An Infrared and Visible Image Fusion Network Based on Res2Net and Multiscale Transformer


Abstract
1. Introduction
- We put forward a novel and efficient network that combines CNN and Transformer for the fusion of infrared and visible images. The proposed network performs well in integrating complementary information by effectively utilizing both local and global features of source images.
- We devise a densely shaped LFE-RN to effectively exploit local features and reuse information that could be lost during the feature extraction operation. A Transformer module and global feature integration module (GFIM) are devised in GFE-MT to further preserve global contextual information.
- A targeted perceptual loss function is devised to retain the high similarity between source images and the fused result.
- Extensive experiments on two dominant datasets, i.e., TNO and RoadScene, illustrate that our method surpasses other state-of-the-art image fusion methods in terms of both subjective effects and objective evaluations.
2. Related Work
2.1. Deep-Learning-Based Image Fusion Methods
2.1.1. CNN-Based Fusion Methods
2.1.2. AE-Based Fusion Methods
2.1.3. GAN-Based Fusion Methods
2.2. Res2Net
2.3. Vision Transformer
3. Methods
3.1. Overall Framework
3.2. Network Architecture
3.2.1. Local Feature Extraction Module Based on Res2Net
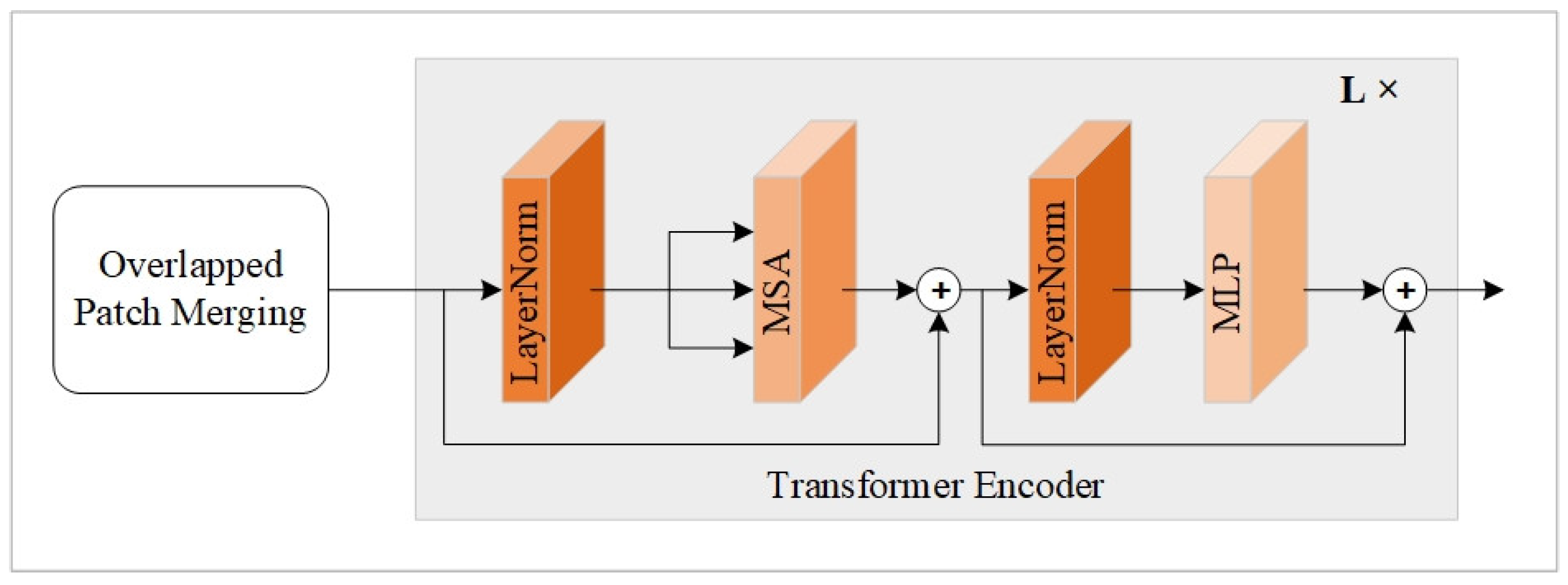
3.2.2. Global Feature Extraction Module Based on Multiscale Transformer
- (1)
- Transformer Module
- (2)
- Global Feature Integration Module
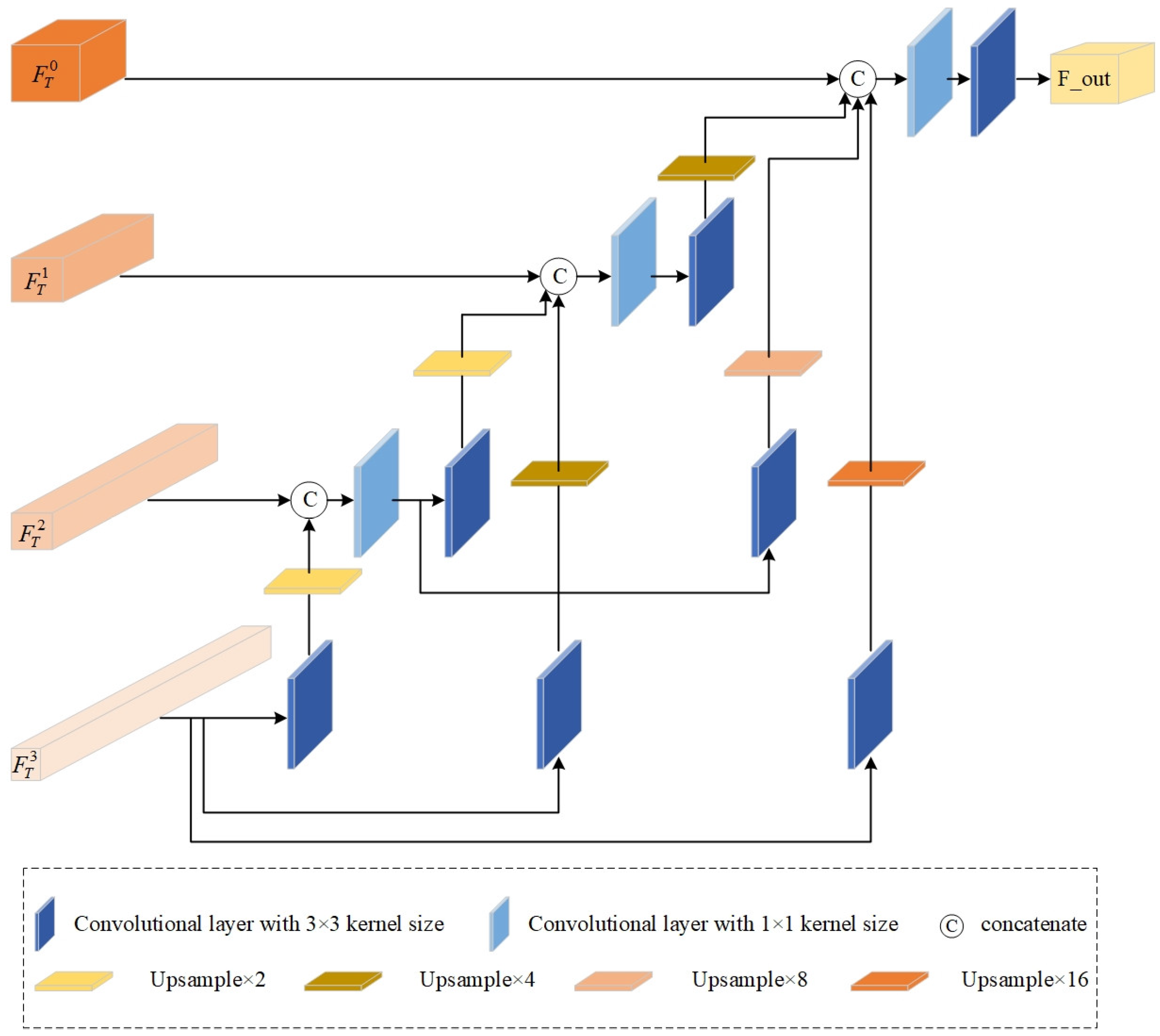
3.2.3. Image Reconstructor
3.3. Loss Function
3.3.1. Per-Pixel Loss
3.3.2. Perceptual Loss
4. Experiments and Discussion
4.1. Training Details
4.2. Comparison Methods and Objective Indices
4.3. Ablation Experiments
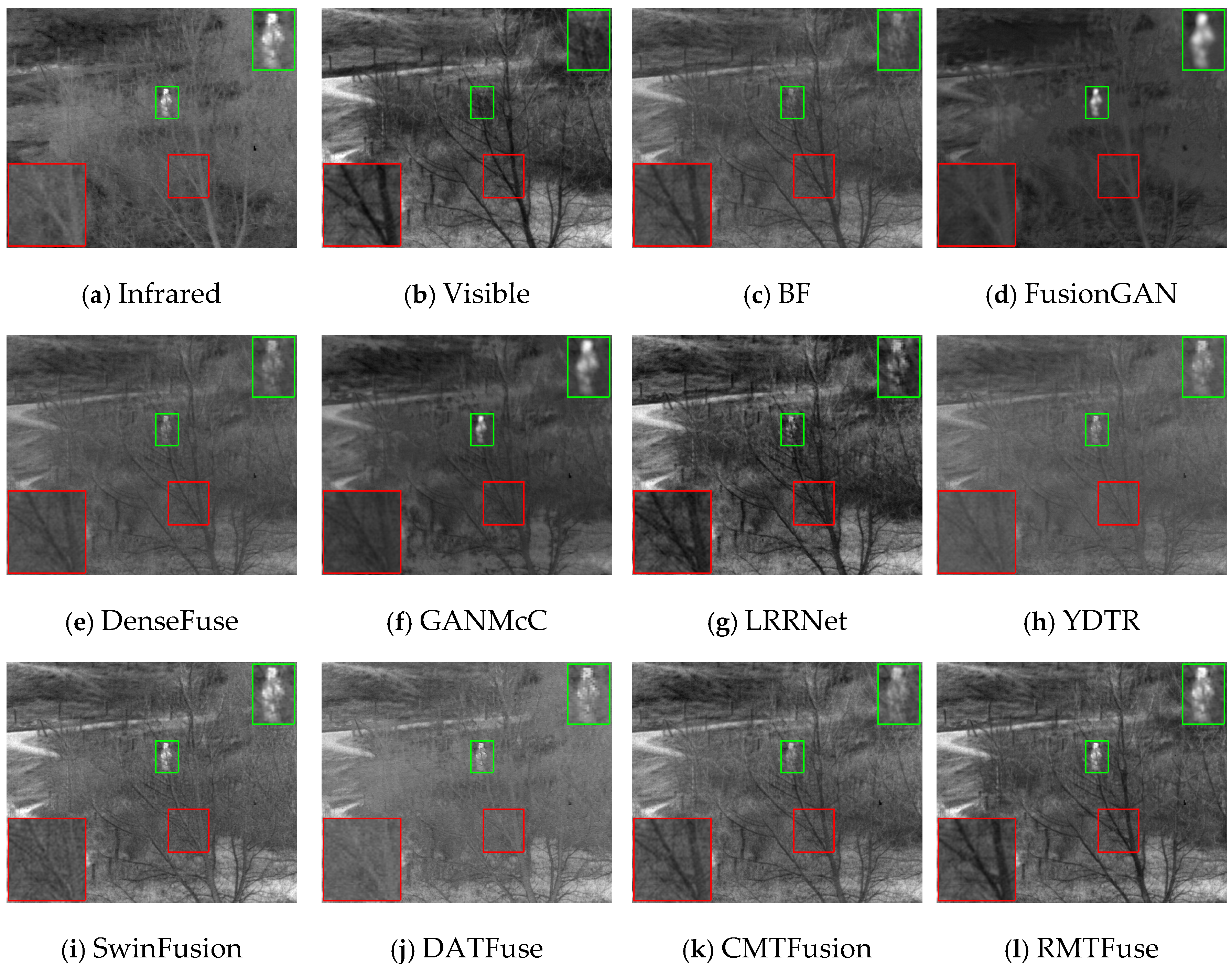
4.4. Comparative Experiments
4.5. Generalization Experiments
4.6. Computational Complexity Analysis
4.7. Detection Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, H.; Xu, H.; Tian, X.; Jiang, J.; Ma, J. Image fusion meets deep learning: A survey and perspective. Inf. Fusion 2021, 76, 323–336. [Google Scholar] [CrossRef]
- Zhang, X.; Demiris, Y. Visible and infrared image fusion using deep learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10535–10554. [Google Scholar] [CrossRef] [PubMed]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar] [CrossRef]
- Chandrakanth, V.; Murthy, V.S.N.; Channappayya, S. Siamese cross domain tracker design for seamless tracking of targets in RGB and thermal videos. IEEE Trans. Artif. Intell. 2023, 4, 161–172. [Google Scholar] [CrossRef]
- Li, K.; Cai, L.; He, G.; Gong, X. MATI: Multimodal Adaptive Tracking Integrator for Robust Visual Object Tracking. Sensors 2024, 24, 4911. [Google Scholar] [CrossRef] [PubMed]
- Tian, D.; Yan, X.; Wang, C.; Zhang, W. IV-YOLO: A Lightweight Dual-Branch Object Detection Network. Sensors 2024, 24, 6181. [Google Scholar] [CrossRef] [PubMed]
- Ariffin, S.; Jamil, N.; Rahman, P. Can thermal and visible image fusion improves ear recognition? In Proceedings of the 2017 8th International Conference on Information Technology (ICIT), Amman, Jordan, 17–18 May 2017; pp. 780–784. [Google Scholar]
- Liu, Y.; Wu, Z.; Han, X.; Sun, Q.; Zhao, J.; Liu, J. Infrared and Visible Image Fusion Based on Visual Saliency Map and Image Contrast Enhancement. Sensors 2022, 22, 6390. [Google Scholar] [CrossRef]
- Chen, J.; Li, X.; Luo, L.; Mei, X.; Ma, J. Infrared and visible image fusion based on target-enhanced multiscale transform decomposition. Inf. Sci. 2020, 508, 64–78. [Google Scholar] [CrossRef]
- Cvejic, N.; Bull, D.; Canagarajah, N. Region-based multimodal image fusion using ICA bases. IEEE Sens. J. 2007, 7, 743–751. [Google Scholar] [CrossRef]
- Li, Y.; Liu, G.; Bavirisetti, D.; Gu, X.; Zhou, X. Infrared-visible image fusion method based on sparse and prior joint saliency detection and LatLRR-FPDE. Digit. Signal Process. 2023, 134, 103910. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H. Infrared and visible image fusion based on visual saliency map and weighted least square optimization. Infrared Phys. Technol. 2017, 82, 8–17. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Zhang, C.; Liu, J.; Zhang, J. Bayesian fusion for infrared and visible images. Signal Process. 2020, 177, 107734. [Google Scholar] [CrossRef]
- Yin, R.; Yang, B.; Huang, Z.; Zhang, X. DSA-Net: Infrared and Visible Image Fusion via Dual-Stream Asymmetric Network. Sensors 2023, 23, 7079. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J.; Kittler, J. RFN-Nest: An end-to-end residual fusion network for infrared and visible images. Inf. Fusion 2021, 73, 72–86. [Google Scholar] [CrossRef]
- Wang, J.; Jiang, M.; Kong, J. MDAN: Multilevel dual-branch attention network for infrared and visible image fusion. Opt. Lasers Eng. 2024, 176, 108042. [Google Scholar] [CrossRef]
- Li, K.; Liu, G.; Gu, X.; Tang, H.; Xiong, J.; Qian, Y. DANT-GAN: A dual attention-based of nested training network for infrared and visible image fusion. Digit. Signal Process. 2024, 145, 104316. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Yan, C.; Meng, L.; Li, L.; Zhang, J.; Wang, Z.; Yin, J.; Zhang, J.; Sun, Y.; Zheng, B. Age-invariant face recognition by multi-feature fusion and decomposition with self-attention. ACM Trans. Multimed. Comput. Commun. Appl. 2022, 18, 1–18. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Peng, H.; Wang, Z. Multi-focus image fusion with a deep convolutional neural network. Inf. Fusion 2017, 36, 191–207. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Xu, H.; Ma, J.; Jiang, J.; Guo, X.; Ling, H. U2fusion: A unified unsupervised image fusion network. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 502–518. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Fan, D.; Jiang, Z.; Zhang, D. MDFN: Mask deep fusion network for visible and infrared image fusion without reference ground-truth. Expert Syst. Appl. 2023, 211, 118631. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.-J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2019, 28, 2614–2623. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Wu, X.-J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Wang, Z.; Wu, Y.; Wang, J.; Xu, J.; Shao, W. Res2Fusion: Infrared and visible image fusion based on dense Res2net and double nonlocal attention models. IEEE Trans. Instrum. Meas. 2022, 71, 5005012. [Google Scholar] [CrossRef]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2021, 70, 5005014. [Google Scholar] [CrossRef]
- Liu, J.; Fan, X.; Huang, Z.; Wu, G.; Liu, R.; Zhong, W.; Luo, Z. Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5792–5801. [Google Scholar] [CrossRef]
- Huang, S.; Song, Z.; Yang, Y.; Wan, W.; Kong, X. MAGAN: Multiattention generative adversarial network for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2023, 72, 5016614. [Google Scholar] [CrossRef]
- Gao, S.; Cheng, M.; Zhao, K.; Zhang, X.; Yang, M.; Torr, P. Res2Net: A new multi-scale backbone architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 652–662. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Vs, V.; Valanarasu, J.M.J.; Oza, P.; Patel, V.M. Image fusion transformer. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3566–3570. [Google Scholar]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. Autom. Sin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y.; Duan, Y.; Si, T. DATFuse: Infrared and visible image fusion via dual attention transformer. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 3159–3172. [Google Scholar] [CrossRef]
- Chen, J.; Ding, J.; Yu, Y.; Gong, W. THFuse: An infrared and visible image fusion network using transformer and hybrid feature extractor. Neurocomputing 2023, 527, 71–82. [Google Scholar] [CrossRef]
- Li, W.; Zhang, Y.; Wang, G.; Huang, Y.; Li, R. DFENet: A dual-branch feature enhanced network integrating transformers and convolutional feature learning for multimodal medical image fusion. Biomed. Signal Process. Control 2023, 80, 104402. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. arXiv 2021, arXiv:2105.15203. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y. VIF-Net: An Unsupervised Framework for Infrared and Visible Image Fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Toet, A. TNO Image Fusion Dataset. 2014. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029 (accessed on 10 June 2024).
- Li, H.; Xu, T.; Wu, X.-J.; Lu, J.; Kittler, J. LRRNet: A novel representation learning guided fusion network for infrared and visible images. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11040–11052. [Google Scholar] [CrossRef]
- Tang, W.; He, F.; Liu, Y. YDTR: Infrared and visible image fusion via Y-shape dynamic transformer. IEEE Trans. Multimed. 2023, 25, 5413–5428. [Google Scholar] [CrossRef]
- Park, S.; Vien, A.G.; Lee, C. Cross-modal transformers for infrared and visible image fusion. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 770–785. [Google Scholar] [CrossRef]
- Rao, Y.-J. In-fibre Bragg grating sensors. Meas. Sci. Technol. 1997, 8, 355. [Google Scholar] [CrossRef]
- Han, Y.; Cai, Y.; Cao, Y.; Xu, X. A new image fusion performance metric based on visual information fidelity. Inf. Fusion 2013, 14, 127–135. [Google Scholar] [CrossRef]
- Roberts, J.W.; Van Aardt, J.A.; Ahmed, F.B. Assessment of image fusion procedures using entropy, image quality, and multispectral classification. J. Appl. Remote Sens. 2008, 2, 023522. [Google Scholar] [CrossRef]
- Xydeas, C.S.; Petrović, V. Objective image fusion performance measure. Electron. Lett. 2000, 36, 308–309. [Google Scholar] [CrossRef]
- Eskicioglu, A.M.; Fisher, P.S. Image quality measures and their performance. IEEE Trans. Commun. 1995, 43, 2959–2965. [Google Scholar] [CrossRef]
- Kumar, B.K.S. Multifocus and multispectral image fusion based on pixel significance using discrete cosine harmonic wavelet transform. Signal, Image Video Process. 2013, 7, 1125–1143. [Google Scholar] [CrossRef]
- Ma, K.; Zeng, K.; Wang, Z. Perceptual quality assessment for multi-exposure image fusion. IEEE Trans. Image Process. 2015, 24, 3345–3356. [Google Scholar] [CrossRef] [PubMed]
- Haghighat, M.; Razian, M.A. Fast-FMI: Non-reference image fusion metric. In Proceedings of the 2014 IEEE 8th International Conference on Application of Information and Communication Technologies (AICT), Astana, Kazakhstan, 15–17 October 2014; pp. 1–3. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Description |
|---|---|
| SFEM | Shallow feature extraction module |
| LFE-RN | Local feature extraction module based on Res2Net |
| GFE-MT | Global feature extraction module based on multiscale Transformer |
| GFIM | Global feature integration module |
| MSA | Multi-head self-attention |
| MLP | Multi-layer perceptron |
| Layer | Output Size | Input Channel | Output Channel | Kerner Size | Stride | Activation |
|---|---|---|---|---|---|---|
| RB1 | 16 | 16 | --- | --- | --- | |
| RB2 | 32 | 16 | --- | --- | --- | |
| 48 | 32 | 1 | 1 | LReLU |
| Output Size | Layer | O-C | K | S | P | E-D | N-B | |
|---|---|---|---|---|---|---|---|---|
| TB1 | Overlapped Patch Merging | 32 | 7 | 4 | 3 | --- | ---- | |
| Transformer Encoder | --- | --- | --- | --- | 32 | 3 | ||
| TB2 | Overlapped Patch Merging | 64 | 3 | 2 | 1 | --- | --- | |
| Transformer Encoder | --- | --- | --- | --- | 64 | 4 | ||
| TB3 | Overlapped Patch Merging | 128 | 3 | 2 | 1 | --- | --- | |
| Transformer Encoder | --- | --- | --- | --- | 128 | 6 |
| Method | SD | VIF | EN | Qabf | SF | Nabf | MS-SSIM | FMIpixel |
|---|---|---|---|---|---|---|---|---|
| w/o RN | 39.3140 | 0.7510 | 7.0783 | 0.5486 | 11.3897 | 0.0277 | 0.9340 | 0.9045 |
| w/o GFE-MT | 34.3967 | 0.6418 | 6.8303 | 0.4948 | 11.2254 | 0.0311 | 0.9291 | 0.9029 |
| w/o MT | 38.3660 | 0.7093 | 7.0015 | 0.5338 | 11.2353 | 0.0259 | 0.9293 | 0.9040 |
| RMTFuse | 40.5153 | 0.7713 | 7.0949 | 0.5621 | 11.9282 | 0.0255 | 0.9342 | 0.9085 |
| Method | SD | VIF | EN | Qabf | SF | Nabf | MS-SSIM | FMIpixel |
|---|---|---|---|---|---|---|---|---|
| BF | 29.3930 | 0.6704 | 6.5879 | 0.4422 | 8.2445 | 0.0993 | 0.8677 | 0.9080 |
| FusionGAN | 29.1010 | 0.4183 | 6.4850 | 0.2245 | 6.2654 | 0.0772 | 0.7288 | 0.8858 |
| DenseFuse | 25.2951 | 0.5869 | 6.4495 | 0.3521 | 6.8819 | 0.0830 | 0.8739 | 0.9048 |
| GANMcC | 31.6695 | 0.5246 | 6.6922 | 0.2770 | 6.3030 | 0.0687 | 0.8557 | 0.8964 |
| LRRNet | 39.2691 | 0.5604 | 6.9719 | 0.3626 | 9.6324 | 0.0562 | 0.8514 | 0.8921 |
| YDTR | 26.9168 | 0.6130 | 6.4626 | 0.3937 | 7.9214 | 0.0586 | 0.8505 | 0.8988 |
| SwinFusion | 39.4348 | 0.7592 | 6.9321 | 0.5321 | 11.3832 | 0.0359 | 0.8931 | 0.9059 |
| DATFuse | 28.0275 | 0.6929 | 6.5187 | 0.4966 | 9.8825 | 0.0435 | 0.8054 | 0.8740 |
| CMTFusion | 36.0810 | 0.6755 | 6.9769 | 0.4890 | 10.6160 | 0.0527 | 0.9233 | 0.9037 |
| RMTFuse | 40.5153 | 0.7713 | 7.0949 | 0.5621 | 11.9282 | 0.0255 | 0.9342 | 0.9085 |
| Method | SD | VIF | EN | Qabf | SF | Nabf | MS-SSIM | FMIpixel |
|---|---|---|---|---|---|---|---|---|
| BF | 30.4217 | 0.5909 | 6.7010 | 0.3348 | 7.7928 | 0.1841 | 0.7795 | 0.8680 |
| FusionGAN | 38.0279 | 0.3806 | 7.0412 | 0.2562 | 8.0454 | 0.1458 | 0.7562 | 0.8533 |
| DenseFuse | 31.7208 | 0.5791 | 6.8133 | 0.3928 | 8.3005 | 0.1470 | 0.8588 | 0.8641 |
| GANMcC | 41.7463 | 0.5135 | 7.1743 | 0.3473 | 8.6212 | 0.1291 | 0.8495 | 0.8560 |
| LRRNet | 41.9076 | 0.4855 | 7.1070 | 0.3403 | 11.8798 | 0.1054 | 0.7976 | 0.8511 |
| YDTR | 35.8128 | 0.5833 | 6.8862 | 0.4483 | 10.2754 | 0.0992 | 0.8622 | 0.8616 |
| SwinFusion | 44.6716 | 0.6288 | 6.9886 | 0.4676 | 11.7787 | 0.0742 | 0.8499 | 0.8593 |
| DATFuse | 32.3401 | 0.5970 | 6.7239 | 0.4871 | 11.4661 | 0.0834 | 0.7611 | 0.8546 |
| CMTFusion | 45.3994 | 0.6226 | 7.3355 | 0.4433 | 11.6916 | 0.0983 | 0.8919 | 0.8584 |
| RMTFuse | 47.2999 | 0.6549 | 7.3002 | 0.5610 | 13.8569 | 0.0359 | 0.9339 | 0.8654 |
| Method | TNO | RoadScene |
|---|---|---|
| BF | 1.5734 | 0.2803 |
| FusionGAN | 0.2686 | 0.2924 |
| DenseFuse | 0.1025 | 0.0521 |
| GANMcC | 0.4600 | 0.5215 |
| LRRNet | 0.1722 | 0.0918 |
| YDTR | 0.3961 | 0.1085 |
| SwinFusion | 1.8124 | 0.8726 |
| DATFuse | 0.0609 | 0.0377 |
| CMTFusion | 0.2208 | 0.1294 |
| RMTFuse | 0.2802 | 0.1072 |
| Method | mAP@0.5 | mAP@0.9 | ||||
|---|---|---|---|---|---|---|
| Person | Car | Avg. | Person | Car | Avg. | |
| IR | 0.7315 | 0.2547 | 0.4931 | 0.2657 | 0.2498 | 0.2578 |
| VIS | 0.5362 | 0.7330 | 0.6346 | 0.2103 | 0.5049 | 0.3576 |
| BF | 0.6227 | 0.6742 | 0.6485 | 0.2616 | 0.4381 | 0.3499 |
| FusionGAN | 0.5173 | 0.5335 | 0.5254 | 0.1166 | 0.3426 | 0.2296 |
| DenseFuse | 0.7250 | 0.6437 | 0.6844 | 0.2712 | 0.4279 | 0.3496 |
| GANMcC | 0.7114 | 0.6809 | 0.6962 | 0.2170 | 0.4142 | 0.3156 |
| LRRNet | 0.6884 | 0.7395 | 0.7140 | 0.2242 | 0.4581 | 0.3412 |
| YDTR | 0.7350 | 0.7070 | 0.7210 | 0.2668 | 0.4593 | 0.3631 |
| SwinFusion | 0.7195 | 0.7388 | 0.7292 | 0.2611 | 0.4267 | 0.3439 |
| DATFuse | 0.7655 | 0.7253 | 0.7454 | 0.2777 | 0.3853 | 0.3315 |
| CMTFusion | 0.6962 | 0.7012 | 0.6987 | 0.2665 | 0.4086 | 0.3376 |
| RMTFuse | 0.7365 | 0.7549 | 0.7457 | 0.2685 | 0.4698 | 0.3692 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, B.; Yang, B. An Infrared and Visible Image Fusion Network Based on Res2Net and Multiscale Transformer. Sensors 2025, 25, 791. https://doi.org/10.3390/s25030791
Tan B, Yang B. An Infrared and Visible Image Fusion Network Based on Res2Net and Multiscale Transformer. Sensors. 2025; 25(3):791. https://doi.org/10.3390/s25030791
Chicago/Turabian StyleTan, Binxi, and Bin Yang. 2025. "An Infrared and Visible Image Fusion Network Based on Res2Net and Multiscale Transformer" Sensors 25, no. 3: 791. https://doi.org/10.3390/s25030791
APA StyleTan, B., & Yang, B. (2025). An Infrared and Visible Image Fusion Network Based on Res2Net and Multiscale Transformer. Sensors, 25(3), 791. https://doi.org/10.3390/s25030791