Abstract
Cross-scene classification of hyperspectral images poses significant challenges due to the lack of a priori knowledge and the differences in data distribution across scenes. While traditional studies have had limited use of a priori knowledge from other modalities, recent advancements in pre-trained large-scale language-vision models have shown strong performance on various downstream tasks, highlighting the potential of cross-modal assisted learning. In this paper, we propose a Semantic-aware Collaborative Parallel Network (SCPNet) to mitigate the impact of data distribution differences by incorporating linguistic modalities to assist in learning cross-domain invariant representations of hyperspectral images. SCPNet uses a parallel architecture consisting of a spatial–spectral feature extraction module and a multiscale feature extraction module, designed to capture rich image information during the feature extraction phase. The extracted features are then mapped into an optimized semantic space, where improved supervised contrastive learning clusters image features from the same category together while separating those from different categories. Semantic space bridges the gap between visual and linguistic modalities, enabling the model to mine cross-domain invariant representations from the linguistic modality. Experimental results demonstrate that SCPNet significantly outperforms existing methods on three publicly available datasets, confirming its effectiveness for cross-scene hyperspectral image classification tasks.
1. Introduction
Deep learning techniques have made significant advancements in hyperspectral image (HSI) classification, with convolutional neural networks (CNNs) being a key component [1,2,3]. CNNs are used to extract and analyze the rich information embedded in hyperspectral images and have been successfully applied to various fields, including environmental monitoring [4], medical imaging [5], agriculture [6], and geological exploration [7]. These networks have demonstrated outstanding performance across these domains. In the context of cross-scene hyperspectral classification, however, training and testing samples often originate from different scenes with distinct spectral and spatial characteristics, resulting in domain shift or distribution mismatch. Such discrepancies may stem from variations in environmental conditions—such as lighting, weather, or geographic location—as well as differences in sensors. Consequently, models trained in one scene may struggle to generalize to others, which can significantly degrade performance. Addressing this challenge requires the development of methods that can effectively learn domain-invariant features and improve model generalization across diverse scenes.
Excitingly, transfer learning has emerged as a powerful approach to address this challenge, with domain adaptation (DA) being the most widely used method for cross-scene classification [8]. A common DA technique is feature alignment [9], which aims to align source and target domain samples into a shared feature space through a mapping, ensuring consistency across different domains [10]. For instance, Long et al. [11] proposed a network, which employs maximum mean discrepancy to reduce domain differences. Additionally, Ganin et al. [12] pioneered the use of adversarial techniques for DA with the development of the domain adversarial neural network. It trains the network to extract similar features from both the source and target domains, thus facilitating domain alignment. These methods focus on aligning features between domains to improve cross-scene classification performance.
During training, DA utilizes data samples and labels from the source domain, along with data samples from the target domain. In recent years, domain generalization (DG) has emerged as a more challenging task than DA. Unlike DA, where data samples and labels from the source domain are used while target domain samples are visible, DG aims to train a model on one or more related domains while ensuring that the target domain remains unseen during training [13]. The goal of DG is to achieve effective generalization to the target domain. To address this, Jin et al. [14] introduced a framework for feature alignment and recovery, which aligns cross-domain features using aligned moments and encourages the separation of relevant from irrelevant features. Meanwhile, Lu et al. [15] proposed the first classification of domain-invariant features into two types: internally invariant features and mutually invariant features, thereby enabling a more comprehensive and diverse extraction of domain-invariant features.
Current deep generalization modeling methods typically focus on manipulating data, learning representations, and developing learning strategies. Among these, representation learning has emerged as the dominant approach [16]. In image classification, the focus is on training models to reduce the representation differences across one or more source domains. Research in multimodal learning has demonstrated that linguistic features can significantly enhance the learning of visual representations [17,18,19], yet this has not been explored in the context of DG. Furthermore, HSI lacks textual descriptive information that can directly reflect feature categories, and the challenge of effectively aligning text and image data remains an open question. To address this, we propose the construction of a semantic space for text-image alignment and optimize supervised contrastive loss to achieve our goal.
This paper proposes a solution to the challenge: a Semantic-aware Collaborative Parallel Network (SCPNet). The network is a multimodal framework that incorporates prior textual knowledge for each category to construct a semantic space. Within this space, features extracted by the spatial–spectral feature extraction module and the multiscale feature extraction module undergo optimized alignment, reducing cross-domain differences. The main contributions of this work are summarized below:
- We propose a multimodal network for cross-scene hyperspectral image classification, where image features are aligned by category in semantic space to enhance inter-class separability and learn cross-domain invariant representations.
- We extract rich image features through the collaborative efforts of the spatial–spectral feature extraction module and the multiscale feature extraction module. Compared to using a single module, our parallel network achieves superior feature extraction performance.
- We construct semantic spaces that facilitate information sharing between the two modalities, enabling the learning of cross-domain invariant representations. We also optimize supervised contrastive loss to ensure better tuning of feature distributions by category.
- Experiments show that our method outperforms all comparison methods, achieving the best classification results across all three datasets and demonstrating strong generalization ability.
2. Related Works
2.1. CNN in HSI Classification
CNN-based HSI classification algorithms can be categorized into three groups based on their feature extraction methods: spectral feature extraction, spatial feature extraction, and spatial–spectral feature extraction. Spectral feature extraction typically uses 1D-CNN, which extracts deep spectral features continuously during the convolution process. Chen et al. [20] achieved excellent results at the time using 1D-CNN to extract spectral information from individual pixels. Incorporating spatial information is crucial for hyperspectral image classification, and 2D-CNN is effective in capturing hidden spatial patterns within the image. Song et al. [21] introduced DFFN, which uses PCA for dimensionality reduction and deeply fuses spatial features. DSGSF employs both channel and spatial attention mechanisms to extract and fuse spectral and spatial features, respectively, thereby enhancing the learning of comprehensive global spatial features [22]. Spatial–spectral features are often extracted using 3D-CNN, which offers better feature representation, though it requires more computational resources. Ahmad et al. [23] applied 3D convolution to generate 3D feature maps over multiple contiguous spectral bands. Zhou et al. [24] combined 3D-CNN with feature pyramids to propose SSPN, which captures various spatial–spectral features. More recently, hybrid approaches combining 2D and 3D convolutions for feature extraction, such as CO-PCN [25] and 3D-2D-SSHDR [26], have also been explored. In fact, dual-stream architectures have been widely adopted, such as SimPoolFormer proposed by Roy et al. [27], which has made new progress in hyperspectral image classification and further demonstrated the effectiveness of the dual-stream design in feature modeling. This paper investigates the effectiveness of using convolution for different purposes in two parallel branches of a network for collaborative feature extraction.
2.2. Domain Generalization
DG presents a greater challenge compared to DA due to the inclusion of target domain data during training in DA, which is not the case in DG. An approach to address the DG problem is to augment and diversify the source domain data by adding out-of-domain samples, which are then used in training alongside the source domain samples. Zunair et al. [28] proposed MSL, feeding both pre-masking and post-masking images into two identical encoders simultaneously, and enhancing the model’s generalization performance through label consistency. Additionally, variational autoencoders [29] and generative adversarial networks [30] can be employed to generate data samples that aid model generalization. Representation learning is currently a key research direction for DG problems. Hu et al. [31] introduced multidomain discriminant analysis, which maps all source domain data to a high-dimensional feature space, achieving desirable properties. Krueger et al. [32] proposed variance of training risks (VREx) to improve robustness against domain distribution bias. Furthermore, domain adversarial learning [33] can reduce cross-domain variance, and all these methods aim to promote domain-invariant learning.
Another category of research focuses on improving generalization ability through specific learning strategies. For instance, Sagawa et al. [34] significantly improved the accuracy of worst-grouping by combining group distributionally robust optimization (GroupDRO) with stronger regularization. Dong et al. [35] enhances medical image segmentation models by providing additional source domain a priori knowledge through the construction of a memory bank. We draw inspiration from representation learning and aim to learn domain-invariant representations through semantic spaces. This approach involves not only relying on traditional training datasets but also incorporating rich linguistic modalities to enhance the model’s generalization ability. By doing so, we expect the learned representations to be better suited for adaptation to different scenarios.
2.3. Vision-Language Model
The learning of visual language models involves the analysis and fusion of heterogeneous data from two distinct sources: text and images. These models can be categorized into single-stream and dual-stream architectures based on whether the data undergoes feature extraction before fusion. Single-stream architectures typically treat textual and image information as equally important, feeding both directly into the fusion module for pre-training, as seen in models like OSCAR [36], UNITER [37], and SimVLM [38]. The advantage of dual-stream architectures lies in their flexibility, as different encoders can be used to process each modality’s data before fusion, allowing for more efficient integration. CLIP [39] employs this approach, utilizing contrastive learning. Similarly, DALSCLIP [40] learns better domain-invariant representations from both images and textual cues. Coca [41], among others, aims to bring positive feature pairs closer together while pushing negative pairs farther apart to extract meaningful representations. This approach not only enhances the performance of traditional visual tasks but also opens new possibilities for processing large-scale remote sensing datasets. By effectively fusing image and text information, visual language models can transcend domain and task boundaries, supporting more complex scene understanding. These models have been applied to key remote sensing tasks, including image retrieval based on text [42,43], image generation from text [44,45], scene categorization [46,47], and object detection [48,49].
3. Proposed Method
Our proposed method consists of two main components: the image encoder and the optimized semantic space. Figure 1 illustrates the overall training framework of the method. In the image encoder section, we combine a spatial–spectral feature extraction module (SSEM) and a multiscale feature extraction module (MSEM) to comprehensively extract spatial and spectral features from the image. The extracted features are then mapped to the optimized semantic space (OSS), which can enhance the model’s domain generalization capability.
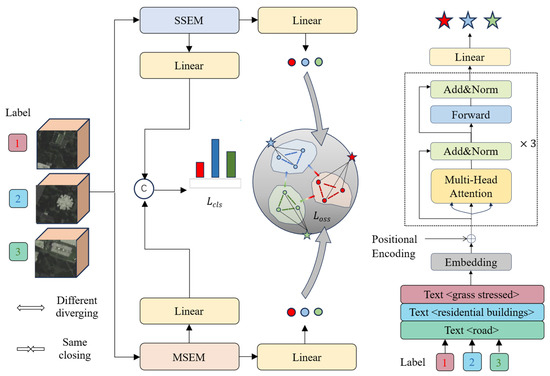
Figure 1.
Diagram of SCPnet’s general training framework.
3.1. Image Encoder
SCPNet’s image encoder follows a parallel network framework. Within this framework, the SSEM, based on 3D convolution, and the MSEM, based on a residual pyramid structure, form two branches of the same encoder that work synergistically for hyperspectral image feature extraction. The SSEM extracts spatial–spectral features by leveraging 3D information, while the MSEM captures multilevel, detail-rich features through the multiscale residual pyramid structure. The combined efforts of these two modules effectively capture both spatial and spectral information in hyperspectral images, thereby enhancing the comprehensiveness and accuracy of feature representation.
Three-dimensional convolution has become increasingly popular in HSI classification. Such networks stack multiple convolution–pooling layers to form a deep architecture, where the input 3D feature maps are convolved with 3D filters and passed through nonlinear activations to produce output feature maps. The process of 3D convolution can be described as follows:
where denotes the value of the neuron at the jth feature sample in the ith layer of the network. , , and are the length, width, and the number of channels of the 3D convolution, respectively. denotes the weight of the ( feature map in the convolution kernel, and denotes the network bias.
In the SSEM, as shown in Figure 2, spatial–spectral features are extracted using two 3D convolutional residual blocks, two max-pooling layers, and a 3D convolution. Each residual block contains two Conv3D-BN3D-ReLU modules and a Conv3D layer, with the outputs of the first and last modules combined via residual concatenation.
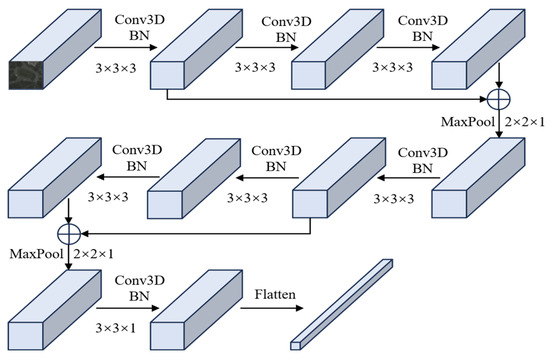
Figure 2.
Flowchart of the SSEM of the image encoder.
In the MSEM, the graph pyramid bottleneck residual structure is utilized. Unlike conventional convolutional bottleneck cells, where the depth remains constant across layers, the output of the pyramidal bottleneck residual cell increases in size as the layers progress.
The network flow of the MSEM is shown in Figure 3. It starts with a Conv2d-BN2d block with a convolutional kernel size of 3 and then goes through three pyramidal residual modules . Where contains three residual modules of the same structure, in each residual module, three BN2d-Conv2d blocks and one BN2d-ReLU block, with a kernel size of 7 for the second convolutional layer, and a kernel size of 3 for the remaining kernels. Every first residual module in and in which the second convolutional layer has a kernel size of 8 and a step size of 2, and the rest is like that in . At the end of the unit, a downsampling layer is added to reduce the data space. The structure of the last two residual units, in and , is exactly similar to that of . The network is also connected to an average pooling layer at the end for down sampling to diminish data variance and extract low-level features of the spatial neighborhood for input into the subsequent layer. To systematically augment the depth of the feature map in each layer, set the initial value to when . In all other cases, is computed according to the following recursive relationship:
where is the initial number of channels, is the depth of the jth unit in the ith pyramid residual module, and is the total number of residual units in the entire network. At this point the depth of each layer of the feature map depends on and .
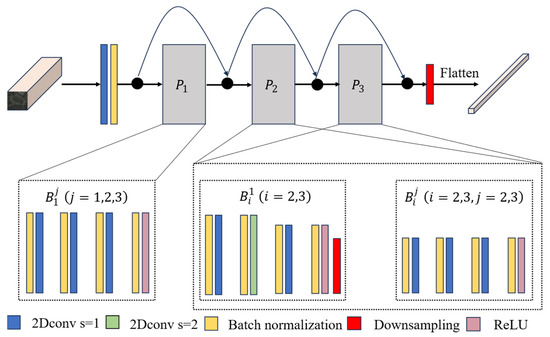
Figure 3.
Flowchart of the MSEM of the image encoder.
The features extracted from SSEM and MSEM are concatenated, and the classification probabilities are produced through the classification header. Subsequently, the cross entropy is calculated using the ground truth. The classification loss of the network is defined as follows:
where denotes the one-hot vector representing the ground-truth category of sample , and is the predicted probability.
3.2. Optimized Semantic Space
Given a source domain and a target domain , where is the data and is the label, the data distribution in the is not the same as , i.e., . Our goal is to learn two robust and generalized functions from the that can be tested on the unseen with the smallest possible prediction error:
where is the expectation.
We introduce a semantic space that enables the learning of cross-domain invariant representations by learning a cross-domain shared representation space in which images from the source and target domains can be similarly represented. Establishing this semantic space requires introducing prior knowledge, which is processed by the transformer to obtain text features. For the knowledge base , each textual prior knowledge corresponds one-to-one to a label . The textual prior knowledge describes the spatial relations and imaging features of the category to which the label corresponds, thus providing each label with semantic information related to its category. Given a label , we can find the text corresponding to it by a simple mapping relation :
Calculating the above for the labels of a batch of data eventually results in the prior knowledge for that batch. Next, we need to encode the text, convert it to a text embedding, and add a positional encoding. The formula is as follows:
where is the lowercase byte pair encoding with a vocabulary size of 49,152, is the token embedding operation, and is positional encoding.
After that, is extracted by transformer architecture to obtain text features. Like a traditional transformer, we utilize a multi-head attention mechanism. The tokenized text is divided into parts, each of which is set to , . Where is the size of batch, represents the maximum sentence length, while denotes the size of the embedding dimension, h is the number of headers. is linearly transformed to obtain , , and . The following formula describes the transformation:
where , and are learnable matrices.
Then, the attention weight matrix of each head is computed, and the attention matrices of all heads are combined with the formula defined as follows:
where is used to do SoftMax operation on each sequence of data and combines the attention matrix of each head into a single attention matrix.
The equation for the overall transformer process is simplified as follows:
where and are layer normalization operations and is a feed forward neural network.
The described process only involves one layer, and the number of iterations is determined by the number of layers. The transformer consists of three layers, eight headers, and a width of 512. To have a better initial state when the text encoder starts training, the pre-training parameters of ViT-B-32 are used. The final feature obtained is the maximum value for each text sequence. Subsequently, we use textual features to build a semantic space representation and project image features into the semantic space. The formula representation is as follows:
where is the learnable matrix and is the bias term. The linear layer is responsible for mapping the image features into semantic space. Currently, the semantic space and image feature data dimensions are consistent, which is convenient for subsequent operations.
If the model exhibits strong class separability and cross-domain invariance, the visual feature is expected to be located closer in the semantic space to the corresponding linguistic feature associated with its ground-truth label. The following equation describes the calculation process for this similarity:
where and belong to features of two different modalities. Based on this similarity, the supervised contrastive loss formula can be described as follows:
where and are the positive and negative sample sets in ; and are one of the positive and negative samples.
Supervised contrastive learning can reduce the distance between similar features, achieved by calculating the similarity between positive and negative samples. To emphasize the critical role of similarity, we propose an optimized similarity calculation method. Specifically, we square to highlight similarity. The optimized contrastive loss can be described as follows:
We differentiate the with respect to the two types of supervised contrastive loss. For simplicity, we omit the summation and obtain the following two equations:
where if is large (i.e., the positive pairs are already close), the squared term introduces an amplification factor of . This ensures that the optimizer still produces a significant pulling effect, thereby avoiding the vanishing-gradient problem of the original supervised contrastive loss when similarities are high and preventing training stagnation. If is small (i.e., negative or irrelevant pairs), the squared value rapidly decays, and the gradient approaches zero. This mitigates excessive repulsion of irrelevant negative samples. The final loss in optimized semantic space can be described as follows:
where the contribution weight serves to adjust the degree of influence of the image features of the two branches within the optimized semantic space. With this approach, features from the same class of labels are clustered together, while features from different classes of labels are distanced. Meanwhile, the method crosses the modal divide and successfully learns representations from different modalities, enhancing the generalization ability of the model. The overall loss during model training is defined as follows:
where the hyperparameter serves to balance the effects of the optimized semantic space on the overall model training.
In the testing phase, features are extracted and classified using SCPNet’s image encoder incorporating SSEM and MSEM. The training and testing process of SCPNet is shown in Algorithm 1.
| Algorithm 1: Pseudocode of SCPNet | |
| 1 | Training stage: |
| 2 | Input: Source domain samples , total epoch number T, knowledge base . |
| 3 | Output: The parameters , |
| 4 | Initialize:,. Load Pretrain parameters |
| 5 | Load: Pretrain parameters |
| 6 | For epoch = 1: T do: |
| 7 | Extract image features and text features |
| 8 | |
| 9 | through Equations (5)–(11) |
| 10 | Establish an optimized semantic space and map image features through Equations (12)–(14) |
| 11 | For all, : |
| 12 | Calculate the loss through Equation (3) |
| 13 | Calculate the loss through Equations (15)–(20) |
| 14 | Calculate the total loss through Equation (21) |
| 15 | End For |
| 16 | Update , , by gradient descent |
| 17 | End For |
| 18 | Testing stage: |
| 19 | Input: Target domain samples |
| 20 | Load: The parameters , |
| 21 | Extract image features |
| 22 | |
| 23 | Output: (Classification Vector) |
4. Experiment and Discussion
4.1. Description of Datasets
To verify the effectiveness of our approach, we incorporate three publicly available datasets: Houston, Pavia, and Indiana. Each dataset comprises two scenes, which are elaborated upon below.
The Houston dataset, collected from the University of Houston and its surroundings, includes two scenes: Houston 13 [50] (349 × 1905 pixels, 144 bands) as the source domain and Houston 18 [51] (209 × 955 pixels, 48 bands) as the target domain, both with a spatial resolution of 2.5 m. Acquired at different conditions in 2013 and 2018, the datasets were aligned by selecting the 48 common bands from Houston13 and cropping the overlapping region (209 × 955). Both datasets contain the same seven land cover classes, as detailed in Table 1. The pseudo-color and true value maps for both datasets are shown in Figure 4. Due to the fewer source samples in Houston 13, we applied data augmentation such as random flipping and radiometric enhancement, to expand the training set fourfold.

Table 1.
The name of class and number of samples in Houston dataset.

Figure 4.
Houston dataset.
The Pavia dataset was collected from Italy in 2003 using the POSIS sensor [52]. It is divided into two segments: the University of Pavia (UP), which serves as the source domain, containing 610 × 340 image elements and 103 spectral bands, and the Pavia Center (PC), which serves as the target domain, comprising 1096 × 715 image elements and 102 spectral bands. The dataset has a spatial resolution of 1.3 m. By removing the 103rd band, the number of bands in the UP dataset was adjusted to 102 to match the PC dataset. The dataset contains seven feature columns, as detailed in Table 2, and the pseudo-color and true value maps are shown in Figure 5.
Table 2.
The name of class and number of samples in Pavia dataset.

Figure 5.
Pavia dataset.
The Indiana dataset was acquired by AVIRIS sensors in the Indian Pine Barrens of northwestern Indiana in 1992. In order to distinguish the source and target domains, the scene is divided into two datasets without overlapping image elements as suggested in the literature [53], which we call IndianaSD and IndianaTD, respectively. The dataset consists of 400 × 300 image elements and 220 spectral bands. The scene includes various land features, such as crops, orchards, and more, with further details provided in Table 3. The pseudo-color and true value maps are shown in Figure 6.
Table 3.
The name of class and number of samples in Indiana dataset.
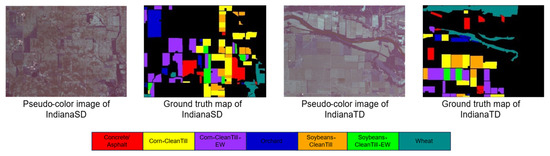
Figure 6.
Indiana dataset.
4.2. Experiment Setting
All experiments were run in the python 3.6 and pytorch 11.3 environments. The default weight decay for L2 regularization across all modules was set to 1 × 10−4. The image encoder and text encoder were optimized by Adam. The CPU was an AMD EPYC 7642 48-core Processor, and the GPU was an RTX 3090 with 24GB of RAM. We created knowledge bases for each of the three datasets, where each category corresponds to a piece of prior knowledge. The knowledge bases for three datasets are shown in Table 4, Table 5 and Table 6.
Table 4.
Knowledge base for the Houston dataset.
Table 5.
Knowledge base for the Pavia dataset.
Table 6.
Knowledge base for the Indiana dataset.
4.3. Parameter Tuning
To exploit the model potential, we tuned the regularization parameter and the contribution weight . Figure 7, Figure 8 and Figure 9 show results across three datasets. We recommend , which reflects the same importance of SSEM and MSEM in semantic space. For the Houston and Pavia datasets, the is set to 1 × 10−0, which is effective in preventing overfitting and improving the stability of the model. In contrast, for the Indiana dataset, of 1 × 101 will help to deal with the problem of large feature differences in this dataset, thus improving the classification performance.
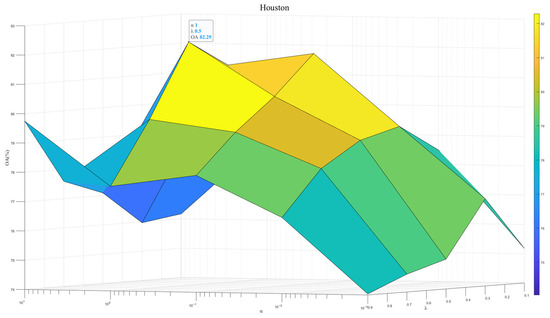
Figure 7.
Model performance at different and in Houston dataset.
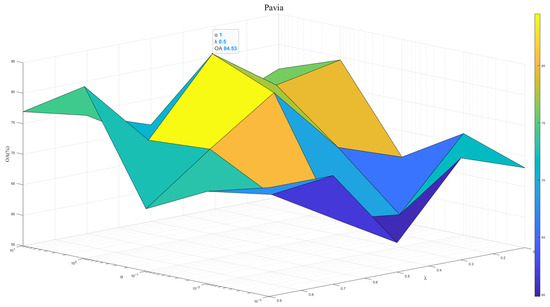
Figure 8.
Model performance at different and in Pavia dataset.
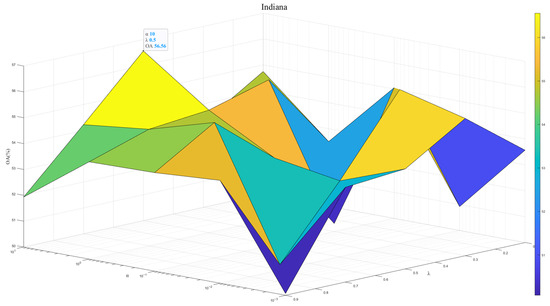
Figure 9.
Model performance at different and in Indiana dataset.
4.4. Ablation Study
To verify the effectiveness of our proposed modules, we designed ablation experiments. In the experiments, we separately evaluated the effectiveness of SSEM, MSEM, and OSS. Additionally, SS denotes the use of original supervised contrastive learning. By comparing the experimental results of SS and OSS, we demonstrate the effectiveness of the proposed contrastive learning loss optimization method.
According to Table 7, experimental results show that the proposed SCPNet has superior performance compared to these variants. Specifically, designing SSEM and MSEM as two branches of a parallel network and training them together can give full play to their advantages and achieve complementary advantages. The semantic space and optimized contrastive loss then improve model generalization.
Table 7.
Ablation experiment results.
4.5. Comparison Experiment
To evaluate cross-domain classification performance, we compared our framework with SDEnet [54], S2ECnet [55], LLURnet [56] and FDGnet [57]. Since the existing cross-scene hyperspectral classification methods are limited, we additionally chose four DG methods for RGB images, namely GroupDRO [34], ANDMask [58], VREx [3], and DIFEX [15], to further validate the effectiveness of our methods. Source domain data and labels were used for training (50% training/50% validation, except 80% training for Houston), while the entire target domain was used for testing. The patch size, batch size, and learning rate were set to 13, 256, and 0.001, respectively. Each method was independently executed ten times with random seeds from 0 to 9, and the results are presented as mean ±95% confidence intervals (CI) to indicate statistical reliability. To measure the accuracy and consistency between the true label and the predicted values, the overall accuracy (OA) and the kappa coefficient (KC) on the target domain were used as the evaluation metrics of the algorithms.
The results are shown in Table 8, Table 9 and Table 10. On the Houston and Pavia datasets, LLURNet achieved the best performance among the compared methods, while our SCPNet further improved OA by 4.22 and 0.86 and KC by 7.16 and 0.96, respectively. On the Indiana dataset, FDGnet performed best among the baselines, but SCPNet still outperformed it by 1.59 in OA and 5.78 in KC. It is also worth noting that although the RGB-based DG methods did not achieve the best results, their competitive performance demonstrates the potential of transferring RGB-based DG strategies to cross-scene hyperspectral classification. In the Indiana dataset, the standard deviation of some categories even exceeded their mean accuracy, indicating large fluctuations and highlighting the challenge of classifying these categories. Our method effectively mitigates this issue and, overall, achieves superior classification performance compared with existing methods.
Table 8.
Comparison of class-specific, OA (%) and KC (κ) of different methods for the target scene Houston 2018.
Table 9.
Comparison of class-specific, OA (%) and KC (κ) of different methods for the target scene Pavia Center.
Table 10.
Comparison of class-specific, OA (%) and KC (κ) of different methods for the target scene IndianaTD.
The classification maps for three datasets are shown in Figure 10, Figure 11 and Figure 12. Each pixel with an unspecified category is used as the background and pixels with categories are predicted for comparison. Each figure contains a truth map and a presentation of the predictions from all models. In Figure 10, we can clearly see that the 2nd and 5th classes are better predicted by SCPnet.

Figure 10.
Ground truth and classification maps for IndianaTD. (a) GT. (b) SDEnet. (c) S2ECnet. (d) LLURnet. (a) GT. (b) GroupDRO. (c) ANDMask. (d) VREx. (e) DIFEX. (f) SDEnet. (g) S2ECnet. (h) LLURnet. (i) FDGnet. (j) Ours.
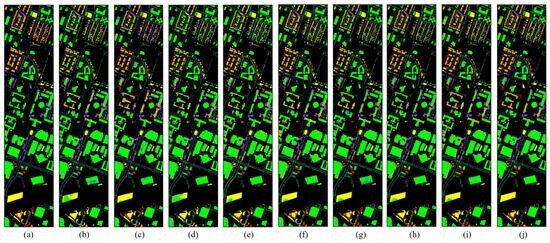
Figure 11.
Ground truth and classification maps for Houston 2018. (a) GT. (b) SDEnet. (c) S2ECnet. (d) LLURnet. (a) GT. (b) GroupDRO. (c) ANDMask. (d) VREx. (e) DIFEX. (f) SDEnet. (g) S2ECnet. (h) LLURnet. (i) FDGnet. (j) Ours.

Figure 12.
Ground truth and classification maps for Pavia Center. (a) GT. (b) SDEnet. (c) S2ECnet. (d) LLURnet. (a) GT. (b) GroupDRO. (c) ANDMask. (d) VREx. (e) DIFEX. (f) SDEnet. (g) S2ECnet. (h) LLURnet. (i) FDGnet. (j) Ours.
In addition, to test the parameter sensitivity of the parameters, we evaluated four DG methods for cross-scene HSI classification and SCPnet under varying training ratios. Figure 13, Figure 14 and Figure 15 illustrate the results on three datasets, it can be seen that SCPNet consistently exhibits superior generalization across all datasets, demonstrating its robustness to fluctuations in the amount of available training data.
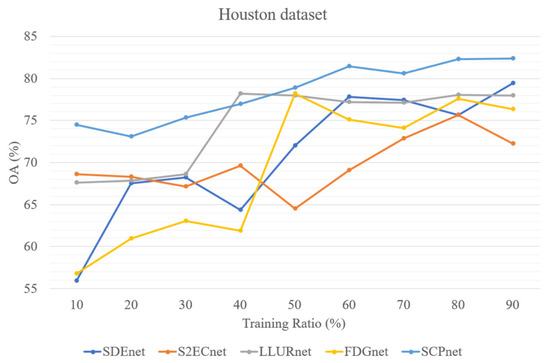
Figure 13.
Five methods’ performance at different training ratio on Houston dataset.
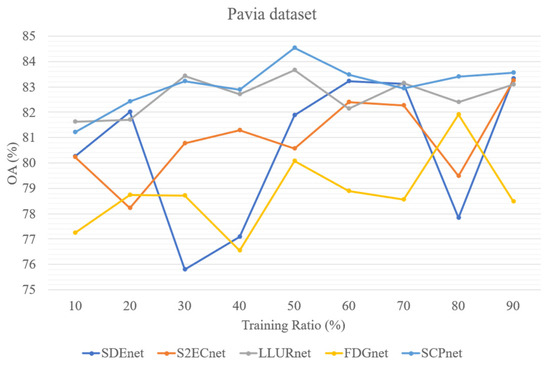
Figure 14.
Five methods’ performance at different training ratio on Pavia dataset.
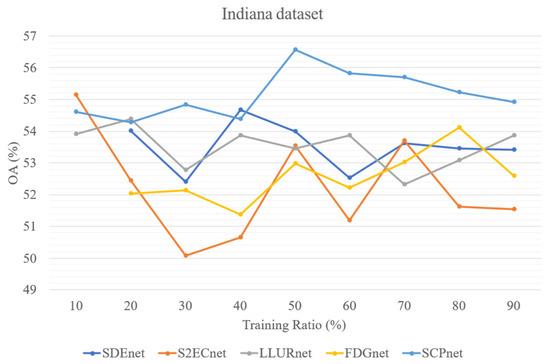
Figure 15.
Five methods’ performance at different training ratio on Indiana dataset.
The training time and inference speed are indicative of the computational cost of a model. Accordingly, we measured the training time, testing time, and number of parameters for all models, as summarized in Table 11. SCPNet exhibits a relatively higher computational cost across all three datasets. Specifically, it contains approximately 38.88 M, 47.87 M, and 56.25 M parameters on the Houston, Pavia, and Indiana datasets, respectively, which are considerably larger than those of other approaches. This increase primarily stems from the inclusion of the pretrained language model and the 3D-CNNs used in the SSEM, which enhance feature expressiveness at the expense of additional computation. In terms of training and inference efficiency, SCPNet also requires longer training times (40.27 s, 139.22 s, and 221.39 s, respectively) and testing times (44.75 s, 53.45 s, and 92.31 s, respectively) per batch compared with most competing methods. However, this computational overhead is accompanied by notable improvements in classification accuracy and cross-scene generalization performance.
Table 11.
Comparison of computational costs across all methods on three datasets.
5. Conclusions
We propose the Semantic-aware Collaborative Parallel Network (SCPNet), a domain generalization network, for the cross-scene HSI classification. The key innovation of SCPNet lies in its dual-branch feature extraction modules and the construction of an optimized semantic space, which enable the model to collaboratively extract features and learn domain-invariant representations. Extensive experiments on three benchmark datasets confirm that SCPNet consistently outperforms state-of-the-art baselines, achieving robustness under varying training ratios and across heterogeneous domains. These findings highlight the scientific contribution of integrating semantic-aware learning with co-parallel feature extraction. However, the experiments on computational cost reveal that SCPNet requires substantial computational resources, mainly in terms of longer training and testing time as well as a larger number of model parameters. Nevertheless, these costs are acceptable considering the significant improvements in classification performance achieved by the proposed model. Future research may focus on incorporating prior knowledges from other modalities, or developing lightweight text and image encoders to further reduce the computational burden.
Author Contributions
Conceptualization, X.L. and X.Y.; methodology, C.J.; software, C.J.; validation, X.Y. and Y.T.; formal analysis, Y.T.; investigation, X.L.; resources, K.X.; data curation, C.J.; writing—original draft preparation, C.J. and Y.T.; writing—review and editing, X.L.; visualization, Y.T.; supervision, K.X.; project administration, X.Y.; funding acquisition, X.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This project was supported by the open research fund of Heilongjiang Key Laboratory of Analysis on Machine Learning and Dynamic System (Grant No. HLJKL2503) and the Provincial and Ministerial Co-construction Collaborative Innovation Center Project for Sustainable Development of Urban and Rural Construction in Cold Regions (Grant No. HQ0024) and (Grant No. HQ0025).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors would like to express their gratitude to colleagues who provided valuable insights and technical assistance during the course of this research..
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alkhatib, M.Q.; Al-Saad, M.; Aburaed, N.; Almansoori, S.; Zabalza, J.; Marshall, S.; Al-Ahmad, H. Tri-CNN: A three branch model for hyperspectral image classification. Remote Sens. 2023, 15, 316. [Google Scholar] [CrossRef]
- Cao, X.; Yao, J.; Xu, Z.; Meng, D. Hyperspectral image classification with convolutional neural network and active learning. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4604–4616. [Google Scholar] [CrossRef]
- Ortac, G.; Ozcan, G. Comparative study of hyperspectral image classification by multidimensional Convolutional Neural Network approaches to improve accuracy. Expert Syst. Appl. 2021, 182, 115280. [Google Scholar] [CrossRef]
- Song, A.; Kim, Y. Deep learning-based hyperspectral image classification with application to environmental geographic information systems. Korean J. Remote Sens. 2017, 33, 1061–1073. [Google Scholar]
- Zhang, X.; Li, W.; Gao, C.; Yang, Y.; Chang, K. Hyperspectral pathology image classification using dimension-driven multi-path attention residual network. Expert Syst. Appl. 2023, 230, 120615. [Google Scholar] [CrossRef]
- Wang, C.; Liu, B.; Liu, L.; Zhu, Y.; Hou, J.; Liu, P.; Li, X. A review of deep learning used in the hyperspectral image analysis for agriculture. Artif. Intell. Rev. 2021, 54, 5205–5253. [Google Scholar] [CrossRef]
- Galdames, F.J.; Perez, C.A.; Estevez, P.A.; Adams, M. Rock lithological instance classification by hyperspectral images using dimensionality reduction and deep learning. Chemom. Intell. Lab. Syst. 2022, 224, 104538. [Google Scholar] [CrossRef]
- Farahani, A.; Voghoei, S.; Rasheed, K.; Arabnia, H.R. A brief review of domain adaptation. In Advances in Data Science and Information Engineering; Springer: Cham, Switzerland, 2021; pp. 877–894. [Google Scholar] [CrossRef]
- Wang, M.; Deng, W. Deep visual domain adaptation: A survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef]
- Li, J.; Lu, K.; Huang, Z.; Zhu, L.; Shen, H.T. Heterogeneous domain adaptation through progressive alignment. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1381–1391. [Google Scholar] [CrossRef]
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR: Cambridge, MA, USA, 2015; pp. 97–105. [Google Scholar] [CrossRef]
- Ganin, Y.; Ustinova, E.; Ajakan, H.; Germain, P.; Larochelle, H.; Laviolette, F.; March, M.; Lempitsky, V. Domain-adversarial training of neural networks. J. Mach. Learn. Res. 2016, 17, 1–35. [Google Scholar] [CrossRef]
- Blanchard, G.; Lee, G.; Scott, C. Generalizing from several related classification tasks to a new unlabeled sample. Adv. Neural Inf. Process. Syst. 2011, 24, 2178–2186. [Google Scholar]
- Jin, X.; Lan, C.; Zeng, W.; Chen, Z. Feature alignment and restoration for domain generalization and adaptation. arXiv 2020, arXiv:2006.12009. [Google Scholar] [CrossRef]
- Lu, W.; Wang, J.; Li, H.; Chen, Y.; Xie, X. Domain-invariant feature exploration for domain generalization. arXiv 2022, arXiv:2207.12020. [Google Scholar] [CrossRef]
- Wang, J.; Lan, C.; Liu, C.; Ouyang, Y.; Qin, T.; Lu, W.; Chen, Y.; Zeng, W.; Yu, P. Generalizing to unseen domains: A survey on domain generalization. IEEE Trans. Knowl. Data Eng. 2022, 35, 8052–8072. [Google Scholar] [CrossRef]
- Devillers, B.; Choksi, B.; Bielawski, R.; VanRullen, R. Does language help generalization in vision models? arXiv 2021, arXiv:2104.08313. [Google Scholar] [CrossRef]
- Wu, W.; Sun, Z.; Song, Y.; Wang, J.; Ouyang, W. Transferring vision-language models for visual recognition: A classifier perspective. Int. J. Comput. Vis. 2024, 132, 392–409. [Google Scholar] [CrossRef]
- Zhang, P.; Li, X.; Hu, X.; Yang, J.; Zhang, L.; Wang, L.; Choi, Y.; Gao, J. Vinvl: Revisiting visual representations in vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 19–25 June 2021; IEEE: New York, NY, USA, 2021; pp. 5579–5588. [Google Scholar] [CrossRef]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef]
- Song, W.; Li, S.; Fang, L.; Lu, T. Hyperspectral image classification with deep feature fusion network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3173–3184. [Google Scholar] [CrossRef]
- Guo, T.; Wang, R.; Luo, F.; Gong, X.; Zhang, L.; Gao, X. Dual-view spectral and global spatial feature fusion network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–13. [Google Scholar] [CrossRef]
- Ahmad, M.; Khan, A.M.; Mazzara, M.; Distefano, S.; Ali, M.; Sarfraz, M.S. A fast and compact 3-D CNN for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2020, 19, 1–5. [Google Scholar] [CrossRef]
- Zhou, J.; Zeng, S.; Gao, G.; Chen, Y.; Tang, Y. A novel spatial-spectral pyramid network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Sima, H.; Gao, F.; Zhang, Y.; Sun, J.; Guo, P. Collaborative optimization of spatial-spectrum parallel convolutional network (CO-PCN) for hyperspectral image classification. Int. J. Mach. Learn. Cybern. 2023, 14, 2353–2366. [Google Scholar] [CrossRef]
- Cao, F.; Guo, W. Deep hybrid dilated residual networks for hyperspectral image classification. Neurocomputing 2020, 384, 170–181. [Google Scholar] [CrossRef]
- Roy, S.K.; Jamali, A.; Chanussot, J.; Ghamisi, P.; Ghaderpour, E.; Shahabi, H. SimPoolFormer: A two-stream vision transformer for hyperspectral image classification. Remote Sens. Appl. Soc. Environ. 2025, 37, 101478. [Google Scholar] [CrossRef]
- Zunair, H.; Ben Hamza, A. Learning to recognize occluded and small objects with partial inputs. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; IEEE: New York, NY, USA, 2024; pp. 675–684. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Hu, S.; Zhang, K.; Chen, Z.; Chan, L. Domain generalization via multidomain discriminant analysis. In Uncertainty in Artificial Intelligence; PMLR: Cambridge, MA, USA, 2020; pp. 292–302. [Google Scholar]
- Krueger, D.; Caballero, E.; Jacobsen, J.-H.; Zhang, A.; Binas, J.; Zhang, D.; Le Priol, R.; Courville, A. Out-of-distribution generalization via risk extrapolation (rex). In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 June 2021; PMLR: Cambridge, MA, USA, 2021; pp. 5815–5826. [Google Scholar]
- Du, Y.; Wang, J.; Feng, W.; Pan, S.; Qin, T.; Xu, R.; Wang, C. Adarnn: Adaptive learning and forecasting of time series. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Queensland, Australia, 1–5 November 2021; ACM: New York, NY, USA, 2021; pp. 402–411. [Google Scholar] [CrossRef]
- Sagawa, S.; Koh, P.W.; Hashimoto, T.B.; Liang, P. Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization. arXiv 2019, arXiv:1911.08731. [Google Scholar] [CrossRef]
- Dong, W.; Du, B.; Xu, Y. Source domain prior-assisted segment anything model for single domain generalization in medical image segmentation. Image Vis. Comput. 2024, 150, 105216. [Google Scholar] [CrossRef]
- Li, X.; Yin, X.; Li, C.; Zhang, P.; Hu, X.; Zhang, L.; Wang, L.; Hu, H.; Dong, L.; Wei, F. Oscar: Object-semantics aligned pre-training for vision-language tasks. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020, Proceedings, Part XXX16; Springer: Cham, Switzerland, 2020; pp. 121–137. [Google Scholar] [CrossRef]
- Chen, Y.-C.; Li, L.; Yu, L.; El Kholy, A.; Ahmed, F.; Gan, Z.; Cheng, Y.; Liu, J. Uniter: Universal image-text representation learning. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 104–120. [Google Scholar]
- Wang, Z.; Yu, J.; Yu, A.W.; Dai, Z.; Tsvetkov, Y.; Cao, Y. Simvlm: Simple visual language model pretraining with weak supervision. arXiv 2021, arXiv:2108.10904. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J. Learning transferable visual models from natural language supervision. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 18–24 June 2021; PMLR: Cambridge, MA, USA, 2021; pp. 8748–8763. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, J.; Tang, H.; Qin, R. DALSCLIP: Domain aggregation via learning stronger domain-invariant features for CLIP. Image Vis. Comput. 2024, 154, 105359. [Google Scholar] [CrossRef]
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. Coca: Contrastive captioners are image-text foundation models. arXiv 2022, arXiv:2205.01917. [Google Scholar]
- Cheng, Q.; Zhou, Y.; Fu, P.; Xu, Y.; Zhang, L. A deep semantic alignment network for the cross-modal image-text retrieval in remote sensing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4284–4297. [Google Scholar] [CrossRef]
- Yuan, Z.; Zhang, W.; Tian, C.; Rong, X.; Zhang, Z.; Wang, H.; Fu, K.; Sun, X. Remote sensing cross-modal text-image retrieval based on global and local information. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, W.; Ghamisi, P.; Kopp, M.; Hochreiter, S. Txt2Img-MHN: Remote sensing image generation from text using modern Hopfield networks. IEEE Trans. Image Process. 2023, 32, 5737–5750. [Google Scholar] [CrossRef]
- Zhao, R.; Shi, Z. Text-to-remote-sensing-image generation with structured generative adversarial networks. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, Z.; Yu, J.-G.; Zhang, Y. Learning deep cross-modal embedding networks for zero-shot remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10590–10603. [Google Scholar] [CrossRef]
- Sumbul, G.; Cinbis, R.G.; Aksoy, S. Fine-grained object recognition and zero-shot learning in remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2017, 56, 770–779. [Google Scholar] [CrossRef]
- Cheng, G.; Yan, B.; Shi, P.; Li, K.; Yao, X.; Guo, L.; Han, J. Prototype-CNN for few-shot object detection in remote sensing images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–10. [Google Scholar] [CrossRef]
- Huang, X.; He, B.; Tong, M.; Wang, D.; He, C. Few-shot object detection on remote sensing images via shared attention module and balanced fine-tuning strategy. Remote Sens. 2021, 13, 3816. [Google Scholar] [CrossRef]
- Debes, C.; Merentitis, A.; Heremans, R.; Hahn, J.; Frangiadakis, N.; van Kasteren, T.; Liao, W.; Bellens, R.; Pižurica, A.; Gautama, S. Hyperspectral and LiDAR data fusion: Outcome of the 2013 GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2405–2418. [Google Scholar] [CrossRef]
- Le Saux, B.; Yokoya, N.; Hänsch, R.; Prasad, S. 2018 IEEE GRSS data fusion contest: Multimodal land use classification [technical committees]. IEEE Geosci. Remote Sens. Mag. 2018, 6, 52–54. [Google Scholar] [CrossRef]
- Licciardi, G.; Pacifici, F.; Tuia, D.; Prasad, S.; West, T.; Giacco, F.; Thiel, C.; Inglada, J.; Christophe, E.; Chanussot, J. Decision fusion for the classification of hyperspectral data: Outcome of the 2008 GRS-S data fusion contest. IEEE Trans. Geosci. Remote Sens. 2009, 47, 3857–3865. [Google Scholar] [CrossRef]
- Ye, M.; Qian, Y.; Zhou, J.; Tang, Y.Y. Dictionary learning-based feature-level domain adaptation for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1544–1562. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, W.; Sun, W.; Tao, R.; Du, Q. Single-source domain expansion network for cross-scene hyperspectral image classification. IEEE Trans. Image Process. 2023, 32, 1498–1512. [Google Scholar] [CrossRef] [PubMed]
- Dong, L.; Geng, J.; Jiang, W. Spectral-Spatial Enhancement and Causal Constraint for Hyperspectral Image Cross-Scene Classification. IEEE Trans. Geosci. Remote Sens. 2024, 62, 5507013. [Google Scholar] [CrossRef]
- Zhao, H.; Zhang, J.; Lin, L.; Wang, J.; Gao, S.; Zhang, Z. Locally linear unbiased randomization network for cross-scene hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5526512. [Google Scholar] [CrossRef]
- Qin, B.; Feng, S.; Zhao, C.; Xi, B.; Li, W.; Tao, R. FDGNet: Frequency disentanglement and data geometry for domain generalization in cross-scene hyperspectral image classification. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 10297–10310. [Google Scholar] [CrossRef]
- Parascandolo, G.; Neitz, A.; Orvieto, A.; Gresele, L.; Schölkopf, B. Learning explanations that are hard to vary. arXiv 2020, arXiv:2009.00329. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).