




Incorporating Uncertainty Estimation and Interpretability in Personalized Glucose Prediction Using the Temporal Fusion Transformer

 , ,
, ,  ,
,  and
and
Abstract
1. Introduction
2. Materials and Methods
2.1. Datasets
2.1.1. WARIFA Dataset
- Wearing the same CGM sensor for at least one year.
- Wearing a CGM sensor with a sampling period of 15 min.
2.1.2. OhioT1DM Dataset
2.2. Data Preparation and Partition
2.2.1. WARIFA Dataset
2.2.2. OhioT1DM Dataset
2.3. Temporal Fusion Transformer
- (1)
- Gating mechanisms to adapt network complexity for a given dataset by skipping unused components of the architecture (e.g., if a dataset does not contain static covariates, the corresponding encoder will not be present in the final implementation of the model). This provides flexibility to perform different experiments to analyze the impact of a given input feature on model performance without further changes in the model.
- (2)
- Variable selection networks to select the most relevant input features at each time step.
- (3)
- Static covariate encoders to condition temporal dynamics through the integration of the static covariates.
- (4)
- Temporal processing to learn long-term (through multi-head attention layers) and short-term (through LSTM) temporal relationships.
2.4. Experiment Design
2.5. Model Training
- Number of attention heads.
- Hidden size (common within all TFT DL layers).
- Hidden size to process continuous variables.
- Maximum gradient norm (i.e., the maximum value a gradient update can have).
- Learning rate.
- Drop-out rate.
2.6. Evaluation Metrics
2.6.1. Deterministic Metrics
2.6.2. ISO-Based Metrics
- First, 95% of the measured (in this context, predicted) glucose values must be within ±15 mg/dL for blood glucose concentrations below 100 mg/dL. For values equal to or greater than 100 mg/dL, the margin of error is fixed to ±15% of the reference value. The metric we call ISOZone represents the number of points that fall within this range.
- Second, 99% of the measured (in this context, predicted) glucose values should fall within zones A and B (considered clinically safe) of the Consensus Error Grid (CEG) for T1D [50]. The metric we call ParkesAB indicates the number of points that meet this requirement.
2.6.3. Uncertainty Metrics
2.6.4. Interpretability Evaluation
3. Experimental Results and Discussion
3.1. Prediction Performance and Uncertainty Estimation
3.1.1. Results of the WARIFA Dataset
3.1.2. Results of the OhioT1DM Dataset
3.2. Analysis of the Model Interpretability
3.2.1. Model Interpretability with the WARIFA Dataset
3.2.2. Model Interpretability with the OhioT1DM Dataset
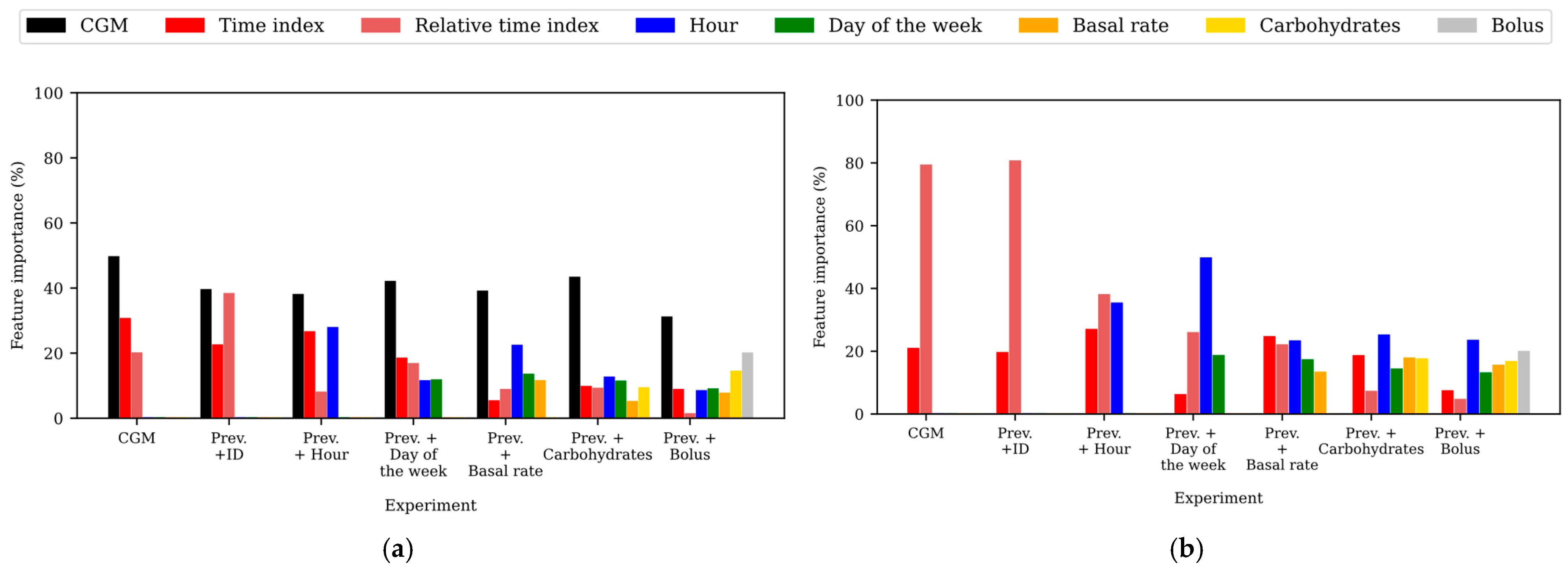
3.3. Analysis of the Importance of the Features in the Model
3.3.1. Feature Importance in the WARIFA Dataset
3.3.2. Feature Importance in the OhioT1DM Dataset
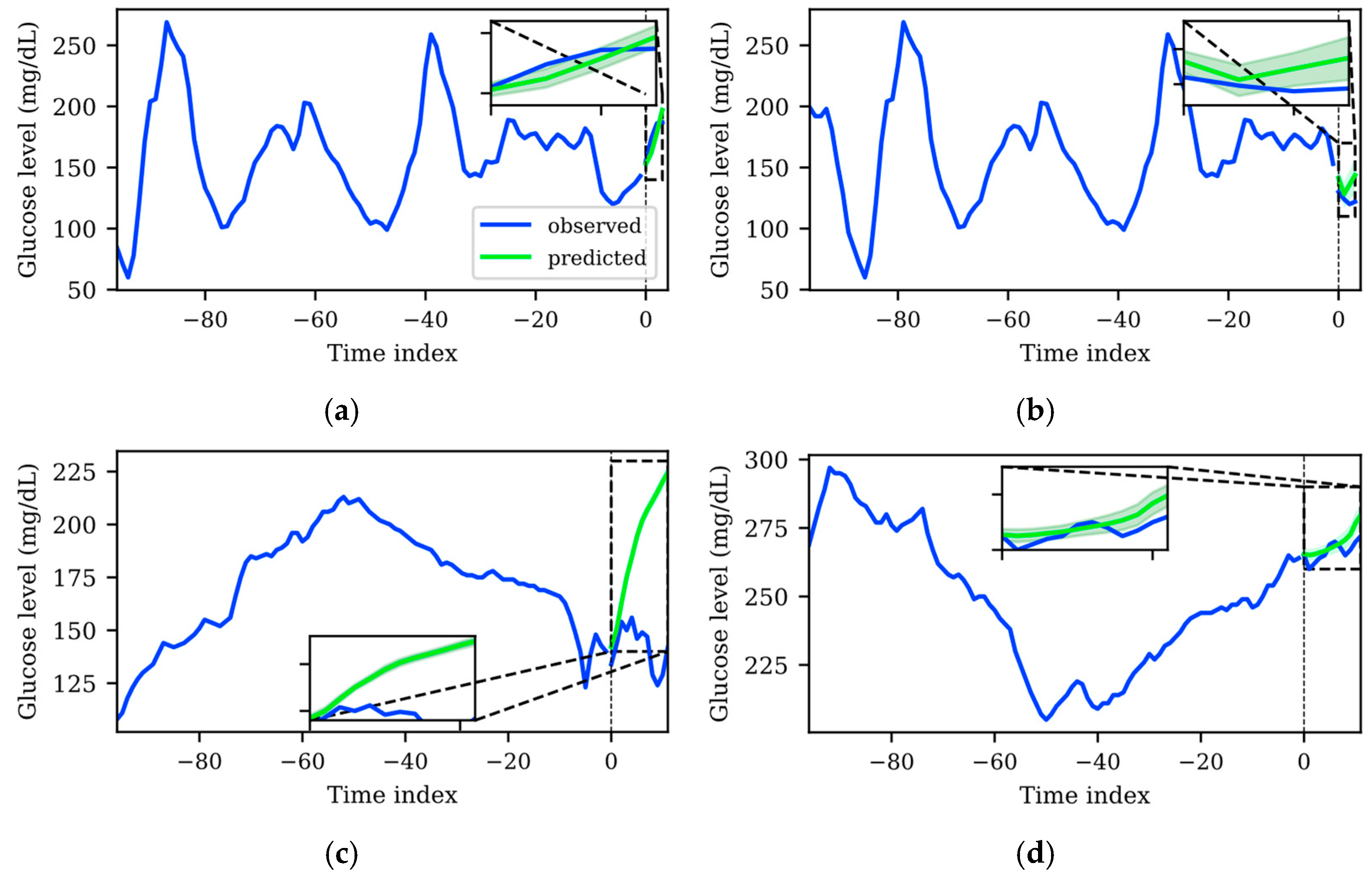
3.4. Uncertainty Qualitative Analysis
3.5. Comparison with the State of the Art
4. Current Limitations and Future Work
4.1. Dataset Harmonization for the Development of AI-Based Glucose Forecasting Models
4.2. Open Questions in AI-Based Glucose Forecasting Input Data
4.3. Assessing the Feasibility of the TFT for T1D Monitoring Applications
- Decreasing the sampling rate implies energy savings, which would prolong the lifespan of the CGM sensor batteries. This is related to fewer sensor replacements and, subsequently, fewer interruptions in the glucose level monitoring.
- Data generation would be three times lower for the same timeframe, so data storage (and its associated energetic and economic costs [59]) would be drastically decreased. Related to this, given the same input temporal window, generated models would require less memory and fewer computational resources to execute them.
- Achieving accurate predictions using only the CGM data would avoid the need for harmonizing heterogeneous timestamps and would also decrease the noise and reading interruptions associated with an increased number of sensor measurements.
4.4. Diabetes-Specific Loss Function Development
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Diabetes. Available online: https://www.who.int/news-room/fact-sheets/detail/diabetes (accessed on 12 February 2025).
- IDF Diabetes Atlas 2021|IDF Diabetes Atlas. Available online: https://diabetesatlas.org/atlas/tenth-edition/ (accessed on 12 February 2025).
- Mackenzie, S.C.; Sainsbury, C.A.R.; Wake, D.J. Diabetes and artificial intelligence beyond the closed loop: A review of the landscape, promise and challenges. Diabetologia 2024, 67, 223–235. [Google Scholar] [CrossRef]
- Deshpande, A.D.; Harris-Hayes, M.; Schootman, M. Epidemiology of diabetes and diabetes-related complications. Phys. Ther. 2008, 88, 1254–1264. [Google Scholar] [CrossRef]
- McCrimmon, R.J.; Sherwin, R.S. Hypoglycemia in type 1 diabetes. Diabetes 2010, 59, 2333–2339. [Google Scholar] [CrossRef]
- Syed, F.Z. Type 1 Diabetes Mellitus. Ann. Intern. Med. 2022, 175, ITC34–ITC48. [Google Scholar] [CrossRef]
- Group, D.C. CTR Effect of intensive diabetes treatment on the development and progression of long-term complications in adolescents with insulin-dependent diabetes mellitus: Diabetes Control and Complications Trial. J. Pediatr. 1994, 125, 177–188. [Google Scholar]
- Vettoretti, M.; Cappon, G.; Acciaroli, G.; Facchinetti, A.; Sparacino, G. Continuous Glucose Monitoring: Current Use in Diabetes Management and Possible Future Applications. J. Diabetes Sci. Technol. 2018, 12, 1064–1071. [Google Scholar] [CrossRef]
- Subramanian, S.; Khan, F.; Hirsch, I.B. New advances in type 1 diabetes. BMJ 2024, 384, 075681. [Google Scholar] [CrossRef]
- Perkins, B.A.; Sherr, J.L.; Mathieu, C. Type 1 diabetes glycemic management: Insulin therapy, glucose monitoring, and automation. Science 2021, 373, 522–527. [Google Scholar] [CrossRef]
- Group, T.J.D.R.F.C.G.M.S. Continuous Glucose Monitoring and Intensive Treatment of Type 1 Diabetes. N. Engl. J. Med. 2008, 359, 1464–1476. [Google Scholar]
- Bequette, B.W. Challenges and recent progress in the development of a closed-loop artificial pancreas. Annu. Rev. Control 2012, 36, 255–266. [Google Scholar] [CrossRef]
- Li, K.; Liu, C.; Zhu, T.; Herrero, P.; Georgiou, P. GluNet: A Deep Learning Framework for Accurate Glucose Forecasting. IEEE J. Biomed. Health Inform. 2020, 24, 414–423. [Google Scholar] [CrossRef]
- Zaidi, S.M.A.; Chandola, V.; Ibrahim, M.; Romanski, B.; Mastrandrea, L.D.; Singh, T. Multi-step ahead predictive model for blood glucose concentrations of type-1 diabetic patients. Sci. Rep. 2021, 11, 24332. [Google Scholar] [CrossRef]
- Freiburghaus, J.; Rizzotti-Kaddouri ıcha Albertetti, F. A Deep Learning Approach for Blood Glucose Prediction of Type 1 Diabetes. In Proceedings of the 5th International Workshop on Knowledge Discovery in Healthcare Data co-located with 24th European Conference on Artificial Intelligence (ECAI 2020), Santiago de Compostela, Spain, 29–30 August 2020. [Google Scholar]
- Zhang, M.; Flores, K.B.; Tran, H.T. Deep learning and regression approaches to forecasting blood glucose levels for type 1 diabetes. Biomed. Signal Process Control 2021, 69, 102923. [Google Scholar] [CrossRef]
- Hwong, H.H.; Sivakumar, S.; Lim, K.H. Machine Learning-Based Glucose Monitoring Techniques for Diabetes Management: A Review. In Proceedings of the 2023 International Conference on Digital Applications, Transformation and Economy, ICDATE 2023, Miri, Malaysia, 14–16 July 2023. [Google Scholar] [CrossRef]
- Faruqui, S.H.A.; Du, Y.; Meka, R.; Alaeddini, A.; Li, C.; Shirinkam, S.; Wang, J. Development of a deep learning model for dynamic forecasting of blood glucose level for type 2 diabetes mellitus: Secondary analysis of a randomized controlled trial. JMIR Mhealth Uhealth 2019, 7, e14452. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Allen, P.G.; Lee, S.-I. A Unified Approach to Interpreting Model Predictions. Adv. Neural. Inf. Process. Syst. 2017, 30. Available online: https://github.com/slundberg/shap (accessed on 9 July 2025).
- Bhatt, P.; Liu, J.; Gong, Y.; Wang, J.; Guo, Y. Emerging Artificial Intelligence-Empowered mHealth: Scoping Review. JMIR Mhealth Uhealth 2022, 10, e35053. [Google Scholar] [CrossRef]
- Tyralis, H.; Papacharalampous, G. A review of predictive uncertainty estimation with machine learning. Artif. Intell. Rev. 2024, 57, 1–65. [Google Scholar] [CrossRef]
- Barbano, R.; Arridge, S.; Jin, B.; Tanno, R. Uncertainty quantification in medical image synthesis. In Biomedical Image Synthesis and Simulation: Methods and Applications; Elsevier: Amsterdam, The Netherlands, 2022; pp. 601–641. [Google Scholar]
- Gal, Y.; Ghahramani, Z. Dropout as a Bayesian Approximation: Representing Model Uncertainty in Deep Learning. In Proceedings of the 33rd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, 19–24 June 2016; Volume 3, pp. 1651–1660. [Google Scholar]
- Salinas, D.; Flunkert, V.; Gasthaus, J.; Januschowski, T. DeepAR: Probabilistic forecasting with autoregressive recurrent networks. Int. J. Forecast. 2020, 36, 1181–1191. [Google Scholar] [CrossRef]
- Sergazinov, R.; Armandpour, M.; Gaynanova, I. Gluformer: Transformer-based Personalized glucose Forecasting with uncertainty quantification. In Proceedings of the ICASSP, IEEE International Conference on Acoustics, Speech and Signal Processing—Proceedings, Rhodes Island, Greece, 4–9 June 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023; Epub ahead of print 2023. [Google Scholar] [CrossRef]
- Wen, R.; Torkkola, K.; Narayanaswamy, B.; Madeka, D. A Multi-Horizon Quantile Recurrent Forecaster. arXiv 2017, arXiv:1711.11053. [Google Scholar]
- Pacchiardi, L.; Adewoyin, R.; Dueben, P.; Dutta, R. Probabilistic Forecasting with Generative Networks via Scoring Rule Minimization. arXiv 2021, arXiv:2112.08217. [Google Scholar]
- Amann, J.; Blasimme, A.; Vayena, E.; Frey, D.; Madai, V.I.; Precise4Q Consortium. Explainability for artificial intelligence in healthcare: A multidisciplinary perspective. BMC Med. Inform. Decis. Mak. 2020, 20, 310. [Google Scholar] [CrossRef]
- Barredo Arrieta, A.; Díaz-Rodríguez, N.; Del Ser, J.; Bennetot, A.; Tabik, S.; Barbado, A.; Garcia, S.; Gil-Lopez, S.; Molina, D.; Benjamins, R.; et al. Explainable Artificial Intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Inf. Fusion 2020, 58, 82–115. [Google Scholar] [CrossRef]
- Sulaiman, M.; Håkansson, A.; Karlsen, R. AI-Enabled Proactive mHealth: A Review. In Communications in Computer and Information Science; Springer Science and Business Media Deutschland GmbH: Berlin/Heidelberg, Germany, 2021; pp. 94–108. [Google Scholar]
- Theissler, A.; Spinnato, F.; Schlegel, U.; Guidotti, R. Explainable AI for Time Series Classification: A Review, Taxonomy and Research Directions. IEEE Access 2022, 10, 100700–100724. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Kulkarni, A.; Shivananda, A.; Kulkarni, A.; Gudivada, D. The ChatGPT Architecture: An In-Depth Exploration of OpenAI’s Conversational Language Model. In Applied Generative AI for Beginners; Apress: New York, NY, USA, 2023; pp. 55–77. [Google Scholar]
- Zeng, A.; Chen, M.; Zhang, L.; Xu, Q. Are Transformers Effective for Time Series Forecasting? In Proceedings of the 37th AAAI Conference on Artificial Intelligence, AAAI 2023, Washington, DC, USA, 7–14 February 2023; AAAI Press: Washington, DC, USA, 2023; pp. 11121–11128. [Google Scholar] [CrossRef]
- Lim, B.; Arik, S.O.; Loeff, N.; Pfister, T. Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. Int. J. Forecast. 2019, 37, 1748–1764. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; MacGregor, J.F. Some Recent Advances in Forecasting and Control. Appl. Stat. 1974, 23, 158. [Google Scholar] [CrossRef]
- Zhu, T.; Kuang, L.; Piao, C.; Zeng, J.; Li, K.; Georgiou, P. Population-Specific Glucose Prediction in Diabetes Care With Transformer-Based Deep Learning on the Edge. IEEE Trans. Biomed. Circuits Syst. 2024, 18, 236–246. [Google Scholar] [CrossRef]
- Warifa. Available online: https://www.warifa.eu/es/home-es/ (accessed on 17 February 2025).
- Rodriguez-Almeida, A.J.; Socorro-Marrero, G.V.; Betancort, C.; Zamora-Zamorano, G.; Deniz-Garcia, A.; Álvarez-Malé, M.L.; Årsand, E.; Soguero-Ruiz, C.; Wägner, A.M.; Granja, C.; et al. An AI-based module for interstitial glucose forecasting enabling a “Do-It-Yourself” application for people with type 1 diabetes. Front. Digit. Health 2025, 7, 1534830. [Google Scholar] [CrossRef]
- Marling, C.; Bunescu, R. The ohioT1DM dataset for blood glucose level prediction: Update 2020. In Proceedings of the CEUR Workshop Proceedings, Kyiv, Ukraine, 15–16 September 2020; CEUR-WS. pp. 71–74. [Google Scholar]
- Belsare, P.; Lu, B.; Bartolome, A.; Prioleau, T. Investigating Temporal Patterns of Glycemic Control around Holidays. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, EMBS 2022, Glasgow, UK, 11–15 July 2022; pp. 1074–1077. [Google Scholar]
- Belsare, P.; Bartolome, A.; Stanger, C.; Prioleau, T. Understanding temporal changes and seasonal variations in glycemic trends using wearable data. Sci. Adv. 2023, 9, eadg2132. [Google Scholar] [CrossRef]
- PyTorch Forecasting Documentation—Pytorch-Forecasting Documentation. Available online: https://pytorch-forecasting.readthedocs.io/en/stable/index.html (accessed on 12 February 2025).
- Python Release Python 3.9.0|Python.org. Available online: https://www.python.org/downloads/release/python-390/ (accessed on 12 February 2025).
- PyTorch. Available online: https://pytorch.org/ (accessed on 12 February 2025).
- Optuna—A Hyperparameter Optimization Framework. Available online: https://optuna.org/ (accessed on 18 February 2025).
- Optuna.Samplers.TPESampler—Optuna 4.2.1 Documentation. Available online: https://optuna.readthedocs.io/en/stable/reference/samplers/generated/optuna.samplers.TPESampler.html#optuna.samplers.TPESampler (accessed on 21 February 2025).
- Watanabe, S. Tree-Structured Parzen Estimator: Understanding Its Algorithm Components and Their Roles for Better Empirical Performance. arXiv 2023. [Google Scholar] [CrossRef]
- Optuna.Pruners.MedianPruner—Optuna 4.2.1 Documentation. Available online: https://optuna.readthedocs.io/en/stable/reference/generated/optuna.pruners.MedianPruner.html#optuna.pruners.MedianPruner (accessed on 21 February 2025).
- International Organization for Standardization. In Vitro Diagnostic Test Systems: Requirements for Blood-Glucose Monitoring Systems for Self-Testing in Managing Diabetes Mellitus; International Organization for Standardization: Geneva, Switzerland, 2015. [Google Scholar]
- Antonio Santoyo-Ramón, J.; Casilari, E.; Manuel Cano-García, J. A study of the influence of the sensor sampling frequency on the performance of wearable fall detectors. Measurement 2022, 193, 110945. [Google Scholar] [CrossRef]
- Atkinson, M.A.; Eisenbarth, G.S.; Michels, A.W. Type 1 diabetes. Lancet 2014, 383, 69–82. [Google Scholar] [CrossRef]
- Wolff, M.K.; Royston, S.; Fougner, A.L.; Schaathun, H.G.; Steinert, M.; Volden, R. A perspective on harmonizing diabetes management datasets. Data Brief. 2025, 59, 111399. [Google Scholar] [CrossRef]
- Kovatchev, B.P.; Patek, S.D.; Ortiz, E.A.; Breton, M.D. Assessing Sensor Accuracy for Non-Adjunct Use of Continuous Glucose Monitoring. Diabetes Technol. Ther. 2014, 17, 177–186. [Google Scholar] [CrossRef]
- Mosquera-Lopez, C.; Jacobs, P.G. Incorporating Glucose Variability into Glucose Forecasting Accuracy Assessment Using the New Glucose Variability Impact Index and the Prediction Consistency Index: An LSTM Case Example. J. Diabetes Sci. Technol. 2022, 16, 7–18. [Google Scholar] [CrossRef]
- Heinemann, L. Variability of Insulin Absorption and Insulin Action. Diabetes Technol. Ther. 2004, 4, 673–682. [Google Scholar] [CrossRef]
- Maiorino, M.I.; Bellastella, G.; Casciano, O.; Petrizzo, M.; Gicchino, M.; Caputo, M.; Sarnataro, A.; Giugliano, D.; Esposito, K. Gender-differences in glycemic control and diabetes related factors in young adults with type 1 diabetes: Results from the METRO study. Endocrine 2018, 61, 240–247. [Google Scholar] [CrossRef]
- Deniz-Garcia, A.; Fabelo, H.; Rodriguez-Almeida, A.J.; Zamora-Zamorano, G.; Castro-Fernandez, M.; Ruano, M.d.P.A.; Solvoll, T.; Granja, C.; Schopf, T.R.; Callico, G.M.; et al. Quality, Usability, and Effectiveness of mHealth Apps and the Role of Artificial Intelligence: Current Scenario and Challenges. J. Med. Internet Res. 2023, 25, e44030. [Google Scholar] [CrossRef]
- Monserrate, S.G. The Cloud Is Material: On the Environmental Impacts of Computation and Data Storage. MIT Case Stud. Soc. Ethical Responsib. Comput. 2022; Epub ahead of print. [Google Scholar] [CrossRef]
- Ebert-Uphoff, I.; Lagerquist, R.; Hilburn, K.; Lee, Y.; Haynes, K.; Stock, J.; Kumler, C.; Stewart, J.Q. CIRA Guide to Custom Loss Functions for Neural Networks in Environmental Sciences—Version 1. arXiv 2017, arXiv:2106.09757v1. [Google Scholar]
- Martinsson, J.; Schliep, A.; Eliasson, B.; Mogren, O. Blood Glucose Prediction with Variance Estimation Using Recurrent Neural Networks. J. Health Inform. Res. 2019, 4, 1. [Google Scholar] [CrossRef]
- Ciampiconi, L.; Elwood, A.; Leonardi, M.; Mohamed, A.; Rozza, A. A survey and taxonomy of loss functions in machine learning. arXiv 2023. [Google Scholar] [CrossRef]
- Hughes, A.; Shandhi, M.M.H.; Master, H.; Dunn, J.; Brittain, E. Wearable Devices in Cardiovascular Medicine. Circ. Res. 2023, 132, 652–670. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Included Variable | OhioT1DM | WARIFA | Variable Type |
|---|---|---|---|
| CGM | ✓ | ✓ | Time-varying real (input and target) |
| ID | ✓ | ✓ | Static categorical |
| Hour | ✓ | ✓ | Time-varying real |
| Day of the week | ✓ | ✓ | Time-varying categorical |
| Day of the month | ✕ | ✓ | Time-varying real |
| Month | ✕ | ✓ | Time-varying categorical |
| Insulin basal rate | ✓ | ✕ | Time-varying real |
| Carbohydrate intake | ✓ | ✕ | Time-varying real |
| Bolus insulin | ✓ | ✕ | Time-varying real |
| Monitoring period | 2 weeks | 1 year | |
| CGM sensor sampling period | 5 min | 15 min | |
| n | 12 | 29 | |
| Total number of experiments: | 7 | 6 |
| Input Features | Deterministic Metrics | ISO-Based Metrics | Uncertainty Metrics | TFT Parameters | |||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mg/dL) | MAE (mg/dL) | MAPE (%) | ParkesAB (%) | ISOZone (%) | p10 | p50 | p90 | ||
| CGM reading | 29.26 | 20.93 | 13.77 | 98.71 | 69.64 | 0.042 | 0.084 | 0.048 | 4,132,609 |
| Prev. + ID | 26.59 | 18.76 | 12.40 | 99.00 | 73.85 | 0.039 | 0.078 | 0.043 | 4,465,497 |
| Prev. + Hour | 23.24 | 16.06 | 10.64 | 99.30 | 79.30 | 0.036 | 0.069 | 0.037 | 4,907,208 |
| Prev. + Day of the week | 23.32 | 15.88 | 10.47 | 99.32 | 79.72 | 0.036 | 0.069 | 0.040 | 5,076,316 |
| Prev. + Day of the month | 24.22 | 16.85 | 11.17 | 99.18 | 77.63 | 0.036 | 0.072 | 0.039 | 5,108,758 |
| Prev. + Month | 19.78 | 13.09 | 8.62 | 99.54 | 85.13 | 0.032 | 0.060 | 0.035 | 5,013,680 |
| Input Features | Deterministic Metrics | ISO-Based Metrics | Uncertainty Metrics | TFT Parameters | |||||
|---|---|---|---|---|---|---|---|---|---|
| RMSE (mg/dL) | MAE (mg/dL) | MAPE (%) | ParkesAB (%) | ISOZone (%) | p10 | p50 | p90 | ||
| CGM reading | 43.24 | 31.92 | 22.02 | 96.21 | 50.23 | 0.098 | 0.119 | 0.101 | 4,840,380 |
| Prev. + ID | 44.33 | 32.85 | 22.93 | 95.87 | 49.09 | 0.097 | 0.123 | 0.103 | 4,694,258 |
| Prev. + Hour | 42.80 | 31.19 | 21.62 | 96.00 | 51.76 | 0.095 | 0.118 | 0.100 | 5,271,167 |
| Prev. + Day of the week | 44.58 | 32.13 | 21.91 | 96.35 | 49.92 | 0.100 | 0.121 | 0.102 | 4,662,862 |
| Prev. + Basal insulin rate | 44.34 | 32.20 | 22.18 | 95.95 | 50.85 | 0.105 | 0.124 | 0.103 | 3,487,822 |
| Prev. + Carbohydrates | 41.66 | 30.27 | 20.91 | 96.56 | 52.79 | 0.098 | 0.115 | 0.099 | 5,757,020 |
| Prev. + Bolus insulin | 39.67 | 29.29 | 19.93 | 97.26 | 53.15 | 0.096 | 0.112 | 0.097 | 4,777,105 |
| AI-Based Model | WARIFA Dataset | |||||
|---|---|---|---|---|---|---|
| RMSE (mg/dL) | ParkesAB (%) | ISOZone (%) | Personalization | Interpretability Analysis | Uncertainty Quantification | |
| Stacked-LSTM [39] | 38.44 | 97.77 | 56.09 | Yes | No | No |
| Proposed TFT model | 19.78 | 99.54 | 85.13 | Yes | Yes | Yes |
| OhioT1DM dataset | ||||||
| TFT Zhu et al. [37] | 32.3 * | n/a | n/a | No | Yes | No |
| GluNet Li et al. [13] | 31.28 * | n/a | n/a | No | No | No |
| Proposed TFT model | 27.02 * (39.67) | 97.26 | 53.15 | Yes | Yes | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez-Almeida, A.J.; Betancort, C.; Wägner, A.M.; Callico, G.M.; Fabelo, H.; on behalf of the WARIFA Consortium. Incorporating Uncertainty Estimation and Interpretability in Personalized Glucose Prediction Using the Temporal Fusion Transformer. Sensors 2025, 25, 4647. https://doi.org/10.3390/s25154647
Rodriguez-Almeida AJ, Betancort C, Wägner AM, Callico GM, Fabelo H, on behalf of the WARIFA Consortium. Incorporating Uncertainty Estimation and Interpretability in Personalized Glucose Prediction Using the Temporal Fusion Transformer. Sensors. 2025; 25(15):4647. https://doi.org/10.3390/s25154647
Chicago/Turabian StyleRodriguez-Almeida, Antonio J., Carmelo Betancort, Ana M. Wägner, Gustavo M. Callico, Himar Fabelo, and on behalf of the WARIFA Consortium. 2025. "Incorporating Uncertainty Estimation and Interpretability in Personalized Glucose Prediction Using the Temporal Fusion Transformer" Sensors 25, no. 15: 4647. https://doi.org/10.3390/s25154647
APA StyleRodriguez-Almeida, A. J., Betancort, C., Wägner, A. M., Callico, G. M., Fabelo, H., & on behalf of the WARIFA Consortium. (2025). Incorporating Uncertainty Estimation and Interpretability in Personalized Glucose Prediction Using the Temporal Fusion Transformer. Sensors, 25(15), 4647. https://doi.org/10.3390/s25154647