Abstract
Event-based cameras, as a revolutionary class of dynamic vision sensors, offer transformative advantages for capturing transient mechanical phenomena through their asynchronous, per-pixel brightness change detection mechanism. These neuromorphic sensors excel in challenging industrial environments with their microsecond-level temporal resolution, ultra-low power requirements, and exceptional dynamic range that significantly outperform conventional imaging systems. In this way, the event-based camera provides a promising tool for machine vibration sensing and fault diagnosis. However, the dynamic vision data from the event-based cameras have a complex structure, which cannot be directly processed by the mainstream methods. This paper proposes a dynamic vision-based non-contact machine fault diagnosis method. The Eagle Vision Transformer (EViT) architecture is proposed, which incorporates biologically plausible computational mechanisms through its innovative Bi-Fovea Self-Attention and Bi-Fovea Feedforward Network designs. The proposed method introduces an original computational framework that effectively processes asynchronous event streams while preserving their inherent temporal precision and dynamic response characteristics. The proposed methodology demonstrates exceptional fault diagnosis performance across diverse operational scenarios through its unique combination of multi-scale spatiotemporal feature analysis, adaptive learning capabilities, and transparent decision pathways. The effectiveness of the proposed method is extensively validated by the practical condition monitoring data of rotating machines. By successfully bridging cutting-edge bio-inspired vision processing with practical industrial monitoring requirements, this work creates a new paradigm for dynamic vision-based non-contact machinery fault diagnosis that addresses critical limitations of conventional approaches. The proposed method provides new insights for predictive maintenance applications in smart manufacturing environments.
1. Introduction
Over the past few decades, intelligent machinery fault diagnosis methods have garnered considerable attention. Driven by the swift progress in artificial intelligence technologies, data-intensive fault diagnosis approaches have made remarkable achievements in machine maintenance [1,2,3]. Current studies employ diverse signal modalities for machinery health assessment [4], such as vibrational, electrical, acoustic, and emission-based measurements. Notably, vibration analysis has proven especially effective in characterizing equipment condition, given that mechanical faults typically induce measurable oscillatory responses during operation. Accelerometers [5] have become a common choice for vibration signal acquisition, and the majority of studies on machine fault diagnosis rely on vibration data obtained from accelerometers. Nevertheless, contact sensors are not always the preferred option for machine condition monitoring in numerous industrial settings [6]. In contrast, non-contact sensing eliminates the need for physical attachment, drastically reducing installation time, labor cost, and the risk of sensor-induced mechanical imbalance or resonance. It averts contamination and wear in corrosive, high-temperature, or high-speed environments, ensuring continuous operation without periodic sensor replacement or recalibration. Because there is no mechanical coupling, the technique measures the true surface motion of the target, free from mass-loading effects or frequency distortion. This preserves the fidelity of high-frequency and low-amplitude vibration signatures that are critical for early fault detection. Additionally, non-contact devices such as event-based or laser sensors can monitor multiple machines from a safe standoff distance, simplifying retrofitting on legacy equipment and enabling unobtrusive surveillance of sealed or rotating assemblies where cabling is impossible.
Convolutional Neural Networks (CNNs) [7] have achieved remarkable success in the field of computer vision, driven by advancements in deep learning technologies and hardware computing capabilities. Their effectiveness can be largely attributed to the pyramidal structure of CNNs and their inherent inductive biases, such as translation invariance and local sensitivity. Despite their success in computer vision tasks, Convolutional Neural Networks face several limitations when applied to mechanical fault diagnosis [8]. These limitations include inadequate modeling of global contextual information, computational complexity, sensitivity to data quality and noise, lack of sensitivity to local features and details, and data-intensive training requirements.
This article presents a novel signal modality, dynamic machine vision data [9,10], and utilizes Eagle Vision Transformers (EViTs) [11,12,13] model to process the event data, thereby achieving minimally contact vibration measurement and accurate fault diagnosis of machinery. Dynamic vision data are captured by event-based cameras [12,13], as shown in Figure 1, which emulate the functionality of biological retinas and have been commercially available over the past decade.

Figure 1.
Schematic diagram of the dynamic vision data collected by the event-based camera.
These cameras are asynchronous sensors that record per-pixel brightness changes, referred to as events, instead of capturing the brightness values of all pixels within a frame. In contrast to traditional standard cameras, event-based cameras offer substantial advantages for industrial applications, such as high temporal resolution, high dynamic range, high-speed motion estimation, low latency, and low power consumption. Event-based cameras are particularly effective for addressing dynamic scene sensing challenges, including motion recognition, high-speed counting, and drone vision. Specifically, their microsecond-level temporal resolution (up to 10 kHz equivalent frame rate) enables the capture of impulsive vibrations or tool chatter that would be smeared out by conventional 30–120 fps imagers, while a dynamic range exceeding 120 dB allows for reliable operation under the extreme lighting contrasts found near welding arcs or bright conveyor belts. Because each pixel operates autonomously, data throughput—and thus latency—scales only with scene dynamics; in practice, end-to-end delays below 1 ms are routinely achieved on edge hardware, and idle pixels consume mere microwatts, yielding a 10–100× power reduction versus streaming RGB sensors. These merits translate directly to industrial use cases: on high-speed spindles, event cameras track sub-micron run-out by observing microscopic laser-dot displacements without additional encoders; on bottling lines, they count up to 50,000 parts per second by detecting the edges of passing caps with zero motion blur; in steel mills, they monitor strip-flatness in real time by measuring the vibration of reflective edges under strong ambient glare; and on autonomous forklifts, they provide robust obstacle detection when sudden brightness changes (e.g., exiting a dark aisle into sunlight) would saturate conventional vision.
EViTs integrate the unique physiological and visual characteristics of eagle eyes with the architecture of vision transformers, thereby harnessing the potential advantages of both. Unlike CNNs, which rely on fixed local kernels and full-frame grids, EViT replaces convolution with global Bi-Fovea Self-Attention that operates directly on sparse, timestamped events. The Bi-Fovea Visual Interaction (BFVI) structure of EViTs is designed to combine the benefits of both cascaded and parallel architectures, including hierarchical organization and parallel information processing. Building on this foundation, EViTs employ a novel Bi-Fovea Self-Attention (BFSA) mechanism [13] and a Bi-Fovea Feedforward Network (BFFN). These components mimic the hierarchical and parallel information processing scheme of the biological visual cortex. As improved variants of self-attention and feedforward networks, respectively, BFSA and BFFN enable the network to extract features in a coarse-to-fine manner, resulting in high computational efficiency and scalability. Its coarse-to-fine BFVI pipeline cuts computation while preserving microsecond timing, enabling low-power, minimally intrusive monitoring of industrial machinery.
Although event-based sensing holds substantial promise for machine fault detection, its practical implementation faces notable technical hurdles. The operational paradigm of event cameras differs fundamentally from traditional imaging systems, demanding specialized computational frameworks for reliable anomaly detection. To our knowledge, this work pioneers the systematic investigation of this research gap. The key innovations of this article are listed as follows.
- A novel non-contact fault diagnosis method based on dynamic vision sensing is proposed. Experimental results demonstrate the viability of utilizing dynamic vision data acquired from event-based cameras for mechanical fault detection.
- The EViT model is proposed for the first time to process vision data, addressing a critical research gap in mechanical fault diagnosis applications.
- Experimental validation was conducted using real-world rotor machinery data to verify the performance of the EViT model for mechanical fault diagnosis.
2. Related Work
2.1. Intelligent Machinery Fault Diagnosis
Industrial equipment reliability critically depends on effective condition monitoring systems. Precise malfunction identification at early stages significantly improves operational security while optimizing upkeep expenditures [14,15,16]. Recent advances in computational intelligence [17] have led to substantial progress in automated equipment failure detection techniques. Among various sensing modalities, oscillatory motion measurements remain the predominant data source for equipment wellness assessment, with vibration analysis consistently demonstrating superior diagnostic performance. Innovative signal processing techniques, such as the enhanced empirical mode decomposition approach developed by Wang [16] and colleagues, have shown remarkable efficacy in isolating critical failure signatures from mechanical vibration patterns. Complementary research by Martin-Diaz [18] and collaborators established a pioneering technique for incipient defect identification in electric motors through sophisticated analysis of electromagnetic signatures across temporal and spectral domains, incorporating adaptive boosting with refined data acquisition strategies. Alternative monitoring approaches, including stress wave detection methodologies, have also proven valuable, as evidenced by successful applications in rail transportation bearing systems [19].
The advent of sophisticated connectionist systems has revolutionized equipment failure analysis, with hierarchical learning architectures demonstrating exceptional proficiency in deciphering intricate data correlations [20,21,22]. Modern diagnostic systems increasingly incorporate diverse neural network topologies, including spatial feature extractors, temporal sequence analyzers, and memory-enhanced architectures, to process mechanical oscillation data. Notable contributions include Shao’s hierarchical feature learning system for rotational equipment [23], employing deep autoencoding structures for automated signature extraction and classification. Jia’s team [24] advanced the field through their normalized spatial filtering network, specifically designed for handling uneven failure category distributions, with incorporated feature visualization for model interpretability. Yu’s innovative one-dimensional convolutional architecture demonstrated superior performance in vibration-based failure categorization [5], incorporating bilateral weighting mechanisms for enhanced generalization to novel fault conditions. Parallel developments by Huang [25] introduced sophisticated learning systems for fluid power apparatus diagnostics, enabling automated processing of heterogeneous temporal data without requiring specialized domain knowledge.
Contemporary research predominantly focuses on acceleration-based monitoring systems, with relatively limited exploration of alternative sensing modalities. Particularly scarce are investigations into non-contact optical measurement techniques for mechanical vibration analysis, representing a significant gap in current condition monitoring literature.
2.2. Event-Based Machine Vision
Bioinspired vision sensors, emerging over the past twenty years, have revolutionized dynamic scene capture through their unique ability to record asynchronous pixel-level luminance variations which are termed events [26]. These neuromorphic imaging devices and their generated data streams possess distinct advantages including minimal energy requirements and exceptional temporal precision, making them particularly suitable for applications demanding ultra-fast motion analysis. Contemporary research has demonstrated the versatility of these sensors across diverse fields, ranging from 3D scene reconstruction and motion vector calculation to robotic navigation, image enhancement, and microscopic particle tracking [27].
The automotive industry has particularly benefited from these innovative sensors, with numerous driver assistance systems now incorporating event-based visual processing [15]. The sensors’ wide dynamic ranges and near-instantaneous responses enable superior vehicular perception capabilities. Notable implementations include Zhou’s navigation system [28] that maintains reliable operation under extreme lighting variations while requiring only standard computational resources. Jin’s team [29] developed a sophisticated six-degree-of-freedom position estimation framework combining convolutional and recurrent neural architectures for processing event-based visual streams, achieving both computational efficiency and precision. Another breakthrough came from Lagorce’s motion tracking algorithm [30], which exploits spatiotemporal event correlations to enhance system resilience while effectively solving object recognition challenges through innovative optical flow computation in velocity-direction coordinates.
Despite these advancements, the potential of dynamic vision in mechanical system monitoring remains largely unexplored. Traditional visual inspection techniques face inherent limitations in vibration analysis due to noise susceptibility and motion capture constraints. This investigation systematically evaluates the applicability of neuromorphic sensing for equipment diagnostics, presenting comprehensive experimental validation of its effectiveness for fault detection applications.
3. Event-Based Fault Diagnosis Method
3.1. Event Vision Data and Representations
This research presents a novel framework for equipment fault detection utilizing dynamic vision technology. The event-based camera generates asynchronous data streams where individual events encode discrete brightness variations at specific pixels and timestamps. Each event comprises a four-dimensional vector e = [x, y, t, p], with (x,y) indicating spatial coordinates, t representing the precise timing, and p ∈ {−1, +1} denoting brightness decrease or increase, respectively. These sensors operate by continuously monitoring pixel-level intensity changes and triggering events only when variations exceed predetermined thresholds.
For mechanical system monitoring applications, the event vision data in the time sequence are recorded as , where denotes the th event, and is the number of all the events in the concerned data collection time period . The inherent asynchronicity and sparse nature of event data pose unique challenges for conventional deep learning approaches designed for regular 1D temporal or 2D spatial data. To address this, we introduce a novel two-channel image-like representation that preserves the spatiotemporal characteristics of event streams. As depicted in Figure 2, this representation separately accumulates positive and negative polarity events at each pixel location, creating complementary information channels that capture the dynamic evolution of machine vibrations.
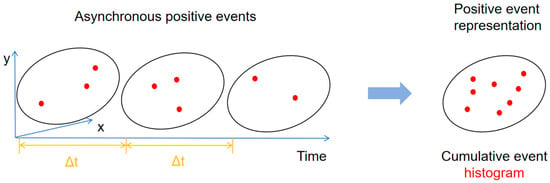
Figure 2.
Illustration of the generation of the event representations. The positive event representation is shown for instance.
The proposed methodology establishes a formal training framework , where each sample consists of polarity-separated event count matrices with dimensions Nx × Ny matching the sensor resolution. And means the corresponding machine health condition label, is the number of the training samples, while and are the channels for the positive and negative cumulative event number, respectively. The corresponding health state labels enable supervised learning of the diagnostic model. All training samples maintain consistent event counts, which are denoted as , to ensure dimensional uniformity. The core technical objective involves developing a deep neural network (EViTs) mapping function f that establishes the relationship h = f(r) between event-based representations and equipment health conditions.
3.2. Deep Neural Network Model
Our research concentrates on improving both event data interpretation and diagnostic reliability for mechanical fault detection. The central innovation involves implementing a specialized deep neural network, which is Eagle Vision Transformers (EViTs) [13], whose architecture is visually documented in Figure 3.
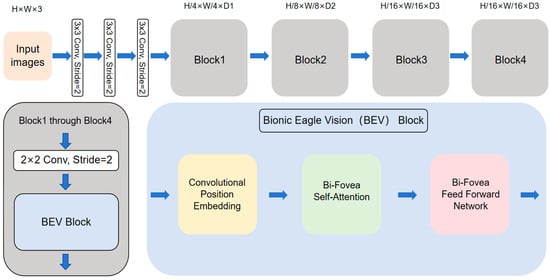
Figure 3.
Illustration of the EViT. The EViT architecture features a convolutional stem followed by a four-stage pyramid. Within each stage, a 2 × 2 convolution operating at a stride of 2 precedes multiple Bionic Eagle Vision (BEV) blocks. Structurally, every BEV block integrates three core elements: a Convolutional Positional Embedding (CPE), a Bi-Fovea Self-Attention (BFSA) module, and a Bi-Fovea Feedforward Network (BFFN).
The architectural framework of EViT incorporates three fundamental components: a convolutional stem, multiple 2 × 2 convolutional operations, and Bionic Eagle Vision (BEV) modules. Critical implementation details include: the 2 × 2 convolutional operators employ a stride setting of 2 layers to facilitate patch embedding; adhering to established hierarchical paradigms [31,32,33], the network organizes its computation into four structurally homologous stages; and progressive feature resolution reduction (4×, 8×, 16×, and 32× scaling factors across stages 1–4, respectively) coupled with channel dimension expansion (D1 through D4).
Processing flow initiates with an H × W × 3 dimensional input undergoing initial feature extraction via the convolutional stem—a triple-stacked 3 × 3 convolutional configuration where the initial layer’s stride-2 operation enhances early-stage training stability. Subsequent feature transformation occurs through an alternating sequence of 2 × 2 convolutional layers and BEV modules, progressively building multi-scale target representations. For mechanical fault classification applications, the system terminates with a classification head comprising layer normalization, global average pooling, and a final fully connected projection layer to generate diagnostic predictions.
As the foundational structural elements of EViTs, BEV blocks synergistically combine the strengths of convolutional operations and visual transformer architectures. Each BEV block incorporates three core modules: a Convolutional Position Embedding (CPE) mechanism, a Bi-Fovea Self-Attention (BFSA) module, and a Bi-Fovea Feedforward Network (BFFN). Spatial relationships are fundamentally important for characterizing visual data representations. Conventional vision transformer implementations typically employ two approaches for position encoding: Absolute Position Embedding (APE) [34] and Relative Position Embedding (RPE) [35]. These embedding schemes generally utilize either sinusoidal functions with different frequency parameters or trainable parameter matrices.
APE implementations face notable limitations as they are resolution-dependent, requiring modification when feature token dimensions change, due to their lack of scale adaptability. Conversely, RPE mechanisms account for inter-token spatial relationships within input sequences, demonstrating translation-invariant characteristics. Nevertheless, RPE introduces computational overhead when determining pairwise feature token distances. More critically, computer vision applications often demand absolute positional data, which RPE cannot inherently supply.
To address these challenges, EViT first embeds every token with Convolutional Position Embedding (CPE). By replacing sinusoidal or learned absolute/relative encodings with a light-weight depth-wise convolution, CPE gains two unique properties: (i) zero-padded convolutions let the same layer adapt to arbitrary input resolutions without re-training, yielding true plug-and-play behaviour, and (ii) the inductive locality inherent in depth-wise kernels injects translation-equivariance into the otherwise bias-free Transformer, lifting the model’s effective capacity ceiling.
Within each Bionic Eagle Vision (BEV) block, CPE’s positional features are processed by the Bi-Fovea Self-Attention (BFSA) mechanism. Mimicking the eagle’s shallow and deep foveae, BFSA splits computation into a coarse global branch (Shallow-Fovea Attention) that downsamples keys/values to capture scene gist, and a fine-grained branch (Deep-Fovea Attention) that re-uses the global summary to refine every spatial location. Their outputs are additively fused, achieving simultaneous wide-field context and pinpoint detail without cascading stages or heavy dense maps.
Complementing BFSA, the Bi-Fovea Feed-Forward Network (BFFN) adopts a two-scale depth-wise design: an initial 3 × 3 kernel enlarges receptive fields to harvest local textures, followed by a 1 × 1 projection that mixes channels and re-weights features. GELU non-linearity and residual paths are retained to stabilize gradients. Together, CPE, BFSA and BFFN form a unified “coarse-to-fine yet parallel” pipeline that marries the efficiency of CNNs with the expressiveness of self-attention, all within a single, scalable block.
3.3. Loss Function Method
This article introduces an advanced loss function method to optimize the discriminative capability for mechanical fault pattern recognition. CrossEntropyLoss [36], also known as categorical cross-entropy, is a widely used loss function in deep learning for classification tasks. It measures the dissimilarity between the predicted probability distribution and the true label distribution, guiding the model to adjust its parameters to minimize this discrepancy. Unlike regression losses such as Mean Squared Error (MSE), CrossEntropyLoss is specifically designed for probabilistic classification, making it more effective for tasks where outputs represent class probabilities.
Given a true label y (typically one-hot encoded) and a predicted probability p (obtained via Softmax activation), the CrossEntropyLoss for a single sample is defined as:
where is the number of classes. Since is non-zero only for the correct class, the loss simplifies to the negative log-likelihood of the true class probability. This formulation penalizes incorrect predictions more severely as approaches zero, ensuring rapid gradient updates during training. Before computing CrossEntropyLoss, raw model outputs(logits) [37] are transformed into probabilities using the Softmax function. Softmax normalizes logits into a probability distribution, ensuring . This step is crucial because CrossEntropyLoss operates on probabilities rather than unbounded logits.
3.4. General Implementation
Figure 4 presents the operational pipeline of our novel event-vision based approach for intelligent mechanical fault detection [38,39,40,41]. The system workflow initiates with data acquisition, where event-based cameras capture dynamic visual streams from operational machinery across various health states to create annotated training datasets. These asynchronous event streams undergo specialized preprocessing to generate structured event representations suitable for computational analysis.

Figure 4.
General implementation flowchart of the proposed event vision- based fault diagnosis method.
The training phase commences with initialization of the deep neural network model (EViTs), which subsequently undergoes iterative optimization using the annotated dataset [42,43,44,45]. During each epoch, the algorithm first selects a random minibatch from the original samples and generates complementary augmented instances.
The training procedure follows an iterative optimization cycle where samples are dynamically generated and utilized within each epoch. Upon completing parameter updates for a given epoch, the temporarily generated augmented instances are purged from memory before initiating the subsequent training cycle [46,47,48]. This process involves: reapplication of the data augmentation protocol to create fresh synthetic samples, forward-backward propagation through the network architecture, and continuous repetition of this sequence until convergence criteria are satisfied. The evaluation phase subsequently assesses model generalization capability by processing previously unseen unlabeled test data through the trained network to quantify diagnostic accuracy.
4. Experiments
4.1. Event Vision Dataset for Fault Diagnosis
This research evaluates the proposed methodology using experimental data acquired from a dedicated rolling element bearing test platform. As shown in Figure 5, the experimental setup comprises an electric motor driving a shaft supported by ER-16K bearings, designed to simulate four distinct mechanical health states: healthy operation, inner race defect, rolling element defect, and outer race defect, collectively establishing a multi-category fault identification challenge. The schematic diagrams of the three types of bearings used in the experiment are shown in Figure 6. Artificially induced defects with approximate 1mm depth were carefully introduced at various bearing locations using precision machining tools to replicate realistic failure modes. Comprehensive testing was conducted across three operational speeds (1200, 1500, and 1800 RPM), generating vibration datasets encompassing all fault conditions under varying rotational velocities. Vibration monitoring was performed using a strategically positioned accelerometer mounted directly on the bearing housing, with all measurements captured at 12.8 kHz sampling frequency to ensure adequate temporal resolution for fault signature analysis.

Figure 5.
Test rig of the rotating machine condition monitoring problem in this study.

Figure 6.
Schematic diagrams of the three types of bearings.
A third-generation Prophesee neuromorphic vision sensor (Gen 3.1) was positioned adjacent to the test bearing to acquire asynchronous event streams. The device specifications include a 640 × 480 pixel array, 200 μs event latency, and peak event throughput of 50 million events per second. Synchronized acquisition of vibration signals and event-based visual data was performed across multiple rotational velocities and bearing conditions under controlled illumination. For targeted vibration analysis, a 64 × 64 pixel region centered on the bearing housing was isolated from the raw event data for subsequent fault detection processing.
4.2. Fault Diagnosis Tasks and Comparisons
The dynamic vision data is evaluated for fault diagnosis in this study. For the event vision data, 2000 events are considered in each sample, which is prepared using the method described in Section 3.1. The experimental configuration employs a fixed sample length of 4096 data points, with each fault diagnosis task (combining specific health states and rotational speeds) containing 500 training instances and 250 testing instances. To comprehensively assess diagnostic performance of different deep neural network models, we conduct parallel evaluations across four distinct fault detection scenarios using both CNN and EViTs models. The comprehensive information of the related fault diagnosis tasks is presented in Table 1.

Table 1.
Fault diagnosis tasks in this study.
This study conducted comparative analyses of fault diagnosis performance using diverse deep neural network architectures. For tasks A1 through A4, conventional CNN models were employed to process event-based vision data, while tasks B1 to B4 utilized the proposed EViT framework as detailed in Section 3.2 for event data analysis. The experimental configurations and data acquisition procedures remain basically consistent with the proposed method. Classification accuracy serves as a well-established evaluation criterion in pattern recognition applications, particularly suitable for mechanical fault detection scenarios. This metric is consequently adopted for performance assessment throughout our experimental analysis. Formally, given a test set containing samples, where represents the count of accurately classified instances matching the true fault labels, the diagnostic accuracy is computed as (/) × 100%. The complete parameter configuration is documented in Table 2, with parameter optimization playing a critical role in our methodology.
Table 2.
Parameters used in this study.
As delineated in Table 2, the parameters are systematically categorized into: (1) trainable network parameters θ, and (2) tunable hyper-parameters. Regarding the model parameters, they are optimized within the deep neural network framework using training data and preset hyper-parameters. These parameters can be determined once the hyper-parameters and training data are provided, although minor variations may occur across different training runs due to inherent model stochasticity. For this study, both the CNN and EViT models were configured with identical fundamental parameters. Hyper-parameter optimization follows standard data-driven machine learning practices through dedicated validation procedures. In our experimental framework, this involves: (1) establishing a validation set under 1200 r/min operating conditions with 1000 training and 1000 test samples, which is completely independent from tasks A1–A4 datasets, and (2) adopting 300 training epochs as the benchmark based on observed convergence behavior and evidenced by stabilized loss metrics. For real-world deployment, the parameter configuration process maintains methodological consistency: operational data from target equipment forms the validation basis for hyper-parameter tuning. While field applications often face data scarcity challenges, two practical solutions are implemented: minimum viable validation using binary health states (normal/faulty), or temporal segmentation of extended unlabeled operational records into distinct condition periods. This approach ensures rigorous parameter optimization while accommodating industrial implementation constraints.
4.3. Experimental Results and Performance Evaluations
Table 3 presents the comprehensive experimental results of different deep learning models across various fault diagnosis tasks. The proposed model consistently achieves testing accuracies above 95% under different operating conditions, demonstrating significant advantages for mechanical fault diagnosis problems and thereby validating the effectiveness of the event-vision-based diagnostic paradigm. All evaluated tasks exhibit similar patterns of result distribution.
Table 3.
Testing accuracy of different methods in different fault diagnosis tasks.
Furthermore, this study conducts a comparative analysis of diagnostic performance between CNN and EViT models. Taking task B1 as an example, the EViT model achieves a testing accuracy of 99.0%, slightly outperforming the CNN model’s 96.1% accuracy, with similar performance trends observed across other tasks. These results demonstrate the superior competitiveness of EViT models over conventional CNN architectures for mechanical fault diagnosis applications. The experiments were implemented on a hardware platform consisting of a GeForce RTX 4060ti GPU and Intel i7 CPU, utilizing the PyTorch 1.12 programming framework. Computational efficiency tests reveal average training times of 672.5 s for tasks A1–A3 and 2136.7 s for task A4, indicating computationally acceptable overhead for an offline diagnostic approach.
The comparative performance evaluation of different diagnostic models is illustrated in Figure 7, which presents the confusion matrices for both CNN and EViT architectures when processing tasks A1 and A3. The experimental data reveals remarkable diagnostic capabilities across all fault categories, with classification accuracy consistently surpassing 95% for each fault mode while maintaining minimal false positive rates—findings that align perfectly with the outstanding test accuracy documented in Table 3. Notably, the transformer-based EViT approach demonstrates significantly better fault identification performance than conventional CNN, particularly in detecting mechanical anomalies, thereby conclusively confirming the methodological advantages of the proposed framework.
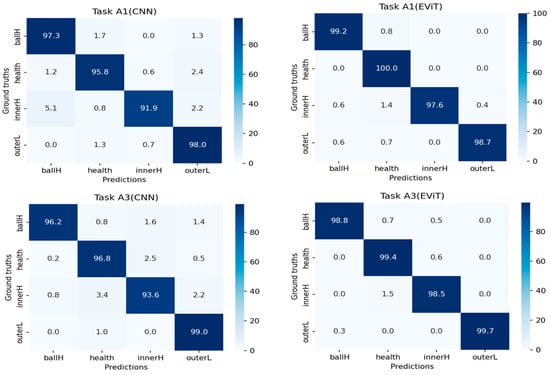
Figure 7.
Confusion matrices of two models in the fault diagnosis tasks A1 and A3.
In practical mechanical systems, operational conditions often exhibit significant variability. This study evaluates the performance of CNN and EViT models under such condition shifts, utilizing fault diagnosis datasets with wide operational ranges due to limited availability of specialized rotating machinery event datasets. As detailed in Table 4, eight cross-condition tasks were designed: Tasks C1 and C2 incorporate both 1200 rpm (limited) and 1500 rpm (abundant) training data but test on 1200 rpm, whereas Tasks C3 and C4 exclude 1500 rpm data entirely. Comparative analysis of C1 versus C3 and C2 versus C4 reveals that models trained only on limited same-condition data (C3 and C4) achieve suboptimal accuracy, while introducing cross-condition data (C1 and C2) yields substantial improvements—particularly for EViT, which shows greater performance gains than CNN when leveraging heterogeneous operational data (C2 and D2 compared to C1 and D1).
Table 4.
Experimental results in the fault diagnosis tasks with variations in machine operating conditions.
These results demonstrate that cross-condition training data effectively compensates for single-condition data scarcity, enhancing model robustness to operational variations. EViT’s superior adaptability stems from its inherent capacity to extract condition-invariant features: its attention mechanism aligns naturally with the sparse spatiotemporal characteristics of mechanical event data, while its explicit clustering of feature distributions across conditions contrasts with CNN’s implicit learning approach that remains more sensitive to domain shifts. This architectural advantage allows EViT to more fully exploit complementary information embedded in multi-condition datasets, establishing it as a more versatile solution for real-world applications where operational parameters fluctuate.
Subsequently, visual validation was performed on the features extracted from event data using different methods. Specifically, the fully connected features from the final layer of the deep neural network were extracted and visualized through t-SNE dimensionality reduction. The results for tasks A1 and A3 are presented in Figure 8. The visualization demonstrates that compared to the CNN model, samples processed by the EViT model exhibit tighter intra-class clustering and more distinct inter-class boundaries across different health states. This clearly illustrates EViT’s superior effectiveness in event data-based fault pattern recognition.
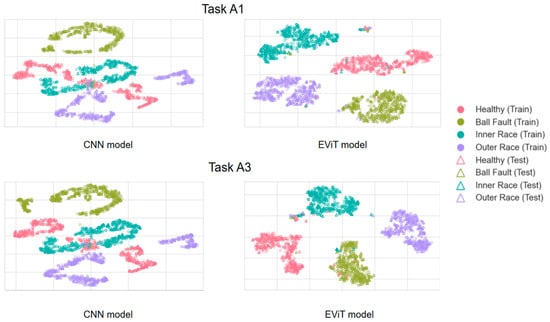
Figure 8.
Visualization results of the learned features from the data by different models in the tasks A1 and A3.
To comprehensively validate the performance advantages of EViT over conventional CNNs, Table 5 presents a comparative analysis of diagnostic accuracy among different models. As shown in Table 5, Task E1 employs the EViT model, while Tasks E2 and E3 utilize CNN architectures with varying network depths, and Task E4 adopts a CBAM-enhanced CNN model (CBAM-CNN), with all other experimental conditions maintained identical. The experimental results demonstrate that Task E1 achieves marginally higher accuracy compared to other tasks, thereby substantiating the superior diagnostic performance of the proposed EViT framework for mechanical fault detection.
Table 5.
Experimental results in the fault diagnosis tasks with different models.
In order to validate the effectiveness of individual modules in the EViT model for fault diagnosis, we conducted ablation studies on the BFSA, BFFN, and CPE modules. Experimental Group 1 employed the complete EViT model, Group 2 replaced the BFSA with standard MHSA, Group 3 substituted the BFFN with a standard FFN, and Group 4 removed the Convolutional Position Embedding (CPE). All groups were tested on the identical Task A1 dataset. As shown in Figure 9, the experimental results demonstrate significant performance impacts when removing these modules. Specifically, replacing BFSA with standard MHSA caused a 2.5% accuracy decrease, while substituting BFFN with FFN reduced accuracy by 1.8%. The complete removal of CPE led to the most substantial performance degradation. These findings clearly establish the critical importance of all three modules for optimal model performance.
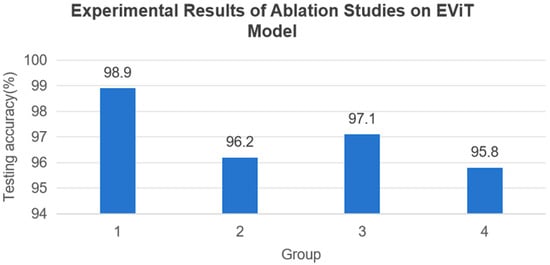
Figure 9.
Effects of each module in the EViT model on fault diagnosis.
Moreover, conventional vibration-based fault diagnosis techniques predominantly rely on single-point data acquisition. However, adopting a machine dynamic vision approach enables monitoring of extended spatial regions beyond the immediate target component. Notably, bearing defects can generate minute disturbances in shaft dynamics that often elude detection by conventional sensors. This research systematically examines how varying event frame regions of interest (ROI) affect model performance, evaluating both CNN and EViT architectures across multiple ROI configurations: the default 200 × 300 pixel area plus three bearing-centered regions measuring 100 × 200, 250 × 350, and 300 × 400 pixels.
As evidenced in Figure 10, experimental findings reveal a general trend where expanded ROIs correlate with enhanced classification accuracy for both architectures. This improvement stems from the incorporation of more comprehensive vibration signatures encompassing both bearing and shaft dynamics. Nevertheless, the performance gains diminish considerably when exceeding the 200 × 300 pixel threshold. Given the substantial computational overhead associated with larger sample dimensions, the 200 × 300 pixel ROI remains the optimal selection for practical implementation.
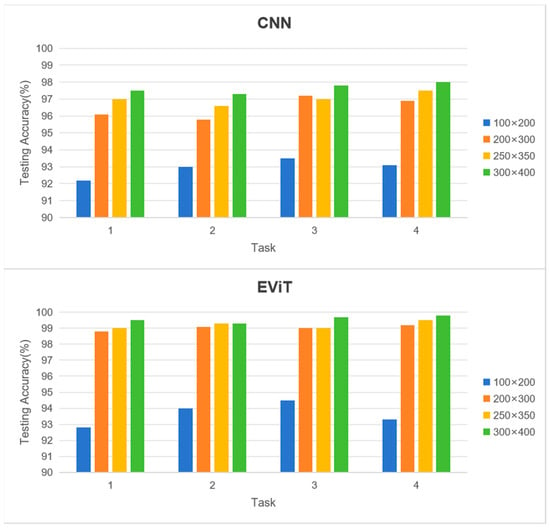
Figure 10.
Effects of the ROI of the event frame on the fault diagnosis model performance in different tasks.
A particularly noteworthy observation concerns the differential impact of ROI scaling—the EViT architecture demonstrates significantly greater accuracy enhancement compared to its CNN counterpart as ROI dimensions increase. This phenomenon underscores EViT’s superior capacity for processing expanded input domains, attributed to its enhanced ability to capture extensive spatial dependencies and integrate global contextual features. Such characteristics substantiate the transformer-based model’s advantages in machine condition monitoring applications.
It should be noted that although the EViT model demonstrates superior performance over CNN in fault diagnosis tasks, both architectures face common challenges in processing event-based vision data. Firstly, vibration feature extraction through visual perception is inherently challenging, particularly in identifying subtle differences between various fault modes, which is constrained by the spatiotemporal resolution of event sensors and environmental noise interference. Secondly, current research has yet to establish standardized frameworks for feature extraction and fault recognition specifically for event vision data, leaving room for optimization in processing efficiency—both in CNN’s local convolutional characteristics and EViT’s global attention mechanism when handling event streams. As the first study to apply EViT to mechanical fault diagnosis, this work provides a benchmark investigation by systematically comparing the performance differences between these two architectures. The results demonstrate EViT’s advantages in both accuracy and cross-condition adaptability, promising for further investigation in this direction.
5. Conclusions
This article presents the first integration of event-based cameras with an Eagle Vision Transformer (EViT) to propose a novel non-contact fault diagnosis method for rotating machinery. As an innovative neural network architecture, the EViT model demonstrates the capability to distinguish features corresponding to different health states, thereby addressing a critical research gap in the application of EViT for mechanical fault diagnosis. Through a systematic comparison of EViT and conventional Convolutional Neural Networks (CNN) in processing event-based vision data, this work elucidates the performance differences between these two models in fault diagnosis tasks.
The research highlights three key advantages of EViT over CNN. First, the Bi-Fovea Self-Attention (BFSA) mechanism in EViT mimics the central-peripheral visual processing of eagle eyes, enabling multi-scale vibration feature extraction and overcoming the limitations of CNN’s localized receptive fields. Experimental results confirm that this mechanism more effectively identifies invariant features across varying rotational speeds, whereas CNN struggles to adapt due to the fixed kernel sizes of its convolutional layers. Second, EViT’s hierarchical feature fusion architecture, facilitated by the Bi-Fovea Feedforward Network (BFFN), achieves superior synergy between global and local features, outperforming CNN in diagnosing compound bearing faults. Third, EViT exhibits significantly enhanced spatiotemporal modeling capabilities for event data, particularly in large Region-of-Interest (ROI) scenarios like exceeding 200 × 300 pixels, where its accuracy improvement surpasses that of CNN. This advantage stems from the self-attention mechanism’s ability to capture long-range spatial dependencies.
Notably, EViT’s superiority is most pronounced in cross-condition tasks. When trained on multi-speed operational data, EViT demonstrates a greater improvement in generalization performance compared to CNN, owing to its explicit feature distribution alignment strategy. In contrast, CNN relies on implicit regularization techniques such as data augmentation, leading to higher performance variability under unseen operating conditions. These findings provide a new solution for variable-condition diagnosis in industrial applications.
However, the study also identifies two limitations of EViT. First, the quadratic spatial complexity of the Bi-Fovea Self-Attention mechanism increases FLOPs by four to seven times and GPU memory usage by three to five times, rendering real-time deployment impractical on resource-constrained edge devices. Second, the Transformer backbone requires substantial labeled data to achieve optimal performance; in small-sample scenarios, EViT’s accuracy drops below that of lightweight CNNs, nullifying its theoretical advantages. These insights highlight critical directions for future research, which will focus on enhancing the model’s environmental generalization capability and optimizing its network architecture.
Author Contributions
Conceptualization, Z.J.; methodology, X.L.; formal analysis, C.S.; writing—original draft preparation, Z.J. All authors have read and agreed to the published version of the manuscript.
Funding
The material in this paper is based on work supported by Aviation Science Foundation under Grant 2024Z071070001.
Data Availability Statement
Dataset available on request from the author.
Conflicts of Interest
Author Cuiying Sun was employed by the company Weichai Power Co., Ltd. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Hu, Y.; Liu, R.; Li, X. Task-sequencing meta learning for intelligent few-shot fault diagnosis with limited data. IEEE Trans. Ind. Inform. 2021, 18, 3894–3904. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H. Open-set domain adaptation in machinery fault diagnostics using instance-level weighted adversarial learning. IEEE Trans. Ind. Inform. 2021, 17, 7445–7455. [Google Scholar] [CrossRef]
- Hu, Y.; Xie, Q.; Yang, X. An Attention-Based Multidimensional Fault Information Sharing Framework for Bearing Fault Diagnosis. Sensors 2025, 25, 224. [Google Scholar] [CrossRef]
- Wang, F.; Liu, A.; Qu, C. A deep-learning method for remaining useful life prediction of power machinery via dual-attention mechanism. Sensors 2025, 25, 497. [Google Scholar] [CrossRef]
- Zhang, W.; Xu, M.; Yang, H. Data-driven deep learning approach for thrust prediction of solid rocket motors. Measurement 2024, 225, 114051. [Google Scholar] [CrossRef]
- Yu, X.; Zhao, Z.; Zhang, X. Deep-learning-based open set fault diagnosis by extreme value theory. IEEE Trans. Ind. Inform. 2021, 18, 185–196. [Google Scholar] [CrossRef]
- Zhong, Z.; Xie, H.; Wang, Z. Domain Adversarial Transfer Learning Bearing Fault Diagnosis Model Incorporating Structural Adjustment Modules. Sensors 2025, 25, 1851. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W. A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef]
- Liu, C.; Li, X.; Chen, X. Neuromorphic computing-enabled generalized machine fault diagnosis with dynamic vision. Adv. Eng. Inform. 2025, 65, 103300. [Google Scholar] [CrossRef]
- Gallego, G.; Lund, J.E.A.; Mueggler, E. Event-based, 6-DOF camera tracking from photometric depth maps. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2402–2412. [Google Scholar] [CrossRef]
- Ceolini, E.; Frenkel, C.; Shrestha, S.B. Hand-gesture recognition based on EMG and event-based camera sensor fusion: A benchmark in neuromorphic computing. Front. Neurosci. 2020, 14, 637. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X. Federated transfer learning for intelligent fault diagnostics using deep adversarial networks with data privacy. IEEE/ASME Trans. Mechatron. 2021, 27, 430–439. [Google Scholar] [CrossRef]
- Shi, Y.; Sun, M.; Wang, Y. Evit: An eagle vision transformer with bi-fovea self-attention. IEEE Trans. Cybern. 2025, 55, 1288–1300. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Meng, H.; Zhu, Y. Enhancing 3-D LiDAR point clouds with event-based camera. IEEE Trans. Instrum. Meas. 2021, 70, 1–12. [Google Scholar] [CrossRef]
- Chen, G.; Cao, H.; Conradt, J. Event-based neuromorphic vision for autonomous driving: A paradigm shift for bio-inspired visual sensing and perception. IEEE Signal Process. Mag. 2020, 37, 34–49. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X. Data privacy preserving federated transfer learning in machinery fault diagnostics using prior distributions. Struct. Health Monit. 2022, 21, 1329–1344. [Google Scholar] [CrossRef]
- Xiao, B.; Yin, S. A deep learning based data-driven thruster fault diagnosis approach for satellite attitude control system. IEEE Trans. Ind. Electron. 2020, 68, 10162–10170. [Google Scholar] [CrossRef]
- Zhao, J.; Yuan, M.; Cui, Y. A Cross-Machine Intelligent Fault Diagnosis Method with Small and Imbalanced Data Based on the ResFCN Deep Transfer Learning Model. Sensors 2025, 25, 1189. [Google Scholar] [CrossRef]
- Wang, J.; Du, G.; Zhu, Z. Fault diagnosis of rotating machines based on the EMD manifold. Mech. Syst. Signal Process. 2020, 135, 106443. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Li, X. Deep learning-based prognostic approach for lithium-ion batteries with adaptive time-series prediction and on-line validation. Measurement 2020, 164, 108052. [Google Scholar] [CrossRef]
- Martin-Diaz, I.; Morinigo-Sotelo, D.; Duque-Perez, O. Early fault detection in induction motors using AdaBoost with imbalanced small data and optimized sampling. IEEE Trans. Ind. Appl. 2016, 53, 3066–3075. [Google Scholar] [CrossRef]
- Hou, D.; Qi, H.; Wang, C. High-speed train wheel set bearing fault diagnosis and prognostics: Fingerprint feature recognition method based on acoustic emission. Mech. Syst. Signal Process. 2022, 171, 108947. [Google Scholar] [CrossRef]
- Zhang, W.; Li, X.; Ma, H. Transfer learning using deep representation regularization in remaining useful life prediction across operating conditions. Reliab. Eng. Syst. Saf. 2021, 211, 107556. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Z.; Li, X. Blockchain-based decentralized federated transfer learning methodology for collaborative machinery fault diagnosis. Reliab. Eng. Syst. Saf. 2023, 229, 108885. [Google Scholar]
- Shao, H.; Jiang, H.; Lin, Y. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Process. 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lu, N. Deep normalized convolutional neural network for imbalanced fault classification of machinery and its understanding via visualization. Mech. Syst. Signal Process. 2018, 110, 349–367. [Google Scholar] [CrossRef]
- Huang, K.; Wu, S.; Li, F. Fault diagnosis of hydraulic systems based on deep learning model with multirate data samples. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6789–6801. [Google Scholar]
- Mueggler, E.; Rebecq, H.; Gallego, G. The event-camera dataset and simulator: Event-based data for pose estimation, visual odometry, and SLAM. Int. J. Robot. Res. 2017, 36, 142–149. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, J.; Li, X. Deep-learning-based information fusion methodology for oil film coefficient identification of squeeze film dampers. IEEE Sens. J. 2022, 22, 20816–20827. [Google Scholar]
- Fischer, T.; Milford, M. Event-based visual place recognition with ensembles of temporal windows. IEEE Robot. Autom. Lett. 2020, 5, 6924–6931. [Google Scholar] [CrossRef]
- Zhou, Y.; Gallego, G.; Lu, X. Event-based motion segmentation with spatio-temporal graph cuts. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 4868–4880. [Google Scholar] [CrossRef] [PubMed]
- Jin, Y.; Yu, L.; Li, G. A 6-DOFs event-based camera relocalization system by CNN-LSTM and image denoising. Expert Syst. Appl. 2021, 170, 114535. [Google Scholar] [CrossRef]
- Lagorce, X.; Meyer, C.; Ieng, S.H. Asynchronous event-based multikernel algorithm for high-speed visual features tracking. IEEE Trans. Neural Netw. Learn. Syst. 2014, 26, 1710–1720. [Google Scholar] [CrossRef]
- Yao, T.; Li, Y.; Pan, Y. Dual vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10870–10882. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z. Biformer: Vision transformer with bi-level routing attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Wang, W.; Xie, E.; Li, X. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 568–578. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Wang, C.; Xu, H.; Zhang, X. Convolutional embedding makes hierarchical vision transformer stronger. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 739–756. [Google Scholar]
- Mao, A.; Mohri, M.; Zhong, Y. Cross-entropy loss functions: Theoretical analysis and applications. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 23803–23828. [Google Scholar]
- Zhang, Z.; Sabuncu, M. Generalized cross entropy loss for training deep neural networks with noisy labels. Adv. Neural Inf. Process. Syst. 2018, 32, 8792–8802. [Google Scholar]
- Connor, R.; Dearle, A.; Claydon, B. Correlations of cross-entropy loss in machine learning. Entropy 2024, 26, 491. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Jiang, N.; Yang, S. Federated transfer learning for remaining useful life prediction in prognostics with data privacy. Meas. Sci. Technol. 2025, 36, 076107. [Google Scholar] [CrossRef]
- Yang, S.; Ling, L.; Li, X. Industrial battery state-of-health estimation with incomplete limited data toward second-life applications. J. Dyn. Monit. Diagn. 2024, 3, 246–257. [Google Scholar] [CrossRef]
- Li, W.; Daman, A.A.A.; Smith, W. Wear Performance and Wear Monitoring of Nylon Gears Made Using Conventional and Additive Manufacturing Techniques. J. Dyn. Monit. Diagn. 2025, 4, 101–110. [Google Scholar] [CrossRef]
- Thakuri, S.K.; Li, H.; Ruan, D. The RUL Prediction of Li-Ion Batteries Based on Adaptive LSTM. J. Dyn. Monit. Diagn. 2025, 4, 53–64. [Google Scholar] [CrossRef]
- Sepasiahooyi, S.; Abdollahi, F. Fault detection of new and aged lithium-ion battery cells in electric vehicles. Green Energy Intell. Transp. 2024, 3, 100165. [Google Scholar] [CrossRef]
- Li, S.; Zhang, C.; Du, J. Fault diagnosis for lithium-ion batteries in electric vehicles based on signal decomposition and two-dimensional feature clustering. Green Energy Intell. Transp. 2022, 1, 100009. [Google Scholar] [CrossRef]
- Chen, C.; Zhao, K.; Leng, J. Integrating large language model and digital twins in the context of industry 5.0: Framework, challenges and opportunities. Robot. Comput.-Integr. Manuf. 2025, 94, 102982. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).