


Balancing Complexity and Performance in Convolutional Neural Network Models for QUIC Traffic Classification




Abstract
1. Introduction
1.1. Related Work on QUIC
1.2. Main Contribution
- Recognizing the limited research on QUIC traffic despite its growing adoption, particularly within IoT scenarios, our study evaluates various CNN-based architectures for NTC of QUIC-encrypted communications;
- We extend the results of previous works [27] by proposing a simple CNN-based architecture with minimal computational requirements, achieving good accuracy (nearly 92%) while being suitable for real-world implementation.
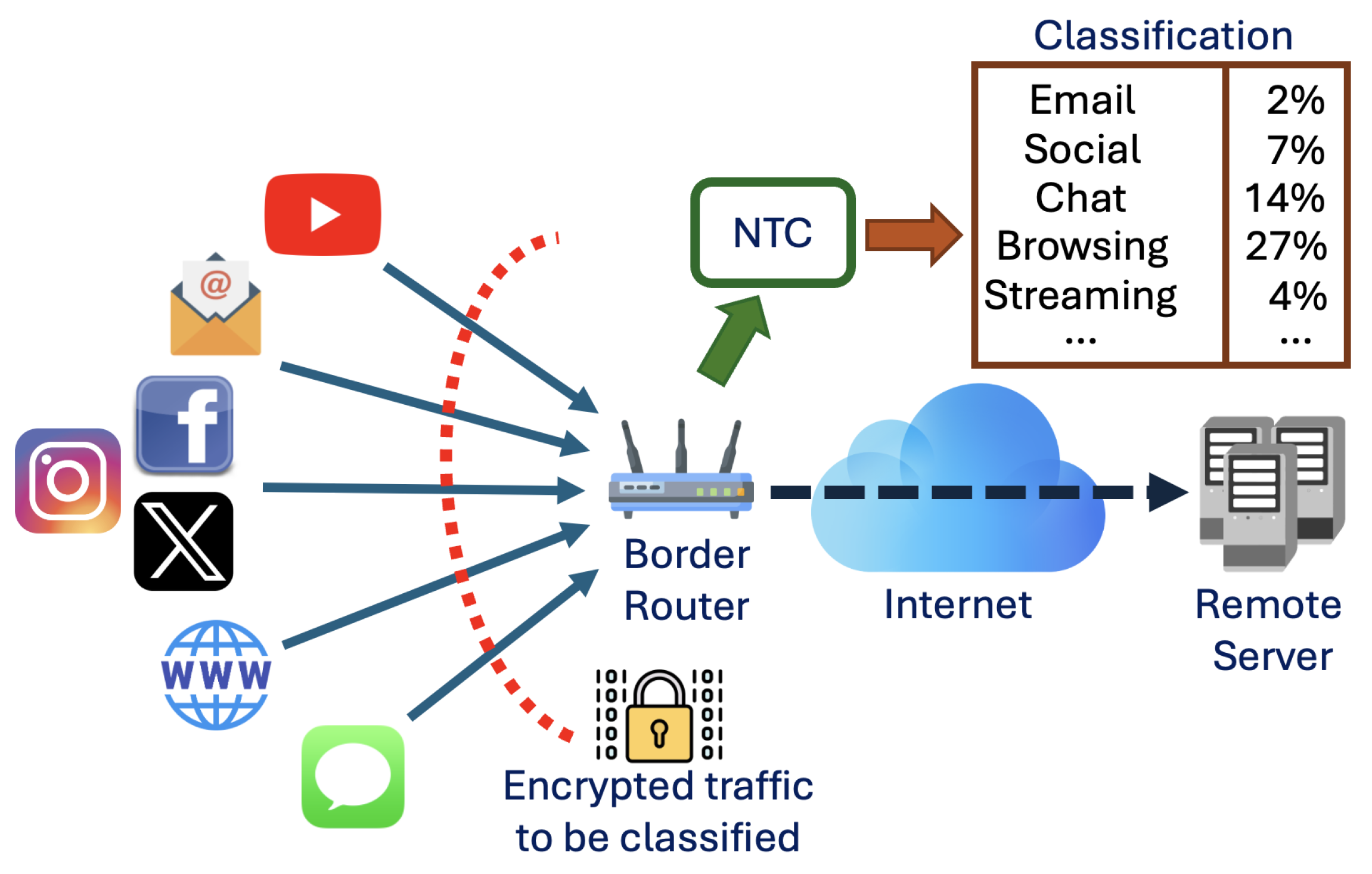
2. Reference Scenario
- Packet collection: In the initial stage, the router gathers a (possibly huge) amount of packets from diverse users and services on the network;
- Feature extraction: The collected packets are analyzed to extract relevant features that allow for distinguishing the different traffic classes;
- Classification: The traffic classes are identified using a classification algorithm.
3. Network Traffic Classification Scheme
3.1. Baseline Setup
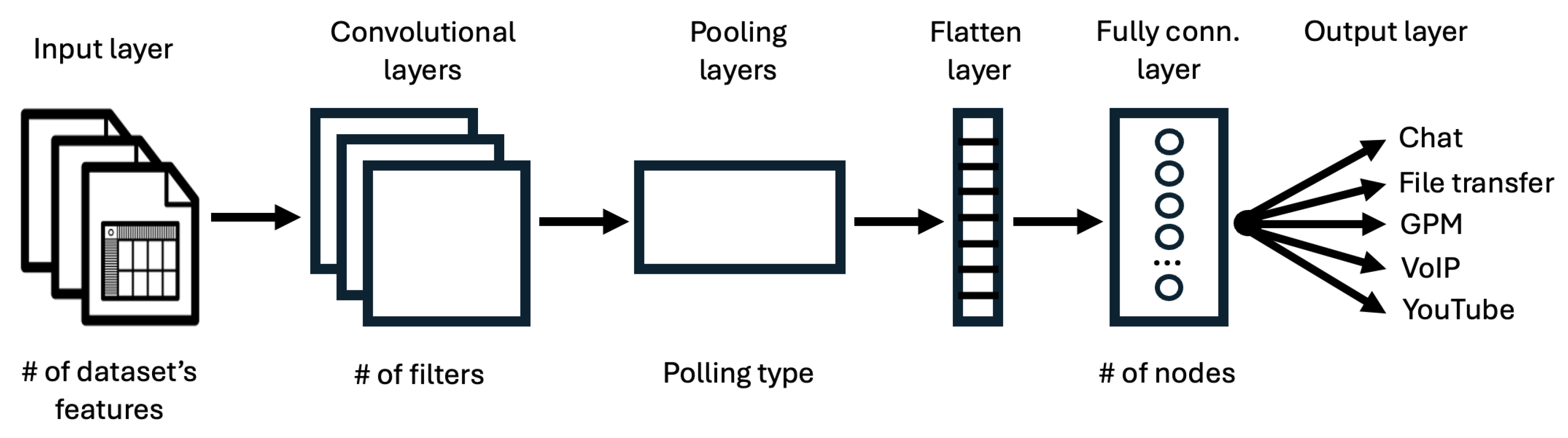
- Input layer, which receives input data and passes it to the CNN.
- Convolutional layer (one or more), which performs a convolution operation on the input data using trainable filters to create a feature map that encapsulates the various features present in the input data.
- Pooling layer (one or more), which reduces the spatial dimensions of the feature maps generated by the convolutional layer, thus allowing the capture of prominent features while reducing computational complexity. In this category, we include Max Pooling and the Dropout layer.
- Flatten layer, which reshapes the output of previous layers into a one-dimensional array to be input in the following stage.
- Fully Connected layer (one or more), in which neurons are connected to every activation in the previous layer, enabling high-level feature learning.
- Output layer, which produces the final model’s predictions or outputs, i.e., the traffic classes.
3.2. Proposed Models
3.3. Traffic Flow Features
- Packet length;
- Time relative elapsed since the first packet;
- Time elapsed since the previous packet;
- Percentage of large packets in a flow;
- Percentage of small packets in a flow;
- Flow size;
- Flow duration.
4. Performance Evaluation
4.1. Reference Dataset and Preprocessing
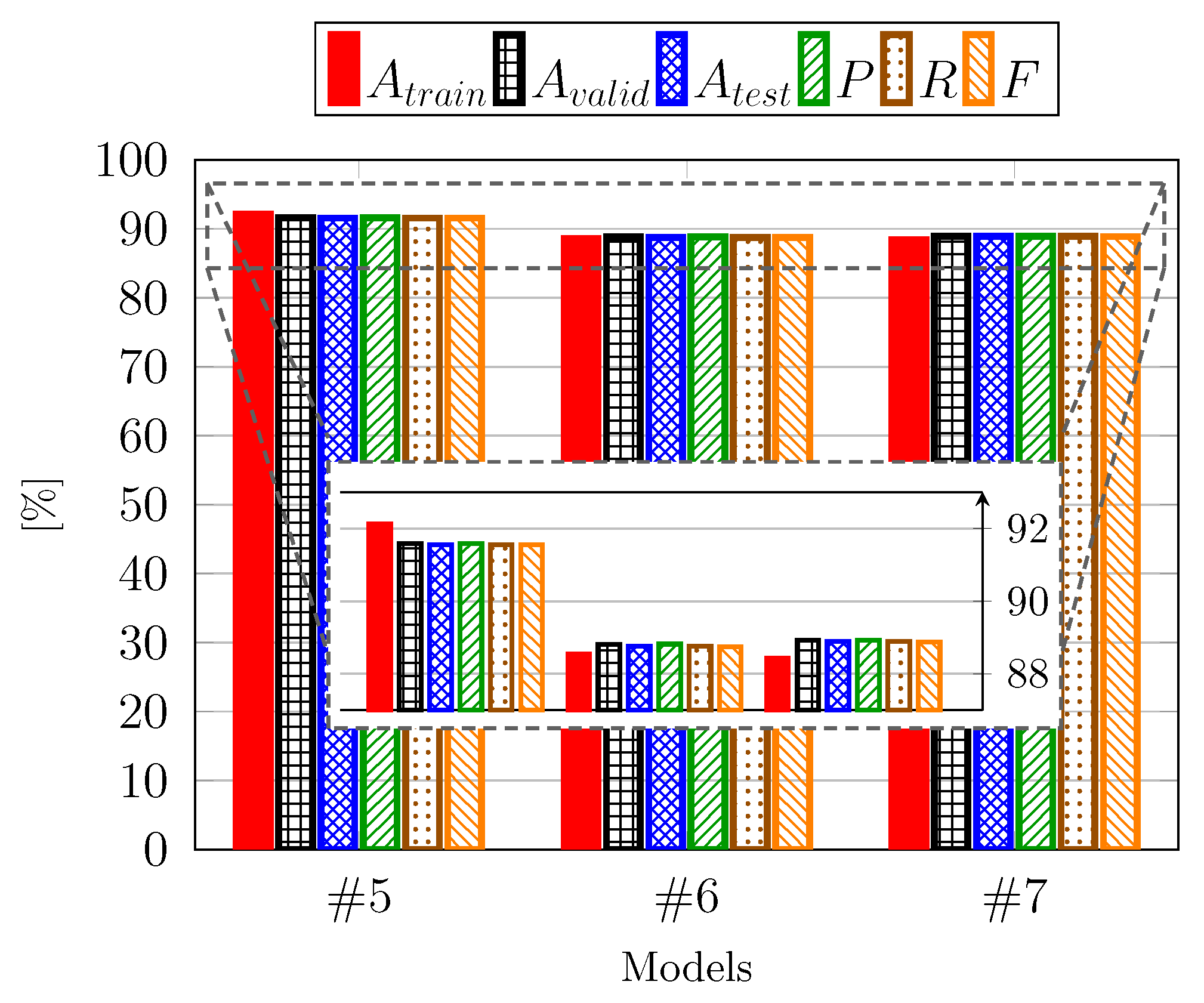
4.2. Numerical Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bariah, L.; Mohjazi, L.; Muhaidat, S.; Sofotasios, P.C.; Kurt, G.K.; Yanikomeroglu, H.; Dobre, O.A. A prospective look: Key enabling technologies, applications and open research topics in 6G networks. IEEE Access 2020, 8, 174792–174820. [Google Scholar] [CrossRef]
- Ji, B.; Wang, Y.; Song, K.; Li, C.; Wen, H.; Menon, V.G.; Mumtaz, S. A Survey of Computational Intelligence for 6G: Key Technologies, Applications and Trends. IEEE Trans. Ind. Inform. 2021, 17, 7145–7154. [Google Scholar] [CrossRef]
- Mahmud, R.; Toosi, A.N. Con-Pi: A Distributed Container-Based Edge and Fog Computing Framework. IEEE Internet Things J. 2022, 9, 4125–4138. [Google Scholar] [CrossRef]
- Ng, H.A.; Mahmoodi, T. Intelligent Traffic Engineering for 6G Heterogeneous Transport Networks. Computers 2024, 13, 74. [Google Scholar] [CrossRef]
- Nguyen, T.T.T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. Comput. Sci. Technol. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Rachmawati, S.M.; Kim, D.-S.; Lee, J.-M. Machine Learning Algorithm in Network Traffic Classification. In Proceedings of the International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Korea, 20–22 October 2021; pp. 1010–1013. [Google Scholar] [CrossRef]
- Abbasi, M.; Shahraki, A.; Taherkordi, A. Deep Learning for Network Traffic Monitoring and Analysis (NTMA): A Survey. Comput. Commun. 2021, 170, 19–41. [Google Scholar] [CrossRef]
- Özdel, S.; Ateş, Ç.; Ateş, P.D.; Koca, M.; Anarım, E. Payload-Based Network Traffic Analysis for Application Classification and Intrusion Detection. In Proceedings of the European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 638–642. [Google Scholar] [CrossRef]
- Google HTTPS Encryption on the Web. 2023. Available online: https://transparencyreport.google.com/https/overview (accessed on 23 July 2025).
- Shen, M.; Ye, K.; Liu, X.; Zhu, L.; Kang, J.; Yu, S.; Li, Q.; Xu, K. Machine Learning-Powered Encrypted Network Traffic Analysis: A Comprehensive Survey. Comput. Sci. Technol. 2023, 25, 791–824. [Google Scholar] [CrossRef]
- Raza, M.S.; Bhatti, K.A.; Malik, F.M.; Sheikh, S.A. Network Traffic Classification using Deep Neural Networks. In Proceedings of the 2023 International Conference on Frontiers of Information Technology (FIT), Islamabad, Pakistan, 11–12 December 2023. [Google Scholar]
- Ma, Q.; Huang, W.; Jin, Y.; Mao, J. Encrypted Traffic Classification Based on Traffic Reconstruction. In Proceedings of the 4th International Conference on Artificial Intelligence and Big Data (ICAIBD), Chengdu, China, 28–31 May 2021; pp. 572–576. [Google Scholar] [CrossRef]
- Kumar, P.H.; Samanta, T. Deep Learning Based Optimal Traffic Classification Model for Modern Wireless Networks. In Proceedings of the 19th India Council International Conference (INDICON), Kochi, India, 24–26 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhou, Y.; Shi, H.; Zhao, Y.; Gao, W.; Zhang, W. Encrypted Network Traffic Identification Based on 2D-CNN Model. In Proceedings of the 22nd Asia-Pacific Network Operations and Management Symposium (APNOMS), Tainan, Taiwan, 8–10 September 2021; pp. 238–241. [Google Scholar] [CrossRef]
- Shbair, W.; Cholez, T.; Francois, J.; Chrisment, I. HTTPS Websites Dataset. 2016. Available online: http://betternet.lhs.loria.fr/datasets/https/ (accessed on 23 July 2025).
- Draper-Gil, G.; Lashkari, A.H.; Mamun, M.S.I.; Ghorbani, A.A. Characterization of Encrypted and VPN Traffic using Time-related Features. In Proceedings of the 2nd International Conference on Information Systems Security and Privacy (ICISSP), Rome, Italy, 19–21 February 2016; Volume 1, pp. 407–414. [Google Scholar] [CrossRef]
- Iyengar, J.; Thomson, M. RFC 9000, QUIC: A UDP-Based Multiplexed and Secure Transport. 2021. Available online: https://www.rfc-editor.org/info/rfc9000 (accessed on 23 July 2025).
- Vu Khanh, Q.; Chehri, A.; Quy, N.M.; Han, N.D.; Ban, N.T. Innovative Trends in the 6G Era: A Comprehensive Survey of Architecture, Applications, Technologies, and Challenges. IEEE Access 2023, 11, 39824–39844. [Google Scholar] [CrossRef]
- Martalò, M.; Pettorru, G.; Atzori, L. A Cross-Layer Survey on Secure and Low-Latency Communications in Next-Generation IoT. IEEE Trans. Netw. Serv. Manag. 2024, 21, 4669–4685. [Google Scholar] [CrossRef]
- Shreedhar, T.; Panda, R.; Podanev, S.; Bajpai, V. Evaluating QUIC Performance Over Web, Cloud Storage, and Video Workloads. IEEE Trans. Netw. Serv. Manag. 2022, 19, 1366–1381. [Google Scholar] [CrossRef]
- Wilk, A.; Hamilton, R.; Swett, I. A QUIC Update on Google’s Experimental Transport. Google Blog. 2015. Available online: https://blog.chromium.org/2015/04/a-quic-update-on-googles-experimental.html (accessed on 23 July 2025).
- Fernández, F.; Zverev, M.; Garrido, P.; Juárez, J.R.; Bilbao, J.; Agüero, R. And QUIC meets IoT: Performance assessment of MQTT over QUIC. In Proceedings of the 16th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob), Thessaloniki, Greece, 12–14 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Pettorru, G.; Martalò, M. QUIC and WebSocket for secure and low-latency IoT communications: An experimental analysis. In Proceedings of the IEEE International Conference on Communications (ICC), Rome, Italy, 28 May–1 June 2023; pp. 628–633. [Google Scholar] [CrossRef]
- Rezaei, S.; Liu, X. Multitask Learning for Network Traffic Classification. In Proceedings of the 2020 29th International Conference on Computer Communications and Networks (ICCCN), Honolulu, HI, USA, 3–6 August 2020; (held as virtual). pp. 1–9. [Google Scholar] [CrossRef]
- Akbari, I.; Salahuddin, M.A.; Ven, L.; Limam, N.; Boutaba, R.; Mathieu, B.; Moteau, S.; Tuffin, S. Traffic classification in an increasingly encrypted web. Commun. ACM 2022, 65, 75–83. [Google Scholar] [CrossRef]
- Luxemburk, J.; Hynek, K.; Čejka, T. Encrypted traffic classification: The QUIC case. In Proceedings of the 2023 7th Network Traffic Measurement and Analysis Conference (TMA), Naples, Italy, 26–29 June 2023; pp. 1–10. [Google Scholar] [CrossRef]
- Tong, V.; Tran, H.A.; Souihi, S.; Mellouk, A. A novel QUIC traffic classifier based on convolutional neural networks. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, United Arab Emirates, 9–13 December 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Shafiq, M.; Yu, X.; Laghari, A.A.; Yao, L.; Karn, N.K.; Abdessamia, F. Network traffic classification techniques and comparative analysis using machine learning algorithms. In Proceedings of the International Conference on Computer and Communications (ICCC), Chengdu, China, 14–17 October 2016; pp. 2451–2455. [Google Scholar] [CrossRef]
- Yan, J. A survey of traffic classification validation and ground truth collection. In Proceedings of the International Conference on Electrical Information and Emergency Communications (ICEIEC), Beijing, China, 15–17 June 2018; pp. 255–259. [Google Scholar] [CrossRef]
- Krichen, M. Convolutional neural networks: A survey. Computers 2023, 12, 8. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Kouretas, I.; Paliouras, V. Simplified hardware implementation of the Softmax activation function. In Proceedings of the International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 13–15 May 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Tong, V. Netflow-QUIC. 2018. Available online: https://github.com/vanvantong/quic-traffic (accessed on 23 July 2025).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Type | Convolutional | Pooling Layer | Flatten | Fully Connect. | |
|---|---|---|---|---|---|---|
| Max Pool. | Dropout | |||||
| ANN | - | - | 1 | 1 | 8 (5 × 512 + 3 × 256) | |
| CNN | 3 (2 × 128 + 64) | 2 | - | 1 | 4 (4 × 256) | |
| CNN | 8 (512 + 256 + 6 × 128) | 1 | 1 | 1 | 1 (256) | |
| CNN | 6 (512 + 256 + 4 × 128) | 1 | 1 | 1 | 1 (256) | |
| CNN | 5 (512 + 256 + 3 × 128) | 1 | 1 | 1 | 1 (256) | |
| CNN | 4 (128 + 64 + 2 × 32) | 1 | 1 | 1 | 1 (128) | |
| CNN | 4 (2 × 64 + 2 × 32) | 1 | 1 | 1 | 1 (64) | |
| Metric | Model | ||||
|---|---|---|---|---|---|
| 89.53 (±1.84) | 91.68 (±1.47) | 91.55 (±1.51) | 91.97 (±1.22) | 92.12 (±1.19) | |
| 90.12 (±1.91) | 90.77 (±1.73) | 90.79 (±1.69) | 91.09 (±1.38) | 91.58 (±1.14) | |
| 90.10 (±1.96) | 90.82 (±1.87) | 90.88 (±1.71) | 91.08 (±1.49) | 91.55 (±1.33) | |
| P | 90.10 (±1.95) | 90.86 (±1.75) | 90.88 (±1.62) | 91.07 (±1.41) | 91.58 (±1.18) |
| R | 90.10 (±1.88) | 90.82 (±1.69) | 90.88 (±1.57) | 91.10 (±1.29) | 91.55 (±1.11) |
| F | 90.10 (±1.87) | 90.81 (±1.66) | 90.86 (±1.54) | 91.08 (±1.28) | 91.55 (±1.09) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pettorru, G.; Flumini, M.; Martalò, M. Balancing Complexity and Performance in Convolutional Neural Network Models for QUIC Traffic Classification. Sensors 2025, 25, 4576. https://doi.org/10.3390/s25154576
Pettorru G, Flumini M, Martalò M. Balancing Complexity and Performance in Convolutional Neural Network Models for QUIC Traffic Classification. Sensors. 2025; 25(15):4576. https://doi.org/10.3390/s25154576
Chicago/Turabian StylePettorru, Giovanni, Matteo Flumini, and Marco Martalò. 2025. "Balancing Complexity and Performance in Convolutional Neural Network Models for QUIC Traffic Classification" Sensors 25, no. 15: 4576. https://doi.org/10.3390/s25154576
APA StylePettorru, G., Flumini, M., & Martalò, M. (2025). Balancing Complexity and Performance in Convolutional Neural Network Models for QUIC Traffic Classification. Sensors, 25(15), 4576. https://doi.org/10.3390/s25154576