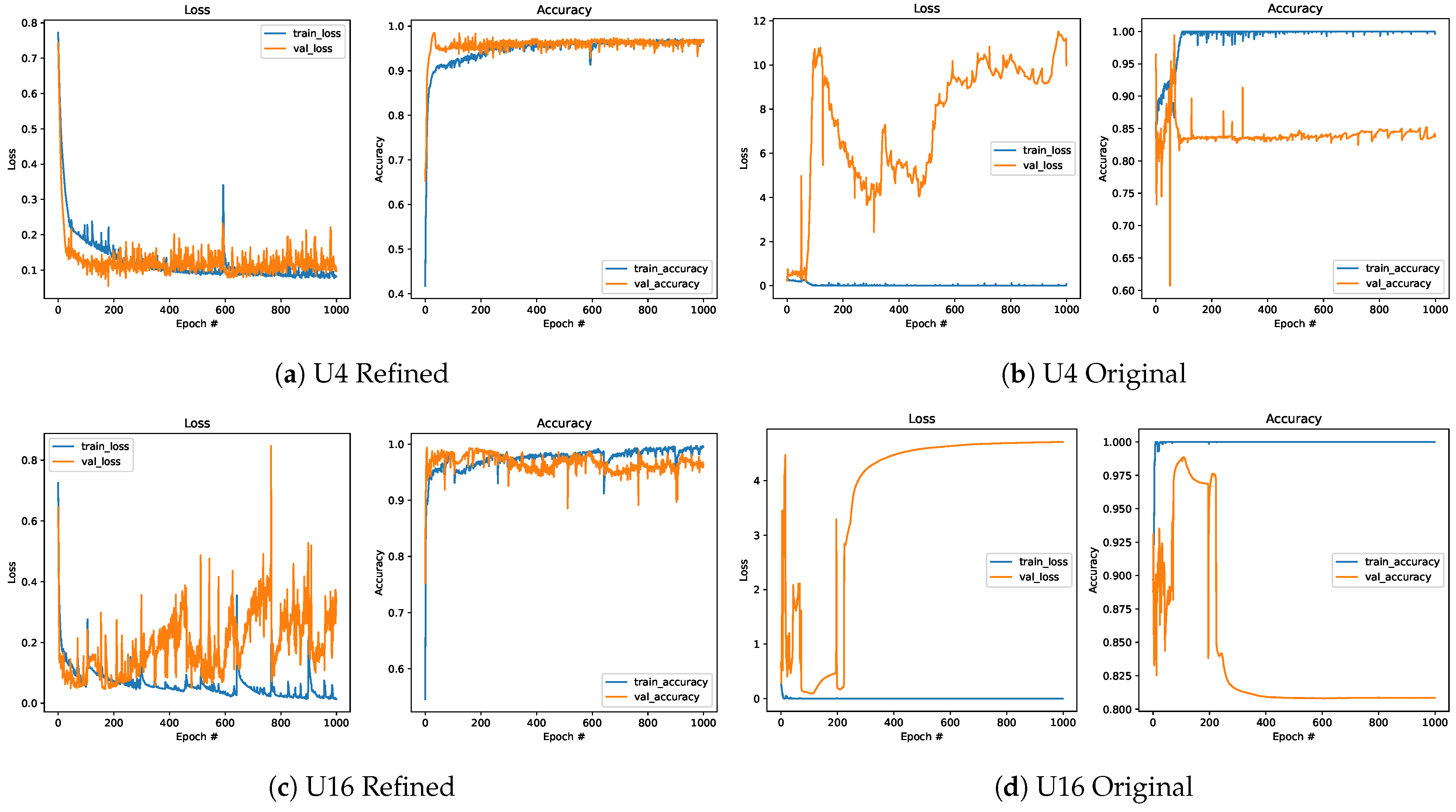
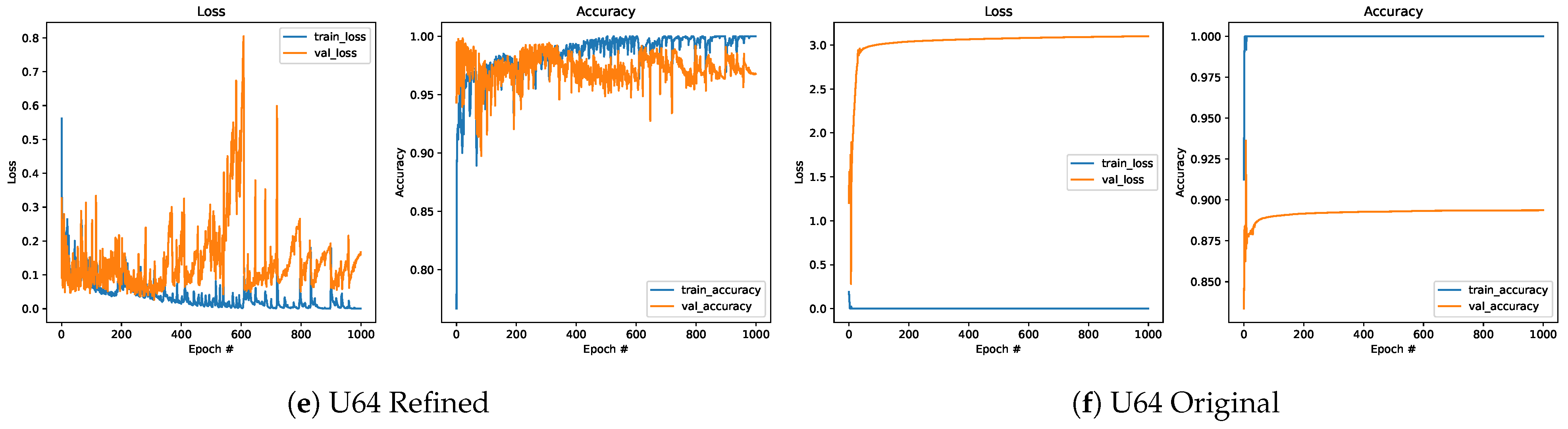
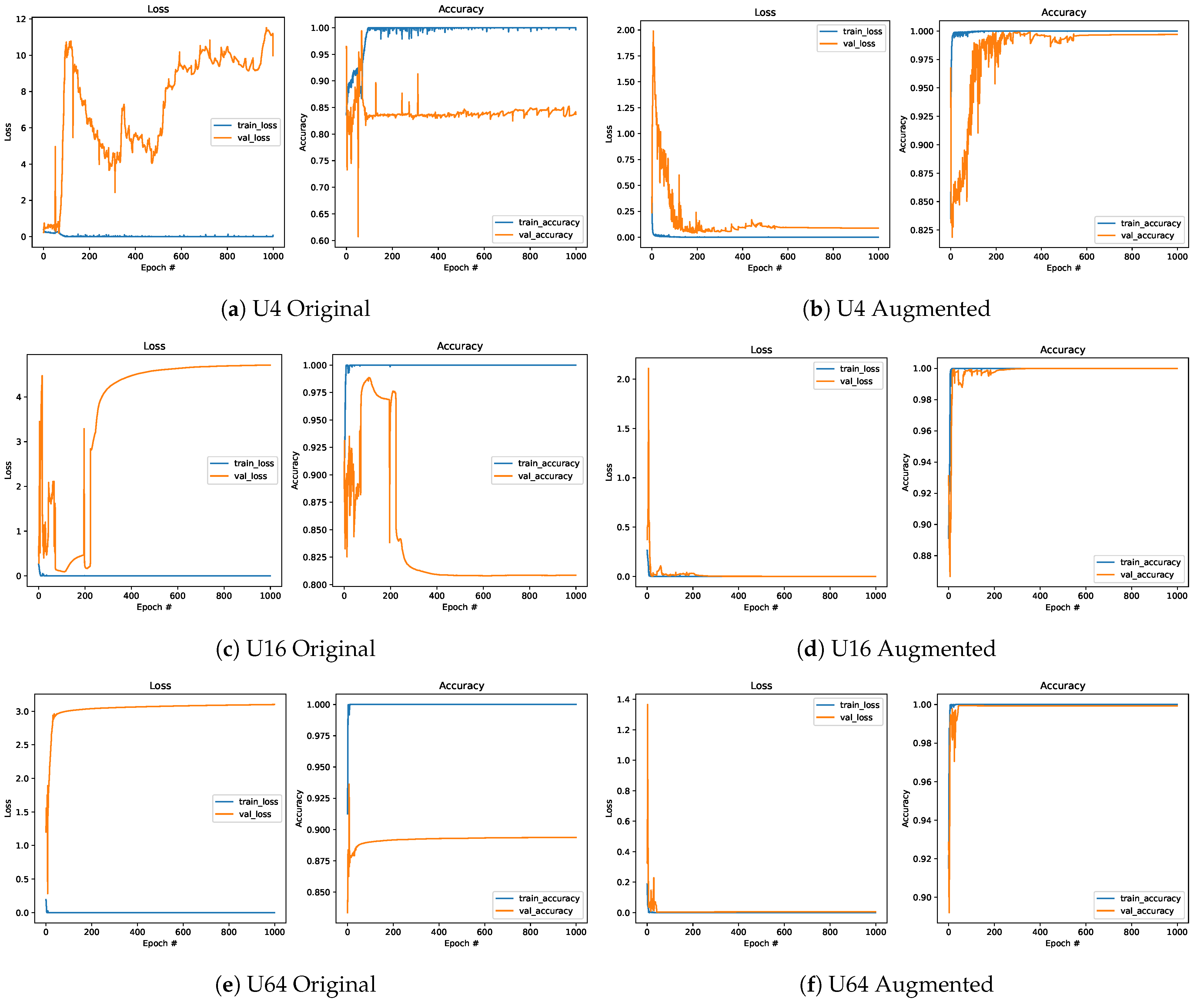
3.2. Sample Usage of Refined Data for Improving Classification
4. Discussion and Conclusions
- The value of the largest Lyapunov exponent (positivity for chaotic systems),
- The fractal dimension (smaller than topological dimension for chaotic systems),
- KS-Entropy (positivity for chaotic systems),
- The results of statistical test, consisting of comparing the original set with the so-called surrogate data (generated data from the original set with random chaos). The method is implemented by randomizing phases in the frequency domain while maintaining the amplitude of the Fourier spectrum of the original data—the significance of the difference of Lyapunov coefficients between the original data and for the surrogate data indicates chaos.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kanani, P.; Padole, M. ECG Heartbeat Arrhythmia Classification Using Time-Series Augmented Signals and Deep Learning Approach. Procedia Comput. Sci. 2020, 171, 524–531. [Google Scholar] [CrossRef]
- Vandith Sreenivas, K.; Ganesan, M.; Lavanya, R. Classification of Arrhythmia in Time Series ECG Signals Using Image Encoding And Convolutional Neural Networks. In Proceedings of the 2021 Seventh International Conference on Bio Signals, Images, and Instrumentation (ICBSII), Chennai, India, 25–27 March 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Wan, Z.; Yang, R.; Huang, M.; Zeng, N.; Liu, X. A review on transfer learning in EEG signal analysis. Neurocomputing 2021, 421, 1–14. [Google Scholar] [CrossRef]
- Szczęsna, A.; Augustyn, D.R.; Josiński, H.; Harężlak, K.; Świtoński, A.; Kasprowski, P. Chaotic biomedical time signal analysis via wavelet scattering transform. J. Comput. Sci. 2023, 72, 102080. [Google Scholar] [CrossRef]
- Rucco, R.; Agosti, V.; Jacini, F.; Sorrentino, P.; Varriale, P.; De Stefano, M.; Milan, G.; Montella, P.; Sorrentino, G. Spatio-temporal and kinematic gait analysis in patients with Frontotemporal dementia and Alzheimer’s disease through 3D motion capture. Gait Posture 2017, 52, 312–317. [Google Scholar] [CrossRef] [PubMed]
- Jakob, V.; Küderle, A.; Kluge, F.; Klucken, J.; Eskofier, B.M.; Winkler, J.; Winterholler, M.; Gassner, H. Validation of a sensor-based gait analysis system with a gold-standard motion capture system in patients with Parkinson’s disease. Sensors 2021, 21, 7680. [Google Scholar] [CrossRef]
- Harężlak, K.; Kasprowski, P. Application of eye tracking in medicine: A survey, research issues and challenges. Comput. Med. Imaging Graph. 2018, 65, 176–190. [Google Scholar] [CrossRef] [PubMed]
- Walleczek, J. Self-Organized Biological Dynamics and Nonlinear Control: Toward Understanding Complexity, Chaos and Emergent Function in Living Systems; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Sledzianowski, A.; Urbanowicz, K.; Glac, W.; Slota, R.; Wojtowicz, M.; Nowak, M.; Przybyszewski, A. Face emotional responses correlate with chaotic dynamics of eye movements. Procedia Comput. Sci. 2021, 192, 2881–2892. [Google Scholar] [CrossRef]
- Yuan, Y.; Li, Y.; Mandic, D.P. A comparison analysis of embedding dimensions between normal and epileptic EEG time series. J. Physiol. Sci. 2008, 58, 239–247. [Google Scholar] [CrossRef]
- Majumdar, K.; Myers, M.H. Amplitude suppression and chaos control in epileptic EEG signals. Comput. Math. Methods Med. 2006, 7, 53–66. [Google Scholar] [CrossRef] [PubMed]
- Iaconis, F.R.; Jiménez Gandica, A.A.; Del Punta, J.A.; Delrieux, C.A.; Gasaneo, G. Information-theoretic characterization of eye-tracking signals with relation to cognitive tasks. Chaos Interdiscip. J. Nonlinear Sci. 2021, 31, 033107. [Google Scholar] [CrossRef]
- Kantz, H.; Schreiber, T. Human ECG: Nonlinear deterministic versus stochastic aspects. IEE Proc.-Sci. Meas. Technol. 1998, 145, 279–284. [Google Scholar] [CrossRef]
- Perc, M. Nonlinear time series analysis of the human electrocardiogram. Eur. J. Phys. 2005, 26, 757. [Google Scholar] [CrossRef]
- Boullé, N.; Dallas, V.; Nakatsukasa, Y.; Samaddar, D. Classification of chaotic time series with deep learning. Phys. D Nonlinear Phenom. 2020, 403, 132261. [Google Scholar] [CrossRef]
- Uzun, S. Machine learning-based classification of time series of chaotic systems. Eur. Phys. J. Spec. Top. 2022, 231, 493–503. [Google Scholar] [CrossRef]
- Szczęsna, A.; Augustyn, D.R.; Harężlak, K.; Josiński, H.; Świtoński, A.; Kasprowski, P. Datasets for learning of unknown characteristics of dynamical systems. Sci. Data 2023, 10, 79. [Google Scholar] [CrossRef] [PubMed]
- Szczęsna, A.; Augustyn, D.R.; Josiński, H.; Świtoński, A.; Kasprowski, P.; Harężlak, K. Novel Photoplethysmographic Signal Analysis via Wavelet Scattering Transform. In Proceedings of the Computational Science—ICCS 2022: 22nd International Conference, London, UK, 21–23 June 2022; Proceedings, Part III. Springer: Berlin/Heidelberg, Germany, 2022; pp. 641–653. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Kantz, H.; Schreiber, T. Nonlinear Time Series Analysis; Cambridge Nonlinear Science Series; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Lakshmanan, M.; Senthilkumar, D.V. Dynamics of Nonlinear Time-Delay Systems; Springer Series in Synergetics; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Chiu, S. An improved fuzzy c-means clustering algorithm. Pattern Recognit. Lett. 1995, 11, 825–833. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; 2015. [Google Scholar]
- Ilan, Y. Making use of noise in biological systems. Prog. Biophys. Mol. Biol. 2023, 178, 83–90. [Google Scholar] [CrossRef]
- Toker, D.; Sommer, F.T.; D’Esposito, M. A simple method for detecting chaos in nature. Commun. Biol. 2020, 3, 11. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ||||
|---|---|---|---|---|
| Time Series | Refined | Original | Augmented | Test |
| All | 1200 | 70,000 | 71,200 | 48,840 |
| Chaotic | 500 | 30,000 | 30,500 | 18,840 |
| Non-chaotic | 700 | 40,000 | 40,700 | 30,000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Augustyn, D.R.; Harężlak, K.; Szczęsna, A.; Josiński, H.; Kasprowski, P.; Świtoński, A. Creating Refined Datasets for Better Chaos Detection. Sensors 2025, 25, 796. https://doi.org/10.3390/s25030796
Augustyn DR, Harężlak K, Szczęsna A, Josiński H, Kasprowski P, Świtoński A. Creating Refined Datasets for Better Chaos Detection. Sensors. 2025; 25(3):796. https://doi.org/10.3390/s25030796
Chicago/Turabian StyleAugustyn, Dariusz R., Katarzyna Harężlak, Agnieszka Szczęsna, Henryk Josiński, Paweł Kasprowski, and Adam Świtoński. 2025. "Creating Refined Datasets for Better Chaos Detection" Sensors 25, no. 3: 796. https://doi.org/10.3390/s25030796
APA StyleAugustyn, D. R., Harężlak, K., Szczęsna, A., Josiński, H., Kasprowski, P., & Świtoński, A. (2025). Creating Refined Datasets for Better Chaos Detection. Sensors, 25(3), 796. https://doi.org/10.3390/s25030796