
Eye-Guided Multimodal Fusion: Toward an Adaptive Learning Framework Using Explainable Artificial Intelligence


 , and
, and
Abstract
1. Introduction
- Eye-Guided Framework: The Multimodal Fusion Framework incorporates attention mechanisms to capture the most crucial aspects of the stimulus. The model with a shared backbone mitigates the impact of noisy fixation data and separates the processing of modalities to improve the performance of automatic abnormality detection in CXRs.
- Explanatory Support for Transparency: We provide post-hoc feature attribution explanations to help radiology trainees better understand lesion classification in chest X-rays.
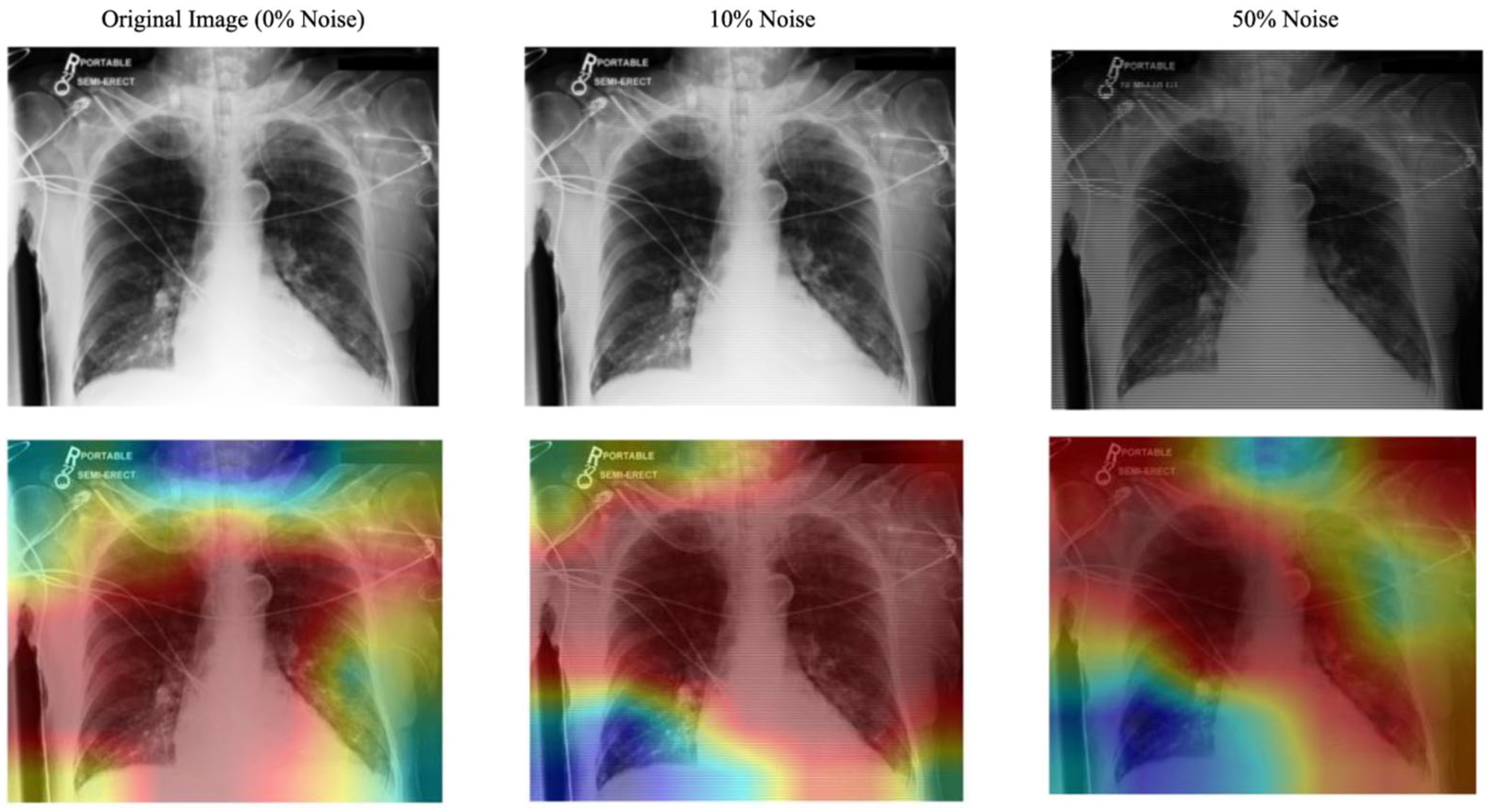
- Evaluation of the Approach. We evaluate our approach and demonstrate robust performance under noisy conditions, showing resilience to misaligned fixation maps. We further assess the interpretability of the model by utilizing Grad-CAM, ensuring that the generated visual explanations align with expert-annotated ROIs. This alignment enhances the clinical reliability of the model’s predictions.
2. Related Work
2.1. Eye-Gaze Tracking in Radiology
2.2. Multimodal in Medical Data
2.3. Explainable Artificial Intelligence
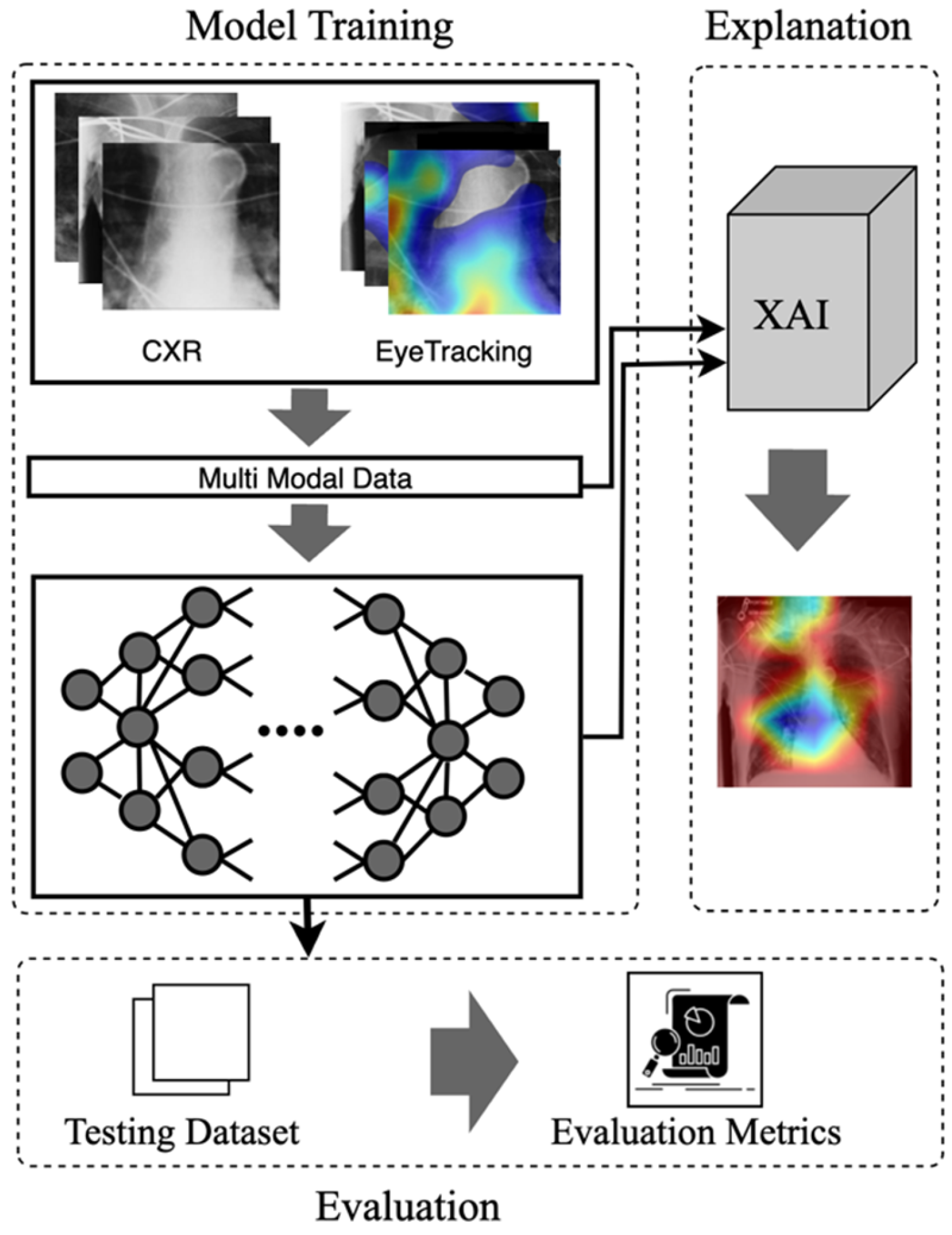
3. The Proposed Model
3.1. Multimodal Input Data
3.2. Mode
3.3. Explanation
4. Experiments and Results
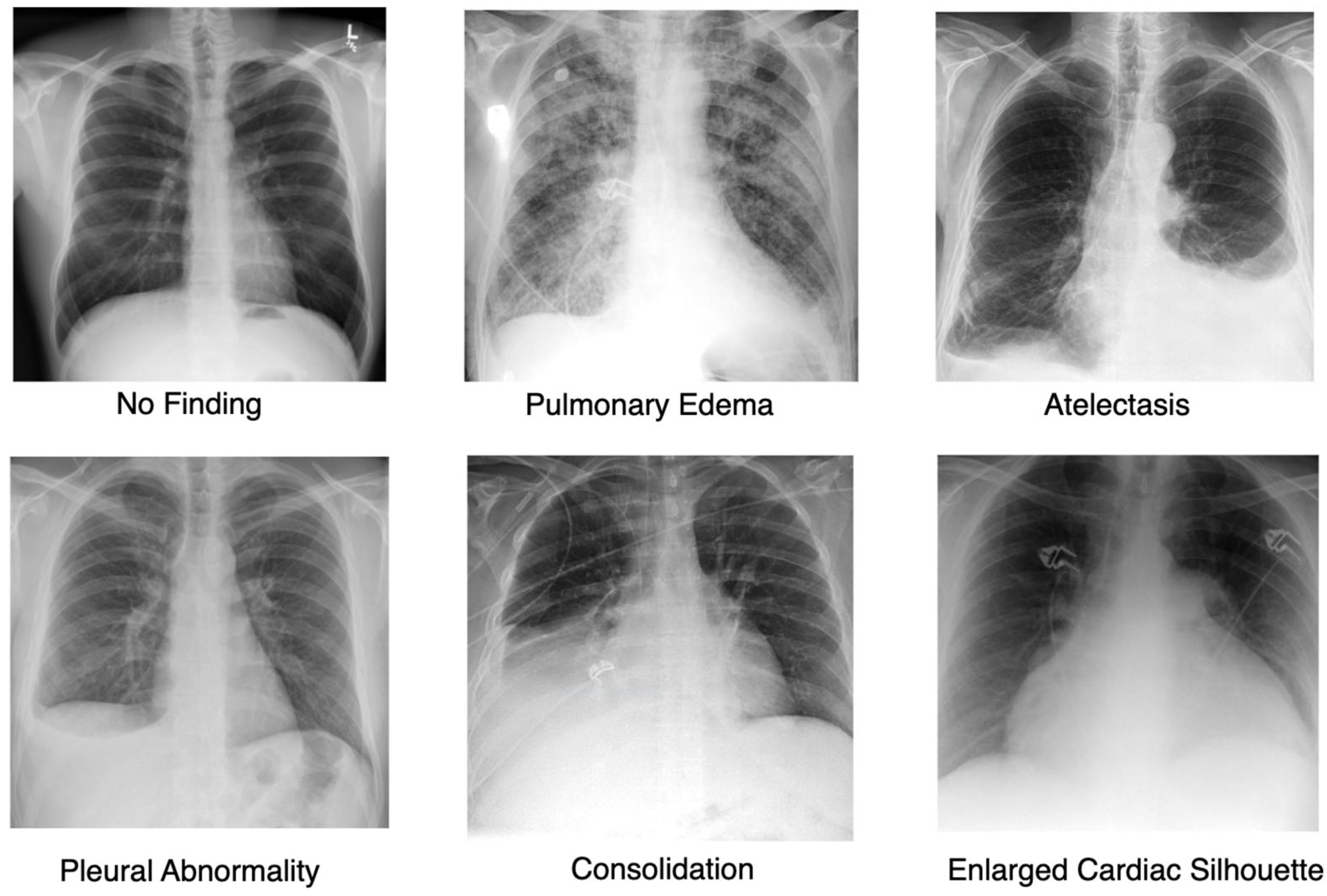
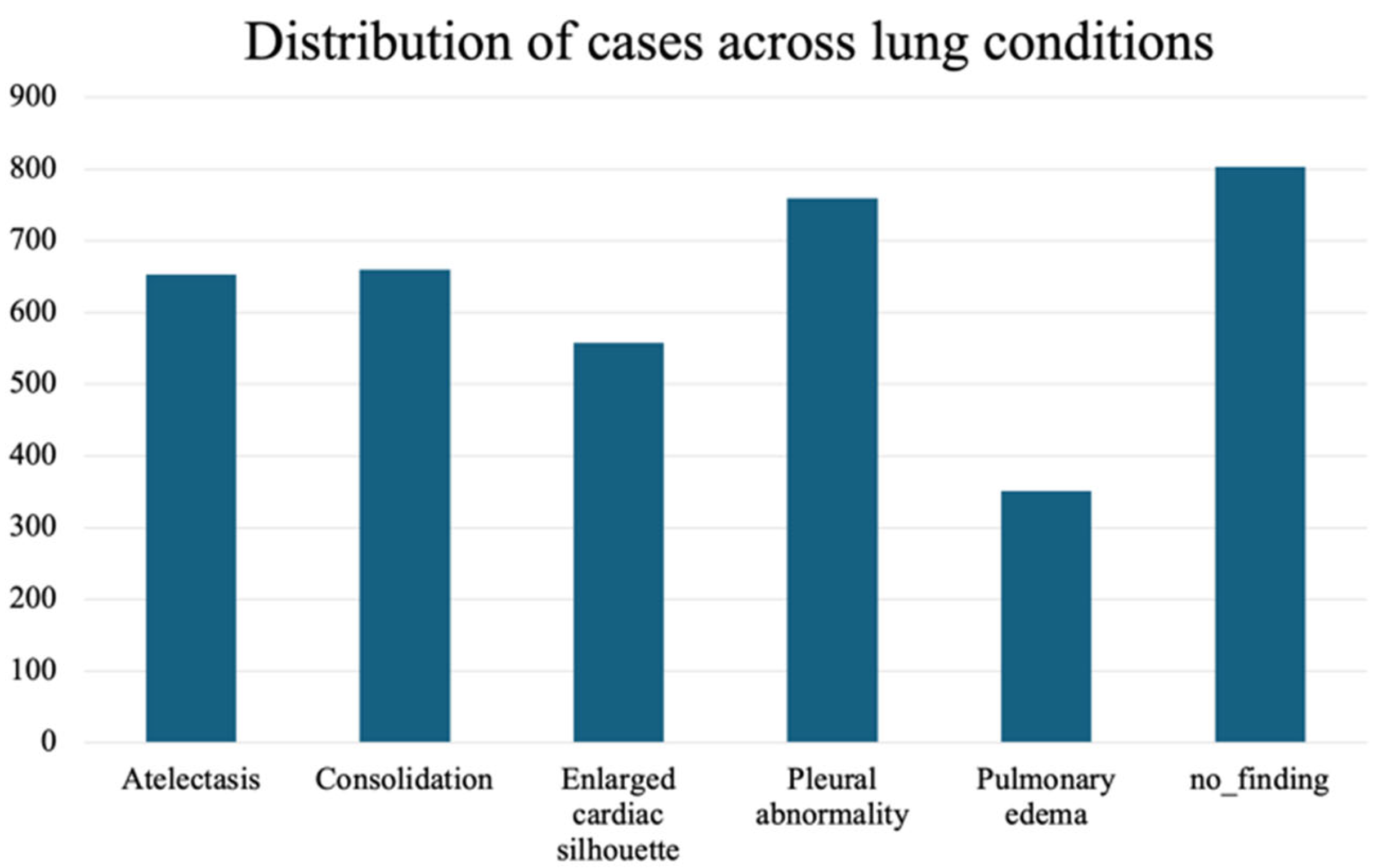
4.1. Dataset
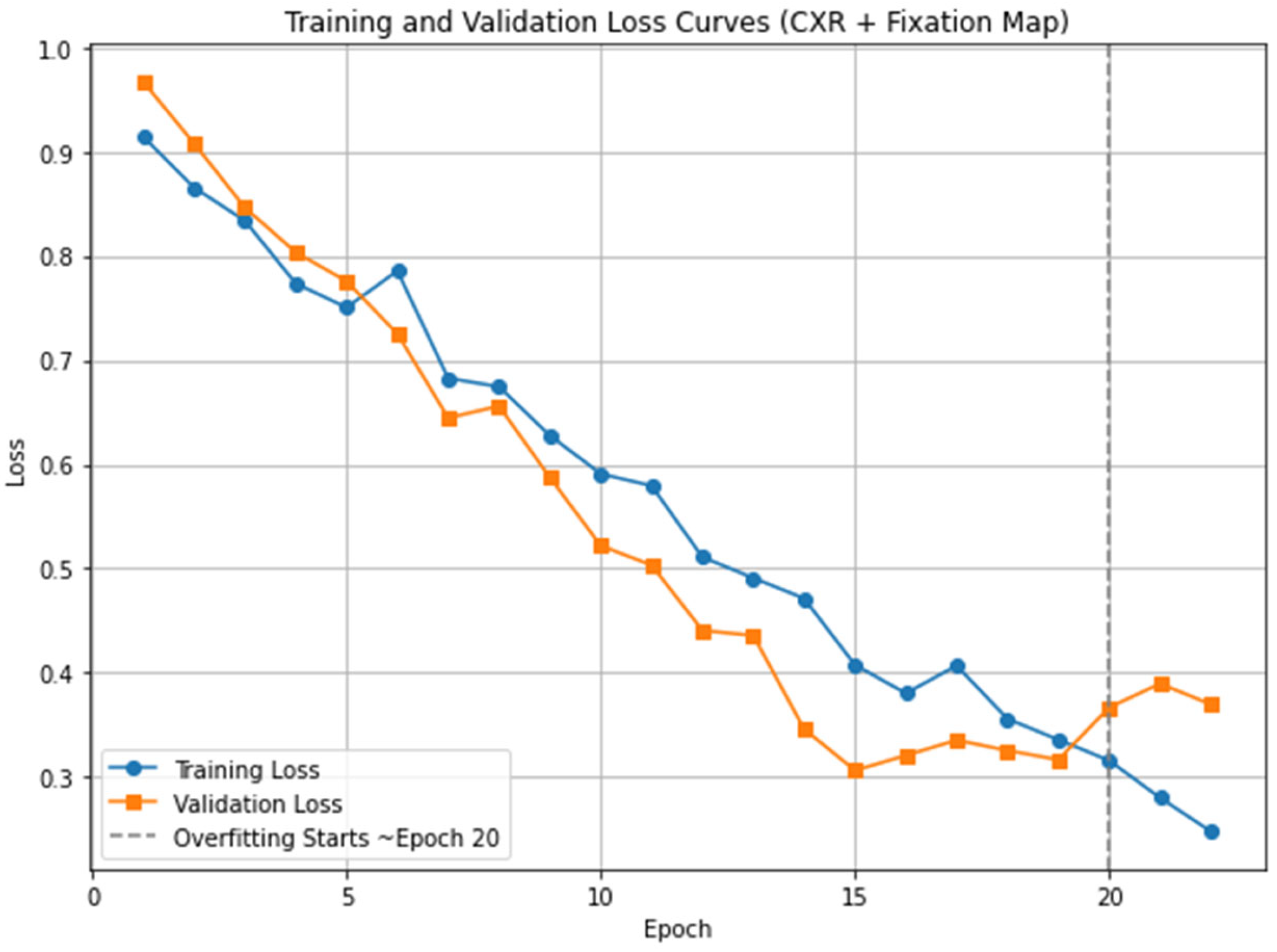
4.2. Implementation Details
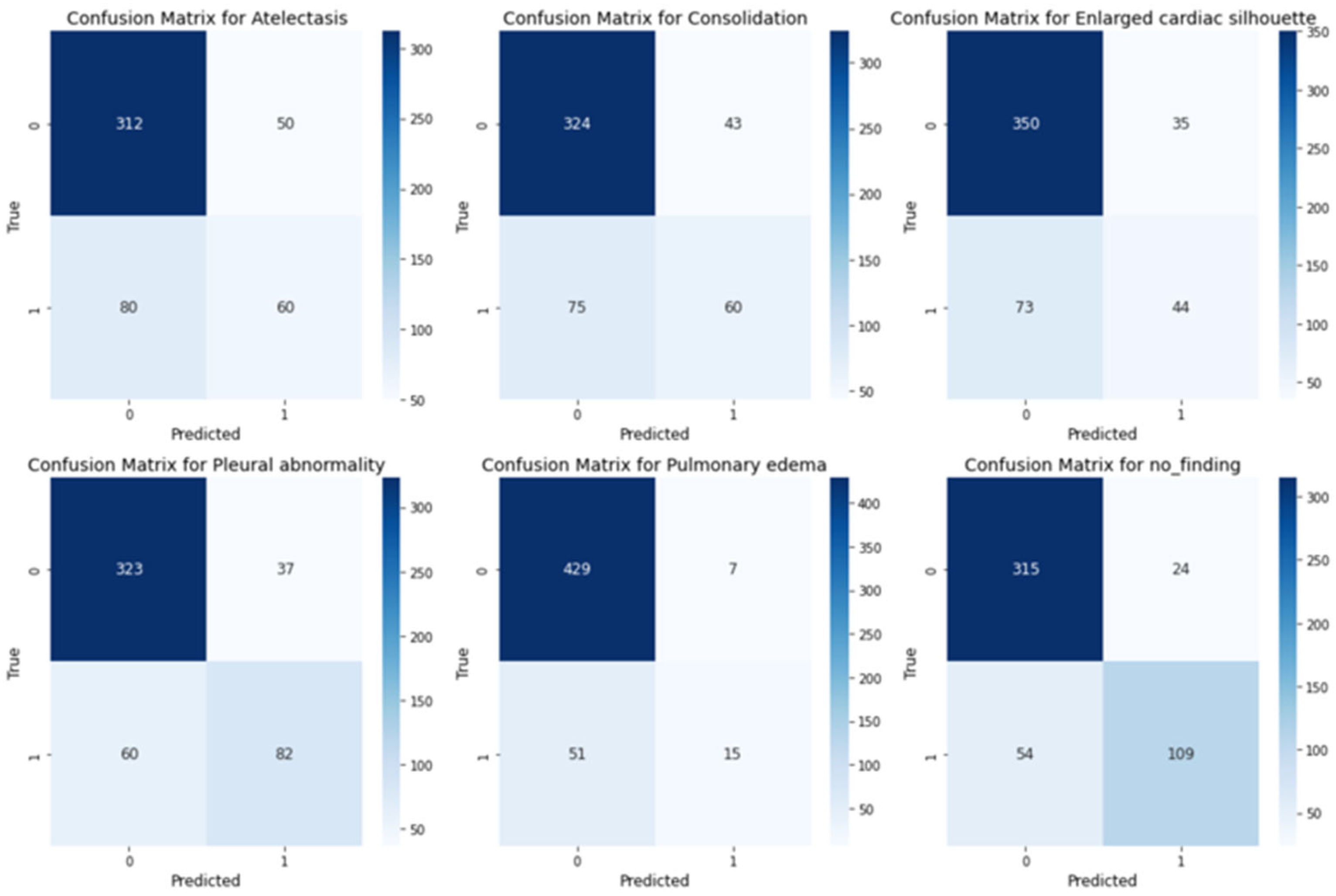
4.3. Evaluation Results
5. Discussion
6. Conclusions
6.1. Potential Impacts
6.2. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Holmqvist, K.; Nystr, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; OUP: Oxford, UK, 2011. [Google Scholar]
- O’Brien, H.L.; Cairns, P.; Hall, M. A practical approach to measuring user engagement with the refined user engagement scale (ues) and new ues short form. Int. J. Hum.-Comput. Stud. 2018, 112, 28–39. [Google Scholar] [CrossRef]
- Moreira, C.; Nobre, I.B.; Sousa, S.C.; Pereira, J.M.; Jorge, J. Improving x-ray diagnostics through eye-tracking and xr. In Proceedings of the 2022 IEEE Conference on Virtual Reality and 3D User Interfaces Abstracts and Workshops (VRW), Christchurch, New Zealand, 12–16 March 2022; pp. 450–453. [Google Scholar]
- Chen, X.; Wang, X.; Zhang, K.; Fung, K.-M.; Thai, T.C.; Moore, K.; Mannel, R.S.; Liu, H.; Zheng, B.; Qiu, Y. Recent advances and clinical applications of deep learning in medical image analysis. Med. Image Anal. 2022, 79, 102444. [Google Scholar] [CrossRef] [PubMed]
- Borys, K.; Schmitt, Y.A.; Nauta, M.; Seifert, C.; Kr, N.; Friedrich, C.M.; Nensa, F. Explainable ai in medical imaging: An overview for clinical practitioners–beyond saliency-based xai approaches. Eur. J. Radiol. 2023, 162, 110786. [Google Scholar] [CrossRef] [PubMed]
- Mohajir, B.E.E. Identifying learning style through eye tracking technology in adaptive learning systems. Int. J. Electr. Comput. Eng. 2019, 9, 4408–4416. [Google Scholar]
- Castner, N.; Eivazi, S.; Scheiter, K.; Kasneci, E. Using Eye Tracking to Evaluate and Develop Innovative Teaching Strategies for Fostering Image Reading Skills of Novices in Medical Training. Eye Tracking Enhanced Learning (ETEL2017). 2017. Available online: https://www.hci.uni-tuebingen.de/assets/pdf/publications/NSKE092017.pdf (accessed on 20 July 2025).
- Kok, E.M.; Jarodzka, H. Before your very eyes: The value and limitations of eye tracking in medical education. Med. Educ. 2017, 51, 114–122. [Google Scholar] [CrossRef] [PubMed]
- Ashraf, H.; Sodergren, M.H.; Merali, N.; Mylonas, G.; Singh, H.; Darzi, A. Eye-tracking technology in medical education: A systematic review. Med. Teach. 2018, 40, 62–69. [Google Scholar] [CrossRef] [PubMed]
- Newport, R.A.; Liu, S.; Di Ieva, A. Analyzing eye paths using fractals. In The Fractal Geometry of the Brain; Springer: Berlin/Heidelberg, Germany, 2024; pp. 827–848. [Google Scholar]
- Duchowski, A.T. A breadth-first survey of eye-tracking applications. Behav. Res. Methods Instrum. Comput. 2002, 34, 455–470. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zhuang, Z.; Ouyang, X.; Zhang, L.; Li, Z.; Ma, C.; Liu, T.; Shen, D.; Wang, Q. Learning better contrastive view from radiologist’s gaze. arXiv 2023, arXiv:2305.08826. [Google Scholar] [CrossRef]
- Ma, C.; Jiang, H.; Chen, W.; Li, Y.; Wu, Z.; Yu, X.; Liu, Z.; Guo, L.; Zhu, D.; Zhang, T.; et al. Eye-gaze guided multimodal alignment for medical representation learning. In Proceedings of the The Thirty-Eighth Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 9–15 December 2024. [Google Scholar]
- Moradizeyveh, S.; Tabassum, M.; Liu, S.; Newport, R.A.; Beheshti, A.; Di Ieva, A. When eye-tracking meets machine learning: A systematic review on applications in medical image analysis. arXiv 2024, arXiv:2403.07834. [Google Scholar] [CrossRef]
- Zhu, H.; Salcudean, S.; Rohling, R. Gaze-guided class activation mapping: Leverage human visual attention for network attention in chest x-rays classification. In Proceedings of the 15th International Symposium on Visual Information Communication and Interaction, Chur, Switzerland, 16–18 August 2022; pp. 1–8. [Google Scholar]
- Ji, C.; Du, C.; Zhang, Q.; Wang, S.; Ma, C.; Xie, J.; Zhou, Y.; He, H.; Shen, D. Mammo-net: Integrating gaze supervision and interactive information in multi-view mammogram classification. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2023; pp. 68–78. [Google Scholar]
- Zhu, H.; Rohling, R.; Salcudean, S. Jointly boosting saliency prediction and disease classification on chest x-ray images with multi-task unet. In Annual Conference on Medical Image Understanding and Analysis; Springer: Berlin/Heidelberg, Germany, 2022; pp. 594–608. [Google Scholar]
- Teng, C.; Lee, L.H.; Lander, J.; Drukker, L.; Papageorghiou, A.T.; Noble, J.A. Skill characterisation of sonographer gaze patterns during second trimester clinical fetal ultrasounds using time curves. In Proceedings of the 2022 Symposium on Eye Tracking Research and Applications, Seattle, WA, USA, 8–11 June 2022; pp. 1–7. [Google Scholar]
- Mariam, K.; Afzal, O.M.; Hussain, W.; Javed, M.U.; Kiyani, A.; Rajpoot, N.; Khurram, S.A.; Khan, H.A. On smart gaze-based annotation of histopathology images for training of deep convolutional neural networks. IEEE J. Biomed. Health Inform. 2022, 26, 3025–3036. [Google Scholar] [CrossRef] [PubMed]
- Stember, J.N.; Celik, H.; Gutman, D.; Swinburne, N.; Young, R.; Eskreis-Winkler, S.; Holodny, A.; Jambawalikar, S.; Wood, B.J.; Chang, P.D.; et al. Integrating eye tracking and speech recognition accurately annotates mr brain images for deep learning: Proof of principle. Radiol. Artif. Intell. 2020, 3, e200047. [Google Scholar] [CrossRef] [PubMed]
- Pershin, I.; Mustafaev, T.; Ibragimova, D.; Ibragimov, B. Changes in radiologists’ gaze patterns against lung x-rays with different abnormalities: A randomized experiment. J. Digit. Imaging 2023, 36, 767–775. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Jia, F.; Hu, Q. Automatic segmentation of liver tumor in ct images with deep convolutional neural networks. J. Comput. Commun. 2015, 3, 146–151. [Google Scholar] [CrossRef]
- Peng, P.; Fan, W.; Shen, Y.; Liu, W.; Yang, X.; Zhang, Q.; Wei, X.; Zhou, D. Eye gaze guided cross-modal alignment network for radiology report generation. IEEE J. Biomed. Health Inform. 2024, 28, 7406–7419. [Google Scholar] [CrossRef] [PubMed]
- Drew, T.; Evans, K.; Võ, M.L.-H.; Jacobson, F.L.; Wolfe, J.M. Informatics in radiology: What can you see in a single glance and how might this guide visual search in medical images? Radiographics 2013, 33, 263–274. [Google Scholar] [CrossRef] [PubMed]
- Ma, C.; Zhao, L.; Chen, Y.; Wang, S.; Guo, L.; Zhang, T.; Shen, D.; Jiang, X.; Liu, T. Eye-gaze-guided vision transformer for rectifying shortcut learning. IEEE Trans. Med. Imaging 2023, 42, 3384–3394. [Google Scholar] [CrossRef] [PubMed]
- Hsieh, C.; Luís, A.; Neves, J.; Nobre, I.B.; Sousa, S.C.; Ouyang, C.; Jorge, J.; Moreira, C. Eyexnet: Enhancing abnormality detection and diagnosis via eye-tracking and x-ray fusion. Mach. Learn. Knowl. Extr. 2024, 6, 1055–1071. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking Inside the Black-Box: A Survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Carvalho, D.V.; Pereira, E.M.; Cardoso, J.S. Machine Learning Interpretability: A Survey on Methods and Metrics. Electronics 2019, 8, 832. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Pedreschi, D.; Giannotti, F. A Survey of Methods For Explaining Black Box Models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Miller, T. Explanation in artificial intelligence: Insights from the social sciences. Artif. Intell. 2019, 267, 1–38. [Google Scholar] [CrossRef]
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef] [PubMed]
- Van der Velden, B.H.; Kuijf, H.J.; Gilhuijs, K.G.; Viergever, M.A. Explainable artificial intelligence (xai) in deep learning-based medical image analysis. Med. Image Anal. 2022, 79, 102470. [Google Scholar] [CrossRef] [PubMed]
- Gomez, T.; Mouch, H. Computing and evaluating saliency maps for image classification: A tutorial. J. Electron. Imaging 2023, 32, 020801. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Bigolin Lanfredi, R.; Zhang, M.; Auffermann, W.F.; Chan, J.; Duong, P.A.T.; Srikumar, V.; Drew, T.; Schroeder, J.D.; Tasdizen, T. REFLACX, a dataset of reports and eye-tracking data for localization of abnormalities in chest x-rays. Sci. Data 2022, 9, 350. [Google Scholar] [CrossRef] [PubMed]
- Johnson, A.E.; Pollard, T.J.; Greenbaum, N.R.; Lungren, M.P.; Deng, C.Y.; Peng, Y.; Lu, Z.; Mark, R.G.; Berkowitz, S.J.; Horng, S. MIMIC-CXR-JPG, a large publicly available database of labeled chest radiographs. arXiv 2019, arXiv:1901.07042. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Koonce, B. ResNet 50. In Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: Berkeley, CA, USA, 2021; pp. 63–72. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pulmonary Conditions | CXR Only | CXR + Fixation Map | ||||||
|---|---|---|---|---|---|---|---|---|
| ACC | Precision | Recall | F1 | ACC | Precision | Recall | F1 | |
| Model: ResNet18 | ||||||||
| Atelectasis | 0.724 | 0.575 | 0.534 | 0.554 | 0.749 | 0.527 | 0.584 | 0.554 |
| Consolidation | 0.739 | 0.663 | 0.587 | 0.623 | 0.782 | 0.619 | 0.609 | 0.614 |
| Pleural Abnormality | 0.812 | 0.425 | 0.496 | 0.458 | 0.801 | 0.457 | 0.496 | 0.476 |
| Pulmonary Edema | 0.757 | 0.454 | 0.485 | 0.469 | 0.794 | 0.351 | 0.485 | 0.407 |
| No-Finding | 0.835 | 0.400 | 0.535 | 0.458 | 0.806 | 0.407 | 0.535 | 0.462 |
| Enlarged Cardiac Silhouette | 0.796 | 0.630 | 0.567 | 0.597 | 0.826 | 0.784 | 0.567 | 0.658 |
| AVG | 0.777 | 0.525 | 0.534 | 0.527 | 0.790 | 0.524 | 0.546 | 0.529 |
| Model: ResNet50 | ||||||||
| Atelectasis | 0.768 | 0.467 | 0.564 | 0.511 | 0.769 | 0.561 | 0.581 | 0.571 |
| Consolidation | 0.781 | 0.525 | 0.525 | 0.525 | 0.788 | 0.579 | 0.585 | 0.582 |
| Pleural Abnormality | 0.818 | 0.483 | 0.522 | 0.502 | 0.853 | 0.551 | 0.618 | 0.583 |
| Pulmonary Edema | 0.793 | 0.526 | 0.542 | 0.534 | 0.828 | 0.687 | 0.592 | 0.636 |
| No-Finding | 0.834 | 0.684 | 0.536 | 0.601 | 0.847 | 0.719 | 0.643 | 0.679 |
| Enlarged Cardiac Silhouette | 0.816 | 0.523 | 0.563 | 0.542 | 0.849 | 0.637 | 0.617 | 0.627 |
| AVG | 0.801 | 0.529 | 0.542 | 0.535 | 0.824 | 0.620 | 0.606 | 0.613 |
| Noise Level (%) | CXR AUC | CXR+ Fixation Map AUC (No Shared Params) |
|---|---|---|
| 0 | 81.41 | 83.30 |
| 10 | 80.28 | 81.08 |
| 50 | 74.61 | 75.86 |
| Model | IoU Score (Mean ± Std. Dev.) |
|---|---|
| CXR Only | |
| CXR + FixationMap |
| Criteria | Average Rating (1 to 5) |
|---|---|
| Interpretability | 4.25 |
| Clinical Relevance | 4.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moradizeyveh, S.; Hanif, A.; Liu, S.; Qi, Y.; Beheshti, A.; Di Ieva, A. Eye-Guided Multimodal Fusion: Toward an Adaptive Learning Framework Using Explainable Artificial Intelligence. Sensors 2025, 25, 4575. https://doi.org/10.3390/s25154575
Moradizeyveh S, Hanif A, Liu S, Qi Y, Beheshti A, Di Ieva A. Eye-Guided Multimodal Fusion: Toward an Adaptive Learning Framework Using Explainable Artificial Intelligence. Sensors. 2025; 25(15):4575. https://doi.org/10.3390/s25154575
Chicago/Turabian StyleMoradizeyveh, Sahar, Ambreen Hanif, Sidong Liu, Yuankai Qi, Amin Beheshti, and Antonio Di Ieva. 2025. "Eye-Guided Multimodal Fusion: Toward an Adaptive Learning Framework Using Explainable Artificial Intelligence" Sensors 25, no. 15: 4575. https://doi.org/10.3390/s25154575
APA StyleMoradizeyveh, S., Hanif, A., Liu, S., Qi, Y., Beheshti, A., & Di Ieva, A. (2025). Eye-Guided Multimodal Fusion: Toward an Adaptive Learning Framework Using Explainable Artificial Intelligence. Sensors, 25(15), 4575. https://doi.org/10.3390/s25154575