Abstract
Unmanned Aerial Vehicles (UAVs) exhibit significant potential in enhancing the wireless communication coverage and service quality of Mobile Edge Computing (MEC) systems due to their superior flexibility and ease of deployment. However, the rapid growth of tasks leads to transmission queuing in edge networks, while the uneven distribution of user nodes and services causes network load imbalance, resulting in increased user waiting delays. To address these issues, we propose a multi-UAV collaborative MEC network model based on Non-Orthogonal Multiple Access (NOMA). In this model, UAVs are endowed with the capability to dynamically offload tasks among one another, thereby fostering a more equitable load distribution across the UAV swarm. Furthermore, the integration of NOMA is strategically employed to alleviating the inherent queuing delays in the communication infrastructure. Considering delay and energy consumption constraints, we formulate a task offloading strategy optimization problem with the objective of minimizing the overall system delay. To solve this problem, we design a delay-optimized offloading strategy based on the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm. By jointly optimizing task offloading decisions and UAV flight trajectories, the system delay is significantly reduced. Simulation results show that, compared to traditional approaches, the proposed algorithm achieves a delay reduction of 20.2%, 9.8%, 17.0%, 12.7%, 15.0%, and 11.6% under different scenarios, including varying task volumes, the number of IoT devices, UAV flight speed, flight time, IoT device computing capacity, and UAV computing capability. These results demonstrate the effectiveness of the proposed solution and offloading decisions in reducing the overall system delay.
1. Introduction
With the rapid growth of Internet of Things (IoT) devices, how to process large volumes of distributed data efficiently at the network edge has become an urgent challenge for wireless communications. Mobile Edge Computing (MEC) is widely seen as an effective way to offload computation and ease the resource constraints of IoT devices. However, fixed edge servers often struggle to adapt in dynamic environments or remote areas [1]. In this context, Unmanned Aerial Vehicles (UAVs) have gained attention for expanding MEC coverage thanks to their strong mobility, flexible deployment, wide-area coverage, and relatively low cost. Especially when ground infrastructure is lacking or out of service, UAVs can quickly set up temporary computing and communication support [1,2,3,4,5].
Although UAV-assisted MEC has been studied extensively, many existing works still rely on the assumption of a single UAV acting as a flying base station or computing node. This approach falls short when dealing with large-scale, highly dynamic IoT environments, where sudden spikes in workload or coverage gaps are common. Moreover, most prior studies tackle either communication resource allocation or flight trajectory planning in isolation, and rarely consider how to jointly coordinate UAV movement, user access, and task distribution in a unified, adaptive way. Therefore, how to design a joint task offloading and trajectory optimization strategy in a multi-UAV collaborative MEC network, which supporting high user concurrency and optimize the overall system delay is still an severe problem.
To address the obove problem, we propose a joint task offloading and trajectory control scheme. We frame this as a Markov Decision Process (MDP) and design an algorithm based on the Twin Delayed Deep Deterministic Policy Gradient (TD3). The algorithm can adapt task offloading and UAV paths at the same time, responding to changing IoT demands to keep total system delay as low as possible. This joint perspective is different from prior work that handles offloading and trajectory planning separately or relies only on heuristics.
In summary, the key contributions of this paper are:
(1) A collaborative computing framework for multiple UAVs in dynamic IoT settings: By allowing real-time task sharing and offloading among UAVs, the system can better handle uneven loads and sudden task surges than single-node or fixed-server setups.
(2) The integration of NOMA to enhance UAV swarm cooperation: With NOMA, multiple users can connect and offload tasks simultaneously, which improves spectrum utilization and throughput compared to traditional orthogonal access.
(3) A joint optimization design for task offloading and UAV trajectory planning: Task offloading and UAV trajectory planning are modeled together as a MDP, and a TD3-based algorithm helps UAVs adapt their actions dynamically to minimize total delay.
(4) Comprehensive simulations to verify the design: Various experiments show that the proposed solution achieves lower delays than traditional methods under different network loads and conditions, proving its practical value and scalability.
The remainder of this paper is organized as follows. Section 2 reviews related work and analyzes the current research gaps. Section 3 describes the system model, problem formulation, and the proposed joint optimization algorithm. Section 4 presents the simulation setup and discusses the results. Section 5 discusses the impact of each system component on overall performance and the expected practical implications of the proposed approach. Finally, Section 6 concludes the paper and outlines directions for future research.
2. Related Works
In recent years, with the proliferation of Internet of Things (IoT) devices and mobile terminals, new mobile applications, such as real-time navigation, image processing, and video streaming, have increasingly posed important challenges for communication networks [4], including high costs and long time delays. These applications are often compute-intensive and latency-sensitive, which seriously tests the performance of traditional network architectures [6]. In order to address the above challenges, MEC, as an emerging distributed computing model, has been widely used to reduce the computing burden of terminal devices by deploying computing resources at the user’s proximal end, thereby improving network service efficiency and user experience [7,8]. Recent surveys, such as Javanmardi et al. [9], have further highlighted the importance of integrating security, privacy, and resource efficiency in IoT-Fog networks. However, these studies rarely address the specific challenges of multi-UAV collaborative MEC networks with high user concurrency and strict delay requirements. Although MEC can significantly improve the computing power of user equipment, it still faces the limitations of geographical environment and infrastructure construction during actual deployment, especially when the base station coverage is insufficient or the base station malfunctions, the stability and reliability of network services will be severely affected.
UAVs have become an ideal MEC auxiliary equipment due to its advantages of flexible mobility and rapid deployment. Especially in emergency situations, when the target area lacks effective base station support, UAVs can quickly fly to the target area to provide instant computing offloading and network coverage services. In the context of UAV-assisted MEC, a large number of related studies have been devoted to improving UAV service performance and network efficiency in recent years. Reference [10] presented a method that jointly optimizes resource allocation and task scheduling, aiming to reduce the weighted sum of UAV energy consumption and latency to improve the overall performance of UAV auxiliary services. Although the scheme performs well in a single UAV scenario, there remains a lack of sufficient in-depth research in the multi-UAV collaborative work scenarios. Tian et al. [11] proposed an optimization approach that jointly considers area partitioning and UAV trajectory planning to minimize the overall energy consumption of UAVs, with the objective of prolonging both flight duration and the operational lifespan of the network. However, the static scenarios assumed in their scheme are not suitable for complex dynamic environments, and it is difficult to cope with the rapid changes and unexpected situations of user needs, especially in the case of large-scale and multi-user collaboration, thus its adaptability and flexibility are limited. In addition, most of the above studies focus on the application scenarios of single-UAV-assisted computing, and fail to fully consider that a single UAV is difficult to meet the growing computing needs due to energy consumption and load limitations, which restricts the scalability and flexibility of UAVs in practical applications [12,13].
Therefore, with the gradual development of multi-UAV collaborative computing technology, more and more studies have begun to focus on the problem of UAV swarm collaboration, and explore how to solve the bottleneck of a single UAV in terms of computing power, load balancing, and delay control through multi-UAV collaboration, so as to improve the overall performance and service quality of the MEC system. Cheng et al. [14] formulated a joint optimization problem involving power control, task compression ratio, communication resource allocation, and UAV trajectory for wireless devices in a UAV-assisted edge computing data compression scenario. They employed an iterative block coordinate descent algorithm to reduce the overall energy consumption of the devices. In order to improve the computing power and response speed of the system, Zhuang et al. [15] studied the application of multi-UAV collaborative computing in edge computing, and proposed a multi-UAV collaboration strategy based on deep reinforcement learning to optimize computational offloading and flight paths. To improve the communication security in the multi-UAV scenario, Liu et al. [16] constructed an optimization problem of joint subcarrier allocation and UAV flight trajectory, and an iterative alternation algorithm with high computational efficiency was designed to solve the problem. Although the above study considers the multi-UAV environment, it mainly focuses on energy consumption optimization, fails to effectively combine the real-time requirements of latency and computing offloading, and has weak adaptability to the multi-user environment. In addition, Wu et al. [17] proposed a security-aware design for multi-UAV deployment, task offloading, and service placement using deep reinforcement learning to improve computational efficiency and system security. However, their work mainly focuses on security and service placement issues, rather than delay minimization in high-concurrency scenarios with NOMA. In order to solve the real-time problem, a multi-UAV collaborative task offloading scheme was developed in [18] to optimize the UAV flight trajectory and task assignment to cope with the high latency requirements in the dynamic environment. However, there is no consideration for how to optimize latency in a multi-user environment. Sun et al. [19] introduced a collaborative task offloading strategy for multiple UAVs aiming to enhance offloading efficiency and minimize latency by jointly optimizing flight trajectory planning and computational resource allocation. Li et al. [20] focuses on the task offloading and flight trajectory optimization of multi-UAV cooperation, and adopts the strategy of joint power control and trajectory planning, with the goal of minimizing delay and improving system capacity. However, the above two schemes do not take into account the transmission queuing problem that may be caused by multi-user simultaneous upload tasks, which may affect the throughput and overall performance of the system in high-concurrency scenarios. In order to solve the problem of multi-user transmission queuing, Dehkordi et al. [21] considered the transmission queuing problem in UAV-assisted MEC system, and proposed a joint task offloading and transmission scheduling strategy to optimize the delay and system throughput. However, the DQN method used in the paper may have significant limitations in handling continuous action spaces, as it is prone to getting stuck in local optima and has poor adaptability to environmental changes. Wang et al. [22] proposed an optimization model based on queuing theory to reduce latency by rationally arranging task offloading and data transmission. Although this method is effective in a single-drone environment, it fails to fully consider the delay caused by multi-user simultaneous offloading tasks when it is extended to multi-UAV collaboration, and does not combine more efficient technologies (such as NOMA) to further optimize the delay. Reference [23] employed the Deep Deterministic Policy Gradient (DDPG) algorithm to coordinate and optimize the behavior of multi-UAV swarms. The authors introduced a central controller responsible for training on observed data and broadcasting the learned policy to the swarm network. However, the DDPG algorithm only considers the optimal action in the current state and requires pre-training, which limits its adaptability during real-time execution.
Although significant advancements have been achieved in areas such as computational capability enhancement, energy efficiency, and task offloading through multi-UAV collaboration, current research still exhibits notable limitations in effectively tackling delay optimization in multi-user scenarios. In particular, challenges related to transmission queuing and delay management under dynamic and time-varying conditions remain insufficiently addressed, leaving a gap in achieving truly responsive and efficient edge computing systems. Most existing solutions prioritize energy efficiency while neglecting the queuing delays caused by concurrent task offloading. Moreover, traditional optimization methods often struggle with large-scale, dynamic environments, demonstrating significant limitations in real-time performance and system adaptability.
To address these issues, NOMA technology provides a practical approach to enhancing spectrum efficiency and increasing system capacity. It effectively addresses resource contention in traditional wireless networks by allowing multiple users to communicate simultaneously over the same spectrum. Moreover, NOMA technology not only improves spectrum utilization but also minimizes user interference, thereby enhancing communication effectiveness and task offloading efficiency in multi-user scenarios.
Therefore, leveraging the advantages of Non-Orthogonal Multiple Access (NOMA) technology, this paper addresses the issues of transmission queuing and load imbalance in UAV-assisted collaborative computing by proposing a multi-UAV collaborative Mobile Edge Computing (MEC) network model integrated with NOMA. The proposed model is constructed for multi-UAV-assisted MEC scenarios, where tasks can be transferred among UAVs to achieve load balancing. Meanwhile, NOMA technology is introduced to alleviate transmission queuing caused by concurrent task uploads from multiple users. Taking into account both system latency and energy consumption constraints, this study formulates a comprehensive joint optimization problem that simultaneously addresses task offloading decisions and UAV trajectory planning, with the primary objective of minimizing total system delay. To effectively solve this complex problem, a tailored optimization approach based on the Twin Delayed Deep Deterministic Policy Gradient (TD3) algorithm is developed. By integrating the optimization of both task offloading strategies and UAV flight paths, the proposed framework achieves a further reduction in overall system delay, thereby enhancing the responsiveness and efficiency of the UAV-assisted edge computing environment.
From the above, it is clear that there is still a lack of practical models that integrate multi-UAV collaboration, NOMA-based access, and the joint optimization of task offloading and trajectory planning within a unified framework. Moreover, recent work by Zhang et al. [24] explored a digital twin-driven framework to enhance task offloading in UAV-assisted vehicle edge computing networks, indicating the potential of virtual representations for system awareness and adaptive control. Inspired by this, our work integrates NOMA and multi-UAV collaboration into a unified framework to address queuing delay and trajectory optimization more effectively.
3. Proposed Approach
This section introduces the system architecture within the context of edge computing, along with the computational and communication models involved in the task offloading procedure. Table 1 summarizes the main symbols employed throughout the text, accompanied by their respective physical interpretations.

Table 1.
Main symbols and their physical meanings.
3.1. System Model
This study investigates a UAV-assisted mobile edge computing (UAV-assisted MEC) system consisting of several terminal devices and two UAVs, as shown in Figure 1. In this model, the entire area is divided into multiple subregions, with the classification of UAVs as either edge or cloud UAVs based on whether users within each region can directly offload tasks to the UAV. Specifically, the edge UAVs act as the edge layer of edge computing, responsible for providing computational services to IoT devices within their coverage area, while cloud UAVs, similar to cloud computing, are responsible for receiving tasks transmitted from other UAVs and performing computations. That is, each UAV can function as both an edge and a cloud UAV, receiving tasks from users within its own coverage area while also receiving tasks from other UAVs. This forms the collaborative principle of UAVs. To ensure flight safety and comply with relevant flight control policies, each UAV can only operate within a specified altitude range and is restricted by geographical boundaries, preventing it from crossing the defined area boundaries.
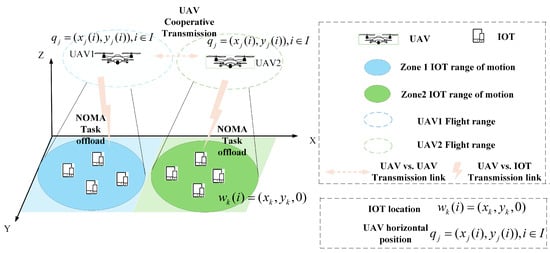
Figure 1.
Model of multi-UAV collaborative edge computing system based on NOMA.
In this system, we consider a scenario without base stations, where J UAVs equipped with distributed micro-cloud servers are deployed across J regions. Each region contains one UAV and K IoT devices. For the sake of analysis, let represent the set of divided regions, and represent the set of IoT devices within region . The UAV in region is denoted as j, and the UAV in region is denoted as o. In each time slot, the UAV in region r remains stationary and initiates a connection for communication with the IoT devices falling within its coverage zone. The IoT devices offload part of their tasks to the UAV using NOMA technology, which then performs computation and analysis. In order to reduce transmission queuing delay for IoT devices, UAVs in different regions can also transfer tasks to each other.
For the sake of convenience in discussion, the entire communication period T is discretized into I equal time slots , . Meanwhile, a three-dimensional Cartesian coordinate system is adopted to represent the space, with the unit of measurement in meters (m).
The coordinates of IoT in region r are denoted as . Assuming that all UAVs fly at a fixed safe altitude, the horizontal trajectory of UAV j in region r can be approximately represented as . Suppose denotes the flight distance of the UAV during time slot i, and represents the angle of the UAV’s horizontal direction relative to the positive X-axis in the XY plane. It is given that , . Here, stands for the theoretical maximum flight distance that the UAV can cover within a single time slot, and it must satisfy .
Therefore, in each time slot, the flight trajectory along which the UAV moves is [25]:
where , represents the flight time, and represents the flight speed. Considering that the speed of the UAV remains constant, , where stands for the starting speed of the UAV. Moreover, the UAV can only fly within the specified area, which must satisfy and , where and stand for the length and breadth of the region in sequence. Furthermore, due to the flight speed limitations, the flight path length of each UAV in any given time slot cannot exceed the maximum distance. Additionally, UAVs must maintain a minimum safe flight distance from each other to avoid collisions. Based on the above analysis, the mobility constraints that the UAV trajectories must satisfy are as follows:
where represents the minimum safe distance between UAV j and UAV o within sub-region r. In this paper, each UAV is equipped with a mobile edge computing server and has communication relay capabilities. Therefore, a binary indicator is used to represent whether UAV j and UAV o within sub-region r communicate. Let indicate that UAV j offloads data to UAV o, and indicate that UAV j does not offload data to UAV o. Then, we have
The IoT devices move in a random manner while maintaining a constant speed within a flat region. In region r, the coordinates of IoT device k are indicated as . In each time slot, the IoT devices in region r transmit using NOMA technology to complete partial offloading of computation. In this paper, is used to indicate whether the near-end UAV provides computing services to IoT devices in time slot i. It is also assumed that the maximum number of tasks that each UAV can process simultaneously is . Therefore, the scheduling of IoT devices and the constraint on the number of tasks for the UAV are as follows:
where represents the number of tasks transmitted by the IoT devices within the coverage area of this UAV in time slot i, and represents the number of tasks transmitted to this UAV from other UAVs.
As mentioned earlier, the IoT devices within each region transmit tasks using NOMA technology. Therefore, the time-varying straight-line distance in Euclidean space between UAV j in region r and the IoT device is given by the following formula:
where H denotes the flight altitude of the UAV. In this paper, we maintain the UAV’s flight altitude at a fixed value. We assume that the communication link between the UAV and the ground IoT devices follows a Line-of-Sight (LoS) propagation model. Therefore, according to Shannon’s theorem, the UAV-related time-varying channel and the IoT devices within its coverage area can be described as:
where signifies the channel gains at the reference distance of m. In this paper, tasks are transmitted between the IoT devices and UAVs using NOMA and Successive Interference Cancellation (SIC) technologies. According to Shannon’s theorem, the expression for the data transmission speed from the IoT device to the UAV is given by:
where represents the sum of the interference generated by devices smaller than device k, which is the product of the transmission power and the channel gain, represents the Gaussian noise power, represents the channel bandwidth between the device and the UAV, and represents the transmission power between the device and the UAV. Similarly, the transmission rate between UAV j and UAV o is:
where represents the channel bandwidth between the UAVs, represents the time-varying Euclidean distance between UAV j and UAV o, and represents the transmission power between the UAVs. Here, , with [26,27,28] is a constant, and represents the channel gain when m during transmission.
In the UAV-assisted MEC framework proposed in this study, the data coming from each IoT device is processed by means of three components: local computation by the IoT device, edge UAV, and cloud UAV for auxiliary offloading and computation. Let , , and denote the offloading decisions of the UAVs for the IoT devices, where the constraint must be satisfied. As the volume of data which is returned to the IoT device subsequent to the processing of the task by the MEC server is trifling in comparison with the original data, the UAV offloading computation model expounded below will not consider the transmission delay and energy consumption regarding task return.
In this work, is used to represent the computational tasks originating from the IoT device in each time slot. Let denote the size of the computational task in bits (bit), and denote the number of the CPU cycles needed to fulfill the task. The relationship between and must satisfy . Here, signifies the number of CPU cycles which are necessary to process one unit of computational task.
When the IoT device processes the computational task locally, the local computation delay for the IoT device in time slot i is expressed as:
The IoT device offloads the computational task to the edge UAV. Based on the transmission rate discussed above, the transmission delay for the IoT device offloading the task to the UAV can be expressed as:
The computation delay required for processing tasks by the UAV is:
where represents the computational capacity of the UAV. The energy consumption produced by the UAV for computing tasks is:
In this case, denotes the power consumption parameter decided by the effective charge, and denotes the factor that the chip structure impacts on the CPU’s computational capacity, typically valued at [29].
The delay required for the task offloading process consists of both transmission delay and computation delay. Therefore, the total delay for offloading to the edge UAVs is:
The IoT device offloads the computational task to the edge UAV, which then transmits it to the cloud UAV for computation. Based on the transmission rate discussed above, the transmission delay for the IoT device offloading the task to the cloud UAV is:
The computation delay required for processing tasks by the cloud UAVs is:
Similarly, the energy consumption generated by the remote UAV for computing tasks is:
The delay required for the task offloading process consists of the transmission delay and the computation delay. Therefore, the total delay for offloading to the cloud UAV is:
In summary, the delay consumed in each time slot within region r can be expressed as:
Generally, the total energy consumption of a UAV can be categorized into three primary components: flight energy consumption, computation-related energy consumption, and hovering energy consumption. The flight energy consumption mainly depends on the UAV’s flight speed, flight distance, and hardware parameters. As described in [24], it is formulated as a function of the UAV’s mass , expressed through the following value function:
In this paper, we do not take into account the energy consumption of UAVs during hovering [30]. Consequently, the total energy expenditure of a UAV in region r is expressed as:
To guarantee the required quality of service, the total energy consumed by the UAV in executing all assigned computational tasks must remain within the limits of its initial battery capacity: .
3.2. Problem Statement
In this paper, our objective is to minimize the system latency, subject to the constraints associated with discrete variables and energy consumption. To achieve this, NOMA technology is employed, coupled with the joint optimization of UAV trajectories and task offloading ratios. In the current research, let the pair be used to characterize the UAV’s flight trajectory over time, while is employed to denote the offloading decision variables corresponding to the IoT device. Each IoT device in a region can simultaneously perform local computation and task offloading. Therefore, the total delay for the entire system to complete all tasks depends on the maximum value of the time taken to complete local computation, edge computation, and remote computation in each region. Thus, the total delay for the entire system to complete all tasks is:
The specific optimization problem is modeled as:
Subject to:
wherein, the constraint indicates that the IoT device performs local computation and decision-making. represents the computation and decision-making offloading to the proximal drone, while represents the computation and decision-making offloading to the distal drone. ensures that the computation tasks of the IoT device consist of local computation, proximal drone offloading, and distal drone offloading, and establishes constraints on the decision relationships among these three parts of the computational tasks to ensure reasonable task allocation. Constraints and are associated with the flight distance and angle of the drone. and represent the flight range constraints for the drone, ensuring that its flight position remains within the allowed range. ensures that the flight distance of the drone during any time slot does not exceed the theoretical maximum value. Constraint is designed to avoid collisions during flight, while accounts for the drone’s energy constraints. Finally, ensures that all tasks are completed within the entire task cycle, imposing the constraint that the system must finish all tasks.
In summary, there are non-convex restrictions and objective functions in this paper, and the optimization variables are mutually associated. Traditional optimization methods are often constrained by their dependence on the initial solution, which limits their ability to thoroughly explore the entire search space and typically leads to suboptimal results. In addition, these approaches tend to struggle with complex and dynamic environments, particularly when faced with continuous action spaces, where their performance becomes significantly limited [24,30]. Although DDPG has improved in dealing with continuous action space, it is prone to Q overestimation and instability during training. The TD3 algorithm effectively solves the challenges of traditional optimization algorithms and DDPG by introducing double delayed updates, target strategy smoothing, and noise processing, and provides more stable and accurate optimization results, especially in continuous action space problems such as task offloading and trajectory optimization, showing stronger performance and robustness [31].
3.3. Proposed TD3-Based Optimization Approach
TD3 is an advanced deep reinforcement learning algorithm, which is an extension of the deterministic policy gradient method. Compared with the traditional algorithm, TD3 significantly improves the stability and performance of the algorithm through the double Q learning mechanism, delayed policy update and target strategy smoothing, so that it can more efficiently cope with the optimization problem in the continuous action space. The TD3 algorithm can be used to optimize the delay problem, which can effectively enhance the global search ability of task offloading decisions, improve the convergence speed and adaptability of the algorithm, and make it better suited for task offloading as well as trajectory optimization in complex dynamic environments. To address this challenge, this study introduces a TD3-based algorithm aimed at minimizing latency in multi-user environments by jointly optimizing the UAV’s flight trajectory and the task offloading strategies of ground IoT devices. Based on the MDP model, the algorithm uses the state-action-reward quadruple as the training sample to optimize the trajectory of the drone instantaneously and determine the optimal task offloading ratio, so as to reduce the delay.
To enable the application of the TD3 algorithm to the optimization task, the original problem is reformulated within an MDP framework. Within this structure, the state space, action space, and reward function of the computation offloading problem are defined as follows:
State space:
In the equation, represents the remaining battery of the UAV, represents the size of the remaining task, and it must satisfy . Where , , and .
Action space: The action space in this article is defined as the proportion of the task offloading and the flight trajectory of the drone. Therefore, the action space is:
Reward function: The primary objective of this study is to minimize task execution delay as effectively as possible. Since each selected action is directed toward reducing latency, the reward function is accordingly defined to reflect this goal and can be formulated as follows:
Building upon the MDP formulation outlined in Section 4.1, this paper proposes a task offloading and trajectory optimization algorithm based on the TD3 framework. The algorithm is specifically tailored to effectively handle the high-dimensional and continuous nature of the action space inherent in the task offloading optimization problem. The TD3 algorithm is a deterministic deep reinforcement learning method based on the Actor-Critic framework, which improves the stability and learning effect of the algorithm by improving the Critic network structure and update mechanism. The TD3 algorithm employs a dual-network framework composed of the main network and the target network. In this setup, each of these networks encompasses an actor network along with two Critic networks, specifically designated as Critic1 and Critic2. The target network plays a crucial role in generating steady target values, which serves to enhance the stability of the learning process. Meanwhile, the main network takes on the responsibility of conducting real-time policy evaluation and implementing updates.
Among them, the Actor network generates specific action strategies based on the state inputs of the environment, optimized with the goal of maximizing future cumulative returns, and its parameters are updated as shown in Equation (34). The two Critic networks receive the state and action as input, evaluate the quality of the current policy, and output the value of the state-action pair. In order to alleviate the problem of overestimation of Q value in the traditional method, TD3 adopts the double-Q network mechanism, and updates the target value by selecting the smaller value of the output value of Critic1 and Critic2 networks, and the target value is calculated as shown in Equation (32). The Critic network parameters are updated by reducing the error between the predicted and target values, as detailed in (33).
To enhance the stability of the target value, the TD3 algorithm incorporates a smoothing regularization mechanism during its computation. This is achieved by introducing controlled random noise to the target action value, which helps to mitigate abrupt fluctuations. The resulting adjusted target action value is presented in Equation (31). The elements of the target network which act as parameters are adjusted step by step by the soft update method, and the update rules are shown in Equation (35), so as to ensure the smoothness and reliability of the output throughout the training process.
Additionally, the TD3 algorithm adopts an experience replay mechanism. The interaction data generated between the actor network and the environment is stored as experience tuples in a replay buffer. During training, small batches are randomly sampled from this buffer to update the network parameters, promoting learning stability and efficiency. This approach not only effectively lessens the dependence and correlation among samples, but also significantly improves the convergence speed and stability of the algorithm.
Therefore, the TD3 algorithm improves the accuracy of Q value calculation through the double-Q network architecture, and significantly enhances the stability and performance of the algorithm by combining the delayed update mechanism and target value smoothing. Figure 2 illustrates the framework diagram of the TD3 algorithm.
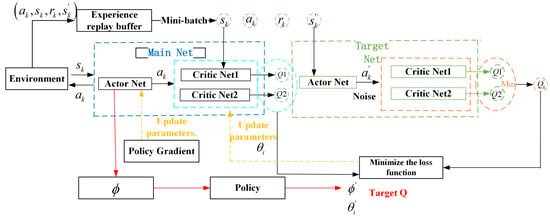
Figure 2.
TD3 algorithm framework.
First, the network parameters are initialized, and then the initial state is input into the Actor network. In each iteration, the drone selects action a based on the Actor network and random noise , and after performing the current action, it gets a reward and the state of the next moment, so it gets a quadruple . Then the quadruple is stored in the empirical buffer R, when the buffer space is stored, N tuples will be randomly sampled in the replay pool, assuming that the data we sample is , then the action of the state is:
Then, based on the target network policy smoothing regularization, random noise is added to the Actor network, then the modified target action value is:
Then, based on the idea of a dual network, the goals of the Critic network are defined as:
The parameter of the two Critic networks is then updated by minimizing the loss function:
Then, combined with the Q function of the Critic training network, the policy gradient of the actor when the parameters are updated can be obtained:
Finally, update target networks and :
In the optimal task offloading decision-making process based on the TD3 algorithm proposed in this paper, the Actor and Critic network parameters are updated iteratively. Simultaneously, the UAV’s flight trajectory and task offloading strategy are refined to minimize delay. Algorithm 1 outlines the algorithm flow. Initially, the network framework is set up, including random parameter initialization for the Critic and Actor networks, along with their respective target networks. An experience buffer is then established to store interaction data. The iterative training process follows, with lines 1 to 18 forming the complete training procedure. In each iteration, the system first initializes the environment, receives the state , and selects action according to the current strategy and Gaussian noise, which includes the flight direction, flight distance and task offloading decision of the drone. After the action is executed, the system calculates the reward and the next state , and deposits the generated quadruple into the empirical buffer R, as shown in line 9. Lines 10 to 15 involve randomly sampling mini-batches of empirical data from the buffer and adjusting the network parameters based on Equations (33)–(35). This process is iteratively carried out until the maximum number of steps, Max_Step, is achieved. Ultimately, the algorithm generates the optimal UAV flight path, task offloading strategy, and minimizes the system’s delay. Algorithm 1 details the implementation of the optimal task offloading strategy using the TD3 framework.
In this study, the TD3 algorithm is used to optimize the offloading decisions of multi-UAV collaborative computing tasks and the selection of flight trajectories. The computational complexity of the neural network is influenced by various factors, including the size of the data, the complexity of the model, and the overall algorithmic framework. To simplify this, we focus on analyzing the computational complexity of generating the optimal action. In each iteration, each agent in TD3 traverses all actions to find the optimal action with the maximum Q-value. In the system model proposed in this paper, there are K IoT devices and J UAVs in each time slot. The offloading decision of each IoT and the flight trajectory of each UAV together form an action space, denoted as , where N refers to the number of offloading decisions for each IoT device. Therefore, the total action space size is . In each iteration, the TD3 algorithm selects the optimal action by having the agent traverse the action space. Thus, the computational complexity is , with T representing the iteration period. That is, the overall complexity is .
| Algorithm 1 Optimal Task Offloading Decision Algorithm Based on TD3 | |
| Input: number of iterations, learning rate for the Actor network, learning rate for the | |
| Critic network, discount factor, and soft update coefficient | |
| Output: offloading decisions, UAV trajectory, and minimum delay | |
| 1 | Randomly initialize parameters , for the Critic networks; randomly initialize parameter for the Actor network |
| 2 | Initialize target networks: , , |
| 3 | Initialize the experience replay buffer: R |
| 4 | for episode to Max_Step do |
| 5 | Reset environment and observe initial state |
| 6 | for time step to T do |
| 7 | Select action , represents Gaussian noise |
| 8 | Execute , the reward and the next state are obtained |
| 9 | Store its data tuple into the experience buffer R |
| 10 | if R is full, update the experience buffer |
| 11 | Randomly sample a batch of N values from the multidimensional array , from |
| 12 | Update the Critic network by minimizing the target loss using Equation (33) |
| 13 | if then |
| 14 | Update the Actor online network using Equation (34) |
| 15 | Update the weights of the target network according to Equation (35) |
| 16 | end if |
| 17 | end for |
| 18 | end for |
4. Performance Evaluation
4.1. Simulation Setup
This section conducts a performance evaluation of the proposed TD3-based scheme for task offloading and trajectory optimization in a multi-UAV-assisted edge computing environment, with an emphasis on reducing overall system delay. The experimental setup was implemented using Python 3.8 and the TensorFlow framework, running on a PC powered by an AMD Ryzen 7 4800U processor (AMD, Santa Clara, CA, USA). In the experiment, we deployed two UAVs and eight IoT devices. The IoT devices are randomly deployed across two adjacent rectangular regions. Area 1 covers a 200 m × 200 m square, while Area 2—an equally sized 200 m × 200 m region—is positioned adjacent to Area 1 along the X-axis, spanning coordinates from 200 m to 400 m. Thus, the X-coordinate range for Area 2 is defined as (200 m, 400 m), with both areas sharing identical Y-axis dimensions.
4.1.1. Simulation Metrics
To evaluate the performance of the proposed approach, comparative experiments were conducted using the DDPG algorithm [32], the Deep Q-Network (DQN) algorithm [33], the Actor-Critic (AC) algorithm [34], the UAV no-coordination scheme, and local processing schemes under the same system model environment. The evaluation indicators include the convergence of the algorithm in this scheme and the cost when using different algorithms to process the same task. To provide an objective comparison of various solutions, the evaluation focused on five key aspects: task volume, number of IoT devices, flight speed, flight duration, IoT computing capacity, and UAV computing capacity.
4.1.2. Simulation Scenarios
The UAVs maintain a fixed altitude within their respective areas, covering their designated service ranges and assisting in task offloading. The task size was configured at 80 Mbits, while the computing capacities of the UAV and IoT devices were set to 1.2 GHz and 0.6 GHz, respectively. Additional parameters can be found in Table 2, as detailed in Refs. [35,36]. The experiments involved running multiple iterations of Algorithm 1 under identical conditions. Finally, the collected data were systematically analyzed for performance comparison.
Table 2.
Main simulation parameters.
4.2. Experimental Results
To gain a deeper understanding of the algorithm’s performance and stability, we conducted a detailed analysis of the key hyperparameters during the experimental process. This includes adjustments to memory capacity MEMORY_CAPACITY, learning rate , and discount factor . By comparing the relationship between the number of training iterations and cumulative rewards under different hyperparameter configurations, we ultimately selected the optimal parameter combination that balances training stability and convergence efficiency. It is important to note that the reward used in this paper is the negative value of the total system delay, which serves as the agent’s feedback signal in reinforcement learning to guide policy optimization. Although this reward is constructed based on delay with physical units, within the reinforcement learning framework, it essentially serves as a relative measure of policy quality and does not retain the original physical units.
As shown in Figure 3, the best performance is achieved when the memory capacity is set to MEMORY_CAPACITY = 10,000. This is because, at this setting, the replay pool can store more samples, allowing the training process to learn from a more diverse set of experiences, which helps the algorithm find a more stable convergence path. However, when the memory capacity is set too large, such as MEMORY_CAPACITY = 100,000, the reward variation throughout the learning process is small, with almost no significant fluctuations, showing an overly smooth trend. This may be due to the excessively large memory capacity causing the agent to overfit the data in the training environment, preventing it from learning more generalized strategies. When the memory capacity is set to MEMORY_CAPACITY = 5000, we observe significant fluctuations in the agent’s learning process, and it ultimately fails to converge. This is because with a smaller memory capacity, the experience replay pool used during training may not provide enough diverse samples, leading to overly similar experiences being sampled during training, which can cause overfitting or unstable convergence. Therefore, a moderate memory capacity usually yields the best results, and in this chapter, the memory capacity is set to MEMORY_CAPACITY = 10,000.
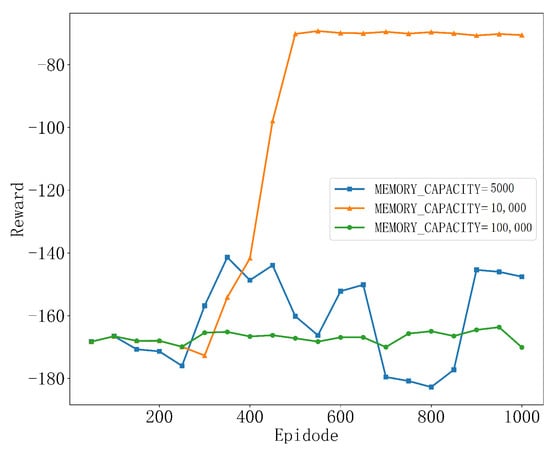
Figure 3.
Convergence performance at different memory capacities.
As shown in Figure 4, the selection of the learning rate plays a significant role in determining the agent’s learning efficiency and strategic performance. When the learning rate is , , it shows the best performance among the three settings, and the reward value experiences a rapid increase in the initial stage and quickly converges to a high stable value after about 400 rounds. This indicates that this learning rate configuration achieves a good balance between exploration and utilization, so that the agent can learn and optimize the strategy efficiently. When the learning rate is small, , , the region is stable at 400 to 800 rounds, but after 800 rounds, it shows large fluctuations and the reward is very reduced, which indicates that the algorithm may have difficulty finding effective strategies at low learning and exploration rates. Although it stabilized in the medium term, the overall performance was not as good as , . When the learning rate is excessively high, , , the reward value of this setting is basically stable around −170. This may indicate that the high learning and exploration rates have led to the algorithm’s exploration being too aggressive and may not have made full use of what has been learned to optimize its decision-making, resulting in an average performance. Therefore, this paper chooses to set the learning rate to , , which supports the trade-off between effective learning and stable performance of the algorithm, so that it gradually converges to a better strategy during the training process, effectively minimizing the negative value of the reward, that is, maximizing the efficiency. These results show that moderate learning and exploration rates are essential for the success of deep reinforcement learning algorithms.
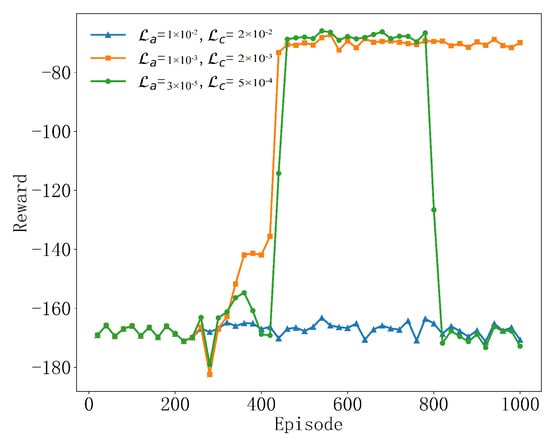
Figure 4.
Convergence performance at different learning rates.
Figure 5 shows the variation in rewards of the TD3 algorithm under different discount factor values. The simulation results clearly indicate that the choice of discount factor performs the best in the simulation. This reflects that, when considering long-term strategies, the TD3 algorithm effectively balances immediate and future rewards, enabling the agent to develop a more comprehensive and optimized behavior strategy, ultimately achieving higher cumulative rewards. Compared to other choices of discount factors, such as and , although they show stability in rewards, their overall performance is lower than that of . This is because, compared to , these values place less weight on long-term rewards. The algorithm tends to be more conservative when considering future rewards, placing more focus on short-term rewards, which may lead the model to rely too heavily on immediate rewards during the learning process, neglecting long-term planning. This is reflected in the fact that the reward value shows little to no change throughout the entire training process, which could be due to the specific settings of the TD3 algorithm at this discount rate not being suitable for this environment, leading to a lack of motivation in the learning process to explore better solutions. Experimental results show that an appropriately high discount factor helps seek optimal long-term strategies in complex decision-making environments. Therefore, in this chapter, the discount factor is set to .
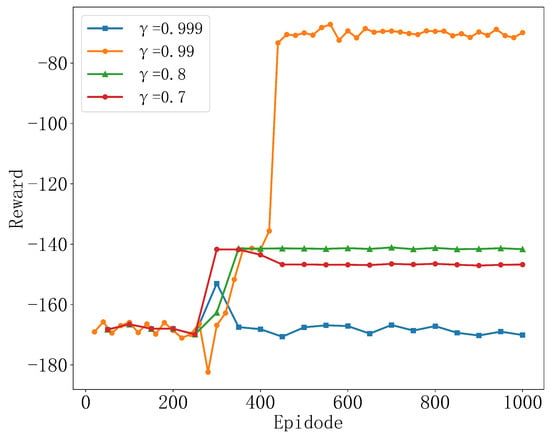
Figure 5.
Convergence performance at different discount factors.
Figure 6 shows the delay of five computational schemes with task sizes ranging from 1 MBit to 3 MBits. Overall, the TD3 algorithm consistently performs the best, with the lowest delay and slowest growth, while local computation has the highest delay, which increases rapidly in a linear fashion as the task size increases. The delays of other schemes fall between these two extremes, with DDPG performing second best. DQN remains competitive at smaller task sizes, but its performance deteriorates significantly as the task size grows. The non-collaborative scheme shows the lowest overall efficiency.
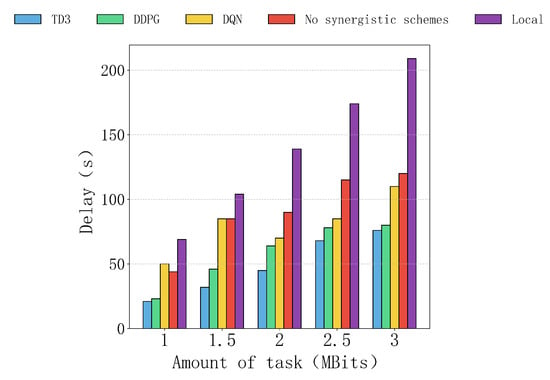
Figure 6.
The impact of different task sizes on delay.
In terms of specific performance, the TD3 algorithm has a clear advantage at any task size, indicating that it is the most efficient in task allocation and resource utilization, able to handle tasks of varying sizes stably. The DDPG algorithm performs similarly to TD3 at a task size of 2 MBits but slightly lags behind at higher task sizes. DQN performs decently at a task size of 1 MBit, but as the task size increases, its delay grows significantly, indicating poor resource utilization efficiency. The delays of the non-collaborative scheme and local computation are much higher than those of other collaborative schemes. The non-collaborative scheme relies entirely on the local edge server, which leads to idle remote UAVs and low efficiency. Local computation, relying solely on the device’s own resources, performs particularly poorly at larger task sizes, with delays significantly higher than other schemes.
Figure 7 shows the delay performance of various algorithms under different scenarios with the number of devices ranging from 1 to 10. From the results, it can be observed that the TD3 algorithm consistently demonstrates the best delay control capability, with the delay growth being the most gradual, exhibiting significant performance advantages. In contrast, the DDPG and DQN algorithms perform second best, while the non-collaborative and local computation schemes have significantly higher delays than the other algorithms, with a steeper growth trend.
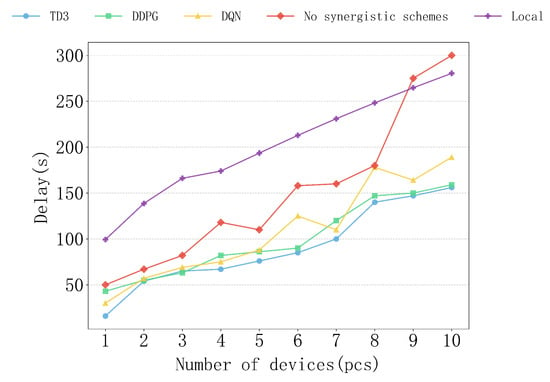
Figure 7.
The impact of different device numbers on delay.
Upon analysis, it can be seen that the TD3 algorithm performs particularly well when the number of devices is high, such as 8–10 devices. Its excellent resource allocation and collaborative computing capabilities keep the delay at a lower level, demonstrating strong stability and adaptability. The DDPG algorithm performs similarly to TD3 with fewer devices but shows a slightly faster delay growth as the number of devices increases, with performance slightly lagging behind TD3. The DQN algorithm performs decently with 1–3 devices but experiences a rapid increase in delay as the number of devices grows, showing unstable performance. The delays of the non-collaborative and local computation schemes remain high throughout, especially the local computation scheme, where the delay almost increases linearly as the number of devices grows, resulting in the lowest efficiency. Therefore, the TD3 algorithm demonstrates the best delay optimization ability in the research environment.
Figure 8 shows the delay performance of various algorithms, as well as the non-collaborative and local computation schemes, under different flight speeds. Overall, the TD3 algorithm consistently maintains the lowest delay at all flight speeds. In contrast, the DDPG algorithm performs similarly to TD3 at low speeds (10–20 m/s), but shows slight fluctuations and a slight increase in delay when the speed increases to 30–40 m/s. The performance of the DQN algorithm is relatively significant, with its delay peaking at speeds of 20–30 m/s, followed by a slight decrease. This may be due to the algorithm’s limited flexibility in resource scheduling.
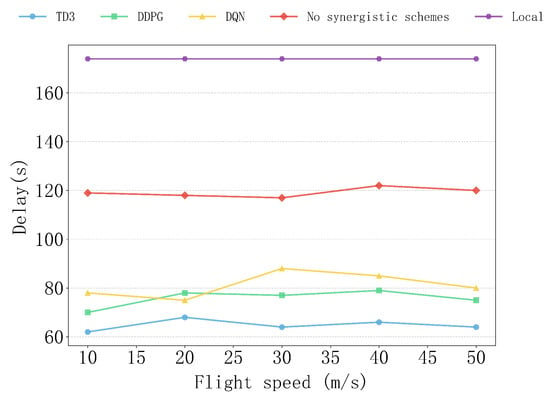
Figure 8.
The impact of different flight speeds on delay.
The delays of the non-collaborative and local computation schemes are always higher than those of the other algorithms, especially the local computation scheme, where the delay remains at the highest level and is completely unaffected by the flight speed. This is because the local computation scheme relies entirely on the user device for computation, so the delay depends solely on the device’s computing performance and is independent of the flight speed. As a result, the delay follows a steady high-level curve, consistently higher than the other schemes. The non-collaborative scheme, relying entirely on the user device and UAV to perform computations independently without collaboration, has relatively stable and high delays. Therefore, compared to the other schemes, the TD3 algorithm is more efficient in adapting to changes in flight speed, fully demonstrating its superior performance in handling multi-task problems in dynamic environments.
Figure 9 shows the delay performance of various algorithms, as well as the non-collaborative and local computation schemes, under different flight times. The TD3 algorithm demonstrates extremely high stability with changing flight times, with its delay curve being smooth and the lowest, significantly outperforming other algorithms. In contrast, although the DDPG algorithm maintains relatively stable delay performance as the flight time increases, it is still slightly inferior to TD3. The delay of the DQN algorithm is relatively higher and shows some fluctuations, which is due to the inherent discreteness of the DQN algorithm, leading to less adaptability in continuous dynamic environments. The delays of the non-collaborative and local computation schemes remain consistently high. The delay of the non-collaborative scheme increases gradually as the flight time increases, mainly due to the prolonged UAV flight time, which exacerbates communication delays and accumulates task processing time.
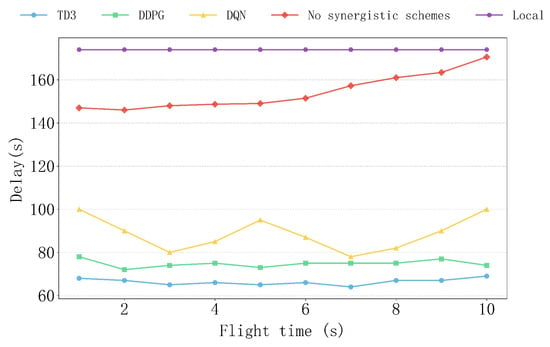
Figure 9.
The impact of different flight time on delay.
Figure 10 shows the delay performance of various algorithms, as well as the non-collaborative and local computation schemes, under different device computation capabilities. Overall, the TD3 algorithm consistently exhibits the lowest delay under all device computation capabilities, significantly outperforming other algorithms and demonstrating its excellent task scheduling performance. In contrast, the delays of the DDPG and DQN algorithms are relatively higher but still maintain a low level, especially at higher computation capabilities, around 0.6 GHz, where their performance is close to that of TD3.
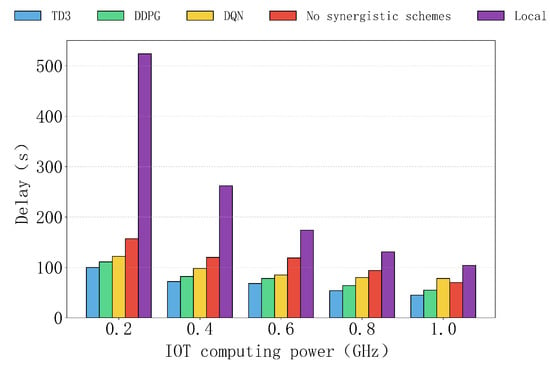
Figure 10.
The impact of computing power of different IOTs on delay.
The delays of the non-collaborative and local computation schemes remain consistently high, with the local computation scheme experiencing a sharp increase in delay at lower computation capabilities, such as 0.2 GHz. This is because, for the local computation scheme, as the task depends entirely on the device’s computation, delays increase sharply when the user’s computation capability is low, reaching its maximum value. While the delay of the non-collaborative scheme gradually decreases, it remains higher than that of TD3, DDPG, and DQN, indicating that the lack of a collaboration mechanism limits its performance even as user computation resources improve. Therefore, the TD3 algorithm significantly optimizes user experience under varying local device computation capabilities and provides an effective solution for task optimization in low-computation- capability scenarios.
Figure 11 shows the delay performance of various algorithms, as well as the non-collaborative and local computation schemes, under different UAV computation capabilities. Overall, as UAV computation capabilities increase, the delay of the TD3 algorithm gradually decreases and outperforms all other schemes. In contrast, the delays of DDPG and DQN are relatively higher, but they still significantly outperform the non-collaborative and local computation schemes, especially in high computation capability scenarios. The local computation scheme, relying entirely on IoT devices, does not show a significant decrease in delay under different computation capability conditions. Although the delay of the non-collaborative scheme decreases with improved computation capability, due to the lack of a collaboration mechanism, its delay remains relatively high.
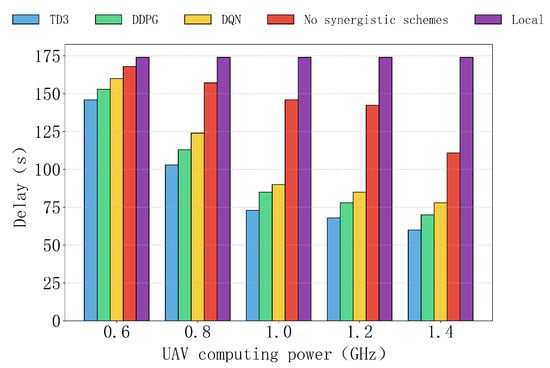
Figure 11.
The impact of computing power of different UAVs on delay.
Figure 12 and Figure 13 show the 2D and 3D flight trajectory maps of the UAVs under different periods, where UE represents the ground IoT devices. From the figures, it can be observed that, in the case of a 400-s period, the UAV’s coverage area significantly expands due to the longer flight time. This allows the UAV to reach more ground IoT devices, providing offloading services for their computational tasks, reducing their load, and improving task processing efficiency. By flying to more distant terminal locations, the UAV can establish higher-quality communication links, thereby reducing task offloading time and optimizing the overall system performance.
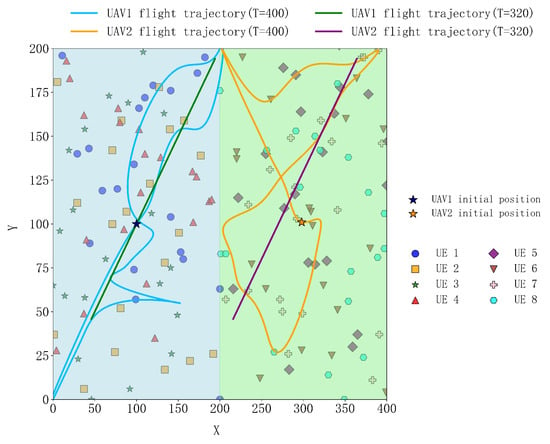
Figure 12.
Two-dimensional flight trajectory of the UAV.
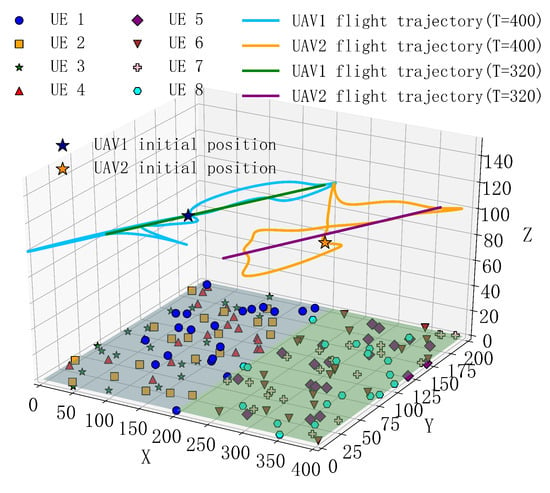
Figure 13.
Three-dimensional flight trajectory of the UAV.
In contrast, under the 320-s period, the UAV’s flight range is smaller, but it is still able to effectively cover the concentrated areas of users and provide efficient task offloading services. Despite the smaller flight range, the UAV trajectory planning for this period is more precise, allowing task offloading and processing to be completed in a shorter time, thus reducing communication and computation delays. In this case, by concentrating coverage on a local area, the UAV can optimize task allocation, avoid system overload, and reduce unnecessary communication overhead. Additionally, to make these trajectories more aligned with actual flight paths, the time slot data collected was smoothed. Through this smoothing process, the trajectory becomes smoother and more coherent, reducing jumps between sampling points, thereby enhancing the authenticity and visual effects of the trajectory. This processing not only improves the accuracy of the trajectory but also makes the simulation results closer to actual flight conditions.
Overall, the proposed scheme in this paper has significant advantages. The long-period coverage is wide and can provide computational offloading services for more users, reducing overall delay. Although the short-period coverage is smaller, it can serve more users distributed at greater distances in a shorter time, further optimizing system performance, reducing delays, and enhancing the user experience. This multi-period scheduling strategy enables the UAV to flexibly respond to different scenarios during task offloading, maximizing resource utilization efficiency.
To further evaluate the advantages of the TD3 algorithm in task offloading and trajectory optimization, this paper compares its average delay performance with that of the DDPG algorithm across various scenarios. As shown in Table 3, the TD3 algorithm consistently achieves significantly lower latency than the DDPG algorithm in all scenarios. Among them, the delay reduction in the task volume scenario is the largest, reaching 20.2%, the delay reduction in the flight speed and IoT computing power scenarios is 17.0% and 15.0%, respectively, and the delay reduction in the other scenarios is also more than 9.8%. The results show that the TD3 algorithm has significant optimization ability in the multi-user collaborative computing environment, which can effectively reduce the system delay and improve the real-time performance and stability of the system under high load and dynamic conditions.
Table 3.
Comparison of the average delay performance.
Therefore, the task offloading and trajectory optimization method based on NOMA technology and multi-UAV collaboration proposed in this paper is superior to other existing schemes in reducing delay and improving mission offloading efficiency. By combining NOMA technology and TD3 algorithm, the unloading decision and flight trajectory of the UAV are optimized, which significantly improves the communication and computing capabilities of the UAV in a complex multi-user environment, balances the resource competition between multiple users, and effectively reduces the transmission queuing problem during task offloading.
5. Discussion
This section discusses the contributions of each key component of the proposed framework and its practical implications for real-world deployment.
From the overall framework design and the comparative results, the roles of each component can be indirectly inferred. Specifically, the integration of NOMA directly enhances spectrum efficiency and multi-user access capability, thereby reducing queuing delays and supporting a larger number of IoT devices. The multi-UAV collaboration strengthens load balancing and service coverage, mitigating the limitations of a single node’s computing capacity. The TD3-based joint optimization further enables the system to dynamically adapt task offloading and trajectory planning according to real-time network states, achieving lower system latency compared to static or heuristic strategies.
In practical deployment, the proposed multi-UAV collaborative MEC framework integrated with NOMA could be applied in scenarios such as post-disaster rescue, large-scale outdoor events, and remote area connectivity, where rapid network setup and flexible computing support are required. In these environments, the UAV swarm’s ability to dynamically adjust its trajectories and balance computing tasks through cooperative offloading helps mitigate coverage holes and computing bottlenecks. However, practical challenges such as energy constraints, UAV flight safety regulations, and unpredictable weather conditions must be considered. To address these issues, the proposed joint optimization algorithm can be further extended by incorporating energy-aware trajectory planning and adaptive task scheduling strategies. This ensures that the system remains robust and responsive, even under varying real-world conditions.
Overall, these insights highlight not only the effectiveness of the proposed scheme but also the practical considerations and future improvements needed to bridge the gap between theoretical optimization and real-world UAV-assisted MEC applications.
6. Conclusions
To address joint task offloading and trajectory optimization problem in UAV-assisted edge computing systems, in this paper, we propose a UAV-assisted edge computing system model that integrates NOMA technology and multi-UAV collaborative computing. To optimize system delay, a task offloading and trajectory optimization method based on the TD3 algorithm is designed. By establishing an information exchange mechanism between UAVs and IoT devices, our scheme alleviates UAV computational resource bottlenecks and the transmission queuing problem caused by multiple IoT devices offloading tasks simultaneously, thereby minimizing system delay. By transforming the non-convex optimization problem into an MDP decision-making problem, the offloading decisions and flight trajectories of UAVs are jointly optimized, effectively reducing computation delay in multi-IoT scenarios. Simulation results show that, compared to traditional approaches, our proposed scheme reduces delay by 20.2%, 9.8%, 17.0%, 12.7%, 15.0%, and 11.6% in scenarios with varying task volumes, the number of IoT devices, UAV flight speed, flight time, IoT device computing capabilities, and UAV computing capacities, respectively. In future work, we plan to extend the proposed framework to scenarios involving multi-task and heterogeneous UAV clusters. As network scale and task complexity continue to grow, a homogeneous UAV fleet may not be sufficient to handle diverse computing and sensing demands. To address this, we will explore the design of heterogeneous UAV systems that combine heavy-computation UAVs with lightweight reconnaissance drones, forming a flexible aerial cluster capable of efficiently coping with increasing ground device density and task loads.
Author Contributions
Conceptualization, J.L. (Jiajia Liu) and X.B.; methodology, H.H., J.L. (Jiajia Liu) and G.L.; software, H.H., X.B., X.Z., H.Z. and H.L.; validation, J.L. (Jiajia Liu), X.B. and J.L. (Jianhua Liu); formal analysis, H.H.; data curation, X.B.; writing—original draft preparation, J.L. (Jiajia Liu) and X.B.; writing—review and editing, J.L. (Jiajia Liu), J.L. (Jianhua Liu) and X.B.; supervision, H.L. and J.L. (Jianhua Liu); project administration, J.L. (Jiajia Liu); funding acquisition, J.L. (Jiajia Liu) and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Fundamental Research Funds for the Central Universities under grant number 25CAFUC03093, and the CAAC Key laboratory of General Aviation Operation (Civil Aviation Management Institute of China) under grant number CAMICKFJJ-2024-03.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data will be made available on request.
Acknowledgments
The authors thank colleagues from Civil Aviation Flight University of China for their constructive comments–they really helped us improve this paper.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Zhang, L.; Qamar, F.; Liaqat, M.; Hindia, M.N.; Ariffin, K.A.Z. Towards efficient 6G IoT networks: A perspective on resource optimization strategies, challenges, and future directions. IEEE Access 2024, 12, 76606–76633. [Google Scholar] [CrossRef]
- Zeng, H.; Zhu, Z.; Wang, Y.; Xiang, Z.; Gao, H. Periodic collaboration and real-time dispatch using an actor–critic framework for uav movement in mobile edge computing. IEEE Internet Things J. 2024, 11, 21215–21226. [Google Scholar] [CrossRef]
- Yan, M.; Zhang, L.; Jiang, W.; Chan, C.A.; Gygax, A.F.; Nirmalathas, A. Energy consumption modeling and optimization of UAV-assisted MEC networks using deep reinforcement learning. IEEE Sensors J. 2024, 24, 13629–13639. [Google Scholar] [CrossRef]
- Yuan, H.; Wang, M.; Bi, J.; Shi, S.; Yang, J.; Zhang, J.; Zhou, M.; Buyya, R. Cost-efficient Task Offloading in Mobile Edge Computing with Layered Unmanned Aerial Vehicles. IEEE Internet Things J. 2024, 11, 30496–30509. [Google Scholar] [CrossRef]
- Vardakis, C.; Dimolitsas, I.; Spatharakis, D.; Dechouniotis, D.; Zafeiropoulos, A.; Papavassiliou, S. A Petri Net-based framework for modeling and simulation of resource scheduling policies in Edge Cloud Continuum. Simul. Model. Pract. Theory 2025, 141, 103098. [Google Scholar] [CrossRef]
- Yu, C.; Yong, Y.; Liu, Y.; Cheng, J.; Tong, Q. A Multi-Objective Evolutionary Approach: Task Offloading and Resource Allocation Using Enhanced Decomposition-Based Algorithm in Mobile Edge Computing. IEEE Access 2024, 12, 123640–123655. [Google Scholar] [CrossRef]
- Moreschini, S.; Pecorelli, F.; Li, X.; Naz, S.; Hästbacka, D.; Taibi, D. Cloud continuum: The definition. IEEE Access 2022, 10, 131876–131886. [Google Scholar] [CrossRef]
- Hossain, M.A.; Liu, W.; Ansari, N. Computation-efficient offloading and power control for MEC in IoT networks by meta-reinforcement learning. IEEE Internet Things J. 2024, 11, 16722–16730. [Google Scholar] [CrossRef]
- Javanmardi, S.; Nascita, A.; Pescapè, A.; Merlino, G.; Scarpa, M. An integration perspective of security, privacy, and resource efficiency in IoT-Fog networks: A comprehensive survey. Comput. Netw. 2025, 270, 111470. [Google Scholar] [CrossRef]
- Yu, Z.; Fan, G. Joint differential evolution and successive convex approximation in UAV-enabled mobile edge computing. IEEE Access 2022, 10, 57413–57426. [Google Scholar] [CrossRef]
- Tian, Y.; Khan, A.; Ahmad, S.; Mohsan, S.A.; Karim, F.K.; Hayat, B.; Mostafa, S.M. An Optimized Deep Learning Framework for Energy-Efficient Resource Allocation in UAV-Assisted Wireless Networks. IEEE Access 2025, 13, 40632–40648. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, T.; Liu, Y.; Yang, D.; Xiao, L.; Tao, M. 3D multi-uav computing networks: Computation capacity and energy consumption tradeoff. IEEE Trans. Veh. Technol. 2024, 73, 10627–10641. [Google Scholar] [CrossRef]
- Lu, H.; He, X.; Du, M.; Ruan, X.; Sun, Y.; Wang, K. Edge QoE: Computation offloading with deep reinforcement learning for Internet of Things. IEEE Internet Things J. 2020, 7, 9255–9265. [Google Scholar] [CrossRef]
- Cheng, K.; Fang, X.; Wang, X. Energy efficient edge computing and data compression collaboration scheme for UAV-assisted network. IEEE Trans. Veh. Technol. 2023, 72, 16395–16408. [Google Scholar] [CrossRef]
- Zhuang, J.; Han, G.; Xia, Z.; Wang, B.; Li, W.; Wang, D.; Hao, Z.; Cai, R.; Fan, Z. Robust Policy Learning for Multi-UAV Collision Avoidance with Causal Feature Selection. arXiv 2024, arXiv:2407.04056. [Google Scholar] [CrossRef]
- Liu, B.; Wan, Y.; Zhou, F.; Wu, Q.; Hu, R.Q. Resource allocation and trajectory design for MISO UAV-assisted MEC networks. IEEE Trans. Veh. Technol. 2022, 71, 4933–4948. [Google Scholar] [CrossRef]
- Wu, M.; Wu, H.; Lu, W.; Guo, L.; Lee, I.; Jamalipour, A. Security-Aware Designs of Multi-UAV Deployment, Task Offloading and Service Placement in Edge Computing Networks. IEEE Trans. Mob. Comput. 2025. [CrossRef]
- Hao, H.; Xu, C.; Zhang, W.; Yang, S.; Muntean, G.M. Joint task offloading, resource allocation, and trajectory design for multi-uav cooperative edge computing with task priority. IEEE Trans. Mob. Comput. 2024, 23, 8649–8663. [Google Scholar] [CrossRef]
- Sun, G.; He, L.; Sun, Z.; Wu, Q.; Liang, S.; Li, J.; Niyato, D.; Leung, V.C. Joint task offloading and resource allocation in aerial-terrestrial UAV networks with edge and fog computing for post-disaster rescue. IEEE Trans. Mob. Comput. 2024, 23, 8582–8600. [Google Scholar]
- Li, K.; Yan, X.; Han, Y. Multi-mechanism swarm optimization for multi-UAV task assignment and path planning in transmission line inspection under multi-wind field. Appl. Soft Comput. 2024, 150, 111033. [Google Scholar] [CrossRef]
- Dehkordi, M.F.; Jabbari, B. Joint long-term processed task and communication delay optimization in UAV-assisted MEC systems using DQN. In Proceedings of the MILCOM 2024-2024 IEEE Military Communications Conference (MILCOM), Washington, DC, USA, 28 October–1 November 2024; pp. 294–299. [Google Scholar]
- Wang, Y.; Gao, H.; Xiang, Z.; Zhu, Z.; Al-Dulaimi, A. RSMR: A Reliable and Sustainable Multi-Path Routing Scheme for Vehicle Electronics in Edge Computing Networks. IEEE Trans. Consum. Electron. 2024, 71, 2090–2106. [Google Scholar] [CrossRef]
- Zhang, B.; Lin, X.; Zhu, Y.; Tian, J.I.; Zhu, Z. Enhancing multi-UAV reconnaissance and search through double critic DDPG with belief probability maps. IEEE Trans. Intell. Veh. 2024, 9, 3827–3842. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, F.; Cao, M.; Feng, C.; Chen, D. Enhancing UAV-assisted vehicle edge computing networks through a digital twin-driven task offloading framework. Wirel. Netw. 2025, 31, 965–981. [Google Scholar] [CrossRef]
- Zhang, G. Energy Consumption Optimization of UAV-Assisted Edge Computing System Based on Deep Learning. J. Electron. Inf. Technol. 2023, 45, 1635–1643. (In Chinese) [Google Scholar]
- Xia, J.; Wang, L. Multi-UAV Cooperative Computing and Task Offloading Strategy Based on Non-Orthogonal Multiple Access. Comput. Digit. Eng. 2024, 52, 1298–1303. (In Chinese) [Google Scholar]
- Hua, H.; Li, Y.; Wang, T.; Dong, N.; Li, W.; Cao, J. Edge computing with artificial intelligence: A machine learning perspective. ACM Comput. Surv. 2023, 55, 1–35. [Google Scholar] [CrossRef]
- Wang, P.; Yang, H.; Han, G.; Yu, R.; Yang, L.; Sun, G.; Qi, H.; Wei, X.; Zhang, Q. Decentralized navigation with heterogeneous federated reinforcement learning for UAV-enabled mobile edge computing. IEEE Trans. Mob. Comput. 2024, 23, 13621–23638. [Google Scholar] [CrossRef]
- Zhuang, W.; Xing, F.; Lu, Y. Task Offloading Strategy for Unmanned Aerial Vehicle Power Inspection Based on Deep Reinforcement Learning. Sensors 2024, 24, 2070. [Google Scholar] [CrossRef]
- Löppenberg, M.; Yuwono, S.; Diprasetya, M.R.; Schwung, A. Dynamic robot routing optimization: State–space decomposition for operations research-informed reinforcement learning. Robot.-Comput.-Integr. Manuf. 2024, 90, 102812. [Google Scholar] [CrossRef]
- Xu, X.Y.; Chen, Y.Y.; Liu, T.R. TD3-BC-PPO: Twin delayed DDPG-based and behavior cloning-enhanced proximal policy optimization for dynamic optimization affine formation. J. Frankl. Inst. 2024, 361, 107018. [Google Scholar] [CrossRef]
- Li, C.; Jiang, K.; He, G.; Bing, F.; Luo, Y. A Computation Offloading Method for Multi-UAVs Assisted MEC Based on Improved Federated DDPG Algorithm. IEEE Trans. Ind. Inform. 2024, 20, 14062–104071. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y. Deep ME Cagent: Multi-agent computing resource allocation for UAV-assisted mobile edge computing in distributed IoT system. Appl. Intell. 2023, 53, 1180–1191. [Google Scholar] [CrossRef]
- Abdulazeez, D.H.; Askar, S.K. A Novel Offloading Mechanism Leveraging Fuzzy Logic and Deep Reinforcement Learning to Improve IoT Application Performance in a Three-Layer Architecture Within the Fog-Cloud Environment. IEEE Access 2024, 12, 39936–39952. [Google Scholar] [CrossRef]
- Hu, H.; Sheng, Z.; Nasir, A.A.; Yu, H.; Fang, Y. Computation capacity maximization for UAV and RIS cooperative MEC system with NOMA. IEEE Commun. Lett. 2024, 28, 592–596. [Google Scholar] [CrossRef]
- Zhang, D.; Zhang, Z.; Zhang, J.; Zhang, T.; Zhang, L.; Chen, H. UAV-assisted task offloading system using dung beetle optimization algorithm and deep reinforcement learning. Ad Hoc Netw. 2024, 156, 103434. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).